Note: Descriptions are shown in the official language in which they were submitted.
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
PERSONALIZED METABROWSER
CROSS-REFERENCE TO RELATED APPLICATIONS
The following patent claims the benefit of a Provisional
U.S. Patent Application Serial No. 60/137,302, entitled
"Information for Personalized Browsing/Intelligent Agent
Software, which was filed on June 3, 1999 and is incorporated
herein by reference.
BACKGROUND OF THE INVENTION
Field of the Invention
The present invention relates to the presentation of data
retrieved from the Internet, and more specifically to building
a~'presentation template for presenting various data segments of
multiple Internet documents dynamically on a display screen.
Description of the Background of the Invention
The onset of Internet technology has made it possible for
users of computing devices connected to the Internet to access
vast and ever-increasing sources of information. However,
despite the wide availability and volume of such information,
the means of bringing diverse elements of such information
together in real-time for the purpose of displaying them on a
single presentation page or screen is still evolving.
Commercially available programs designed for retrieving
1
CA 02375988 2001-11-30
WO 00/75812 PCT/LTS00/14665
and displaying Internet documents are called browsers.
Examples include Microsoft Internet ExplorerTM and Netscape
NavigatorTM. Browsers download and display Internet documents,
which may be found in hyper-text markup language (HTML) or
embedded extensible markup language (XML) format, one document
at a time. These documents may be retrieved from Internet-
connected devices, called Internet sites, which are assigned
discrete Uniform Resource Locator (URL) addresses.
Where a single browser is employed, two separate documents
may be viewed by requesting, retrieving, and viewing a first
document, followed by the request, retrieval, and viewing of
the second document. However, the first retrieved document
will be lost from view when the second is viewed, although BACK
and FORWARD browser navigation commands may allow fast re-
presentation of a previously retrieved (and now lost to view)
document. This problem can be somewhat alleviated by using
more than one copy of a browser. Where multiple copies of a
browser are employed, multiple separate documents may be viewed
by requesting each copy of the browser being used to retrieve
and display a separate document. In the windowing environment
of most current operating systems, e.g., WindowsNTTM, multiple
documents retrieved by individual browsers may be viewed
simultaneously, side by side, or in whatever manner the user
chooses to arrange the viewable windows.
To facilitate solutions to problems of simultaneous
retrieval of a plurality of Internet documents, intelligent
agent software may also be used. Intelligent agent software,
shown in Figure 1, is used to perform a wide variety of
activities on the Internet, including an assortment of
computing tasks such as searching, evaluating, reconfiguring,
and filtering of documents. Intelligent agent software may act
2
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
autonomously on behalf of users, and may sense the state of
their computing environment, adapt to changes, and perform
intended activities according to predefined and learned
parameters.
When mufti-tasking intelligent agent software is used to
download Internet documents, it may automatically load a
plurality of predetermined documents from a variety of Internet
sites to the user's desktop at one time. This mufti-tasking
ability allows intelligent agent software to create a "personal
portal" on the user's device, which may facilitate finding,
qualifying, comparing, and procuring products and services
online.
The one issue that intelligent agent software does not
address or resolve, is the arrangement and presentation of the
aggregated content to the user on a single display page.
Products currently available to search and display multiple
Internet documents include applications such as CatchTheWeb, a
description of which may be found at
http://www.catchtheweb.com/. CatchTheWeb's site describes the
application as follows:
"... an integrated development environment
for managing your page archive. You can
view the pages, re-organize their order,
remove them, change their titles, and
revise your notes about them."
Although programs such as CatchTheWeb may solve the
problem of collecting related information, the end product of
CatchTheWeb is a list of Internet documents (pages) which can
only be viewed one document at a time. The comprehensive
presentation of data of interest filtered and collected from
more than one page and displayed on a single page display is
not addressed by this product.
3
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
Presently, a need exists to customize the display of
retrieved Internet documents. Customized displays may include
a whole document, a part of the document, or just one data
segment presented in a document. A single data segment may be
static or it may be dynamically modified on a regular or
irregular basis by its host Internet site. For example, a
vacation resort may have an HTML/XML document that describes
the resort, its room availability and its prices. Another
related HTML/XML document may describe local amenities, i.e.,
restaurants, hotels, theaters, and recreation facilities near
the hotel. A different Internet document may include daily
weather reports for each city in the state where the target
vacation resort is located, including water and air
temperatures updated hourly.
Using today's browsing technology, an Internet user is
required to retrieve and view each of these documents
separately: the resort document, then the entertainment
document, followed by the weather document, although not
necessarily in that order. And, as noted above, viewing one
document may preclude viewing another at the same time.
Additionally, users interested only in the resort's weather
would be required to retrieve and display the entire HTML/XML
document containing that information, an inconvenient process
when only one element of the page on which such information
appears is desired.
Therefore, what is needed is a mechanism to retrieve
multiple HTML/XML documents located in a variety of separate
URL locations, select the information from them in which the
user is interested, and display that information all at once on
a pre-formatted presentation document, according to
4
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
instructions found in a presentation template, and all on a
single page. Furthermore, the size (in bits) of the
presentation template must be minimal so that the aggregated
content may be displayed on Internet connected devices of
various capacities.
SUMMARY OF THE INVENTION
The present invention allows a user of an Internet
connected device to build presentation templates for the
display of data segments from multiple documents. These
documents may be retrieved by browsers or intelligent agent
software.
All requested documents are gathered and parsed into nodes
containing data segments. These documents are then displayed
showing selectable data segments separated by lines. The user
peruses and selects wanted data segments. A display re-
presentation is then built by arranging selected data segments
in appropriate windows of the display re-presentation.
Display re-presentations may also be constructed from a
prefabricated set of display re-presentations and multi-media
presentation metaphors. To complete the formation, the
following data for all selected data segments may be stored in
the presentation template:
1. the address of the document, e.g., the URL;
2. the location of each data segment within its parent
document, as described by counting "begin" and "end" tags from
the start of the document;
3. the size of the display re-presentation and the
arrangement location of each data segment within the display
re-presentation; and
4. attribute information for each data segment.
5
CA 02375988 2001-11-30
WO 00/75812 PCT/LTS00/14665
After completion, the presentation template may comprise
instructions for making Internet requests for target Internet
documents, intelligently selecting data segments from these
Internet documents, and presenting these data segments in an
organized fashion to a viewer.
Upon being employed by a presentation segment of the
inventive software, at a user's request or on a scheduled
basis, the presentation template may provide instructions to
retrieve specific documents, translate exact content locations
of these documents, and display these contents in specified
formats. The user pre-configured presentation template allows
for real-time retrieval and selection of multiple data segments
from multiple Internet sites and other sources, locally or via
the Internet. The presentation template may be used for
execution by the inventive application or may be executed by
any off-the-shelf browser.
BRIEF DESCRIPTION OF DRAWINGS
The foregoing objects and advantages of the present
invention may be more readily understood by one skilled in the
art with reference being had to the following detailed
description of a preferred embodiment thereof, taken in
conjunction with the accompanying drawings wherein like
elements are designated by identical reference numerals
throughout the several views, and in which:
Figure la is a pictorial representation of the environment
in which the inventive software creates a "personal portal" for
accessing a plurality of documents.
6
CA 02375988 2001-11-30
WO 00/75812 PCT/L1S00/14665
Figure 1b is a diagram of a computer system used for
implementing the present invention.
Figure 2 is a sample retrieved document.
Figure 3 represents the data of the document shown in
Figure 2.
Figure 4 is a flowchart of an inventive process for
retrieving and parsing documents and for building a
presentation template.
Figure 5 is a flowchart of an inventive process for
parsing individual retrieved documents.
Figure 6a shows the document data of Figure 3 after it has
been parsed by the parsing process of Figure 4.
Figure 6b is an illustration of an object tree constructed
in accordance with the document 20 as shown in Figure 2.
Figures 7a-d are samples of retrieved document of Figure
2, displaying separated, selectable data segments.
Figure 8a is an user interface view combining component
programs of the invention and a document display.
Figure 8b is an user interface view for building the
presentation template.
Figure 9a is a flowchart of an inventive process for
building the inventive presentation template.
7
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
Figures 9b and c represent a data file or a blueprint for
storing pointers to data segments.
Figure 10a is a diagram of a computer system used for
displaying the presentation template of the present invention.
Figure lOb is a flowchart of an inventive process for
displaying the inventive presentation template.
Figure 11 is a flowchart of an inventive process for
translating and displaying retrieved selected Internet
documents according to the inventive presentation template.
Figure 12 is a flowchart of an inventive error checking
process.
Figure 13 is a display of rearranged data segments from
the document of Figure 8a.
DETAILED DESCRIPTION OF A PREFERRED EMBODIMENT OF THE INVENTION
Referring now to the drawings and in particular to Figure
la, there is shown a network system 10, which comprises a
computer system 12 upon which the software of this invention is
executed, a plurality of Internet-connected devices or websites
14a-g,-a plurality of databases 16a and b, and a network 11 for
interconnecting the computer system 12 to each of the websites
14 and the databases 16. In one illustrative embodiment, the
present invention may be implemented over a network 11, such as
the Internet or intranet. Alternatively, a network may not be
necessary, where the data may be retrieved from a storage
device.
8
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
Where the network 11 takes the form of the Internet, the
computer system 12 may be engineered to work with existing
products built using interactive Internet (web) development
tools such as a common gateway interface (CGI) 18 using Perl
scripts, and an active server agent l8, which works with
documents written in Java and Java/Visual languages. Through
the use of these tools, the present invention may
simultaneously access and retrieve data from the plurality of
Internet or web sites 14a-g, as well as the Internet connected
databases 16a and b.
Referring now to Figure 1b, the details of the computer
system 12 are shown. In one illustrative embodiment of this
invention, the computer system 12 comprises a bus 1, which is
connected directly to each of a central processing unit (CPU)
2, a memory 3, a video interface 4, an input/output (I/O)
interface 6, and a communications interface 8. The common bus
1 is connected by the I/0 interface 6 to a storage device 7,
which. may illustratively take the form of memory gates, disks,
diskettes, compact disks(CD), digital video disks (DVD), etc.
The video interface 4 couples a display 5 to the common bus 1.
The communications interface 8, e.g., a modem, is coupled to
an Internet connection 9, e.g., an Internet Service Provider
(ISP), which in turn is connected to the network 11, whereby a
data path is provided between the network 11 and the computer
system 12 and, in particular, its common bus 1.
The computer system 12, as shown in Figures 1 a and b,
operates in the context of this invention to transmit requests
via the network 11 to selected websites 14 to access and
download therefrom data, which represent a document 20 as
illustrated in Figure 2. The document 20 is transferred to the
9
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
computer system 12, where it is processed one data element at a
time and displayed on the display 5 as the document 20 shown in
Figure 2. The downloaded document data as processed corresponds
to the text shown in Figure 2, i.e., "Our rates and prices:" as
well as the rest of the illustrated text. In addition, the
document data also includes a collection of embedded codes that
explain the meaning or desired formatting for the marked text.
The embedded codes include instructions or commands, which
control what the document will look like and/or where it will
be positioned within the document 20. Though the markup
language illustratively shown herein is the well-known Hyper
Text and Extensible Markup Languages (HTML or XML), it is
appreciated that there are other such delimited formats, e.g.,
"Acrobat" or "WordPerfect", which may be employed in this
invention. It is appreciated that only the marked up text, but
not the markup language itself, will appear in the displayed
document 20 of Figure 2.
The document data transmitted over the network 11 from a
selected website 14 is comprised of the data text shown in
Figure 2 and the embedded codes for imparting the arrangement
of that text as shown in Figure 2. Physical arrangement of the
document data is re-arranged in Figure 3 to illustrate how the
embedded codes delimit data containers, and how those data
containers are nested at different levels within the document
data.
As~will be explained below, the data containers are
assigned various numbers. As also shown in Figure 3, each of
the plurality of data containers comprises the content that is
identified by the numeral 24, and a pair of embedded codes,
known in computer terminology as "tags" or "tokens" 22 and 26.
These tags 22 and 26 are disposed on either side of their data
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
content 24 and are respectively known as "begin" tags 22 and
"end" tags 36, respectively. The begin tags 22 and the end tags
26 are both constructed of closed brackets "< >", but differ
from each other in that only the end tags 26 include a "/". In
one embodiment of this invention, the data container is
identified by the numeral 32a and enclosed by a rectangularly
shaped block to readily recognize the data container 32a. The
begin tag 22 "<H1>" and the end tag 26 "</H1>" are disposed in
the data container 32a directly on either side of the data text
24, "Our rates and prices". Contrast this configuration of
data container 32a with that of container 32b, where the begin
tag 22 <TABLE> and the end tag 24 </TABLE> are surrounded by
the rectangularly shaped box 34b; the begin tag 22 and the end
tag 26 are displaced from each other and serve to delimit the
data content 24 contained in the box 32d. Though the data
content 24 has been described in terms of text and shown in
Figure 2 as such, it is appreciated that such content may
comprise video data, images and/or links to other websites 14
that are connected to the network 11.
The boxes shown in Figure 3 illustrate the nesting of the
data containers with respect to each other and at a plurality
of levels. Figure 3 shows an illustrative embodiment of this
invention in which the nesting of the data containers occurs at
6 levels. The container segments 32a and 32b, which are
identified by the rectangular boxes identified by these
numerals, are the data containers at the highest level of the
nested structure shown in Figure 3; this highest level is also
known as level 1. There are no containers nested within the
data container 32a. However, there are a number of data
containers nested within the container 32b; in particular,
there are 3 data containers 34a, 34b and 34c, which are all
level 2 containers and are nested within the level 1 container
11
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
32b. Further, there are 2 level 3 data containers 40a and 40b
which are nested within the level 2 data container 34b. In
turn, there is 1 level 4 container 42, which is nested within
the level 3 container 40 b. Still further, there are 3 level 5
containers 44a, 44b and 44c, which are nested within the level
container 42. Finally in this illustrative embodiment, there
are 2 level 6 containers 46a and 46b, which are nested within
the level 5 container 44a.
As will be explained below, the document 20 (Figure 2),
which is downloaded from one of the websites 14 (Figure la), is
subdivided or parsed into a plurality of data segments, which
are identified by the numerals 132a and 132b as shown in Figure
7a. The parsing routine parses the nested data elements 32a-b,
34a-c, 42, 44a-c, etc., by identifying and counting the number
of begin tags 22 and end tags 26 within the document 20 to
determine the relative location of each of the data containers
within the document page 20. This identify and count operation
may be performed on the entire document 20 until all nested
data containers 32a-b, 34a-c, 42, 44a-c, etc. within that
document 20 have been identified and located.
The begin tag 22 and end 26 tag for each data container
may also be marked with other types of codes known as content
attributes that determine for example the graphics, the manner
of text display, the structure of the text as a table, etc.
Container relationships similar to those described above
may also be found in most existing documents created by
programs like Microsoft WordTM, Microsoft ExcelT~', Microsoft
PowerpointTM, Lotus NotesTM, WordPerfectTM, Adobe AcrobatTM,
etc., as well as existing database programs. As long as the
document data are delimited according to some defined rules,
12
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
the present invention may be used to subdivide or parse the
document 20 (Figure 2) into typically smaller data structures
which are termed herein data segments. Capitalizing on the
fact that interactive Internet software services produce
S documents organized in the container fashion, e.g., in HTML/XML
format, the present invention may interpret the organization of
data elements in these documents and may reorganize data
elements dynamically at a graphical interface level for
viewing.
Figure 4 shows the steps of the information retrieving and
parsing operations of this invention. At step 60, the URL
addresses for the websites 14 (Figure la), where document 20
(Figure 2) of potential interest may be found, are retrieved to
the computer system 12 (Figure la). The addresses may be
provided manually one at a time or automatically in a canned
file. Additionally, since some computer systems 12 (Fig. la)
may be located behind Internet firewalls, an HTTP proxy may be
used. For this reason, the inventive application may have the
ability to configure such a proxy, so that all Internet
activity may proceed through that proxy.
A determination is made at step 62, whether all of
the needed data have been found. If retrieved documents 20
(Figure 2) do not contain the needed data segments, the process
returns to step 60 for further document retrieval. If the
documents 20 of interest have been found, the parsing of the
retrieved documents commences at step 64 as shown in Figure 4.
The detailed steps of parsing will be explained below with
respect to Figure 5. Basically, step 60 parses or subdivides
the selected document 20 (Figure 2) into a plurality data
segments 132a-b (Figure 7a). The number of the data segments
may be increased as needed by the user (Figures 7b, 7c and 7d).
13
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
After selecting the desired degree of granularity, the user in
step 66 selects which data segments of the displayed document
20 (Figure 2) contain the data of interest and then saves a
pointer to that segment so that its data may be retrieved
later. In step 68, the user indicates whether there are
further data segments to be identified either from the same
website or perhaps another. If further data segments are to be
identified, the process returns to step 60 and the document
selection and parsing in steps 60, 62 and 64 are repeated until
l0 all of the desired data segments have been identified. If all
the necessary data segments have been identified in step 68,
the user saves the pointers or addresses to each of the
selected data segments.
The detailed steps of the parsing process 64 (Figure 4)
will now be explained in detail with respect to-Figure 5.
Initially at step 70, data representing the document 20 (Figure
2) as retrieved from its website 14 (Figure 1a) is downloaded
to the computer system 12 (Figure la). The document data, as
explained above, is a sequence of data elements, some of which
are data content and others are embedded codes, and is shown in
Figure 3 in a manner to illustrate the nesting structure of the
data containers. At step 72, each data element is examined and
the begin tags 22 and the end tags 26 are saved, while all
other data content elements are discarded. The output of step
73 is illustrated in Figure 6a to show the sequence of the
begin tags 22 and the end tags 26, where all data content 24
have been removed.
Each tag of this output is examined in Step 74 to
determine whether the tag is a begin tag 22 and, if so, a node
A and a corresponding branch of an object tree 89 is
constructed as shown in Figure 6b for each begin tag 22 that is
14
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
so identified. The object tree 89 has a single root node that
is identified as A1, where the building process begins. Next,
step 78 extracts the data type from the begin tag 22 and, in
step 80, applies a label to the node A that identifies the data
type of that begin tag 22, i.e., whether it is an image, text,
etc. tag. Thereafter the process returns to step 73 to examine
the next data element.
If step 74 determines that the tag is an end tag 26, i.e.,
it is not a begin tag 22, step 86 determines whether the
detected end tag 26 is the final end tag in the document 20
(Figure 2). As shown in Figure 3, the final end tag 26 is the
</TR> tag at the bottom of the Figure 3, which marks the end of
the document data that represents the page document 20 (Figure
2). If such a final end tag 26 is identified, step 88
terminates the construction of the object tree 89 (Figure 6b).
If step 86 decides that the end tag 26 is not the final end
tag, step 82 traverses the object tree 89 one level or branch
back towards the root node A1. There is only one path from any
node A to the root node A1 for the tree constructing process to
return to the root node A1. After traversing back up the tree
89, the process returns to step 73 to examine the next data
element. This parsing process 64 is repeated through steps 71
- 88, until each data element of the document data has been
examined and step 88 has identified the final end tag 26. The
final structure of the tree 89 that corresponds to the document
20 (Figure 2) is shown in Figure 6b.
Referring now to Figures 6a and b, the object tree
constructing process 64 begins at the root node Al and
initially detects the first begin tag <H1> 22 of the data
container 32a, whereby the first branch connecting the root
node A1 to node A2 is added to the tree 89. Next, the process
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
64 detects the closing node </H1> 26 of the data container 32a
and moves back up the tree 89 from node A2 backwards to the
root node A1. Constructing is carried out such that when a
begin node 22 is detected, the process moves away from the root
node A1 and backwards toward the root node A1 when an end tag
26 is, detected. The process 64 next detects the first begin
tag <TABLE> 22 of the next data container 32b and constructs a
branch leading to a node A3. The begin node <TR> 22 of the
data container 34a is detected next, whereby the branch to node
A4 is constructed. Next, the first opening node <TH align =
left> 22 of the nested data container 36a is detected, and the
branch to node A7 is constructed. Next, the closing tag </TH>
26 of the data container 36a is detected and the constructing
process moves back toward the root node A1 to node A4. Next
the begin tag <TD> 22 of the data container 36b is detected,
whereby a branch to node A8 is added. Next, the end tag </TD>
26 of the data container 36b is detected, whereby the process
moves backward to node A4. Next, the end tag <TR> 26 of the
data container 34a is detected, and the process moves backward
to the node A3.
The tree building process 64 continues in this manner
until the process has constructed all of the nodes Al - A19 and
the process 64 has returned to the root node Al, which occurs
when the final return node </TABLE> 26 of the document 20 has
been detected in step 88 of the process 64. As seen in Figure
6a, each data container may be identified by that node A, which
the process 64 constructed upon detection of the first begin
tag examined in that data container. The structure of the
object tree 89 identifies each connection between adjacent data
containers and the level of that data container in the nesting
structure. As will be explained below the relative position of
the first begin tag 22 of the data container 32b marks the
16
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
beginning of that data container and the structure of the
nested data containers as indicated by the object tree 89
dictate the placement of its end tag 26 and thus the end of the
data container 32a. Likewise, the beginning tag 22 of the
remaining data containers mark the beginning and end of their
respective data containers as identified by each of the nodes
A2 - A19 (Figure 6b). As will be explained below, the begin
tags 22 will be used to mark the beginning and end of each data
segment of a document 20, whereby the document 20 may be parsed
or subdivided.
An alternative to this comprehensive approach to parsing
may be a simple content stripping routine. Such a routine may
simply find a data content element 24 (Figure 3) included
between its begin tag 22 (Figure 3) and end tag 26 and strip
that data content. In other words, a copy of document data
without its data content but with all the tags 22, 26 (Figure
3) intact may be sufficient for the parsing process 64 (Figures
4 and 5) to examine and successfully parse. This approach
although acceptable is not as thorough and comprehensive as the
one described in conjunction with Figures 5, 6a and 6b, where
additional information is collected and used by sequentially
reading in and processing each element of document data.
Selection Of Data Segments
When all of the data containers 32a-b, 34a-c, 36a-b, 38a-
b, 40a-b, 42, 44a-c, 46a-b, 48a-b, SOa-b (Figure 6) of the
document 20 (Figure 2) are identified and parsed, the document
20 (Figure 7a-c) may be graphically displayed with each of
these nested data containers shown upon the display 5, whereby
the user may identify specific data of the downloaded document
data and the size or granularity of the data segment
encompassing the selected document data. The user may now
17
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
point, click, and drag any or all of selectable data segments
shown on the display 5 (Figure 1) to build a presentation
template. After choosing all of the needed data segments from
all of the parsed documents 20, the process configures a target
presentation template.
The document 20 shown in Figure 7a may be displayed on the
display 5 to the user with each of its data segment 132a-b
visually separated by lines 54a and b. These lines separate
and delineate the document 20 into data segments 132a-b, i.e.,
line 54b delineates the data segment 132a from the data segment
132b. The lines 54a and 54b are generated in accordance with
the respective position of the first begin tag <H1> 22 of the
data container 32a and the first begin tag <TABLE> 22 of the
date container 32b. It is also appreciated that the data
segments 132a and 132b display the same data content as their
related data containers 32a and 32b, respectively. Further as
seen in Figure 6a, the data segments 132a and 132b display data
from the same level of their data containers 32a and 32b,
namely level 1. The presentation of the document 20 may be
scrollable. Moreover, additional icons 56a may be superimposed
by the display 5 on a particular data segment to indicate, for
example, that the data segment 132b may be parsed or subdivided
into further data segments. This is achieved purposefully so
as not to inundate the user with the granularity of a display
which may be too small and unnecessary. If the user desires to
increase the granularity for example of data segment 132b, the
user merely clicks on the icon 56a to cause the document 20 to
be further divided, as shown in Figure 7b, into data segments
134a, 134b and 134c, which display content from the level 2
containers 34a, 34b and 34c. Similarly, the icon 56a may be
again clicked to further parse the document 20 as shown in
Figure 7c to further include the data segments 136a-b, 138a-b,
18
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
and 140a-b, which display data from the level 3 containers 36a-
b, 38a-b and 40a-b. If the icon 56a is again clicked, the
document 20 will be further subdivided to include as shown in
Figure 7d segments 146a-b, 148a-b and 150a-b, which display
data from the level 6 data containers 46a, 46b and 46c.
Additionally, where document data elements are found to
use embedded logic, frames, and pointers to other documents,
then those items may be activated, loaded and parsed as if they
all came from the same document data. This may be achieved
recursively until there is no more data to process.
For further discussion please consider, as shown in Figure
8a, document 90 having data segments 92 separated by lines 54.
The document 90 is presented as a window in the inventive user
interface 94, which may be shown on display 5 (Figure 1). By a
selection of a menu 96 of icons 98, a user may control which
operations are called into service. For example, the user may
click on any of an icon 100 to initiate the retrieving and
parsing .operations 60 and 64 described above, an icon 102 to
initiate the compiling and building functions as will be
described, and an icon 104 to initiate the distributing and
opening of completed presentation templates as will be
described, and an icon 106 to call the displaying and
translating operations as will be described. All component
parts of the invention may be included within the user
interface 94, individually or in combination.
Presentation Template Builder
After the compiling/building 102, icon is activated
and all of the retrieved documents 20 have been parsed, each
user desired data segment 92 may be selected with a mouse or a
keyboard. Selecting the data segment places that data segment
19
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
and its related pointers, such as the address of the parent
document 20 and a list of the begin tags 22 and tags 26 (Figure
6) from the start of the document data 20 (Figure 3) to the
first begin tag 22 of the data segment comprising the data
container; these pointers are stored in the builder file and
may be displayed in a builder window 110 (Figure 8b).
The builder window 110 may be displayed within the user
interface 94. That window 110 comprises data segments 92a
selected from the document 90 (Figure 8a) and the segment 92b
selected from another document, not shown. Once data segments
are displayed in the builder window 110, they may be moved to
form a presentation template.
By activating the compile/build icon 102, the parsing step
- 64 (Figure 2) is initiated. A user may pre-select the size of
a presentation template array 112. Depending on how many data
segments 92a-b are expected to be displayed within the formed
presentation template. For example if the resultant
presentation template display will have four items, the
appropriate size of the presentation template array 112 may be
two boxes by two boxes. The presentation template array 112
shown in Figure 8b is four by four boxes and is able to
accommodate 16 data segments. The individual boxes of the
presentation template array 112 may dynamically change shape
and size to accommodate the required number of data segments
92a-b to be displayed therein. To build a presentation
template, the user may simply click on a selected one of the
data segments 92a-b and drag and drop the selected segment into
a desired presentation template array box 114. The letter
identifying the object 116 will appear in the presentation
template array box 114.
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
Figure 9a shows the progression of steps in the builder
process of the invention. After all of the desired data
objects are selected, step 120 selects the coordinate of each
data segment's coordinates from the object tree 89 generated by
the parsing process 64 (Figure 4). The data segment's
coordinates comprise a target website 14, e.g., the URL
address, and the path to the desired data segment in the object
tree 89. The path comprises all begin tags 22 and end tags 26
starting from the first begin tag 22 in the document 20 to the
begin tag of the selected data segment. Before this address
information is saved at step 128, it is stored in a holding
area in step 122, and the user ascertains that no rearrangement
of the data segments is necessary at step 124. Otherwise data
segments are rearranged at step 126 and the user acceptance is
again sought at step 124.
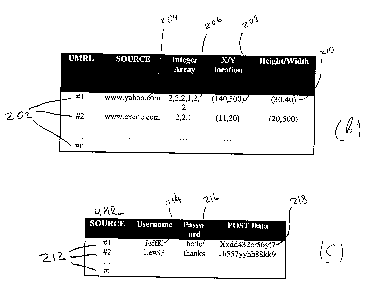
Pointers to data segments are saved in one illustrative
embodiment of this invention as a set or collection of records
called Uniform Micro Resource Locators (UMRL). As shown in
Figure 9b, each pointer or UMRL 202 may contain elements listed
below.
1) An address 204, such as the URL address for the website
14 (Figure la) where the document 20 (Figure 20) may be
found.
2) An array or a string of integers 206, each integer
referring to a unique container at each level in the object
tree, described above in conjunction with Figure 6b. In the
object tree shown in Figure 6b, containers are labeled at
each branch from left to right with integers 1 A2, A4, A7,
A9, A11, A14, A16, A18, 2 A3, A5, A8, A10, A12, A15, A17,
A19, and 3 A6. Higher integers may be used where more
container branches exist. The container A19 in the lower
21
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
right hand corner of the object tree 89 may be addressed
with the set of integers (2 A3, 2 A5, 2 A10, 1 A13, 2 A15,
and 2 A19 ) .
3) Screen display coordinates 208 (Figure 9b) for
displaying the data segment. In one embodiment of the
present invention these coordinates may be specified with X,
Y coordinates, for example a screen column number for the X
axis coordinate and a screen row number for the Y axis
coordinate. In a different embodiment of the present
invention these coordinates may be specified with the
location and size of the data segment as it may appear on a
computer screen, these coordinate having been defined when
the data segment was positioned in the presentation template
array 112 (Figure 8b), where the location may be represented
by coordinates (1,1) of the cell 114 (Figure 8b) within the
array 112 (Figure 8b).
4) The height and width attributes 210 (Figure 9b) of the
data segment, attributes may be these retrieved during
parsing of the document 20 (Figure 2) or user defined.
Optional authentication information may be necessary for
accessing password protected documents requiring user
authentication. As shown in Figure 9c, if an authentication
method is used at a particular document associated with an UMRL
212, then information comprising of a username 214 and password
216 pair is saved as supplementary data fields. If the
authentication method used requires a POST request, a command
that may be given to a computer system so that it returns a
particular input form to be filled out by the requestor, then
information required to submit the POST request to authenticate
the user at the host 218 may also be stored.
22
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
This completes the description of the construction of the
presentation template data file. The resulting data file may
now be delivered by any means available, i.e., a diskette, e-
mail, Internet download, etc. to any intended user and loaded
into the user's device. To execute the presentation template
data file a user's device 220, as shown in Figure 10a, may
comprise a bus 221 which is connected directly to each of a CPU
222, a memory 223, a video interface 226, and a communications
interface 228. No additional storage, e.g., a disk storage 7
(Figure 1b), is required; therefore the invention may be
utilized on devices such as digital phones, palm top devices,
personal digital assistant (PDA) devices, and digital
television's set top boxes, among others. Proxy services may
be utilized for smaller digital appliances to facilitate the
implementation of the invention.
Presentation Template Display
Figure lOb shows the process for displaying the
presentation template formed according to this invention. At
step 130, the presentation template or blueprint is loaded and
individual data segments are extracted. At step 132, all
information associated with each data segment is fed into the
translator routine until all data segments are translated.
Then at step 134, a dynamic view designed with the help of the
builder section of the invention, where the presentation
template array was constructed, is filled in with all of the
found arid retrieved data segments. The filled-in presentation
template document is then displayed to the user, after which
the process terminates at step 136.
The detailed steps of the translator process 132 are shown
at Figure 11. There at step 152, the URL address of the
23
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
website 14 from which the document 20 and data segment's
relative location in the parsed tree 89 is accepted. At step
154, the data segment's parent document 20 is retrieved,
followed by a determination by an error routine at step 156 of
whether the retrieved data segment is valid, non-existent, or
whether different unrelated information now occupies the
selected data segment's location in the retrieved parent
document 20. If it is determined that the retrieved data
segment is not the intended data, an error message is generated
at step 158 and the erroneous data segment will not be
displayed. If step 160 determines that the data segment is
valid, then step 160 retrieves its data in accordance with
saved data segment attributes.
The error checking step 156 may be performed for each data
segment individually, or the validity of all data segments of a
loaded presentation template may be examined at the same time.
The routine shown in Figure 12 may load data segments'
addresses into a buffer or a set of registers at step 162. An
iterative loop may be initialized at step 164, and each data
segment may be processed one at a time until all of the data
segments have been examined and the process returns to routine
132 (Figure 11) at step 174. At step 166 a determination is
made as to whether the requested document 20 still exists at a
given website 14, which matches the URL saved by the
presentation template. If it does not, the requested data
segment is no longer valid. In such a case, step 168 generates
an error message and the process returns to the translator
routine 132 (Figure 11).
On the other hand if the requested document is found, the
document is read in at step 170 and its contents are parsed in
the same manner described above in connection with Figure 5 at
24
CA 02375988 2001-11-30
WO 00/75812 PCT/LTS00/14665
step 172. Furthermore at step 172, the newly calculated object
tree 89 and those trees saved in the presentation template are
compared. If the tree structures match, the data segments are
accepted as valid, and the process returns to the top of the
loop at step 164 to continue checking addresses until all data
segments are tested. If however the tree structures 89 do not
match, the data segment is no longer deemed valid. In such
case, step 168 generates an error message and the process
returns to routine 132 (Figure 11). In a further embodiment of
this invention, it is contemplated that the comparison software
may be able to detect whether a newly generated tree that
differs from the stored tree may nevertheless by acceptable
dependent on the nature and degree of the differences of these
tree structures.
When the display process of Figure lOb is started, a list
of available presentation templates may be displayed to the
user, who may be asked to chose from among these presentation
templates. The name of each presentation template may be the
same name that was given when the presentation template was
created and saved. Clicking on any one presentation template
may cause the inventive application to load the presentation
template into memory and to begin retrieving and parsing these
documents. After all of the documents referenced in the
presentation template are retrieved and parsed, selected data
segments from each of these documents may be copied and
displayed at coordinates and with attributes described in the
presentation template. The displayed content itself is not
saved in the presentation template of this invention, rather
the data content is retrieved from the websites on as needed
basis which allows for any content updates to be reflected.
Figure 13 shows a presentation template display 180 which
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
is a display of rearranged data found in the document 90
(Figure 8a).
Time Slicing
Another embodiment of the present invention may include a
time slicing feature. This feature may be used with data
segments as described above, as well as with video broadcast
content. With time slicing, a plurality of data segments 92a-b
(Figure 8b) are entered into each presentation template box 114
(Figure 8b). Utilizing simple programming techniques, each
entered data segment may be displayed for a certain time
duration in a round robin or any other order according to the
user's preferences. Time slicing for video broadcast content
may be performed by substituting begin tags with start time and
end tags with end times and by displaying the video segments
accordingly.
Uses
The present invention may be used to customize and to
individualize presentations and functionality of information
services available through the public networks and subscription
based network services such as cable television. Specifically,
these applications may include empowering stock brokers, real
estate agents, travel agents, and other info-media based
businesses to build presentation templates for their customers
throughout the customer care continuum, i.e., the find-it,
qualify-it, compare-it, shop-it, buy-it, deliver-it and
service-it stages of the purchasing process.
Consumer applications may allow consumers to build virtual
compilations of information such as the presentation templates
described above to share with other consumers thus creating a
community aspect of information sharing. An example of this
26
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
may be enabling users to aggregate a virtual CD by assembling
links and song titles of MP3 files on the Internet. The chosen
song titles are stored in the presentation template together
with a metaphoric CD player. Such a template may be sent to a
receiving party, who may then view the aggregated song links
and then download and play the intended audio segments from
their Internet-connected devices or offload the presentation
template to a MP3 player for later playback.
Presentation template files may contain username/password
pairs for securing presentation templates from unauthorized
use. These user names and passwords should be saved in the
presentation templates in an encrypted format. When the
presentation template is saved, the user may be asked for a
password. This password may be used to generate the Triple
Data Encryption Standard (DES) key that is used for encryption
and must be remembered for the time when presentation templates
are reloaded in the future. If the Dresentat;nn tAmr,W tc ;c
sent to another user, then the password must also be provided
to that person. The user may also have the option of saving an
unencrypted presentation template so that no password may be
required.
Additionally, some Internet and non-Internet documents may
be secured with a user name/password pair. To address such a
documents either a hyper text transport protocol (http)
authentication or a custom mechanism that utilizes Point of
Sales Terminal (POST) requests from the user's browser may be
used. In either situation, the user must provide needed user
names and passwords to be stored with the presentation
template.
While the invention has been particularly shown and
27
CA 02375988 2001-11-30
WO 00/75812 PCT/US00/14665
described with respect to illustrative and preferred
embodiments thereof, it will be understood by those skilled in
the art that the foregoing and other changes in form and
details may be made therein without departing from the spirit
and scope of the invention that should be limited only by the
scope of the appended claims.
28