Note: Descriptions are shown in the official language in which they were submitted.
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
SECRETED PROTEINS AND POLYNUCLEOTIDES ENCODING THEM
- This application is a continuation-in-part of application Ser. No.
08/887,195, filed
July 2,1997.
FIELD OF THE INVENTION
The present invention provides novel polynucleotides and proteins encoded by
such polynucleotides, along with therapeutic, diagnostic and research
utilities for these
polynucleotides and proteins.
BACKGROUND OF THE IIWENTION
Technology aimed at the discovery of protein factors (including e.g.,
cytokines,
such as lymphokines, interferons, CSFs and interleukins) has matured rapidly
over the
past decade. The now routine hybridization cloning and expression cloning
techniques
clone novel polynucleotides "directly" in the sense that they rely on
information directly
related to the discovered protein (i.e., partial DNA/amino acid sequence of
the protein
in the case of hybridization cloning; activity of the protein in the case of
expression
2 0 cloning). More recent "indirect" cloning techniques such as signal
sequence cloning, which
isolates DNA sequences based on the presence of a now well-recognized
secretory leader
sequence motif, as well as various PCR-based or low stringency hybridization
cloning
techniques, have advanced the state of the art by making available large
numbers of
DNA/amino acid sequences for proteins that are known to have biological
activity by
2 5 virtue of their secreted nature in the case of leader sequence cloning, or
by virtue of the
cell or tissue source in the case of PCR-based techniques. It is to these
proteins and the
polynucleotides encoding them that the present invention is directed.
35
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
SUMMARY OF THE INVENTION
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
- (a) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:1;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:1 from nucleotide 516 to nucleotide 797;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:1 from nucleotide 606 to nucleotide 797;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:1 from nucleotide 1 to nucleotide 773;
(e) a poiynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone bf228_14 deposited under accession
number ATCC 98482;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone bf228_14 deposited under accession number ATCC 98482;
(g) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone bf228_14 deposited under accession number
ATCC 98482;
2 0 (h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone bf228_14 deposited under accession number ATCC 98482;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:2;
(j) a polynucleotide encoding a protein comprising a fragment of the
2 5 amino acid sequence of SEQ ID N0:2 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
3 0 (m) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
NO:1 from nucleotide 516 to nucleotide 797; the nucleotide sequence of SEQ ID
NO:1 from
nucleotide 606 to nucleotide 797; the nucleotide sequence of SEQ ID NO:1 from
CA 02295212 1999-12-31
WO 99/01466 PGT/US98/13813
nucleotide 1 to nucleotide 773; the nucleotide sequence of the full-length
protein coding
sequence of clone bf228_14 deposited under accession number ATCC 98482; or the
nucleotide sequence of the mature protein coding sequence of clone bf228_14
deposited
' under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone bf228_14 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:2 from amino acid 1 to amino
acid 86.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID NO:1.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:2;
(b) the amino acid sequence of SEQ ID N0:2 from amino acid 1 to
amino acid 86;
(c) fragments of the amino acid sequence of SEQ ID N0:2; and
(d) the amino acid sequence encoded by the cDNA insert of clone
bf228_14 deposited under accession number ATCC 98482;
2 0 the protein being substantially free from other mammalian proteins.
Preferably such
protein comprises the amino acid sequence of SEQ ID N0:2 or the amino acid
sequence
of SEQ ID N0:2 from amino acid 1 to amino acid 86.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
2 5 (a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:3;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:3 from nucleotide 137 to nucleotide 1240;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
3 0 N0:3 from nucleotide 1 to nucleotide 1153;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone bg249_1 deposited under accession
number ATCC 98482;
3
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(e) a poiynucleotide encoding the full-length protein encoded by the
cDNA insert of clone bg249_1 deposited under accession number ATCC 98482;
(f} a polynucleotide comprising the nucleotide sequence of the mature
_ protein coding sequence of clone bg249_1 deposited under accession number
ATCC 98482;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone bg249_1 deposited under accession number ATCC 98482;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:4;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:4 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucieotides specified in (a)-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:3 from nucleotide 137 to nucleotide 1240; the nucleotide sequence of SEQ ID
N0:3
2 0 from nucleotide 1 to nucleotide 1153; the nucleotide sequence of the full-
length protein
coding sequence of clone bg249_1 deposited under accession number ATCC 98482;
or the
nucleotide sequence of the mature protein coding sequence of clone bg249_1
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
2 5 clone bg249_1 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:4 from amino acid 1 to amino
acid 339.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:3.
3 0 In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:4;
4
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
{b) the amino acid sequence of SEQ ID N0:4 from amino acid 1 to
amino acid 339;
(c) fragments of the amino acid sequence of SEQ ID N0:4; and
' _ (d) the amino acid sequence encoded by the cDNA insert of clone
bg249_1 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:4 or the amino acid
sequence
of SEQ ID N0:4 from amino acid 1 to amino acid 339.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:5 from nucleotide 26 to nucleotide 301;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5 from nucleotide 104 to nucleotide 301;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5 from nucleotide 1 to nucleotide 119;
(e) a polynucleotide comprising the nucleotide sequence of the full-
2 0 length protein coding sequence of clone bv286_1 deposited under accession
number ATCC 98482;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone bv286_1 deposited under accession number ATCC 98482;
(g) a polynucleotide comprising the nucleotide sequence of the mature
2 5 protein coding sequence of clone bv286_1 deposited under accession number
ATCC 98482;
(h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone bv286_1 deposited under accession number ATCC 98482;
(i) a polynucleotide encoding a protein comprising the amino acid
3 0 sequence of SEQ ID N0:6;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:6 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
5
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or {j) above ; and
(m) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:5 from nucleotide 26 to nucleotide 301; the nucleotide sequence of SEQ ID
NO:S from
nucleotide 104 to nucleotide 301; the nucleotide sequence of SEQ ID N0:5 from
nucleotide 1 to nucleotide 119; the nucleotide sequence of the full-length
protein coding
sequence of clone bv286_1 deposited under accession number ATCC 98482; or the
nucleotide sequence of the mature protein coding sequence of clone bv286_1
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone bv286_1 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
1 S comprising the amino acid sequence of SEQ ID N0:6 from amino acid 1 to
amino acid 31.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:5.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
2 0 consisting of:
(a) the amino acid sequence of SEQ ID N0:6;
(b) the amino acid sequence of SEQ ID N0:6 from amino acid 1 to
amino acid 31;
(c) fragments of the amino acid sequence of SEQ ID N0:6; and
2 5 (d) the amino acid sequence encoded by the cDNA insert of clone
bv286_1 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:6 or the amino acid
sequence
of SEQ ID N0:6 from amino acid 1 to amino acid 31.
3 0 1n one embodiment, the present invention provides a composition comprising
an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7;
6
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 663 to nucleotide 755;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
' N0:7 from nucleotide 1 to nucleotide 850;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone co36_1 deposited under accession
number
ATCC 98482;
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone co36_1 deposited under accession number ATCC 98482;
(f) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone co36_1 deposited under accession number ATCC
98482;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone co36_1 deposited under accession number ATCC 98482;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:8;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:8 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
2 0 (a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (ar(i).
2 5 Preferably, such polynucleotide comprises the nucleotide sequence of SEQ
ID
N0:7 from nucleotide 663 to nucleotide 755; the nucleotide sequence of SEQ ID
N0:7
from nucleotide 1 to nucleotide 850; the nucleotide sequence of the full-
length protein
coding sequence of clone co36_1 deposited under accession number ATCC 98482;
or the
nucleotide sequence of the mature protein coding sequence of clone co36_1
deposited
3 0 under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone co36_1 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:8 from amino acid 1 to amino
acid 22.
7
CA 02295212 1999-12-31
WO 99101466 PCT/US98/13813
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:7.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:8;
(b) the amino acid sequence of SEQ ID NO:B from amino acid 1 to
amino acid 22;
(c) fragments of the amino acid sequence of SEQ ID N0:8; and
(d) the amino acid sequence encoded by the cDNA insert of clone
co36_1 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:8 or the amino acid
sequence
of SEQ ID N0:8 from amino acid 1 to amino acid 22.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
2 0 N0:9 from nucleotide 127 to nucleotide 783;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 172 to nucleotide 783;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 7 to nucleotide 462;
2 5 (e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone cp116_1 deposited under accession
number ATCC 98482;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone cp116_1 deposited under accession number ATCC 98482;
3 0 (g) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone cp116_1 deposited under accession number
ATCC 98482;
(h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone cp116_1 deposited under accession number ATCC 98482;
8
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID NO:10;
(j) a polynucleotide encoding a protein comprising a fragment of the
' _ amino acid sequence of SEQ ID NO:10 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a poiynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:9 from nucleotide 127 to nucleotide 783; the nucleotide sequence of SEQ ID
N0:9 from
nucleotide 172 to nucleotide 783; the nucleotide sequence of SEQ ID N0:9 from
nucleotide 7 to nucleotide 462; the nucleotide sequence of the full-length
protein coding
sequence of clone cp116_1 deposited under accession number ATCC 98482; or the
nucleotide sequence of the mature protein coding sequence of clone cp116_1
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone cp116_1 deposited under accession number ATCC 98482. In yet other
preferred
2 0 embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID NO:10 from amino acid 1 to amino
acid
112.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:9.
2 5 In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:10;
(b) the amino acid sequence of SEQ ID N0:10 from amino acid 1 to
3 0 amino acid 112;
(c) fragments of the amino acid sequence of SEQ ID NO:10; and
(d) the amino acid sequence encoded by the cDNA insert of clone
cp116_1 deposited under accession number ATCC 98482;
9
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:10 or the amino acid
sequence
of SEQ ID NO:10 from amino acid 1 to amino acid 112.
- In one embodiment, the present invention provides a composition comprising
an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:12;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:12 from nucleotide 231 to nucleotide 533;
(c) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone cw1195 2 deposited under accession
number ATCC 98482;
(d) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone cw1195_2 deposited under accession number ATCC 98482;
(e) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone cw1195_2 deposited under accession number
ATCC 98482;
{f) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone cw1195_2 deposited under accession number ATCC 98482;
2 0 (g) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:13;
(h) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:13 having biological activity;
(i) a polynucleotide which is an allelic variant of a polynucleotide of
2 5 (a)-(f) above;
{j) a polynucleotide which encodes a species homologue of the protein
of (g) or (h) above ; and
(k) a polynucleotide capable of hybridizing under stringent conditions
to any one of the poiynucleotides specified in (a)-(h).
3 0 Preferably, such polynucleotide comprises the nucleotide sequence of SEQ
ID
N0:12 from nucleotide 231 to nucleotide 533; the nucleotide sequence of the
full-length
protein coding sequence of clone cw1195_2 deposited under accession number
ATCC
98482; or the nucleotide sequence of the mature protein coding sequence of
clone
cw1195_2 deposited under accession number ATCC 98482. In other preferred
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
embodiments, the polynucleotide encodes the full-length or mature protein
encoded by
the cDNA insert of clone cw1195_2 deposited under accession number ATCC 98482.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:12, SEQ ID NO:11 or SEQ ID N0:14 .
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:13;
(b) fragments of the amino acid sequence of SEQ ID N0:13; and
(c) the amino acid sequence encoded by the cDNA insert of clone
cw1195 2 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:13.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15 from nucleotide 645 to nucleotide 782;
2 0 (c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:15 from nucleotide 10 to nucleotide 773;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone fhl3_10 deposited under accession
number ATCC 98482;
2 5 (e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone fhl3_10 deposited under accession number ATCC 98482;
(f) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone fhl3_10 deposited under accession number
ATCC 98482;
3 0 (g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone fhl3_10 deposited under accession number ATCC 98482;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:16;
CA 02295212 1999-12-31
WO 99/01466 PC1'/US98/13813
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:16 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a}-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:15 from nucleotide 645 to nucleotide 782; the nucleotide sequence of SEQ ID
N0:15
from nucleotide 10 to nucleotide 773; the nucleotide sequence of the full-
length protein
coding sequence of clone fhl3_IO deposited under accession number ATCC 98482;
or the
nucleotide sequence of the mature protein coding sequence of clone fhl3_10
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone fhl3_10 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:16 from amino acid 1 to amino
acid
43.
2 0 Other embodiments provide the gene corresponding to the cDNA sequence of
SEQ
ID N0:15.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
2 5 (a) the amino acid sequence of SEQ ID N0:16;
(b) the amino acid sequence of SEQ ID N0:16 from amino acid 1 to
amino acid 43;
(c) fragments of the amino acid sequence of SEQ ID N0:16; and
(d) the amino acid sequence encoded by the cDNA insert of clone
3 0 fhl3_10 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:16 or the amino acid
sequence
of SEQ ID N0:16 from amino acid 1 to amino acid 43.
12
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/138I3
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:I7;
(b) a polynudeotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 94 to nucleotide 216;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 160 to nucleotide 216;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:17 from nucleotide 20 to nucleotide 193;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone gc57_4 deposited under accession
number
ATCC 98482;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone gc57_4 deposited under accession number ATCC 98482;
(g) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone gc57_4 deposited under accession number ATCC
98482;
(h) a polynucleotide encoding the mature protein encoded by the
2 0 cDNA insert of clone gc57 4 deposited under accession number ATCC 98482;
(i) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:18;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:18 having biological activity;
2 5 (k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide capable of hybridizing under stringent conditions
3 0 to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:17 from nucleotide 94 to nucleotide 216; the nucleotide sequence of SEQ ID
N0:17
from nucleotide 160 to nucleotide 216; the nucleotide sequence of SEQ ID N0:17
from
nucleotide 20 to nucleotide 193; the nucleotide sequence of the full-length
protein coding
13
CA 02295212 1999-12-31
WO 99/01466 PCT/US98113813
sequence of clone gc57_4 deposited under accession number ATCC 98482; or the
nucleotide sequence of the mature protein coding sequence of clone gc57_4
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone gc57_4 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:18 from amino acid 1 to amino
acid
33.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:17.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:18;
(b) the amino acid sequence of SEQ ID N0:18 from amino acid 1 to
amino acid 33;
(c) fragments of the amino acid sequence of SEQ ID N0:18; and
(d) the amino acid sequence encoded by the cDNA insert of clone
gc57 4 deposited under accession number ATCC 98482;
2 0 the protein being substantially free from other mammalian proteins.
Preferably such
protein comprises the amino acid sequence of SEQ ID N0:18 or the amino acid
sequence
of SEQ ID N0:18 from amino acid 1 to amino acid 33.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
2 5 (a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:19 from nucleotide 2 to nucleotide 943;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
3 0 N0:19 from nucleotide 2 to nucleotide 670;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone h1165_3 deposited under accession
number ATCC 98482;
14
CA 02295212 1999-12-31
WO 99101466 PCT/US98/13813
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone h1165_3 deposited under accession number ATCC 98482;
(f) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone h1165_3 deposited under accession number
ATCC 98482;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone h1165_3 deposited under accession number ATCC 98482;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:20;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:20 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:19 from nucleotide 2 to nucleotide 943; the nucleotide sequence of SEQ ID
N0:19 from
2 0 nucleotide 2 to nucleotide 670; the nucleotide sequence of the full-length
protein coding
sequence of clone h1165_3 deposited under accession number ATCC 98482; or the
nucleotide sequence of the mature protein coding sequence of clone h1165_3
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
2 5 clone h1165 3 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:20 from amino acid 1 to amino
acid
223.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
3 0 ID N0:19.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:20;
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(b) the amino acid sequence of SEQ ID N0:20 from amino acid 1 to
amino acid 223;
(c) fragments of the amino acid sequence of SEQ ID N0:20; and
(d) the amino acid sequence encoded by the cDNA insert of clone
h1165_3 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino and sequence of SEQ ID N0:20 or the amino acid
sequence
of SEQ ID N0:20 from amino acid 1 to amino acid 223.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21 from nucleotide 1242 to nucleotide 1457;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21 from nucleotide 1326 to nucleotide 1457;
(d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21 from nucleotide 869 to nucleotide 1544;
(e) a polynucleotide comprising the nucleotide sequence of the full-
2 0 length protein coding sequence of clone hb752_1 deposited under accession
number ATCC 98482;
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone hb752_1 deposited under accession number ATCC 98482;
(g) a polynucleotide comprising the nucleotide sequence of the mature
2 5 protein coding sequence of clone hb752_1 deposited under accession number
ATCC 98482;
(h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone hb752_1 deposited under accession number ATCC 98482;
(i) a polynucleotide encoding a protein comprising the amino acid
3 0 sequence of SEQ ID N0:22;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:22 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
16
CA 02295212 1999-12-31
WO 99/01466 PGT/US98/13813
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:21 from nucleotide 1242 to nucleotide 1457; the nucleotide sequence of SEQ
ID N0:21
from nucleotide 1326 to nucleotide 1457; the nucleotide sequence of SEQ ID
N0:21 from
nucleotide 869 to nucleotide 1544; the nucleotide sequence of the full-length
protein
coding sequence of clone hb752_1 deposited under accession number ATCC 98482;
or the
nucleotide sequence of the mature protein coding sequence of clone hb752_1
deposited
under accession number ATCC 98482. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone hb752_1 deposited under accession number ATCC 98482. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:22 from amino acid 1 to amino
acid
69.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:21.
In other embodiments, the present invention provides a composition comprising
2 0 a protein, wherein said protein comprises an amino acid sequence selected
from the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:22;
(b) the amino acid sequence of SEQ ID N0:22 from amino acid 1 to
amino acid 69;
2 5 (c) fragments of the amino acid sequence of SEQ ID N0:22; and
(d) the amino acid sequence encoded by the cDNA insert of clone
hb752_1 deposited under accession number ATCC 98482;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:22 or the amino acid
sequence
3 0 of SEQ ID NO:22 from amino acid 1 to amino acid 69.
In certain preferred embodiments, the polynucleotide is operably linked to an
expression control sequence. The invention also provides a host cell,
including bacterial,
yeast, insect and mammalian cells, transformed with such polynucleotide
compositions.
Processes are also provided for producing a protein, which comprise:
17
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/138I3
(a) growing a culture of the host cell transformed with such
polynucleotide compositions in a suitable culture medium; and
(b) purifying the protein from the culture.
The protein produced according to such methods is also provided by the present
invention. Preferred embodiments include those in which the protein produced
by such
process is a mature form of the protein.
Protein compositions of the present invention may further comprise a
pharmaceutically acceptable carrier. Compositions comprising an antibody which
specifically reacts with such protein are also provided by the present
invention.
Methods are also provided for preventing, treating or ameliorating a medical
condition which comprises administering to a mammalian subject a
therapeutically
effective amount of a composition comprising a protein of the present
invention and a
pharmaceutically acceptable carrier.
BRIEF DESCRIPTION OF THE DRAWINGS
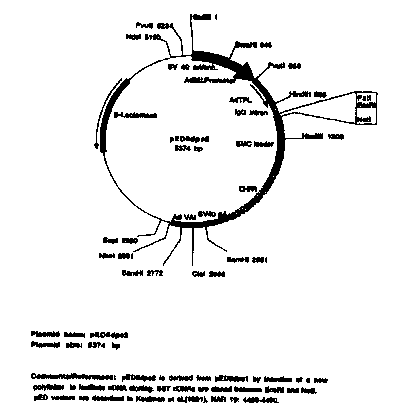
Fig. 1 is a schematic representation of the pED6 and pNOTs vectors used for
deposit of clones disclosed herein.
DETAILED DESCRIPTION
2 0 ISOLATED PROTEINS AND POLYNUCLEOTIDES
Nucleotide and amino acid sequences, as presently determined, are reported
below for each clone and protein disclosed in the present application. The
nucleotide
sequence of each clone can readily be determined by sequencing of the
deposited clone
in accordance with known methods. The predicted amino acid sequence (both full-
length
2 5 and mature) can then be determined from such nucleotide sequence. The
amino acid
sequence of the protein encoded by a particular clone can also be determined
by
expression of the clone in a suitable host cell, collecting the protein and
determining its
sequence. For each disclosed protein applicants have identified what they have
determined to be the reading frame best identifiable with sequence information
available
3 0 at the time of filing.
As used herein a "secreted" protein is one which, when expressed in a suitable
host
cell, is transported across or through a membrane, including transport as a
result of signal
sequences in its amino acid sequence. "Secreted" proteins include without
limitation
proteins secreted wholly (e.g., soluble proteins) or partially (e.g. ,
receptors) from the cell
18
CA 02295212 1999-12-31
WO 99101466 PCT/US98/13813
in which they are expressed. "Secreted" proteins also include without
limitation proteins
which are transported across the membrane of the endoplasmic reticulum.
Clone"bf228 14"
A polynucleotide of the present invention has been identified as clone
"bf228_14".
bf228_14 was isolated from a human fetal brain cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. bf228_14 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "bf228 14 protein').
The nucleotide sequence of bf228_14 as presently determined is reported in SEQ
ID NO:1. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the bf228_14 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:2. Amino acids 18 to 30 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 31, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
bf228_l4 should be approximately 1400 bp.
2 0 The nucleotide sequence disclosed herein for bf228_14 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. bf228_14 demonstrated at least some homology with
sequences
identified as AA069549 (zm52e03.s1 Stratagene fibroblast (#937212) Homo
sapiens cDNA
clone 529276 3'), H83278 (yq49h09.r1 Homo sapiens cDNA clone 199169 5'), and
N94898
2 5 (zb31b01.s1 Homo sapiens cDNA clone 305161 3' similar to contains Alu
repetitive
element;contains element MSR1 repetitive element). Based upon homology,
bf228_14
proteins and each homologous protein or peptide may share at least some
activity. The
nucleotide sequence of bf228_14 indicates that it may contain an Alu
repetitive element.
3 0 Clone "bg249 1 "
A polynucleotide of the present invention has been identified as clone
"bg249_1".
bg249_1 was isolated from a human adult brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
19
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
analysis of the amino acid sequence of the encoded protein. bg249_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"bg249_1 protein')
The nucleotide sequence of bg249_1 as presently determined is reported in SEQ
ID N0:3. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the bg249_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:4.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
bg249_1 should be approximately 2700 bp.
The nucleotide sequence disclosed herein for bg249_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. bg249_1 demonstrated at least some homology with
sequences
identified as AA151021 (z147c04.r1 Soares pregnant uterus NbHPU Homo sapiens
cDNA
clone 505062 5'), AA278781 (zs79a01.r1 Soares NbHTGBC Homo sapiens cDNA clone
703656 5'), 875099 (MDB1032R Mouse brain, Stratagene Mus musculus cDNA 5'end),
and
T06990 (EST04879 Homo sapiens cDNA clone HFBEB91). Based upon homology,
bg249_1
proteins and each homologous protein or peptide may share at least some
activity.
Clone"bv286 1"
2 0 A polynucleotide of the present invention has been identified as clone
"bv286_1".
bv286_1 was isolated from a human adult brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. bv286_1 is a full-
length clone,
2 5 including the entire coding sequence of a secreted protein (also referred
to herein as
"bv286_1 protein').
The nucleotide sequence of bv286_1 as presently determined is reported in SEQ
ID N0:5. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the bv286_l protein corresponding to the
foregoing
3 0 nucleotide sequence is reported in SEQ ID N0:6. Amino acids 14 to 26 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 27, or are a transmembrane domain.
The EcoRI/Notl restriction fragment obtainable from the deposit containing
clone
bv286_1 should be approximately 550 bp.
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
The nucleotide sequence disclosed herein for bv286_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. bv286_1 demonstrated at least some homology with
sequences
identified as AA132163 (z138c07.r1 Soares pregnant uterus NbHPU Homo sapiens
cDNA
clone 504204 5' similar to WP:F55A11.1 CE05943 EF HAND DOMAINS), AA552888
(nk57h08.s1 NCI_CGAP_Pr7 Homo sapiens cDNA clone IMAGE:1017663 similar to
WP:F55A11.1 CE05943 EF HAND DOMAINS), and H12316 (yj11d07.s1 Homo sapiens
cDNA clone 148429 3' similar to SP:JS0027 JS0027 PROBABLE CALCIUM-BINDING
PROTEIN). The predicted amino acid sequence disclosed herein for bv286_1 was
searched against the GenPept and GeneSeq amino acid sequence databases using
the
BLASTX search protocol. The predicted bv286_1 protein demonstrated at least
some
identity with sequences identified as L22647 (prostaglandin receptor ep1
subtype [Homo
sapiens]). Based upon homology, bv286_1 proteins and each homologous protein
or
peptide may share at least some activity. The nucleotide sequence of bv286_1
indicates
that it may contain an Alu repetitive element.
Clone "co36 1"
A polynucleotide of the present invention has been identified as clone
"co36_1".
co36_1 was isolated from a human adult brain cDNA library using methods which
are
2 0 selective for cDNAs encoding secreted proteins (see U.S. Pat. No.
5,536,637), or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. co36_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"co36_1 protein")
2 5 The nucleotide sequence of co36_1 as presently determined is reported in
SEQ ID
N0:7. What applicants presently believe to be the proper reading frame and the
predicted
amino acid sequence of the co36_1 protein corresponding to the foregoing
nucleotide
sequence is reported in SEQ ID NO:8.
The EcoRI/Notl restriction fragment obtainable from the deposit containing
clone
3 0 co36_1 should be approximately 3300 bp.
The nucleotide sequence disclosed herein for co36_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. No hits were found in the database.
21
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Clone "cp116 1"
A polynucleotide of the present invention has been identified as clone
"cp116_1".
cp116_1 was isolated from a human adult salivary gland cDNA library using
methods
which are selective for cDNAs encoding secreted proteins (see U.S. Pat. No.
5,536,637), or
was identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. cp116_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"cp116_1 protein").
The nucleotide sequence of cp116_1 as presently determined is reported in SEQ
ID N0:9. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the cp116_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID NO:10. Amino acids 3 to 15 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 16, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
cp116_1 should be approximately 1600 bp.
The nucleotide sequence disclosed herein for cp116_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. No hits were found in the database.
Clone "cw1195 2"
A polynucleotide of the present invention has been identified as clone
"cw1195_2".
cw1195 2 was isolated from a human fetal brain cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
2 5 identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. cw1195 2 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "cw1195_2 protein").
The nucleotide sequence of the 5' portion of cw1195 2 as presently determined
is
3 0 reported in SEQ ID NO:11. An additional internal nucleotide sequence from
cw1195 2
as presently determined is reported in SEQ ID N0:12. What applicants believe
is the
proper reading frame and the predicted amino acid sequence encoded by such
internal
sequence is reported in SEQ ID N0:13. Additional nucleotide sequence from the
3'
portion of cw1195 2, including the polyA tail, is reported in SEQ ID N0:14.
22
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
cw1195_2 should be approximately 3300 bp.
The nucleotide sequence disclosed herein for cw1195 2 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. cw1195 2 demonstrated at least some homology with
sequences
identified as AA205460 (zq66f07.s1 Stratagene neuroepithelium (#937231) Homo
sapiens
cDNA clone 646597 3') and AA362052 (EST71451 MCF7 cell line Homo sapiens cDNA
5'
end similar to EST containing Alu repeat). Based upon homology, cw1195 2
proteins and
each homologous protein or peptide may share at least some activity. The
nucleotide
sequence of cw1195 2 indicates that it may contain an Alu repetitive element.
Clone "fhl3 10"
A polynucleotide of the present invention has been identified as clone
"fhl3_10".
fhl3_10 was isolated from a human fetal brain cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. fhl3_10 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"fhl3_10 protein').
2 0 The nucleotide sequence of fhl3_10 as presently determined is reported in
SEQ ID
N0:15. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the fhl3_10 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:16.
The EcoRI /Notl restriction fragment obtainable from the deposit containing
clone
2 5 fhl3_10 should be approximately 1400 bp.
The nucleotide sequence disclosed herein for fhl3_10 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. fhl3_10 demonstrated at least some homology with
sequences
identified as J00089 (Human Alu family interspersed repeat; clone BLUR6) and
X00481
3 0 (Human non-alu family interspersed repeat). Based upon homology, fhl3_10
proteins
and each homologous protein or peptide may share at least some activity. The
nucleotide
sequence of fhl3_10 indicates that it may contain a repetitive element.
23
CA 02295212 1999-12-31
WO 99101466 PCT/US98/13813
Clone " c~; 57 4"
A polynucleotide of the present invention has been identified as clone
"gc57_4".
gc57_4 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. gc57 4 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"gc57_4 protein '}.
The nucleotide sequence of gc57 4 as presently determined is reported in SEQ
ID
N0:17. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the gc57_4 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:18. Amino acids 10 to 22 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 23, or are a transmembrane domain.
The EcoRI/Notl restriction fragment obtainable from the deposit containing
clone
gc57 4 should be approximately 1900 bp.
The nucleotide sequence disclosed herein for gc57 4 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. gc57_4 demonstrated at least some homology with
sequences
2 0 identified as AA095328 (13005.seq.F Fetal heart, Lambda ZAP Express Homo
sapiens
cDNA 5'), AA126440 (zk94e02.s1 Soares pregnant uterus NbHPU Homo sapiens cDNA
clone 490490 3'), and 282195 (Human DNA sequence from clone J274L71). Based
upon
homology, gc57 4 proteins and each homologous protein or peptide may share at
least
some activity. The nucleotide sequence of gc57_4 indicates that it may contain
an Alu
2 5 repetitive element.
Clone"h1165 3"
A polynucleotide of the present invention has been identified as clone
"h1165_3".
h1165 3 was isolated from a human adult blood (peripheral blood mononuclear
cells
3 0 treated with phytohemagglutinin and phorbol meristate acetate and mixed
lymphocyte
reaction) cDNA library using methods which are selective for cDNAs encoding
secreted
proteins (see U.S. Pat. No. 5,536,637), or was identified as encoding a
secreted or
transmembrane protein on the basis of computer analysis of the amino acid
sequence of
24
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
the encoded protein. h1165 3 is a full-length clone, including the entire
coding sequence
of a secreted protein (also referred to herein as "h1165_3 protein").
The nucleotide sequence of h1165_3 as presently determined is reported in SEQ
ID N0:19. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the h1165_3 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:20.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
h1165 3 should be approximately 1250 bp.
The nucleotide sequence disclosed herein for h1165 3 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. h1165 3 demonstrated at least some homology with
sequences
identified as AA173098 (zp31d03.r1 Stratagene neuroepithelium (#937231) Homo
sapiens
cDNA clone 611045 5' similar to contains element TAR1 repetitive element),
AA305139
(EST176159 Colon carcinoma (Caco-2) cell line II Homo sapiens cDNA 5' end),
AA426375
(zv54h02.s1 Scares testis NHT Homo Sapiens cDNA clone 757491 3'), and N72370
(yv38c11.r1 Homo sapiens cDNA clone 245012 5'). The predicted amino acid
sequence
disclosed herein for h1165_3 was searched against the GenPept and GeneSeq
amino acid
sequence databases using the BLASTX search protocol. The predicted h1165 3
protein
demonstrated at least some identity with sequences identified as U58758 (coded
for by C.
2 0 elegans cDNA yk83a5.3; coded for by C.elegans cDNA yk83a5.5
[Caenorhabditis
elegans]). Based upon homology, h1165 3 proteins and each homologous protein
or
peptide may share at least some activity.
Clone "hb752 1"
2 5 A polynucleotide of the present invention has been identified as clone
"hb752_1".
hb752_1 was isolated from a human fetal kidney cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. hb752_1 is a full-
length clone,
3 0 including the entire coding sequence of a secreted protein (also referred
to herein as
"hb752_1 protein').
The nucleotide sequence of hb752_1 as presently determined is reported in SEQ
ID N0:21. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the hb752_1 protein corresponding to the
foregoing
CA 02295212 1999-12-31
WO 99/0146b PCT/US98/13813
nucleotide sequence is reported in SEQ ID N0:22. Amino acids 16 to 28 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 29, or are a transmembrane domain.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
hb752_1 should be approximately 1800 bp.
The nucleotide sequence disclosed herein for hb752_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. hb752_1 demonstrated at least some homology with
sequences
identified as AA100979 (zm26f09.s1 Stratagene pancreas (#937208) Homo sapiens
cDNA
clone 526793 3'), AA490528 (aa51g11.s1 NCI_CGAP_GCBl Homo sapiens cDNA clone
824516 3'), H65670 (yr72g12.r1 Homo sapiens cDNA clone 210886 5'), H86790
(ys72c03.s1
Homo sapiens cDNA clone 220324 3'), N58917 (yy6lfll.sl Homo sapiens cDNA clone
278061 3'), and 243307 (H. sapiens partial cDNA sequence; clone c-18g09).
Based upon
homology, hb752_1 proteins and each homologous protein or peptide may share at
least
some activity.
D~osit of Clones
Clones bf228_14, bg249_l, bv286_l, co36_l, cp116_1, cw1195_2, fhl3_10, gc57_4,
h1165_3 and hb752_1 were deposited on July 2, 1997 with the American Type
Culture
2 0 Collection as an original deposit under the Budapest Treaty and were given
the accession
number ATCC 98482, from which each clone comprising a particular
polynucleotide is
obtainable. All restrictions on the availability to the public of the
deposited material will
be irrevocably removed upon the granting of the patent, except for the
requirements
specified in 37 C.F.R. ~ 1.808(b).
Each clone has been transfected into separate bacterial cells (E. toll) in
this
composite deposit. Each clone can be removed from the vector in which it was
deposited
by performing an EcoRI/NotI digestion (5' site, EcoRI; 3' site, NotI) to
produce the
appropriate fragment for such clone. Each clone was deposited in either the
pED6 or
pNOTs vector depicted in Fig. 1. The pED6dpc2 vector ("pED6") was derived from
3 0 pED6dpc1 by insertion of a new polylinker to facilitate cDNA cloning
(Kaufman et al.,
1991, Nucleic Acids Res. 19: 4485-4490); the pNOTs vector was derived from
pMT2
(Kaufman et al., 1989, Mol. Cell. Biol. 9: 946-958) by deletion of the DHFR
sequences,
insertion of a new polylinker, and insertion of the M13 origin of replication
in the CIaI site.
In some instances, the deposited clone can become "flipped" (i.e., in the
reverse
26
CA 02295212 1999-12-31
WO 99101466 PCT/US98/13813
orientation) in the deposited isolate. In such instances, the cDNA insert can
still be
isolated by digestion with EcoRI and NotI. However, NotI will then produce the
5' site
and EcoRI will produce the 3' site for placement of the cDNA in proper
orientation for
expression in a suitable vector. The cDNA may also be expressed from the
vectors in
which they were deposited.
Bacterial cells containing a particular clone can be obtained from the
composite
deposit as follows:
An oligonucleotide probe or probes should be designed to the sequence that is
known for that particular clone. This sequence can be derived from the
sequences
provided herein, or from a combination of those sequences. The sequence of the
oligonucleotide probe that was used to isolate each full-length clone is
identified below,
and should be most reliable in isolating the clone of interest.
Clone Probe ,, uence
bf228 14 SEQ ID N0:23
bg249_1 SEQ ID N0:24
bv286 1 SEQ ID N0:25
co36_1 SEQ ID N0:26
2 0 cp116_1 SEQ ID N0:27
cw1195 2 SEQ ID N0:28
fhl3 10 SEQ TD N0:29
gc57_4 SEQ ID N0:30
h1165_3 SEQ ID N0:31
2 5 hb752_1 SEQ ID N0:32
In the sequences listed above which include an N at position 2, that position
is occupied
in preferred probes/primers by a biotinylated phosphoaramidite residue rather
than a
nucleotide (such as , for example, that produced by use of biotin
phosphoramidite (1-
3 0 dimethoxytrityloxy-2-(N-biotinyl-4-aminobutyl)-propyl-3-O-(2-cyanoethyl)-
(N,N-
diisopropyl)-phosphoramadite) (Glen Research, cat. no. 10-1953)).
The design of the oligonucleotide probe should preferably follow these
parameters:
27
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(a) It should be designed to an area of the sequence which has the fewest
ambiguous bases ("N's'"}, if any;
(b) It should be designed to have a Tm of approx. 80 ° C (assuming
2° for each
A or T and 4 degrees for each G or C).
The oligonucleotide should preferably be labeled with g-32P ATP (specific
activity 6000
Ci/mmole) and T4 polynucleotide kinase using commonly employed techniques for
labeling oligonucleotides. Other labeling techniques can also be used.
Unincorporated
label should preferably be removed by gel filtration chromatography or other
established
methods. The amount of radioactivity incorporated into the probe should be
quantitated
by measurement in a scintillation counter. Preferably, specific activity of
the resulting
probe should be approximately 4e+6 dpm/pmole.
The bacterial culture containing the pool of full-length clones should
preferably
be thawed and 100 }xl of the stock used to inoculate a sterile culture flask
containing 25 ml
of sterile L-broth containing ampicillin at 100 ug/ml. The culture should
preferably be
grown to saturation at 37°C, and the saturated culture should
preferably be diluted in
fresh L-broth. Aliquots of these dilutions should preferably be plated to
determine the
dilution and volume which will yield approximately 5000 distinct and well-
separated
colonies on solid bacteriological media containing L-broth containing
ampicillin at 100
Ilg/mi and agar at 1.5% in a 150 mm petri dish when grown overnight at
37°C. Other
2 0 known methods of obtaining distinct, well-separated colonies can also be
employed.
Standard colony hybridization procedures should then be used to transfer the
colonies to nitrocellulose filters and lyse, denature and bake them.
The filter is then preferably incubated at 65°C for 1 hour with gentle
agitation in
6X SSC (20X stock is 175.3 g NaCl/liter, 88.2 g Na citrate/liter, adjusted to
pH 7.0 with
2 5 NaOH) containing 0.5% SDS,100 ug/ml of yeast RNA, and 10 mM EDTA
(approximately
10 mL per 150 mm filter). Preferably, the probe is then added to the
hybridization mix at
a concentration greater than or equal to le+6 dpm/mL. The filter is then
preferably
incubated at 65°C with gentle agitation overnight. The filter is then
preferably washed in
500 mL of 2X SSC/0.5% SDS at room temperature without agitation, preferably
followed
3 0 by 500 mL of 2X SSC/0.1% SDS at room temperature with gentle shaking for
15 minutes.
A third wash with 0.1X SSC/0.5% SDS at 65°C for 30 minutes to 1 hour is
optional. The
filter is then preferably dried and subjected to autoradiography for
sufficient time to
visualize the positives on the X-ray film. Other known hybridization methods
can also
be employed.
28
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
The positive colonies axe picked, grown in culture, and plasmid DNA isolated
using standard procedures. The clones can then be verified by restriction
analysis,
hybridization analysis, or DNA sequencing.
Fragments of the proteins of the present invention which are capable of
exhibiting
biological activity are also encompassed by the present invention. Fragments
of the
protein may be in linear form or they may be cyclized using known methods, for
example,
as described in H.U. Saragovi, et al., Bio/Technology ,~, 773-778 (1992) and
in R.S.
McDowell, et al., J. Amer. Chem. Soc. ~4 9245-9253 (1992), both of which are
incorporated
herein by reference. Such fragments may be fused to carrier molecules such as
immunoglobulins for many purposes, including increasing the valency of protein
binding
sites. For example, fragments of the protein may be fused through "linker"
sequences to
the Fc portion of an immunoglobulin. For a bivalent form of the protein, such
a fusion
could be to the Fc portion of an IgG molecule. Other immunoglobulin isotypes
may also
be used to generate such fusions. For example, a protein - IgM fusion would
generate a
decavalent form of the protein of the invention.
The present invention also provides both full-length and mature forms of the
disclosed proteins. The full-length form of the such proteins is identified in
the sequence
listing by translation of the nucleotide sequence of each disclosed clone. The
mature form
of such protein may be obtained by expression of the disclosed full-length
polynucleotide
2 0 (preferably those deposited with ATCC) in a suitable mammalian cell or
other host cell.
The sequence of the mature form of the protein may also be determinable from
the amino
acid sequence of the full-length form.
The present invention also provides genes corresponding to the cDNA sequences
disclosed herein. "Corresponding genes" are the regions of the genome that are
2 5 transcribed to produce the mRNAs from which the cDNA sequences are derived
and any
contiguous regions of the genome necessary for the regulated expression of
such genes,
including but not limited to coding sequences, 5' and 3' untranslated regions,
alternatively
spliced exons, introns, promoters, enhancers, and silencer or suppressor
elements. The
corresponding genes can be isolated in accordance with known methods using the
3 0 sequence information disclosed herein. Such methods include the
preparation of probes
or primers from the disclosed sequence information for identification and/or
amplification of genes in appropriate genomic libraries or other sources of
genomic
materials.
29
CA 02295212 1999-12-31
WO 99/01466 PC1'/US98/13813
Where the protein of the present invention is membrane-bound (e.g., is a
receptor),
the present invention also provides for soluble forms of such protein. In such
forms part
or all of the intracellular and transmembrane domains of the protein are
deleted such that
the protein is fully secreted from the cell in which it is expressed. The
intracellular and
transmembrane domains of proteins of the invention can be identified in
accordance with
known techniques for determination of such domains from sequence information.
Proteins and protein fragments of the present invention include proteins with
amino acid sequence lengths that are at least 25%(more preferably at least
50%, and most
preferably at least 75%) of the length of a disclosed protein and have at
least 60% sequence
identity (more preferably, at least 75% identity; most preferably at least 90%
or 95%
identity) with that disclosed protein, where sequence identity is determined
by comparing
the amino acid sequences of the proteins when aligned so as to maximize
overlap and
identity while minimizing sequence gaps. Also included in the present
invention are
proteins and protein fragments that contain a segment preferably comprising 8
or more
(more preferably 20 or more, most preferably 30 or more) contiguous amino
acids that
shares at least 75% sequence identity (more preferably, at least 85% identity;
most
preferably at least 95% identity) with any such segment of any of the
disclosed proteins.
Species homologs of the disclosed polynucleotides and proteins are also
provided
by the present invention. Species homologs may be isolated and identified by
making
2 0 suitable probes or primers from the sequences provided herein and
screening a suitable
nucleic acid source from the desired species.
The invention also encompasses allelic variants of the disclosed
polynucleotides
or proteins; that is, naturally-occurring alternative forms of the isolated
poiynucleotide
which also encode proteins which are identical, homologous or related to that
encoded
2 5 by the polynucleotides .
The invention also includes polynucleotides with sequences complementary to
those of the polynucleotides disclosed herein.
The present invention also includes polynucleotides capable of hybridizing
under reduced stringency conditions, more preferably stringent conditions, and
most
3 0 preferably highly stringent conditions, to polynucleotides described
herein. Examples of
stringency conditions are shown in the table below: highly stringent
conditions are those
that are at least as stringent as, for example, conditions A-F; stringent
conditions are at
least as stringent as, for example, conditions G-L; and reduced stringency
conditions are
at least as stringent as, for example, conditions M-R.
CA 02295212 1999-12-31
WO 99/01466 PCT/I1S98/I3813
StringencyPolynucleotideHybridHybridization TemperatureWash
ConditionHybrid Lengthand Temperature
(bp); Buffer' and Buffer'
A DNA:DNA Z 50 65C; lxSSC -or- 65C; 0.3xSSC
42C; lxSSC, 50% formamide
B DNA:DNA <50 Ts*; IxSSC TB*; lxSSC
C DNA:RNA 2 50 67C; lxSSC-or- 67C;0.3xSSC
45C; lxSSC, 50% formamide
D DNA:RNA <50 Tp*; lxSSC Tp*; lxSSC
E RNA:RNA 2 50 70C; lxSSC -or- 70C; 0.3xSSC
50C; lxSSC, 50% formamide
F RNA:RNA <50 TF*; lxSSC TF*; lxSSC
G DNA:DNA 2 50 65C; 4xSSC -or- 65C; lxSSC
42C; 4xSSC, 50% formamide
H DNA:DNA <50 TH"; 4xSSC T"*; 4xSSC
I DNA:RNA s 50 67C; 4xSSC -or- 67C; lxSSC
45C; 4xSSC, 50% formamide
J DNA:RNA <50 T~*; 4xSSC T~*; 4xSSC
K RNA:RNA Z 50 70C; 4xSSC -or- 67C; lxSSC
50C; 4xSSC, SO% formamide
L RNA:RNA <50 T, *; 2xSSC T, *; 2xSSC
M DNA:DNA Z 50 SO C; 4xSSC -or- 50 C; 2xSSC
40C; 6xSSC, 50% formamide
N DNA:DNA <50 T~*; 6xSSC T"*; 6xSSC
O DNA:RNA x 50 55 C; 4xSSC -or- 55 C; 2xSSC
42C; 6xSSC, 50% formamide
P DNA:RNA <50 T,.*; 6xSSC T~*; 6xSSC
Q RNA:RNA 2 50 60C; 4xSSC -or- 60C; 2xSSC
45C; 6xSSC, 50% formamide
2 R RNA:RNA <50 TR*; 4xSSC TR*; 4xSSC
0
_: The hybrid length is that anticipated for the hybridized regions) of the
hybridizing polynucieotides. When
hybridizing a polynucleotide to a target polynucleotide of unknown sequence,
the hybrid length is assumed
to be that of the hybridizing polynucleotide. When polynucleotides of known
sequence are hybridized, the
2 5 hybrid length can be determined by aligning the sequences of the
polynucleotides and identifying the region
or regions of optimal sequence complementarity.
t: SSPE (lxSSPE is 0.15M NaCI, lOmM NaH~POa, and 1.25mM EDTA, pH 7.4) can be
substituted for SSC
(lxSSC -is 0.15M NaCI and l5mM sodium citrate) in the hybridization and wash
buffers; washes are
performed for 15 minutes after hybridization is complete.
3 0 "Te - TR: The hybridization temperature for hybrids anticipated to be less
than 50 base pairs in length should
be 5-10°C less than the melting temperature (Tm) of the hybrid, where
Tm is determined according to the
following equations. For hybrids less than 18 base pairs in length,
Tm(°C) = 2(# of A + T bases} + 4(# of G +
C bases). For hybrids between 18 and 49 base pairs in length, Tm(°C) =
81.5 + 16.6(log,o[Na']) + 0.41(%G+C)
(600/N), where N is the number of bases in the hybrid, and [Na'] is the
concentration of sodium ions in the
3 5 hybridization buffer ([Na'] for lxSSC = 0.165 M).
31
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Additional examples of stringency conditions for polynucleotide hybridization
are
provided in Sambrook, J., E.F. Fritsch, and T. Maniatis, 1989, Molecular
Cloning: A
Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor,
NY,
chapters 9 and 11, and Current Protocols in Molecular Biology,1995, F.M.
Ausubel et al., eds.,
John Wiley & Sons, Inc., sections 2.10 and 6.3-6.4, incorporated herein by
reference.
Preferably, each such hybridizing polynucleotide has a length that is at least
25%(more preferably at least 50%, and most preferably at least 75%) of the
length of the
polynucleotide of the present invention to which it hybridizes, and has at
least 60%
sequence identity (more preferably, at least 75% identity; most preferably at
least 90% or
95% identity) with the polynucleotide of the present invention to which it
hybridizes,
where sequence identity is determined by comparing the sequences of the
hybridizing
polynucleotides when aligned so as to maximize overlap and identity while
minimizing
sequence gaps.
The isolated polynucleotide of the invention may be operably linked to an
expression control sequence such as the pMT2 or pED expression vectors
disclosed in
Kaufman et al., Nucleic Acids Res. 19. 4485-4490 (1991), in order to produce
the protein
recombinantly. Many suitable expression control sequences are known in the
art. General
methods of expressing recombinant proteins are also known and are exemplified
in R.
Kaufman, Methods in Enzymology ~ 537-566 (1990). As defined herein "operably
2 0 linked" means that the isolated polynucleotide of the invention and an
expression control
sequence are situated within a vector or cell in such a way that the protein
is expressed
by a host cell which has been transformed (transfected) with the ligated
polynucleotide/expression control sequence.
A number of types of cells may act as suitable host cells for expression of
the
2 5 protein. Mammalian host cells include, for example, monkey COS cells,
Chinese Hamster
Ovary (CHO) cells, human kidney 293 cells, human epidermal A431 cells, human
Co1o205
cells, 3T3 cells, CV-1 cells, other transformed primate cell lines, normal
diploid cells, cell
strains derived from in vitr culture of primary tissue, primary explants, HeLa
cells,
mouse L cells, BHK, HL-60, U937, HaK or jurkat cells.
3 0 Alternatively, it may be possible to produce the protein in lower
eukaryotes such
as yeast or in prokaryotes such as bacteria. Potentially suitable yeast
strains include
Saccharomyces cerevisiae, Schizosaccharomyces pombe, Kluyveromyces strains,
Candida, or any
yeast strain capable of expressing heterologous proteins. Potentially suitable
bacterial
strains include Escherichia coli, Bacillus subtilis, Salmonella typhimurium,
or any bacterial
32
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
strain capable of expressing heterologous proteins. If the protein is made in
yeast or
bacteria, it may be necessary to modify the protein produced therein, for
example by
phosphorylation or glycosylation of the appropriate sites, in order to obtain
the functional
' protein. Such covalent attachments may be accomplished using known chemical
or
enzymatic methods.
The protein may also be produced by operably linking the isolated
polynucleotide
of the invention to suitable control sequences in one or more insect
expression vectors,
and employing an insect expression system. Materials and methods for
baculovirus/insect cell expression systems are commercially available in kit
form from,
e.g., Invitrogen, San Diego, California, U.S.A. (the MaxBacC~ kit), and such
methods are
well known in the art, as described in Summers and Smith, Texas Agricultural
Ex,~~eriment
Station Bulletin No 1555 {19871 incorporated herein by reference. As used
herein, an
insect cell capable of expressing a polynucleotide of the present invention is
"transformed."
The protein of the invention may be prepared by culturing transformed host
cells
under culture conditions suitable to express the recombinant protein. The
resulting
expressed protein may then be purified from such culture (i.e., from culture
medium or
cell extracts) using known purification processes, such as gel filtration and
ion exchange
chromatography. The purification of the protein may also include an affinity
column
2 0 containing agents which will bind to the protein; one or more column steps
over such
affinity resins as concanavalin A-agarose, heparin-toyopearl~ or Cibacrom blue
3GA
Sepharose~; one or more steps involving hydrophobic interaction chromatography
using
such resins as phenyl ether, butyl ether, or propyl ether; or immunoaffiruty
chromatography.
2 5 Alternatively, the protein of the invention may also be expressed in a
form which
will facilitate purification. For example, it may be expressed as a fusion
protein, such as
those of maltose binding protein (MBP), glutathione-S-transferase (GST) or
thioredoxin
{TR?C). Kits for expression and purification of such fusion proteins are
commercially
available from New England BioLab (Beverly, MA), Pharmacia (Piscataway, NJ)
and
3 0 InVitrogen, respectively. The protein can also be tagged with an epitope
and
subsequently purified by using a specific antibody directed to such epitope.
One such
epitope ("Flag") is commercially available from Kodak (New Haven, CT).
Finally, one or more reverse-phase high performance liquid chromatography {RP-
HPLC) steps employing hydrophobic RP-HPLC media, e.g., silica gel having
pendant
33
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
methyl or other aliphatic groups, can be employed to further purify the
protein. Some or
all of the foregoing purification steps, in various combinations, can also be
employed to
provide a substantially homogeneous isolated recombinant protein. The protein
thus
purified is substantially free of other mammalian proteins and is defined in
accordance
with the present invention as an "isolated protein."
The protein of the invention may also be expressed as a product of transgenic
animals, e.g., as a component of the milk of transgenic cows, goats, pigs, or
sheep which
are characterized by somatic or germ cells containing a nucleotide sequence
encoding the
protein.
The protein may also be produced by known conventional chemical synthesis.
Methods for constructing the proteins of the present invention by synthetic
means are
known to those skilled in the art. The synthetically-constructed protein
sequences, by
virtue of sharing primary, secondary or tertiary structural and/or
conformational
characteristics with proteins may possess biological properties in common
therewith,
including protein activity. Thus, they may be employed as biologically active
or
immunological substitutes for natural, purified proteins in screening of
therapeutic
compounds and in immunological processes for the development of antibodies.
The proteins provided herein also include proteins characterized by amino acid
sequences similar to those of purified proteins but into which modification
are naturally
2 0 provided or deliberately engineered. For example, modifications in the
peptide or DNA
sequences can be made by those skilled in the art using known techniques.
Modifications
of interest in the protein sequences may include the alteration, substitution,
replacement,
insertion or deletion of a selected amino acid residue in the coding sequence.
For
example, one or more of the cysteine residues may be deleted or replaced with
another
2 5 amino acid to alter the conformation of the molecule. Techniques for such
alteration,
substitution, replacement, insertion or deletion are well known to those
skilled in the art
(see, e.g., U.S. Patent No. 4,518,584). Preferably, such alteration,
substitution, replacement,
insertion or deletion retains the desired activity of the protein.
Other fragments and derivatives of the sequences of proteins which would be
3 0 expected to retain protein activity in whole or in part and may thus be
useful for screening
or other immunological methodologies may also be easily made by those skilled
in the art
given the disclosures herein. Such modifications are believed to be
encompassed by the
present invention.
34
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
USES AND BIOLOGICAL ACTIVITY
The polynucleotides and proteins of the present invention are expected to
exhibit
one or more of the uses or biological activities (including those associated
with assays
cited herein) identified below. Uses or activities described for proteins of
the present
invention may be provided by administration or use of such proteins or by
administration
or use of polynucleotides encoding such proteins (such as, for example, in
gene therapies
or vectors suitable for introduction of DNA).
Research Uses and Utilities
The polynucleotides provided by the present invention can be used by the
research
community for various purposes. The polynucleotides can be used to express
recombinant protein for analysis, characterization or therapeutic use; as
markers for
tissues in which the corresponding protein is preferentially expressed (either
constitutively or at a particular stage of tissue differentiation or
development or in disease
states); as molecular weight markers on Southern gels; as chromosome markers
or tags
(when labeled) to identify chromosomes or to map related gene positions; to
compare
with endogenous DNA sequences in patients to identify potential genetic
disorders; as
probes to hybridize and thus discover novel, related DNA sequences; as a
source of
information to derive PCR primers for genetic fingerprinting; as a probe to
"subtract-out"
2 0 known sequences in the process of discovering other novel polynucleotides;
for selecting
and making oligomers for attachment to a "gene chip" or other support,
including for
examination of expression patterns; to raise anti-protein antibodies using DNA
immunization techniques; and as an antigen to raise anti-DNA antibodies or
elicit another
immune response. Where the polynucleotide encodes a protein which binds or
potentially
2 5 binds to another protein (such as, for example, in a receptor-ligand
interaction), the
polynucleotide can also be used in interaction trap assays (such as, for
example, that
described in Gyuris et al., Cell 75:791-803 (1993)) to identify
polynucleotides encoding the
other protein with which binding occurs or to identify inhibitors of the
binding
interaction.
. 3 0 The proteins provided by the present invention can similarly be used in
assay to
determine biological activity, including in a panel of multiple proteins for
high-
. throughput screening; to raise antibodies or to elicit another immune
response; as a
reagent (including the labeled reagent) in assays designed to quantitatively
determine
levels of the protein (or its receptor) in biological fluids; as markers for
tissues in which
CA 02295212 1999-12-31
WO 99/01466 PCT/IJS98/13813
the corresponding protein is preferentially expressed (either constitutively
or at a
particular stage of tissue differentiation or development or in a disease
state); and, of
course, to isolate correlative receptors or ligands. Where the protein binds
or potentially
binds to another protein (such as, for example, in a receptor-ligand
interaction), the
protein can be used to identify the other protein with which binding occurs or
to identify
inhibitors of the binding interaction. Proteins involved in these binding
interactions can
also be used to screen for peptide or small molecule inhibitors or agonists of
the binding
interaction.
Any or all of these research utilities are capable of being developed into
reagent
grade or kit format for commercialization as research products.
Methods for performing the uses listed above are well known to those skilled
in
the art. References disclosing such methods include without limitation
"Molecular
Cloning: A Laboratory Manual", 2d ed., Cold Spring Harbor Laboratory Press,
Sambrook,
J., E.F. Fritsch and T. Maniatis eds., 1989, and "Methods in Enzymology: Guide
to
Molecular Cloning Techniques", Academic Press, Berger, S.L. and A.R. Kimmel
eds.,1987.
Nutritional Uses
Polynucleotides and proteins of the present invention can also be used as
nutritional sources or supplements. Such uses include without limitation use
as a protein
2 0 or amino acid supplement, use as a carbon source, use as a nitrogen source
and use as a
source of carbohydrate. In such cases the protein or polynucleotide of the
invention can
be added to the feed of a particular organism or can be administered as a
separate solid
or liquid preparation, such as in the form of powder, pills, solutions,
suspensions or
capsules. In the case of microorganisms, the protein or polynucleotide of the
invention
2 5 can be added to the medium in or on which the microorganism is cultured.
Cytokine and Cell Proiiferation/Differentiation Activity
A protein of the present invention may exhibit cytokine, cell proliferation
(either
inducing or inhibiting) or cell differentiation (either inducing or
inhibiting} activity or may
3 0 induce production of other cytokines in certain cell populations. Many
protein factors
discovered to date, including all known cytokines, have exhibited activity in
one or more
factor dependent cell proliferation assays, and hence the assays serve as a
convenient
confirmation of cytokine activity. The activity of a protein of the present
invention is
evidenced by any one of a number of routine factor dependent cell
proliferation assays
36
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
for cell lines including, without limitation, 32D, DA2, DA1G, T10, B9, B9/11,
BaF3,
MC9/G, M+ (preB M+), 2E8, RBS, DA1,123, TI165, HT2, CTLL2, TF-1, Mo7e and CMK.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for T-cell or thymocyte proliferation include without limitation those
described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W Strober, Pub. Greene Publishing Associates and
Wiley-
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
7, Immunologic studies in Humans); Takai et al., J. Immunol. 137:3494-3500,
1986;
Bertagnolli et al., J. Immunol.145:1706-1712, 1990; Bertagnolli et al.,
Cellular Immunology
133:327-341, 1991; Bertagnolli, et al., ]. Immunol. 149:3778-3783,1992; Bowman
et al., J.
Immunol. 152: 1756-1761, 1994.
Assays for cytokine production and/or proliferation of spleen cells, lymph
node
cells or thymocytes include, without limitation, those described in:
Polyclonal T cell
stimulation, Kruisbeek, A.M. and Shevach, E.M. In Current Protocols in
Immunology. J.E.e.a.
Coligan eds. Vol 1 pp. 3.12.1-3.12.14, john Wiley and Sons, Toronto. 1994; and
Measurement of mouse and human Interferon y, Schreiber, R.D. In Current
Protocols in
Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.8.1-6.8.8, John Wiley and Sons,
Toronto.1994.
2 0 Assays for proliferation and differentiation of hematopoietic and
lymphopoietic
cells include, without limitation, those described in: Measurement of Human
and Murine
Interleukin 2 and Interleukin 4, Bottomly, K., Davis, L.S. and Lipsky, P.E. In
Current
Protocols in Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.3.1-6.3.12, John
Wiley and Sons,
Toronto. 1991; deVries et al., J. Exp. Med. 173:1205-1211, 1991; Moreau et
al., Nature
2 5 336:690-692, 1988; Greenberger et al., Proc. Natl. Acad. Sci. U.S.A.
80:2931-2938, 1983;
Measurement of mouse and human interleukin 6 - Nordan, R. In Current Protocols
in
Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.6.1-6.6.5, John Wiley and Sons,
Toronto.1991;
Smith et al., Proc. Natl. Acad. Sci. U.S.A. 83:1857-1861, 1986; Measurement of
human
lnterleukin 11- Bennett, F., Giannotti, J., Clark, S.C. and Turner, K. j. In
Current Protocols
3 0 in Immunology. J.E.e.a. Coligan eds. Vol 1 pp. 6.15.1 John Wiley and Sons,
Toronto.1991;
Measurement of mouse and human Interleukin 9 - Ciarletta, A., Giannotti, J.,
Clark, S.C.
and Turner, K.J. In Current Protocols in Immunology. J.E.e.a. Coligan eds. Vol
1 pp. 6.13.1,
John Wiley and Sons, Toronto.1991.
37
CA 02295212 1999-12-31
WO 99/01466 PCT/US98113813
Assays for T-cell clone responses to antigens (which will identify, among
others,
proteins that affect APC-T cell interactions as well as direct T-cell effects
by measuring
proliferation and cytokine production) include, without limitation, those
described in:
Current Protocols in Immunology, Ed by J. E. Coligan, A.M. Kruisbeek, D.H.
Margulies,
E.M. Shevach, W Strober, Pub. Greene Publishing Associates and Wiley-
Interscience
(Chapter 3, In Vitro assays for Mouse Lymphocyte Function; Chapter 6,
Cytokines and
their cellular receptors; Chapter 7, Immunologic studies in Humans);
Weinberger et al.,
Proc. Natl. Acad. Sci. USA 77:6091-6095, 1980; Weinberger et al., Eur. J.
Immun.
11:405-411, 1981; Takai et al., J. Immunol. 137:3494-3500, 1986; Takai et al.,
J. Immunol.
140:508-512, 1988.
Immune Stimulatin og r Suppressing Activity
A protein of the present invention may also exhibit immune stimulating or
immune suppressing activity, including without limitation the activities for
which assays
are described herein. A protein may be useful in the treatment of various
immune
deficiencies and disorders (including severe combined immunodeficiency
(SCID)), e.g.,
in regulating (up or down) growth and proliferation of T and/or B lymphocytes,
as well
as effecting the cytolytic activity of NK cells and other cell populations.
These immune
deficiencies may be genetic or be caused by viral (e.g., HIV) as well as
bacterial or fungal
2 0 infections, or may result from autoimmune disorders. More specifically,
infectious
diseases causes by viral, bacterial, fungal or other infection may be
treatable using a
protein of the present invention, including infections by HIV, hepatitis
viruses,
herpesviruses, mycobacteria, Leishmania spp., malaria spp. and various fungal
infections
such as candidiasis. Of course, in this regard, a protein of the present
invention may also
2 5 be useful where a boost to the immune system generally may be desirable,
i.e., in the
treatment of cancer.
Autoimmune disorders which may be treated using a protein of the present
invention include, for example, connective tissue disease, multiple sclerosis,
systemic
lupus erythematosus, rheumatoid arthritis, autoimmune pulmonary inflammation,
3 0 Guillain-Barre syndrome, autoimmune thyroiditis, insulin dependent
diabetes mellitis,
myasthenia gravis, graft-versus-host disease and autoimmune inflammatory eye
disease.
Such a protein of the present invention may also to be useful in the treatment
of allergic
reactions and conditions, such as asthma (particularly allergic asthma) or
other respiratory
problems. Other conditions, in which immune suppression is desired (including,
for
38
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
example, organ transplantation), may also be treatable using a protein of the
present
invention.
Using the proteins of the invention it may also be possible to immune
responses,
in a number of ways. Down regulation may be in the form of inhibiting or
blocking an
immune response already in progress or may involve preventing the induction of
an
immune response. The functions of activated T cells may be inhibited by
suppressing T
cell responses or by inducing specific tolerance in T cells, or both.
Immunosuppression
of T cell responses is generally an active, non-antigen-specific, process
which requires
continuous exposure of the T cells to the suppressive agent. Tolerance, which
involves
inducing non-responsiveness or anergy in T cells, is distinguishable from
immunosuppression in that it is generally antigen-specific and persists after
exposure to
the tolerizing agent has ceased. Operationally, tolerance can be demonstrated
by the lack
of a T cell response upon reexposure to specific antigen in the absence of the
tolerizing
agent.
Down regulating or preventing one or more antigen functions (including without
limitation B lymphocyte antigen functions (such as , for example, B7)), e.g.,
preventing
high level lymphokine synthesis by activated T cells, will be useful in
situations of tissue,
skin and organ transplantation and in graft-versus-host disease (GVHD). For
example,
blockage of T cell function should result in reduced tissue destruction in
tissue
2 0 transplantation. Typically, in tissue transplants, rejection of the
transplant is initiated
through its recognition as foreign by T cells, followed by an immune reaction
that destroys
the transplant. The administration of a molecule which inhibits or blocks
interaction of
a B7 lymphocyte antigen with its natural ligand(s) on immune cells (such as a
soluble,
monomeric form of a peptide having B7-2 activity alone or in conjunction with
a
2 5 monomeric form of a peptide having an activity of another B lymphocyte
antigen (e.g., B7-
1, B7-3) or blocking antibody), prior to transplantation can lead to the
binding of the
molecule to the natural ligand(s) on the immune cells without transmitting the
corresponding costimulatory signal. Blocking B lymphocyte antigen function in
this
matter prevents cytokine synthesis by immune cells, such as T cells, and thus
acts as an
3 0 immunosuppressant. Moreover, the lack of costimulation may also be
sufficient to
anergize the T cells, thereby inducing tolerance in a subject. Induction of
long-term
tolerance by B lymphocyte antigen-blocking reagents may avoid the necessity of
repeated
administration of these blocking reagents. To achieve sufficient
immunosuppression or
39
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
tolerance in a subject, it may also be necessary to block the function of a
combination of
B lymphocyte antigens.
The efficacy of particular blocking reagents in preventing organ transplant
rejection or GVHD can be assessed using animal models that are predictive of
efficacy in
humans. Examples of appropriate systems which can be used include allogeneic
cardiac
grafts in rats and xenogeneic pancreatic islet cell grafts in mice, both of
which have been
used to examine the immunosuppressive effects of CTLA4Ig fusion proteins in
vivo as
described in Lenschow et al., Science 257:789-792 (1992) and Turka et al.,
Proc. Natl. Acad.
Sci USA, 89:11102-11105 (1992). In addition, murine models of GVHD (see Paul
ed.,
Fundamental Immunology, Raven Press, New York, 1989, pp. 846-847) can be used
to
determine the effect of blocking B lymphocyte antigen function in vivo on the
development
of that disease.
Blocking antigen function may also be therapeutically useful for treating
autoimmune diseases. Many autoimmune disorders are the result of inappropriate
activation of T cells that are reactive against self tissue and which promote
the production
of cytokines and autoantibodies involved in the pathology of the diseases.
Preventing the
activation of autoreactive T cells may reduce or eliminate disease symptoms.
Administration of reagents which block costimulation of T cells by disrupting
receptor:ligand interactions of B lymphocyte antigens can be used to inhibit T
cell
2 0 activation and prevent production of autoantibodies or T cell-derived
cytokines which
may be involved in the disease process. Additionally, blocking reagents may
induce
antigen-specific tolerance of autoreactive T cells which could lead to long-
term relief from
the disease. The efficacy of blocking reagents in preventing or alleviating
autoimmune
disorders can be determined using a number of well-characterized animal models
of
2 5 human autoimmune diseases. Examples include murine experimental autoimmune
encephalitis, systemic lupus erythmatosis in MRL/lpr/Ipr mice or NZB hybrid
mice,
marine autoimmune collagen arthritis, diabetes mellitus in NOD mice and BB
rats, and
marine experimental myasthenia gravis (see Paul ed., Fundamental Immunology,
Raven
Press, New York,1989, pp. 840-856).
3 0 Upregulation of an antigen function (preferably a B lymphocyte antigen
function),
as a means of up regulating immune responses, may also be useful in therapy.
Upregulation of immune responses may be in the form of enhancing an existing
immune
response or eliciting an initial immune response. For example, enhancing an
immune
response through stimulating B lymphocyte antigen function may be useful in
cases of
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
viral infection. In addition, systemic viral diseases such as influenza, the
common cold,
and encephalitis might be alleviated by the administration of stimulatory
forms of B
lymphocyte antigens systemically.
Alternatively, anti-viral immune responses may be enhanced in an infected
patient
by removing T cells from the patient, cosdmulating the T cells in vitro with
viral antigen-
pulsed APCs either expressing a peptide of the present invention or together
with a
stimulatory form of a soluble peptide of the present invention and
reintroducing the in
vitro activated T cells into the patient. Another method of enhancing anti-
viral immune
responses would be to isolate infected cells from a patient, transfect them
with a nucleic
acid encoding a protein of the present invention as described herein such that
the cells
express all or a portion of the protein on their surface, and reintroduce the
transfected
cells into the patient. The infected cells would now be capable of delivering
a
costimulatory signal to, and thereby activate, T cells in vivo.
1n another application, up regulation or enhancement of antigen function
(preferably B lymphocyte antigen function) may be useful in the induction of
tumor
immunity. Tumor cells (e.g., sarcoma, melanoma, lymphoma, leukemia,
neuroblastoma,
carcinoma) transfected with a nucleic acid encoding at least one peptide of
the present
invention can be administered to a subject to overcome tumor-specific
tolerance in the
subject. If desired, the tumor cell can be transfected to express a
combination of peptides.
2 0 For example, tumor cells obtained from a patient can be transfected ex
vivo with an
expression vector directing the expression of a peptide having B7-2-like
activity alone, or
in conjunction with a peptide having B7-1-like activity and/or B7-3-like
activity. The
transfected tumor cells are returned to the patient to result in expression of
the peptides
on the surface of the transfected cell. Alternatively, gene therapy techniques
can be used
2 5 to target a tumor cell for transfection in vivo.
The presence of the peptide of the present invention having the activity of a
B
lymphocyte antigens) on the surface of the tumor cell provides the necessary
costimulation signal to T cells to induce a T cell mediated immune response
against the
transfected tumor cells. In addition, tumor cells which lack MHC class I or
MHC class II
3 0 molecules, or which fail to reexpress sufficient amounts of MHC class I or
MHC class II
molecules, can be transfected with nucleic acid encoding all or a portion of
(e.g., a
cytoplasmic-domain truncated portion) of an MHC class I a chain protein and
(3Z
microglobulin protein or an MHC class II a chain protein and an MHC class II
ji chain
protein to thereby express MHC class I or MHC class II proteins on the cell
surface.
41
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Expression of the appropriate class I or class II MHC in conjunction with a
peptide having
the activity of a B lymphocyte antigen (e.g., B7-1, B7-2, B7-3) induces a T
cell mediated
immune response against the transfected tumor cell. Optionally, a gene
encoding an
antisense construct which blocks expression of an MHC class II associated
protein, such
as the invariant chain, can also be cotransfected with a DNA encoding a
peptide having
the activity of a B lymphocyte antigen to promote presentation of tumor
associated
antigens and induce tumor specific immunity. Thus, the induction of a T cell
mediated
immune response in a human subject may be sufficient to overcome tumor-
specific
tolerance in the subject.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Suitable assays for thymocyte or splenocyte cytotoxicity include, without
limitation, those described in: Current Protocols in Immunology, Ed by J. E.
Coligan, A.M.
Kruisbeek, D.H. Margulies, E.M. Shevach, W Strober, Pub. Greene Publishing
Associates
and Wiley-Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte
Function 3.1-
3.19; Chapter 7, Immunologic studies in Humans); Hemnann et al., Proc. Natl.
Acad. Sci.
USA 78:2488-2492,1981; Herrmann et al., J. Immunol. 128:1968-1974, 1982; Handa
et al.,
J. Immunol.135:1564-1572,1985; Takai et al., J. Immunol.137:3494-3500,1986;
Takai et al.,
J. Immunol. 140:508-512, 1988; Herrmann et al., Proc. Natl. Acad. Sci. USA
78:2488-2492,
2 0 1981; Herrmann et al., J. Immunol. 128:1968-1974, 1982; Handa et al., J.
Immunol.
135:1564-1572, 1985; Takai et al., J. Immunol. 137:3494-3500, 1986; Bowmanet
al., J.
Virology 61:1992-1998; Takai et al., J. immunol. 140:508-512, 1988;
Bertagnolli et al.,
Cellular Immunology 133:327-341,1991; Brown et al., J. Immunol. 153:3079-3092,
1994.
Assays for T-cell-dependent immunoglobulin responses and isotype switching
2 5 (which will identify, among others, proteins that modulate T-cell
dependent antibody
responses and that affect Thl /Th2 profiles) include, without limitation,
those described
in: Maiiszewski, j. immunol. 144:3028-3033, 1990; and Assays for B cell
function: In vitro
antibody production, Mond, J.J. and Brunswick, M. In Currenf Protocols in
Immunology.
J.E.e.a. Coligan eds. Vol 1 pp. 3.8.1-3.8.16, john Wiley and Sons,
Toronto.1994.
3 0 Mixed lymphocyte reaction (MLR) assays (which will identify, among others,
proteins that generate predominantly Thl and CTL responses) include, without
limitation,
those described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
ICruisbeek,
D.H. Margulies, E.M. Shevach, W Strober, Pub. Greene Publishing Associates and
Wiley-
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
42
CA 02295212 1999-12-31
WO 99/01466 PCT1US98/13813
7, Immunologic studies in Humans); Takai et al., J. Immunol. 137:3494-3500,
1986; Takai
et al., J. Immunol. 140:508-512, 1988; Bertagnolli et al., J. Immunol.149:3778-
3783,1992.
Dendritic cell-dependent assays (which will identify, among others, proteins
expressed by dendritic cells that activate naive T-cells) include, without
limitation, those
described in: Guery et al., j. Immunol. 134:536-544, 1995; Inaba et al.,
Journal of
Experimental Medicine 173:549-559, 1991; Macatonia et al., Journal of
Immunology
154:5071-5079,1995; Porgador et al., Journal of Experimental Medicine 182:255-
260,1995;
Nair et al., Journal of Virology 67:4062-4069, 1993; Huang et al., Science
264:961-965,
1994; Macatonia et al., Journal of Experimental Medicine 169:1255-1264,1989;
Bhardwaj
et al., Journal of Clinical Investigation 94:797-807, 1994; and Inaba et al.,
Journal of
Experimental Medicine 172:631-640,1990.
Assays for lymphocyte survival/apoptosis (which will identify, among others,
proteins that prevent apoptosis after superantigen induction and proteins that
regulate
lymphocyte homeostasis) include, without limitation, those described in:
Darzynkiewicz
et al., Cytometry 13:795-808,1992; Gorczyca et al., Leukemia 7:659-670,1993;
Gorczyca et
al., Cancer Research 53:1945-1951, 1993; Itoh et al., Cell 66:233-243, 1991;
Zacharchuk,
Journal of Immunology 145:4037-4045, 1990; Zamai et al., Cytometry 14:891-897,
1993;
Gorczyca et al., International Journal of Oncology 1:639-648,1992.
Assays for proteins that influence early steps of T-cell commitment and
2 0 development include, without limitation, those described in: Antica et
al., Blood
84:111-117, 1994; Fine et al., Cellular Immunology 155:111-122, 1994; Galy et
al., Blood
85:2770-2778,1995; Toki et al., Proc. Nat. Acad Sci. USA 88:7548-7551,1991.
HEamatp~ ' ci. pQUlatig~ ACtIVI
2 5 A protein of the present invention may be useful in regulation of
hematopoiesis
and, consequently, in the treatment of myeloid or lymphoid cell deficiencies.
Even
marginal biological activity in support of colony forming cells or of factor-
dependent cell
lines indicates involvement in regulating hematopoiesis, e.g. in supporting
the growth and
proliferation of erythroid progenitor cells alone or in combination with other
cytokines,
3 0 thereby indicating utility, for example, in treating various anemias or
for use in
conjunction with ixradiation/chemotherapy to stimulate the production of
erythroid
precursors and/or erythroid cells; in supporting the growth and proliferation
of myeloid
cells such as granulocytes and monocytes/macrophages (i.e., traditional CSF
activity)
useful, for example, in conjunction with chemotherapy to prevent or treat
consequent
43
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
myelo-suppression; in supporting the growth and proliferation of
megakaryocytes and
consequently of platelets thereby allowing prevention or treatment of various
platelet
disorders such as thrombocytopenia, and generally for use in place of or
complimentary
to platelet transfusions; and/or in supporting the growth and proliferation of
hematopoietic stem cells which are capable of maturing to any and all of the
above-
mentioned hematopoietic cells and therefore find therapeutic utility in
various stem cell
disorders (such as those usually treated with transplantation, including,
without
limitation, aplastic anemia and paroxysmal nocturnal hemoglobinuria), as well
as in
repopulating the stem cell compartment post irradiation/chemotherapy, either
in-vivo or
ex-vivo (i.e., in conjunction with bone marrow transplantation or with
peripheral
progenitor cell transplantation (homologous or heterologous)) as normal cells
or
genetically manipulated for gene therapy.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Suitable assays for proliferation and differentiation of various hematopoietic
lines
are cited above.
Assays for embryonic stem cell differentiation (which will identify, among
others,
proteins that influence embryonic differentiation hematopoiesis) include,
without
limitation, those described in: Johansson et al. Cellular Biology 15:141-151,
1995; Keller et
2 0 al., Molecular and Cellular Biology 13:473-486, 1993; McClanahan et al.,
Blood
81:2903-2915,1993.
Assays for stem cell survival and differentiation (which will identify, among
others, proteins that regulate lympho-hematopoiesis) include, without
limitation, those
described in: Methylcellulose colony forming assays, Freshney, M.G. In Culture
of
2 5 Hematopoietic Cells. R.I. Freshney, et al. eds. Vol pp. 265-268, Wiley-
Liss, Inc., New York,
NY. 1994; Hirayama et al., Proc. Natl. Acad. Sci. USA 89:5907-5911, 1992;
Primitive
hematopoietic colony forming cells with high proliferative potential, McNiece,
LK. and
Briddell, R.A. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds.
Vol pp. 23-39,
Wiley-Liss, Inc., New York, NY.1994; Neben et aL, Experimental Hematology
22:353-359,
3 0 1994; Cobblestone area forming cell assay, Ploemacher, R.E. In Culture of
Hematopoietic
Cells. R.I. Freshney, et al. eds. Vol pp.1-21, Wiley-Liss, Inc.., New York,
NY.1994; Long
term bone marrow cultures in the presence of stromal cells, Spooncer, E.,
Dexter, M. and
Allen, T. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds. Vol
pp. 163-179,
Wiley-Liss, Inc., New York, NY.1994; Long term culture initiating cell assay,
Sutherland,
44
CA 02295212 1999-12-31
WO 99/01466 PGT/US98/13813
H.J. In Culture of Hematopoietic Cells. R.I. Freshney, et al. eds. Vol pp. 139-
162, Wiley-Liss,
Inc., New York, NY. 1994.
Tissue Growth A.ctivi r
A protein of the present invention also may have utility in compositions used
for
bone, cartilage, tendon, ligament and/or nerve tissue growth or regeneration,
as well as
for wound healing and tissue repair and replacement, and in the treatment of
burns,
incisions and ulcers.
A protein of the present invention, which induces cartilage and/or bone growth
in circumstances where bone is not normally formed, has application in the
healing of
bone fractures and cartilage damage or defects in humans and other animals.
Such a
preparation employing a protein of the invention may have prophylactic use in
closed as
well as open fracture reduction and also in the improved fixation of
artificial joints: De
novo bone formation induced by an osteogenic agent contributes to the repair
of
congenital, trauma induced, or oncologic resection induced craniofacial
defects, and also
is useful in cosmetic plastic surgery.
A protein of this invention may also be used in the treatment of periodontal
disease, and in other tooth repair processes. Such agents may provide an
environment
to attract bone-forming cells, stimulate growth of bone-forming cells or
induce
2 0 differentiation of progenitors of bone-forming cells. A protein of the
invention may also
be useful in the treatment of osteoporosis or osteoarthritis, such as through
stimulation
of bone and/or cartilage repair or by blocking inflammation or processes of
tissue
destruction (collagenase activity, osteoclast activity, etc.) mediated by
inflammatory
processes.
2 5 Another category of tissue regeneration activity that may be attributable
to the
protein of the present invention is tendon/ligament formation. A protein of
the present
invention, which induces tendon/ligament-like tissue or other tissue formation
in
circumstances where such tissue is not normally formed, has application in the
healing of
tendon or ligament tears, deformities and other tendon or ligament defects in
humans and
3 0 other animals. Such a preparation employing a tendon/ligament-like tissue
inducing
protein may have prophylactic use in preventing damage to tendon or ligament
tissue, as
well as use in the improved fixation of tendon or ligament to bone or other
tissues, and
in repairing defects to tendon or ligament tissue. De novo tendon/ligament-
like tissue
formation induced by a composition of the present invention contributes to the
repair of
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
congenital, trauma induced, or other tendon or ligament defects of other
origin, and is also
useful in cosmetic plastic surgery for attachment or repair of tendons or
ligaments. The
compositions of the present invention may provide an environment to attract
tendon- or
ligament-forming cells, stimulate growth of tendon- or ligament-forming cells,
induce
differentiation of progenitors of tendon- or ligament-forming cells, or induce
growth of
tendon/ligament cells or progenitors ex vivo for return in vivo to effect
tissue repair. The
compositions of the invention may also be useful in the treatment of
tendinitis, carpal
tunnel syndrome and other tendon or ligament defects. The compositions may
also
include an appropriate matrix and/or sequestering agent as a carrier as is
well known in
the art.
The protein of the present invention may also be useful for proliferation of
neural
cells and for regeneration of nerve and brain tissue, i.e. for the treatment
of central and
peripheral nervous system diseases and neuropathies, as well as mechanical and
traumatic disorders, which involve degeneration, death or trauma to neural
cells or nerve
tissue. More specifically, a protein may be used in the treatment of diseases
of the
peripheral nervous system, such as peripheral nerve injuries, peripheral
neuropathy and
localized neuropathies, and central nervous system diseases, such as Alzheimer
s,
Parkinson s disease, Huntingtori s disease, amyotrophic lateral sclerosis, and
Shy-Drager
syndrome. Further conditions which may be treated in accordance with the
present
2 0 invention include mechanical and traumatic disorders, such as spinal cord
disorders, head
trauma and cerebrovascular diseases such as stroke. Peripheral neuropathies
resulting
from chemotherapy or other medical therapies may also be treatable using a
protein of the
invention.
Proteins of the invention may also be useful to promote better or faster
closure of
2 5 non-healing wounds, including without limitation pressure ulcers, ulcers
associated with
vascular insufficiency, surgical and traumatic wounds, and the like.
It is expected that a protein of the present invention may also exhibit
activity for
generation or regeneration of other tissues, such as organs (including, for
example,
pancreas, liver, intestine, kidney, skin, endothelium), muscle (smooth,
skeletal or cardiac)
3 0 and vascular (including vascular endothelium) tissue, or for promoting the
growth of cells
comprising such tissues. Part of the desired effects may be by inhibition or
modulation
of fibrotic scarring to allow normal tissue to regenerate. A protein of the
invention may
also exhibit angiogenic activity.
46
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/I3813
A protein of the present invention may also be useful for gut protection or
regeneration and treatment of lung or liver fibrosis, reperfusion injury in
various tissues,
and conditions resulting from systemic cytokine damage.
A protein of the present invention may also be useful for promoting or
inhibiting
differentiation of tissues described above from precursor tissues or cells; or
for inhibiting
the growth of tissues described above.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for tissue generation activity include, without limitation, those
described
in: International Patent Publication No. W095/16035 (bone, cartilage, tendon);
International Patent Publication No. W095/05846 (nerve, neuronal);
International Patent
Publication No. W091/07491 (skin, endothelium ).
Assays for wound healing activity include, without limitation, those described
in:
Winter, l~;,pidermal Wound Healing, pps. 71-112 {Maibach, HI and Rovee, DT,
eds.), Year
Book Medical Publishers, Inc., Chicago, as modified by Eaglstein and Mertz, J.
Invest.
Dermatol 71:382-84 {1978).
Activin/Inhibin Activity
A protein of the present invention may also exhibit activin- or inhibin-
related
2 0 activities. lnhibins are characterized by their ability to inhibit the
release of follicle
stimulating hormone (FSH), while activins and are characterized by their
ability to
stimulate the release of follicle stimulating hormone (FSH). Thus, a protein
of the present
invention, alone or in heterodimers with a member of the inhibin a family, may
be useful
as a contraceptive based on the ability of inhibins to decrease fertility in
female mammals
2 5 and decrease spermatogenesis in male mammals. Administration of sufficient
amounts
of other inhibins can induce infertility in these mammals. Alternatively, the
protein of the
invention, as a homodimer or as a heterodimer with other protein subunits of
the inhibin-
~i group, may be useful as a fertility inducing therapeutic, based upon the
ability of activin
molecules in stimulating FSH release from cells of the anterior pituitary.
See, for example,
3 0 United States Patent 4,798,885. A protein of the invention may also be
useful for
advancement of the onset of fertility in sexually immature mammals, so as to
increase the
lifetime reproductive performance of domestic animals such as cows, sheep and
pigs.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
47
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Assays for activin/inhibin activity include, without limitation, those
described in:
Vale et al., Endocrinology 91:562-572, 1972; Ling et aL, Nature 321:779-
782,1986; Vale et
al., Nature 321:776-779,1986; Mason et al., Nature 318:659-663, 1985; Forage
et al., Proc.
Natl. Acad. Sci. USA 83:3091-3095,1986.
Chemotactic/~emokinetic Activity
A protein of the present invention may have chemotactic or chemokinetic
activity
(e.g., act as a chemokine) for mammalian cells, including, for example,
monocytes,
fibroblasts, neutrophils, T-cells, mast cells, eosinophils, epithelial and/or
endothelial cells.
Chemotactic and chemokinetic proteins can be used to mobilize or attract a
desired cell
population to a desired site of action. Chemotactic or chemokinetic proteins
provide
particular advantages in treatment of wounds and other trauma to tissues, as
well as in
treatment of localized infections. For example, attraction of lymphocytes,
monocytes or
neutrophils to tumors or sites of infection may result in improved immune
responses
against the tumor or infecting agent.
A protein or peptide has chemotactic activity for a particular cell population
if it
can stimulate, directly or indirectly, the directed orientation or movement of
such cell
population. Preferabiy, the protein or peptide has the ability to directly
stimulate directed
movement of cells. Whether a particular protein has chemotactic activity for a
population
2 0 of cells can be readily determined by employing such protein or peptide in
any known
assay for cell chemotaxis.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for chemotactic activity (which will identify proteins that induce or
prevent
2 5 chemotaxis) consist of assays that measure the ability of a protein to
induce the migration
of cells across a membrane as well as the ability of a protein to induce the
adhesion of one
cell population to another cell population. Suitable assays for movement and
adhesion
include, without limitation, those described in: Current Protocols in
Immunology, Ed by
J.E. Coligan, A.M. Kruisbeek, D.H. Margulies, E.M. Shevach, W.Strober, Pub.
Greene
3 0 Publishing Associates and Wiley-Interscience (Chapter 6.12, Measurement of
alpha and
beta Chemokines 6.12.1-6.12.28; Taub et al. J. Clin. Invest. 95:1370-
1376,1995; Lind et al.
APMIS 103:140-146, 1995; Muller et al Eur. J. Immunol. 25: 1744-1748; Gruber
et al. J. of
Immunol. 152:5860-5867, 1994; Johnston et al. J. of Immunol. 153: 1762-1768,
1994.
48
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Hemnstatic and Thrombo~tic Activity
A protein of the invention may also exhibit hemostatic or thrombolytic
activity.
As a result, such a protein is expected to be useful in treatment of various
coagulation
disorders (including hereditary disorders, such as hemophiiias) or to enhance
coagulation
and other hemostatic events in treating wounds resulting from trauma, surgery
or other
causes. A protein of the invention may also be useful for dissolving or
inhibiting
formation of thromboses and for treatment and prevention of conditions
resulting
therefrom (such as, for example, infarction of cardiac and central nervous
system vessels
(e.g., stroke).
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assay for hemostatic and thrombolytic activity include, without limitation,
those
described in: Linet et al., J. Clin. Pharmacol. 26:131-140, 1986; Burdick et
al., Thrombosis
Res. 45:413-419,1987; Humphrey et al., Fibrinolysis 5:71-79 (1991); Schaub,
Prostaglandins
35:467-474,1988.
R~tor/LiQand Activity
A protein of the present invention may also demonstrate activity as receptors,
receptor ligands or inhibitors or agonists of receptor/ligand interactions.
Examples of
2 0 such receptors and ligands include, without limitation, cytokine receptors
and their
ligands, receptor kinases and their ligands, receptor phosphatases and their
ligands,
receptors involved in cell-cell interactions and their ligands (including
without limitation,
cellular adhesion molecules (such as selectins, integrins and their ligands)
and
receptor/ligand pairs involved in antigen presentation, antigen recognition
and
2 5 development of cellular and humoral immune responses). Receptors and
ligands are also
useful for screening of potential peptide or small molecule inhibitors of the
relevant
receptor/ligand interaction. A protein of the present invention (including,
without
limitation, fragments of receptors and ligands) may themselves be useful as
inhibitors of
receptor/ligand interactions.
3 0 The activity of a protein of the invention may, among other means, be
measured
by the following methods:
Suitable assays for receptor-ligand activity include without limitation those
described in:Current Protocols in Immunology, Ed by J.E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W.Strober, Pub. Greene Publishing Associates and
49
CA 02295212 1999-12-31
WO 99/01466 PCT1US98/13813
Wiley-Interscience (Chapter 7.28, Measurement of Cellular Adhesion under
static
conditions 7.28.1-7.28.22), Takai et al., Proc. Natl. Acad. Sci. USA 84:6864-
6868, 1987;
Bierer et al., J. Exp. Med.168:1145-1156, 1988; Rosenstein et al., J. Exp.
Med. 169:149-160
1989; Stoltenborg et al., J. Immunol. Methods 175:59-68,1994; Stitt et al.,
Cell 80:661-670,
1995.
Anti-Inflammatory Activity
Proteins of the present invention may also exhibit anti-inflammatory activity.
The
anti-inflammatory activity may be achieved by providing a stimulus to cells
involved in
the inflammatory response, by inhibiting or promoting cell-cell interactions
(such as, for
example, cell adhesion), by inhibiting or promoting chemotaxis of cells
involved in the
inflammatory process, inhibiting or promoting cell extravasation, or by
stimulating or
suppressing production of other factors which more directly inhibit or promote
an
inflammatory response. Proteins exhibiting such activities can be used to
treat
inflammatory conditions including chronic or acute conditions), including
without
limitation inflammation associated with infection (such as septic shock,
sepsis or systemic
inflammatory response syndrome (SIRS)), ischemia-reperfusion injury, endotoxin
lethality, arthritis, complement-mediated hyperacute rejection, nephritis,
cytokine or
chemokine-induced lung injury, inflammatory bowel disease, Crohn's disease or
resulting
2 0 from over production of cytokines such as TNF or IL-1. Proteins of the
invention may also
be useful to treat anaphylaxis and hypersensitivity to an antigenic substance
or material.
Cadherin/Tumor Invasion Suppressor Activity
Cadherins are calcium-dependent adhesion molecules that appear to play major
2 5 roles during development, particularly in defining specific cell types.
Loss or alteration
of normal cadherin. expression can lead to changes in cell adhesion properties
linked to
tumor growth and metastasis. Cadherin malfunction is also implicated in other
human
diseases, such as pemphigus vulgaris and pemphigus foliaceus (auto-immune
blistering
skin diseases), Crohn's disease, and some developmental abnormalities.
3 0 The cadherin superfamily includes well over forty members, each with a
distinct
pattern of expression. All members of the superfamily have in common conserved
extracellular repeats (cadherin domains), but structural differences are found
in other
parts of the molecule. The cadherin domains bind calcium to form their
tertiary structure
and thus calcium is required to mediate their adhesion. Only a few amino acids
in the
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/I3813
first cadherin domain provide the basis for homophilic adhesion; modification
of this
recognition site can change the specificity of a cadherin so that instead of
recognizing only
itself, the mutant molecule can now also bind to a different cadherin. In
addition, some
cadherins engage in heterophilic adhesion with other cadherins.
E-cadherin, one member of the cadherin superfamily, is expressed in epithelial
cell
types. Pathologically, if E-cadherin expression is lost in a tumor, the
malignant cells
become invasive and the cancer metastasizes. Transfection of cancer cell lines
with
polynucleotides expressing E-cadherin has reversed cancer-associated changes
by
returning altered cell shapes to normal, restoring cells' adhesiveness to each
other and to
their substrate, decreasing the cell growth rate, and drastically reducing
anchorage-
independent cell growth. Thus, reintroducing E-cadherin expression reverts
carcinomas
to a less advanced stage. it is likely that other cadherins have the same
invasion
suppressor role in carcinomas derived from other tissue types. Therefore,
proteins of the
present invention with cadherin activity, and polynucleotides of the present
invention
encoding such proteins, can be used to treat cancer. Introducing such proteins
or
polynucleotides into cancer cells can reduce or eliminate the cancerous
changes observed
in these cells by providing normal cadherin expression.
Cancer cells have also been shown to express cadherins of a different tissue
type
than their origin, thus allowing these cells to invade and metastasize in a
different tissue
2 0 in the body. Proteins of the present invention with cadherin activity, and
polynucleotides
of the present invention encoding such proteins, can be substituted in these
cells for the
inappropriately expressed cadherins, restoring normal cell adhesive properties
and
reducing or eliminating the tendency of the cells to metastasize.
Additionally, proteins of the present invention with cadherin activity, and
2 5 polynucleotides of the present invention encoding such proteins, can used
to generate
antibodies recognizing and binding to cadherins. Such antibodies can be used
to block
the adhesion of inappropriately expressed tumor-cell cadherins, preventing the
cells from
forming a tumor elsewhere. Such an anti-cadherin antibody can also be used as
a marker
for the grade, pathological type, and prognosis of a cancer, i.e. the more
progressed the
3 0 cancer, the less cadherin expression there will be, and this decrease in
cadherin expression
can be detected by the use of a cadherin-binding antibody.
Fragments of proteins of the present invention with cadherin activity,
preferably
a polypeptide comprising a decapeptide of the cadherin recognition site, and
poly-
nucleotides of the present invention encoding such protein fragments, can also
be used
51
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
to block cadherin function by binding to cadherins and preventing them from
binding in
ways that produce undesirable effects. Additionally, fragments of proteins of
the present
invention with cadherin activity, preferably truncated soluble cadherin
fragments which
have been found to be stable in the circulation of cancer patients, and
polynucleotides
encoding such protein fragments, can be used to disturb proper cell-cell
adhesion.
Assays for cadherin adhesive and invasive suppressor activity include, without
limitation, those described in: Hortsch et al. J Biol Chem 270 (32): 18809-
18817, 1995;
Miyaki et al. Oncogene 11: 2547-2552.1995; Ozawa et al. Cell 63:1033-
1038,1990.
Tumor Inhibition Activity
In addition to the activities described above for immunological treatment or
prevention of tumors, a protein of the invention may exhibit other anti-tumor
activities.
A protein may inhibit tumor growth directly or indirectly (such as, for
example, via
ADCC). A protein may exhibit its tumor inhibitory activity by acting on tumor
tissue or
tumor precursor tissue, by inhibiting formation of tissues necessary to
support tumor
growth (such as, for example, by inhibiting angiogenesis), by causing
production of other
factors, agents or cell types which inhibit tumor growth, or by suppressing,
eliminating
or inhibiting factors, agents or cell types which promote tumor growth.
2 0 Other Activities
A protein of the invention may also exhibit one or more of the following
additional
activities or effects: inhibiting the growth, infection or function of, or
killing, infectious
agents, including, without limitation, bacteria, viruses, fungi and other
parasites; effecting
(suppressing or enhancing) bodily characteristics, including, without
limitation, height,
2 5 weight, hair color, eye color, skin, fat to lean ratio or other tissue
pigmentation, or organ
or body part size or shape (such as, for example, breast augmentation or
diminution,
change in bone form or shape); effecting biorhythms or caricadic cycles or
rhythms;
effecting the fertility of male or female subjects; effecting the metabolism,
catabolism,
anabolism, processing, utilization, storage or elimination of dietary fat,
lipid, protein,
3 0 carbohydrate, vitamins, minerals, cofactors or other nutritional factors
or component(s);
effecting behavioral characteristics, including, without limitation, appetite,
libido, stress,
cognition (including cognitive disorders), depression (including depressive
disorders) and
violent behaviors; providing analgesic effects or other pain reducing effects;
promoting
differentiation and growth of embryonic stem cells in lineages other than
hematopoietic
52
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
lineages; hormonal or endocrine activity; in the case of enzymes, correcting
deficiencies
of the enzyme and treating deficiency-related diseases; treatment of
hyperproliferative
disorders (such as, for example, psoriasis); immunoglobulin-like activity
(such as, for
e~cample, the ability to bind antigens or complement); and the ability to
act.as an antigen
in a vaccine composition to raise an immune response against such protein or
another
material or entity which is cross-reactive with such protein.
ADMI~1ISTRATION AND DOSING
A protein of the present invention (from whatever source derived, including
without limitation from recombinant and non-recombinant sources) may be used
in a
pharmaceutical composition when combined with a pharmaceutically acceptable
carrier.
Such a composition may also contain (in addition to protein and a carrier)
diluents, fillers,
salts, buffers, stabilizers, solubilizers, and other materials well known in
the art. The term
"pharmaceutically acceptable" means a non-toxic material that does not
interfere with the
effectiveness of the biological activity of the active ingredient(s). The
characteristics of the
carrier will depend on the route of administration. The pharmaceutical
composition of
the invention may also contain cytokines, lymphokines, or other hematopoietic
factors
such as M-CSF, GM-CSF, TNF, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-
9, IL-10, IL-11,
2 0 IL-12, IL-13, IL-14, IL-15, IFN, TNFO, TNFl, TNF2, G-CSF, Meg-CSF,
thrombopoietin, stem
cell factor, and erythropoietin. The pharmaceutical composition may further
contain other
agents which either enhance the activity of the protein or compliment its
activity or use
in treatment. Such additional factors and/or agents may be included in the
pharmaceutical composition to produce a synergistic effect with protein of the
invention,
2 5 or to minimize side effects. Conversely, protein of the present invention
may be included
in formulations of the particular cytokine, lymphokine, other hematopoietic
factor,
thrombolytic or anti-thrombotic factor, or anti-inflammatory agent to minimize
side effects
of the cytokine, lymphokine, other hematopoietic factor, thrombolytic or anti-
thrombotic
factor, or anti-inflammatory agent.
3 0 A protein of the present invention may be active in multimers (e.g.,
heterodimers
or homodimers) or complexes with itself or other proteins. As a result,
pharmaceutical
compositions of the invention may comprise a protein of the invention in such
multimeric
or complexed form.
53
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
The pharmaceutical composition of the invention may be in the form of a
complex
of the proteins) of present invention along with protein or peptide antigens.
The protein
and/or peptide antigen will deliver a stimulatory signal to both B and T
lymphocytes. B
lymphocytes will respond to antigen through their surface immunoglobulin
receptor. T
lymphocytes will respond to antigen through the T cell receptor (TCR)
following
presentation of the antigen by MHC proteins. MHC and structurally related
proteins
including those encoded by class I and class II MHC genes on host cells will
serve to
present the peptide antigen{s) to T lymphocytes. The antigen components could
also be
supplied as purified MHC-peptide complexes alone or with co-stimulatory
molecules that
can directly signal T cells. Alternatively antibodies able to bind surface
immunolgobulin
and other molecules on B cells as well as antibodies able to bind the TCR and
other
molecules on T cells can be combined with the pharmaceutical composition of
the
invention.
The pharmaceutical composition of the invention may be in the form of a
liposome
in which protein of the present invention is combined, in addition to other
pharmaceutically acceptable carriers, with amphipathic agents such as lipids
which exist
in aggregated form as micelles, insoluble monolayers, liquid crystals, or
lamellar layers
in aqueous solution. Suitable lipids for liposomal formulation include,
without limitation,
monoglycerides, diglycerides, sulfatides, lysolecithin, phospholipids,
saponin, bile acids,
2 0 and the like. Preparation of such liposomal formulations is within the lev
el of skill in the
art, as disclosed, for example, in U.S. Patent No. 4,235,871; U.S. Patent No.
4,501,728; U.S.
Patent No. 4,837,028; and U.S. Patent No. 4,737,323, all of which are
incorporated herein
by reference.
As used herein, the term "therapeutically effective amount" means the total
2 5 amount of each active component of the pharmaceutical composition or
method that is
sufficient to show a meaningful patient benefit, i.e., treatment, healing,
prevention or
amelioration of the relevant medical condition, or an increase in rate of
treatment, healing,
prevention or amelioration of such conditions. When applied to an individual
active
ingredient, administered alone, the term refers to that ingredient alone. When
applied to
3 0 a combination, the term refers to combined amounts of the active
ingredients that result
in the therapeutic effect, whether administered in combination, serially or
simultaneously.
In practicing the method of treatment or use of the present invention, a
therapeutically effective amount of protein of the present invention is
administered to a
mammal having a condition to be treated. Protein of the present invention may
be
54
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
administered in accordance with the method of the invention either alone or in
combination with other therapies such as treatments employing cytokines,
lymphokines
or other hematopoietic factors. When co-administered with one or more
cytokines,
lymphokines or other hematopoietic factors, protein of the present invention
may be
administered either simultaneously with the cytokine(s), lymphokine(s), other
hematopoietic factor(s), thrombolytic or anti-thrombotic factors, or
sequentially. If
administered sequentially, the attending physician will decide on the
appropriate
sequence of administering protein of the present invention in combination with
cytokine(s), lymphokine(s), other hematopoietic factor(s), thrombolytic or
anti-thrombotic
1 0 factors.
Administration of protein of the present invention used in the pharmaceutical
composition or to practice the method of the present invention can be carned
out in a
variety of conventional ways, such as oral ingestion, inhalation, topical
application or
cutaneous, subcutaneous, intraperitoneal, parenteral or intravenous injection.
Intravenous administration to the patient is preferred.
When a therapeutically effective amount of protein of the present invention is
administered orally, protein of the present invention will be in the form of a
tablet,
capsule, powder, solution or elixir. When administered in tablet form, the
pharmaceutical
composition of the invention may additionally contain a solid carrier such as
a gelatin or
2 0 an adjuvant. The tablet, capsule, and powder contain from about 5 to 95%
protein of the
present invention, and preferably from about 25 to 90% protein of the present
invention.
When administered in liquid form, a liquid carrier such as water, petroleum,
oils of animal
or plant origin such as peanut oil, mineral oil, soybean oil, or sesame oil,
or synthetic oils
may be added. The liquid form of the pharmaceutical composition may further
contain
2 5 physiological saline solution, dextrose or other saccharide solution, or
glycols such as
ethylene glycol, propylene glycol or polyethylene glycol. When administered in
liquid
form, the pharmaceutical composition contains from about 0.5 to 90% by weight
of protein
of the present invention, and preferably from about 1 to 50% protein of the
present
invention.
3 0 When a therapeutically effective amount of protein of the present
invention is
administered by intravenous, cutaneous or subcutaneous injection, protein of
the present
invention will be in the form of a pyrogen-free, parenterally acceptable
aqueous solution.
The preparation of such parenterally acceptable protein solutions, having due
regard to
pH, isotonicity, stability, and the like, is within the skill in the art. A
preferred
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
pharmaceutical composition for intravenous, cutaneous, or subcutaneous
injection should
contain, in addition to protein of the present invention, an isotonic vehicle
such as Sodium
Chloride Injection, Ringer's Injection, Dextrose Injection, Dextrose and
Sodium Chloride
Injection, Lactated Ringer s Injection, or other vehicle as known in the art.
The
pharmaceutical composition of the present invention may also contain
stabilizers,
preservatives, buffers, antioxidants, or other additives known to those of
skill in the art.
The amount of protein of the present invention in the pharmaceutical
composition
of the present invention will depend upon the nature and severity of the
condition being
treated, and on the nature of prior treatments which the patient has
undergone.
Ultimately, the attending physician will decide the amount of protein of the
present
invention with which to treat each individual patient. Initially, the
attending physician
will administer low doses of protein of the present invention and observe the
patient's
response. Larger doses of protein of the present invention may be administered
until the
optimal therapeutic effect is obtained for the patient, and at that point the
dosage is not
increased further. It is contemplated that the various pharmaceutical
compositions used
to practice the method of the present invention should contain about 0.01 pg
to about 100
mg (preferably about O.lng to about 10 mg, more preferably about 0.1 pg to
about 1 mg)
of protein of the present invention per kg body weight.
The duration of intravenous therapy using the pharmaceutical composition of
the
2 0 present invention will vary, depending on the severity of the disease
being treated and
the condition and potential idiosyncratic response of each individual patient.
It is
contemplated that the duration of each application of the protein of the
present invention
will be in the range of 12 to 24 hours of continuous intravenous
administration.
Ultimately the attending physician will decide on the appropriate duration of
intravenous
2 5 therapy using the pharmaceutical composition of the present invention.
Protein of the invention may also be used to immunize animals to obtain
polyclonal and monoclonal antibodies which specifically react with the
protein. Such
antibodies may be obtained using either the entire protein or fragments
thereof as an
immunogen. The peptide immunogens additionally may contain a cysteine residue
at the
3 0 carboxyl terminus, and are conjugated to a hapten such as keyhole limpet
hemocyanin
(KLH). Methods for synthesizing such peptides are known in the art, for
example, as in
R.P. Merrifield, J. Amer.Chem.Soc. ~, 2149-2154 (1963); J.L. Krstenansky, et
al., FEBS Lett.
211, 10 (1987). Monoclonal antibodies binding to the protein of the invention
may be
useful diagnostic agents for the immunodetection of the protein. Neutralizing
monoclonal
56
CA 02295212 1999-12-31
WO 99/01466 PCF/US98/13813
antibodies binding to the protein may also be useful therapeutics for both
conditions
associated with the protein and also in the treatment of some forms of cancer
where
abnormal expression of the protein is involved. In the case of cancerous cells
or leukemic
cells, neutralizing monoclonal antibodies against the protein may be useful in
detecting
and preventing the metastatic spread of the cancerous cells, which may be
mediated by
the protein.
For compositions of the present invention which are useful for bone,
cartilage,
tendon or ligament regeneration, the therapeutic method includes administering
the
composition topically, systematically, or locally as an implant or device.
When
administered, the therapeutic composition for use in this invention is, of
course, in a
pyrogen-free, physiologically acceptable form. Further, the composition may
desirably
be encapsulated or injected in a viscous form for delivery to the site of
bone, cartilage or
tissue damage. Topical administration may be suitable for wound healing and
tissue
repair. Therapeutically useful agents other than a protein of the invention
which may also
optionally be included in the composition as described above, may
alternatively or
additionally, be administered simultaneously or sequentially with the
composition in the
methods of the invention. Preferably for bone and/or cartilage formation, the
composition would include a matrix capable of delivering the protein-
containing
composition to the site of bone and/or cartilage damage, providing a structure
for the
2 0 developing bone and cartilage and optimally capable of being resorbed into
the body.
Such matrices may be formed of materials presently in use for other implanted
medical
applications.
The choice of matrix material is based on biocompatibility, biodegradability,
mechanical properties, cosmetic appearance and interface properties. The
particular
2 5 application of the compositions will define the appropriate formulation.
Potential
matrices for the compositions may be biodegradable and chemically defined
calcium
sulfate, tricalciumphosphate, hydroxyapatite, polylactic acid, polyglycolic
acid and
polyanhydrides. Other potential materials are biodegradable and biologically
well-
defined, such as bone or dermal collagen. Further matrices are comprised of
pure proteins
3 0 or extracellular matrix components. Other potential matrices are
nonbiodegradable and
chemically defined, such as sintered hydroxapatite, bioglass, aluminates, or
other
' ceramics. Matrices may be comprised of combinations of any of the above
mentioned
types of material, such as polylactic acid and hydroxyapatite or collagen and
tricalciumphosphate. The bioceramics may be altered in composition, such as in
calcium-
57
CA 02295212 1999-12-31
WO 99/01466 PCT/US98113813
aluminate-phosphate and processing to alter pore size, particle size, particle
shape, and
biodegradability.
Presently preferred is a 50:50 (mole weight) copolymer of lactic acid and
glycolic
acid in the form of porous particles having diameters ranging from 150 to 800
microns.
In some applications, it will be useful to utilize a sequestering agent, such
as
carboxymethyl cellulose or autologous blood clot, to prevent the protein
compositions
from disassociating from the matrix.
A preferred family of sequestering agents is cellulosic materials such as
alkylcelluloses (including hydroxyalkylcelluloses), including methylcellulose,
ethyicellulose, hydroxyethylcellulose, hydroxypropylcellulose, hydroxypropyl-
methylcellulose, and carboxymethylcellulose, the most preferred being cationic
salts of
carboxymethylcellulose (CMC). Other preferred sequestering agents include
hyaluronic
acid, sodium alginate, polyethylene glycol), polyoxyethylene oxide,
carboxyvinyl
polymer and polyvinyl alcohol). The amount of sequestering agent useful herein
is 0.5-20
wt%, preferably 1-10 wt% based on total formulation weight, which represents
the
amount necessary to prevent desorbtion of the protein from the polymer matrix
and to
provide appropriate handling of the composition, yet not so much that the
progenitor cells
are prevented from infiltrating the matrix, thereby providing the protein the
opportunity
to assist the osteogenic activity of the progenitor cells.
2 0 In further compositions, proteins of the invention may be combined with
other
agents beneficial to the treatment of the bone and/or cartilage defect, wound,
or tissue in
question. These agents include various growth factors such as epidermal growth
factor
(EGF), platelet derived growth factor {PDGF), transforming growth factors {TGF-
a and
TGF-Vii), and insulin-like growth factor (IGF).
2 5 The therapeutic compositions are also presently valuable for veterinary
applications. Particularly domestic animals and thoroughbred horses, in
addition to
humans, are desired patients for such treatment with proteins of the present
invention.
The dosage regimen of a protein-containing pharmaceutical composition to be
used in tissue regeneration will be determined by the attending physician
considering
3 0 various factors which modify the action of the proteins, e.g., amount of
tissue weight
desired to be formed, the site of damage, the condition of the damaged tissue,
the size of
a wound, type of damaged tissue (e.g., bone), the patient's age, sex, and
diet, the severity
of any infection, time of administration and other clinical factors. The
dosage may vary
with the type of matrix used in the reconstitution and with inclusion of other
proteins in
58
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
the pharmaceutical composition. For example, the addition of other known
growth
factors, such as IGF I (insulin like growth factor I), to the final
composition, may also effect
the dosage. Progress can be monitored by periodic assessment of tissue/bone
growth
and/or repair, for example, X-rays, histomorphometric determinations and
tetracycline
labeling.
Polynucleotides of the present invention can also be used for gene therapy.
Such
polynucleotides can be introduced either in vivo or ex vivo into cells for
expression in a
mammalian subject. Polynucleotides of the invention may also be administered
by other
known methods for introduction of nucleic acid into a cell or organism
(including, without
limitation, in the form of viral vectors or naked DNA).
Cells may also be cultured ex vivo in the presence of proteins of the present
invention in order to proliferate or to produce a desired effect on or
activity in such cells.
Treated cells can then be introduced in vivo for therapeutic purposes.
Patent and literature references cited herein are incorporated by reference as
if
fully set forth.
59
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
SEQUENCE LISTING
(1) GENERAL INFORMATION:
(i) APPLICANT: Jacobs, Kenneth
McCoy, John M.
LaVallie, Edward R.
Racie, Lisa A.
Treacy, Maurice
Spaulding, Vikki
Agostino, Michael J.
(ii) TITLE OF INVENTION: SECRETED PROTEINS AND POLYNUCLEOTIDES
ENCODING THEM
(iii) NUMBER OF SEQUENCES: 32
(ivy CORRESPONDENCE ADDRESS:
(A) ADDRESSEE: Genetics Institute, Inc.
(B) STREET: 87 CambridgePark Drive
(C) CITY: Cambridge
(D) STATE: MA
(E) COUNTRY: U.S.A.
(F) ZIP: 02140
(v) COMPUTER READABLE FORM:
(A) MEDIUM TYPE: Floppy disk
(B) COMPUTER: IBM PC compatible
(C) OPERATING SYSTEM: PC-DOS/MS-DOS
(D) SOFTWARE: PatentIn Release #1.0, Version #1.30
(vi) CURRENT APPLICATION DATA:
(A) APPLICATION NUMBER:
(B) FILING DATE:
(C) CLASSIFICATION:
(viii) ATTORNEY/AGENT INFORMATION:
(A) NAME: Sprunger, Suzanne A.
(B) REGISTRATION NUMBER: 41,323
(ix) TELECOMMUNICATION INFORMATION:
(A) TELEPHONE: (617) 498-8284
(B) TELEFAX: (61?) 876-5851
(2) INFORMATION FOR SEQ ID N0:1:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1425 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(xi) SEQUENCE DESCRIPTION: SEQ ID NO: l:
GCTAATTTGA GAAGAAAACA AGTAGGATTT TTGTTTTGTT TTGCATTTTG CAATATGGAG 60
GAGAAATGAT TAGACCTTAG GAAGTGCCAG TGGGTTGGTC CTTTCATGAA CATGCCATCA 120
GTAAAAGCCC TGGAAACAAG GTCATACCAG AGATTCATTG TGCCTTGTCA CAACTGCAAA 180
CAATATCTGA GTGGAATATT CAAAAACTTG CTTAGAAAGA AAACTCTAGG ACAGATGGCT 240
CCACTGAAGT TATTCCAAAT ATTTAATAAA TAAAGCATAC CAGGCTTTTA TAAACTCTTC 300
TAGAAGAAAA AAGTTGGAAC TTTTCCAATT CAGTTTTTCA GGCCAGTGCA ACCTTGATAC 360
CAAAACCAAT AAAACAAACA AACAAACAAA AAACATAAAG CTATAGACCA AAGTCTCATA 420
GATTTAGATG CAAAATCCTA AAATTGAAAA AAAAAGTCTA GTCATATCCA TAAACTGTAT 480
CATCACCAAG AGATGTTTAT TAGGGCAATC AAAAGATGAT TTATTATTTT TTAAAAAATC 540
AATGTGGCCT TCCCTTCCTC TTTCTTTTGA TTCCCCTCTT TGAGTTTTTA TGTGTCTCTT 600
TTGCCTTCCC TTCCCAGAGT GGAGGAGTTA GACCTGCATT GTGGGATGAG AGGAGTTGTG 660
GCTATGTGTC TGCTGGCACC AAGAGGGCTG AGGGTGAGGT GTGGAAGGGA CAGGGGGAGG 720
AGATGGGCAG CATTGTTAAG AGATTGGTAC CACTGAGCAA ATATGTTGAG AATGATGATG 780
GCAAGGTTTC TCCCTGTTAG AGAAGGTATT TGTAGAAATA GGAATGAGGA GAGCTAGAAA 840
ACCTGGAGTG TGGGATTAGA ATAGAACTCA TATCTTTTAA ATACATAGGA ACAATAGAGA 900
AATTGTTGGG TGTGCCCATA TACATATATT TTGTGATTCA TTCTACCGAG AGGACATAAA 960
TGCAGTCACA GCTCAGTAAC AGTAAACACA CCAACTGCCA AGTTATTATT TCCTAAATAC 1020
TATCCACAAA AAAGGGGACC AGGGATGATT CCTAGTCGGA GATTGGGAGA AAAAGAAGAT 1080
GAGCCTGAAT CATTTCATGT ACCTAACAGA AAGAAAATAC TCTGGCTGGG CTCAGWGGCT 1140
CATGTTTGTA ATTCTAGCAT GTTAGGAGGT CGAGGTGGGT GTGTTGCTTG AGCCCAGGAG 1200
TTTGAGACCA GCCCAGGCAA CATGGCAAAA CTGTCTCTAC AAAAAATATA AAAGTTAGCC 1260
AGGCGTGGTG GCATGCGCCT GTCGTCCGAG ATACTCGGGA GGCAGAGAGG TGGGAGGATC 1320
ACTTGAGCCT GGGAGATTGA GACTGCATCG AGCTGTGGTC ATGCCACTGC ACTCCAGCCT 1380
GGAGGACAGA GTGAGACCCT GTCTCAGGAA 1?,~~i~,AAAAAP.A AAAAA 142
5
(2) INFORMATION FOR SEQ ID N0:2:
61
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 94 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:2:
Met Ile Tyr Tyr Phe Leu Lys Asn Gln Cys Gly Leu Pro Phe Leu Phe
1 5 10 15
Leu Leu Ile Pro Leu Phe Glu Phe Leu Cys Val Ser Phe Ala Phe Pro
20 25 30
Ser Gln Ser Gly Gly Val Arg Pro Ala Leu Trp Asp Glu Arg Ser Cys
35 40 45
Gly Tyr Val Ser Ala Gly Thr Lys Arg Ala Glu Gly Glu Val Trp Lys
50 55 60
Gly Gln Gly Glu Glu Met Gly Ser Ile Val Lys Arg Leu Val Pro Leu
65 70 75 80
Ser Lys Tyr Val Glu Asn Asp Asp Gly Lys Val Ser Pro Cys
85 90
(2) INFORMATION FOR SEQ ID N0:3:
(i) SEøUENCE CHARACTERISTICS:
(A) LENGTH: 2859 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:3:
CGCACCCAGC CGCGCCGGCG AGGACATGGG CAGCCGCGGC GCGCCCACCC CCCGCGCCGA 60
TGTGAATTAT TAAAAAGAAA ATGGCCCAAC GGAGCACTGT ATTTCCTTCT CGTGTCACCA 120
AGGAAAGGTA TAATATATGG AAAATATGCA TCTAAGGCGA GTGAGAACCA TGCCCCGACA 180
CAGCCAGTCC CTGACCATGG CACCATACTC ATCTGTAAGC CTCGTGGAGC AGCTGGAAGA 240
CAGGATCCTC TGCCATGAGA AAACCACCGC CGCCCTCGTA GAGCACGCCT TTCGGATTAA 300
62
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
AGATGACATT GTCAACAGTT TGCAGAAAAT GCAAAACAAA GGGGGAGGTG ACCGCTTGGC 360
CAGGCTTTTC TTGGAGGAGC ATATCAGAAA CATAACTGCC ATAGTGAAGC AACTTAATCG 420
GGATATCGAG GTACTCCAGG AGCAGATTCG TGCTCGGGAC AACATTAGCT ATGGAACTAA 480
TTCTGCCTTA AAGACCCTGG AGATGCGCCA GCTCTCCGGT TTGGGAGATC TTCGAGGAAG 540
AGTGGCAAGA TGTGATGCCA GCATAGCTAG ACTTTCTGCA GAGCACAAAA CGACCTATGA 600
GGGGCTCCAG CACTTGAACA AAGAACAGCA GGCTGCCAAA CTTATCTTGG AAACGAAAAT 660
CAAAGATGCA GAGGGACAGA TTTCTCAGCT TTTGAACAGA GTGGACTTGT CAATATCAGA 720
GCAGAGCACC AAACTGAAGA TGTCTCACAG AGACAGTAAC CACCAGCTTC AGCTTTTGGA 780
CACTAAATTT AAAGGTACAG TTGAGGAACT CAGTAACCAG ATATTATCTG CACGGAGTTG 840
GTTGCAACAG GAACAAGAAC GGATAGAAAA AGAGCTTTTA CAGAAAATTG ATCAGCTTTC 900
CTTGATTGTT AAGGAAAACA GTGGAGCCAG TGAAAGGGAT ATGGAGAAGA AGCTCAGCCA 960
GATGTCAGCC AGGCTTGACA AAATAGAAGA GGGTCAAAAG AAGACTTTTG ATGGTCAGAG 1020
AACAAGGCAA GAAGAGGAGA AGATGCACGG GCGAATCACC AAGCTGGAGT TACAGATGAA 1080
CCAGAACATC AAGGAAATGA AAGCAGAAGT TAATGCTGGG TTTACAGCCG TCTATGAAAG 1140
CATAGGATCC CTCAGGCAAG TTCTCGAGGC CAAGATGAAG CTGGACAGGG ACCAGCTACA 1200
GAAGCAAATC CAGCTGATGC AGAAGCCAGA GACCCCCATG TGAAGGGAGC TGGGACAAGG 1260
TCCTAAAAGA CAGTTTTGCC AGTGGGGCTA GGAGCCGGAT ACCTCTGTAG CCAGGCCATC 1320
GCTGCATTCA GGATTGTTCC ATCCATGGCG TGCATGTGCC AAGAAATGTG TTTTTATGGG 1380
TCTAAATGTT TACCTTGAGT CTTGAAAATA CTCTTTTGTT AAAAGTATGA AATACAGTTT 1440
TTACCAGTTT ATTTCACTTC TCTAAATTCA ATGGAAATCC CCCGCCCTGG ATTTTGAAAG 1500
GCTTTTATCT TCTTCATTTT ACGAATGGAA AGACGACAAT TTTTCTTCAA TGCTTGATGC 1560
ACTAATGAAG ACTGTTTACT ATTTTGAAAA ATGTCATGGG GATTTTTTTT TAATTAAGAA 1620
ACTAATGAAT CATCACAGGA ATGTGTTGCT CCTCACCCTA AATTAAGAGA ATGTCCCAGT 1680
AGATTAGACT TCAACCTTTG AGTCCAATTT GGATTTTATT ATCGTTGTCT ATGCACTTCT 1740
TATATTGGTT ATCTTCTTGT AAATCTTCTG TCTTTTGTAA GGGGAAAGGA TTTAACATTT 1800
AGAATAAACC CCACCATTTA TGTAATGGAA ATAGTTTAAA AATTGCTAAC TGCCATGTGG 1860
ATTGCAAATT AAATGGAAAC TTATTTAGAT AACGTAAGGC TCAATATCTG CGTTGACCAC 1920
CTAGATATTA CAGGTTTTAA TATTTAAAAC TATTTTTGAA TTATCCACAA CCTGTATAGT 1980
63
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
GATAGCCATATATTTAATAA TGGAATGGTGGTTAACAGTCTATTTACTGC ACAATTAATT2040
GTTCACTAATCAAATAGAAT GTGGTAATTTTTCAGACTTTATGATCTGTT TCCAAAATTG2100
GCACAAAGTGCTAGGGTTTA TATACACTTATCGTAACTGTATTTTTGTGC CTTGGTTTTA2160
TCATGTCAATGCACTGTACT CTGTAAAAGTTTTGCAGACAAAATAGAAAG TATGATAATC2220
CGTCAGAAGTATGATGTAAA ACTGGAATCCTCTGTATTTTTTAAATGTTC TAAAAATTTT2280
ATCGCTGTTAAGGTATTAAT CATTCAGTATTACTAATGGAATAGAAATTC ATACTTTTGT2340
ATGGACAACAAATTGATATT GCATTTATAGCACTGTAAGAAACTTTCATC TTGAGCAACT2400
TTGTAGATGATGGGTGTTTT ATTTTCAATCGCCATATTTGATCAGTCATT GAAAATTGGC2460
CCCAGTGCTGTTTGTTCATC TCTGTATGTAAAAACTGACAGTGAGACACA ACTTTCTGAA2520
CTGTGAGGGTGTCCCAGGAA AAAGAAAAACAGGAATACTTTAACAATTAA AAAGAAAAAA2580
ATGTTTTTTGTTTGCCAAGG ACTCAGGAAAATAAAAAGCATTTTCTATTT TTAGGACAAA2640
TCACAAATGAAGTGTCTAAC TGGCTATTACTGTTTACCCATATAAAATAT GCTGCTAAAG2700
TACATATTTTGCTGTCAATG GCTTGACAATTTTTTTTTTCAAATTTGGAC ATGAGAGGTT2760
ATATAGGGACTATATTATCC AACACATATTTTCTTATTTTGCCACAAATT TCCACTTAAC2820
AAATAAAAA.AAGGCGAATGC TGTTTTGCAAAAAAAAAAA 2859
(2) INFORMATION
FOR
SEQ
ID N0:4:
(i) S EQUENCE CHARACTERISTICS:
(A) LENGTH: 368 acids
amino
(By TYPE: amino
acid
(Cy STRANDEDNESS:
(D) TOPOLOGY: linear
(ii)
MOLECULE
TYPE:
protein
(xi)SEQUENCE DESCRIPTION:
SEQ
ID
N0:4:
MetGluAsn MetHis LeuArgArg ValArgThr MetProArg HisSer
1 5 10 15
GlnSerLeu ThrMet AlaProTyr SerSerVal SerLeuVal GluGln
20 25 30
LeuGluAsp ArgIle LeuCysHis GluLysThr ThrAlaAla LeuVal
35 40 45
GluHisAla PheArg ileLysAsp AspIleVal AsnSerLeu GlnLys
64
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
50 55 60
Met Gln Asn Lys Gly Gly Gly Asp Arg Leu Ala Arg Leu Phe Leu Glu
65 70 75 80
Glu His Ile Arg Asn Ile Thr Ala Ile Val Lys Gln Leu Asn Arg Asp
85 90 95
Ile Glu Val Leu Gln Glu Gln Ile Arg Ala Arg Asp Asn Ile Ser Tyr
100 105 110
Gly Thr Asn Ser Ala Leu Lys Thr Leu Glu Met Arg Gln Leu Ser Gly
115 120 125
Leu Gly Asp Leu Arg Gly Arg Val Ala Arg Cys Asp Ala Ser Ile Ala
130 135 140
Arg Leu Ser Ala Glu His Lys Thr Thr Tyr Glu Gly Leu Gln His Leu
145 150 155 160
Asn Lys Glu Gln Gln Ala Ala Lys Leu Ile Leu Glu Thr Lys Ile Lys
165 170 175
Asp Ala Glu Gly Gln Ile Ser Gln Leu Leu Asn Arg Val Asp Leu Ser
180 185 190
Ile Ser Glu Gln Ser Thr Lys Leu Lys Met Ser His Arg Asp Ser Asn
195 200 205
His Gln Leu Gln Leu Leu Asp Thr Lys Phe Lys Giy Thr Val Glu Glu
210 215 220
Leu Ser Asn Gln Ile Leu Ser Ala Arg Ser Trp Leu Gln Gln Glu Gln
225 230 235 240
Glu Arg Ile Glu Lys Glu Leu Leu Gln Lys Ile Asp Gln Leu Ser Leu
245 250 255
Ile Val Lys Glu Asn Ser Gly Ala Ser Glu Arg Asp Met Glu Lys Lys
260 265 270
Leu Ser Gln Met Ser Ala Arg Leu Asp Lys Ile Glu Glu Gly Gln Lys
275 280 285
Lys Thr Phe Asp Gly Gln Arg Thr Arg Gln Glu Glu Glu Lys Met His
290 295 300
Gly Arg Ile Thr Lys Leu Glu Leu Gln Met Asn Gln Asn Ile Lys Glu
305 310 315 320
Met Lys Ala Glu Val Asn Ala Gly Phe Thr Ala Val Tyr Glu Ser Ile
325 330 335
Gly Ser Leu Arg Gln Val Leu Glu Ala Lys Met Lys Leu Asp Arg Asp
340 345 350
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Gln Leu Gln Lys Gln Ile Gln Leu Met Gln Lys Pro Glu Thr Pro Met
355 360 365
(2) INFORMATION FOR SEQ ID N0:5:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 933 base pairs
(B) TYPE: nucleic acid
iC) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi} SEQUENCE
DESCRIPTION:
SEQ ID
N0:5:
TGCTTCGGAGACCGTAAGGATATTGATGAC CATGAGATCCCTGCTCAGAA CCCCCTTCCT60
GTGTGGCCTGCTCTGGGCCTTTTGTGCCCC AGGCGCCAGGGCTGAGGAGC CTGCAGCCAG120
CTTCTCCCAACCCGGCAGCATGGGCCTGGA TAAGAACACAGTGCACGACC AAGAGTACGT180
ATTCAGCCCGGGCTGTGGTCCAGTGGCCTC CCCATCATCTGCAGCTGAGC CAGCGGCAAG240
GGCATGCTCAGTCCTCCTTTCCTTCTTCCT GTTTCTATGGCTCCTTGACA TTCTTCAAGG300
ATGATTCTTATTCCTTATTGCCACCTATAA GTCAGGTATTCTTTTTTCAT CATTGTATCA360
CAGGTGGAAGATCTTTAGGCCCAAATGGGG CACATTACTTGTCTGAATCC GGTCTCTCCT420
TTTTTTCACCACAGACAGACACACACACAT ACAAATAGACACACAGGTAC ACATACACAG480
TCATAGTAGCAGAATCCAGAAAATAGCTAA GGTTTCTTGACTATAACAAG ACCTTTTTTA540
AATCAACACATTCAAACATTGAATCATTTG TTGCAGCTTTTGTCTTGGGC CAGTTAGCCT600
CACGCATTATACTCGGTTATCCTTTGTTTT TAAGGCTGGGTGCAGTGGCT CACACCTGTA660
ATCCCAGTGCTTTGGGAGGCTGAGGCAGGT GGATTACTTGAGCCCAGGAA TTCGAGACCA720
GCCTAGGCAATATAGGGAAAACCTGTCTCT AYTAAAAAATTGCAAAAAAT TAGCTGGATG780
TGGCAGTACATGCCTATGGTCCCAGCTACT TGGGGGGCTGAAGTGGGAGA ATCAAMTGAG840
CTTGGGAAGTTGAGGCTACAATGAGCCAAG ATCACGCTCCTGCACTCCAG CCTGGGTGGC900
AGAGTGAGACCCTGTCTCAAP,~~e'~.AAAAAAA 933
AAA
(2) INFORMATION
FOR SEQ
ID N0:6:
(i} S EQUENCE
CHARACTERISTICS:
(A) LENGTH:92 amino acids
66
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:6:
Met Thr Met Arg Ser Leu Leu Arg Thr Pro Phe Leu Cys Gly Leu Leu
1 5 10 15
Trp Ala Phe Cys Ala Pro Gly Ala Arg Ala Glu Glu Pro Ala Ala Ser
20 25 30
Phe Ser Gln Pro Gly Ser Met Gly Leu Asp Lys Asn Thr Val His Asp
35 40 45
Gln Glu Tyr Val Phe Ser Pro Gly Cys Gly Pro Val Ala Ser Pro Ser
50 55 60
Ser Ala Ala Glu Pro Ala Ala Arg Ala Cys Ser Val Leu Leu Ser Phe
ss 70 75 80
Phe Leu Phe Leu Trp Leu Leu Asp Ile Leu Gln Gly
85 90
(2) INFORMATION FOR SEQ ID N0:7:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 2956 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION:
SEQ ID N0:7:
GGTGTGTGGT GGTTTAAGAA TGTATATCATAGGGTCAGGTGGCCTGGGTT CATTCCCCAG60
CTACGTAACC TTTCTATGCC TGAGTTTCCTCATCTATAAAACAAGGATAA TAATAGTGTG120
TACTTCTTAG GATTGTTTTG GAGACTCATAAATGAGAAATACGTGAAAAA CTCCCTCAAG180
GCAGTGCTTG ACACATAATG AGCACTCAGTTATCATGGTCATCATGGTCA TCATCACTGC240
TACCACCACT GCTGCTGCTA TTACCACTCTACCTCTTCCCCCTGAAACTC TAATCACTTA300
CCCTAGAAAC AGTTAAATTA CACTTCAGTGGGAAGGATCTCAGATTTCTT AATGGCACCT360
67
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
GCATTTATAT AATGTTGATA TTGCACGTTCCTAGAAAACATATCAAGAAG 420
AAACCAAAAT
GTGTTTCTGT ACTTTGTAAA CCTGTACAATAGTTAGAGATTAGAGGACCTTTATAATCTA480
CTACTAATTA CTGTGAAAGT AAACATTGTTTAATATACCAGTTCTTAAAGAAATATTTTG540
TCTAGTCATT AATATTCTAG TTCATCTCAAAGCTTCCATTTGACAATTTAAAATTACTTA600
AATTTTAATA TTAAAGGAAA CAGTTTTCCTGATTCTCATGAAAGTTCCTATTTGCACTGA660
AGATGACTAA ACCTTTTAGT CATAGTTTTAGAAGAATTGGCTTTTTTATAGCCATTTTAT720
TTACATATGG GTACTGCATA GCAAAGGCAGCAGATTAGCCCTGTTTGTTTTGCAGGGATG780
AAAGGTAGCA TTCCCAGAGA TTAAGTTGTTCTTGCTATTCCCATTCTCTGCTACATTTGC840
CTACATTCTT TGGTCCTTTC TATTATTTGTTTCTTTGGTGGAATCCCCTTGTTGCTTATG900
GCTGGATATT GTTATTCAGC AGATGAATCACAAGTTTAGCCTGAGGGCCCTAAAGCATCA960
GAAATAAATT AGAGCCGAGC AAAGTTTAACTTCTCTGGAACTTGCACCTTTAGTTTCCAT1020
GTATTTCTGG AACCAAGATA TTTCAAAGGCTTACTTTATTTCAGACACCTATTATCTTCA1080
AGTCACAGAT AACTATTGAT TCTGTAAAGTGTTTCAAAGATTTTTGTCCACTAGACATTT1140
TTAAATTTGT TCAACTCCTC CTCATCATTTTAGAAATTATTTCTGTTAGGTAAAATTAAA1200
ACTAACAATG TATTTTAGTT TATTTTTCTAATGATACCAGTCACCTTTCGGGGCTAACTA1260
AACATTTTGT GCAGCATTCT CTTAGTTTACATCCTCCTTTCTTTCAGTCTTCCTGTTTAT1320
TAAGGCTGTC CTGTAGCAAA CAAAAGAGTGACTCATGTTAAAAGTATTTTAACTGCTCTA1380
ATATATCTGA GGAAGAATAA CTTTCTAAATTAAAGTAATGTATTTTATTAAATATTAAAA1440
TGCATTTTTT GGCTATTCAT TTCTGTATGTAAAAGAAAAGTTAACTTTATGGTGTTATGC1500
AAAATATGCT AAATTTAGAT TTTAGAGCAATATATAGGGAGATATGTCACAAATTTCTAC1560
ATTTTGGTTA AATTATTAGT ATTTTTTTATATTCAAATGTGCCTTGATATTTAAATAATA1620
TACTGAATGC AGAATTTATG TTATGTGAACCATTATGGAAAATGTTAATGTTAACAAAAT1680
GAGGTGTATT GACTTTTCAA CAATGTAAATTAAAGATGGTACATCTACTGTTTAAGGGCA1740
GAGGAATTAA AAGAGTATAG ATACTGAAATGTATCACTTACTAGTAGTGTGGCTATAATC1800
AAATTAATTA ATCTCTCTCT AGGCTTTAGCTTCCTCATCTTAGTTTGTTCAGGCTACTGT1860
AACAAAATAA CATAGATTAT GTACTTTTAAATGACAGAAGTTTATTCGGCATGGTTTGGG1920
AGACTAGGAA GTCTAAGATT AAAGAACCAGCAAATTTGGTGTCTGATGAGGACCCATTCC1980
TTTGTTCACA GATGATGCCT TCTCATTGTGTTTTCAAATGTTAGAAGGAGCTAGCTAGCT2040
68
CA 02295212 1999-12-31
WO 99/01466 PG"T/US98/13813
TTCTGGGGTC TCTTTTGTAA AGGCACTAAT CCCAGTCATT AGGGCAAATT GGCTCCTACA 2100
GGCCCCACCT ATCTCCTAAT ACCATCACCT TGAGGATTAA GATTTCTACA TATGAATGAA 2160
GCAGGTGTTG TAGAAGGTCA GTCAGTTAGA CCATAGCACC ATCTGTAAAA TTGAATAGTA 2220
ATTTACTGCC TCATTGGATG TCAGGATTAA AGGAGATAAG ATTTTATTAG TTACTAGTTA 2280
CCATAGTGGT TTTTTTTTTA CACTATAATG TTCGTTTTTT TGTTTCATGC TTGTACCTTC 2340
AACATTTCCT TCCATTTGAA TACTTCTTTT GTCTCCTGTA GGCCTGTCTG TCCACTTAGG 2400
TGTAAGATGT GTTTTTGTGT CAGGAATGAT GGTGCAATGC TAATGTTCCA TTGCCCTATT 2460
TGGCAATACT CTGATCATTA ACTATAAAGA ATAACACCAG TGTTAACTAA CTCTCCTTGC 2520
CTGACAGTAG TGCTGCCACT ATTCCTTGTT TCTGTGGTAA TAGATGAGGT TTGTATGGTC 2580
CTGTTATTCC AGCCTCCAGA CACCATTCCA GATCAACTGG TGCCYTCWAC GCCCCCGAAG 2640
TGTATGGGGC CTCAGGTGAA GGATGAGWAC ATTTTCACTA TCATCTGGCA TTCATCTCAG 2700
ATTTTATCCT TTTCAGTTTC CATTAAATAA TATTCATGTT TTAAAATTGA TTTTTTATTA 2760
TTTAAATTTA ATTTGTTGGA GAATAAACTT TTTTTTTTCT TTTCTCCCAA GTAACGTTTT 2820
CCCCTTTAGC AACTGTATTG AGCATTTTTC TCACTGGTAT ATGGACATTT TTTTGTATAA 2880
CCTGTTGTGT CATTTTTAAA TATAGAATTG TTTTTATGTT CTCATCTTTG TATATATGTT 2940
TAAAAAAAAA Ap~P,Ap.A 2
9
5
6
(2) INFORMATION FOR SEQ ID N0:8:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 31 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:8:
Met Thr Lys Pro Phe Ser His Ser Phe Arg Arg Iie Gly Phe Phe Ile
1 5 10 15
Ala Ile Leu Phe Thr Tyr Gly Tyr Cys Ile Ala Lys Ala Ala Asp
20 25 30
(2) INFORMATION FOR SEQ ID N0:9:
69
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1325 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID
N0:9:
AATCGGGAAAAAAAGCCATGTATTCTTTCGTTTCTCTCTAAAAGAAGAAAAATATAATTT60
AAAAATACATTGCGTATTTTCTAAAACAATAAATTTATAGTGTTAATATTCATAGGGTCA120
ATCAAAATGAAGCTTCTCCTTTGGGCCTGCATTGTATGTGTTGCTTTTGCAAGGAAGAGA180
CGGTTCCCCTTCATTGGTGAGGATGACAATGACGATGGTCACCCACTTCATCCATCTCTG240
AATATTCCTTATGGCATACGGAATTTACCACCTCCTCTTTATTATCGCCCAGTGAATACA300
GTCCCCAGTTACCCTGGGAATACTTACACTGACACAGGGTTACCTTCGTATCCCTGGATT360
CTAACTTCTCCTGGATTCCCCTATGTCTATCACATCCGTGGTTTTCCCTTAGCTACTCAG420
TTGAATGTTCCTCCTCTCCCTCCTAGGGGTTTCCCGTTTGTCCCTCCTTCAAGGTTTTTT480
TCAGCAGCTGCAGCACCCGCTGCCCCACCTATTGCAGCTGAGCCTGCTGCAGCTGCACCT540
CTTACATCCACACCTGTAGCATCTGAGCCTGCTGCAGGGGCCCCTGTTGCAGCTGAGCCT600
GCTGCAGAGGCACCTGTTGGAGCTGAGCCTGCTGCAGAGGCACCTGTTGCAGCTGAGCCT660
GCTGCAGAGGCACCTGTTGGAGTGGAGCCAGCTGCAGAGGAACCTTCACCAGCTGAGCCT720
GCTACAGCCAAGCCTGCTGCCCCAGAACCTCACCCTTCTCCCTCTCTTGAACAGGCAAAT780
CAGTGAAATTCTCTAGAAGAGTACCATGGGTTCATTTCTATACTGATGCAGAAATAAGTG840
AAATCTACAAAAGTTTTCTTTCTTTTCCAAAGACTATTTCATTCTGTAGTATTCAGAGTA900
TTCATCTCACTACATAGATTTGTTTGTGGTAGTTATTTCCTTGGACTTAATTTATATTGA960
AAAAACATTGATAATTAAATAAATAAAATAGATAATTTAGACCAATGGTGATAAGGTCTG1020
GATGAAAACTACGCTATGGAGGACTGAAATGGCAATCATTCAGCCTAGCCTGGAGTCTGA1080
TTATACAGCTACTATAGGATGATGTTAGTATTGGTTTTGAGTGCAATAGGTTTTTTCCTA1140
AACAAACATATTTTGTAGTCAATGAACTTTTTGTCACAAAACAGTAAAACATCTGTGTTT1200
AACCTATGGTAAACAACATGTTAATGAACTATGCTATCCATGACTTAATGGACAGTTCAA1260
CA 02295212 1999-12-31
WO 99/01466 PCT/US98I13813
~A F~,~~i~,AAAAAAA p~~i~AAAAAAP. AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA 13 2 0
AAAAA 1325
(2) INFORMATION FOR SEQ ID N0:10:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 219 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:10:
Met Lys Leu Leu Leu Trp Ala Cys Ile Val Cys Val Ala Phe Ala Arg
1 5 10 15
Lys Arg Arg Phe Pro Phe Ile Gly Glu Asp Asp Asn Asp Asp Gly His
20 25 30
Pro Leu His Pro Ser Leu Asn Ile Pro Tyr Gly Ile Arg Asn Leu Pro
35 40 45
Pro Pro Leu Tyr Tyr Arg Pro Val Asn Thr Val Pro Ser Tyr Pro Gly
50 55 60
Asn Thr Tyr Thr Asp Thr Gly Leu Pro Ser Tyr Pro Trp Ile Leu Thr
65 70 75 80
Ser Pro Gly Phe Pro Tyr Val Tyr His Ile Arg Gly Phe Pro Leu Ala
85 90 95
Thr Gln Leu Asn Val Pro Pro Leu Pro Pro Arg Gly Phe Pro Phe Val
100 105 110
Pro Pro Ser Arg Phe Phe Ser Ala Ala Ala Ala Pro Ala Ala Pro Pro
115 120 125
Ile Ala Ala Glu Pro Ala Ala Ala Ala Pro Leu Thr Ser Thr Pro Val
130 135 140
Ala Ser Glu Pro Ala Ala Gly Ala Pro Val Ala Ala Glu Pro Ala Ala
145 150 155 160
Glu Ala Pro Val Gly Ala Glu Pro Ala Ala Glu Ala Pro Val Ala Ala
165 170 175
Glu Pro Ala Ala Glu Ala Pro Val Gly Val Glu Pro Ala Ala Glu Glu
180 185 190
71
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Pro Ser Pro Ala Glu Pro Ala Thr Ala Lys Pro Ala Ala Pro Glu Pro
195 200 205
His Pro Ser Pro Ser Leu Glu Gln Ala Asn Gln
210 215
(2) INFORMATION FOR SEQ ID N0:21:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 225 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION: SEQ ID NO:11:
TGCGGGCTCA CANGAANAGT CTCACCTCAG TGCCAAGGGG TGTCAGAGAT GCTCACTGCC 60
CTCCTCTCCT TGGGGTTGCA TGNAGGCATG ATGGCGCTTG GCCGTGGCAG GGTAAGGAAC 120
CGGCGACNGA GGCCCATCAC GTGTTCACAT GCTCTCCTGC GTCNGTGCTT GGGAGATATG 180
GACTGTCNTG TCCTTAGACC ACATTTATNT CAAGGCAAGG GGAGC 225
(2) INFORMATION FOR SEQ ID N0:12:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 533 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi)
SEQUENCE
DESCRIPTION:
SEQ
ID N0:12:
GGTTCAAAATGAGGCAAAGATAGGAAAGTGCTTCTTACAGATAATTTTCAAGGCCAGTGA 60
CTGGAGAGAGGGGTAGGTCTGTCAATCGAGTGCTTGCTGACTGCACATATCACAGGGCGT 120
GTGACGACTGCTGGGAGAGGAAAGCGAGACATCATTCCAACCCTCCAGAAGCTAAAGATC 180
CTGGAACTCAAGGGGAAAACTAACGTAAGTGCGAAAGCGAACAAGCAAACATGTCCTCAA 240
CGGGGCAGGCAGGCTGTCGGGGTACAGAGCTGGGATCTGGGAAGGAACAGAGAGGGCCGC 300
TCAGGGAGAGGAAGCACAGTGCCACCGGAGGCACGCACTCAGCAGGCACTCGCAGGCTGG 360
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
GCAGAGGTAG AGAAGCAGCG CTGCACAGGC AGGCAGCTGA CCCAGGGCTC TTAGAGCCGG 420
GCAGGAGAGC TGGTGTGGGA CCTGGGAGGA GGACAGGAGC CTTCAAAGCA GCACCGCCTG 480
ATTGCAGCCA GGAGGGTAGC ATCAAGGAAG ATGGAACTGC GGCCAGGCCA CAT 533
(2) INFORMATION FOR SEQ ID N0:13:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 101 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:13:
Met Ser Ser Thr Gly Gln Ala Gly Cys Arg Gly Thr Glu Leu Gly Ser
1 5 10 15
Gly Lys Glu Gln Arg Gly Pro Leu Arg Glu Arg Lys His Ser Ala Thr
20 25 30
Gly Gly Thr His Ser Ala Gly Thr Arg Arg Leu Gly Arg Gly Arg Glu
35 40 45
Ala Ala Leu His Arg Gln Ala Ala Asp Pro Gly Leu Leu Glu Pro Gly
50 55 60
Arg Arg Ala Gly Val Gly Pro Gly Arg Arg Thr Gly Ala Phe Lys Ala
65 70 75 80
Ala Pro Pro Asp Cys Ser Gln Glu Gly Ser Ile Lys Glu Asp Gly Thr
85 90 95
Ala Ala Arg Pro His
100
(2) INFORMATION FOR SEQ ID N0:14:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 458 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
, (D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
73
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(xi) SEQUENCE DESCRIPTION: SEQ ID
N0:14:
TAGGCAGTCA TCTTTGTAAA CCTCCACTGG GTTTAGAACA TACTCCATAT60
TGCTGGCTGC
AAAACAGGCC CTGGGATTAC AGGCATGAGC GGCCCCCTTT TTTTTAATTA120
TACCGTGCCT
CAGAGAAATA AGTTACACCT TAGTATCAGA CTTCAGTGTT CAGGCAATTA180
TATTAATTTT
GTATTTAGAA AGCTCTTGTC ATGAGATGGC GATGATGATT GTTGGGATTG240
TCTGGGATGT
AAAAAATGGT AGTATCATGG AGAGATCATA AGTATTAAAA GTGGTTTTGC300
ATAAATTCTT
TTTCAGTTAG GGAGAAAAAT TAGATTGTAC CTATGATTTC CTTCAGTTAT360
TATTTTTCCT
CTTCCAAATG TTGTTTTTTC CCCACAGCCC GTTCTCTATG CACTTCTCAA420
CCTTAACATT
TACATTTTCA TTTGTTTCTC AAAAAAAAAA 458
AAAAAAAA
(2) INFORMATION FOR SEQ ID N0:15:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1350 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi)
SEQUENCE
DESCRIPTION:
SEQ
ID N0:15:
TTTTTTTTTTTTTTTGTAGAGACAGGGTCT TGCCATTTTGCCCAGGTTGGTCTCAAACTT 60
CTGAGCTCAGGCTATCTGCCCACCTTGGCC TCCCAAAGTGCTGGGATTACAGGTGTGAGC 120
CACTGTGCCCGGCCTGTATTGTTTTAAGTT ACACTTATTCCTTTTAAAATTCAGAATTTG 180
TTAAGCATTTAAAACAAATTCATAAATTAA AACCTCCTTGAGATACCATTTACCATGTAG 240
TTTGATGAACATAATACATGGTGCATTACA TTGGCAAAAGCAGTGGGGAAAAAGATGCTT 300
TTATAAATGTCTGGTGGGAGTTAAATTGTG TAACTTCTATTACACTTTTGTAATAGCTAC 360
CAAAATATGTTATTTCTATCTACCTCTCTC TCTCTGACTCAACAGTTCCATTTCTAGGTT 420
TTGTGTTGTGGATATTCTTGAACATTGTGA AATGTATACAGGGAGGCTTCACAGCAGCAC 480
TGTTTGTTTCAAATGATTTGAAAACAACCT CTCCATAAACGAGATAGGCTAAATCAAGCA 540
TGGCACACCTATACAATGGATGCGGCCATT AAAAAGAACAAGGCAGCTCATATGCATCAA 600
TATAAAAAGGTCTATAAACTATACTATCAA ATGAAAATAGCAAGATGCTACCATTTATAT 660
74
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
TAAAAAGAGG ACAAAATATT AATATATTCA TGGTTGCTTG TCTATGTGGA ATATTTCTGG 720
ATATATACAT AAGAAGTTAC ATTGGTTACC TATGGGCAGG TTACTACTGG GTGGCTTGTG 780
GGTGAGGGCA GGAAGAGCTT ACTTTCCATG GTAAACCTTT TTGTATATTT TGCAGCATTC 840
AAAAATTCTA ATTTAAAGTT TATTTTAGAA AAATGCCCCC ATGTATACAA GTGATTTCCA 900
AGTTCCTCCT TCAATATTTT TAATGATTAT GGAACACACT GAACTTCTTT TTTATTATTC 960
TAGCTGTGAA CTCTGTCTGC TGTCTACATG CACATATATA ATCTATGTAA TATTTAAATT 1020
TATATCCTTT ATATGTCAGT TGGGTGGTGA GTAAAAGAAA AATATATTTT TATCAGCAAA 1080
CTTGGTAAAT TGTTGAGGTT TCTGATATAG TCAGAGGTAG TTGCTTATCA CAACATTAGG 1140
TAAGTTTTTA AARACACCTA TTTAAAACAC ACTGATGTAT ATATATATTG GTCTGTTTTC 1200
ATGCTGCTGA TAAAGACATA TCCAAGACTG GGAAGAAAAA GAGGTTTAAT TGGGCTTATA 1260
GTTCCACATG GCTGGGGAGG CCTCAGAATC ATTGCGGGAG GCAAAAGGCA CTTCTTACAT 1320
GGCAGTGGCA AGAGAAAAAA p,~~i~P~AAAAAA 13
5
0
(2) INFORMATION FOR SEQ ID N0:16:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 46 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:16:
Met Leu Pro Phe Ile Leu Lys Arg Gly Gln Asn Ile Asn Ile Phe Met
1 5 10 15
Val Ala Cys Leu Cys Gly Ile Phe Leu Asp Ile Tyr Ile Arg Ser Tyr
20 25 30
Ile Gly Tyr Leu Trp Ala Gly Tyr Tyr Trp Val Ala Cys Gly
35 40 45
(2) INFORMATION FOR SEQ ID N0:17:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1598 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
CA 02295212 1999-12-31
WO 99/01466 PCTNS98/13813
(ii) MOLECULE TYPE: cDNA
(xi)
SEQUENCE
DESCRIPTION:
SEQ
ID N0:17:
TCGGGACACTACATGAAGTCCTGAAAATAACAGAGAAACTGTTATATCTTTTTAATGATT60
TATTTGCAAGTATTGAGGTTGACCTGAAAAACAATGAAACACATGAACACACTTCCGATT120
TTCTCCTCGCTGATTAGCTTCCTGCCTGCTGTCAGTGCTGGACGAAGTGCTATAACTACT180
TTATGTAACATTACAGAACAGCTAGAGGTCCTGGGGTAAGAGAAAAAAAGCACATCACAA240
CAAATGTGAAAGCCTTCATTATTACACGTTCCAGTTTGTCTCGCTGTGTAGGCATAAGCT300
AATGGTTTATTTTCAGAAAGCTGCCTGAAACGTTGCTTTGTATTCTTCTAGGAAGAACTT360
TAATTCCTCCTGAGGAACTCTACTTTCTGAGCCAAACTGCTAATTTTCTGCGGAACTGTC420
TAGAAGATCATTCAAGAGACCCTGCAGTTGCACTTTCTCGTAAAAGTTAAAAAAAAAAAA480
F,PAP.AP.P.AAGGTTTTTCCCGGCCTTTGAACATTTTGCCTATGAGAGTTTTGCATATATTT540
TATACTTGAGTAGACAACTTTAATAATCCATATTTATACTATCGCAGAAGTAAGCATTTG600
GCAAACGTTCAGCCATTAGCACTCATTTAACCCTGTTAGCAATATTCTTTTGAAAAAAGT660
GCCAGTCCTTATGTGATAAACTAAGAAGCCCATTGAATATAAAANTGTGTNGGACTGAAA720
CNGTGACCTTATATTATTGCTAAGGGAATATGAGATTAACTTCCTACAGGGGCCANAACC780
ANANAAAGGCTTCCAGCAACTTCGATNAAANTANTTTGGCCACATNTCAAGCCAATTGTT840
TGTACTATTTATGTACCTTTTTCATAACTGGAATTGCCAAATAAGCATGGAGATCTAAAT900
GRAAAAAAAAAAAAAAAAAAAAAGCGGCCGCAGGTCTAGAATTCAATCGGAAAAAACAAA960
GAGAAGAAACATACTGCCCCATCTTGTTTGCATGAAACTCTAGAATCTGGTGTTTCTCTA1020
TTTATCTGCTCCCTCTTTGCCTACCTTGGNATTTCTTTTTTTTTTTCTTTGTAACTATGG1080
TTTTTACCTAAAGTTTAAACTTTTTATTATTATTTTCTCTCTAAATTCTTGCTAGTTAAT1140
AACATTATTAACTTCAAGATTTTAGAAGAGCAGTGATGATAGTAATGATCGATAACTAGA1200
CTATCGAGTTTCAGAAGAAACTTCCAAGTATATATAATGTTTGACATAGCCTTTATTTCT1260
ACAAATCTACTACCTGTAAACTAACATTTTAAAATACCTGTATATGGCTGGGTGTGGTGG1320
CTTACACCTGTAATCCCAGCAGTTTGGGAGCCTGAGGTGGGCAGATTGCTTGAGCCCAGG1380
AGTTGGAGACAAGCCTGGACAAAATAGACCTCTCTCTACAAAAAGTACAAAAAATTGGCT1440
76
CA 02295212 1999-12-31
WO 99/01466 PGT1US98/13813
GGGTGTGGTG GCACACGCCT GTGGTCCCAG CTACTCGGGA GGCTGAGGTG GGAGGATTGC 1500
CTGAGCCCGG GAGATGGTGG TTGCAGTGAG CTGAGATCAC CCCATTGCAC TCCAGCCTGG 1560
ATAACAGAAT AAGATGCTGT CTTAAAAAAA AAAAAAAA 1598
(2) INFORMATION FOR SEQ ID N0:18:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 91 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
{D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
{xi) SEQUENCE DESCRIPTION: SEQ ID N0:18:
Met Lys His Met Asn Thr Leu Pro Ile Phe Ser Ser Leu Ile Ser Phe
1 5 10 15
Leu Pro Ala Val Ser Ala Gly Arg Ser Ala Ile Thr Thr Leu Cys Asn
20 25 30
Ile Thr Glu Gln Leu Glu Val Leu Gly
35 40
(2) INFORMATION FOR SEQ ID N0:19:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1257 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
{xi) SEQUENCE DESCRIPTION: SEQ ID N0:19:
CATGGCGTCC AGGTCTAAGC GGCGTGCCGT GGAAAGTGGG GTTCCGCAGC CGCCGGATCC 60
CCCAGTCCAG CGCGACGAGG AAGAGGAAAA AGAAGTCGAA AATGAGGATG AAGACGATGA 120
TGACAGTGAC AAGGAAAAGG ATGAAGAGGA CGAGGTCATT GACGAGGAAG TGAATATTGA 180
ATTTGAAGCT TATTCCCTAT CAGATAATGA TTATGACGGA ATTAAGAAAT TACTGCAGCA 240
GCTTTTTCTA AAGGCTCCTG TGAACACTGC AGAACTAACA GATCTCTTAA TTCAACAGAA 300
77
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
CCATATTGGG AGTGTGATTA AGCAAACGGA 360
TGTTTCAGAA GACAGCAATG ATGATATGGA
TGAAGATGAG GTTTTTGGTT TCATAAGCCT ACTGAAAGAA AGGGTACCCA420
TTTAAATTTA
GTGTGTTGAA CAAATTCAAG AGTTGGTTMT GAGAAGAACT GTGAAAAGAG480
ACGCTTCTGT
CATGGTTGAA CAGCTGGACA AGTTTTTAAA AAGCCTGTGG GCCTTCTCCT540
TGACACCACC
AAGTGAAAGA TTCATTAATG TCCCTCCACA CCCATGTACC AGCAGCTTCA600
GATCGCTCTG
GAAAGAACTG KCGGGGGCAC ACAGAACCAA GGGAAGTGCT ACTTTTACCT660
TAAGCCATGT
TCTGATTAGT AAGACATTTG TGGAAGCAGG TCCAAAAAGA AACCTAGCAA720
AAAAAACAAT
CAAAAAGAAA GCTGCGTTAA TGTTTGCAAA GAATTTTTCT ATGAGAAGGC780
TGCAGAGGAA
AATTCTCAAG TTCAACTACT CAGTGCAGGA ACTTGTCTGG GAGGCAAATG840
GGAGAGCGAC
GTCTTTTGAT GACGTACCAA TGACGCCCTT ATGTTAATTC CAGGCGACAA900
GCGAACTGTG
GATGAACGAA ATCATGGATA AACTGAAAGA GTCTAACCCA TTTCCAATGG960
ATATCTATCT
ACAGTGATGG GCTTGTTTTT GTAAAATTAC AGTGGAGATT TACTGAAAAA1020
CAGAAAACTC
CTCAGACTTT ATTCAGATTA AGTTCCTCTA GGTTCTGTCC CATGTGTYTC1080
CAAAAAGTAG
TGACACATTT ACAAAATACC AGTTTTTTAA AAATTATGAG TGGTTGATTT1140
AATTTTGGTC
AAAAACTTTT CCAAGAAGAA GAAAAGCATG TTAAAGAACT C.~ATAAAAAC1200
GAGTAGTAAT
TTCTATTTTT TATTTTAAAA TAATAAAAAA AAAAAAAAAA AAAAAAA 1257
AAAAAAAAAA
(2) INFORMATION FOR SEQ ID N0:20:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 314 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:20:
Met Ala Ser Arg Ser Lys Arg Arg Ala Val Glu Ser Gly Val Pro Gln
1 5 20 15
Pro Pro Asp Pro Pro Val Gln Arg Asp Glu Glu Glu Glu Lys Glu Val
20 25 30
Glu Asn Glu Asp Glu Asp Asp Asp Asp Ser Asp Lys Glu Lys Asp Glu
35 40 45
78
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
Glu Asp Glu Val Ile Asp Glu Glu Val Asn Ile Glu Phe Glu Ala Tyr
50 55 60
Ser Leu Ser Asp Asn Asp Tyr Asp Gly Ile Lys Lys Leu Leu Gln Gln
65 70 75 80
Leu Phe Leu Lys Ala Pro Val Asn Thr Ala Glu Leu Thr Asp Leu Leu
85 90 95
Ile Gln Gln Asn His Ile Gly Ser Val Ile Lys Gln Thr Asp Val Ser
100 105 110
Glu Asp Ser Asn Asp Asp Met Asp Glu Asp Glu Val Phe Gly Phe Ile
115 120 125
Ser Leu Leu Asn Leu Thr Glu Arg Lys Gly Thr Gln Cys Val Glu Gln
130 135 140
Ile Gln Glu Leu Val Xaa Arg Phe Cys Glu Lys Asn Cys Glu Lys Ser
145 150 155 160
Met Val Glu Gln Leu Asp Lys Phe Leu Asn Asp Thr Thr Lys Pro Val
165 170 175
Gly Leu Leu Leu Ser Glu Arg Phe Ile Asn Val Pro Pro Gln Ile Ala
lao 1s5 190
Leu Pro Met Tyr Gln Gln Leu Gln Lys Glu Leu Xaa Gly Ala His Arg
195 200 205
Thr Asn Lys Pro Cys Gly Lys Cys Tyr Phe Tyr Leu Leu Ile Ser Lys
210 215 220
Thr Phe Val Glu Ala Gly Lys Asn Asn Ser Lys Lys Lys Pro Ser Asn
225 230 235 240
Lys Lys Lys Ala Ala Leu Met Phe Ala Asn Ala Glu Glu Glu Phe Phe
245 250 255
Tyr Glu Lys Ala Ile Leu Lys Phe Asn Tyr Ser Val Gln Glu Glu Ser
260 265 270
Asp Thr Cys Leu Gly Gly Lys Trp Ser Phe Asp Asp Val Pro Met Thr
275 280 285
Pro Leu Arg Thr Val Met Leu Ile Pro Gly Asp Lys Met Asn Glu Ile
290 295 300
Met Asp Lys Leu Lys Glu Tyr Leu Ser Val
305 310
(2) INFORMATION FOR SEQ ID N0:21:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1544 base pairs
79
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi)
SEQUENCE
DESCRIPTION:
SEQ
ID N0:21:
GCGGTCCTGCCACACAAGCTGGGCGGCGGAGGCCACGCAGCCGGGCCTTCTTCTCTCTGG60
GACCCTCCGCCAGCGCATAGCCGCAGGCCGGTGTGACTTCTGCACCCTCGGTTCTGAGGG120
TACGGTGACCCCTAGTGGGCAGTTTGCAAAATGTGATTCCTTCTTCCCAACTCCCCATCC180
CCCCTTCCCTTCCCGTCACGTCCTGTTTGGGGGTTAATTCGGTTTTTTCTCTGTTGCATC240
GCGCCTACTGTGCGTGTGCGATARCGTGTGTGGGGGTGAGAGTTTGTTTTCTGGAATGGT300
AGGTGCTGGGAGGAGGAGTTTGATGGAGGGCTTCCTGGCTGCTTCTGGCCCTCACCTCGT360
GGAGGCCTTCACAGAGACCCTGTGGGCCCTGGCCCTGTGCTGGCACTGTGCCAGTCATGA420
GGCAGCTCTGATCACTTCCCCACTGTGGAAACAGGACTGACCCAGCCTTCAGTGTGGGCT480
GCTGAAGCTATCCTCCTCAGGCCTCAGGGATGACCTCCTGCCTGAGCCTCTCACAGGCTG540
GCTGTGGGCCAGTTTCATCTGCTTTCCTGTTGGGGGTCCCGGGCCTCTGCTGTCCTTGAC600
CCACTGGTGTTCTGTGCAAGGCTTCTTCCCATTCACCAAGTGCACACCTTGCATCTGCCG660
CTCGGCATGCACCAGTTCCACACACCATCCCATTTTACAGACAAGGACGCTGAGGCCTGC720
AGCAGCAGTGTGACTTGCTCAAGGTCCAGTGAGTGACCTCATTCCCCAGAAAAGGCTCCT780
CCCACACCAGAGTACAGCCTGGGTAGGGGGAAAATCAGTTCTTTCAGCTACCACCCATCC840
AACCTTTGGGCCTATGTGAAAAGAAAGGAACTAAGCTGGGTGTGTTCTGTCTGGACCTGG900
GGAGGCCCCTGAAGGCAAAGAGGGAAACTGTCCCAGCTGTTCTGTCCTAGGGGAGGGGGA960
CATAGCCCTAGCAGGAGCTCCCAGCCCCTCTTGGCACTCTGACACACAAGTACACCCATC1020
TGGGGCCCGCTTTGCCACGAAGAGCTGGGCAGGCCTGCAGGGTGTGGGGAAGGAGGACAC1080
AACCTCAAGAAAGGAAGCGTGAACCCCAGGGAACAGCGGGTCCCTTCCCTCCTCAGACAC1140
AAGCCACCTCAGCTTGTGGCTCTTGGCCCCCAGCCCCACCAACCCACCTGTTCATTTATT1200
CAACAGACAATGACAGCTGATATTTATTGGACATTTGCACCATGCCAAGCATTCGGCTTG1260
GATTATCCCATTTGTTTCTCACAGCCGGTATTTATTGTCTGCTCCTCTGTGCCAGGTGCT1320
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
GTGCTCTGGG CAGGGGCACT GCATGGGCTG CCTGCCCTGG TGGAGCTTGT GGTCTGATGG 1380
GTGAGGCTGA CCCAAGCCCA CCCCATTGCC AACAGGGCCA GGGCAAGAGT ACACACAGGG 1440
GCCTCATACC ATATGTCTAA ATATTTAAAA GTTATCAATC AAGCTAACAA CTGTTAAATA 1500
AAATATGTTC TATTCTCCTA CTTTGAAAAA AAAAAAAAAA AAAA 1544
(2) INFORMATION FOR SEQ ID N0:22:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 72 amino acids
(B) TYPE: amino acid
(C) STR.ANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:22:
Met Pro Ser Ile Arg Leu Gly Leu Ser His Leu Phe Leu Thr Ala Gly
1 5 10 15
Ile Tyr Cys Leu Leu Leu Cys Ala Arg Cys Cys Ala Leu Gly Arg Gly
20 25 30
Thr Ala Trp Ala Ala Cys Pro Gly Gly Ala Cys Gly Leu Met Gly Glu
35 40 45
Ala Asp Pro Ser Pro Pro His Cys Gln Gln Gly Gln Gly Lys Ser Thr
50 55 60
His Arg Gly Leu Ile Pro Tyr Val
65 70
(2) INFORMATION FOR SEQ ID N0:23:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:23:
CNATGCAGGTC TAACTCCTCC ACTCTGGG 29
81
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(2) INFORMATION FOR SEQ ID N0:24:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:24:
TNAGTTTGGTG CTCTGCTCTG ATATTGAC 29
(2) INFORMATION FOR SEQ ID N0:25:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:25:
GNCATCAATAT CCTTACGGTC TCCGAAGC 29
(2) INFORMATION FOR SEQ ID N0:26:
(i} SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A} DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:26:
GNAAATAGGAA CTTTCATGAG AATCAGGA 29
(2) INFORMATION FOR SEQ ID N0:27:
82
CA 02295212 1999-12-31
WO 99/01466 PCT/US98/13813
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:27:
ANACAATGCAG GCCCAAAGGA GAAGCTTC 29
(2) INFORMATION FOR SEQ ID N0:28:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:28:
GNTTGCTTGTT CGCTTTCGCA CTTACGTT 29
(2) INFORMATION FOR SEQ ID N0:29:
(i) SEQUENCE CHARACTERISTICS:
(Ay LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(iiy MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucelotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:29:
ANTGGTAGCAT CTTGCTATTT TCATTTGA 29
(2) INFORMATION FOR SEQ ID N0:30:
(i) SEQUENCE CHARACTERISTICS:
83
CA 02295212 1999-12-31
WO 99/0!466 PCT/US98/13813
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
_ (ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:30:
TNGGAAGTGTG TTCATGTGTT TCATTGTT 29
(2) INFORMATION FOR SEQ ID N0:31:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C} STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii} MOLECULE TYPE. other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:31:
GNCCTCGTCCT CTTCATCCTT TTCCTTGT 29
(2) INFORMATION FOR SEQ ID N0:32:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii} MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:32:
ANCACCTGGCA CAGAGGAGCA GACAATAA 29
84