Note: Descriptions are shown in the official language in which they were submitted.
CA 02421673 2003-03-11
1
TITLE OF THE INVENTION
CHARACTER RECOGNITION SYSTEM AND METHOD
FIELD OF THE INVENTION
The present invention relates to character and pattern
recognition systems and methods.
BACKGROUND OF THE INVENTION
Most of known optical character recognition (OCR) methods
start with a pre segmentation stage in which part of a digitized document
is first segmented (isolated) into individual symbols, words and/or
characters, followed by a character recognition step to translate these
symbols, words and/or characters into pre-determined computer-readable
entities.
A template-based Optical Character Recognition (OCR)
method which does not require pre-segmentation has been suggested by
Levin et al. in the International Application No.'W093/18483 published on
September 16, 1993, and entitled "Method and Apparatus for Image
Recognition". A drawback of this method is that it has difficulty recognizing
patterns because of intra-class variability of the patterns.
As it is well-known in the art, each character which needs to
be recognized is considered to be a different class.
CA 02421673 2003-03-11
2
The recognition of a character includes the characterization
of their features or patterns. While there are generally different views on
the definition of the features of patterns, many studies made on the
recognition of characters as well as on the recognition of patterns have
shown that the so-called quasi-topological features of a character or
pattern such as the concavity, loop, and connectivity are key features for
the recognition. To date, many different methods have been proposed for
the purpose of extracting such features. For example, some of these
methods use analysis of the progressive slopes of the black pixels.
On-line handwriting recognition systems have been designed
which compute feature vectors as functions of time. An example of such
systems is described in T. Starner, J. Makhoul, R. Schwartz and G. Chou;
'°On-Line Cursive hiandwriting Recognition Using Speech Recognition
Methods; IEEE International Conference on Acoustics, Speech, and
Signal Processing, Adelaide, Australia, Apr. 19-22, 1994, Vol. V. pp. 125-
128. However, on-line handwriting recognitions systems are not suitable
for OCR applications since these applications are faced with the problem
of recognizing a whole page of text which presents a two-dimensional
problem for which there is no obvious way of defining a feature vector as a
function of one independent variable.
United States Patent No. 5,727,130, issued to Hung on
March 10, 1998 and entitled "Genetic Algorithm For Constructing And
Tuning Logic System" describes the use of a fuzzy logic system for OCR.
"Fuzzy Logic" was developed to enable data processors
based on binary logic to provide an answer between "yes" and "no." Fuzzy
CA 02421673 2003-03-11
3
logic is a logic system which has membership functions with fuzzy
boundaries. Membership functions translate subjective expressions, such
as "temperature is warm," into a value which typical data processors can
recognize. A label such as "warm" is used to identify a range of input
values whose boundaries are not points at which the label is true on one
side and false on the other side. Rather, in a system which implements
fuzzy logic, the boundaries of the membership functions gradually change
and may overlap a boundary of an adjacent membership set. Therefore, a
degree of membership is typically assigned to an input value. For
example, given two membership functions over a range of temperatures,
an input temperature may fall in the overlapping areas of both the
functions labelled "cool" and "warm." Further processing would then be
required to determine a degree of membership in each of the membership
functions.
Fuzzy logic control systems have become increasingly
popular in practical applications. Traditionally, the design of the knowledge
base including membership functions and rules relies on a subjective
human "rule-of-thumb" approach for decision-making. In addition, the
control system is adapted (tuned) to the desired performance through trial
and error. As a result, designing and adapting the fuzzy logic control
system becomes a time-consuming task. To overcome this drawback,
neural network techniques have been used in assisting designers to
generate rules and adapt the fuzzy logic control system automatically.
A fuzzy logic system is inherently well-suited for dealing with
imprecise data such as handwritten character and processing rules in
parallel. However, the actual implementation of fuzzy rule-based systems
CA 02421673 2003-03-11
4
for this type of application often relies on a substantial amount of heuristic
observation to express the knowledge of the system. In addition, it is not
easy to design an optimal fuzzy system to capture the necessary features
of each character.
Typically, one rule is used to recognize one character, and
each character is represented as one consequent of a rule. The actual
implementation of fuzzy rule-based systems for this type of application
often reties on a substantial amount of heuristic observation to express the
membership functions for the antecedents of each rule. Each rule consists
of several antecedents and consequents depending on the number of
inputs and outputs, respectfully. Each antecedent in a given rule is defined
as an input membership function, and each consequent is defined as an
output membership function.
Neural networks consist of highly interconnected processing
units that can learn and globally estimate input-output functions in a
parallel-distribution framework. Fuzzy logic system store and process rules
that output fuzzy sets associated with input fuzzy sets in parallel. The
similar parallelism properties of neural nets and fuzzy logic systems have
lead to their integration in studies of the behaviour of highly complex
systems.
The process of designing a fuzzy rule-based system is
tedious and critical for the success of the recognition. It must be done as
efficiently and accurately as possible if it is to sufficiently address the
OCR
problem.
CA 02421673 2003-03-11
However, the output of Neural networks is dependent on the
exact sequence of «learning» of the knowledge base. If the same
knowledge base is fed twice to a neural Network with only one substitution
in the learning sequence, the end result will be different in each case. This
5 can be a major disadvantage for any OCR system.
In the United States Patent No. 5,727,130, Hung describes
the use of Learning Vector Quantization ("LVQ"). LVQ, which is well-
known in the art, accomplishes learning by placing input data in a finite
number of known classes. The result is that this method provides the
supervised effect of learning and enhances the classification accuracy of
input patterns. It is also independent of the learning sequence.
It is desirable to design more robust input membership
functions that correspond to a rule. The linguistic term of a rule's
antecedent, such as "input 1 is small", depends upon how accurately the
input space is qualified while defining membership functions. LVQ can
group similar input data into the same class by adjusting the connection
weights between the inputs and their corresponding output. In other
words, through supervised learning, the features of each class can be
extracted from its associated inputs.
Hence, a learning vector quantization neural network may be
used to optimize the features of each handwritten character. Ming-Kuei
Hu, in "Visual Pattern Recognition Moment Invariant," IEEE Transaction
on Information Theory, pp. 179-186, 1962, describes such a system. A
LVQ network, is also disclosed in Teuvo Kohonen, "The Self-Organizing
CA 02421673 2003-03-11
6
Map," Proceeding of the IEEE, Vol. 78, No. 9, pp. 1364-1479, September
1990.
A LVQ learning system can be seen as a two-layered
network. The first layer is the input layer; the second is the competitive
layer, which is organized as a two-dimensional grid. All units (a "unit" is
represented as one input variable, such as x1, of one input pattern (x1,
x2, : . .)) from the first layer to the second are fully interconnected. In
the
OCFt example, the units of the second layer are grouped into classes,
each of which pertains to one character. For purposes of training, an input
pattern consists of the values of each input variable and its corresponding
class (i.e. the character that it represents). A quantization unit in the
competitive layer has an associated vector comprising the values of each
interconnection from all the units in the input layer to itself. This vector
implicitly defines an ideal form of character within a given class.
The LVQ learning system determines the class borders
using a nearest-neighbour method. This method computes the smallest
distance between the input vector X: (x1, x2, . . . xn) and each
quantization vector. In known systems, this computation is done in terms
of Euclidean distance (straight line distance in multi-dimensional space).
Input vector X belongs to class C(x), and quantization vector
w(1) belongs to class C(w). If C(x) and C(w) belong to different classes, the
w(1) is pulled away from the class border to increase the classification
accuracy. It C(x) and C(w) have the same class, the w(I) closes to the
center of the class. Then each input pattern is presented sequentially in
the input layer and several iterations. The weights of the quantization units
CA 02421673 2003-03-11
7
in each class are fine-tuned to group around the center of the class.
Therefore, the weight vector of the center unit within the class is
represented as the optimum classification for the corresponding class. The
result of the LVQ learning process is an optimized vector for each
alphanumeric character.
United States Patent No. 5,832,474, entitled "Document
Search And Retrieval System With Partial I~Jiatch Searching Of User-
Drawn Annotations" and issued to Lopresti,et al. on November 3rd, 1998
also describes the use of vector quantization in a document search and
retrieval system that does not require the recognition of individual
characters.
However, most of the prior art character recognition systems
are based on the concept of seeking to classify the greatest number of
characters as possible. This means that such systems seek to attribute
each character to be recognized to a class even if a certain degree of
"guesswork" is necessary. As a result, such systems are far from being
sufficiently accurate for many applications.
A specific example of a LVQ learning system is the optimal
linear separation. It can be described summarily as follows
~ each class vector has important dimensions (from
100 to 350 components;
for each pair of classes it is possible to find an hyper
plan allowing to separate them. In the case of. N
CA 02421673 2003-03-11
classes, they are separated two by two by N (N-1 )12
hyperplans.
The equation of each hyperplan is simple:
S(ai xi) = 0.
Therefore, for all members of class A, S(ai xi) > 0 and for all
members of class B, S(ai xi) < 0. By the use of a simple algorithm, the
various coefficients ai converge toward the most efficient value. This
known system can be useful when used with characters which are very
close to those in the database. This is the case, for example, of typed
characters.
However, it has drawbacks, the most important of which is
the difficulty to find a hyperplan to separate very complex objects such as
hand-printed characters. Because a plan is by definition open ended, it is
difficult to reject characters which are relatively distanced from the
characters which are sought to be read (commas, exclamation marks,
question marks, etc...).
Multi-layer perception is a well known application of neural
networks. This method can be excellent if great care is used in the training
phase. However, because no theoretical base exist to improve the result in
a structured way, one must rely on trial and error processes which are
extremely costly. As a result, if the multi-layer perception system is
"taught" the same data twice, two different results will be obtained.
Very often, it is impossible to be 100% certain that the
character which was read is in reality the digital representation which was
CA 02421673 2003-03-11
g
assigned to such character by the recognition method. Therefore, it is
advantageous to establish a measure of confidence in the accuracy of the
recognition method. The confusion rate is defined as the number of
characters which were thought to have been recognized but were in fact
wrongly recognized divided by the total number of characters read. The
rejection rate is the number of characters which the recognition method
has failed to recognize over the total number of characters read. The read
rate consists in the total number of characters that were accurately read
over the total number of characters read. Therefore, the read rate plus the
confusion rate plus the rejection rate should equal 100%.
In many applications, it is preferable to consider a character
to be unrecognizable even if it is one of the ASCII characters that the
system is seeking to recognize than to assign a wrong ASCII value to the
character which was read. This is especially the case in financial
applications.
This being said, the read rate has to be high enough for the
recognition system to be worthwhile. Therefore, the ideal system is the
one in which the confusion rate is zero and the read rate is as close as
possible to perfect. Limiting factors for the read rate include:
~ poor quality images including poor contrast images
caused by the use of a low quality writing instrument
or a color that is not easy to digitize;
~ an image that is poorly recognized by the digitizing
sub-system or the presence of a background image;
» a poor definition of the zone in which the characters
CA 02421673 2003-03-11
1~
are to be written; and
~ printed characters that extend outside the area
reserved for the field which can include characters
which are too large, character that are patched
together or open characters.
Poor class separation performance may also result from the
quality or quantity of the vector examples in the vector database or the
inability of the recognition engine to generalize. Indeed, hand-printed
documents are by definition nearly never identical from one person to the
next or from one expression to the next even when written by the same
person.
SUMMARY OF THE INVENTION
In accordance with a first aspect of present invention, there
is provided a method for translating a written document into a computer
readable document comprising:
providing a pixel representation of the written document;
identifying at least one field into the pixel representation of
the written document;
segmenting each the at least ore field, yielding at least one
segmented symbol;
applying a character recognition method on each segmented
symbol; and
assigning a computer-readable code to each recognized
character resulting from the character recognition method.
CA 02421673 2003-03-11
1 '1
More specifically, in accordance with a second aspect of the
present invention, a method for recognizing a character corresponding to a
written symbol, comprising:
providing a pixel representation of the written symbol;
segmenting the pixel representation, yielding a segmented
symbol;
doing a vector quantization on the segmented symbol,
yielding a vector representation of the symbol;
for possible class(i), r ranging from 1 to N, N being the
number of different possible classes:
providing a vector representation(i) for each class(i);
computing a similarity score(i) using the vector
representation (i) of the symbol and the vector representation for class(i);
and
comparing the similarity score(i) to a threshold(i); and
if only one of the similarity score(x) is superior than the
corresponding threshold(x), x ranging form 1 to N: and
assigning to the written symbol a computer-readable code
corresponding to the class(x) is provided.
In accordance with a third aspect of the present invention, a
method for creating a vector base for a character recognition method
comprising:
for each of a plurality of characters(i), i ranging from 1 to N,
N being the number of characters;
providing a pixel representation (i)
CA 02421673 2003-03-11
12
doing a vector quantization on each pixel
representation(i), yielding a vector representation (i) for each pixel
representation (i);
computing a similarity score (x) for each of a plurality of
predetermined classes, x ranging from 1 to M, III being the number of
predetermined classes, by comparing the vector representation (i) of each
pixel representation to a provided vector quantization (x) corresponding to
the each of a plurality of predetermined class;
a) if, for one of the plurality of predetermined classes
(x), the similarity score(x) is superior to a predetermined
threshold(x), the character (i) being considered already
known;
b) if not, verifying if the character (i) belongs to one
of the classes (x);
i. if no, the character (i) is rejected;
if yes, the character (i) is associated to the corresponding
class (x) is provided.
In accordance with a fourth aspect of the present invention,
there is also provided a character recognition learning method comprising:
providing a database of recognized characters; each
recognized characters belonging to a class and being represented by a
quantization vector; the number of different classes being C;
for each recognized character (i) in the database, measuring
a distance(i) between a first quantization vector representing the each
recognized character(i) and a second quantization vector representing a
character from another class; the second quantization vector having the
shortest distance(i) with the first quantization vector among all quantization
CA 02421673 2003-03-11
13
vectors representing characters from a class different than the class to
which the each character (i) belongs; and
for each class(j), j ranging from 1 to C:
for a predetermined number of recognized character(k)
member of class(j):
defining a same class sphere(k) comprising only
quantization vectors which are members of class(j) and having a distance
with the quantization vectors(k) less than distance(k); and
determining a number(k) of quantization vectors
representing a character from class(j) and being part of same class
sphere(k);
for each same class sphere(k), from the same class
sphere having the largest number(k) to the same class sphere having the
smallest number(k), applying an elliptic deformation until members of
other classes are reached, yielding an optimized quantization vector for
class(k).
Finally, in accordance with a fifth aspect of the present
invention, there is a provided a system for translating a written document
into a computer-readable document:
a document digitizer for creating a pixel representation of the
document;
a controller coupled to the digitizer for:
receiving the pixel representation of the document;
identifying at least one field in the pixel representation of
the document;
segmenting each the at least one field, yielding at least
one segmented symbol for each the at least one field;
CA 02421673 2003-03-11
14
applying a character recognition method on each
segmented symbol; and
assigning a computer-readable code to each recognized
character resulting from the character recognition method;
an output device coupled to the controller for displaying
segmented symbols, from the at least one segmented symbol,
unrecognized by the character recognition method; and
at least one input device coupled to the controller for
entering a computer-readable code of humanly recognized character
among displayed segmented symbols.
Methods and systems according to the present invention
have the following desirable characteristics and features:
~ It allows to reduce the confusion rate near zero.
It aims at recognizing typed or printed, especially
hand-printed or handwritten characters, in the various
fields of a form;
~ It aims at picking out well known alphanumeric
characters from an image which includes a great
many patterns of types not previously taught to the
machine: this is made possible since measurements
of unknown shapes advantageously have high
correlation with previously taught shapes before they
are even considered;
It allows to achieve a substitution rate (the
percentage of wrongly chosen class names divided
by the number of class names correctly chosen by a
CA 02421673 2003-03-11
human judge working from only the same images) of
near zero; and
~ It is adaptive in the sense that it can learn previously
unknown patterns and automatically generate new
5 recognition eguations which are carefully crafted to
be non conflicting with previously (earned patterns.
Typically the manual operator will provide a correct
classification for a rejected character;
non supervised learning can also take place, e.g.,
10 learning using an automatic dictionary.
Even though the present invention is described herein
referring generally to character recognition, the expression "character"
should be construed as including any written symbols or shapes, including
15 but not limiting to letters (in any alphabet), numbers, etc.
Other objects, advantages and features of the present
invention will become more apparent upon reading the following non
restrictive description of preferred embodiments thereof, given by way of
example only with reference to the accompanying drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
fn the appended drawings:
Figure 1 is a perspective view of a system for translating a
written document into a computer readable document according to an
embodiment of a first aspect of the present invention;
CA 02421673 2003-03-11
16
Figure 2 is a flowchart illustrating a method for translating a
written document into a computer readable document according to an
embodiment of a second aspect the present invention;
Figure 3 is a bitmap representation of the document
illustrated in Figure 1, illustrating the separation of the document into
fields;
Figure 4 is a flowchart illustrating a method for character
recognition according to an embodiment of a third aspect of the present
invention;
Figure 5 is a flowchart illustrating a method of creation of a
vector base, according to an embodiment of a fourth aspect of the present
invention; and
Figure 6 is a flowchart illustrating a learning method
according to an embodiment of a fifth aspect of the present invention.
DESCRIPTION OF THE PREFERRED EMBODIMENT
Turning now to Figure 1 of the appended drawings, a system
10 for translating a written document 8 into a computer readable
document according to an embodiment of a first aspect of the present
invention will be described.
The system 1 ~ comprises a controller 12, input devices such
CA 02421673 2003-03-11
17
as a pointing device 14 and a keyboard 7 6, a display device 18, a
document digitizer 20, and a storing device knot shown).
The input devices 14 and 16, and display device 18 are
coupled to the controller 12 through conventional coupling means.
The display device 18 and input devices 14 and 16 are
optional but may allow a system operator to perform the verification of
unrecognized characters as will be explained hereinbelow in more detail.
The display device 18 is in the form of a computer monitor,
but may alternatively be in the form of a liquid crystal display or of any
device that allows display of digitized printed character or of the actual
printed or handwritten characters as found on the document.
According to an embodiment of the present invention, the
pointing device 1.4 is in the form of a computer mouse. Of course, a single
input device may be used to operate the system 10 depending on the user
interface programmed in the controller 12.
The document digitizer 20 includes an optical reader allowing
to image at least part of the document 8 and 'to create a pixel or bitmap
representation thereof. Of course, the document digitizer 20 is configured
so as to transform the image of document 8 into a binary document.
Means for achieving this transformation may be included in the controller
12, for example in the form of a digitization module, or part of a device that
includes the optical reader.
CA 02421673 2003-03-11
18
Although a conventional scanner may be used, commercial
applications may require the use of both a camera, such as a CCD
(charge-coupled device) camera, and a dedicated processing power of the
controller 12.
The controller 12 is advantageously in the form of a
computer. The controller 12 may alternatively take many forms such as an
electronic control circuit or a programmed chip.
The storing device (not shown) may take many form
including: a disk, cdrw, or dvd drive, a hard disk, memory card, computer
RAM (Read Only Memory), etc. The storing device may be included in the
controller, or be embodied in a device (not shown) coupled to the
controller 12.
The controller 12 is advantageously programmed so as to
embody a method 100 for translating a written document 8 into a
computer readable document according to an embodiment of a second
aspect of the present invention, as will now be described with reference to
Figure 2.
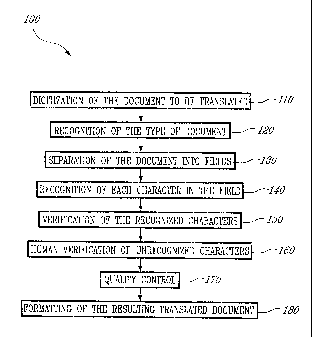
The method 100 comprises the following steps:
110 - Digitization of the document to be translated;
120 - Recognition of the type of document;
130 - Separation of the document into fields;
CA 02421673 2003-03-11
19
140 - Recognition of each character in the field;
150 - Verification of the recognized characters;
160 - Human verification of unrecognized characters;
170 - Quality control; and
180 - Formatting of the resulting translated document.
Each of these general steps will now be described in more
detail.
1n step 110, the written document 8 to be translated into a
computer-readable file is digitized using the system 10 and more
specifically the digitizing device 20. The result of the digitization step 110
is a pixel representation 22 of the document to be translated, which is
exemplified in Figure 3.
The pixel representation 22 of the document may be either
stored into the storing device (not shown) for later processing or be made
available to the controller 12 for further processing.
Since digitization methods, applications and modules are
believed to be well known in the art, they will not be described herein in
more detail.
CA 02421673 2003-03-11
Alternatively to the digitization step 110, a pixel
representation ofi the document may be provided to the controller 12. This
pixel representation may result firom a prior independent segmentation
process.
5
In step 120 the type of document is determined. This step is
optional, but allow to facilitate the next step (130) which is the separation
of the digitized document 22 into fields 24 in those cases where many
different types of documents may be read by the system 10.
Indeed, since the separation into field depends on the format
of the document 8, it is prefierable to pre-determined the type of document.
Step 120 is achieved on the digitized document by
identifying certain characteristics such as markings or a configuration that
is expected for a pre-determined type of docuri~ents. Of course, the nature
and characteristics of those markings or configuration are pre-determined
and stored, for example in the controller 12, to be used in step 120.
Examples of characteristics that can be used to identify a document type
include: text block, dimension, lines.
Alternatively, the type of document is recognized by the
operator and inputted in the controller.
In step 130, the document is then separated into fields 24
(see Figure 3).
A field is a generally rectangular section of the document
CA 02421673 2003-03-11
21
known to include predetermined information coded as a one or more
characters. For example, on a bank related document, a bank account
identifier is to be found in a predetermined portion of the document that
includes characters identifying the account.
Different fields in a document may have different sizes.
Alternatively, a field may have a different shape then a rectangle. Of
course, in those cases, the segmentation algorithm (first sub-step of step
140) has to be adapted to the specific shape of the field.
The identification of fields in the pixel representation 22 of
the document 8 is advantageous since, in most applications, one does not
have to read every characters on the document 8. It is therefore more
efficient (both time and money wise) to concentrate the character
recognition process on fields having relevant information.
The result of step 130 is a rectangular bitmap (see 24 on
Figure 3).
In step 140, the information in each field 24 is extracted.
More specifically, the bitmap information 24 in an identified field (step 130)
is translated into a predetermined computer-readable format such as
ASCII or EBCDIC.
Of course the number of characters included in a field may
vary and in some cases a field may include only one character.
Step 140 includes the following two substeps:
CA 02421673 2003-03-11
22
~ The segmentation of the field so as to separate the
bitmap representations of characters 26 in the field
24 from one another In other words, the different
shapes or symbols in a field are discriminated; and
~ Using each segment 26 in a field, to identify a
character from a list of possible characters (see
method 200, Figure 4), so as to represent the
identified character by a value in a predetermined
computer-readable format (or digital representation),
such as ASCII.
Regarding the segmentation substep, it is to be noted that
the segmentation method used takes into account the fact that size of the
bitmap representation 26 of a character can vary considerably from one
character to another and, in the field 24 including handwritten characters,
from one writer to another.
Since segmentation methods are believed to be well known
in the art, and for concision purposes, such methods will not be described
herein in more detail.
Character recognition
The next substep of step 140 concerns the actual character
recognition. This operation seeks to associate a given digital character to
each character image (symbol) 26 defined during the segmentation
substep. A similarity score is associated to each predetermined possibility
CA 02421673 2003-03-11
23
among the a list of possible digital characters. This operation presumes
that each discriminated symbol resulting from the segmented process is
the image of a single character.
Turning now to Figure 4, a method 200 for character
recognition according to an embodiment of third aspect of the present
invention is illustrated.
The character recognition method 200 is determined and
characterized by the following choices:
~ a vector quantization method;
~ a vector classificationlseparation method;
~ the determination of valid digital characters or
"vocabulary" chosen among a computer readable
model (for example ASCII); and
~ the creation of a vector base.
The character recognition method per se includes two
substeps: the vector quantization (substep 202), and the vector
classification (substeps 204-210). Substeps 204-210 are done using a
vector base as will be explained herein in more detail.
Regarding substep 202, as it is well known in the art, a
quantization vector is a mathematical representation including many
components, each describing a characteristic of symbol or shape to be
analyzed. These vectorial representations allow to recognize a character
from a visually non-ambiguous shape. Many quantization vectors are
CA 02421673 2003-03-11
24
known and can be used in the character recognition method according to
the present invention. Substep 202 therefore yields a mathematical
representation of each segmented bitmap character representations. Of
course, the same quantization model has to be used for the character
recognition process and for the vector base definition process.
In substep 204, a similarity score is computed by comparing
the vector quantization of the current character to be recognized and
predetermined vector quantization of each possible output among the
possible predetermined valid characters computed with the same model.
According to a most preferred embodiment of the present invention, the
comparison is achieved using an optimal spherical separation method as
will be described hereinbelow with reference to the learning process.
Alternatively, other separation method, such as the optimal
linear separation method (LDC) or a mufti layer perception ( MLP) method
briefly described hereinabove or one of the following method may also be
used:
~ SVM (Support Vector Machine) ;
~ QDF (Quadratic Discriminant Function) ;
~ MQDF (Modified Quadratic Discriminant Function) ;
~ KNN (K Nearest Neighbour).
Since these separation methods are believed to be well
known in the art, and for concision purposes, these methods will not be
described herein in more detail.
In substep 206, the similarity score for each class is
CA 02421673 2003-03-11
compared to a predetermined threshold.
The threshold is a function of scores which result from the
learning base, and of the predetermined acceptable error rate. For
5 example, if one notice that the characters "3" and "9" are confounded with
scores of 0.5, thresholds should be increased above 0.5 for each
character.
The comparison process consists in verifying if the vector
10 characterisation of the current character to be recognized is close enough
to one of the members populating each classes (each character which
needs to be recognized is considered to be a different class).
If the similarity score has not reached the threshold or if
15 more then one class threshold are reached (step 208), the character is not
recognized and the method returns to the human inspection step (step
160 from Figure 2).
If not, the ASCU code corresponding to the recognized
20 character class is attributed (substep 210), and the method proceeds with
the next segmented bitmap 26 (also called pixel cluster) representation in
the current field 24.
After all the pixel clusters 26 of a field 24 have been
25 processed, the method proceeds with the verification of the character
(step 150 from Figure 2).
It is to be noted that the use of an optimal elliptic separation
CA 02421673 2003-03-11
26
method to pre-determine each class population allows to minimized the
simultaneous reach of two different classes threshold.
As will be described hereinbelow in more detail, the resulted
vectors are then classified or separated into a number of classes each
corresponding to one shape which is sought to be recognised. Each such
shape is usually one of the characters in the universe of valid characters in
the application. However, it may also be useful to include vectors relating
to frequently used invalid characters or marks, such as alphabetic
characters in a numeric field or a minus sign.
It is to be noted that the character recognition method and
system is preferably optimized for a specific use. For example, if the field
to be recognized is a numeric field, the class separation will be optimized
to produce a digit from zero to nine and to exclude all others. In such an
example, there are ten distinct outputs, each being associated with a
similarity score as will be described hereinbefow. Then, the different
outputs and their associated scores are sorted by decreasing similarity
scores. In those cases where one output does not have a similarity score
which is high enough to determine the "winning" character, further
processing is required. These steps will be described hereinbelow in more
detail.
Different character recognition methods may be used for
translating a single document. For example, different recognition method
may be specifically assigned for different types of field (numeric,
alphabetical or other). A character recognition method may comprise a
number of recognition engines each being composed of a particular vector
CA 02421673 2003-03-11
27
quantization and a class separation method as well as a voting method
allowing the combination of the results of the various recognition engines
using simple averages, weighted averages or veto rules.
After the character recognition step (140), the method 100
proceeds, in step 150, with the verification of the recognized characters.
This step consists in verifying the character obtained in step 140 by
applying pre-determined field validity rules (for example the algorithm or
key to validate a bank account number or a social security number). Of
course, depending on the type of document, other verification process
may alternatively be used such as:
~ Verification in a stored database;
~ Predetermined rule; and
~ Verification in a thesaurus.
Alternatively, the verification step may consist in further
deciding if the level of confidence on the character found is high enough to
be considered recognized, or should the method 100 proceeds with the
next step (160).
Also, the verification step 150 may consist in better
assessing the class of the character to be identified by analyzing it in the
context of its neighbor characters. For example, in the case where the
character is expected to be a letter part of a word, an ICR (Intelligence
Character Recognition) module, advantageously included in the computer
12, may be used to identify the word and thereby the letters forming it.
Since, fCR module are believed to be well known in the art, they will not
CA 02421673 2003-03-11
28
be discussed herein in more detail.
Then, in step 160, unrecognized characters are verified by
the operator of the system 10.
The operator reviews each field for which no similarity score
is higher then the predetermined thresholds, and also, optionally those
fields not corresponding to managing rules predetermined for the identified
type of document.
Step 160 allows the operator to input any missing
information following the automatic character recognition process. It is to
be noted that this step allows also to correct errors resulting from the
original input by a person.
A quality control is then optionally executed in step 170.
This step includes sampling some of the resulting recognized
characters, and the operator visually verifying their validity by comparison
with the corresponding initial character on the document 8.
Of course the sampling rate may vary depending on the
application and the desired success rate. Also, the sampled characters
may be chosen randomly or systematically.
Finally, in step 180, the computer-readable codes that have
been assigned to the recognized characters (humanly or resulting from the
character recognition method) are assembled an formatted so as to be
CA 02421673 2003-03-11
29
displayed or stored for later display.
Of course, only one or some of the recognized characters
may be formatted and/or displayed in step 180.
Creation of a vector base
As discussed hereinabove, the vector base is a database
including a plurality of quantization vector for each given class. A learning
process is used to create or to add to a base of vectors of known
specimens of the vocabulary, each assigned to a given class. A method
of creation of a vector base will be described in more detail hereinbelow.
The method of creation of a vector base 300 according to an
embodiment of a fourth aspect of the present invention is illustrated in
Figure 5.
In step 302 a plurality of characters or shapes are provided.
A bitmap (pixel) representation of each character or shape is
then created in step 304.
This bitmap representation is then passed through the
predetermined vector quantization method (step 306).
A similarity score, similar to those described for the character
recognition method 200, is then assigned for the character in respect of all
classes (308). If the similarity score exceeds a predetermined threshold
CA 02421673 2003-03-11
(310) it means the character is already known and can thus be ignored
(312). If not, it is examined by an operator of the system 10 to determine if
it belongs to the desired vocabulary (314). If not, it is rejected (316). if
it
belongs to the vocabulary, the current vector representation is stored to be
5 added to the vector base and associated to the proper class (318) as
assigned by the operator.
This last threshold is determined through experimentation
and depends on the expected success rate. Indeed, a high threshold
10 should be used to obtain a highly precise table, at the risk of rejecting
numerous elements and of adding elements already present in the table.
It has been found that generally, a character having a
similarity score above 0.8 when comparing to a class should be
15 considered part of that class and therefore recognized, and a character
with a similarity score below 0'.04 should be considered invalid. Between
these two thresholds, the choice belong to the operator.
Learning process
There follows a learning process (see Figure 6) that
comprises a series of iterative adjustments of network coefficient to
optimize the performance of the recognition engine. These network
coefficients are related to the quantization vector components for each
characters.
As will become more apparent upon reading the following
description, it can thus be seen that the recognition engine so created
CA 02421673 2003-03-11
31
cannot provide other results than the classes for which it was built.
The learning process 400 is completed as described in
Figure 5. The learning process described hereinbelow is based on the
optimal elliptic separation method.
The learning process is as follows.
For each pattern in a database, the shortest distance
between the quantization vector representing the pattern and the closest
quantization vector of another class is measured (402). Many well-known
mathematical methods may be used to compute the distance between
these two vectors.
This distance is then used to define, for each class, a sphere
which will comprise only vectors which are rr~embers of the same class
(404). Therefore, the closed surface formed by this sphere separates all
the members of the class contained in the sphere from all other classes.
The number of same class vectors contained in the sphere is determined
and the database is sorted using such number (from the largest to the
smallest) (406).
Each N-dimension sphere (starting by the one containing the
largest number of members) (408) is then deformed into a N-dimension
ellipsoid, N being the size of the quantization vector until the optimization
process is completed (410) through an iterative process as follows:
CA 02421673 2003-03-11
32
having ~(atxa2)=0 ,
which is the equation of an N-dimension sphere, one tries to find the
optimal a; coefficients;
i ranging from 1 to N; and
x; representing the axis of the sphere in all each
dimensions.
It has been found that by using elliptical separation class
members can be regrouped more efficiently.
Reading hand-printed characters are particularly difficult
because it is impossible to ever have a database of vectors representing
every possible variation in handwritten characters. However, the use of the
optimal elliptical separation method considerably reduces the negative
impact resulting from the use of "incomplete" vector databases. However,
by searching all the various ellipsoids and retaining all of those which may
relate to the proposed character and by assigning a similarity score, it is
possible to "learn" where the character belongs and make the appropriate
adjustments to the various ellipsoids.
One way to assign a score to each particular member of
an ellipsoid is to attribute a score of zero if the given character is located
at the perimeter of the ellipsoid while attributing a score of one if such
character is located at its "centre". 'the appropriate scoring equation ise
1 -exp-E(a; x 2).
CA 02421673 2003-03-11
3J
The equation for an hyper ellipses is the following
E(a;x?)=0.
Optimization is used in order to find the optimal a , coefficient.
At first, all a; coefficients are set to 1, except for the constant
oc,~ which is set to 1. oco represents is the square of the radius of the
sphere.
Following the first iterations, as soon as the space is
separable, the learning base is re-examined to add all characters from the
corresponding class that fit within the ellipsoid.
An algorithm similar to those used for the well known
hyperplan separation method is used to optimize the separation between
the various members contained in the ellipsoid from all others.
Alternatively, other optimisation algorithm can be used. The ellipsoid is
deformed until members of other classes are reached (step 412). The
result is the best vector available because more members of the same
class are now found in the ellipsoid.
It is to be noted that, typically, hundreds of members of a
same class may be submitted for the learning process. Of course, this
number may vary, depending on the expected rejectian rate, nature of the
characters to be recognized, etc.
Since such iterations may consume a large quantity of
processing time and power, it is preferable to end the iterations when a
CA 02421673 2003-03-11
34
predetermined percentage of the perfect separation solution is reached. It
has been found, in the case where the characters are numbers, that the
predetermined percentage is preferably 99.5%. It has been found that a
using a percentage of 99.5% is an acceptable compromised between
efficiency of the learning process and the time required for the process.
Of course, alternatively, any percentage between 0 and
100% may be used with variable results.
The above-described iteration process is repeated for all
classes (step 416) and then stops.
It is to be noted that the a; coefficients may be adjusted over
time to yield vectors that better discriminate different characters and
symbols. The goal is to repeat the learning process each time a new
character or symbol added to the learning base cause the classes to
become linearly un-separable, i.e. the vectors do not allow to distinguish
between two characters or symbols.
Moreover, each time the iterative process becomes
insufficient, new components may be added to the vectors.
It is to be noted that, even though, the invention has been
described with references to characters being fetters or numbers, the
present invention may also be used to recognized any symbols.
Also, the present methods and systems according to the
present invention may be used to recognized both printed and handwritten
CA 02421673 2003-03-11
characters or symbols.
Although the present invention has been described
hereinabove by way of preferred embodimenia thereof, it can be modified
5 without departing from the spirit and nature of the subject invention, as
defined in the appended claims.