Note: Descriptions are shown in the official language in which they were submitted.
~L~7~96
BIDIRE~IIQ~L ~flN~H PRED~~IQ~ ie~ Z~
~b~
The ~bility to n3kc decislDns by condltional branchin~ is ~n essent~al
requirerent for ~ny co~putar systen whlch perforrs useful work. The
declsion to br~nch or not to branch r~y be based on one or rore events.
These event , often referred to a5 conditions, include: positive, neD~tivo
or zero nu~bers, overflow, underflow, or c~rry fro~ the l~st ~rithnetic
oporetion, even or odd p~rity, ~nd rany others. Condition~l br~nches are
perforned in dioltal conputers by conditional br~nch lnstruction~.
Conditlonal br~nch ln~tructions noy be u~ed tD construct such high level
progr~nninD constructs as loops ~nd if-then-el~e st~enents. ~ecsuse the
loops ~nd if-then-else prograrrlng constructs ~re so conron, lt i5 essentl~l
th~t.the conditionel branch instructions ~hich inplerent then execute ~s
efficiently e5 possible.
co~puter instruction i5 executed by perfornin~ one or rore steps.
Typic~lly, these steps ~re first to fetch the lnatruction pointed to by a
pro~raM counter, second to decode and perforn the operation indic~ted by the
instruction and fln~lly to save the results. fl si~ple br~nch instruction
changes the contents o~ the progr~ counter ln order to cause execution to
~ju~p~ to ~o~ewhere else in the progr~. In order to speed up the execution
of corputer in~tructian~, e technique of executing ~ore than one instruct~on
t the sAre tire, c~lled pipelinin~, W~5 developed. Pipelining per~its, for
ex~rple, the centr~l processin~ unlt, CPU, to fetch one instruction whlle
,:
: :`
.. , :, .
. ~:: ~ : '''
: : :
1272;~9~
executlno unother lnstruction ~nd whlle ~vlno the results of a thlrd
ln~tructlon at the 3are tl~e. In pipolined cc~puter archltectures,
brunchlng is an expenslve oper~tlon bec~use branch lnstructlon~ ~ey c~use
other lnstructlons in the pipeline to be held up pondlng the outcore o~ the
branch instruction. When ~ conditlon~l branch instruction is executed with
the condition true, lt cnuses the CPU to continue execution ~t ~ new addross
referred to ns a tar~et address. Since lnstructlon fetchlng is goln~ on
slnultaneously wlth lnstruction decodin~ and executlon ln a pipelined
corputer, the co~puter has Dlroady fetched the inatructlon followlng the
branch instructlon ln the proorar. Th$~ 15 a different instructio~ than the
~natructlon at the t~rget ~ddress. Therofore, tho CPU MUSt hDld up the
instruction pipeline followlno the br~nch inatruction until tho sutcore of
the brunch in~tructlon ls known ~nd the proper lnstructlon fctch~d. In
,: ~
order to n~xirl~e throughput of the co~p~ter, co~puter dcqloners have
nttenpted to design conputers which ~xi~ize throughput by ~ini~$zino the
~` need to hold up tha lnstruction pipelin~.
~ In the prlor art, sovcr~l sche~es h~vc been used to avold hsldlng up
i~ the lnstructlon plpeline for condltion~l branches. Flrst, so~e h$~h
perforrance procesaors h~ve usod vnrious branch prediction schere~ to ~U05~
~hether Sh~ condltlonul br~nch wlll be t~en or not~ This npproech requlres
extensive h~rdw~re ~nd lS unaccept~ble in nll but the highest perfor~ance
corputers becau~q cf the exponslve hnrdwnre re~ulred. Second, other
i ~rchitectures have fetched both the instruction in the progru~ followino the
br~nch nnd the instruct$on ~t the branch tar~et ~ddre~s. Th$s npproach 15
:
~.' .
:
. . . ~
~L~7~9~
unacceptable beccuoe lt ~130 rcquires expensive hardware and cddltion~l
~e~ory accesses to elways fetch both instruction~. Thlrd, so~e
archltectures have a bit ln thc inatructlon to tell the co~putor whether it
is ~ore probable for the instruction follo~in~ the br~nch or the instruction
at the brnnch taroet ~ddre~ to be executed. The conputor then fetches the
rore probeble instructian ~nd holds up the pipelino only if the ~uess i5
wrono. Thi~ appro~ch requires expen~ive hardw~re and if the guess is wronq
causes addition~l ti~e to be spent backing up the pipellne end fetching
~ppropricte lnstructlon. Fourth, other ~rchitectures allow two bits which
lnstruct the CPU to ~lw~ys or ncver execute the instruction following the
bra~ch in~tructlon based on whether the branch is taken or not taken. This
architecture u~es too rAny bits fro~ the instruction thereby reducing the
~axi~u~ renDe of the branch instruction. Fin~lly, still other archltcctures
ol~ay~ execute the lnstruction in the progrn~ follo~ing the branch
instruction before tJking or not taking the branch.
The technique of executin~ the in~truction in the pro~ran followinD the
branch instructlon ls known as delayed branchin~. Del~yed branchin~ ib
desirable sinGe the lnstruction in the pipeline i~ always executed cnd th~
pipeline is not held up. This occurs because delayed branchin~ oives the
co~puter tire to execute the br~nch instruction ~nd corpute the ~ddress of
the next lnstruction while exocutinQ the instruction in the pipeline.
Although this technique avoids holdinD up the instruction pipeline, it May
require placlno a no oper~tion instruction following the branch instruction,
which would not i~prove perforrance since the additlonal Me~Ory access
,''`', .
;~ 3
~: ~ ............................. . ;:. ~:,
: :
ne~ntea ony irpro~erent.
One software technique whlch t4kes advant~9e of del~yed br~nchin9 1~ me~er.
The concept of merger described here is where the loop branch instruction
is at the end of the loop. Meroer teke~ ~dv~nt~e of deloyed br~nching by
duplicating the fir-t lnstruction of the loop followlng the loop'~ brcnch
instructlon ond rakin~ the bronch ter~et ~ddres~ the ~econd lnstruction of
the loop. One potential proble~ wlth ~erl~er 15 that on exit fror the loo~,
the progran does not necessarily warrt to e)tecute the rr.erged instruction follcwing the branch
instruction again. This la ~ proble~ for archltecture~ whir,h ~lw~ys ù~e
delayed branching.
When n~ny prior ~rt co~puter ~ysters deter~in~ that ~ branch ls obout
to be executed, the co~puter sy3te~s hold up, or interlock, the instructlon
pipeline. Interlockino the pipoline ~nvolves stoppln0 the co~puter fro~
fetchino the next instruction and preventing the pipellne fro~ ddvenclno the
execution of any of the instructions in the pipoline. Interlockino redures
the perforM~nee increase g~ined by pipelinino nnd therefore i5 to be
~voidad.
Wh~t i5 needed 17 n ~ethod of eonditionel branching which ~ini~izes the
o~ount of hard~re end perforn~nce reduction~. The rethod should t~ke ~s
fe~ bit~ of tho lnstruct~on s po~slble since each blt taken effectlvely
helves the na~iru~ ronoe o f t he branch instruction.
:~
. ~ SUMMf~Ry
In accordance with the preferred eMbodinent of the present invention,
' .
~ 4
:~:
~,
";~,
~ ' ` ., ::
,~:
- ,
: , -. :
~L~7~9~i
~ethod and appar~tus ~re provided for conditional bronchlno wlthln ~ dio~t~l
conputer. The preferred e~bodlMent of the present lnventlon provldes ~
br~nch instructlon whlch statlcnlly predlct~ whether the br~nch wlll be
t~ken or not t~ken b~ed on tho brench dlspldcenont. The nethod u~es
del~yed branchino where possible but ~150 provlde~ for nulllfic3tlon of the
del~y slot instruction following the br~nch in~truction where the delay slot
instruction c~nnot be used efflciently.
The pre~ent invention i5 superior to the prior ~rt in sever~l w~ys.
First the preferred enbodinent of the pre~ent lnvention i5 capable of e
branch frequently/branch r~rely prediction for condltion~l br~nch
instructions b~ed on the existin~ ~ign blt of the br~nch dlaplace~ent
~ithout rcquiring ~ny other bit in the in~tructlon. Second the preferred
enbodi~ent of the pre~ent invention optini~e~ the uae of the instruction
innedl~tely followlng the condltion~l brDnch which reduce~ the probability
of holdlno up the in~truction pipeline and its resultino reduction in
perforn~nce. Third the preferred erbodinent of the present lnvention
nulllfie~ the instruction followino the branch only in cnses ~hen the
in~truction csnnot be u~ed. Fin~lly the pref~rred enbodinent of the
present inventlon provides ~ nore flexible nnd cfticient nullification
schene ba~ed on dlrectlon of branching r~ther th~n alway~ exccuting or never
executlng th~ lnstruction following the br~nch.
,~
~ S `.
`:
:
.~ i. ., ~ . .
::; ~ -. ~ : .
. ~ :
... ~ :
36
Various aspects of the invention are as follows:
A method for nullifying an instruction having a
nullify field with true and false states which performs
an operation and is capable of generating results,
errors, traps and interrupts in a pipelined computer
system having memory, the method comprising:
fetching the instruction from memory into the
instruction pipeline;
performiny the operation indicated by the
instruction, and preventing, if the nullify field is
true, any results, errors, traps or interrupts generated
by fetching or performing the operation indicated by the
instruction from being stored in the computer system or
affecting the operation of the computer system.
An apparatus for permitting in a computer system a
first instruction, having a nullify signal with a true
and false state, to nullify a second instruction, which
with a write signal stores the results of the second
instruction into the computer or generates errors,
traps, and interrupts in the computer system, the
apparatus comprising:
means for retaining the state of the nullify signal
after the execution of the first instruction; and
means for qualifying the write signal of the second
instruction with the retained state of the nullify
signal in order to prevent results from the execution of
the instruction from being stored in the computer system
or any errors, traps or interrupts from affecting the
operation of the computer system.
DESCRIPTION OF DRAWINGS
Figure 1 is a branch instruction in accordance with
preferred embodiments of this invention.
- 5a -
~72~
FiDure Z lllustr~tes ~ ~ethod of branchino in ~ccordcnce ~lth the
prefcrred erbodi~ent of the present lnv~ntion.
Fioure 3 is ~ flow chcrt of the ~ethod of branching.
Figure 4 i~ c functional hlock diagr~l~ of an ~pp~ratus in ~ccord~nce
with the preferred erbodlrent of the prcsent inventlon.
Figure 5 i5 ~ tiring st~te diaora~ of the ~pp~r~tu3 in Fl~ure 4.
;'
DESCRIPTION OF T~E pREFERREQ ~0DIMENT
Figuro 1 is ~ branch instruction in ascord~nc~ with the preferr~d
e~bodi~ent of the pres~nt invention. Th~ bronch instructlon 501 con~ists of
32 bits of inforn~tion used by the corputer to execute the instruction.
Thls in~truction co~blnos thc functlon of br~nchlnD with the oper~tlon of
conp~rino t~o oper~nd~, although the pre~ent lnvention could be i~plenented
by a br~nch only instruetion ~s well. The instruction 501 contDins a 5iX
bit oper~tion codo Field 502, a five bit first sourco register ~ddress field
- 503, e five bit second source re~istcr ~ddre~s fleld 504, ~ three blt
:
condition code field 505, ~ eleven bit br~nch d~splace~ent field 506 ~nd one
bit di~place~ent field sion blt 508, ~nd ~ nulllfy blt 507. The oper~tion
code ~leld 502 idontities ~hls ln~tructlon ~9 a co~p4ro end br~nch
lnstructlon, The flrst end second ~ourco regi~ter ~ddress fields 503 and
504 identlfy the re~lsters whoio content~ wlll be co~p~red. The brDnch
dlsplDcerent, which n~y be positlve or negstive, is deter~ined by fields 50
ond 506. This displDce~ent i5 used to colcul~t~ thc t~r~et address for the
; ,
:~'
.. : . :: . - ,
.,., ~ ' , - :
:, ;
.
~7~96
brcnch. The next ln~tructlon in the ln~truction pipeline ray be nulllflod
accordlnD to the preferred erbodinent of the present inventlon by settino
the nulllfy bit 507.
In the preferred e~bodl~ent of the present lnvention, the execution of
the current instruction ~y be nullified. The purpo~e of nulllfication is
to ~ake the instructlon ~ppear es if it n~ever existed in ~he pipeline even
though the instruction ~cy h~ve been fetched ~nd its oper~tion perforned.
; Nulllfication i~ acco~plished by preventino th~t instruction fror chanoinD
any st~te of the CPU. To prevent chanDino the stotc of the conputer, the
nullification proces~ ~u~t prevent the ~ritino of ~ny results of thc
nulliflcd instruction to any registers or nenory loc~tion snd prevent any
~ide effccts fron occurring, for ex~rple, the gener~tion of interrupts
caused by the nullified instruction. Thi~ i~ perPor~ad ln th~ preferred
erbodinent by qu~lifyino any ~rite ~ign~ls ~ith the nullify sign~l genereted
in the previous instruction thus preventin~ the instruction fro~ storino ~ny
results of eny cDlculation or otherwise ch~noin~ the atate of the co~puter
syster. A sirple wsy of ~ualifyin~ the write signals of the current
instruction is by 'AND'ing the write signal~ with a retained copy of the
nulliiy aion~l DenerDted in the previou~ in~truction. The nulllfy
sion~l gencr~ted by ~n instruction ney, for ex~ple, be seved ln the
proces~or status word for u~e in the follo~ing in~truction. Nulllflc~tion
is ~ very useful techni~uo because lt perrit~ ~n lnstruction to be fetched
into the pipeline without concern as to whether ~ declsion being ~de by
~npth~r lnstructlon in the plp~llne -~y causc this instructlon not Lo be
-:: ' ' ',, :
. : ~
~X72;~9~
cxecuted. The instruction si~ply prooresses throuoh the plpellne untll lt
cone~ tine to storc lts results ~nd the instructlon ~ay then be nulllfied ot
the laat rinute with the ~e effect ~s lf the lnstructlon never existed ln
the pipeline.
In ~ plpellned conputer systen there ~re two distinct concepts a5 to
the next lnstruction to be executed. The first concept 15 e tire sequentiel
instruction, ~hlch i5 the next instruction in the instruction plpellne after
the current lnstruction. This instruction wlll be executed after the
current instructlon ~nd the result~ of the operatlon ~tored unless
nulllfled. The ~cond roncept i5 a space sequential instruction. This i~
the instruction in~edlately followino the current lnstruction ln the
pro~ran. 6enerally, the space sequentl~l instructlon for the curr~nt
instruction will be the ti~e sequenti~l instructlon. The exception to the
rule occurs with t~ken br~nch instructlons, where th~ ti~e sequenti~l
instruction i5 the instruction et the tar~et addres~ which is generally not
the space sequentiAl instruction of the branch lnstruction.
The delay slot instruction is the ti~e sequential instruction of a
branch lnstruction. 6ener~11y, the delay slot instruction will be the spdce
sequential instruction of the branch instructlon. The exception to this
rule is the case Df C br~nch followlno ~ branch instruction. For this cese,
the delay slot instruction for the ~econd branch instruction will be the
t~rget ~ddress of the first branch instruction rather than the space
sequenti~l instructlon of thc second branch instruction.
Uncondltional br~nching in the preferred enbodinent of the present
~. '
~ : .. - .; . . .
::~ ::: , ,. ~ . :
:: : ,. :: .: : . :
1~7~g~;
lnventlon clet~rly lllu~trates the toncept af nullltlcotlon and th~3
delay slot instruction. With the nullify bit off, the delay slo~
instruction of the unconditional branch instruction is always
executed. With the nullify bit off, the delay slot
~nstruction of the unconditional br~nch instruction is ~lweys nulllfied.
Thls is equlv~lent to nevtr executino the dolay slot lnstructlon.
Fioure Z illuatrates c ~thod of condition~l branchin~ ln accordance
wlth proforred enbodiront of the present inventlon. ~ co~puter practlclnD
the nethod of F19ure 2 h~s a prooran 101 consi5tino of in~tru&tions 100
includlnD a conditlon~l br~nch instructlon 102. Tht 3pace se4uent~al
instruction to the br~nch lnatruction 102 is lnstructlon 103. For a
conditional brt3nch ln5tructlon 102 with neo~t~ve brt~nch displtlct3rent
instrUction l04 lS at the t~r~et addro~s. For a ctJnditional br~nch
ln~truct~on 102 wlth ~ positlvt~ branch di~placorent, lnatruction 105 ls ~t
the taroet address. The execution of the proor~M is illustr~ted by oraphs
110, 111, 112, 113, snd 114. Durin~ nornal ex~cUtion the proort~ executes
the current lnstructlon ~nJ then executes the spat:e scquonti~l in~truction
to the current instrUCtlOn.
6raphs 110 lll and 113 illu3tr~tc the oper~tion of a branch
instructlon with the nullify blt off. Thi~ corre3ponds to tho novor
nulllfy' or 'elwaya execute~ c~se. The delay 310t lnstruetion followino the
br~nch ~nstruction is ~lw~ys exetuted reo~rdle~s of ~hether the br~nch lf
taken or not and whether it h~s a positive or ne~tlve displace~entO When
the br~nch condition ls f~lae, executi n continues with the space setluentlal
,
: . .
: :
', ', ,,, '
` " " '
~7~9~
lnatructlon 103 as ~hown ln Draph l10. When th~ brench condltlon ia true,
the deley slot in3truction is executed an~l then the lnatruction et the
tcr~et addre3s ls e~ecuted ~5 shown in or~lph ll~ Por a neg~tive displace~ent
branch ~nd ln or~ph 113 for a positive dlsplacenent brench.
6rcph ll~. lll, l12 and l14 lllustrate the operatlon of a branch
in~truction wlth the nullify bit on. Thia corresponos to the 'sonetines
nullify' caae as de~cribed below. With the nullify bit on, the del~y slot
instruction ~ay be nullified depending on the direction of the br~nch and
whether the condition deternining whether the br~nch i5 takon or not is true
or false. 6r~phs l10 ~nd l14 lllustrate the oper~tion of the br~nch
instruction when th~ condition tri~gerlno the brench i5 f~lae causino the
branch not to be t~ken. If the branch displace~ent is positive, the del~y
slot in~truction la executed as ahown by r~raph l10. If the branch
.
displ~cenent ls ne~ative~ the delay slot instructlon ls nullified ~a shown
by graph 114. The dotted line in Draphs 1IZ end 114 indicate that the delay
slot instruction, ~lthough fetched, will be nullified ~s if it nev~r existed
` in the instruction pipeline.
6raphs lll and l12 illustr~te the operation of the br~n~h instruction
with the nullify bit on when the condition trig~erin~ the br~nch is true
c~uaing the branoh to be taken. If the br~nch di~place~ent i5 posltive, the
; delay slot lnstruction is nullified as shown in ~raph 1l2 and e~ecution
; continuea at the tar~ct addresa. If the branch displRcenent i5 nerative,
the delay 510t instruction is e~ecuted as ahown in gr~ph lll before
continuino at the target address.
, 10
:~
. ', . ,! .
' .
~ ~72~9~
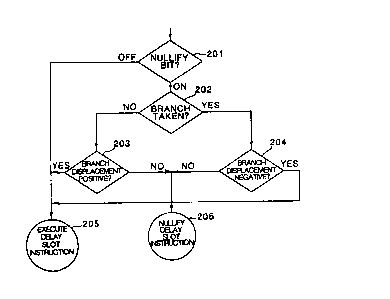
Fl~ure 3 ia e flo~ chart of the ~ethod of branchino. The or~phs ~11
throuoh 11~ ray be nore cle~rly understoocl by referrin~ to the flow chflrt.
The flrst ~tep ls to deter~ine whother th~ nulll~y bLt l~ on. If the
nulllfy blt ls off then the d~lay ~lot instructlon for the brench
inatructlon ls alway~ executed. This occurs whether or not the br~nch ls
taken. If the nulllfy bit 1~ on then the del~y slot instruction follow~no
the branch l~ not e~cuted unlesa the br~nch i5 t~ken and the brench
displaconont ia neg~tive or unle-s the branch is not t~ken and the br~nch
displacerent i5 positive.
The oper~tion of the preferred erbodi~ent of the pres~nt inventlon
e~bodies a very ~i~ple but effectivc ~ethod of stotlc br~nch pr~dictlon
~hich predicts whether the br~nch will be t~ken or not and therefore which
instruction to fetch baasd on whether positive or neQative dlsploc~rent
br~nche~ are taken. Ita cffectlvene~s depends on conputer softw~re
followin~ a set of software conventions ln i~ple~entin~ cert~ln hioher level
pro9r~n control construct~ by ~e~n~ of ~ condition~l branch instruction.
For exarple e loop construct is i~ple~ented by fl backw~rd ~ondition~l
branch so th~t d br~neh instruction with a neg~tive displ~cenent wlll be
t~ken frequently. In f~ct lt will be teken N-1 out of N tl~ea for 3 loop
that ia exocutod H tl~es. ~nother ex~rple of the software conv~ntlon~
Hs~uned i5 that an lf-thon-el~e construct 15 irple~ented by o forw~rd branch
to the rarely t~ken part ~llowlnD the rore frequently executed p~rt to lie
irnedi~tely following the br~nch lnstruction ln the not t~ken branch p~th.
For exanple the forward branch n~y be to ~n error handling routinc which
~ :,
~ .
.: . . . .
. .:
.: ~ ;
:: :
: ~ - , . .. .
~ ~72~9$
rarely oees exeeuted in a norrol proor~. In ~ddltion, the prçforrod
erbodlnent of th~ present invention havinD ~ nullify blt generallzes and
Optinizes the uae of the del~y olot lnstruetion in eonjunctlon wl~h the
static brDnch prediction technique described above. With the nulllfy bit
on, d beckward condition~l br~nch that i~ t~ken or a foruard eenditional
branch that i5 not taken, bein~ the tasks that are predicted to be frequent
by the ~tatic br~nch prediction technique, c~use the delay ~lot inatruetion
to be executed. Hence, 50~e useful instruction in the frequent p~th ~ay be
executed as the delay slot instruction, for exnrple, a5 de~cribed in the
~ergor technique abov~. With the nullify bit on, o beck~rd condltionel
braneh th~t is not taken or a forw~rd eondition~l braneh th~t is t~ken,
being the t~sks that are predieted to be rare, cause the delay slot
lnstructlon to be nullified. Hence, nulllfication which reduc~s perforr~nce
occurs only ln the rare ea~e.
With the nullify bit off, the delay slot instruction i5 always
executed. This corresponds to the c~se where an instruction connon to both
the branch taken and the br~neh not tDken paths can be de~lgn~ted ~5 th~
~ delay slot inatruction.
`~ Figure 4 i5 a function~l bloek dia~ra~ of an apparatus in ~rcordanco
~ with the preferred ç~bodi~ont of the pre~ont invention. The ~pp~rMtus
`~ contains six function~l elerent~: an in3truetion Menory 39~, ~n option~l
virtual address trAnslat1on unlt 302, an instruction unit 303, an exocution
unit 304, ~n option~l floatinD polnt unit 305 and an optional re~ister filo
~ 306. These functional ele~ent~ are connected together throu~h flve busses:
; .
; l2
` ~ ~
~ .
. ..
:
~L~7~9~
a re~ult bus 310, a flr~t oper~nd bus 311 a next lnatruction bus 312 a
second oper~nd bus 313 end ~n address bus 314. Only the execution unlt 304
and the lnstructlon unlt 303 are Involved in perfornlng the oper~tion of the
preferred erbodinent of the present invention. Thc cxecution unit penerates
end/or stores the conditlon~ on whlch the decl~ion to branch or not to
br~nch is ~ade. The instruction unit perforns the branch by ~cneratin~ the
~ddre~s of the next instruction to be fetched fro~ the nerory and provides
neens for storing the ~ddress into the pro~r~n counter. In the preferred
enbodi~ent of the present invention the ncrory unit ls c hiDh speed cache
wlth speed on the order of the loDic used in the oxecution unit.
Fioure 5 is ~ tinino state diDor~n of the app~r~tus in Figure 4. The
tinin~ diagr3n illustrates four stages involved in the execution of
instructions 401 402 403 and 404. Ti~e line 460 is divided Snto st~oes
wlth the ti~e progre~in~ to the rl~ht. The four tinin~ st~es for eech
instruction are: an instruction eddress generation stage 410 an instruction
fetch sta~e 411 ~n execute st~oe 412 ~nd 2 write st~ge 413. The execution
of instructions Mey be pipelined to any depth desired. The preferred
erbodinent of the present invention contains ~ four st~e pipeline. As
shown in Fi~ure 5 four instructions ~ro being executed at ~ny one tine. At
tlne 450 the ~rSte ste~e of instruction 401 is overl~pped with the ex~rution
sta~e of instruction 402 the instruction fetch ~t~e of lnstruction 403 ~nd
the instruction address ~oner~tion st~ge of lnstructlon 404. This re~ns for
a br~nch instruction that next instruction will have been fetched while the
branch lnstruction is in the e~ecution staoe. During the lnstructlon
: ' .
,. ..
.: . . ,
~: ... ' ' . : '
~l2~2;~9~
addre~ gener~tion ots~e the ~ddrea~ of the noxt lnstructlon is c~lculctod
~ fron the pro~r~n counter which contalns the ~ddreas of the next In~tructlon
`~ to be executed ~nd i~ loc~tod in the lnstruction unlt 303. Ouring the
instruction fetch sta~e the next in~truction i5 fetched fror the
instruction Me~ory 301. This i~ perfor~ed by epplyino the contents of the
~ddre~ c~lculated in the lnstruction address ~eneretion stfl~e onto the
addre~s bus 314 ~nd tranaferrin~ the contonts of th~t addre~s to the next
in~truction bus 312 where lt i~ decoded by the instruction unit. The branch
ln~truction r~y b~ corbined wlth other operatlons for ~x~ple ~ conpare
operation whlch would be ~150 decodod end porfor~ed ~t thls t~ne in the
execution unit 304.
~; In the execute ~taoe 412 the branch instruction ls perforned. ~urin~
the execute ph~se 412 both the t~r~et addrea~ of the br~nch instruction ~nd
the ad~re~s of the ~pac~ ~e~uenti~l in3truction to the br~nch in~tructlon
are ~enerated. flt this tire if the instruction i5 coMbined with another
oper~tion that operation ls perforn~d. At the end of the execution phase
ono of the two addre3~e3 i~ tr~n~forred into the proora~ counter. Which
~ddresa to transfer to the proor~n counter i5 deterMined by the condltion generated or
stored in the execution unlt 304. Durino tha write phas~ 413 no operction
occurs unless a re~ult fron ~ co~bined ln~truction needa to be stored. ay
perfornlng ~ll writin~ of any re~ulta to ~erory or r~gisters and ~ny side
effects llke interrupt ~cknowledge~ent c~used by ~n instruction no earller
than stage 41Z and 413 this approRch en~bles ~ si~pler i~plerentation of
the concept of nullifying an instructlon which is ~lw~y~ in the plpeline.
14
.~ `
:: .
:.~ . . :
: , .,., , : .
;. ::