Note: Descriptions are shown in the official language in which they were submitted.
CA 02308592 2000-OS-12
Method And System For Determining Reputation
Of Interlinked Electronic Pages
FIELD OF THE INVENTION
This invention concerns determining the reputation of a web page.
BACKGROUND OF THE INVENTION
The use of search engines on the World Wide Web (the "Web") such as those
provided
by YAHOO.COM, GOOGLE.COM, and ALTAVISTA.COM has provided access to a
comprehensive collection of information on the Web. Information provided
through these search
engines primarily consists of pages encoded in hypertext markup language ("web
pages")
referenced in search engine outputs, which essentially consists of the
universal resource
locator (URL) of each page.
Ordering the pages returned in response to a search engine query is of growing
importance. In the absence of such an ordering, the user may face the prospect
of wading
through hundred, if not thousands, of resources. For example, a query to the
ALTAVISTA.COM search facility yields references to over 1.2 million web pages
for the search
phrase "search engine"; even the human-maintained YAHOO.COM returned 960 web
sites for
the same phrase. In practice, it is unlikely that a user will examine in
excess of a hundred
returned resources; empirical results even indicate that users will not
examine more than five to
ten pages. Therefore, there is a need for a way to order web pages as returned
from a query on
a particular topic.
Furthermore, search engines such as YAHOO.COM are, in reality, a hierarchical
directory. These search engines require categorization of web pages under the
classification
scheme of its directory. Such directories employ large contingents of persons
to manually
categorize new web pages. This can be inefficient, inaccurate and expensive
process. The
need to automatically classify web pages is obvious.
A number of approaches to solve these problems are in existence. One approach
is a
recursive method for ranking the importance of a Web page based on the
importance of its
incoming links. (See S. Brin and L. Page, "The anatomy of a large-scale
hypertextual web
CA 02308592 2000-OS-12
search engine", In Proceedings of the 7th International World Wide Web
Conference, pages
107--117, Brisbane, Australia, April 1998. Elsevier Science) The ranking is
based on simulating
the behavior of a "random surfer" who either selects an outgoing link
uniformly at random, or
jumps to a new page chosen uniformly at random from the entire collection of
pages. The rank
of a page corresponds to the number of visits the "random surfer" makes to the
page. However
the disadvantage of this approach is that it ranks all the pages collectively
without regard for the
topic, which is not helpful to a person seeking information on a particular
subject.
Another method is for the search engine to record for each and every query
typed by a
user the number of subsequent visits made by the user to individual web pages
consequent
upon such a query. For example, if "java" is entered and the search engine
yields and displays
results in a particular order; depending on which page is clicked on
subsequently, the ranks
of these 10 pages are adjusted. When a subsequent user queries "Java", the
order of
presentation of the 10 web pages may be different.
The main problem with this scheme is that there are millions of pages that can
match a
particular query, and there is no way to present all of them to the user. The
search engine
needs to be selective; this makes the ranking more biased toward those pages
shown first
without real justification. A further problem has to do with the learning
mechanism of the engine.
Since the system learns from the previous hits, the system might be useful for
its frequent
users. However, such users often want to see new pages as well. In addition,
the learning
mechanism may not be useful for new users and getting a few bad results are
enough for a
new user to switch to another search engine.
A further method finds authorities on specified topics based on a hubs and
authorities
model with the assumption that authority is conferred on a page by a set of
hub pages, which is
recursively defined as a set of pages with links to many relevant authority
pages. The weights
of these authority and hub pages are then determined by matrix computation.
This approach does not yield a measure of the topics for which a web page is
relevant.
Therefore, there exists a need to provide a method to addressing the problems
of
weighting topics for a chosen web page, and automating classification of web
pages.
2
CA 02308592 2000-OS-12
SUMMARY OF THE INVENTION
The invention includes a method for providing a reputation of a page among a
set of
electronic pages on a distributed network comprising determining a reputation
term for the page
from a probabilistic model of a topical term search strategy for the pages.
One embodiment of the invention relates to a method to provide a user with a
page
having a reputation relating to a topical term, the page among a set of
electronic pages on a
distributed network , the method comprising:
(a) obtaining a topical term from the user;
(b) determining a reputation term for each page from a probabilistic model of
the topical
term search strategy for the pages; and
(c) providing the user with a reputation page class output.
Another embodiment of the invention includes a method to provide a user with a
distributed network search output from a search engine, comprising:
a) obtaining a topical term input from the user;
b) providing a search engine output display in response to the topical term
input; and
c) providing a reputation term display in response to the topical term input,
wherein the
reputation term display is displayed proximate to the search engine output
display and
wherein the reputation term for each page of the search engine output display
is
obtained from a probabilistic model of the topical term search strategy for
the pages.
Another embodiment of the invention includes a method to provide a user with a
topical
term class output of topical terms relating to a page in a set of electronic
pages, comprising:
(a) determining the set of topical terms related to the pages of the set of
electronic pages.
(b) determining the reputation term for the page for each of the set of
topical terms, the
reputation term being determined from a probabilistic model of the topical
term search
strategy for the pages; and
(c) providing a topical term class output.
3
CA 02308592 2000-OS-12
Another embodiment of the invention includes a method where the reputation
term of
the page is determined by a method comprising the following steps:
(a) forming a reputation term matrix based on a plurality of pages and a
plurality of topical
terms, each element including the random likelihood of the page containing the
topical
term;
(b) updating the reputation term matrix, so that each element includes the
likelihood of
visiting the related page in search of the specific topical term after taking
a step in a
Markovian random walk process;
(c) recursively iterating step (b), one further Markovian step at a time,
until the probability
term converges; and
(d) forming the reputation term as the related element of the converged
reputation term
matrix.
Another embodiment of the invention includes a method to provide a user with a
page
having a reputation relating to a topical term, the page among a set of
electronic pages on a
distributed network , the method comprising:
(a) obtaining a topical term from the user;
(b) determining a referential term for each page from a probabilistic model of
the topical
term search strategy for the pages; and
(c) providing the user with a referential page class output.
Another embodiment of the invention includes where the referential term of the
page is
determined by a method comprising the following steps:
a) forming a reputation term matrix based on a plurality of pages and a
plurality of topical
terms, each element being the random likelihood of the page containing the
topical term;
b) updating the reputation term matrix, so that each element includes the
likelihood of
visiting the related page in search of the specific topical term after taking
a step in a
Markovian random walk process;
c) recursively iterating step (b), one further Markovian step at a time, until
the probability
term converges; and
d) forming the referential term as the related element of the converged
reputation term
matrix.
CA 02308592 2000-OS-12
The invention includes a system for providing a reputation of a page among a
set of
electronic pages on a distributed network comprising a) means for determining
a reputation
term for the page from a probabilistic model of a topical term search strategy
for the pages and
b) means for providing the user with a reputation term output.
One embodiment of the invention relates to a system to provide a user with a
page
having a reputation relating to a topical term, the page among a set of
electronic pages on a
distributed network , the system comprising:
(a) means for obtaining a topical term from the user;
(b) means for determining a reputation term for each page from a probabilistic
model of the
topical term search strategy for the pages; and
(c) means for providing the user with a reputation page class output.
Another embodiment of the invention includes a system to provide a user with a
distributed network search output from a search engine, comprising:
(a) means for obtaining a topical term input from the user;
(b) means for providing a search engine output display in response to the
topical term input;
and
(c) means for providing a reputation term display in response to the topical
term input,
wherein the reputation term display is displayed proximate to the search
engine output
display and wherein the reputation term for each page of the search engine
output display is
obtained from a probabilistic model of the topical term search strategy for
the pages.
Another embodiment of the invention includes a system to provide a user with a
topical
term class output of topical terms relating to a page in a set of electronic
pages, comprising:
(a) means for determining the set of topical terms related to the pages of the
set of
electronic pages.
(b) means for determining the reputation term for the page for each of the set
of topical
terms, the reputation term being determined from a probabilistic model of the
topical
CA 02308592 2000-OS-12
term search strategy for the pages; and
(c) means for providing a topical term class output.
Another embodiment of the invention includes a system where the system further
comprises:
(a) means for forming a reputation term matrix based on a plurality of pages
and a plurality
of topical terms, each element including the random likelihood of the page
containing the
topical term;
(b) means for updating the reputation term matrix, so that each element
includes the
likelihood of visiting the related page in search of the specific topical term
after taking a
step in a Markovian random walk process;
(c) means for recursively iterating step (b), one further Markovian step at a
time, until the
probability term converges; and
(e) means for forming the reputation term as a related element of the
converged reputation
term matrix.
Another embodiment of the invention includes a system to provide a user with a
page
having a reputation relating to a topical term, the page among a set of
electronic pages on a
distributed network , the system comprising:
(a) means for obtaining a topical term from the user;
(b) means for determining a referential term for each page from a
probabilistic model of the
topical term search strategy for the pages; and
(c) means for providing the user with a referential page class output.
Another embodiment of the invention includes a system comprising:
a) means for forming a reputation term matrix based on a plurality of pages
and a plurality
of topical terms, each element being the random likelihood of the page
containing the
topical term;
b) means for updating the reputation term matrix, so that each element
includes the
likelihood of visiting the related page in search of the specific topical term
after taking a
step in a Markovian random walk process;
CA 02308592 2000-OS-12
c) means for recursively iterating step (b), one further Markovian step at a
time, until the
probability term converges; and
d) means for forming the referential term as the related element of the
converged
reputation term matrix.
BRIEF DESCRIPTION OF THE DRAWINGS
Embodiments of the invention will be described by way of example and with
reference to
the drawings in which:
FIG. 1 is diagram of preferred embodiments of the present invention.
FIG. 2 is diagram of a preferred embodiment of the present invention involving
search engine
output.
FIG. 3 is diagram of preferred embodiments of the present invention for
determining a topical
term class output.
FIG. 4 is diagram of a preferred embodiment of the present invention to
determine a reference
output class.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
The invention involves the notion of the reputation of a page: pages with a
good
reputation should be given preferential treatment when reporting the results
of a search; and
that the hyperlink structure of web pages can be mined to extract such
reputation measures, on
the assumption that a link from page p to page q is, to some degree, an
endorsement of the
contents of q by the creator of p.
However, there are some difficulties in formalizing the concept of
'reputation' effectively.
The assumption that links are endorsements suggests that the number of
incoming links of a
page indicates its reputation. But in practice, links represent a wide variety
of relationships such
as navigation, subsumption, relatedness, refutation, justification, etc. In
addition, the focus of
this invention concerns not just the overall reputation of a page, but its
reputation on certain
topics.
CA 02308592 2000-OS-12
This invention involves two methods for determining the reputation of a page,
each
based on a Markovian random walk model. A random walk on the Web is in the
form of
navigation between pages, where each page represents a possible state, and
each link
represents a possible transition. A random walk is Markovian if the transition
at each step is
independent of the previous steps and it only depends on the current state.
The first method is based on one-level weight propagation where the reputation
of a
page on a topic is proportional to the sum of the reputation weights of pages
pointing to it on
the same topic. In other words, links emanating from pages with high
reputations are weighted
more. For example, a page can acquire a high reputation on a topic because the
page is
pointed to by many pages on that topic, or because the page is pointed to by
some high
reputation pages on that topic.
Consider a 'random surfer' who wanders the Web, searching for pages on topic
t. At
each step, the surfer either jumps into a page uniformly chosen at random from
the set of
pages that contain the term t, or follows a link uniformly chosen at random
from the set of
outgoing links of the current page. If the random surfer continues this walk
forever, then the
number of visits he or she makes to a page is its reputation on t. Pages with
relatively high
reputations on a topic are more likely to be visited by the random surfer
searching for that topic.
A justification for this is that the reputation of a page on a topic naturally
depends both on the
number of pages on the same topic that point to it, and on the reputations of
these pages on
the same topic as well. The number of visits the surfer makes to a page
depends on the same
two factors.
At each step, with probability d the random surfer jumps into a page uniformly
chosen at
random from the set of pages that contain the term t, and with probability (1-
d) he or she
follows an outgoing link from the current page. Let Nt denote the total number
of pages on the
Web that contain the term t. The probability that the surfer at each step
visits page p in a
random jump is d I N, if page p contains term t and zero otherwise.
To the person skilled in the art, assuming that every web page has at least
one outgoing
hyperlink, d > 0 and Nt > 0, the above formulation allows determination of two
probability
values: (1) the probability R"(p,,t) that the surfer visits page p, at step n,
and (2) the transitional
CA 02308592 2000-OS-12
probability from page p, to page p~. The latter leads to a solution for the
equilibrium probability
R"(p,,t) for visiting p, for topic t as the number of random steps n
approaches infinity by
determining the eigenvector of the stochastic matrix associated with
eigenvalue 1. Each
element of this eigenvector is the stationary probability of a surfer visiting
a page p, for topic t.
The reputation (or reputation rank or reputation term) of a web page p
associated with a topic t
using this first Markovian random walk method is defined as this stationary
probability.
In the setting of the Web, the assumption that every page has at least one
outgoing link
may not be true; there are often pages that have no outgoing link, or the
outgoing links may not
be valid. A reasonable solution to accommodate these web pages is to
implicitly add links from
every such page to all pages in the base set, i.e. the set of pages that
contain the term. The
interpretation is that when the surfer reaches a dead end, he or she jumps to
a page in the
base set chosen uniformly at random.
The probability d that the random surfer jumps into a page uniformly chosen at
random
from the set of pages that contain the term t is a value that may be varied
according to the
prevailing conditions of the web crawling. The value (1-d) is proportional to
the average walk
length or to the average weight propagation radius. If d is chosen close to
the value of 0, the
reputation rank of a page on any topic t mainly depends on its linkage
structure and is much
independent of the topic t. If a value for d close to 1 is selected, only
pages that explicitly
contain t will have a non-zero reputation rank associated with topic t.
Choosing d between 0
and 1 results in the reputation rank depending on both the linkage structure
and the textual
content, and the fractions of each varies with d.
The second Markovian random walk approach is based on two-level weight
propagation,
generalizing the Hubs and Authorities model. In this model, a page is deemed
an authority on a
topic if it is pointed to by good hubs on the topic, and a good hub is one
that points to good
authorities.
In order to clearly explain the method, define a transition as one of (a) jump
to a page on
topic t chosen uniformly at random from the whole collection, or (b) follow an
outgoing link of
the current page chosen uniformly at random. When the current page is p, the
surfer has two
choices: either make a transition out of page p, or randomly pick any page q
that has a link into
page p and make a transition out of page q. The intuitive justification is
this: when the surfer
CA 02308592 2000-OS-12
reaches a page p that seems useful for topic t, this does not mean that p is a
good source of
further links; but it does mean that pages q that point to p may be good
sources of links, since
they already led to page p.
The surfer follows links both forward (out of page p) and backward (into page
q). The
walk alternates strictly between forward and backward steps, except that after
option (a) is
chosen, the direction of the next step is picked at random.
If the random surfer continues the walk forever, then the number of forward
visits he or
she makes to a page is its authority reputation and the number of backward
visits he or she
makes to a page is its hub reputation. Clearly pages with relatively high
authority reputations on
a topic are more likely to be visited through their incoming links, and pages
with relatively high
hub reputations on a topic are more likely to be visited through their
outgoing links. The
authority reputation of a page p on topic t depends not only on the number of
pages on topic t
that point to p, but on the hub reputations of these pages on topic t as well.
Similarly, the hub
reputation of a page p on topic t depends not only on the number of pages on
topic t that page
p points to, but on the authority reputations of these pages on topic t as
well.
Define the authority reputation of a page p on a topic t as the probability
that the random
surfer looking for topic t makes a forward visit to page p and the hub
reputation of a page p on
topic t as the probability that the random surfer looking for topic t makes a
backward visit to
page p. Under two level influence propagation, the reputation of a web page
constitutes the
authority reputation and the hub authority.
Suppose at each step, with probability d the random surfer picks a direction
and jumps
into a page uniformly chosen at random from the set of pages on topic t, and
with probability (1
- d) the surfer follows a link. The probability that at each step the surfer
makes a forward visit
(and similarly a backward visit) to page p in a random jump is d/2N, if page p
contains term t
and zero otherwise.
To the person versed in the art, assuming that every page has an outgoing and
an
incoming hyperlink, d > 0 and N~ > 0, this formulation allows determination of
a number of
probabilistic values: (1) the probabilities A"(p,,t) that the surfer makes a
forward visit and H"-
'(p,,t) that the surfer makes a backward visit, to page p at step n, and (2)
the transitional
ID
CA 02308592 2000-OS-12
probabilities for a forward and a backward visit from page page p, to page p~.
The latter lead to
a solution for the equilibrium probabilities A"(p,,t) of visiting p, in the
case of a forward visit and
H"(p,,t) of a backward visit for topic t as the number of steps n approaches
infinity by
determining the eigenvector of the stochastic matrix associated with
eigenvalue 1. The
elements of this eigenvector are the stationary probabilities of a surfer
visiting the pages p, for
topic t. The authority reputation (or authority reputation rank) and hub
reputation (or hub
reputation rank) of a web page p associated with a topic t using this second
Markovian random
walk method is defined as these stationary probabilities.
In the setting of the Web, the assumption that a page has at least one
incoming link and
one outgoing link may not hold. One solution to accommodate such pages is to
assign a hub
(or authority) rank of zero for every page with no outgoing (incoming) links.
The random walk
process accordingly can be modified by restricting random jumps only to pages
with at least
either one incoming link or one outgoing link. Another solution is to add a
link from every page
to itself. This ensures that every page will acquire a fixed minimum authority
and hub rank on
topics of the page independent from its links.
The probability d that the random surfer jumps into a page uniformly chosen at
random
from the set of pages -- whether forward or backward -- that contain the term
t is a value that
may be varied according to the prevailing conditions of the web crawling. The
earlier discussion
on this matter in the case of one level influence propagation applies equally.
The above methods allowing determination of the reputation for all linked web
pages on
the world wide web and all topics. In reality, this may be a computationally
unfeasible and
objectively unnecessary task. According to two preferred embodiments of this
invention, the
reputations of a collection of web pages, possibly the contents of a directory
of web pages, for
all terms that appear in the content of the pages may be determined by using
the following
examples of approaches associated with the one-level and two-level influence
propagation
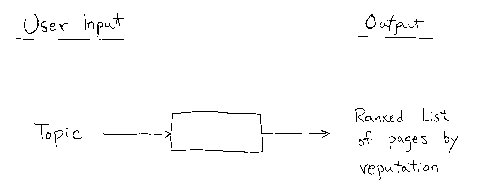
models (Figure 1 ). The user, whether a human person or not as in the case of
an automatic
process, starts the process embodying the invention and enters as input a
topical term. The
output consists of a display of the pages, possibly each page next to its
reputation term for the
topical term. The display may be visual in form, such as screen or printed
output, or it may be
non-visual, such as that for an automatic process. When displayed, the display
may be by way
of its URL or another representation, such as an icon or an annotated
hyperlink. Similarly, a
CA 02308592 2000-OS-12
representation other than a numerical value may indicate the reputation term,
for example, a
number of icons (whether identical or not), an adjective, or a noun. These
extended definitions
apply for all embodiments of this invention.
The reputation ranks in the one-level influence propagation model are in the
form of a
sparse matrix, say R, with rows representing Web pages and columns denoting
each term or
phrase that appears in some document (after removing stop words, etc.) The
process involves
initializing R and repeatedly updating it until convergence.
Example 1: Determining one-level Reputation Ranks
For every page p and term t,
Initialize R(p, t) =1 / N, if t appears in page p; otherwise R( p, t) = 0 .
While R has not converged,
Set R'(p,t) = 0 for every page p and term t,
For every link q ~ p ,
R'( p,t) = R'( p,t) + R(q, t) l O(q)
R( p, t) _ (1- d )R'( p, t) for every page p and term t,
R( p, t) = R( p, t) + d l N~ if term t appears in page p.
Each column of R converges to the principal eigenvector of the matrix of
transition
probabilities for a term t and eigenvalue one. The principal eigenvector
associated to each term
is the stationary distribution of pages in the random walk process.
The reputation in the two-level influence propagation model can be represented
in the
form of two sparse matrixes, say H and A, respectively denoting the hub and
the authority
reputations of pages.
Example 2: Determining Two-Level Reputation Ranks
For every page p and term t,
Initialize H( p, t) = A( p, t) =1 / 2N, if t appears in page p; otherwise H(
p, t) = A( p, t) = 0 .
While both H and A have not converged,
Set H'( p, t) = A'( p, t) = 0 for every page p and term t,
For every link q -~ p ,
H'(q,t) = H'(q,t)+A(p,t)lI(p)
A'( p, t) = A'( p, t) + H(q, t) l O(q)
H( p, t) _ (1- d )H'( p, t) and A( p, t) _ (1- d )A'( p, t) for every page p
and term t,
H( p, t) = H( p, t) + d l 2N, and A( p, t) = A( p, t) + d l 2Nt if term t
appears in page p.
12
CA 02308592 2000-OS-12
Again, the processing for each term is guaranteed to converge to the principal
eigenvector of the matrix of transition probabilities for that term and
eigenvalue one. The
principal eigenvector is the stationary distribution provided every page has
at least one
incoming and one outgoing link.
Using the above methods, it is theoretically possible to determine the
reputation for all
linked web pages on the world wide web (or a large collection of the web
pages) and all topics
(or a large subset thereof). However in reality, this may be a computationally
unfeasible and
objectively unnecessary task. According to another four preferred embodiments
with the same
functional objectives as the four embodiments just outlined (two models with
two ways of
processing each), approximations to the true reputation ranks may be
determined. Given a
page p and a parameter d > 0, and the reputations of the page within the one-
level influence
propagation model is sought, if the page acquires a high rank on an
arbitrarily chosen term t
carrying out the full process described by Example 1, then at least one of the
following must
hold:
(1) term t appears in page p,
(2) many pages on topic t point to p, or
(3) there are pages with high reputations on t that point to p.
This observation provides a practical way of identifying the candidate terms.
Start from
page p and collect all terms that appear in it. Then examine at the incoming
links of the page
and collect all possible terms from those pages. Continue this process until
either there is no
incoming link or the incoming links have very small effects on the reputations
of page p.
Denoting the maximum number of iterations by k, the method can be expressed as
follows:
Example 3: Approximating One-Level Reputation
R(p,t) = d lNr for every term t that appears in p
For 1=1,2,...,k
d' = d if l < k , 1 otherwise
For every path q' -~ ~ ~ ~ ~ q' ~ p of length 1 and every term t in page q, ,
R( p, t) = 0 if term t has not been seen before
R( p, t) = R( p, t ) + ((1- d )' / II l=, O(q' ))(d' l Nr )
The parameter k can be chosen such that (1 - d)k becomes very close to zero;
i.e. there
t3
CA 02308592 2000-OS-12
is no need to look at a page if the terms that appear in the page have little
or no effect in the
reputations of page p.
Similarly, the hub and the authority reputations of a page can be approximated
within
the two-level influence propagation model as follows:
Example 4: Approximating Two-Level Reputation
H( p, t) = A( p, t) = d l 2Nr for every term t that appears in p
For l =1,2,...,k
d' = d if l < k , 1 otherwise
If I is odd
For every path qr -~ qr_1 <-- qr_Z ~ ~ ~ ~ p of length I and every term t in
page q, ,
A( p, t) = 0 if term t has not been seen before
A(P~ t) = A(P~ t) + ((1- d ) r l (~(qr )1 (qr-i ) ~ . . p(qi )))d ~ l(2Nr )
For every path p -~ ~ ~ ~ qr_x ~ qr-~ ~ 9l of length I and every term t in
page qr ,
H( p, t) = 0 if term t has not been seen before
H(P~ t) = H(P~ t ) ~- ((1- d )r l(I (qr )~(qr-i ) ~ . . I(q~ )))d ~ l(2Nr )
else
For every path qr <- qr_1 ~ ~ ~ ~ -~ p of length I and every term t in page gr
,
A( p, t) = 0 if term t has not been seen before
A(P~ t) = A(P~ t) + ((i d )r l(1 (9r )~(qr-i ) ~ . .))d~ /(2Nr )
For every path p -~ ~ ~ ~ -> qr_1 E- qr of length I and every term t in page
qr ,
H(p,t) = 0 if term t has not been seen before
H(P~ t) = H(P~ t) + ((l d ) r l (~(qr )I (qr-~ ) ~ . .))d ~ /(2Nr )
Examples 3 and 4 are approximations of Examples 1 and 2 in the following
respects.
First, for a given page p, instead of examining all pages from which a user
can reach p within a
random walk, only pages that have significant influences are examined. The
claim here is that a
highly-ranked page q which is far away from p cannot have a significant
influence on p as long
as (1 - d)k is chosen close to zero. To put it in another way, Examples 3 and
4 simulate
Examples 1 and 2 just for k iterations. If Examples 1 and 2 converge within k
iterations, both
approximate and exact computations will give the same results. Secondly,
instead of computing
the ranks for all pages, the rank is only computed for a given page p.
In both Examples 3 and 4, a breadth-first search of the pages that can affect
the
reputations of a page p is adopted, i.e. all pages within depth I are visited
before any page in
CA 02308592 2000-OS-12
depth I+1. A benefit of this ordering is that the user can stop the search at
any point and be
sure that pages that are expected to have a high influence on p are visited.
This may happen,
for example, if the search takes longer than expected. However, it should be
noted that the
number of outgoing or incoming links for each page being visited must be
remembered, if this
information is not already stored. An alternative to a breadth-first search is
to conduct a depth-
first search, if it can be assumed that always the same set of pages with the
same ordering are
visited in each level along the paths. The only benefit of such a search is
that only the current
path needs to be remembered. However, this assumption may not hold, for
example, when
pages are retrieved from real search engines. In addition, there is the danger
of spending most
of the time on pages that have a very small effect on the reputations of page
p before visiting
more important pages.
To the person skilled in the art, the approaches outlined in Examples Three
and Four, in
terms of the how the reputation term for a topical term of a page is
generated, are easily
adaptable to be used for determining reputation terms for a set of pages
relating to a topical
term as in the first four preferred embodiments. The topical term t is held
constant during the
actual processing of a modified version of the Examples.
According to another four preferred embodiments of the invention the topics
for which a
web page p has highest reputation rank are identified (Figure 3). Thus the
user, whether human
or non-human, enters the URL of the web page p, and the output of the
embodiments is a list of
topics that the web page has high reputation for, i.e. the topical term class
output
One of Examples One to Four is utilized under each of the embodiment to
generate the
converged reputation matrix or matrices, the columns of which represent the
stationary
probability distribution corresponding to the topics (or an approximation
thereof), i.e. the
reputation ranks of all the pages for the topics. The preferred embodiment
goes on to determine
and indicate the web pages corresponding to the highest reputation rank values
in the matrix or
matrices for the specified topic t.
In terms of rank determinations, the earlier-mentioned embodiments
corresponding to
Examples One and Two determine the reputations of every page p on every topic
t. Therefore,
the highly-weighted pages for a given topic can be easily identified. In
practice, however, full
processing for every possible term may be very expensive; or an approximate
solution might be
~5
CA 02308592 2000-OS-12
as good as an exact solution. The earlier-mentioned embodiments adopting
Examples Three
and Four approximately find the topics on which a page has a high reputation.
Two preferred
embodiments to determine approximately web pages with relatively high
reputations on a given
topic are now described.
Given a topic t, an arbitrarily chosen page p can potentially acquire a
relatively high
rank, within the one-level influence propagation model, on topic t if at least
one of the following
hold:
(1) term t appears in page p,
(2) many pages on topic t point to p, or
(3) there are pages with high reputations on t that point to p.
Thus, a page with high reputation on topic t must either contain term t or be
reachable
within a few steps from a large set of pages on topic t. An approximate way of
determining the
one-level reputation ranks of pages on topic t is as follows:
Example 5: Approximating One-Level Reputation
(a) identify pages that are either on topic t or reachable within a short
distance from a
page on topic t;
(b) construct the matrix U of stochastic transition probabilities for the
resulting set of
pages; and
(c) compute the principal eigenvector of UT for eigenvalue 1.
The principal eigenvector will give the approximate reputation ranks of pages
that are
expected to have high reputations, i.e. every page which is not identified in
Step (a) is assumed
to have a rank of zero.
For the two-level influence propagation model, given a topic t, an arbitrarily
chosen page
p can acquire a relatively high rank on topic t if either term t appears in
page p or it is reachable
within a short path of alternating forward and backward links (or vice versa)
from a large set of
pages on topic t. An approximate way of determining the two-level reputation
ranks of pages on
topic t is as follows:
Example 6: Approximating Two-Level Reputation
CA 02308592 2000-OS-12
(a) identify pages that are either on topic t or reachable within few steps
from a page on
topic t, alternately following links forward and backward or vice versa;
(b) construct the matrix U of transition probabilities for the resulting set
of pages;
(c) compute the principal eigenvector of UT for eigenvalue 1.
The principal eigenvector will give the approximate reputation ranks of pages
that are
expected to have high reputations. Again, every page which is not identified
in Step (a) is
assumed to have a rank of zero.
With another embodiment of the present invention, the categorization process
of web
pages, which is otherwise performed manually, may be automated by adopting one
of the
above-mentioned approaches to determining the list of topics that a web page
has high
reputation for. This list of topics, once produced, may be used in the
categorization process,
either as a sole means of classification modifying the directory without human
intervention, or
as an aid to further processing whether manual or automatic. Variations
predicated on the
particular process of determination as shown in the prior Examples are clear
to the skilled
person in the art, as for the following preferred embodiments.
According to another embodiment of the invention, this invention may be used
as a
means of ranking web pages corresponding to a chosen topic (Figure 2). As
discussed earlier,
there are a number of such ranking methodologies in the market used by search
engines.
Given a particular topic, the reputation rank of a page is proportional to the
degree of
preference which should be accorded to the page. A page with a higher
reputation rank on the
topic should thus be placed higher in the list of web pages presented to the
searcher. The
embodiment includes one component, implementing one-level or two-level
influence
propagation, to determine the reputation of all pages for the chosen topic,
preferably that which
produces approximately the reputation ranks of the web pages for the topic.
Another
component displays to the user the distributed network search output, pages
returned by the
search engine for the specified topical term and the reputation values.
Instead of replacing a ranking scheme for web pages, a preferred embodiment
uses the
reputation of web pages to complement or supplement a pre-existing ranking
scheme. Thus two
or more schemes may be used to offer the searcher either a broader selection
of web pages
,'1
CA 02308592 2000-OS-12
than that obtainable with only one scheme, or multiple measures of the
relevance of a web
page presented. In either case, it involves first the determination of the
reputation rank of the
pages corresponding to the chosen topic. This is followed by combining
(removing
redundancies) and presenting (ordered by either schemes) to the searcher these
web pages
with the set of pages produced by another scheme. In the case where ranking by
reputation is
to complement an existing or an alternative scheme, the reputation ranks of
web pages are
preferably displayed along with whatever numerical ranking values are produced
by the other
scheme. This offers to the searcher two or more guides to relevance.
According to another preferred embodiment, the owner or operator of a web page
is
enabled to perform a more comprehensive assessment of its web services.
Organizations
routinely expend a great deal of effort and money in determining how they are
perceived by the
public; evaluating the reputation of their Web site on specific topics, or
determining those topics
on which its reputation is highest (or abnormally low) could be a valuable
part of this self-
evaluation. A variation of this embodiment involves an assessment of a web
page by a third
party for the purpose of market analysis and comparison.
Another preferred embodiment determines the referential term of a page (or
pages)
using hub reputation to rank the value of the page in providing links to web
pages on a topic
(Figure 4). Since hub reputation is the probabilistic measure of a surfer
seeking content on a
topic of making a backward link visit to a web page, it is reflective of the
worth of a web page as
a source of links to relevant pages on the topic. This is of use to web pages
which aim to
provide hyperlinks to specified topics, as for example web pages on niche
subject matters, as a
means of assessing the quality of the service. The user enters the topical
term, which initiates
the processing of the page or pages, resulting in the display of a referential
output class.
Although the above preferred embodiments refer to a single web page, it is
clear that one or
more web pages taken collectively, such as those comprising the pages of a web
site, may be
the subject matter of a reputation rank or topics determination. The
methodology or
methodologies listed above may determine reputation ranks using, instead of
the links which
emerge from a single web page, all links from the pages that go out of the web
site; hyperlinks
coming to any one of the web pages are taken collectively; and content of any
one is attributed
to the collective. Consequently, the reputation of the collection is assessed
en semble. Of
course, this can be artificial and misleading in the case of a massive
collection of unrelated web
Ig
CA 02308592 2000-OS-12
pages; however, for a small number of related web pages taken as a whole, such
as those of a
web site, this can be useful.
The preferred embodiments of this inventions further include a software
product to
provide a reputation of a page among a set of electronic pages on a
distributed network by
determining a reputation term for the page from a probabilistic model of a
topical term search
strategy for the pages. The software product is preferably executed on a
computer to
implement the methods of the invention as set out above.
Additional preferred embodiments take the form of computer-readable media such
as
diskettes, CD-ROM's, tapes, DVD disks, ROM chips, etc., containing a computer-
executable
software product implementing a method of the invention as described earlier.
Other possible embodiments of this invention need not be solely addressed to
pages
encoded in hypertext markup language available on the world wide web. Provided
that a holder
of content is uniquely addressable and possessing of links to other such
content holders, the
invention may be employed to determine the reputation of the content holder
for a topic in a
finite collection of such content holders.
For example, the content holder may be other Internet resources, such as FTP
files,
Usenet entries, and even email messages. All of these are of unique addresses
(the URL), and
are capable of hyperlinking to other such Internet resources. Another possible
embodiment of
the invention is in the context of intranets and extranets, where Internet-
capable resources such
as hypertext pages and FTP files are made available in a network of one or
more computers
employing TCP/IP network communication protocol. In fact, any computer-based
entity, such as
a database object, may be made the subject matter of reputation determination
by using this
invention, whether the computer be stand-alone or existing as one node in a
distributed
network. Tangible documents may also be subject to analysis by way of this
invention, such as
published journal articles or judicial case reports, which make references to
other such
documents. In the case of the latter, a possible use of the reputation scheme
is to gauge the
authoritative or persuasive nature of cases on a particular subject matter or
in general.
The description of preliminary evaluations of this invention follows. A
simplified version
of Example 3 (and also part of Example 4 that computes the authority
reputation of a page)
1 °I
CA 02308592 2000-OS-12
where k was set to 1, d to 0.10 and O(q; ) for every page q, to 7.2, the
estimated average
number of outgoing links of a page (R. Kumar, P. Raghavan, S. Rajagopalan, and
A. Tomkins,
"Extracting large-scale knowledge bases from the Web", In Proceedings of fihe
25th
International Conference on Very Large Databases, pages 639--650, September
1999.). The
best value for parameter d needs to be determined empirically. Further details
of the
implementation are as follows:
(1) Only a limited number of incoming links are examined; at most 500 incoming
links of
a page are obtained, but the number of links returned by the search engine,
currently ALTAVISTA.COM, can be less than that.
(2) For each incoming link, terms are extracted from the 'snippet' returned by
the search
engine, rather than the page itself. A justification for this is that the
snippet of a
page, to some degree, represents the topic of the page. In addition, the
number of
distinct terms and as a result the number of count queries needed to be sent
to the
search engine are dramatically reduced.
(3) Internal links and duplicate snippets are removed.
(4) Stop words and every term t with N< < (1 + r x L) are removed, where L is
the
number of incoming links collected and r is the near-duplicate ratio of the
search
engine, currently set to 0.01. This reduces the number of count queries and
also
removes unusual terms such as 'AAATT' that rarely appear in any page but might
acquire high weights.
Experiments with the prototype, called TOPIC, are set out.
In the first experiment, a set of known authoritative pages on queries (Java)
and
(+censorship +net), as reported by Kleinberg's HITS algorithm (J. M.
Kleinberg, "Authoritative
sources in a hyperlinked environment", In Proceedings of ACM-SIAM Symposium on
Discrete
Algorithms, pages 668--677, January 1998) was picked, and TOPIC computed the
topics that
each page was an authority on. As shown in Table 1, the term 'java' is the
most frequent term
among pages that point to an authority on Java. There are other frequent terms
such as
'search' or'Microsoft' which have nothing to do with the topic; their high
frequency represents
CA 02308592 2000-OS-12
the fact that authorities on Java are frequently cocited with search engines
or Microsoft. This
usually happens in cases where the number of links examined is much less than
the number of
links available. However, the highly-weighted terms for each page in both
Tables 1 and 2
largely describe the topics that the page is an authority on consistently with
the results of HITS.
URL : java.sun.com -- 500 links examined (out of 128653 available)
Highly weighted terms: Developers, JavaSoft, JDK, Java applets, Sun
Microsystems,
API, Programming, Solaris, tutorial
Frequent terms: Java, Software, Computer, Programming, Sun, Development,
Microsoft, Search
URL : sunsite.unc.edu~avafaq~avafaq.html
Highly weighted terms: Java FAQ Java, comp.lang.java FAQ, Java Tutorials, Java
Stuff, Applets, IBM Java, Javasoft, Java Resources, API Java, Learning Java
Frequent terms: FAQ, Sun, Computer, Language, Tutorial, Java FAQ, Software
Table 1. Authorities on (Java)
URL : ~.eff.org -- 500 links examined (out of 181899 available)
Highly weighted terms: Anti-Censorship, Join the Blue Ribbon, Blue Ribbon
Campaign, Electronic Frontier Foundation, Free Speech
URL : www.cdt.org --500 links examined (out of 12922 available)
Highly weighted terms: Center for Democracy and Technology, Communications
Decency Act, Censorship, Free speech, Blue Ribbon, Syllabus, encryption
URL : www.vtw.org -- 500 links examined (out of 7948 available)
Highly weighted terms: decision is near in the fight to overturn the
Communication
Decency Act, Blue Ribbon Campaign, Censorship, American Civil Liberties Union,
free
speech
URL : www.aclu.org -- 500 links examined (out of 22087 available)
Highly weighted terms: ACLU, American Civil Liberties Union, Communications
Decency Act, Amendment, CDA, Criminal Law, Censorship
Table 2. Authorities on (+censorship +net)
In another experiment, Inquirus is used (S. Lawrence and C.L. Giles, "Context
and page
analysis for improved {Web} search", IEEE Internet Computing, 2(4):38--46,
1998), the NECI
meta-search engine, which computes authorities using an unspecified algorithm.
Inquirus was
provided with the query ('data warehousing') and set the number of hits to its
maximum, which
was 1,000, to get the best authorities, as suggested by the system. The top
four authorities
returned by Inquirus was picked and used with the TOPIC system to compute the
topics those
pages have high reputations on. The result, as shown in Table 3, is again
consistent with the
2~
CA 02308592 2000-OS-12
judgments of Inquirus.
URL : www.dw-institute.com -- 390 links examined (out of 785 available)
Highly weighted terms: TDWI, Data Warehousing Information Center, www.dw-
institute.com, Data Warehousing Institute, data warehouse
URL : pwp.starnetinc.comllarryg -- 500 links examined (out of 1017 available)
Highly weighted terms: Data Warehousing Information Center, OLAP and Data,
Analytical Processing, Data Mining, data warehouse, Decision Support Systems
URL : www.datawarehousing.com -- 188 links examined (out of 229 available)
Highly weighted terms: Data Warehousing Information, OLAP, Data Mining
URL : www.dmreview.com -- 270 links examined (out of 1258 available)
Highly weighted terms: Data Warehouse 100, Powel Publishing, Review Magazine,
data Warehousing, Business Intelligence, Cognos, Data Mining, Product Review
Table 3. Authorities on ('data warehousing')
In another experiment, a set of personal home pages was selected and TOPIC
used to
find the high reputation topics for each page. This was expected to describe
in some way the
reputation of the owner of the page. The results are shown in Table 4 are
revealing. Tim
Berners-Lee's reputation on the 'History of the Internet,' Don Knuth's fame on
'TeX' and 'Latex'
and Jeff Ullman's reputation on 'database systems' and 'programming languages'
are to be
expected. The humour site Dilbert Zone seems to be frequently cited by Don
Knuth's fans.
Alberto Mendelzon's high reputation on 'data warehousing,' on the other hand,
is mainly due to
an online research bibliography he maintains on data warehousing and OLAP in
his home
page, and not to any merits of his own.
URL : www.w3.orglPeoplelBerners-Lee -- 500 links examined (out of 933
available)
Highly weighted terms: History Of The Internet, Tim Berners-Lee, Internet
History,
W3C
URL : www cs-faculty.stanford.edul knuth -- 500 links examined (out of 1733
available)
Highly weighted terms: Don Knuth, Donald E Knuth, TeX, Dilbert Zone, Latex,
ACM
URL : www db.stanford.edul ullman -- 238 links examined (out of 466 available)
Highly weighted terms: Jeffrey D Ullman, Database Systems, Database
Management,
Data Mining, Programming Languages, Computer Science, Stanford University
URL : www.cs.toronto.edul mendel -- 139 links examined (out of 259 available)
Highly weighted terms: Alberto Mendelzon, Data Warehousing and OLAP, SIGMOD,
DBMS
Table 4. Personal home pages
22
CA 02308592 2000-OS-12
In the last experiment, the home pages of a number of Computer Science
Departments
on the Web are selected. The main characteristic of these pages is that the
sites are
unregulated, in the sense that users store any documents they desire in their
own pages. The
results are shown in Table 5. The Computer Science Department at the
University of Toronto
has a high reputation on 'Russia' and 'Images,' mainly because a Russian
graduate student of
the department has put online a large collection of images of Russia, and many
pages on
Russia link to it. The high reputation on 'hockey' is due to a former
studentwho used to play on
the Canadian national women's hockey team. The Faculty of Mathematics,
Computer Science,
Physics and Astronomy at the University of Amsterdam (www.wins.uva.nl) has a
high reputation
on 'Solaris 2 FAQ' because the site maintains a FAQ on the Solaris operating
system. It also
has a high reputation on the musician Frank Zappa because it has a set of
pages dedicated to
him and the FAQ of the alt.fan.frank-zappa newsgroup. The Computer Science
Department of
the University of Helsinki (www.cs.helsinki.fi) has a high reputation on Linux
because of the
many pages on Linux that point to Linus Torvalds's page.
URL : wvvw.cs.toronto.edu - 500 links examined (out of 7814 available)
Highly weighted terms: Russia, Computer Vision, Linux, Images, Orthodox,
Hockey
URL : www.wins.uva.nl - 500 links examined (out of 6174 available)
Highly weighted terms: Solaris 2 FAQ, Wiskunde, Frank Zappa, FreeBSD, Recipes
URL : www.cs.helsinki.fi - 500 links examined (out of 9664 available)
Highly weighted terms: Linux Applications, Linux Gazette, Linux Software,
Knowledge
Discovery, Linus Torvalds, Data Mining
Table 5. Computer science departments
It will be appreciated that the above description relates to the preferred
embodiments by
way of example only. Many variations on the apparatus for delivering the
invention will be
obvious to those knowledgeable in the field, and such obvious variations are
within the scope of
the invention as described and claimed, whether or not expressly described.
All publications referred to in this paper are incorporated by reference in
their entirety.
z3