Note: Descriptions are shown in the official language in which they were submitted.
CA 02310652 2007-05-02
WO 99/33275 PCT/US98/27223
PARTIAL DECODING OF COMPRESSED VIDEO SEQUENCES
BACKGROUND OF THE INVENTION
Field of the Invention
The present invention relates to video processing, and, in particular. to the
decoding of
compressed video sequences.
Statement RegardingFederally Snonsored Research or DevelQpment
The Government of the United States of America has certain rights in at least
part of this
invention pursuant to Government Contract No. MDA-904-95-C-3126.
DescriQtion of the Related Art
Video images (i.e., frames) in a digital video sequence are typically
represented by arrays of
picture elements or pixels, where each pixel is represented by one or more
different components. For
example, in a monochrome gray-scale image, each pixel is represented by a
component whose value
corresponds to the intensity of the pixel. In an RGB color format, each pixel
is represented by a red
component, a green component, and a blue component. Similarly, in a YUV color
format. each pixel is
represented by an intensity (or luminance) component Y and two color (or
chrominance) components
U and V. In 24-bit versions of these color formats, each pixel component is
represented by an 8-bit
value.
A typical video sequence is made up of sets of consecutive frames called
shots, where the
frames of a given shot correspond to the same basic scene. A shot is an
unbroken sequence of frames
from one camera. There is currently considerable interest in the parsing of
digital video into its
constituent shots. This is driven by the rapidly increasing availability of
video material, and the need to
create indexes for video databases. Parsing is also useful for video editing
and compression.
One way to distinguish different shots in a digital video sequence is to
analyze histograms
corresponding to the video frames. A frame histogram is a representation of
the distribution of
component values for a frame of video data. For example, a 32-bin histogram
may be generated for the
8-bit Y components of a video frame represented in a 24-bit YUV color fonmat,
where the first bin
indicates how many pixels in the frame have Y values between 0 and 7
inclusive, the second bin
indicates how many pixels have Y values between 8 and 15 inclusive, and so on
until the thirty-second
bin indicates how many pixels have Y values between 248 and 255 inclusive.
CA 02310652 2000-05-18
WO 99/33275 PCT/US98127223
Multi-dimensional histograms can also be generated based on combinations of
bits from
different components. For example, a three-dimensional (3D) histogram can be
generated for YUV
data using the 4 most significant bits (MSBs) of the Y components and the 3
MSBs of the U and V
components. Where each bin in the 3D histogram corresponds to the number of
pixels in the frame
having the same 4 MSBs of Y, the same 3 MSBs of U, and the same 3 MSBs of V.
One general characteristic of video sequences is that, for certain types of
histograms, the
histograms for frames within a given shot are typically more similar than the
histograms for frames in
shots corresponding to different scenes. As such, one way to parse digital
video into its constituent-,
shots is to look for the transitions between shots by comparing histograms
generated for the frames in
the video sequence. In general, frames with similar histograms are more likely
to correspond to the
same scene than frames with dissimilar histograms.
Video sequences are typically stored and/or transmitted in a compressed
digital form, in which
the original pixel data are processed to exploit redundancy that occurs both
within a video frame and
between video frames. There are many known algorithms for compressing video
data. Some of these
algorithms employ a transform, such as a discrete cosine transform (DCT), that
transforms pixel
intensity data into transform coefficients in a spatial frequency domain. A
DCT transform may be
applied directly to pixel values or, when motion estimation is employed, the
DCT transform is applied
to inter-frame pixel differences corresponding to differences between pixel
data in the current frame
and motion-compensated pixel data from a reference frame. Inter-frame
differencing can be
implemented with or without motion estimation and motion compensation. After
applying the DCT
transform to the appropriate pixel data, the resulting DCT coefficients may be
quantized and then run-
length (RL) encoded using, for example, a zig-zag RL pattern. The RL encoded
data may then
optionally be further encoded for storage andlor transmission as a compressed
video data stream. The
motion vectors derived during motion estimation and used during motion-
compensated inter-frame
differencing are also encoded into the compressed video data stream. For multi-
component video data,
such as RGB and YUV data, the different planes of pixel component values for
each video frame are
typically compressed separately.
When video sequences are to be recovered from a compressed video stream, the
encoding steps
are reversed to recover full video images for display. For example, for the
compression algorithm
described above, the compressed data are RL decoded and dequantized, as
necessary, to recover
decoded DCT coefficients. An inverse DCT transform is then applied to the
decoded DCT coefficients
to recover pixel data. If the pixel data correspond to inter-frame
differences, then motion-compensated
inter-frame addition is performed using motion vectors (decoded from the
compressed video stream) to
generate decoded pixel intensity values for the current frame of the decoded
video sequence.
One way to parse a compressed video sequence into its constituent shots is to
completely
decompress the compressed video stream to recover fully decoded video frames,
and then apply
-2-
CA 02310652 2000-05-18
WO 99/33275 PCT/US98/27223
histogram analysis to the decompressed video sequence. This can be
computationally expensive and
slow, because, for example, the inverse DCT transform is computationally
intense.
An alternative technique for parsing compressed video sequences that have been
generated
using a compression algorithm based on a transform, such as the DCT transform,
is based on a low-
resolution decoding scheme. In this low-resolution decoding scheme, all but
the lowest spatial
frequency DCT coefficient in the compressed video stream (i.e., the DC
coefficient for the DCT
transform) are ignored and only the DC coefficient is used to generate a low-
resolution decoded image
for each frame in the compressed video stream, where each pixel in the low-
resolution decoded image
is the DC coefficient for a block of pixels in the corresponding frame of the
original video sequence.
Histogram analysis is then performed on the low-resolution images.
Figs. 1(A) and 1(B) show original frame 102 in an original video sequence and
low-resolution
frame 104 in a corresponding low-resolution decoded video sequence,
respectively. Original frame
102 has 480 rows and 512 columns of pixels. According to one possible
compression algorithm,
original frame 102 is divided into (8x8) blocks of pixels, wherein original
frame 102 has 60 rows and
64 columns of such (8x8) blocks. Motion estimation is performed for each (8x8)
block to identify a
motion vector that relates each (8x8) block to a corresponding (8x8) block in
a reference frame (not
shown). Motion-compensated inter-frame differencing is applied to generate an
(8x8) block of inter-
frame pixel differences for each (8x8) block in original frame 102. An (8x8)
DCT transfonn is applied
to each (8x8) block of inter-frame pixels differences to generate an (8x8)
block of DCT coefficients,
where the DC coefficient is typically located in the upper left corner. Each
(8x8) block of DCT
coefficients is then quantized, run-length encoded, and possibly further
encoded, along with the motion
vectors, for storage and/or transmission as a compressed video stream.
According to the low-resolution decoding scheme, in order to parse the
compressed video
stream (e.g., to identify transitions between shots), run-length decoding is
applied to the compressed
video data to recover the quantized DCT coefficients. If appropriate, the
quantized DC coefficient
from each set of DCT coefficients is dequantized and motion-compensated inter-
frame addition is
applied to the decoded DC coefficients (using decoded motion vectors properly
scaled by a factor of 8)
to generate low-resolution frame 104 of Fig. 1, where each pixel in low-
resolution frame 104
corresponds to only the decoded DC coefficient. As such, each (8x8) block in
original frame 102 is
represented by a single pixel in low-resolution frame 104, which therefore has
only 60 (i.e., 480/8)
rows and 64 (i.e., 512/8) columns of pixels. Since the DC coefficient of the
DCT transform is
equivalent to the average intensity value for the 64 pixels in the
corresponding (8x8) pixel block, low-
resolution frame 104 is a low-resolution approximation of original frame 102.
Histogram analysis is then applied to the sequence of low-resolution frames to
parse the
compressed video sequence into its constituent shots. Since this low-
resolution decoding scheme
avoids the computationally expensive inverse DCT processing, parsing of
compressed video sequences
-3-
CA 02310652 2000-05-18
WO 99/33275 PCT/US98/27223
can be accomplished faster and more cheaply than if the histogram analysis is
applied to fully decoded
images that are generated using inverse DCT processing. Unfortunately, the
resolution of the decoded
frames using this conventional low-resolution decoding scheme may be too low
to provide accurate
parsing results, leading to too many false positives (i.e., identification of
transitions between shots that
are not true transitions in the original video sequence) and/or false
negatives (i.e., missing true
transitions in the original video sequence).
SUMMARY OF THE INVENTION
The present invention is directed to a scheme for partially decoding
compressed video streams
for such applications as video parsing. According to one embodiment, the
compressed video stream is
decoded to recover one or more low-frequency transform coefficients for each
block of original image
data. A block of low-frequency image data is generated from each set of low-
frequency transform
coefficients corresponding to each block of original image data. Motion-
compensated inter-frame
differencing is applied to each block of low-frequency image data to generate
a partially decoded
image for each frame in the compressed video stream.
BRIEF DESCRIPTION OF THE DRAWINGS
Other aspects, features, and advantages of the present invention will become
more fully
apparent from the following detailed description, the appended claims, and the
accompanying drawings
in which:
Figs. 1(A) and 1(B) show an original frame in an original video sequence and a
low-resolution
frame in a conresponding low-resolution decoded video sequence, respectively;
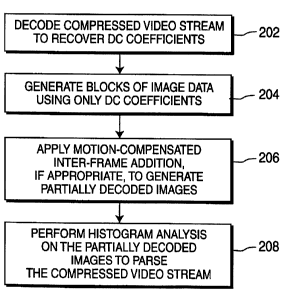
Fig. 2 shows a flow diagram of the processing, according to one embodiment of
the present
invention;
Figs. 3(A) and 3(B) show an original frame in an original video sequence and a
partially
decoded frame in a corresponding partially decoded video sequence,
respectively, according to the
processing of Fig. 2;
Fig. 3(C) shows a (4x4) block of replicated DC coefficients representative of
the sub-blocks
used to generate the partially decoded image of Fig. 3(B); and
Figs. 4(A)-4(D) show graphical representations of inter-frame histogram
differences (with
arbitrary scale along the Y axis) plotted against frame number for a 1500-
frame test sequence encoded
using the Px64 video compression scheme for four different DC-component block
sizes.
DETAILED DESCRIPTION
-4-
CA 02310652 2000-05-18
WO 99/33275 PCT/US98/27223
According to embodiments of the present invention, a transform-based
compressed video
stream is partially decoded to generate partially decoded images that may then
be subjected to
subsequent processing, such as histogram analysis for video parsing. The
partially decoded images are
generated by building blocks using only the decoded DC transform coefficients
from the compressed
video stream.
Fig. 2 shows a flow diagram of the processing, according to one embodiment of
the present
invention. The compressed video stream is partially decoded to recover the DC
coefficients of the
encoded transform coefficients (step 202 of Fig. 2). For example, if the
compressed video stream was
encoded using an (8x8) DCT transform, step 202 would involve decoding of the
compressed video
stream (e.g., run-length decoding and possibly dequantization) just enough to
recover from the
bitstream the decoded DC DCT coefficient corresponding to each (8x8) block of
pixels in the original
video sequence.
Blocks of image data are then generated using only the DC coefficients by
replicating the
conesponding DC coefficient for each pixel in a block (step 204). In one
embodiment, each block is a
sub-block that is smaller than the corresponding region of the original video
sequence used to generate
the transform coefficients. For example, if the DCT transform was applied to
(8x8) blocks in the
original video sequence, then the sub-blocks generated in step 204 might be
only (2x2) or (4x4)
(although other sizes can also be used). Alternatively, the blocks of
replicated DC coefficients could
be the same size (e.g., 8x8) as the transform.
If appropriate, motion-compensated inter-frame addition is then performed to
generate partially
decoded images (step 206), which can then be subjected to additional
processing, such as histogram
analysis for video parsing (step 208). If the blocks of replicated DC
coefficients are smaller than the
size of the original transform, then the decoded motion vectors used during
motion-compensated inter-
frame addition must be scaled accordingly. One advantage to using (4x4) or
(2x2) sub-blocks is that
motion vectors can be scaled down by factors of 2 or 4, respectively, simply
by shifting bits, rather than
having to implement a divide operation.
Figs. 3(A) and 3(B) show original frame 302 in an original video sequence and
partially
decoded frame 304 in a con:esponding partially decoded video sequence,
respectively, according to one
implementation of the processing of Fig. 2. Original frame 302 is a(480x512)
frame, similar to frame
102 of Fig. 1(A). Partially decoded image 304 is generated from (4x4) blocks
of replicated DC
coefficients and therefore has 240 rows and 256 columns of pixels.
Fig. 3(C) shows a (4x4) block 306 of replicated DC coefficients representative
of the sub-
blocks used to generate partially decoded image 304 of Fig. 3(B). Although
each pixel for a given sub-
block of replicated DC coefficients contains the same piece of information,
when motion-compensated
inter-frame addition is performed using properly scaled decoded motion
vectors, the corresponding
-5-
CA 02310652 2000-05-18
WO 99/33275 PCT/US98/27223
sub-blocks in the resulting partially decoded images will typically not
contain replications of the same
data, since most motion vectors will have components other than integer
multiples of 4.
The inventors have found that this partial decoding scheme provides better
video parsing of
compressed video streams (i.e., fewer false positives and/or fewer false
negatives) than does the low-
resolution decoding scheme of the prior art. Although there is some additional
coniputational load due,
for example, to performing motion-compensated inter-frame addition for larger
decoded images, the
partial decoding scheme of the present invention shares the advantage of
avoiding implementation of
the reverse transform of the prior-art low-resolution decoding scheme. Thus,
depending on the
processing constraints, the present invention may provide better results at an
affordable increase in
computational cost.
Figs. 4(A)-4(D) show graphical representations of inter-frame histogram
differences (with
arbitrary scale along the Y axis) plotted against frame number for a 1500-
frame test sequence encoded
using the Px64 video compression scheme for four different DC-component block
sizes. Fig. 4(A)
corresponds to the prior-art processing in which each (8x8) block of pixels is
represented by a single
DC value (i.e., a(lxl) block) in a low-resolution image. Fig. 4(B) corresponds
to processing
according to the present invention in which each (8x8) block of pixels is
represented by a(2x2) block
of replicated DC values in a partially decoded image. Similarly, Figs. 4(C)
and 4(D) correspond to
processing according to the present invention in which each (8x8) block of
pixels if represented by a
(4x4) and an (8x8) block, respectively, of replicated DC values in a partially
decoded image. The large
peaks in these figures indicate scene changes in the video sequence.
Figs. 4(A)-(D) show that as the block of replicated DC values increases from
(lxl) to (8x8),
the background noise level in the results decreases. This is one of the
advantages of the present
invention over the prior-art, low-resolution scheme of Fig. 4(A).
Although the present invention has been described in the context of two-
dimensional (8x8)
DCT transforms, those skilled in the art will understand that the present
invention can be implemented
using other DCT transforms, such as two-dimensional DCT transforms of sizes
other than (8x8) and
one-dimensional DCT transforms, as well as other transforms, such as one-
dimensional or two-
dimensional slant or Haar transforms. Similarly, although the invention has
been described in the
context of motion estimation and motion compensation being performed on (8x8)
blocks of pixel data,
it will be understood that motion analysis can be performed on blocks of other
sizes and that these
other sizes may differ from the size of the transform. For example, a common
video compression
scheme has motion estimation and compensation performed on (16x16) blocks of
pixel data, while the
transform is an (8x8) DCT transform.
-6-
CA 02310652 2000-05-18
WO 99/33275 PCT/US98/27223
Moreover, although the present invention has been described in the context of
generating
partially decoded images using only the DC transform coefficients, those
skilled in the art will
understand that, in alternative implementations, two or more of the low-
frequency transform
coefficients (including the DC coefficient) can be used to generate partially
decoded images.
Similarly, although the present invention has been described in the context of
video parsing
based on histogram analysis, those skilled in the art will understand that the
present invention can be
used for other applications in which low-resolution are acceptable, such as
picture-in-a-picture
generation, fast-forward replays of video sequences, target recognition, and
motion detection.
The present invention can be embodied in the form of methods and apparatuses
for practicing
those methods. The present invention can also be embodied in the form of
program code embodied in
tangible media, such as floppy diskettes, CD-ROMs, hard drives, or any other
machine-readable
storage medium, wherein, when the program code is loaded into and executed by
a machine, such as a
computer, the machine becomes an apparatus for practicing the invention. The
present invention can
also be embodied in the form of program code, for example, whether stored in a
storage medium,
loaded into and/or executed by a machine, or transmitted over some
transmission medium, such as over
electrical wiring or cabling, through fiber optics, or via electromagnetic
radiation, wherein, when the
program code is loaded into and executed by a machine, such as a computer, the
machine becomes an
apparatus for practicing the invention. When implemented on a general-purpose
processor, the
program code segments combine with the processor to provide a unique device
that operates
analogously to specific logic circuits.
It will be further understood that various changes in the details, materials,
and arrangements of
the parts which have been described and illustrated in order to explain the
nature of this invention may
be made by those skilled in the art without departing from the principle and
scope of the invention as
expressed in the following claims.
-7-