Note: Descriptions are shown in the official language in which they were submitted.
CA 02271669 2000-02-15
Y
1
METHOD AND SYSTEM FOR SCHEDULING PACKETS IN A
TELECOMMUNICATIONS NETWORK
FIELD OF THE INVENTION
This invention relates to a method and system for scheduling packets in a
telecommunications network and more particularly relates to a method and
system for
scheduling data packets in a telecommunications network that strives to meet
predetermined quality of service objectives set by a service provider
operating the
telecommunications network.
BACKGROUND OF THE INVENTION
An increasing amount of traffic on packet switched networks is time-critical.
This traffic includes traditional real-time services such as telephony as well
as new
services including video on demand, multicast video and virtual reality
applications.
There are also numerous non-time critical applications in which delay may
still
affect user perception of service quality, such as Web browsing and file
transfer.
For such applications to be successful, networks must provide sufficient
Quality of Service (QoS) to user sessions with respect to several quality
measures such
as packet delay and packet loss rates. Guarantees with respect to QoS can be
achieved
through a combination of effective admission control and real-time scheduling.
However, the services mentioned above typically have relatively bursty traffic
profiles and at session set up, where a customer wishes to transmit data
across a
network, the customers are not usually able to accurately describe their
traffic profile.
Therefore, unless peak bandwidth admission control is employed, it is
inevitable that
moments of transient congestion will occur in the network.
As discussed in "Hardware Implementation of Fair Queueing Algorithms for
Asynchronous Transfer Mode Networks", by A. Varma and D. Stiliadis, IEEE
Communications Magazine, Volume 35, pp.54-68, December 1997, traffic
scheduling
systems should possess certain desirable characteristics which are summarised
as
follows:
(a) the system must be able to treat individual data traffic streams
separately;
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
2
(b) the system should be able to provide local delay guarantees for each
traffic
stream, thus providing implicit end-to-end delay guarantees.
(c) there must be efficient use of available bandwidth;
(d) the system must be simple to implement in order to enable hardware
implementation so as to meet the requirements for high speed links;
(e) the system must be scalable in that it must be able to perform well over a
large
number of sessions over a wide range of link speeds, and
(f) the system must be able to allocate bandwidth amongst traffic streams in a
fair
and reasonable manner.
Many previous and existing packet scheduling systems have been designed in
an attempt to meet the above requirements two of which will be described
briefly.
The first system is First In - First Out (FIFO) which is a simple system to
implement.
In FIFO systems, ,each packet (or cell in cell-relay based protocols) is
placed in an
outgoing transmit buffer in the order of arnval of each packet or cell. The
size of the
transmit buffer determines the maximum delay that a packet will experience at
the
particular link. If the buffer is full when a packet arrives, the packet is
simply
discarded. While FIFO systems are simple to implement, they are unsuitable for
support of real-time applications as they are unable to isolate flows and
treat
individual traffic streams separately and are not necessarily fair across all
user
sessions. The latter is of concern because a single high volume traffic stream
may
generate such large volumes of traffic as to cause severely degraded service
for all
other sessions on the link or in the network.
The second scheduling system relates to Fair Queueing (FQ) which was
introduced by A. Demers, S. Keshav and S. Shenker in an article entitled
"Analysis
and Simulation of a Fair Queueing Algorithm", Proc. SIGCOMM'89, 1989. In Fair
Queueing, the available bandwidth is shared equally among all competing
sessions
and therefore users with moderate bandwidth requirements are not penalised
because
of the excessive demands of other users. As a result of equalizing the
bandwidth,
these Fair Queueing schemes typically provide satisfactory QoS for sessions
whose
bandwidth requirements are less than their fair share. The concept of Fair
Queueing
has since been enhanced to allow for weighted assignment of bandwidth, called
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
3
Weighted Fair Queueing (WFQ), which allows more general access to available
bandwidth by traffic streams. In the WFQ scheme a scheduler may assign
different
weights to each session. This approach has yielded a vast range of adaptations
each
seeking to improve on minor perceived shortcomings in fairness, implementation
detail or scalability in the original WFQ approach.
However, in all of these variants, fairness is an intrinsic goal of the
scheduling
discipline and the idea of fairness is applied on a very small time scale. The
focus on
fairness and small time scales tends to obscure the fact that fairness is an
attempt at
inferring user QoS from quantities that may be directly measured by the
network,
rather than an actual measure of the user perceived QoS. Fairness is not a
direct
measure of user perceived QoS because a user is unable to determine the
quality of
service received by other users nor the bandwidth received by other users.
Fairness is
a measure of how the network assigns resources during periods of congestion, a
measure that the user is not able to directly perceive. Fairness is not a
guarantee of
good service quality, for example, a given link may be carrying two real-time
sessions
and both simultaneously have a burst at a data rate slightly over half of the
link
capacity. If each session is allocated half of the available bandwidth, the
queues for
both sessions will grow until no packets arrive within their delay limits.
Therefore the
effective throughput is zero and both users are dissatisfied. However, the
system has
ample capacity to provide one customer with the required QoS and by doing so
may
not make the other customer less satisfied than in the "fair" case.
When the system is lightly loaded, the QoS requirements of all sessions can
usually be met. However, during periods of congestion, some or all sessions
will
receive service which does not meet their QoS requirements. Hence, it is
necessary to
decide which traffic streams should receive a degraded service, either in
terms of loss,
delay or both. This is a particular problem of real-time bandwidth scheduling.
It is considered that the more relevant measures of QoS are the proportion of
customers that are receiving poor service at any time during their session or
during a
congestion episode because this reflects the number of customers that might
complain
to the service provider. The service provider will be motivated by minimising
the
number of complaints they receive from their customers concerning their
perceived
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
4
QoS. Therefore, the network and the scheduling systems it employs should
attempt to
maximise the number of users that are receiving acceptable service, rather
than strive
for a fairness of which the customers are unaware. This is analogous to the
reasons for
implementing network admission controls to protect user QoS for sessions in
progress.
However such a scheduling system should provide the mechanisms to enforce
fairness as well if the service provider deems it important. In this way,
decisions on
the desirability of fairness in a network may be left to the service providers
as a
business decision.
Scheduling systems such as FIFO and FQ do not achieve the abovementioned
aims. In FIFO systems a single misbehaving session can result in all traffic
streams
receiving poor service which is measured by the fraction of packets discarded
or
excessively delayed per traffic stream. In FQ systems, if all traffic streams
burst
simultaneously, they are all treated equally and all receive degraded service.
It is
considered that fairness on very small time scales is not necessarily a good
measure of
the performance of a scheduling system for real-time services such as multi
media
data, motion pictures expert group (MPEG) video streaming and Internet
protocol (IP)
telephony, nor necessarily for non-real time service such as file transfer
(FTP) and
Web browsing (HTTP).
SUMMARY OF THE INVENTION
It is an object of the invention to provide a scheduling infrastructure which
allows service providers and network operators to select and implement their
own
QoS objectives. A new approach to the management of transient congestion is
presented by the invention. Rather than aiming to maximise fairness and
letting good
performance follow, the present invention provides an infrastructure that
allows
selectable QoS measures, including maximising the number of users receiving
good
service. This aim is achieved by selecting certain sessions to bear the brunt
of
degraded services during periods of congestion. On short time scales, the
approach
may be very unfair, giving very poor service to a small number of sessions in
order to
provide sufficient resources for the remaining sessions. However, the
invention
provides a packet scheduling system wherein fairness can be obtained over
moderate
time scales, of the order of seconds, and still provide substantially better
overall
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
quality of service than FQ systems. The present invention supports a range of
QoS
goals, from traditional concepts of fairness through to maximising the number
of users
receiving excellent service over their entire session. This is not addressed
by any
existing scheduling discipline such as FIFO or FQ.
5 Accordingly, there is provided in a first aspect of the invention a method
for
scheduling data packets in a telecommunications network, said method
comprising the
steps of
receiving and storing in a first buffer means at a node in the network packets
of
data representative of one or more sessions;
monitoring the used capacity or occupancy of packets stored in said first
buffer
means;
buffering data packets in a second buffer means at said node on initiation of
a
trigger condition, so as to avoid the first buffer means from overflowing
during a
congestion period.
The trigger condition may be a derivative-based threshold such that when the
rate of increase of the amount of data stored in the first buffer means
exceeds said
derivative-based threshold, data packets are buffered in the second buffer
means.
Alternatively, the trigger condition may be the crossing of a first or
subsequent
capacity threshold in the first buffer means due to the arrival of a data
packet in the
first buffer means. The first data packet in the first buffer means that
crosses the first
or subsequent capacity threshold may be buffered in the second buffer means
and any
subsequently arnving packets of a session to which the first data packet
belongs may
also be buffered in the second buffer means.
The invention fizrther provides in a second aspect a system for scheduling
data
packets in a telecommunications network, said system comprising;
first buffer means located at a node in the network for receiving data packets
representative of one or more sessions;
a second buffer means located at said node in the network;
wherein data packets are buffered in the second buffer means on initiation of
a
trigger condition so as to avoid overflow in the first buffer means during a
congestion
period.
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
6
According to a third aspect of the invention there is provided a data packet
scheduling system for scheduling packets in a telecommunications network, in
accordance with a quality of service standard set by a telecommunications
service
provider wherein said packets are representative of one or more sessions, said
system
comprising;
a first buffer means for receiving and temporarily storing data packets of one
or
more sessions transmitted in the telecommunications network;
a second buffer means wherein data packets are buffered in said second buffer
means upon initiation of a trigger condition set in the first buffer means due
to the
arrival of a data packet in said first buffer means such that the first buffer
means is
prevented from overflowing during a congestion period in the network.
BRIEF DESCRIPTION OF THE DRAWINGS
Preferred embodiments will hereinafter be described, by way of example only,
with reference to the following drawings wherein;
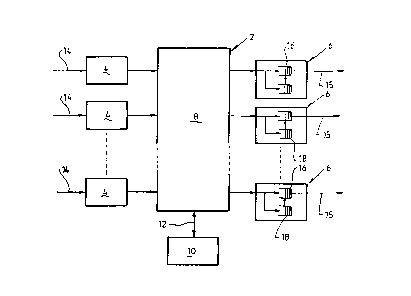
Figure 1 is a schematic diagram of a packet switch or node of a
telecommunications network implementing the system and method of the present
invention according to a first embodiment;
Figure 2 is a schematic diagram showing the buffering of data packets in a
second buffer means intended for a first buffer means;
Figure 3 is a schematic diagram showing the transfer of data packets from a
second buffer means to the first buffer means for transmission on an output
link from
the first buffer means;
Figure 4 is a schematic diagram of a packet switch or node of a
telecommunications network implementing the system and method of the present
invention according to a second embodiment;
Figure 5 is a schematic diagram showing a first, second and third buffer means
and the treatment of data packets arriving at the node of Figure 4;
Figure 6 hows a block diagram of a system used to simulate a number of traffic
sources being input into a node having first buffer means and second buffer
means;
Figure 7 s a series of plots showing the cumulative probability distributions
of
packet delay of a number of sessions using the FIFO, DRRexp and DQ
simulations;
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
Figure 8a and b show a series of plots of the highest packet delay per second
against the simulation time for a number of sessions with an increased link
transmission
rate using the FIFO, DRRexp and DQ simulations;
Figure 9 is a plot of a number of sessions receiving "good service" in a one
second period for each of the FIFO, DRRexp and DQ simulations;
Figure 10 shows a plot for each of the DRRexp and DQ simulations of degraded
service experienced by all sessions;
Figure 11 shows a plot for each of the DRRexp and DQ simulations showing the
number of degraded seconds for each of the sessions shown in Figure 3 with a
reduced
line transmission rate;
Figure 12 is a plot similar to Figure 9 but with a still further reduced line
transmission rate;
Figure 13 is similar to Figures 9 and 10 wherein degraded seconds are shown
for
a set of different sessions at a low line transmission rate;
Figure 14 is a plot showing the degraded seconds for a further set of
different
sessions using the DRRexp and DQ simulations at an increased line transmission
rate;
Figure 15 is a plot of the overall percentage of degraded packets for each of
the
FIFO, DRR, DRRexp and DQ algorithms for different average offered loads that
are
normalised to the link transmission rate,
2 o Figure 16 is a flow diagram showing the processes involved on receipt of a
packet of a session on a link associated with a node,
Figure 17a and b are flow diagrams having the processes involved when a packet
is transferred from the second buffer means to the first buffer means, and
Figure 18 a and b are flow diagrams showing the processes involved in treating
2 5 one or more packets arriving at the third buffer means of Figure 5.
DETAILED DESCRIPTION
Shown in Figure 1 there is a packet switch or node 2 which forms part of a
telecommunications network, such as a packet switching network. The switch 2
consists
30 of a number of input ports 4 and a number of output ports 6 and a switching
CA 02271669 2000-02-15
8
fabric 8 that is connected between the input ports 4 and the output ports 6. A
routing
processor 10 is linked to the switching fabric 8 over link 12 which is
responsible for
the routing or switching of data packets between any one of the input ports 4
to any
one of the output ports 6. Data packets that are input to the switch 2 are
received by
any one of the input ports 4 on input links 14. The data packets are then
switched by
the switching fabric 8 to one of the output ports 6. The data packets are then
either
received by a first buffer means 16 or a second buffer means 18 located in
each one of
the output ports 6 depending on how those input packets are to be treated,
which will
be hereinafter described. All data packets, apart from discarded packets,
leave the
output ports 6 from each of the first buffer means 16 on links 15.
Alternatively, the
first buffer means 16 and second buffer means 18 may be located in each of the
input
ports 4.
Shown in Figure 2 there is a more detailed view of the first buffer means 16
and the second buffer means 18. When the system or network, or even a switch
of the
network is not congested, all sessions (a session being a series of packets
that are
dedicated to one particular user for one application) are received by the
first buffer
means 16 which is preferably in the form of a single short FIFO queue, and
which is
denoted as the a-queue. The length of the a-queue is selected such that any
packet
passing straight through the a- queue will meet the tightest delay
requirements of any
particular session. The length of the a-queue corresponds to the longest delay
that can
be considered "good service" in terms of delay. At the onset of congestion,
when the
level of the a- queue rises, due to the arrival of a packet from a particular
session, and
exceeds a capacity threshold T o,~et,l and it is decided that the packets from
this session
contribute to the possibility of the a-queue overflowing, this packet and
subsequent
packets from the session are time stamped and buffered in the second buffer
means
18, hereinafter referred to as the 13-queue. The exceeding of the capacity
threshold
Tor~ec,l represents a trigger condition under which a fraction of the packets
intended to
be received in the a-queue are buffered in the 13-queue. The 13-queue may be
significantly longer than the a-queue. As subsequent capacity thresholds, T
o~et~, j >1,
are crossed then further sessions are also buffered in the 13-queue. The
length of the
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
9
a-queue, and the settings of each threshold To,~et~~j>1 are constituted by
memory size,
in bytes, such that as each threshold is crossed a predetermined amount of
memory in
the a-queue is used by the data packets stored therein ready for transmission
on an
output link.
There is a wide range of possible algorithms that may be used for selecting
those sessions or packets of sessions that are to be transferred either from
the a-queue
to the 13-queue or buffered in the 13-queue before arriving in the a-queue
depending on
the properties desired. Such algorithms include the following:
(a) Random:
A session is chosen randomly from those currently in progress. Such a
selection attempts to spread performance degradation across all sessions over
their lifetime, but not instantaneously across all sessions. The packets of
the
sessions may be chosen randomly in accordance with, for example, random
numbers generated in the system that match a specific count number associated
with the packets.
(b) Fair:
The session with the most packets in the a-queue at the time the threshold is
crossed is chosen. Such a choice attempts to penalise those sessions whose
instantaneous bandwidth requirement is higher than the fair share. It attempts
to be instantaneously fair in deciding which sessions to penalise but has the
benefit of minimizing the number of sessions simultaneously affected. In this
case, each packet of each session stored in the a-queue is identified and
recorded by the a-queue and subsequently counted.
(c) Next Packet:
The session of the packet which first breaks the first or subsequent capacity
thresholds which is not already in the 13-queue or the session of the packet
which breaks the first capacity threshold is chosen. Such a choice is a mix
between being fair (the next packet arriving is likely to be from a session
with
the highest instantaneous bandwidth) and randomising sessions to be penalised.
It has the added advantage of being the simplest algorithm to implement.
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
(d) Historical:
A session that has been in the 13-queue at some stage in the past, but is now
in
the a-queue is selected. Such a decision attempts to keep penalising sessions
that have already been penalised. It minimises the amount of inconvenience
5 experienced by other sessions during the entire duration and thus attempts
to
maximise the number of users receiving good service over their entire session.
The above algorithms may be implemented in either software or hardware.
Shown in Figure 3 are a number of sessions that have been stored in the second
buffer 18 or the 13-queue. A time-out threshold, teXp~.e, is set and all
packets that have
10 been in the 13-queue longer than te,~ue are discarded. For example in the
13-queue of
Figure 3, the oldest packets stored therein are discarded in the order that
they were
input to the 13-queue. If the 13-queue overflows, due to the packets stored
therein
exceeding the memory capacity of the 13-queue, the system may either drop
newly
arriving packets from various sessions or push out or discard the oldest
packet in the
13- queue. The latter approach attempts to minimise the age of the packets in
the queue
and therefore maximise the chance that the transmitted packets will meet their
end to
end delay requirements.
A number of time-out thresholds, te,~,;re, ~, may be set depending on the
types of
data traffic stored in the second buffer means 18. For example, if the data
traffic
consists of video or voice packets, a small teXpre will be set, because a
delayed packet
in a real time stream is of very limited value and will only serve to delay
subsequent
packets. At the other extreme, packets may be representative of a file
transfer from a
server on the Internet. In this case, the texpire may be larger as the
information need not
be delivered in real time. Therefore, a slight delay is more acceptable than
losing a
packet, which would then require retransmission.
When the length or occupancy by packets of the a-queue drops to an
abatement threshold, TabateW'herein the memory presently being used in the a-
queue
drops to a specified size, then packets from the 13-queue are moved back to
the a-
queue. Packets from a session cease being redirected to the 13-queue when
there are no
packets from that session left in the 13-queue. All packets moved from the 13-
queue to
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
11
the a-queue are marked as "delayed". There are a number of algorithms for
deciding
which packets are moved first from the 13-queue to the a-queue, these being:
(a) FIFO:
This is the simplest 13-queue algorithm to implement and simply moves the
packets to the a-queue in order of arrival in the 13-queue when the length of
the
a-queue drops to Tabate- The number of packets from each session in the 13-
queue must be recorded so that the a-queue will know when to stop redirecting
a session. For example, in session 20 which is the most recent session stored
in
the 13- queue there are 3 packets so that when the last or third packet of
session
20 is transferred to the a-queue, the a-queue or the first buffer means 16
will
be notified that it is the last packet in that session. Therefore any
subsequent
packets for session 20 that are input to the a-queue will only be transmitted
after the first 3 packets of session 20 have been transmitted or output from
the
a-queue. This recordal also applies to the algorithms described under (b), (c)
and (d) below.
(b) FIFO - FIFO:
This is where each session transferred to or buffered in the 13-queue is
maintained separately. When the a-queue drops to below Tabate~ packets from
the first session placed in the 13-queue are moved to the a-queue, that is,
sessions are handled in a first in - first out order. The packets from this
session
are given priority over other sessions contained in the 13-queue. Within a
session, packets are also transferred in first in - first out order to
preserve
sequencing within a session.
(c) LIFO - FIFO:
Each session transferred to or buffered in the 13-queue is maintained
separately.
When the a-queue drops to below Tabate~ packets from the session most
recently placed in the 13-queue are moved to the a-queue, that is, sessions
are
handled in a last in - first out fashion. The packets from this session are
given
priority over other sessions contained in the 13-queue. Within a session
however, packets are still transferred in first in - first out order to
preserve
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
12
sequencing within a session. Such an algorithm attempts to maximise the
number of sessions receiving acceptable delay performance at any time.
(d) Fair:
Packets are transferred from the 13-queue to the a-queue using a Fair Queueing
approach when the length of the a-queue is less than or equal to Tabale~ Thus,
the sessions in the 13-queue use the residual bandwidths left over by the
sessions
still using the a-queue. Such a policy attempts to be fair to those sessions
currently being penalised.
It is to be noted that all packets leave the output port 6 via the a-queue.
Packets that have gone through the second buffer means 18 are marked to
allow for identification by other nodes or switches in the network. At
subsequent
nodes these packets may be the first choice for buffering in the second buffer
means
18 during a congestion period. In this manner, the network can co-ordinate
which
sessions are penalised if congestion occurs simultaneously at more than one
point in
the network. For example, if a session has been buffered in the second buffer
means
18 at one node, then the first packet or subsequent packets transmitted from
that
session to another node or nodes in the network will have an indication, in
its header,
that the session to which it belongs has been buffered previously. Thus other
nodes
may choose to continue buffering that session.
Another embodiment of the present invention is shown in Figures 4 and 5. The
input ports 4, output ports 6 and switching fabric 8 are represented as in
Figure 1. The
first buffer means 16 is in the form of an output queue and receives data
packets
representative of one or more sessions from either the second buffer means 18
or a
third buffer means 19. Each of the second buffer means 18 and third buffer
means 19,
in this alternative embodiment, comprise a series of per-session queues 21.
That is
data packets from each session are received and temporarily stored in
individual
queues 21. It is to be noted that the second buffer means 18 and third buffer
means 19
are simply subsets of a single collection of per-session queues 21. These
queues 21
can be dynamically reclassified as either part of the second buffer means or
the third
buffer means 19. Generally the packets stored in the per-session queues of
third buffer
means 19 are transferred to the first buffer means 16 according to the
scheduling
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
13
discipline chosen, such as FIFO or Fair Queueing as discussed previously. The
packets in the per-session queues of the buffer means 19 are polled or read at
a rate
significantly higher than the rate at which packets are read from the first
buffer means
16 onto an output link 15. Packets in the first buffer means 16 are then
transmitted in
FIFO order onto output link 15. The second and third buffer means 18, 19 may
be
implemented as logical queues. As with the first embodiment, at the onset of
congestion, when the level of the first buffer means rises due to the arrival
of packets
from the third buffer means one or more capacity thresholds To,~et> ; J > 1
may be
exceeded. If a particular packet arriving in buffer means 16 causes the
capacity of the
buffer means 16 to exceed a first threshold To,~et,l, this represents a
trigger condition
under which the session belonging to that packet is subsequently buffered in
the
second buffer means 18 into a respective queue in the buffer means 18. This
will
assist in preventing the first buffer means 16 from overflowing. As subsequent
capacity thresholds are crossed, further sessions are buffered in the second
buffer
means 18. The buffering of data packets from various sessions is done
according to
any one of the algorithms mentioned earlier, that is either random, fair, next
packet or
historical algorithms.
A time-out threshold teXp;re is set for those packets that have been buffered
in the
second buffer means so that any packets buffered longer than texpue are
discarded.
Different time-out thresholds teXp;res may be set depending on the type of
data stream
buffered, such as voice, video or web-browsing as with the previous
embodiment.
When the length of the first buffer means drops to an abatement threshold,
Tabate~ packets are moved from the second buffer means 18 to the first buffer
means 16.
This may be performed by the previous algorithms mentioned with respect to the
first
embodiment, such as FIFO, FIFO-FIFO or LIFO-FIFO but preferably the LIFO-FIFO
algorithm is used whereby the most recent session is transferred from buffer
means 18
to buffer means 16. Each packet within that most recent session is transferred
in the
order in which they entered the respective per-session queue so that
sequencing is
maintained.
In a filrther embodiment, the third buffer means may act as the first buffer
means wherein packets of sessions would be output onto output link 15 directly
from
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
14
the per-session queues 21. In this embodiment there is no need for an output
buffer as
with the previous embodiment. The capacity thresholds, To~e~, would be based
on the
current logical contents of the third buffer means, that is, the sum of the
capacity taken
up by individual sessions in each of the per-session queues 21. Therefore any
packets
of particular sessions that cross the thresholds would be treated according to
any one
of the previously mentioned situations.
Some simulation experiments have been performed and the results of those
experiments will be hereinafter described. The simulation set up is shown in
Figure 6
where a number of traffic sources 1 to N, identified by numeral 22, generating
MPEG
data streams originating from video servers are multiplexed together by a node
or
switch 24 onto a single data link 26 to be transmitted to sink 28. The sink 28
acts as a
discarder for packets in the simulation. Any other type of server from which
higher
volume traffic may be multiplexed may also be used in this example.
The frame sizes from real MPEG traces generated by O. Rose in the
publication "Statistical Properties of MPEG Video Traffic and their Impact on
Traffic
Modelling in ATM Systems", in Proceedings of the 20th annual conference on
local
computer networks, 1995, pp. 397-406 (MPEG traces at ftp: //ftp-info3.
informatik.
uni-wuerzburg.de/pub/MPEG), are used for sources in the simulation. Table 1
summarises the characteristics of the MPEG sources. All sources have a peak
rate of
4 Mbps at 25 frames per second and are 1600 seconds in duration (except for
the
newsl trace which is 1260 seconds). They are randomly started over a 1600
second
interval and measurements are taken between 1600 seconds and 3200 seconds.
When
an MPEG trace comes to the end it is cycled. The frames are broken into 1500
byte
packets for transmission with a 40 byte minimum packet size.
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
TABLE 1
No. Name Mean bits/frame Peak/Mean Frame Number
Size of
Frames
1 asterix 22,349 6.6 40000
2 apt 21,890 8.7 40000
3 bond 24,308 10.1 40000
4 dino 13,078 9.1 40000
S lambs 7,312 18.4 40000
6 movie 14,288 12.1 40000
7 mrbean 17,647 13.0 40000
8 mtv 1 24,604 9.3 40000
9 mtv 2 19,780 12.7 40000
10 newsl 20,664 9.4 31515
11 news2 15,358 12.3 40000
12 race 30,749 6.6 40000
13 sbowl 23,506 6.0 40000
14 simpsons 18,576 12.9 40000
15 soccerl 27,129 6.9 40000
16 soccer2 25,110 7.6 40000
17 starwars 9,313 13.4 40000
18 talkl 14,537 7.3 40000
19 talk2 17,914 7.4 40000
terminator 10,905 7.3 40000
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
16
The following measurements are collected for each session:
- End to end delay for each packet
- Actual packets lost
S - Degraded packets (packets delayed > SOms)
- Degraded frames (frames with degraded or lost packets)
- Degraded seconds (one second intervals with degraded frames).
A session is receiving "good service" during any particular second if no
frames
of the session have been degraded. Any session not receiving "good service" is
deemed to be receiving "degraded service".
The method of the present invention is implemented in these simulation
experiments to provide as many sessions as possible with good service during a
particular transient congestion period. The second buffer means 18 or the 13-
queue
follows the LIFO - FIFO principle earlier described. Packets from the f3-queue
are
transferred to the a-queue only when the a- queue is empty, in other words
when
Tabate equals 0. The thresholds for redirecting packets to the 13-queue,
To~et~ are set at
L-L/(3 +j-1) for j>_ 1 where L is the length of the a-queue in the simulation.
Sources
are removed from the redirection list when there are no packets from that
source (or
session) in the 13-queue. In a real network with a changing number of sessions
in
progress, the threshold assignment can be made dynamic by simply replacing the
number of sessions in the simulation with the number of sessions in progress.
The
packet time out threshold texpire is set to 400ms.
In this set of experiments the simplest method of selecting which sessions are
redirected to the 13-queue is chosen. That method is the next packet method
where the
session of the first packet to break To"Set~ is chosen to be redirected to the
13- queue.
The 13-queue uses an oldest packet push out mechanism on overflow of the f3-
queue.
In Table 2 there is listed a set of simulation experiments used to compare the
performance of the algorithm or method of the present invention, termed dual
queue
(DQ), with the existing FIFO and Fair Queueing methods. A deficit round robin
(DRR) technique is used for the Fair Queueing comparison, but is enhanced to
include
old packet discard (DRRexp) to make a fairer comparison with DQ.
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
17
ExperimentNumber Offered MPEG Buffer Transmission
Number of load (Mbps)Sources Space rate (Mbps)
Sources used (Bytes)
1 20 9.5 all 20 500x103 8,9,10
& 12
2 4 1.6 1,2,3 & 100x103 1.3,1.65,
5 &
2
3 40 19 all twice 1x106 16, 20
& 24
4 20 30.7 race 1.5x106 24,30 &
36
TABLE 2
A DRR technique was introduced by M. Shreedhar and G. Varghese in a
document titled "Efficient Fair Queueing Using Deficit Round Robin", IEEE/ACM
Trans. Networking, Volume 4 No. 3, 1996, pp. 375-385.
As mentioned previously a packet is degraded if it is delayed more than SOms.
This is used as an estimate of the maximum delay allowed before a frame cannot
be
displayed to a viewer or user. Packets that have been queued for longer than
te,~pue =
400ms are discarded in the DRRexp and DQ algorithms. However, an MPEG frame
that arrives too late for display may still be useful for the decoding of
future frames
which may not be so badly delayed.
All queues are given the same total buffer size and kept constant for the bit
rates used in each simulation experiment. The a-queue of the DQ implementation
has
a size that is changed whenever the link transmission speed is changed so as
to give a
maximum packet delay of 50 ms. It should also be noted that the worst case
service
delay overhead in DRR introduced by the round robin scheduling is less than
the good
service delay threshold of SOms.
In experiment 1 shown in Table 2 all 20 heterogeneous MPEG sources are
multiplexed onto link 26. Four representative sessions, being numbers 3, 10,
14 and
have arbitrarily been selected to give a detailed comparison between the FIFO,
20 DRRexp and DQ scheduling algorithms.
Figure 7 shows graphs of the cumulative probability distributions of packet
delay for session 3 (represented by graph 30), session 10 (represented by
graph 32),
session 14 (represented by graph 34) and session 20 (represented by graph 36)
when
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
18
the link transmission rate is lOMbps (compared with the total average offered
rate of
9.SMbps). Dropped packets are considered to have infinite delay in Figure 5. A
highly loaded case has been chosen in order to exaggerate the difference
between the
algorithms during congestion. A line is drawn at the 50 ms good service cut
off point.
It is seen that the DQ algorithm provides the highest fraction of packets
receiving a
delay of less than SOms. This is achieved by giving some packets a delay much
greater than SOms. Given that the service provided to such packets is already
considered degraded, the amount by which the delay exceeds SOms is considered
to be
of little relevance. Note that DRRexp gives better service to session number
20 than
the other sessions as it is usually operating at less than its fair share of
the bandwidth
as expected from a Fair Queueing based discipline. Note that this is also true
of the
DQ algorithm.
In Figure 8 there is shown a plot of the highest packet delays per second for
each of the sources or sessions 3, 10, 14 and 20 against the simulation time
where the
transmission rate on link 26 has been increased to 12 Mbps. Plots 38, 40, 42
and 44
are for the respective sessions 3, 10, 14 and 20. A line is drawn at SOms mark
to
indicate the good service cut off point. The time range as shown is chosen so
as to
include a number of transient congestion periods for comparison between the
different
algorithms. The FIFO is fair at the packet level and all sessions' packets, on
average,
experience the same delay passing through the node 24 on a FIFO basis. The
DRRexp
performs a little better but fails to deliver good service when the bandwidth
has to be
shared in such a way that many of the sessions receive less than their
required service.
The priority nature of the FQ can cause longer delays to a burst of packets
than
encountered in a FIFO scheme. Therefore these extra delays can cause packets
from a
particular session to become degraded even when the link is not congested as
is
illustrated in the top trace 38 of source 3 in Figure 8. The DQ discipline
selected tries
to maximise the instantaneous number of sessions receiving good service so we
see
that one of the sessions receives very poor delay performance, so that the
other
sessions are spared service degradation, at times of 1925 seconds and 1975
seconds.
A better illustration of the level of QoS by all of the 20 sessions is
illustrated in
Figure 9 which shows a plot 46 of the percentage of all sessions
simultaneously
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
19
receiving good service during similar one second periods. It is to be noted
that the
FIFO and DRRexp algorithms present degraded service to many sessions at times
of
1855 seconds, 1925 seconds and 1975 seconds. These QoS figures can be
represented
in binary form where service is either good or degraded. A binary
representation of
service per session is generally all that is required for comparisons between
each of the
scheduling disciplines. Figure 10 shows such a representation 48 for the
DRRexp
algorithm and a representation 50 for the DQ algorithm over the full
measurement
time scale for each session at a link transmission rate of l2Mbps. A vertical
bar is
drawn for every degraded second experienced by any particular session. The
more
white space on the graph, the better the service a session is receiving. All
the results
that are shown in subsequent figures will use this method of comparison. From
Figure
8 we see that the DQ approach results in fewer sessions being affected by
congestion
than DRRexp at any particular time.
As the transmission rate is reduced to lOMbps, shown in Figure 1 l, and 8Mbps
in Figure 12 the contrast between DRRexp and DQ becomes even more evident. The
plots 52 and 54 are respectively for the DRRexp and DQ algorithms in Figure 11
and
the plots 56 and 58 are respectively for the DRRexp and DQ algorithms in
Figure 12.
It is apparent that the DQ approach provides good service to most of the
sessions even
under extreme overload conditions as compared to the DRRexp algorithm.
Although
these experiments or simulations have provided the simplest possible
implementation
of the DQ approach, it is possible to provide significantly better performance
for real-
time services than can DRRexp.
Refernng to Table 2, experiments 2 and 3 use 4 and 40 sources respectively
and are conducted to determine the scalability of DQ algorithm. Experiment 2
has the
added complexity that the peak bit rates of any of the sessions is higher than
the link
transmission rate and therefore cause the a-queue to begin to fill. In Figure
13 four
sources are used and it is evident that even when presented with an
unmanageable
load, the DQ algorithm depicted in plot 60 performs as well as the DRRexp
algorithm
depicted in plot 62, if not slightly better especially for sources 3 and 4. In
experiment 3
both scheduling disciplines provided good performance almost all of the time
and
figures have not been provided in this case. For DRRexp, 13 sessions
experienced
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
degraded service during a single congestion event whereas only one session
experienced degraded service using the DQ algorithm during the equivalent
period. In
the DQ algorithm, there was only one second in which sessions had degraded
service,
whereas there was one other second in which degraded service occurred using
the
5 DRRexp. It is therefore concluded that the DQ approach scales reasonably
well when
compared to DRR Exp.
To examine fairness over moderate time scales, 20 homogeneous sources were
used in experiment 4. The sessions consisted of 20 copies of the race trace
which
started at random times over the period 0 to 1600 seconds. Figure 14 shows the
10 degraded seconds plots 64 and 66 respectively for the DRRexp and DQ
algorithms for
each session where it is seen that DRRexp provides fair, although very
degraded
service to each session. Qualitatively, the DQ algorithm also provides fair
service to
each session over the entire length of the simulation rather than
instantaneously. As
seen earlier, the overall QoS of each session is significantly better in DQ
than that
15 provided by DRRexp.
Overall it is seen that when there is no congestion all of the schemes
compared
provide good service. However as the periods of congestion increase, a greater
contrast can be seen between the 3 algorithms. In Figure 15 there is shown the
plot 68
of the percentage of degraded packets for the FIFO, DRR, DRRexp and DQ
20 algorithms for different average offered loads (normalised to the link
transmission
rate). Apart from achieving its aim of giving good service to as many sessions
as
possible during transient congestion periods, the DQ algorithm also minimises
the
overall proportion of degraded packets. It is to be noted that the percentage
of
degraded packets even under the simple implementation of the DQ approach is
close
to the excess offered load above one Erlang, and hence is near optimal. While
this
would also be true for a short FIFO queue, the short FIFO queue has the
disadvantage
of resulting in unnecessary loss during transient congestion periods when the
offered
load is close to, but less than the transmission link speed. The short FIFO
queue also
loses packets randomly rather than selectively as in DQ.
During transient congestion episodes, packets entering a normal FIFO queue all
experience similar degraded service. If the congestion is caused by a small
number of
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
21
sessions, Fair Queueing provides relief for the other sessions. However,
results
presented hereinbefore indicate that this is not always the case as transient
congestion
is often caused by many sessions whose combined traffic fills the queue. Fair
Queueing divides bandwidth equally and therefore degrading the service of a
large
number of sessions and therefore a large number of packets. The DQ algorithm
outperforms Fair Queueing because it degrades the service of only enough
sessions so
as to obtain good service for the rest of the sessions during the congestion
period and
therefore also increases throughput.
As mentioned previously, the service provider may wish to maximise the
number of users receiving "perfect" service, that is, showing no sign of
congestion so
as to minimise the number of complaints received by users when they make a
connection and receive unsatisfactory QoS. This can be achieved by recording
in a
"target" list or file the connections which have been redirected to the 13-
queue at some
stage, and increasing the probability that they will be redirected again the
next time the
1 S system is congested. Therefore the degradation is not spread evenly among
users,
even over considerable time scales, increasing the probability of a connection
remaining unaffected by the congestion. The probability of redirecting
connections in
the target list or file may be increased to one so that no new connection will
be
redirected until all connections which have previously been redirected are
currently
being redirected. Another alternative is to consider several factors including
the
current data rate as well as the presence of the connections in the target
list or file.
If the aim of the service provider is to maximise the number of the satisfied
customers at any moment in time, the optimal strategy is to redirect the
highest rate
sessions. If the statistics of a given connection change significantly with
time, the
above approach of repeatedly targeting a particular user for the entire
connection may
not be appropriate. Instead, sessions could be removed from the target list or
file after
some time, t~get. This would result in bursts of bad service on a time scale
of tt~.get, but
may improve the total number of customer minutes of high QoS.
Alternatively a telecommunications regulatory body may require a stricter
guarantee of fairness over moderate time scales than that provided by the
hereinbefore
described DQ implementation. This is also possible again by recording those
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
22
connections or sessions which have been redirected. This time, these sessions
will be
less likely to be redirected again. Once again there is a trade-off with the
total number
of customer minutes of high QoS which can be achieved.
Even greater flexibility is possible if other service disciplines are
considered for
S the 13-queue rather than only the LIFO-FIFO system hereinbefore mentioned.
For
example, the 13-queue could use Fair Queueing. Let L denote the set of low-
rate users
who require less than their fair share of the bandwidth. In pure Fair
Queueing,
sessions in L are allocated their full bandwidth and the residual bandwidth is
allocated
to the remaining sessions. In the hybrid DQ/FQ system, the set of sessions
which
have been selected to receive good services at time t, G(t), takes the role of
L so that
the residual bandwidth after serving users in G(t) is fairly divided. If G(t)
= L for all t,
or if the size of the a-queue is set to zero, then the hybrid approach reduces
to Fair
Queueing. Conversely, if G(t) is the set of all users, FIFO results. However,
it is often
possible to have G(t) a strict superset of L whose total instantaneous
bandwidth is still
less than the output link capacity, increasing the number of satisfied
customers without
penalising any well behaved users.
As an alternative to using threshold crossing based schemes for initiating the
redirection of sessions from the a-queue to the 13-queue, there is a wide
variety of
possible trigger conditions. Some examples include the use of derivative based
schemes such that when the rate of increase of the amount of data stored in
the a-
queue exceeds the derivative-based threshold, the data packets are redirected
to the
second buffer means. Fuzzy logic based approaches may also be used. Thus
whenever
a predetermined rate of increase of the amount of packets stored in the a-
queue is
reached, packets of a session or sessions are redirected to the f3-queue.
Shown in Figure 16 is a flow diagram 100 illustrating the steps or processes
involved on receipt of a packet representative of a session on an output link
to the
output port 6 or node 24. At step 102 the received packet is time stamped to
enable
the buffers 16 and 1$ to place the packet in a particular sequence based on
time. At
step 104 a check is made to see if other packets associated with that session
are in the
13-queue redirection list. If there are no previous packets in the 13-queue
then at step
106 a decision is made as to whether or not the received packet will cross a
capacity
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
23
threshold if it was placed in the a-queue. If the packet does not cross the
capacity
threshold it is placed in the a-queue at step 108 or if it will cross the
capacity
threshold a stream identifier or session identifier is placed in the I3-queue
redirection
list at step 110 and at step 112 the next capacity threshold is then used.
Thereafter, the
packet is placed in the 13-queue at step 114. Going back to step 104, if there
are
previous packets from that session already in the 13-queue redirection list
then the
received packet is immediately placed in the 13-queue again at step 114.
In Figure 17 there is shown a flow diagram 200 illustrating the processes and
steps involved when a packet is transferred from the 13-queue (or the second
buffer
means 18) to the a-queue (or the first buffer means 16). At step 202 a
determination
is made as to whether there are packets in the 13-queue and if there are none,
then the
process does nothing at step 204. If there are packets queued then at step 206
the
oldest packet is retrieved from the most recent session redirected to the 13-
queue
(LIFO-FIFO). A determination is made at step 208 as to whether the packet is
too old
and has gone beyond te,~,ue. If this is the case then the packet is discarded
at step 220
and a decision is made at step 222 as to whether that discarded packet was the
last
packet from that session. If it was the last packet, then at step 224 the
session owning
that packet is removed from the 13-queue redirection list and at step 226 the
previous
a-queue abatement threshold is then implemented. The process then reverts back
to
step 202. If the discarded packet was not the last packet from that session in
the 13-
queue, then the process reverts again to step 202. Referring back to step 208,
if the
packet is not too old and is within the time limits set by teXpue, the packet
is then placed
in the a-queue at step 210 and a determination is made at step 212 as to
whether that
placed packet is the last packet from the session in the 13-queue. If it is
not the last
packet then the process does nothing at step 214. If it was the last packet in
the 13-
queue belonging to that session, then at step 216 the session is removed from
the 13-
queue redirection list and at step 218 the previous a-queue abatement
threshold is
implemented.
Shown in Figure 18 is a flow chart 300 showing processes involved in placing
packets of sessions from a third buffer means into a first buffer means and
the steps
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
24
involved for dealing with such packets or sessions at the onset of congestion
in the
first buffer means (refer to Figures 4 and 5). Incoming packets are received
at one of
the output ports 6 in the third buffer means 19. At step 302 a check is made
as to
whether or not packets are temporarily stored in the third buffer means in any
one of
the per-session queues 21. If there are packets stored in any one of the per-
session
queues 21, the packet is selected according to the chosen scheduling
discipline from
one of these queues at step 304 and then placed in the first buffer means 16,
or output
queue at step 306. At step 308 if the selected packet crosses a current
capacity
threshold in the first buffer means 16 then at step 310 the session that that
particular
packet belongs to is identified and is buffered in one of the per-session
queues in the
second buffer means 18. Again at step 308 if the packet has not crossed a
current
capacity threshold then the process reverts to step 302. At step 312 the next
capacity
threshold that has been set in the first buffer means 16 is used and assessed
against for
further packets that are input to the first buffer means 16. In this regard
step 308 is
repeated to test whether incoming packets cross subsequent capacity
thresholds.
If at step 302, there are no packets queued in the third buffer means 19 the
process moves to step 314 where a determination is made as to whether the
capacity of
the first buffer means has dropped below the abatement threshold, Tabate~ If
it has then
at step 316 a determination is made as to whether there are any packets
temporarily
stored in the second buffer means in any one of the per-session queues. If the
capacity
in the first buffer means has not dropped below Tabate at step 314, the
process returns to
step 302. At step 316 if there are packets queued in the second buffer means
18 the
packet from the most recent stream or session that is identified as part of
the logical
queue forming the second buffer means is retrieved at step 318. If there are
no packets
queued in the second buffer means 18, the process reverts to step 302. At Step
320 a
determination is made as to whether the retrieved packet from the second
buffer
means 18 is too old or has exceeded its time-out threshold, teXpire~ If a
packet has been
in the second buffer means too long and beyond its time-out threshold the
packet is
discarded at step 322 or if it has not exceeded its time out threshold the
packet is
placed in the first buffer means 16 at step 324. A determination is then made
at step
326 as to whether or not the most recently retrieved packet is the last packet
in that
reo:fph:#31281.CAP 7 May 1999
CA 02271669 2000-02-15
particular stream or session stored in any one of the per-session queues 21 of
the
second buffer means 18. If this is the case the stream is then identified as
part of a
stream originating from the third buffer means 19 at step 328 and at step 330
the
previous capacity threshold is then used or implemented. If at step 326 the
most
5 recently retrieved packet is not the last packet in that particular stream
or session then
the process returns to step 302. At step 330 after the previous capacity
threshold has
been implemented then the process also returns to step 302.
It will also be appreciated that various modifications and alterations may be
made to the preferred embodiments above, without departing from the scope and
spirit
10 of the present invention.
reo:fph:#31281.CAP 7 May 1999