Note: Descriptions are shown in the official language in which they were submitted.
- 1 - CM00450HP
2037899
DIGll'AL SPEECH CODER HAVING IMPROVED
SUB-SAMPLE RESOLUTION LONG-TERM PREDICTOR
10 ~rlrprollnti of the rnvention
Code-excited linear prediction (CELP) is a speech coding
trrhni-lu~ which has the potential of producing high quality
synthesized speech at low bit rates, i.e., 4.8 to 9.6 kilobits-per-
second (kbps). This class of speech coding, also krLown as
20 vector-excited linear prediction or stnrh~ptir coding, will most
likely be used in numerous speech c~lmm~nir itirln~ and
speech synthesis ~r~lir~ti~n~ CELP may prove to be
particularly ~rrlir~hl~ to digital speech encryption and digital
radiotelephone comml-nic~tinn systems wherein speech
25 qu~lity, data rate, size, and cost are Pi~nif;~r~nt issues.
The term "code-excited" or "vector-excited" is derived
from the fact that the ryrit~tinn sequence for the speech coder
is vector quantized, i.e., a single codeword is used to represent
a sequence, a vector, of P~rit~tirn samples. In this way, data
30 rates of less than one bit per sample are possible for coding the
f~Yrits~ m sequence. The stored PlrritAtinn code vectors
generally consist of infl~p~n~irnt random white Gaussian
sequences. One code vector from the codebook is chosen to
represent each block of N r~rit~tit~n samples. Each stored code
."~
-
Z~33~B9~
- 2 - CM00450HP
vector is lc~ Dc~ d by a codeword, i.e., the address of the
code vector memory location. It is this codeword that is
81lh9eq~1Pnt1y sent over a comml~nirot;onc channel to the
speech synthesizer to reconstruct the speech frame at the
5 receiver. See M.R. Schroeder and B.S. Atal, "Code-Excited
Linear Prediction (CELP): High-Quality Speech at Very Lo Bit
Rates", P~o~c_li~ of the IEEE rntPrno.~;onAl Conference on
Aro~ ;rR, Speech and Signal P-o~ec :- g (ICASSP), Vol. 3, pp.
937-40, March 1985, for a more detailed ~yrlonot;on of CELP.
In a CELP speech coder, the PYrit~otion code vector from
the codebook is applied to two time-varying linear filters which
model the cl~rc.~,Lc.istics of the input speech signal. The first
filter includes a long-term predictor in its feedback loop, which
has a long delay, i.e., 2 to 15 millice~nn~lc, used to introduce
15 the pitch p_.;odi~;~y of voiced speech. The second filter
includes a short-term predictor in its feedback loop, which has
a short delay, i.e., less than 2 msec, used to introduce a
spectral envelope or format structure. For each frame of
speech, the speech coder applies each individual code vector to
20 the filters to generate a l__~lrlDtl u~t~d speech signal, the
compares the original input speech signal to the reconstructed
signal to create an error signal. The error signal is then
weighted by passing it through a weighting filter having a
response based on human auditory perception. The optimum
25 o~ritot;on signal is ~letprminod by selecting the code vector
which produces the weighted error signal having the
... ;.. ;.. energy for the current frame. The codeword for the
optimum code vector is then transmitted over a
comml1ni-otinnc channel.
In a CELP speech synthesizer, the codeword received
from the channel is used to address the codebook of PY~'itotiOn
vectors. The single code vector is then ml~ltirlied by a gain
factor, and filtered by the long-term and short-term filters to
obtain a reconstructed speech vector. The gain factor and t~le
~3'~ 9
- 3 - CM00450HP
predictor parameters sre also obtained from the channel. It
has been found that a better quality synthesized signal can be
L~ad if the actual p~.,a~,~tel used by the synthesizer are
used in the analysis stage, thus ~.;~I;I..;~;IIg the ql~nti7~ti~
5 errors. Hence, the use of these synthesis parameters in the
CELP speech analysis stage to produce higher quality speech
is referred to as analysis-by-synthesis speech coding.
The short-term predictor attempts to predict the current
output sample s(n) by a linear rrlmhin:~hon of the imnnp~i~tply
10 preceding output samples s(n-i), according to the equation:
s(n) = als(n-l) + ~2S(n-2) + . . . + c~ps(n-p) +e(n)
where p is the order of the short-term predictor, and e(n) i9 the
15 prediction residual, i.e., that part of s(n) that cannot be
3~ d by the weighted sum of p previous samples. The
predictor order p typically ranges from 8 to 12, assuming an 8
kiloHertz (kHz) sampling rate. The weights al, 2, op, in this
equation are called the predictor roPffiriPntc The short-term
20 predictor ~oPffiriPntc are determined from the speech signal
using conventional linear predictive coding (LPC) techniques.
The output response of the short-term filter may be expressed
in ~transform notation as:
25 _ . 1
A(z) =
p
Z- 1
i=l
30 Refer to the article entitled "Predictive Coding of Speech at Low
Bit Rates", IEEE Trans. Commun., Vol. COM-30, pp. 600-14,
April 1982, by B.S. Atal, for further fligc~lc.cir~n of the short-
term filter parameters.
7~ 9~
- 4 - CM00450HP
The long-term filter, on the other hand, must predict the
next output sample from preceding samples that extend over a
much longer time period. If only a single past sample is used
in the predictor, then the predictor is a single-tap predictor.
5 Typically, one to three taps are used. The output response for
a long-term filter inc~.~u1a~ a single-tap, long-term
predictor is given in z-transform notation as:.
B(z) =
1- 13Z-L
Note that this output response is a function of only the delay or
lag L of the filter and the filter ~u~ . .B. For voiced
speech, the lag L would typically be the pitch period of the
speech, or a multiple of it. At a sampling rate of 8 kHz, a
15 suitable range for the lag L would be between 16 and 143,
which C~ u,1~9 to a pitch range between 500 Hz to 56 Hz.
The long-term predictor lag L and long-term predictor
~o~ .13 can be d~l., llilled from either an open-loop or a
closed loop Cuuilli u~a~iOn. Using the open-loop configuration,
20 the lag L and roPfflripnt B are computed from the input signal
(or its residual) directly. In the closed loop configuration the
lag L, and the r~ PffiriPnt B are computed at the frame rate
from coded data 1~lU,Cr~ g the past output of the long-term
filter and the input speech signal. rn using the coded data, the
25 long-term predictor lag dPtPrminAti~n is based ûn the actual
long-term filter state that will exist at the synthesizer. Hence,
the closed-loop configuration gives better p~ Arl~P than
the open-loop method, since the pitch filter itself would be
,.. ~, il...~;.~, to the ~JL~ of the error sigr~l. Moreover,
30 a single-tap predictor works very well in the closed-loop
configuration.
Using the closed-loop configuration, the long-term filter
output response b(n) is determined from only past output
2~)3~7~399
- 5 - CM00450HP
samples from the long-term filter, and from the current input
speech samples s(n) according to the equation:
b(n) = s(n) + ~3 b(n-L)
This t~rhniq lP is ~lal~ ruL ~a1d for pitch lags L which are
5 greater than the frame length N, i.e., when L 2 N, since the
term b(n-L) will always represent a past sample for all sample
numbers n, 0 S n S N-l. Fu1ll1~1 uO1~, in the case of L > N, the
p~rit~tir~n gain factor Y and the long-term predictor coefficient
B can be ~imlllt~n~f)usly optimi7~d for given values of log L
10 and codeword i. It has been found that this joint optimization
technique y~elds a noticeable iLU~lVt:LU~l~t in speech quality.
If, however, long-term predictor lags L of less than the
frame length N must be ~c~ cl~tpfl~ the closed-loop
approach false. This problem can readily occur in the case of
15 high-pitched female speech. For example, a female voice
~v1.~ ,-J.~ to a pitch rl~uue..~ of 250 Hz may require a
long-term predictor lag L equal to 4 mi11i~ec~onrl~ (msec). A
pitch of 250 Hz at an 8 kHz sampling rate ~.,.1e~,,.ul~ds to along-
term predictor lag L of 32 samples. It is not desirable,
20 however, to employ frame length N of less than 4 msec, since
the CELP P~it~ti~n vector can be coded more efficiently when
longer frame lengths are used. A~c~,1Lu~ly, utilizing a frame
length time of 7.5 msec at a sampling rate of 8 kHz, the frame
length N would be equal to 60 samples. This means only 32
25 , J , ~ would be available to predict the next 60 samples
of the frame. Hence, if the long-term predictor lag L is less
than the frame length N, only L past samples of the required N
samples are defined.
Several alternative a~ ac11~3 have been taken in the
30 prior art to address the problem of pitch lags L being less than
frame length N. In Itt~ to jointly optimize the long-
term predictor lag L and coefficient 13, the first approach would
be to attempt to solve the equations directly, assuming no
P-rit~tion gignal to present. Thig approach is explained in the
-
2~78g~
.
- . 6 - CM00450HP
article entitled "Regular-Pulse ~.Y~ :læ~;.... - A NoYel Approach
to Effective and Efficient Mllltirl.1A_ Coding of Speech" by
Kroon, et al., IEEE TrAn~.^ti^n~ on A^^,l-.-^tirD Speech, and
Signal Plu~ Dil g~ Vol. ASSP - 34, No. 5, October 1986, pp.
1054-1063. However, in follûwing this approach, a nûnlinear
equation in the single pLIcl~clc. B must be solved. The
solution of the quadratic or cubic in B must be solved. The
solution of the quadratic or cubic in B is . .~ ^,nAlly
i~u~ L Moreover, jointly u,u~ the coPffi~^iPnt 13
with the gain factor ~ is still not possible with this approach.
A second solution, that of limiting the long-term
predictor delay L to be greater than the frame length N, is
proposed by Singhal and Atal in the article "Improving
Performance of Multi-Pulse LPC Coders at Low Bit Rates",
PIOCC~ D of the IEEE International Conference on
Ar.^,l~-^t;^D, Speech, and Signal P~ù~,c,~Dil~g~ Vol. 1, March 19-
21,1984, pp. 1.3.1-1.3.4. This artificial ~;U~IDll~ on the pitch
lag L often does not accurately represent the pitch
information. Ac~u.dil.~ly, using this approach, the voice
quality is degraded for high-pitched speech.
A third solution is to reduce the size of the frame length
N. With a shortcr frame length, the long-term predictor lag L
can always be ~ ;..Pd from past sample3. This approach,
however, suffers from a severe bit rate penalty. With a shorter
25 frame length, a greater number of long-term predictor
l.--.i.. -l.. D and PY.^.itAti.^n vectors must be coded, and
a~ .. Jil. Iy, the bit rate of the channel must be greater to
~ tP the e~tra coding.
A second problem e~ists for high pitch speakers. The
30 sampling rate used in the coder places an upper limit on the
pc,rul...~ c of a single-tap pitch predictor. For example, if
the pitch rle.~ue.,~.~ is actually 485 Hz, the closest lag value
would be 16 which .iul leD~uullds to 500 Hz. This results in an
error of 15 Hz for the î~...-l_....~..l~l pitch frequency which
2Q;~789~3
7- CM00450HP
degrades voice quality. This error is mllltirlied for the
h~rmnnir~ of the pitch I`lèqu~ .y causing further degradation.
A need, therefore, exists to provide an improved method
for determining the long-term predictor lag L. The optimum
5 solution must address both the problems of rnmrllt~tinn 1l
c~ y and voice quality for the coding of high-pitched
speech.
Sllmm~rv nf thP rnvpntinn
Ac~o~Lll~;ly, a general object of the present invention is
to provide an improved digital speech coding technique that
produces high quality speech at low bit rates.
A more specific object of the present invention is to
15 provide a method to ~-k-,...;..~ long-term predictor ~ Le.
using the closed-loop approach.
Another object of the present invention is to provide an
improved metbod for determining the output response of a
long-term predictor in the case of when the long-term
20 predictor lag ~ ullel~l L is a non-integer number.
A furtber object of the present invention is to provide an
improved CELP speech coder which permits joint optimi7~tinn
of the gain factor Y and the long-term predictor roPffiriPnt. B
during the codebook search for the optimum excitation code
25 ve~tQr.
A~o.LIlg to a novel aspect of the invention, the
.e~lu~ioll of the ~c~laLue~èl L i8 increased by allov~ing L to take
on values which are not integers. This is achieved by the use
of ill~é~ iillg filters to provide interpolated samples of the
30 long-term predictor state. In a closed loop imrlPmpnt~tinn)
future samples of the long-term predictor state are not
available to the interpolating filters. This problem is
ci-~uLu~ i,ed by pitch-~yll~lllol~uusly P~tPn~1inE the long-term
predictor state into the future for use by the interpolation filter.
X03'7~399
- - 8 - CM00450HP
When the actual P~r~it.~tir~n samples for the next frame become
available, the long-term predictor state is updated to reflect the
actual P~rit it;rln samples (replacing those based on the pitch-
,v.lously extended samples). For e%ample, the
5 iL~.~olaLion can be used to interpolate one sample between
each existing sample thus doubling the resolution of L to half a
sample. A higher interpolation factor could also be chosen,
such as three or four, which would increase the resolution of L
to a third or a fourth of a sample.
1 0
BriPf Descrinfi~ n of the DrawinP~
The features of the present invention which are believed
to be novel are set forth with particularity in the appended
claims. The invention, together with further objects and
avv~.Lc h~,~ thereof, may best be ulld~-~load by reference to the
following description taken in conjunction with the
.Iyillg drawings, in the several figures of which like-
l~f~ numerals identify like elements, and in which:
Figure 1 is a general block diagram of a code-e~cited
linear p.~L~.,iv~ speech coder, ill.,~l...l.;..~ the location of a
long-term filter for use with the present invention;
Figure 2A is a detailed block diagram of an PmhoflimPnt
of the longterm filter of Figure 1, illustrating the long-term
25 pr~dictor response where filter lag L is an integer;
Figure 2B is a ~imrlifipd diagram of a shift register
which can be used to illustrate the operation of the ~ong-term
predictor in Figure 2A;
Figure 2C is a detailed block diagram of another
30 PmhoAimPnt of the long-term filter of Figure 1, illustrating the
long-term predictor response where filter lag L i8 an integer;
Figure 3 is a detailed flowchart diagram illustrating the
operations p~rvlllled by the long-term filter of Figure 2A;
;~)3
g- CM00450HP
Figure 4 is a general block diagram of a speech
synthesizer for use in accordance with the present invention;
Figure 5 is a detailed block diagram of the long-term
filter of Figure 1, illustrating the sub-sample resolution long-
term predictor response in accordance with the present
invention;
Figures 6A and 6B are detailed flowchart diagrams
illustrating the operations performed by the long-term filter of
Figure 5; and
Figure 7 is a detailed block diagram of a pitch post filter
fûr int~u~lulil~ the short term filter and D/A converter of the
speech synthesizer in Figure 4.
I)Pts~ilp~l l)escTi~tionofthPPreferred h:...h~..l;...~.,t
Referring now to Figure 1, there is shov~n a general
block diagram of code cited linear ~ iv~ speech coder 100
utilizing the long-term filter in ac~u.dancc, with the present
invention. An acoustic input signal to be analyzed is applied to
speech coder 100 at I~ .u,uhol~ 102. The input signal,
typically a speech signal, is then applied to filter 104. Filter 104
generally will exhibit bandpass filter ~ listics.
However, if the speech bandwidth is already adequate, filter
104 may comprise a direct wire cnnnPrt;~-n
_ The analog speech signal from filter 104 is then
converted into a sequence of N pulse samples, and the
lit~l~lP of each pulse sample is then represented by a
digital code in analog-to-digital (A/D) converter 108, as known
in the art. The sampling rate is d~PtPrmin~Pd by sample clock
SC, which l~:,U~3._.1i:~ an 8.0 kHz rate in the preferred
~mho~limPnt The sample clock SC is generated along with the
frame clock FC via clock 112.
The digital output of A/D 108, which may be represented
as input speech vector s(n), is then applied to roPf~ iPnt
~! 2 ~ 3 ~ 8 9 9
- 10 - CM00450HP
analyzer 110. This input speech vector s(n) is repetitively
obtained in separate frames, i.e., blocks of time, the length of
which is flptprminpd by the frame clock FC. In the preferred
~.,.ho-l;...~..~., input speech vector s(n), 0 < n ~ N-l, represents a
5 7.6 msec frame cnntQinin~ N=60 samples, wherein each
sample is e~ éd by 12 to 16 bits of a digital code, In this
~ - I-o ~ ., for each block of speech, a set of linear predictive
coding (LPC) parameters are produced by coPffiriPnt analyzer
110 in an open-loop con~iguration. The short-term predictor
10 parameters ai, long-term predictor c(~Pffiripnt ~, nominal
long-term predictor lag 1.~., ~llel~. L, weighting filter
r~r~mPtPrs WFP, and excitation gain factor ~ (along with the
best eYrit~t;~n codeword r as described later) are applied to
ml~ltipl^YPr 150 and sent over the channel for use by the
15 speech ,,yll~lles;~ .. Refer to the article entitled "Predictive
Coding of Speech at Low Bit Rates," Th:F.~. Tr~nc Comml~n .
Vol. COM-30, pp. 600-14, April 1982, by B.S. Atal, for
lelJlesell~live methods of generating these parameters for
this Pmho~imPnt The input speech vector s(n) is also applied
20 to subtractor 130 the function of which will subsequently be
described.
Codebook ROM 120 contains a set of M PY~it~ti~m vectors
u;(n),. wherein 1 < i M, each ctlmrriced of N samples,
wherein 0 < n ~ N-1. Codebook ROM 120 is preferably
25 yl~ - ~ as described in US Patent No. 4,817,1~7,
Codebook ROM 120 generates these
"~ excitation vectors in response
to a particular one of a set of ~ co~ 1s i. Each of
the M PYrit~tinn vectors are comprised of a seriês of random
30 white Gaussian samples, although other types of excitation
vectors may be used with the present invention. If the
P.rit5.tinn signal were coded at a rate of 0.2 bits per sample for
each of the 60 samples, then there would be 4096 codewords i
~ull~,~olld~g to the possible excitation vectors.
2~3~$9'`9
. 11- CM00450HP
For each individual PYrit~t;~ln vector u;(n), 8
. ucLed speech vector s';(n) i8 generated for comparison
to the input speech vector s(n). Gain block 122 scales the
PYrih~tion vector ui(n) by the PYrit~tinn gain factor Y, which is
5 content for the frame. The PYrit51ti~n g~un factor Y may be pre-
computed by copfflripnt analyzer 110 and used to analyze all
on vectors as shown in Figure 1, or may be optimized
jointly with the search for the best P~rit~ti~n eodeword I and
d by codebook search controller 140.
The scaled Pyritpti~n signal Y u;(n) iB then filtered by
long-term filter 124 and short-term filter 126 to generate the
l u~Led speech vector s'j(n). Filter 124 utilizes the long-
term predictor p~..lleLel~, B and L to introduce voice
p~,.iodicily, and filter 126 utilizes the short-term predictor
pal~dldl~ to introduce the spectral envelope, as described
above. Long-term filter 124 will be described in detail in the
following figures. Note that blocks 124 and 126 are actually
recursive filters which contain the long-term predictor and
short-term predictor in their lc,~e~ feedback paths.
The reconstructed speech vector s';(n) for the i-th
P~rit~tinn code vector is compared to the same block of the
input speech vector s(n) by ~ubllc~ g these two signals in
~,u~ 130. The difference vector e;(n) le:pl~S~:11t.5 the
dill~ e between the original and the ~ I-u~led bloeks of
speech. The di~ lc~ vector is p~ l,ually weighted by
61.1illg filter 132, utilizing the ~,.61lLillg filter p~
WFP generated by coefficient analyzer 110. Refer to tbe
preceding reference for a representative weighting filter
transfer function. r~l~d~lUal weighting ~c~ell~uates those
frequencies where the error is perceptually more important to
the human ear, and ~tt~ tPq other frequencies.
Energy calculator 134 computes the energy of the
weighted di~l~llce vector e';(n), and applies this error signal
E; to codebook search controller 140. The search controller
.~
20~7~9
. 12 - CM00450HP
compares the i-th error signal for the present excitation vector
ui(n) against previous error signals to determine the
p~rjt~ti(7n vector producing the minimllm error. The code of
the i-th Pyrit~tion vector having a minimllm error is then
5 output over the channel as the best P~rit~tion code I. In the
alternative, search controller 140 may determine a particular
codeword which provides an error signal having some
pre~3Pt~PrminPd criteria, such as meeting a predefined error
threshold.
Figure 1 illustrates one PmhorlimPnt. of the invention for
a code-excited linear predictive speech coder. In this
...ho.l;,.,~,.t, the long-term filter parameters L and 13 are
~Pie. .,,;l,Pd in an open-loop cullfii,ula~ion by roP~ Pnt
analyzer 110. AlLdlllaLi~ly, the long-term filter parameters
15 can be determined in a closed-loop configuration as described
in the tlru~ nPd Singhal and Atal reference. Generally,
p~,.r~ uàl~ce of the speech coder is improved using long-term
filter p~l6lll~cLel~ dptprminpd in the closed-loop configuration.
The nûvel structure of the long-term predictor according to the
20 present invention greatly f irilit~tPR the use of the closed-loop
~1.-1,.. ",;..~1 ~n of these parameters for lags L less than the
frame length N.
Figure 2A illustrates an Pmho~imPnt of long-term filter
124 of Figure 1, where L is constrained to be an integer.
25 Al hough Figure 1 shows the scaled PY~it~ti~n vector ~ u;(n)
from i~un block 122 as being input to long-term filter 124, a
representative input speech vector s(n) has been used in
Figure 2A for purposes of P~rrl~n~ti~n Hence, a frame of N
samples of input speech vector s(n) is applied to adder 210.
30 The output of adder 210 produces the output vector b(n) for the
long-term filter 124. The output vector b(n) is fed back to delay
block 230 of the long-term predictor. The Nominal long-term
predictor lag p~ lUl~ ZI L iB also input to delay block 230. The
long term predictor delay block provides output vector q(n) to
2Q~78~
13- CM00450HP ~~~~~
long-term predictor mllltirli~r block 220, which scales the
long-term predictor response bythe long-term predictor
roPffiri~nt B. The scaled output Bq(n) is then applied to adder
210 to complete the feedback loop of the recursive filter.
The output response Hn(z) of long-term filter 124 is
defined in Z-LI; Ll~rul~ notation as:
Hn(Z) =
L(n+L)/L~L)
I-sz ~
10 wherein n L~le~ a sample number of frame cnntAining
N samples, 0 ~ n ~ N-1, wherein B I ~ s~ a filter
roeffiriPnt wherein L represents the nominal lag or delay of
the long-term predictor, and wherein L(n+L)/L~ S~ b the
closest integer less than or equal to (n+L)/L. The long-term
1 5 predictor delay L (n+L)/L~ L varies as a function of the sample
number n. Thus, according to the present invention, the
actual long-term predictor delay becomes kL, wherein L is the
basic or nominal long-term predictor lag, and wherein k is an
integer chosen from the set ~1, 2, 3, 4, .. } as a function of the
20 sample number n. A~,.,vldi~l~ly, the long-term filter output
response b(n) is a function of the nominal long-term predictor
lag p~la LL~l~l L and the filter state FS which e~ists at the
beg;nnine of the frame. This st~t~mPnt holds true for all
vai~es of L -- even for the problematic case of when the pitch
25 lag L is less than the frame length N.
The function of the long-term predictor delay block 230 is
to store the current input samples in order to predict future
samples. Figure 2B represents a ~innrlified diagram of a shift
register, which may be helpful in understanding the operation
30 of long-term predictor delay block 230 of Figure 2A. For
sample number Q such that n=Q, the current output sample
b(n) is applied to the input of the shift register, which is shown
on the right on Figure 2B. For the ne~t sample n-~+1, the
2~337~9
.
. 14- CM00450HP
previous sample b(n) is shifted left into the shift register. This
sample now becomes the first past sample b(n-1). For the next
sample n=1+2, another sample of b(n) is shifted into the
register, and the original sample is again shifted left to
become the second past sample b(n-2). After L samples have
been shifted in, the original sample has been shifted lert L
number of times such that it may be .cl~lc~.lldd as b(n-L).
As m~nt;~nPd above, the lag L would typically be the
pitch period of voiced speech or a multiple of it. rf the lag L is
at least as long as the frame length N, a su~icient number of
past samples have been shifted in and stored to predict the
next frame of speech. Even in the extreme case of where L=N,
and where n=N-1, b(n-L) will be b(-1), which is indeed a past
sample. Hence, the sample b(n-L) would be output from the
shift register as the output sample q(n).
If however, the long-term predictor lag parameter L is
shorter th~n the frame length N, then an in~1lffi~Pnt number
of samples would have been shifted into the shift register by
the bPeinnine of the next frame. Using the above example a
250 Hz pitch period, the pitch lag L would be equal to 32. Thus,
where L=32 and N=60, and where k=N-1=59, b(n-L) would
normally be b(27), which IC~JI~, .,.ll8 a future sample with
respect to the beeinnine of the frame of 60 samples. In other
words, not enough past samples have been stored to provide a
complete long-term predictor response. The complete long-
term predictor response is needed at the b~;....;..~ of the
frame such that closed-loop analysis of the predictor
clc.i~ can be p~.r~ d. According to the invention in
that case, the same stored samples b(n-L), 0 < n < L, are
30 repeated such that the output response of the long-term
predictor is alwsys a function of samples which have been
input into the long-term predictor delay block prior to the start
of the current frarne. In terrns of Figure 2B, the shift register
has thus been e~tended to store another kL samples, which
;~Q~713~9
- 15 - CM00450HP
represent modifying the structure of the long-term predictor
delay block 230. Hence, as the shift register fills with new
samples b(n), k must be chosen such that b(n-kL) represents a
sample which existed in the shift register prior to the start of
5 the frame. Using the previous example of L=32 and N=60,
output sample q(32) would be a repeat of sample q(0), which is
b(0-L)=b(32-2L) or b(-32).
Hence, the output response q(n) of the long-term
predictor delay block 230 would CC~ ,.olld to:
q(n) = b(n-kL)
wherein 0 < n c N-l, where k is chosen as the smallest
integer such that (n-kL) is negative. More ~perifir~lly~ if a
frame of N samples of s(n) is input into long-term predictor
filter 124, each sample number n is j<n~N+j-1 where j is the
15 index for the first samp~e of a frame of N samples. Hence, the
variable k would vary such that (n-kL) is always less than j.
This ensures that the long-term predictor utilizes only
samples available prior to the bP~innin~ of the frame to predict
the output response.
The operation of long-term filter 124 of Figure 2A will
now be described in accordance with the flowchart of Figure 3.
Starting at step 350, the sample number n is initialized to zero
at step 351. The nominal long-term predictor lag parameter L
and the long-term predictor roPffiriPnt 13 are input from
rnPfl;riPnt analyzer 110 in step 352. In step 353, the sample
number n is tested to see if an entire frame has been output. If
n > N, operation ends at step 361. If all samples have not yet
been romrllt~ptl~ a signal sample s(n) is input in step 354. In
step 355, the output response of long-term predictor delay block
230 is f~ tPd according to the equation:
q(n)= b(n-L(n+L)/L~L)
wherein L(n+L)/L~ represents the closes integer less than or
equal to (n+L)lL. For example, if n=56 and L=32, then
~0~7~39~
. ~
- 16- C.~rO0450HP
L(n+L)/L~L) becomes L(56+32/32~L, which is L(2 75)~ L or 2L. In
step 356, the output response b(n) of the long-term filter is
computed according to the equation:
b(n) = 13 q(n) + s(n)
This represents the function of m.lltirliPr 220 and adder 210.
In step 357, the sample in the shift register is shifted left one
position, for all register locations between b(n-2) and b(n-
LMAX), where LMAX ~ e~ s the ~ -r- Iong-term
predictor lag that can be assigned. In the preferred
.... hQ.l;.. "."t, LMAX would be equal to 143. In step 358, the
output sample b(n) is input into the first location b(n- 1) of the
shift register. Step 359 outputs the filtered sample b(n). The
sample number n i8 then in..~ ed in step 360, and then
tested in step 353. When all N samples have been computed,
the process ends at step 361.
Figure 2C is an altcrnative PmhorlimPnt of a longter~n
filter i.~c~ ing the present Invention. Filter 124' is the
f~ul ~-d inverse version of the recursive filter
configuration of Figure 2A. ~nput vector s(n) is applied to both
subtractor 240 and long-term predictor delay block 260.
Delayed vector q(n) is output to ml~ltirliPr 250, which scales the
vector by the long-term predictor ~oefficient. 13. The output
response Hn(z) of digital filter 124' is given in z-transforrn
notation as:
_ L(n+L)/LlL)
Hn(z) =l -13z-
wherein n le~ .lts the sample number of a frame
~r~nts~inin~ N samples, 0 5 n ~ N-l, wherein n represents the
long-term filter coPffi~iPnt, wherein L lepl<,s~--L~ the nominal
lag or delay of the long-term predictor, and wherein L(n+L)/L~
l~ the closest integer less than or equal to (n+L)/L.
The output signal b(n) of filter 124' may also be defined in
terms of the input signal s(n) as:
b(n) = s(n) -13 s(n -L(n+L)/L~L)
. 17 - CM00450HP
for 0 < n ~ N-1. As can be appreciated by those skilled in the
art, the structure of the long-term predictor has again been
modified so as to repeatedly output the same stored samples o~
the long-term predictor in the case of when the long-term
5 predictor lag L is less than the frame length N.
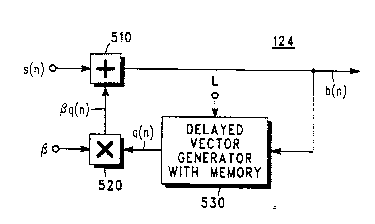
Referring next to Figure 5, there is illustrated the
preferred Pmho~limPnt of the long-term filter 124 of Figure 1
which allows for sllh~nnrlP resolution for the lag parameter
L. A frame of N samples of input speech vector s(n) is applied
l 0 to adder 510. The output of adder 510 produces the output
vector b(n) for the long term filter 124. The output vector b(n) is
fed back to delayed vector generator block 530 of the long-term
predictor. The nominal long-term predictor lag parameter L
is also input to delayed vector generator block 530. The long-
15 term predictor lag palalll-tel L can take on non-integer
rational number values. The preferred Pmho~limPnt allows L
to take on values which are a multiple of one half. Alternate
impl- ~ t;~m~ of the sub-sample resolution long-term
predictor of the present invention could allow values which are
20 multiples of one third or one fourth or any other rational
fraction.
~n the preferred Pmho-iimPnt the delayed vector
O~ 530 includes a memory which holds past samples of
b(n). In addition, interpolated samples of b(n) are also
25 ~~ tpd by delayed vector generator 530 and stored in its
memory. In the preferred Pmho~1imPnt, the state of the long-
term predictor which is contained in delayed vector generator
530 has two samples for every stored sample of b(n). One
sample is for b(n) and the other sample represents an
30 interpolated sample between two consecutive b(n) samples. In
this way, samples of b(n) can be obtained from delayed vector
o. 530 which correspond to integer delays or multiples
of half 3ample delays. The interpolation is done using
interpolating finite impulse response filters as described in
z~
-18- C~00450HP
tirate Dis1ital Si~n~l Prm~?c~inF by R. Crochiere and L.
Rabiner, published by Prentice Hall Rubin Donally, 1983. The
operation of vector delay generator 530 i9 described in further
detail he~ bclo~ in conjunction with the flowcharts in
5 Figure 6A and 6B.
Delayed vector generator 630 provides output ~ ector q(n)
to long-term mllltirli~r block 520, which scales the long-term
predictor response by the long-term predictor coefEicien~ 13.
The 6caled output ~q(n) is then applied to adder 510 to complete
10 the feedback loop of the recursive filter 124 in Figure 5.
Referring to Figures 6A and 6B, there are illustrated
detailed flowchart diagrams detailing the operations
p~ f~ d by the long-term filter of Figure 5. According to the
preferred ~mhotlim~nt. of the present invention, the resolution
15 of the long-term predictor memory is extended by mapping an
N point sequence b(n), onto a 2N point vector e:~(i). The
negative indexed samples of ex(i) contain the extended
resolution past values of the long-term filter output b(n~,
f~Yritslti~ n, or the extended resolution long term history. The
20 mapping process doubles the temporal resolution of the long-
term predictor memory, each time it is applied. Here for
simplicity single stage mapping is rl~rrihe~l although
i~libnnsll stages may be imrl~m~nted in other f~mhorlim.~ntc
of the present invention.
25 _ Entering at START step 602 in Figure 6A, the flowchart
proceeds to step 604, where L, ~ and s(n) are inputted. At step
608, vector q(n) is uull~ll u~,led according to the equation:
q(n) = ex(2n - 2LL(n+L)/L~)
for O<n~N-l
30 wherein L(n+L)lL~ represents the closes integer less than or
equal to (n+L)/L and wherein L is the long term predictor lag.
For voiced speech, long term predictor lag L may be the pitch
period or a multiple of the pitch period. L may be an integer ûr
a real number whose fractional part is 0.5 in the preferred
;~3~8~9
- 19- CM00450HP
~mhorlimPnt When the fractional part of L is 0.5, L has an
effective resolution of half a sample.
In step 610, vector b(n) of the long-term filter is
computed according to the equation:
b(n) = B q(n) + s(n)
for O<n~N-1
In step 612, Yector b(n) of the long-term filter is outputted. In
step 614, the extended resolution state ex(n) is updated to
generate and store the interpolated values of q(n) in the
memory of delayed vector generator 530. Step 614 is illustrated
in more detail in Figure 6B. Next, at step 616 the process has
been ~ t~d and stops.
Entering at START step 622 in Figure 6B, the tlowchart
proceeds to step 624, where the samples in ex(i) to be calculated
in this subframe are zeroed out, ex(i) = O for i = -M, -M+2,
2N-I, where M is chosen to be odd for a filter of order 2M+1.
For example, if the order of the filter is 39, M is 19. Although
M has been chosen to be odd for simplicity, M may also be
even. At step 626, every other sample of ex(i) for i = O, 2,
2(N-1) is initi ili7~d with samples of b(n) according to the
equation:
ex(2i) = b(i)
fori=O, 1,...,N-1.
Thus ex(i) for i = O, 2, ..., 2(N-1) now holds the output vector
25 b(nl for the current subframe mapped onto its even indices,
while the odd indices of exd(i) for i = 1, 3, ..., 2(N-1)+1 are
initi~li7~d with zeros.
At step 628, the interpolated samples of ex(i) iniii~li7~d
to zero are reconstructed through FIR interpolation, using a
30 symmetric, zero-phase shift filter, assuming that the order of
such FIR filter is 2M+1 as explained hereinabove. The FIR
filter co~ffiri~nt~ are a(j), where j = -M, -M+2, ..., M-1, M and
where a(j) = a(j). Only even samples pointed to be the FIR
filter taps are used in sample reconstruction, since odd
20- C~I00450HP
ssmples have been set to zero. As a result, M+l sanlples
instead of 2M+1 samples are actually weightPd snd summed
for each l~ l,Lru~Led sample. The FIR interpolation is
performed according to the equation:
(M+l)
~x(i) s 2 ~ a2j fex(i-2j+1)+cx(i+2j- l)],
j,l
for i=-M,-M+2,...,2(N-l)-M-2,2(N-l)-M
Note that the first ssmple to be reconstructed is ex(-M),
not ex(l) as one might expect. This is becsuse interpolated
ssmples at indices -M,-M+2,..,-1 were reconstructed at the
10 previous frsme using an estimate of the P~rritAtinn in the
current frame, since the actual PYrit~ti~n ssmples were then
~n~iPfinef1 At the current frsme those samples are known (
we have b(n) ), and thus the samples of ex(i), for i=-M,-M+2,..,-
1 are now reconstructed again, with the filter tsps pointing to
15 the actual and not p~t;m~tPd vslues b(n).
The largest value of i in the above equation, is 2(N-l)-M.
This means that (M+1)12 odd samples of ex(i), for i=2N-M,2N-
M+2,...,2(N-l)+l, still are to be reconstructed. However, for
those values of index i, the upper tsps of the interpolating filter
20 point to the future samples of the PYrit~tir~n which are as yet
~ln~1PfinP~1 To calculate the values of ex(i) for those indices,
the future state of ex(i) for i=2N,2N+2,.. ,2N+M-1 i8 extended
by evaluating at step 630:
ex(i) = ~ ex(i-2L),
for i=2N,2N+2,........................... ,2N+M-l
The minim~lm value of 2L to be used in this scheme is 2M+l.
This c - .~11,.;..l may be lifted if we define:
ex(i) = ~ ex( F(i-2L)),
for i=2N,2N+2,...,2N+M-l;
30 where F(i-2L) for i-2L equal to odd numbers is given by:
i-2L, for i-2L S 2(N-I)-M
F(i-2L) = i-2L-2L ~i 2(N21)+M 2~, for i-2L > 2(N-I)-M
~O~B~i9
- 21- CM00450HP
and where F(i-2L) for i-2L equal to even numbers is giYen by:
r i-2L, for i-2L ~ 2(N-I)
F(i-2L) = ~ i 2L 2L[~i-2(N-1)-2~ fo i 2L>2(N 1)
The parameter ~, the history extension scaling factor, may be
set equal to ~, which is the pitch predictor coefficient, or set to
5 unity.
At step 632, with the Plrrit~ti~n history thus extended,
the last (M+1)/2 zeroed samples of the current extended
resolution subframe are ~ t~d using:
~M+l)
ex(i) = 2 ~ a~j l [ex(i-2j+1)+ex(i+2j-1)],
j=l
for i=2N-M,2N-M+2,.. , 2(N-1)+1
These samples will be rPc~lr~ t~d at the next subframe, once
the actual P~l~it~ti~n samples for ex(i), i=2N,2N+2,...,2N+M-1
become available.
Thus b(n), for n=O,N-1 has been mapped onto vector
15 ex(i), i=0,2,...,2(N-l). The missing zeroed samples have been
reconstructed using an FIR interpolating filter. Note that the
FIR interpolation is applied only to the missing samples. This
ensures that no distortion is unnecessarily introduced into the
known samples, which are stored at even indices of ex(i). An
20 ~ itinn~l benefit of ~IU~ lg only the missing samples, is
that ~ullllJuL~tion ~Uri~t~d with the i~f~ olalion is halved.
At step 634, finally the long term predictor history is
updated by shifting down the contents of the extended
resolution f~Yrit~tinn vector ex(i) by 2N points:
ex(i) = ex(i+2N),
for i=-2Max_L,-1
where Max_L is the lI~ IIIIII Iong term predictor delay
used Next, at step 636 the process has been cnmrlcted and
stops.
- ~ 2037899
.
. 22 - C~00450HP
Referring now to Figure 4, a spcech synthesizcr block
diagram is illustrated using the long-term filter of the present
invention. Synthesizer 400 obtains the short-term predictor
parameters ai, long-term predictor y~ ~.;, B and L,
P.rit~t;~n gain factor ~ and the codeword I received ~rom the
chanr~el, via de-m~lltirlPYpr 450. The codeword I is applied to
codebook ROM 420 to address the codebook of PY~it~t;~n vectors.
Codebook ROM 420 is preferably ;",pl. ,.~ P~1 as described in
US Patent No. 4,817,157. The
single Py~it~t;~n vector ul(n) is then mll~tirliPd by the gain
factor ~ in block 422, filtered by long-term predictor filter 424
and short-term predictor filter 426 to obtain reconstructed
speech vector s'l(n). This vector, which ~ Lb a frame of
L~u,./.~.ucted speech, is then applied to analog-to-digital (A/D)
convertor 408 to produce a reconstructed analog signal, which
is then low pass filtered to reduce aliasing by filter 404, and
applied to an output transducer such as speaker 402.
~Pn-~P th~ CELP synthesizer utilizes the same codebook, gain
block, long-term filter, and short-term filter as the CELP
analyzer of Figure 1.
Figure 7 is a detailed block diagram of a pitch post filter
for i~ .g the short term filter 426 and D/A converter
408 of the speech synthesizer in Figure 4. A pitch post filter
enhances the speech quality by removing noise introduced by
thQfilters 424 and 426. A frame of N samples of reconstructed
speech vector s'l(n) is applied to adder 710, The output of adder
710 produces the output vector s"(n) for the pitch post filter.
The output vector s"(n) is fed back to delayed sample generator
block 630 of the pitch post filter. The nominal longterm
predictor lag p~ l L i9 also input to delayed sample
generator block 730. L may take on non-integer values for the
present invention. If L is a non-integer, an interpolating FIR
filter is used to generate the fractional sample delay needed.
Delayed sample ~ Ol 730 provides output vector q(n) to
B
~ 20~7~
- 23 - CM004~0HP
ml-ltirliDr block 720, which scales the pitch post filter response
by coPf~ Dnt R which is a function of the long-term predictor
13. The scaled output Rq(n) is then applied to adder
710 to complete the feedback loop of the pitch post filter in
5 Fii~ure 7.
In utilizing the long-term predictor response according
to the present invention, the P~ritat;~n gain factor Y and the
long-term predictor i oDffii~ient 13 can be ~imlllt:~nDously
opt.mi~ed for all values of L in a closed-loop configuration.
10 This joint optimi7at;~n technique wa3 heretofore impractical
for values of L < N, since the joint ,,yi:...; ,.,.l: .. . equations
would become nonlinear in the single p~.~e~e. B. The
present invention modifies the structure of the long-term
predictor to allow a linear joint v~ n equation. In
15 addition, the present invention allows the long-term predictor
lag to have better resolution than one sample thereby
Pnhaniine its performance.
Moreover, the codebook search IJ~v~.~.luld has been
further .~imrlifiDtl since the zero state response of the long-
20 term filter becomes zero for lags less than the frame length.This pd~litiona1 feature permits those skilled in the art to
remove the effect of the long-term filter from the codebook
search l~lvl~dllle. Hence, a CELP speech codêr has been
shown which can provide higher quality speech for all pitch
25 rates while retaining the advantages of practical
, ' ' ' and low bit rate.
While specific Dmho~imi~ntc of the present invention
have been shown and described herein, further mo-lifii~atinnc
and hlll~lvvell~ may be made without departing from the
30 invention in its broadêr aspects. For example, any type of
speech coding (e.g., RELP, multipulse, RPE, LPC, etc.) may be
used with the sub-sample resolution long-term predictor
filtering t~D/~hniqni? described herein. Moreover, a~ itiilnal
equivalent configurations of the sub-sample resolution long-
;;~03~89
- 24 - CM00450HP
term predictor structure may be made which perform the
same ~ as those illustrated above.