Note: Descriptions are shown in the official language in which they were submitted.
-- 21 99588
Field of the Invention
The present invention relates to a hierarchical artificial neural network
(HANN) for automating the recognition and identification of patterns in data
matrices. It has particular, although not exclusive, application to the
identification of severe storm events (SSEs) from spatial precipitation
patterns, derived from conventional volumetric radar imagery.
Background
The present invention was developed with a meteorological application
and will be discussed in that connection in the following. It is to be
understood, however, that the invention has other applications as will be
appreciated by those knowledgeable in the relevant arts. It may be applied
wherever a pattern in a data matrix is to be recognized and identified,
regardless of the orientation, position or scale of the pattern.
Severe storm events ~SSEs) include tornadoes, downbursts (including
macrobursts - damaging straight line winds caused by downbursts - wind
shear, microbursts), large hail and heavy rains. These events, particularly
tornadoes, may form quickly, vanish suddenly, and may leave behind great
damage to property and life. It is therefore of importance to be able to
provide some prediction and warning of the occurrence of these events.
Weather systems are known to be chaotic in behaviour. Indeed, chaos
theory was originally introduced to describe unpredictability in meteorology.
The equations that describe the temporal behaviour of weather systems are
nonlinear and involve several variables. They are very sensitive to initial
conditions. Small changes in initial conditions can yield vast differences in
future states. This is often referred to as the "butterfly effect."
Consequently, weather prediction is highly uncertain. This uncertainty is likelyto be more pronounced when attempting to forecast severe storms, because
2 1 99588
their structure, intensity and morphology, are presented over a broad
spectrum of spatial and temporal scales.
In a storm warning system, problems of prediction originate at the level
of storm identification. The uncertainty in initial conditions manifests itself in
two distinct forms:
(i) the internal precision and resolution of storm monitoring
instruments; and
(ii) the speed at which a storm can be pinpointed.
Furthermore, the recognition of storm patterns based on local
observations is not always possible, since the patterns are inherently
temporal in nature, with a sensitive dependence on previous states that may
not have been observed.
Real-time recognition and identification of SSE patterns from weather
radar imagery have been an instrumental component of operational storm
alert systems, serving the military, aerospace, and civilian sectors since the
early 1950's. This research theme continues to be among the most difficult,
complex, and challenging issues confronting the meteorological community.
While weather services around the globe have been improving methods of
storm surveillance to facilitate the identification and forecasting of SSEs, theresulting increase in both the size and diversity of the resultant data fields
have escalated the difficulty with assimilating and interpreting this
information.
Factors at the heart of the problem include:
(i) The life cycle of SSEs is very short, in the order of 10 to 30
minutes. They are often of shorter duration than the opportunity to capture,
dissect, and analyze the event on radar, let alone interpret the information.
21 99588
(ii) Unlike real or physical entities, radar patterns do not manifest
themselves in a life-like form, but are mere artifacts that resemble the type ofreflectivity return expected from bona fide precipitation distributions
accompanying SSEs. The relationship between SSEs and these abstractions
is analogous to the correspondence between fire and smoke. Just like smoke
can prevail after a fire ceases existence, so can a storm pattern be observed
in the wake of a SSE. This time lag interferes with the perception of current
conditions .
(iii) The features which do assist in the discrimination of SSE patterns
rarely display themselves on a single radar image level, but are present at
every level on a three dimensional grid. This complication is attributed to the
fact that the severity of a storm is a function of buoyancy, the potential
energy available to lift a parcel air and initiate convection. Since buoyancy ismaximized during SSEs, the convective currents initiated give rise to non-
uniform precipitation distributions at various altitudes. Furthermore, since
feature structure (pattern boundaries) in the high dimensional data of radar
imagery is usually quite sparse, most of the data is redundant. As such, it
will likely require an extensive amount of visual processing to extract a
sufficient number of features to secure class separability.
(iv) Distinctive SSE signatures: bow; line; hook; and (B)WER, have
been universally accepted as indicators of specific storm features: squall
lines; strong rotating updrafts; downbursts; and storm tilt. However, their
tremendous spatial and temporal variability through translation, rotation,
scale, intensity and structure, give rise to non-linear and multiple attendant
mappings in the radar image domain, often resulting in two very different
events being perceived as one and the same pattern.
2~ 99588
(v) Often some of the most severe SSEs, tornadoes and macrobursts,
do not visually present themselves on radar reflectivity (Z) imagery, since
they occur in the virtual absence of precipitation. Any weak Z patterns
displayed are usually buried in noise: radar clutter; side-lobe distortion; and
range folding, causing subtle but distinguishing features to be obscured and
overlooked .
(vi) The human brain is not conditioned to recognize SSE patterns.
This is a complex task at least as difficult to learn as facial and object
identification, and speech recognition.
As difficult as the human act of SSE recognition may seem, the more
perplexing issue is to translate this process into the algorithmic and machine
domain. To date, most approaches to this problem have relied on traditional
artificial intelligence (Al) technology, with emphasis on two paradigms: (i)
statistical methods; and (ii) artificial rule based experts. W.R. Moninger, "TheArtificial Intelligence Shootout: A comparison of Severe Storm Forecasting
Systems," Proc. 16th Conf. on Severe Local Storms, Kananaslcis Park, Alta.,
Canada, Amer. Meteor. Soc., pp. 1-6, 1990 provides a comparative analysis
of the implementation of such models in thunderstorm identification systems.
K.C. Young, "Quantitative Results for Shootout-89," Proc. 1 6th Conf. on
Severe Local Storms, Kananaskis Park, Alta., Canada, Amer. Meteor. Soc.,
pp. 112-1 15, 1990. elaborates on this study with some quantitative results.
These systems are unnatural in terms of their pattern encoding
mechanisms. They make false assumptions about the underlying processes
in question and require explicit knowledge, massive amounts of memory or
extensive processing to encode, recall, and maintain information.
Statistical methods either make Gaussian assumptions or require
a priori information about the underlying distribution of the pattern classes.
- - 21 99588
Since there is insufficient information to fully express the relationships
between radar patterns and SSEs, this technique produces unsatisfactory
results.
Artificial experts, which rely on the use of explicit rules to emulate the
qualitative reasoning and subjective analysis skills of a trained expert, are not
appropriate because the nonlinear behaviour of SSEs gives rise to non-explicit
descriptions of these relationships.
What is needed is a system that is capable of learning what it needs to
know about a particular problem, without prior knowledge of an explicit
solution, one which can be incrementally trained to extract and generate its
own pattern features from exposure to real time quantitative radar data
(stimuli). This type of system, commonly referred to as an artificial neural
network (ANN) has been a focus of attention in the Al community for several
years, but it was not until recently that ANNs have been applied successfully
to solve real-world problems, such as speech recognition, three dimensional
object identification and financial forecasting.
There are several other facets that make ANNs a very attractive
approach for storm identification, namely, they:
(i) are inherently suited to function well in environments displaying
chaotic behaviour (like the weather);
(ii) can excel at deriving complex decision regions in highly nonlinear
and high dimensional data spaces (radar data);
(iii) are capable of generalizing the recognition of previous input
patterns (in-sample) to new ones (out-of-sample);
(iv) can extract relevant features from an incomplete or distorted set
of data - noisy returns from radar clutter, range folding, and side lobe
distortion;
-
2 1 9~588
(v) can accelerate the coding of new information (relative to expert and
statistical methods) by:
(a) adapting in response to changes in the environmental stimuli;
and
(b) allowing details of its structural connections to be specified
by the network's input correlation history; and
(vi) can process data distributively, making it possible to implement
these systems in very high speed parallel computers.
McCann at the National Severe Storms Forecast Center was one of the
first to demonstrate the effectiveness of ANNs in an operational storm alert
system reported in D.W. McCann, UA Neural Network Short-Term Forecast of
Significant Thunderstorms," Weather and Forecasting, Vol. 7, pp. 525-534,
1992. His research included both the training of two backpropagation ANNs
(BPNs), to forecast significant thunderstorms from fields of surface-based
lifted index and surface moisture convergence, as well as combining their
results into a single hourly product, to enhance the meteorologist's pattern
analysis skills. While this approach does not directly address the issue of
identifying specific SSEs from high dimensional radar imagery, it is taken that
the success of ANNs in a real-time storm environment depends on the
computer power available to scale up from small networks and low-
dimensional "toy" problems to massive networks of several thousands or
millions of nodes and high-dimensional data. Other applications of ANNs in
meteorology have also been limited to using low dimensional raw,
unstructured data and a single BPN. These include:
Rainfall forecasting from satellite imagery in T. Chen and M. Takagi,
"Rainfall Prediction of Geostationary Meteorological Satellite Images Using
Artificial Neural Network," IGARSS, Vol. 2, pp. 1247-1249, 1993, and M.N.
21 99588
French, W.F. Krajewski, and R.R. Cuykendall, "Rainfall Forecasting in Time
Using a Neural Network," Journal of Hydrology, Vol. 137, pp. 1-31, 1992;
The prediction of lightning strikes, and most recently, weather
radar image prediction in K. Shinozawa, M. Fujii, and N. Sonehara, UA
weather radar image prediction method in local parallel computation," Proc.
of the Int. Conf. on Neural Networks, Vol. 7, pp. 4210-4215, 1994; and
The diagnosis of tornadic and sever-weather-yielding storm-scale
circulations in C. Marzban and G.J. Stumpf, UA Neural Network for the
Diagnosis of Tornadic and Severe-weather-yielding Storm-scale Circulations,"
Submitted to the AMS 27th Conference on Radar Meteorology, Vail Colorado.
Research reported in A. Langi, K. Ferens, W. Kinsner, T. Kect,
and G. Sawatzky, ~Intelligent Storm Identification System Using a Hierarchical
Neural Network,n WESCANEX '95, pp. 1-4, Nov. 30, 1994 and conducted in
conjunction with the University of Manitoba (TR Labs), InfoMagnetics
Technologies Corporation (IMT), and the Atmospheric Environment Services
(AES) of Environment Canada, have demonstrated that by combining classical
image processing with ANNs in a hierarchical configuration, there is no longer
a need for scaling up to a massive single ANN when confronted with high
dimensional data, such as radar imagery. Their approach decomposes the
problem of storm identification into three levels of data processing:
1 ) dimensional reduction of CAPPI (constant altitude plan position
indicator) radar images using data slicing, fragmentation, and classical
preprocessing;
2) feature extraction and vector quantization in the form of learned
codebooks using self-organizing feature maps (SOFM); and
3) pattern recognition and classification using a backpropagation network
(BPN) as described in W. Kinsner, A. Indrayanto, and A. Langi, "A study of
21 99588
BP, CPN, and ART Neural Network Models," Proc. 12th Int. Conv. IEEE Eng.
in Med. and Biology Soc., IEEE CH2936-3/90, Vol. 3, pp. 1471-1473, 1990.
The present invention relates to certain improvements in a
system of this latter type. The present HANN storm identification system
makes use of the processing stages of the prior art and incorporates
additional levels of hierarchy with a more sophisticated and interactive engine
of ANNs and training mechanisms.
The attributes which are most important in a real-time adaptive storm
identification system include:
(i) Real-Time/High-Dimensional Data Processing:
The surveillance of high-dimensional radar precipitation imagery (up to
481x481 pixels) on a continuous and short term basis (~5 min.) demands
that the system not only be capable of processing data of such magnitude,
but also in a sufficiently short time to give the meteorologist the opportunity
to observe the displayed pattern before the next radar signal is captured.
(ii) Non-Stationary/Real-Time Adaptable Knowledge Resource
Since SSEs are governed by air transfer mechanisms, -- buoyancy,
convection -- which are nonstationary and unpredictable in nature, these
variable characteristics are ultimately reflected in the radar image. Therefore,the system should be capable of continuously adapting to focus on those
features in the radar images which are most prevalent in the dynamic
environment. This requirement gives rise to the need for a self-stabilization
mechanism in the system.
(iii) Self-Stabilization:
21 99588
With radar image sizes as large as 481x481 pixels, the number of
permutations of SSE patterns that can potentialy occur within the image
space can exceed 1O6xl05. The vast size of this space coupled with the
inherent variability of SSE patterns can lead to temporal instability. When the
number of inputs exceeds the internal storage capacity of the system, novel
patterns can only be learned at the expense of destabilizing prior knowledge,
eliminating previously learned patterns. Therefore, the tendency of the system
to adapt to novel inputs must be either inhibited by a supervisor or self-
stabilized to allow for the future encoding of arbitrarily many inputs of any
complexity.
(iv) Compact Representation of Information Resource
Since the environment is constantly changing, there is insufficient
opportunity to perform exhaustive information searches in the event that a
demand forecast is requested. Therefore, the system should be capable of
encoding information in a compact format to facilitate data retrieval and fast
~best guess" approximations at any instant.
(v) Self-Organization:
The subjectivity, uncertainty, and incompleteness of current SSE
models, calls for a system that can self-organize its recognition code -- a
direct and unsupervised interaction with the input environment, which causes
the system to adaptively assume a form that best represents the structure of
the input vectors.
(vi) Data Abstraction/Noise Immunity
21 99588
The system should be capable of extracting and recognizing relevant
information from: (a) redundant data; (b) incompletely specified data e.g. data
corrupted by noise; and (c) unspecifiable data which does not independently
reflect the class to which it belongs. To prevent these artifacts from
obscuring the effect of more distinguishing features, the system should
employ models which are highly tolerant and immune to noise.
(vii) Nonlinear Behavior:
The system should be capable of deriving arbitrarily complex decision
regions in highly nonlinear data, because, many of the relationships
describing the dynamic and spatial behavior between SSEs and attendant
radar patterns, are subtle, non-explicit, non-linear, and at times chaotic.
(viii) Specialization and Generalization
The system should be capable of balancing its representation of the
input environment, in terms of both local and global details. In a storm
environment, there is a strong correlation between the presence of local SSE
patterns on radar and the global structure of the complex in which they form.
For example, the formation of a tornado is correlated with the spatial
organization of hail and rain.
(xi) Ergonomic User Interface:
The system should be capable of interacting with the user in an
ergonomic fashion. The output produced by the system should be displayed
in a consistent format that can be interpreted quickly, accurately, and
reliably.
2 1 99588
According to one aspect of the present invention there is
provided a method of processing a data matrix to identify characteristic
features therein, said method comprising:
processing the data matrix with a self organizing network to produce a
self organizing feature space mapping;
processing the self organizing feature space mapping to produce a
density characterization of the feature space mapping.
According to another aspect of the present invention there is provided
a system for processing a data matrix to identify characteristic features
therein, said system comprising:
self organizing network means for processing the data matrix to
produce a self organizing feature space mapping;
density map processing means for processing the self organizing
feature space mapping to produce a density characterization of the feature
space mapping.
The self organizing network is preferably completely unsupervised. It
may, under some circumstances include a supervised layer, but it must
include at least an unsupervised component for the purposes of the invention.
The "self organizing feature space" is intended to include any map with
the self organizing characteristics of the Kohonen Self Organizing Feature
Map.
The SOFM technique is the network of choice on a number of
accounts. The SOFM has the remarkable ability to quantize a pattern space
into homogeneous regions, while at the same time developing a faithful
representation of neighborhood relations between pattern and feature space,
in the absence of supervision. The unsupervised learning is of importance as
part of the process, since pattern vectors derived from radar images during
2 1 99588
image slicing and fragmentation, may not independently represent the pattern
event classes we are seeking to recognize and identify. Therefore, it is
advantageous to use SOFMs first, as a means of quantizing the pattern
vectors corresponding to all storm classes, and then to construct an abstract
representation of each image based on the codebook developed by the
SOFM. Since the image constructed will be utilized as a source of input to a
classification network, it is desirable that the data be in a highly separable
form, where the similarity measure used to map neighborhood relations from
the pattern to feature space, conforms with the distance relations in the input
of the classification network. This is not always possible, for strange patternscan exist or occur on occasion.
Ordering the vector components of the density maps in terms of their
energy functions not only provides an ordered frequency distribution of the
features present in the original radar image, but also provides a mechanism
for perceiving different orientations, including translations, rotations and
scales, of the same pattern as being similar. In addition, a frequency
distribution display is well suited for distinguishing between different
patterns. At this stage a frequency vector of a CAPPI image has been derived
and this data abstraction can be displayed directly for examination. In
preferred embodiments, it will be presented to a classification network for
classifying the density vector representation of the three dimensiona~ data
and displaying a representation of classified features in the three dimensional
data.
For classification, the standard CPN network is inherently fast because
it utilizes a competitive learning procedure in its first layer and simply a unity
activation function in its output layer. In addition, since features
corresponding to different classes and CAPPI images are able to undergo
2 1 99588
further feature extraction in the outstar layer, class separability can be
improved prior to training the output layer.
A novel methodology is preferably used for incorporating vigilance and
conscience mechanisms in the forward counterpropagation network during
tralnlng.
According to another aspect of the present invention there is provided
a method of training a counterpropagation network having an instar
component comprising an input layer, a classification layer and an instar
connection matrix joining the input layer to the classification layer, an outstar
component comprising the classification layer, an output layer and an outstar
connection matrix joining the classification layer to the output layer,
conscience means for distributing input data vectors amongst processing
elements of the classification layer, and vigilance means for invoking
additional processing elements in the classification layer, said method
comprising:
inhibiting the vigilance means with a high activation threshold;
activating the conscience means; and
reducing the threshold for invoking the vigilance means as training
proceeds.
The vigilance means may be inhibited after invoking a new processing
element until the instar component reaches an equiprobable configuration.
This results in increased training speed as convergence of learning on
strange patterns reduces to a one-shot updating process.
Brief Description Of The Drawings
In the accompanying drawings, which illustrate an exemplary
embodiment of the present invention:
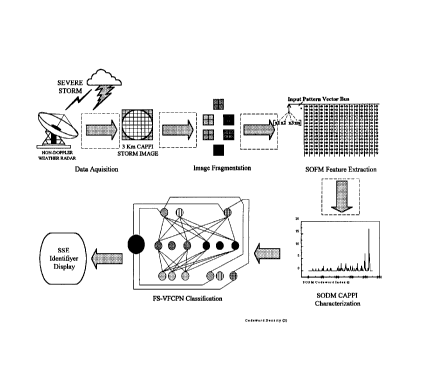
Figure 1 is a block diagram of the storm identification system;
21 99588
14
Figure 2 is a schematic diagram of the SOFM;
Figure 3 is an illustration of the structure of the Kohonen self
organizing map;
Figure 4 illustrates the structure of the FCPN;
Figure 5 shows the energy surface of an SOFM codebook;
Matrix 5 is the energy matrix plotted in Figure 5;
Figures 6 to 27 are SODM contour maps generated in system training;
Matrices 6 to 27 are energy matrices corresponding to the maps of
Figures 6 to 27.
Detailed Description
Referring to the accompanying drawings, Figure 1 is a block diagram of
the storm identification system 10. It has seven components, which
communicate in a feedforward fashion to produce and process radar image
data.
The first step is data acquisition. A non-Doppler weather radar antenna
12 scans for reflectivity patterns in a volume of the atmosphere occupied by
a severe storm event (SSE) 14. From this raw data, a radar product
processor (PP) 16 derives a set of constant altitude plan position indicator
(CAPPI) images 18. The CAPPI images depict the precipitation distribution of
the SSE at various altitudes.
Perceptual processing is performed in the following stage to prepare
the images in a format suitable for classification. First, a processor 20
performs classical image fragmentation of the images to reduce the size of
the data set. The CAPPI images are fragmented into equal sized blocks 22.
A processor 24 then applies a thresholding scheme to discard blocks
containing redundant information. The remaining blocks serve as inputs to a
first ANN stage, where a SOFM feature extractor 26 associates a feature
21 99588
primitive for each block. A processor 28 derives a SODM characterization on
the basis of the features extracted by the feature extractor 26.
A third processing stage is a second ANN stage that performs pattern
classification. A FCPN 30 classifies the SODM characterization and
associates a SSE identity for each CAPPI image on the basis of this
classification. An SSE identifier display 32 displays the results in a format
suitable for human analysis.
In use of the systern, rather than transforming the entire three
dimensional radar pattern onto a single SOFM map, separate SOFMs are
trained to extract local features from only the most discrirninating radar
levels, the high (9 Km), mid (5 Km), and low (3 Km) altitude CAPPI images.
This not only sensitizes the maps to become attuned to locally under-
represented patterns of often critical importance, but also reduces the size of
the map, and therefore, accelerates training.
At this point, each pattern vector is presented to each codebook for
the respective altitude. The Euclidean energies of the codewords most similar
to the pattern vectors are concatenated to form a multi-codebook distributive
representation of all of the pattern vectors. A Euclidean energy function is
utilized because it conforms with the distortion metric used to develop the
neighborhood relations in the map, as well as providing a means for further
quantization of the image space by reducing a high-dimensional pattern
vector to a scalar value.
Once all pattern vectors belonging to a particular image have been
presented to the SOFMs, the vector components are ordered in terms of their
energy functions. This approach not only provides an ordered frequency
distribution of the features present in the original radar image, but also
provides a mechanism for perceiving different orientations of the same
2 ~ 99588
16
pattern as being similar. In addition, a frequency distribution display is well
suited for distinguishing between different patterns. At this stage a frequency
vector of a CAPPI image has been derived and this data abstraction will be
presented to the classification network.
The CPN functions as a statistically near-optimal key-value lookup table
and is capable of organizing itself to implement an approximation of a non-
linear mapping of feature to classification space.
The standard CPN network is inherently fast because it utilizes a
competitive learning procedure in its first layer and simply a unity activation
function in its output layer. In addition, since features corresponding to
different classes and CAPPI images are able to undergo further feature
extraction in the outstar layer, class separability can be improved prior to
training the output layer.
The CPN incorporates Hecht Neilson's interpolation [R. Hecht-Neilsen,
"Applications of Counterpropagation Networks," Neural Networks, Vol. 1, No.
2, pp. 131-139, 1988], Wang's winning-weighted competitive learning
(frequency-sensitive learning) [Z. Wang, "Winning-Weighted Competitive
Learning: A Generalization of Kohonen Learning," Proc. of the Int. Joint
Conf. on Neural Networks, Vol. 4, pp. 2452-2455, 1993] based on DeSinno's
conscience mechanism[D. DeSieno, "Adding a Conscience to Competitive
Learning,"], and Freisleben's Vigilance mechanism [B. Friesleben, "Pattern
Classification with Vigilant Counterpropagation," Second Int. Conf. on
Artificial Neural Networks, No. 349, pp. 252-256, Nov. 1991] to provide a
Vigilant feedforward CPN (V-FS-FCPN). This further enhances its
generalization and resultant classification performance. It achieves equi-
statistical representation of the feature mapping between all processing
elements, while at the same time accelerating convergence. It also allows
21 99588
proper classification of storm patterns that have similar features but
significantly different outputs.
A novel methodology is used for interfacing the vigilance and
conscience mechanisms in a unified framework. During the self-organizing
stages of the CPN network, when the Kohonen layer tries to develop an
equiprobable representation of the feature space, the vigilance mechanism is
inhibited and the conscience mechanism proceeds to establish equiprobability.
Rather than heuristically determine when to initiate the vigilance mechanism
after equiprobability and while the Grossberg layer begins to associate an
output vector class with a given Kohonen codeword, the threshold of the
vigilance mechanism is set to a high value initially, and it is monotonically
reduced with time as Grossberg training progresses. Therefore, at the
inception of training, when the output error is expected to be high, the
vigilance mechanism prevents the inducement of new Kohonen and
Grossberg vectors to accommodate the classification of strange patterns
when the outputs of a select few patterns with similar inputs have
significantly different outputs. As training progresses, the likelihood of an
input pattern belonging to a specific class increases with time and therefore
the vigilance threshold is decreased. The next time a pattern is presented, the
conscience mechanism is obviously inhibited if a vigilance induced codeword
is selected as a winner, since they do not conform to the general type of
expected patterns. At this point the output of the Grossberg weight
associated with this codeword is compared to the actual output of the
training pattern presented, and similarly, if they differ by a value greater than
the threshold, then once again a new codeword is grown. But, if they are
somewhat similar, then the vigilance induced Kohonen and Grossberg
codeword weights are pulled in the direction of the centroids of the actual
21 9q588
18
training pattern values presented to that codeword over time. As a result,
training speed is increased substantially as convergence of learning on those
strange patterns reduces to a one-shot updating process.
Theory
A more detailed description of the theoretical basis of the invention is
given in the following.
Object Data
Formally, object data can be represented as a set of n feature vectors,
x= [x"x2,...,xn] in a p-dimensional feature space, ~P . The jthobserved
object datum, x; can be thought of as a numeric vector abstraction of some
physical entity -- in our case precipitation distributions of SSEs in one or more
radar images. Each of these vectors comprise of p characteristics (features),
which can represent the precipitation intensity of a single radar image pixel.
Feature Extraction
Feature extraction can be characterized mathematically as a
transformation ~ of the set of all subsets (power set) in 9~P: P(~P), to the
power set of ~4 ~q), with an image y= q (x) ~P(~q) . Although
transformations of the form p 2 q are sometimes desirable in applications
where the original data space is too small to visualize feature structure, in our
case, where the object space corresponding to radar data is much too vast,
p is quantized to q<<p (dimensional reduction) to reduce the space and time
complexity of computations that make use of the extracted data.
While many ANN approaches to feature extraction are supervised
~training with a priori knowledge of input class distributions), in many
practical cases, we need to analyze and extract some information from a set
2199588
19
of data, and classify them into several categories, while we do not know in
advance what training samples are associated with each group. In such
instances, we must rely on unsupervised learning techniques (training with
incomplete knowledge of class distributions). The need for this approach in
the context of this thesis will become self-evident in the System Architecture,
when we explain why limitations in processor speed and memory capacity
drives us to shift our classification decisions from known object classes in
whole radar images to smaller, more localized regions of the data, whose
object classes are unspecifiable in terms of truth data.
There are many traditional clustering methods, to wit, the K-means
algorithm, however, these techniques are designed under some assumptions
regarding the style of the class distributions. But, if the data population in
question (SSE radar patterns) varies significantly, the clustering results can be
completely meaningless. Therefore, it is difficult to select the most
appropriate algorithm and to obtain the correct results. Unlike the previously
mentioned models, the Kohonen self-organizing feature map (SOFM) can
overcome these difficulties, because its self-organizing procedure is inherentlyunsupervised in nature [T. Kohonen, "The Self-Organizing Map," Proc. IEEE,
Vol. 78, pp. 1464-1480, Sep. 1990.].
Furthermore, in order for dimensional reduction to enhance classifier
performance, it is imperative that the feature extraction technique eliminate
redundancies without discarding the relevant feature primitives inherent in the
original data. It is an equally important issue to select the most desirable
property of ~ to preserve in q~, such that the transformation produces a
characterization that is most suitable for subsequent processing (in our case,
classification) .
- 21 9958PJ
While one could maximize preservation of sample variance using
principle component analysis or conserve interpoint distance pairs using the
Sammon algorithm, the topology preserving property of the Kohonen self-
organizing feature map (SOFM) is preferable on a number of accounts.
Self-Organizing Feature Maps
The SOFM has been applied successfully to a variety of image
processing and pattern recognition problems: character, facial and speech
recognition; feature space design; and vector quantization. In the present
context, the focus on the SOFM will be in terms of its ability to quantize high-dimensional radar imagery into a smaller dimensional space, while at the same
time extracting enough feature information to provide an invariant
representation of each storm pattern.
The SOFM is advocated by many as a truly genuine ANN paradigm, in
terms of two unique properties which are reminiscent of biological learning.
The SOFM has the ability to facilitate the visualization and interpretation of
complex clustering interrelations, feature structure and density population, in
high dimensional spaces, by projecting these relations on to a lower
dimensional viewing plane comprising a q-dimensional lattice of display cells
Oq c V(~q), such that the shape of the distribution and the topological
(spatial) order of the clusters, are near-optimally preserved. The SOFM is
tolerant to very low accuracy in the representation of its signals and adaptive
weights. These properties enable the SOFM to isolate the variability
(inter/intra class) of noisy patterns, and consequently, makes it much simpler
to assess the quality of the mapping.
The SOFM is also attractive from a number of other perspectives. The
SOFMs generally converge at a faster rate than other unsupervised ANN
21 99588
models, performing a similar function. They have been shown to be
convergent not only for a map with a high-dimensional lattice neighborhood
but also for one on a simple two dimensional grid. Experimental results on
numerous accounts have demonstrated the convergence to a reasonably
optimal level on the basis of actual classification error rate performance.
The present discussion makes use of a two dimensional ( m x m )
viewing plane lattice ~2 CV(~2)~ because: (i) there is no practical advantage
of visualizing data in a space containing more than 3 dimensions (q23); and
(ii) the time complexity of feature extraction grows exponentially as the
dimension of the map increases. .
SOFM Network Structure
The SOFM can be implemented for this case through the network
architecture described in the following section.
As shown above in Figure 2, the SOFM comprises two structural
components: (i) an input (fan-out) layer 34 consisting of p fan-out units 36
(grey circles) corresponding to each element of the input vector x~P; and
(ii) a competitive layer 38 made up of a linear array of m2 neurons or
processing elements 40 (PEs: black circles), that are logically associated with
the display cell coordinates r = (i,J) in the m x m viewing plane lattice 42.
The medium for communication between the fanout and competitive
layers is a synaptic connection matrix C, which forwardly links each fan-out
unit 36 to all PEs 40 in the competitive layer 38. Each PE connection in C
has an associated weight vector vr = [vrl,vr2,...,vrp] that is selectively adapted
during training to become a prototype tcodeword) of a specific input vector.
Therefore, the SOFM comprises p parameter maps, one for each component
of x. The set of m2 vr's forms the weight matrix V, denoted by:
- 21 99588
22
Op = (vjj}c~P~ As depicted by the horizontal arrows between the competitive
layer and the viewing plane in Figure 2, there is a one-to-one correspondence
between Op and the set of mx m display grid cells ~2 = {r} c ~2, in the sense
that the reference set {1,2,...m} x {1,2,...,m} is both the logical address of
the cell, and the geometric vector with coordinates r, center of the cell (i, ~).
SOFM Training Procedure
The mechanisms and algorithm responsible for adjusting V are
described in the following section.
There are two diametrically opposing forces at work during the SOFM
training process, namely: (i) the weight vectors v, in Op become adaptively
placed into the input space ~tP, such that they assume a shape which
approximates the probability density function of x (pdf (x) ); and (ii~ the self-
organizing interaction among neighboring PEs in ~2 causes each PE to
become a selective decoder of a specific cluster of input patterns, such that,
the projection of Op onto ~2 preserves the topology and continuity of x. It
is from this property that the network derives its identity, the self-organizingfeature map.
The SOFM is trained using an iterative algorithm, comprising four basic
steps. These are: (i) input selection and presentation; (ii) competition; (iii)
adaptation; and (iv) evaluation for termination of training. To minimize the
likelihood of PEs from becoming biased to a particular input pattern, V is
typically initialized to small random values prior to training the network. Let
t denote the current iteration.
The first step involves the appropriate selection ~random or sequential
ordering in accordance with the probability density function pdf(x) of the
pattern space, ~P) of an input vector x, for presentation to the fan-out PEs
2 1 99588
23
36, and ultimate distribution to each of the competitive PEs 40, through the
connection matrix C.
In the second step, a competition is held among the competitive PEs
40, to determine which PE has an associated weight vector vr(t) in Op that
lies nearest to x, in the sense of some minimum distortion metric in ~P.
Denote the index of the winner's position on the viewing plane as rC =(ic~jc):
the logical address of the prototype index iC = arg min{¦¦x- vj(t)¦¦} . Although the
Euclidean metric is usually preferred as the measure of similarity because it is
in direct correspondence with the side dimension of the map and the
mathematical representation of energy, there are no constraints placed on the
type of distance relation desired.
In order to make a cluster of PEs centred at rc, detectors of the current
input class, the following step rotates the weight vector components of the
prototype iC ~[l,m2] as well as those within a certain spatial neighborhood of
rc: Nr(t), toward ~, in accordance with the "short-cut" Kohonen learning
rule: vi(t + 1) = v(t) + hr i(tXX - vi(t)) -
Two parameters are used to define Nr (t). Its shape is typically
represented as a hexagonal or square region in ~2- Its size covers the entire
map initially as depicted by Nr(t) (region in ~2 bounded by lightly shaded
display cells in Figure 2), and decreases monotonically with time a very
narrow width Nr(t+k) (region in ~2 bounded by darkly shaded display cells
in Figure 2). The lateral excitation coupling function hrC(t) expresses the
strength of interaction between PEs at coordinate rc and i in ~2 (the degree to
which the weight vector is pulled towards X) as a function of two variables:
(i) time t; and (ii) the distance from rc to i~i. A typical form for hri~t) is
Gaussian, and is defined as: hri(t) =a(tJ(-In-rC~ where a(t) = a~af / aO)t~T
2 1 99588
24
and ~(t)= C~(~f /~O)"T are chosen as suitably monotonically decreasing
functions of t. Therefore, hri (t) decreases with t, and for fixed t, it
decreases as the distance from i to r in ~2 increases. It has been
demonstrated that the algorithm's performance is relatively insensitive to the
actual choice of these two parameters and the manner in which they are
decreased during the learning process. The combined effect of monotonically
decreasing N, (t) and h,~,(t) causes the map initially to induce a course
spatial resolution (a rough global ordering of the weight vectors vr) and
gradually to allow a smooth transition to a finer resolution by preserving localorder without destroying global relations.
The fourth and final step uses one of a combination of criterion
functions to assess when training should be terminated. An extensive review
of many papers on this subject indicate that the three most widely accepted
criteria in practice are: ~i) the decreasing lateral width of Nr (t); (ii) the
diminishing rate of change of V(i,t); and (iii) the distortion metric, D.
At the termination of training, a final pass is made through {X}, to
obtain a display of its feature structure in V(~2). This display is typically
produced by 'lighting up' (marking) each unit r in ~2 that corresponds with
the PE Vr c Op, which is most similar to the current member of {X} being
passed. However, this technique breaks down when~ the number of
clusters are unspecifiable before the algorithm is completed (as will be the
case with radar images); and ~ii) multiple inputs project onto the same
position in the map.
A data visualization tool, known as self-organizing map (SOM) analysis,
has been applied successfully to resolve these issues. An extension of SOM
analysis which will be referred to as the self-organizing density map (SODM)
is applied to: (i) visualize the density distribution of SOFM codewords
-
21 99588
corresponding to blocks elements in a single pattern vector (radar image); and
(ii) construct a feature representation of whole radar images, for the purpose
of classification. A description of SOM analysis will follow, to provide the
preliminary material needed to formulate the SODM.
Experimental results demonstrate that SOM analysis is suitable for
many different clustering problems and is considerably less dependent on
assumptions regarding the distribution of data classes. Furthermore, it
specifies the correct number of clusters on the map, and in cases where only
limited a priori knowledge is available, its advantages are more pronounced.
Although SOFMs converge at a faster rate than most unsupervised
learning models, the computational demand of the competitive process, the
search for a nearest neighbor (NN) (the distance between the referenced
weight vectors (test vectors) of all PEs and the current input stimuli), not only
dominates the learning algorithm, but is also impractical when operating in an
environment characterized by high-dimensional inputs, because the
algorithmic complexity of conventional brute-force NN-search methods
increases exponentially with both the dimension of the data space and the
size of the map needed to accommodate the cardinality of the training set.
Therefore, if the application of the SOFM is to be practical, in terms of
extracting features from high-dimensional radar data, then it is ess~ntial that
a mechanism be incorporated to deal with this problem.
The issue of accelerating the information encoding training process has
been addressed implicitly from the standpoint of improving the utilization of
weights in the map: conscience and orphan learning; chaotic versus linear
activation functions, and also adding a momentum term to the learning rule,
similar to that of backpropagation (BP). The benefit of these techniques in
terms of the recall process is not addressed. Since NN-searches need to be
.
21 99588
26
performed repetitively, both during the encoding and recall stages, it is
desirable to resolve the issue by applying a fast NN-search mechanism. For
present purposes, the probing algorithm has been adopted.
The probing algorithm is capable of achieving a significant training
speed gain, when operating on input spaces larger than 16 dimensions. The
probing algorithm can effectively achieve a 6 to 10 fold reduction in training
time, by exploiting the properties of self-organization and topological
preservation inherent in the SOFM. Furthermore, the average complexity of
the algorithm and the effective size of the search space decreases as the size
of the input space increases. Therefore, if the cardinality and/or
dimensionality of the training set needs to be expanded in the future, this
algorithm will not adversely effect the SOFMs training speed. The mechanics
of this algorithm are described in the following.
Probing Algorithm
The probing algorithm is a stochastic, iterative process, which
comprises two steps. Given a set of reference vectors {vr}, it:
(i) searches for the NN to a test point, x (candidate) with any
algorithm in a predetermined number of steps (typically 2-6 steps~. Each step
consists of: (a) computing the distance (l lvr-xl 1) to the test point; and (b)
comparing the computed distance with the current minimum distance.
(ii) navigates or Uprobes'' around the lattice neighborhood region of the
current candidate to find the NN, and if the region contains better candidates,
then the best of them (winner) is selected, otherwise, the search is
terminated .
The preliminary search in stage (i) uses the basic Friedman algorithm
[J.H. Friedman, F. Basket, and L.J. Shustek, "An Algorithm for Finding
21 9~588
Nearest Neighbors," IEEE Trans. Comput., Vol. C-24, pp. 1000-1006, Oct.1975.] The reference vectors are ordered periodically during training, with
respect to their projection values on a cyclically selected coordinate axis
(each axis selected in turn), as shown in Figure 2. This stochastic selection
injects another source of non-deterministic behaviour in the SOFM. The
smallest projected distance from the test point is then selected as the first
candidate for the NN, and its vector distance (Euclidean) from the test point
becomes the "current candidate" for the minimum distance. The remaining
reference vectors are now examined in order of their projected distance, and
if the minimum of their set of vector distances is smaller than the Ncurrent
candidate," then the reference vector corresponding to this minimum is
chosen as the Nnext candidate.N The search is terminated when the first local
minimum is found, when the vector distance between the Nnext candidaten
and the test point, becomes larger than that of the Ncurrent candidate."
Although the full Friedman procedure, which orders reference vectors
on all of the coordinate axes and selects the one with the smallest local
projected density in the neighborhood of the test point for searching, provides
a more accurate approximation of the NN, this approach is not used, because
in spaces greater than 14 dimensions the computational demands are
excessive.
Since stage (ii) of the algorithm is based on the smooth topology of the
map, with neighborhood relations among the reference vectors induced by
the lattice of corresponding PEs, it is essential for the map to be roughly
organized prior to initiating the procedure. Therefore, the exact NN-search
method is used for the first few iterations of training.
Now that the procedure has been described, the reason why this
algorithm functions so effectively will now be explained.
21 99588
At the inception of training, while the map is in a relatively disorganized
state, the Friedman search will have a higher probability of getting trapped in
a local minimum, and consequently, a higher error rate at finding the NN. This
problem is further pronounced when the inputs are very large (more than
sixteen dimensions), because more folding is required to fit a two dimensional
map into a higher dimensional space. However, the error rate does not have a
significant effect on the performance. With nc(t) quite large during the initialstages of training, the fold causes the local minimum to migrate towards the
minimum and eventually smooth out. Since errors (local minima) in finding
the closest reference vector to an input pattern occur systematically at the
same locations on the map, they assume an alternative mapping from the
input space onto the lattice, which projects a test point and its neighborhood
on the same PE (without disturbing self-organization). Although the error
probability of finding the exact NN by the Probing algorithm is quite high
(17%), the classification error rate is considerably lower ( 9.2%). This is
consistent with the inherent tolerance of the map to very low accuracy in the
representation of its signals and adaptive weights.
Forward Counterpropagation Network
The FCPN network functions as a self-adaptive, near-optimal key-value
lookup table in the sense that key entries in the table are statistically
equiprobable approximations of a continuous mathematical mapping
function,~:X~"~Y~M. The objective function is to learn the intrinsic
relationships between feature structure (SODM characterizations) in
precipitation imagery and observed SSE events (classes). The network
becomes attuned to this mapping through adaptation in response to training
examplars, (x,~,y~,);~[l,Q] of the mapping's action. An overview of the
network's structure and signal flow follows.
2 1 99588
29
FCPN Network Structure
The FCPN is a hybrid structure, having four basic components, as
shown in Figure 4. These include: an input layer consisting of n fanout
units; a SOFM classification layer (K-Layer) made up of a linear array of N
instar PEs; a Grossberg identification layer (G-Layer) containing M outstar
(output) PEs; and a training layer, consisting of M training PEs. The medium
for communication between each processing layer is a synaptic connection
matrix, C which forwardly links each PE in a given layer to every PE in the
following layer in a fully connected topology. The inward pointing
connections from the n fanout units to the ith K-layer PE forms an instar
topology, which has an associated adaptive weight vector,
Wi = [Wil~Wi2~ Wij~ Win];i ~[l,N], j ~[l,n]. The outward pointing connections
from each of the N instar PEs to the M G-layer PEs forms a set of outstar
structures, which have an associated set of adaptive weight vectors,
Uk=[Ukl~Uk2~ UkJ~ Ukn];k~[l~M]~j~[l~N]~ These vectors make up the K-layer
and G-layer weight matrices, W and U, respectively.
The ith fan-out unit receives the ith component of an external input
vector (key-entry stimuli), x",=[x"",x"2,...,xO"~...,x,l""]; j~[l,n], and multiplexes
(distributes) this scalar value to each instar PE. The ith instar pE produces a
scalar activation signal, Zi; i ~[1,Nl, and propagates this value to each
outstar PE. The kth training PE receives the kth component of the training
vector (desired output vector), y", = [.~1 ,Y",2, ,Y,~,k, ~Y..~ ]; k ~[l,M~ and sends
this value to the kth outstar PE. The kth outstar then generates its output
mapping approximation (lookup table value), y,~'; k ~[l,M] on the basis of the
zj and training signals.
FCPN Training Procedure
- - 21 99588
The instar and outstar structures complement each other in a two
stage training process to learn the desired mapping function. First, the instar
PEs are given Uperceptual skills" by nurturing them to recognize different
regions of the input space ~n that are representative of specific input
clusters. Second, the outstar PEs are given Uassociative skills" by training
them to assign an identity to the selected cluster. The standard FCPN
network imposes a number of constraints on the mapping. The
correspondence between input and output vectors should be continuous. A
group of input vectors that are spatially close together relative to other
vectors in ~" forms a cluster region which is representative of a distinct
class. The training set should be statistically representative of the mapping
domain. The second constraint does not preclude multiple instar PEs from
sharing a common class.
Instar Encoding Mechanisms and Training Algorithms
Individual instar PEs become conditioned to input vectors of a single
cluster through a mechanism known as stochastic competitive unsupervised
learning. Stochastic refers to the random selection of training exemplars,
competitive relates to the process through which individual instar PEs
compete for excitation to input stimuli, and unsupervised implies that learning
is a self-organizing process that does not require reinforcement or graded
training from an external supervisor.
The objective of competitive instar learning is to encode adaptively a
quantization of the input vector space ~n into N Voronoi regions (Pattern
clusters), ~(Wt) = {X ~ ~n d(x,wi) < 4x w,); j jt i~ [1 N~ such that the
partition property, 9~n = Vl ~J Y2~J...U Vj U VN; Vi r~ Vj = O; i ~ j, self-organizes
and distributes the instar weight vectors w; in ~tn~ to approximate the
unknown probability density function p(x) of the stochastic input vectors, x.
In other words, the instar layer is said to have learned the classification of
2 1 99588
31
any input vector in ~n, when each of the i instar PEs responds maximally for
any given input in Vj. Therefore, the training exemplars should be statisticallyrepresentative of the input mapping domain. However, a novel method has
been derived from vigilance and conscience learning to minimize the
degradation of quantization accuracy when lifting this constraint.
As in the SOFM, the FCPN network uses a variant of Kohonen learning
to minimize the average quantization distortion of the instar weight vectors,
wi. This objective can be accomplished using the following sequence of
training steps.
As in the SOFM, the wqs are initialized to small random values prior to
training. First, a pattern vector XW is selected randomly from the training set
in accordance with its pdf, and is then presented to the fan-out layer, which
distributes x through the instar weight matrix W. A competition is held among
every PE in this layer, to determine which PE has a wq most similar to x.
Typically, a Minkowski distance metric of order 2 (Euclidean norm) is used as
the measure of similarity. At this stage, it is assumed that all instar activation
signals z; are initialized to zero. The PE that is most similar is declared the
"winner,N and its activation signal is set to unity ("1"). The z/s are then usedto specify which W;Js need to be adapted, in accordance with the training
rule. As in the SOFM, (xw~wjj) represents the scalar error between x and w,
and a(t) denotes the training rate. The degree to which the error is corrected
decreases monotonically with time in the range from unity to zero. Since z;
multiplies the correction signal a(t)(xWJ~wq), only the winner (zj=1) will be
updated (unless there is absolutely no error between a and w). After many
presentations of the training set X, the adaptation rule causes the instar PEs
to spread into those regions of the input space in which training examplars
occur and ultimately carve out a decision region that corresponds to the
region of the input space in which all input vectors are closer to a particular
PE than any other. But, since no mechanism is built into the adaptation rule
2 1 9958&
to ensure that the distribution of instar PEs are equiprobable with a weight
distribution which is partitioned into Voronoi regions of relatively equal sizesand weight vectors which spread across input clusters with equal frequency,
an additional mechanism, known as Uconscience'', is incorporated in the
instar learning algorithm to resolve this issue.
Outstar Encoding Mechanisms and Training Algorithm
The behaviour of the outstar PEs resembles classical Pavlovian
conditioning in terms of Hebbian learning.
During the conditioning period, the winner of the competition in the
instar layer propagates its activation signals z; through the connection matrix
C, providing a single conditioned stimulus (CS) z; to one of the outstar PEs.
At the same time, an unconditioned (supervised) stimulus (UCS) y~, from the
training layer is supplied to the outstar PEs. Since the objective function of
the outstar layer is to make the network learn the correct lookup value (target
value) y =SZ7(X), the outstar weight matrix U is adjusted such that the
unconditioned response (UCR) is pulled towards y (within a constant
multiplicative factor). Once conditioning is complete, the presence of the CS
(triggered by x) alone (UCS = O) should be able to produce a conditioned
response (CR) y'=~ ) that adequately approximates y =~(x) (without
exciting any of the other outstar PEs).
The conditioning scheme described above can be accomplished by
applying the Grossberg learning rule. Once again, the degree to which the
error is corrected decreases monotonically with time in the range from unity
to zero. The output vector components Yk' Of the kth outstar PE is generated
by taking the vector dot product of its weight vector Vkj with the z~s
produced by the instar PEs. Since only the winning instar PE produces a non-
zero activation (z;= 1), y' reduces to nothing more than the outstar vector ujk
associated with the winning PE.
2 1 99588
While the form of the learning rule may appear similar to that of the
instar layer, its effect is very different, in the sense that the u~s of each
outstar PE converge to the statistical averages of the training vectors y
associated with the input exemplars x that activated the corresponding instar
PEs. Since the w/ s tend toward an equiprobable state during instar training,
the outstar PEs are also equiprobable in the sense that they take on values
that are on average best representative of the lookup value in each training
case. Therefore, the FCPN network functions as a st,atistically near optimal
key-value lookup table.
Although the FCPN is both simple and powerful in its operation as a
mapping network, there are pitfalls in its basic design and training algorithm
that can impede its performance, especially when classifying SSEs. These
include: a difficulty with establishing and maintaining equiprobability of
Kohonen weight vectors; sub-optimal mapping approximation accuracy and
generalization performance, especially when training on small data sets with a
high degree of variability; and a failure to distinguish between similar patterns
in the metric sense, which have significantly different outputs. These
problems are discussed in the following.
Randomly selected input vectors from high-dimensional spaces, such as
radar imagery, are typically orthogonal. Additionally, input vectors are likely
to cluster into various regions with different frequencies, e.g. in isolated
regions of space. It is therefore possible that the random configuration of the
initial weight matrix W to be such that only a limited number of weight
vectors migrate toward the vicinity of the inputs. If such a condition were to
prevail, then independently of which input pattern is presented, only a few or
even single instar PE(s) would win the competition and have their weight
vectors move toward the centroid of those patterns. All other weight vectors
- ~ 2 1 ~9588
34
would remain Ustuck'' in their initial positions. Consequently, the network
would be grossly under-utilized, and would only learn to distinguish among a
few isolated input classes.
Since input vectors emanating from weather radar can be non-
stationary in nature, the distribution of vectors from each class can change
with time, and cause those few classes that were originally coded by the
instar PEs, to get recoded (destabilized) during the course of training to
represent other classes, at the expense of forgetting the original data. The
use of such a network in an operational storm environment would lead to
unacceptable classification errors.
Conscience Learning
To cope with difficulties discussed above, conscience learning is
incorporated into the HANN. The essence of conscience learning is to
provide each instar PE with an equal opportunity to win the competition, so
as to achieve an equiprobable distribution of instar weights, and consequently
a more balanced representation of the input vectors. This is accomplished by
instilling within each instar PE a ~conscience", such that, the more frequently
it wins the competition than other instar PEs (>1/N), it has a tendency to
shut down and unstick "stuck vectors" by allowing other PEs to win. The
mechanism used to implement this competitive process is based on Wang's
extension of DeSinno's "winning weighted distortion measure" [Z. Wang,
"Winning-Weighted Competitive Learning: A Generalization of Kohonen
Learning," Proc. of the Int. Joint Conf. on Neural Networks, Vol. 4, pp. 2452-
2455, 1993].
While the simple "winner take all" strategy of the standard FCPN
network is suitable for classification problems requiring little generalization,
2 ~ 9958~
when mappings are relatively simple and rigid, this approach becomes highly
inadequate when training on complex mappings, especially if little training
data is available. This strategy imposes a constraint on the ability of the
network to generalize, because it becomes inherently quantized to N levels,
the number of Kohonen neurons in the competitive layer. Consequently, the
mapping accuracy of the network can only be improved at the expense of
increasing the number of Kohonen neurons. However, simply increasing the
number of available neurons to accommodate additional input classes may
actually aggravate/exacerbate the problem by forcing the neurons to
memorize, instead of generalize. To increase the mapping approximation
accuracy and the balance between generalization and specialization
performance, an interpolation mechanism may be used.
The primary objective of this mechanism is to enable the network to
function as a multiclass Bayesian Classifier. This is accomplished by allowing
a blending of multiple network outputs. The most effective method for
partitioning the unit output signals is derived from Barycentric calculus,
originating from the works of mathematician August Mobius in 1827 .
Vigilance Mechanism
Although it is usually advantageous for a multi-layer neural network, in
the present case the FCPN network, to form a continuous mapping of a
feature space to a classification space, there are situations and, in the
context of SSE identification, critical instances, where this type of projectionprocess would fail. This may occur for example, when two similar SSE
features project onto two distinct SSE classes, e.g. a life threatening tornado
and non life-threatening heavy rain. Although measures are taken to ensure
that the feature space established during self-organization is separable, there
21 ~q58~
36
may be occasions where patterns appear similar in the metric sense by
stimulating the same neurons in the instar layer, but represent different
output classes. The standard FCPN network would merely map these
features onto the same Kohonen neuron, and subsequently gravitate the
Grossberg weights associated with the Kohonen neuron in the direction of the
fading window centroid of the class outputs associated with these features.
But, when two distinct output classes are represented as a binary vector, the
centroid is no longer representative of either class, resulting in a large and
possibly significant network error. This problem can be avoided by
invoking an additional neuron in the FCPN, known as the vigilance unit, to
monitor, evaluate, and control the quality of the network output during the
training phase. The application of this mechanism in the FCPN network was
originally proposed in O. Seipp, "Competition and Competitive Learning in
Neural Networks," Master's thesis, Dept. of Computer Science, University of
Darmstadt, Germany, 1991., and investigated by Friesleben in B. Friesleben,
"Pattern Classification with Vigilant Counterpropagation," Second Int. Conf.
on Artificial Neural Networks, No. 349, pp. 252-256, Nov. 1991. It was
inspired by a similar vigilance neuron employed in Carpenter and Grossberg's
adaptive resonance theory (ART). The ART model originally introduced this
mechanism to control the importance of encoded patterns, in order to prevent
the network from continuously readjusting to previously recognized patterns
and to adapt to and acquire features for novel patterns without discarding
learned ones.
Although the standard SOFM has many virtues, it is also plagued with
a number bottlenecks, namely: i) the sensitivity of initial weights resulting inunder/over-fitting of the input pdf; and ii) the UNearest Neighbor (NN) Search
Overload resulting from the "curse of dimensionality" -- exponentially
- - 2 1 99588
increasing processing time required to perform a nearest neighbor (NN) search
as both the dimensionality of the data space and cardinality of the training setbecome large. In addition, on the basis of my review of various SOFM
applications, it was found that is it not only the convergence of the map that
is important to ensure reasonable classification results, but also the manner inwhich we form abstractions of patterns on the basis of features extracted by
the SOFM. An extension of SOM analysis, which we will call the self-
organizing density map (SODM), will be presented in this section to resolve
the issue of: (i) visualizing pattern clustering tendencies in X that have
multiple attendant mappings in 02; and (ii) constructing a feature
representation of whole radar images, for subsequent classification.
Case Study
The following discussion presents a case study of the HANN's pattern
recognition performance using real-world volumetric radar data. This study
involves two fundamental experiments: (i) a software simulation of the SOFM,
to determine how well the feature extraction stage is capable of constructing
a visually distinct representation of each SSE radar pattern class; and (ii) a
software simulation of the CPN, to demonstrate whether the characterization
derived in experiment (i) is separable on the basis of the CPN's classification
accuracy. Furthermore, there is an evaluation of the relative efficiencies of
two CPN variants, the FS-VCPN and the V-FS-FCPN, in terms of the minimum
number of neurons needed to correctly classify a set of CAPPI images into
one of a combination of four categories: (i) tornadoes, (ii) hail; (iii) rain; or (iv)
macrobursts.
Classification Performance Measures
~ 21 9 158~
38
To assess the error rate three contingency table derived measures are
used to quantify the classification accuracy of the HANN. These are: (i) the
probability of detection (POD: conditional probability that the network
correctly identifies the presence of an event); (ii) false alarm rate (FAR:
conditional probability that the network incorrectly identifies the presence of
an event); and (iii) Hanssen-Kuipers skill index (V-lndex).
Selection and Acquisition of Training Set Data
In our experiments, we will classify a training set comprising 18 SSE
events observed by the AES in the Canadian Prairies during the summers' of
1991 and 1993. These events were captured by a conventional volumetric
weather radar in Vivian, MB, and Regina, SK, and then derived as a set of
constant altitude plan position indicator (CAPPI: top view of precipitation
along a horizontal plane) images at various altitudes.
To reduce the network's learning time, only a single CAPPI level will be
used for training. Although it would appear preferable to select an altitude
where the most features are present from each SSE class, namely, the 5 km
level, the 3 km CAPPI was chosen, because this data field is smaller in size.
Although 3 km CAPPls are as large as 297x297 pixels, 5 km CAPPls can
exceed 481x481 pixels, and cover a radius of up to 200 km (image space
dimensionality: 4812 = 231,361, containing up to 1 o6X1~5 vectors) . This
reduction in vector dimension will likely translate into a computational savingsduring training.
However, it is expected that the HANN will have some difficulty
distinguishing SSEs. The close spatial proximity of hail and tornadoes often
results in the same distinctive echo for both classes (bow echo, line wave
pattern, hook echo, (B)WER). Furthermore, SSEs do not always present
themselves simultaneously at every CAPPI level [radar]. Since the reflectivity
patterns of precipitation are only detected when the radar beam bounces off
- ~ 21 99588
39
wet particles, ~dryN hail and tornadoes/wind that are not accompanied by
precipitation are not displayed on the CAPPI, and are therefore non-
observable. Therefore, improved results can be anticipated by incorporating
both three dimensional information of a storm's vertical structure, and image
fields that are not sensitive to precipitation, but rather to the internal
structure, movement, and rotation of a storm complex (Doppler data --
velocity and spectrum width). [See M. Foster, "NEXTRAD Operational Issues:
Meteorological Considerations in Configuring the Radar," Proc. 16th Conf. on
Severe Local Storms, Kananaskis Park, Alta., Canada, Amer. Meteor. Soc.,
pp. 189-192, 1990].
The table below lists the ground truth information associated with each
3 km CAPPI training image:
(i) CAPPI Class # -- comprises two parts:
(i) the type of SSE event (T - Tornado; H - Hail; R - Heavy Rain;
W- High Winds and/or Macrobursts); and
(ii) the index of the sample associated with the event type.
For example, RW2 refers to the second training sample associated with a
Heavy Rain and Wind Storm.
(ii) Storm Complex -- the structural organization of the storm
environment associated with the event type. A combination of five categories
are used to classify each storm complex within a given CAPPI:
(a) Pulsed Cell (PS) -- a single celled storm (as called by Wilk et
al (1979) ) that possesses brief bursts of intense updrafts, associated with
large hail/tornadoes and popcorn shaped cumulonimbus clouds (CBs);
(b) Multicell (MC) -- the most common type of storm complex,
which are individually impulsive, but collectively persistent, and associated
with all types of SSE events;
21 99588
(c) Supercell (SC) -- the less common, but most dangerous type
of storm complex; assumes the form of an extensive plume or hook shaped
echo, and associated with strong rotating updrafts, extremely strong echoes
bounding regions of weak reflectivity (BWER) -- strong precipitation gradients,
and severe tornadoes (up to F5 intensity), wind shear/macrobursts/microburst
and extremely large hail;
(d) Squall Line (SQL) -- continuous or broken complex of storm
cells that are aligned laterally over a distance large in comparison to the
dimension of an individual cell, and associated with strong echoes, large hail,
and occasionally weak tornadoes embedded at the leading edge; or
(e) Intersecting Squall Line (I-SQL) -- the most rare type of storm
complex, associated with the same events as a SQL, but usually more brief
and intense.
(iii) Observed Location -- the approximate location where the event
occurred
(iv) Observed Date and Time -- Y/M/D and AM/PM notation.
- 2 1 99588
CAPPI . DateObserved # of 4*4 Block
Class #Storm ComplexObserved T~ n (Y/M/D) Time F~
Tl MPC/SC 7kmWofWynyard 91/08/02 9:30AM 1389
T2 PS SE of Vanguard 91/07/04 5:40 PM 28
T3 I-C-SQL SEofCFGMooseJaw 91/07/06 4:10PM 894
T4 B-SQL 16km~omAvonlea 91/07/06 5:15 PM 880
T5 MPC/B-SQL/SC 24kmNofEaston 91/07/10 11:55AM 882
T6 MPC/B-SQL/SC FoxValley 91/07/10 5:10 PM 759
T7 MPC 5 km W of Brookdale 93/06/12 6:00 PM 104
T8 SC Fort~l~Y~ r 93/06/12 11:50 PM 146
T9 MPC Gladstone 93/06/22 8:45 PM 129
THl I-C-SQL 16 bn W of Blic~ l 91/07/06 4:30 PM 936
Hl MPC/B-SQL Grass River 93/06/11 9:30 PM 179
H2 PS S of Gilbert Plains 93/06/12 5:00 PM 52
H3 PS Cowan 93/06/12 7:00 PM 25
RHl MPC/SCWestKildonn& Crestview 93/08/08 10:05 PM 708
RH2 MPC/SC N/A N/A N/A 908
RWl PS 3 km W of Fisher Branch 93/06/12 8:30 PM 25
RW2 MC/SC Portage La Prairie 93/09/08 7:45 PM 3005
Wl MC/SC Portage La Praine 93/09/08 7:40 PM 3062
Table 1 Training Set Information
Formulation of HANN (SOFM) Input Vectors
In order to prepare the data in a format suitable for presentation to the
HANN (SOFM), the CAPPI images were preprocessed in three stages.
First, given that the CAPPI data are too iarge to be processed by the
SOFM, each of the 18 images was partitioned into mutually exclusive block
vectors using an image fragmentation module. The size of the block was
selected such that the network training time would be tractable on a PC
computer, while at the same time large enough for a trained analyst to
accurately detect features in the data. A 4x4 pixel region ( ~ 16 km2) was
selected because this size is small enough to capture features of the most
severe microscale phenomena, namely, tornadoes and microbursts/
macroburst.
- 21 99588
42
Second, to prevent the SOFM from mistakenly interpreting redundant
data as relevant features, a thresholding scheme was applied to sift out
blocks with significant precipitation intensity. Therefore, the threshold was
set to reject blocks with an energy (quadratic sum of all 16 block pixel
values) less than 4. Although this value is very low in relation to the upper
practical limit (maximum precipitation intensity = 70dB; therefore, maximum
energy=16x702 = 78,400), these weak intensity blocks may be part of a
global structure, such as distinctive SSE echo (WER, Line, hook; (weak echo
overhang or strong gradient are indicative of hail and tornadoes), and
therefore have a significant impact on the gradient context of neighboring
blocks.
By partitioning the image into equal sized blocks, all localities are
treated with equal importance. The feature representation is made more
resilient to isolated regions that might be obscured by noisy echo returns
(side lobe distortion, range folding).
To obtain a more robust classification, in terms of recognizing that the
macro-structure of a storm complex is often indicative of the type of events
embedded within it locally, the third stage of preprocessing entailed the
construction of an input vector that makes use of contextual information.
Therefore, in addition to preserving local block features, statistical information
(mean, variance, and maximum values) from a 9 block nearest neighbor
region were concatenated with the 16 block components, to form a 19
dimensional input vector. Blocks with inconclusive contextual information
(regions with artifacts or near edges of image), were omitted from the training
set. Images that are concentrated with relevant data in these areas may lack
a sufficient amount of statistical information to be separable in the feature
space. Therefore, to allow information to be captured along the centre and
boundaries of the viewing plane, future studies should incorporate CAPPI data
21 99588
43
from multiple radar orientations. The distribution of CAPPI image blocks
resulting from the above procedure is shown in the last column of Table 1.
The training set patterns have now been prepared for presentation to
the SOFM.
Experiment #1: Feature Representation of CAPPI Storm Images
The objective of this experiment is twofold, namely, (i) to develop a
codebook of SOFM features for the training set; and (ii) to derive from the
codebook a SOM density characterization of each CAPPI image. Furthermore,
a discussion of the experimental results as they relate to the mapping's
separability will be presented.
Experimental Procedure
The SOFM simulator was configured to extract a codebook of features
from the training set. The selected network structure comprises 19 input
neurons ( 16 inputs originating from the 4x4 block vector and 3 inputs
associated with the statistical vector (contextual information of neighboring
blocks, mean, variance, and maximum), and 225 output neurons arranged on
a two dimensional lattice, corresponding to the size of the codebook. The
criteria used to select the map size is based on a similar argument used to
select the training block dimension, namely, (i) minimization of training time;
and (ii) maximization of available memory resources.
The network was initialized in the following manner: The weights were
set to small random values (0.1 to 0.2) so that no particular neuron in the
map would be biased to respond to any particular pattern in the training set.
Although it has been shown that convergence of the map can be accelerated
by initializing the weights to the average value of the training set (with smallrandom perturbations), this approach was dismissed for the following
reasons: (i) if the distribution of CAPPI patterns (patterns not completely
2 1 99588
44
represented by the training set) lies close to the mean, the resulting dynamic
range of the network weights would be narrow, rnaking the SOFM more
vulnerable to unstable states; and (ii) to adjust for this problem, the learningrate would have to be tailored to a smaller value. Therefore, we relied on the
self-organizing process to pull the weights towards an optimal configuration.
The adaptation parameters were initialized. A square shaped
neighborhood update region was used, and set to a radius of 7, such that
when the central neuron fired, the region spanned the entire map. The size of
the neighborhood was decreased monotonically with time to a value of 1, to
allow the SOFM to settle gradually from a rough global ordering to a finer
local ordering. Although some applications allow the update radius to shrink
to O [SOM] (when the winner of the competition is the only neuron that
adjusts its weights), so that the cells can become more finely tuned to
different patterns, this approach is not used because the SOM density
characterization that will be derived from the SOFM tends to produce better
clustering results when the neighborhood is not kept too small.
Following network initialization, the SOFM was trained on the entire
input set (randomly selected inputs without replacement), using the topology
preserving learning algorithm and probing mechanism as discussed above.
Training patterns were presented to the SOFM in random order, to prevent
the entire map from responding too sharply to patterns, whose class
frequencies are higher than others in the training set.
The win frequency variance was chosen as the primary indicator of
convergence over two other prominent measures, stability and the
maximum/mean squared error. Stability is the rate of change of weight
vectors between training steps. The maximum/mean squared error is the
ratio of the maximum/mean correction vector length and the learning rate.
The motivation for this selection is threefold: (i) the stability indicator was
dismissed because there were insufficient memory resources available to
2 1 99588
maintain both the network's current and previous state; (ii) since the
objective is not about maximizing the SOFMs quantization accuracy, but
rather about preserving the quality of the map's feature separability, a
convergence measure based on an error criterion would be inappropriate.
Furthermore, since SOFM learning is an unsupervised process, the error
cannot actually be used to quantify this measure. Unlike these other
measures, the win frequency variance is a more natural indicator of
convergence, because its roots are based on the well founded partition
property of the map. Using the nearest neighbor rule to mediate the
competition among neurons tends toward an equilibrium partition of the map
into equal size Veronoi regions [Winning weighted]. This partition property
implies that the win frequency of neurons have a tendency to converge
towards a statistically equiprobable state. Ideally, convergence is attained
when the variance of the neural matching rates (win frequency variance) are
zero. In practice, this value may never be reached, because there is no
mechanism in the SOFM, external to its neighborhood learning rule, that will
allow it to escape from local minima. Therefore, it is assumed that
convergence is near when both the win frequency variance approaches zero
and does not fluctuate between training steps. This measure (win frequency
variance) was monitored on an epoch by epoch basis until the convergence
criteria were satisfied, at which point training was terminated.
Experimental Results and Discussion
Figure 5 shows the energy surface of the SOFM codebook upon
convergence of training -- after 4 epochs.
The smooth gradation from low (light grey) to high energy (dark grey)
codewords along the two dimensional surface of the map indicates as
expected, a continuous landscape in the global sense. Observation of Matrix
5, corresponding to Figure 5, shows that nearby codewords in the map have
2 I q~588
46
similar energy features. The energy matrix corresponds with the plot of the
SOFMs energy surface. The elements are labeled in standard matrix notation,
but plotted as a reflection. The first value in the table (93854) was omitted
from the plot to enhance its global dynamic range for visual observation.
As expected through the use of the NN-probing search, small folds
and a few local discontinuities (singularities) are present in regions with bothmid (-12,000; center of map) and high energies (-25,000; west edge of
map). This result confirms the theoretical need for a vigilance mechanism in
the FCPN, as discussed in the foregoing.
A sample of the frequency distribution of codebook features for each
class of CAPPI images is depicted by the SODMs, as shown in Figures 6 to 8.
and the corresponding matrices. Visual inspection of the SODM shows a
clearly defined feature structure for each image class, indicating that decisionregions are somewhat separable and distinct. Dark and Light regions in the
SODM identify dense and sparse clusters respectively of training blocks in the
CAPPI that have feature projections characterized by the weights of neurons
in corresponding energy regions of the SOFM. Since the topology preserving
learning algorithm has preserved the neighborhood relations between the
training patterns in the image and feature space, the degree of feature
diversity for each CAPPI can be assessed qualitatively by examining the
geometric distances between the clusters centers (dense regions carved out
by contour lines) in the SODM.
The SODMs in Figures 6 to 8 show characteristic training patterns for
various weather events. The training patterns from tornadic CAPPls have a
broad spectrum of features that are densely distributed in the northwest/west
portion of the map. Hail CAPPls have a narrow spectrum of features that are
densely populated in the north-east region of the map. Wind CAPPls have
features that are densely packed in the north-central sector of the map.
CAPPls with multiple storm classes (tornado-hail, rain-wind, rain-hail) have
21 99588
feature distributions that vary from either class, indicating that singularities,
for example discontinuities or inconsistencies may be present in the mapping.
This result re-confirms the theoretical need for a vigilance mechanism in the
FCPN, as stated above. The SODMs corresponding to the remainder of the
CAPPI images are shown in Figures 10 to 23 and the corresponding Matrices.
The correspondence between cluster regions in the SODM and the
energy of neural weights in the SOFM were analyzed to determine whether
the energy distributions of CAPPI features are consistent with our
understanding of SSEs. They appear to be consistent, because the events
associated with intense and weak precipitation patterns project onto regions
of the SODM that correspond with intense and weak energy weights in the
SOFM. Heavy rain, tornadoes, and hail mapped onto strong energy regions,
while wind projected onto weaker ones. Since the input vectors are not solely
derived from the precipitation intensity of pixels in the image block, but also
from statistical information of surrounding blocks, SSEs associated with
strong precipitation gradients (BWER), but weak overall precipitation intensity
(tornadoes, hail), would cause the Euclidean energy competition/distortion
metric to produce the same mapping for events accompanied by strong
precipitation and weak gradients.
An input vector will now be constructed from the SODM prior to
training the CPN. The hierarchy of the HANN has now been truly revealed, for
classification cannot take place until the first ANN stage has developed a
faithful representation of the CAPPI feature space.
Formulation of CPN Input Vectors
Since the CPN uses supervised learning for classification, two input
vectors were established for presentation to the network, a feature vector
derived from the SODM for input to the fan out layer, and an associated
target vector for input to the training layer. The feature vector was selected,
2 1 99588
48
such that, without elaborate preprocessing, it would satisfy three geometric
properties. These are invariance to: (i) lateral scale; (ii) translation; and (iii)
rotation -- rigid body motion. Property (i) must be enforced for two reasons
The atmospheric mechanisms which are responsible for a given SSE radar
structure generally do not change with size. The lateral extent of a storm
complex, ceteris paribus, does not usually reflect the severity of local SSE
features. Pulsed cells (small popcorn shaped CBs) can be just as intense as
larger multi-cell clusters. The same can not be said for a storm's vertical
structure, because the height of a CB is often related to its severity.
However, some difficulties in the feature representation may occur, because
the environmental condition responsible for a storm's physical structure,
unicell, multicell, squall line or supercell, can influence its dimension. For
instance, even though different SSEs accompany different structures, the
density characterization of a storm would simply treat a large single cluster ofreflectivity echoes (supercell) as it would a group of smaller clusters. While
this may appear to be a serious dilemma, its resolution is a nonvoluntary
action of the SODM, because the density distribution of SOFM features can
be used to distinguish: between clusters of different structures and, in
essence, between SSEs of different classes.
The latter two properties are based on the premise that the structure of
distinctive SSE echoes are similar for a storm that occurs in Winnipeg or
Regina, or approaches from the northwest or south-east.
The concatenation of elements in the SODM is a prime candidate for
the feature vector, because "density," the basis of the mapping, is by
definition a characteristic property. The elements of this vector are normalizedto unit length to preserve the intra density characteristic of a each class; andrelative importance of one feature in relation to another.
Experiment #2: Justification of SOFM Feature Separability
21 q9588
49
The primary objective of this experiment is to evaluate the efficiency of
the CPN training algorithm FS-VFCPN in terms of the minimum number of
neurons needed to correctly classify the set of 18 CAPPI images into one of a
combination of four categories: (a) tornadoes, (b) hail; (c) heavy rain; and (d)macrobursts. Furthermore, these results will be used to verify the quality of
the SODM feature characterization.
Experimental Procedure for Evaluation of FS-VFCPN
The CPN simulator was configured to learn the classification of the
SODM CAPPI characterizations using vigilant frequency sensitive (conscience)
learning, as described above. The CPN structure was selected to have 225
fanout PEs, corresponding to each element of the normalized SODM, 8 instar
PEs, and 4 outstar PEs, corresponding to each of the SSE classes.
Although the lower bound of the instar complexity fit is 4 (because
there are 4 possible output identities: tornado; hail; rain; wind), experimentalresults from the first HANN stage (observation of training patterns) show that
there are some CAPPI images which have similar SODM profiles, but different
output identities or have the same output identity, but different cluster
centers (as depicted by the geometric distance between dark (dense) regions
in the map. (tornado1, 2 ,3 appear similar; hail1, hail2, hail3 + distances).
While the separation of the latter patterns require a separate instar PE to
become attuned to each pattern through competitive learning, the former
patterns can be correctly identified by using the vigilance mechanism to
encode the correct pattern class relationship in a one shot learning process.
Therefore, the size of the basic instar layer was selected to be twice the
width of the outstar layer, to allow for a minimum of two instar PEs to
respond to patterns from a single class. Four instar PEs were reserved for
vigilance learning, to accommodate the classification of the
singular/discontinuous mappings.
2i 99588
The network was initialized as follows. Although the conscience
mechanism does not place any constraints on the initial values of the instar
and outstar weights, they were set to small random values (0.1,0.2) for
reasons similar to the previous experiment. The adaptation parameters were
also appropriately set in accordance with the heuristics prescribed in the
preceding discussion.
Since the CPN training process comprises two stages, two measures
were used to asses its convergence. The win frequency variance of instar
PEs was used an indicator of the Vernoi equilibrium partition property. The
Hanssen Kuipers index ~V-lndex) was used as an indicator of the network's
classification skill in relation to that of an unskilled classifier. Unlike in the
SOFM experiment, an indication of the win frequency variance can also be
obtained by observing either the win frequency bias values (~=1/N) or the
bias term vector ~constant biases for all terms; B=O).
Once the network was fully configured, it was trained on randomly
selected patterns (without replacement) from the entire training set, for the
same reasons as outlined in the previous experiment. However, the process
of training (as defined in the steps below), was more elaborate than that of
the SOFM, because the CPN incorporates more training mechanisms and
processing layers, which have nonlinear interactions between them.
The instar layer was trained until equiprobability was achieved (4
epochs; as indicated by the win frequency, Figure 24), at which point,
outstar training commenced.
The vigilance mechanism was inhibited until the outstar PEs learned to
associate an identity for each instar class (as indicated by an steady increase
in V-index values, followed by a plateau in Figure 27).
If some patterns were misclassified, the vigilance mechanism was
activated with a single reserved instar PE (R= 1), otherwise, training was
terminated. Although it would seem that q reserved neurons would be needed
- 2! 99588
to accommodate the classification of q incorrectly identified patterns (problem
pattern), results in the following section indicate otherwise, because some of
these patterns did not actually belong to singular classes ( 1 t3,3t4) . This
result can be accounted for. Since the network self-organizes in response to
the entire training set prior to the activation of vigilance learning, the
inducement of a single reserved neuron would filter out a "problem pattern"
from partaking in this process, and as such would give the network more
freedom to self-organize in response to the remaining patterns (incorrectly
identified) .
Therefore, every time a reserved neuron was activated, the vigilance
mechanism was shut off, until the instar layer reached an equiprobable
configuration.
If all patterns were identified correctly (V-lndex = 1 ) at this point,
training was terminated, otherwise, the vigilance mechanism was not
reactivated (with an additional reserved neuron; R = R + 1; now R = 2), until
outstar training resulted in another V-index plateau.
The process was reiterated until 100% classification accuracy was
obtained, at which point the optimal ~minimum) complexity fit of the network
was established.
The results of the case study confirm the effectiveness of the HANN
for recognizing and identifying SSE patterns in the weather radar images.
These results can be extrapolated to other data matrices, where the
recognition of characteristic patterns would be useful. Examples are some
forms of financial and medical data where the sheer volume of data makes it
difficult to ascertain manually whether any identifiable pattern exists.
Thus, while one embodiment and application of the present invention
have been described in the foregoing, it is to be understood that other
embodiments and applications are possible within the scope of the invention
2 1 99588
52
and are intended to be included herein. The invention is to be considered
limited solely by the scope of the appended claims.