Note: Descriptions are shown in the official language in which they were submitted.
- 1 -
SPECIFICATION
TITLE OF THE INVENTION
VECTOR CODING METHOD, ENCODER USING THE SAME AND DECODER
THEREFOR
BACKGROUND OF THE INVEI~1'TION
The present invention relates to a vector coding
method that is used to encode speech, images and various
other pieces of information and is particularly suited to
encoding of information that is transmitted over an error-
prone channel such as a mobile radio channel and encodes
an input vector through the use of a plurality of
codebooks each composed of plural representative vectors.
The invention also pertains to a vector encoder using the
above-mentioned vector coding method and a vector decoder
for decoding codes encoded by the vector encoder.
Methods that have been proposed to transmit vectors
over channels prone to channel errors are to set
representative vectors in anticipation of possible channel
errors and to take into account the channel errors when
labeling representative vectors. These methods are
disclosed in Kumazawa, Kasahara and Namekawa, "A
Communication of Vector Quantizers for Noisy Channels,"
Transactions of the Institute of Electronics, Information
and Communication Engineers of Japan , Val. J67-B, No. 1,
pp. 1-8, 1984, zeger and Gersho, "Pseudo-Gray Coding,"
IEEE Trans. an Ca mm., Vol. 38, No. 12, pp. 2147-2158, 1990,
and other literature. These methods bald all
representative vectors directly in one codebook, and hence
require large storage capacity far storing the codebook.
As a method that does not need large storage capacity
in transmitting vectors over channels prone to channel
220188
- 2 -
errors, there has been proposed to transmit vectors after
quantizing them through the use of two structured
codebooks. This is disclosed in Moriya, "Two-Channel
Vector Quantizer Applied to Speech coding," Transactions
of the Institute of Electronics, Information and
Communication Engineers of Japan, IT87-106, pp. 25-30,
1887 and other literature. This method has two small-
scale codebooks and uses two representative vectors in
combination to reduce the storage capacity needed and
transmits two labels indicative of the two representative
vectors to lessen the influence of channel errors. This
method will be described with reference to Figs. 1A and 1B.
The representative vectors of the cadebooks are generated
beforehand by learning, for instance. In an encoder
depicted in Fig. 1A, one representative vector z1i is
fetched from a codebook CB1 and one representative vector
z2j from a codebaok CB2, then they are added together in a
vector combining part 3 to generate a vector sum
Yij=zlifz2j. and the distance, d(X,yij?, between the
combined representative vector yij and an input vector X
via an input terminal ~ is calculated, as distortion, in a
distance calculating part 5. A control part 6 controls
representative vector select switches 7 and 8 for the
codebooks CB1 and CB2 and searches them for the
representative vectors z1i and z~j that minimize the
output d(X,yij) from the distance calculating part 5. The
control part 6 provides, as an encoded outputs to an
output terminal 9, labels i and j of the representative
vectors z1i and z~j that provides minimum distance.
In a decoder shown in Fig. 1B, the control part 6
controls representative vector select switches 13 and 14
in accordance with the labels i and j in the input code
via an input terminal 11 and reads out representative
CA 02201858 1999-06-10
- 3 -
vectors z1i and z2j from codebooks CB3 and CB4,
respectively. The thus read-out representative vectors
z1i and z2j are combined in a vector combining part 17
into a reconstructed vector yij=z1i+z2j, which is provided
to an output terminal 18. Incidentally, the codebooks CB3
and CB4 are identical to CB1 and CB2, respectively.
The method described above in respect of Figs. 1A and
1B reduces the storage capacity of the codebooks needed for
storing the representative vectors and lessens the influence
of channel errors by combining the vectors in the decoder
through utilization of the two labels corresponding thereto.
With this method, however, if an error arises in the
labels during transmission over the channel, then
distortion will occur in all elements of the received
vector. According to the circumstances, the error will
cause an abnormally large amount of distortion in the
decoded output.
Another problem of this method is that the amount of
processing required is very large because it involves the
calculation of the distance d(X,yij) for every
combination of representative vectors of the two codebooks
in search for the pair of representative vectors that
minimizes the distance.
SUMMARY OF THE INVENTION
An object of the present invention is to provide a
vector coding method that prevents an error in the input
code to the decoder from causing serious distortion of its
output.
Another object of the present invention is to provide
a vector coding method that prevents an error in the input
code to the decoder from causing serious distortion of its
2201858
- 4 -
output and permits reduction of the amount of processing
required.
Another object of the present invention is to provide
a vector encoder that embodies the above-mentioned vector
coding method.
Still another object of the present invention is to
provide a vector decoder that decodes a vector encoded by
the vector coding method that serves the above-mentioned
objects.
According to the vector coding method and the encoder
of the first aspect of the present invention,
representative vectors from respective codebooks are
combined and the distance between the combined
representative vector and the input vector is calculated;
in this instance, the representative vectors to be
combined are those multiplied by predetermined different
weighting coefficient vectors, each of which is composed
of the same number of components. At least ane of the
components in each weighting coefficient vector assumes a
maximum value, and the positions of the maximum components
in the respective weighting coefficient vectors differ
with the codebooks. The multiplication of each
representative vector by the weighting coefficient vector
is done on the representative vector read out of each
codebook, or weighted representative vectors respectively
premultiplied by the weighting coefficient vectors are
prestored in each codebook.
According to the vector coding method and the vector
encoder of a second aspect of the present invention, in
the first aspect, the distribution of the set of weighted
representative vectors multiplied by the weighting
coefficient vectors for each codebook are approximated
with straight lines, then the input vector is projected on
' 2201858
_ 5 _
each straight line and a plurality of weighted
representative vectors present around the projection are
chosen for each codebook. The thus chosen weighted
representative vectors of the respective codebooks are
combined in pairs and that one of the combined vectors
which has the minimum distance to the input vector is
selected as the combined representative vector.
In a third aspect, the present invention relates to a
decoder for codes encoded into vectors according to the
first or second aspect. The representative vectors read
out of respective cadebooks are multiplied by weighting
coefficient vectors by multiplying means and the
multiplied weighted representative vectors are combined
into a reconstructed vector; the weighting coefficient
vectors are selected in the same fashion as in the first
aspect of the invention.
BRIEF DESCRIPTION OF THE DR~t~TINGS
Fig. 1A is a block diagram showing the configuration
of an encoder embodying a conventional vector coding
method;
Fig. 1B is a block diagram showing a conventional
decoder for use with the encoder of Fig. 2A;
Fig. 2A is a block diagram illustrating an example of
the encoder embodying the present invention;
Fig. 2B is a block diagram illustrating an embodiment
of the decoder according to the present invention;
Fig. 3A is a graph showing each representative vector
z1i of a codebook CB1;
Fig. 3B is a graph. showing a vector obtained by
multiplying each representative vector zli by a weighting
coefficient vector w1;
CA 02201858 1999-06-10
- 6 -
Fig. 3C is a graph showing each representative vector
z2~ of a codebook CB2;
Fig. 3D is a graph showing a vector obtained by
multiplying each representative vector z2~ by a weighting
coefficient vector w2;
Fig. 3E is a graph showing examples of a combined
vector and an erroneous combined vector in the present
invention;
Fig. 3F is a graph showing examples of a combined
vector and an erroneous combined vector in the prior art;
Fig. 4 is a graph showing a set of weighted
representative vectors and a straight line for
approximation, for explaining the vector coding method of
the present invention;
Fig. 5 is a block diagram illustrating an example of
the encoder of the present invention applied to the CELP
scheme;
Fig. 6A is a table showing a first codebook with
weighted gain vectors stored therein;
Fig. 6B is a table showing a second codebook with
weighted gain vectors stored therein;
Fig. 7 is a graph showing weighted gain vectors of
Figs. 6A and 6B on a coordinate system;
Fig. 8 is a block diagram illustrating the encoder of
the present invention applied to the quantization of
random excitation vectors;
Fig. 9 is a block diagram illustrating the encoder of
the present invention applied to the quantization of pitch
excitation vectors;
Fig. 10 is a block diagram illustrating the encoder
of the present invention applied to the vSELP scheme;
Fig. 11 is a graph showing segmental SN ratio of
reconstructed speech with respect to a channel error rate
2~~1858
in the cases of using one gain cadebook and two gain
cadebooks far vector encoding of gains gp and gc in Fig.
5%
Fig. 12 is a graph showing, as an equivalent Q value,
the MOS of the reconstructed speech with respect to the
channel error rate in the two cases of Fig. 11; and
Fig. 13 is a graph showing the segmental SN ratio of
reconstructed speech with respect to the channel--error
rate in the case of the present invention that uses two
weighted gain codebooks for vector encoding of the gains
gp and gc in Fig. 5.
DESCRIPTION OF THE PREFERRED EMBODIMENTS
In Figs. 2A and 2B there are illustrated in block
form an embodiment of the present invention, in which the
parts corresponding to those in Figs. 1A and 1B are
identified by the same reference numerals. In the encoder
of Fig. 2A, multipliers 21 and 22 are provided between the
representative selection switches 7, 8 and the vector
combining part 3, by which components of L-dimensional
(where L is an integer equal to or greater than 2)
representative vectors z11=(zlil. zli2, ..., z
1iL) and
z2j=(z2jl. z2j2, ..., z2jL) selected from the cadebooks
CB1 and CB2 are multiplied by the corresponding components
of L-dimensional weighting coefficient vectors w1=(w11.
w12, ..., w1L) and w2=(w21, w22, ..., w2L), respectively.
At least one of the L components forming each of the
weighting coefficient vectors w1 and w2 assumes a maximum
value and the positions of the maximum components .in the
respective weighting coefficient vectors w1 and w2 differ
with the codebooks CB1 and CB2. According to the present
invention, letting the weighting coefficient vectors w1
and w2 be represented by the following weighting
220858
coefficient matrixes W1 and W2 that have, as diagonal
elements, the values w11. w12. ..., w1L of the components
by which the respective components of the representative
vectors are multiplied:
Wll 0 ... ... p
p W12 p ... 0
Wi = . 0 . . t1~
. a
Q ... ... Q W1L
W21 Q ...
Q W22 a
W2 = . 0
. p
Q ... ... Q W2L
the weighting coefficient vectors w1 and w2 may preferably
be selected so that the sum of the weighting coefficient
matrixes W1 and W2 of the codebooks CBl and CB2 becomes a
constant multiple of the unit matrix as follows:
W11 0 ... ... p W21 0 ... ... p
Q W12 a ... Q a W22 a ... ()
0 . . -I- . a
a . . . a
Q ... ... Q W1L (~ ... ... a W2L
1 a ... ... Q
0 1 a
- . . . x K ~3~
. . 0
0 0 ~~~ 0 2
22~1~58
where K is a predetermined constant. Vectors wlzli and
w2z2j, obtained by multiplying the representative vectors
z1i and z2j by the weighting coefficient vectors w~ and w2,
respectively, are combined in the vector combining part 3,
and the codebooks CB1 and CB2 are searched for
representative vectors zli and z2j that minimize the
distance between the combined nectar yij and the input
vector X.
With such a configuration as described above, for
example, when L=2, the representative vectors z1i and z2j
are expressed by two-dimensional vectors zli=(zlil,zli2)
and z2j=(z2j1,z2j2), respectively. Suppose that k=2 and
that the weighting coefficients which satisfy Eq. (3) are
w1=(w11=1.8, w12=0.2) and w2=(w21=0.2, w22=1.8). Assuming
that representative vectors zll, z12, ... of the codebook
CB1 are distributed substantially uniformly all over a
plane of a certain two-dimensional range defined by zlil
in the first-dimensional direction and zli2 in the second-
dimensional direction as shown in Fig. 3A, weighted
representative vectors zl1' and z12', ..., obtained by
multiplying each representative vector z1i=(zlil. zli2) bY
the weighting coefficient vector w1=(1.8, 0.2), are
concentrated close to the first-dimensional axis as shown
in Fig. 3B. Similarly, assuming that representative
vectors z21, z22, ... of the codebook CB2 are distributed
substantially uniformly all aver the plane of a certain
two-dimensional range defined by two axes as depicted in
Fig. 3C, weighted representative vectors, obtained by
multiplying the representative vectors z21, z22, ... by
the weighting coefficient vectors w2=(0.2, 1.8), are
concentrated close to the second-dimensional axis as shown
in Fig. 3D.
220188
Suppose, for example, that when it is judged at the
transmitting side that the weighted combined vector yij of
the representative vectors z21 and z1i has the minimum
distortion with respect to the input signal X, the label
of the one weighted representative vector z1i becomes z1i'
because of a channel error as shown in Fig. 3E. In this
instance, the combined vector yij changes to yij' at the
receiving side. There is a possibility that the weighted
representative vector z1i changes to any other weighted
representative vectors z1i', but since the vector z1i has
a biased distribution, the value of the second-dimensional
component of an error vector, ~y=dyij-yij', between the
combined vectors yij and yij' is relatively small, no
matter how much the vector z1i may change. In contrast to
this, in the case where the combined nectar is not
multiplied by the weighting coefficient, if the one
representative vector z1i changes to a representative
vector z1i', combined vectors of these vectors z1i and
z1i' and the other representative vector z2j become yij
and yij', respectively, as shown in Fig. 3F. Since there
is a likelihood of the representative vector z1i changing
to any of the representative vectors of the codebook C81
and since the representative vectors z11, z12. ..- are
distributed over a wide range, the error vector dy between
the combined vector yij and the changed combined vector
yij' is likely to have appreciably large first- and
second-dimensional components.
In other words, in the example of Fig. ~E, when the
weighted representative vector wlzli=(w11z1i1. w12z1i2)
becomes wlzli'=(wllzlil', w12z1i1') because of a channel
error, distortion is concentrated on the first-dimensional
component w11z1i1' to keep down distortion of the secand-
CA 02201858 1999-06-10
- 11 -
dimensional component w12z1i2'~ bY which distortion is
reduced as a whole.
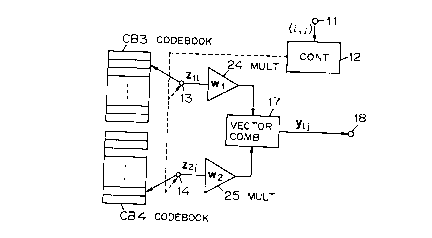
Fig. 2B illustrates in block form an embodiment of
the decoder of the present invention, which is supplied
with the labels i and j and the weighting coefficient
vectors w1 and w2 from the encoder of Fig. 2A and decodes
the code yip. The decoder has the same codebooks CB3 and
C$4 as those CB1 and CB2 in Fig. 2A, reads out
representative vectors of the labels i and j of the
inputted code from the codebooks CB3 and CB4 and combines
them as is the case with Fig. 1B. In this embodiment,
multipliers 24 and 25 are provided between the switches 13,
14 and the vector combining part 17, by which
representative vectors z1i and z2j read out of the
codebooks CB3 and CB4 are multiplied by the same weighting
coefficient vectors vv1 and w2 as those used by the
corresponding multipliers 21 and 22 of the Fig. 2A encoder.
The thus multiplied representative vectors wlzli and w2z2j
are combined in the vector combining part 17 into the
reconstructed vector yip. As will be evident from the
above, it is also possible to omit the multipliers 21, 22,
24 and 25 by prestoring in the codebooks CBl, CB3 and CB2,
CB4 in Figs. 2A and 2B weighted representative vectors
obtained by multiplying the representative vectors z1i and
z2~ by the weighting coefficient vectors w1 and w2,
respectively.
In the encoder of Fig. 2A, the combined vector yip is
determined for every combination of representative
vectors z1i and z2~ prestored in the codebooks CB1 and CB2,
then the distortion of each combined vector is calculated
with respect to the input signal vector X, and a decision
is made of which pair of representative vectors zli and
z2~ provides the minimum distortion. With this method,
CA 02201858 1999-06-10
- 12 -
however, the number of calculations increases sharply as
the codebooks CB1 and CB2 increase in size. Next, a
description will be given of a scheme which pre-selects
small numbers of representative vectors z1i and z2j and
determines the pair of representative vectors of the
minimum distortion among them, thereby reducing the
computational complexity and hence shortening the
operation time.
Let it be assumed, for example, that the codebooks
CB1 and CB2 in Fig. 2A have 8 and 16 representative
vectors, respectively, and that the vectors z1i and z2j
are all two-dimensional. In Fig. 4, eight weighted
representative vectors, obtained by multiplying the eight
representative vectors z1i of the codebook CB1 by the
weighting coefficient vector w1=(w11=1.8, w12=0.2), are
indicated by crosses; 16 weighted representative vectors,
similarly obtained by multiplying the 16 representative
vectors z2j of the codebook CB2 by the weighting
coefficient vectors w2=(w21=0.2, w22=1.8), are indicated
by white circles. The input signal vector is indicated by
X,. which is composed of a predetermined number of signal
samples of each frame, two samples in this example.
The two-dimensional weighting coefficient vectors w1
and w2 for the two-dimensional vectors zli and z2j are
determined such that they satisfy Eq. (3);
w11+w21=w12+w22=2 in this example. As depicted in Fig. 4,
the weighted representative vectors marked with the white
circles and the weighted representative vectors marked
with the crosses are distributed separately on opposite sides
of a straight line of a 45°-gradient passing through the
origin (0, 0). The following description will be given on the
assumption that there are stored such weighted representative
vectors in the
CA 02201858 1999-06-10
- 13 -
codebooks CB1 and CB2 in Fig. 2A and in the CB3 and CB4 in
Fig, 2B, with the multipliers 21, 22, 24 and 25 left out.
With this scheme, the set of weighted representative
vectors (indicated by the crosses) of the codebook CB1 is
approximated with a straight line 27. That is, the
straight line 27 is determined so that the sum of
distances, D11, D12. ..., Dlg, between it and the
respective crosses (or distances in the second-dimensional
axis direction) is minimum. Likewise, the set of weighted
representative vectors (indicated by the white circles) of
the codebook CB2 is approximated with a straight line 28.
The straight line 28 is also determined so that the sum of
distances, D21, D22. .... D216. between it and the
respective white circles (or distances in the first-
dimensional axis direction) is minimum.
The input vector X is projected on the approximating
straight lines 27 and 28 and pluralities of weighted
representative vectors present around the projections are
selected. That is, a calculation is made of the value on
the abscissa and hence a first-dimensional value p1x at
the intersection P1 of a straight line 29 passing through
the input signal vector X and parallel to the
approximating straight line 28 and the approximating
straight line 27, then the value P1x and first-dimensional
values (values of first components) of the cross-marked
weighted representative vectors having a wide first-
dimensional distribution are compared, and a predetermined
number, for example, three, of weighted representative
vectors are selected, as a subgroup H1, in increasing
order of the difference between the value p1x and the
first-dimensional value of the respective weighted
representative vector. In this way, the weighted
representative vectors are pre-selected for the codebook
CA 02201858 1999-06-10
- 14 -
CB1. Similarly, a calculation is made of a value on the
ordinate and hence a second-dimensional value p2y at the
intersection P2 of a straight line 31 passing through the
input signal vector X and parallel to the approximating
straight line 27 and the approximating straight line 28,
then the second-dimensional value p2y and second-
dimensional values (values of second components) of the
white-circled weighted representative vectors having a
wide second-dimensional distribution, and a predetermined
number, for example, three, of weighted representative
vectors are selected, as a subgroup H2, in the order of
increasing differences between the value p2y and the
second-dimensional values of the weighted representative
vectors. This is the pre-selection of the weighted
representative vectors for the codebook CB2.
Only the weighted representative vectors thus pre-
selected from the codebooks CB1 and CB2 are searched for a
pair of weighted representative vectors that provides the
minimum distance between their combined vector and the
input signal vector. In this example, since three
weighted representative vectors are pre-selected from each
of the codebooks CB1 and CB2, the number of their
combinations is nine, and hence the number of combined
vectors is nine. When the pre-selection scheme is not
adopted, the number of combinations of the weighted
representative vectors (the number of combined
representative vectors) is 8x16=128, and when the pre-
selection is made, the number of calculations for the
distance to the input signal vector X is reduced down to
9/128 of the number of calculations needed when no pre-
selection takes place. In this pre-selection scheme, when
M codebooks are used, the number of dimensions of
representative vectors is also set to M. The M weighting
22Q18~~
- 15 -
coefficient vectors each have at least one maximum
component at a different component position (that is, in a
different dimension), and by multiplying the
representative vector by the weighting coefficient vector,
that dimension is emphasized more than the other
dimensions.
Fig. 5 illustrates an embodiment of the coding method
of the present invention applied to speech coding of the
CELP (Code-Excited Linear Prediction Lading) system. In
the CELP system, as disclosed by M.R. Schroeder and B.S.
Atal .in "Code-Excited Linear Prediction (CELP): High-
Quality Speech at Very Low Bit Rates", Proc. ICASSP'85, pp,
937-940, 1985, for instance, pitch excitation vectors read
out of a pitch excitation source codebook and random
excitation vectors read out of a random excitation source
codebook are respectively provided with gains and are
combined in pairs, then the combined vectors are each fed
as an excitation signal to a synthesis filter to obtain
synthesized speech, then two vectors and two gains
therefor are determined which minimize distortion of the
synthesized speech with respect to input speech, and
labels of these vectors arid labels of the gains are
outputted as encoded results of the input speech, together
with the filter coefficients of the synthesis filter. By
applying the vector coding method of the present invention
to the encoding of the gains for the two vectors in the
CELP system, it is possible to prevent the occurrence of
gross distortion in the decoded or reconstructed speech by
a channel error in the codes representing the gains.
The input speech signal x fed via an input terminal
34 is sampled with a fixed period and is expressed as a
vector that is provided as a sequence of digital sample
values for each frame period. The input signal vector X
Y
22~~858
of every frame is subjected to, for example, an LPC
analysis in a filter-coefficient determining part 35, from
which linear predictive coefficients are provided. The
linear predictive coefficients are used to calculate a
spectrum envelope parameter, which is quantized in a
filter coefficient quantizing part 36, and the quantized
value is set as the filter coefficient of a synthesis
filter 37. In a pitch excitation source codebook 39 there
are stored sequences of sample values of waveforms
respectively containing different pitch period components
and labeled as pitch e:~ccitation vectors. In a random-
excitation source codebook 43 there are stored sequences
of sample values of various random waveforms respectively
labeled as random-excitation vectors. The pitch-
excitation vectors and the random-excitation vectors
stored in the pitch-excitation source codebook 39 and the
random-excitation source codebook 43 are each composed of
components of the same number as that of samples of one
frame. ~1 selection switch 38 is controlled by the control
part ~ to select one of the pitch-excitation vectors in
the pitch-excitation source codebook 39, and the selected
pitch-excitation vector is multiplied by a given gain in a
gain providing part ~1, thereafter being applied to the
synthesis filter 37. The difference between synthesized
speech Xp from the synthesis filter 37 and the input
speech signal X is calculated .by a subtractor 48, and in
the distortion calculating part 5 the difference is used
to calculate distortion D as D=~~X-Xp~~2. Similarly, the
other pitch-excitation vectors are sequentially taken out
from the pitch-excitation source codebook 39 via the
switch 38 under the control of the control part 6, then
the above-mentioned distortion is calculated for each
pitch-excitation vector, and the pitch-excitation vector
CA 02201858 1999-06-10
- 17 -
of the minimum distortion is determined. Next, one of the
random-excitation vectors stored in the random-excitation
source codebook 43 is taken out through a switch 42 and
amplified by a given gain in a gain providing part 46,
thereafter being fed to an adder 47 wherein it is combined
with the already determined pitch-excitation vector into an
excitation signal vector E. The excitation signal vector
E is provided to the synthesis filter 37 to generate
synthesized speech and its distortion with respect to the
input speech signal is similarly calculated. Likewise,
such distortion is also calculated for each of the other
remaining random-excitation vectors in the random-
excitation source codebook 43 and the random excitation
vector of the minimum distortion is determined.
After the selection of the pitch excitation vector
and the random excitation vector as mentioned above, gains
gp and gc of the gain providing parts 41 and 46 are so
determined as to minimize the distortion as described
hereafter. In gain coebooks CB1 and CB2 there are stored
gain vectors zli (where i=1, ..., a) and z2j (where
j=1, ..., b), respectively. The gain vectors z
1i and z2j
are each composed of two components and expressed as
zli=(zlil. zli2) and z2j=(z2jl, z2j2). respectively. The
gain vectors zli and z2j taken out of the gain codebooks
CB1 and CB2 are multiplied by weighting coefficient
vectors w1=(wll, wl2) and w2=(w21, w22) bY multipliers 21
and 22, respectively, from which weighted gain vectors
Yi=(Yil. Yi2) and yj=(yji, yj2) are provided. Here,
Yil=zlilwll~ Yi2=z1i2w12~ Yj1=z2j1w21~ Yj2=z2j2w22 (4)
In a vector combining part 3 the weighted gain vectors yi
and yj are combined into a combined gain vector G=(gp, gc)
which is composed of such components as follows:
gp=Yi1+Yjl~ gc=Yi2+Yj2 (5)
CA 02201858 1999-06-10
- 18 -
The first and second components gp and gc of the combined
gain vector G are provided as first and second gains to
the gain providing parts 41 and 46, wherein they are used
to multiply the pitch excitation vector Cp and the random
excitation vector CR from the pitch excitation source
codebook 39 and the random excitation source codebook 43,
respectively.
The pitch excitation vector gpCp and the random
excitation vector gcCR multiplied by the gains gp and CR
in the gain providing parts 41 and 46, respectively, are
added together by the adder 47 and the added output is fed
as an excitation vector E=gpCp+gcCR to the synthesis
filter 37 to synthesize speech X. The difference between
the synthesized speech X and the input speech signal X is
calculated by the subtractor 48 and the difference is
provided to the distortion calculating part 5, wherein
D=~~X-X~~2 is calculated as the distortion of the
synthesized speech X with respect to the input speech
signal X. The control part 6 controls the selection
switches 7 and 8 to control the selection of the gain
vectors of the gain codebooks CB1 and CB2, and the
selected gain vectors z1i and z2j are multiplied by the
different weighting coefficient vectors w1 and w2 by the
multipliers 21 and 22, respectively, thereafter being
provided to the vector combining part 3. The weighting
coefficient vectors w1 and w2 are two-dimensional vectors
that satisfy Eq. (3), and the two elements of each vector
differ from each other. The gain vectors of the codebooks
CB1 and CB2 are selected so that they minimize the
distortion which is calculated in the distortion
calculating part 5. Upon selection of the gain vectors
that minimize the distortion, gain labels indicating the
selected gain vectors of the gain codebooks CB1 and CB2,
2201858
- 19 -
labels indicating the excitation vector and the random
excitation vector of the pitch excitation source codebook
39 and the random e:~ccitation source codebook 43 determined
as described previously and label indicating the filter
coefficient set in the synthesis filter 37 are outputted,
as encoded results of the input speech signal X, from a
code outputting part 49.
In the Fig. 5 embodiment, the distortion is
calculated for every combination of gain vectors selected
from the gain codebooks CB1 and CB2 so as to determined
the pair of gain vectors that provides the minimum
distortion. As referred to previously with respect to Fig.
4, however, the pair of gain vectors, which provides the
minimum distortion, may also be determined by pre-
selecting pluralities of candidates of gain vectors zli
and z2j and calculating the distortion for every
combination of such pre-selected gain vectors in the case
where they are combined with the pitch excitation vector
Cp and the random excitation vector CR. In this instance,
as is the case with Fig. 4, weighted gain codebooks CB1'
and CB2' are prepared, for example, as Tables I and II as
shown in Figs. 6A and 6B, by precalculating weighted gain
vectors
y1i=zliwl=(zlilwll, z1i2w12)=(Ylil.Yli2)
y2j=z2jw2=(z2j1w21, z2j2w22)=(Y2jl. Y2j2)
which are the products of the gain vectors z1i and z2j of
the gain codebooks CBl and CB2 and the weighting
coefficient vectors wl=(w11, w12) and w2=(w21,w22), and
the cadebooks CB1' and CB2' are used as substitutes for
the codebooks CB1 and CB2 in Fig. 5 and the multipliers
are left out. As in the case of Fig. 4, all two-
dimensional weighted vectors y1i of the weighted gain
codebook CB1' are plotted as points on a two-dimensional
220188
~ _
coordinate system as indicated by black circles in Fig. 7
and a straight line Ll closest to the group of such points
is precalculated by the method of least squares.
Similarly, all two-dimensional weighted vectors y2~ of the
weighted gain codebook CB2' are plotted as points on the
two-dimensional coordinate system as indicated by white
circles in Fig. 7 and a straight line L2 closest to the
group of such points is precalculated by the method of
least squares.
As is the case with the Fig. 5 example, the gains of
the gain providing parts 41 and 46 are set arbitrary and
the pitch excitation vector Cp that provides the minimum
distortion is determined, which is followed by the
determination of the random excitation vector CR that
provides the minimum distortion. Next, the output X p from
the synthesis filter 37 is measured when only the pitch
excitation vector Cp is applied thereto as an excitation
signal with the gains gp=1 and gc =0. Likewise, the output
from the synthesis filter 37 is measured when only the
random excitation vector CR is applied thereto as an
excitation signal with the gains gp=0 and gc=1. Since the
synthesized speech output X from the synthesis filter 37,
which is provided when the vectors Cp and CR selected
from the codebaoks 39 and 43 are multiplied by the gains
gp and gc, respectively, is expressed as X =gp X p+gc XR,
the distortion D of the synthesized speech X with respect
to the input speech signal X is given by the following
equation:
D=I IX-gp X P-gc X RI I2
3 0 =XtX+gp2 Xpt Xp+gc2 XRt XR
-2gpXtXP-2gcXtXR-2gpgcXPtXR (~)
where t indicates a transposition. By partially
differentiating the above equation by the gains gp and gc
'1 - 220 ~ 858
21 -
to obtain those which minimize the distortion D, the
following equations are obtained:
~D/r~gp =2gpXptXp - 2XtXp-2gcXPtXR (~)
aD/c~gc =2gcXRtXR-2XtXR-2gpXptXR (g)
Since the distortion D is a downward convex function with
respect to each of the gains gp and gc as is evident from
Eq. (6), the gains gp and gc that minimize the distortion
D are values when c~D/agp=0 and aD/c~gc=0. Hence, we have
gpXptXP-gcXptXR=XtXp (9)
-gc Xpt XR+gc XRt XR= Xt XR ( 10 )
from Eqs. (7) and (8), respectively. From the following
equation,
XptXP -XPtXR gp XtXP
- (11)
- Xpt XR XRt XR gc Xt XR
the gains gp and gc that satisfy Eqs. (9) and (10)
simultaneously are expressed as follows:
-1
gp XptXP -XptXR XtXp
(12)
gc -XPtXR XRtXR XtXR
Expanding Eq(12), the gains gp and gc are given by the
following equations, respectively:
gp=k~ XRtXR. XtXp+XptXR-XtXR} ( 13 )
gc=k~ XptXp~ XtXR+XptXR~XtXp} ( 1~)
where k=1I ( XptXp~ XRtXR-2 ~ptXR) . The pair of gains {gp,
gc} thus obtained is the combination of gains that
minimizes the distortion D. This pair is plotted as the
optimum gain vector as indicated by a point PO in Fig. 7
and straight lines parallel to the straight lines L2 and
L1 are drawn from the paint Pp, determining their
. ' 2201858
- 22 -
intersections P2 and P2 with the lines L2 and L2. A
plurality of weighted gain vectors y2i=(yli2. yli2) whose
ordinate values are close to the point P1 are selected
from the codebook CB1' (Table I shown in Fig. 6A) to form
a first subgroup. Similarly, a plurality of weighted gain
vectors y2j=(y2jl. y~j~) whose abscissa values are close
to the point P2 are selected from the codeboak CB2' (Table
IT shown in Fig. 6B) to form a second subgroup.
In this case, predetermined numbers of weighted gain
vectors (for example, four from Table I with respect to
the paint P2 and eight from Table II with respect to the
point P2) are selected in increasing order of distance
from the points P1 and P2. Another method is to select
weighted gain vectors that lie within predetermined
25 distances d2 and d2 from the points P2 and P2,
respectively. Alternatively, since eight vectors y2i are
prestored in the codebook CB2', mean values of i=n-th and
i=(n+4)th ones of the gain components y2i~ are calculated
for n=2, 2, 3, 4, respectively, and the thus obtained
values are set as threshold values Th2, Th2, Th3 and The.
If the ordinate value p2c at the intersection P1 is
p2c~Thl. then (i=1, ..., 4)th weighted gain vectors are
selected, and if Thn<p2c<Thn+2 where n=1, 2, 3, 4, then
(i=n+2, ..., n+4)th weighted gain vectors are selected.
Similarly, since the number of vectors y2j stored in the
codebook CB2' is 26, mean values of (j=myth and (j=m+8)th
ones of gain components y2ji are calculated for m=1, ...,
8, respectively, and the values thus obtained are set as
threshold values Th2, ..., Thg. If the abscissa value p2p
at the intersection P3 is p2p<Th2, (j=2, ..., 8)th
weighted gain vectors are selected, and if Thm<p2p~Thm+2
where m=2, ..., 8, (j=m+1, ..., m+8)th vectors are
CA 02201858 1999-06-10
- 23 -
selected. It is also possible to use various other
selecting methods.
A description will be given of still another method
of pre-selecting candidates of vectors from the codebooks
without using the afore-mentioned approximating straight
lines L1 and L2 based on the method of least squares. At
first, the synthesized speech signal Xp is measured when
only the pitch excitation vector Cp from the pitch
excitation source codebook 39 is provided as the
excitation signal vector E to the synthesis filter 37,
with the gain vectors set to gp=1 and gc=0. Similarly,
the synthesized speech signal XC is measured when only the
random excitation vector CR from the random excitation
source codebook 43 is provided as the excitation signal
vector E, with the gain vectors set to gp=0 and gc=1. For
the pre-selection of the gain vectors stored in the gain
codebook CB1, a value D1(i) is calculated for every i as
follows:
D1(i)=~~X-w11z1i1XPII2 (15)
Then, a predetermined number, for example, of three gain
vectors are pre-selected from the gain codebook CB1 in
increasing order of the value D1(i). For the pre-
selection of the gain vectors stored in the gain codebook
CB2, a value D2(j) is similarly calculated for every j as
follows:
D2 ( j ) =I IX-w11 z 2 j 2 XCI I2 ( 16 )
Then, a predetermined number, for example, of three gain
vectors are pre-selected from the gain codebook CB2 in
increasing order of the value D2(j). Only for the
triplets of gain vectors z1i and z2j thus pre-selected
from the codebooks CB1 and CB2, a value D(i, j) is
calculated as follows:
D(i, j)=~~X-(w11z1i1+w12z1i2) Xp
CA 02201858 1999-06-10
- 24 -
-(w12z2j1+w11z2j2) XCII2 (17)
Then, i and j that minimize the value are provided as
encoded outputs. This method also permits reduction of
the computational complexity involved.
All pairs of thus pre-selected weighted gain vectors
that are selected one by one from the first and second
subgroups, respectively, are searched for a pair of
weighted gain vectors that provide the minimum distortion
from the input speech signal X, that is, an optimum pair
of first and second gains gp and gc is thus determined and
combined. Then, labels, which represent the pair of pitch
excitation vector and random excitation vector determined
previously and the combined gain vector (gp, gc), that is,
a label of the pitch excitation vector in the pitch
excitation source codebook 39, a label of the random
excitation vector in the random excitation source codebook
43, labels of the gain vectors in the weighted gain
codebooks CB1~ and CB2~ (or gain codebooks CB1 and CB2)
and a label produced by quantizing the filter coefficient
are outputted as encoded results of the input speech
vector X.
At any rate, the multiplication of the weighting
coefficient vectors w1 and w2 by the multipliers 21 and 22
begins to bring about the effect of preventing a channel
error from seriously distorting the decoded output when
the ratio of corresponding components, for example, w11
and w21 of the weighting coefficient vectors exceeds a
value 2:1. Even if the ratio is set to 10:1 or more,
however, the distortion by the channel error cannot
appreciably be improved or suppressed; on the contrary,
the decoded output is rather distorted seriously when no
channel error arises, that is, when the channel is normal.
- 25 -
In the Fig. 5 embodiment, the weighting coefficient
vectors, the weighted gain vectors and the combined gain
vector have all been. described to be two-dimensional
vectors with a view to providing gains to the excitation
vectors read out from both of the pitch excitation source
codebook 39 and the random excitation source codebook 43.
In the CELP system, however, there are cases where
pluralities of pitch excitation source codebooks and
random excitation source codebooks (which will hereinafter
be referred to simply as excitation source cadebooks} are
provided and excitation vectors read out of the excitation
cadebooks are respectively multiplied by gains and
combined into the excitation signal vector E. In general,
according to the present invention, when M excitation gain
cadebooks are used, M gain cadebooks (or weighted gain
cadebooks} are prepared to provide gains to M excitation
vectors and the combined gain vector, the weighting
coefficient vectors and the weighted gain vectors are all
set to M-dimensional vectors accordingly.
In the Fig. 5 embodiment, the random excitation
source codebook ~3 may be formed by a plurality of
codebooks. For example, as shown in Fig. 8, the random
excitation source codebook 43 is formed by two cadebooks
43a and 43b; in this instance, one random excitation
vector is selected from either of the codebooks 43a and
43b and the thus selected random excitation vectors are
multiplied by weighting coefficient vectors wRa and wRb by
weighting coefficient multipliers 51a and 51b,
respectively. The weighting coefficient vectors wRa and
wRa are selected such that they bear the same relationship
as that between the weighting coefficient vectors w1 and
w2 described previously with reference to Fig. 2A. The
outputs from the multipliers 51a and 51b are combined in a
CA 02201858 1999-06-10
- 26 -
random vector combining part 52 and the combined output is
provided, as the random excitation vector selected from
the random excitation source codebook 43 in Fig. 5, to
the gain providing part 46. As described previously with
respect to Fig. 5, random excitation vectors are selected
from the random excitation source codebooks 43a and 43b
under the control of the control part 6 in such a manner
that the distortion of the synthesized speech signal x
from the input speech signal x becomes minimum.
As is the case with the encoding of the random
excitation vector, the present invention is also
applicable to the encoding of the pitch excitation vector
in the configuration of Fig. 5. That is to say, as shown
in Fig. 9, the pitch excitation source codebook is formed
by two codebooks 39a and 39b; one pitch excitation vector is
selected from either of the codebooks 39a and 39b, then
they are multiplied by weighting coefficient vectors wpa
and wpb by weighting coefficient multipliers 53a and 53b,
respectively, then these multiplied outputs are combined
in a pitch excitation vector combining part 54, and the
combined output is provided, as the pitch excitation
vector selected from the pitch excitation source vector
codebook 43 in Fig. 5, to the multiplier 41. The
weighting coefficient vectors wpa and wpb that are set in
the multipliers 53a and 53b are determined in the same
fashion as the weighting coefficient vectors w1 and w2 in
Fig. 2A.
The present invention can be applied to the quantization
in the filter coefficient quantizing part shown in Fig. 5
by configuring the filter coefficient quantizing part 36
in the same manner as depicted in Fig. 2A. That is,
representative spectrum envelope vectors are prestored in
the codebooks CB1 and CB2 in Fig. 2A, then one
' ~~a ~ ~~s
- 27 -
representative spectrum envelope vector selected from
either of the codebooks CB1 and CB2 is multiplied by the
corresponding one of the weighting coefficient vectors w1
and w2, and the multiplied vectors are combined in the
vector combining part 3. The representative spectrum
envelope vectors that are selected from the codebooks CB1
and CB2 are searched for a combination of representative
spectrum envelope vectors that provide the minimum
distance between their combined vector and the input
spectrum envelope vector from the filter coefficient
determining part 35 Fig. 5).
The vector coding method of the present invention is
applicable to the VSELP system as well. Fig. 1d
illustrates the principal parts of its embodiment. In
this instance, the random excitation source codebook 43 in
Fig. 5 is formed by a number of basic vector codebooks 431
to 43n in each of which there is stored one random
excitation vector. The random excitation vectors read out
of the basic vector codebooks 431 to 43n are polarized
positive or negative in polarity control parts 561 to 56n
and the polarity-controlled random excitation vectors are
multiplied by weighting coefficient vectors wR1 to wRn by
weighting coefficient multipliers 571 to 57n. The
multiplied outputs are added together by an adder 58 and
the added output is provided as the random excitation
vector to the multiplier 46 in Fig. 5. The polarity
control parts 561 to 56n are individually controlled by
the control part 6 in Fig. 5 so that the distortion of the
synthesized speech signal from the input speech signal is
minimized. In other words, each pair of basic vector
codebook 43i (where i=1, 2, ..., n) and polarity control
part 56i constitutes one random excitation source codebook
and one of two positive and negative random excitation
' 22D1858
- 28 -
vectors is selected by the control part 5. The weighting
coefficient vectors wRl to wRn of the weighting
coefficient multipliers 571 to 57n are set to bear the
same relationship as that between the weighting
coefficient vectors referred to previously with respect to
Fig. 2A.
As will be understood from the description given
above with reference to Fig. 10, the random excitation
source codebook ~3 in Fig. 5 may also be substituted with
the basic vector codebooks X31 to 43n and the polarity
control parts 5~1 to 56n in Fig. 20. The same goes for
the codebooks 43a and 43b in Fig. 8. The pitch excitation
source codebook 39 in Fig. 5 may also be formed by what is
called an adaptive codebook which adaptively generates the
pitch excitation vector from the pitch period obtained by
analyzing the input speech signal and the excitation
signal vector E of the previous frame. This adaptive
cadebook can be used as the pitch excitation source
cadebook 39 when the configuration of Fig. 8 ar 10 is
employed as a substitute for the random excitation source
cadebook ~3. Furthermore, the present invention is also
applicable to an arbitrary combination of the vector
coding of the power of a speech signal, the vector coding
of a spectrum envelope parameter, the vector coding of a
pitch excitation source codebook and the vector coding of
a random excitation source cadebook.
As described previously, the multipliers 21 and 22 in
Fig. 2A may be omitted by prestaring, as the
representative vectors, weighted representative vectors
3n wlzli and w2z2j obtained by multiplying the representative
vectors in the cadebooks CB1 and CB2 by the weighting
coefficient vectors w1 and w2. Similarly, the multipliers
24 and 25 in Fig. 2B may be omitted by prestoring the
_ 29 _ 2201858
weighted representative vectors wlzli and w2z2~ in the
codebooks CB3 and CB4, respectively. Also in the Fig. 5
embodiment, the multipliers 21 and 22 may be omitted by
prestoring weighted gain vectors in the gain codebooks CB1
and CB2. In Figs. ~ and 9, too, the multipliers 51a, 51b
and 53a and 53b may be omitted by prestoring weighted
vectors in the codebooks 43a, 43b and 39a, 39b.
While in the above representative vectors read out of two
cadebaoks are nectar-combined, the present invention is
also applicable to a system wherein representative vectors
read out of three or more codebooks are vector-combined.
Moreover, the Fig. 5 embodiment of the present invention
has been described as being applied to the coding of the
input speech signal, but it is needless to say that the
invention is applicable to the encoding of ordinary
acoustic signals as well as to the encoding of the speech
signal.
Next, a description will be given of characteristics
that are obtained in the cases of applying conventional
2d techniques and the present invention to the vector coding
of the gains gp and gc in the CELP speech coding shown in
Fig. 5.
(A) A first conventional technique substitutes the
two gain codebooks CB1 and CB2 in Fig. 5 with one gain
cadebook which specifies one two-dimensional gain vector
by seven-bit label and has 2~=128 labels. The one
component of the two-dimensional vector read out of the
gain cadebaok is used as the gain gp for the pitch
excitation vector and the other element as the gain gc for
the random excitation vector.
(B) A second conventional technique uses the two gain
codebooks CB1 and CB2 shown in Fig. 5 but does not use the
weighting coefficient nectars. The codebook CB1 prestores
22018~~
~a _
therein 2~ two-dimensional vectors each of which is
specified by a three-bit label, and the cadebook CB2
prestores therein 24 two-dimensional vectors each of which
is specified by a four-bit label. The vectors selected
from the two codebooks, respectively, are combined into
one two-dimensional combined vector; the one element of
the combined vector is used as the gain gp and the other
element as the gain gc.
(C) Tn the example of the present invention applied
to the encoding of gain vectors in Fig. 5, the gain
vectors read out of the gain codebooks CB1 and CB2 in the
above-mentioned ease (B) are multiplied by the weighting
coefficient vectors w1=(1.8, 0.2) and w~=(0.2, 1.8) and
then added together into a combined vector. The gain
codebooks CB1' and CB2', which store weighted gain vectors
obtained by multiplying the gain vectors read out of the
two codebooks CB1 and CB2 by the weighting coefficient
vectors w1 and w~, respectively, are the same as those in
Figs. 6A and 6B.
In Fig. 11 there are indicated, by the curves A11 and
B11, measured results of the segmental 5N ratio of
reconstructed speech to the error rate when a channel
error occurred in the gain labels in the encoded outputs
of speech by the configurations of Cases (A) and (B) in
Fig. 5. The segmental sN ratio is obtained by measuring
the sN ratio of each frame for several minutes and
averaging the measured values. The use of two codebooks
(curve B11) attains a more excellent segmental sN ratio to
the channel error than in the case of using one codebook
(curve A11).
In Fig. 12 there are shown, by curves A12 and B12,
equivalent Q values converted from mean opinion scores of
24 ordinary people about the reconstructed speech with
2201858
31 -
respect to the channel error rate of the gain labels in
the case of Fig. 11. As is evident from Fig. 12, the use
of two codebooks is preferable from the viewpoint of the
channel error rate, and even if the two cases shown in Fig.
11 do not greatly differ in their sN ratio characteristic,
they greatly differ psycho-acoustically.
Fig. 13 shows, by the curve C13, measured values of
the segmental SN ratio of reconstructed speech to the
channel error rate in the Case (C) as in the case of Fig.
11, the curve B11 in the Case (B) being shown for
comparison use. Apparently, the SN ratio of the
reconstructed speech to the channel error rate in the case
of the present invention is better than in the prior art.
In view of the fact that the difference between the SN
ratios Shawn in Figs. 11 and 12 exerts a great influence
on the equivalent Q value, it is expected that the present
invention, which uses two weighted codebooks, improves the
equivalent Q value more than in the case of using two
unweighted codebooks.
As described above, according to the present
invention, in the case of encoding vectors through the use
of a plurality (M) of codebooks each having L-dimensional
vectors, L-dimensional weighting coefficient vectors
w1, ... , wiz for the codebooks are selected so that the
sum of weighting coefficient matrixes W1, ..., WM, each
having components of the weighting coefficient vectors as
diagonal elements, becomes a constant multiple of the unit
matrix. As the result of this, the vector distribution of
each codebook is deviated or biased by the L weighting
coefficient vectors in such a manner that the individual
vectors approach different coordinate axes of the L-
dimensional coordinate system (that is, compress component
values of other dimensions). In the case where a signal
22~~858
- 32 -
is encoded by a pair of such weighted vectors for each
codebook in a manner to minimize the distortion and the
labels of the M cadebooks corresponding to the weighting
coefficient vectors are transmitted, if an error occurs,
far example, in one of the labels during transmission aver
the channel, there is a possibility that an error in the
coordinate-axis direction of one dimension is large, but
since errors in the coordinate-axis direction of all the
other dimensions are compressed, the error of the absolute
value of the combined nectar does not became so large.
Hence, the application of the present invention to the
encoding of speech signals is effective in suppressing
abnormalities that result from channel errors.
Furthermore, according to the present invention, a
plurality of weighted vectors of each codebook are pre-
selected for input signal vectors and the distortion by
encoding is calculated with respect to such pre-selected
weighted vectors alone--this appreciably reduces the
amount of calculations involved in the encoding and speeds
up the encoding.
The present invention is also applicable to what is
called a CELP ar VSELP speech coding scheme, in which case
the invention can be applied to the nectar coding of
spectrum envelope parameters, the vector coding of power
and the vector coding of each cadebook individually or
simultaneously.
It will be apparent that many modifications and
variations may be effected without departing from the
scope of the novel concepts of the present invention.