Note: Descriptions are shown in the official language in which they were submitted.
DEMANDES OU BREVETS VOLUMINEUX
LA PRESENTE PARTiE DE CETTE DEMANDE OU CE BREVET
COMPREND PLUS D'UN TOME.
CECI EST LE TOME DE ~
NOTE: Pour les tomes additionels, veuiilez contacter le Bureau canadien des
brevets
-JUM BO APPLICATiO NS/PATENTS
THIS SECTION OF THE APPLICATION/PATENT CONTAINS MORE
THAN ONE VOLUME
= THIS IS VOLUME OF
NOTi=: For additional volumes-please contact the Canadian Patent Office= =
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-1-
A CAMERA WITH INTERNAL PRINTING SYSTEM
Field of the Invention
The present invention relates to an image processing method and apparatus and,
in particular, discloses a
Digital Instant Camera with Image Processing Capability.
The present invention further relates to the field of digital camera
technology and, particularly, discloses a
digital camera having an integral color printer.
Background of the Invention
= Traditional camera technology has for many years relied upon the provision
of an optical processing system
which relies on a negative of an image which is projected onto a
photosensitive film which is subsequently
chemically processed so as to "fix" the film and to allow for positive prints
to be produced which reproduce the
original image. Such an image processing technology, although it has become a
standard, can be unduly complex, as
expensive and difficult technologies are involved in full color processing of
images. Recently, digital cameras have
become available. These cameras normally rely upon the utilization of a
charged coupled device (CCD) to sense a
particular image. The camera nonnally includes storage media for the storage
of the sensed scenes in addition to a
connector for the transfer of images to a computer device for subsequent
manipulation and printing out.
Such devices are generally inconvenient in that all images must be stored by
the camera and printed out at
some later stage. Hence, the camera must have sufficient storage capabilities
for the storing of multiple images and,
additiornally, the user of the camera must have access to a subsequent
computer system for the downloading of the
images and printing out by a computer printer or the like.
Further, PolaroidT"' type instant cameras have been available for some time
which allow for the production
of instant images. However, this type of camera has limited utility producing
only limited sized images and many
problems exist with the chemicals utilised and, in particuiar, in the aging of
photographs produced from these types of
cameras.
When using such devices and other image capture devices it will be desirable
to be able to suitably deal
with audio and other environmental information when taking a picture.
Further, the creation of stereoscopic views, with a first image being
presented to the left eye and second
image being presented to the right eye, thereby creating an illusion of a
three dimensional surface is well known.
However, previous systems have required complex preparation and high fidelity
images have generally not been
possible. Further, the general choice of images has been limited with the
images normally only being specially
prepared images.
There is a general need for being able to produce high fidelity stereoscopic
images on demand and in
particular for producing images by means of a portable camera device wherein
the stereoscopic image can be
taken at will.
Further, it would be highly convenient if such a camera picture image
production system was able to create
automatic customised postcards which, on a first surface contained the image
captured by the camera device and, on a
second surface, contains pre-paid postage marks and address details.
Recently, it has become more and more popuiar in respect of photographic
reproduction techniques to
produce longer and longer "panoramic" views of a image. These images can be
produced on photographic paper or
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-2-
the like and the structure of the image is normally to have longer and longer
lengths in comparison to the width so as
to produce the more "panoramic" type views. Unfortunately, this imposes a
problem where the photographic paper to
be imaged upon originally was stored on a roll of small diameter.
Recently, it has become quite popular to provide filters which produce effects
on images similar to popular
artistic painting styles. These filters are designed to take an image and
produce a resultant secondary image which
appears to be an artistic rendition of the primary image in one of the
artistic styles. One extremely popular artist in
modem times was Vincent van Gogh. It is a characteristic of art works produced
by this artist that the direction of
brush strokes in f[at areas of his paintings strongly follow the direction of
edges of dominant features in the painting.
For example, his works entitled "Road with Cypress and Star", "Starry Night"
and "Portrait of Doctor Gachet" are
illustrative examples of this process. It would be desirable to provide a
computer algorithm which can automatically
produce a "van Gogh" effect on an arbitrary input image an output it on a
portable camera system..
Unfortunately, warping systems generally utilised high end computers and are
generally inconvenient in that
an image must be scanned into the computer processed and then printed out.
This is generally inconvenient,
especially where images are captured utilising a hand held camera or the like
as there is a need to, at a later stage,
transfer the captured images to a computer system for manipulation and to
subsequently manipulate them in
accordance with requirements.
Further, new and unusual effects which simulate various painting styles are
often considered to be of great
value. Further, if these effects can be combined into one simple form of
implementation they would be suitable for
incorporation into a portable camera device including digital imaging
capabilities and thereby able to produce desire
filtered images of scenes taken by a camera device.
Unfortunately, changing digital imaging technologies and changing filter
technologies result in onerous
system requirements in that cameras produced today obviously are unable to
take advantages of technologies not yet
available nor are they able to take advantage of filters which have not, as
yet, been created or conceived.
One extremely popular form of camera technology is the traditional negative
film and positive print
photographs. In this case, a camera is utilized to image a scene onto a
negative which is then processed so as to fix
the negative. Subsequently, a set of prints is made from the negative. Further
sets of prints can be instantly created at
any time from the set of negatives. The prints normally having a resolution
close to that of the original set of prints.
Unfortunately, with digital camera devices, including those proposed by the
present applicant, it would be necessary
to permanently store in a digital form the photograph captured and printed out
if further copies of the image were
desired at a later time. This would be generally inconvenient in that,
ideally, a copy of a "photograph" should merely
require the initial print. Of course, altematively, the original print may be
copied utilising a high quality colour
photocopying device. Unfortunately, any such device has limited copy
capabilities and signal degradation will often
be the result when such a form of copying is used. Obviously, more suitable
forms of producing copies of camera
prints are desirable.
Further, Almost any artistic painting of a scene utilises a restricted gamut
in that the artist is limited in the
colours produced as a result of the choice of medium in rendering the image.
This restriction is itself often
exploited by the artist to produce various artistic effects. Classic examples
of this process include the following
well known artistic works:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-3-
- Camille Pissaro "L' ie Lacroix - Rouen, effect de brouillard" 1888. Museum
of Art,
Philadelphie
- Charles Angrand "Le Seine - L'aube" - 1889
collection du Petit Palais, Geneve
- Henri van de Velde "Crepuscule" - 1892. Rijksmuseum Krtiller Muller, Otterlo
= - Georges Seurat. "La cote du Bas-Butin, Honfleur" 1886 - Muse des Beaux -
Arts, Tournai
It would be desirable to produce, from an arbitrary input image, an output
image having similar effects or
characteristics to those in the above list.
A number of creative judgements are made when any garment is created. Firstly,
there is the shape and
styling of the garment and additionally, there is the fabric colours and
style. Often, a fashion designer will try
many different alternatives and may even attempt to draw the final fashion
product before creating the finished
garment.
Such a process is generally unsatisfactory in providing a rapid and flexible
tum around of the garments and
also providing rapid opportunities judgement of the fmal appearance of a
fashion product on a person.
A number of creative judgements are made when any garment is created. Firstly,
there is the shape and
styling of the garment and additionally, there is the fabric colours and
style. Often, a fashion designer will try
many different alternatives and may even attempt to draw the final fashion
product before creating the finished
garment.
Such a process is generally unsatisfactory in providing a rapid and flexible
turn around of the garments and
also providing rapid judgement of the fmal appearance of a fashion product on
a person.
Binocular and telescope devices are well known. In particular, taking the
example of a binocular device,
the device provides for telescopic magnification of a scene so as to enhance
the user's visual capabilities. Further,
devices such as night glasses etc. also operate to enhance the user's visual
system. Unfortunately, these systems
tend to rely upon real time analog optical components and a permanent record
of the viewed scene is difficult to
achieve. One methodology perhaps suitable for recording a permanent copy of a
scene is to attach a sensor device
such as a CCD or the like so as to catch the scene and store it on a storage
device for later printing out.
Unfortunately, such an arrangement can be unduly cumbersome especially where
it is desired to utilize the
binocular system in the field in a highly portable manner.
Many forms of condensed information storage are well known. For example, in
the field of computer
devices, it is common to utilize magnetic disc drives which can be of a fixed
or portable nature. In respect of
portable discs, "Floppy Discs", "Zip Discs", and other forms of portable
magnetic storage media have to achieve
to date a large degree of acceptance in the market place. Another form of
portable storage is the compact disc
"CD" which utilizes a series of elongated pits along a spiral track which is
read by a laser beam device. The
utilization of CD's provides for an extremely low cost form of storage.
However, the technologies involved are
quite complex and the use of rewritable CD type devices is extremely limited.
Other forms of storage include magnetic cards, often utilized for credit cards
or the like. These cards
normally have a magnetic strip on the back for recording information which is
of relevance to the card user.
Recently, the convenience of magnetic cards has been extended in the form of
SmartCard technology which includes
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-4-
incorporation of integrated circuit type devices on to the card.
Unfortunately, the cost of such devices is often high
and the complexity of the technology utilized can also be significant.
Traditionally silver halide camera processing systems have given rise to the
well known utilisation of a
"negative" for the production of multiple prints. The negative normally forms
the source of the production prints and
the practice has grown up for the independent care and protection of negatives
for their subsequent continual
utilisation.
With any form of encoding system which is to be sensed in a fault tolerant
manner, there is the significant
question of how best to encode the data so that it can be effectively and
efficiently decoded. It is therefore desirable
to provide for an effective encoding system.
Summary of the Invention
The present invention relates to providing an alternative form of camera
system which includes a digital
camera with an integral color printer. Additionally, the camera provides
hardware and software for the increasing of
the apparent resolution of the image sensing system and the conversion of the
image to a wide range of "artistic
styles" and a graphic enhancement.
In accordance with a further aspect of the present invention, there is
provided a camera system comprising at
least one area image sensor for imaging a scene, a camera processor means for
processing said imaged scene in
accordance with a predetermined scene transformation requirement, a printer
for printing out said processed image
scene on print media, print media and printing ink stored in a single
detachable module inside said camera system,
said camera system comprising a portable hand held unit for the imaging of
scenes by said area image sensor and
printing said scenes directly out of said camera system via said printer.
Preferably the camera system includes a print roll for the storage of print
media and printing ink for
utilization by the printer, the print roll being detachable from the camera
system. Further, the print roll can include an
authentication chip containing authentication information and the camera
processing means is adapted to interrogate
the authentication chip so as to determine the authenticity of said print roll
when inserted within said camera system.
Further, the printer can include a drop on demand ink printer and guillotine
means for the separation of
printed photographs.
In accordance with a first aspect of the present invention, there is provided
a camera system comprising at
least one area image sensor for imaging a scene, a camera processor means for
processing said image scene in
accordance with a predetermined scene transformation requirement, a printer
for printing out said processed image
scene on print media said printer, print media and printing ink stored in a
single detachable module inside said camera
system, said camera system comprising a portable hand held unit for the
imaging of scenes by said area image sensor
and printing said scenes directly out of said camera system via said printer.
Preferably the camera system includes a print roll for the storage of print
media and printing ink for
utilisation by the printer, s the aid print roll being detachable from the
camera system. Further, the print roll can
include an authentication chip containing authentication information and the
camera processing means is adapted to
interrogate the authentication chip so as to determine the authenticity of
said print roll when inserted within said
camera system.
Further, the printer can include a drop on demand ink printer and guillotine
means for the separation of
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-5-
printed photographs.
In accordance with a further aspect of the invention there is provided a user
interface for operating a device,
said user interface comprising a card which is inserted in a machine and on
the face of the card is contained a visual
representation of the effect the card will have on the output of the machine.
In accordance with a further aspect of the invention there is provided the
camera system comprising:
at least one area image sensor for imaging a scene;
a camera processor means for processing said imaged scene in accordance with a
predetermined scene
transformation requirement;
a printer for printing out said processed image scene on print media said
printer;
a detachable module for storing said print media and printing ink for said
printer;
said camera system comprising a portable hand held unit for the imaging of
scenes by said area image sensor
and printing said scenes directly out of said camera system via said printer.
In accordance with a further aspect of the present invention, there is
provided a camera system
comprising a sensor means for sensing an image; a processing means for
processing the sensed image in
accordance with a predetermined processing requirement, if any; audio
recording means for according an audio
signal to be associated with the sensed image; printer means for printing the
processed sensed image on a first area
of a print media supplied with the camera system, in addition to printing an
encoded version of the audio signal on
a second area of the print media. Preferably the sensed image is printed on a
first surface of the print media and
the encoded version of the audio signal is printed on a second surface of the
print media.
In accordance with the present invention there is provided a camera system
having:
an area image sensor means for sensing an image;
an image storage means for storing the sense image;
an orientation means for sensing the camera's orientation when sensing the
image; and
a processing means for processing said sensed image utilising said sensed
camera orientation.
In accordance with the present invention there is provided a camera system
having:
an area image sensor means for sensing an image;
an image storage means for storing the sense image;
an orientation means for sensing the camera's orientation when sensing the
image; and
a processing means for processing said sensed image utilising said sensed
camera orientation.
In accordance with a further aspect of the present invention there is provided
a method of processing a digital
image comprising:
capturing the image utilising an adjustable focusing technique;
utilising the focusing settings as an indicator of the position of structures
within the image;
processing the image, utilising the said focus settings to produce effects
specific to said focus settings; and
printing out the image.
Preferably the image can be captured utilising a zooming technique; and the
zooming settings can be used in a
heuristic manner so as to process portions of said image.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-6-
In accordance with a further aspect of the invention there is provided a
method of processing an image taken
with a digital camera including an eye position sensing means said method
comprising the step of utilizing the eye
position information within the sensed image to process the image in a
spatially varying sense, depending upon said
location information.
The utilizing step can comprise utilizing the eye position information to
locate an area of interest within
said sensed image. The processing can includes the placement of speech bubbles
within said image or applying a
region specific warp to said image. Altematively the processing can include
applying a brush stroke filter to the
image having greater detail in the area of said eye position information.
Ideally the camera is able to substantially
immediately print out the results of the processing.
In accordance with a further aspect of the invention there is provided a
method of processing an image taken
with a digital camera including an auto exposure setting, said method
comprising the step of utilising said information
to process a sensed image.
The utilising step can comprise utilising the auto exposure setting to
determine an advantageous re-mapping
of colours within the image so as to produce an amended image having colours
within an image transformed to
account of the auto exposure setting. The processing can comprise re-mapping
image colours so they appear deeper
and richer when the exposure setting indicates low light conditions and re-
mapping image colours to be brighter and
more saturated when the auto exposure setting indicates bright light
conditions.
The utilising step includes adding exposure specific graphics or manipulations
to the image.
Recently, digital cameras have become increasingly popular. These cameras
normally operate by means of
imaging a desired image utilising a charge coupled device (CCD) array and
storing the imaged scene on an electronic
storage medium for later down loading onto a computer system for subsequent
manipulation and printing out.
Normally, when utilising a computer system to print out an image,
sophisticated software may available to manipulate
the image in accordance with requirements.
Unfortunately such systems require significant post processing of a captured
image and normally present the
image in an orientation to which is was taken, relying on the post processing
process to perfonn any necessary or
required modifications of the captured image. Further, much of the
environmental information available when the
picture was taken is lost.
Recently, digital cameras have become increasingly popular. These cameras
normally operate by means of
imaging a desired image utilising a charge coupled device (CCD) array and
storing the imaged scene on an electronic
storage medium for later down loading onto a computer system for subsequent
manipulation and printing out.
Normally, when utilising a computer system to print out an image,
sophisticated software may available to manipulate
the image in accordance with requirements.
Unfortunately such systems require significant post processing of a captured
image and normally present the
image in an orientation to which is was taken, relying on the post processing
process to perform any necessary or
required modifications of the captured image. Further, much of the
environmental information available when the
picture was taken is lost.
In accordance with a further aspect of the present invention there is provided
a method of processing an
image captured utilising a digital camera and a flash said method comprising
the steps of:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-7-
a) locating distortions of said captured image due to the utilisation of said
flash;
b) retouching said image so as to locally reduce the effect of said
distortions.
In accordance with the second aspect of the present invention there is
provided a digital camera having
reduced flash distortion effects on captured images comprising;
(a) a digital means capturing image for the capture of images;
(b) a distortion location means for locating flash induced colour distortions
in the captured
image; and
(c) image inversed distortion means connected to said distortion location
means and said
digital image capture means and adapted to process said captured image to
reduce the effects of said distortions;
(d) display means connected to said distortion for displaying.
In accordance with a further aspect of the present invention there is provided
a method of creating a
stereoscopic photographic image comprising:
(a) utilising a camera device to image a scene stereographically;
(b) printing said stereographic image as an integrally formed image at
predetermined positions on a
first surface portion of a transparent printing media, said transparent
printing media having a second surface
including a lensing system so as to stereographically image said scene to the
left and right eye of a viewer of said
printed stereographic image.
In accordance with a fiarther aspect of the present invention there is
provided a print media and ink supply
means adapted to supply a printing mechanism with ink and printing media upon
which the ink is to be deposited,
said media and ink supply means including a roll of media rolled upon a media
former within said media and ink
supply means and at least one ink reservoir integrally formed within said
media and ink supply means and adapted to
be connected to said printing mechanism for the supply of ink and printing
media to said printing mechanism.
In accordance with a further aspect of the present invention there is provided
a print media and ink supply
means adapted to supply a printing mechanism with ink and printing media upon
which the ink is to be deposited,
said media and ink supply means including a roll of media rolled upon a media
former within said media and ink
supply means and at least one ink reservoir integrally formed within said
media and ink supply means and adapted to
be connected to said printing mechanism for the supply of ink and printing
media to said printing mechanism.
In accordance with a further aspect of the present invention there is provided
a print roll for use in a camera
imaging system said print roll having a backing surface having a plurality of
formatted postcard information printed
at pre-determined intervals.
In accordance with the second aspect of the present invention there is
provided a method of creating
customised postcards comprising the steps of: utilising a camera device having
a print roll having a backing surface
including a plurality of formatted postcard information sections at pre-
determined positions on said backing surface;
imaging a customised image on a corresponding imaging surface of said print
roll; and
utilising said print roll to produce postcards via said camera device.
In accordance with the third aspect of the present invention there is provided
a method of sending
postcards comprising camera images through the postal system said method
comprising steps of:
selling a print roll having prepaid postage contained within the print roll;
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-a-
utilising the print roll in a camera imaging system to produce postcards
having prepaid postage; and
sending said prepaid postcards through the mail.
The present invention is further directed to a camera system with an integral
printer type device. The print
media being detachable from the camera system and including a means for the
storage of significant information in
respect of the print media.
The present invention is further directed to a camera system with an integral
printer type device. The print
media being detachable from the camera system and including means for
providing an authentication access to the
print media.
In accordance with a further aspect of the present invention there is provided
a plane print media having a
reduced degree of curling in use, said print media having anisotropic
stifTness in the direction of said planes.
In accordance with the second aspect of the present invention there is
provided a method of reducing the curl in an
image printed on plane print media having an anisotropic stiffness said method
comprising applying a localised
pressure to a portion of said print media.
The present invention is further directed to a camera system with an integral
printer type device. The camera
system including an indicator for the number of images left in the printer,
with the indicator able to display the
number of prints left in a number of different modes.
In accordance with a further aspect of the present invention there is provided
a method of automatically
processing an image comprising locating within the image features having a
high spatial variance and stroking the
image with a series of brush strokes emanating from those areas having high
spatial variance. Preferably, the
brush strokes have decreasing sizes near important features of the image.
Additionally, the position of a
predetermined portion of brush strokes can undergo random jittering.
In accordance with a further aspect of the invention there is provided a
method of warping of producing a
warped image from an input image, said method comprising the steps of:
inputting a warp map for an arbitrary output image having predetermined
dimensions A x B, each element of
said warp map mapping a corresponding region in a theoretical input image to a
pixel location of said arbitrary output
image corresponding to the co-ordinate location of said element within said
warp map;
scaling said warp map to the dimensions of said warped image so as to produce
a scaled warp map;
for substantially each element in said scaled warp map, calculating a
contribution region in said input image
through utilization of said element value and adjacent element values; and
determining an output image colour for a pixel of said warped image
corresponding to said element from
said contribution region.
In accordance with a further aspect of the present invention, there is
provided a method of increasing the
resiiience of data stored on a medium for reading by a sensor device pricing
the steps of:
(a) modulating the stored data in a recoverable fashion with the modulating
signal having a
high frequency component.
(b) storing the data on said medium in a modulated form;
(c) sensing the modulated stored data by said sensor device;
(d) neutralising the modulation of the modulated stored data to track the
spread of location of
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-9-
said modulated stored data on said medium; and
(e) recovering the unmodulated stored data from the modulated stored data.
The preferred embodiment of the present invention will be described with
reference to a card reading system
for reading data via a CCD type device into a camera system for subsequent
decoding. Further, the discussion of the
preferred embodiment relies heavily upon the field of error control systems.
Hence, the person to which this
specification is directed should be an expert in error of control systems and
in particular, be fumly familiar with such
standard texts such as "Error control systems for Digital Communication and
Storage" by Stephen B Wicker
published 1995 by Prentice - Hall Inc. and in particular, the discussion of
Reed - Solomon codes contained therein
and in other standard text.
It is an object of the present invention to provide for a method of converting
a scanned image comprising
scanned pixels to a corresponding bitmap image, said method comprising the
steps of, for each bit in the bitmap
image;
a. determining an expected location in said scanned image of a current bit
from the location of
surrounding bits in said scanned image;
b. determining a likely value of said bit from the values at the locations of
expected corresponding
pixels in said scanned image;
c. determining a centroid measures of the centre of the centre of the expected
intensity at the said
expected location;
d. determining similar centroid measures for adjacent pixels surrounding said
current bit in said
scanned image and;
e. where said centroid measure is improved relative to said expected location,
adjusting said expected
location to be an adjacent pixel having an improved centroid measure.
In accordance with a further aspect of the present invention there is provided
an apparatus for text editing
an image comprising a digital camera device able to sense an image; a
manipulation data entry card adapted to be
inserted into said digital camera device and to provide manipulation
instructions to said digital camera device for
manipulating said image, said manipulation instructions including the addition
of text to said image; a text entry
device connected to said digital camera device for the entry of said text for
addition to said image wherein said
text entry device includes a series of non-roman font characters utilised by
said digital camera device in
conjunction with said manipulation instructions so as to create new text
characters for addition to said image.
Preferably, the font characters are transmitted to said digital camera device
when required and rendered
by said apparatus in accordance with said manipulation instructions so as to
create said new text characters. The
manipulation data entry card can include a rendered roman font character set
and the non-roman characters
include at least one of Hebrew, Cyrillic, Arabic, Kanji or Chinese characters.
In accordance with a further aspect of the present invention there is provided
an apparatus for text editing
an image comprising a digital camera device able to sense an image; a
manipulation data entry card adapted to be
inserted into said digital camera device and to provide manipulation
instructions to said digital camera device for
manipulating said image, said manipulation instructions including the addition
of text to said image; a text entry
device connected to said digital camera device for the entry of said text for
addition to said image wherein said
_ _..._.._._.~._.__..~_w..~.._......~. _m ~ . _ _.....__ _._.__._ _.__ ~ __
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-10-
text entry device includes a series of non-roman font characters utilised by
said digital camera device in
conjunction with said manipulation instructions so as to create new text
characters for addition to said image.
Preferably, the font characters are transmitted to said digital camera device
when required and rendered
by said apparatus in accordance with said manipulation instructions so as to
create said new text characters. The
manipulation data entry card can include a rendered roman font character set
and the non-roman characters
include at least one of Hebrew, Cyrillic, Arabic, Kanji or Chinese characters.
It is an object of the present invention to provide a system which readily is
able to take advantage of updated
technologies in a addition to taking advantage of new filters being created
and, in addition, providing a readily
adaptable form of image processing of digitally captured images for printing
out.
In accordance with a further aspect of the present invention, there is
provided an image copying device for
reproduction of an input image which comprises a series of ink dots, said
device comprising:
(a) imaging array means for imaging said input image at a sampling rate higher
than the frequency of
said dots so as to produce a corresponding sampled image;
(b) processing means for processing said image so as to determine the location
of said print dots in said
sample image;
(c) print means for printing ink dots on print media at locations
corresponding to the locations of said
print dots.
2. An image copying device as claimed in claim I wherein said copying device
prints a full color
copies of said input image.
In accordance with a further aspect of the present invention there is provided
a camera system for
outputting deblurred images, said system comprising;
an image sensor for sensing an image; a velocity detection means for
determining any motion of
said image relative to an external environment and to produce a velocity
output indicative thereof, a processor
means interconnected to said image sensor and said velocity detection means
and adapted to process said sensed
image utilising the velocity output so as to deblurr said image and to output
said deblurred image.
Preferably, the camera system is connected to a printer means for immediate
output of said deblurred
image and is a portable handheld unit. The velocity detection means can
comprise an accelerometer such as a
micro-electro mechanical (MEMS) device.
In accordance with a further aspect of the present invention, there is
provided a photosensor reader preform
comprising:
(a) a series of light emitter recesses for the insertion of light emitted
devices;
(b) light emitter focusing means for focusing light emitted from the series of
light emitter devices onto
the surface of an object to be imaged as it traverses the surface of said
preform;
(c) a photosensor recess for the insertion of a linear photosensor array; and
(d) focussing means for focussing light reflected from said object to be
imaged onto a distinct portion
of said CCD array.
In accordance with an aspect of the present invention, there is provided a
printer device for
interconnection with a computer system comprising a printer head unit
including an ink jet print head for printing
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-11-
images on print media and further having a cavity therein for insertion of a
consumable print roll unit and a print
roll unit containing a consumable print media and ink for insertion into said
cavity, said ink being utilised by said
ink jet print head for printing images on said print media.
In accordance with a further aspect of the present invention, there is
provided a digital camera system
comprising a sensing means for sensing an image; modification means for
modifying the sensed image in
accordance with modification instructions input into the camera; and an output
means for outputting the modified
image; wherein the modification means includes a series of processing elements
arranged around a central
crossbar switch. Preferably, the processing elements include an Arithmetic
Logic Unit (ALU) acting under the
control of a microcode store wherein the microcode store comprises a writeable
control store. The processing
elements can include an internal input and output FIFO for storing pixel data
utilized by the processing elements
and the modification means is interconnected to a read and write FIFO for
reading and writing pixel data of
images to the modification means.
Each of the processing elements can be arranged in a ring and each element is
also separately connected
to its nearest neighbours. The ALU accepts a series of inputs interconnected
via an internal crossbar switch to a
series of core processing units within the ALU and includes a number of
internal registers for the storage of
temporary data. The core processing units can include at least one one of a
multiplier, an adder and a barrel
shifter.
The processing elements are further connected to a common data bus for the
transfer of pixel data to the
processing elements and the data bus is interconnected to a data cache which
acts as an intermediate cache between
the processing elements and a memory store for storing the images.
In accordance with a further aspect of the present invention there is provided
a method of rapidly
decoding, in real time, sensed image data stored at a high pitch rate on a
card, said method comprising the steps
of;
detecting the initial position of said image data;
decoding the image data so as to determine a corresponding bit pattern of said
image data.
In accordance with a further aspect of the present invention there is provided
a method of rapidly
decoding sensed image data in a fault tolerant manner, said data stored at a
high pitch rate on a card and subject to
rotations, warping and marking, said mehtod comprising the steps of:
determining an initial location of a start of said image data;
sensing said image data at a sampling rate greater than said pitch rate;
processing said sensed image data in a column by column process, keeping an
expected location of the
center of each dot (centroid) of a next column and utilising fme adjustments
of said centroid when processing each
= column so as to update the location of an expected next centroid.
In accordance with a further aspect of the present invention there is provided
a method of accurately
= 35 detecting the value of a dot of sensed image data, said image data
comprising an array of dots and said sensed image
data comprising a sampling of said image data at a rate greater than the pitch
frequency of said array of dots so as to
produce an array of pixels, said method comprising the steps of:
determining an expected middle pixel of said array of pixels, said middle
pixel corresponding to an expected
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-12-
central location of a corresponding dot;
utilising the sensed value of said middle pixel and the sensed value of a
number of adjacent pixels as an
index to a lookup table having an output corresponding to the value of a dot
centred around the corresponding
location of said pixel.
In accordance with a further aspect of the present invention there is provided
a method of accurately
determining the location of dots of sensed image data amongst an array of dots
of image data in a fault tolerant
manner, said data stored at a high pitch rate on a card and subject to
rotations, warping and marking effects, said
method comprising the steps of:
processing the image data in a column by column format;
recording the dot pattern of previously processed columns of pixels;
generating an expected dot pattem at a current column position from the
recorded dot pattem of previously
processed pixels;
comparing the expected dot pattern with an actual dot pattern of sensed image
data at said current column
position;
if said comparison produces a match within a predetermined error, utilising
said current column position as
an actual dot position otherwise altering said current column position to
produce a better fit to said expected dot
pattern to thereby produce new actual dot position, and
utilising said actual dot position of the dot at a current column position in
the determining of dot location of
dots of subsequent columns.
In accordance with a further aspect of the present invention there is provided
a method of combining
image bump maps to simulate the effect of painting on an image, the method
comprising:
defining an image canvas bump map approximating the surface to be painted on;
defining a painting bump map of a painting object to be painted on said
surface;
combining said image canvas bump map and said painting bump map to produce a
finai
composited bump map utilising a stiffness factor, said stiffness factor
determining the degree of modulation of
said painting bump map by said image canvas bump map.
In accordance with a further aspect of the present invention there is provided
a method of automatically
manipulating an input image to produce an artistic effect comprising:
predetermining a mapping of an input gamut to a desired output gamut so as to
produce a
desired artistic effect;
utilising said mapping to map said input image to an output image having a
predetermined
output gamut;
Preferably, the method further comprises the step of post processing the
output image utilising a brush
stroke filter.
Further, preferably the output gamut is formed from mapping a predetermined
number of input gamut
values to corresponding output colour gamut values and interpolating the
remaining mapping of input gamut
values to output colour gamut values. The interpolation process can include
utilising a weighted sum of said
mapping of a predetermined number of input gamut values to corresponding
output colour gamut values.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-13-
In accordance with the second aspect of the present invention there is
provided a method of compressing
an input colour gamut to be within an output colour gamut, said method
comprising the steps of:
determining a zero chrominance value point at a current input colour
intensity;
determining a source distance being the distance from said zero chrominance
value to
the edge of said input colour gamut;
determining a suitable edge of said output colour gamut;
determining a target distance being the distance from said zero chrominance
value to the edge of
said output colour gamut; and
scaling the current input colour intensity by a factor derived from the ratio
of source
distance to target distance;
Preferably said current input colour intensity is further scaled by a factor
dependent on the distance for
said current input colour from said zero chrominance value point.
In accordance with a further aspect of the present invention, there is
provided a handheld camera for the
output of an image sensed by the camera, with the camera including:
sensing means for sensing an image;
tiling means for adding tiling effects to the sensed image to produce a tiled
image; and
display means for displaying the tiled image.
In accordance with a further aspect of the present invention, there is
provided a handheld camera for the
output of an image sensed by the camera, with the camera including:
sensing means for sensing an image;
texture mapping means for adding texturing effects to the sensed image to
produce a textured image; and
display means for displaying the textured image.
In accordance with a further aspect of the present invention, there is
provided a handheld camera for the
output of an image sensed by the camera, with the camera including:
sensing means for sensing an image;
lighting means for adding lighting to the sensed image to produce an
illuminated image which simulates the
effect of light sources projected at the sensed image; and
display means for displaying the illuminated image.
In accordance with a further aspect of the present invention there is provided
a garment creation system
comprising:
a series of input tokens for inputting to a camera device for manipulation of
a sensed image for
outputting on a display device depicting a garment constructed of fabric
having characteristics of said sensed
image;
a camera device adapted to read said input tokens and sense an image and
manipulate said image
- 35 in accordance with a read input token so as to produce said output image;
and a display device adapted to display
said output image
In accordance with a further aspect of the present invention there is provided
A garment creation system
comprising:
_ . . ....~ ,,,...... ~.. ~ _. , . ...,:.. . . _ ___.__.~. ..~..~.. ~... ____
_ .
CA 02296439 2000-01-17
WO 99/04368 -14 PCT/AU98/00544
-
an expected image creation system including an image sensor device and an
image display device, said
image creation system mapping portions of an arbitrary image sensed by said
image sensor device onto a garment
and outputting on said display device a depiction of said garment;
a garment fabric printer adapted to be interconnected to said image creation
system for printing out
corresponding pieces of said garment including said mapped portions..
In accordance with a further aspect of the present invention as provided a
method of creating a
manipulated image comprising interconnecting a series of camera manipulation
units, each of said camera
manipulation unit applying an image manipulation to an inputted image so as to
produce a manipulated output
image, an initial one of said camera manipulation units sensing an image from
an environment and at least a final
one of said camera manipulation units producing a permanent output image.
In accordance with a further aspect of the present invention there is provided
a portable imaging system
for viewing distant objects comprising an optical lensing system for
magnifying a viewed distant object; a sensing
system for simultaneously sensing said viewed distant object; a processor
means interconnected to said sensing
system for processing said sensed image and forwarding it to a printer
mechanism; and a printer mechanism
connected to said processor means for printing out on print media said sensed
image on demand by said portable
imaging system.
Preferably the system further comprises a detachable print media supply means
provided in a detachable
module for interconnection with said printer mechanism for the supply of a
roll of print media and ink to said
printer mechanism.
The printer mechanism can comprise an ink jet printing mechanism providing a
full color printer for the
output of sensed images.
Further, the preferred embodiment is implemented as a system of binoculars
with a beam splitting device
which projects said distant object onto said sensing system.
In accordance with a further aspect of the present invention, there is
provided a system for playing
prerecorded audio encoded in a fault tolerant manner as a series of dots
printed on a card, the system comprising
an optical scanner means for scanning the visual form of the prerecorded
audio; a processor means interconnected
to the optical scanner means for decoding the scanned audio encoding to
produce a corresponding audio signal;
and audio emitter means interconnected to the processor means for emitting or
playing the corresponding audio
signal on demand.
The encoding can include Reed-Solomon encoding of the prerecorded audio and
can comprise an array
of ink dots which are high frequency modulated to aid scanning.
The system can include a wand-like arm having a slot through which is inserted
the card.
In accordance with a further aspect of the present invention, there is
provided a method of information
distribution on printed cards, the method comprising the steps of dividing the
surface of the card into a number of
predetermined areas; printing a first collection of data to be stored in a
first one of the predetermined areas;
utilising the printed first predetermined area when reading information stored
on the card; and, when the
information stored on the card is to be updated, determining a second one of
the predetermined areas to print
further information stored on the card, the second area not having being
previously utilized to print data.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-15-
Preferably, the areas are selected in a predetermined order and the printing
utilizes a high resolution ink
dot printer for printing data having a degree of fault tolerance with the
fault tolerance, for example, coming from
Reed-Solomon encoding of the data. Printed border regions delineating the
border of the area can be provided, in
addition to a number of border target markers to assist in indicating the
location of the regions. The border targets
can comprise a large area of a first colour with a small region of a second
colour located centrally in the first area.
Preferably, the data is printed utilising a high frequency modulating signal
such as a checkerboard
pattern. The printing can be an array of dots having a resolution of greater
then substantially 1200 dots per inch
and preferably at least 1600 dots per inch. The predetermined areas can be
arranged in a regular array on the
surface of the card and the card can be of a generally rectangular credit card
sized shape.
In accordance with a further aspect of the present invention, there is
provided a method of creating a set
of instructions for the manipulation of an image, the method comprising the
steps of displaying an initial array of
sample images for a user to select from; accepting a user's selection of at
least one of the sample images; utilizing
attributes of the images selected to produce a further array of sample images;
iteratively applying the previous
steps until such time as the user selects at least one fmal suitable image;
utilising the steps used in the creation of
the sample image as the set of instructions; outputting the set of
instructions.
The method can further include scanning a user's photograph and utilising the
scanned photograph as an
initial image in the creation of each of the sample images. The instructions
can be printed out in an encoded form
on one surface of a card in addition to printing out a visual representation
of the instructions on a second surface
of the card. Additionally, the manipulated image can itself be printed out.
Various techniques can be used in the creation of images including genetic
algorithm or genetic
programming techniques to create the array. Further, `best so far' images can
be saved for use in the creation of
further images.
The method is preferably implemented in the form of a computer system
incorporated into a vending
machine for dispensing cards and photos.
In accordance with a further aspect of the present invention, there is
provided an information storage
apparatus for storing infonnation on inserted cards the apparatus comprising a
sensing means for sensing printed
patterns on the surface stored on the card, the patterns arranged in a
predetennined number of possible active areas
of the card; a decoding means for decoding the sensed printed patterns into
corresponding data; a printing means
for printing dot patterns on the card in at least one of the active areas; a
positioning means for positioning the
sensed card at known locations relative to the sensing means and the printing
means; wherein the sensing means is
adapted to sense the printed patterns in a current active printed area of the
card, the decoding means is adapted to
decode the sensed printed patterns into corresponding current data and, when
the current data requires updating,
the printing means is adapted to print the updated current data at a new one
of the active areas after activation of
the positioning means for correctly position the card.
Preferably, the printing means comprises an ink jet printer device having a
card width print head able to
print a line width of the card at a time. The positioning means can comprise a
series of pinch rollers to pinch the
card and control the movement of the card. The printed patterns can be laid
out in a fault tolerant manner, for
, ........ ~..~...._.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-~6-
example, using Reed - Solomon decoding, and the decoding means includes a
suitable decoder for the fault
tolerant pattem.
In accordance with a further aspect of the present invention, there is
provided a digital camera system
comprising an image sensor for sensing an image; storage means for storing the
sensed image and associated
system structures; data input means for the insertion of an image modification
data module for modification of the
sensed image; processor means interconnected to the image sensor, the storage
means and the data input means for
the control of the camera system in addition to the manipulation of the sensed
image; printer means for printing
out the sensed image on demand on print media supplied to the printer means;
and a method of providing an
image modification data module adapted to cause the processor means to modify
the operation of the digital
camera system upon the insertion of further image modification modules.
Preferably, the image modification data module comprises a card having the
data encoded on the surface
thereof and the data encoding is in the form of printing and the data input
means includes an optical scanner for
scanning a surface of the card. The modification of operation can include
applying each image modification in
turn of a series of inserted image modification modules to the same image in a
repetitive manner.
In accordance with a further aspect of the present invention, there is
provided a digital camera system
comprising an image sensor for sensing an image; storage means for storing the
sensed image and associated
system structures; data input means for the insertion of an image modification
data module for modification of the
sensed image; processor means interconnected to the image sensor, the storage
means and the data input means for
the control of the camera system in addition to the manipulation of the sensed
image; printer means for printing
out the sensed image on demand on print media supplied to the printer means;
including providing an image
modification data module adapted to cause the processor means to perform a
series of diagnostic tests on the
digital camera system and to print out the results via the printer means.
Preferably, the image modification module can comprise a card having
instruction data encoded on one
surface thereof and the processor means includes means for interpreting the
instruction data encoded on the card.
The diagnostic tests can include a cleaning cycle for the printer means so as
to improve the operation of the printer
means such as by printing a continuous all black strip. Alternatively, the
diagnostic tests can include modulating
the operation of the nozzles so as to improve the operation of the ink jet
printer. Additionally, various internal
operational parameters of the camera system can be printed out. Where the
camera system is equipped with a
gravitational shock sensor, the diagnostic tests can include printing out an
extreme value of the sensor.
In accordance with a further aspect of the present invention, there is
provided a camera system for the
creation of images, the camera system comprising a sensor for sensing an
image; a processing means for
processing the sensed image in accordance with any predetermined processing
requirements; a printer means for
printing the sensed image on the surface of print media, the print media
including a magnetically sensitive surface;
a magnetic recording means for recording associated information on the
magnetically sensitive surface.
The associated information can comprises audio information associated with the
sensed image and the printer
means preferably prints the sensed image on a first surface of the print media
and the magnetic recording means
records the associated information on a second surface of the print media. The
print media can be stored on an
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-17-
internal detachable roll in the camera system. In one embodiment, the magnetic
sensitive surface can comprise a
strip affixed to the back surface of the print media.
In accordance with a further aspect of the present invention, there is
provided a method of creating a
permanent copy of an image captured on an image sensor of a handheld camera
device having an interconnected
integral computer device and an integral printer means for printing out on
print media stored with the camera
device, the method comprising the steps of sensing an image on the image
sensor; converting the image to an
encoded form of the image, the encoded form having fault tolerant encoding
properties; printing out the encoded
form of the image as a permanent record of the image utilizing the integral
printer means.
Preferably, the integral printer means includes means for printing on a first
and second surface of the
print media and the sensed image or a visual manipulation thereof is printed
on the first surface thereof and the
encoded form is printed on the second surface thereof. A thumbnail of the
sensed image can be printed alongside
the encoded form of the image and the fault tolerant encoding can include
forming a Reed-Solomon encoded
version of the image in addition to applying a high frequency modulation
signal such as a checkerboard pattern to
the encoded form such that the permanent record includes repeatable high
frequency spectral components. The
print media can be supplied in a print roll means which is detachable from the
camera device.
In accordance with a first aspect of the present invention, there is provided
a distribution system for the
distribution of image manipulation cards for utilization in camera devices
having a card manipulation interface for
the insertion of the image manipulation cards for the manipulation of images
within the camera devices, the
distribution system including a plurality of printer devices for outputting
the image manipulation cards; each of
the printer devices being interconnected to a corresponding computer system
for the storage of a series of image
manipulation card data necessary for the construction of the image
manipulation cards; the computer systems
being interconnected via a computer network to a card distribution computer
responsible for the distribution of
card lists to the computer systems for printing out corresponding cards by the
printer systems.
Preferably the computer systems store the series of image manipulation card
data in a cached manner
over the computer network and card distribution computer is also responsible
for the distribution of new image
manipulation cards to the computer systems.
The present invention has particular application when the image manipulation
cards include seasonal
event cards which are distributed to the computer systems for the printing out
of cards for utilization in respect of
seasonal events.
In accordance with a further aspect of the present invention, there is
provided a data structure encoded on the
surface of an object comprising a series of block data regions with each of
the block data regions including: an
encoded data region containing data to be decoded in an encoded form; a series
of clock marks structures located
around a first peripheral portion of the encoded data region; and a series of
easily identifiable target structures located
around a second peripheral portion of the encoded data region.
' 35 The block data regions can further include an orientation data structure
located round a third peripheral
portion of the encoded data region. The orientation data structure can
comprises a line of equal data points along an
edge of the peripheral portion.
The clock marks structures can include a first line of equal data points in
addition to a substantially adjacent
CA 02296439 2000-01-17
WO 99/04368 -18 PCT/AU98/00544
-
second line of alternating data points located along an edge of the encoded
data region. The clock mark structures can
be located on mutually opposite sides of the encoded data region.
The target structures can comprise a series of spaced apart block sets of data
points having a substantially
constant value of a first magnitude except for a core portion of a
substantially opposite magnitude to the first
magnitude. The block sets can further includes a target number indicator
structure comprising a contiguous group of
the values of the substantially opposite magnitude.
The data structure is ideally utilized in a series of printed dots on a
substrate surface.
In accordance with a second aspect of the present invention, there is provided
a method of decoding a data
structure encoded on the surface of an object, the data structure comprising a
series of block data regions with each of
the block data regions including: an encoded data region containing data to be
decoded in an encoded form; a series
of clock marks structures located around a first peripheral portion of the
encoded data region; a series of easily
identifiable target structures located around a second peripheral portion of
the encoded data region; the method
comprising the steps of: (a) scanning the data structure; (b) locating the
start of the data structure; (c) locating the
target structures including determining a current orientation of the target
structures; (d) locating the clock mark
structures from the position of the target structures; (e) utilizing the clock
mark structures to determine an expected
location of bit data of the encoded data region; and (f) determining an
expected data value for each of the bit data.
The clock marks structures can include a first line of equal data points in
addition to a substantially adjacent
second line of alternating data points located along an edge of the encoded
data region and the utilising step (e) can
comprise running along the second line of alternating data points utilizing a
pseudo phase locked loop type algorithm
so as to maintain a current location within the clock mark structures.
Further, the determining step (f) can comprise dividing a sensed bit value
into three contiguous regions
comprising a middle region and a first lower and a second upper extreme
regions, and with those values within a first
lower region, determining the corresponding bit value to be a first lower
value; with those values within a second
upper region, determining the corresponding bit value to be a second upper
value; and with those values in the middle
regions, utilising the spatially surrounding values to determine whether the
value is of a first lower value or a second
upper value.
In accordance with a further aspect of the present invention, there is
provided a method of determining an
output data value of sensed data comprising: (a) dividing a sensed data value
into three contiguous regions
comprising a middle region and a first lower and a second upper extreme
regions, and, with those values within a first
lower region, determining the corresponding bit value to be a first lower
value; with those values within a second
upper region, determining the corresponding bit value to be a second upper
value; and with those values in the middle
regions, utilising the spatially surrounding values to determine whether the
value is of a first lower value or a second
upper value.
In accordance with a further aspect of the present invention, there is
provided a fluid supply means for
supplying a plurality of different fluids to a plurality of different supply
slots, wherein the supply slots are being
spaced apart at periodic intervals in an interleaved manner, the fluid supply
means comprising a fluid inlet means for
each of the plurality of different fluids, a main channel flow means for each
of the different fluids, connected to said
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
~s-
fluid inlet means and running past each of the supply slots, and sub-channel
flow means connecting each of the
supply slots to a corresponding main channel flow means. The number of fluids
is greater than 2 and at least two of
the main channel flow means run along the fust surface of a moulded flow
supply unit and another of the main
channel flow means runs along the top surface of the moulded piece with the
subchannel flow means being
interconnected with the slots by means of through-holes through the surface of
the moulded piece.
Preferably, the supply means is plastic injection moulded and the pitch rate
of the slots is substantially fess
than, or equal to 1,000 slots per inch. Further the collection of slots runs
substantially the width of a photograph.
Preferably, the fluid supply means further comprises a plurality of roller
slot means for the reception of one or more
pinch rollers and the fluid comprises ink and the rollers are utilised to
control the passage of a print media across a
print-head interconnected to the slots. The slots are divided into
corresponding colour slots with each series of colour
slots being arranged in columns.
Preferably, at least one of the channels of the fluid supply means is exposed
when fabricated and is sealed by
means of utilising sealing tape to seal the exposed surface of the channel.
Advantageously, the fluid supply means is
further provided with a TAB slot for the reception of tape automated bonded
(TAB) wires.
In accordance with a further aspect of the present invention, there is
provided a fluid supply means for
supplying a plurality of different fluids to a plurality of different supply
slots, wherein the supply slots are being
spaced apart at periodic intervals in an interleaved manner, the fluid supply
means comprising a fluid inlet means for
each of the plurality of different fluids, a main channel flow means for each
of the different fluids, connected to said
fluid inlet means and running past each of the supply slots, and sub-channel
flow means connecting each of the
supply slots to a corresponding main channel flow means. The number of fluids
is greater than 2 and at least two of
the main channel flow means run along the first surface of a moulded flow
supply unit and another of the main
channel flow means runs along the top surface of the moulded piece with the
subchannel flow means being
interconnected with the slots by means of through-holes through the surface of
the moulded piece.
Preferably, the supply means is plastic injection moulded and the pitch rate
of the slots is substantially less
than, or equal to 1,000 slots per inch. Further the collection of slots runs
substantially the width of a photograph.
Preferably, the fluid supply means further comprises a plurality of roller
slot means for the reception of one or more
pinch rollers and the fluid comprises ink and the rollers are utilised to
control the passage of a print media across a
print-head interconnected to the slots. The slots are divided into
corresponding colour slots with each series of colour
slots being arranged in columns.
Preferably, at least one of the channels of the fluid supply means is exposed
when fabricated and is sealed by
means of utilising sealing tape to seal the exposed surface of the channel.
Advantageously, the fluid supply means is
further provided with a TAB slot for the reception of tape automated bonded
(TAB) wires.
In accordance with a further aspect of the present invention, there is
provided a printer mechanism for
printing images utilizing at least one ink ejection mechanism supplied through
an ink supply channel, the
mechanism comprising a series of ink supply portals at least one per output
color, adapted to engage a
corresponding ink supply mechanism for the supply of ink to the printer; a
series of conductive connector pads
along an external surface of the printer mechanism; a page width print head
having a series of ink ejection
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-20-
mechanisms for the ejection of ink; an ink distribution system for
distribution of ink from the ink supply portals to
the ink ejection mechanisms of the page width print head; a plurality of
interconnect control wires interconnecting
the page width print head to the conductive connector pads; wherein the
printer mechanism is adapted to be
detachably inserted in a housing mechanism containing interconnection portions
for interconnecting to the
conductive connector pads and the ink supply connector of interconnection to
the ink supply portals for the supply
of ink by the ink supply mechanism.
Preferably, the plurality of interconnect control wires form a tape automated
bonded sheet which wraps
around an external surface of the printer mechanism and which is
interconnected to the conductive connector
pads. The interconnect control wires can comprise a first set of wires
interconnecting the conductive connector
pads and running along the length of the print head, substantially parallel to
one another and a second set of wires
running substantially parallel to one another from the surface of the print
head, each of the first set of wires being
interconnected to a number of the second set of wires. The ink supply portals
can include a thin diaphragm
portion which is pierced by the ink supply connector upon insertion into the
housing mechanism.
The page width print head can includes a number of substantially identical
repeatable units each
containing a predetermined number of ink ejection mechanisms, each of the
repeatable units including a standard
interface mechanism containing a predetermined number of interconnect wires,
each of the standard interface
mechanism interconnecting as a group with the conductive connector pads. The
print head itself can be conducted
from a silicon wafer, separated into page width wide strips.
In accordance with a further aspect of the present invention there is provided
a method of providing for
resistance to monitoring of an integrated circuit by means of monitoring
current changes, said method comprising the
step of including a spurious noise generation circuit as part of said
integrated circuit.
The noise generation circuit can comprises a random number generator such as a
LFSR (Linear Feedback
Shift Register).
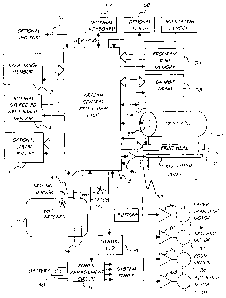
In accordance with a further aspect of the present invention there is provided
a CMOS circuit having a low power
consumption, said circuit including a p-type transistor having a gate
connected to a first clock and to an input and an
n-type transistor connected to a second clock and said input and wherein said
CMOS circuit is operated by
transitioning said first and second clocks wherein said transitions occur in a
non-overlapping manner.
The circuit can be positioned substantially adjacent a second circuit having
high power switching
characteristics. The second circuit can comprise a noise generation circuit.
In accordance with a further aspect of the present invention, there is
provided a method of providing
for resistance to monitoring of an memory circuit having multiple level states
corresponding to different output states,
said method comprising utilizing the intermediate states only for valid output
state. The memory can comprise flash
memory and can further include one or more parity bits.
In accordance with a further aspect of the present invention, there is
provided a method of providing
for resistance to tampering of an integrated circuit comprising utilizing a
circuit path attached to a random noise
generator to monitor attempts at tampering with the integrated circuit.
The circuit path can include a first path and a second path which are
substantially inverses of one
another and which are further connected to various test circuitry and which
are exclusive ORed together to produce a
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-21-
reset output signal. The circuit paths can substantially cover the random
noise generator.
In accordance with a second aspect of the present invention, there is provided
a tamper detection line
connected at one end to a large resistance attached to ground and at a second
end to a second large resistor attached to
a power supply, the tamper detection line further being interconnected to a
comparator that compares against the
expected voltage to within a predetermined tolerance, further in between the
resistance are interconnected a series of
= test, each outputting a large resistance such that if tampering is detected
by one of the tests the comparator is caused to
output a reset signal.
In accordance with a further aspect of the present invention there is provided
an authentication system for
detenmining the validity of an attached unit to be authenticated comprising: a
central system unit for interrogation of
first and second secure key holding units; first and second secure key holding
objects attached to the centrai system
unit, wherein the second key holding object is further permanently attached to
the attached unit; wherein the central
system unit is adapted to interrogate the first secure key holding object so
as to determine a first response and to
utilize the first response to interrogate the second secure key holding object
to detennine a second response, and to
further compare the first and second response to determine whether the second
secure key holding object is attached
to a valid attached unit.
The second secure key holding object can further include a response having an
effectively monotonically decreasing
magnitude factor such that, after a predetermined utilization of the attached
unit, the attaclied unit ceases to function.
Hence the attached unit can comprises a consumable product.
Further, the the central system unit can interrogate the first secure key
holding object with a substantially random
number to receives the first response, the central system then utilizes the
first response in the interrogation of the
second secure key holding object to determine the second response, the central
system unit then utilizes the second
response to interrogate the first secure key holding unit to determine a
validity measure of the second response.
The system is ideally utilized to authenticate a consumable for a printer such
as ink for an ink jet printer.
Indeed the preferred embodiment will specifically be discussed with reference
to the consumable of ink in a camera
system having an internal ink jet printer although the present invention is
not limited thereto.
...... _..._ ..._., _._..___._...._...._
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-22-
Brief Description of the Drawings
Notwithstanding any other forms which may fall within the scope of the present
invention, preferred forms of
the invention will now be described, by way of example only, with reference to
the accompanying drawings in which:
Fig. I illustrates an Artcam device constructed in accordance with the
preferred embodiment.
Fig. 2 is a schematic block diagram of the main Artcam electronic components.
Fig. 3 is a schematic block diagram of the Artcam Central Processor.
Fig. 3(a) illustrates the VLIW Vector Processor in more detail.
Fig. 4 illustrates the Processing Unit in more detail.
Fig. 5 illustrates the ALU 188 in more detail.
Fig. 6 illustrates the In block in more detail.
Fig. 7 illustrates the Out block in more detail.
Fig. 8 illustrates the Registers block in more detail.
Fig. 9 illustrates the Crossbarl in more detail.
Fig. 10 illustrates the Crossbar2 in more detail.
Fig. 11 illustrates the read process block in more detail.
Fig. 12 illustrates the read process block in more detail.
Fig. 13 illustrates the barrel shifter block in more detail.
Fig. 14 illustrates the adder/logic block in more detail.
Fig. 15 illustrates the multiply block in more detail.
Fig. 16 illustrates the 1/0 address generator block in more detail.
Fig. 17 illustrates a pixel storage format.
Fig. 18 illustrates a sequential read iterator process.
Fig. 19 illustrates a box read iterator process.
Fig. 20 illustrates a box write iterator process.
Fig. 21 illustrates the vertical strip read/write iterator process.
Fig. 22 illustrates the vertical strip read/write iterator process.
Fig. 23 illustrates the generate sequential process.
Fig. 24 illustrates the generate sequential process.
Fig. 25 illustrates the generate vertical strip process.
Fig. 26 illustrates the generate vertical strip process.
Fig. 27 illustrates a pixel data configuration.
Fig. 28 illustrates a pixel processing process.
Fig. 29 illustrates a schematic block diagram of the display controller.
Fig. 30 illustrates the CCD image organization.
Fig. 31 illustrates the storage format for a logical image.
Fig. 32 illustrates the internal image memory storage format.
Fig. 33 illustrates the image pyramid storage format.
Fig. 34 illustrates a time line of the process of sampling an Artcard.
Fig. 35 illustrates the super sampling process.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-23-
Fig. 36 illustrates the process of reading a rotated Artcard.
Fig. 37 illustrates a flow chart of the steps necessary to decode an Artcard.
Fig. 38 illustrates an enlargement of the left hand corner of a single
Artcard.
Fig. 39 illustrates a single target for detection.
Fig. 40 illustrates the method utilised to detect targets.
Fig. 41 illustrates the method of calculating the distance between two
targets.
Fig. 42 illustrates the process of centroid drift.
Fig. 43 shows one form of centroid lookup table.
Fig. 44 illustrates the centroid updating process.
Fig. 45 illustrates a delta processing lookup table utilised in the preferred
embodiment.
Fig. 46 illustrates the process of unscrambling Artcard data.
Fig. 47 illustrates a magnified view of a series of dots.
Fig. 48 illustrates the data surface of a dot card.
Fig. 49 illustrates schematically the layout of a single datablock.
Fig. 50 illustrates a single datablock.
Fig. 51 and Fig. 52 illustrate magnified views of portions of the datablock of
Fig. 50.
Fig. 53 illustrates a single target structure.
Fig. 54 illustrates the target structure of a datablock.
Fig. 55 illustrates the positional relationship of targets relative to border
clocking regions of a data region.
Fig. 56 illustrates the orientation columns of a datablock.
Fig. 57 illustrates the array of dots of a datablock.
Fig. 58 illustrates schematically the structure of data for Reed-Solomon
encoding.
Fig. 59 illustrates an example Reed-Solomon encoding.
Fig. 60 illustrates the Reed-Solomon encoding process.
Fig. 61 illustrates the layout of encoded data within a datablock.
Fig. 62 illustrates the sampling process in sampling an alternative Artcard.
Fig. 63 illustrates, in exaggerated form, an example of sampling a rotated
alternative Artcard.
Fig. 64 illustrates the scanning process.
Fig. 65 illustrates the likely scanning distribution of the scanning process.
Fig. 66 illustrates the relationship between probability of symbol errors and
Reed-Solomon block errors.
Fig. 67 illustrates a flow chart of the decoding process.
Fig. 68 illustrates a process utilization diagram of the decoding process.
Fig. 69 illustrates the dataflow steps in decoding.
Fig. 70 illustrates the reading process in more detail.
Fig. 71 illustrates the process of detection of the start of an alternative
Artcard in more detail.
Fig. 72 illustrates the extraction of bit data process in more detail.
Fig. 73 illustrates the segmentation process utilized in the decoding process.
Fig. 74 illustrates the decoding process of fmding targets in more detail.
Fig. 75 illustrates the data structures utilized in locating targets.
~ _.._ ..._
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-24-
Fig. 76 illustrates the Lancos 3 function structure.
Fig. 77 illustrates an enlarged portion of a datablock illustrating the
clockmark and border region.
Fig. 78 illustrates the processing steps in decoding a bit image.
Fig. 79 illustrates the dataflow steps in decoding a bit image.
Fig. 80 illustrates the descrambling process of the preferred embodiment.
Fig. 81 illustrates one form of implementation of the convolver.
Fig. 82 illustrates a convolution process.
Fig. 83 illustrates the compositing process.
Fig. 84 illustrates the regular compositing process in more detail.
Fig. 85 illustrates the process of warping using a warp map.
Fig. 86 illustrates the warping bi-linear interpolation process.
Fig. 87 illustrates the process of span calculation.
Fig. 88 illustrates the basic span calculation process.
Fig. 89 illustrates one form of detail implementation of the span calculation
process.
Fig. 90 illustrates the process of reading image pyramid levels.
Fig. 91 illustrates using the pyramid table for blinear interpolation.
Fig. 92 illustrates the histogram collection process.
Fig. 93 illustrates the color transform process.
Fig. 94 illustrates the color conversion process.
Fig. 95 illustrates the color space conversion process in more detail.
Fig. 96 illustrates the process of calculating an input coordinate.
Fig. 97 illustrates the process of compositing with feedback.
Fig. 98 illustrates the generalized scaling process.
Fig. 99 illustrates the scale in X scaling process.
Fig. 100 illustrates the scale in Y scaling process.
Fig. 101 illustrates the tessellation process.
Fig. 102 illustrates the sub-pixel translation process.
Fig. 103 illustrates the compositing process.
Fig. 104 illustrates the process of compositing with feedback.
Fig. 105 illustrates the process of tiling with color from the input image.
Fig. 106 illustrates the process of tiling with feedback.
Fig. 107 illustrates the process of tiling with texture replacement.
Fig. 108 illustrates the process of tiling with color from the input image.
Fig. 109 illustrates the process of applying a texture without feedback.
Fig. 110 illustrates the process of applying a texture with feedback.
Fig. 111 illustrates the process of rotation of CCD pixels.
Fig. 112 illustrates the process of interpolation of Green subpixels.
Fig. 113 illustrates the process of interpolation of Blue subpixels.
Fig. 114 illustrates the process of interpolation of Red subpixels.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-25-
Fig. 115 illustrates the process of CCD pixel interpolation with 0 degree
rotation for odd pixel lines.
Fig. 116 illustrates the process of CCD pixel interpolation with 0 degree
rotation for even pixel lines.
Fig. 117 illustrates the process of color conversion to Lab color space.
Fig. 118 illustrates the process of calculation of 1NX.
Fig. 119 illustrates the implementation of the calculation of 1/JX in more
detail.
Fig. 120 illustrates the process of Normal calculation with a bump map.
Fig. 121 illustrates the process of illumination calculation with a bump map.
Fig. 122 illustrates the process of illumination calculation with a bump map
in more detail.
Fig. 123 illustrates the process of calculation of L using a directional
light.
Fig. 124 illustrates the process of calculation of L using a Omni lights and
spotlights.
Fig. 125 illustrates one form of implementation of calculation of L using a
Omni lights and spotlights.
Fig. 126 illustrates the process of calculating the N.L dot product.
Fig. 127 illustrates the process of calculating the N.L dot product in more
detail.
Fig. 128 illustrates the process of calculating the R.V dot product.
Fig. 129 illustrates the process of calculating the R.V dot product in more
detail.
Fig. 130 illustrates the attenuation calculation inputs and outputs.
Fig. 131 illustrates an actual implementation of attenuation calculation.
Fig. 132 illustrates an graph of the cone factor.
Fig. 133 illustrates the process of penumbra calculation.
Fig. 134 illustrates the angles utilised in penumbra calculation.
Fig. 135 illustrates the inputs and outputs to penumbra calculation.
Fig. 136 illustrates an actual implementation of penumbra calculation.
Fig. 137 illustrates the inputs and outputs to ambient calculation.
Fig. 138 illustrates an actual implementation of ambient calculation.
Fig. 139 illustrates an actual implementation of diffuse calculation.
Fig. 140 illustrates the inputs and outputs to a diffuse calculation.
Fig. 141 illustrates an actual implementation of a diffuse calculation.
Fig. 142 illustrates the inputs and outputs to a specular calculation.
Fig. 143 illustrates an actual implementation of a specular calculation.
Fig. 144 illustrates the inputs and outputs to a specular calculation.
Fig. 145 illustrates an actual implementation of a specular calculation.
Fig. 146 illustrates an actual implementation of a ambient only calculation.
Fig. 147 illustrates the process overview of light calculation.
Fig. 148 illustrates an example illumination calculation for a single infmite
light source.
Fig. 149 illustrates an example illumination calculation for a Omni light
source without a bump map.
Fig. 150 illustrates an example illumination calculation for a Omni light
source with a bump map.
Fig. 151 illustrates an example illumination calculation for a Spotlight light
source without a bump map.
Fig. 152 illustrates the process of applying a single Spotlight onto an image
with an associated bump-map.
Fig. 153 illustrates the logical layout of a single printhead.
~ _._._._...._..~..~_ ._..._..._ _ _ . _
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-2s-
Fig. 154 illustrates the structure of the printhead interface.
Fig. 155 illustrates the process of rotation of a Lab image.
Fig. 156 illustrates the format of a pixel of the printed image.
Fig. 157 illustrates the dithering process.
Fig. 158 illustrates the process of generating an 8 bit dot output.
Fig. 159 illustrates a perspective view of the card reader.
Fig. 160 illustrates an exploded perspective of a card reader.
Fig. 161 illustrates a close up view of the Artcard reader.
Fig. 162 illustrates a perspective view of the print roll and print head.
Fig. 163 illustrates a first exploded perspective view of the print roll.
Fig. 164 illustrates a second exploded perspective view of the print roll.
Fig. 165 illustrates the print roll authentication chip.
Fig. 166 illustrates an enlarged view of the print roll authentication chip.
Fig. 167 illustrates a single authentication chip data protocol.
Fig. 168 illustrates a dual authentication chip data protocol.
Fig. 169 illustrates a first presence only protocol.
Fig. 170 illustrates a second presence only protocol.
Fig. 171 illustrates a third data protocol.
Fig. 172 illustrates a fourth data protocol.
Fig. 173 is a schematic block diagram of a maximal period LFSR.
Fig. 174 is a schematic block diagram of a clock limiting filter.
Fig. 175 is a schematic block diagram of the tamper detection lines.
Fig. 176 illustrates an oversized nMOS transistor.
Fig. 177 illustrates the taking of multiple XORs from the Tamper Detect Line
Fig. 178 illustrate how the Tamper Lines cover the noise generator circuitry.
Fig. 179 illustrates the normal form of FET implementation.
Fig. 180 illustrates the modified form of FET implementation of the preferred
embodiment.
Fig. 181 illustrates a schematic block diagram of the authentication chip.
Fig. 182 illustrates an example memory map.
Fig. 183 illustrates an example of the constants memory map.
Fig. 184 illustrates an example of the RAM memory map.
Fig. 185 illustrates an example of the Flash memory variables memory map.
Fig. 186 illustrates an example of the Flash memory program memory map.
Fig. 187 shows the data flow and relationship between components of the State
Machine.
Fig. 188 shows the data flow and relationship between components of the 1/0
Unit.
Fig. 189 illustrates a schematic block diagram of the Arithmetic Logic Unit.
Fig. 190 illustrates a schematic block diagram of the RPL unit.
Fig. 191 illustrates a schematic block diagram of the ROR block of the ALU.
Fig. 192 is a block diagram of the Program Counter Unit.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
_27-
Fig. 193 is a block diagram of the Memory Unit.
Fig. 194 shows a schematic block diagram for the Address Generator Unit.
Fig. 195 shows a schematic block diagram for the JSIGEN Unit.
Fig. 196 shows a schematic block diagram for the JSRGEN Unit.
Fig. 197 shows a schematic block diagram for the DBRGEN Unit.
Fig. 198 shows a schematic block diagram for the LDKGEN Unit.
Fig. 199 shows a schematic block diagram for the RPLGEN Unit.
Fig. 200 shows a schematic block diagram for the VARGEN Unit.
Fig. 201 shows a schematic block diagram for the CLRGEN Unit.
Fig. 202 shows a schematic block diagram for the BITGEN Unit.
Fig. 203 sets out the information stored on the print roll authentication
chip.
Fig. 204 illustrates the data stored within the Artcam authorization chip.
Fig. 205 illustrates the process of print head pulse characterization.
Fig. 206 is an exploded perspective, in section, of the print head ink supply
mechanism.
Fig. 207 is a bottom perspective of the ink head supply unit.
Fig. 208 is a bottom side sectional view of the ink head supply unit.
Fig. 209 is a top perspective of the ink head supply unit.
Fig. 210 is a top side sectional view of the ink head supply unit.
Fig. 211 illustrates a perspective view of a small portion of the print head.
Fig. 212 illustrates is an exploded perspective of the print head unit.
Fig. 213 illustrates a top side perspective view of the internal portions of
an Artcam camera, showing the parts
flattened out.
Fig. 214 illustrates a bottom side perspective view of the internal portions
of an Artcam camera, showing the parts
flattened out.
Fig. 215 illustrates a first top side perspective view of the intemal portions
of an Artcam camera, showing the parts as
encased in an Artcam.
Fig. 216 illustrates a second top side perspective view of the internal
portions of an Artcam camera, showing the parts
as encased in an Artcam.
Fig. 217 illustrates a second top side perspective view of the internal
portions of an Artcam camera, showing the parts
as encased in an Artcam.
Fig. 218 illustrates the backing portion of a postcard print roll.
Fig. 219 illustrates the corresponding front image on the postcard print roll
after printing out images.
Fig. 220 illustrates a form of print roll ready for purchase by a consumer.
Fig. 221 illustrates a layout of the software/hardware modules of the overall
Artcam application.
Fig. 222 illustrates a layout of the software/hardware modules of the Camera
Manager.
Fig. 223 illustrates a layout of the software/hardware modules of the Image
Processing Manager.
Fig. 224 illustrates a layout of the software/hardware modules of the Printer
Manager.
Fig. 225 illustrates a layout of the software/hardware modules of the Image
Processing Manager.
Fig. 226 illustrates a layout of the software/hardware modules of the File
Manager.
_ _.....__. _ .__._.w...~ .._..._._ _
___.___.__.__._......_..._ ~ ..
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-28-
Fig. 227 illustrates a perspective view, partly in section, of an altemative
form of printroll.
Fig. 228 is a left side exploded perspective view of the print roll of Fig.
227.
Fig. 229 is a right side exploded perspective view of a single printroll.
Fig. 230 is an exploded perspective view, partly in section, of the core
portion of the printroll.
Fig. 231 is a second exploded perspective view of the core portion of the
printroll.
Fig. 232 illustrates a front view of a`Bizcard'.
Fig. 233 illustrates schematically the camera system constructed in accordance
to a further refinement.
Fig. 234 illustrates schematically a printer mechanism for printing on the
front and back of output media.
Fig. 235 illustrates a format of the output data on the back of the photo.
Fig. 236 illustrates an enlarged portion of the output media.
Fig. 237 illustrates a reader device utilized to read data from the back of a
photograph.
Fig. 238 illustrates the utilization of an apparatus of a further refinement.
Fig. 239 illustrates a schematic example of image orientation specific
processing.
Fig. 240 illustrates a method of producing an image specific effect when
utilizing a camera as constructed in
accordance with a further refinement.
Fig. 241 illustrates a print roll in accordance with a further refmement.
Fig. 242 illustrates the method of a further refined embodiment.
Fig. 243 illustrates the method of operation of a further refinement.
Fig. 244 illustrates one form of image processing in accordance with a further
refinement.
Fig. 245 illustrates the method of operation of a further refinement.
Fig. 246 illustrates the process of capturing and outputting an image.
Fig. 247 illustrates the process of red-eye removal.
Fig. 248 illustrates a photo printing arrangement as constructed in accordance
with a standard artcam device.
Fig. 249 illustrates a dual print-head arrangement as constructed in
accordance with a further refinement.
Fig. 250 illustrates the de-curling mechanism of a further refinement.
Fig. 251 illustrates the process of viewing a stereo photographic image.
Fig. 252 illustrates the rectilinear system of a further refinements designed
to produce a stereo photographic effect.
Fig. 253 is a partial perspective view illustrating the creation of a stereo
photographic image.
Fig. 254 illustrates an apparatus for producing stereo photographic images in
accordance with a further refinements.
Fig. 255 illustrates the positioning unit of Fig. 254 in more detail.
Fig. 256 illustrates a camera device suitable for production of stereo
photographic images.
Fig. 257 illustrates the process of using an opaque backing to improve the
stereo photographic effect.
Fig. 258 illustrates schematically a method of creation of images on print
media.
Fig. 259 and Fig. illustrate the structure of the printing media constructed
in accordance with the present invention.
Fig. 260 illustrates utilization of the print media constructed in accordance
with a further refinement.
Fig. 261 illustrates a first form of construction of print media in accordance
with a further refinement.
Fig. 262 illustrates a further form of construction of print media in
accordance with the present invention.
Fig. 263 and Fig. 264 illustrate schematic cross-sectional views of a further
form of construction of print media in
accordance with the present invention.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-29-
Fig. 265 illustrates one form of manufacture of the print media construction
in accordance with Fig. 263 and 7.
Fig. 266 illustrates an alternative form of manufacture by extruding fibrous
material for utilization with the
arrangement of Fig. 265.
Fig. 267 illustrates the major steps in a further refmement.
Fig. 268 illustrates the Sobel filter co-efficients utilized within a further
refinement.
Fig. 269 and Fig. 270 illustrate the process of offsetting curves utilized in
a further refinements.
Fig. 271 illustrates a standard image including a face to be recognised.
Fig. 272 illustrates a fist flowchart for determining a region of interest.
Fig. 273 illustrates a second flowchart for determining a region of interest.
Fig. 274 illustrates an initial process of tiling an image.
Fig. 275 illustrates an altecnative tile pattern for tiling an image.
Fig. 276 illustrates a tile opacity mask.
Fig. 277 and Fig. 278 illustrate a corresponding surface texture height field
for the tile of Fig. 276.
Fig. 279 illustrates the process of using a global opacity to modify the
image.
Fig. 280 illustrates the process of modifying the stroking effect so as to
simulate the effect of combining real paints.
Fig. 281 illustrates the process of brush stroke table creation.
Fig. 282 illustrates the process of creating stroke color palettes.
Fig. 283 illustrates the consequential painting process.
Fig. 284 illustrates a flow chart of the steps in a further embodiment in
compositing brush strokes.
Fig. 285 illustrates the process conversion of Bezier curves to piecewise line
segments.
Fig. 286 illustrates the brush stroking process.
Fig. 287 illustrates suitable brush stamps for use by a further embodiment.
Fig. 288 illustrates a first arrangement of a further refmement.
Fig. 289 illustrates a flow chart of the operation of a further refinement.
Fig. 290 illustrates the structure of a high resolution printed image.
Fig. 291 illustrates an apparatus for process the image of Fig. 290 so as to
produce a copy.
Fig. 292 illustrates the centroid processing steps.
Fig. 293 illustrates a series of likely sensed pattern.
Fig. 294 illustrates a schematic implementation of a further refinement.
Fig. 295 illustrates a further refinement.
Fig. 296 illustrates the card reading arrangement of a further embodiment.
Fig. 297 and Fig. 298 illustrate a brush bump map.
Fig. 299 and Fig. 300 illustrate a background canvas bump map.
Fig. 301 and Fig. 302 illustrate the process of combining bump maps.
Fig. 303 illustrates a background of the map.
Fig. 304 and Fig. 305 iilustrate the process of combining bump maps in
accordance with a further refinement.
Fig. 306 illustrates the steps in the method of a further refinement in
production of an artistic image.
Fig. 307 illustrates the process of mapping one gamut to a second gamut.
Fig. 308 illustrates one form of implementation of a further refinement.
_ __.._.._..._...,....__, _ .__~ . __
. r __.___....._ ___.. ~...._.__ _
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-30-
Fig. 309 illustrates the preferred form of gamut remapping.
Fig. 310 illustrates one form of gamut morphing as utilized in a further
refmement.
Fig. 311 illustrates the basic operation of an Artcam device.
Fig. 312 illustrates a series of Artcards for use with a further refinement.
Fig. 313 is a flow diagram of the algorithm utilized by a further refinement.
Fig. 314 is a schematic illustration of the outputting of printed fabrics
produced in accordance with the present
invention.
Fig. 315 illustrates the form of interconnection of a further refinement.
Fig. 316 illustrates a perspective view, partly in section of a further
refinement.
Fig. 317 illustrates a card having an array of written data areas.
Fig. 318 illustrates a card having only a limited number of written data
areas.
Fig. 319 illustrates the structure of a data area.
Fig. 320 illustrates the structure of a target.
Fig. 321 illustrates an apparatus of a further refinement.
Fig. 322 illustrates a closer view of Fig. 321.
Fig. 323 illustrates the process of inserting a card into a reader device.
Fig. 324 illustrates the process of ejecting a card.
Fig. 325 illustrates the process of writing a data area on a card.
Fig. 326 is a schematic of the architecture of a card reader.
Fig. 327 is a schematic arrangement of a further refinement.
Fig. 328 illustrates an example interface of a further refinement.
Fig. 329 illustrates one form of arrangement of software modules within a
further refinement.
Fig. 330 is a schematic of the operation of an Artcam system.
Fig. 331 illustrates a first example modified operation of a Artcam system.
Fig. 332 illustrates a repetition card which modifies the operation of that
Artcam device.
Fig. 333 illustrates a Artcard test card for modification of the operation of
an Artcam device.
Fig. 334 illustrates the output test results of an Artcam device.
Fig. 335 illustrates schematically the camera system constructed in accordance
to a further refinement.
Fig. 336 illustrates schematically a printer mechanism and recording mechanism
of a further refinement.
Fig. 337 illustrates a format of the magnetic strip on the back of the photo.
Fig. 338 illustrates a reader device utilized to read data recorded on the
back of a photograph.
Fig. 339 illustrates the utilization of an apparatus of a further refinement.
Fig. 340 illustrates a schematic of the functional portions an Artcam device.
Fig. 341 illustrates the steps utilizing a further refinement.
Fig. 342 illustrates the operation of an Artcam device in accordance with a
further refinement.
Fig. 343 illustrates an alternative embodiment of printing out on the back
surface of an output "photo".
Fig. 344 illustrates the intemal portions of a printer device constructed in
accordance with a further embodiment.
Fig. 345 illustrates a network distribution system as constructed in
accordance with a further embodiment.
Fig. 346 illustrates schematically the operation of a printer computer of Fig.
345.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-31-
Description of Preferred and Other Embodiments
The digital image processing camera system constructed in accordance with the
preferred embodiment is as
illustrated in Fig. 1. The camera unit 1 includes means for the insertion of
an integral print roll (not shown). The
camera unit 1 can include an area image sensor 2 which sensors an image 3 for
captured by the camera. Optionally,
the second area image sensor can be provided to also image the scene 3 and to
optionally provide for the production of
stereographic output effects.
The camera 1 can include an optional color display 5 for the display of the
image being sensed by the sensor
2. When a simple image is being displayed on the display 5, the button 6 can
be depressed resulting in the printed
image 8 being output by the camera unit 1. A series of cards, herein after
known as "Artcards" 9 contain, on one
surface encoded information and on the other surface, contain an image
distorted by the particular effect produced by
the Artcard 9. The Artcard 9 is inserted in an Artcard reader 10 in the side
of camera 1 and, upon insertion, results in
output image 8 being distorted in the same manner as the distortion appearing
on the surface of Artcard 9. Hence, by
means of this simple user interface a user wishing to produce a particular
effect can insert one of many Artcards 9 into
the Artcard reader 10 and utilize button 19 to take a picture of the image 3
resulting in a corresponding distorted output
image 8.
The camera unit I can also include a number of other control button 13, 14 in
addition to a simple LCD output
display 15 for the display of informative information including the number of
printouts left on the internal print roll on
the camera unit. Additionally, different output formats can be controlled by
CHP switch 17.
Turning now to Fig. 2, there is illustrated a schematic view of the internal
hardware of the camera unit 1. The
internal hardware is based around an Artcam central processor unit (ACP) 31.
Artcam Central Processor 31
The Artcam central processor 31 provides many functions which form the 'heart'
of the system. The ACP 31
is preferably implemented as a complex, high speed, CMOS system on-a-chip.
Utilising standard cell design with
some full custom regions is recommended. Fabrication on a 0.25 CMOS process
will provide the density and speed
required, along with a reasonably small die area.
The functions provided by the ACP 31 include:
1. Control and digitization of the area image sensor 2. A 3D stereoscopic
version of the ACP requires
two area image sensor interfaces with a second optional image sensor 4 being
provided for stereoscopic effects.
2. Area image sensor compensation, reformatting, and image enhancement.
3. Memory interface and management to a memory store 33.
4. Interface, control, and analog to digital conversion of an Artcard reader
linear image sensor 34 which
is provided for the reading of data from the Artcards 9.
5. Extraction of the raw Artcard data from the digitized and encoded Artcard
image.
6. Reed-Solomon error detection and correction of the Artcard encoded data.
The encoded surface of
the Artcard 9 includes information on how to process an image to produce the
effects displayed on the image distorted
surface of the Artcard 9. This information is in the form of a script,
hereinafter known as a "Vark script". The Vark
script is utilised by an interpreter running within the ACP 31 to produce the
desired effect.
7. Interpretation of the Vark script on the Artcard 9.
8. Performing image processing operations as specified by the Vark script.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-32-
9. Controlling various motors for the paper transport 36, zoom lens 38,
autofocus 39 and Artcard driver
37.
10. Controlling a guillotine actuator 40 for the operation of a guiliotine 41
for the cutting of photographs
8 from print roll 42.
11. Half-toning of the image data for printing.
12. Providing the print data to a print-head 44 at the appropriate times.
13. Controlling the print head 44.
14. Controlling the ink pressure feed to print-head 44.
15. Controlling optional flash unit 56.
16. Reading and acting on various sensors in the camera, including camera
orientation sensor 46,
autofocus 47 and Artcard insertion sensor 49.
17. Reading and acting on the user interface buttons 6, 13, 14.
18. Controlling the status display 15.
19. Providing viewfinder and preview images to the color display 5.
20. Control of the system power consumption, including the ACP power
consumption via power
management circuit 51 .
21. Providing external communications 52 to general purpose computers (using
part USB).
22. Reading and storing information in a printing roll authentication chip 53.
23. Reading and storing information in a camera authentication chip 54.
24. Communicating with an optional mini-keyboard 57 for text modification.
Ouartz crystal 58
A quartz crystal 58 is used as a frequency reference for the system clock. As
the system clock is very high,
the ACP 31 includes a phase locked loop clock circuit to increase the
frequency derived from the crystal 58.
Image Sensing
Area imaQe sensor 2
The area image sensor 2 converts an image through its lens into an electrical
signal. It can either be a charge
coupled device (CCD) or an active pixel sensor (APS)CMOS image sector. At
present, available CCD's normally
have a higher image quality, however, there is currently much development
occurring in CMOS imagers. CMOS
imagers are eventually expected to be substantially cheaper than CCD's have
smaller pixel areas, and be able to
incorporate drive circuitry and signal processing. They can also be made in
CMOS fabs, which are transitioning to 12"
wafers. CCD's are usually built in 6" wafer fabs, and economics may not allow
a conversion to 12" fabs. Therefore,
the difference in fabrication cost between CCD's and CMOS imagers is likely to
increase, progressively favoring
CMOS imagers. However, at present, a CCD is probably the best option.
The Artcam unit will produce suitable results with a 1,500 x 1,000 area image
sensor. However, smaller
sensors, such as 750 x 500, wilf be adequate for many markets. The Artcam is
less sensitive to image sensor resolution
than are conventional digital cameras. This is because many of the styles
contained on Artcards 9 process the image in
such a way as to obscure the lack of resolution. For example, if the image is
distorted to simulate the effect of being
converted to an impressionistic painting, low source image resolution can be
used with minimal effect. Further
examples for which low resolution input images will typically not be noticed
include image warps which produce high
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-33-
distorted images, multiple miniature copies of the of the image (eg. passport
photos), textural processing such as bump
mapping for a base relief metal look, and photo-compositing into structured
scenes.
This tolerance of low resolution image sensors may be a significant factor in
reducing the manufacturing cost
of an Artcam unit 1 camera. An Artcam with a low cost 750 x 500 image sensor
will often produce superior results to
a conventional digital camera with a much more expensive 1,500 x 1,000 image
sensor.
Optional stereosconic 3D image sensor 4
The 3D versions of the Artcam unit 1 have an additional image sensor 4, for
stereoscopic operation. This
image sensor is identical to the main image sensor. The circuitry to drive the
optional image sensor may be included as
a standard part of the ACP chip 31 to reduce incremental design cost.
Alternatively, a separate 3D Artcam ACP can be
designed. This option will reduce the manufacturing cost of a mainstream
single sensor Artcam.
Print roll authentication chin 53
A small chip 53 is included in each print roll 42. This chip replaced the
functions of the bar code, optical
sensor and wheel, and ISO/ASA sensor on other forms of camera film units such
as Advanced Photo Systems film
cartridges.
The authentication chip also provides other features:
1. The storage of data rather than that which is mechanically and optically
sensed from APS rolls
2. A remaining media length indication, accurate to high resolution.
3. Authentication Information to prevent inferior clone print roll copies.
The authentication chip 53 contains 1024 bits of Flash memory, of which 128
bits is an authentication key,
and 512 bits is the authentication information. Also included is an encryption
circuit to ensure that the authentication
key cannot be accessed directly.
Print-head 44
The Artcam unit I can utilize any color print technology which is small
enough, low enough power, fast
enough, high enough quality, and low enough cost, and is compatible with the
print roll. Relevant printheads wiil be
specifically discussed hereinafter.
The specifications of the ink jet head are:
Image type Bi-level, dithered
Color CMY Process Color
Resolution 1600 dpi
Print head length `Page-width' (100mm)
Print speed 2 seconds per photo
Ontional ink pressure Controller (not shown)
The function of the ink pressure controller depends upon the type of ink jet
print head 44 incorporated in the
Artcam. For some types of ink jet, the use of an ink pressure controller can
be eliminated, as the ink pressure is simply
atmospheric pressure. Other types of print head require a regulated positive
ink pressure. In this case, the in pressure
controller consists of a pump and pressure transducer.
Other print heads may require an ultrasonic transducer to cause regular
oscillations in the ink pressure,
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-34-
typically at frequencies around 100KHz. In the case, the ACP 31 controls the
frequency phase and amplitude of these
oscillations.
Paper transport motor 36
The paper transport motor 36 moves the paper from within the print roll 42
past the print head at a relatively
constant rate. The motor 36 is a miniature motor geared down to an appropriate
speed to drive rollers which move the
paper. A high quality motor and mechanical gears are required to achieve high
image quality, as mechanical rumble or
other vibrations will affect the printed dot row spacing.
P=r transport motor driver 60
The motor driver 60 is a smail circuit which amplifies the digital motor
control signals from the APC 31 to
levels suitable for driving the motor 36.
Paper Qull sensor
A paper pull sensor 50 detects a user's attempt to pull a photo from the
camera unit during the printing
process. The APC 31 reads this sensor 50, and activates the guillotine 41 if
the condition occurs. The paper pull
sensor 50 is incorporated to make the camera more 'foolproof' in operation.
Were the user to pull the paper out
forcefully during printing, the print mechanism 44 or print roll 42 may (in
extreme cases) be damaged. Since it is
acceptable to pull out the `pod' from a Polaroid type camera before it is
fully ejected, the public has been 'trained' to
do this. Therefore, they are unlikely to heed printed instructions not to pull
the paper.
The Artcam preferably restarts the photo print process after the guillotine 41
has cut the paper after pull
sensing.
The pull sensor can be implemented as a strain gauge sensor, or as an optical
sensor detecting a small plastic
flag which is deflected by the torque that occurs on the paper drive rollers
when the paper is pulled. The latter
implementation is recommendation for low cost.
Paper guillotine actuator 40
The paper guillotine actuator 40 is a small actuator which causes the
guillotine 41 to cut the paper either at the
end of a photograph, or when the paper pull sensor 50 is activated.
The guillotine actuator 40 is a small circuit which amplifies a guillotine
control signal from the APC tot the
level required by the actuator 41.
Artcard 9
The Artcard 9 is a program storage medium for the Artcam unit. As noted
previously, the programs are in the
form of Vark scripts. Vark is a powerful image processing language especially
developed for the Artcam unit. Each
Artcard 9 contains one Vark script, and thereby defines one image processing
style.
Preferably, the VARK language is highly image processing specific. By being
highly image processing
specific, the amount of storage required to store the details on the card are
substantially reduced. Further, the ease with
which new programs can be created, including enhanced effects, is also
substantially increased. Preferably, the
language includes facilities for handling many image processing functions
including image warping via a warp map,
convolution, color lookup tables, posterizing an image, adding noise to an
image, image enhancement filters, painting
algorithms, brush jittering and manipulation edge detection filters, tiling,
illumination via light sources, bump maps,
text, face detection and object detection attributes, fonts, including three
dimensional fonts, and arbitrary complexity
pre-rendered icons. Further details of the operation of the Vark language
interpreter are contained hereinafter.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-35-
Hence, by utilizing the language constructs as defined by the created
language, new affects on arbitrary
images can be created and constructed for inexpensive storage on Artcard and
subsequent distribution to camera
owners. Further, on one surface of the card can be provided an example
illustrating the effect that a particular VARK
script, stored on the other surface of the card, will have on an arbitrary
captured image.
By utilizing such a system, camera technology can be distributed without a
great fear of obsolescence in that,
provided a VARK interpreter is incorporated in the camera device, a device
independent scenario is provided whereby
the underlying technology can be completely varied over time. Further, the
VARK scripts can be updated as new
filters are created and distributed in an inexpensive manner, such as via
simple cards for card reading.
The Artcard 9 is a piece of thin white plastic with the same format as a
credit card (86mm long by 54mm
wide). The Artcard is printed on both sides using a high resolution ink jet
printer. The inkjet printer technology is
assumed to be the same as that used in the Artcam, with 1600 dpi (63dpmm)
resolution. A major feature of the
Artcard 9 is low manufacturing cost. Artcards can be manufactured at high
speeds as a wide web of plastic film. The
plastic web is coated on both sides with a hydrophilic dye fixing layer. The
web is printed simultaneously on both
sides using a 'pagewidth' color ink jet printer. The web is then cut and
punched into individual cards. On one face of
the card is printed a human readable representation of the effect the Artcard
9 will have on the sensed image. This can
be simply a standard image which has been processed using the Vark script
stored on the back face of the card.
On the back face of the card is printed an array of dots which can be decoded
into the Vark script that defines
the image processing sequence. The print area is 80mm x 50mm, giving a total
of 15,876,000 dots. This array of dots
could represent at least 1.89 Mbytes of data. To achieve high reliability,
extensive error detection and correction is
incorporated in the array of dots. This allows a substantial portion of the
card to be defaced, worn, creased, or dirty
with no effect on data integrity. The data coding used is Reed-Solomon coding,
with half of the data devoted to error
correction. This allows the storage of 967 Kbytes of error corrected data on
each Artcard 9.
Linear image sensor 34
The Artcard linear sensor 34 converts the aforementioned Artcard data image to
electrical signals. As with
the area image sensor 2, 4, the linear image sensor can be fabricated using
either CCD or APS CMOS technology. The
active length of the image sensor 34 is 50mm, equal to the width of the data
array on the Artcard 9. To satisfy
Nyquist's sampling theorem, the resolution of the linear image sensor 34 must
be at least twice the highest spatial
frequency of the Artcard optical image reaching the image sensor. In practice,
data detection is easier if the image
sensor resolution is substantially above this. A resolution of 4800 dpi (189
dpmm) is chosen, giving a total of 9,450
pixels. This resolution requires a pixel sensor pitch of 5.3 m. This can
readily be achieved by using four staggered
rows of 20 m pixel sensors.
The linear image sensor is mounted in a special package which includes a LED
65 to illuminate the Artcard 9
via a light-pipe (not shown).
The Artcard reader light-pipe can be a molded light-pipe which has several
function:
1. It diffuses the light from the LED over the width of the card using total
internal reflection facets.
2. It focuses the light onto a 16 m wide strip of the Artcard 9 using an
integrated cylindrical lens.
3. It focuses light reflected from the Artcard onto the linear image sensor
pixels using a molded array of
microlenses.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-36-
The operation of the Artcard reader is explained further hereinafter.
Artcard reader motor 37
The Artcard reader motor propels the Artcard past the linear image sensor 34
at a relatively constant rate. As
it may not be cost effective to include extreme precision mechanical
components in the Artcard reader, the motor 37 is
a standard miniature motor geared down to an appropriate speed to drive a pair
of rollers which move the Artcard 9.
The speed variations, rumble, and other vibrations will affect the raw image
data as circuitry within the APC 31
includes extensive compensation for these effects to reliably read the Artcard
data.
The motor 37 is driven in reverse when the Artcard is to be ejected.
Artcard motor driver 61
The Artcard motor driver 61 is a small circuit which amplifies the digital
motor control signals from the APC
31 to levels suitable for driving the motor 37.
Card Insertion sensor 49
The card insertion sensor 49 is an optical sensor which detects the presence
of a card as it is being inserted in
the card reader 34. Upon a signal from this sensor 49, the APC 31 initiates
the card reading process, including the
activation of the Artcard reader motor 37.
Card eiect button 16
A card eject button 16 (Fig. 1) is used by the user to eject the current
Artcard, so that another Artcard can be
inserted. The APC 31 detects the pressing of the button, and reverses the
Artcard reader motor 37 to eject the card.
Card status indicator 66
A card status indicator 66 is provided to signal the user as to the status of
the Artcard reading process. This
can be a standard bi-color (red/green) LED. When the card is successfully
read, and data integrity has been verified,
the LED lights up green continually. If the card is faulty, then the LED
lights up red.
If the camera is powered from a 1.5 V instead of 3V battery, then the power
supply voltage is less than the
forward voltage drop of the greed LED, and the LED will not light. In this
case, red LEDs can be used, or the LED
can be powered from a voltage pump which also powers other circuits in the
Artcam which require higher voltage.
64 Mbit DRAM 33
To perform the wide variety of image processing effects, the camera utilizes 8
Mbytes of memory 33. This
can be provided by a singie 64 Mbit memory chip. Of course, with changing
memory technology increased Dram
storage sizes may be substituted.
High speed access to the memory chip is required. This can be achieved by
using a Rambus DRAM (burst
access rate of 500 Mbytes per second) or chips using the new open standards
such as double data rate (DDR) SDRAM
or Synclink DRAM.
Camera authentication chip
The camera authentication chip 54 is identical to the print roll
authentication chip 53, except that it has
different information stored in it. The camera authentication chip 54 has
three main purposes:
1. To provide a secure means of comparing authentication codes with the print
roll authentication chip;
2. To provide storage for manufacturing information, such as the serial number
of the camera;
3. To provide a small amount of non-volatile memory for storage of user
information.
Displays
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-37-
The Artcam includes an optional color display 5 and small status display 15.
Lowest cost consumer cameras
may include a color image display, such as a small TFT LCD 5 similar to those
found on some digital cameras and
camcorders. The color display 5 is a major cost element of these versions of
Artcam, and the display 5 plus back light
are a major power consumption drain.
Status displa~15
The status display 15 is a small passive segment based LCD, similar to those
currently provided on silver
halide and digital cameras. Its main function is to show the number of prints
remaining in the print roll 42 and icons
for various standard camera features, such as flash and battery status.
Color display 5
The color display 5 is a full motion image display which operates as a
viewfinder, as a verification of the
image to be printed, and as a user interface display. The cost of the display
5 is approximately proportional to its area,
so large displays (say 4" diagonal) unit will be restricted to expensive
versions of the Artcam unit. Smaller displays,
such as color camcorder viewfinder TFI"s at around 1", may be effective for
mid-range Artcams.
Zoom lens (not shown)
The Artcam can include a zoom lens. This can be a standard electronically
controlled zoom lens, identical to
one which would be used on a standard electronic camera, and similar to pocket
camera zoom lenses. A referred
version of the Artcam unit may include standard interchangeable 35mm SLR
lenses.
Autofocus motor 39
The autofocus motor 39 changes the focus of the zoom lens. The motor is a
miniature motor geared down to
an appropriate speed to drive the autofocus mechanism.
Autofocus motor driver 63
The autofocus motor driver 63 is a small circuit which amplifies the digital
motor control signals from the
APC 31 to levels suitable for driving the motor 39.
Zoom motor 38
The zoom motor 38 moves the zoom front lenses in and out. The motor is a
miniature motor geared down to
an appropriate speed to drive the zoom mechanism.
Zoom motor driver 62
The zoom motor driver 62 is a small circuit which amplifies the digital motor
control signals from the APC 31
to levels suitable for driving the motor.
Communications
The ACP 31 contains a universal serial bus (USB) interface 52 for
communication with personal computers.
Not all Artcam models are intended to include the USB connector. However, the
silicon area required for a USB
circuit 52 is small, so the interface can be included in the standard ACP.
Optional Keyboard 57
The Artcam unit may include an optional miniature keyboard 57 for customizing
text specified by the
Artcard. Any text appearing in an Artcard image may be editable, even if it is
in a complex metallic 3D font. The
miniature keyboard includes a single line alphanumeric LCD to display the
original text and edited text. The keyboard
may be a standard accessory.
The ACP 31 contains a serial communications circuit for transferring data to
and from the miniature ---.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-38-
keyboard.
Power Sutmlv
The Artcam unit uses a battery 48. Depending upon the Artcam options, this is
either a 3V Lithium cell, 1.5
V AA alkaline cells, or other battery arrangement.
Power Management Unit 51
Power consumption is an important design constraint in the Artcam. It is
desirable that either standard camera
batteries (such as 3V lithium batters) or standard AA or AAA alkaline cells
can be used. While the electronic
complexity of the Artcam unit is dramatically higher than 35mm photographic
cameras, the power consumption need
not be commensurately higher. Power in the Artcam can be carefully managed
with all unit being turned off when not
in use.
The most significant current drains are the ACP 31, the area image sensors
2,4, the printer 44 various motors,
the flash unit 56, and the optional color display 5 dealing with each part
separately:
1. ACP: If fabricated using 0.25 m CMOS, and running on 1.5V, the ACP power
consumption can be
quite low. Clocks to various parts of the ACP chip can be quite low. Clocks to
various parts of the ACP chip can be
turned off when not in use, virtually eliminating standby current consumption.
The ACP will only fully used for
approximately 4 seconds for each photograph printed.
2. Area image sensor: power is only supplied to the area image sensor when the
user has their finger on
the button.
3. The printer power is only supplied to the printer when actually printing.
This is for around 2 seconds
for each photograph. Even so, suitably lower power consumption printing should
be used.
4. The motors required in the Artcam are all low power miniature motors, and
are typically only
activated for a few seconds per photo.
5. The flash unit 45 is only used for some photographs. Its power consumption
can readily be provided
by a 3V lithium battery for a reasonably battery life.
6. The optional color display 5 is a major current drain for two reasons: it
must be on for the whole time
that the camera is in use, and a backlight will be required if a liquid
crystal display is used. Cameras which incorporate
a color display will require a larger battery to achieve acceptable batter
life.
Flash unit 56
The flash unit 56 can be a standard miniature electronic flash for consumer
cameras.
Overview of the ACP 31
Fig. 3 illustrates the Artcam Central Processor (ACP) 31 in more detail. The
Artcam Central Processor provides all of
the processing power for Artcam. It is designed for a 0.25 micron CMOS
process, with approximately 1.5 nlillion
transistors and an area of around 50 mm 2. The ACP 31 is a complex design, but
design effort can be reduced by the use
of datapath compilation techniques, macrocells, and IP cores. The ACP 31
contains:
A RISC CPU core 72
A 4 way parallel VLIW Vector Processor 74
A Direct RAMbus interface 81
A CMOS image sensor interface 83
A CMOS linear image sensor interface 88
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-39-
A USB serial interface 52
An infrared keyboard interface 55
A numeric LCD interface 84, and
A color TFT LCD interface 88
A 4Mbyte Flash memory 70 for program storage 70
The RISC CPU, Direct RAMbus interface 81, CMOS sensor interface 83 and USB
serial interface 52 can be vendor
supplied cores. The ACP 31 is intended to run at a clock speed of 200 MHz on
3V externally and 1.5V internally to
minimize power consumption. The CPU core needs only to run at 100 MHz. The
following two block diagrams give
two views of the ACP 31:
A view of the ACP 31 in isolation
An example Artcam showing a high-level view of the ACP 31 connected to the
rest of the Artcam hardware.
Image Access
As stated previously, the DRAM Interface 81 is responsible for interfacing
between other client portions of
the ACP chip and the RAMBUS DRAM. In effect, each module within the DRAM
Interface is an address generator.
There are three logical types of images manipulated by the ACP. They are:
-CCD Image, which is the Input Image captured from the CCD.
-Internal Image format - the Image format utilised internally by the Artcam
device.
Print Image - the Output Image format printed by the Artcam
These images are typically different in color space, resolution, and the
output & input color spaces which can
vary from camera to camera. For example, a CCD image on a low-end camera may
be a different resolution, or have
different color characteristics from that used in a high-end camera. However
all internal image formats are the same
format in terms of color space across all cameras.
In addition, the three image types can vary with respect to which direction is
'up'. The physical orientation of
the camera causes the notion of a portrait or landscape image, and this must
be maintained throughout processing. For
this reason, the internal image is always oriented correctly, and rotation is
performed on images obtained from the
CCD and during the print operation.
CPU Core (CPU) 72
The ACP 31 incorporates a 32 bit RISC CPU 72 to run the Vark image processing
language interpreter and to perform
Artcam's general operating system duties. A wide variety of CPU cores are
suitable: it can be any processor core with
sufficient processing power to perform the required core calculations and
control functions fast enough to met
consumer expectations. Examples of suitable cores are: MIPS R4000 core from
LSI Logic, StrongARM core. There
is no need to maintain instruction set continuity between different Artcam
models. Artcard compatibility is maintained
irrespective of future processor advances and changes, because the Vark
interpreter is simply re-compiled for each new
instruction set. The ACP 31 architecture is therefore also free to evolve.
Different ACP 31 chip designs may be
fabricated by different manufacturers, without requiring to license or port
the CPU core. This device independence
avoids the chip vendor lock-in such as has occurred in the PC market with
Intel. The CPU operates at 100 MHz, with
a single cycle time of i0ns. It must be fast enough to run the Vark
interpreter, although the VLIW Vector Processor 74
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-40-
is responsible for most of the time-critical operations.
Program cache 72
Although the program code is stored in on-chip Flash memory 70, it is unlikely
that well packed Flash memory 70 will
be able to operate at the lOns cycle time required by the CPU. Consequently a
small cache is required for good
performance. 16 cache lines of 32 bytes each are sufficient, for a total of
512 bytes. The program cache 72 is defined in
the chapter entitled Program cache 72.
Data cache 76
A small data cache 76 is required for good performance. This requirement is
mostly due to the use of a RAMbus
DRAM, which can provide high-speed data in bursts, but is inefficient for
single byte accesses. The CPU has access to
a memory caching system that allows flexible manipulation of CPU data cache 76
sizes. A minimum of 16 cache lines
(512 bytes) is recommended for good performance.
CPU Memory Model
An Artcam's CPU memory model consists of a 32MB area. It consists of 8MB of
physical RDRAM off-chip in the
base model of Artcam, with provision for up to 16MB of off-chip memory. There
is a 4MB Flash memory 70 on the
ACP 31 for program storage, and finally a 4MB address space mapped to the
various registers and controls of the ACP
31. The memory map then, for an Artcam is as follows:
Contents Size
Base Artcam DRAM 8 MB
Extended DRAM 8 MB
Program memory (on ACP 31 in Flash memory 70) 4 MB
Reserved for extension of program memory 4 MB
ACP 31 registers and memory-mapped 1/0 4 MB
Reserved 4 MB
TOTAL 32 MB
A straightforward way of decoding addresses is to use address bits 23-24:
If bit 24 is clear, the address is in the lower 16-MB range, and hence can be
satisfied from DRAM and
the Data cache 76. In most cases the DRAM will only be 8 MB, but 16 MB is
allocated to cater for
a higher memory model Artcams.
If bit 24 is set, and bit 23 is clear, then the address represents the Flash
memory 70 4Mbyte range and is
satisfied by the Program cache 72.
If bit 24 = I and bit 23 = 1, the address is translated into an access over
the low speed bus to the
requested component in the AC by the CPU Memory Decoder 68.
Flash memory 70
The ACP 31 contains a 4Mbyte Flash memory 70 for storing the Artcam program.
It is envisaged that Flash memory
70 will have denser packing coefficients than masked ROM, and allows for
greater flexibility for testing camera
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-41-
program code. The downside of the Flash memory 70 is the access time, which is
unlikely to be fast enough for the
100 MHz operating speed (IOns cycle time) of the CPU. A fast Program
Instruction cache 77 therefore acts as the
interface between the CPU and the slower Flash memory 70.
Program cache 72
A small cache is required for good CPU performance. This requirement is due to
the slow speed Flash memory 70
which stores the Program code. 16 cache lines of 32 bytes each are sufficient,
for a total of 512 bytes. The Program
cache 72 is a read only cache. The data used by CPU programs comes through the
CPU Memory Decoder 68 and if the
address is in DRAM, through the general Data cache 76. The separation allows
the CPU to operate independently of
the VLIW Vector Processor 74. If the data requirements are low for a given
process, it can consequently operate
completely out of cache.
Finally, the Program cache 72 can be read as data by the CPU rather than
purely as program instructions. This allows
tables, microcode for the VLIW etc to be loaded from the Flash memory 70.
Addresses with bit 24 set and bit 23 clear
are satisfied from the Program cache 72.
CPU Memory Decoder 68
The CPU Memory Decoder 68 is a simple decoder for satisfying CPU data
accesses. The Decoder translates data
addresses into internal ACP register accesses over the internal low speed bus,
and therefore allows for memory
mapped I/O of ACP registers. The CPU Memory Decoder 68 only interprets
addresses that have bit 24 set and bit 23
clear. There is no caching in the CPU Memory Decoder 68.
DRAM interface 81
The DRAM used by the Artcam is a single channel 64Mbit (8MB) RAMbus RDRAM
operating at 1.6GB/sec.
RDRAM accesses are by a single channel (16-bit data path) controller. The
RDRAM also has several useful operating
modes for low power operation. Although the Rambus specification describes a
system with random 32 byte transfers
as capable of achieving a greater than 95% efficiency, this is not true if
only part of the 32 bytes are used. Two reads
followed by two writes to the same device yields over 86% efficiency. The
primary latency is required for bus turn-
around going from a Write to a Read, and since there is a Delayed Write
mechanism, efficiency can be further
improved. With regards to writes, Write Masks allow specific subsets of bytes
to be written to. These write masks
would be set via internal cache "dirty bits". The upshot of the Rambus Direct
RDRAM is a throughput of >1 GB/sec is
easily achievable, and with multiple reads for every write (most processes)
combined with intelligent algorithms
making good use of 32 byte transfer knowledge, transfer rates of >1.3 GB/sec
are expected. Every lOns, 16 bytes can
be transferred to or from the core.
DRAM Organization
The DRAM organization for a base model (8MB RDRAM) Artcam is as follows:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-42-
Contents Size
Program scratch RAM 0.50 MB
Artcard data 1.00 MB
Photo Image, captured from CMOS Sensor 0.50 MB
Print Image (compressed) 2.25 MB
I Channel of expanded Photo Image 1.50 MB
I Image Pyramid of single channel 1.00 MB
Intermediate Image Processing 1.25 MB
TOTAL 8 MB
Notes:
Uncompressed, the Print Image requires 4.5MB (1.5MB per channel). To
accommodate other objects in the 8MB
model, the Print Image needs to be compressed. If the chrominance channels are
compressed by 4:1 they require
only 0.375MB each).
The memory model described here assumes a single 8 MB RDRAM. Other models of
the Artcam may have more
memory, and thus not require compression of the Print Image. In addition, with
more memory a larger part of the
final image can be worked on at once, potentially giving a speed improvement.
Note that ejecting or inserting an Artcard invalidates the 5.5MB area holding
the Print Image, I channel of expanded
photo image, and the image pyramid. This space may be safely used by the
Artcard Interface for decoding the
Artcard data.
Data cache 76
The ACP 31 contains a dedicated CPU instruction cache 77 and a general data
cache 76. The Data cache 76 handles all
DRAM requests (reads and writes of data) from the CPU, the VLIW Vector
Processor 74, and the Display Controller
88. These requests may have very different profiles in ter,ms of memory usage
and algorithmic timing requirements.
For example, a VLIW process may be processing an image in linear memory, and
lookup a value in a table for each
value in the image. There is little need to cache much of the image, but it
may be desirable to cache the entire lookup
table so that no real memory access is required. Because of these differing
requirements, the Data cache 76 allows for
an intelligent definition of caching.
Although the Rambus DRAM interface 81 is capable of very high-speed memory
access (an average throughput of 32
bytes in 25ns), it is not efficient dealing with single byte requests. In
order to reduce effective memory latency, the
ACP 31 contains 128 cache lines. Each cache line is 32 bytes wide. Thus the
total amount of data cache 76 is 4096
bytes (4KB). The 128 cache lines are configured into 16 programmable-sized
groups. Each of the 16 groups must be a
contiguous set of cache lines. The CPU is responsible for determining how many
cache lines to allocate to each group.
Within each group cache lines are filled according to a simple Least Recently
Used algorithm. In terms of CPU data
requests, the Data cache 76 handles memory access requests that have address
bit 24 clear. If bit 24 is clear, the address
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-43-
is in the lower 16 MB range, and hence can be satisfied from DRAM and the Data
cache 76. In most cases the DRAM
will only be 8 MB, but 16 MB is allocated to cater for a higher memory model
Artcam. If bit 24 is set, the address is
ignored by the Data cache 76.
All CPU data requests are satisfied from Cache Group 0. A minimum of 16 cache
lines is recommended for good CPU
performance, although the CPU can assign any number of cache lines (except
none) to Cache Group 0. The remaining
Cache Groups (1 to 15) are allocated according to the current requirements.
This could mean allocation to a VLIW
Vector Processor 74 program or the Display Controller 88. For example, a 256
byte lookup table required to be
permanently available would require 8 cache lines. Writing out a sequential
image would only require 2-4 cache lines
(depending on the size of record being generated and whether write requests
are being Write Delayed for a significant
number of cycles). Associated with each cache line byte is a dirty bit, used
for creating a Write Mask when writing
memory to DRAM. Associated with each cache line is another dirty bit, which
indicates whether any of the cache line
bytes has been written to (and therefore the cache line must be written back
to DRAM before it can be reused). Note
that it is possible for two different Cache Groups to be accessing the same
address in memory and to get out of sync.
The VLIW program writer is responsible to ensure that this is not an issue. It
could be perfectly reasonable, for
example, to have a Cache Group responsible for reading an image, and another
Cache Group responsible for writing
the changed image back to memory again. If the images are read or written
sequentially there may be advantages in
allocating cache lines in this manner. A total of 8 buses 182 connect the VLIW
Vector Processor 74 to the Data cache
76. Each bus is connected to an I/O Address Generator. (There are 2 UO Address
Generators 189, 190 per Processing
Unit 178, and there are 4 Processing Units in the VLIW Vector Processor 74.
The total number of buses is therefore 8.)
In any given cycle, in addition to a single 32 bit (4 byte) access to the
CPU's cache group (Group 0), 4 simultaneous
accesses of 16 bits (2 bytes) to remaining cache groups are permitted on the 8
VLIW Vector Processor 74 buses. The
Data cache 76 is responsible for fairly processing the requests. On a given
cycle, no more than 1 request to a specific
Cache Group will be processed. Given that there are 8 Address Generators 189,
190 in the VLIW Vector Processor
74, each one of these has the potential to refer to an individual Cache Group.
However it is possible and occasionally
reasonable for 2 or more Address Generators 189, 190 to access the same Cache
Group. The CPU is responsible for
ensuring that the Cache Groups have been allocated the correct number of cache
lines, and that the various Address
Generators 189, 190 in the VLIW Vector Processor 74 reference the specific
Cache Groups correctly.
The Data cache 76 as described allows for the Display Controller 88 and VLIW
Vector Processor 74 to be active
simultaneously. If the operation of these two components were deemed to never
occur simultaneously, a total 9 Cache
Groups would suffice. The CPU would use Cache Group 0, and the VLIW Vector
Processor 74 and the Display
Controller 88 would share the remaining 8 Cache Groups, requiring only 3 bits
(rather than 4) to define which Cache
Group would satisfy a particular request.
JTAG Interface 85
A standard JTAG (Joint Test Action Group) Interface is included in the ACP 31
for testing purposes. Due to the
complexity of the chip, a variety of testing techniques are required,
including BIST (Built In Self Test) and functional
block isolation. An overhead of 10% in chip area is assumed for overall chip
testing circuitry. The test circuitry is
beyond the scope of this document.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-44-
Serial Interfaces
USB serial port interface 52
This is a standard USB serial port, which is connected to the internal chip
low speed bus, thereby allowing the CPU to
control it.
Keyboard interface 65
This is a standard low-speed serial port, which is connected to the internal
chip low speed bus, thereby allowing the
CPU to control it. It is designed to be optionally connected to a keyboard to
allow simple data input to customize
prints.
Authentication chip serial interfaces 64
These are 2 standard low-speed serial ports, which are connected to the
internal chip low speed bus, thereby allowing
the CPU to control them. The reason for having 2 ports is to connect to both
the on-camera Authentication chip, and to
the print-roll Authentication chip using separate lines. Only using I line may
make it possible for a clone print-roll
manufacturer to design a chip which, instead of generating an authentication
code, tricks the camera into using the
code generated by the authentication chip in the camera.
Parallel Interface 67
The parallel interface connects the ACP 31 to individual static electrical
signals. The CPU is able to control each of
these connections as memory-mapped I/O via the low speed bus The following
table is a list of connections to the
parallel interface:
Connection Direction Pins
Paper transport stepper motor Out 4
Artcard stepper motor Out 4
Zoom stepper motor Out 4
Guillotine motor Out 1
Flash trigger Out l
Status LCD segment drivers Out 7
Status LCD common drivers Out 4
Artcard illumination LED Out 1
Artcard status LED (red/green) In 2
Artcard sensor In 1
Paper pull sensor In 1
Orientation sensor In 2
Buttons In 4
TOTAL 36
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-45-
VLIW Input and Output FIFOs 78, 79
The VLIW Input and Output FIFOs are 8 bit wide FIFOs used for communicating
between processes and the VLIW
Vector Processor 74. Both FIFOs are under the control of the VLIW Vector
Processor 74, but can be cleared and
queried (e.g. for status) etc by the CPU.
VLIW Input FTFO 78
A client writes 8-bit data to the VLIW Input FIFO 78 in order to have the data
processed by the VLIW Vector
Processor 74. Clients include the Image Sensor Interface, Artcard Interface,
and CPU. Each of these processes is able
to offload processing by simply writing the data to the FIFO, and letting the
VLIW Vector Processor 74 do all the hard
work. An example of the use of a client's use of the VLIW Input FIFO 78 is the
Image Sensor Interface (ISI 83). The
ISI 83 takes data from the Image Sensor and writes it to the FIFO. A VLIW
process takes it from the FIFO,
transforming it into the correct image data format, and writing it out to
DRAM. The ISI 83 becomes much simpler as a
result.
VLIW Output FIFO 79
The VLIW Vector Processor 74 writes 8-bit data to the VLIW Output FIFO 79
where clients can read it. Clients
include the Print Head Interface and the CPU. Both of these clients is able to
offload processing by simply reading the
already processed data from the FIFO, and letting the VLIW Vector Processor 74
do all the hard work. The CPU can
also be interrupted whenever data is placed into the VLIW Output FIFO 79,
aliowing it to only process the data as it
becomes available rather than polling the FIFO continuously. An example of the
use of a client's use of the VLIW
Output FIFO 79 is the Print Head Interface (PHI 62). A VLIW process takes an
image, rotates it to the correct
orientation, color converts it, and dithers the resulting image according to
the print head requirements. The PHI 62
reads the dithered formatted 8-bit data from the VLIW Output FIFO 79 and
simply passes it on to the Print Head
external to the ACP 31. The PHI 62 becomes much simpler as a result.
VLIW Vector Processor 74
To achieve the high processing requirements of Artcam, the ACP 31 contains a
VLIW (Very Long Instruction Word)
Vector Processor. The VLIW processor is a set of 4 identical Processing Units
(PU e.g 178) working in parallel,
connected by a crossbar switch 183. Each PU e.g 178 can perform four 8-bit
multiplications, eight 8-bit additions,
three 32-bit additions, 1/0 processing, and various logical operations in each
cycle. The PUs e.g 178 are nvcrocoded,
and each has two Address Generators 189, 190 to allow full use of available
cycles for data processing. The four PUs
e.g 178 are normally synchronized to provide a tightly interacting VLIW
processor. Clocking at 200 MHz, the VLIW
Vector Processor 74 runs at 12 Gops (12 billion operations per second).
Instructions are tuned for image processing
functions such as warping, artistic brushing, complex synthetic illumination,
color transforms, image filtering, and
compositing. These are accelerated by two orders of magnitude over desktop
computers.
As shown in more detail in Fig. 3(a), the VLIW Vector Processor 74 is 4 PUs
e.g 178 connected by a crossbar switch
183 such that each PU e.g 178 provides two inputs to, and takes two outputs
from, the crossbar switch 183. Two
common registers fonn a control and synchronization mechanism for the PUs e.g
178. 8 Cache buses 182 allow
connectivity to DRAM via the Data cache 76, with 2 buses going to each PU e.g
178 (1 bus per 1/0 Address
Generator).
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-46-
Each PU e.g 178 consists of an ALU 188 (containing a number of registers &
some arithmetic logic for processing
data), some microcode RAM 196, and connections to the outside world (including
other ALUs). A local PU state
machine runs in microcode and is the means by which the PU e.g 178 is
controlled. Each PU e.g 178 contains two 1/0
Address Generators 189, 190 controlling data flow between DRAM (via the Data
cache 76) and the ALU 188 (via
Input FIFO and Output FIFO). The address generator is able to read and write
data (specifically images in a variety of
formats) as well as tables and simulated FIFOs in DRAM. The formats are
customizable under software control, but
are not microcoded. Data taken from the Data cache 76 is transferred to the
ALU 188 via the 16-bit wide Input FIFO.
Output data is written to the 16-bit wide Output FIFO and from there to the
Data cache 76. Finally, all PUs e.g 178
share a single 8-bit wide VLIW Input FIFO 78 and a single 8-bit wide VLIW
Output FIFO 79. The low speed data bus
connection allows the CPU to read and write registers in the PU e.g 178,
update microcode, as well as the common
registers shared by all PUs e.g 178 in the VLIW Vector Processor 74. Turning
now to Fig. 4, a closer detail of the
internals of a single PU e.g 178 can be seen, with components and control
signals detailed in subsequent hereinafter:
Microcode
Each PU e.g 178 contains a microcode RAM 196 to hold the program for that
particular PU e.g 178. Rather than have
the microcode in ROM, the microcode is in RAM, with the CPU responsible for
loading it up. For the same space on
chip, this tradeoff reduces the maximum size of any one function to the size
of the RAM, but allows an unlimited
number of functions to be written in microcode. Functions implemented using
microcode include Vark acceleration,
Artcard reading, and Printing. The VLIW Vector Processor 74 scheme has several
advantages for the case of the ACP
31:
Hardware design complexity is reduced
Hardware risk is reduced due to reduction in complexity
Hardware design time does not depend on all Vark functionality being
implemented in dedicated silicon
Space on chip is reduced overall (due to large number of processes able to be
implemented as
microcode)
Functionality can be added to Vark (via microcode) with no impact on hardware
design time
Size and Content
The CPU loaded microcode RAM 196 for controlling each PU e.g 178 is 128 words,
with each word being 96 bits
wide. A summary of the nucrocode size for control of various units of the PU
e.g 178 is listed in the following table:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-47-
Process Block Size (bits)
Status Output 3
Branching (microcode control) 11
In 8
Out 6
Registers 7
Read 10
Write 6
Barrel Shifter 12
Adder/Logical 14
Multiply/Interpolate 19
TOTAL 96
With 128 instruction words, the total microcode RAM 196 per PU e.g 178 is
12,288 bits, or 1.5KB exactly. Since the
VLIW Vector Processor 74 consists of 4 identical PUs e.g 178 this equates to
6,144 bytes, exactly 6KB. Some of the
bits in a microcode word are directly used as control bits, while others are
decoded. See the various unit descriptions
that detail the interpretation of each of the bits of the microcode word.
Synchronization Between PUs e.g 178
Each PU e.g 178contains a 4 bit Synchronization Register 197. It is a mask
used to deterniine which PUs e.g 178 work
together, and has one bit set for each of the corresponding PUs e.g 178 that
are functioning as a single process. For
example, if all of the PUs e.g 178 were functioning as a single process, each
of the 4 Synchronization Register 197s
would have all 4 bits set. If there were two asynchronous processes of 2 PUs
e.g 178 each, two of the PUs e.g 178
would have 2 bits set in their Synchronization Register 197s (corresponding to
themselves), and the other two would
have the other 2 bits set in their Synchronization Register 197s
(corresponding to themselves).
The Synchronization Register 197 is used in two basic ways:
Stopping and starting a given process in synchrony
Suspending execution within a process
StoppinQ and Starting Processes
The CPU is responsible for loading the microcode RAM 196 and loading the
execution address for the first instruction
(usually 0). When the CPU starts executing microcode, it begins at the
specified address.
Execution of microcode only occurs when all the bits of the Synchronization
Register 197 are also set in the Common
Synchronization Register 197. The CPU therefore sets up all the PUs e.g 178
and then starts or stops processes with a
single write to the Common Synchronization Register 197.
This synchronization scheme allows multiple processes to be running
asynchronously on the PUs e.g 178, being
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-48-
stopped and started as processes rather than one PU e.g 178 at a time.
Suspending Execution within a Process
In a given cycle, a PU e.g 178 may need to read from or write to a FIFO (based
on the opcode of the current microcode
instruction). If the FIFO is empty on a read request, or full on a write
request, the FIFO request cannot be completed.
The PU e.g 178 will therefore assert its SuspendProcess control signal 198.
The SuspendProcess signals from all PUs
e.g 178 are fed back to all the PUs e.g 178. The Synchronization Register 197
is ANDed with the 4 SuspendProcess
bits, and if the result is non-zero, none of the PU e.g 178's register
WriteEnables or FIFO strobes will be set.
Consequently none of the PUs e.g 178 that form the same process group as the
PU e.g 178 that was unable to complete
its task will have their registers or FIFOs updated during that cycle. This
simple technique keeps a given process group
in synchronization. Each subsequent cycle the PU e.g 178's state machine will
attempt to re-execute the microcode
instruction at the same address, and will continue to do so until successful.
Of course the Conunon Synchronization
Register 197 can be written to by the CPU to stop the entire process if
necessary. This synchronization scheme allows
any combinations of PUs e.g 178 to work together, each group only affecting
its co-workers with regards to suspension
due to data not being ready for reading or writing.
Control and Branchine
During each cycle, each of the four basic input and calculation units within a
PU e.g 178's ALU 188 (Read,
Adder/Logic, Multiply/Interpolate, and Barrel Shifter) produces two status
bits: a Zero flag and a Negative flag
indicating whether the result of the operation during that cycle was 0 or
negative. Each cycle one of those 4 status bits
is chosen by microcode instructions to be output from the PU e.g 178. The 4
status bits (1 per PU e.g 178's ALU 188)
are combined into a 4 bit Common Status Register 200. During the next cycle,
each PU e.g 178's microcode program
can select one of the bits from the Common Status Register 200, and branch to
another microcode address dependant
on the value of the status bit.
Status bit
Each PU e.g 178's ALU 188 contains a number of input and calculation units.
Each unit produces 2 status bits - a
negative flag and a zero flag. One of these status bits is output from the PU
e.g 178 when a particular unit asserts the
value on the 1-bit tri-state status bit bus. The single status bit is output
from the PU e.g 178, and then combined with
the other PU e.g 178 status bits to update the Common Status Register 200. The
microcode for determining the output
status bit takes the following form:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-49-
# Bits Description
2 Select unit whose status bit is to be output
00 = Adder unit
01 = Multiply/Logic unit
= Barrel Shift unit
11 = Reader unit
1 0=Zeroflag
1 = Negative flag
3 TOTAL
Within the ALU 188, the 2-bit Select Processor Block value is decoded into
four 1-bit enable bits, with a different
enable bit sent to each processor unit block. The status select bit (choosing
Zero or Negative) is passed into all units to
determine which bit is to be output onto the status bit bus.
Branchiniz Within Microcode
Each PU e.g 178 contains a 7 bit Program Counter (PC) that holds the current
microcode address being executed.
Normal program execution is linear, moving from address N in one cycle to
address N+l in the next cycle. Every cycle
however, a microcode program has the ability to branch to a different
location, or to test a status bit from the Common
Status Register 200 and branch. The microcode for determining the next
execution address takes the following form:
# Bits Description
2 00 = NOP (PC = PC+1)
01 = Branch always
10 = Branch if status bit clear
11 = Branch if status bit set
2 Select status bit from status word
7 Address to branch to (absolute address, 00-7F)
I1 TOTAL
ALU 188
Fig. 5 illustrates the ALU 188 in more detail. Inside the ALU 188 are a number
of specialized processing blocks,
controlled by a microcode program. The specialized processing blocks include:
Read Block 202, for accepting data from the input FIFOs
Write Block 203, for sending data out via the output FIFOs
Adder/Logical block 204, for addition & subtraction, comparisons and logical
operations
Multiply/Interpolate block 205, for multiple types of interpolations and
multiply/accumulates
Barrel Shift block 206, for shifting data as required
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-50-
In block 207, for accepting data from the external crossbar switch 183
Out block 208, for sending data to the external crossbar switch 183
Registers block 215, for holding data in temporary storage
Four specialized 32 bit registers hold the results of the 4 main proccssing
biocks:
M register 209 holds the result of the Multiply/Interpolate block
L register 209 holds the result of the Adder/Logic block
S register 209 holds the result of the Barrel Shifter block
R register 209 holds the result of the Read Block 202
In addition there are two internal crossbar switches 213m 214 for data
transport. The various process blocks are further
expanded in the following sections, together with the microcode definitions
that pertain to each block. Note that the
microcode is decoded within a block to provide the control signals to the
various units within.
Data Transfers Between PUs e.e 178
Each PU e.g 178 is able to exchange data via the external crossbar. A PU e.g
178 takes two inputs and outputs two
values to the external crossbar. In this way two operands for processing can
be obtained in a single cycle, but cannot be
actually used in an operation until the following cycle.
In 207
This block is illustrated in Fig. 6 and contains two registers, Inl and In2
that accept data from the external crossbar. The
registers can be loaded each cycle, or can remain unchanged. The selection
bits for choosing from among the 8 inputs
are output to the external crossbar switch 183. The microcode takes the
following form:
# Bits Description
1 0 = NOP
1= Load Ini from crossbar
3 Select Input 1 from external crossbar
I 0 = NOP
1= Load In2 from crossbar
3 Select Input 2 from external crossbar
8 TOTAL
Out 208
Complementing In is Out 208. The Out block is illustrated in more detail in
Fig. 7. Out contains two registers, Out, and
Out2, both of which are output to the external crossbar each cycle for use by
other PUs e.g 178. The Write unit is also
able to write one of Out, or Out2 to one of the output FIFOs attached to the
ALU 188. Finally, both registers are
available as inputs to Crossbarl 213, which therefore makes the register
values available as inputs to other units within
the ALU 188. Each cycle either of the two registers can be updated according
to microcode selection. The data loaded
into the specified register can be one of Do - D3 (selected from Crossbarl
213) one of M, L, S, and R (selected from
Crossbar2 214), one of 2 programmable constants, or the fixed values 0 or I.
The microcode for Out takes the
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-51-
following form:
# Bits Description
1 0 = NOP
1 = Load Register
1 Select Register to load [Outt or Out2]
4 Select input [Ini,Inz,Outl,OutZ,Do,D1 ,DZ,D3,M,L,S,R,Ki,K2,0,1]
6 TOTAL
Local Registers and Data Transfers within ALU 188
As noted previously, the ALU 188 contains four specialized 32-bit registers to
hold the results of the 4 main processing
blocks:
M register 209 holds the result of the Multiply/Interpolate block
L register 209 holds the result of the Adder/Logic block
S register 209 holds the result of the Barrel Shifter block
R register 209 holds the result of the Read Biock 202
The CPU has direct access to these registers, and other units can select them
as inputs via Crossbar2 214. Sometimes it
is necessary to delay an operation for one or more cycles. The Registers block
contains four 32-bit registers Do - D3 to
hold temporary variables during processing. Each cycle one of the reoisters
can be updated, while all the registers are
output for other units to use via Crossbarl 213 (which also includes Ini, In,,
Out, and Out,). The CPU has direct access
to these registers. The data loaded into the specified register can be one of
Do - D, (selected from Crossbarl 213) one
of M, L, S, and R (selected from Crossbar2 214), one of 2 programmable
constants, or the fixed values 0 or 1_ The
Registers block 215 is illustrated in more detail in Fig. 8. The microcode for
Registers takes the following form:
# Bits Description
1 0 = NOP
1 = Load Register
2 Select Register to load [Do - D3]
4 Select input [Ini,In,,Outi,Out,,Do,D,,D,,D,,M,L,S,R,K1,K,,0,1]
7 TOTAL
Crossbar ] 213
Crossbarl 213 is illustrated in more detail in Fig. 9. Crossbarl 213 is used
to select from inputs Ini, In,, Outi, Out,, Do-
D3. 7 outputs are generated from Crossbarl 213: 3 to the Multiply/Interpolate
Unit, 2 to the Adder Unit, I to the
Registers unit and 1 to the Out unit. The control signals for Crossbarl 213
come from the various units that use the
Crossbar inputs. There is no specific microcode that is separate for Crossbarl
213.
Crossbar2 214
Crossbar2 214 is illustrated in more detail in Fig. 10.Crossbar2 214 is used
to select from the general ALU 188
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-52-
registers M, L, S and R. 6 outputs are generated from Crossbarl 213: 2 to the
Multiply/Interpolate Unit, 2 to the Adder
Unit, I to the Registers unit and I to the Out unit. The control signals for
Crossbar2 214 come from the various units
that use the Crossbar inputs. There is no specific microcode that is separate
for Crossbar2 214.
Data Transfers Between PUs e.e 178 and DRAM or External Processes
Returning to Fig. 4, PUs e.g 178 share data with each other directly via the
external crossbar. They also transfer data to
and from external processes as well as DRAM. Each PU e.g 178 has 2 UO Address
Generators 189, 190 for
transferring data to and from DRAM. A PU e.g 178 can send data to DRAM via an
UO Address Generator's Output
FIFO e.g. 186, or accept data from DRAM via an I/O Address Generator's Input
FIFO 187. These FIFOs are local to
the PU e.g 178. There is also a mechanism for transferring data to and from
external processes in the form of a
common VLIW Input FIFO 78 and a common VLIW Output FIFO 79, shared between all
ALUs. The VLIW Input
and Output FIFOs are only 8 bits wide, and are used for printing, Artcard
reading, transferring data to the CPU etc. The
local Input and Output FIFOs are 16 bits wide.
Read
The Read process block 202 of Fig. 5 is responsible for updating the ALU 188's
R register 209, which represents the
external input data to a VLIW microcoded process. Each cycle the Read Unit is
able to read from either the common
VLIW Input FIFO 78 (8 bits) or one of two local Input FIFOs (16 bits). A 32-
bit value is generated, and then all or part
of that data is transferred to the R register 209. The process can be seen in
Ficy. 11. The microcode for Read is
described in the following table. Note that the interpretations of some bit
patterns are deliberately chosen to aid
decoding.
- ------- -----
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-53-
# Bits Description
2 00 = NOP
01 = Read from VLIW Input FIFO 78
= Read from Local FIFO 1
I I= Read from Local FIFO 2
1 How many significant bits
0 = 8 bits (pad with 0 or sign extend)
1= 16 bits (only valid for Local FIFO reads)
1 0 = Treat data as unsigned (pad with 0)
I= Treat data as signed (sign extend when reading from FIFO)r
2 How much to shift data left by:
00 = 0 bits (no change)
01 = 8 bits
10 = 16 bits
I 1 = 24 bits
4 Which bytes of R to update (hi to lo order byte)
Each of the 4 bits represents I byte WriteEnable on R
10 TOTAL
Write
The Write process block is able to write to either the common VLIW Output FIFO
79 or one of the two local Output
FIFOs each cycle. Note that since only I FIFO is written to in a given cycle,
only one 16-bit value is output to all
FIFOs, with the low 8 bits going to the VLIW Output FIFO 79. The microcode
controls which of the FIFOs gates in
the value. The process of data selection can be seen in more detail in Fig.
12. The source values Outi and Out, come
from the Out block. They are simply two registers. The microcode for Write
takes the following form:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-54-
# Bits Description
2 00 = NOP
01 = Write VLIW Output FIFO 79
= Write local Output FIFO I
11 = Write local Output FIFO 2
1 Select Output Value [Outi or Out2]
3 Select part of Output Value to write (32 bits = 4 bytes ABCD)
000 = OD
001 = 0D
010=aB
011 = 0A
100 = CD
101 = BC
110 = AB
1l1 =0
6 TOTAL
Computational Blocks
Each ALU 188 has two computational process blocks, namely an Adder/Logic
process block 204, and a
Multiply/Interpolate process block 205. In addition there is a Barrel Shifter
block to provide help to these
computational blocks. Registers from the Registers block 215 can be used for
temporary storage during pipelined
operations.
Barrel Shifter
The Barrel Shifter process block 206 is shown in more detail in Fig. 13 and
takes its input from the output of
Adder/Logic or Multiply/Interpolate process blocks or the previous cycle's
results from those blocks (ALU registers L
and M). The 32 bits selected are barrel shifted an arbitrary number of bits in
either direction (with sign extension as
necessary), and output to the ALU 188's S register 209. The microcode for the
Barrel Shift process block is described
in the following table. Note that the interpretations of some bit patterns are
deliberately chosen to aid decoding.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-55-
# Bits Description
3 000=NOP
001 = Shift Left (unsigned)
010 = Reserved
011 = Shift Left (signed)
100 = Shift right (unsigned, no rounding)
101 = Shift right (unsigned, with rounding)
110 = Shift right (signed, no rounding)
III = Shift right (signed, with rounding)
2 Select Input to barrel shift:
00 = Multiply/Interpolate result
01=M
= Adder/Logic result
11 =L
5 # bits to shift
1 Ceiling of 255
1 Floor of 0 (signed data)
12 TOTAL
Adder/Lo ic 204
The Adder/Logic process block is shown in more detail in Fig. 14 and is
designed for simple 32-bit
addition/subtraction, comparisons, and logical operations. In a single cycle a
single addition, comparison, or logical
operation can be performed, with the result stored in the ALU 188's L register
209. There are two primary operands, A
and B, which are selected from either of the two crossbars or from the 4
constant registers. One crossbar selection
allows the results of the previous cycle's arithmetic operation to be used
while the second provides access to operands
previously calculated by this or another ALU 188. The CPU is the only unit
that has write access to the four constants
(KI-K4). In cases where an operation such as (A+B) x 4 is desired, the direct
output from the adder can be used as
input to the Barrel Shifter, and can thus be shifted left 2 places without
needing to be latched into the L register 209
first. The output from the adder can also be made available to the multiply
unit for a multiply-accumulate operation.
The microcode for the Adder/Logic process block is described in the following
table. The interpretations of some bit
patterns are deliberately chosen to aid decoding. Microcode bit interpretation
for Adder/Logic unit
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-56-
# Bits Description
4 0000 = A+B (carry in = 0)
0001 = A+B (carry in = carry out of previous operation)
0010 = A+B+1 (carry in = 1)
0011 = A+1 (increments A)
0100 = A-B-1 (carry in = 0)
0101 = A-B (carry in = carry out of previous operation)
01 10 = A-B (carry in = 1)
01 11 = A-1 (decrements A)
1000 = NOP
1001 = ABS(A-B)
1010 = MIN(A, B)
1011 = MAX(A, B)
1100 = A AND B (both A & B can be inverted, see below)
1101 = A OR B (both A & B can be inverted, see below)
1110 = A XOR B (both A & B can be inverted, see below)
IIII = A (A can be inverted, see below)
1 If logical operation:
0=A=A
1 = A=NOT(A)
If Adder operation:
0 = A is unsigned
1 = A is signed
I If logical operation:
0=B=B
I = B=NOT(B)
If Adder operation
0 = B is unsigned
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-57-
1 = B is signed
4 Select A [Ini,In2,Outl,Out2,Do,D1,DZ,D3,M,L,S,R,K1,K2,K3,K4]
4 Select B [Ini,In,,Out1,OutZ,Do,D1 ,DZ,D3,M,L,S,R,Ki,K-2,K3,K4]
14 TOTAL
Multiply/Interpolate 205
The Multiply/Interpolate process block is shown in more detail in Fig. 15 and
is a set of four 8 x 8 interpolator units
that are capable of performing four individual 8 x 8 interpolates per cycle,
or can be combined to perform a single 16 x
16 multiply. This gives the possibility to perform up to 4 linear
interpolations, a single bi-linear interpolation, or half of
a tri-linear interpolation in a single cycle. The result of the interpolations
or multiplication is stored in the ALU 188's
M register 209. There are two primary operands, A and B, which are selected
from any of the general registers in the
ALU 188 or froni four programmable constants internal to the
Multiply/Interpolate process block. Each interpolator
block functions as a simple 8 bit interpolator [result = A+(B-A)f] or as a
simple 8 x 8 multiply [result = A * B]. When
the operation is interpolation, A and B are treated as four 8 bit numbers Aa
thru A3 (Ao is the low order byte), and BQ
thru B3. Agen, Bgen, and Fgen are responsible for ordering the inputs to the
Interpolate units so that they match the
operation being performed. For example, to perform bilinear interpolation,
each of the 4 values must be multiplied by a
different factor & the result summed, while a 16 x 16 bit multiplication
requires the factors to be 0. The microcode for
the Adder/Logic process block is described in the following table. Note that
the interpretations of some bit patterns are
deliberately chosen to aid decoding.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-58-
# Bits Description
4 0000 = (Alo * Blo) + V
0001=(A0*B0)+(AI *B1)+V
0010=(A,o*Blo)-V
0011 = V - (Alo * Blo)
0100 = Interpolate Ao,Bo by fo
0101 = Interpolate Ao,Bo by fo, Ai,B1 by f,
0110 = Interpolate Ao,Bo by fo, Ai,Bi by fl, Az,B, by f~,
01 11 = Interpolate Ao,Bo by fo, A1,Bi by fi, A,,Bz by f~,, A3,B3 by f~
1000 = Interpolate 16 bits stage 1[M = Aio * flo]
1001 = Interpolate 16 bits stage 2 [M = M+(Alo * flo)]
1010 = Tri-linear interpolate A by f stage 1[M=Aofo+A i f,+A,f,+A3f3]
1011 = Tri-linear interpolate A by f stage 2[M=M+Aofo+Ajfj+A~f,+A3f3]
1100 = Bi-linear interpolate A by f stage 1[M=Aofo+Aifj]
1101 = Bi-linear interpolate A by f stage 2[M=M+Aofo+A,fj]
1110 = Bi-linear interpolate A by f complete [M=Aofo+A,fi+A,fZ+A3f3]
1111 = NOP
4 Select A [Inl,In,,Out1 ,Out2,Do,Di,D,,D;,M,L,S,R,Ki,KI,K3,K4]
4 Select B [Inl,In,,Outi,Out2,Do,D1,D2,D3,M,L,S,R,Ki,K,,K3,Ka1
If
Mult:
4 Select V [InI,In,,Outl,OutziDo,D1,D~,D;,Ki,K~,K3,K4,Adder result,M,0,1]
1 Treat A as signed
1 Treat B as signed
1 Treat V as signed
If
Interp:
4 Select basis for f[Inl,1n2,Outi,Out,,Do,Di,D,,D3,Ki,K2,K3,Ka,X,X,X,X]
1 Select interpolation f generation from P, or P,
Põ is interpreted as # fractional bits in f
If Põ=0, f is range 0..255 representing 0..1
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-59-
2 Reserved
19 TOTAL
The same 4 bits are used for the selection of V and f, although the last 4
options for V don't generally make sense as f
values. Interpolating with a factor of I or 0 is pointless, and the previous
multiplication or current result is unlikely to
be a meaningful value for f.
I/O Address GeneratorS 189. 190
The 1/0 Address Generators are shown in more detail in Fig. 16. A VLIW process
does not access DRAM directly.
Access is via 2 I/O Address Generators 189, 190, each with its own Input and
Output FIFO. A PU e.g 178 reads data
from one of two local Input FIFOs, and writes data to one of two local Output
FIFOs. Each 1/0 Address Generator is
responsible for reading data from DRAM and placing it into its Input FIFO,
where it can be read by the PU e.g 178,
and is responsible for taking the data from its Output FIFO (placed there by
the PU e.g 178) and writing it to DRAM.
The 1/0 Address Generator is a state machine responsible for generating
addresses and control for data retrieval and
storage in DRAM via the Data cache 76. It is customizable under CPU software
control, but cannot be microcoded.
The address generator produces addresses in two broad categories:
Image Iterators, used to iterate (reading, writing or both) through pixels of
an image in a variety of ways
Table UO, used to randon-dy access pixels in images, data in tables, and to
simulate FIFOs in DRAM
Each of the 1/0 Address Generators 189, 190 has its own bus connection to the
Data cache 76, making 2 bus
connections per PU e.g 178, and a total of 8 buses over the entire VLIW Vector
Processor 74. The Data cache 76 is
able to service 4 of the maximum 8 requests from the 4 PUs e.g 178 each cycle.
The Input and Output FIFOs are 8
entry deep 16-bit wide FIFOs. The various types of address generation (Image
Iterators and Table 1/0) are described in
the subsequent sections.
Registers
The I/O Address Generator has a set of registers for that are used to control
address generation. The addressing mode
also determines how the data is formatted and sent into the local Input FIFO,
and how data is interpreted from the local
Output FIFO. The CPU is able to access the registers of the I/O Address
Generator via the low speed bus. The first set
of registers define the housekeeping parameters for the 1/0 Generator:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-60-
Register Name # bits Description
Reset 0 A write to this register halts any operations, and writes Os to all
the data
registers of the 1/0 Generator. The input and output FIFOs are not
cleared.
Go 0 A write to this register restarts the counters according to the current
setup. For example, if the UO Generator is a Read Iterator, and the
Iterator is currently halfway through the image, a write to Go will cause
the reading to begin at the start of the image again. While the 1/0
Generator is performing, the Active bit of the Status register will be set.
Halt 0 A write to this register stops any current activity and clears the
Active
bit of the Status register. If the Active bit is already cleared, writing to
this register has no effect.
Continue 0 A write to this register continues the I/O Generator from the
current
setup. Counters are not reset, and FIFOs are not cleared. A write to this
register while the 1/0 Generator is active has no effect.
ClearFIFOsOnGo 1 0 = Don't clear FIFOs on a write to the Go bit.
1= Do clear FIFOs on a write to the Go bit.
Status 8 Status flags
The Status register has the following values
Register Name # bits Description
Active 1 0 = Currently inactive
1 = Currently active
Reserved 7 -
Cachine
Several registers are used to control the caching mechanism, specifying which
cache group to use for inputs, outputs
etc. See the section on the Data cache 76 for more information about cache
groups.
Register Name # bits Description
CacheGroupt 4 Defines cache group to read data from
CacheGroup2 4 Defines which cache group to write data to, and in the case of
the ImagePyramidLookup 1/0 mode, defines the cache to use
for reading the Level Information Table.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-61-
Image Iterators = Sequential Automatic Access to pixels
The primary image pixel access method for software and hardware algorithms is
via Image Iterators. Image iterators
perform all of the addressing and access to the caches of the pixels within an
image channel and read, write or read &
write pixels for their client. Read Iterators read pixels in a specific order
for their clients, and Write Iterators write
pixels in a specific order for their clients. Clients of Iterators read pixels
from the local Input FIFO or write pixels via
the local Output FIFO.
Read Image Iterators read through an image in a specific order, placing the
pixel data into the local Input FIFO.
Every time a client reads a pixel from the Input FIFO, the Read Iterator
places the next pixel from the image (via the
Data cache 76) into the FIFO.
Write Image Iterators write pixels in a specific order to write out the entire
ima=e. Clients write pixels to the Output
FIFO that is in turn read by the Write Image Iterator and written to DRAM via
the Data cache 76.
Typically a VLIW process will have its input tied to a Read Iterator, and
output tied to a corresponding Write Iterator.
From the PU e.g 178 microcode program's perspective, the FIFO is the effective
interface to DRAM. The actual
method of carrying out the storage (apart from the logical ordering of the
data) is not of concern. Although the FIFO is
perceived to be effectively unlimited in length, in practice the FIFO is of
limited length, and there can be delays storing
and retrieving data, especially if several niemory accesses are competing. A
variety of Image Iterators exist to cope
with the most common addressing requirements of image processing algorithms.
In most cases there is a corresponding
Write Iterator for each Read Iterator. The different Iterators are listed in
the following table:
Read Iterators Write Iterators
Sequential Read Sequential Write
Box Read -
Vertical Strip Read Vertical Strip Write
The 4 bit Address Mode Register is used to determine the Iterator type:
Bit # Address Mode
3 0 = This addressing mode is an Iterator
2 to 0 Iterator Mode
001 = Sequential Iterator
010 = Box [read only]
100 = Vertical Strip
remaining bit patterns are reserved
The Access Specific registers are used as follows:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-62-
Register Name LocalName Description
AccessSpecific, Flags Flags used for reading and writing
AccessSpecific2 XBoxSize Determines the size in X of Box Read. Valid values
are
3, 5, and 7.
AccessSpecific3 YBoxSize Determines the size in Y of Box Read. Valid values
are
3, 5, and 7.
AccessSpecific4 BoxOffset Offset between one pixel center and the next during
a
Box Read only.
Usual value is 1, but other useful values include 2, 4, 8...
See Box Read for more details.
The Flags register (AccessSpecificl) contains a number of flags used to
determine factors affecting the reading and
writing of data. The Flags register has the following composition:
Label #bits Description
ReadEnable 1 Read data from DRAM
WriteEnable 1 Write data to DRAM [not valid for Box mode]
PassX I Pass X (pixel) ordinate back to Input FIFO
PassY I Pass Y (row) ordinate back to Input FIFO
Loop l 0 = Do not loop through data
I = Loop through data
Reserved I I Must be 0
Notes on ReadEnable and WriteEnable:
When ReadEnable is set, the UO Address Generator acts as a Read Iterator, and
therefore reads the
image in a particular order, placing the pixels into the Input FIFO.
When WriteEnable is set, the UO Address Generator acts as a Write Iterator,
and therefore writes the
image in a particular order, taking the pixels from the Output FIFO.
When both ReadEnable and WriteEnable are set, the UO Address Generator acts as
a Read Iterator
and as a Write Iterator, reading pixels into the Input FIFO, and writing
pixels from the Output
FIFO. Pixels are only written after they have been read - i.e. the Write
Iterator will never go faster
than the Read Iterator. Whenever this mode is used, care should be taken to
ensure balance between
in and out processing by the VLIW microcode. Note that separate cache groups
can be specified on
reads and writes by loading different values in CacheGroupl and CacheGroup2.
Notes on PassX and PassY:
If PassX and PassY are both set, the Y ordinate is placed into the Input FIFO
before the X ordinate.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-63-
PassX and PassY are only intended to be set when the ReadEnable bit is clear.
Instead of passing the
ordinates to the address generator, the ordinates are placed directly into the
Input FIFO. The
ordinates advance as they are removed from the FIFO.
If WriteEnable bit is set, the VLIW program must ensure that it balances reads
of ordinates from the
Input FIFO with writes to the Output FIFO, as writes will only occur up to the
ordinates (see note
on ReadEnable and WriteEnable above).
Notes on Loon:
If the Loop bit is set, reads will recommence at [StartPixel, StartRow] once
it has reached [EndPixel,
EndRow]. This is ideal for processing a structure such a convolution kernel or
a dither cell matrix,
where the data must be read repeatedly.
Looping with ReadEnable and WriteEnable set can be useful in an environment
keeping a single line
history, but only where it is useful to have reading occur before writing. For
a FIFO effect (where
writing occurs before reading in a length constrained fashion), use an
appropriate Table UO
addressing mode instead of an Image Iterator.
Looping with only WriteEnable set creates a written window of the last N
pixels. This can be used with
an asynchronous process that reads the data from the window. The Artcard
Reading algorithm
makes use of this mode.
Sequential Read and Write Iterators
Fig. 17 illustrates the pixel data format. The simplest Image Iterators are
the Sequential Read Iterator and
conesponding Sequential Write Iterator. The Sequential Read Iterator presents
the pixels from a channel one line at a
time from top to bottom, and within a line, pixels are presented left to
right. The padding bytes are not presented to the
client. It is most useful for algorithms that must perform some process on
each pixel from an image but don't care
about the order of the pixels being processed, or want the data specifically
in this order. Complementing the
Sequential Read Iterator is the Sequential Write Iterator. Clients write
pixels to the Output FIFO. A Sequential Write
Iterator subsequently writes out a valid image using appropriate cachinc-, and
appropriate padding bytes. Each
Sequential Iterator requires access to 2 cache lines. When reading, while 32
pixels are presented from one cache line,
the other cache line can be loaded from memory. When writing, while 32 pixels
are being filled up in one cache line,
the other can be being written to memory.
A process that performs an operation on each pixel of an image independently
would typically use a Sequential Read
Iterator to obtain pixels, and a Sequential Write Iterator to write the new
pixel values to their corresponding locations
within the destination image. Such a process is shown in Fig. 18.
In most cases, the source and destination images are different, and are
represented by 2 UO Address Generators 189,
190. However it can be valid to have the source image and destination image to
be the same, since a given input pixel
is not read more than once. In that case, then the same Iterator can be used
for both input and output, with both the
ReadEnable and WriteEnable registers set appropriately. For maximum
efficiency, 2 different cache groups should
be used - one for reading and the other for writing. If data is being created
by a VLIW process to be written via a
Sequential Write Iterator, the PassX and PassY flags can be used to generate
coordinates that are then passed down the
Input FIFO. The VLIW process can use these coordinates and create the output
data appropriately.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-64-
Box Read Iterator
The Box Read Iterator is used to present pixels in an order most useful for
performing operations such as general-
purpose filters and convolve. The Iterator presents pixel values in a square
box around the sequentially read pixels. The
box is limited to being 1, 3, 5, or 7 pixels wide in X and Y (set XBoxSize and
YBoxSize- they must be the same value
or I in one dimension and 3, 5, or 7 in the other). The process is shown in
Fig. 19:
BoxOffset: This special purpose register is used to determine a sub-sampling
in terms of which input pixels will be
used as the center of the box. The usual value is 1, which means that each
pixel is used as the center of the box. The
value "2" would be useful in scaling an image down by 4:1 as in the case of
building an image pyramid. Using pixel
addresses from the previous diagram, the box would be centered on pixel 0,
then 2, 8, and 10. The Box Read Iterator
requires access to a maximum of 14 (2 x 7) cache lines. While pixels are
presented from one set of 7 lines, the other
cache lines can be loaded from memory.
Box Write Iterator
There is no corresponding Box Write Iterator, since the duplication of pixels
is only required on input. A process that
uses the Box Read Iterator for input would most likely use the Sequential
Write Iterator for output since they are in
sync. A good example is the convolver, where N input pixels are read to
calculate I output pixel. The process flow is
as illustrated in Fig. 20. The source and destination images should not occupy
the same memory when using a Box
Read Iterator, as subsequent lines of an ima-e require the original (not newly
calculated) values.
Vertical-Strip Read and Write Iterators
In some instances it is necessary to write an image in output pixel order, but
there is no knowledge about the direction
of coherence in input pixeis in relation to output pixels. An example of this
is rotation. If an image is rotated 90
degrees, and we process the output pixels horizontally, there is a complete
loss of cache coherence. On the other hand,
if we process the output image one cache line's width of pixels at a time and
then advance to the next line (rather than
advance to the next cache-line's worth of pixels on the same line), we will
gain cache coherence for our input image
pixels. It can also be the case that there is known `block' coherence in the
input pixels (such as color coherence), in
which case the read governs the processing order, and the write, to be
synchronized, must follow the same pixel order.
The order of pixels presented as input (Vertical-Strip Read), or expected for
output (Vertical-Strip Write) is the same.
The order is pixels 0 to 31 from line 0, then pixels 0 to 31 of line I etc for
all lines of the image, then pixels 32 to 63 of
line 0, pixels 32 to 63 of line I etc. In the final vertical strip there may
not be exactly 32 pixels wide. In this case only
the actual pixels in the image are presented or expected as input. This
process is illustrated in Fig. 21.
process that requires only a Vertical-Strip Write Iterator will typically have
a way of mapping input pixel coordinates
given an output pixel coordinate. It would access the input image pixels
according to this mapping, and coherence is
determined by having sufficient cache lines on the `random-access' reader for
the input image. The coordinates will
typically be generated by setting the PassX and PassY flags on the
VerticalStripWrite Iterator, as shown in the process
overview illustrated in Fig. 22.
It is not meaningful to pair a Write Iterator with a Sequential Read Iterator
or a Box read Iterator, but a Vertical-Strip
Write Iterator does give significant improvements in performance when there is
a non trivial mapping between input
and output coordinates.
It can be meaningful to pair a Vertical Strip Read Iterator and Vertical Strip
Write Iterator. In this case it is possible to
assign both to a single ALU 188 if input and output images are the same. If
coordinates are required, a further Iterator
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-65-
must be used with PassX and PassY flags set. The Vertical Strip Read/Write
Iterator presents pixels to the Input FIFO,
and accepts output pixels from the Output FIFO. Appropriate padding bytes will
be inserted on the write. Input and
output require a minimum of 2 cache lines each for good performance.
Table I/O Addressina Modes
It is often necessary to lookup values in a table (such as an image). Table UO
addressing modes provide this
functionality, requiring the client to place the index/es into the Output
FIFO. The 1/0 Address Generatnr then processes
the index/es, looks up the data appropriately, and returns the looked-up
values in the Input FIFO for subsequent
processing by the VLIW client.
ID, 2D and 3D tables are supported, with particular modes targeted at
interpolation. To reduce complexity on the
VLIW client side, the index values are treated as fixed-point numbers, with
AccessSpecific registers defining the fixed
point and therefore which bits should be treated as the integer portion of the
index. Data formats are restricted forms of
the general Image Characteristics in that the PixelOffset register is ignored,
the data is assumed to be contiguous
within a row, and can only be 8 or 16 bits (1 or 2 bytes) per data element.
The 4 bit Address Mode Register is used to
determine the I/O type:
Bit # Address Mode
3 1 = This addressing mode is Table 1/0
2 to 0 000 = 1 D Direct Lookup
001 = 1D Interpolate (linear)
010 = DRAM FIFO
011 = Reserved
100 = 2D Interpolate (bi-linear)
101 = Reserved
110 = 3D Interpolate (tri-linear)
III = Image Pyramid Lookup
The access specific registers are:
Register Name LocalName #bits Description
AccessSpecific, Flags 8 General flags for reading and writing.
See below for more information.
AccessSpecific2 FractX 8 Number of fractional bits in X index
AccessSpecific3 FractY 8 Number of fractional bits in Y index
AccessSpecific4 FractZ 8 Number of fractional bits in Z index
(low 8 bits / next 12 or 24 ZOffset 12 or See below
bits)) 24
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-66-
FractX, FractY, and FractZ are used to generate addresses based on indexes,
and interpret the format of the index in
terms of significant bits and integer/fractional components. The various
parameters are only defined as required by the
number of dimensions in the table being indexed. A ID table only needs FractX,
a 2D table requires FractX and
FractY. Each Fract- value consists of the number of fractional bits in the
corresponding index. For example, an X
index may be in the format 5:3. This would indicate 5 bits of integer, and 3
bits of fraction. FractX would therefore be
set to 3. A simple 1 D lookup could have the format 8:0, i.e. no fractional
component at all. FractX would therefore be
0. ZOffset is only required for 3D lookup and takes on two different
interpretations. It is described more fully in the
3D-table lookup section. The Flags register (AccessSpecificl) contains a
number of flags used to determine factors
affecting the reading (and in one case, writing) of data. The Flags register
has the following composition:
Label #bits Description
ReadEnable I Read data from DRAM
WriteEnable I Write data to DRAM [only valid for I D direct lookup]
DataSize 1 0 = 8 bit data
I = 16 bit data
Reserved 5 Must be 0
With the exception of the 1D Direct Lookup and DRAM FIFO, all Table 1/0 modes
only support reading, and not
writing. Therefore the ReadEnable bit will be set and the WriteEnable bit will
be clear for all 1/0 modes other than
these two modes. The 1D Direct Lookup supports 3 modes:
Read only, where the ReadEnable bit is set and the WriteEnable bit is clear
Write only, where the ReadEnable bit is clear and the WriteEnable bit is clear
Read-Modify-Write, where both ReadEnable and the WriteEnable bits are set
The different modes are described in the ID Direct Lookup section below. The
DRAM FIFO mode supports only I
mode:
Write-Read mode, where both ReadEnable and the WriteEnable bits are set
This mode is described in the DRAM FIFO section below. The DataSize flag
determines whether the size of each
data elements of the table is 8 or 16 bits. Only the two data sizes are
supported. 32 bit elements can be created in either
of 2 ways depending on the requirements of the process:
Reading from 2 16-bit tables simultaneously and combining the result. This is
convenient if timing is an
issue, but has the disadvantage of consuming 2 UO Address Generators 189, 190,
and each 32-bit
element is not readable by the CPU as a 32-bit entity.
Reading from a 16-bit table twice and combining the result. This is convenient
since only 1 lookup is
used, although different indexes must be generated and passed into the lookup.
I Dimensional Structures
Direct Lookup
A direct lookup is a simple indexing into a 1 dimensional lookup table.
Clients can choose between 3 access modes by
setting appropriate bits in the Flags register:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-67-
Read only
Write only
Read-Modify-Write
Read Only
= A client passes the fixed-point index X into the Output FIFO, and the 8 or
16-bit value at Table[Int(X)] is retumed in
the Input FIFO. The fractional component of the index is completely ignored.
If the index is out of bounds, the
DuplicateE+dge flag determines whether the edge pixel or ConstantPixel is
returned. The address generation is
straightforward:
If DataSize indicates 8 bits, X is barrel-shifted right FractX bits, and the
result is added to the table's
base address ImageStart.
If DataSize indicates 16 bits, X is barrel-shifted right FractX bits, and the
result shifted left I bit (bitO
becomes 0) is added to the table's base address ImageStart.
The 8 or 16-bit data value at the resultant address is placed into the Input
FIFO. Address generation takes I cycle, and
transferring the requested data from the cache to the Output FIFO also takes I
cycle (assuming a cache hit). For
example, assume we are looking up values in a 256-entry table, where each
entry is 16 bits, and the index is a 12 bit
fixed-point format of 8:4. FractX should be 4, and DataSize 1. When an index
is passed to the lookup, we shift right 4
bits, then add the result shifted left I bit to ImageStart.
Write Only
A client passes the fixed-point index X into the Output FIFO followed by the 8
or 16-bit value that is to be written to
the specified location in the table. A complete transfer takes a minimum of 2
cycles. I cycle for address generation,
and I cycle to transfer the data from the FIFO to DRAM. There can be an
arbitrary number of cycles between a VLIW
process placing the index into the FIFO and placing the value to be written
into the FIFO. Address generation occurs in
the same way as Read Only mode, but instead of the data being read from the
address, the data from the Output FIFO
is written to the address. If the address is outside the table range, the data
is removed from the FIFO but not written to
DRAM.
Read-Modify-Write
A client passes the fixed-point index X into the Output FIFO, and the 8 or 16-
bit value at Table[Int(X)] is returned in
the Input FIFO. The next value placed into the Output FIFO is then written to
Table[Int(X)], replacing the value that
had been returned earlier. The general processing loop then, is that a process
reads from a location, modifies the value,
and writes it back. The overall time is 4 cycles:
Generate address from index
Return value from table
Modify value in some way
Write it back to the table
There is no specific read/write mode where a client passes in a flag saying
"read from X" or "write to X". Clients can
simulate a "read from X" by writing the original value, and a "write to X" by
simply ignoring the returned value.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-68-
However such use of the mode is not encouraged since each action consumes a
minimum of 3 cycles (the modify is not
required) and 2 data accesses instead of 1 access as provided by the specific
Read and Write modes.
Interpolate table
This is the same as a Direct Lookup in Read mode except that two values are
returned for a given fixed-point index X
instead of one. The values returned are Table[Int(X)], and Table[Int(X)+1]. If
either index is out of bounds the
DuplicateEdge flag determines whether the edge pixel or ConstantPixel is
returned. Address generation is the same
as Direct Lookup, with the exception that the second address is simply
Addressl+ 1 or 2 depending on 8 or 16 bit data.
Transferring the requested data to the Output FIFO takes 2 cycles (assuming a
cache hit), although two 8-bit values
may actually be returned from the cache to the Address Generator in a single
16-bit fetch.
DRAM FIFO
A special case of a read/write ID tablc is a DRAM FIFO. It is often necessary
to have a simulated FIFO of a given
length using DRAM and associated caches. With a DRAM FIFO, clients do not
index explicitly into the table, but
write to the Output FIFO as if it was one end of a FIFO and read from the
Input FIFO as if it was the other end of the
same logical FIFO. 2 counters keep track of input and output positions in the
simulated FIFO, and cache to DRAM as
needed. Clients need to set both ReadEnable and WriteEnable bits in the Flags
register.
An example use of a DRAM FIFO is keeping a single line history of some value.
The initial history is written before
processing begins. As the seneral process goes through a line, the previous
line's value is retrieved from the FIFO, and
this line's value is placed into the FIFO (this line will be the previous line
when we process the next line). So long as
input and outputs match each other on average, the Output FIFO should always
be full. Consequently there is
effectively no access delay for this kind of FIFO (unless the total FIFO
length is very small - say 3 or 4 bytes, but that
would defeat the purpose of the FIFO).
2 Dimensional Tables
Direct Lookup
A 2 dimensional direct lookup is not supported. Since all cases of 2D lookups
are expected to be accessed for bi-linear
interpolation, a special bi-linear lookup has been implemented.
Bi-Linear lookup
This kind of lookup is necessary for bi-linear interpolation of data from a 2D
table. Given fixed-point X and Y
coordinates (placed into the Output FIFO in the order Y, X), 4 values are
returned after lookup. The values (in order)
are:
Table[Int(X), Int(Y)]
Table[Int(X)+1, Int(Y)]
Table[Int(X), Int(Y)+1 ]
Table[Int(X)+1, Int(Y)+1 ]
The order of values returned gives the best cache coherence. If the data is 8-
bit, 2 values are returned each cycle over 2
cycles with the low order byte being the first data element. If the data is 16-
bit, the 4 values are returned in 4 cycles, 1
entry per cycle. Address generation takes 2 cycles. The first cycle has the
index (Y) barrel-shifted right FractY bits
being multiplied by RowOffset, with the result added to ImageStart. The second
cycle shifts the X index right by
FractX bits, and then either the result (in the case of 8 bit data) or the
result shifted left I bit (in the case of 16 bit data)
is added to the result from the first cycle. This gives us address Adr =
address of Table[Int(X), Int(Y)]:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-69-
Adr = ImagcStart
+ ShiftRight(Y, FractY)* RowOffset)
+ ShiftRight(X, FractX)
We keep a copy of Adr in AdrOld for use fetching subsequent entries.
If the data is 8 bits, the timing is 2 cycles of address generation, followed
by 2 cycles of data being
returned (2 table entries per cycle).
If the data is 16 bits, the timing is 2 cycles of address generation, followed
by 4 cycles of data being
retumed (1 entry per cycle)
The following 2 tables show the method of address calculation for 8 and 16 bit
data sizes:
Cycle Calculation while fetching 2 x 8-bit data entries from Adr
1 Adr = Adr + RowOffset
2 <preparing next lookup>
Cycle Calculation while fetching I x 16-bit data entry from Adr
I Adr = Adr + 2
2 Adr = AdrOld + RowOffset
3 Adr=Adr+2
4 <preparing next lookup>
In both cases, the first cycle of address generation can overlap the insertion
of the X index into the FIFO, so the
effective timing can be as low as 1 cycle for address generation, and 4 cycles
of return data. If the generation of
indexes is 2 steps ahead of the results, then there is no effective address
generation time, and the data is simply
produced at the appropriate rate (2 or 4 cycles per set).
3 Dimensional Lookun
Direct Lookut)
Since all cases of 2D lookups are expected to be accessed for tri-linear
interpolation, two special tri-linear lookups
have been implemented. The first is a straightforward lookup table, while the
second is for tri-linear interpolation from
an Image Pyramid.
Tri-linear lookua
This type of lookup is useful for 3D tables of data, such as color conversion
tables. The standard image parameters
define a single XY plane of the data - i.e. each plane consists of ImageHeight
rows, each row containing RowOffset
bytes. In most circumstances, assuming contiguous planes, one XY plane will be
ImageHeight x RowOffset bytes
after another. Rather than assume or calculate this offset, the software via
the CPU must provide it in the form of a 12-
bit ZOffset register. In this form of lookup, given 3 fixed-point indexes in
the order Z, Y, X, 8 values are returned in
order from the lookup table:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-70-
Table[Int(X), Int(Y), Int(Z)]
Table[Int(X)+1, Int(Y), Int(Z)]
Table[Int(X), Int(Y)+1, Int(Z)]
Table[Int(X)+1, Int(Y)+1, Int(Z)]
Table[Int(X), Int(Y), Int(Z)+1]
Table[Int(X)+1, Int(Y), Int(Z)+11
Table[Int(X), Int(Y)+1, Int(Z)+11
Table[Int(X)+ 1, Int(Y)+ 1, Int(Z)+1 ]
The order of values returned gives the best cache coherence. If the data is 8-
bit, 2 values are returned each cycle over 4
cycles with the low order byte being the first data element. If the data is 16-
bit, the 4 values are returned in 8 cycles, I
entry per cycle. Address generation takes 3 cycles. The first cycle has the
index (Z) barrel-shifted right FractZ bits
being multiplied by the 12-bit ZOffset and added to ImageStart. The second
cycle has the index (Y) barrel-shifted
right FractY bits being multiplied by RowOffset, with the result added to the
result of the previous cycle. The second
cycle shifts the X index right by FractX bits, and then either the result (in
the case of 8 bit data) or the result shifted
left I bit (in the case of 16 bit data) is added to the result from the second
cycle. This gives us address Adr = address of
Table[Int(X), Int(Y), Int(Z)]:
Adr = ImageStart
+ (ShiftRight(Z, FractZ) * ZOffset)
+ (ShiftRight(Y, FractY)* RowOffset)
+ ShiftRight(X, FractX)
We keep a copy of Adr in AdrOld for use fetching subsequent entries.
If the data is 8 bits, the timing is 2 cycles of address generation, followed
by 2 cycles of data being
returned (2 table entries per cycle).
If the data is 16 bits, the timing is 2 cycles of address generation, followed
by 4 cycles of data being
returned (1 entry per cycle)
The following 2 tables show the method of address calculation for 8 and 16 bit
data sizes:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-71-
Cycle Calculation while fetching 2 x 8-bit data entries from Adr
1 Adr = Adr + RowOffset
2 Adr = AdrOld + ZOffset
3 Adr = Adr + RowOffset
4 <preparing next lookup>
Cyde Calculation while fetching 1 x 16-bit data entries from Adr
1 Adr=Adr+2
2 Adr = AdrOld + RowOffset
3 Adr = Adr + 2
4 Adr, AdrOld =AdrOld + Zoffset
Adr=Adr+2
6 Adr = AdrOld + RowOffset
7 Adr = Adr + 2
8 <preparing next lookup>
In both cases, the cycles of address generation can overlap the insertion of
the indexes into the FIFO, so the effective
timing for a single one-off lookup can be as low as I cycle for address
generation, and 4 cycles of return data. If the
generation of indexes is 2 steps ahead of the results, then there is no
effective address generation time, and the data is
simply produced at the appropriate rate (4 or 8 cycles per set).
Image Pyramid Lookup
During brushing, tiling, and warping it is necessary to compute the average
color of' a particular area in an image.
Rather than calculate the value for each area given, these functions niake use
of an image pyramid. The description and
construction of an image pyramid is detailed in the section on Internal Image
Formats in the DRAM interface 81
chapter of this document. This section is concerned with a method of
addressing given pixels in the pyramid in terms
of 3 fixed-point indexes ordered: level (Z), Y, and X. Notc that Image Pyramid
lookup assumes 8 bit data entries, so
the DataSize flag is completely ignored. After specification of Z, Y, and X,
the following 8 pixels are returned via the
Input FIFO:
The pixel at [Int(X), Int(Y)J, level Int(Z)
The pixel at [Int(X)+I, Int(Y)J, level Int(Z)
The pixel at [Int(X), Int(Y)+1], level Int(Z)
The pixel at [Int(X)+1, Int(Y)+1], level Int(Z)
The pixel at [Int(X), Int(Y)], level Int(Z)+l
The pixel at [Int(X)+], Int(Y)], level Int(Z)+1
The pixel at [Int(X), Int(Y)+11, level Int(Z)+1
The pixel at [Int(X)+1, Int(Y)+11, level Int(Z)+l
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-72-
The 8 pixels are returned as 4 x 16 bit entries, with X and X+1 entries
combined hi/lo. For example, if the scaled (X,
Y) coordinate was (10.4, 12.7) the first 4 pixels returned would be: (10, 12),
(11, 12), (10, 13) and (11, 13). When a
coordinate is outside the valid range, clients have the choice of edge pixel
duplication or returning of a constant color
value via the DuplicateEdgePixels and ConstantPixel registers (only the low 8
bits are used). When the Image
Pyramid has been constructed, there is a simple mapping from level 0
coordinates to level Z coordinates. The method
is simply to shift the X or Y coordinate right by Z bits. This must be done in
addition to the number of bits already
shifted to retrieve the integer portion of the coordinate (i.e. shifting right
FractX and FractY bits for X and Y
ordinates respectively). To find the ImageStart and RowOffset value for a
given level of the image pyramid, the 24-bit
ZOffset register is used as a pointer to a Level Information Table. The table
is an array of records, each representing a
given level of the pyramid, ordered by level number. Each record consists of a
16-bit offset ZOffset from ImageStart
to that level of the pyramid (64-byte aligned address as lower 6 bits of the
offset are not present), and a 12 bit
ZRowOffset for that level. Element 0 of the table would contain a ZOffset of
0, and a ZRowOffset equal to the general
register RowOffset, as it simply points to the full sized image. The ZOffset
value at element N of the table should be
added to ImageStart to yield the effective ImageStart of level N of the image
pyramid. The RowOffset value in
element N of the table contains the RowOffset value for level N. The software
running on the CPU must set up the
table appropriately before using this addressing mode. The actual address
generation is outlined here in a cycle by
cycle description:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-73-
Load From
Cycle Register Other Operations
Address
0 - - ZAdr = ShiftRight(Z, FractZ) + ZOffset
ZInt = ShiftRight(Z, FractZ)
1 ZOffset Zadr ZAdr += 2
Ylnt = ShiftRight(Y, FractY)
2 ZRowOffset ZAdr ZAdr += 2
Ylnt = ShiftRight(Ylnt, Zlnt)
Adr = ZOffset + ImageStart
3 ZOffset ZAdr ZAdr += 2
Adr += ZrowOffset * Ylnt
XInt = ShiftRight(X, FractX)
4 ZAdr ZAdr Adr += ShiftRight(Xlnt, Zlnt)
ZOffset += ShiftRight(Xlnt. 1)
FIFO Adr Adr += ZrowOffset
ZOffset += ImageStart
6 FIFO Adr Adr = (ZAdr * ShiftRight(Yint,1)) + ZOff'set
7 FIFO Adr Adr += Zadr
8 FIFO Adr < Cycle 0 for next retrieval>
The address generation as described can be achieved using a single Barrel
Shifter, 2 adders, and a single 16x16
multiply/add unit yielding 24 bits. Although some cycles have 2 shifts, they
are either the same shift value (i.e. the
output of the Barrel Shifter is used two times) or the shift is 1 bit, and can
be hard wired. The following internal
registers are required: ZAdr, Adr, Zlnt, Ylnt, Xlnt, ZRowOffset, and
ZImageStart. The _Int registers only need to be 8
bits maximum, while the others can be up to 24 bits. Since this access method
only reads from, and does not write to
image pyramids, the CacheGroup2 is used to lookup the Image Pyramid Address
Table (via ZAdr). CacheGroupl is
used for lookups to the image pyramid itself (via Adr). The address table is
around 22 entries (depending on original
image size), each of 4 bytes. Therefore 3 or 4 cache lines should be allocated
to CacheGroup2, while as many cache
lines as possible should be allocated to CacheGroupl. The timing is 8 cycles
for returning a set of data, assuming that
Cycle 8 and Cycle 0 overlap in operation - i.e. the next request's Cycle 0
occurs during Cycle 8. This is acceptable
since Cycle 0 has no memory access, and Cycle 8 has no specific operations.
Generation of Coordinates using VLIW Vector Processor 74
Some functions that are linked to Write Iterators require the X and/or Y
coordinates of the current pixel being
processed in part of the processing pipeline. Particular processing may also
need to take place at the end of each row,
or column being processed. In most cases, the PassX and PassY flags should be
sufficient to completely generate all
coordinates. However, if there are special requirements, the following
functions can be used. The calculation can be
_ .._ ...m._._ _ ... _.._.__ _.. _.__ , .__. .. _ ....W_. _ . .
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-74-
spread over a number of ALUs, for a single cycle generation, or be in a single
ALU 188 for a multi-cycle generation.
Generate Seauential fX, Yl
When a process is processing pixels in sequential order according to the
Sequential Read Iterator (or generating pixels
and writing them out to a Sequential Write Iterator), the following process
can be used to generate X, Y coordinates
instead of PassX/PassY flags as shown in Fig. 23.
The coordinate generator counts up to ImageWidth in the X ordinate, and once
per ImageWidth pixels increments
the Y ordinate. The actual process is illustrated in Fig. 24, where the
following constants are set by software:
Constant Value
K, ImageWidth
K, ImaoeHeight (optional)
The following registers are used to hold temporary variables:
Variable Value
Reg, X (starts at 0 each line)
Reg2 Y (starts at 0)
The requirements are summarized as follows:
Requirements *+ + R K LU Iterators
General 0 3/4 2 1/2 0 0
TOTAL 0 3/4 2 1/2 O 0
Generate Vertical Strin (X. Yl
When a process is processing pixels in order to write them to a Vertical Strip
Write Iterator, and for sonie reason
cannot use the PassX/PassY flags, the process as illustrated in Fig. 25 can be
used to generate X, Y coordinates. The
coordinate generator simply counts up to ImageWidth in the X ordinate, and
once per ImageWidth pixels increments
the Y ordinate. The actual process is illustrated in Fig. 26, where the
following constants are set by software:
Constant Value
K, 32
K, ImageWidth
K3 ImageHeight
The following registers are used to hold temporary variables:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-75-
Variable Value
Reg, StartX (starts at 0, and is incremented by 32 once per vertical strip)
RegZ X
Reg3 EndX (starts at 32 and is incremented by 32 to a maximum of ImageWidth)
once
per vertical strip)
Reg4 Y
The requirements are summarized as follows:
Requirements *+ + R K LU Iterators
General 0 4 4 3 0 0
TOTAL 0 4 4 3 0 0
The calculations that occur once per vertical strip (2 additions, one of which
has an associated MIN) are not included in
the general timing statistics because they are not really part of the per
pixel timing. However they do need to be taken
into account for the programming of the microcode for the particular function.
Image Sensor Interface (ISI 83)
The Image Sensor Interface (ISI 83) takes data from the CMOS Image Sensor and
makes it available for storage in
DRAM. The image sensor has an aspect ratio of 3:2, with a typical resolution
of 750 x 500 samples, yieldina 375K (8
bits per pixel). Each 2x2 pixel block has the configuration as shown in Fig.
27. The ISI 83 is a state machine that sends
control information to the Image Sensor, including frame sync pulses and pixel
clock pulses in order to read the image.
Pixels are read from the image sensor and placed into the VLIW Input FIFO 78.
The VLIW is then able to process
and/or store the pixels. This is illustrated further in Fig. 28. The ISI 83 is
used in conjunction with a VLIW program
that stores the sensed Photo Image in DRAM. Processing occurs in 2 steps:
A small VLIW program reads the pixels from the FIFO and writes them to DRAM
via a Sequential
Write Iterator.
The Photo Image in DRAM is rotated 90, 180 or 270 degrees according to the
orientation of the camera
when the photo was taken.
If the rotation is 0 degrees, then step I merely writes the Photo Image out to
the final Photo Image location and step 2
is not performed. If the rotation is other than 0 degrees, the image is
written out to a temporary area (for example into
the Print Image memory area), and then rotated during step 2 into the final
Photo Image location. Step I is very simple
microcode, taking data from the VLIW Input FIFO 78 and writing it to a
Sequential Write Iterator. Step 2's rotation is
accomplished by using the accelerated Vark Affine Transform function. The
processing is performed in 2 steps in
order to reduce design complexity and to re-use the Vark affine transform
rotate logic already required for images. This
is acceptable since both steps are completed in approximately 0.03 seconds, a
time imperceptible to the operator of the
Artcam. Even so, the read process is sensor speed bound, taking 0.02 seconds
to read the full frame, and approximately
0.01 seconds to rotate the image.
The orientation is important for converting between the sensed Photo Image and
the internal format image, since the
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-76-
relative positioning of R, G, and B pixcls changes with orientation.. The
processed image may also have to be rotated
during the Print process in order to be in the correct orientation for
printing. The 3D model of the Artcam has 2 image
sensors, with their inputs multiplexed to a single ISI 83 (different
microcode, but same ACP 31). Since each sensor is a
frame store, both images can be taken simultaneously, and then transferred to
memory one at a time.
Display Controller 88
When the "Take" button on an Artcam is half depressed, the TFT will display
the current image from the image sensor
(converted via a simple VLIW process). Once the Take button is fully
depressed, the Taken Image is displayed. When
the user presses the Print button and image processing begins, the TFT is
turned off. Once the image has been printed
the TFT is turned on again. The Display Controller 88 is used in those Ancam
models that incorporate a flat panel
display. An example display is a TFT LCD of resolution 240 x 160 pixels. The
structure of the Display Controller 88
isl illustrated in Fig. 29. The Display Controller 88 State Machine contains
registers that control the timing of the
Sync Generation, where the display image is to be taken from (in DRAM via the
Data cache 76 via a specific Cache
Group), and whether the TFT should be active or not (via TFT Enable) at the
moment. The CPU can write to these
registers via the low speed bus. Displaying a 240 x 160 pixel image on an RGB
TFT requires 3 components per pixel.
The image taken from DRAM is displayed via 3 DACs, one for each of the R, G,
and B output signals. At an image
refresh rate of 30 frames per second (60 fields per second) the Display
Controller 88 requires data transfer rates of:
240 x 160 x 3 x 30 = 3.5MB per second
This data rate is low compared to the rest of the system. However it is high
enough to cause VLIW programs to slow
down during the intensive image processing. The general principles of TFT
operation should reflect this.
Image Data Formats
As stated previously, the DRAM Interface 81 is responsible for interfacing
between other client portions of
the ACP chip and the RAMBUS DRAM. In effect, each module within the DRAM
Interface is an address generator.
There are three logical types of imases manipulated by the ACP. They are:
-CCD Image, which is the Input Image captured from the CCD.
-Internal Image format - the Image format utilised internally by the Artcam
device.
Print Image - the Output Image format printed by the Artcam
These images are typically different in color space, resolution, and the
output & input color spaces which can
vary from camera to camera. For example, a CCD image on a low-end camera may
be a different resolution, or have
different color characteristics from that used in a high-end camera. However
all internal image formats are the same
format in terms of color space across all cameras.
In addition, the three image types can vary with respect to which direction is
`up'. The physical orientation of
the camera causes the notion of a portrait or landscape image, and this must
be maintained throughout processing. For
this reason, the internal image is always oriented correctly, and rotation is
performed on images obtained from the
CCD and during the print operation.
CCD Ima2e Oreanization
Although many different CCD image sensors could be utilised, it will be
assumed that the CCD itself is a 750
x 500 image sensor, yielding 375,000 bytes (8 bits per pixel). Each 2x2 pixel
block having the configuration as
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-77-
depicted in Fig. 30.
A CCD Image as stored in DRAM has consecutive pixels with a given line
contiguous in memory. Each line
is stored one after the other. The image sensor Interface 83 is responsible
for taking data from the CCD and storing it in
the DRAM correctly oriented. Thus a CCD image with rotation 0 degrees has its
first line G, R, G, R, G, R... and its
second line as B, G, B, G, B, G.... If the CCD image should be portrait,
rotated 90 degrees, the first line will be R, G,
R, G, R, G and the second line G, B, G, B, G, B...etc.
Pixels are stored in an interleaved fashion since all color components are
required in order to convert to the
internal image format.
It should be noted that the ACP 31 makes no assumptions about the CCD pixel
format, since the actual CCDs
for imaging may vary from Artcam to Artcam, and over time. All processing that
takes place via the hardware is
controlled by major microcode in an attempt to extend the usefulness of the
ACP 31.
Internal Image Organization
Internal images typically consist of a number of channels. Vark images can
include, but are not limited to:
Lab
Laba
LabA
aA
L
L, a and b correspond to components of the Lab color space, a is a matte
channel (used for compositing), and
A is a bump-map channel (used during brushing, tiling and illuminating).
The VLIW processor 74 requires images to be organized in a planar
configuration. Thus a Lab image would
be stored as 3 separate blocks of memory:
one block for the L channel,
one block for the a channel, and
one block for the b channel
Within each channel block, pixels are stored contiguously for a given row
(plus some optional padding bytes),
and rows are stored one after the other.
Turning to Fig. 31 there is illustrated an example form of storage of a
logical image 100. The logical image
100 is stored in a planar fashion having L 101, a 102 and b 103 color
components stored one after another.
Alternatively, the logical image 100 can be stored in a compressed format
having an uncompressed L component 101
and compressed A and B components 105, 106.
Turning to Fig. 32, the pixels of for line n 110 are stored together before
the pixels of for line and n + 1( I 11).
With the image being stored in contiguous memory within a single channel.
In the 8MB-memory model, the final Print Image after all processing is
finished, needs to be compressed in
the chrominance channels. Compression of chrominance channels can be 4:1,
causing an overall compression of 12:6,
or 2:1.
Other than the final Print Image, images in the Artcam are typically not
compressed. Because of memory
constraints, software may choose to compress the final Print Image in the
chrominance channels by scaling each of
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-78-
these channels by 2:1. If this has been done, the PR.INT Vark function call
utilised to print an image must be told to
treat the specified chrominance channels as compressed. The PRINT function is
the only function that knows how to
deal with compressed chrominance, and even so, it only deals with a fixed 2:1
compression ratio.
Although it is possible to compress an image and then operate on the
compressed image to create the final
print image, it is not recommended due to a loss in resolution. In addition,
an ima;e should only be compressed once -
as the final stage before printou-. While one compression is virtually
undetectable, multiple compressions may cause
substantial image degradation.
Clip image Organization
Clip images stored on Artcards have no explicit support by the ACP 31.
Software is responsible for taking any
images from the current Artcard and organizing the data into a form known by
the ACP. If images are stored
compressed on an Artcard, software is responsible for decompressing them, as
there is no specific hardware support for
decompression of Artcard images.
Image Pyramid Oreanization
During brushing, tiling, and warping processes utilised to manipulate an image
it is often necessary to
compute the average color of a particular area in an image. Rather than
calculate the value for each area given, these
functions make use of an image pyramid. As illustrated in Fig. 33, an image
pyramid is effectively a multi-
resolutionpixel- map. The original image 115 is a 1:1 representation. Low-pass
filtering and sub-sampline by 2:1 in
each dimension produces an image 1/4 the original size 116. This process
continues until the entire image is represented
by a single pixel. An image pyramid is constructed from an original internal
format image, and consumes 1/3 of the
size taken up by the original image (1/4 + 1/16 + 1/64 + ...). For an original
image of 1500 x 1000 the corresponding
image pyramid is approximately'/2MB. An image pyramid is constructed by a
specific Vark function, and is used as a
parameter to other Vark functions.
Print Imave Organization
The entire processed image is required at the same time in order to print it.
However the Print Image output
can comprise a CMY dithered image and is only a transient image format, used
within the Print Image functionality.
However, it should be noted that color conversion will need to take place from
the internal color space to the print
color space. In addition, color conversion can be tuned to be different for
different print rolis in the camera with
different ink characteristics e.g. Sepia output can be accomplished by using a
specific sepia toning Artcard, or by using
a sepia tone print-roll (so all Artcards will work in sepia tone).
Color Spaces
As noted previously there are 3 color spaces used in the Artcam, coiTesponding
to the different image types.
The ACP has no direct knowledge of specific color spaces. Instead, it relies
on client color space conversion
tables to convert between CCD, internal, and printer color spaces:
CCD:RGB
Internal:Lab
Printer:CMY
Removing the color space conversion from the ACP 31 allows:
-Different CCDs to be used in different cameras
-Different inks (in different print rolls over time) to be used in the same
camera
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-79-
-Separation of CCD selection from ACP design path
-A well defined internal color space for accurate color processing
Artcard Interface 87
The Artcard Interface (AI) takes data from the linear image Sensor while an
Artcard is passing under it, and makes that
data available for storage in DRAM. The image sensor produces 11,000 8-bit
samples per scanline, sampling the
Artcard at 4800 dpi. The Al is a state machine that sends control information
to the linear sensor, including LineSync
pulses and PixelCiock pulses in order to read the image. Pixels are read from
the linear sensor and placed into the
VLIW Input FIFO 78. The VLIW is then able to process and/or store the pixels.
The Al has only a few registers:
Register Name Description
NumPixels The number of pixels in a sensor line (approx 11,000)
Status The Print Head Interface's Status Register
PixelsRemaining The number of bytes remaining in the current line
Actions
Reset A write to this register resets the Al, stops any scanning, and loads
all
registers with 0.
Scan A write to this register with a non-zero value sets the Scanning bit of
the
Status register, and causes the Artcard Interface Scan cycle to start.
A write to this register with 0 stops the scanning process and clears the
Scanning bit in the Status register.
The Scan cycle causes the AI to transfer NumPixels bytes from the sensor
to the VLIW Input FIFO 78, producing the PixelClock signals
appropriately. Upon completion of NumPixels bytes, a LineSync pulse is
given and the Scan cycle restarts.
The PixeisRemaining register holds the number of pixels remaining to be
read on the current scanline.
Note that the CPU should clear the VLIW Input FIFO 78 before initiating a
Scan. The Status register has bit
interpretations as follows:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-80-
Bit Name Bits Description
Scanning I If set, the Al is currently scanning, with the number of pixels
remaining to be transferred from the current line recorded in
PixelsRemaining.
If clear, the AI is not currently scanning, so is not transferring pixels
to the VLIW Input FIFO 78.
Artcard Interface (AI) 87
The Artcard Interface (Al) 87 is responsible for taking an Artcard image from
the Artcard Reader 34 , and
decoding it into the original data (usually a Vark script). Specifically, the
Al 87 accepts signals from the Artcard
scanner linear CCD 34, detects the bit pattern printed on the card, and
converts the bit pattern into the original data,
correcting read errors.
With no Artcard 9 inserted, the image printed from an Artcam is simply the
sensed Photo Iinage cleaned up
by any standard image processing routines. The Artcard 9 is the means by which
users are able to rnodify a photo
before printing it out. By the simple task of inserting a specific Artcard 9
into an Artcam, a user is able to define
complex image processing to be performed on the Photo Image.
With no Artcard inserted the Photo Image is processed in a standard way to
create the Print Image. When a single
Artcard 9 is inserted into the Artcam, that Artcard's effect is applied to the
Photo Image to generate the Print Image.
When the Artcard 9 is removed (ejected), the printed image reverts to the
Photo Image processed in a standard way.
When the user presses the button to eject an Artcard, an event is placed in
the event queue maintained by the operating
system running on the Artcam Central Processor 31. When the event is processed
(for example after the current Print
has occurred), the following thinas occur:
If the current Artcard is valid, then the Print Image is marked as invalid and
a 'Process Standard' event is
placed in the event queue. When the event is eventually processed it will
perform the standard image processing
operations on the Photo Image to produce the Print Image.
The motor is started to eject the Artcard and a time-specific 'Stop-Motor'
Event is added to the event queue.
Inserting an Artcard
When a user inserts an Artcard 9, the Artcard Sensor 49 detects it notifying
the ACP72. This results in the
software inserting an 'Artcard Inserted' event into the event queue. When the
event is processed several things occur:
The current Artcard is marked as invalid (as opposed to 'none').
The Print Image is marked as invalid.
The Artcard motor 37 is started up to load the Artcard
The Artcard Interface 87 is instructed to read the Artcard
The Artcard Interface 87 accepts signals from the Artcard scanner linear CCD
34, detects the bit pattern
printed on the card, and corrects errors in the detected bit pattern,
producing a valid Artcard data block in DRAM.
Reading Data from the Artcard CCD - General Considerations
As illustrated in Fig. 34, the Data Card reading process has 4 phases operated
while the pixel data is read from
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-81-
the card. The phases are as follows:
Phase 1. Detect data area on Artcard
Phase 2. Detect bit pattern from Artcard based on CCD pixels, and write as
bytes.
Phase 3. Descramble and XOR the byte-pattern
Phase 4. Decode data (Reed-Solomon decode)
As illustrated in Fig. 35, the Artcard 9 must be sampled at least at double
the printed resolution to satisfy
Nyquist's Theorem. In practice it is better to sample at a higher rate than
this. Preferably, the pixels are sampled 230 at
3 times the resolution of a printed dot in each dimension, requiring 9 pixels
to define a single dot. Thus if the
resolution of the Artcard 9 is 1600 dpi, and the resolution of the sensor 34
is 4800 dpi, then using a 50mm CCD image
sensor results in 9450 pixels per column. Therefore if we require 2MB of dot
data (at 9 pixels per dot) then this
requires 2MB*8*9/9450 = 15,978 columns = approximately 16,000 columns. Of
course if a dot is not exactly aligned
with the sampling CCD the worst and most likely case is that a dot will be
sensed over a 16 pixel area (4x4) 231.
An Artcard 9 may be slightly warped due to heat damage, slightly rotated (up
to, say I degree) due to
differences in insertion into an Artcard reader, and can have slight
differences in true data rate due to fluctuations in the
speed of the reader motor 37. These changes will cause columns of data irom
the card not to be read as corresponding
columns of pixel data. As illustrated in Fig. 36, a I degree rotation in the
Artcard 9 can cause the pixels from a column
on the card to be read as pixels across 166 columns:
Finally, the Artcard 9 should be read in a reasonable amount of time with
respect to the human operator. The
data on the Artcard covers most of the Artcard surface, so timing concerns can
be limited to the Artcard data itself. A
reading time of 1.5 seconds is adequate for Artcard reading.
The Artcard should be loaded in 1.5 seconds. Therefore all 16,000 columns of
pixel data must be read from
the CCD 34 in 1.5 second, i.e. 10,667 columns per second. Therefore the time
available to read one column is 1/10667
seconds, or 93,747ns. Pixel data can be written to the DRAM one coiumn at a
time, completely independently from
any processes that are readin- the pixel data.
The time to write one column of data (9450/2 bytes since the reading can be 4
bits per pixel giving 2 x 4 bit
pixels per byte) to DRAM is reduced by using 8 cache lines. If 4 lines were
written out at one time, the 4 banks can be
written to independently, and thus overlap latency reduced. Thus the 4725
bytes can be written in 11,840ns (4725/128
* 320ns). Thus the time taken to write a given column's data to DRAM uses just
under 13% of the available
bandwidth.
Decodin=an Artcard
A simple look at the data sizes shows the impossibility of fitting the process
into the 8MB of memory 33 if the
entire Artcard pixel data (140 MB if each bit is read as a 3x3 array) as read
by the linear CCD 34 is kept. For this
reason, the reading of the linear CCD, decoding of the bitmap, and the un-
bitmap process should take place in real-
time (while the Artcard 9 is traveling past the linear CCD 34), and these
processes must effectively work without
having entire data stores available.
When an Artcard 9 is inserted, the old stored Print Image and any expanded
Photo Image becomes invalid.
The new Artcard 9 can contain directions for creating a new image based on the
currently captured Photo Image. The
old Print Image is invalid, and the area holding expanded Photo Image data and
image pyramid is invalid, leaving more
than 5MB that can be used as scratch memory during the read process. Strictly
speaking, the IMB area where the
.. . . . . .___.._.7...-....._.,...,......,_...,.........W...._._._....~-___
.___.... __...._................_..__......... .__..._.___.___- ..._ ..
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-82-
Artcard raw data is to be written can also be used as scratch data during the
Artcard read process as long as by the time
the final Reed-Solomon decode is to occur, that IMB area is free again. The
reading process described here does not
make use of the extra 1MB area (except as a final destination for the data).
It should also be noted that the unscrambling process requires two sets of 2MB
areas of memory since
unscrambling cannot occur in place. Fortunately the 5MB scratch area contains
enouoh space for this process.
Turning now to Fig. 37, there is shown a flowchart 220 of the steps necessary
to decode the Artcard data.
These steps include reading in the Artcard 221, decoding the read data to
produce corresponding encoded XORed
scrambled bitmap data 223. Next a checkerboard XOR is applied to the data to
produces encoded scrambled data 224.
This data is then unscrambled 227 to produce data 225 before this data is
subjected to Reed-Solomon decoding to
produce the original raw data 226. Alternatively, unscrambling and XOR process
can take place together, not requiring
a separate pass of the data. Each of the above steps is discussed in further
detail hereinafter. As noted previously with
reference to Fig. 37, the Artcard Interface, therefore, has 4 phases, the
first 2 of which are time-critical, and must take
place while pixel data is being read from the CCD:
Phase 1. Detect data area on Artcard
Phase 2. Detect bit pattern from Artcard based on CCD pixels, and write as
bytes.
Phase 3. Descramble and XOR the byte-pattern
Phase 4. Decode data (Reed-Solomon decode)
The four phases are described in more detail as follows:
Phase 1. As the Artcard 9 moves past the CCD 34 the Al niust detect the start
of the data area by robustly
detecting special targets on the Artcard to the left of the data area. If
these cannot be detected, the card is marked as
invalid. The detection must occur in real-time, while the Artcard 9 is moving
past the CCD 34.
If necessary, rotation invariance can be provided. In this case, the targets
are repeated on the right side of the
Artcard, but relative to the bottom right corner instead of the top corner. In
this way the targets end up in the correct
orientation if the card is inserted the "wrong" way. Phase 3 below can be
altered to detect the orientation of the data,
and account for the potential rotation.
Phase 2. Once the data area has been determined, the main read process begins,
placing pixel data from the
CCD into an `Artcard data window', detecting bits from this window, assembling
the detected bits into bytes, and
constructing a byte-image in DRAM. This must all be done while the Artcard is
moving past the CCD.
Phase 3. Once all the pixels have been read from the Artcard data area, the
Artcard motor 37 can be stopped,
and the byte image descrambled and XORed. Although not requiring real-time
performance, the process should be fast
enough not to annoy the human operator. The process must take 2 MB of
scrambled bit-image and write the
unscrambled/XORed bit-image to a separate 2MB image.
Phase 4. The final phase in the Artcard read process is the Reed-Solomon
decoding process, where the 2MB
bit-image is decoded into a 1MB valid Artcard data area. Again, while not
requiring real-time performance it is still
necessary to decode quickly with regard to the human operator. If the decode
process is valid, the card is marked as
valid. If the decode failed, any duplicates of data in the bit-image are
attempted to be decoded, a process that is
repeated until success or until there are no more duplicate images of the data
in the bit image.
The four phase process described requires 4.5 MB of DRAM. 2MB is reserved for
Phase 2 output, and 0.5MB
is reserved for scratch data during phases I and 2. The remaining 2MB of space
can hold over 440 columns at 4725
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-83-
byes per column. In practice, the pixel data being read is a few columns ahead
of the phase I algorithm, and in the
worst case, about 180 columns behind phase 2, comfortably inside the 440
column limit.
A description of the actual operation of each phase will now be provided in
greater detail.
Phase I - Detect data area on Artcard
This phase is concerned with robustly detecting the left-hand side of the data
area on the Artcard 9. Accurate
detection of the data area is achieved by accurate detection of special
targets printed on the left side of the card. These
targets are especially designed to be easy to detect even if rotated up to I
degree.
Turning to Fig. 38, there is shown an enlargement of the left hand side of an
Artcard 9. The side of the card is
divided into 16 bands, 239 with a target eg. 241 located at the center of each
band. The bands are logical in that there is
no line drawn to separate bands. Turning to Fig. 39, there is shown a single
target 241. The target 241, is a printed
black square containing a single white dot. The idea is to detect firstly as
many targets 241 as possible, and then to join
at least 8 of the detected white-dot locations into a single logical straight
line. If this can be done, the start of the data
area 243 is a fixed distance from this logical line. If it cannot be done,
then the card is rejected as invalid.
As shown in Fig. 38, the height of the card 9 is 3150 dots. A target (TargetO)
241 is placed a fixed distance of
24 dots away from the top left corner 244 of the data area so that it falls
well within the first of 16 equal sized regions
239 of 192 dots (576 pixels) with no target in the final pixel region of the
card. The target 241 must be big enough to
be easy to detect, yet be small enough not to go outside the height of the
region if the card is rotated I degree. A
suitable size for the target is a 31 x 31 dot (93 x 93 sensed pixels) black
square 241 with the white dot 242.
At the worst rotation of I degree, a I column shift occurs every 57 pixels.
Therefore in a 590 pixel sized band,
we cannot place any part of our symbol in the top or bottom 12 pixels or so of
the band or they could be detected in the
wrong band at CCD read time if the card is worst case rotated.
Therefore, if the black part of the rectangle is 57 pixels high (19 dots) we
can be sure that at least 9.5 black
pixels will be read in the same column by the CCD (worst case is half the
pixels are in one column and half in the
next). To be sure of reading at least 10 black dots in the same column, we
must have a height of 20 dots. To give room
for erroneous detection on the edge of the start of the black dots, we
increase the number of dots to 31, giving us 15 on
either side of the white dot at the target's local coordinate (15, 15). 31
dots is 91 pixels, which at most suffers a 3 pixel
shift in column, easily within the 576 pixel band.
Thus each target is a block of 31 x 31 dots (93 x 93 pixels) each with the
composition:
15 columns of 31 black dots each (45 pixel width columns of 93 pixels).
I column of 15 black dots (45 pixels) followed by I white dot (3 pixels) and
then a further 15 black dots (45
pixels)
15 columns of 31 black dots each (45 pixel width columns of 93 pixels)
Detect targets
Targets are detected by reading colutnns of pixels, one column at a time
rather than by detecting dots. It is
necessary to look within a given band for a number of columns consisting of
large numbers of contiguous black pixels
to build up the left side of a target. Next, it is expected to see a white
region in the center of further black columns, and
finally the black columns to the left of the target center.
Eight cache lines are required for good cache performance on the reading of
the pixels. Each logical read fills
4 cache lines via 4 sub-reads while the other 4 cache-lines are being used.
This effectively uses up 13% of the available
.. ..... _.._ ....._.__ _..._...._._........ _. ....... .
.__.___..._.......,_......r..._..___._..._,__.__,.__._... ......_._..__.....-
..._..~,__. .._... .
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-84-
DRAM bandwidth.
As illustrated in Fig. 40, the detection mechanism FIFO for detecting the
targets uses a filter 245, run-length
encoder 246, and a FIFO 247 that requires special wiring of the top 3 elements
(S1, S2, and S3) for random access.
The columns of input pixels are processed one at a time until either all the
targets are found, or until a
specified number of columns have been processed. To process a column, the
pixels are read from DRAM, passed
through a filter 245 to detect a 0 or 1, and then run length encoded 246. The
bit value and the number of contiguous
bits of the same value are placed in FIFO 247. Each entry of the FIFO 249 is
in 8 bits, 7 bits 250 to hold the run-length,
and I bit 249 to hold the value of the bit detected.
The run-length encoder 246 only encodes contiguous pixels within a 576 pixel
(192 dot) region.
The top 3 elements in the FIFO 247 can be accessed 252 in any random order.
The run lengths (in pixels) of
these entries are filtered into 3 values: short, niediuni, and long in
accordance with the following table:
Short Used to detect white dot. RunLength < 16
Medium Used to detect runs of black above or below the 16<= RunLenoth < 48
white dot in the center of the target.
Long Used to detect run lengths of black to the left and RunLength >= 48
right of the center dot in the target.
Looking at the top three entries in the FIFO 247 there are 3 specific cases of
interest:
Case I S 1= white long We have detected a black column of the target to
S2 = black long the left of or to the right of the white center dot.
S3 = white medium/long
Case 2 S 1= white lon~ If we've been processing a series of columns of
S2 = black medium Case Is, then we have probably detected the
S3 = white short white dot in this column. We know that the next
Previous 8 columns were Case I entry will be black (or it would have been
included in the white S3 entry), but the number of
black pixels is in question. Need to verify by
checking after the next FIFO advance (see Case
3).
Case 3 Prev = Case 2 We have detected part of the white dot. We
S3 = black med expect around 3 of these, and then some more
columns of Case 1.
Preferably, the followinR information per region band is kept:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-85-
TargetDetected I bit
BlackDetectCount 4 bits
WhiteDetectCount 3 bits
PrevColumnStartPixel 15 bits
TargetColumn ordinate 16 bits (15:1)
TargetRow ordinate 16 bits (15:1)
TOTAL 7 bytes (rounded to 8 bytes for easy addressing)
Given a total of 7 bytes. It makes address generation easier if the total is
assumed to be 8 bytes. Thus 16
entries requires 16 * 8 = 128 bytes, which fits in 4 cache lines. The address
range should be inside the scratch 0.5MB
DRAIvI area since other phases make use of the remaining 4MB data area.
When beeinning to process a given pixel column, the register value
S2StartPixel 254 is reset to 0. As entries
in the FIFO advance from S2 to SI, they are also added 255 to the existing
S2StartPixel value, giving the exact pixel
position of the run currently defined in S2. Looking at each of the 3 cases of
interest in the FIFO, S2StartPixel can be
used to determine the stan of the black area of a target (Cases I and 2), and
also the start of the white dot in the center
of the target (Case 3). An algorithm for processing columns can be as follows:
1 TargetDetected[0-15] := 0
B1ackDetectCount[0-151 := 0
WhiteDetectCount[0-15] := 0
TargetRow[0-15] := 0
TargetColumn[0-15] := 0
PrevColStartPixel[0-15] := 0
CurrentColumn := 0
2 Do ProcessColumn
3 CurrentColumn++
4 If (CurrentColumn <= LastValidColumn)
Goto 2
The steps involved in the processing a column (Process Column) are as follows:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-86-
1 S2StartPixcl := 0
FIFO := 0
B1ackDetectCount 0
WhiteDetectCount := 0
ThisColumnDetected := FALSE
PrevCaseWasCase2 := FALSE
2 If (! TargetDetected[Target]) & (! ColumnDetected[Target])
ProcessCases
Endlf
3 PrevCaseWasCase2 := Case=2
4 Advance FIFO
The processing for each of the 3 (Process Cases) cases is as follows:
Case 1:
BlackDetectCount[target] < 8 = := ABS(S2StartPixel -
PrevColStartPixel["I'arget])
OR If (0<== < 2)
WhiteDetectCount[Target] = 0 BlackDetectCount[Target}++ (max value =8)
Else
BlackDetectCount[Target] := 1
WhiteDetectCount[Target] := 0
Endlf
PrevColStartPixel[Target] := S2StartPixel
ColumnDetected[Target] := TRUE
BitDctected = I
B lackDetectCount[ target] >= 8 PrevColStartPixel[Target] := S2StartPixel
WhiteDetectCount[Target] != 0 ColumnDetected[Target] := TRUE
BitDetected = ]
TargetDetected[Target] := TRUE
TargetColumn[Target] := CurrentColumn - 8 -
(WhiteDetectCount[Target]/2)
Case 2:
No special processing is recorded except for setting the `PrevCaseWasCase2'
flag for identifying Case 3 (see
Step 3 of processing a column described above)
Case 3:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-87-
PrevCaseWasCase2 = TRUE If (WhiteDetectCount[Target] < 2)
BlackDetectCount[Target] >= 8 TargetRow[Target] = S2StartPixel +
(S2R,,,,Leõg,i,/2)
WhiteDetectCount=l Endlf
= := ABS(S2StartPixel - PrevColStartPixel[Target])
If (0<== < 2)
WhiteDetectCount[Target]++
Else
WhiteDetectCount[Target] := 1
Endif
PrevColStartPixel[Target] := S2StartPixel
ThisColumnDetected := TRUE
BitDetected = 0
At the end of processing a given column, a comparison is made of the current
column to the maximum
number of columns for target detection. If the number of columns allowed has
been exceeded, then it is necessary to
check how many targets have been found. If fewer than 8 have been found, the
card is considered invalid.
Process tar=
After the targets have been detected, they should be processed. All the
targets may be available or merely
some of them. Some targets may also have been erroneously detected.
This phase of processing is to determine a mathematical line that passes
through the center of as many targets
as possible. The more targets that the line passes through, the niore
confident the target position has been found. The
limit is set to be 8 targets. If a line passes through at least 8 targets,
then it is taken to be the right one.
It is all right to take a brute-force but straightforward approach since there
is the time to do so (see below), and
lowering complexity makes testing easier. It is necessary to determine the
line between targets 0 and 1(if both targets
are considered valid) and then determine how many targets fall on this line.
Then we determine the line between
targets 0 and 2, and repeat the process. Eventually we do the same for the
line between targets I and 2, I and 3 etc. and
finally for the line between targets 14 and 15. Assuming all the targets have
been found, we need to perform
15+14+13+ ...= 90 sets of calculations (with each set of calculations
requiring 16 tests = 1440 actual calculations), and
choose the line which has the maximum number of targets found along the line.
The algorithm for target location can
be as follows:
TargetA := 0
MaxFound := 0
BestLine := 0
While (TargetA < 15)
If (TargetA is Valid)
TargetB:= TargetA + I
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-88-
While (TargetB<= 15)
If (TargetB is valid)
CurrentLine := line between TargetA and TargetB
TargetC := 0;
While (TargetC <= 15)
If (TargetC valid AND TargetC on line AB)
TargetsHit++
Endif
If (TargetsHit > MaxFound)
MaxFound := TargetsHit
BestLine := CurrentLine
Endif
TargetC++
EndWhile
Endlf
TargetB ++
EndWhile
Endlf
TargetA++
EndWhile
If (MaxFound < 8)
Card is Invalid
Else
Store expected centroids for rows based on BestLine
Endif
As illustrated in Fig. 34, in the algorithm above, to determine a CurrentLine
260 from Target A 261 and target
B, it is necessary to calculate Orow (264) & Acolumn (263) between targets
261, 262, and the location of Target A. It is
then possible to move from Target 0 to Target I etc. by adding Arow and
Acolumn. The found (if actually found)
location of target N can be compared to the calculated expected position of
Target N on the line, and if it falls within
the tolerance, then Target N is determined to be on the line.
To calculate Arow & Acolumn:
Arow = (roWTargetA'rOW TargetB)/(B-A)
Ocolumn = (columnTarge, - columnT,rge,B)/(B-A)
Then we calculate the position of TargetO:
row = rowTargetA - (A * Arow)
column = columnTargetA - (A * Ocolumn )
And compare (row, column) against the actual rowTargem and columnTgm. To move
from one expected target
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-89-
to the next (e.g. from TargetO to Targetl ), we simply add Arow and Ocolumn to
row and column respectively. To
check if each target is on the line, we must calculate the expected position
of TargetO, and then perform one add and
one comparison for each target ordinate.
At the end of comparing all 16 targets against a maximum of 90 lines, the
result is the best line through the
valid targets. If that line passes through at least 8 targets (i.e. MaxFound
>= 8), it can be said that enough targets have
been found to fotm a line, and thus the card can be processed. If the best
line passes through fewer than 8, then the card
is considered invalid.
The resulting algorithm takes 180 divides to calculate Orow and Ocolumn, 180
multiply/adds to calculate
target0 position, and then 2880 adds/comparisons. The time we have to perform
this processing is the time taken to
read 36 columns of pixel data = 3,374,892ns. Not even accounting for the fact
that an add takes less time than a divide,
it is necessary to perform 3240 mathematical operations in 3,374,892ns. That
gives approximately 1040ns per
operation, or 104 cycles. The CPU can therefore safely perform the entire
processing of targets, reducing complexity of
design.
Update centroids based on data edoe border and clockmarks
Step 0: Locate the data area
From Target 0(241 of Fig. 38) it is a predetermined tixed distance in rows and
columns to the top
left border 244 of the data area, and then a further 1 dot column to the
vertical clock marks 276. So we use TargetA,
Arow and Acolumn found in the previous stage (Arow and Acolumn refer to
distances between targets) to calculate
the centroid or expected location for TargetO as described previously.
Since the fixed pixel offset from TargetO to the data area is related to the
distance between targets (192 dots
between targets, and 24 dots between TargetO and the data area 243), simply
add Arow/8 to TargetO's centroid column
coordinate (aspect ratio of dots is 1:1). Thus the top co-ordinate can be
defined as:
(columnpotColumnTop = columnTar,,O + (Arow/8)
(rowpolColunuiTop = rowTuge,O + (Acolumn /8)
Next Arow and Acolumn are updated to give the number of pixels between dots in
a single column (instead of
between targets) by dividing them by the number of dots between targets:
Arow = Orow/192
Acolumn = Ocolumn /t92
We also set the currentColumn register (see Phase 2) to be -1 so that after
step 2, when phase 2 begins, the
currentColumn register will increment from -1 to 0.
Step 1: Write out the initial centroid deltas (A) and bit history
This simply involves writing setup information required for Phase 2.
This can be achieved by writing Os to all the Arow and Acolumn entries for
each row, and a bit history. The
bit history is actually an expected bit history since it is known that to the
left of the clock mark column 276 is a border
column 277, and before that, a white area. The bit history therefore is 011,
010, 011, 010 etc.
Step 2: Update the centroids based on actual pixels read.
The bit history is set up in Step I according to the expected clock marks and
data border. The actual centroids
for each dot row can now be more accurately set (they were initially 0) by
comparing the expected data against the
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-90-
actual pixel values. The centroid updating mechanism is achieved by simply
performing step 3 of Phase 2.
Phase 2 - Detect bit pattern from Artcard based on Pixels read, and write as
bLes.
Since a dot from the Artcard 9 requires a minimum of 9 sensed pixels over 3
columns to be represented, there
is little point in performing dot detection calculations every sensed pixel
column. It is better to average the time
required for processing over the average dot occurrence, and thus make the
most of the available processing time. This
allows processing of a column of dots from an Artcard 9 in the time it takes
to read 3 columns of data from the Artcard.
Although the most likely case is that it takes 4 columns to represent a dot,
the 40'column will be the last column of one
dot and the first column of a next dot. Processing should therefore be limited
to only 3 columns.
As the pixels from the CCD are written to the DRAM in 13% of the time
available, 83% of the time is
available for processing of I column of dots i.e. 83% of (93,747*3) = 83% of
281,241 ns = 233,430ns.
In the available time, it is necessary to detect 3150 dots, and write their
bit values into the raw data area of
memory. The processing therefore requires the following steps:
For each column of dots on the Artcard:
Step 0: Advance to the next dot column
Step 1: Detect the top and bottom of an Artcard dot column (check clock marks)
Step 2: Process the dot column, detecting bits and storing them appropriately
Step 3: Update the centroids
Since we are processing the Artcard's logical dot columns, and these may shift
over 165 pixels, the worst case
is that we cannot process the first column until at least 165 columns have
been read into DRAM. Phase 2 would
therefore finish the same amount of time after the read process had
tertninated. The worst case time is: 165 * 93,747ns
= 15,468,255ns or 0.015 seconds.
Step 0: Advance to the next dot column
In order to advance to the next column of dots we add Orow and Acolunln to the
dotColumnTop to give us the
centroid of the dot at the top of the column. The first time we do this, we ai-
e currently at the clock marks colunin 276
to the left of the bit image data area, and so we advance to the first column
of data. Since Arow and Ocolumn refer to
distance between dots within a column, to move between dot columns it is
necessary to add Arow to columndotCoi,,,õõTop
and Acolumn to rowao,cot,.ToP=
To keep track of what column number is being processed, the column number is
recorded in a register called
CurrentColumn. Every time the sensor advances to the next dot column it is
necessary to increment the CurrentColumn
register. The first time it is incremented, it is incremented from -1 to 0
(see Step 0 Phase 1). The CurrentColumn
register determines when to terminate the read process (when reaching
maxColumns), and also is used to advance the
DataOut Pointer to the next column of byte information once all 8 bits have
been written to the byte (once every 8 dot
columns). The lower 3 bits determine what bit we're up to within the current
byte. It will be the same bit being written
for the whole column.
Step 1: Detect the top and bottom of an Artcard dot column.
In order to process a dot column from an Artcard, it is necessary to detect
the top and bottom of a column.
The column should form a straight line between the top and bottom of the
column (except for local warping etc.).
Initially dotColumnTop points to the clock mark column 276. We simply toggle
the expected value, write it out into
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-91-
the bit history, and move on to step 2, whose first task will be to add the
Arow and Acolumn values to dotColumnTop
to arrive at the first data dot of the column.
Step 2: Process an Artcard's dot column
Given the centroids of the top and bottom of a column in pixel coordinates the
column should form a straight
line between them, with possible minor variances due to warping etc.
Assuming the processing is to start at the top of a column (at the top
centroid coordinate) and move down to
the bottom of the column, subsequent expected dot centroids are given as:
rOwnext = row + Orow
columnneXt = column + Acolumn
This gives us the address of the expected centroid for the next dot of the
column. However to account for
local warping and error we add another Orow and Acolumn based on the last time
we found the dot in a given row. In
this way we can account for small drifts that accumulate into a maximum drift
of some percentage from the straight
line joining the top of the column to the bottom.
We therefore keep 2 values for each row, but store them in separate tables
since the row history is used in step
3 of this phase.
* Arow and Ocolumn (2 @ 4 bits each = I byte)
* row history (3 bits per row, 2 rows are stored per byte)
For each row we need to read a Arow and Acolumn to determine the change to the
centroid. The read process
takes 5% of the bandwidth and 2 cache lines:
76*(3150/32) + 2*3150 = 13,824ns = 5% of bandwidth
Once the centroid has been determined, the pixels around the centroid need to
be examined to detect the status
of the dot and hence the value of the bit. In the worst case a dot covers a
4x4 pixel area. However, thanks to the fact
that we are sampling at 3 times the resolution of the dot, the number of
pixels required to detect the status of the dot
and hence the bit value is much less than this. We only require access to 3
columns of pixel columns at any one time.
In the worst case of pixel drift due to a 1% rotation, centroids will shift I
column every 57 pixel rows, but
since a dot is 3 pixels in diameter, a given column will be valid for 171
pixel rows (3*57). As a byte contains 2 pixels,
the number of bytes valid in each buffered read (4 cache lines) will be a
worst case of 86 (out of 128 read).
Once the bit has been detected it must be written out to DRAM. We store the
bits from 8 columns as a set of
contiguous bytes to minimize DRAM delay. Since all the bits from a given dot
column will correspond to the next bit
position in a data byte, we can read the old value for the byte, shift and OR
in the new bit, and write the byte back.
The read / shift&OR / write process requires 2 cache lines.
We need to read and write the bit history for the given row as we update it.
We only require 3 bits of history
per row, allowing the storage of 2 rows of history in a single byte. The read
/ shift&OR / write process requires 2 cache
lines.
The total bandwidth required for the bit detection and storage is summarised
in the following table:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-92-
Read centroid A 5%
Read 3 columns of pixel data 19%
Read/Write detected bits into byte buffer 10%
Read/Write bit history 5%
TOTAL 39%
Detecting a dot
The process of detecting the value of a dot (and hence the value of a bit)
given a centroid is accomplished by
examining 3 pixel values and getting the result from a lookup table. The
process is fairly simple and is illustrated in
Fig. 42. A dot 290 has a radius of about 1.5 pixels. Therefore the pixel 291
that holds the centroid, regardless of the
actual position of the centroid within that pixel, should be 100% of the dot's
value. If the centroid is exactly in the
center of the pixel 291, then the pixels above 292 & below 293 the centroid's
pixel. as well as the pixels to the left 294
& right 295 of the centroid's pixel will contain a majority of the dot's
value. The further a centroid is away from the
exact center of the pixel 295, the more likely that more than the center pixei
will have 100% coverage by the dot.
Although Fig. 42 only shows centroids differing to the left and below the
center, the same relationship
obviously holds for centroids above and to the right of center. center. In
Case 1, the centroid is exactly in the center of
the middle pixel 295. The center pixel 295 is completely covered by the dot,
and the pixels above, below, left, and
right are also well covered by the dot. In Case 2, the centroid is to the left
of the center of the middle pixel 291. The
center pixel is still completely covered by the dot, and the pixel 294 to the
left of the center is now completely covered
by the dot. The pixels above 292 and below 293 are still well covered. In Case
3, the centroid is below the center of
the middle pixel 291. The ccnter pixel 291 is still completely covered by the
dot 291, and the pixel below center is now
completely covered by the dot. The pixels left 294 and right 295 of center are
still well covered. In Case 4, the
centroid is left and below the center of the middle pixel. The center pixel
291 is still completely covered by the dot,
and both the pixel to the left of center 294 and the pixel below center 293
are conipletely covered by the dot.
The algorithm for updating the centroid uses the distance of the centroid from
the center of the middle pixel
291 in order to select 3 representative pixels and thus decide the value of
the dot:
Pixel 1: the pixel containing the centroid
Pixel 2: the pixel to the left of Pixel I if the centroid's X coordinate
(column value) is <'/2, otherwise the pixel
to the right of Pixel 1.
Pixel 3: the pixel above pixel I if the centroid's Y coordinate (row value) is
<'/2, otherwise the pixel below
Pixel 1.
As shown in Fig. 43, the value of each pixel is output to a pre-calculated
lookup table 301. The 3 pixels are
fed into a 12-bit lookup table, which outputs a single bit indicating the
value of the dot - on or off. The lookup
table 301 is constructed at chip definition time, and can be compiled into
about 500 gates. The lookup table can be a
simple threshold table, with the exception that the center pixel (Pixel 1) is
weighted more heavily.
Step 3: Update the centroid As for each row in the column
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-93-
The idea of the As processing is to use the previous bit history to generate
a`perfect' dot at the expected
centroid location for each row in a current column. The actual pixels (from
the CCD) are compared with the expected
`perfect' pixels. If the two match, then the actual centroid location must be
exactly in the expected position, so the
centroid As must be valid and not need updating. Otherwise a process of
changing the centroid As needs to occur in
order to best fit the expected centroid location to the actual data. The new
centroid As will be used for processing the
dot in the next column.
Updating the centroid As is done as a subsequent process from Step 2 for the
following reasons:
to reduce complexity in design, so that it can be performed as Step 2 of Phase
1 there is enough bandwidth
remaining to allow it to allow reuse of DRAM buffers, and
to ensure that all the data required for centroid updating is available at the
start of the process without special
pipelining.
The centroid A are processed as Acolumn Arow respectively to reduce
complexity.
Although a given dot is 3 pixels in diameter, it is likely to occur in a 4x4
pixel area. However the edge of one
dot will as a result be in the same pixel as the edge of the next dot. For
this reason, centroid updating requires more
than simply the information about a given single dot.
Fig. 44 shows a single dot 310 from the previous column with a given centroid
311. In this example, the dot
310 extend A over 4 pixel columns 312-315 and in fact, part of the previous
dot column's dot (coordinate =
(Prevcolumn, Current Row)) has entered the current column for the dot on the
current row. If the dot in the current row
and column was white, we would expect the rightmost pixel column 314 from the
previous dot column to be a low
value, since there is only the dot information from the previous column's dot
(the current column's dot is white). From
this we can see that the higher the pixel value is in this pixel column 315,
the more the centroid should be to the right
Of course, if the dot to the right was also black, we cannot adjust the
centroid as we cannot get information sub-pixel.
The same can be said for the dots to the left, above and below -he dot at dot
coordinates (PrevColumn, CurrentRow).
From this we can say that a maximum of 5 pixel colu-nns and rows are required.
It is possible to simplify the
situation by taking the cases of row and column centroid As separately,
treating them as the same problem, only rotated
90 degrees.
Taking the horizontal case first, it is necessary to change the column
centroid As if the expected pixels don't
match the detected pixels. From the bit history, the value of the bits found
for the Current Row in the current dot
column, the previous dot column, and the (previous-1)th dot column are known.
The expected centroid location is also
known. Using these two pieces of information, it is possible to generate a 20
bit expected bit pattern should the read be
`perfect'. The 20 bit bit-pattern represents the expected A values for each of
the 5 pixels across the horizontal
dimension. The first nibble would represent the rightmost pixel of the
leftmost dot. The next 3 nibbles represent the 3
pixels across the center of the dot 310 from the previous column, and the last
nibble would be the leftmost pixel 317 of
the rightmost dot (from the current column).
If the expected centroid is in the center of the pixel, we would expect a 20
bit pattern based on the following
table:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-94-
Bit history Expected pixels
000 00000
001 0000D
010 ODFDO
011 ODFDD
100 D0000
101 D000D
110 DDFDO
I 11 DDFDD
The pixels to the left and right of the center dot are either 0 or D depending
on whether the bit was a 0 or I
respectively. The center three pixels are either 000 or DFD depending on
whether the bit was a 0 or 1 respectively.
These values are based on the physical area taken by a dot for a given pixel.
Depending on the distance of the centroid
from the exact center of the pixel, we would expect data shifted slightly,
which really only affects the pixels either side
of the center pixel. Since there are 16 possibilities, it is possible to
divide the distance from the center by 16 and use
that amount to shift the expected pixels.
Once the 20 bit 5 pixel expected value has been determined it can be compared
against the actual pixels read.
This can proceed by subtracting the expected pixels from the actual pixels
read on a pixel by pixel basis, and finally
adding the differences together to obtain a distance from the expected A
values.
Fig. 45 illustrates one form of implementation of the above algorithm which
includes a look up table 320
which receives the bit history 322 and central fractional component 323 and
outputs 324 the corresponding 20 bit
number which is subtracted 321 from the central pixel input 326 to produce a
pixel difference 327.
This process is carried out for the expected centroid and once for a shift of
the centroid left and right by 1
amount in Acolumn. The centroid with the smallest difference from the actual
pixels is considered to be the 'winner'
and the Acolumn updated accordingly (which hopefully is 'no change'). As a
result, a Acolumn cannot change by
more than I each dot column.
The process is repeated for the vertical pixels, and Arow is consequentially
updated.
There is a larae amount of scope here for parallelism. Depending on the rate
of the clock chosen for the ACP
unit 31 these units can be placed in series (and thus the testing of 3
different A could occur in consecutive clock
cycles), or in parallel where all 3 can be tested simultaneously. If the clock
rate is fast enough, there is less need for
parallelism.
Bandwidth utilization
It is necessary to read the old A of the As, and to write them out again. This
takes 10% of the bandwidth:
2 * (76(3150/32) + 2*3150) = 27,648ns = 10% of bandwidth
It is necessary to read the bit history for the given row as we update its As.
Each byte contains 2 row's bit
histories, thus taking 2.5% of the bandwidth:
76((3150/2)/32) + 2*(3150/2) = 4,085ns = 2.5% of bandwidth
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-95-
In the worst case of pixel drift due to a 1% rotation, centroids will shift 1
column every 57 pixel rows, but
since a dot is 3 pixels in diameter, a given pixel column will be valid for
171 pixel rows (3*57). As a byte contains 2
pixels, the number of bytes valid in cached reads will be a worst case of 86
(out of 128 read). The worst case timing for
columns is therefore 31 % bandwidth.
5*(((9450/(128 * 2)) * 320) * 128/86) = 88, 112ns = 31 % of bandwidth.
The total bandwidth required for the updating the centroid 0 is summarised in
the following table:
Read/Write centroid 0 10%
Read bit history 2.5%
Read 5 columns of pixel data 31%
TOTAL 43.5%
Memory usage for Phase 2:
The 2MB bit-image DRAM area is read from and written to during Phase 2
processing. The 2MB pixel-data
DRAM area is read.
The 0.5MB scratch DRAM area is used for storing row data, namely:
Centroid array 24bits (16:8) * 2 * 3150 = 18.900 byes
Bit History array 3 bits * 3150 entries (2 per byte) = 1575 bytes
Phase 3 -Unscramble and XOR the raw data
Returning to Fig. 37, the next step in decoding is to unscramble and XOR the
raw data. The 2MB byte image,
as taken from the Artcard, is in a scrambled XORed form. It must be
unscrambled and re-XORed to retrieve the bit
image necessary for the Reed Solomon decoder in phase 4.
Turning to Fig. 46, the unscrambling process 330 takes a 2MB scrambled byte
image 331 and writes an
unscrambled 2MB image 332. The process cannot reasonably be performed in-
place, so 2 sets of 2MB areas are
utilised. The scrambled data 331 is in symbol block order arranged in a 16x 16
array, with symbol block 0(334) having
all the symbol 0's from all the code words in random order. Symbol block I has
all the symbol 1's from all the code
words in random order etc. Since there are only 255 symbols, the 256'h symbol
block is currently unused.
A linear feedback shift register is used to determine the relationship between
the position within a symbol
block eg. 334 and what code word eg. 355 it came from. This works as long as
the same seed is used when generating
the original Artcard images. The XOR of bytes from alternative source lines
with OxAA and 0x55 respectively is
effectively free (in time) since the bottleneck of time is waiting for the
DRAM to be ready to read/write to non-
sequential addresses.
The timing of the unscrambling XOR process is effectively 2MB of random byte-
reads, and 2MB of random
byte-writes i.e. 2 * (2MB * 76ns + 2MB * 2ns) = 327,155,712ns or approximately
0.33 seconds. This timing assumes
_._....___ _ _ _____....._..~._..~...~...... _
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-96-
no caching.
Phase 4 - Reed Solomon decode
This phase is a loop, iterating through copies of the data in the bit image,
passing them to the Reed-Solomon
decode module until either a successful decode is made or until there are no
more copies to attempt decode from.
The Reed-Solomon decoder used can be the VLIW processor, suitably programmed
or, alternatively, a
separate hardwired core such as LSI Logic's L64712. The L64712 has a
throughput of 50Mbits per second (around
6.25MB per second), so the time may be bound by the speed of the Reed-Solomon
decoder rather than the 2MB read
and 1 MB write memory access time (500MB/sec for sequential accesses). The
time taken in the worst case is thus
2/6.25s = approximately 0.32 seconds.
Phase 5 Running the Vark script
The overall time taken to read the Artcard 9 and decode it is therefore
approxitnately 2.15 seconds. The
apparent delay to the user is actually only 0.65 seconds (the total of Phases
3 and 4), since the Artcard stops moving
after 1.5 seconds.
Once the Artcard is loaded, the Artvark script must be interpreted, Rather
than run the script immediately, the
script is only run upon the pressing of the `Print' button 13 (Fig. 1). The
taken to run the script will vary depending on
the complexity of the script, and must be taken into account for the perceived
delay between pressing the print button
and the actuai print button and the actual printing.
Alternative Artcard Fomat
Of course, other artcard formats are possible. There will now be described one
such alternative artcard format with a
number of preferable feature. Described hereinafter will be the alternative
Artcard data format, a mechanism for
mapping user data onto dots on an alternative Artcard, and a fast alternative
Artcard reading algorithm for use in
embedded systems where resources are scarce.
Alternative Artcard Overview
The Alternative Artcards can be used in both embedded and PC type
applications, providing a user-friendly
interface to large amounts of data or configuration information.
While the back side of an alternative Artcard has the same visual appearance
regardless of the application
(since it stores the data), the front of an alternative Artcard can be
application dependent. It must make sense to the user
in the context of the application.
Alternative Artcard technology can also be independent of the printing
resolution. Ttie notion of storing data
as dots on a card simply means that if it is possible put more dots in the
same space (by increasing resolution), then
those dots can represent more data. The preferred embodiment assumes
utilisation of 1600 dpi printing on a 86 mm x
55 mm card as the sample Artcard, but it is simple to detennine alternative
equivalent layouts and data sizes for other
card sizes and/or other print resolutions. Regardless of the print resolution,
the reading technique remain the same.
After all decoding and other overhead has been taken into account, alternative
Artcards are capable of storing up to I
Megabyte of data at print resolutions up to 1600 dpi. Alternative Artcards can
store megabytes of data at print
resolutions greater than 1600 dpi. The following two tables summarize the
effective alternative Artcard data storage
capacity for certain print resolutions:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-97-
Format of an alternative Artcard
The structure of data on the alternative Artcard is therefore specifically
designed to aid the recovery of data.
This section describes the format of the data (back) side of an alternative
Artcard.
Dots
The dots on the data side of an alternative Artcard can be monochrome. For
example, black dots printed on a
white background at a predetermined desired print resolution. Consequently a
"black dot" is physically different from a
"white dot". Fig. 47 illustrates various examples of magnified views of black
and white dots. The monochromatic
scheme of black dots on a white background is preferably chosen to maximize
dynamic range in blurry reading
environments. Although the black dots are printed at a particular pitch (eg.
1600 dpi), the dots themselves are
slightly larger in order to create continuous lines when dots are printed
contiguously. In the example images of Fig. 47,
the dots are not as merged as they may be in reality as a result of bleeding.
There would be more smoothing out of the
black indentations. Although the alternative Artcard system described in the
preferred embodiment allows for flexibly
different dot sizes, exact dot sizes and ink/printing behaviour for a
particular printing technology should be studied in
more detail in order to obtain best results.
In describing this artcard embodiment, the term dot refers to a physical
printed dot (ink, thermal. electro-
photographic, silver-halide etc) on an alternative Artcard. When an
alternative Artcard reader scans an alternative
Artcard, the dots must be sampled at least double the printed resolution to
satisfy Nyquist's Theorem. The term pixel
refers to a sample value from an alternative Artcard reader device. For
example, when 1600 dpi dots are scanned at
4800 dpi there are 3 pixels in each dimension of a dot, or 9 pixels per dot.
The sampling process will be further
explained hereinafter.
Turning to Fig. 48, there is shown the data surface 1 101 a sample of
alternative Artcard. Each alternative
Artcard consists of an "active" region 1102 surrounded by a white border
region 1103. The white border 1103
contains no data information, but can be used by an alternative Artcard reader
to calibrate white levels. The active
region is an array of data blocks eg. 1104, with each data block separated
from the next by a gap of 8 white dots eg.
1106. Depending on the print resolution, the number of data blocks on an
alternative Artcard will vary. On a 1600 dpi
alternative Artcard, the array can be 8 x 8. Each data block 1104 has
dimensions of 627 x 394 dots. With an inter-
block gap 1106 of 8 white dots, the active area of an alternative Artcard is
therefore 5072 x 3208 dots (8.1mm x
5.1 mm at 1600 dpi).
Data blocks
Turning now to Fig. 49, there is shown a single data block 1107. The active
region of an alternative Artcard
consists of an array of identically structured data blocks 1107. Each of the
data blocks has the following structure: a
data region 1108 surrounded by clock-marks 1109, borders 11 10, and targets
111 1. The data region holds the encoded
data proper, while the clock-marks, borders and targets are present
specifically to help locate the data region and ensure
accurate recovery of data from within the region.
Each data block 1107 has dimensions of 627 x 394 dots. Of this, the central
area of 595 x 384 dots is the data
region 1108. The surrounding dots are used to hold the clock-marks, borders,
and targets.
Borders and Clockmarks
Fig. 50 illustrates a data block with Fig. 51 and Fig. 52 illustrating
magnified edge portions thereof. As
illustrated in Fig. 51 and Fig. 52, there are two 5 dot high border and
clockmark regions 1170, 1177 in each data block:
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-98-
one above and one below the data region. For example, The top 5 dot high
region consists of an outer black dot border
line 1112 (which stretches the length of the data block), a white dot
separator line 1113 (to ensure the border line is
independent), and a 3 dot high set of clock marks 1114. The cfock marks
alternate between a white and black row,
starting with a black clock mark at the 8th column from either end of the data
block. There is no separation between
clockmark dots and dots in the data region.
The clock marks are symmetric in that if the alternative Artcard is inserted
rotated 180 degrees, the same
relative border/clockmark regions will be encountered. The border 1112, 1113
is intended for use by an alternative
Artcard reader to keep vertical tracking as data is read from the data region.
The clockmarks 1114 are intended to keep
horizontal tracking as data is read from the data region. The separation
between the border and clockmarks by a white
line of dots is desirable as a result of blurring occurring during reading.
The border thus becomes a black line with
white on either side, making for a good frequency response on reading. The
clockmarks alternating between white and
black have a similar result, except in the horizontal rather than the vertical
dimension. Any alternative Artcard reader
must locate the clockmarks and border if it intends to use them for trackin(Y.
The next section deals with targets, which
are designed to point the way to the clockmarks, border and data.
Targets in the Target region
As shown in Fig. 54, there are two 15-dot wide target regions 1116, 11 17 in
each data block: one to the left
and one to the right of the data region. The target regions are separated from
the data region by a single column of dots
used for orientation. The purpose of the Target Regions 1116, 1117 is to point
the way to the clockmarks, border and
data regions. Each Target Region contains 6 targets eg. 1118 that are designed
to be easy to find by an alternative
Artcard reader. Turning now to Fig. 53 there is shown the structure of a
single target 1120. Each target 1 120 is a 15 x
15 dot black square with a center structure 1121 and a run-length encoded
tarset number 1122. The center structure
1121 is a simple white cross, and the target number component 1122 is simply
two columns of white dots, each being 2
dots lons! for each part of the target number. Thus target number 1's target
id 1 122 is 2 dots long, target number 2's
target id 1122 is 4 dots wide etc.
As shown in Fig. 54, the targets are arranged so that they are rotation
invariant with resards to card insertion.
This means that the left targets and right targets are the same, except
rotated 180 degrees. In the left Target Region
1116, the targets are arranged such that targets I to 6 are located top to
bottom respectively. In the right Target Region,
the targets are arranged so that target numbers I to 6 are located bottom to
top. The target number id is always in the
half closest to the data region. The magnified view portions of Fig. 54
reveals clearly the how the right targets are
simply the same as the left targets, except rotated 180 degrees.
As shown in Fig. 55, the targets 1124, 1125 are specifically placed within the
Target Region with centers 55
dots apart. In addition, there is a distance of 55 dots from the center of
target 1(1124) to the first clockmark dot 1126 in
the upper clockmark region, and a distance of 55 dots from the center of the
target to the first clockmark dot in the
lower clockmark resion (not shown). The first black clockmark in both regions
begins directly in line with the target
center (the 8th dot position is the center of the 15 dot-wide target).
The simplified schematic illustrations of Fig. 55 illustrates the distances
between target centers as well as the
distance from Target 1(1124) to the first dot of the first black clockmark
(1126) in the upper border/clockmark region.
Since there is a distance of 55 dots to the clockmarks from both the upper and
lower targets, and both sides of the
alternative Artcard are symmetrical (rotated through 180 degrees), the card
can be read left to right or right-to-left.
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-99-
Regardless of reading direction, the orientation does need to be determined in
order to extract the data from the data
region.
Orientation columns
As illustrated in Fig. 56, there are two I dot wide Orientation Columns 1127,
1128 in each data block: one
directly to the left and one directly to the right of the data region. The
Orientation Columns are present to give
orientation information to an alternative Artcard reader: On the left side of
the data region (to the right of the Left
Targets) is a single column of white dots 1127. On the right side of the data
region (to the left of the Right Targets) is a
single column of black dots 1128. Since the targets are rotation invariant,
these two columns of dots allow an
alternative Artcard reader to determine the orientation of the alternative
Artcard - has the card been inserted the right
way, or back to front. From the alternative Artcard reader's point of view,
assuming no degradation to the dots,
there are two possibilities:
* If the column of dots to the left of the data region is white, and the
column to the right of the data
region is black, then the reader will know that the card has been inserted the
saine way as it was written.
* If the column of dots to the left of the data region is black. and the
column to the right of the data
region is white, then the reader will know that the card has been inserted
backwards, and the data region is
appropriately rotated. The reader must take appropriate action to correctly
recover the information froni the alternative
Artcard.
Data Region
As shown in Fig. 57, the data region of a data block consists of 595 columns
of 384 dots each, for a total of
228,480 dots. These dots must be interpreted and decoded to yield the original
data. Each dot represents a single bit, so
the 228,480 dots represent 228,480 bits, or 28,560 bytes. The interpretation
of each dot can be as follows:
Black I
White 0
The actual interpretation of the bits derived from the dots, however, requires
understanding of the mapping
from the original data to the dots in the data regions of the alternative
Artcard.
Mapping original data to data region dots
There will now be described the process of taking an original data file of
maximum size 910,082 bytes and
mapping it to the dots in the data regions of the 64 data blocks on a 1600 dpi
alternative Artcard. An alternative
Artcard reader would reverse the process in order to extract the original data
from the dots on an alternative Artcard.
At first glance it seems trivial to map data onto dots: binary data is
comprised of Is and Os, so it would be possible to
simply write black and white dots onto the card. This scheme however, does not
allow for the fact that ink can fade,
parts of a card may be damaged with dirt, grime, or even scratches. Without
etror-detection encoding, there is no way
to detect if the data retrieved from the card is correct. And without
redundancy encoding, there is no way to correct the
detected errors. The aim of the mapping process then, is to make the data
recovery highly robust, and also give the
alternative Artcard reader the ability to know it read the data correctly.
There are three basic steps involved in mapping an original data file to data
region dots:
* Redundancy encode the original data
* Shuffle the encoded data in a deterministic way to reduce the effect of
localized alternative Artcard
CA 02296439 2000-01-17
WO 99/04368 PCT/AU98/00544
-100-
damage
* Write out the shuffled, encoded data as dots to the data blocks on the
alternative Artcard
Each of these steps is examined in detail in the followine sections.
Redundancy encode using Reed-Solomon encoding
The mapping of data to alternative Artcard dots relies heavily on the method
of redundancy encoding
employed. Reed-Solomon encoding is preferably chosen for its ability to deal
with burst errors and effectively detect
and correct errors using a minimum of redundancy. Reed Solomon encoding is
adequately discussed in the standard
texts such as Wicker, S., and Bhargava, V., 1994, Reed-Solomon Codes and their
Applications, IEEE Press.
Rorabaugh, C, 1996, Error Coding Cookbook, McGraw-Hill. Lyppens, H., 1997,
Reed-Solomon Error Correction,
Dr. Dobb's Journal, January 1997 (Volume 22, Issue 1).
A variety of different parameters for Reed-Solomon encoding can be used,
including different symbol sizes
and different levels of redundancy. Preferably, the following encoding
parameters are used:
* m=8
* t=64
Having m=8 means that the symbol size is 8 bits (I byte). It also means that
each Reed-Solomon encoded
block size n is 255 bytes (28 - I symbols). In order to allow correction of up
to t symbols, 2t symbols in the final block
size must be taken up with redundancy symbols. Having t=64 means that 64 bytes
(symbols) can be corrected per
block if they are in error. Each 255 byte block therefore has 128 (2 x 64)
redundancy bytes, and the remaining 127
bytes (k=127) are used to hold original data. Thus:
* n=255
* k=127
The practical result is that 127 bytes of original data are encoded to become
a 255-byte block of Reed-
Solomon encoded data. The encoded 255-byte blocks are stored on the
alternative Artcard and later decoded back to
the original 127 bytes again by the alternative Artcard reader. The 384 dots
in a single column of a data block's data
region can hold 48 bytes (384/8). 595 of these columns can hold 28,560 bytes.
This amounts to 112 Reed-Solomon
blocks (each block having 255 bytes). The 64 data blocks of a complete
alternative Artcard can hold a total of 7168
Reed-Solomon blocks (1,827,840 bytes, at 255 bytes per Reed-Solomon block).
Two of the 7,168 Reed-Solomon
blocks are reserved for control information, but the remaining 7166 are used
to store data. Since each Reed-Solomon
block holds 127 bytes of actual data, the total amount of data that can be
stored on an alternative Artcard is 910,082
bytes (7166 x 127). If the original data is less than this amount, the data
can be encoded to fit an exact number of Reed-
Solomon blocks, and then the encoded blocks can be replicated until all 7,166
are used. Fig. 58 illustrates the overall
form of encoding utilised.
Each of the 2 Control blocks 1132, 1133 contain the same encoded information
required for decoding the
remaining 7,166 Reed-Soloinon blocks:
The number of Reed-Solomon blocks in a full message (16 bits stored to/hi),
and
The number of data bytes in the last Reed-Solomon block of the message (8
bits)
These two numbers are repeated 32 times (consuming. 96 bytes) with the
remaining 31 bytes reserved and set
to 0. Each control block is then Reed-Solomon encoded, turning the 127 bytes
of control information into 255 bytes of
Reed-Solomon encoded data.
DEMANDES OU BREVETS VOLUMINEUX
LA PRESF3VTE PARTIE DE CETTE DEMANDE OU CE BREVET
COMPREND PLUS D'UN TOME.
CECI EST LE TOME DE 3
NOTE: Pour les tomes additionels, veuiilez contacter le Bureau canadien des
brevets
-JUMBO APPLfCAT1ONS/PATFjVTS
THIS SECTION OF THE APPLICATION/PATENT CONTAINS MORE
THAN ONE VOLUME
THIS tS VOLUME OF
._-~- -
NOTE' For additional volumes-please contact the Canadian Patent Office~