Note: Descriptions are shown in the official language in which they were submitted.
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
SECRETED PROTEINS AND POLYNUCLEOTIDES ENCODING THEM
This application is a continuation-in-part of application Ser. No. 60/XXX,XXX
(converted to a provisional application from non-provisional application Ser.
No.
08/878,715), filed June 19, 1997, which is incorporated by reference herein.
FIELD OF THE INVENTION
The present invention provides novel polynucleotides and proteins encoded by
such
polynucleotides, along with therapeutic, diagnostic and research utilities for
these
polynucleotides and proteins.
BACKGROUND OF THE INVENTION
Technology aimed at the discovery of protein factors (including e.g.,
cytokines, such
as lymphokines, interferons, CSFs and interleukins) has matured rapidly over
the past
decade. The now routine hybridization cloning and expression cloning
techniques clone
novel polynucleotides "directly" in the sense that they rely on information
directly related to
the discovered protein (i.e., partial DNA/amino acid sequence of the protein
in the case of
hybridization cloning; activity of the protein in the case of expression
cloning). More recent
"indirect" cloning techniques such as signal sequence cloning, which isolates
DNA sequences
based on the presence of a now well-recognized secretory leader sequence
motif, as well as
various PCR-based or low stringency hybridization cloning techniques, have
advanced the
state of the art by making available large numbers of DNA/amino acid sequences
for
proteins that are known to have biological activity by virtue of their
secreted nature in the
case of leader sequence cloning, or by virtue of the cell or tissue source in
the case of PCR-
based techniques. It is to these proteins and the polynucleotides encoding
them that the
present invention is directed.
SUBSTITUTE SHEET (RULE 26)
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
SUMMARY OF THE INVENTION
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:1;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:1 from nucleotide 185 to nucleotide 1600;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:1 from nucleotide 1403 to nucleotide 1600;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:1 from nucleotide 1 to nucleotide 850;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone dol5 4 deposited under accession
number ATCC 98468;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone dol5 4 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone dol5_4 deposited under accession number
ATCC 98468;
2 0 (h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone dol5 4 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:2;
(j) a polynucleotide encoding a protein comprising a fragment of the
2 5 amino acid sequence of SEQ ID N0:2 having biological activity, the
fragment
comprising eight consecutive amino acids of SEQ ID N0:2;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
3 0 of (i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-{j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
NO:1 from nucleotide 185 to nucleotide 1600; the nucleotide sequence of SEQ ID
N0:1
2
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
from nucleotide 1403 to nucleotide 1600; the nucleotide sequence of SEQ ID
N0:1 from
nucleotide 1 to nucleotide 850; the nucleotide sequence of the full-length
protein coding
sequence of clone dol5_4 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone dol5 4
deposited under
accession number ATCC 98468. In other preferred embodiments, the
polynucleotide
encodes the full-length or a mature protein encoded by the cDNA insert of
clone dol5_4
deposited under accession number ATCC 98468. In yet other preferred
embodiments,
the present invention provides a polynucleotide encoding a protein comprising
the amino
acid sequence of SEQ ID N0:2 from amino acid 1 to amino acid 222. In further
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising a fragment of the amino acid sequence of SEQ ID N0:2 having
biological
activity, the fragment preferably comprising eight (more preferably twenty,
most
preferably thirty) consecutive amino acids of SEQ ID N0:2, or a polynucleotide
encoding
a protein comprising a fragment of the amino acid sequence of SEQ ID N0:2
having
biological activity, the fragment comprising the amino acid sequence from
amino acid 231
to amino acid 240 of SEQ ID N0:2.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:1.
In other embodiments, the present invention provides a composition comprising
2 0 a protein, wherein said protein comprises an amino acid sequence selected
from the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:2;
(b) the amino acid sequence of SEQ ID N0:2 from amino acid 1 to
amino acid 222;
2 5 (c) fragments of the amino acid sequence of SEQ ID N0:2 comprising
eight consecutive amino acids of SEQ ID N0:2; and
(d) the amino acid sequence encoded by the cDNA insert of clone
dol5 4 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
3 0 protein comprises the amino acid sequence of SEQ ID N0:2 or the amino acid
sequence
of SEQ ID N0:2 from amino acid 1 to amino acid 222. In further preferred
embodiments,
the present invention provides a protein comprising a fragment of the amino
acid
sequence of SEQ ID N0:2 having biological activity, the fragment preferably
comprising
eight (more preferably twenty, most preferably thirty) consecutive amino acids
of SEQ ID
3
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
N0:2, or a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:2having biological activity, the fragment comprising the amino acid
sequence from
amino acid 231 to amino acid 240 of SEQ ID N0:2.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:3;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:3 from nucleotide 47 to nucleotide 2065;
(c} a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:3 from nucleotide 1086 to nucleotide 1848;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone dx290_1 deposited under accession
number ATCC 98468;
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone dx290_1 deposited under accession number ATCC 98468;
(f) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone dx290_1 deposited under accession number
ATCC 98468;
2 0 (g) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone dx290_1 deposited under accession number ATCC 98468;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:4;
(i) a polynucleotide encoding a protein comprising a fragment of the
2 5 amino acid sequence of SEQ ID N0:4 having biological activity, the
fragment
comprising eight consecutive amino acids of SEQ ID N0:4;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
3 0 of (h) or (i) above ; and
(1) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:3 from nucleotide 47 to nucleotide 2065; the nucleotide sequence of SEQ ID
N0:3
4
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
from nucleotide 1086 to nucleotide 1848; the nucleotide sequence of the full-
length protein
coding sequence of clone dx290_1 deposited under accession number ATCC 98468;
or the
nucleotide sequence of a mature protein coding sequence of clone dx290_1
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone dx290_1 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:4 from amino acid 312 to amino
acid
600. In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:4
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:4, or a
polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:4 having biological activity, the fragment comprising the amino acid
sequence
from amino acid 331 to amino acid 340 of SEQ ID N0:4.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:3.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
2 0 consisting of:
(a) the amino acid sequence of SEQ ID N0:4;
(b) the amino acid sequence of SEQ ID N0:4 from amino acid 312 to
amino acid 600;
(c) fragments of the amino acid sequence of SEQ ID N0:4 comprising
2 5 eight consecutive amino acids of SEQ ID N0:4; and
(d) the amino acid sequence encoded by the cDNA insert of clone
dx290_1 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:4 or the amino acid
sequence
3 0 of SEQ ID N0:4 from amino acid 312 to amino acid 600. In further preferred
embodiments, the present invention provides a protein comprising a fragment of
the
amino acid sequence of SEQ ID N0:4 having biological activity, the fragment
preferably
comprising eight (more preferably twenty, most preferably thirty) consecutive
amino
acids of SEQ ID N0:4, or a protein comprising a fragment of the amino acid
sequence of
5
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
SEQ ID N0:4having biological activity, the fragment comprising the amino acid
sequence
from amino acid 331 to amino acid 340 of SEQ ID N0:4.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5 from nucleotide 107 to nucleotide 724;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5 from nucleotide 218 to nucleotide 724;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5 from nucleotide 536 to nucleotide 866;
{e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone ek390 4 deposited under accession
number ATCC 98468;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone ek390 4 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone ek390_4 deposited under accession number
2 0 ATCC 98468;
{h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone ek390 4 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:6;
2 5 (j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:6 having biological activity, the fragment
comprising eight consecutive amino acids of SEQ ID N0:6;
{k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
3 0 (1) a polynucleotide which encodes a species homologue of the protein
of {i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
6
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:5 from nucleotide 107 to nucleotide 724; the nucleotide sequence of SEQ ID
N0:5 from
nucleotide 218 to nucleotide 724; the nucleotide sequence of SEQ ID N0:5 from
nucleotide 536 to nucleotide 866; the nucleotide sequence of the full-length
protein coding
sequence of clone ek390 4 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone ek390_4
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone ek390 4 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:6 from amino acid 6 to amino
acid 92.
In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:6
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:6, or a
polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:6 having biological activity, the fragment comprising the amino acid
sequence
from amino acid 97 to amino acid 106 of SEQ ID N0:6.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
2 0 ID N0:5.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:6;
2 5 (b) the amino acid sequence of SEQ ID N0:6 from amino acid 6 to
amino acid 92;
(c) fragments of the amino acid sequence of SEQ ID N0:6 comprising
eight consecutive amino acids of SEQ ID N0:6; and
(d) the amino acid sequence encoded by the cDNA insert of clone
3 0 ek390 4 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:6 or the amino acid
sequence
of SEQ ID N0:6 from amino acid 6 to amino acid 92. In further preferred
embodiments,
the present invention provides a protein comprising a fragment of the amino
acid
7
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
sequence of SEQ ID N0:6 having biological activity, the fragment preferably
comprising
eight (more preferably twenty, most preferably thirty) consecutive amino acids
of SEQ ID
N0:6, or a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:6having biological activity, the fragment comprising the amino acid
sequence from
amino acid 97 to amino acid 106 of SEQ ID N0:6.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7;
1 p (b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 31 to nucleotide 1230;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 289 to nucleotide 1230;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 344 to nucleotide 1119;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone er471 7 deposited under accession
number ATCC 98468;
{f) a polynucleotide encoding the full-length protein encoded by the
2 0 cDNA _insert of clone er471 7 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone er471 7 deposited under accession number
ATCC 98468;
(h) a polynucleotide encoding a mature protein encoded by the cDNA
2 5 insert of clone er471 7 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:8;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:8 having biological activity, the fragment
3 0 comprising eight consecutive amino acids of SEQ ID N0:8;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of {i) or (j) above ; and
8
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:7 from nucleotide 31 to nucleotide 1230; the nucleotide sequence of SEQ ID
N0:7 from
nucleotide 289 to nucleotide 1230; the nucleotide sequence of SEQ ID N0:7 from
nucleotide 344 to nucleotide 1119; the nucleotide sequence of the full-length
protein
coding sequence of clone er471 7 deposited under accession number ATCC 98468;
or the
nucleotide sequence of a mature protein coding sequence of clone er471 7
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone er471 7 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:8 from amino acid 111 to amino
acid
363. In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:8
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:8, or a
polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:8 having biological activity, the fragment comprising the amino acid
sequence
2 0 from amino acid 195 to amino acid 204 of SEQ ID N0:8.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:7.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
2 5 consisting of:
(a) the amino acid sequence of SEQ ID N0:8;
(b) the amino acid sequence of SEQ ID N0:8 from amino acid 111 to
amino acid 363;
(c) fragments of the amino acid sequence of SEQ ID N0:8 comprising
3 0 eight consecutive amino acids of SEQ ID N0:8; and
(d) the amino acid sequence encoded by the cDNA insert of clone
er471 7 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID NO:B or the amino acid
sequence
9
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
of SEQ ID N0:8 from amino acid 111 to amino acid 363. In further preferred
embodiments, the present invention provides a protein comprising a fragment of
the
amino acid sequence of SEQ ID N0:8 having biological activity, the fragment
preferably
comprising eight (more preferably twenty, most preferably thirty) consecutive
amino
acids of SEQ ID N0:8, or a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:8having biological activity, the fragment comprising the amino acid
sequence
from amino acid 195 to amino acid 204 of SEQ ID N0:8.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 62 to nucleotide 322;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 571 to nucleotide 878;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone fs40 3 deposited under accession
number
ATCC 98468;
{e) a polynucleotide encoding the full-length protein encoded by the
2 0 cDNA insert of clone fs40_3 deposited under accession number ATCC 98468;
(f) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone fs40 3 deposited under accession number ATCC
98468;
(g) a polynucleotide encoding a mature protein encoded by the cDNA
2 5 insert of clone fs40_3 deposited under accession number ATCC 98468;
{h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID NO:10;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID NO:10 having biological activity, the fragment
3 0 comprising eight consecutive amino acids of SEQ ID N0:10;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or {i) above ; and
CA 02294569 1999-12-17
WO 98/57976 PCTNS98/12516
(1) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:9 from nucleotide 62 to nucleotide 322; the nucleotide sequence of SEQ ID
N0:9 from
nucleotide 571 to nucleotide 878; the nucleotide sequence of the full-length
protein coding
sequence of clone fs40 3 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone fs40_3
deposited under
accession number ATCC 98468. In other preferred embodiments, the
polynucleotide
encodes the full-length or a mature protein encoded by the cDNA insert of
clone fs40 3
deposited under accession number ATCC 98468. In further preferred embodiments,
the
present invention provides a polynucleotide encoding a protein comprising a
fragment
of the amino acid sequence of SEQ ID N0:10 having biological activity, the
fragment
preferably comprising eight (more preferably twenty, most preferably thirty)
consecutive
amino acids of SEQ ID N0:10, or a polynucleotide encoding a protein comprising
a
fragment of the amino acid sequence of SEQ ID N0:10 having biological
activity, the
fragment comprising the amino acid sequence from amino acid 38 to amino acid
47 of SEQ
ID NO:10.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:9.
2 0 In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:10;
(b) fragments of the amino acid sequence of SEQ ID NO:10 comprising
2 5 eight consecutive amino acids of SEQ ID NO:10; and
(c) the amino acid sequence encoded by the cDNA insert of clone
fs40 3 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:10. In further
preferred
3 0 embodiments, the present invention provides a protein comprising a
fragment of the
amino acid sequence of SEQ ID N0:10 having biological activity, the fragment
preferably
comprising eight (more preferably twenty, most preferably thirty) consecutive
amino
acids of SEQ ID N0:10, or a protein comprising a fragment of the amino acid
sequence of
I1
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
SEQ ID N0:10 having biological activity, the fragment comprising the amino
acid
sequence from amino acid 38 to amino acid 47 of SEQ ID N0:10.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:11;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:11 from nucleotide 43 to nucleotide 1671;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:11 from nucleotide 112 to nucleotide 1671;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:11 from nucleotide 224 to nucleotide 679;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone ga63_6 deposited under accession
number
ATCC 98468;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA _insert of clone ga63_6 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone ga63_6 deposited under accession number ATCC
2 0 98468;
(h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone ga63 6 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:12;
2 5 (j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:12 having biological activity, the fragment
comprising eight consecutive amino acids of SEQ ID N0:12;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
3 0 (1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in {a)-(j).
12
CA 02294569 1999-12-17
WO 98/57976 PCTNS98/12516
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:11 from nucleotide 43 to nucleotide 1671; the nucleotide sequence of SEQ ID
N0:11
from nucleotide 112 to nucleotide 1671; the nucleotide sequence of SEQ ID
N0:11 from
nucleotide 224 to nucleotide 679; the nucleotide sequence of the full-length
protein coding
sequence of clone ga63 6 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone ga63_6
deposited under
accession number ATCC 98468. In other preferred embodiments, the
polynucleotide
encodes the full-length or a mature protein encoded by the cDNA insert of
clone ga63_6
deposited under accession number ATCC 98468. In yet other preferred
embodiments,
the present invention provides a polynucleotide encoding a protein comprising
the amino
acid sequence of SEQ ID N0:12 from amino acid 62 to amino acid 212. In further
preferred embodiments, the present invention provides a polynucleotide
encoding a
protein comprising a fragment of the amino acid sequence of SEQ ID N0:12
having
biological activity, the fragment preferably comprising eight (more preferably
twenty,
most preferably thirty) consecutive amino acids of SEQ ID N0:12, or a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:12
having biological activity, the fragment comprising the amino acid sequence
from amino
acid 266 to amino acid 275 of SEQ ID N0:12.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
2 0 ID NO:11.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:12;
2 5 {b) the amino acid sequence of SEQ ID N0:12 from amino acid 62 to
amino acid 212;
(c) fragments of the amino acid sequence of SEQ ID N0:12 comprising
eight consecutive amino acids of SEQ ID N0:12; and
(d) the amino acid sequence encoded by the cDNA insert of clone
3 0 ga63_6 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:12 or the amino acid
sequence
of SEQ ID N0:12 from amino acid 62 to amino acid 212. In further preferred
embodiments, the present invention provides a protein comprising a fragment of
the
13
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
amino acid sequence of SEQ ID N0:12 having biological activity, the fragment
preferably
comprising eight (more preferably twenty, most preferably thirty) consecutive
amino
acids of SEQ ID N0:12, or a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:12having biological activity, the fragment comprising the amino acid
sequence from amino acid 266 to amino acid 275 of SEQ ID N0:12.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:13;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:13 from nucleotide 17 to nucleotide 523;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:13 from nucleotide 77 to nucleotide 523;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:13 from nucleotide 1 to nucleotide 392;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone gm335 4 deposited under accession
number ATCC 98468;
(f) a polynucleotide encoding the full-length protein encoded by the
2 0 cDNA insert of clone gm335 4 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone gm335 4 deposited under accession number
ATCC 98468;
(h) a polynucleotide encoding a mature protein encoded by the cDNA
2 5 insert of clone gm335 4 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:14;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:14 having biological activity, the fragment
3 0 comprising eight consecutive amino acids of SEQ ID N0:14;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
14
CA 02294569 1999-12-17
WO 98/57976 PCTNS98/12516
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
. N0:13 from nucleotide 17 to nucleotide 523; the nucleotide sequence of SEQ
ID N0:13
from nucleotide 77 to nucleotide 523; the nucleotide sequence of SEQ ID N0:13
from
nucleotide 1 to nucleotide 392; the nucleotide sequence of the full-length
protein coding
sequence of clone gm335 4 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone gm335_4
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone gm335 4 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:14 from amino acid 1 to amino
acid
125. In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:14
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:14, or a
polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:14 having biological activity, the fragment comprising the amino
acid
2 0 sequence from amino acid 79 to amino acid 88 of SEQ ID N0:14.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:13.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
2 5 consisting of:
(a) the amino acid sequence of SEQ ID N0:14;
(b) the amino acid sequence of SEQ ID N0:14 from amino acid 1 to
amino acid 125;
{c) fragments of the amino acid sequence of SEQ ID N0:14 comprising
3 0 eight consecutive amino acids of SEQ ID N0:14; and
(d) the amino acid sequence encoded by the cDNA insert of clone
gm335_4 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:14 or the amino acid
sequence
CA 02294569 1999-12-17
WO 98/57976 PCT1US98/12516
of SEQ ID N0:14 from amino acid 1 to amino acid 125. 1n further preferred
embodiments,
the present invention provides a protein comprising a fragment of the amino
acid
sequence of SEQ ID N0:14 having biological activity, the fragment preferably
comprising
eight (more preferably twenty, most preferably thirty) consecutive amino acids
of SEQ ID
N0:14, or a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:14having biological activity, the fragment comprising the amino acid
sequence from
amino acid 79 to amino acid 88 of SEQ ID N0:14.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:I5 from nucleotide 2 to nucleotide 991;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15 from nucleotide 62 to nucleotide 991;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15 from nucleotide 2 to nucleotide 504;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone hy370 9 deposited under accession
2 0 number ATCC 98468;
{f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone hy370_9 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone hy370_9 deposited under accession number
2 5 ATCC 98468;
(h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone hy370 9 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:16;
3 0 (j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:16 having biological activity, the fragment
comprising eight consecutive amino acids of SEQ ID N0:16;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
16
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:15 from nucleotide 2 to nucleotide 991; the nucleotide sequence of SEQ ID
N0:15 from
nucleotide 62 to nucleotide 991; the nucleotide sequence of SEQ ID N0:15 from
nucleotide 2 to nucleotide 504; the nucleotide sequence of the full-length
protein coding
sequence of clone hy370_9 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone hy370 9
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone hy370 9 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:16 from amino acid 1 to amino
acid
167. In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:16
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:16, or a
2 0 polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:16 having biological activity, the fragment comprising the amino
acid
sequence from amino acid 160 to amino acid 169 of SEQ ID N0:16.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:15.
2 5 In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:16;
(b) the amino acid sequence of SEQ ID N0:16 from amino acid 1 to
3 0 amino acid 167;
(c) fragments of the amino acid sequence of SEQ ID N0:16 comprising
eight consecutive amino acids of SEQ ID N0:16; and
(d) the amino acid sequence encoded by the cDNA insert of clone
hy370_9 deposited under accession number ATCC 98468;
17
CA 02294569 1999-12-17
WO 98/57976 PCTNS98/12516
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:16 or the amino acid
sequence
of SEQ ID N0:16 from amino acid 1 to amino acid 167. In further preferred
embodiments,
the present invention provides a protein comprising a fragment of the amino
acid
sequence of SEQ ID N0:16 having biological activity, the fragment preferably
comprising
eight (more preferably twenty, most preferably thirty) consecutive amino acids
of SEQ ID
N0:16, or a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:16having biological activity, the fragment comprising the amino acid
sequence from
amino acid 160 to amino acid 169 of SEQ ID N0:16.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
{a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 77 to nucleotide 616;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 164 to nucleotide 616;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 1 to nucleotide 415;
2 0 (e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone ie47_4 deposited under accession
number
ATCC 98468;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone ie47 4 deposited under accession number ATCC 98468;
2 5 (g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone ie47 4 deposited under accession number ATCC
98468;
(h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone ie47 4 deposited under accession number ATCC 98468;
3 0 (i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:18;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:18 having biological activity, the fragment
comprising eight consecutive amino acids of SEQ ID N0:18;
18
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
{k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:17 from nucleotide 77 to nucleotide 616; the nucleotide sequence of SEQ ID
N0:17
from nucleotide 164 to nucleotide 616; the nucleotide sequence of SEQ ID N0:17
from
nucleotide 1 to nucleotide 415; the nucleotide sequence of the full-length
protein coding
sequence of clone ie47_4 deposited under accession number ATCC 98468; or the
nucleotide sequence of a mature protein coding sequence of clone ie47 4
deposited under
accession number ATCC 98468. In other preferred embodiments, the
polynucleotide
encodes the full-length or a mature protein encoded by the cDNA insert of
clone ie47_4
deposited under accession number ATCC 98468. In yet other preferred
embodiments,
the present invention provides a polynucleotide encoding a protein comprising
the amino
acid sequence of SEQ ID N0:18 from amino acid 1 to amino acid 113. In further
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising a fragment of the amino acid sequence of SEQ ID N0:18 having
biological
2 0 activity, the fragment preferably comprising eight (more preferably
twenty, most
preferably thirty) consecutive amino acids of SEQ ID N0:18, or a
polynucleotide encoding
a protein comprising a fragment of the amino acid sequence of SEQ ID N0:18
having
biological activity, the fragment comprising the amino acid sequence from
amino acid 85
to amino acid 94 of SEQ ID N0:18.
2 5 Other embodiments provide the gene corresponding to the cDNA sequence of
SEQ
ID N0:17.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
3 0 (a) the amino acid sequence of SEQ ID N0:18;
(b) the amino acid sequence of SEQ ID N0:18 from amino acid 1 to
amino acid 113;
{c) fragments of the amino acid sequence of SEQ ID N0:18 comprising
eight consecutive amino acids of SEQ ID N0:18; and
19
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(d) the amino acid sequence encoded by the cDNA insert of clone
ie47 4 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID NO:18 or the amino acid
sequence
of SEQ ID N0:18 from amino acid 2 to amino acid 113. In further preferred
embodiments,
the present invention provides a protein comprising a fragment of the amino
acid
sequence of SEQ ID N0:18 having biological activity, the fragment preferably
comprising
eight (more preferably twenty, most preferably thirty) consecutive amino acids
of SEQ ID
N0:18, or a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:18having biological activity, the fragment comprising the amino acid
sequence from
amino acid 85 to amino acid 94 of SEQ ID N0:18.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19 from nucleotide 564 to nucleotide 2813;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19 from nucleotide 705 to nucleotide 2813;
2 0 (d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19 from nucleotide 793 to nucleotide 1628;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone s195_10 deposited under accession
number ATCC 98468;
2 5 (f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone s195_10 deposited under accession number ATCC 98468;
(g) a polynucleotide comprising the nucleotide sequence of a mature
protein coding sequence of clone s195_10 deposited under accession number
ATCC 98468;
3 0 (h) a polynucleotide encoding a mature protein encoded by the cDNA
insert of clone s195_10 deposited under accession number ATCC 98468;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:20;
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/1251G
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:20 having biological activity, the fragment
comprising eight consecutive amino acids of SEQ ID N0:20;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide that hybridizes under stringent conditions to any
one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:19 from nucleotide 564 to nucleotide 2813; the nucleotide sequence of SEQ
ID N0:19
from nucleotide 705 to nucleotide 2813; the nucleotide sequence of SEQ ID
N0:19 from
nucleotide 793 to nucleotide 1628; the nucleotide sequence of the full-length
protein
coding sequence of clone s195_10 deposited under accession number ATCC 98468;
or the
1 S nucleotide sequence of a mature protein coding sequence of clone s195_10
deposited
under accession number ATCC 98468. In other preferred embodiments, the
polynucleotide encodes the full-length or a mature protein encoded by the cDNA
insert
of clone s195_10 deposited under accession number ATCC 98468. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
2 0 comprising the amino acid sequence of SEQ ID N0:20 from amino acid 78 to
amino acid
355. In further preferred embodiments, the present invention provides a
polynucleotide
encoding a protein comprising a fragment of the amino acid sequence of SEQ ID
N0:20
having biological activity, the fragment preferably comprising eight (more
preferably
twenty, most preferably thirty) consecutive amino acids of SEQ ID N0:20, or a
2 5 polynucleotide encoding a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:20 having biological activity, the fragment comprising the amino
acid
sequence from amino acid 370 to amino acid 379 of SEQ ID N0:20.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:19.
3 0 In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:20;
21
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(b) the amino acid sequence of SEQ ID N0:20 from amino acid 78 to
amino acid 355;
(c) fragments of the amino acid sequence of SEQ ID N0:20 comprising
eight consecutive amino acids of SEQ ID N0:20; and
(d) the amino acid sequence encoded by the cDNA insert of clone
s195_10 deposited under accession number ATCC 98468;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:20 or the amino acid
sequence
of SEQ ID N0:20 from amino acid 78 to amino acid 355. In further preferred
embodiments, the present invention provides a protein comprising a fragment of
the
amino acid sequence of SEQ ID N0:20 having biological activity, the fragment
preferably
comprising eight (more preferably twenty, most preferably thirty) consecutive
amino
acids of SEQ ID N0:20, or a protein comprising a fragment of the amino acid
sequence of
SEQ ID N0:20having biological activity, the fragment comprising the amino acid
sequence from amino acid 370 to amino acid 379 of SEQ ID N0:20.
In certain preferred embodiments, the polynucleotide is operably linked to an
expression control sequence. The invention also provides a host cell,
including bacterial,
yeast, insect and mammalian cells, transformed with such polynucleotide
compositions.
Also provided by the present invention are organisms that have enhanced,
reduced, or
2 0 modified expression of the genes) corresponding to the polynucleotide
sequences
disclosed herein.
Processes are also provided for producing a protein, which comprise:
(a) growing a culture of the host cell transformed with such
polynucleotide compositions in a suitable culture medium; and
2 5 (b) purifying the protein from the culture.
The protein produced according to such methods is also provided by the present
invention.
Protein compositions of the present invention may further comprise a
pharmaceutically acceptable carrier. Compositions comprising an antibody which
3 0 specifically reacts with such protein are also provided by the present
invention.
Methods are also provided for preventing, treating or ameliorating a medical
condition which comprises administering to a mammalian subject a
therapeutically
effective amount of a composition comprising a protein of the present
invention and a
pharmaceutically acceptable carrier.
22
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
BRIEF DESCRIPTION OF THE DRAWINGS
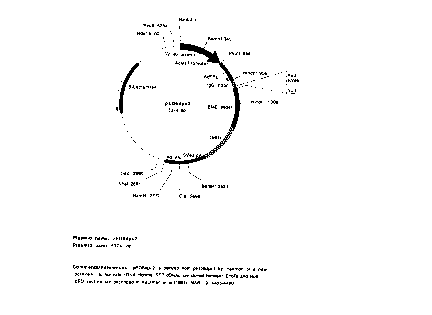
Figures lA and 1B are schematic representations of the pED6 and pNOTs vectors,
respectively, used for deposit of clones disclosed herein.
DETAILED DESCRIPTION
ISOLATED PROTEINS AND POLYNUCLEOTIDES
Nucleotide and amino acid sequences, as presently determined, are reported
below for each clone and protein disclosed in the present application. The
nucleotide
sequence of each clone can readily be determined by sequencing of the
deposited clone
in accordance with known methods. The predicted amino acid sequence (both full-
length
and mature forms) can then be determined from such nucleotide sequence. The
amino
acid sequence of the protein encoded by a particular clone can also be
determined by
expression of the clone in a suitable host cell, collecting the protein and
determining its
sequence. For each disclosed protein applicants have identified what they have
determined to be the reading frame best identifiable with sequence information
available
at the time of filing.
As used herein a "secreted" protein is one which, when expressed in a suitable
host
cell, is transported across or through a membrane, including transport as a
result of signal
2 0 sequences in its amino acid sequence. "Secreted" proteins include without
limitation
proteins secreted wholly {e.g., soluble proteins) or partially (e.g. ,
receptors) from the cell
in which they are expressed. "Secreted" proteins also include without
limitation proteins
which are transported across the membrane of the endoplasmic reticulum.
2 5 Clone "dol5 4"
A polynucleotide of the present invention has been identified as clone "dol5
4".
dol5 4 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins {see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
3 0 analysis of the amino acid sequence of the encoded protein. dol5_4 is a
full-length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"dol5 4 protein").
The nucleotide sequence of dol5 4 as presently determined is reported in SEQ
ID
N0:1. What applicants presently believe to be the proper reading frame and the
predicted
23
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
amino acid sequence of the dol5 4 protein corresponding to the foregoing
nucleotide
sequence is reported in SEQ ID N0:2. Amino acids 394 to 406 are a predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 407, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
dol5 4 should be approximately 1900 bp.
The nucleotide sequence disclosed herein for dol5 4 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. dol5_4 demonstrated at least some similarity with
sequences
identified as AA 113909 (zm80f 12.r1 Stratagene neuroepithelium (#937231 )
Homo sapiens
cDNA clone 531983 5'), AA189888 (mu55h06.r1 Soares mouse lymph node NbMLN Mus
musculus cDNA clone 643355 5'), and U52052 (Human S6 A-8 mRNA expressed in
chromosome 6-suppressed melanoma cells). Based upon sequence similarity, dol5
4
proteins and each similar protein or peptide may share at least some activity.
Clone "dx290 1"
A polynucleotide of the present invention has been identified as clone
"dx290_1".
dx290_1 was isolated from a human adult testes cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
2 0 identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. dx290_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"dx290_1 protein").
The nucleotide sequence of dx290_1 as presently determined is reported in SEQ
2 5 ID N0:3. What applicants presently believe to be the proper reading frame
and the
predicted amino acid sequence of the dx290_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:4.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
dx290_1 should be approximately 2300 bp.
3 0 The nucleotide sequence disclosed herein for dx290_1 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. dx290_1 demonstrated at least some similarity with the
sequence identified as AA064383 (m147h02.rI Stratagene mouse testis (#937308)
Mus
24
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
musculus cDNA clone 515187 5'). Based upon sequence similarity, dx290_1
proteins and
each similar protein or peptide may share at least some activity.
Clone "ek390 4"
A polynucleotide of the present invention has been identified as clone "ek390
4".
ek390_4 was isolated from a human fetal brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. ek390 4 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"ek390 4 protein"}.
The nucleotide sequence of ek390 4 as presently determined is reported in SEQ
ID N0:5. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the ek390 4 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:6. Amino acids 25 to 37 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 38, or are a transmembrane domain.
The EcoIZI/NotI restriction fragment obtainable from the deposit containing
clone
ek390_4 should be approximately 1000 bp.
2 0 The nucleotide sequence disclosed herein for ek390 4 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. ek390_4 demonstrated at least some similarity with
sequences
identified as AA075783 {zm89h02.r1 Stratagene ovarian cancer (#937219) Homo
sapiens
cDNA clone 545139 5'), AA427538 (zw32g04.r1 Soares ovary tumor NbHOT Homo
2 5 sapiens cDNA clone 771030 5'), AA427539 (zw32g04.s 1 Soares ovary tumor
NbHOT
Homo Sapiens cDNA clone 771030 3'), AA453353 (zx47a06.r1 Soares testis NHT
Homo
sapiens cDNA clone 795346 5'), C20637 (HUMGS0004639, Human Gene Signature,
3'-directed cDNA sequence), R?4326 (y101c07.s1 Homo sapiens cDNA clone 156972
3'),
874420 (ylO1c07.r1 Homo sapiens cDNA clone 156972 5'), T22914 (Human gene
3 0 signature), U41197 (Human [TTTC] 10 short tandem repeat polymorphism UM65,
D 1751340), and X58237 (Human mRNA for anti-lectin antibody epitope (clone
p36/8-6)).
Based upon sequence similarity, ek390 4 proteins and each similar protein or
peptide may
share at least some activity. The TopPredII computer program predicts a
potential
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
transmembrane domain within the ek390 4 protein sequence centered around amino
acid
160 of SEQ ID N0:6. The nucleotide sequence of ek390 4 indicates that it may
contain
GGGA repeat sequences.
Clone "er471 7"
A polynucleotide of the present invention has been identified as clone "er471
7".
er471 7 was isolated from a human fetal brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins {see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. er471 7 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"er471 7 protein").
The nucleotide sequence of er471 7 as presently determined is reported in SEQ
ID
N0:7. What applicants presently believe to be the proper reading frame and the
predicted
amino acid sequence of the er471 7 protein corresponding to the foregoing
nucleotide
sequence is reported in SEQ ID N0:8. Amino acids 74 to 86 are a predicted
leader/signal
sequence, with the predicted mature amino acid sequence beginning at amino
acid 87, or
are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
2 0 er471 7 should be approximately 2250 bp.
The nucleotide sequence disclosed herein for er471 7 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. er471 7 demonstrated at least some similarity with
sequences
identified as AA039137 (mi98h06.r1 Soares mouse embryo NbME13.5 14.5 Mus
2 5 musculus cDNA clone 474683 5'), AA066962 (mm38g05.r1 Stratagene mouse
melanoma
(#937312) Mus musculus cDNA clone 523832 5'), AA189170 (zq47hO5.s1 Stratagene
hNT neuron (#937233) Homo sapiens cDNA clone 632889 3'), AA609188 (af12c10.s1
Soares testis NHT Homo sapiens cDNA clone 1031442 3'), and W07704 (zb02e02.r1
Soares fetal lung NbHLI9W Homo sapiens cDNA clone 300890 5' similar to
3 0 SW:YN66_YEAST P40164 HYPOTHETICAL 98.1 KD PROTEIN IN SPX19-GCR2
INTERGENIC REGION). The predicted amino acid sequence disclosed herein for
er471 7 was searched against the GenPept and GeneSeq amino acid sequence
databases
using the BLASTX search protocol. The predicted er471 7 protein demonstrated
at least
26
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
some similarity to sequences identified as AF016448 (Cosmid F41E6
[Caenorhabditis
elegans]) and L08407 (collagen type XVII [Mus musculus]). Based upon sequence
similarity, er471 7 proteins and each similar protein or peptide may share at
least some
activity. The TopPredII computer program predicts three potential
transmembrane
domains within the er471 7 protein sequence, centered around amino acids 40,
80, and
110 of SEQ ID N0:8, respectively.
Clone "fs40 3"
A polynucleotide of the present invention has been identified as clone "fs40
3".
fs40 3 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. fs40 3 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"fs40_3 protein").
The nucleotide sequence of fs40_3 as presently determined is reported in SEQ
ID
N0:9. What applicants presently believe to be the proper reading frame and the
predicted
amino acid sequence of the fs40 3 protein corresponding to the foregoing
nucleotide
sequence is reported in SEQ ID NO:10.
2 0 The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
fs40_3 should be approximately 1000 bp.
The nucleotide sequence disclosed herein for fs40_3 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. fs40_3 demonstrated at least some similarity with
sequences
2 5 identified as AA411142 (zt37gOl .rl Soares ovary tumor NbHOT Homo sapiens
cDNA
clone 724560 5'), AA412527 (zu 12a03.s 1 Soares testis NHT Homo sapiens cDNA
clone
731596 3'), AA565855 (nj32d09.s1 NCI CGAP_AAl Homo sapiens cDNA clone
IMAGE:994193), H17042 (ym39f12.s1 Homo sapiens cDNA clone 50584 3'), and
T33280
(EST57284 Homo sapiens cDNA 3' end similar to None). Based upon sequence
similarity,
3 0 fs40_3 proteins and each similar protein or peptide may share at least
some activity. The
TopPredII computer program predicts a potential transmembrane domain within
the
fs40_3 protein sequence at the C-terminus of SEQ ID N0:10.
27
CA 02294569 1999-12-17
WO 98/57976 PCTlUS98/12516
Clone "ga63 6"
A polynucleotide of the present invention has been identified as clone
"ga63_6".
ga63_6 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. ga63_6 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"ga63_6 protein")
The nucleotide sequence of ga63_6 as presently determined is reported in SEQ
ID
N0:11. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the ga63_6 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:12. Amino acids 11 to 23 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 24, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
ga63_6 should be approximately 2300 bp.
The nucleotide sequence disclosed herein for ga63_6 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. ga63_6 demonstrated at least some similarity with
sequences
identified as AA405433 (zu13h10.r1 Soares testis NHT Homo sapiens cDNA clone
731779 5'similar to TR 6474970 6474970 SP32 PRECURSOR), AA406076 (zu67c02.s1
Soares testis NHT Homo Sapiens cDNA clone 743042 3' similar to TR:G475021
6475021
SP32 PRECURSOR), AA424694 (zu13h10.sI Soares testis NHT Homo sapiens cDNA
clone 731779 3' similar to TR 6475021 6475021 SP32 PRECURSOR; contains element
2 5 TAR 1 repetitive element), D 16200 (Pig mRNA for sp32, partial sequence),
D 16203
(Guinea pig mRNA for sp32, complete cds), and D 17573 (Mouse mRNA for
proacrosin-binding protein (sp32), complete cds). The predicted amino acid
sequence
disclosed herein for ga63_6 was searched against the GenPept and GeneSeq amino
acid
sequence databases using the BLASTX search protocol. The predicted ga63_6
protein
3 0 demonstrated at least some similarity to sequences identified as D16200
(sp32 precursor
[Sus scrofa]), and D17574 (alternative splicing product for proacrosin-binding
protein
(sp32) [Mus musculus]). The sp32 protein is found in the acrosomal vescicle of
sperm,
which is involved in egg-sperm fusion in fertilization. This protein is
initially synthesized
28
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
as a 61-kDa precursor protein with a putative signal peptide at the amino
terminus. The
carboxyl-terminal half of the precursor molecule corresponds to the mature
sp32 protein.
Thus, sp32 is produced by post-translational modification of the precursor.
The binding of
sp32 to proacrosin may be involved in packaging the acrosin zymogen into the
acrosomal
matrix. (Baba et al., 1994, J. Biol. Chem. 269 (13): 10133-10140, which is
incorporated
by reference herein). Based upon sequence similarity, ga63_6 proteins and each
similar
protein or peptide may share at least some activity.
Clone "gm335 4"
A polynucleotide of the present invention has been identified as clone "gm335
4".
gm335 4 was isolated from a human adult uterus cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. gm335 4 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "gm335 4 protein")
The nucleotide sequence of gm335 4 as presently determined is reported in SEQ
ID N0:13. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the gm335 4 protein corresponding to the
foregoing
2 0 nucleotide sequence is reported in SEQ ID N0:14. Amino acids 8 to 20 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 21, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
gm335_4 should be approximately 800 bp.
2 5 The nucleotide sequence disclosed herein for gm335_4 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. gm335 4 demonstrated at least some similarity with
sequences
identified as AAOSS367 (zf20bOS.r1 Soares fetal heart NbHHI9W Homo sapiens
cDNA
clone 377457 S'), AC002389 (Human DNA from chromosome 19 specific cosmid
828461,
3 0 genomic sequence, complete sequence), W08S22 (mb46h10.r1 Soares mouse
p3NMF19.S
Mus musculus cDNA clone 332S1S S'), and X93916 (S.scrofa mRNA (clone VIB11;
expressed sequence tag)). Based upon sequence similarity, gm335_4 proteins and
each
similar protein or peptide may share at least some activity.
29
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Clone "hv370 9"
A polynucleotide of the present invention has been identified as clone
"hy370_9".
hy370 9 was isolated from a human adult trachea cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. hy370_9 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"hy370 9 protein")
The nucleotide sequence of hy370 9 as presently determined is reported in SEQ
ID N0:15. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the hy370 9 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:16. Amino acids 8 to 20 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 21, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
hy370 9 should be approximately 1200 bp.
The nucleotide sequence disclosed herein for hy370 9 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. hy370_9 demonstrated at least some similarity with the
sequence identified as AA763313 (vv89h07.r1 Stratagene mouse skin (#937313)
Mus
musculus cDNA clone 1229629 5'). Based upon sequence similarity, hy370_9
proteins
and each similar protein or peptide may share at least some activity. The
TopPredII
computer program predicts an additional potential transmembrane domain within
the
hy370_9 protein sequence centered around amino acid 140 of SEQ ID N0:16.
Clone "ie47 4"
A polynucleotide of the present invention has been identified as clone
"ie47_4".
ie47 4 was isolated from a human fetal brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
3 0 identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. ie47 4 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"ie47_4 protein")
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
The nucleotide sequence of ie47_4 as presently determined is reported in SEQ
ID
N0:27. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the ie47_4 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:18. Amino acids 17 to 29 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 30, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
ie47_4 should be approximately 2300 bp.
The nucleotide sequence disclosed herein for ie47_4 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. ie47_4 demonstrated at least some similarity with
sequences
identified as AA071953 (mf17h08.r1 Life Tech mouse brain Mus musculus cDNA
clone
405375 5' similar to TR 6304421 6304421 SILENCER ELEMENT), AA207250
(zq82dO5.s1 Stratagene hNT neuron (#937233) Homo Sapiens cDNA clone 648105 3'
similar to TR 6304421 6304421 SILENCER ELEMENT), L14938 (Chicken SCG10
protein mRNA, complete cds), L20260 (Mouse SCG10 gene sequence), 849053
(yg58cO5.s1 Homo Sapiens cDNA clone 37017 3'), S82024 (SCG10 neuron-specific
growth-associated protein/stathmin homolog [human, embryo, mRNA]), T25428
(Human
gene signature HUMGS07594, T25428 standard; cDNA to mRNA), W54204 (md04al2.rl
2 0 Soares mouse embryo NbME13.5 14.5 Mus musculus cDNA clone 367390 5'
similar to
SW:SCGB XENLA Q09002 SCG10 PROTEIN HOMOLOG A), X71433 (X. laevis
SCG 10 mRNA), and 299916 (Human DNA sequence *** SEQUENCING IN PROGRESS
* * * from clone 221 G9; HTGS phase 1 ). The predicted amino acid sequence
disclosed
herein for ie47_4 was searched against the GenPept and GeneSeq amino acid
sequence
2 5 databases using the BLASTX search protocol. The predicted ie47 4 protein
demonstrated
at least some similarity to sequences identified as L14938 (SCG 10 protein
[Gallus gallus])
and S82024 (SCG10 neuron-specific growth-associated protein/stathmin homolog
[human,
embryo, Peptide] [Homo Sapiens]). SCG10 protein is considered to be a membrane-
bound
protein present in neural growth cones and developing neurons (Maucuer et al.,
1993, J.
3 0 Biol. Chem. 268: 16420-16429; Stein et al.,1988, Neuron 1:463-476; which
are incorporated
by reference herein). Based upon sequence similarity, ie47_4 proteins and each
similar
protein or peptide may share at least some activity.
31
CA 02294569 1999-12-17
WO 98/57976 PCT/iJS98/12516
Clone "s195 10"
A polynucleotide of the present invention has been identified as clone
"s195_10".
s195_10 was isolated from a human adult neural tissue cDNA library using
methods
which are selective for cDNAs encoding secreted proteins (see U.S. Pat. No.
5,536,637), or
was identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. s195_10 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"s195_10 protein").
The nucleotide sequence of s195_10 as presently determined is reported in SEQ
ID
N0:19. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the s195_10 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:20. Amino acids 35 to 47 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 48, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
s195 10 should be approximately 3500 bp.
The nucleotide sequence disclosed herein for s195_10 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. s195_10 demonstrated at least some similarity with
sequences
2 0 identified as AA 113800 (zn65bO5.s 1 Stratagene HeLa cell s3 937216 Homo
sapiens
cDNA clone 563025 3' similar to TR:G600018 6600018 SSM4P), AA114062
(zn65bO5.rl
Stratagene HeLa cell s3 937216 Homo sapiens cDNA clone 563025 5'), AA280316
(zt10f06.s1 Soares NbHTGBC Homo Sapiens cDNA clone 712739 3'), AF009301 (Homo
sapiens TEB4 protein mRNA, complete cds), N70344 (za60f 10. s 1 Homo Sapiens
cDNA
clone 296971 3'), 860474 (yh13g07.r1 Homo sapiens cDNA clone 43058 5'), and
T26266
(standard; cDNA to mRNA; 148 BP, Human gene signature HUMGS08505). The
predicted amino acid sequence disclosed herein for s195_10 was searched
against the
GenPept and GeneSeq amino acid sequence databases using the BLASTX search
protocol.
The predicted s195_10 protein demonstrated at least some similarity to
sequences
3 0 identified as AF009301 (TEB4 protein [Homo sapiens]), X76715 (SSM4 gene
product
[Saccharomyces cerevisiae]), 246861 (Ssm4p [Saccharomyces cerevisiae]), and
247047
(Ssm4p [Saccharomyces cerevisiae]). Based upon sequence similarity, s195_10
proteins
and each similar protein or peptide may share at least some activity. The
TopPredII
32
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
computer program predicts eleven additional potential transmembrane domains
within
the s195_10 protein sequence, centered around amino acids 130, 170, 210, 260,
320, 470,
520, 560, 600, 650, and 690 of SEQ ID N0:20, respectively. The nucleotide
sequence of
s195_10 indicates that it may contain a simple GAA repeat region.
Deposit of Clones
Clones dol5_4, dx290_1, ek390 4, er471 7, fs40_3, ga63_6, gm335 4, hy370 9,
ie47_4, and s195_10 were deposited on June 19, 1997 with the American Type
Culture
Collection (10801 University Boulevard, Manassas, Virginia 20110-2209 U.S.A.)
as an
original deposit under the Budapest Treaty and were given the accession number
ATCC
98468, from which each clone comprising a particular polynucleotide is
obtainable. All
restrictions on the availability to the public of the deposited material will
be irrevocably
removed upon the granting of the patent, except for the requirements specified
in 37
C.F.R. ~ 1.808(b), and the term of the deposit will comply with 37 C.F.R. ~
1.806.
Each clone has been transfected into separate bacterial cells (E. coli) in
this
composite deposit. Each clone can be removed from the vector in which it was
deposited
by performing an EcoRI/NotI digestion (5' site, EcoRI; 3' site, NotI) to
produce the
appropriate fragment for such clone. Each clone was deposited in either the
pED6 or
pNOTs vector depicted in Figures 1A and 1B, respectively. The pED6dpc2 vector
2 0 {"pED6") was derived from pED6dpc1 by insertion of a new polylinker to
facilitate
cDNA cloning (Kaufman et al., 1991, Nucleic Acids Res. 19: 4485-4490); the
pNOTs vector
was derived from pMT2 (Kaufman et al., 1989, Mol. Cell. Biol. 9: 946-958) by
deletion of
the DHFR sequences, insertion of a new polylinker, and insertion of the M13
origin of
replication in the CIaI site. In some instances, the deposited clone can
become "flipped"
2 5 (i.e., in the reverse orientation) in the deposited isolate. In such
instances, the cDNA insert
can still be isolated by digestion with EcoRI and NotI. However, NotI will
then produce
the 5' site and EcoRI will produce the 3' site for placement of the cDNA in
proper
orientation for expression in a suitable vector. The cDNA may also be
expressed from the
vectors in which they were deposited.
3 0 Bacterial cells containing a particular clone can be obtained from the
composite
deposit as follows:
An oligonucleotide probe or probes should be designed to the sequence that is
known for that particular clone. This sequence can be derived from the
sequences
provided herein, or from a combination of those sequences. The sequence of an
33
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
oligonucleotide probe that was used to isolate or to sequence each full-length
clone is
identified below, and should be most reliable in isolating the clone of
interest.
Clone Probe Seduence
dol5 4 SEQ ID N0:21
dx290 1 SEQ ID N0:22
ek390 4 SEQ ID N0:23
er471 7 SEQ ID N0:24
fs40_3 SEQ ID N0:25
ga63_6 SEQ ID N0:26
gm335 4 SEQ ID N0:27
hy370 9 SEQ ID N0:28
ie47 4 SEQ ID N0:29
s195 10 SEQ ID N0:30
In the sequences listed above which include an N at position 2, that position
is occupied
in preferred probes/primers by a biotinylated phosphoaramidite residue rather
than a
nucleotide (such as , for example, that produced by use of biotin
phosphoramidite (1-
dimethoxytrityloxy-2-(N-biotinyl-4-aminobutyl)-propyl-3-O-(2-cyanoethyl)-(N,N-
2 0 diisopropyl)-phosphoramadite) (Glen Research, cat. no. 10-1953)).
The design of the oligonucleotide probe should preferably follow these
parameters:
(a) It should be designed to an area of the sequence which has the fewest
ambiguous bases ("N's"), if any;
2 5 (b) It should be designed to have a Tm of approx. 80 ° C (assuming
2° for each
A or T and 4 degrees for each G or C).
The oligonucleotide should preferably be labeled with g-3zP ATP (specific
activity 6000
Ci/mmole) and T4 polynucleotide kinase using commonly employed techniques for
labeling oligonucleotides. Other labeling techniques can also be used.
Unincorporated
3 0 label should preferably be removed by gel filtration chromatography or
other established
methods. The amount of radioactivity incorporated into the probe should be
quantitated
by measurement in a scintillation counter. Preferably, specific activity of
the resulting
probe should be approximately 4e+6 dpm/pmole.
34
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
The bacterial culture containing the pool of full-length clones should
preferably
be thawed and 100 ul of the stock used to inoculate a sterile culture flask
containing 25 ml
of sterile L-broth containing ampicillin at 100 ug/ml. The culture should
preferably be
grown to saturation at 37°C, and the saturated culture should
preferably be diluted in
fresh L-broth. Aliquots of these dilutions should preferably be plated to
determine the
dilution and volume which will yield approximately 5000 distinct and well-
separated
colonies on solid bacteriological media containing L-broth containing
ampicillin at 100
~g/ml and agar at 1.5% in a 150 mm petri dish when grown overnight at
37°C. Other
known methods of obtaining distinct, well-separated colonies can also be
employed.
Standard colony hybridization procedures should then be used to transfer the
colonies to nitrocellulose filters and lyse, denature and bake them.
The filter is then preferably incubated at 65°C for 1 hour with gentle
agitation in
6X SSC (20X stock is 175.3 g NaCI/liter, 88.2 g Na citrate/liter, adjusted to
pH 7.0 with
NaOH) containing 0.5% SDS,100 ug/ml of yeast RNA, and 10 mM EDTA
(approximately
10 mL per 150 mm filter). Preferably, the probe is then added to the
hybridization mix at
a concentration greater than or equal to le+6 dpm/mL. The filter is then
preferably
incubated at 65°C with gentle agitation overnight. The filter is then
preferably washed in
500 mL of 2X SSC/0.5% SDS at room temperature without agitation, preferably
followed
by 500 mL of 2X SSC/0.1% SDS at room temperature with gentle shaking for 15
minutes.
2 0 A third wash with O.1X SSC/0.5% SDS at 65°C for 30 minutes to 1
hour is optional. The
filter is then preferably dried and subjected to autoradiography for
sufficient time to
visualize the positives on the X-ray film. Other known hybridization methods
can also
be employed.
The positive colonies are picked, grown in culture, and plasmid DNA isolated
2 5 using standard procedures. The clones can then be verified by restriction
analysis,
hybridization analysis, or DNA sequencing.
Fragments of the proteins of the present invention which are capable of
exhibiting
biological activity are also encompassed by the present invention. Fragments
of the
protein may be in linear form or they may be cyclized using known methods, for
example,
3 0 as described in H.U. Saragovi, et al., Bio/Technology 0 773-778 (1992) and
in R.S.
McDowell, et al., J. Amer. Chem. Soc.114, 9245-9253 (1992), both of which are
incorporated
herein by reference. Such fragments may be fused to carrier molecules such as
immunoglobulins for many purposes, including increasing the valency of protein
binding
sites. For example, fragments of the protein may be fused through "linker"
sequences to
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
the Fc portion of an immunoglobulin. For a bivalent form of the protein, such
a fusion
could be to the Fc portion of an IgG molecule. Other immunoglobulin isotypes
may also
be used to generate such fusions. For example, a protein - IgM fusion would
generate a
decavalent form of the protein of the invention.
The present invention also provides both full-length and mature forms of the
disclosed proteins. The full-length form of the such proteins is identified in
the sequence
listing by translation of the nucleotide sequence of each disclosed clone. The
mature
forms) of such protein may be obtained by expression of the disclosed full-
length
polynucleotide (preferably those deposited with ATCC) in a suitable mammalian
cell or
other host cell. The sequences) of the mature forms) of the protein may also
be
determinable from the amino acid sequence of the full-length form.
The present invention also provides genes corresponding to the polynucleotide
sequences disclosed herein. "Corresponding genes" are the regions of the
genome that
are transcribed to produce the mRNAs from which cDNA polynucleotide sequences
are
derived and may include contiguous regions of the genome necessary for the
regulated
expression of such genes. Corresponding genes may therefore include but are
not limited
to coding sequences, 5' and 3' untranslated regions, alternatively spliced
exons, introns,
promoters, enhancers, and silencer or suppressor elements. The corresponding
genes can
be isolated in accordance with known methods using the sequence information
disclosed
2 0 herein. Such methods include the preparation of probes or primers from the
disclosed
sequence information for identification and/or amplification of genes in
appropriate
genomic libraries or other sources of genomic materials. An "isolated gene" is
a gene that
has been separated from the adjacent coding sequences, if any, present in the
genome of
the organism from which the gene was isolated.
2 5 Organisms that have enhanced, reduced, or modified expression of the
genes)
corresponding to the polynucleotide sequences disclosed herein are provided.
The
desired change in gene expression can be achieved through the use of antisense
polynucleotides or ribozymes that bind and/or cleave the mRNA transcribed from
the
gene (Albert and Morris,1994, Trends Pharmacol. Sci. 25(7): 250-254; Lavarosky
et al., 1997,
3 0 Biochem. Mol. Med. 62(1):11-22; and Hampel,1998, Prog. Nucleic Acid Res.
Mol. Biol. 58: 1-
39; all of which are incorporated by reference herein). Transgenic animals
that have
multiple copies of the genes) corresponding to the polynucleotide sequences
disclosed
herein, preferably produced by transformation of cells with genetic constructs
that are
stably maintained within the transformed cells and their progeny, are
provided.
36
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Transgenic animals that have modified genetic control regions that increase or
reduce
gene expression levels, or that change temporal or spatial patterns of gene
expression, are
also provided (see European Patent No. 0 649 464 B1, incorporated by reference
herein).
In addition, organisms are provided in which the genes) corresponding to the
polynucleotide sequences disclosed herein have been partially or completely
inactivated,
through insertion of extraneous sequences into the corresponding genes) or
through
deletion of all or part of the corresponding gene(s). Partial or complete gene
inactivation
can be accomplished through insertion, preferably followed by imprecise
excision, of
transposable elements {Plasterk,1992, Bioessays 14(9): 629-633; Zwaal et
al.,1993, Proc. Natl.
Acad. Sci. USA 90(16): 7431-7435; Clark et al.,1994, Proc. Natl. Acad. Sci.
USA 91(2): 719-722;
all of which are incorporated by reference herein), or through homologous
recombination,
preferably detected by positive/negative genetic selection strategies (Mansour
et al.,1988,
Nature 336: 348-352; U.S. Patent Nos. 5,464,764; 5,487,992; 5,627,059;
5,631,153; 5,614, 396;
5,616,491; and 5,679,523; all of which are incorporated by reference herein).
These
organisms with altered gene expression are preferably eukaryotes and more
preferably
are mammals. Such organisms are useful for the development of non-human models
for
the study of disorders involving the corresponding gene(s), and for the
development of
assay systems for the identification of molecules that interact with the
protein products)
of the corresponding gene(s).
2 0 Where the protein of the present invention is membrane-bound (e.g., is a
receptor),
the present invention also provides for soluble forms of such protein. In such
forms part
or all of the intracellular and transmembrane domains of the protein are
deleted such that
the protein is fully secreted from the cell in which it is expressed. The
intracellular and
transmembrane domains of proteins of the invention can be identified in
accordance with
2 5 known techniques for determination of such domains from sequence
information.
Proteins and protein fragments of the present invention include proteins with
amino acid sequence lengths that are at least 25%(more preferably at least
50%, and most
preferably at least 75%) of the length of a disclosed protein and have at
least 60% sequence
identity (more preferably, at least 75% identity; most preferably at least 90%
or 95%
3 0 identity) with that disclosed protein, where sequence identity is
determined by comparing
the amino acid sequences of the proteins when aligned so as to maximize
overlap and
identity while minimizing sequence gaps. Also included in the present
invention are
proteins and protein fragments that contain a segment preferably comprising 8
or more
(more preferably 20 or more, most preferably 30 or more) contiguous amino
acids that
37
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
shares at least 75% sequence identity (more preferably, at least 85% identity;
most
preferably at least 95% identity) with any such segment of any of the
disclosed proteins.
Species homologues of the disclosed polynucleotides and proteins are also
provided by the present invention. As used herein, a "species homologue" is a
protein or
polynucleotide with a different species of origin from that of a given protein
or
polynucleotide, but with significant sequence similarity to the given protein
or
polynucleotide. Preferably, polynucleotide species homologues have at least
60% sequence
identity (more preferably, at least 75% identity; most preferably at least 90%
identity) with
the given polynucleotide, and protein species homologues have at least 30%
sequence
identity (more preferably, at least 45% identity; most preferably at least 60%
identity) with
the given protein, where sequence identity is determined by comparing the
nucleotide
sequences of the polynucleotides or the amino acid sequences of the proteins
when
aligned so as to maximize overlap and identity while minimizing sequence gaps.
Species
homologues may be isolated and identified by making suitable probes or primers
from
the sequences provided herein and screening a suitable nucleic acid source
from the
desired species. Preferably, species homologues are those isolated from
mammalian
species. Most preferably, species homologues are those isolated from certain
mammalian
species such as, for example, Pan troglodytes, Gorilla gorilla, Pongo
pygmaeus, Hylobates
concolor, Macaca mulatta, Papio papio, Papio hamadryas, Cercopithecus
aethiops, Cebus capucinus,
2 0 Aotus trivirgatus, Sanguinus Oedipus, Microcebus murinus, Mus musculus,
Rattus norvegicus,
Cricetulus griseus, Felis catus, Mustela visors, Canis familiaris, Oryctolagus
cuniculus, Bos taurus,
Ovis cries, Sics scrofa, and E9uus caballus, for which genetic maps have been
created
allowing the identification of syntenic relationships between the genomic
organization of
genes in one species and the genomic organization of the related genes in
another species
2 5 (O'Brien and Seuanez, 1988, Ann. Rev. Genet. 22: 323-351; O'Brien et al.,
1993, Nature
Genetics 3:103-112; Johansson et al., 1995, Genomics 25: 682-690; Lyons et
al.,1997, Nature
Genetics 15: 47-56; O'Brien et al.,1997, Trends in Genetics 13(10): 393-399;
Carver and Stubbs,
1997, Genome Research 7:1123-1137; all of which are incorporated by reference
herein).
The invention also encompasses allelic variants of the disclosed
polynucleotides
3 0 or proteins; that is, naturally-occurring alternative forms of the
isolated polynucleotides
which also encode proteins which are identical or have significantly similar
sequences to
those encoded by the disclosed polynucleotides. Preferably, allelic variants
have at least
60% sequence identity (more preferably, at least 75% identity; most preferably
at least 90%
38
CA 02294569 1999-12-17
WO 98/5797b PCT/US98/12516
identity) with the given polynucleotide, where sequence identity is determined
by
comparing the nucleotide sequences of the polynucleotides when aligned so as
to maximize
overlap and identity while minimizing sequence gaps. Allelic variants may be
isolated and
identified by making suitable probes or primers from the sequences provided
herein and
screening a suitable nucleic acid source from individuals of the appropriate
species.
The invention also includes polynucleotides with sequences complementary to
those of the polynucleotides disclosed herein.
The present invention also includes polynucleotides that hybridize under
reduced
stringency conditions, more preferably stringent conditions, and most
preferably highly
stringent conditions, to polynucleotides described herein. Examples of
stringency
conditions are shown in the table below: highly stringent conditions are those
that are at
least as stringent as, for example, conditions A-F; stringent conditions are
at least as
stringent as, for example, conditions G-L; and reduced stringency conditions
are at least
as stringent as, for example, conditions M-R.
39
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
StringencyPolynucleotideHybridHybridization TemperatureWash
ConditionHybrid Lengthand Temperature
(bp)~ Buffer' and Buffer'
A DNA:DNA Z 50 65C; lxSSC -or- 65C; 0.3xSSC
42C; lxSSC, 50% formamide
B DNA:DNA <50 TB*; lxSSC TB*; lxSSC
C DNA:RNA z 50 67C; lxSSC -or- 67C; 0.3xSSC
45C; lxSSC, 50% formamide
D DNA:RNA <50 Tp*; lxSSC To*; lxSSC
E RNA:RNA z 50 70C; lxSSC -or- 70C; 0.3xSSC
50C; lxSSC, 50% formamide
F RNA:RNA <50 TF*; lxSSC TF*; lxSSC
G DNA:DNA s 50 65C; 4xSSC -or- 65C; lxSSC
42C; 4xSSC, 50% formamide
H DNA:DNA <50 T,,*; 4xSSC TH*; 4xSSC
I DNA:RNA z 50 67C; 4xSSC -or- 67C; lxSSC
45C; 4xSSC, 50% formamide
J DNA:RNA <50 T~*; 4xSSC T~*; 4xSSC
K RNA:RNA s 50 70C; 4xSSC -or- 67C; lxSSC
50C; 4xSSC, 50% formamide
L RNA:RNA <50 T~*; 2xSSC T~*; 2xSSC
M DNA:DNA s 50 50C; 4xSSC -or- 50C; 2xSSC
40C; 6xSSC, 50% formamide
N DNA:DNA <50 TN*; 6xSSC T"*; 6xSSC
O DNA:RNA s 50 55C; 4xSSC -or- 55C; 2xSSC
42C; 6xSSC, 50% formamide
P DNA:RNA <50 T,~*; 6xSSC TP*; 6xSSC
Q RNA:RNA z 50 60C; 4xSSC -or- 60C; 2xSSC
45C; 6xSSC, 50% formamide
2 R RNA:RNA <50 TR*; 4xSSC TR*; 4xSSC
0
$: The hybrid length is that anticipated for the hybridized regions) of the
hybridizing polynucleotides. When
hybridizing a polynucleotide to a target polynucleotide of unknown sequence,
the hybrid length is assumed
to be that of the hybridizing polynucleotide. When polynucleotides of known
sequence are hybridized, the
2 5 hybrid length can be determined by aligning the sequences of the
polynucleotides and identifying the region
or regions of optimal sequence complementarity.
t: SSPE (lxSSPE is 0.15M NaCI, lOmM NaHZPO" and 1.25mM EDTA, pH 7.4) can be
substituted for SSC
(lxSSC is 0.15M NaCI and lSmM sodium citrate) in the hybridization and wash
buffers; washes are
performed for 15 nvnutes after hybridization is complete.
3 0 *TB - TR: The hybridization temperature for hybrids anticipated to be less
than 50 base pairs in length should
be 5-10°C less than the melting temperature (Tm) of the hybrid, where
Tm is determined according to the
following equations. For hybrids less than 18 base pairs in length,
Tm(°C) = 2(# of A + T bases) + 4(# of G +
C bases). For hybrids between 18 and 49 base pairs in length, Tm(°C) =
81.5 + 16.6{log,o[Na']) + 0.41(%G+C)
{600/N), where N is the number of bases in the hybrid, and [Na'] is the
concentration of sodium ions in the
3 5 hybridization buffer ([Na'] for IxSSC = 0.165 M).
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Additional examples of stringency conditions for polynucleotide hybridization
are
provided in Sambrook, J., E.F. Fritsch, and T. Maniatis, 1989, Moleca~Iar
Cloning: A
Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor,
NY,
chapters 9 and 11, and Current Protocols in Molecular Biology,1995, F.M.
Ausubel et al., eds.,
John Wiley & Sons, Inc., sections 2.10 and 6.3-6.4, incorporated herein by
reference.
Preferably, each such hybridizing polynucleotide has a length that is at least
25%{more preferably at least 50%, and most preferably at least 75%) of the
length of the
polynucleotide of the present invention to which it hybridizes, and has at
least 60%
sequence identity (more preferably, at least 75% identity; most preferably at
least 90% or
95% identity) with the polynucleotide of the present invention to which it
hybridizes,
where sequence identity is determined by comparing the sequences of the
hybridizing
polynucleotides when aligned so as to maximize overlap and identity while
minimizing
sequence gaps.
The isolated polynucleotide of the invention may be operably linked to an
expression control sequence such as the pMT2 or pED expression vectors
disclosed in
Kaufman et al., Nucleic Acids Res. 9 4485-4490 (1991), in order to produce the
protein
recombinantly. Many suitable expression control sequences are known in the
art. General
methods of expressing recombinant proteins are also known and are exemplified
in R.
Kaufman, Methods in Enzymology 185, 537-566 (1990). As defined herein
"operably
2 0 linked" means that the isolated polynucleotide of the invention and an
expression control
sequence are situated within a vector or cell in such a way that the protein
is expressed
by a host cell which has been transformed (transfected) with the ligated
polynucleotide/expression control sequence.
A number of types of cells may act as suitable host cells for expression of
the
2 5 protein. Mammalian host cells include, for example, monkey COS cells,
Chinese Hamster
Ovary (CHO) cells, human kidney 293 cells, human epidermal A431 cells, human
Co1o205
cells, 3T3 cells, CV-1 cells, other transformed primate cell lines, normal
diploid cells, cell
strains derived from in vitro culture of primary tissue, primary explants,
HeLa cells,
mouse L cells, BHK, HL-60, U937, HaK or Jurkat cells.
3 0 Alternatively, it may be possible to produce the protein in lower
eukaryotes such
as yeast or in prokaryotes such as bacteria. Potentially suitable yeast
strains include
Saccharomyces cerevisiae, Schizosaccharomyces pombe, Kluyveromyces strains,
Candida, or any
yeast strain capable of expressing heterologous proteins. Potentially suitable
bacterial
strains include Escherichia coli, Bacillus subtilis, Salmonella typhimurium,
or any bacterial
41
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
strain capable of expressing heterologous proteins. If the protein is made in
yeast or
bacteria, it may be necessary to modify the protein produced therein, for
example by
phosphorylation or glycosylation of the appropriate sites, in order to obtain
the functional
protein. Such covalent attachments may be accomplished using known chemical or
S enzymatic methods.
The protein may also be produced by operably linking the isolated
polynucleotide
of the invention to suitable control sequences in one or more insect
expression vectors,
and employing an insect expression system. Materials and methods for
baculovirus/insect cell expression systems are commercially available in kit
form from,
e.g., Invitrogen, San Diego, California, U.S.A. (the MaxBac~ kit), and such
methods are
well known in the art, as described in Summers and Smith, Texas Agricultural
Experiment
Station Bulletin No. 1555 (1987), incorporated herein by reference. As used
herein, an
insect cell capable of expressing a polynucleotide of the present invention is
"transformed."
I5 The protein of the invention may be prepared by culturing transformed host
cells
under culture conditions suitable to express the recombinant protein. The
resulting
expressed protein may then be purified from such culture (i.e., from culture
medium or
cell extracts) using known purification processes, such as gel filtration and
ion exchange
chromatography. The purification of the protein may also include an affinity
column
2 0 containing agents which will bind to the protein; one or more column steps
over such
affinity resins as concanavalin A-agarose, heparin-toyopearl~ or Cibacrom blue
3GA
Sepharose~; one or more steps involving hydrophobic interaction chromatography
using
such resins as phenyl ether, butyl ether, or propyl ether; or immunoaffinity
chromatography.
2 5 Alternatively, the protein of the invention may also be expressed in a
form which
will facilitate purification. For example, it may be expressed as a fusion
protein, such as
those of maltose binding protein (MBP), glutathione-S-transferase (GST) or
thioredoxin
(TRX). Kits for expression and purification of such fusion proteins are
commercially
available from New England BioLab (Beverly, MA), Pharmacia (Piscataway, NJ)
and
3 0 InVitrogen, respectively. The protein can also be tagged with an epitope
and
subsequently purified by using a specific antibody directed to such epitope.
One such
epitope ("Flag") is commercially available from Kodak (New Haven, CT).
Finally, one or more reverse-phase high performance liquid chromatography (RP-
HPLC) steps employing hydrophobic Rl'-HPLC media, e.g., silica gel having
pendant
42
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
methyl or other aliphatic groups, can be employed to further purify the
protein. Some or
all of the foregoing purification steps, in various combinations, can also be
employed to
provide a substantially homogeneous isolated recombinant protein. The protein
thus
purified is substantially free of other mammalian proteins and is defined in
accordance
with the present invention as an "isolated protein."
The protein of the invention may also be expressed as a product of transgenic
animals, e.g., as a component of the milk of transgenic cows, goats, pigs, or
sheep which
are characterized by somatic or germ cells containing a nucleotide sequence
encoding the
protein.
The protein may also be produced by known conventional chemical synthesis.
Methods for constructing the proteins of the present invention by synthetic
means are
known to those skilled in the art. The synthetically-constructed protein
sequences, by
virtue of sharing primary, secondary or tertiary structural and/or
conformational
characteristics with proteins may possess biological properties in common
therewith,
including protein activity. Thus, they may be employed as biologically active
or
immunological substitutes for natural, purified proteins in screening of
therapeutic
compounds and in immunological processes for the development of antibodies.
The proteins provided herein also include proteins characterized by amino acid
sequences similar to those of purified proteins but into which modification
are naturally
2 0 provided or deliberately engineered. For example, modifications in the
peptide or DNA
sequences can be made by those skilled in the art using known techniques.
Modifications
of interest in the protein sequences may include the alteration, substitution,
replacement,
insertion or deletion of a selected amino acid residue in the coding sequence.
For
example, one or more of the cysteine residues may be deleted or replaced with
another
2 5 amino acid to alter the conformation of the molecule. Techniques for such
alteration,
substitution, replacement, insertion or deletion are well known to those
skilled in the art
(see, e.g., U.S. Patent No. 4,518,584). Preferably, such alteration,
substitution, replacement,
insertion or deletion retains the desired activity of the protein.
Other fragments and derivatives of the sequences of proteins which would be
3 0 expected to retain protein activity in whole or in part and may thus be
useful for screening
or other immunological methodologies may also be easily made by those skilled
in the art
given the disclosures herein. Such modifications are believed to be
encompassed by the
present invention.
43
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
USES AND BIOLOGICAL ACTIVITY
The polynucleotides and proteins of the present invention are expected to
exhibit
one or more of the uses or biological activities (including those associated
with assays
cited herein) identified below. Uses or activities described for proteins of
the present
invention may be provided by administration or use of such proteins or by
administration
or use of polynucleotides encoding such proteins (such as, for example, in
gene therapies
or vectors suitable for introduction of DNA).
Research Uses and Utilities
The polynucleotides provided by the present invention can be used by the
research
community for various purposes. The polynucleotides can be used to express
recombinant protein for analysis, characterization or therapeutic use; as
markers for
tissues in which the corresponding protein is preferentially expressed (either
constitutively or at a particular stage of tissue differentiation or
development or in disease
states); as molecular weight markers on Southern gels; as chromosome markers
or tags
(when labeled) to identify chromosomes or to map related gene positions; to
compare
with endogenous DNA sequences in patients to identify potential genetic
disorders; as
probes to hybridize and thus discover novel, related DNA sequences; as a
source of
information to derive PCR primers for genetic fingerprinting; as a probe to
"subtract-out"
2 0 known sequences in the process of discovering other novel polynucleotides;
for selecting
and making oligomers for attachment to a "gene chip" or other support,
including for
examination of expression patterns; to raise anti-protein antibodies using DNA
immunization techniques; and as an antigen to raise anti-DNA antibodies or
elicit another
immune response. Where the polynucleotide encodes a protein which binds or
2 5 potentially binds to another protein (such as, for example, in a receptor-
ligand
interaction}, the polynucleotide can also be used in interaction trap assays
(such as, for
example, those described in Gyuris et al., 1993, Cell 75: 791-803 and in Rossi
et al., 1997,
Proc. Natl. Acad. Sci. USA 94: 8405-8410, all of which are incorporated by
reference herein)
to identify polynucleotides encoding the other protein with which binding
occurs or to
3 0 identify inhibitors of the binding interaction.
The proteins provided by the present invention can similarly be used in assay
to
determine biological activity, including in a panel of multiple proteins for
high-
throughput screening; to raise antibodies or to elicit another immune
response; as a
reagent (including the labeled reagent) in assays designed to quantitatively
determine
44
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
levels of the protein (or its receptor) in biological fluids; as markers for
tissues in which
the corresponding protein is preferentially expressed (either constitutively
or at a
particular stage of tissue differentiation or development or in a disease
state); and, of
course, to isolate correlative receptors or ligands. Where the protein binds
or potentially
binds to another protein (such as, for example, in a receptor-ligand
interaction), the
protein can be used to identify the other protein with which binding occurs or
to identify
inhibitors of the binding interaction. Proteins involved in these binding
interactions can
also be used to screen for peptide or small molecule inhibitors or agonists of
the binding
interaction.
Any or all of these research utilities are capable of being developed into
reagent
grade or kit format for commercialization as research products.
Methods for performing the uses listed above are well known to those skilled
in
the art. References disclosing such methods include without limitation
"Molecular
Cloning: A Laboratory Manual", 2d ed., Cold Spring Harbor Laboratory Press,
Sambrook,
J., E.F. Fritsch and T. Maniatis eds., 1989, and "Methods in Enzymology: Guide
to
Molecular Cloning Techniques", Academic Press, Berger, S.L. and A.R. Kimmel
eds.,1987.
Nutritional Uses
Polynucleotides and proteins of the present invention can also be used as
2 0 nutritional sources or supplements. Such uses include without limitation
use as a protein
or amino acid supplement, use as a carbon source, use as a nitrogen source and
use as a
source of carbohydrate. In such cases the protein or polynucleotide of the
invention can
be added to the feed of a particular organism or can be administered as a
separate solid
or liquid preparation, such as in the form of powder, pills, solutions,
suspensions or
2 5 capsules. In the case of microorganisms, the protein or polynucleotide of
the invention
can be added to the medium in or on which the microorganism is cultured.
Cytokine and Cell Proliferation/Differentiation Activity
A protein of the present invention may exhibit cytokine, cell proliferation
(either
3 0 inducing or inhibiting) or cell differentiation (either inducing or
inhibiting) activity or may
induce production of other cytokines in certain cell populations. Many protein
factors
discovered to date, including all known cytokines, have exhibited activity in
one or more
factor dependent cell proliferation assays, and hence the assays serve as a
convenient
confirmation of cytokine activity. The activity of a protein of the present
invention is
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
evidenced by any one of a number of routine factor dependent cell
proliferation assays
for cell lines including, without limitation, 32D, DA2, DA1G, T10, B9, B9/11,
BaF3,
MC9/G, M+ (preB M+), 2E8, RBS, DA1, 123, T1165, HT2, CTLL2, TF-1, Mo7e and
CMK.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for T-cell or thymocyte proliferation include without limitation those
described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W Strober, Pub. Greene Publishing Associates and
Wiley-
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
7, Immunologic studies in Humans); Takai et al., J. Immunol. 137:3494-3500,
1986;
Bertagnolli et al., J. Immunol. 145:1706-1712, 1990; Bertagnolli et al.,
Cellular Immunology
133:327-341, 1991; Bertagnolli, et al., J. Immunol. 149:3778-3783, 1992;
Bowman et al., J.
Immunol. 152: 1756-1761, 1994.
Assays for cytokine production and /or proliferation of spleen cells, lymph
node
cells or thymocytes include, without limitation, those described in:
Polyclonal T cell
stimulation, Kruisbeek, A.M. and Shevach, E.M. In Current Protocols in
Immunology. J.E.e.a.
Coligan eds. Vol 1 pp. 3.12.1-3.12.14, John Wiley and Sons, Toronto. 1994; and
Measurement of mouse and human Interferon y, Schreiber, R.D. In Current
Protocols in
2 0 Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.8.1-6.8.8, John Wiley and
Sons, Toronto.1994.
Assays for proliferation and differentiation of hematopoietic and
lymphopoietic
cells include, without limitation, those described in: Measurement of Human
and Murine
Interleukin 2 and Interleukin 4, Bottomly, K., Davis, L.S. and Lipsky, P.E. In
Current
Protocols in Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.3.1-6.3.12, john
Wiley and Sons,
2 5 Toronto. 1991; deVries et al., J. Exp. Med. 173:1205-1211, 1991; Moreau et
al., Nature
336:690-692, 1988; Greenberger et al., Proc. Natl. Acad. Sci. U.S.A. 80:2931-
2938, 1983;
Measurement of mouse and human interleukin 6 - Nordan, R. In Current Protocols
in
Immunology. j.E.e.a. Coligan eds. Vol 1 pp. 6.6.1-6.6.5, John Wiley and Sons,
Toronto.1991;
Smith et al., Proc. Natl. Acad. Sci. U.S.A. 83:1857-1861, 1986; Measurement of
human
3 0 Interleukin 11- Bennett, F., Giannotti, J., Clark, S.C. and Turner, K. J.
In Current Protocols
in Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.15.1 John Wiley and Sons,
Toronto. 1991;
Measurement of mouse and human Interleukin 9 - Ciarletta, A., Giannotti, J.,
Clark; S.C.
and Turner, K.J. In Current Protocols in Immunology. J.E.e.a. Coligan eds. Vol
1 pp. 6.13.1,
John Wiley and Sons, Toronto. 1991.
46
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Assays for T-cell clone responses to antigens (which will identify, among
others,
proteins that affect APC-T cell interactions as well as direct T-cell effects
by measuring
proliferation and cytokine production) include, without limitation, those
described in:
Current Protocols in Immunology, Ed by J. E. Coligan, A.M. Kruisbeek, D.H.
Margulies,
E.M. Shevach, W Strober, Pub. Greene Publishing Associates and Wiley-
Interscience
(Chapter 3, In Vitro assays for Mouse Lymphocyte Function; Chapter 6,
Cytokines and
their cellular receptors; Chapter 7, Immunologic studies in Humans);
Weinberger et al.,
Proc. Natl. Acad. Sci. USA 77:6091-6095, 1980; Weinberger et al., Eur. J.
Immun.
11:405-411, 1981; Takai et al., J. Immunol. 137:3494-3500, 1986; Takai et al.,
J. Immunol.
140:508-512, 1988.
Immune Stimulating- oar Suppressing Activity
A protein of the present invention may also exhibit immune stimulating or
immune suppressing activity, including without limitation the activities for
which assays
are described herein. A protein may be useful in the treatment of various
immune
deficiencies and disorders (including severe combined immunodeficiency
(SCID)), e.g.,
in regulating (up or down) growth and proliferation of T and/or B lymphocytes,
as well
as effecting the cytolytic activity of NK cells and other cell populations.
These immune
deficiencies may be genetic or be caused by viral (e.g., HIV) as well as
bacterial or fungal
2 0 infections, or may result from autoimmune disorders. More specifically,
infectious
diseases causes by viral, bacterial, fungal or other infection may be
treatable using a
protein of the present invention, including infections by HIV, hepatitis
viruses,
herpesviruses, mycobacteria, Leishmania spp., malaria spp. and various fungal
infections
such as candidiasis. Of course, in this regard, a protein of the present
invention may also
2 5 be useful where a boost to the immune system generally may be desirable,
i.e., in the
treatment of cancer.
Autoimmune disorders which may be treated using a protein of the present
invention include, for example, connective tissue disease, multiple sclerosis,
systemic
lupus erythematosus, rheumatoid arthritis, autoimmune pulmonary inflammation,
3 0 Guillain-Barre syndrome, autoimmune thyroiditis, insulin dependent
diabetes mellitis,
myasthenia gravis, graft-versus-host disease and autoimmune inflammatory eye
disease.
Such a protein of the present invention may also to be useful in the treatment
of allergic
reactions and conditions, such as asthma (particularly allergic asthma) or
other respiratory
problems. Other conditions, in which immune suppression is desired {including,
for
47
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
example, organ transplantation), may also be treatable using a protein of the
present
invention.
Using the proteins of the invention it may also be possible to immune
responses,
in a number of ways. Down regulation may be in the form of inhibiting or
blocking an
immune response already in progress or may involve preventing the induction of
an
immune response. The functions of activated T cells may be inhibited by
suppressing T
cell responses or by inducing specific tolerance in T cells, or both.
Immunosuppression
of T cell responses is generally an active, non-antigen-specific, process
which requires
continuous exposure of the T cells to the suppressive agent. Tolerance, which
involves
inducing non-responsiveness or anergy in T cells, is distinguishable from
immunosuppression in that it is generally antigen-specific and persists after
exposure to
the tolerizing agent has ceased. Operationally, tolerance can be demonstrated
by the lack
of a T cell response upon reexposure to specific antigen in the absence of the
tolerizing
agent.
Down regulating or preventing one or more antigen functions (including without
limitation B lymphocyte antigen functions (such as , for example, B7)), e.g.,
preventing
high level lymphokine synthesis by activated T cells, will be useful in
situations of tissue,
skin and organ transplantation and in graft-versus-host disease (GVHD). For
example,
blockage of T cell function should result in reduced tissue destruction in
tissue
2 0 transplantation. Typically, in tissue transplants, rejection of the
transplant is initiated
through its recognition as foreign by T cells, followed by an immune reaction
that
destroys the transplant. The administration of a molecule which inhibits or
blocks
interaction of a B7 lymphocyte antigen with its natural ligand(s) on immune
cells (such
as a soluble, monomeric form of a peptide having B7-2 activity alone or in
conjunction
2 5 with a monomeric form of a peptide having an activity of another B
lymphocyte antigen
(e.g., B7-l, B7-3) or blocking antibody), prior to transplantation can lead to
the binding of
the molecule to the natural ligand(s) on the immune cells without transmitting
the
corresponding costimulatory signal. Blocking B lymphocyte antigen function in
this
matter prevents cytokine synthesis by immune cells, such as T cells, and thus
acts as an
3 0 immunosuppressant. Moreover, the lack of costimulation may also be
sufficient to
anergize the T cells, thereby inducing tolerance in a subject. Induction of
long-term
tolerance by B lymphocyte antigen blocking reagents may avoid the necessity of
repeated
administration of these blocking reagents. To achieve sufficient
immunosuppression or
48
CA 02294569 1999-12-17
WO 98/57976 PCTNS98/12516
tolerance in a subject, it may also be necessary to block the function of a
combination of
B lymphocyte antigens.
The efficacy of particular blocking reagents in preventing organ transplant
rejection or GVHD can be assessed using animal models that are predictive of
efficacy in
humans. Examples of appropriate systems which can be used include allogeneic
cardiac
grafts in rats and xenogeneic pancreatic islet cell grafts in mice, both of
which have been
used to examine the immunosuppressive effects of CTLA4Ig fusion proteins in
vivo as
described in Lenschow et al., Science 257:789-792 (1992) and Turka et al.,
Proc. Nati. Acad.
Sci USA, 89:11102-11105 (1992). In addition, marine models of GVHD (see Paul
ed.,
Fundamental Immunology, Raven Press, New York, 1989, pp. 846-847) can be used
to
determine the effect of blocking B lymphocyte antigen function in vivo on the
development
of that disease.
Blocking antigen function may also be therapeutically useful for treating
autoimmune diseases. Many autoimmune disorders are the result of inappropriate
activation of T cells that are reactive against self tissue and which promote
the production
of cytokines and autoantibodies involved in the pathology of the diseases.
Preventing the
activation of autoreactive T cells may reduce or eliminate disease symptoms.
Administration of reagents which block costimulation of T cells by disrupting
receptor:ligand interactions of B lymphocyte antigens can be used to inhibit T
cell
2 0 activation and prevent production of autoantibodies or T cell-derived
cytokines which
may be involved in the disease process. Additionally, blocking reagents may
induce
antigen-specific tolerance of autoreactive T cells which could lead to long-
term relief from
the disease. The efficacy of blocking reagents in preventing or alleviating
autoimmune
disorders can be determined using a number of well-characterized animal models
of
2 5 human autoimmune diseases. Examples include marine experimental autoimmune
encephalitis, systemic lupus erythmatosis in MRL/lpr/lpr mice or NZB hybrid
mice,
marine autoimmune collagen arthritis, diabetes mellitus in NOD mice and BB
rats, and
marine experimental myasthenia gravis (see Paul ed., Fundamental Immunology,
Raven
Press, New York,1989, pp. 840-856).
3 0 Upregulation of an antigen function (preferably a B lymphocyte antigen
function),
as a means of up regulating immune responses, may also be useful in therapy.
Upregulation of immune responses may be in the form of enhancing an existing
immune
response or eliciting an initial immune response. For example, enhancing an
immune
response through stimulating B lymphocyte antigen function may be useful in
cases of
49
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
viral infection. In addition, systemic viral diseases such as influenza, the
common cold,
and encephalitis might be alleviated by the administration of stimulatory
forms of B
lymphocyte antigens systemically.
Alternatively, anti-viral immune responses may be enhanced in an infected
patient
by removing T cells from the patient, costimulating the T cells in vitro with
viral antigen-
pulsed APCs either expressing a peptide of the present invention or together
with a
stimulatory form of a soluble peptide of the present invention and
reintroducing the in
vitro activated T cells into the patient. Another method of enhancing anti-
viral immune
responses would be to isolate infected cells from a patient, transfect them
with a nucleic
acid encoding a protein of the present invention as described herein such that
the cells
express all or a portion of the protein on their surface, and reintroduce the
transfected
cells into the patient. The infected cells would now be capable of delivering
a
costimulatory signal to, and thereby activate, T cells in vivo.
In another application, up regulation or enhancement of antigen function
(preferably B lymphocyte antigen function) may be useful in the induction of
tumor
immunity. Tumor cells (e.g., sarcoma, melanoma, lymphoma, leukemia,
neuroblastoma,
carcinoma) transfected with a nucleic acid encoding at least one peptide of
the present
invention can be administered to a subject to overcome tumor-specific
tolerance in the
subject. If desired, the tumor cell can be transfected to express a
combination of peptides.
2 0 For example, tumor cells obtained from a patient can be transfected ex
vivo with an
expression vector directing the expression of a peptide having B7-2-like
activity alone, or
in conjunction with a peptide having B7-1-like activity and/or B7-3-like
activity. The
transfected tumor cells are returned to the patient to result in expression of
the peptides
on the surface of the transfected cell. Alternatively, gene therapy techniques
can be used
2 5 to target a tumor cell for transfection in vivo.
The presence of the peptide of the present invention having the activity of a
B
lymphocyte antigens) on the surface of the tumor cell provides the necessary
costimulation signal to T cells to induce a T cell mediated immune response
against the
transfected tumor cells. In addition, tumor cells which lack MHC class I or
MHC class II
3 0 molecules, or which fail to reexpress sufficient amounts of MHC class I or
MHC class II
molecules, can be transfected with nucleic acid encoding all or a portion of
(e.g., a
cytoplasmic-domain truncated portion) of an MHC class I a chain protein and
X32
microglobulin protein or an MHC class II a chain protein and an MHC class II
~i chain
protein to thereby express MHC class I or MHC class II proteins on the cell
surface.
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Expression of the appropriate class I or class II MHC in conjunction with a
peptide having
the activity of a B lymphocyte antigen (e.g., B7-1, B7-2, B7-3) induces a T
cell mediated
immune response against the transfected tumor cell. Optionally, a gene
encoding an
antisense construct which blocks expression of an MHC class II associated
protein, such
as the invariant chain, can also be cotransfected with a DNA encoding a
peptide having
the activity of a B lymphocyte antigen to promote presentation of tumor
associated
antigens and induce tumor specific immunity. Thus, the induction of a T cell
mediated
immune response in a human subject may be sufficient to overcome tumor-
specific
tolerance in the subject.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Suitable assays for thymocyte or splenocyte cytotoxicity include, without
limitation, those described in: Current Protocols in Immunology, Ed by J. E.
Coligan,
A.M. Kruisbeek, D.H. Margulies, E.M. Shevach, W Strober, Pub. Greene
Publishing
Associates and Wiley-Interscience (Chapter 3, In Vitro assays for Mouse
Lymphocyte
Function 3.1-3.19; Chapter 7, Immunologic studies in Humans); Herrmann et al.,
Proc.
Natl. Acad. Sci. USA 78:2488-2492, 1981; Herrmann et al., J. Immunol. 128:1968-
1974,
1982; Handa et al., J. Immunol. 135:1564-1572, 1985; Takai et al., J. Immunol.
137:3494-3500, 1986; Takai et al., J. Immunol. 140:508-512, 1988; Herrmann et
al., Proc.
2 0 Natl. Acad. Sci. USA 78:2488-2492, 1981; Herrmann et al., J. Immunol.
128:1968-1974,
1982; Handa et al., J. Immunol. 135:1564-1572, 1985; Takai et al., J. Immunol.
137:3494-3500, 1986; Bowmanet al., J. Virology 61:1992-1998; Takai et al., J.
Immunol.
140:508-512, 1988; Bertagnolli et al., Cellular Immunology 133:327-341,1991;
Brown et al.,
J.Immunol. 153:3079-3092, 1994.
2 5 Assays for T-cell-dependent immunoglobulin responses and isotype switching
(which will identify, among others, proteins that modulate T-cell dependent
antibody
responses and that affect Thl /Th2 profiles) include, without limitation,
those described
in: Maliszewski, J. Immunol. 144:3028-3033, 1990; and Assays for B cell
function: In vitro
antibody production, Mond, J.J. and Brunswick, M. In Current Protocols in
Immunology.
3 0 J.E.e.a. Coligan eds. Vol 1 pp. 3.8.1-3.8.16, John Wiley and Sons,
Toronto.1994.
Mixed lymphocyte reaction {MLR) assays (which will identify, among others,
proteins that generate predominantly Thl and CTL responses) include, without
limitation,
those described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
Kruisbeek,
D.H. Margulies, E.M. Shevach, W Strober, Pub. Greene Publishing Associates and
Wiley-
51
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
7, Immunologic studies in Humans); Takai et al., J. Immunol. 137:3494-3500,
1986; Takai
et al., J. Immunol. 140:508-512, 1988; Bertagnolli et al., J. Immunol.
149:3778-3783, 1992.
Dendritic cell-dependent assays (which will identify, among others, proteins
expressed by dendritic cells that activate naive T-cells) include, without
limitation, those
described in: Guery et al., J. Immunol. 134:536-544, 1995; Inaba et al.,
Journal of
Experimental Medicine 173:549-559, 1991; Macatorua et al., Journal of
Immunology
154:5071-5079,1995; Porgador et al., Journal of Experimental Medicine 182:255-
260, 1995;
Nair et al., Journal of Virology 67:4062-4069, 1993; Huang et al., Science
264:961-965,
1994; Macatonia et al., Journal of Experimental Medicine 169:1255-1264,1989;
Bhardwaj
et al., Journal of Clinical Investigation 94:797-807, 1994; and Inaba et al.,
Journal of
Experimental Medicine 172:631-640, 1990.
Assays for lymphocyte survival/apoptosis (which will identify, among others,
proteins that prevent apoptosis after superantigen induction and proteins that
regulate
lymphocyte homeostasis) include, without limitation, those described in:
Darzynkiewicz
et al., Cytometry 13:795-808,1992; Gorczyca et al., Leukemia 7:659-670,1993;
Gorczyca et
al., Cancer Research 53:1945-1951, 1993; Itoh et al., Cell 66:233-243, 1991;
Zacharchuk,
journal of Immunology 145:4037-4045, 1990; Zamai et al., Cytometry 14:891-897,
1993;
Gorczyca et al., International Journal of Oncology 1:639-648,1992.
2 0 Assays for proteins that influence early steps of T-cell commitment and
development include, without limitation, those described in: Antica et al.,
Blood
84:111-117, 1994; Fine et al., Cellular Immunology 155:111-122, 1994; Galy et
al., Blood
85:2770-2778, 1995; Toki et al., Proc. Nat. Acad Sci. USA 88:7548-7551, 1991.
2 5 Hematopoiesis Re ug lating Act
A protein of the present invention may be useful in regulation of
hematopoiesis
and, consequently, in the treatment of myeloid or lymphoid cell deficiencies.
Even
marginal biological activity in support of colony forming cells or of factor-
dependent cell
lines indicates involvement in regulating hematopoiesis, e.g. in supporting
the growth
3 0 and proliferation of erythroid progenitor cells alone or in combination
with other
cytokines, thereby indicating utility, for example, in treating various
anemias or for use
in conjunction with irradiation/chemotherapy to stimulate the production of
erythroid
precursors and/or erythroid cells; in supporting the growth and proliferation
of myeloid
cells such as granulocytes and monocytes/macrophages (i.e., traditional CSF
activity)
52
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/1251b
useful, for example, in conjunction with chemotherapy to prevent or treat
consequent
myelo-suppression; in supporting the growth and proliferation of
megakaryocytes and
consequently of platelets thereby allowing prevention or treatment of various
platelet
disorders such as thrombocytopenia, and generally for use in place of or
complimentary
to platelet transfusions; and/or in supporting the growth and proliferation of
hematopoietic stem cells which are capable of maturing to any and all of the
above-
mentioned hematopoietic cells and therefore find therapeutic utility in
various stem cell
disorders {such as those usually treated with transplantation, including,
without
limitation, aplastic anemia and paroxysmal nocturnal hemoglobinuria), as well
as in
repopulating the stem cell compartment post irradiation/chemotherapy, either
in-vivo or
ex-vivo (i.e., in conjunction with bone marrow transplantation or with
peripheral
progenitor cell transplantation (homologous or heterologous)) as normal cells
or
genetically manipulated for gene therapy.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Suitable assays for proliferation and differentiation of various hematopoietic
lines
are cited above.
Assays for embryonic stem cell differentiation (which will identify, among
others,
proteins that influence embryonic differentiation hematopoiesis) include,
without
2 0 limitation, those described in: Johansson et al. Cellular Biology 15:141-
151, 1995; Keller et
al., Molecular and Cellular Biology 13:473-486, 1993; McClanahan et al., Blood
81:2903-2915, 1993.
Assays for stem cell survival and differentiation (which will identify, among
others, proteins that regulate lympho-hematopoiesis) include, without
limitation, those
2 5 described in: Methylcellulose colony forming assays, Freshney, M.G. In
Culture of
Hematopoietic Cells. R.I. Freshney, et al. eds. Vol pp. 265-268, Wiley-Liss,
Inc., New York,
NY. 1994; Hirayama et al., Proc. Natl. Acad. Sci. USA 89:5907-5911, 1992;
Primitive
hematopoietic colony forming cells with high proliferative potential, McNiece,
I:K. and
Briddell, R.A. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds.
Vol pp. 23-39,
3 0 Wiley-Liss, Inc., New York, NY. 1994; Neben et al., Experimental
Hematology 22:353-359,
1994; Cobblestone area forming cell assay, Ploemacher, R.E. In Culture of
Hematopoietic
Cells. R.I. Freshney, et al. eds. Vol pp. 1-21, Wiley-Liss, Inc.., New York,
NY. 1994; Long
term bone marrow cultures in the presence of stromal cells, Spooncer, E.,
Dexter, M. and
Allen, T. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds. Vol
pp. 163-179,
53
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Wiley-Liss, Inc., New York, NY.1994; Long term culture initiating cell assay,
Sutherland,
H.J. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds. Vol pp. 139-
162, Wiley-Liss,
Inc., New York, NY. 1994.
Tissue Growth Activity
A protein of the present invention also may have utility in compositions used
for
bone, cartilage, tendon, ligament and/or nerve tissue growth or regeneration,
as well as
for wound healing and tissue repair and replacement, and in the treatment of
burns,
incisions and ulcers.
A protein of the present invention, which induces cartilage and/or bone growth
in circumstances where bone is not normally formed, has application in the
healing of
bone fractures and cartilage damage or defects in humans and other animals.
Such a
preparation employing a protein of the invention may have prophylactic use in
closed as
well as open fracture reduction and also in the improved fixation of
artificial joints. De
novo bone formation induced by an osteogenic agent contributes to the repair
of
congenital, trauma induced, or oncologic resection induced craniofacial
defects, and also
is useful in cosmetic plastic surgery.
A protein of this invention may also be used in the treatment of periodontal
disease, and in other tooth repair processes. Such agents may provide an
environment
2 0 to attract bone-forming cells, stimulate growth of bone-forming cells or
induce
differentiation of progenitors of bone-forming cells. A protein of the
invention may also
be useful in the treatment of osteoporosis or osteoarthritis, such as through
stimulation
of bone and/or cartilage repair or by blocking inflammation or processes of
tissue
destruction (collagenase activity, osteoclast activity, etc.) mediated by
inflammatory
2 5 processes.
Another category of tissue regeneration activity that may be attributable to
the
protein of the present invention is tendon/ligament formation. A protein of
the present
invention, which induces tendon/ligament-like tissue or other tissue formation
in
circumstances where such tissue is not normally formed, has application in the
healing of
3 0 tendon or ligament tears, deformities and other tendon or ligament defects
in humans and
other animals. Such a preparation employing a tendon/ligament-like tissue
inducing
protein may have prophylactic use in preventing damage to tendon or ligament
tissue, as
well as use in the improved fixation of tendon or ligament to bone or other
tissues, and
in repairing defects to tendon or ligament tissue. De novo tendon/ligament-
like tissue
54
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
formation induced by a composition of the present invention contributes to the
repair of
congenital, trauma induced, or other tendon or ligament defects of other
origin, and is
also useful in cosmetic plastic surgery for attachment or repair of tendons or
ligaments.
The compositions of the present invention may provide an environment to
attract tendon-
or ligament-forming cells, stimulate growth of tendon- or ligament-forming
cells, induce
differentiation of progenitors of tendon- or ligament-forming cells, or induce
growth of
tendon/ligament cells or progenitors ex vivo for return in vivo to effect
tissue repair. The
compositions of the invention may also be useful in the treatment of
tendinitis, carpal
tunnel syndrome and other tendon or ligament defects. The compositions may
also
include an appropriate matrix and/or sequestering agent as a carrier as is
well known in
the art.
The protein of the present invention may also be useful for proliferation of
neural
cells and for regeneration of nerve and brain tissue, i.e. for the treatment
of central and
peripheral nervous system diseases and neuropathies, as well as mechanical and
traumatic disorders, which involve degeneration, death or trauma to neural
cells or nerve
tissue. More specifically, a protein may be used in the treatment of diseases
of the
peripheral nervous system, such as peripheral nerve injuries, peripheral
neuropathy and
localized neuropathies, and central nervous system diseases, such as
Alzheimer's,
Parkinson s disease, Huntingtori s disease, amyotrophic lateral sclerosis, and
Shy-Drager
2 0 syndrome. Further conditions which may be treated in accordance with the
present
invention include mechanical and traumatic disorders, such as spinal cord
disorders, head
trauma and cerebrovascular diseases such as stroke. Peripheral neuropathies
resulting
from chemotherapy or other medical therapies may also be treatable using a
protein of the
invention.
2 5 Proteins of the invention may also be useful to promote better or faster
closure of
non-healing wounds, including without limitation pressure ulcers, ulcers
associated with
vascular insufficiency, surgical and traumatic wounds, and the like.
It is expected that a protein of the present invention may also exhibit
activity for
generation or regeneration of other tissues, such as organs (including, for
example,
3 0 pancreas, liver, intestine, kidney, skin, endothelium), muscle (smooth,
skeletal or cardiac)
and vascular (including vascular endothelium) tissue, or for promoting the
growth of cells
comprising such tissues. Part of the desired effects may be by inhibition or
modulation
of fibrotic scarnng to allow normal tissue to regenerate. A protein of the
invention may
also exhibit angiogenic activity.
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
A protein of the present invention may also be useful for gut protection or
regeneration and treatment of lung or liver fibrosis, reperfusion injury in
various tissues,
and conditions resulting from systemic cytokine damage.
A protein of the present invention may also be useful for promoting or
inhibiting
differentiation of tissues described above from precursor tissues or cells; or
for inhibiting
the growth of tissues described above.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for tissue generation activity include, without limitation, those
described
in: International Patent Publication No. W095/16035 (bone, cartilage, tendon);
International Patent Publication No. W095/05846 (nerve, neuronal);
International Patent
Publication No. W091/07491 (skin, endothelium ).
Assays for wound healing activity include, without limitation, those described
in:
Winter, Epidermal Wound Healing,, pps. 71-112 (Maibach, HI and Rovee, DT,
eds.), Year
Book Medical Publishers, lnc., Chicago, as modified by Eaglstein and Mertz, J.
Invest.
Dermatol 71:382-84 (1978).
Activin/Inhibin Activity
A protein of the present invention may also exhibit activin- or inhibin-
related
2 0 activities. Inhibins are characterized by their ability to inhibit the
release of follicle
stimulating hormone (FSH), while activins and are characterized by their
ability to
stimulate the release of follicle stimulating hormone (FSH). Thus, a protein
of the present
invention, alone or in heterodimers with a member of the inhibin a family, may
be useful
as a contraceptive based on the ability of inhibins to decrease fertility in
female mammals
2 5 and decrease spermatogenesis in male mammals. Administration of sufficient
amounts
of other inhibins can induce infertility in these mammals. Alternatively, the
protein of the
invention, as a homodimer or as a heterodimer with other protein subunits of
the inhibin-
(i group; may be useful as a fertility inducing therapeutic; based upon the
ability of activin
molecules in stimulating FSH release from cells of the anterior pituitary.
See, for example,
3 0 United States Patent 4,798,885. A protein of the invention may also be
useful for
advancement of the onset of fertility in sexually immature mammals, so as to
increase the
lifetime reproductive performance of domestic animals such as cows, sheep and
pigs.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
56
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Assays for activin/inhibin activity include, without limitation, those
described in:
Vale et al., Endocrinology 91:562-572, 1972; Ling et al., Nature 321:779-782,
1986; Vale et
al., Nature 321:776-779,1986; Mason et al., Nature 318:659-663, 1985; Forage
et al., Proc.
Natl. Acad. Sci. USA 83:3091-3095, 1986.
Chemotactic/Chemokinetic ActivitX
A protein of the present invention may have chemotactic or chemokinetic
activity
(e.g., act as a chemokine) for mammalian cells, including, for example,
monocytes,
fibroblasts, neutrophils, T-cells, mast cells, eosinophils, epithelial and/or
endothelial cells.
Chemotactic and chemokinetic proteins can be used to mobilize or attract a
desired cell
population to a desired site of action. Chemotactic or chemokinetic proteins
provide
particular advantages in treatment of wounds and other trauma to tissues, as
well as in
treatment of localized infections. For example, attraction of lymphocytes,
monocytes or
neutrophils to tumors or sites of infection may result in improved immune
responses
against the tumor or infecting agent.
A protein or peptide has chemotactic activity for a particular cell population
if it
can stimulate, directly or indirectly, the directed orientation or movement of
such cell
population. Preferably, the protein or peptide has the ability to directly
stimulate directed
movement of cells. Whether a particular protein has chemotactic activity for a
population
2 0 of cells can be readily determined by employing such protein or peptide in
any known
assay for cell chemotaxis.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for chemotactic activity (which will identify proteins that induce or
prevent
2 5 chemotaxis) consist of assays that measure the ability of a protein to
induce the migration
of cells across a membrane as well as the ability of a protein to induce the
adhesion of one
cell population to another cell population. Suitable assays for movement and
adhesion
include, without limitation, those described in: Current Protocols in
Immunology, Ed by
J.E. Coligan, A.M. Kruisbeek, D.H. Margulies, E.M. Shevach, W.Strober, Pub.
Greene
3 0 Publishing Associates and Wiley-Interscience (Chapter 6.22, Measurement of
alpha and
beta Chemokines 6.12.1-6.12.28; Taub et al. J. Clin. Invest. 95:1370-
1376,1995; Lind et al.
APMIS 103:140-146, 1995; Muller et al Eur. J. Immunol. 25: 1744-1748; Gruber
et al. J. of
Immunol. 152:5860-5867, 1994; Johnston et al. J. of Immunol. 153: 1762-
1768,1994.
57
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Hemostatic and Thrombolytic Activity
A protein of the invention may also exhibit hemostatic or thrombolytic
activity.
As a result, such a protein is expected to be useful in treatment of various
coagulation
disorders (including hereditary disorders, such as hemophilias) or to enhance
coagulation
and other hemostatic events in treating wounds resulting from trauma, surgery
or other
causes. A protein of the invention may also be useful for dissolving or
inhibiting
formation of thromboses and for treatment and prevention of conditions
resulting
therefrom (such as, for example, infarction of cardiac and central nervous
system vessels
(e.g., stroke).
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assay for hemostatic and thrombolytic activity include, without limitation,
those
described in: Linet et al., J. Clin. Pharmacol. 26:131-140, 1986; Burdick et
al., Thrombosis
Res. 45:413-419,1987; Humphrey et al., Fibrinolysis 5:71-79 (1991); Schaub,
Prostaglandins
35:467-474, 1988.
Receptor/Ligand Activity
A protein of the present invention may also demonstrate activity as receptors,
receptor ligands or inhibitors or agonists of receptor/ligand interactions.
Examples of
2 0 such receptors and ligands include, without limitation, cytokine receptors
and their
ligands, receptor kinases and their ligands, receptor phosphatases and their
ligands,
receptors involved in cell-cell interactions and their ligands (including
without limitation,
cellular adhesion molecules (such as selectins, integrins and their ligands)
and
receptor/ligand pairs involved in antigen presentation, antigen recognition
and
2 5 development of cellular and humoral immune responses). Receptors and
ligands are also
useful for screening of potential peptide or small molecule inhibitors of the
relevant
receptor/ligand interaction. A protein of the present invention (including,
without
limitation, fragments of receptors and ligands) may themselves be useful as
inhibitors of
receptor/ligand interactions.
3 0 The activity of a protein of the invention may, among other means, be
measured
by the following methods:
Suitable assays for receptor-ligand activity include without limitation those
described in:Current Protocols in Immunology, Ed by J.E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W.Strober, Pub. Greene Publishing Associates and
58
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Wiley-Interscience (Chapter 7.28, Measurement of Cellular Adhesion under
static
conditions 7.28.1-7.28.22), Takai et al., Proc. Natl. Acad. Sci. USA 84:6864-
6868, 1987;
Bierer et al., J. Exp. Med.168:1145-1156, 1988; Rosenstein et al., J. Exp.
Med.169:149-160
1989; Stoltenborg et al., J. Immunol. Methods 175:59-68,1994; Stitt et al.,
Cell 80:661-670,
1995.
Anti-Inflammatonr Activity
Proteins of the present invention may also exhibit anti-inflammatory activity.
The
anti-inflammatory activity may be achieved by providing a stimulus to cells
involved in
the inflammatory response, by inhibiting or promoting cell-cell interactions
(such as, for
example, cell adhesion), by inhibiting or promoting chemotaxis of cells
involved in the
inflammatory process, inhibiting or promoting cell extravasation, or by
stimulating or
suppressing production of other factors which more directly inhibit or promote
an
inflammatory response. Proteins exhibiting such activities can be used to
treat
inflammatory conditions including chronic or acute conditions), including
without
limitation inflammation associated with infection (such as septic shock,
sepsis or systemic
inflammatory response syndrome (SIRS)), ischemia-reperfusion injury, endotoxin
lethality, arthritis, complement-mediated hyperacute rejection, nephritis,
cytokine or
chemokine-induced lung injury, inflammatory bowel disease, Crohn's disease or
resulting
2 0 from over production of cytokines such as TNF or IL-1. Proteins of the
invention may also
be useful to treat anaphylaxis and hypersensitivity to an antigenic substance
or material.
Cadherin/Tumor Invasion Supyressor Activity
Cadherins are calcium-dependent adhesion molecules that appear to play major
2 S roles during development, particularly in defining specific cell types.
Loss or alteration
of normal cadherin expression can lead to changes in cell adhesion properties
linked to
tumor growth and metastasis. Cadherin malfunction is also implicated in other
human
diseases, such as pemphigus vulgaris and pemphigus foliaceus (auto-immune
blistering
skin diseases), Crohn's disease, and some developmental abnormalities.
3 0 The cadherin superfamily includes well over forty members, each with a
distinct
pattern of expression. All members of the superfamily have in common conserved
extracellular repeats (cadherin domains), but structural differences are found
in other
parts of the molecule. The cadherin domains bind calcium to form their
tertiary structure
and thus calcium is required to mediate their adhesion. Only a few amino acids
in the
59
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
first cadherin domain provide the basis for homophilic adhesion; modification
of this
recognition site can change the specificity of a cadherin so that instead of
recognizing only
itself, the mutant molecule can now also bind to a different cadherin. In
addition, some
cadherins engage in heterophilic adhesion with other cadherins.
E-cadherin, one member of the cadherin superfamily, is expressed in epithelial
cell
types. Pathologically, if E-cadherin expression is lost in a tumor, the
malignant cells
become invasive and the cancer metastasizes. Transfection of cancer cell lines
with
polynucleotides expressing E-cadherin has reversed cancer-associated changes
by
returning altered cell shapes to normal, restoring cells' adhesiveness to each
other and to
their substrate, decreasing the cell growth rate, and drastically reducing
anchorage-
independent cell growth. Thus, reintroducing E-cadherin expression reverts
carcinomas
to a less advanced stage. It is likely that other cadherins have the same
invasion
suppressor role in carcinomas derived from other tissue types. Therefore,
proteins of the
present invention with cadherin activity, and polynucleotides of the present
invention
encoding such proteins, can be used to treat cancer. Introducing such proteins
or
polynucleotides into cancer cells can reduce or eliminate the cancerous
changes observed
in these cells by providing normal cadherin expression.
Cancer cells have also been shown to express cadherins of a different tissue
type
than their origin, thus allowing these cells to invade and metastasize in a
different tissue
2 0 in the body. Proteins of the present invention with cadherin activity, and
polynucleotides
of the present invention encoding such proteins, can be substituted in these
cells for the
inappropriately expressed cadherins, restoring normal cell adhesive properties
and
reducing or eliminating the tendency of the cells to metastasize.
Additionally, proteins of the present invention with cadherin activity, and
2 5 polynucleotides of the present invention encoding such proteins, can used
to generate
antibodies recognizing and binding to cadherins. Such antibodies can be used
to block
the adhesion of inappropriately expressed tumor-cell cadherins, preventing the
cells from
forming a tumor elsewhere. Such an anti-cadherin antibody can also be used as
a marker
for the grade, pathological type, and prognosis of a cancer, i.e. the more
progressed the
3 0 cancer, the less cadherin expression there will be, and this decrease in
cadherin expression
can be detected by the use of a cadherin-binding antibody.
Fragments of proteins of the present invention with cadherin activity,
preferably
a polypeptide comprising a decapeptide of the cadherin recognition site, and
poly-
nucleotides of the present invention encoding such protein fragments, can also
be used
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
to block cadherin function by binding to cadherins and preventing them from
binding in
ways that produce undesirable effects. Additionally, fragments of proteins of
the present
invention with cadherin activity, preferably truncated soluble cadherin
fragments which
have been found to be stable in the circulation of cancer patients, and
polynucleotides
encoding such protein fragments, can be used to disturb proper cell-cell
adhesion.
Assays for cadherin adhesive and invasive suppressor activity include, without
limitation, those described in: Hortsch et al. J Biol Chem 270 (32): 18809-
18817, 1995;
Miyaki et al. Oncogene 11: 2547-2552, 1995; Ozawa et al. Cell 63: 1033-
1038,1990.
Tumor Inhibition Activity
In addition to the activities described above for immunological treatment or
prevention of tumors, a protein of the invention may exhibit other anti-tumor
activities.
A protein may inhibit tumor growth directly or indirectly (such as, for
example, via
ADCC). A protein may exhibit its tumor inhibitory activity by acting on tumor
tissue or
tumor precursor tissue, by inhibiting formation of tissues necessary to
support tumor
growth (such as, for example, by inhibiting angiogenesis), by causing
production of other
factors, agents or cell types which inhibit tumor growth, or by suppressing,
eliminating
or inhibiting factors, agents or cell types which promote tumor growth.
2 0 Other Activities
A protein of the invention may also exhibit one or more of the following
additional
activities or effects: inhibiting the growth, infection or function of, or
killing, infectious
agents, including, without limitation, bacteria, viruses, fungi and other
parasites; effecting
(suppressing or enhancing) bodily characteristics, including, without
limitation, height,
2 5 weight, hair color, eye color, skin, fat to lean ratio or other tissue
pigmentation, or organ
or body part size or shape (such as, for example, breast augmentation or
diminution,
change in bone form or shape); effecting biorhythms or caricadic cycles or
rhythms;
effecting the fertility of male or female subjects; effecting the metabolism,
catabolism,
anabolism, processing, utilization, storage or elimination of dietary fat,
lipid, protein,
3 0 carbohydrate, vitamins, minerals, cofactors or other nutritional factors
or component(s);
effecting behavioral characteristics, including, without limitation, appetite,
libido, stress,
cognition (including cognitive disorders), depression (including depressive
disorders) and
violent behaviors; providing analgesic effects or other pain reducing effects;
promoting
differentiation and growth of embryonic stem cells in lineages other than
hematopoietic
61
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
lineages; hormonal or endocrine activity; in the case of enzymes, correcting
deficiencies
of the enzyme and treating deficiency-related diseases; treatment of
hyperproliferative
disorders (such as, for example, psoriasis); immunoglobulin-like activity
(such as, for
example, the ability to bind antigens or complement); and the ability to act
as an antigen
in a vaccine composition to raise an immune response against such protein or
another
material or entity which is cross-reactive with such protein.
ADMINISTRATION AND DOSING
A protein of the present invention (from whatever source derived, including
without limitation from recombinant and non-recombinant sources) may be used
in a
pharmaceutical composition when combined with a pharmaceutically acceptable
carrier.
Such a composition may also contain (in addition to protein and a carrier)
diluents, fillers,
salts, buffers, stabilizers, solubilizers, and other materials well known in
the art. The term
"pharmaceutically acceptable" means a non-toxic material that does not
interfere with the
effectiveness of the biological activity of the active ingredient(s). The
characteristics of the
carrier will depend on the route of administration. The pharmaceutical
composition of
the invention may also contain cytokines, lymphokines, or other hematopoietic
factors
such as M-CSF, GM-CSF, TNF, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-
9, IL-10, IL-11,
2 0 IL-12, IL-13, IL-14, IL-15, IFN, TNFO, TNF1, TNF2, G-CSF, Meg-CSF,
thrombopoietin, stem
cell factor, and erythropoietin. The pharmaceutical composition may further
contain other
agents which either enhance the activity of the protein or compliment its
activity or use
in treatment. Such additional factors and/or agents may be included in the
pharmaceutical composition to produce a synergistic effect with protein of the
invention,
2 5 or to minimize side effects. Conversely, protein of the present invention
may be included
in formulations of the particular cytokine, lymphokine, other hematopoietic
factor,
thrombolytic or anti-thrombotic factor, or anti-inflammatory agent to minimize
side effects
of the cytokine, lymphokine, other hematopoietic factor, thrombolytic or anti-
thrombotic
factor, or anti-inflammatory agent.
3 0 A protein of the present invention may be active in multimers (e.g.,
heterodimers
or homodimers) or complexes with itself or other proteins. As a result,
pharmaceutical
compositions of the invention may comprise a protein of the invention in such
multimeric
or complexed form.
62
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
The pharmaceutical composition of the invention may be in the form of a
complex
of the proteins) of present invention along with protein or peptide antigens.
The protein
and/or peptide antigen will deliver a stimulatory signal to both B and T
lymphocytes. B
lymphocytes will respond to antigen through their surface immunoglobulin
receptor. T
lymphocytes will respond to antigen through the T cell receptor (TCR)
following
presentation of the antigen by MHC proteins. MHC and structurally related
proteins
including those encoded by class I and class II MHC genes on host cells will
serve to
present the peptide antigens) to T lymphocytes. The antigen components could
also be
supplied as purified MHC-peptide complexes alone or with co-stimulatory
molecules that
can directly signal T cells. Alternatively antibodies able to bind surface
immunolgobulin
and other molecules on B cells as well as antibodies able to bind the TCR and
other
molecules on T cells can be combined with the pharmaceutical composition of
the
invention.
The pharmaceutical composition of the invention may be in the form of a
liposome
in which protein of the present invention is combined, in addition to other
pharmaceutically acceptable carriers, with amphipathic agents such as lipids
which exist
in aggregated form as micelles, insoluble monolayers, liquid crystals, or
lamellar layers
in aqueous solution. Suitable lipids for liposomal formulation include,
without limitation,
monoglycerides, diglycerides, sulfatides, lysolecithin, phospholipids,
saporun, bile acids,
2 0 and the like. Preparation of such liposomal formulations is within the
level of skill in the
art, as disclosed, for example, in U.S. Patent No. 4,235,871; U.S. Patent No.
4,501,728; U.S.
Patent No. 4,837,028; and U.S. Patent No. 4,737,323, all of which are
incorporated herein
by reference.
As used herein, the term "therapeutically effective amount" means the total
2 5 amount of each active component of the pharmaceutical composition or
method that is
sufficient to show a meaningful patient benefit, i.e., treatment, healing,
prevention or
amelioration of the relevant medical condition, or an increase in rate of
treatment, healing,
prevention or amelioration of such conditions. When applied to an individual
active
ingredient, administered alone, the term refers to that ingredient alone. When
applied to
3 0 a combination, the term refers to combined amounts of the active
ingredients that result
in the therapeutic effect, whether administered in combination, serially or
simultaneously.
In practicing the method of treatment or use of the present invention, a
therapeutically effective amount of protein of the present invention is
administered to a
mammal having a condition to be treated. Protein of the present invention may
be
63
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
administered in accordance with the method of the invention either alone or in
combination with other therapies such as treatments employing cytokines,
lymphokines
or other hematopoietic factors. When co-administered with one or more
cytokines,
lymphokines or other hematopoietic factors, protein of the present invention
may be
administered either simultaneously with the cytokine(s), lymphokine(s), other
hematopoietic factor(s), thrombolytic or anti-thrombotic factors, or
sequentially. If
administered sequentially, the attending physician will decide on the
appropriate
sequence of administering protein of the present invention in combination with
cytokine(s), lymphokine(s), other hematopoietic factor(s), thrombolytic or
anti-thrombotic
factors.
Administration of protein of the present invention used in the pharmaceutical
composition or to practice the method of the present invention can be carried
out in a
variety of conventional ways, such as oral ingestion, inhalation, topical
application or
cutaneous, subcutaneous, intraperitoneal, parenteral or intravenous injection.
Intravenous administration to the patient is preferred.
When a therapeutically effective amount of protein of the present invention is
administered orally, protein of the present invention will be in the form of a
tablet,
capsule, powder, solution or elixir. When administered in tablet form, the
pharmaceutical
composition of the invention may additionally contain a solid carrier such as
a gelatin or
2 0 an adjuvant. The tablet, capsule, and powder contain from about 5 to 95%
protein of the
present invention, and preferably from about 25 to 90% protein of the present
invention.
When administered in liquid form, a liquid carrier such as water, petroleum,
oils of animal
or plant origin such as peanut oil, mineral oil, soybean oil, or sesame oil,
or synthetic oils
may be added. The liquid form of the pharmaceutical composition may further
contain
2 5 physiological saline solution, dextrose or other saccharide solution, or
glycols such as
ethylene glycol, propylene glycol or polyethylene glycol. When administered in
liquid
form, the pharmaceutical composition contains from about 0.5 to 90% by weight
of protein
of the present invention, and preferably from about 1 to 50% protein of the
present
invention.
3 0 When a therapeutically effective amount of protein of the present
invention is
administered by intravenous, cutaneous or subcutaneous injection, protein of
the present
invention will be in the form of a pyrogen-free, parenterally acceptable
aqueous solution.
The preparation of such parenterally acceptable protein solutions, having due
regard to
pH, isotonicity, stability, and the like, is within the skill in the art. A
preferred
64
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
pharmaceutical composition for intravenous, cutaneous, or subcutaneous
injection should
contain, in addition to protein of the present invention, an isotonic vehicle
such as Sodium
Chloride Injection, Ringer's Injection, Dextrose Injection, Dextrose and
Sodium Chloride
Injection, Lactated Ringer's Injection, or other vehicle as known in the art.
The
pharmaceutical composition of the present invention may also contain
stabilizers,
preservatives, buffers, antioxidants, or other additives known to those of
skill in the art.
The amount of protein of the present invention in the pharmaceutical
composition
of the present invention will depend upon the nature and severity of the
condition being
treated, and on the nature of prior treatments which the patient has
undergone.
Ultimately, the attending physician will decide the amount of protein of the
present
invention with which to treat each individual patient. Initially, the
attending physician
will administer low doses of protein of the present invention and observe the
patient's
response. Larger doses of protein of the present invention may be administered
until the
optimal therapeutic effect is obtained for the patient, and at that point the
dosage is not
increased further. It is contemplated that the various pharmaceutical
compositions used
to practice the method of the present invention should contain about 0.01 lxg
to about 100
mg (preferably about 0.lng to about 10 mg, more preferably about 0.1 ug to
about 1 mg)
of protein of the present invention per kg body weight.
The duration of intravenous therapy using the pharmaceutical composition of
the
2 0 present invention will vary, depending on the severity of the disease
being treated and
the condition and potential idiosyncratic response of each individual patient.
It is
contemplated that the duration of each application of the protein of the
present invention
will be in the range of 12 to 24 hours of continuous intravenous
administration.
Ultimately the attending physician will decide on the appropriate duration of
intravenous
2 5 therapy using the pharmaceutical composition of the present invention.
Protein of the invention may also be used to immunize animals to obtain
polyclonal and monoclonal antibodies which specifically react with the
protein. Such
antibodies may be obtained using either the entire protein or fragments
thereof as an
immunogen. T'he peptide immunogens additionally may contain a cysteine residue
at the
3 0 carboxyl terminus, and are conjugated to a hapten such as keyhole limpet
hemocyanin
(KLH). Methods for synthesizing such peptides are known in the art, for
example, as in
R.P. Merrifield, J. Amer.Chem.Soc. 85 2149-2154 (1963); J.L. Krstenansky, et
al., FEBS Lett.
211. 10 (1987). Monoclonal antibodies binding to the protein of the invention
may be
useful diagnostic agents for the immunodetection of the protein. Neutralizing
monoclonal
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
antibodies binding to the protein may also be useful therapeutics for both
conditions
associated with the protein and also in the treatment of some forms of cancer
where
abnormal expression of the protein is involved. In the case of cancerous cells
or leukemic
cells, neutralizing monoclonal antibodies against the protein may be useful in
detecting
and preventing the metastatic spread of the cancerous cells, which may be
mediated by
the protein.
For compositions of the present invention which are useful for bone,
cartilage,
tendon or ligament regeneration, the therapeutic method includes administering
the
composition topically, systematically, or locally as an implant or device.
When
administered, the therapeutic composition for use in this invention is, of
course, in a
pyrogen-free, physiologically acceptable form. Further, the composition may
desirably
be encapsulated or injected in a viscous form for delivery to the site of
bone, cartilage or
tissue damage. Topical administration may be suitable for wound healing and
tissue
repair. Therapeutically useful agents other than a protein of the invention
which may also
optionally be included in the composition as described above, may
alternatively or
additionally, be administered simultaneously or sequentially with the
composition in the
methods of the invention. Preferably for bone and/or cartilage formation, the
composition would include a matrix capable of delivering the protein-
containing
composition to the site of bone and/or cartilage damage, providing a structure
for the
2 0 developing bone and cartilage and optimally capable of being resorbed into
the body.
Such matrices may be formed of materials presently in use for other implanted
medical
applications.
The choice of matrix material is based on biocompatibility, biodegradability,
mechanical properties, cosmetic appearance and interface properties. The
particular
2 5 application of the compositions will define the appropriate formulation.
Potential
matrices for the compositions may be biodegradable and chemically defined
calcium
sulfate, tricalciumphosphate, hydroxyapatite, polylactic acid, polyglycolic
acid and
polyanhydrides. Other potential materials are biodegradable and biologically
well-
defined, such as bone or dermal collagen. Further matrices are comprised of
pure proteins
3 0 or extracellular matrix components. Other potential matrices are
nonbiodegradable and
chemically defined, such as sintered hydroxapatite, bioglass, aluminates, or
other
ceramics. Matrices may be comprised of combinations of any of the above
mentioned
types of material, such as polylactic acid and hydroxyapatite or collagen and
tricalciumphosphate. The bioceramics may be altered in composition, such as in
calcium-
66
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
aluminate-phosphate and processing to alter pore size, particle size, particle
shape, and
biodegradability.
Presently preferred is a 50:50 (mole weight) copolymer of lactic acid and
glycolic
acid in the form of porous particles having diameters ranging from 150 to 800
microns.
In some applications, it will be useful to utilize a sequestering agent, such
as
carboxymethyl cellulose or autologous blood clot, to prevent the protein
compositions
from disassociating from the matrix.
A preferred family of sequestering agents is cellulosic materials such as
alkylcelluloses (including hydroxyalkylcelluloses), including methylcellulose,
ethylcellulose, hydroxyethylcellulose, hydroxypropylcellulose, hydroxypropyl-
methylcellulose, and carboxymethylcellulose, the most preferred being cationic
salts of
carboxymethylcellulose (CMC). Other preferred sequestering agents include
hyaluronic
acid, sodium alginate, polyethylene glycol), polyoxyethylene oxide,
carboxyvinyl
polymer and polyvinyl alcohol). The amount of sequestering agent useful herein
is 0.5-20
wt%, preferably 1-10 wt% based on total formulation weight, which represents
the
amount necessary to prevent desorbtion of the protein from the polymer matrix
and to
provide appropriate handling of the composition, yet not so much that the
progenitor cells
are prevented from infiltrating the matrix, thereby providing the protein the
opportunity
to assist the osteogenic activity of the progenitor cells.
2 0 In further compositions, proteins of the invention may be combined with
other
agents beneficial to the treatment of the bone and/or cartilage defect, wound,
or tissue in
question. These agents include various growth factors such as epidermal growth
factor
(EGF), platelet derived growth factor (PDGF), transforming growth factors (TGF-
a and
TGF-Vii), and insulin-like growth factor (IGF).
2 5 The therapeutic compositions are also presently valuable for veterinary
applications. Particularly domestic animals and thoroughbred horses, in
addition to
humans, are desired patients for such treatment with proteins of the present
invention.
The dosage regimen of a protein-containing pharmaceutical composition to be
used in tissue regeneration will be determined by the attending physician
considering
3 0 various factors which modify the action of the proteins, e.g., amount of
tissue weight
desired to be formed, the site of damage, the condition of the damaged tissue,
the size of
a wound, type of damaged tissue (e.g., bone), the patient's age, sex, and
diet, the severity
of any infection, time of administration and other clinical factors. The
dosage may vary
with the type of matrix used in the reconstitution and with inclusion of other
proteins in
67
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
the pharmaceutical composition. For example, the addition of other known
growth
factors, such as IGF I (insulin like growth factor I), to the final
composition, may also effect
the dosage. Progress can be monitored by periodic assessment of tissue/bone
growth
and/or repair, for example, X-rays, histomorphometric determinations and
tetracycline
labeling.
Polynucleotides of the present invention can also be used for gene therapy.
Such
polynucleotides can be introduced either in vivo or ex vivo into cells for
expression in a
mammalian subject. Polynucleotides of the invention may also be administered
by other
known methods for introduction of nucleic acid into a cell or organism
(including; without
limitation, in the form of viral vectors or naked DNA).
Cells may also be cultured ex vivo in the presence of proteins of the present
invention in order to proliferate or to produce a desired effect on or
activity in such cells.
Treated cells can then be introduced in vivo for therapeutic purposes.
Patent and literature references cited herein are incorporated by reference as
if
fully set forth.
68
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
SEQUENCE LISTING
(1) GENERAL INFORMATION:
(i) APPLICANT: Jacobs, Kenneth
McCoy, John M.
LaVallie, Edward R.
Racie, Lisa A.
Treacy, Maurice
Spaulding, Vikki
Agostino, Michael J.
Hooves, Steven H.
Fechtel, Kim
(ii) TITLE OF INVENTION: SECRETED PROTEINS AND POLYNUCLEOTIDES
ENCODING THEM
(iii) NUMBER OF SEQUENCES: 30
(iv) CORRESPONDENCE ADDRESS:
(A) ADDRESSEE: Genetics Institute, Inc.
(B) STREET: 87 CambridgePark Drive
(C) CITY: Cambridge
2 S (D) STATE: MA
(E) COUNTRY: U.S.A.
(F) ZIP: 02140
(v) COMPUTER READABLE FORM:
3 0 (A) MEDIUM TYPE: Floppy disk
(B) COMPUTER: IBM PC compatible
(C) OPERATING SYSTEM: PC-DOS/MS-DOS
(D) SOFTWARE: PatentIn Release #1.0, Version #1.30
3 S (vi) CURRENT APPLICATION DATA:
(A) APPLICATION NUMBER:
(B) FILING DATE:
(C) CLASSIFICATION:
4O (viii) ATTORNEY/AGENT INFORMATION:
(A) NAME: Sprunger, Suzanne A.
(B) REGISTRATION NUMBER: 41,323
(ix) TELECOMMUNICATION INFORMATION:
4 5 (A) TELEPHONE: (617) 498-8284
(B) TELEFAX: (617) 876-5851
(2) INFORMATION FOR SEQ ID N0:1:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1748 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
69
CA 02294569 1999-12-17
WO 98/57976 PCT/US98112516
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION: SEQ ID
N0:1:
GTTTAGTGAT ACGACACAAG ATCGGGAGAT 60
TTTTGATCAC CATACTGAAG AGGATATAGA
1 TAAAAGTGCT AACAGTGTAT TGATAAAAAACCTGAGCAGGACCCCATCTAGTTGCAGCAG 120
O
CTCTCTGGAT TCAATCAAGG CTGATGGGACCTCTCTGGACTTCAGCACTTACCGCAGTAG 180
TCAAATGGAA TCACAGTTTC TCAGAGATACTATTTGTGAAGAGAGCTTGAGGGAGAAACT 240
CCAAGATGGG AGAATAACAA TAAGGGAGTTCTTTATACTTCTCCAGGTCCACATCTTGAT 300
ACAGAAACCC CGACAGAGCA ATCTCCCAGGCAATTTTACTGTAAACACACCACCTACTCC 360
2 AGAAGACCTG ATGTTAAGTC AATATGTTTACCGACCCAAGATACAGATTTATAGAGAAGA 420
O
TTGTGAGGCT CGTCGCCAAA AGATTGAAGAATTAAAGCTTTCTGCATCGAACCAAGATAA 480
GCTGTTGGTT GATATAAATA AGAACCTGTGGGAAAAAATGAGACACTGCTCTGACAAAGA 540
GCTGAAGGCC TTTGGAATTT ATCTTAACAAAATAAAGTCATGTTTTACCAAGATGACTAA 600
AGTCTTCACT CACCAAGGAA AAGTGGCTCTGTATGGCAAGCTGGTGCAGTCAGCTCAGAA 660
3 TGAGAGGGAG AAACTTCAAA TAAAGATAGATGAGATGGATAAAATACTTAAGAAGATCGA 720
O
TAACTGCCTC ACTGAGATGG AAACAGAAACTAAGAATTTGGAGGATGAAGAGAAAAACAA 780
TCCTGTGGAA GAATGGGATT CTGAAATGAGAGCTGCAGAAAAAGAATTGGAACAGCTGAA 840
AACTGAAGAG GAGGAGCTTC AAAGAAATCTCTTAGAACTGGAGGTACCAAAAGAGCAGAC 900
CCTTGCTCAA ATAGACTTTA TGCAAAAACAAAGAAATAGAACTGAAGAGCTACTGGATCA 960
4O GTTGAGCTTG TCTGAGTGGG ATGTCGTTGAGTGGAGTGATGATCAAGCTGTATTCACCTT 1020
TGTTTATGAC ACGATACAAC TCACCATCACCTTTGAAGAGTCAGTTGTTGGTTTCCCTTT 1080
CCTGGACAAG CGTTATAGGA AGATTGTTGATGTCAATTTTCAATCTCTGTTAGATGAGGA 1140
TCAAGCTCCT CCTTCCTCCC TTTTAGTTCATAAGCTTATTTTCCAGTACGTTGAAGAAAA 1200
GGAATCCTGG AAGAAGACAT GTACAACCCAGCATCAGTTACCCAAGATGCTTGAAGAATT 1260
5 CTCACTGGTA GTGCACCATT GCAGACTCCTTGGAGAGGAGATTGAGTATTTAAAGAGATG 1320
O
GGGACCAAAT TATAACCTAA TGAACATAGATATTAATAATAATGAATTGAGACTTTTATT 1380
CTCTAGCTCC GCAGCATTTG CAAAGTTTGAAATAACTTTGTTTCTCTCAGCCTATTATCC 1440
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
ATCTGTACCA TTACCTTCCA CCATTCAGAA TCACGTTGGG AACACTAGCC AAGATGATAT 1500
TGCTACCATT CTATCTAAAG TGCCACTGGA GAACAACTAC CTGAAGAATG TAGTCAAGCA 1560
AATTTACCAA GATCTGTTTC AGGACTGCCATTTCTACCAC TAGACCCTTG GACCACCATT1620
GGAACAACCA AGCAGAATGT ACTTGATATTATTTCAGGGT CCCATTGCTG TTCAGCCTTT1680
GTTTTTACGT CATTACAAGC TGAGTAAAATTCCTTCTGAT GATGTTATAA A,~~i~AAAAAAA1740
AAAAAAAA 1748
(2) INFORMATION FOR SEQ
ID N0:2:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 472 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE
DESCRIPTION:
SEQ
ID
N0:2:
Met GluSerGln PheLeuArg AspThrIle CysGlu GluSerLeuArg
1 5 10 15
Glu LysLeuGln AspGlyArg IleThrIle ArgGlu PhePheIleLeu
20 25 30
Leu GlnValHis IleLeuIle GlnLysPro ArgGln SerAsnLeuPro
35 40 45
Gly AsnPheThr ValAsnThr ProProThr ProGlu AspLeuMetLeu
50 55 60
Ser GlnTyrVal TyrArgPro LysIleGln IleTyr ArgGluAspCys
65 70 75 80
Glu AlaArgArg GlnLysIle GluGluLeu LysLeu SerAlaSerAsn
85 90 95
Gln AspLysLeu LeuValAsp IleAsnLys AsnLeu TrpGluLysMet
100 105 110
Arg HisCysSer AspLysGlu LeuLysAla PheGly IleTyrLeuAsn
115 120 125
Lys IleLysSer CysPheThr LysMetThr LysVal PheThrHisGln
130 135 140
Gly LysValAla LeuTyrGly LysLeuVal GlnSer AlaGlnAsnGlu
71
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
145 150 155 160
Arg Glu LysLeuGln IleLysIle AspGlu MetAspLys IleLeuLys
165 170 175
Lys Ile AspAsnCys LeuThrGlu MetGlu ThrGluThr LysAsnLeu
180 185 190
Glu Asp GluGluLys AsnAsnPro ValGlu GluTrpAsp SerGluMet
195 200 205
Arg Ala AlaGluLys GluLeuGlu GlnLeu LysThrGlu GluGluGlu
210 215 220
Leu Gln ArgAsnLeu LeuGluLeu GluVal ProLysGlu GlnThrLeu
225 230 235 240
Ala Gln IleAspPhe MetGlnLys GlnArg AsnArgThr GluGluLeu
245 250 255
Leu Asp GlnLeuSer LeuSerGlu TrpAsp ValValGlu TrpSerAsp
260 265 270
Asp Gln AlaValPhe ThrPheVal TyrAsp ThrIleGln LeuThrIle
275 280 285
Thr Phe GluGluSer ValValGly PhePro PheLeuAsp LysArgTyr
290 295 300
3 Arg Lys IleValAsp ValAsnPhe GlnSer LeuLeuAsp GluAspGln
0
305 310 315 320
Ala Pro ProSerSer LeuLeuVal HisLys LeuIlePhe GlnTyrVal
325 330 335
Glu Glu LysGluSer TrpLysLys ThrCys ThrThrGln HisGlnLeu
340 345 350
Pro Lys MetLeuGlu GluPheSer LeuVal ValHisHis CysArgLeu
355 360 365
Leu Gly GluGluIle GluTyrLeu LysArg TrpGlyPro AsnTyrAsn
370 375 380
4 Leu Met AsnIleAsp IleAsnAsn AsnGlu LeuArgLeu LeuPheSer
5
385 390 395 400
Ser Ser AlaAlaPhe AlaLysPhe GluIle ThrLeuPhe LeuSerAla
405 410 415
Tyr Tyr ProSerVal ProLeuPro SerThr IleGlnAsn HisValGly
420 425 430
Asn Thr SerGlnAsp AspIleAla ThrIle LeuSerLys ValProLeu
435 440 445
72
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Glu Asn Asn Tyr Leu Lys Asn Val Val Lys Gln Ile Tyr Gln Asp Leu
450 455 460
Phe Gln Asp Cys His Phe Tyr His
465 470
(2) INFORMATION FOR SEQ ID N0:3:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 2298 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
2 (xi) SEQUENCE DESCRIPTION:
O SEQ ID N0:3:
CTTTTCTTTG ATTGTCTCTGCTTTAGCGTCTCTAAATCCG GTCACCATGTCGGACCCCGA60
AGGCGAGACC TTGCGAAGCACCTTTCCCTCTTATATGGCC GAAGGCGAGCGGCTCTACCT120
GTGCGGGGAA TTTTCTAAAGCCGCGCAGAGCTTCAGCAAC GCTCTTTACCTTCAGGATGG180
AGACAAGAAC TGCCTGGTTGCTCGCTCAAAGTGCTTCCTG AAGATGGGAGACTTGGAGAG240
3 ATCCCTGAAG GATGCTGARGCTTCGCTCCAGAGTGACCCA GCTTTCTGTAAGGGGATTTT300
O
GCAAAAGGCT GAGACACTGTACACCATGGGAGACTTTGAG TTTGCCTTGGTATTCTATCA360
TCGARGCTAC AAGCTGARGCCTGATCGGGAATTCARARTT GGCATTCAGAAAGCCCAGGA420
AGCCATCAAC AACTCAGTGGGAAGTCCTTCTTCCATTAAG CTGGAGAACAAAGGGGACCT480
CTCCTTCTTA AGCAAGCAGGCTGAGAATATAAAAGCCCAG CAGAAGCCTCAGCCCATGAA540
4O ACACCTCTTA CACCCCACCAAGGGAGAGCCCAAGTGGAAG GCCTCGCTCAAGAGTGAGAA600
GACTGTCCGC CAGCTTCTGGGGGAGCTCTACGTGGACAAA GAGTATTTGGAGAAGCTCCT660
ATTGGATGAA GACCTGATCAAAGGCACCATGAAGGGCGGC CTGACTGTGGAGGACCTCAT720
4S
CATGACGGGC ATCAACTACCTGGATACTCACAGCAACTTC TGGAGGCAGCAGAAGCCGAT780
CTACGCCAGG GAGCGGGACCGGAAGCTGATGCAAGAGAAA TGGCTGCGGGACCACAAACG840
S CCGTCCCTCA CAGACAGCCCATTACATCCTCAAGAGCCTG GAGGACATTGATATGTTGCT900
O
CACAAGTGGC AGTGCTGAAGGGAGTCTTCAGAAAGCTGAG AAAGTGCTGAAGAAGGTACT960
GGAATGGAAC AAGGAAGAGGTACCCAACAAGGATGAACTG GTTGGAAACTTGTATAGCTG1020
55
73
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
CATAGGGAAT GCCCAGATTG AGCTGGGGCAGATGGAGGCA GCCCTGCAGAGCCACAGAAA1080
GGACYTGGAG ATCGCCAAGG AATATGACCTTCCTGATGCA AAATCGAGAGCCCTTGACAA1140
CATTGGCAGA GTTTTTGCCA GAGTTGGGAAATTCCAGCAA GCCATTGACACGTGGGAAGA1200
AAAGATCCCT CTGGCAAAAA CCACCCTGGAGAAGACCTGG CTGTTCCACGAGATCGGCCG1260
CTGCTACTTG GAGCTGGACC AGGCCTGGCAGGCCCAGAAT TATGGCGAGAAGTCCCAGCA1320
GTGTGCCGAG GAGGAAGGGG ACATTGAGTGGCAACTGAAT GCCAGTGTTCTGGTGGCCCA1380
GGCACAAGTG AAGCTGAGAG ACTTCGAGTCAGCCGTGAAC AATTTTGAGAAGGCCCTGGA1440
GAGAGCAAAG CTTGTGCATA ACAACGAGGCGCAGCAGGCC ATCATCAGTGCCTTGGACGA2500
TGCCAACAAG GGTATCATCA GAGAACTGAGGAAAACCAAC TACGTGGAGAATCTCAAAGA1560
AAAAAGCGAG GGAGAAGCTT CACTGTATGAAGATAGAATA ATAACAAGAGAGAAGGACAT1620
GAGGAGAGTG AGAGATGAGC CCGAGAAGGTGGTGAAGCAG TGGGACCATAGTGAGGATGA1680
GAAAGAGACA GATGAGGACG ATGAGGCTTTTGGGGAAGCT CTGCAGAGCCCAGCAAGCGG1740
AAAGCAGAGT GTGGAAGCAG GAAAAGCCAGAAGCGATTTG GGAGCAGTTGCCAAGGGCCT1800
GTCAGGAGAA TTAGGCACAA GATCAGGAGAAACAGGCAGG AAGCTACTAGAAGCTGGCAG1860
AAGAGAGTCA AGAGAAATTT ATAGGAGGCCTTCGGGAGAA TTAGAGCAAAGACTCTCAGG1920
AGAATTCAGC AGACAGGAAC CAGAAGAACTAAAGAAACTT TCAGAAGTGGGCAGAAGAGA1980
SCCAGAAGAA YTGGGAAAAA CACAATTTGGAGAAATAGGA GAAACGAAAAAAACAGGAAA2040
3 TGAGATGGAA AAGGAATATG AATGAAGCCATCGGTAGAGA TGAGGATCAGGAAGCTGGTG2100
5
TTCAGAGGGA TCATGGGATT TTATTAAACTGGATTTTCAA GCGATTTGTCTGTTATAGGA2160
AAAATGAGGG TTTTACTTYT GCTGCTTTCCATCACTATTT TGCCATTAAATAGGTGTCTT2220
TCACTCTTGC rf~~AAAAAAAA AAAAAAAAAAAAAAAAAAAA P~~4AAAAAAAP,~~ 2
2
8
0
2298
(2) INFORMATION FOR SEQ ID
N0:4:
(i) SEQUENCE CHARACTERISTIC S:
(A) LENGTH: 672 amino acids
(B) TYPE: amino acid
5O (C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
74
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(xi) SEQUENCE
DESCRIPTION:
SEQ
ID
N0:4:
Met Ser AspProGluGly GluThrLeu ArgSer ThrPhePro SerTyr
1 5 10 15
Met Ala GluGlyGluArg LeuTyrLeu CysGly GluPheSer LysAla
20 25 30
Ala Gln SerPheSerAsn AlaLeuTyr LeuGln AspGlyAsp LysAsn
35 40 45
Cys Leu ValAlaArgSer LysCysPhe LeuLys MetGlyAsp LeuGlu
50 55 60
Arg Ser LeuLysAspAla GluAlaSer LeuGln SerAspPro AlaPhe
65 70 75 80
Cys Lys GlyIleLeuGln LysAlaGlu ThrLeu TyrThrMet GlyAsp
85 90 95
Phe Glu PheAlaLeuVal PheTyrHis ArgXaa TyrLysLeu XaaPro
100 105 110
2 Asp Arg GluPheXaaXaa GlyIleGln LysAla GlnGluAla IleAsn
5
115 120 125
Asn Ser ValGlySerPro SerSerIle LysLeu GluAsnLys GlyAsp
130 135 140
Leu Ser PheLeuSerLys GlnAlaGlu AsnIle LysAlaGln GlnLys
145 150 155 160
Pro Gln ProMetLysHis LeuLeuHis ProThr LysGlyGlu ProLys
165 170 175
Trp Lys AlaSerLeuLys SerGluLys ThrVal ArgGlnLeu LeuGly
180 185 190
Glu Leu TyrValAspLys GluTyrLeu GluLys LeuLeuLeu AspGlu
195 200 205
Asp Leu IleLysGlyThr MetLysGly GlyLeu ThrValGlu AspLeu
210 215 220
Ile Met ThrGlyIleAsn TyrLeuAsp ThrHis SerAsnPhe TrpArg
225 230 235 240
Gln Gln LysProIleTyr AlaArgGlu ArgAsp ArgLysLeu MetGln
245 250 255
Glu Lys TrpLeuArgAsp HisLysArg ArgPro SerGlnThr AlaHis
260 265 270
Tyr Ile LeuLysSerLeu GluAspIle AspMet LeuLeuThr SerGly
7$
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
275 280 285
Ser AlaGluGly SerLeuGln LysAla GluLysVal LeuLysLys Val
290 295 300
Leu GluTrpAsn LysGluGlu ValPro AsnLysAsp GluLeuVal Gly
305 310 315 320
Asn LeuTyrSer CysIleGly AsnAla GlnIleGlu LeuGlyGln Met
325 330 335
Glu AlaAlaLeu GlnSerHis ArgLys AspLeuGlu IleAlaLys Glu
340 345 350
Tyr AspLeuPro AspAlaLys SerArg AlaLeuAsp AsnIleGly Arg
355 360 365
Val PheAlaArg ValGlyLys PheGln GlnAlaIle AspThrTrp Glu
370 375 380
Glu LysIlePro LeuAlaLys ThrThr LeuGluLys ThrTrpLeu Phe
385 390 395 400
His GluIleGly ArgCysTyr LeuGlu LeuAspGln AlaTrpGln Ala
405 410 415
Gln AsnTyrGly GluLysSer GlnGln CysAlaGlu GluGluGly Asp
420 425 430
3 0 Ile GluTrpGln LeuAsnAla SerVal LeuValAla GlnAlaGln Val
435 440 445
Lys LeuArgAsp PheGluSer AlaVal AsnAsnPhe GluLysAla Leu
450 455 460
Glu ArgAlaLys LeuValHis AsnAsn GluAlaGln GlnAlaIle Ile
465 470 475 480
Ser AlaLeuAsp AspAlaAsn LysGly IleIleArg GluLeuArg Lys
485 490 495
Thr AsnTyrVal GluAsnLeu LysGlu LysSerGlu GlyGluAla Ser
500 505 510
Leu TyrGluAsp ArgIleIle ThrArg GluLysAsp MetArgArg Val
515 520 525
Arg AspGluPro GluLysVal ValLys GlnTrpAsp HisSerGlu Asp
530 535 540
Glu LysGluThr AspGluAsp AspGlu AlaPheGly GluAlaLeu Gln
545 550 555 560
Ser ProAlaSer GlyLysGln SerVal GluAlaGly LysAlaArg Ser
565 570 575
76
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Asp Leu Gly Ala Val Ala Lys Gly Leu Ser Gly Glu Leu Gly Thr Arg
580 585 590
Ser Gly Glu Thr Gly Arg Lys Leu Leu Glu Ala Gly Arg Arg Glu Ser
595 600 605
Arg Glu Ile Tyr Arg Arg Pro Ser Gly Glu Leu Glu Gln Arg Leu Ser
610 615 620
Gly Glu Phe Ser Arg Gln Glu Pro Glu Glu Leu Lys Lys Leu Ser Glu
625 630 635 640
Val Gly Arg Arg Xaa Pro Glu Glu Leu Gly Lys Thr Gln Phe Gly Glu
645 650 655
Ile Gly Glu Thr Lys Lys Thr Gly Asn Glu Met Glu Lys Glu Tyr Glu
660 665 670
2 O (2) INFORMATION FOR SEQ ID N0:5:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1010 base pairs
{B) TYPE: nucleic acid
2 5 {C) STRANDEDNESS: double
(D) TOPOLOGY: linear
{ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID
N0:5:
3 GGAAGAGCCACCATCCCTGCCCCCGTTTTCCCACCGGGGAGTCTGTACAGAGATTTTTCT60
5
ACGTTTTTATTTTTTGCCTCAGAGGGATGGGATTGGGGAGGAGGGGATGGGCAGCGGAGG120
GTTGGGGGCATGGTCTGCAGGCTCATCTGTGTCCGCCTTTCACTCCACTAATGCTGTCTC180
AGTGTTTTCTCTCTCTCTCTTTCGAGCTTGCACTCCGGTACCCGACCCGGCGCCCTGGCC240
CATCCCATGCCGGGGGGCCAGTGGAAAGAAGACAGGCCGTCCAGCCCGTGCCCGCCTGCG300
4 GCGGGGGCACCCAGCAAGCCCGCCCACCGCCCGCTGCCTCACCTGCTTCGCCACAGACTC360
5
TTGTTCCCAGCCCCTTGGGGCCTCCGTGTTTGGGGTGGGGGAGCTGCTTAGAGACTGTGC420
CCGTCCTCGGCCCCCCACCCTGAAGTGCCAGCACCACCAGCACCAGATCTTCCGCCGCCA480
CACCGCATTGAGGACACGCCGGCCGGGCCGCTTCGTCTCAAGTTGTATAAAGTTGTCTCC540
GTGTCCCCTCCTCCCTCTGCCCCCAGTGTTTCTTCTGATTTTTTTTTCCCCTTTCCCTCC600
55CTCCCTCTCCGCATTCTTCCCTTGGTTCAGCACAGGTAAAACGGTTCCCCTCCCTCCCTG660
77
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
CCTTCATGGA TCACCAGCTC ACGTCATGTTGCCTTCTCTTTTCTTTGTGT GTGTGTTTAT720
TTAAGTTATT TTTCTTCCTC CTCTCCCTTTTCTTTTTGGCCCTCCCTCCC TCCCTCTTCT780
GCCATGTAAC TGGAGGATGT GCTATGAGTTTGCAAACAGCTGGACTGTCA GGCTGCTTTT840
TTTTCCAGAT GTTCTTCTTC TGCTTCCCCTTCCCCTCCTCTCCCCTCCTT TTCCTTCCTT900
CCTTCCTTTC CTTGGAGCAC TGAGCACCATTTGGAAGCTTGAGAGAAACC AAAATTAAAG960
AGAGAAAGAG AGAGCGTGCA CGCTCCTGCTTTGTCAAAAAAAAAAAAAAA 1010
(2) INFORMATION FOR SEQ ID
N0:6:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 205 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE
DESCRIPTION:
SEQ
ID
N0:6:
Met GlySer GlyGlyLeu GlyAla TrpSerAla GlySerSer ValSer
1 5 10 15
Ala PheHis SerThrAsn AlaVal SerValPhe SerLeuSer LeuPhe
20 25 30
Arg AlaCys ThrProVal ProAsp ProAlaPro TrpProIle ProCys
35 40 45
Arg GlyAla SerGlyLys LysThr GlyArgPro AlaArgAla ArgLeu
50 55 60
Arg ArgGly HisProAla SerPro ProThrAla ArgCysLeu ThrCys
65 70 75 80
Phe AlaThr AspSerCys SerGln ProLeuGly AlaSerVal PheGly
85 90 95
Val GlyGlu LeuLeuArg AspCys AlaArgPro ArgProPro ThrLeu
100 105 110
Lys CysGln HisHisGln HisGln IlePheArg ArgHisThr AlaLeu
115 120 125
Arg ThrArg ArgProGly ArgPhe ValSerSer CysIleLys LeuSer
130 135 140
Pro CysPro LeuLeuPro LeuPro ProValPhe LeuLeuIle PhePhe
7g
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
145 150 155 160
Ser Pro Phe Pro Pro Ser Leu Ser Ala Phe Phe Pro Trp Phe Ser Thr
165 170 175
Gly Lys Thr Val Pro Leu Pro Pro Cys Leu His Gly Ser Pro Ala His
180 185 190
Val Met Leu Pro Ser Leu Phe Phe Val Cys Val Phe Ile
195 200 205
(2) INFORMATION FOR SEQ ID N0:7:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 2409 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
2 O (ii) MOLECULE TYPE: cDNA
2 (xi) SEQUENCE DESCRIPTION:
5 SEQ ID N0:7:
ATTTYGCTCA TCAACCTCATTATAGAACATATGATTTGTG ATACAGATCC TGAACTTGGA60
GGAGCAGTCC AGCTTATGGGCCTGCTTCGAACTTTAGTTG ACCCAGAGAA CATGCTAGCC120
30
ACTGCCMATA AAACASAAAAGACTGAATTTCTGGGTTTCT TCTACAAGCA CTGTATGCAT180
GTTCTCWCTG CTCCTTTACTAGCAAATACAACAGAAGACA AACCTAGTAA AGATGATTTT240
3 CAGACTGCCC AACTATTGGCACTTGTATTGGAATTGTTAA CATTTTGTGT GGAGCACCAT300
5
ACCTACCACA TAAAGAACTACATTATTAATAAGGATATCC TCCGGAGAGT GCTAGTTCTT360
ATGGCCTCGA AGCATGCTTTCTTGGCATTATGTGCCCTTC GTTTTAAAAG AAAGATTATT420
40
GGATTAAAAG ATGAGTTTTACAACCGCTACATAATGAAAA GTTTTTTGTT TGAACCAGTA480
GTGAAAGCAT TTCTCAACAATGGATCCCGCTACAATCTGA TGAACTCTGC CATAATAGAG540
4 ATGTTTGAAT TTATTAGAGTGGAAGATATAAAATCATTAA CTGCTCATGT AATTGAAAAT600
5
TACTGGAAAG CACTGGAAGATGTAGATTATGTACAGACAT TTAAAGGATT AAAACTGAGA660
TTTGAACAAC AAAGAGAAAGGCAAGATAATCCCAAACTTG ACAGTATGCG TTCCATTTTG720
50
AGGAATCACA GATATCGAAGAGATGCCAGAACACTAGAAG ATGAAGAAGA GATGTGGTTT780
AACACAGATG AAGATGACATGGAAGATGGAGAAGCTGTAG TGTCTCCATC TGACAAAACT840
55 AAAAATGATG ATGATATTATGGATCCAATAAGTAAATTCA TGGAAAGGAA GAAATTAAAA900
79
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
GAAAGTGAGG AAAAGGAAGTGCTTCTGAAA GAGCCCAAGT960
ACAAACCTTT
CTGGACGGCA
TTCAAGCTTT CCCTGTCCAGTGGAACGAAGACTAACCTCA CCAGCCAGTCATCTACAACA1020
AATCTGCCTG GTTCTCCGGGATCACCTGGATCCCCAGGAT CTCCAGGCTCTCCTGGATCC1080
GTACCTAAAA ATACATCTCAGACGGCAGCTATTACTACAA AGGGAGGCCTCGTGGGTCTG1140
GTAGATTATC CTGATGATGATGAAGATGATGATGAGGATG AAGATAAGGAAGATACGTTA1200
CCATTGTCAA AGAAAGCAAAATTTGATTCATAATAATGGC AACGGCCTAGGATCAGTACC1260
TGTTGAAAAA AACTGGTTCTCCACCCCTCCCCCATACAAA ATCCACAAAAAAGCGCAGTG1320
GTCTCTTGTG AATGACTGACACAGATCAGCCTCTTACACT TGACTTCTGCTCATCAAGTG1380
CCAATTCAAT GGAGCAGGAGGAGGGGATATCATATATTTA GGGGAAAGACTTAAGCCTTT1440
GAGCTCTCCA GCTTGGACCACACATTGCCCTTTTCTCAGG GAAGGAAATGGAAACAAAAA1500
GCCAACAGGG CAGGGGTTTTGTAAGTGGAACTCTGGATTG ACTGGTCAGTTGCTACAATC1560
AGAATATGCT TTCTTGGACCATGTTTGAGACTCAGAAGAA TGGCCTTTCTGCCATAATTC1620
2 TTCACTAGTC AAGAATGCCAGCAGTTTCTTTGTATAAAGA GACCTGCCTTTAAAATCATA1680
5
CATTCTGAAC ATTTTAGTCAAGCTACAACAGGTTTGGAAA ACCTCTGTGGGGGAGGGGCG1740
AGTATAAAGT TTTCCTCTTTTTTAACTGTTCCCTTTGCCC TTCAAACTGCAGATATTTTT1800
TTTTTTAAGT GGGGACTTCTCCCTACTTGATTAAAGATTG AGTGGAATTCTAGATGTGGT1860
CATTTGTGTC ATAATTTTTTTGTTTTATTTTGTTTTTGAT TTTTTTTTTCCTCCCCTGAG1920
3 TGTATGCTTA GTTGTTGAGTATATATATTTGGGACCATTA AAACTTTTTTTGATGTAATA1980
5
TAACCTAACG TTGTGCTGGTACCTGTTTTACCATGTGTAA TTTTTGTTCTACATCACAGT2040
TCTTAATTTG TTTAGAGTTTTATGAAAGATGGTATAGTTT TTATTGACAAAAGCAAAGTA2100
ATCTTACAAC TATGTGCATACAAAAGCAATACTATTTTGT GACTAAATATTTTATATTAA2160
AATTTACATC AGCAACTGTCTTGAGAATTCAGGGAAATAG AATGGAATTTAAAACTTCAA2220
4 CAGTTTTGTT AAATCTAGAAACATGAAATTRGTATTCCAA AGAGATTCTGAAATTTCTTT2280
5
TCTKGGGGAA ATGACGGTACATTAAATCAAAATTGRGGAT GGATGATTTAAAAACATTTG2340
ACTTTTTAAT AATAAAAAGAAAAGTGAAGAGTAAGAGAAA TTGTAAAAAAP~~~.AAP,AAAA2400
AAAAA.AAAA
2409
(2) INFORMATION
FOR SEQ ID N0:8:
(i) SEQUENCE CHARACTERISTICS:
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(A) LENGTH: 400 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION:
SEQ
ID
N0:8:
Met IleCys AspThr AspProGluLeu GlyGlyAla ValGln LeuMet
1 5 10 15
Gly LeuLeu ArgThr LeuValAspPro GluAsnMet LeuAla ThrAla
20 25 30
Xaa LysThr XaaLys ThrGluPheLeu GlyPhePhe TyrLys HisCys
35 40 45
Met HisVal LeuXaa AlaProLeuLeu AlaAsnThr ThrGlu AspLys
50 55 60
2 Pro SerLys AspAsp PheGlnThrAla GlnLeuLeu AlaLeu ValLeu
5
65 70 75 80
Glu LeuLeu ThrPhe CysValGluHis HisThrTyr HisIle LysAsn
85 90 95
Tyr IleIle AsnLys AspIleLeuArg ArgValLeu ValLeu MetAla
100 105 110
Ser LysHis AlaPhe LeuAlaLeuCys AlaLeuArg PheLys ArgLys
3 115 12 12
5 0 5
Ile IleGly LeuLys AspGluPheTyr AsnArgTyr IleMet LysSer
130 135 140
4 Phe LeuPhe GluPro ValValLysAla PheLeuAsn AsnGly SerArg
0
145 150 155 160
Tyr AsnLeu MetAsn SerAlaIleIle GluMetPhe GluPhe IleArg
165 170 175
45
Val GluAsp IleLys SerLeuThrAla HisValIle GluAsn TyrTrp
180 185 190
Lys AlaLeu GluAsp ValAspTyrVal GlnThrPhe LysGly LeuLys
50 195 200 205
Leu ArgPhe GluGln GlnArgGluArg GlnAspAsn ProLys LeuAsp
210 215 220
5 Ser MetArg SerIle LeuArgAsnHis ArgTyrArg ArgAsp AlaArg
5
gl
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
225 230 235 240
Thr LeuGlu AspGluGlu GluMetTrp PheAsnThr AspGluAsp Asp
245 250 255
Met GluAsp GlyGluAla ValValSer ProSerAsp LysThrLys Asn
260 265 270
Asp AspAsp IleMetAsp ProIleSer LysPheMet GluArgLys Lys
275 280 285
Leu LysGlu SerGluGlu LysGluVal LeuLeuLys ThrAsnLeu Ser
290 295 300
Gly ArgGln SerProSer PheLysLeu SerLeuSer SerGlyThr Lys
305 310 315 320
Thr AsnLeu ThrSerGln SerSerThr ThrAsnLeu ProGlySer Pro
325 330 335
Gly SerPro GlySerPro GlySerPro GlySerPro GlySerVal Pro
340 345 350
Lys AsnThr SerGlnThr AlaAlaIle ThrThrLys GlyGlyLeu Val
355 360 365
Gly LeuVal AspTyrPro AspAspAsp GluAspAsp AspGluAsp Glu
370 375 380
3 Asp LysGlu AspThrLeu ProLeuSer LysLysAla LysPheAsp Ser
0
385 390 395 400
(2) INFORMATION FOR SEQ ID N0:9:
(ij SEQUENCE CHARACTERISTICS:
{A) LENGTH: 951 base pairs
{B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
{xi) SEQUENCE DESCRIPTION:
SEQ ID N0:9:
GCCAGGCAGG GTGTGGGGGCAGCTGTGCCAATCTACCTCA CAGGCCCACC CCCTGCCGGG60
CATGCCGTGG GATCATGGGCAGGGAAGGCTCTGGGGGTCG GAGACACCGC TGCTTAGCAC120
CCCCAGCCAG AACACCCTGAGGGTCTCGGGGCTCTGGAGA GAGTGGGGCG GGAGGAAGAA180
TTGGCACCTT CCTAGGGAAGGAGACGAGCGCTTCGCCTTG ATTCTCCGAG AAGCCTCCGA240
82
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
GAAGTGCTTT AAGTGTGTTT GCATGCSCCAGGCGGTGGGCAGCGGGGGCC TGTCCARCCC300
TCTCCCGCCA TCCTTCCCCA AGTGACGTCCACTGCCTTGTCACCAGCGAC CTGCCTGTCA360
TGCCCACCCC CTGAGGAAGC ATGGGGACCCTAACACCCTGGTGCCCTGCA CCAGACAGGC420
CGTGGTCAGG CCCAGGCCAC CGGCCGGGTTCTGCCACARCTTCCCACGTG CTTGCTGACA480
TGCSTGTGCC TGTGTGTGGT GTCTGTTGCTGTGTCGTGAAACTGTGACCA TCACTCAGTC540
CAAACAAGTG AGTGGCCCTS GAGGCCACAGTTATGCAACTTTCAGTGTGT GTCATAACGA600
CGTCACTGCT TTTTAAACTC GATAACTCTTTATTTTAGTAAAATGCCCAG GAGTCCTGGA660
AGCTACGCGG ACTTGCAGAG GTTTTATTTTTTGGCCTTAGAATCTGCAGA AATTAGGAGG720
CACCGAGCCC AGCGCAGCAG CCTCGGACCCGGATTGCGTTTGCCTTAGCG GATATGTTTA780
TACAGATGAA TATAAAATGT TTTTTTCTTTGGGCTTTTTGCTTCTTTTTT CCCCCCCTTC840
TCACCTTCCC TTCTCCCTGA CCCCACCCCCCAAAAAAGCTACTTCTTCAT TCCGTGGTAC900
GATTATTTTT TTTAACTAAA GGAAGATAAAATTCTAAAAAF~~?~AAAAAAA A 951
(2) INFORMATION FOR SEQ
ID NO:10:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 87 amino acids
(B) TYPE: amino acid
3 O (C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION:
SEQ
ID
N0:10:
Met ProTrp AspHisGlyGln GlyArgLeu TrpGly SerGluThr Pro
1 5 10 15
Leu LeuSer ThrProSerGln AsnThrLeu ArgVal SerGlyLeu Trp
20 25 30
Arg GluTrp GlyGlyArgLys AsnTrpHis LeuPro ArgGluGly Asp
35 40 45
Glu ArgPhe AlaLeuIleLeu ArgGluAla SerGlu LysCysPhe Lys
50 55 60
Cys ValCys MetXaaGlnAla ValGlySer GlyGly LeuSerXaa Pro
65 70 75 80
Leu ProPro SerPheProLys
83
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(2) INFORMATION FOR SEQ ID N0:11:
5 (i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1899 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID
NO:11:
GGCCGCTTGTGTCCACGGGACGCGGGCGGATCTTCTCCGGCCATGAGGAAGCCAGCCGCT60
2 GGCTTCCTTCCCTCACTCCTGAAGGTGCTGCTCCTGCCTCTGGCACCTGCCGCAGCCCAG120
O
GATTCGACTCAGGCCTCCACTCCAGGCAGCCCTCTCTCTCCTACCGAATACGAACGCTTC180
TTCGCACTGCTGACTCCAACCTGGAAGGCAGAGACTACCTGCCGTCTCCGTGCAACCCAC240
GGCTGCCGGAATCCCACACTCGTCCAGCTGGACCAATATGAAAACCACGGCTTAGTGCCC300
GATGGTGCTGTCTGCTCCAACCTCCCTTATGCCTCCTGGTTTGAGTCTTTCTGCCAGTTC360
3 ACTCACTACCGTTGCTCCAACCACGTCTACTATGCCAAGAGAGTCCTGTGTTCCCAGCCA420
O
GTCTCTATTCTCTCACCTAACACTCTCAAGGAGATAGAAGCTTCAGCTGAAGTCTCACCC480
ACCACGATGACCTCCCCCATCTCACCCCACTTCACAGTGACAGAACGCCAGACCTTCCAG540
CCCTGGCCTGAGAGGCTCAGCAACAACGTGGAAGAGCTCCTACAATCCTCCTTGTCCCTG600
GGAGGCCAGGAGCAAGCGCCAGAGCACAAGCAGGAGCAAGGAGTGGAGCACAGGCAGGAG660
4 CCGACACAAGAACACAAGCAGGAAGAGGGGCAGAAACAGGAAGAGCAAGAAGAGGAACAG720
O
GAAGAGGAGGGAAAGCAGGAAGAAGGACAGGGGACTAAGGAGGGACGGGAGGCTGTGTCT780
CAGCTGCAGACAGACTCAGAGCCCAAGTTTCACTCTGAATCTCTATCTTCTAACCCTTCC840
TCTTTTGCTCCCCGGGTACGAGAAGTAGAGTCTACTCCTATGATAATGGAGAACATCCAG900
GAGCTCATTCGATCAGCCCAGGAAATAGATGAAATGAATGAAATATATGATGAGAACTCC960
5O TACTGGAGAAACCAAAACCCTGGCAGCCTCCTGCAGCTGCCCCACACAGAGGCCTTGCTG1020
GTGCTGTGCTATTCGATCGTGGAGAATACCTGCATCATAACCCCCACAGCCAAGGCCTGG1080
AAGTACATGGAGGAGGAGATCCTTGGTTTCGGGAAGTCGGTCTGTGACAGCCTTGGGCGG1140
84
CA 02294569 1999-12-17
WO 98/S7976 PCT/US98/12516
CGACACATGT CTACCTGTGC CCTCTGTGAC TTCTGCTCCT TGAAGCTGGA GCAGTGCCAC 1200
TCAGAGGCCA GCCTGCAGCG GCAACAATGC GACACCTCCC ACAAGACTCC CTTTGTCAGC 1260
CCCTTGCTTGCCTCCCAGAG CCTGTCCATCGGCAACCAGGTAGGGTCCCC AGAATCAGGC1320
CGCTTTTACGGGCTGGATTT GTACGGTGGGCTCCACATGGACTTCTGGTG TGCCCGGCTT1380
GCCACGAAAGGCTGTGAAGA TGTCCGAGTCTCTGGGTGGCTCCAGACTGA GTTCCTTAGC1440
TTCCAGGATGGGGATTTCCC TACCAAGATTTGTGACACAGACTATATCCA GTACCCAAAC1500
TACTGTTCCTTCAAAAGCCA GCAGTGTCTGATGAGAAACCGCAATCGGAA GGTGTCCCGC1560
1 ATGAGATGTCTGCAGAATGA GACTTACAGTGCGCTGAGCCTGGCAAAAGT GAGGACGTTG1620
5
TGCTTTCGATGGAGCCAGGA GTTCAGCACCTTGACTCTAGGCCAGTTCGG ATGAGCTKGS1680
GTTTATTTTGCCCACACCCC AGCCCAACCTGCCCASGTTCTCTATTGTTT TGAGACCCCA1740
TTGCTTTCAGGCTGCCCCTT CTGGGTCTGTTACTCGGCCCCTAMTCACAT TTCCTTGGGT1800
TGGAGCAACAGTCCCAGAGA GGGCCACGGTGGGAGCTGCGCCCTCCTTAA AAGATGACTT1860
2 TACATAAAATGTTGATCTTC AAAAAAAAAAp~~AAAAAAA 1899
5
(2) INFORMATION
FOR SEQ
ID N0:12:
(i) S EQUENCE CHARACTERISTICS:
3 (A) LENGTH: 543 acids
0 amino
(B) TYPE: amino
acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
3 (ii) MOLECULE
5 TYPE:
protein
4 (xi) SEQUENCE
0 DESCRIPTION:
SEQ
ID
N0:12:
Met ArgLys AlaAlaGly PheLeuPro SerLeu LeuLysVal Leu
Pro
1 5 10 15
4 Leu LeuPro AlaProAla AlaAlaGln AspSer ThrGlnAla Ser
5 Leu
20 25 30
Thr ProGly ProLeuSer ProThrGlu TyrGlu ArgPhePhe Ala
Ser
35 40 45
50
Leu LeuThr ThrTrpLys AlaGluThr ThrCys ArgLeuArg Ala
Pro
50 55 60
Thr HisGly ArgAsnPro ThrLeuVal GlnLeu AspGlnTyr Glu
Cys
55 65 70 75 80
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Asn His Gly Leu Val Pro Asp Gly Ala Val Cys Ser Asn Leu Pro Tyr
85 90 95
Ala Ser TrpPheGlu SerPhe CysGlnPheThr HisTyr ArgCysSer
100 105 110
Asn His ValTyrTyr AlaLys ArgValLeuCys SerGln ProValSer
115 120 125
Ile Leu SerProAsn ThrLeu LysGluIleGlu AlaSer AlaGluVal
130 135 140
Ser Pro ThrThrMet ThrSer ProIleSerPro HisPhe ThrValThr
145 150 155 160
Glu Arg GlnThrPhe GlnPro TrpProGluArg LeuSer AsnAsnVal
165 170 175
Glu Glu LeuLeuGln SerSer LeuSerLeuGly GlyGln GluGlnAla
180 185 190
Pro Glu HisLysGln GluGln GlyValGluHis ArgGln GluProThr
195 200 205
Gln Glu HisLysGln GluGlu GlyGlnLysGln GluGlu GlnGluGlu
210 215 220
Glu GIn GluGluGlu GlyLys GlnGluGluGly GlnGly ThrLysGlu
225 230 235 240
Gly Arg GluAlaVal SerGln LeuGlnThrAsp SerGlu ProLysPhe
245 250 255
His Ser GluSerLeu SerSer AsnProSerSer PheAla ProArgVal
260 265 270
Arg Glu ValGluSer ThrPro MetIleMetGlu AsnIle GlnGluLeu
275 280 285
Ile Arg SerAlaGln GluIle AspGluMetAsn GluIle TyrAspGlu
290 295 300
Asn Ser TyrTrpArg AsnGln AsnProGlySer LeuLeu GlnLeuPro
305 310 315 320
His Thr GluAlaLeu LeuVal LeuCysTyrSer IleVal GluAsnThr
325 330 335
Cys Ile IleThrPro ThrAla LysAlaTrpLys TyrMet GluGluGlu
340 345 350
Ile Leu GlyPheGly LysSer ValCysAspSer LeuGly ArgArgHis
355 360 365
Met Ser ThrCysAla LeuCys AspPheCysSer LeuLys LeuGluGln
86
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
370 375 380
Cys HisSer AlaSerLeu GlnArgGln GlnCysAsp ThrSerHis
Glu
385 390 395 400
Lys ThrPro ValSerPro LeuLeuAla SerGlnSer LeuSerIle
Phe
405 410 415
Gly AsnGln Gly5erPro GluSerGly ArgPheTyr GlyLeuAsp
Val
420 425 430
Leu TyrGly LeuHisMet AspPheTrp CysAlaArg LeuAlaThr
Gly
435 440 445
15Lys GlyCys AspValArg ValSerGly TrpLeuGln ThrGluPhe
Glu
450 455 460
Leu SerPhe AspGlyAsp PheProThr LysIleCys AspThrAsp
Gln
465 470 475 480
Tyr IleGln ProAsnTyr CysSerPhe LysSerGln GlnCysLeu
Tyr
485 490 495
Met ArgAsn AsnArgLys ValSerArg MetArgCys LeuGlnAsn
Arg
500 505 510
Glu ThrTyr AlaLeuSer LeuAlaLys ValArgThr LeuCysPhe
Ser
515 520 525
3 Arg TrpSer GluPheSer ThrLeuThr LeuGlyGln PheGly
0 Gln
530 535 540
(2) INFORMATI ON FOR ID
SEQ N0:13:
3 (i) SEQUENCE STICS:
5 CHARACTERI
(A)LENGTH:72 2 se
ba pairs
(B)TYPE: acid
nucleic
{C)STRANDEDNESS: double
(D)TOPOLOGY: linear
40
(ii) MOLECULE cDNA
TYPE:
(xi) SEQUENCE
DESCRIPTION:
SEQ ID N0:13:
CGACCTTCCC AGCAATATGCATCTTGCACGTCTGGTCGGC TCCTGCTCCC TCCTTCTGCT60
ACTGGGGGCCCTGTCTGGATGGGCGGCCAGCGATGACCCC ATTGAGAAGG TCATTGAAGG120
GATCAACCGA GGGCTGAGCAATGCAGAGAGAGAGGTGGGC AAGGCCCTGG ATGGCATCAA180
CAGTGGAATC ACGCATGCCGGAAGGGAAGTGGAGAAGGTT TTCAACGGAC TTAGCAACAT240
87
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
GGGGAGCCAC ACCGGCAAGG AGTTGGACAA GGGCTCAACC ACGGCATGGA300
AGGCGTCCAG
CAAGGTTGCC CATGAGATCA ACCATGGTATTGGACAAGCAGGAAAGGAAG CAGAGAAGCT360
TGGCCATGGG GTCAACAACG CTGCTGGACAGGGCAACCATCAAAGCGGAT CTTCCAGCCA420
TCAAGGAGGG GCCACAACCA CGCCGTTAGCCTCTGGGGCCTCGGTCAACA CGCCTTTCAT480
CAACCTTCCC GCCCTGTGGA GGAGCGTCGCCAACATCATGCCCTAAACTG GCATCCGGCC540
TTGCTGGGAG AATAATGTCG CCGTTGTCACATCAGCTGACATGACCTGGA GGGGTTGGGG600
GTGGGGGACA GGTTTCTGAA ATCCCTGAAGGGGGTTGTACTGGGATTTGT GAATAAACTT660
GATACACTAA P,~~~AAAAAAA F~~,AAAAAAAAF,~~~AAAAAAAP~~.AAAAAAAA P,~~~AAAAAAA7
2
0
722
(2) INFORMATION FOR SEQ ID
N0:14:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 169 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
2 (D) TOPOLOGY: linear
5
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE
DESCRIPTION:
SEQ
ID
N0:14:
Met HisLeu AlaArgLeu ValGlySer CysSer LeuLeuLeu LeuLeu
1 s l0 15
Gly AlaLeu SerGlyTrp AlaAlaSer AspAsp ProIleGlu LysVal
20 25 30
Ile GluGly IleAsnArg GlyLeuSer AsnAla GluArgGlu ValGly
35 40 45
Lys AlaLeu AspGlyIle AsnSerGly IleThr HisAlaGly ArgGlu
50 55 60
Val GluLys ValPheAsn GlyLeuSer AsnMet GlySerHis ThrGly
65 70 75 80
Lys GluLeu AspLysGly ValGlnGly LeuAsn HisGlyMet AspLys
85 90 95
Val AlaHis GluIleAsn HisGlyIle GlyGln AlaGlyLys GluAla
100 105 110
Glu LysLeu GlyHisGly ValAsnAsn AlaAla GlyGlnGly AsnHis
gg
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
115 120 125
Gln Ser Gly Ser Ser Ser His Gln Gly Gly Ala Thr Thr
Thr Pro Leu
130 135 140
Ala Ser Gly Ala Ser Val Asn Thr Pro Phe Ile Asn Leu
Pro Ala Leu
145 150 155 160
Trp Arg Ser Val Ala Asn Ile Met Pro
165
(2) INFORMATION
FOR
SEQ
ID N0:15:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1240 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
2 (ii) MOLECULE TYPE: cDNA
O
2 (xi) SEQUENCE DESCRIPTION:
5 SEQ ID N0:15:
AATGGCTTTT CTTCCTTCCTGGGTTTGTGTACTAGTTGGT TCCTTTTCTGCTTCCTTAGC60
AGGGACTTCC AATCTCTCAGAGACAGAGCCCCCTCTGTGG AAGGAGAGTCCTGGTCAGCT120
30
CAGTGACTAC AGGGTGGAGAACAGCATGTACATTATTAAT CCCTGGGTATACCTTGAGAG180
AATGGGGATG TATAAAATCATATTGAATCAGACAGCCAGG TATTTTGCAAAATTTGCACC240
3 AGATAATGAA CAGAATATTTTATGGGGGTTGCCTCTGCAG TATGGCTGGCAATATAGGAC300
5
AGGCAGATTA GCTGATCCAACCCGAAGGACAAACTGTGGC TATGAATCTGGAGATCATAT360
GTGCATCTCT GTGGACAGTTGGTGGGCTGATTTGAATTAT TTTCTGTCTTCATTACCCTT420
40
TCTTGCTGCG GTTGATTCTGGTGTAATGGGGATATCATCA GACCAAGTCAGGCTTTTGCC480
CCCACCCAAG AATGAGAGGAAGTTTTGTTATGATGTTTCT AGCTGTCGTTCATCCTTCCC540
4 TGAGACAATG AACAAGTGGAACACCTTTTACCAGTATTTG CAGTCACCTTTTAGTAAGTT600
5
TGATGATCTG TTGAAGTACTTATGGGCTGCACACACTTCA ACCTTGGCAGATAATATCAA660
AAGTTTTGAA GACAGATATGATTATTATTCTAAAGCAGAA GCGCATTTTGAGAGAAGTTG720
50
GGTACTGGCT GTGGATCATTTAGCTGCAGTCCTCTTTCCT ACAACCTTGATTAGATCATA780
TAAGTTCCAG AAGGGCATGCCACCACGAATTCTTCTTAAT ACTGATGTAGCCCCTTTCAT840
55 CAGTGACTTT ACTGCTTTTCAGAATGTAGTCCTGGTTCTT CTAAATATGCTTGACAATGT900
89
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
GGATAAATCT ATAGGTTATC TTTGTACAGA AAAATCTAATGTATATAGAG ATCATTCGGA960
ATCTAGCTCT AGAAGTTATG GAAATAACTC CTGAAACATTTAACTTCAAA CTTCAGGAAA1020
TGATTAATGA ATTAAAAATG AAAAACTCGA ACTTGACAATCAGTAATTTC AAAAAATTAA1080
TGTCATCATG ACCATGTAGT TTATTCTTTC TGATATTTTTGATTTATGCT TATTTGTTAA1140
GATCTTGTAC ATGTATTAAA AACTTAAATT AAATGCATTCAAGTTAAAAA F,~~AAAAAAA.A1200
P,F~~AA.A.AAAA F,F~A.AAAAAAA A,F~~AAAAAAA 12
p,~I~~AAAAAAA 4
0
(2) INFORMATION FOR SEQ ID N0:16:
1 (i) SEQUENCE CHARACTERISTICS:
5
(A) LENGTH: 330 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE
DESCRIPTION:
SEQ
ID
N0:16:
Met Ala PheLeuPro SerTrp ValCysVal LeuValGly SerPheSer
1 5 10 15
Ala Ser LeuAlaGly ThrSer AsnLeuSer GluThrGlu ProProLeu
20 25 30
Trp Lys GluSerPro GlyGln LeuSerAsp TyrArgVal GluAsnSer
35 40 45
Met Tyr IleIleAsn ProTrp ValTyrLeu GluArgMet GlyMetTyr
50 55 60
Lys Ile IleLeuAsn GlnThr AlaArgTyr PheAlaLys PheAlaPro
65 70 75 80
Asp Asn GluGlnAsn IleLeu TrpGlyLeu ProLeuGln TyrGlyTrp
85 90 95
Gln Tyr ArgThrGly ArgLeu AlaAspPro ThrArgArg ThrAsnCys
100 105 110
Gly Tyr GluSerGly AspHis MetCysIle SerValAsp SerTrpTrp
5 115 120 125
0
Ala Asp LeuAsnTyr PheLeu SerSerLeu ProPheLeu AlaAlaVal
130 135 140
5 Asp Ser GlyVaiMet GlyIle SerSerAsp GlnValArg LeuLeuPro
5
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
145 150 155 160
Pro Pro AsnGlu ArgLysPhe CysTyrAsp ValSerSerCys Arg
Lys
165 170 175
Ser Ser ProGlu ThrMetAsn LysTrpAsn ThrPheTyrGln Tyr
Phe
180 185 190
Leu Gln ProPhe SerLysPhe AspAspLeu LeuLysTyrLeu Trp
Ser
195 200 205
Ala Ala ThrSer ThrLeuAla AspAsnIle LysSerPheGlu Asp
His
210 215 220
Arg Tyr TyrTyr SerLysAla G1uAlaHis PheGluArgSer Trp
Asp
225 230 235 240
Val Leu ValAsp HisLeuAla AlaValLeu PheProThrThr Leu
Ala
245 250 255
Ile Arg TyrLys PheGlnLys GlyMetPro ProArgIleLeu Leu
Ser
260 265 270
Asn Thr ValAla ProPheIle SerAspPhe ThrAlaPheGln Asn
Asp
275 280 285
Val Val ValLeu LeuAsnMet LeuAspAsn ValAspLysSer Ile
Leu
290 295 300
3 Gly Tyr CysThr GluLysSer AsnValTyr ArgAspHisSer Glu
0 Leu
305 310 315 320
Ser Ser ArgSer TyrGlyAsn AsnSer
Ser
325 330
(2) FORSEQ ID :
INFORMATION N0:17
(i) SEQUENCE TERISTICS:
CHARAC
(A) 61 pairs
LENGTH: base
22
(B) nucleicacid
TYPE:
(C) double
STRANDEDNESS:
(D) linear
TOPOLOGY:
(ii) MOLECULE cDNA
TYPE:
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:17:
GCAGCACCAG CCGTCTGCAG CTCCGGCCGC CACTTGCGCC TCTCCAGCCT CCGCAGGCCC 60
AACCGCCGCC AGCACCATGG CCAGCACCAT TTCCGCCTAC AAGGAGAAGA TGAAGGAGCT 120
GTCGGTGCTG TCGCTCATCT GCTCCTGCTT CTACACACAG CCGCACCCCA ATACCGTCTA 180
91
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
CCAGTACGGGGACATGGAGGTGAAGCAGCTGGACAAGCGGGCCTCAGGCCAGAGCTTCGA240
GGTCATCCTCAAGTCCCCTTCTGACCTGTCCCCAGAGAGCCCTATGCTCTCCTCCCCACC300
S CAAGAAGAAGGACACCTCCCTGGAGGAGCTGCAAAAGCGGCTGGAGGCAGCCGAGGAGCG360
GAGGAAGACGCAGGAGGCGCAGGTGCTGAAGCAGCTGGCGGAGCGGCGCGAGCACGAGCG420
CGAGGTGCTGCACAAGGCGCTGGAGGAGAATAACAACTTCAGCCGCCAGGCGGAGGAGAA480
GCTCAACTACAAGATGGAGCTCAGCAAGGAGATCCGCGAGGCACACCTGGCCGCACTGCG540
CGAGCGGCTGCGCGAGAAGGAGCTGCACGCGGCCGAGGTGCGCAGGAACAAGGAGCAGCG600
1 AGAAGAGATGTCGGGCTAAGGGCCCGGGACGGGCGGCGCCCATCCTGCGACAGAACACGT660
5
TCGGGTTTTGGTTTTGTTTCGTTCACCTCTGTCTAGATGCAACTTTTGTTCCTCCTCCCC720
CACCCCAGCCCCCAGCTTCATGCTTCTCTTCCGCACTCAGCCGCCCTGCCCTGTCCTCGT780
GGTGAGTCGCTGACCACGGCTTCCCCTGCAGGAGCCGCCGGGCGTGAGACGCGGTCCCTC840
GGTGCAGACACCAGGCCGGGCGCGGCTGGGTCCCCCGGGGGCCCTGTGAGAGAGGTGGCG900
2 GTGACCGTGGTAAACCCAGGGCGGTGGCGTGGGATCGCGGGTCCTTACGCTGGGCTGTCT960
5
GGTCAGCACGTGCAGGTCAGGGCAGGTCCTCTGAGCCGGCGCCCCTGGCCAGCAGGCGAG1020
GCTACAGTACCTGCTGTCTTTCCAGGGGGAAGGGGCTCCCCATGAGGGAGGGGCGACGGG1080
GGAGGGGGGTGATGGTGCCTGGGAGCCTGCGTGTGCAGCCGGTGCTTGTTGAACTGGCAG1140
GCGGGTGGGTGGGGGCTGCAGCTTTCCTTAATGTGGTTGCACAGGGGTCCTCTGAGACCA1200
3 CCTGGCGTGAGGTGGACACCCTGGGCCTTCCTGGAAGCCTGCAGTTGGGGGCCTGCCCTG1260
5
AGTCTGCTGGGGAGTGGGCATTCTCTGCCAGGGACCCATGAGCAGGCTGCATGGTCTAGA1320
GGTTGTGGGCAGCATGGACAGTCCCCCACTCAGAAGTGCAAGAGTTCCAAAGAGCCTCTG1380
GCCCAGGCCCCTCCCCACCAGGGCTTTGCAGATGTCCTTGAAAGACCCACCCTAGAGCCC1440
TTTGGAGTGCTGGCCCCTCCTGTGCCCTCTGCCCTGGTGGAAGCGGCAGCCACAAGTCCT1500
4 CCTCAGGGAGCCCCAAGGGGGATTTTGTGGGACCGCTGCCCACAGATCCAGGTGTTGGAA1560
5
GGGCAGCGGGTAAGGTTCCCAAGCCAGCCCCAACACCCTTCCCACTTGGCACCCAGAGGG1620
GGCTGTGGGTGGAGGCCTGACTCCAGGCCTCTCCTGCCCACACCCTCTGGGCTGAGTTCC1680
TTCTTTCCCTTGGACGCCCAGTGCTGGCCTTGGAGGACGGTCAGCTGGAGGATGGCGGTG1740
GGGGAGGCTGTCTTTGTACCACTGCAGCATCCCCCACTTCTCCACGGAAGCCCCATCCCA1800
S AAGCTGCTGCCTGGCCCCTTGCTGTAAAGTGTGAAGGGGGCGGCTGAGTTCTCTTAGGAC1860
5
92
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
CCAGAGCCAG GGCCCTCAAC TTCCATCCTG CGGGAGGCCT TGGCCGGGCA CTGCCAGTGT 1920
CTTCCAGAGC CACACCCAGG GACCACGGGA GGATCCTGAC CCCTGCAGGG CTCAGGGGTC 1980
AGCAGGGACC CACTGCCCCA TCTCCCTCTCCCCACCAAGACAGCCCCAGA AGGAGCAGCC2040
AGCTGGGATG GGAACCCAAG GCTGTCCACATCTGGCTTTTGTGGGACTCA GAAAGGGAAG2100
CAGAACTGAG GGCTGGGATA TTCCTCATGGTGGCAGCGCTCATAGCGAAA GCCTACTGTA2160
ATATGCACCC ATCTCATCCA CGTAGTAAAGTGAACTTAAAAATTCAATCA AATGAACAAT2220
TAAATAAACA CCTGTGTGTT TAAGAAAAAAP,AAAAAAAAAA 2261
(2) INFORMATION FOR SEQ
ID N0:18:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 180 amino acids
(B) TYPE. amino acid
2 (C) STRANDEDNESS:
O
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE N0:18:
DESCRIPTION:
SEQ
ID
3 Met AlaSer ThrIleSer AlaTyr LysGluLysMet LysGlu LeuSer
0
1 5 10 15
Val LeuSer LeuIleCys SerCys PheTyrThrGln ProHis ProAsn
20 25 30
Thr ValTyr GlnTyrGly AspMet GluValLysGln LeuAsp LysArg
35 40 45
Ala SerGly GlnSerPhe GluVal IleLeuLysSer ProSer AspLeu
50 55 60
Ser ProGlu SerProMet LeuSer SerProProLys LysLys AspThr
65 70 75 80
4 Ser LeuGlu GluLeuGln LysArg LeuGluAlaAla GluGlu ArgArg
5
85 90 95
Lys ThrGln GluAlaGln ValLeu LysGlnLeuAla GluArg ArgGlu
100 105 110
His GluArg GluValLeu HisLys AlaLeuGluGlu AsnAsn AsnPhe
115 120 125
Ser ArgGln AlaGluGlu LysLeu AsnTyrLysMet GluLeu SerLys
130 135 140
93
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Glu Ile Arg Glu Ala His Leu Ala Ala Leu Arg Glu Arg Leu Arg Glu
145 150 155 160
Lys Glu Leu His Ala Ala Glu Val Arg Arg Asn Lys Glu Gln Arg Glu
165 170 175
Glu Met Ser Gly
180
(2) INFORMATION FOR SEQ ID N0:19:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 3109 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID
N0:19:
2S GGCCAAAGAGGCCTAGGAGCCTCGTGGCTGCGTCACCGCC GCCCCCCCAGACAAGATGGA60
CACCGCGGAGGAAGACATATGTAGAGTGTGTCGGTCAGAA GGAACACCTGAGAAACCGCT120
TTATCATCCTTGTGTATGTACTGGCAGTATTAAGTTTATC CATCAAGAATGCTTAGTTCA180
ATGGCTGAAACACAGTCGAAAAGAATACTGTGAATTATGC AAGCACAGATTTGCTTTTAC240
ACCAATTTATTCTCCAGATATGCCTTCACGGCTTCCAATT CAAGACATATTTGCTGGACT300
GGTTACAAGTATTGGCACTGCAATACGATATTGGTTTCAT TATACACTTGTGGCCTTTGC360
ATGGTTGGGAGTTGTTCCTCTTACAGCATGCCGCATCTAC AAGTGCTTGTTTACTGGCTC420
CCGTGAGCTCACTACTGACGCTGCCCATTAGATATGCTGT CAACCGGAAAATTTGTTGGC480
AGATTGTTTGCAGGGTTGTTTTGTGGTGACGTGCACACTG TGTGCATTCATCAGCCTGGT540
GTGGTTGAGAGAGCAGATAGTCCATGGGGGAGCACCAATT TGGTTGGAGCATGCTGCCCC600
ACCGTTCAATGCTGCGGGGCATCACCAAAATGAGGCTCCA GCAGGAGGAAATGGTGCAGA660
AAATGTTGCTGCTGATCAGCCTGCTAACCCACCAGCTGAG AACGCAGTGGTGGGGGAAAA720
CCCTGATGCCCAGGATGACCAGGCAGAAGAGGAGGAGGAG GACAATGAGGAGGAAGATGA780
CGCTGGTGTGGAGGATGGCGGCAGATGCTAATAACGGAGC CCAGGATGACATGAATTGGA840
ATGCTTTAGAATGGGACCGAGCTGCTGAAGAGCTTACATG GGAAAGAATGCTAGGACTTG900
5 ATGGATCACTAGTTTTTCTGGAACATGTCTTCTGGGTGGT ATCTTTAAATACACTGTTCA960
5
94
CA 02294569 1999-12-17
PCT/US98/12516
WO
98/57976
TTCTTGTTTT TGCATTTTGC CCTTACCATA TTGGTCATTT CTCCCTTGTT 1020
GGTTTGGGAT
TTGAAGAACA CGTCCAAGCA TCTCATTTTG AAGGCCTAAT CACAACCATA 1080
GTTGGGTATA
TACTTTTAGC AATAACACTG ATAATTTGTC ATGGCTTGGC AACTCTTGTG 1140
AAATTTCATA
GATCTCGTCG CTTACTGGGA GTCTGCTATA TTGTTGTTAA GGTCTCTTTG 1200
TTAGTGGTGG
TAGAAATTGG AGTATTCCCT CTCATTTGTG GTTGGTGGCT GGATATCTGT 1260
TCCTTGGAAA
TGTTTGATGC TACTCTGAAA GATCGAGAAC TGAGCTTTCA GTCGGCTCCA 1320
GGTACTACCA
TGTTTCTGCA TTGGCTAGTG GGAATGGTAT ATGTCTTCTA CTTTGCCTCC 1380
TTCATTCTAT
1S TACTGAGAGA GGTACTTCGA CCTGGTGTCC TGTGGTTTCT AAGGAATTTG 1440
AATGATCCAG
ATTTCAATCC AGTACAGGAA ATGATCCATT TGCCAATATA TAGGCATCTC 1500
CGAAGATTTA
TTTTGTCAGT GATTGTCTTT GGCTCCATTG TCCTCCTGAT GCTTTGGCTT 1560
CCTATACGTA
TAATTAAGAG TGTGCTGCCT AATTTTCTTC CATACAATGT CATGCTCTAC 1620
AGTGATGCTC
CAGTGAGTGA ACTGTCCCTC GAGCTGCTTC TGCTTCAGGT TGTCTTGCCA 1680
GCATTACTCG
AACAGGGACA CACGAGGCAG TGGCTGAAGG GGCTGGTGCG AGCGTGGACT 1740
GTGACCGCCG
GATACTTGCT GGATCTTCAT TCTTATTTAT TGGGAGACCA GGAAGAAAAT 1800
GAAAACAGTG
CAAATCAACA AGTTAACAAT AATCAGCATG CTCGAAATAA CAACGCTATT 1860
CCTGTGGTGG
3
O
GAGAAGGCCT TCATGCAGCC CACCAAGCCA TACTCCAGCA GGGAGGGCCT 1920
GTTGGCTTTC
AGCCTTACCG CCGACCTTTA AATTTTCCAC TCAGGATATT TCTGTTGATT 1980
GTCTTCATGT
3 GTATAACATT ACTGATTGCC AGCCTCATCT GCCTTACTTT ACCAGTATTT 2040
5 GCTGGCCGTT
GGTTAATGTC GTTTTGGACG GGGACTGCCA AAATCCATGA GCTCTACACA 2100
GCTGCTTGTG
GTCTCTATGT TTGCTGGCTA ACCATAAGGG CTGTGACGGT GATGGTGGCA 2160
TGGATGCCTC
40
AGGGACGCAG AGTGATCTTC CAGAAGGTTA AAGAGTGGTC TCTCATGATC 2220
ATGAAGACTT
TGATAGTTGC GGTGCTGTTG GCTGGAGTTG TCCCTCTCCT TCTGGGGCTC 2280
CTGTTTGAGC
45 TGGTCATTGT GGCTCCCCTG AGGGTTCCCT TGGATCAGAC TCCTCTTTTT 2340
TATCCATGGC
AGGACTGGGC ACTTGGAGTC CTGCATGCCA AAATCATTGC AGCTATAACA 2400
TTGATGGGTC
CTCAGTGGTG GTTGAAAACT GTAATTGAAC AGGTTTACGC AAATGGCATC 2460
CGGAACATTG
SO
ACCTTCACTA TATTGTTCGT AAACTGGCAG CTCCCGTGAT CTCTGTGCTG 2520
TTGCTTTCCC
TGTGTGTACC TTATGTCATA GCTTCTGGTG TTGTTCCTTT ACTAGGTGTT 2580
ACTGCGGAAA
55 TGCAAAACTT AGTCCATCGG CGGATTTATC CATTTTTACT GATGGTCGTG 2640
GTATTGATGG
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
CAATTTTGTC CTTCCAAGTC CGCCAGTTTA AGCGCCTTTA TGAACATATT AAAAATGACA 2700
AGTACCTTGK GGGTCAASGA CTCGGTGAAC TACGAACGGA AATCTGGGCA AACAAGGCTC 2760
ATCTCCACCA CCTCCACAGT CATCCCAAGA TGTCTCAACA ACTTGACCTT2820
ATAAAGTAGT
CCCCTTTACA TGTCCTTTTT TGTGGACTTC GATTTTTCCC AGTGATCTCT2880
TCTCTTKGGA
CAGCGTKGTT TTTAAGTTAA AKGTATTKGA CAGCATTCAG AGAGCAGCGG2940
CTTGTGTTCT
TGTAAGATTC TGCTGTTCTC CCTGGATCTT TGCTGTCTGA GATTTGTATA3000
CTGACATKAC
TGKGTAAATA CAAGTTCCTT GATACCCTAA TAAACAGAAT GTGCATKGTA3060
AACCTTGGAT
CATCTTTAAA CAAAATGKAT ATTAATTTAT AAAAAAAAA 3109
TP~AAAP~P.A
(2) INFORMATION FOR SEQ ID N0:20:
(i) SEQUENCE CHARACTERISTICS:
2 (A) LENGTH: 750 amino acids
0
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
2 (ii) MOLECULE TYPE: protein
5
3 (xi) SEQUENCE DESCRIPTION: N0:20:
O SEQ
ID
Met GlyGlu HisGlnPhe GlyTrp SerMetLeu ProHisArg SerMet
1 5 10 15
3 Leu ArgGly IleThrLys MetArg LeuGlnGln GluGluMet ValGln
5
20 25 30
Lys MetLeu LeuLeuIle SerLeu LeuThrHis GlnLeuArg ThrGln
35 40 45
40
Trp TrpGly LysThrLeu MetPro ArgMetThr ArgGlnLys ArgArg
50 55 60
Arg ArgThr MetArgArg LysMet ThrLeuVal TrpArgMet AlaAla
45 65 70 75 80
Asp AlaAsn AsnGlyAla GlnAsp AspMetAsn TrpAsnAla LeuGlu
g5 90 95
5 Trp AspArg AlaAlaGlu GluLeu ThrTrpGlu ArgMetLeu GlyLeu
0
100 105 110
Asp GlySer LeuValPhe LeuGlu HisValPhe TrpValVal SerLeu
115 120 125
55
96
CA 02294569 1999-12-17
PCTIUS98/12516
WO 98/57976
Asn Thr Leu Phe Ile Leu Val Phe Ala Phe Cys Pro Tyr His Ile Gly
130 135 140
His Phe Ser Leu Val Gly Leu Gly Phe Glu Glu His Val Gln Ala Ser
145 150 155 160
His Phe Glu Gly Leu Ile Thr Thr Ile Val Gly Tyr Ile Leu Leu Ala
165 170 175
Ile Thr Leu Ile Ile Cys His Gly Leu Ala Thr Leu Val Lys Phe His
180 185 190
Arg Ser Arg Arg Leu Leu Gly Val Cys Tyr Ile Val Val Lys Val Ser
195 200 205
Leu Leu Val Val Val Glu Ile Gly Val Phe Pro Leu Ile Cys Gly Trp
210 215 220
Trp Leu Asp Ile Cys Ser Leu Glu Met Phe Asp Ala Thr Leu Lys Asp
2 0 225 230 235 240
Arg Glu Leu Ser Phe Gln Ser Ala Pro Gly Thr Thr Met Phe Leu His
245 250 255
2 5 Trp Leu Val Gly Met Val Tyr Val Phe Tyr Phe Ala Ser Phe Ile Leu
260 265 270
Leu Leu Arg Glu Val Leu Arg Pro Gly Val Leu Trp Phe Leu Arg Asn
275 280 285
Leu Asn Asp Pro Asp Phe Asn Pro Val Gln Glu Met Ile His Leu Pro
290 295 300
Ile Tyr Arg His Leu Arg Arg Phe Ile Leu Ser Val Ile Val Phe Gly
3 5 305 310 315 320
Ser Ile Val Leu Leu Met Leu Trp Leu Pro Ile Arg Ile Ile Lys Ser
325 330 335
4 0 Val Leu Pro Asn Phe Leu Pro Tyr Asn Val Met Leu Tyr Ser Asp Ala
340 345 350
Pro Val Ser Glu Leu Ser Leu Glu Leu Leu Leu Leu Gln Val Val Leu
355 360 365
Pro Ala Leu Leu Glu Gln Gly His Thr Arg Gln Trp Leu Lys Gly Leu
370 375 380
Val Arg Ala Trp Thr Val Thr Ala Gly Tyr Leu Leu Asp Leu His Ser
385 390 395 400
Tyr Leu Leu Gly Asp Gln Glu Glu Asn Glu Asn Ser Ala Asn Gln Gln
405 410 415
Val Asn Asn Asn Gln His Ala Arg Asn Asn Asn Ala Ile Pro Val Val
97
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
420 425 430
Gly Glu GlyLeuHis Ala His AlaIle LeuGlnGln GlyGly
Ala Gln
435 440 445
Pro Val GlyPheGln ProTyrArg ArgProLeu AsnPhePro LeuArg
450 455 460
Ile Phe LeuLeuIle ValPheMet CysIleThr LeuLeuIle AlaSer
465 470 475 480
Leu Ile CysLeuThr LeuProVal PheAlaGly ArgTrpLeu MetSer
485 490 495
Phe Trp ThrGlyThr AlaLysIle HisGluLeu TyrThrAla AlaCys
500 505 510
Gly Leu TyrValCys TrpLeuThr IleArgAla ValThrVal MetVal
515 520 525
Ala Trp MetProGln GlyArgArg ValIlePhe GlnLysVal LysGlu
530 535 540
Trp Ser LeuMetIle MetLysThr LeuIleVal AlaValLeu LeuAla
2 545 550 555 560
5
Gly Val ValProLeu LeuLeuGly LeuLeuPhe GluLeuVal IleVal
565 570 575
3 Ala Pro LeuArgVal ProLeuAsp GlnThrPro LeuPheTyr ProTrp
0
580 585 590
Gln Asp TrpAlaLeu GlyValLeu HisAlaLys IleIleAla AlaIle
595 600 605
35
Thr Leu MetGlyPro GlnTrpTrp LeuLysThr ValIleGlu GlnVal
610 615 620
Tyr Ala AsnGlyIle ArgAsnIle AspLeuHis TyrIleVal ArgLys
4 625 630 635 640
0
Leu Ala AlaProVal IleSerVal LeuLeuLeu SerLeuCys ValPro
645 650 655
4 Tyr Val IleAlaSer GlyValVal ProLeuLeu GlyValThr AlaGlu
5
660 665 670
Met Gln Asn Val HisArg IleTyr PheLeu MetVal
Leu Arg Pro Leu
675 680 685
50
Val Val Leu Ala Leu Phe Arg Arg
Met Ile Ser Gln Gln
Val Phe
Lys
690 695 700
Leu Ile Asn
Tyr Lys Asp
Glu Lys
His Tyr
Leu
Xaa
Gly
Gln
Xaa
Leu
55 705 710 715 720
98
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
Gly Glu Leu Arg Thr Glu Ile Trp Ala Asn Lys Ala His Leu His His
725 730 735
Leu His Ser His Pro Lys Asn Lys Val Val Val Ser Thr Thr
740 745 750
(2) INFORMATION FOR SEQ ID N0:21:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:21:
TNTTTGAAGT TTCTCCCTCT CATTCTGAG 29
2 5 (2) INFORMATION FOR SEQ ID N0:22:
{i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
3 0 (C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:22:
GNTTCTCCAC GTAGTTGGTT TTCCTCAGT 29
(2) INFORMATION FOR SEQ ID N0:23:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
99
CA 02294569 1999-12-17
WO 98/57976 PCT/US98112516
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:23:
CNACATGACG TGAGCTGGTG ATCCATGAA 29
S (2) INFORMATION FOR SEQ ID N0:24:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE. nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY. linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:24:
ANTTGGGCTC TGCCGTCCAG AAAGGTTTG 29
(2) INFORMATION FOR SEQ ID N0:25:
2 5 (i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:25:
GNAGCTACGC GGACTTGCAG AGGTTTTAT 29
(2) INFORMATION FOR SEQ ID N0:26:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
4 S (B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
5 0 (A) DESCRIPTION: /desc = "oligonucleotide"
5 5 (xi) SEQUENCE DESCRIPTION: SEQ ID N0:26:
100
CA 02294569 1999-12-17
W O 98/57976 PCT/US98/1251 G
TNGGTGAGAG AATAGAGACT GGCTGGGAA 29
(2) INFORMATION FOR SEQ ID N0:27:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:27:
ANGAGCCGAC CAGACGTGCA AGATGCATA 29
(2) INFORMATION FOR SEQ ID N0:28:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
2 5 (B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
3 0 (A) DESCRIPTION: /desc = "oligonucleotide"
3 5 (xi) SEQUENCE DESCRIPTION: SEQ ID N0:28:
ANCTGACCAG GACTCTCCTT CCACAGAGG 29
(2) INFORMATION FOR SEQ ID N0:29:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
4 5 (D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:29:
TNTAGGCGGA AATGGTGCTG GCCATGGTG 29
lUl
CA 02294569 1999-12-17
WO 98/57976 PCT/US98/12516
(2) INFORMATION FOR SEQ ID N0:30:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:30:
ANATATCCAG CCACCAACCA CAAATGAGA 29
102