Note: Descriptions are shown in the official language in which they were submitted.
CA 02353442 2001-06-O1
WO 00/34861 PCT/US99/29190
-1-
A METHOD FOR DETERMINING PROGRAM CONTROL FLOW
BACKGROUND OF THE INVENTION
Analysis of binary software executables is a fundamental tool for many
useful applications, such as binary translation (from one computer
architecture to
5 another), post-link optimization, and binary instrumentation. All these
tools need to
distinguish executable code from un-reachable code and other data, and need to
determine the structure of the code in terms of basic blocks and control flow
paths
between them.
For example, Application Serial No. 08/985,052, filed December 4, 1997
10 (Agarwal), incorporated herein by reference in its entirety, discloses a
method of
instrumenting original binary code to create augmented or remediated binary
code,
which can then perform many useful functions such as error detecting and
repair.
Various embodiments of the Agarwal application accomplish tasks including, but
not limited to, remediation, assertion checking, test certification and
coverage,
15 continuous internal value testing, bootstrap regression testing, test path
identification
and statistical pattern matching.
An executable program is the final result of the software development process.
That process consists of compiling source modules written by the programmer
into
object modules which are then linked together to produce the final executable
20 program. The executable program thus consists of the actual machine
instructions of
the program, together with whatever data and descriptive information is needed
to
run those instructions. Higher-level source constructs such as names and
structured
control flow are in general no longer available.
The ability to modify an executable program to, for example, incorporate new
25 functionality, for example as described in the Agarwal application, enables
many
important applications, as it obviates the need to go back to the original
source,
which may not be available, and to re-build the program.
CA 02353442 2001-06-O1
PCT/US99/29190
WO 00/34861
-2-
Modifying the executable program is not straightforward, however, because of
the structure of machine instructions. One problem is displacement update,
which
pertains to the manner in which instructions refer to each other.
Fig. 1 A demonstrates the displacement update problem. A small piece of code
10 accesses registers named rl, r2, r3 and r5 in this example. Instruction l0A
adds
the contents of registers r2 and r3, and places the resulting sum into
register rl .
Instruction lOB tests the contents of register rl, i.e. the sum resulting from
instruction 10A, and if it is less than or equal to zero, jumps 346 bytes to
the last
instruction l OZ of the sample code 10, as indicated by arrow 12. The number
346,
10 called the displacement 1 l, has previously been calculated by the compiler
and is
part of the jump instruction l OB.
In Fig. 1B, additional code 14 has been inserted between the jump instruction
lOB and its target IOZ, perhaps for one or more of the reasons described in
the
Agarwal application. As a result, there are more than 346 bytes in the code 15
15 between the jump l OB and its target l OZ, and the displacement 11 must be
updated
or the jump indicated by arrow 12A will be to the wrong target, possibly with
catastrophic results. In addition, those displacements of any other relative
jump
instructions which cross that new code must also be updated, as must the
target
addresses of any absolute jump instructions where the target instruction has
been
20 shifted. Note that the 346 bytes separating the jump lOB and its target l
OZ in Fig.
1 A may contain both code and data.
Another important issue is register usage. Registers are fast storage
locations
within the computer's central processing unit (CPU}, which typically has only
a
small, fixed number of registers, e.g. thirty-two registers. If the inserted
code needs
25 to make use of registers, then either registers must be chosen that do not
interfere
with the program's use of registers, or the program's register usage must be
changed.
Register usage is a flow-sensitive analysis, since it is unlikely that there
are any
registers that are unused throughout the program. Thus, register usage must be
calculated separately for each point in the program. In general, this analysis
requires
30 knowledge of the program's control flow structure.
Fig. 2 illustrates the concept of register usage. The original code includes
instructions 20A and 20B. Instruction 20A copies the contents of register r5
into
CA 02353442 2001-06-O1
WO 00/34861
-3-
~c~rms~n9i9o
register rl . Instruction 20B is a conditional jump instruction. Since data is
loaded
into register rl at instruction 20A, it is clear that just prior to
instruction 20A there is
no further use of whatever data may be in register rl, so that register rl may
be used
freely for other purposes. Here, two new instructions 22 which use register rl
have
been inserted before instructions 20A and 20B. The new instructions 22
calculate
and save in register rl the sum of the values stored in registers r2 and r3.
The
content of rl, i.e., the sum, is then stored in memory at a location defined
by the
contents of register r6 plus an offset of 12 bytes. Since the following
instruction
20A copies the value of r5 into rl, the insertion of these two instructions 22
does not
affect the execution of the program.
The insertion of these instructions 22 is acceptable because the following
original instruction 20A moves the contents of register r5 into rl, and the
original
program has no further use for register rl at the point where the new
instructions 22
have been inserted. In general, all possible paths from the new instructions
must be
examined to determine which registers are available.
Thus, to perform the analyses that indicate what new code can be inserted at
each point in the program, the control flow structure must be determined. In
some
cases determining this structure is simple. In first example of Figs. lA and
1B, for
instance, the jump target is hard-coded into the instruction. This is not
always true,
however. Often the jump target is computed at run-time.
SUMMARY OF THE INVENTION
The present invention provides an analysis method which, starting from
external entry points, discovers all reachable instructions and the control-
flow paths
between them in an executable program.
25 A major challenge is that control flow is often determined by run-time
values.
For instance, a branch or jump instruction might use register contents or even
memory contents to determine the target. Analysis must thus include constant
propagation to determine control flow.
A further challenge is that standard constant propagation algorithms are
dependent on the control-flow graph, which causes a chicken-and-egg problem in
CA 02353442 2001-06-O1
WO OOI34861
PCT/US99129190
analyzing binaries: constant propagation is needed to determine the control-
flow, but
the control-flow graph is needed to perform constant propagation.
The present invention is an iterative, incremental method that interleaves
control-flow analysis and constant propagation. In brief, control-flow
analysis does
5 as much as it can without constant propagation information. Constant
propagation
then runs on the partial control-flow graph, which enables more control-flow
analysis to be done, and so on.
In accordance with the present invention, a method of generating a program
control flow definition from the program code comprises determining entry
points in
10 the program. The code is followed, or sequentially scanned or examined,
from an
entry point to a control flow instruction such as a branch or jump
instruction. A
code block is then defined as the code from the entry point up to and
including the
control flow instruction. From the control flow instruction, additional entry
points
are identified. This is repeated for each entry point having a known value,
resulting
15 in a partial control flow definition.
For entry points having unknown values, constant propagation analysis is
performed on the partial control flow definition to convert unknown entry
point
values to known values. Finally, the entry points determined by the constant
propagation analysis are used as starting points in the scanning step to
define
20 additional entry points. The steps of scanning from known block entry
points to
determine additional points and using constant propagation for determining
additional block entry points for unknown values are repeated to extend the
control
flow definition. Preferably, constant propagation is only used when there are
no
known block entry points.
25 A preferred embodiment of the present invention uses heuristics to
determine
certain unknown values, and/or uses a knowledge of the operating system under
which the program is running to determine certain unknown values.
A preferred embodiment of the present invention is implemented with a block
worklist which comprises a list of all known blocks within the program and
which
30 defines the partial control flow for the computer program during analysis,
and the
complete control flow upon completion of analysis. A block entry worklist
comprises a list of all known block entry points whose blocks are unknown,
such
CA 02353442 2001-06-O1
PCT/US99/29190
WO 00/34861
-5-
that each block entry point in the block entry worklist is analyzed. When an
end of a
block beginning with the block entry point is encountered, preferably as a
control
flow instruction, the block is placed in the block worklist. New block entry
points
determined by the control flow instruction are placed in the block entry list,
while
constant propagation is used to determine computed block entry points. When
there
are no more block entry points, the block worklist represents a complete
control
flow graph of the program.
BRIEF DESCRIPTION OF THE DRAWINGS
The foregoing and other objects, features and advantages of the invention will
be apparent from the following more particular description of preferred
embodiments of the invention, as illustrated in the accompanying drawings in
which
like reference characters refer to the same parts throughout the different
views. The
drawings are not necessarily to scale, emphasis instead being placed upon
illustrating the principles of the invention.
15 Figs. lA and 1B are executable code listings, using mnemonics, before and
after insertion of additional code respectively. These figures demonstrate the
displacement update problem.
Fig. 2 is an executable code listing illustrating the concept of register
usage.
Fig. 3 is a flow diagram illustrating a control flow instruction having a
target
which is determined at run-time.
Fig. 4A - B is a flowchart of a preferred embodiment of the present invention.
Fig. 5 is a diagram illustrating initialization of a preferred embodiment of
the
present invention.
Fig. 6 is a diagram illustrating the behavior of a preferred embodiment when a
conditional jump with a known target is encountered, where both the jump's
target
instruction and the fall-through instruction are new entry points.
Fig. 7 is a diagram illustrating the behavior of a preferred embodiment when a
conditional jump with a known target is encountered, where both the jump's
target
instruction and the fall-through instruction are known entry points.
CA 02353442 2001-06-O1
WO 00/34861
-6-
PCTNS99/29190
Fig. 8 is a diagram illustrating the behavior of a preferred embodiment when
an unconditional jump with a known target is encountered, where target
instruction
is internal to a known block.
Fig. 9 is a diagram illustrating the behavior of a preferred embodiment when
jump with an unknown target is encountered.
Fig. 10 is a control flow graph corresponding to that of Fig. 9, further
demonstrating constant propagation paths.
Fig. 11 is a diagram illustrating the state of the present invention after
constant
propagation is employed as in Fig. 10.
DETAILED DESCRIPTION OF THE INVENTION
The control-flow analysis algorithm of the present invention maintains a
worklist of block entry, or target, locations, which is initialized with any
known
external entry points. The algorithm makes as much progress as possible
without
knowledge of constant propagation values, for example with instructions such
as
conditional jumps that fall through to the next instruction.
A block of instructions is defined as a sequential sequence of instructions,
starting with an external entry point or an entry point from a control flow
instruction, i.e., a branch or jump, and terminating with a control flow
instruction.
Known entry points are used as starting points from which to scan code until a
20 control flow instruction is encountered, marking the end of a block. Fall-
through
instructions and jump targets are added to the list of known entry points,
while
unknown targets, i.e., those that are computed during a run of the program,
remain
unresolved, until no remaining entry points remain to be analyzed. When there
are
no remaining entry points, constant propagation kicks in.
Fig. 3 provides such an example where the jump target is computed at run-
time. Two different blocks of instructions 30, 32 place some address or
displacement into register rl, i.e., the current address plus 36 and 28,
respectively.
Each block 30, 32 then branches to a common block 34 which is 24 and 14 bytes
away, respectively. Block 34 terminates with a jump to the contents of
register rl,
which could be either the location set up in block 30, or the location set up
in block
CA 02353442 2001-06-O1
WO 00134861 PCTNS99I29190
_'7_
32, depending on which block 30, 32 was the actual predecessor to block 34 at
run-time.
Therefore, to calculate the control flow from block 34, the possible values of
rl must be propagated from the predecessor, or parent, blocks 30, 32. 'This
process
of propagating a needed constant, e.g., the value in rl, is called constant
propagation, and it clearly depends on the control flow.
Any standard constant propagation technique can be used as a basis, such as
those described in Aho, Sethi, and Ullman, "Compilers, Principles, Techniques,
and
Tools", Addison-Wesley, 1986. The key is making the algorithm incremental, or
able to be invoked a piece at a time. A standard worklist algorithm is used.
When a
new block of code is discovered, it is placed on a block worklist. The control-
flow
analysis and code discovery algorithm of the present invention invokes
constant
propagation on the block worklist when necessary.
Fig. 4 is a flowchart of an algorithm employed by a preferred embodiment. In
step 101, the system is initialized by placing known external entry points in
the
15 block entry worklist. In step 103, an entry point is selected from the
block entry
worklist. From this current entry point, instructions are sequentially
scanned, or
examined, until a jump or branch instruction is encountered (step 105). For
convenience, we use the terms "branch" and "jump" interchangeably to represent
all
control flow instructions, including jumps and branches.
20 A control flow instruction defines the end of a block. Since the entry
point
and end of the block are known, the current block has been "discovered" and is
placed into the block worklist. The corresponding entry is removed from the
block
entry worklist (step 107).
If the jump is conditional as determined in step 109, then the next location
25 must be an executable instruction since the jump might not be taken.
Therefore, the
instruction sequentially following the jump is added to block entry worklist
if it
represents a new location (step 113). If it does not represent a new location,
then it
must be a new path to a known block or block entry point, and it is added as a
descendant to the current block's worklist entry (step 117).
30 Next, a determination is made at step 119 as to whether the target of the
jump
instruction is known. If it is known, then either it is a new location, a new
path to a
known block or block entry point, or it is internal to some known block. If
the target
CA 02353442 2001-06-O1
PCT/US99/29190
WO 00/34861
_g_
is a new location, then it is added to the block entry list 123. If the target
represents
a new path to a known block, then at step 127, the target is added to the
current
block's worklist entry as a descendant. Finally, if the target represents an
internal
point of a known block, the known block is split into two smaller blocks, the
first
5 ending just before the target, and the second beginning with the target
(step 131).
Step 133 is eventually reached, and a determination is made as to whether the
block entry worklist is empty, i.e., whether there are more entries in the
block entry
worklist. If it is not empty, the process repeats back to step 103. If, on the
other
hand, the block entry worklist is empty, constant propagation is invoked at
step 135
to discover new code-locations. Finally, the process repeats back to step 103
until
completion.
Figs. 5-11 are now used to further demonstrate the various steps shown in the
flowchart of Fig. 4.
Fig. 5 illustrates step 101 of Fig. 4. Specifically, there is shown a
sequential
15 listing of executable program code 201, a block worklist (BV~ 301, a block
entry
worklist (BEVY 401 and a control flow diagram 501. Assume for the example of
Figs. 5-11 that there are two external entry points to the program. For
example, one
entry point might be used when the program is called up by a certain class of
user,
while the other entry point might be used when the program is called up by
some
20 other class of user, including another process. The known external entry
points are
designated as El and EZ and their locations are shown within the program code
201.
At the beginning of the analysis of the present invention, the remainder of
the code,
that is, everything except for the known entry points, is unknown code or data
203.
At this first step (step 101), the block worklist 301 is empty. The block
entry
25 worklist 401 is initialized by placing therein the known entry points, E,
and EZ. At
this time, the control flow graph SO1 simply has two nodes 503 corresponding
to the
two entry points E, and E2. The format of Fig. 5 is maintained for Figs. 6, 7,
8, 9
and 11, each of which builds on the previous figure.
Fig. 6 illustrates various steps of Fig. 4 which take place when a conditional
30 jump with a known target is encountered, and where both the jump's target
instruction and the fall-through instruction are new entry points.
CA 02353442 2001-06-O1
PCTNS99/29190
WO 00/34861
-9-
In particular, the first entry point in the worklist (E, from Fig. 5) is
selected
(step 103). The code following instruction El is scanned until a control flow
instruction is encountered (step 105). Here, a conditional jump 205 with a
known
target is encountered, defining a first known block, B,. According to step
107, this
5 newly discovered block B,, or actually a reference to it, is stored in the
block
worklist 301.
At step 109, a determination is made that the jump is conditional. The
instruction following the jump, now designated E3, is a new location (step
113) and
is added to the block entry worklist 401. Since entry point E3 is a descendant
of
10 block B,, E3 is listed in block B,'s descendant list in block B,'s block
worklist entry
303. Similarly, block B, is listed as a predecessor in entry E3's block entry
worklist
entry 403.
In this example, the target of the jump instruction 205 is also known and is
designated as E4. As above with E3, E4 is added to the block entry worklist by
15 adding a new entry 405. E4 is listed in block B,'s descendant list in block
B,'s block
worklist entry 303, and block B1 is listed as a predecessor in entry E4's
block entry
worklist entry 405.
Specifically, for illustration purposes, block B,'s worklist entry 303 is
shown
as B,()(E3, E4). The first set of parentheses indicates a list of predecessor
blocks,
20 while the second set of parentheses indicates a list of descendant blocks
or entry
points. Thus, B,()(E3, E4) is meant to indicate that known block B, has no
predecessor blocks, and has two descendant blocks which are yet undiscovered
but
whose entry points are known to be E3 and E4. Similarly, an entry in the block
entry
worklist 401 is designated as E3(B,) to indicate that entry point E3 has one
known
25 predecessor block, namely B,. The actual structure of the worklists and
sublists is
an implementation detail and various well-known methods can be employed. Note
that there are now three unknown areas 203 which may comprise code and/or
data.
The control flow graph 501 has been updated. Two new nodes 505 have been
added for the newly discovered entry points E3 and E4, with arrows 507
depicting the
30 flow of control. Since block B, is now known, its designation has replaced
that of
its entry point E, in node 503A.
CA 02353442 2001-06-O1
WO 00/34861
-10-
PCT/US99/29190
Fig. 7 illustrates additional steps of Fig. 4 which take place when a
conditional
jump with a known target is encountered. In this example, both the jump's
target
instruction and the fall-through instruction are known entry points.
The next entry point in the block entry list, Ez (from Fig. 6) is selected in
step
5 103 (Fig. 4). The code following instruction EZ is scanned until conditional
jump
207 with a known target is encountered, defining a new block, B2, which is
stored in
the block worklist 301. This new block BZ has no predecessor, because it is
external
entry point, but the two known entry points E3 and E4 are placed in its
descendant
list. Because the fall-through instruction E4 and target instruction E3 are
known, no
10 additional entries are made into the block entry list . However, the
existing entries
403, 405 are modified to include the new block B2 in their predecessor lists
(steps
117 and 127 respectively).
The control flow graph 501 represented by the block worklist 301 has again
been updated to show known flow.
15 Fig. 8 illustrates the steps of Fig. 4 which take place when an
unconditional
jump with a known target is encountered. Here, the target of the jump is an
internal
point within a known block.
The next entry point in the block entry list, E3 (from Fig. 7) is selected.
The
code following instruction E3 is scanned until unconditional jump 209 is
20 encountered, defining a new block B3, which is stored in the block worklist
301.
The predecessor list, i.e., (B,, BZ), is copied over to the new block worklist
entry
from the corresponding block entry worklist entry 403 for E3.
The target of the jump 209 is an address 211 located within a known block B2.
According to step 131, block B2 is thus split up into two blocks, BzA and B2B,
with
25 the target address 211 as the splitting point. The entry for B2 in the
block worklist
301 is replaced with two new entries, one for each of block BZA and BZB. Note
that
the first block B2A retains the predecessor information of the removed BZ
block and
has block B2B designated as a descendant. Note also that the second block B2B
has
both the first block BZA and the new block B3 listed as predecessor blocks,
while
30 retaining the descendant blocks or entry points (B3, E4) of the removed
block BZ.
Again, the control flow graph 501 has been updated to show flow as it is now
known.
CA 02353442 2001-06-O1
WO 00/34861 PCTNS99/29190
-11-
Fig. 9 illustrates the steps of Fig. 4 which take place when a jump with an
unknown target, for example, where the target is dependent upon a run-time
value
stored within a register, is encountered.
Here, the next entry point in the block entry list, E4 (from Fig. 8) is
selected.
The code following instruction E4 is scanned until a jump instruction 213 is
encountered, defining new block B4, which is stored in the block worklist 301,
with
its known predecessors B, and BZB.
Now, in this example the jump instruction 213 is a "JMP Rl" instruction,
which means control should flow to the address indicated by the contents of
register
10 R1. However, the contents of register R1 cannot be known until the code is
actually
executed. Furthermore, when jump instruction 213 is executed at different
times,
the contents of register R1 could be different. For example, the control flow
graph
501 now illustrates the control flow of the program as it is currently known.
The
program control could have flowed into block B4 several different ways.
Working
15 backwards from block B4, either by visually inspecting the control flow
graph 501,
or by using (as the present invention does) the block worklist 301, it is seen
that B~
is a predecessor to B4, as is B2B. Furthermore, blocks BZA and B3 are
predecessors to
block B4.
Looking at the code itself 201, block B, contains an instruction "MV Rl,
20 5000" which copies the value "5000" into register R1. Block B3 contains a
system
call which fills register R2 with some value. Block B2A contains an
instruction "MV
R2, 3000" which copies the value "3000" into register R2. Finally, block BZB
contains two instructions "MV R3, 8000" and "ADD Rl, R2, R3", which copy the
the value "8000" into register R3 and then add the values contained in
registers R2
25 and R3, leaving the sum in register Rl .
Fig. 10 illustrates again the control flow graph SO1 of Fig. 9, with the
associated instructions described above next to the corresponding nodes.
Control
flow is followed backwards along three different paths until all possible
values of
register Rl can be determined. For example, by propagating backwards from
block
30 B4 to block B~ along Pathl, it is seen that Rl will always contain the
value "5000"
when this path is taken. Thus, when Pathl is taken, Rl will contain "5000" and
the
CA 02353442 2001-06-O1
WO 00/34861 PCTNS99/29190
-12-
jump instruction 213 will virtually become "JMP 5000". Therefore, the address
5000 becomes a target of the jump instruction 213.
Similarly, propagating backwards along Path2 to block B2B, it is seen that the
value of register Rl is set in block BZB to the sum of registers R2 and R3.
While
5 register R3 is set to the value "8000" in the same block BZB, the value of
register R2
is still unknown. Therefore, the analysis must propagate further back.
One possible path is Path3 to block BZA. Here, it is seen that RZ is set to
the
value "3000". Plugging this value into the ADD instruction of block B2B, it
can be
seen that register R1 will ultimately hold the value R2 + R3 = 3000 + 8000
=11000.
10 Thus, when Path2/Path3, or simply Path2/3, is taken, Rl will contain
"11000" and
the jump instruction 213 is virtually "JMP 11000". Therefore, the address
11000 is
a second target of the jump instruction 213.
Another possible path from block B2B is along Path4 to block B3, which is seen
to contain a system call which fills register R2 with some value. Here, a
preferred
15 embodiment of the present invention may have a priori knowledge of the
specific
operating system, or of the run-time system specific to the language or the
compiler
used to generate the program, or may determine a likely value by using
heuristics, or
may use profile information, i.e., information obtained during one or more
previous
executions of the program. The run-time system includes, for example, a set of
20 library routines linked in by the compiler.
For example, assume that the preferred embodiment knows that this particular
system call always returns the value "2000", for instance. This value is then
propagated forward to block B2B where it is added to "8000", the contents of
register
R3. Thus, when Path2/Path4, or simply Path2/4, is taken, Rl will contain 2000
+
25 8000 = 10000, which is then a third target of the jump instruction 213.
This technique of walking backwards through the control flow graph, fording
constant values, and propagating them forward is called constant propagation,
and is
used by the present invention to discover all possible control-flow paths.
Without
constant propagation, other analyses, such as register usage, will produce
incorrect
30 results. If constant propagation cannot exactly determine the target, then
a safe
approximation must be made, using heuristics or a prior knowledge of system
calls,
as described above.
CA 02353442 2001-06-O1
PCTNS99/29190
-13-
Up to a point, it is sufficient to "discover" some paths that cannot in fact
be
followed, since this will make subsequent analyses more conservative, but not
incorrect. It is important not to confuse code and data however. If, by
mistake,
some data is thought to be a possible jump target and hence to be
instructions, then it
5 is possible that subsequent operations, such as inserting new code and
modifying
displacements, will disturb the data.
Fig. 11 illustrates the result of the constant propagation employed in step
135
of Fig. 4 and just described. Here, the first target address, 5000 is an
internal point
within a known block B4. Therefore, block B4 is split into two smaller blocks
B4A
and B4B just as block B2 was split earlier.
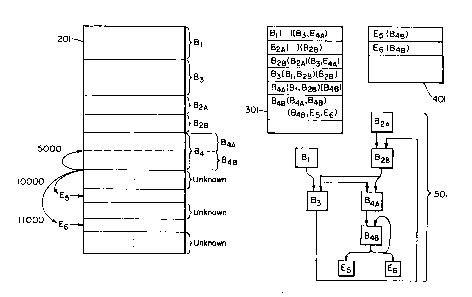
Addresses 10000 and 11000, on the other hand, represent new entry points ES
and E6, which are added to the block entry worklist 401, each having block B4H
listed
as a predecessor block. The representative control flow graph 501 is updated
to
reflect the new information.
15 The constant propagation algorithm must "decorate", or fill, every variable
with every known possible value for that variable. As seen in the flowchart of
Fig.
4, the analyzer then reverts back to normal control flow analysis (step 103),
using
the new entry points ES and E6 contained in the block entry worklist 401.
This process of repeatedly going back and forth between control flow analysis
and constant propagation continues until the full analysis is complete.
When this algorithm is complete, not only do we have a full control-flow
graph 501, detailing all possible paths between blocks of instructions, but we
have
also determined which code is live, or reachable from an external entry point.
Code
that is not live is called dead, and cannot be executed regardless of the
program
input.
With knowledge of the control-flow graph, the program can be safely altered
or patched by modifying jump and branch targets appropriately. As an extra
precaution, protective instructions can be added to dead code to indicate or
prevent
execution of the dead code. Such protective instructions include, for example,
tracing instructions, such as a print statements, or blocking instructions,
such as a
halt instructions.
CA 02353442 2001-06-O1
WO 00/34861 PCT/US99/29190
-14-
While this invention has been particularly shown and described with
references to preferred embodiments thereof, it will be understood by those
skilled
in the art that various changes in form and details may be made therein
without
departing from the spirit and scope of the invention as defined by the
appended
claims.