Note: Descriptions are shown in the official language in which they were submitted.
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
1
Procédé de traitement d'envois postaux avec prise en compte d'un
surcoût d'erreur de distribution
L'invention concerne un procédé de traitement d'envois postaux dans
lequel on forme une image de chaque envoi comportant des informations
d'adresse et on effectue sur la base de l'image de l'envoi et d'une base
d'adresses de référence une reconnaissance automatique par OCR des
informations d'adresse de distribution.
Les opérateurs postaux font un effort considérable de normalisation en
définissant des normes d'adressage et en encourageant l'utilisation de ces
normes. Bien que l'adressage normalisé de courrier soit de plus en plus
répandu et représente une proportion élevée des flux d'envois postaux, les
flux de courrier dont l'adressage n'est pas standard et comporte des erreurs,
des ambiguïtés ou encore des manques d'information restent encore très
importants.
On sait que les systèmes de reconnaissance automatique d'adresses
postales par OCR (« Optical Character Recognition » - Reconnaissance
Optique de Caractères) fonctionnent de manière à réaliser une résolution
univoque de l'adresse pour la réalisation d'un tri au sein d'une tournée du
facteur. Cette opération de reconnaissance est réalisée avec un faux
d'erreur réglable qui influe sur le degré de résolution univoque et il en
résulte
que sur un lot d'envois, un certain nombre sont écartés par le processus de
reconnaissance automatique du fait d'un résultat équivoque de la résolution.
Ces envois écartés ou rejetés par le processus de traitement de
reconnaissance automatique doivent être repris sur un poste de vidéo
codage et/ou insérés manuellement dans les tournées du facteur. La
proportion d'envois écartés par un processus de reconnaissance
aûtomatigue pâr OCR définit un_ taux de rejets dont le niveau est réglé .par
le
niveau d'erreur fixé par l'opérateur postal et sur la base duquel est réglé le
taux d'erreur.
La reconnaissance automatique des informations d'adresse nécessite une
connaissance détaillée de la structure du bloc d'adresse et des règles de
rédaction utilisées par les clients des opérateurs postaux. Pour permettre
une résolution univoque basée sur un annuaire postal ou base d'adresses
de référence, l'adresse postale à reconnaître doit comprendre toutes ses
composantes placées dans un ordre correct, logique et cohérent avec la
base d'adresses de référence.
Une adresse de livraison à un destinataire comporte typiquement un nom
de rue, un numéro dans la rue, un nom de ville, un code postal et un pays.
FEUILLE DE REMPLACEMENT (REGLE 26)
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
2
La reconnaissance automatique par OCR sur un envoi postal se
décompose de façon classique en plusieurs étapes successives:
- on forme une image numérique de l'envoi postal comportant des
informations d'adresse ;
- (image numérique de l'envoi comportant des informations d'adresse est
binarisée ;
- l'image binarisée est segmentée pour localiser le bloc d'adresse ;
- le bloc d'adresse est analysé au niveau syntaxique pour être décomposé
en composantes d'adresse (chaînes de caractères affectées à des
rubriques d'adresse (n° de rue, nom de rue, code postal, ville, pas de
porte, société, ville pays, etc....) ;
- les composantes d'adresse sont analysées au niveau sémantique par
comparaison avec la base d'adresses de référence (annuaire postal)
pour une résolution univoque.
Dans la dernière étape de résolution d'adresse, on identifie parmi un
ensemble de solutions d'adresse celle qui concorde le mieux statistiquement
avec la base d'adresses de référence. Cette étape de résolution est
généralement décomposée en une étape de résolution des informations
d'adresse d'acheminement (pays, ville, code postal) et en une étape de
résolution des informations d'adresse de distribution (numéro de voie, nom
de voie, pas de porte, etc...). Dans ces deux étapès de résolution, on
recherche à chaque fois une concordance statistique avec la base
d'adresses de référence et une solution d'adresse de distribution est
dégagée quand le niveau de concordance statistique est supérieur à un
seuil statistique prédéterminé qui est définï par le taux d'erreur. Dans le
cas
contraire, l'envoi est écarté par le traitement de reconnaissance automatique
comme indiqué plus haut.
Le but de l'invention est de proposer un procédé de traitement d'envois
postaux amélioré pour étre susceptible d'abaisser le taux de rejets pour un
taux d'erreur prédéterminé. En particulier, l'invention vise à optimiser le
degré de résolution univoque en prenant en compte les incidences d'erreurs
de classement des envois dans les tournées du facteur.
A cet effet, l'invention a pour objet un procédé de traitement d'envois
postaux dans lequel on forme une image de chaque envoi comportant des
informations d'adresse et on effectue sur la base de l'image de l'envoi et
d'une base d'adresses de référence une reconnaissance automatique par
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
3
OCR des informations d'adresse de distribution, caractérisé en ce que lors
de la reconnaissance automatique des informations d'adresse de distribution
on exploite une base de données dans laquelle sont organisées des listes
ordonnées des points de distribution pour des tournées du facteur de façon
à prendre en compte un surcoût d'erreur estimé de distribution lié au
traitement de l'envoi si il est livré à un point de distribution erroné.
L'idée à la base de l'invention part du constat qu'un opérateur postal peut
accepter des erreurs de classement des envois dans les tournées du facteur
dans la mesure où les surcoûts de traitement liés à ces erreurs de
classement ne dépassent pas un niveau déterminé. Par exemple, le contenu
de la sacoche du facteur est organisé en fonction du sens de sa tournée de
distribution. Cette organisation définit une relation d'ordre entre les points
de
distribution des envois qui composent ia tournée. Dans cette tournée, des
envois mal classés peuvent ne pas (ou peu) remettre en cause le
déplacement du facteur sur sa tournée. Ces erreurs de classement peuvent
donc être tolérées dans une certaine mesure par l'opérateur postal. Des
erreurs de classement peuvent être tolérées par exemple quand
l'information d'adresse a une qualité insuffisante pour être résolue de façon
univoque Dans un procédé classique de traitement automatique d'envois
postaux, des informations d'adresse de faible qualité ne sont généralement
pas résolues de façon univoque et les envoïs correspondants sont donc
écartës par le processus de reconnaissance automatique d'adresse. Avec le
procédé selon l'invention, avant d'écarter de tels envois, on recherche à
classer ces envois, c'est-à-dire à déterminer un point de distribution pour
chaque envoi en acceptant un certain niveau d'erreur de classement ce qui
revient à augmenter le taux d'erreur et diminuer le taux de rejet du
processus de reconnaissance automatique.
Dans un mode de mise en oeuvre particulier du procédé selon l'invention,
suite à une résolution équivoque de l'adresse de distribution d'un envoi, la
prise en compte du surcoût d'erreur de distribution consiste à regrouper un
ensemble de solutions d'adresse de distribution pour l'envoi, à identifier des
points de distribution correspondant respectivement à ces solutions et à
rechercher si les points de distribution identifiés font partie d'une méme
tournée du facteur.
On conçoit facilement qu'une erreur de classement sur une tournée du
facteur présentant généralement un faible volume de courrier est peu
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
4
pénalisante pour l'exploitant postal. Ainsi, la prise en compte du surcoût
d'erreur de distribution consiste à déterminer, dans le cas où les points de
distribution identifiés font partie d'une même tournée du facteur, un volume
de courrier dans la plage de distribution correspondant aux points de
distribution identifiés pour ladite tournée du facteur. Si ce volume est
inférieur à un seuil prédéterminé réglé par l'opérateur postal, on peut par
exemple choisir comme solution pour la résolution univoque, la solution
d'adresse de distribution qui correspond au premier point de distribution de
la plage de distribution.
Dans un mode de mise en oeuvre particulier du procédé selon l'invention,
la prïse en compte du surcoût d'erreur de distribution consiste à regrouper
un ensemble de solutions d'adresse de distribution pour l'envoi, à identifier
des points de distribution correspondant respectivement à ces solutions, à
identifier des tournées du facteur correspondant respectivement à ces points
de distribution et à identifier des bureaux de distribution correspondant
respectivement à ces tournées du facteur et sur la base des points de
distribution, des tournées du facteur et des bureaux de distribution
identifiés,
à rechercher parmi les solutions d'adresse de distribution celle qui minimise
le surcoût d'erreur de distribution lié au traitement de l'envoi si il est
livré par
un bureau de distribution erroné et/ou dans une tournée du facteur erronée
etlou à un point de distribution erroné.
Selon encore un mode de mise en oeuvre particulier du procédé selon
l'invention, on définit une première information numérique représentative
d'un surcoût d'erreur de distribution lié au traitement d'un envoi si il est
livré
par un bureau de distribution erroné, une seconde information numérique
représentative d'un surcoût d'erreur de distribution lié au traitement d'un
envoi si il est livré dans une tournée du facteur erronée, une troisième
information numérique représentative d'un surcoût d'erreur de distribution lié
au traitement d'un envoi si il est livré à un point de distribution erroné.
Pour
rechercher la solution qui minimise le surcoût d'erreur de distribution, on
compare pour chaque solution courante d'adresse de distribution le bureau
de distribution et/ou la tournée du facteur et/ou le point de distribution
identifiés pour cette solution avec le bureau de distribution, la tournée du
facteur et le point de distribution identifiés pour chacune des autres
solutions d'adresse de distribution de manière à obtenir pour ladite solution
courante d'adresse de distribution une valeur cumulée des surcoûts d'erreur
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
de distribution calculée sur la base desdites première, seconde et troisième
informations numériques.
L'invention s'étend à un système de traitement d'envois postaux
comprenant une caméra pour former une image de chaque envoi comportant
5 des informations d'adresse et une unité de traitement de données qui
effectue sur la base de l'image de l'envoi et d'une base d'adresses de
référence une reconnaissance automatique par OCR des informations
d'adresse de distribution, caractérisé en ce qu'il comprend en outre une
base de données dans laquelle sont organisées des listes ordonnées des
points de distribution pour des tournées du facteur et en ce que l'unité de
traitement est agencée de manière que lors de la reconnaissance
automatique des informations d'adresse de distribution elle exploite ladite
base de données de façon à prendre en compte un surcoût d'erreur estimé
de distribution lié au traitement de l'envoi si il est livré à un point de
distribution erroné.
Ce système de traitement peut présenter les particularités suivantes
- l'unité de traitement est agencée de manière que pour prendre en compte
un surcoût d'erreur de distribution elle regroupe un ensemble de solutions
d'adresse de distribution pour l'envoi, elle identifie des points de
distribution
correspondant respectivement à ces solutions et elle recherche si les points
de distribution identifiés font partie d'une méme tournée du facteur ;
- l'unité de traitement est agencée de manière que pour prendre en compte
un surcoût d'erreur de distribution elle détermine, dans le cas où les points
de distribution identifiés font partie d'une même tournée du facteur, un
volume de courrier dans la plage de distribution correspondant aux points de
distribution identifiés pour ladite tournée du facteur ;
- l'unité de traitement est agencée de manière que pour prendre en compte
un surcoût d'erreur de distribution elle regroupe un ensemble de solutions
d'adresse de distribution pour l'envoi, elle identifie des points de
distribution
correspondant respectivement à ces solutions, elle identifie des tournées du
facteur correspondant respectivement à ces points de distribution et elle
identifie des bureaux de distribution correspondant respectivement à ces
tournées du facteur et sur la base des points de distribution, des tournées
du facteur et des bureaux de distribution identifiés, elle recherche parmi les
solutions d'adresse de distribution celle qui minimise le surcoût d'erreur de
distribution lié au traitement de l'envoi si il est livré par un bureau de
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
6
distribution erroné et/ou dans une tournée du facteur erronée et/ou à un
point de distribution erroné ;
- dans le système sont enregistrées une première information numérique
représentative d'un surcoût d'erreur de distribution lié au traitement d'un
envoi si il est livré par un bureau de distribution erroné, une seconde
information numérique représentative d'un surcoût d'erreur de distribution lié
au traitement d'un envoi si ü est livré dans une tournée du facteur erronée,
une troisième information numérique représentative d'un surcoût d'erreur de
distribution lié au traitement d'un envoi si il est livré à un point de
distribution
erroné et pour rechercher la solution qui minimise le surcoût d'erreur de
distribution l'unité de traitement est agencé de manière à comparer pour
chaque solution courante d'adresse de distribution le bureau de distribution
et/ou la tournée du facteur et/ou le point de distribution identifiés pour
cette
solution avec le bureau de distribution, la tournée du facteur et le point de
distribution identifiés pour chacune des autres solutions d'adresse de
distribution de manière à obtenir pour ladite solution courante d'adresse de
distribution une valeur cumulée des surcoûts d'erreur de distribution
calculée sur la base desdites première, seconde et troisième informations
numériques.
Un exemple de mise en oeuvre du procédé et du système selon l'invention
est décrit plus en détail ci-après en référence avec les dessins.
La figure 7 illustre sous la forme d'un organigramme simplifié le
déroulement d'une opération de reconnaissance automatique d'adresse par
OCR selon l'invention.
La figure 2 illustre sous la forme d'un organigramme simplifié un exemple
du processus de prise en compte d'un surcoût d'erreur de distribution lié au
traitement de l'envoi si il est livré à un point de distribution erroné.
La figure 3 illustre sous la forme d'un organigramme simplifié un autre
exempte du processus de prise en compte d'un surcoût d'erreur de
distribution lié au traitement de l'envoi si il est livré à un point de
distribution
erroné.
La figure 4 montre de façon très schématique la structure de la base de
données dans laquelle sont organïsées des listes ordonnées des points de
distribution pour des tournées du facteur.
La figure 5 illustre l'image d'un envoi postal comportant des informations
d'adresse de distribution.
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
7
Sur la figure 1, le déroulement d'une opération de reconnaissance
automatique par OCR d'une adresse de distribution (adresse de livraison)
d'un envoi postal commence par une étape 1 de saisie par une caméra (non
représentée) de l'image de l'envoi comportant l'adresse postale de livraison
de cet envoi.
La figure 5 illustre l'image d'un envoi comportant dans un bloc d'adresse
A des information d'adresse de distribution.
Cette image est ensuite binarisée en 2.
L'image binarisée est ensuite segmentée en 3 pour extraire le bloc
d'adresse.
On effectue en 4 une analyse syntaxique des informations contenues
dans le bloc d'adresse pour extraire en 5 les informations d'adresse
d'acheminement par une mise en concordance avec les données
enregistrées dans la base d'adresses de référence 6.
Cette étape 5 d'extraction peut fournir un ensemble de solutions
d'adresse d'acheminement qui sont regroupées et évaluées en 7 par une
mise en concordance avec les données enregistrées dans la base
d'adresses de référence 6 jusqu'à obtenir une résolution univoque des
informations d'adresse d'acheminement.
Si une résolution univoque ne peut être obtenue, l'envoi est écarté
(REJET) du processus de reconnaissance automatique. Sinon, les
informations d'adresse de distribution sont ensuite extraites en 8 par une
nouvelle analyse syntaxique des informations contenues dans le bloc
d'adresse en relation avec la base d'adresses de référence 6 ce qui fournit
un ensemble de solutions d'adresse de distribution.
En 9, les solutions d'adresse de distribution sont regroupées et évaluées
en relation avec la base d'adresses de référence 6 jusqu'à obtenir une
résolution univoque des informations d'adresse de distribution.
Comme indiqué plus haut, avec un processus classique de
reconnaissance automatique d'adresse, en l'absence d'une résolution
univoque des informations d'adresse de distribution, l'envoi est écarté ou
rejeté du processus de reconnaissance automatique.
Selon l'invention, si une résolution univoque des information d'adresse de
distribution ne peut pas être obtenue, on poursuit en 10 le traitement de
reconnaissance automatique d'adresse de distribution en exploitant une
bases de données 11 dans laquelle sont organisées des listes ordonnées
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
8
des points de distribution pour des tournées du facteur de façon à prendre
en compte un surcoût d'erreur estimé de distribution lié au traitement de
l'envoi si il est livré à un point de distribution erroné. Par liste ordonnée
des
points de distribution de la tournée du facteur, il faut comprendre une liste
de l'ensemble des points de distribution de la tournée du facteur selon le
sens de la tournée du facteur.
II faut comprendre ici que les traitement 2 à 10 sont réalisés par une unité
de traitement de données qui peut prendre la forme d'un réseau de plusieurs
ordinateurs. La base de données 11 comme la base d'adresses de référence
6 font partie de cette unité de traitement.
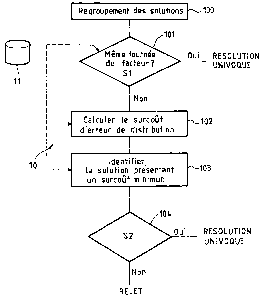
Sur la figure 2, on ~ a illustré différentes étapes d'un processus 10 selon
l'invention de prise en compte d'un surcoût d'erreur de distribution.
En 100, les solutions d'adresse obtenues en 9 ou un sur-ensemble de ces
solutions d'adresse sont regroupées et les points de distribution
correspondant respectivement à ces solutions d'adresse de distribution sont
identifiés par exemple par l'intermédiaire de la base d'adresses de référence
6 qui contient généralement ce type d'information.
En 101, on recherche si les points de distribution identifiés en 100 font ou
non partie d'une même tournée du facteur par l'intermédiaire de la base de
données 11 dont un exemple de structure est illustrée sur la figure 4.
En se référant à la figure 4, la base de données 11 est représentée sous
la forme d'enregistrements organisés en listes de listes.
La tête de la base de données 11 est un enregistrement 11A identifiant
par exemple un centre de tri.
Cet enregistrement de tête 11A pointe sur une liste ordonnée
d'enregistrements 11 B1, 11 B2, 11 Bi identifiant des bureaux de distribution
pour le centre de tri.
Chaque enregistrement 11 B, tel que 11 B1, pointe sur une liste ordonnée
d'enregistrements 11B1T1,11B1T2,11B1Ti identifiant des tournées du
facteur T1,T2,Ti pour le bureau de distribution considéré ici 11 B1.
Chaque enregistrement 11BT, tel que 11B1T1, pointe sur une liste
ordonnée d'enregistrements 11B1T1P1,11B1T1P2,11B1T1Pi,11B1T1Pk
identifiant des points de distribution P1,P2,Pi,Pk pour la tournée du facteur
correspondante du bureau de distribution correspondant.
Dans chaque enregistrement identifiant un point de distribution d'une
tournée du facteur est enregistrée une information VP1,VP2,VPi,VPk
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
9
représentative d'un volume de courrier pour chaque point de distribution de
la tournée du facteur. Les informations VP1,VP2, etc... peuvent être des
valeurs moyennes de volume de courrier connues de l'opérateur postal.
Sur la figure 2, à l'étape 101, si l'ensemble des points de distribution
identifiés à l'étape 100 font partie d'une même tournée du facteur, par
exemple la tournée T1 du bureau de distribution B1, on calcule le volume de
courrier dans la plage de distribution correspondant aux points de
distribution identifiés pour la tournée. La plage de distribution est définie
par
les deux points de distribution extrêmes de l'ensemble des points de
distribution identifiés en 100 dans la liste ordonnée des points de
distributiôn
de la tournée du facteur. Si i et k sont les indices de ces points de
distribution extrêmes, le volume du courrier de la plage de distribution est
défini par la relation suivante
V = Somme;.; à k (VP~ )
Dans l'étape 101, on compare la valeur calculée V à une valeur de seuil
S1 rëglable par l'opërateur postal et si V est inférieur à S1, on choisit
comme
solution pour une résolution univoque de l'adresse de distribution, la
solution correspondante au premier point de distribution de la plage de
distribution, c'est-à-dire la solution correspondant au point de distribution
VPi en se référant à la relation ci-dessus. Cette valeur de seuil S1 pourra
être réglée par l'opérateur postal pour éviter d'accepter une erreur de
classement. de l'envoi dans une tournée du facteur qui présente un grand
volume de courrier.
Sinon, on peut soit écarter l'envoi du traitement de reconnaissance
automatique (REJET) soit raffiner ce traitement selon l'invention par la
poursuite dans une étape 102 de calcul d'un surcoût de distribution lié au
traitement de l'envoi si il est livré par erreur à un bureau de distribution
erroné et/ou dans une tournée du facteur erronée et ou à un point de
distribution erroné. A noter, que la poursuite dans l'étape 102 peut être
commandée aussi si l'ensemble des points de distribution identifiés à l'étape
100 ne font par partie d'une même tournée du facteur comme déterminé à
l'étape 101.
Le détail de ('étape 102 est illustré sur la figure 3.
Sur la figure 3, C1,C2 et C3 sont des informations numériques
représentatives chacune d'un surcoût d'erreur de distribution lié au
traitement d'un envoi si il est livré respectivement à un bureau de
distribution
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
erroné, dans une tournée du facteur erronée, à un point de distribution
erroné.
Dans un exemple de mise en ceuvre simplifié du procédé selon
l'invention, C1,C2 et C3 peuvent être des valeurs numériques réglables
5 définies préalablement par l'opérateur postal.
Sur la figure 3, C; dësigne une valeur cumulée de surcoût de distribution
calculée pour une solution d'adresse courante d'indice i.
A l'étape 300, la valeur cumulée C; est initialisée à une valeur nulle.
A l'étape 301, si le bureau de distribution B de la tournée du facteur T
10 identifiée pour la solution d'adresse courante référencée Si est différent
du
bureau de distribution B de la tournée du facteur T identifiée pour une
solution d'adresse subséquente dans l'ensemble de solutions identifiées à
l'étape 100, ici référencée Sj, alors la valeur cumulée de surcoût d'erreur de
distribution C; est augmentée de la valeur C1 comme indiqué dans le bloc
302 et le processus revient à l'étape 301 pour une nouvelle solution
d'adresse subséquente.
Dans le cas contraire à l'étape 301, on recherche dans l'étape 303 si la
tournée du facteur T identifiée pour la solution d'adresse courante Si est
différente de la tournée du facteur T identifiée pour la solution d'adresse
subséquente Sj. Si c'est le cas, la valeur cumulée de surcoGt d'erreur de
distribution C; est augmentée de la valeur C2 comme indiqué dans le bloc de
traitement 304 et le processus revient à l'étape 301 pour une nouvelle
solution d'adresse subséquente.
Dans le cas contraire, la valeur cumulée de surcoût d'erreur de
distribution est augmentée à l'étape 305 de la valeur C3 et le processus
revient à l'étape 301 pour une nouvelle solution d'adresse subséquente.
A l'issue des étapes 300 à 305, on obtient une valeur cumulée de surcoût
d'erreur de distribution C; pour la solution d'adresse courante Si dans
l'ensemble des solutions d'adresse.
Le processus selon les étapes 300 à 305 est répété pour chaque autre
solution d'adresse de l'ensemble des solutions d'adresse déterminées à
l'étape 100, en tant que solution d'adresse courante pour ce processus.
A la fin du processus selon les étapes 300 à 305, on obtient dans le bloc
de traitement 102 autant de valeurs cumulées de surcoût d'erreur de
distribution Ci que de solutions d'adresse déterminées à l'étape 100.
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
11
A l'étape 103 sur la figure 2, on identifie la solution d'adresse pour
laquelle la valeur cumulée de surcoût d'erreur de distribution C; est la plus
faible.
Dans le bloc de traitement 104, si cette valeur cumulée C, est inférieure à
une valeur de seuil S2 enregistrée préalablement et réglable par l'opérateur
postal , alors cette solution d'adresse est la solution pour la résolution
univoque. Dans le cas contraire, l'envoi est écarté (REJET) par le traitement
de reconnaissance automatique. La valeur de seuil S2 permet d'écarter une
solution d'adresse pour ia résolution univoque qui présenterait un surcoût
d'erreur de distribution prohibitif pour l'opérateur postal.
Le procédé selon l'invention peut encore être raffiné en précision en
choisissant comme information numérique C1 représentative d'un surcoût
d'erreur lié au traitement d'un envoi si il est livré par un bureau de
distribution erroné une matrice de valeurs Ci,j dont chaque valeur est
représentative d'un surcoût d'erreur de distribution entre deux bureaux de
distribution déterminés.
Un exemple de matrice pour l'information numérique C1 peut être le
suivant pour 4 bureaux de distribution B1,B2,B3,B4
81 B2 B3 B4
B1 0 C1,2 C1,3 C1,4
B2 C2,1 0 C2,3 C2,4
B3 C3,1 C3,2 0 C3,4
B4 C4,1 C4,2 C4,3 0
Les informations numériques C2 et C3 peuvent être raffinées de la méme
façon que l'information valeur numérique C1. A la place d'une matrice de
valeurs, on peut utiliser pour l'information numérique C3 dans l'étape 305 un
polynôme qui tient compte de l'écart relatif entre deux points de distribution
d'une même tournée. Un exemple de polynôme pour l'information C3 peut
être le suivant
C3 = Valeur Absolue (C4 (i j)) + C5 ou i et j désignent le rang des points
de distribution dans une même tournée respectivement pour la solution
courante d'adresse Si et pour la solution d'adresse subséquente et C4 et C5
sont des constantes.
CA 02551668 2006-06-23
WO 2005/064508 PCT/FR2004/050038
12
Les informations numériques C1,C2 et C3 peuvent être enregistrées dans
les enregistrements adaptés de la base de données 11 du système de
reconnaissance automatique d'adresse par OCR.
Le procédé selon l'invention permet donc d'introduire quatre niveaux de
risque ou d'erreur dans la résolution univoque d'adresse de distribution.
Un premier niveau est introduit lorsqu'une erreur de classement est faite
entre deux bureaux de distribution.
Un second niveau est introduit lorsqu'une erreur de classement est faite
entre deux tournées du facteur au sein d'un même bureau de distribution,
cette erreur de classement devant nécessïter une seconde distribution de
l'envoi.
Un troisième niveau est introduit lorsqu'une erreur de classement est faite
au sein d'une même tournée du facteur. Cette erreur de classement sera
généralement découverte par le facteur au moment de la livraison du
courrier.
Enfin (e quatrième niveau correspond au niveau utilisé classiquement par
les système de reconnaissance automatique d'adresse par OCR.
Le système de traitement d'envois postaux selon l'invention peut bien
entendu faire partie d'une machine de tri postâl~ avec des sorties de tri
adaptées pour la préparation des tournées du facteur.