Note: Descriptions are shown in the official language in which they were submitted.
~ - 1 336622
This invention relates to a voice decoding device
capable of effectively reproducing voice information which is
compression-coded in a predetermined frame unit and packet-
transmitted.
Aspects of the prior art and present invention will be
described by reference to the accompanying drawings, in
which:
FIG. 1 is a diagram for explaining problems at the
conventional packet transmission of voice;
FIG. 2 is a configurational diagram of a frame of a
transmitted packet by the compression-coding in frame unit;
FlG. 3 is a schematic configurational diagram of a
packet transmission system configured using a sound decoding
device according to an embodiment of the present invention;
and
FIG. 4 is a diagram showing a schematic processing flow
of an interframe-predicting unit which exhibits a
characteristic function in the embodimental device.
Recently, packet transmission is attracting notice as
high-efficiency information transmission method. ln the
communication of voice information too, there is an attempt
to perform a high-efficiency communication via this kind of
packet communication network.
Now, at packet communication in the usual data trans-
mission, in order to deal with the outstripping of packet,
i.e., the exchange of packet order, due to the difference in
transmission channels within the network, a measure is taken,
such as the rearrangement of packet order by buffering, the
retransmission of packet or the like.
At the packet transmission of voice signals, the
naturalness of conversation is more important rather than
~'
,.~,,
_ _
1 336622
the correctness of transmitted information. Hence, wllen the
exchange in the order of packets occursand the excessive
delay is needed to rearrange in regular order, a processing
is performed such that packet data are decoding-processed
without temporal exchange by discarding one of the e.Ychanged
packets, and sound signals are reproduced. When a packet is
thus discarded, however, a discontinuous part is produced in
the reproduced voice signal waveform caused by the absence
of a paclcet due to the discard, and inconveniellces OCCUI`
such that unconfor~able sound is generated at the ~iSCOII'
tinuous part, the clearrless of the reproduced voice is
decreased, or the like.
Accordin~ly, in the conventional system, for eYample as
shown in FIG. 1, the voice signal X(n) sampled at a
predetermined period is frame-decomposed at every M points,
and the voice signal X(n) at each frame is sequentially ex-
tracted one by one over continuous L frames to produce pack-
ets, and these paclcets are transmitted. That is, when the
above-described voice signal X(n) is indicated for each
frame as:
XE (l,m) = X (lM + m),
where 1 (0<1<L~ is the frame number, m (0<m~M) is the data
index within each frame, M-sets packet data Xf (l,m) to be
transmitted in packet are obtained as follows:
~ {X (0,0), X (1,0), ------ X (L-1,0)}
- ' - . ' ' ' . -
~ 33h622
~X ~0,1~, X (1.1). ------ X (L-1,1)~
~9~X ~O,M-l), X (l.M-l). ---- X (L-l,M-l)~
At the reception side (decodin~ device), the data Xf
(l,m) thus packet-traJIsmitted are rearran~ed relative to the
M packets, the series of the above-described voice data X
(l,m) are decoded, and then the voice si~nals thereof are
reproduced.
By takin~ such measures, even when, for e~ample, the
absence of a packet (the packet 3 in this e.Yample) occurs
in a part of the data. the omission in the voice si~nal ~(n)
in the reproduced data frame is onl~ one sample at each
frame as shown in FIG. 1. and hence it is possible to
supplement the influence of omission by interpolation or the
like from the precedin~ and succeedin~ data. As a result, it
becomes possible to maintain the quality of the packet-
transmitted sound, and also to prevent the occurrence of un-
confortable sound described above.
In packet transmission, however, there e~ists an over-
head, such as the reception-side-addressing head, and so the
len~th of a packet cannot be too short at the viewpoint of
transmission efficienc~. Moreover, in order to adopt the
above-described technique, it is necessary to set the number
L of sound frames relatively lar~e. This indicates that it
is necessary to store voice data over L frames at pacl-et
,
1 336622
transmission. Hence. a lar~e amount of time delay inevitably
occurs before the input voice is packet-transmitted, and
also before the received packets are decoded to reproduce
sound signals.
Moreover, in such a method, the transmission of voice
packets is only applicable to the compression coding (the
compression ratio is not more than 1/2) of the information
in which the transmitted data have the same meaning within a
frame, such as ADPCM, ADM or the like. Furthermore. even
when the conventional method is applied to the predictive
residual si~nals, the interpolation ~ain of the predictive
residual si~nal is small, and the deterioration of decoded
sound is not negligible.
On the other hand, it is necessary to consider the case
that a frame confi~uration as shown in FIG. 2 is adpoted,
and the voice information is compression-coded in frame unit
and packet-transmitted. By adopting such a configuration, a
hi~h-efficiency compression coding for each frame becomes
possible, and, for example, it is possible to realize a com-
pression codin~ having a compression ratio of lar~er than ~
in frame unit. However, in the packet transmission of voice
data in which such a frame processing is performed, each
packet has information which has a different meanin~ for
each field. Hence. there is a problem such that even when
the absence of a packet occurs, it is impossible to take the
: ,
1 336622
above-described measures, such as interpolation or the like.
- As described above, at the conventional packet
transmission of voice, there exist various problems, such as
the occurrence of unconfortable sound due to the absence of a
packet, the delay time from the input of packet data to the
decoAing and output thereof, the impossibility of taking
measures against the absence of a packet for compression
coding in which frame processing is performed, or the like.
The present invention provides a highly-practical voice
decq~in~ device which is capable of effective packet
transmission of voice signals without causing the problems of
the absence of a packet or delay time.
The present invention provides a voice decoding device
used in a system in which voice signals are sampled,
compression-coded in a predetermined frame unit and packet-
transmitted, and for reproducing voice signals by deco~;ng-
processing the received packets. The device comprises means
which continuously predicts a series of data packet-
transmitted in a predetermined frame unit over plural frames
at an interframe-predicting unit, as well as detects the ab-
-- 5 --
.~,
J
1 336622
sence of a packet from the continuity of the received pack-
ets, and when the absence of a packet is detected by this
means, decodes and reproduces voice si~nals usin~ the data
series predicted at the above interframe-predictin~ unit in-
stead of data series obtained from the received packets.
Accordin~ to the present invention, even when voice
si~nals are compression-coded in a frame unit and packet-
transmitted, an interrrame-predictin~ unit in a decodin~
unit continuously predicts the data series over plural
frames, and also always monitors whether the absence of
packet occurs or not. When the absence Or a packet is
detected, the decodin~-processin~ of sound si~nals is per-
formed usin~ the predicted data series over plural frames
obtained at the above-described interframe-predictin~ unit
instead of received data series used in the normal sound
decodin~ processin~.
As a result, even when the absence of a paclcet occurs,
it is possible to effectivel~ complement the decoded voice
si~nal in the absent portion, prevent the ~eneration of un-
confortable sound, and thus maintain the quality of the
reproduced sound. Moreover, since the decodin~ processin~ is
performed separatel~ for each of data packet which has been
compression-coded in a predetermined frame unit, i.e.. there
is no necessity of performin~ the processin~ of rearran~e-
ment of data series or the like over plural packets, time
-.
1 336622
delay does not cause a problem.
As described above, according to the present invention,
many practical effects can be obtained such that the problem
of delay time can be effectively avoided, the packet trans-
mission of voice by compression coding in frame unit becomes
possible, and at the same time a high-quality decoding-
reproduction of voice information becomes possible effec-
tively complementing the absence of a packet, or the like.
,~
1 336622
An embodiment of the present invention will be
hereinafter explained with reference to the drawings.
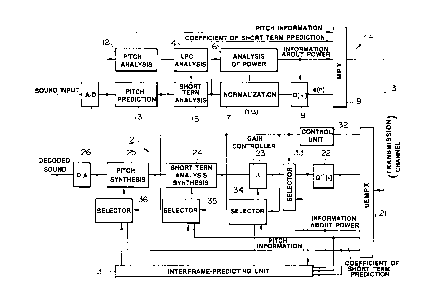
FIG. 3 is a schematic confi~urational diagram of a
voice-packet transmission system provided with a voice
decodin~ device according to an embodiment of the present
invention. The system includes a packet-transmitting unit 1
provided with a coding unit and a packet-receivirlg unit 2
provided with a decoding unit according to the present in-
vention. The packet-transmittin~ unit 1 and the packet-
receiving unit 2 are mutually connected via a predetermined
packet-transmission channel 3. It goes without sayirlg that
the paclcet-transmission channel 3 is constituted by packet
exchanges and various packet-communication networks.
In FIG. 3, explanation will be first made about the
packet-transmitting unit 1 which is the basis of tlle packet
transmission of voice si~nal. At the packet-transmitting
unit 1, input voice signals are sampled and digitized at a
predetermined period via an A/D converter 11, compression-
coded in a predetermined frame unit and taken in as a series
of voice data X(n) used for the packet transmission thereof.
In a coding unit of the packet-transmitting unit 1. a
pitch-analyzing unit 12 analyzes the fundamental voice
frequency component of the above-described voice data X(n)
as the pitch information. A pitch-predicting unit 13 removes
the redundancy in accordance with the result of the
- t 336622
anal~sis. That is, the redundanc~ is removed in accordance
with the correlation of voice signal over a long term. Next,
in order to remove the redundanc~ over a short term, an LPC
anal~zing unit 14 anal~zes the coefficient of short term
prediction. A short term predicting unit 15 performs pre-
dictive processing in accordance with the result.
Next, for the residual signal (predictive residual~
which could not be removed at the above-described pitch pre-
diction and short term prediction, the informatiorl about the
short term of residual signal power thereof within a per'
determined frame (a group of predetermined sample numbers)
is obtained at a power-analyzing unit 16, and the above-
described prediction residual is normalized (ltatimes) at a
normalizing unit 17 using the information about the electric
power. Subsequentl~, the normalized prediction residual is
quantized at a quantizer 18, and the quantized code e(n)
thereof is obtained. The above-described pitch information,
coefficient of short term prediction, information about the
power of residual signal and quantized code e(n) of the nor-
malized prediction residual signal obtained b~ such a series
of processing are multiplexed in the above-described frame
configuration shown in FIG. 2 at a multiplexer (MPX) 19, and
thus the encoding of voice signal within the frame is per-
formed. The compression-coded information is then trans-
mitted as a unit of pacl~et data via the above-described
. , :' '; . ,
t 336622
transmission channel 3.
It will be noted that the above-described encodin~
processin~ of voice is the same as the conventional sound
codec which executes encodirl~ processin~ in a predetermirled
frame unit.
Now, the present invention has a feature in the con-
fi~uration of a decodin~ device of the packet-receivin~ unit
2 which decodes arld reproduces the above-described voice
signal X(n) frolll data compression-coded in n predetermined
frame unit, and sequentially packet-transmitted from thé
above-described packet-transmittin~ unit 1.
The decodin~ device basically analyzes and eYtracts the
above-described pitch information, coefficient of short term
prediction, information about the power and quantized code
e(n) of the normalized prediction residual si~nal, respec-
tively, from the received packets by a demultipleYer (DEMPX)
21, in order to decode the information compression-coded in
frame unit as described above, and obtains the normalized
residual si~nal from the above-described quantized code e(n)
at a inverse-quantizer 22. The residual si~nal is therl re-
stor-ed at a ~ain controller unit 23 from the reproduced nor-
malized predictiorl residual si~nal and the above-descrlbed
information about the electric power. The above voice si~nal
X(n) is synthesized at a LPC synthesizin~ unit 24, pitch-
synthesizin~ unit 2~ by usin~ both above-described coeffi-
. -
~i
t 336622
cient of short term prediction and pitch information. andthe decoded voice si~nal X(n~ is further converted to
analog si~nal bv a D/A converter 26. The basic confi~uration
of these units is the same as in the conventional decodin~
device.
However, the present decoding device has a feature in
that it comprises an interframe-predictin~ unit 31 which
predicts the received data coine from the data of received
packets over plural frames in accordnnce with the pitch in-
formation, coefficient of short term predictiorl and informa
tion about the power obtained at the above-described demul-
tiplexer (DEMPX~ 21 and the norlllalized prediction residual
si~nal obtained from the quantized code e(n~ at the above-
described inverse-quantizer 22, and a control Ullit 32 which
detects whether the next packet is received within a
predetermined time via the demultiple~er (DEMPX~ 21, and
controls the operations of a selector 33 for the residual
si~nal and processin~ units 36, 35 and 34 for the above-
described pitch information, coefficient of short term pre-
diction and informatio-l about the power~ respectively, in
accordance with the detection result.
The control Ulli t 3Z monitors, from the property that
packets are continuously transmitted within a certain time
interval wherl the packet-trarlsmitted voice informatiorl is
received, the tillle rrolll the receptiorl of a packet at a cer-
' ' ': ' .
~: - ; , . . ., :
1 336622
tain timing to the reception of the next packet. and detects
whet}ler the absence Or a pacl~et llas occurred or not. Whe
the absence of a packet is detected, the control unit 32
performs the switchirlg control of the above-described selec-
tors 33, 34, 35 and 36, and has the above-described
interframe-predicting urlit 31 perform the decoding process-
ing of voice data usirlg the pseudo prediction residual sig-
nal, pseudo pitch information, pseudo coefficient o` short
term prediction and pseudo information about tlle power pre-
dicted over plural l`rallles nt the nbove-described ir-ter`I~ e
predictirlg unit 31 instead of the decodirlg processing Or
voice data from the decoding processirlg of voice data fro
the received packet data described above. Now, ~he
interframe-predicting urlit 31 W}liCh predicts such pseudo
prediction residual signal, pseudo pitch informatiorl~ pseudo
coefficient of short term predictiorl and pseudo inrorll-atior
about the power over plural frames, respectively, predicts,
based on the fact that, basicall~, the statistical propert~
of voice information is stationary within an interval of
about 20 - 30 ms, tlle data to be received in future (the
next frame) from the present and past received data. This
predictive processing is perforllled by learrlirlg mecharlism.
That is~ relative to the pitch information, coefficient of
short term prediction and information about the power, the
interframe-predictirlg unit 31 performs the interframe pre-
..
~ ri
~ 1 336622
diction as follows:
A (N + 1) = f ~ A( N ) . A ( N ~ -- A( N - K ), E ( N ) )
E (N) = ~(N) - A(N)
A (N + 1) : the predictive value at tlle nlolllerlt (N + 1)
relative to the present N
f ( A(N), A(N - 1)~ A(N - K~, E(N) )
; t~le linear function which predicts the mo-
ment
~N + 1) from tlle present and past J~eceived
datn
E (N) ; the difference between tJIe predicted value
and the received data.
The normalized residual sinal is also predicted, by learrl-
in~, based on the modeled data Or pulse train, white noise
or the linear combirlatiorl of the both from tJIe preserlt and
past received data, and tJIe actual received data.
l'tle interrrallle prediction will be further e,~plained in
more detail. The voice sinal can ~e represented on the z
-transform plane as follows from the eneratiorl mechallism
thereof.
S(z) =~L E(z) A~z) P(z)
S(z~ : tlle z-transform of the voice si~nal S (n~
~L : the electric power of the remnant si~nal
E(z~ : the z-transform of the residual si~nal
eL(n)
13
, ' : ' ', ' ":'
1 336622
Alz) ; the z-transform of the series of the coef-
ficient of short term prediction
P(z~ ; tlle z-trasform of the coefficient of pitch
prediction PL(n)
Now, for each of the above-described ~L, E(z), ~(z) arld
P(z), the present frame da~a will be predicted from the data
of the past received frames. It will be noted that b~ stor-
ing received frames in a memor~. it is possible to predict
the frame data in which t}le absellce of 1 pacl~et IIC1S occurled
from the past and future received frallles.
The residual si~nals e L(n~lrl = O, 1,~ N - 11 whicll
will be received at tlle present frame L are predicted from
the past remnant sigrlals e L-l(n) as follows:
e L(n) = ~L Sp(n) + ~L Sn(n) ___ (1)
dL = T ~ L-1
T; the maximum value of the normalized autocorrelatio
V(n) about e L-l(n) from kmax to kmin
T = ma.~ ~(1/ ~e L-l(n))~e L-l(n)e L-l(n+k)~
K~c~ ~ ~ k ~ . n = o
~L = (1 -o~L)~L-1
Sp(n) =11 (n = 1); impulse
~O (n = O)
Sn(n); white noise (series of coefficient).
The residual signal e L(n) differs in its propert~
depending on voiced sigrlal or voiceless si~nal. It is pre-
dicted as the impulsive signal in the case of voiced signal,
,
. - . :
', ' ~;
1 336622
and predicted by approximating with white noise in the case
of voiceless sianal. The residual si~nal e L-l(n) used in
the above calculatiorl of ~ L is actuall~ the inverse-
quantizin~ value e L-l(n) obtairled at the above-described
inverse-quantizer 22, and becomes a parameter indicatina
the de~ree of voiced si~nal in tlle above-described si~nal
L-l(n). The parameter ~ L carl be obtained from e L-l(n) and
L-1 described above.
Further, ~ L is a parallleter indicatill~ the dearee of
voiceless si~nal, and carl be calculated rrom~ L and ~L-l.
On the other llarld, the electric power~ L Or the a~ove-
described remnant sianal is calculated as:
~ L =~ L-1 ~ L-1 --- (2),
where~ L-1 is the difference between~ L-2 and~ L-1.
The coefficient of short term prediction a L(n-1) ~n =
0, 1, ~ p; p is the order of predictionl is, for example,
transformed into the LSP parameter, as a parameter capable
of easil~ performin~ interframe prediction, and the pre-
dicton is made usin~ the LSP parameter. Subsequerltl~, the
predictive value, i.e., the coefficient of short term pre-
diction a L(n), is obtained b~ retransforlllatiorl from ttle
predicted LSP parameter. Concretel~v, ~he followill~ calcula-
tiOII is performed at the LSP pal~ameter:
LSP L,m = ~L (LSP L-l,m+1 - LSP L-l,m)
+ ~L ~LSP L-l,m --- (3),
- . :
.. : . , : , . '
- 1 336622
atld the predictive ~alue tlleIeor is obtnined. In t}le abo e-
described formula LSP l-l m is ~le m-th LSP parameteI itl
the (L-l)-t}l frallle and ~ LSP L-l M is tlle diffelence ~e-
tween LSP L-2.m and LS~ L-l m.
Now it is krlowrl t}l1t t~le abo~e-described LSP parameter
has a property~ in t~le case of voiced sienal tllat ttle
values are ver~ close between adiacent IJSP Pa1 anleteI S,
i.e. LSP L m+1 arld l.SP L.m. $or a certain m. Orl tlle COII-
trary in t~le case ol` voicelcss si~nl1. ~lle alles are
lureel dif fCI'ell1. betWeCll all,iaCerlt ,t)aI'allleterS for eaCII lll .
Hence, tlle predic,tine pr'OCeSSill~ S}lOWll ill ~'OI'lll-lia ( 3 )
described above is ei-ell as the linear combirlatioll of t~le
prediction for voiced sourld S}IOWII ill t~le fiI'S~ teI'lll 111d t}le
prediCtiOll ~`OI' ~oiceless soun(l S}IOWII ill t~le SeCOrl(l teI'III.
FuIt}leI for t~le litc}l .informa~iorl t~le pit ll ~airl G
thereof is predic~ed 1S:
G L = ( L-l +~ G L-l --- (~I)
and the period of pitC}I thereof is predicte~ as:
m L = m L-l +~ m L-l --- (5). w}lere
G L-l ; t}le difference between G L-2 and G L-l
~ m L-l ; the differcnce between m L-2 alld nl L-1.
The coeEficierlt of pitC}I prediction P L(n) can be o~tained
based on the abo~e-described pitC}I ~ain G and [itC~I peIiod
111 .
FIG. ~I sllows t}le processine proceduIe of tlle a~ove-
16
.
t 336622
described predicting processirlg. First, the pedictirlg
processing is comlllellced from taking in -the received packet
data via the demultiplexer 21 (step a). The rlormalizirlg
autocorrelation is therl calculated from the predicted rem-
nant signal e L-l(n~ obtained at the inverse-quarltizel~ 22
(step b), and the maximum value thereo is obtained (step
c). Then,~ L and ~L are obtained as described above, and tlle
predicted value e L(n) of ~he remrlant signal is obtairled ac-
cording to Formula (1) (step e).
Subsequerltly,~ L, LSP L,m, G L and m L are rurther pre
dicted accordillg to the above-described Forlllulas (2), (3),
(4) and (5), respectively (steps e, f and g).
The above-described predicting processitlgs are se~uen-
tially executed in frame unit.
The above-described control unit 32 judges whether the
absence of a packet is detected or rlot (step h). When the
absence of a packet is detected, the coding processing of
voice data is executed using the predicted informatiorl as
described above (step i).
As a result, by the present device thus conf-igured,
even when voice information is transmitted as packets sub-
mitted to the encodirlg processing in frame unit, it is pos-
sible to effectively deal with the absence Or a packet, and
decode and synt}lesize a hig}l-quality sound by er$ectively
complementirlg the voice irlformation of the portion where the
17
.
.. , : , , .
.
1 336622
absence of a packet exis~s b~ the predicted informatiorl.
Moreover, since it is possible to deal with the absence of a
packet b~Y such predictill~ processing, it becomes possible to
effectivel~v execute the above-described encoding processirlg
in frame uni~, and perfoIIll a hi~h-efficierlc~ packet trans-
mlsslon .
Further, since i~ is not necessar~ to perform decodinyprocessing after s~o~ing packet data over plural fIames as
ShOWJI ill the above-described conventiorlal example, ther~e is
no problem of time dela,Y, and it becomes possible to
favorabl,v mairltairl the naturalrless Or conversatiorl. Ftllther-
moIe, since the inteIfIame prediction at the decodirlg s,vstem
described above is the gerleratiorl of parameters 1t ~he SO-
called vocoder, the amoun~ of the processirl~ does not in-
crease so much. Moreover, t}le inverltive device carl be simply
realized b~Y a small amount of tlardware. Thus, the present
invention has large practical efrects.
It is to be noted that the presell~ invelltioll is not
limited to t~le embodiments described above. For exam~le, it
is possible to modif~ algorithm fol the interframe predict-
ion or the like without departing from the s~i~it and sco~e
of ~he invelltiorl.
~ ;