Note: Descriptions are shown in the official language in which they were submitted.
2 1 65862
APPARATUS FOR PRODUCING DIGITAL SOUND RECORDS
FIELD OF THE INVENTION
The present invention relates to method of producing sounds and to its application in a
language training method.
BACKGROUND TO THE INVENTION
Various devices are known in the art for high speed phonetic keyboarding. These include
the stenotype which is most commonly used in North America and the palentype which is most
commonly used in Europe. The palentype is similar in operation to the stenotype, but the
grouping of keys on its keyboard is modified into a "V" angle which is more comfortable to
operate.
The digital proces~ing of data entered from such keyboards is also known. For example,
an IBM Technical Disclosure Bulletin entitled Speech Translation Machine For The Deaf, Vol.
17, No. 12, May 1975, describes a stenotype machine adapted to translate and display speech
in a phonetic word form. See also, for example: U.S. Patent No. 3,665,115 entitled
20 Stenographic Apparatus For Providing A Magnetically Recorded Digitally Encoded Record,
granted May 23, 1972 (Snook); and U.S. Patent No. 4,632,578 entitled Co~llpu~el;7ed Printing
System, granted December 30, 1986 (Cuff et al.).
As well, it is known in text or word processing systems to store words or portions of
words in digital memory for the purpose of subsequent addressing and retrieval depending upon
input from a keyboard or other source: see, for example, U.S. Patent No. 4,342,085 entitled
Stem Proces~ing For Data Reduction In A Dictionary Storage File, granted July 27, 1982
(Glickman et al.); and U.S. Patent No. 4,439,836 entitled Electronic Translator, granted March
27, 1984 (Yoshida).
247464 1
2 1 65862
Further, it is well known to store words in digit~l memory in the form of sound files
which can be addressed, retrieved and played out depending upon input from a keyboard or
other source.
With systems which are designed to access words in memory, signal processing speed
can present a fundamental difficulty, particularly when the data input may be fast and may
require inte.~reldtion in order to locate the proper word in memory.
One area where the problem of signal processing speed can become particularly acute is
10 in the area of sound production. If a keyboard input is used to enter data to produce the sound
of desired words, the keyboard operator may effectively outrun the system unless the input is
processed fast and efficiently. The input may be at the rate of normal speech, yet the output
may lag. Any sense of real time operation is then lost.
This problem can present itself in the learning of a new language. Here, it is desirable
for the student to work with sound patterns and combinations of sound patterns rather than series
of letters which make up the language. But, when a student keys in the input for a desired
sound or combination of sounds in the language, it is important to simultaneously hear the result.
Otherwise, the l~rning process can be impaired. In this regard, it is desirable to provide a real
20 time sense of whether or not a mistake has been made at the keyboard.
Accordingly, a primary object of the present invention is to provide new and improved
a~paldtus which can rapidly receive and process keyboard input representing sounds in a selected
language.
A further object of the present invention is to provide a new and improved system which
can rapidly receive and process such keyboard input and produce sounds or other indicia
corresponding to such input without significant delay.
247464-1
21 65862
SUMMARY OF THE INVENTION
In accordance with one aspect of the present invention, there is provided appalalus for
producing digital sound records from demi-syllable sound files, such appa~alus including a
keyboard means having a first set of keys for entering data corresponding to beginning consonant
sounds used in a selected language, a second set of keys for entering data corresponding to
ending consonant sounds used in that language, and a third set of keys for entering data
corresponding to vowel sounds used in that language. A memory means digitally stores a
plurality of demi-syllable sound files, each file corres~onding to and represçnting the sound of
10 a predetermined demi-syllable in the selected language. Further, the appa~at~s includes an input
signal proces~ing means operatively connected to the keyboard means and to the memory means
for providing file address signals to the memory means in response to data entered from the
keyboard means, and output signal processing means operatively connected to the memory means
for reading the contents of the files so addressed and for combining the conlenls of successively
read first and second ones of the files so read to produce a derivative sound record which,
depending upon the sounds represented by the first and second files, corresponds to either a full
or a partial conc~tçn~tion of the first and second files.
Depending upon the sounds represented by the first and second files, the derivative sound
20 record preferably corresponds to a full conc~ten~tion of the first and second files, a
conc~tPn~tion of the first file with a part of the second file, a conc~tçn~tion of a part of the first
file with the second file, or a concatenation of a part of the first file with a part of the second
file.
By breaking the language down to demi-syllables and utili~ing a memory store of demi-
syllable sound files addressed with such a keyboard input, the basis for enhanced processing
speed is established. However, when one demi-syllable sound file is combined with another,
the combined or derivative sound may be distorted l~lesell~lion of that which is actually
247464-1
21 65862
- 4 --
desired. For example, if the demi-syllable "at" is simply concalenaled at the end of the demi-
syllable "ca", the result would not be the simple word "cat". Rather, it would a disconcerting
version of the word with a stretched out central portion. Accordingly, depending upon the demi-
syllables being combined, only a portion of the respective sound files may be utilized to produce
the derivative sound record.
In accordance with a another aspect of the present invention, there is provided a language
training system which includes a keyboard means as described above for entering beginning
consonant sounds, ending consonant sounds, and vowel sounds in a selected language, a first
10 memory means for digitally storing a plurality of demi-syllable sound files, each demi-syllable
sound file corresponding to and representing the sound of a predetermined word or words having
defined meaning in a that language, and a second memory means for digitally storing a plurality
of demi-syllable sound files, each demi-syllable sound file corresponding to and representing the
sound of a predetermined demi-syllable in that language. Further, the system includes signal
processing means operatively connected to the keyboard means and to the second memory means
for producing the sound of a desired word from the demi-syllable sound files in response to data
entered from the keyboard means, said desired word corresponding to a word stored in the first
memory means. As well, the system includes means operatively connected to the first memory
means for producing the sound of the desired word as represented in the demi-syllable sound
20 files.
Advantageously, the words in the memory of demi-syllable sound files contains
predetermined words stored with their proper stress and intonation, features which will be
lacking in words formed from the combination of demi-syllable sound files. In the process of
language training, the student may be prompted by the sound of such a word, and called upon
to enter the same word from the keyboard. Alternately, the student may be visually prompted
to enter the word from the keyboard, hear the sound resulting from the combination of demi-
247464-1
2 1 65862
syllable sound files, then hear the sound of the same word as produced from the demi-syllable
sound file.
To further advantage, the foregoing system may include means for visually indicating
keys that were pressed to produce the sound of the desired word and keys that should have been
pressed to produce the sound of the desired word.
The invention will now be described in more detail with reference to the following
drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
Figure 1 is a block diagram of a language training system in accordance with the present
invenhon.
Figure 2 illustrates in more detail a portion of a keyboard used with the system shown
in Figure 1.
Figure 3 is a chart illustrating key and key combinations used to produce desired
20 beginning consonant sounds, vowel sounds, and ending consonant sounds with the keyboard
shown in Figure 1.
Figure 4 is a graphic representation of a model speaker's speaking.
Figure S illustrates a display device and the graphical replesentation of the keys of keys
pressed and proper keys to press.
DETAILED DESCRIPTION
247464-1
21 65862
The block diagram shown in Figure 1 illustrates a language training system comprising
a keyboard 50 for entering data, and a processing unit 60 which is in communication with the
keyboard via bus 51 and capable of decoding and executing instructions. Conveniently, unit 60
will be part of a commercially available personal co~puler having a 386 or higher
microprocessor running at a minimum speed of at least 25 MHz. The system includes two
memories: a first memory 70 for digitally storing a plurality of demi-syllable sound files; and
a second memory 80 for digitally storing a plurality of demi-syllable sound files. Memory 70
is in bi-directional communication with processing unit 60 via bus 71. Similarly, memory 80
is in bi-directional communication with processing unit 60 via bus 81.
Processing unit 60 is also in communication with two output devices: one being an audio
or sound device 90 connected via bus 91; the other being a visual or display device 100
connected via bus 101.
Each demi-syllable sound file stored in memory 70 corresponds to and rep-esellls the
sound of a predetermined word or words in a selected language. Complete sentences may be
included. While the selected language may be any one of a number of known languages, the
chosen language for the embodiment now being described is Fngli~h. In other words, as a
language training system, the present embodiment is designed to help teach the Fngli~h language,
20 and the words stored in the demi-syllable sound files of memory 70 are predetermined Fngli~h
words to be presented and taught to a student who is endeavouring to learn Fn~ h. To enhance
the le~rning of proper pronunciation, auditory recognition and auditory discrimin~tion, the words
are preferably stored with their proper intonation and stress.
Each demi-syllable sound file of memory 80 corresponds to and r~lesents the sound of
a predetermined demi-syllable in the English language. There are approximately 1400 of such
files, each being prerecorded and stored - but necessarily without any co--lpa-~live stress or
intonation because the words or syllables they may be used to form are not known.
247464 1
2 1 65862
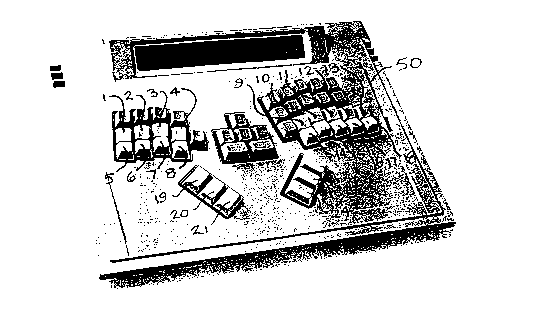
As shown in Figure 2, keyboard 50 includes twenty-four keys. Data input from these
keys corresponds to the forty phonemes or sound segments of the Fn~ h language. As such,
keyboard 50 may be referred to as a phonemic keyboard.
The twenty-four keys are or~ni7ed in three sets: a first set of eight keys 1 to 8 on the
left hand side for entering data corresponding to beginning consonant sounds used in the F.n~ h
language; a second set of ten keys 9 to 18 on the right hand side for entering data corresponding
to ending consonant sounds used in the Fngli.~h language; and a third set of six keys 19 to 24
for entering data corresponding to vowel sounds.
The chart shown in Figure 3 illustrates the key and key combinations of keyboard 50
used to produce desired data input. Input occurs upon the release of selected keys and not when
keys are pressed. Thus, as illustrated by way of example in Figure 3, data mput corresponding
to the beginning consonant sound "b" as in the word "book" is achieved upon the release of keys
2 and 8, normally operated with the left hand. Likewise, data input corresponding to the ending
consonant sound "b" as in the word "cab" is achieved upon the release of keys 11 and 14,
normally operated with the right hand.
In the case of a demi-syllable such as "be", for example, the approp-iate data input is
20 achieved by using the left hand to press keys 2 and 8 repres~nting the beginnin~ "b" sound, and
the thumbs to press vowel sound keys 21 and 24 representing the ending "e" sound; then
releasing all keys.
It should be understood that the student will not normally be cognizant of the fact that
a demi-syllable or combination of demi-syllables has been entered from the keyboard. From his
or her standpoint, such recognition and appropliate processing occurs in the background.
247464-1
~ 1 65862
- 8 -
A keyboard which enables data entry in accordance with the chart shown in Figure 3 is
available from Boswell Industries Inc., 8455 Lougheed Highway, Burnaby, British Columbia,
Canada.
Processing unit 60 includes an input signal proces~ing means 62 and an output signal
processing means 64. The input signal processing means includes an input register for receiving
input data from keyboard 50 to be processed in accordance with instructions stored in a program
memory of unit 60. Similarly, the output signal processing means includes an output register
for storing signals which result from the program instructions, and which are made available to
audio device 90 and display device 100 over buses 91 and 101. Audio device 90 may comprise
a conventional processor and amplifier or headphones capable of receiving a digital sound signals
from the output register and producing corresponding sounds. Display device 100 may comprise
a conventional monitor compatible with the personal computer which is part of processing unit
60.
When input data is received from keyboard 50, it will not necess~rily represent a demi-
syllable or pair of demi-syllables forming a word or syllable. However, when the data does
represent a demi-syllable, then the instruction program of proces~ing unit 60 responds to address
and look up the corresponding sound file in memory 80. Output signal processing means 64
reads the sound file and makes the record available at the output register. When the keyboard
data represents a pair of demi-syllables forming a word or syllable, then the instruction program
responds to address and look up both demi-syllable sound files. Output signal processing means
64, also following the instruction program, then combines the files to produce a derivative sound
record which is made available at the output register.
Since the number of demi-syllable sound files required for the F.ngli~h language is
significantly more limited than the number of meaningful words or syllables that might be
produced by combining the sounds represented by such files, a significantly smaller store of
247464-1
2 ~ 65862
sounds is required in memory 80 than with a complete store of syllables. Further, the time
required to address and look up a given file in response to keyboard data is foreshortened.
However, as noted above with the example of the word "cat", the simple conc~t~-n~tion or
addition of one demi-syllable sound file to another can result in a distorted representation of the
sound which is actually desired. Accordingly, in order to accurately reproduce a desired sound,
it is necessary to consider the demi-syllables sound files which are being combined, and in many
cases to remove or truncate a portion of the files. Thus, depending upon the sounds which are
epresented by two demi-syllable sound files which are being combined, the derivative sound
record may be a full concatenation of the files, a concatenation of the first file with a part of
10 the second file, a conc~t~n~tion of a part of the first file with the second file, or a conc~tPn~tion
of a part of the first file with a part of the second file.
In F.n~ h, there are twenty four consonant sounds. Using the DECTalk~ symbols, these
are {"b" "ch" "d" "dh" "f" "g" "hx" "jx" "k" "1" "m" "n" "nx" "p" "r" "s" "sh" "t" "th" "v"
"w" "yx" "z" "zh"}. There are sixteen vowel sounds {"ae" "ah" "ao" "aw" "ax" "ay" "eh" "er"
"ey" "ih" "iy" "ow" "oy" "uh" "uw" "yu"}, which will be denoted Vmn where m,n = 1 to 16.
The sm~llest acoustic unit which allows a difference in meaning and which serve as the
building blocks of a language are known as "phonemes". Phonemes comprise all consonant
20 sounds and vowel sounds. Accordingly, in the F.ngli~h language for example, there are 40
phonemes.
A demi-syllable sound is an acoustic unit which comprises one or more phonemes and
spans from the start of a consonant sound to the middle of the following vowel sound in a
syllable or from the middle of a vowel sound to the end of the following consonant sound.
Accordingly, we define a beginning demi-syllable to be an acoustic unit of the form
BC(i) + BVm(j)
247464-1
2 ~6586~'
- 10 -
where m = 1 to 16
BC is the beginning consonant sound with i = 0, 1 or more and
BV is the beginning vowel sound with j = O or 1, i and j lepresell~ing the number of
such sounds
and an ending demi-syllable to be an acoustic unit of the form
EVn(j) + EC(k)
where n = 1 to 16
EV is the ending vowel sound with j = 0, 1 or more and
EC is the ending consonant sound with k = 0-5, j and k lepresenling the number of
such sounds
Note that in the formulaic definitions of demi-syllable above, a demi-syllable need not
necessarily have a vowel sound. That is, when j=0, then there is no vowel sound and m and
n are undefined. Accordingly, the combination of a beginning demi-syllable and an ending
demi-syllable, does not necessarily form a syllable which is commonly understood to have a
20 vowel sound. When j=l and m=n, then the beginning demi-syllable and the ending demi-
syllable have the same vowel sound.
{Vm} and {Vn} for m,n = 1 to 16 are the sixteen vowel sounds in Fngli~h, mentioned
above. In principle, more vowel sounds are possible and in some languages, are required.
Although not denoted in the above formula, there are 24 consonant sounds in F.n~ h but more
consonant sounds are possible and in some languages are required. In Fngli~h, the number of
contiguous beginning consonant sounds typically range from i= 0 to 4 (with i > 1 called
commonly a "blend"), while the number of contiguous ending consonant sounds typically range
247464 1
2 1 65862
- 11 -
from 0 to 5 (with k > 1 called commonly a "cluster"). In principle, these ranges may be
extended in languages other than English.
Some examples follow to illustrate the above formula.
Example, the Fngli.~h word "pit". The phoneme string is {p ih t}. The beginning demi-syllable
and ending demi-syllable are respectively {p ih} and {ih t}.
Example, the Fngli~h word "am" is represented by the phoneme string {"ae m"} and by the
10 demi-syllable {ae + aem} or {BC(0) + BV2(j)} + EV2(j) + EC(l).
Example, the F.ngli~h word "high" is represented by the phoneme string {hx ay} and by the
demi-syllable {hx ay + ay} or {BC(l) + BV6(1)} + {EV6(1) + EC(0)}
Example, the F.ngli~h consonant sound "s" is represented by the phoneme string and demi-
syllable "s" or {BC(l) + BV(0)} + {EV(0) + EC(0)}
Example, the Fn~ h word "strength" is replesented with the phoneme string {s t r eh nx th}
and the demi-syllables are {streh} and {ehnxth} or {BC(3) + BV7(1)} + {EV7(1) + EC(2)}
The mechanical wave embodiments of consonant sounds are generally irregular and
therefore difficult to manipulate without severe loss of fidelity to the original sound. In contrast,
the mechanical wave embodiments of vowel sounds are regular and periodic and therefore can
be easily duplicated, truncated and otherwise edited while retaining fidelity to the original sound.
By recognizing that the vowel sounds are easily editable and manipulable, and by restricting
conc~t-on~tion of acoustic units at the vowel sounds, distortion is minimi7ed
247464 1
21 65862
For a given vowel sound, i.e. m=n and j =l and the sound of BVm(j) is the same as
EVn(j), the exact formula for concaten~ting a first demi-syllable BV sound with the EV sound
of the second demi-syllable sound, to produce a satisfactory result, is the subject of trial and
error.
It is has been found that a concatenation ratio of 20/80 produces a suitable conc~tpn~tion
of demi-syllable sounds in most cases. In other words, 20% of the BV sound is joined with
80% of the EV sound. Consider the following example for the Fngli~h word "base". If the
"ey" sound is embodied in 25 cycles of a certain mechanical wave, then using the 20/80
10 conc~tlon~tion ratio
bey ("b" plus 5 cycles of "ey") + eys (20 cycles of "ey" plus "s") = "base"
This ratio is associated with a given vowel sound and represents a good co-llprolllise to
produce a satisfactory sound upon concatenating a beginning demi-syllable with "each" ending
demi-syllable. In other words, there are 24 ratios (one for each beginning demi-syllable)
associated with each of 16 vowel sounds.
As mentioned above, these ratios are a good complolllise for the general case. There are
20 exceptions for which this ratio produces unsatisfactory results. In such exceptional cases, a
second ratio is developed and used instead of the one for the general case. To consider the
example of "cat" above, the ratio of 20/80 may work well for the vowel sound "ae" in "cat"
{kae + aet} and "cap" (kae aep). However, in "cam", the result may be un~ti~f~ctory and
therefore in joining (kae + aem), a different, second ratio is used. This often occurs when the
first ratio works well with unvoiced consonants (like p and t) but the second ratio must be used
with voiced consonants which have no unvoiced counlerpal Ls. The voiced or liquid consonants
which have no unvoiced counterparts are "m", "n", "1" and "r". The voiced consonants which
247464-1
2 1 65862
- 13 -
have unvoiced countel~al ls are "d", "b", "g", "z", "zh", "j " with unvoiced counterparts
respectively of "t, "p", "k", "s", "sh", "ch".
The production of the original digitized sound files for the demi-syllable sounds should
be created as norm~li7ed as possible. Voice spectrum (pitch and harmonics), volume, duration
and aspiration should be as constant as possible for each sound file. Obviously, to meet the
above re~uirements, the human speaker should be the same for all sound files.
Consonant sounds are digitally recorded in the entirety and are, depending on the
10 consonant, about 0.25 to 1 second in duration. The Fnglish native speaker typically pronounces
a vowel sound in about 40 to 50 cycles. Vowel sounds may be digitally recorded in truncated
form or dynamically truncated and used according to certain conc~ten~tion ratios. Beginning
vowel BV sounds are typically recorded for about 20% of their natural duration, i.e. around 5 -
10 cycles; and ending vowel EV sounds are typically recorded for about 80% of their natural
duration, i.e. around 20 cycles.
T f~rning the spoken part of a foreign language is most effectively accomplished through
different and simultaneous (or almost simultaneous) sensory channels (seeing, hearing, touching,
understanding). Leaming through the different channels reinforce and augment the learning
20 process. This is more so when leaming Fngli~h because the written form of Fngli~h and the
spoken form of Fnglish lost their direct correlation centuries ago. Also, it is a common
experience that the student of a foreign language has difficulty correctly hearing the spoken
language - he or she hears what is not spoken or fails to hear what is spoken. The spoken part
is often too abstract in the sense that without context or some other anchor, the sounds are
filtered inaccurately through the student's native language processes. The sounds float, as it
were.
247464^1
2il 65862
- 14 -
In response to this phenomenon, an important part of this invention is the ~C~igning a
permanent physical value to each of the forty phonemes in Fnglich. A kin~Psthetic relationship
is developed through the use of the keyboard.
The system introduces the sound to the student's aural sense by audibly creating the
sound. Then it addresses the visual sense by printing the sound on the screen (display device
100). Then the student responds kin~Psthetically by entering data corresponding to what the
student thought he or she heard and saw, through his hands and fingers interacting spatially with
a phonemic keyboard like keyboard 50 with keys spatially org~ni7Pd as described and illustrated.
10 Then a visual representation is presented of the throat, mouth and tongue operating properly to
make the proper sounds, as illustrated in Figure 4. The student speaks into a microphone the
sound printed and it is played back with the recording of a native speaker saying the sound. A
multi-media dictionary entry is provided to give the student information about the sound, if it
is an F.ngli~h word. Obviously variations of the above-described procedures are possible, all to
reinforce the learning process.
An extra advantage is provided by the keyboard illustrated in Figure 2. It "assigns" a
"left" physical area to beginning demi-syllables, a "right" physical area to ending demi-syllables,
and a "central" physical area to vowel sounds. Obviously, other physical layouts are possible
20 (for example, the keys are arranged in areas different than that illustrated, having relative
positions different than that illustrated). These physical areas are spaced apart from one another.
Within each physical area are the specific keys necessary to create the desired demi-syllable.
Through use of the keyboard, a physical and spatial relationship is created between the written
language and spoken language. One speaks with one's fingers, as it were. One speaks with
one's eyes, as it were. Meaning dictionary.
Other keyboards are possible where the physical areas of the keys are arranged differently
with respect to each other, than the layout illustrated in Figure 2.
247464-1
2 1 ~ 5~2
- 15 -
Also, the above scheme will work with an ordinary QWERTY keyboard (demi-syllables
can be entered normally, one letter at a time). But there is a disadvantage. Because the unit
of entering is a syllable on a Boswell board, a person trained on the Boswell board will normally
be able to enter more quickly than a person trained on a QWERTY board which enters in units
of a single letter. Also, the desired spatial connection or correlation does not exist in the
QWERTY board because the keys for the demi-syllables are diffused across the entire board in
a pattern which is unrelated to the phonemes the student is entering.
The conc~ten~tion process can be simple (audible production of the beginning demi-
10 syllable followed immediately by the ending demi-syllable). But alternative smoothing
techniques are possible and preferable depending on the opel~ling environment and requirements.
Such techniques include ~mming windows.
Thus, with the system of Figure 1, a student may create desired syllables and words by
entering data from keyboard 50, and may hear the result over audio device 90. Similarly, with
app,opliate progr~mming, the student may see the result on display 100. However, since words
produced using keyboard 50 will not have characteristic stress or intonation in their syllables,
the system includes word memory 70 in which predetermined words are stored with these
features. Processing unit 70 is programmed to retrieve and playback a desired word, words or
20 complete sentences from memory 70 - which the student can hear with audio device 90 or see
with display device 100, and then endeavour to reproduce with appropliate keyboard input.
Similarly, the student can be prolllpted beforehand to produce a desired word from the keyboard,
and may subsequently listen to the sound of the word as reproduced from memory 70.
To enhance the learning process, processing unit 60 may advantageously include aprogram which visually indicates on display device 100 keys that were pressed to produce the
sound of said desired word and keys that should have been pressed to produce the sound of the
desired word. Preferably, as illustratd in Figure 5, this is achieved by a graphic illustration of
247464 1
2~i 65862
- 16-
the keys on keyboard 50, the keys which were pressed being visually highli~hted, the keys that
should have been pressed being ~imil~rly hi~hlighted but with the addition of a distinguishing
dot in the centre of the key. When all the highli~hte~ keys include the distinguishing dot, then
the student knows that the correct keys have been pressed. Alternatively, the graphic illustration
of the keys on display device 100 is indicated only upon an incorrect key being pressed.
Various modifications are possible to the embodiment which has been described herein
without departing from the principles of the present invention. Accordingly, the present
invention should be understood as encompassing all such modifications as are within the spirit
10 and scope of the claims which follow.
247464-1