Note: Descriptions are shown in the official language in which they were submitted.
WO 92/00570 PCI/GB90/00987
GRAPHICS RENDERING SYSTEMS
_
This invention relates to graphics rendering systems.
A simple 2-D graphics rendering system rnay comprise a graphics
processor which receives a stream of rendering instructions from a host
computer, and renders the graphical shapes or polygons defined by the
instructions one-by-one in a framestore. A video processor reads out the
data from the frames~ore and displays it on a monitor. If it is desired to
display, say, a small red triangle on a large green triangle, this can be
simply accomplished by supplying the instruction to render the large green
triangle before the instruction to render the small red triangle. The large
green triangle is rendered in the framestore first, and then when the red
triangle is rendered, it par~ially overwrites the large green triangle,
producing the desired effect.
.,,~ , ~.
In order to increase rendering speed, it is desirable to provide a
plurality of processors, which can share the rendering operations between
them. Overlapping of polygons then becomes a problem. In the example
given above, i~ two processors are rendering the large green and small red
triangles, respectiYely, at the same time, it is quite possible that some
pixels of the green triangle in the area of desired overlap by the red
triangle will be rendered green by one processor after those pixels have
been rendered red by the other processor, thus resulting in parts of the
required red triangle being green. In order to overcome this problem, it
may be considered expedient to provide with each instruction an order
code, so that the order codes indicate the order in which the polygons
need to be rendered to prevent any possibility of incorrect overlap. Each
processor would then be operable to determine, be~ore rendçring a
polygon, whether that polygon overlaps with any other polygon which has
an earlier order code and which is still to be rendered, and if so, the
processor would wait until rendering of the polygon with the earlier order
code was complete. In the simple example given above, the processor
which is to render the small red triangle would wait until the
: .. . : :: . : .: :. : : :: :: ::: :: ::
WO 92/00570 PCI/CB90/00987
Z~3J5~3 2
ot' er processor had completed rendering the large green triangle.
Although this overcomes the overlap problem, it will be appreciated that,
in this simple example, the two triangles are rendered sequentially, rather
than simultaneously. This, combined with the time taken for each
processor to check whether the other processor is still rendering an
earlier overlapping polygon, will result in the two-processor system taking
longer to render the two triangles than the single processor system.
The present invention aims to overcome the abnve problem by
providing a memory in parallel with the framestore which stores, for each ;~pixel location in the framestore, the order code of the graphical shape or
polygon to which the pixel currently rendered at that pixel location
belongs. In determining whether to write to a pixel location in the
framestore, each processor can check whether the order code of the shape
it is rendering is later than the stored srder code in the memory (in which
case it writes that pixel), or not (in which case it does not write that
pixel). Accordingly, there is no limitation on the order in which the
processors can render the polygons, and the problem of erroneous
overwriting is overcome.
It is known, in 3-D graphics rendering using a single rendering
processor, to provide a memory in parallel with the framestore which
seOres, for each X, Y pixel location in the framestore, the depth Z of the
pixel currently written to that location. In determining whether to write
to an X,Y pixel location in the framestore9 the processor checks whether
the depth (obtained by interpolation) of the pixel to be rendered is less
than the depth stored in the memory ~in which case it writes that pixel),
or not (in which case it does not write that pixel~. There is thus some
degree of similarity between this known depth-buffered 3-D graphics i
rendering system and the order-buffered 2-D graphics rendering system of
the present invention. It should be noted, however, that with the present
invention the comparison is made in a 2-D system by each of a plurality of
processors between the additional stored data and the order of the shaDe
(or polygon) being rendered, rather than the ~ of a E~ in the shape
(or polygon) being rendered, as in the known single processor 3-D depth
buffered system.
- :: , . . , , : .
WO 92/00570 ,~2~~~r PCI/GB90/00987
There now follows a description, by way of example, of a specific
ernbodiment of the present invention, with reference to the accompanying
drawings, in which:
Figure 1 is a schematic circuit diagram of the rendering system;
Figure 2 illustrates an example content of the framestore;
Figure 3 is a flow diagram of the operation of each of the
processors of Figure 1 in executing a rendering instruction;
... ., . : . .
Figure 4 is a table of steps carried out in rendering a series of
instructions to produce the framestore content as shown in Figure 2; and
Figure 5A to 5C show the contents of the framestore and ordering
buffer before the series of instructions is commenced at two occasions
part-way through the series of lnstrurtions.
., .:
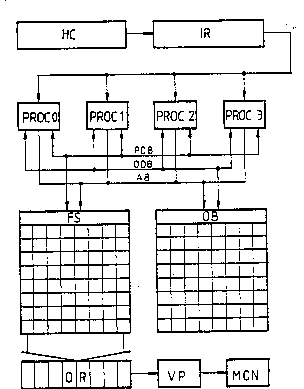
Referring to Flgure 1, in the preferred embodiment, a host
computer HC supplies a set of rendering instructions to an instruction
register IR. The instructions take the form of: (i) an opcode representing
instructions such as draw a rectangle (represented hereinafter by the
mnemonic "rec"); draw a triangle or clear the screen; (ii) parameters
associated with the opcode, such as the coordinates of two opposite
corners (xl, yl), (x2, y2) of the rectangle, or the coordinates of the
vertices (xl, yl), (x2, y2) and (x3, y3) of the triangle, together with a
colour code indicating the colour of, for example, the rectangle or
triangle or the colour to which the screen is to be cleared; and (iii) the
order of the instruction. In the example given in this description the
following set of rendering instructions will be considered:
rec 1,1, 5, 5, Black, 1 -(a)
rec 1, 4, 2, S, Red, 2 -(b)
rec 2, 2, 4, 4, Green, 3 -(c)
rec 4, 1, 5, 2, Cyan, 4 -(d)
rec 4, 4, 4, 5, Yellow, 5 -(e)
,.... . - . ~ , ,: .- .. , :, , ,,. ,, , - ,
: .~ : ~, , , :- ~ . . : .. .,: :
.: ~ , . . : ~ . : ,, ., , , ,.; , :
WO 92/00570 Pcr/cB9~/oo9B7
The meaning of these instructions is as follows:
a: render a black rectangle with corner coordinates (1, 1) and (5, 5);
b: render a red rectangle with corner coordinates (1, 4) and (2, 5) so
that it is not hidden by any pixels rendered in instruction a;
,.
c: render a green rectangle with corner coordinates (2, 2) and (4, 4) so
that it is not hidden by any pixels rendered in instruction a or b;
d: render a cyan rectangle with corner coordinates (4, 1) and (5, 2) so
that it is not hidden by any pixels rendered in instructions a to c;
and
e: render a yellow rectangle with corner coordinates (4, 4) and (4, 5)
so that it is not hidden by any pixels rendered in instructions a to d.
Referring back to Figure 1, in thP preferred embodiment, the
rendering system further comprises four processors PF?OC 0 to PROC 3, a
framestore FS with associated output register OR, an ordering buffer OB,
a video processor VP and a monitor MON. The processors can read
instructions from the instruction register IR asynchronously, so that, for
example, processor PROC 0 can read and perform more than one simple
instruction, while-processor PROC 1 is performing a single more complex
instruction. The processors PROC 0 to PROC 3 are each operable to
address the framestore F5 and the ordering buffer OB with the same
address on an address bus AB. The processors PROC 0 to PROC 3 are also
each operable to read and write data ~o the framestore FS and the
ordering buffer OB via a pixel data bus PDB and an ordering data bus
ODB, respectively. The framestore FS and ordering buffer OB h ve the
same capacity, which is shown in Figure 1 for simplicity as merely 8 x a
words, and by virtue of the common addressing of the framestore F5 and
the ordering buffer OB by the address bus AB, each location in the
framestore FS is associated with a respective location in the ordering
buffer. As is conventional, the output register OR of the frame~tore FS is
.~ .
-
. , ,:. , ,, , : , :
:: ~ . : . , ; '
, ...... .. ,, . ~ . ~ , . .
, : . : . , : ,:~ . .
: ~
W0 92/00570 ;2 ~ ` 3 ~ 3~ PCI /GBgO/00987
loaded row-by-row ~n parallel with pixel data from the framestore FS, and
the pixel data for each row is ou~:put serially from the output register OR
to the video processor VP for display on the monitor MON.
In the preferred ernbodiment, in carrying out an instruction, the
processors PROC O to PROC 3 each perform the sequence of steps shown
in Figure 3. -In the first step Sl, a processor reads an instruction inclubing
the polygon colour PC and polygon order number PO from the instruction
register IR. For example, considering instru~tion "a" above, the processor
reads the instruction "rec 1, 1, 5, 5" and sets PC _ Blaok and PO _ 1. In
the preferred embodiment, an exclusion lock is provided so that only one -
proc~ssor at a time may read an instruction from the instruction register.
Next, in step 52, the processor determines, in a known manner, the
loca~ion of a first pixel to be rendered, such as, in this example, (1, 1~. -
Then in step 53, the processor addresses the ordering buffer OB (and ~he
framestore FS) wi~h the location (x, y), and sets a current order variable
CO equal to the order number OB (X7 y) at that location. Then, in step 54,
~` the processor determines whether the polygon order PO for the polygon of
the instruction being proces~ed is greater than the current order CO read
from the order buffer OB. If S09 then in step 55, the processor writes the
polygon colour PC of the instruction being processed to the framestore FS -~
at the addressed location (x, y), and in step 6 writes the polygon order PO
of the instruction being processed to the ordering buffer OE~ at the
addressed location (x, y). Thus, the pixel is written, and the ordering
buffer 08 is updated. Step 57 then follows. If, in step 54, it is
determined that the polygon order PO is not greater than the stored
current order CO, then steps 55 and 56 are skipped, and accordingly the
pixel is not written and the ordering buffer is not updated. In the
preferred embodiment, an exclusion lock is provided so that only one
proce~sor at a time can be aodressing the framestore FS and the ordering
buffer OE~ in step S3, S~ or 56. Also, once a processor has addressed the
framestore FS and ordering buffer OB in step 537 it places a scan line lock
on the framestore and ordering buffer until either it has completed step
56 or it has been determined in step 54 not to write to the framestore and
ordering buffer. The scan line lock prevents any other
WO 92/00570 PCr/GB90/009B7
,. . .
prncessor accessing a location in the framestore and ordering buffer with
the same "y" address, and thus prevents any other proc~ssor changing the
content of OB (x,y) which has been read by the processor in question at
step S3, wnilst still enabling the other processors to access addresses with
different "y" addresses. In step S7, the processor determines in a known
manner, whether any more pixels need to be rendered to complete the
polygon, and if so, the sequence loops back to step 52j where the next
pixel is considered. If, however, rendering of the polygon is complete,
then the sequence is finished, and the prncessor is ready to read another
instruction from the instruction register IR.
. .. . . ... ..
A table of example steps performed by the four processors PROC 0
to PROC 3 in carrying out the exemplary instructions "a" to ~'e"
mentioned above is set out in Figure 4, based on the assumption that,
initially all of the pixels in the framestore FS are set to white colour, and
a zero order number is stored in all of the locations in the nrdering buffer
08, as shown in Figure 5A. The table of Figure 4 is self-explanatory.
Points to note are that step 12 in the table is the first step ulhere a
processor (PROC 3, in this case) compares the order of the polygon it is
executing with a current order CO (3) of the pixel (4, 2) under
consideration which is not the cleared screen order of zero, because the
pixel was previously wri~ten in step 11. In the case of step 129 the order
of the polygon PO is 4, which is greater than the current order of 3, and
therefore the pixel is written, as shown in Figures 5B and 5C. However,
in the next step 13, the order of the polygon PO of 1 is not greater than
the current order of 4 (produced in step 12), and therefore the pixel is not
written in step 13. A further point to note is that~ at steps 14 and 16, the
processors PROC 1 and PROC 3 have completed rendering their currsnt
instructions b and d. Therefore, in step 1a, processor PROC 1 commences
performing the next instruction "e", and processor PROC 3 falls idle
because there are no further instructions to be executed in the simple 5-
instruction example which is given above.
It will be appreciated from a detailed consideration of Figure 4
that after all of the steps 1 to 44 have been cornpleted, the contents of
- . . : : : . : : . .
WO 92/00570 PCT/GB90/009B7
the framestore FS will be as shown in Figure 2.
For simplicity, the system has been described above as having an 8
x 8 word framestore FS and an 8 x 8 word ordering buffer OB. In
practice, the framestore FS would have a far grPater capacity than this,
for example, 2k x 2k words, and the output register OR would
correspondingly have a capacity of 2k words. The framestore FS may
conveniently be implemented using, for example, a conventional Hitachi
video RAM. The ordering buffer OB has a word capacity equal to that of
the framestore, and may be implement0d by, for example, a conventional
Hitachi D-RAM. Eaeh word o1 the ordering buffer OB may consist of, for
.. . . .
example, 16, 24 or 32 bits, which enable 6~,535, 16,777,215 or
4,294,967,295 polygons, respectively, to be rendered before any overflow
occurs in the ordering buffer.
In the case where the system is to be used to render a number of
polygons sufficiently great to cause s~verflow in the ordering buffer, then
the following procedure may be adopted in the preferred embodiment.
The sequence of instructions to the instruction register IP~ is halted after
the instruction having the maximum order numher, for example order
number 65535 in the 16-bit case. Then, when all of the instructions in the
instruction register have been read and executed, the processors stop
rendering. When all of the processors have stopped, the ordering buffer
OB is cleared to zero, and then a further sequence of instructions is
supplied to the instruction register, with the firs~ instruction having an
order number of 1. Accordingly, the processors recommence rendering,
with the new sequence of instructions causing objects to be rendered
which overwrite the previous contents of the framestore FS before the
temporary halt in execution.
It will be appreciated that many modifications and developrnents
may be made to the system described above. For example, any plural
number of processors may be employed. Also, increasing significance of
the rendering instructions may be denoted by decreasing, rather than
increasing order numbers. Furthermore, the framestore FS and ordering
~'
i
~: , ,.
. . : : ; , - , . :.,; - ;.,,,,: ., :, , :
- .; . : .,.:. , . : : .. ., . .:,. ,. .. ; . ,.,. ,,:: ,. , ., -.
-:,: ,; , ,: :, .:. , -, .. :, :,:.,.: :: ,, :,., ,, : . ,:
.; .: :: :, ,, , : : : : : : :, . :, , ,, , . :
- - : . : . - : : . ., .. '::, :: , ,: :: :
WO 92/00570 PCI/GB90~0S~987
s~
buffer OB cuuld be combined into a single devic~. For example, with a
32-bit framestore, 16 bits could be used to store the pixel data and 16 bits
could be used to store the ordering data.
. :
; :: ; : :~.
:, - . -: :