Note: Descriptions are shown in the official language in which they were submitted.
~ 220 1 275
CA9-97-0 1 0
LOCKING TOOL DATA OBJECTS lN A FRAMEWORK ENVIRONMENT
The present invention relates in general to the data processing field, and particularly relates to a
locking meçh~ni~m for common access tool data.
s
Back~round of the Invention
Our concurrently filed application entitled "An Object Oriented Framework Mech~ni.~m Providing
Common Object Relationship and Context ~n~mPMt for Multiple Tools" (IBM Docket No. CA9-
97-002) relates to aframework ~"e~l"."i~m fortool data management. The locking mech~ni~m ofthe
present invention can be used in such an ellvil o~ lent.
Tools are units of software, programs or application modules within programs, that store, manage
and retrieve data for the user. Every new tool under development incl~ldes work to design, implement
15 and test the storage meçh~nism~ for the tool data. As a result, the costs associated with new tool
development (both in time and money) are generally not in~i~nificant.
Most tools have their own mer.h~ni.~m~ for storing and m~n~ging data which is often "proprietary".
In this context, proprietary means that details of the implementation are not shared with other tool
20 m~mlf~ctllrers or developers. This leads to a number of problems associated with customizing and
e~tPntling Pxi~ting proven tools to meet individual user needs. For example, the interface or "view"
portion of a tool may be intertwined with a storage mech~ni~m or model of a tool, leading to
difficulties in integrating new views with existing ones. This is referred to as a lack of neutrality in
the tool.
Also, data produced by one tool cannot be consumed directly or transparently by another tool.
Tn~te~ operations such as "export", which writes data to a foreign format consistent with other
~ 2201 275
CA9-97-0 1 0
tools, and l'illl~JUI l~', which reads data of a foreign format, are required, and the user of a tool must
consciously choose to export or import data between tools.
In addition, portions of data imported from a foreign format may be meaningless to or incompatible
5 with the data store ofthe importing tool and summarily discarded. This sacrifices round trip integrity
of the illro""aLion, and iterative development of information in more than one tool becomes difficult
or impossible.
Finally, tool developers must monitor revisions to or the invention of other tools that manage similar
10 data, and add new function to export and import the corresponding new data formats. In addition
to the raw expense of developing and testing new import and export functions, there is the time lag
between the introduction of a new format and the availability of import and export functions in other
tools to handle the format.
15 Object oriented (OO) progl~"""il-g and in particular OO framework technology, provide a way to
address the cost associated with co~ ~,lly l~;wo~killg existing tools and provide data integrity in the
use of multiple tools.
Object Oriented Technology v. Procedural Technolog~v
Though the present invention relates to a particular OO technology (i.e., OO framework technology),
the reader must first understand that in general, OO technology is significantly di~re"l then
conventional, process-based technology (often called procedural technology). Both technologies can
be used to solve the same problem, but the llltim~te solutions to the problems are always quite
25 di~ . This difference stems from the fact that the design focus of procedural technology is wholly
di~ele"l than that of OO technology. The focus of process based design is on the overall process that
solves the problem. By contrast, the focus of OO design is on how the problem can be broken down
into a set of autonomous entities that can work together to provide a solution. The autonomous
~ 220 ~ 275
CA9-97-010
entities of OO technology are called objects. In other words, OO technology is significantly di~e~
from procedural technology because problems are broken down into sets of cooperating objects
instead of into hierarchies of nested computer programs or procedures.
5 A significant feature of OO progr~ g is that the objects are reusable software entities that can
be combined in di~l~nl collll)ill~Lions or ascribed di~rellL attributes for di~r~l~L uses. An example
of this is found in U.S. Patent No. 5,550,971 for Method And System For Generating A User
Interface Adaptable To Various Database Management Systems, of U.S. West Technologies, Inc.,
which describes a dynamic model for generating a user interface with various "information forms"
10 illustrating a data base schema. The model is transportable to di~~ L data base management
systems without the user having to learn di~el~;"~ query l~n~l~ges, data base systems and specific
data base records, fields and relationships. The model is implemented by a set of concrete classes
whose instances represent entities and relationships at various distances from an actual data base.
Objects of these classes are created and interrelated to describe the o~ ion of a data base. The
15 model classes provide standard interfaces for exploring the structure of an actual data base to create
a user interface and for caching data base information consumed by the user interface.
Along similar lines is IJ.S. Patent No. 5,428,729 for System And Method Por Computer Aided
Software Fn inepring~ of IBM Corporation, which describes a system designed to track the location
20 of and access to data entities (docnment~tion, source code, test data), and to reference procedures
for the translation of data (compilers, editors, linkers, documentation formatters, test harnesses)
within the context of a software project under development. Each new project under development
is created from a template by the "metaprogrammer" and is presented via a GIJI (graphical user
interface). From this "master view", each user can clone a "user view" consisting of a subset of
25 objects from the master selected according to the access rights of the user. Through a view, specific
flows are described wherein a user can access data entities to edit, define and dispatch build
~ procedures, and define and (li~p~t~h test cases. Access rights relate users to objects via "classes" of
users. This patent is oriented around the appearance and flow of a GUI and how it provides access
~ 220 ~ 275
CA9-97-0 1 0
to files stored in ~ ly but distinct repositories, stores rules for tr~n~l~ting files from source to
target form, and controls access via user-specific views of a project. However, this is not an object
oriented data integration framework, and a fi-n~l~ment~l difference between this system and the
present invention is that the patented system is not designed to promote consistent behavioural feel
5 amongst multiple distinct and unknown tools through specified but ~t~n~ihle framework interfaces
and protocols.
Terms and phrases have evolved in the art which have particular meaning to those skilled in the art
of OO design. However, the word "framework" is one ofthe most loosely defined; it means di~erell~
10 things to di~ L people. Therefore when CO~ illg the characteristics of two supposed framework
me~h~nisms, care should be taken to ensure that the comparison is appropriate.
As described more specifically below? the term "framework" is used in this application to describe an
OO mechanism that has been designed to have core function and extendable function. The core
15 function is that part ofthe L~n~w~k me~h~ni~m that is not subject to modification by the framework
purchaser. The eAlell~ible function, on the other hand, is that part of the framework mech~nism that
has been explicitly designed to be customized and e~t~nded by the framework purchaser.
OO Framework Meçh~ni~cms
20 An OO framework me~h~ni~m can generally be characterized as an OO solution. Nevertheless there
is a ~m-l~m~.nt~l difference between a framework mech~ni~m and a basic OO solution. Framework
me~ " ,~ are deeigned in a way that permits and promotes c~lstomi7~tion and extension of certain
aspects of the solution. In other words, framework mech~nism~ amount to more than just a solution
to the problem. The meçh~ni~m~ provide a "living" solution that can be customized and extended to
25 address individl.~li7ed requirements that change over time. As discussed in the background portion
above, the customization/extension of quality of framework mech~ni~m~ is extremely valuable to
purchasers because the cost of customizing or ~ten~ing a framework is much less than the cost of
replacing or reworking an existing non-framework solution.
2201275
CA9-97-0 1 0
Tht;l~;r~lc;, when ~ 7wulk designers set out to solve a particular problem, they do more than merely
design individual objects and how those object interrelate. They also design the core function of the
framework (ie, that part of the framework that is not to be subject to potential customization and
extension by the ~ c;w~lk consumer) and the extensible function of the framework (ie, that part of
5 the framework that is to be subject to potential cu~o,l~lion and extension). In the end, the ultimate
worth of a framework merh~ni.~m rests not only upon the quality of the object design, but also on the
design choices involving which aspects of the ~amework represent core functions and which aspects
represent extensible functions.
Anexampleofaframeworkisthesubject of U.S. PatentNo. 5,325,533 forEngineering SystemFor
Modelling Computer Programs, of Taligent, Inc. The framework described in this patent provides
incremental interaction, generation and build facilities for a development environment.
Summary of the Invention
The present invention is directed to a mechanism for locking data objects for common tool acccess
in an application development environment. The mech~ni ~m consists of a repository co. ~ l ~; "i l-g lock
objects. Each lock object has a reference counter to indicate when the lock object is fully occupied.
Lock objects may be referenced by the data objects.
~rief Description of the Drawings
The embodiments of the invention will now be described in detail in association with accompanying
drawings in which:
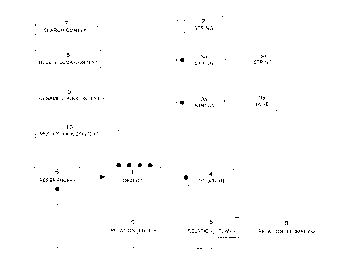
Figure 1 is a s~h~m~tic diagram, using OMT notation, showing a class hierarchy for a model
object, according to the invention;
Figures 2 through 6 are class diagrams, expressed in C~, of a framework mech~ni~m
according to a plerelled embodiment of the invention;
Figure 7 is a schematic diagram, similar to Figure 1, showing the model object as a pair of
classes, according to a further pl~felled embodiment;
~ 2201 275
CA9-97-0 1 0
Figure 8 is a hierarchical category diagram, using OMT notation, of a framework mech~niem
constructed in accordance with the te~çhin~.e of the present invention;
Figure 9 is a state diagram showing locking states of objects;
Figure 10 is a schematic drawing showing a locking merh~niem as implemented in the
5 pr~rel,~d embodiment ofthe invention;
Figure 11 is a flow diagram showing the steps for saving modifications in tool data ut~ ein~
the core functions of the invention; and
Figure 12 is a ~ow diagram showing the steps for issuing notifications of modifications in tool
data ~1tiliein~ the core functions ofthe invention.
Detailed Description of the Preferred Embodiments
The pr~rel-ed embodiment of the invention has been implemented in a common data model
framework that provides a base for sharing part inforrnation among di~el elll tools. The framework
combines a model mech~ni.em for standardizing the information built by individual tools and a
15 common repository for the il~ullll~Lion supporting partitioning and code generation. An example of
a common repository structure as implemented in the pl~rell~;d embodiment is the subject of our
concurrently filed application t*led "A Hierarchical Metadata Store for an Integrated Development
Environment" (I~,M Docket No. CA9-97-003), and is fully described therein. The rem~inder of this
disclosure conta;ns l~r~ nces to the common repository, as needed, in order to fully understand the
20 p~ ~rt;l I ~d embodiment of the present invention.
As discussed above, the principle of the framework is that the tool information is org~ni7ed into
model objects of various classes and relationships between those objects.
25 Each model object is characterized by three items of information: a name, a set of attributes and a
set of relations co"~ references to other model objects in the framework. A model class
hierarchy is shown schematically in Figure 1. Figure 2 illustrates the C~ interface to the object
abstract class ofthe prerelled embodiment.
220 1 275
CA9-97-0 1 0
Referring to Figures 1 and 2, the information associated with the object 1 is defined in a number of
separate strings, such as the name of the object 2 and its attributes generally design~ted by 3 . Each
attribute 3 contains a value which is either a standard string 3a or a "blob" 3b. (The term "blob" is
an acronym for "binary large object", a term commonly used in database technology. Here, it refers
S to an amorphous string of bytes. This is described in more detail below.)
Figure 4 shows a C~ interface to a blob abstract class according to the pler~;lled embodiment.
Values which are too complex or too highly structured to be represented in string form can be
implemented as kinds of blobs. Every blob must provide operations to set and inspect segment.c of
10 its data as keyed by strings whose intel~leLaLion is entirely up to the blob.
Another aspect ofthe framework meçh~ni~m, according to the pl~rt;ll~d embodiment, is that the
relations 4 of the model object shown in Figures 1 and 2 are defined in separate classes and have
mutually unique names. ~igure 3 shows the C~ intP~ce to a relation abstract class ofthe pl~rt;l-~d
15 embodiment that defines some of the attributes set forth below.
Returning to Figure 1, every relation 4 of a model object 1 is characterized by a name 5 which is a
string. Each relation 4 also contains a set of references 6 (0 or more) to other model objects. The
relation 4 must provide operations to inspect its name and to add, inspect or remove any of its
20 references.
The function ofthe reference 6 is to load its model object from disk into memory if the object is not
already in memory. The references must be bidirectional. That is if one object references a second
object, the second object must, in one of its relations, include a reference back to the first object.
25 Also, references are either "strong" or "weak". When a model object 1 is deleted, all model objects
it strongly references are also deleted, whereas when an object which weakly references another
object is deleted, only the bidirectional references to the deleted object in the other objects are
deleted.
- CA 0220127~ 1998-01-30
CA9-97-0 1 0
Two other .~ecl~n~ illustrated in Figure 1 must also be defined. These are the search context 7,
and lock context. The lock context has three aspects, delete lock 8, rename lock 9, and modify lock
10.
5 A model object may assume di~-elll contexts depending upon the path taken through the model to
the object. Figure S shows the C++ interface to a search context abstract class, according to the
pre~,led embodiment. A search context 7 represents a path along the subset of the objects in a
model. A search context provides operations to find and inspect attributes, and when asked to find
an attribute, the search context navigates along its lists of model objects until it either encounters an
10 object with the requested attribute or reaches the end of the list. If an object with the requested
attribute is found, the value of that attribute is returned. Thus, di~re enl search Gontexts allow a single
object in the model to appear to have dirrel~lll attributes.
Model objects in relationships must be locked by a tool before they can be mut~ted by the tool.
15 Locking will be tli~cu5sed in greater detail below in the context of the prt;r~l .ed embodiment of the
framework hierarchy. To change the attributes of a model object, only the object itself needs to be
locked. To rename a model object, the object itself needs to be locked along with all relations
referencing the object by name. To delete a model object, the object itself and any objects directly
or indi~ e~;lly strongly referenced by the object, as well as any relations referencing these objects, must
20 be locked. Each object in each relation is independently lockable, and this basic behaviour is
sufficient for an operation as simple as ch~nging the attributes of an object. The model framework
includes lock context objects to handle the more complex rename and delete scenarios. Figure 6
shows the C++ interfaces to delete lock context 8 and rename lock context 9 abstract classes.
25 A rename lock context can be constructed from a model object prior to lellAIll;l-~ the object. The
rename lock context locks the model object in any relation Col~ g a reference to the object, since
some relations may be key to the object's name.
~ 2201 275
CA9-97-0 1 0
A delete lock context can be constructed from a model object prior to deleting the object. The delete
lock context will lock the model object and any model object reachable by a chain of strong
references (since, under the framework, they will be deleted as well), and any relation co~
references to any of the aforementioned objects. These reference have to be removed from the
5 relations to prevent d~ngling references.
In a further prt;relled implementation, the object classes are actually a pair of classes, namely an
abstraction class and an implementation class. This is illustrated in Figure 7. Every model object
consists of an abstraction object 11 cont~ining a reference 13 to a corresponding implementation
10 object 14.
The complete interface to and behaviour of an object is presented through its abstraction portion.
However, only the name 12 of the object is actually stored there. The attributes 15 and relations 16
ofthe objects are hidden in the implementation portion. Any request for information about an object
15 beyond its name is secretly met by the implementation portion and perhaps by some of the relations
contained in it.
As the abstraction, implP.mP.nt~tion and relation objects are independently persistent, a request for the
name of an object will incur the cost of loading the abstraction portion from disk 17 without the
20 implementation portion or the relations. This technique minimi7:es the amount of data transferred
from disk to satisfy an inquiry and improves the overall performance of the tools under the
framework.
Utilizing the above definitions, the framework of the pl er~;ll ed embodiment provides an environment
25 and supporting mer.l~ " ,.c for implem~nting a flexible co~ m ,ent hierarchy of development parts.
The base classes define standard behaviour for part locking (also called col~ e.nt support),
references between objects, attribute/property access, runtime type identification and persistence.
All tools derive concrete implementations from the base classes.
~ 220 1 275
CA9-97-0 1 0
Figure 9 illustrates an abstract base hierarchy according to a ~ d embodiment of the invention.
The core fim~tinn~ in this hierarchy are Persistence 20, Notification 21 and Locking 22, identified as
base classes in the hierarchy, above the broken line. This is not to say that any of these classes may
not be overwritten as is possible in C++ progl ~ " " l lin~, but some form of persistence, identification
5 and locking are core functions required for the framework of the invention to operate. The classes
below the broken line, beginning with lDE Element 24 illustrate some of the data model types that
can be inc.hldec~ in the framework hierarchy. These additional classes are defined in the Appendix
below, and a number of them are discussed in detail in our concurrently filed application (IBM
Docket No. CA9-97-003),
Inheritance under the framework hi~ ,lly ofthe present invention operates to provide the following.
A persistence service " ~ . "~ the state of a data model in a host computer's file system and shares
this data among several running program--s Model objects derived from the framework hierarchy are
grouped into files in the file system. Objects in the file system are referred to as the "committe~
15 model". When running a program using a framework model, only the data in the committecl model
is visible. All changes to the model are performed on in memory copies of the model objects in the
private address space of a single running program.
A locking service enforces mutual exclusion from modifications to the model. Since each running
20 program makes çh~n~es to private in-memory copies of model objects, no two programs may be
modifying or deleting the same objects concurrently. The locking service provides a mandatory
locking scheme which prohibits concurrent access. This is discussed in detail below.
Referring to Figure 9, inheritance from the Persistence base class 20 provides that model objects are
25 constructed from each program's default local heap and shared, by persistence, through the host
computer's file system. In many C++ implementations, dynamic or runtime binding is normally
implemented as a pointer in each object to class-specific tables of constant method pointers. The
method table pointers are usually stored in a dynamic link library or executable program, but are
~ 220 1 275
CA9-97-0 1 0
in~ccescible because every Px~ t~ble image is dirr~;l ellL and the location of the tables is di~l ell~. As
a result, in ordinary implementations, it is not possible to store C++ objects in shared memory and
access their data from dirrel enL executables.
5 The Per~ t~nce service in the present invention avoids this problem through the default local heap
construction.
The Persistence class 20 also provides the me~hA~ ", for all classes in the framework to write to and
read from disk. All derived classes within the model that extend the base object state must provide
10 their own "read" and "write" methods, but the Persistence class also defines a meçh~ni~m for object
~L,t;alllillg so that a class overrides the streaming operators for use in conversion between the disk
form ofthe object and the in-memory form. The ~L,t;a"""g operators invoke each object's own "read"
and "write" methods to do the actual processing. The following implçment~tion convention is used
in all classes in defining the "read" and "write" methods for a derived class in the pl~r~lled
1 5 embodiment.
The framework provides a standard interface for implementing mandatory mutual exclusion for C++
objects, in the ~It;r~lled embodiment. Classes using this impl~.ment~tion are derived from the Locking
class 22. Since mutual exclusion is only required for objects shared among running programs,
20 Locking 22 is itself a subclass of Persistence 20.
The locking scheme provided by Locking 22 is discussed below. However, there are two cases in
which these me~h~ni.cm~ are inapp~ iate; first, in the global "parts" list, a data structure guaranteed
to contain all objects of a particular type; and second, in the "dirty pool", a meçh~ni~m for updated
25 meta information which is stored with but not as part of a model object.
The Locking class 22 is a model abstraction for a persistent object that can be locked. It provides
the locking primitives used within the model. In general, these primitive are not directly used, but
CA 0220127~ 1998-01-30
CA9-97 010
are rather invoked as part of a composite object lock. An object lock is constructed in two steps:
1. A lock identifier is obtained for the int~nr~ed type of action. In the plt;rell~d embodiment, the
lock pool is a singleton C~ class located in a scalable shared memory pool, described below
that manipulates named shared memory segments of fixed size. Because of this, a lock
identifier is really an array index into a pool.
2. A shared lock or an exclusive lock is then constructed using the obtained lock identifier by
;.,l;"g a lock object type. In the plerelled embodiment, the lock is acquired by way of
a C~ constructor which is usually used as a local instance so that the destructor will be run
automatically no matter how the code block exits. Failure to get a lock is conveyed by way
of an exception. The destructor frees up locks in most cases, one exception being the modify
lock context.
Singleton class refers to the C~ progl ~"" "ing convention that there can be only one instance of the
class alive at a time per process.
The scalable shared memory pool is a peer to peer pooling meçh~ni~m that involves allocating fixed
size segments from the system named shared memory pool. The name of a segment is created by
taking a predefined character sequence and then appending the segment number (starting from 0).
Each process has a singleton pool that manipulates the pool segments for that process. When a new
segment is required, the name is calculated and an attempt is made to find the segment in current
memory. If not found, the segment is allocated. This process is synchro~ ed such that the first
process to require the memory segment will allocate it and every subsequent process will reaccess
it (hence, peer to peer as opposed to client/server). Each singleton pool class in a process keeps an
array of all of the segments it knows about. This allows access to any segment in the process as a
-
~ 220 1 275
CA9-97-0 l 0
quick indirection into the array. In addition to the array of segments, a special named area is allocated
that contains global il~l malion about the pool. The name of this area is fixed and the first process
to start up its pool will allocate it. Access to the global information in the pool is synchronized to
avoid a race condition between two or more processes.
Each segment is treated as a f~ed size array of objects so that each segment is divided into "n" pieces
of size "x" (where "x" is the size of objects to be placed in pool). Each process requests to get a pool
id when it needs a piece of storage. The pool uses the global h~llllaLion segment to find out the
current highest index that has been given out. If the next value is still within a segment (i.e. is not a
10 multiple of n), then it is simply returned. Otherwise, a check is made on all objects currently in the
pool to find an object that is not in use. Each of the "n" pieces of storage in the pool segment must
have an inrli~tor to mark whether it is used, or unused, such that the singleton class can perform this
check. If an unused object is found, its index is passed back and the storage is marked as used,
otherwise a new segment is allocated.
Once an index has been doled out, it can be used to access the shared memory storage via a special
pool method. The pool method simply takes the index and calculates the segment number and the
index within the segment. It then accesses the array of segment addresses and after calculates the
address ofthe object in the segment In this way, the same id can be used by multiple processes, even
20 though the shared memory may be assigned to di~elenL virtual addresses as is the case on some
platforms, such as Windows~ NT. The calculation is as follows:
segmçnt number= poolId / n
segment index = poolId modulus n
The pool is scalable since it allocates segments as needed. It is peer to peer in that it does not matter
how many processes are involved or in what order they are started (no server is required). The
me~,h~ni~m requires only two indirections to access any item by its id.
~ 2201 275
CA9-97-0 1 0
In the ~rer~"ed embodiment ofthe present invention, the lock object types are:
1. shared lock: shared read only access; and
2. exclusive lock: restricts read/write access to one process.
5 As illustrated in the state diagram of Figure 9, constructing a lock object locks access to the
underlying lockable model object. Destruction ofthe lock object is required to unlock access, in most
cases. Thus, by in~t~nti~ting a delete lock type to remove the instantiation of a shared lock type,
shared restricted read/write access to the underlying model object is restored. This guarantees that
the object will not be deleted, and allows others to read or modify it (that is to obtain a shared or
10 exclusive modif~ing lock). The exception is when the underlying locked object is modified. The lock
can be destructed when the modification is saved.
Mandatory locking for construction and destruction is enforced through a convention. The
constructors and destructors of framework classes are "protected". This prevents a program from
15 directly creating or deleting an object. Tn~te~-l class data "create" and "destruct" methods are
provided for every framework class. The create method obtains the lock needed to create and insert
an object into the existing model before constructing the object. The destruct method obtains all the
locks need to remove all references to the objects from the model before deleting the object. Failure
to acquire the lock results in the modification operation being aborted, the model state being
20 unchanged, and an exception being thrown.
The lifetime of a lock is dependent on both the persistence subsystem and the existence of a lock
object r~relellcillg the lock in memory. This is illustrated in Figure 10. The lock object class 100 has
as derivatives Shared Lock 102 and Exclusive Lock 104. The difference between these is that a
25 shared lock can have many processes; an exclusive lock is "exclusive" to one process at a time. A
single process resource can have either one exclusive lock on it, or one or more shared locks.
When a lock object 100 is inst~n~i~ted by a lockable object 106, a lock is located by referencing the
14
220 1 275
CA9-97-0 1 0
lock pool 108 via the lock ID ~i~igned when the lockable object is constructed. The lock 112 within
the lock pool contains the process ID of the lock owner 1 16. If a lock owner ~ pls to reacquire
a lock which it already owns, this is permitted.
5 In the case of shared locks, process IDs are always a dummy or reserved id~ntifier. The same dummy
identifier is used by all ~el"~l~ to ascuire a shared lock. Thus, if a shared lock is already held by any
process, the process IDs will match and the lock will be granted. To keep track of the number of
shared lock owners, a reference counter is used. The counter is incremented every time the lock is
acquired and decremented every time the lock is released. When the counter reaches zero, the lock
10 is no longer owned by any process, and is available for use as either a shared or exclusive lock.
In the case of exclusive locks, the real process ID is used, to prevent sharing. A special type of
exclusive lock is a "modify" lock which keeps track of a locked object's modified state. If the object
is unmodified, the lock is immediately freed when its destructor is run. If the locked object is
15 modified, the modify lock will not be released by the modify lock destructor until all changes to the
locked object are co~ ed by a save or cancelled. If the modify lock is not destructed (even when
a save is performed), the object remains locked. Programs can rely on this behaviour to keep an
object locked across saves.
20 Two exceptions were noted above for use of the locking mech~nism, global parts list and "the dirty
pool".
The global parts list contains a set of uniquely named objects. In the framework of the preferred
embodiment this is contained in a single object, that is a singleton class. When a shared memory list
25 co"~ il,g data structures that detect name clashes is implemented, a part is added to the global list
in one program, and the name of the part is tested for ur~iqueness in both the committed list of parts
and the shared list of ul~cn~ ed part names. If the name is not unique, the add operation fails and
an exception is thrown. Otherwise, the insertion operation completes, and the name is added to the
CA 0220127~ 1998-01-30
CA9-97 010
shared heap to prevent other programs from using it. Each running program ,"~ c a list of
objects it inserted. When a save operation is in progress, the program removes all of these objects.
By storing only the names, scalability is provided, in that the amount of shared memory used to
prevent name clashes in the global part group is ",;n;~"i~ed
The second exception is the dirty pool. This refers to an index pool that tracks whether objects have
been modified without a corresponding update to their source code files. An object must be
regene.~led when its depP.ndPnciPc change. Not modifying the actual object reduces lock contention
among processes as well as h~plovillg pe-rollllal1ce. When the object and its source files lack
10 concurrence, the object is referred to as "tainted" or "dirty", hence the name for the index pool. The
dirty pool uses the scalable shared memory pool Iller.l~ cm to support remote data for a shared
object. Remote data is enr,~ps~ ted object state which does not depend on the object. This data can
be modified without going through the lock the object, modify the object, save the object sequence,
reducing the need for lock contPnti~ n between processes. The pool uses a lock pool indexing scheme
15 and one an object is ac~i~nPd an identifier, a bit segment in the dirty pool index that is permanent for
the life of the model object. Each dirty pool segment is divided in half. the first half has the in-use
bits and the second half has the dirty state bits. The pool is persistent in the pr~rel I ed embodiment.
The dirty pool can stream itself to and from disk. In this way, information on whether source for an
object needs to be regenerated can be queried in subsequent sessions.
There are three requirements on the persistence service when cor.. illing changes to a model:
1. a program cannot read new versions of old objects while operating from the committed
model;
2. failure to complete writing change to files cannot corrupt the committed models; and
25 3. changes made in one program cannot overwrite changes co"""illed by another program.
Save is implemented as a two phase commit into the file system synchronized by an interprocessed
communication protocol. This process is illustrated in the flow diagram of Figure 11.
16
CA 0220127~ 1998-01-30
CA9-97-010
The interprocess communication protocol utilizes two events; "save pending" and "save coll.plete".
These events are implemented with a shared memory flag, a shared memory counter, and two host
system semaphores called "notify" and "acknowledge".
5 The save starts when the saving program sends a "save pendillg"event (block 40). "Sending an event"
consists of setting the events shared memory flag to true, initi~ ing the model shared memory count
to the number of programs ~ cl~ed the model, resetting the "acknowledge" semaphore, and posting
the "notify" semaphore.
10 When the flag files indicate that phase one of a save has started (clock 42), the saving program writes
all files it has modified to temporary files (block 44). Saving to temporary files prevents other
programs from accç~ the tempul~y files if they are still actively utili~ing the model. This satisfies
half of part one of the safe save objective, that other programs cannot mix objects from the committed
model with objects in the temporary files.
Once the saving plU~ IIII colll~ S writing all çh~nged files into temporary files (block 46), it waits
for the "save pending" event to complete. This will be acknowledged to the sending program when
the "acknowledge" semaphore is posted (block 48).
20 The save pending event is processed by a worker thread found in each program attached to the
framework model. When the event is received, the worker threads wake up. The threads delelll~ne
if their program is attached to the model being saved by colllp&ling all models open in the program
with a model which has the saving flag set. If the program is attached to the saving model, a cross
thread package is used to post the notification into the programs main thread. This notification is
25 received asynchronously after the main thread has completed processing all GUI events and
notifications received previous to the saved pending notification (block 58).
When the program main thread receives the same pending notification, it stops dçm~nd-loading or
- CA 0220127~ 1998-01-30
CA9-97-010
changing objects in the model (block 60). This completes require"~enl one, that programs cannot mix
old and new objects.
As the other programs receive and process the save pending event, they acknowledge receipt of the
5 event by decre".enlil-g the shared memory counter (block 62). When the decle"lenlillg counter
equals 1, all programs have processed the "notify", and the events "acknowledge" semaphore is
posted, ;,~ the event is complete (block 64), thereby waking the sending program (block 48).
When the "save pending" event completes, the saving program flags the first phase of the save
lO complete through on disk flag files (block 46). Before this point, an interruption, such as a system
crash, loses all changes but leaves the database in a consistent state.
If no error occurs, all the data needed to access the change version of the model is written to disk,
and it is not possible for a system or program crash to leave the on-disk model in an inconsistent
15 state. The saving program then lena~"es all temporary files to their proper names and removes all
empty data files from the committed model (block 50). This means all çh~nged files have their
contents replaced with the versions in the temporary files, and this satisfies part 2 of the safe save
requirement.
20 The saving program sends the "save complete" event (block 52) to the waiting worker threads and
program main thread, to indicate to all these other programs that the on disk model is con.cict~nt, and
waits for the event to complete (block 54) before cle~ning up (block 56).
The other core function, found in the Notification base class 21 in Figure 8, provides the ",eçh~l-icm
25 for communicating ch~nges in tool data in the framework to other users. This is also illustrated in
Figure 1 1.
All other programs ~tt~.hed to the model wake up when they receive the "save complete" event
~ 220 1 275
CA9-97-010
(block 64). These programs then call the framework refresh method which visits each file the
program has opened and loads the latest revision of each changed object (block 66). Once this
process is complete, every program contains a private in-memory version of the model that is
consistent with the most recently saved changes. If the program contains any objects which were
5 deleted or modified by the saving prograrn, the program receiving the "save complete" event will also
have a model/view/controller notification sent to every observer of the affected objects (block 68).
Observing these notifications is the hook that programs use to make their internal state consistent
with the changes col""~ ecl to the model. ~er pelroll."..g the refresh, each program acknowledges
receipt ofthe save complete event (block 70).
Completing the save complete event wakes the saving program and all the worker threads. The
saving program completes any housekeeping chores and returns from save. The worker threads
return to their waiting state on the save pending interprocess event.
15 As it is not always possible to determine in advance whether an operation ch~nging many model
objects will complete sl1ccçc~fi-lly, in a further pl~r~lt;d embodiment of the invention, the persistence
service provides the ability to return to a known good state in the event of a failure. This process is
illustrated in Figure 12.
20 This check point mech~ni~m restores the private in-memory state of a program. The state to be saved
includes all object deletions, creations and modifications which have occurred since the program
started or saved the model as well as the persistence service data structures used to manage the
objects and data files. During operation of the check point mech~ni~m, this data is preserved in a
temporary ffle.
A program calls the check point mecl~ " l to indicate it is starting a modification which may require
restoring the previous state (block 76). The persistence subsystem then visits each persistence file
opened by the program on the model. The persistence system identifies objects for which the in
~ 220 1 275
CA9-97-0 1 o
memory state is di~lell~ from the committed state (block 78). In memory, modified objects arë
flagged as saved into the temporary file (blocks 80, 82).
When an attempted modification is unseccessful, usually because an exception is thrown and caught
(blocks 84, 86), a "roll back" method is called (block 88). The roll back method recreates objects
deleted after check point, removes objects created since the check point, and restores the state of all
modified objects and of the persistence service data structures to their state when check point was
called (block 90).
If the process cletçrmines that the algorithm completed s~lcces~fi-lly (blocks 84, 86), it calls "commit"
(block 92) to release the resources used by the check point mech~nism and to flag the internal model
state as con~ tçnt
Modifications to the above preferred embodiments of the invention which would be obvious to those
skilled in the art are intended to be covered within the scope of the appended claims.