Note: Descriptions are shown in the official language in which they were submitted.
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
SCHEDULER FOR AUDIO PATTERN RECOGNITION
FIELD OF THE INVENTION
[001] The field of the invention relates to hardware implementations,
especially
integrated circuits, for voice recognition. More particularly, the invention
relates to an
apparatus and method of provisioning recognition tasks within the hardware for
enhanced
performance and reduced power consumption.
BACKGROUND OF THE INVENTION
[002] Linguists, scientists and engineers have endeavored to construct speech
recognition systems for many years. Although this goal has been realized in
some aspects
the currently available systems have not been able to produce results that
emulate human
performance. These difficulties include the extracting and identifying of the
individual
sounds that make up human speech, the wide acoustic variations of even a
single user
according to circumstances, the presence of noise and the wide differences
between
individual speakers.
[003] Simplistically speech may be considered a sequence of sounds taken from
a set
of forty or so basic sounds called "phonemes". But the same speaker may
produce
acoustically different versions of the same phoneme from one rendition to the
next.
[004] Also there are often no identifiable boundaries between sounds or even
words in
our normal speech patterns. This is further exacerbated when background noise,
especially other voices are present in the acoustic signal.
[005] The result is that speech recognition devices that are currently
available today
attempt to minimize these problems and variations by providing only a limited
number of
functions and capabilities. These are generally classed as "speaker-dependent"
or
"speaker-independent" systems.
[006] A speaker-dependent system must be "trained" to a single user's voice by
obtaining and storing a database of patterns for each vocabulary word uttered
by that
speaker. Disadvantages are obviously that the system is accessible by only a
single user,
1
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
although sometimes this may be an advantage with portable electronics, the
vocabulary
size of these is limited to the database, it is a time-consuming process, and
generally
these cannot recognize naturally spoken continuous speech.
[007] Speaker-independent systems are severely limited in function and
although any
user can use them without training they are typically classified by extremely
small
vocabulary and the need to have the words spoken in isolation with distinct
pauses. As
such these systems generally are limited today to telephony based directory
assistance,
customer call centre navigation and call routing type applications. In most
the word to be
spoken is actually given to the user further limiting the vocabulary
requirements.
[008] A typical prior art implementation takes a received audio signal,
digitizes the
signal and provides this as input to a microprocessor. The microprocessor
performs the
speech recognition using software algorithms, such as "Dragon
NaturallySpeaking"TM
that operate on the digitized audio signal. This approach has the disadvantage
of
consuming large amounts of resources and processor time within the
microprocessor,
thereby slowing down the performance of the system. As such these systems are
generally discrete stand-alone PC applications or networked applications
exploiting high-
end server microprocessors to perform the speech recognition remotely from the
user.
Even so such systems are generally limited vocabulary for acceptable cost-
performance
and thereby limited to applications such as form-filling or specialty tasks
such as medical,
for transcribing notes, etc.
[009] In another prior art implementation an application specific audio
recognition
integrated circuit is used that incorporates a dedicated microprocessor with
special
hardware and software for performing the speech recognition. However, these
can
present disadvantages without due care of increasing costs of the overall
system, being
difficult to integrate into many systems due to compatibility of the operating
characteristics of the application specific circuit and the remaining
hardware.
[0010] Additionally, the application specific speech recognition hardware will
be
integrated into a system controlled by a microprocessor. However, as the
applications on
the main processor changed or modified then adaptations and modifications to
the
2
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
application specific speech recognition circuit may be required creating
modifications
which are difficult, costly, and time-consuming and generally not a remote
operation
unlike most software upgrades today to desk-top and portable electronics.
[0011] Further the application specific solutions generally have their own
programming
environments that users must learn in order to implement speech recognition
functionality. Hence design cycles are increased as well as development costs.
Even so
such systems, such as the Sensory Inc RSC-4128 dedicated processor are capable
of only
500 words.
[0012] Today, portable electronics such as the iPODTM, MP3 players and other
devices
would benefit from a speech recognition system that allowed users to
efficiently select
their preferred tune, video or other information using speech rather than
cumbersome
scrolling through large lists of available material. As an example an iPODTM
with 60Gb
of memory can typically store 15,000 songs, 25,000 photos or 150 hours of
compressed
video.
[0013] As such there exists a requirement within a wide range of portable and
non-
portable electronics for a low cost, high performance, flexible speech
recognition system.
SUMMARY OF THE INVENTION
[0014] In accordance with the invention there is provided a task scheduler for
audio
pattern recognition comprising an input port, the input port for receiving a
digitized audio
signal comprising digitized audio information organized into a series of
bytes. Also
provided is a speech unit matching circuit in communication with the input
port and
comprising at least one of a digital signal processor, a buffer memory, a
labeler circuit,
and a Viterbi processor. The speech unit matching circuit for providing an
output signal
and being at least a portion of an audio recognition circuit. Also provided is
a scheduler
circuit, the scheduler circuit having at least a control port for receiving a
control signal,
the scheduler circuit in communication with the at least one of the digital
signal
processor, the buffer memory, the labeler circuit, and the Viterbi processor.
Also in
communication with the speech unit matching circuit is an output port for
receiving the
3
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
output signal; wherein the scheduler circuit for managing the flow of
digitized audio
information through the speech unit matching circuit.
[0015] In accordance with another embodiment of the invention there is
provided a task
scheduler for audio pattern recognition comprising an input port, the input
port for
receiving a digitized audio signal, the digitized audio signal comprising
digitized audio
information organized into a series of bytes. There is also provided a speech
unit
matching circuit, the speech unit matching circuit in communication with the
input port
and comprising at least one of a digital signal processor, a buffer memory, a
labeler
circuit, and a Viterbi processor, the speech unit matching circuit for
providing an output
signal and being at least a portion of an audio recognition circuit. A
scheduler circuit,
having at least a control port for receiving a control signal, the scheduler
circuit in
communication with the at least one of the digital signal processor, the
buffer memory,
the labeler circuit, and the Viterbi processor. Also provided is an output
port, the output
port in communication with the speech unit matching circuit for receiving the
output
signal; wherein the scheduler circuit manages the flow of digitized audio
information
through the speech unit matching circuit.
BRIEF DESCRIPTION OF THE DRAWINGS
[0016] Exemplary embodiments of the invention will now be described in
conjunction
with the following drawings, in which:
[0017] Fig. lA illustrates a typical example of speech recognition today
within an
environment of networking with high power microprocessor access.
[0018] Fig. 1 B illustrates a typical example of an audio music player of
current art
which would benefit from the provision of speech recognition.
[0019] Fig. 1 C illustrates a typical deployment scenario for a portable
multimedia
player.
[0020] Fig. 2 illustrates a typical prior solution using a dedicated
peripheral to provide
speech recognition.
4
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
[0021] Fig. 3 illustrates a prior art solution using multiple processors
associated with
pre-determined lexical trees to provide speech recognition.
[0022] Fig. 4 illustrates a first embodiment of the invention wherein a task
scheduler
manages the loading across the speech recognition elements.
[0023] Fig. 5 illustrates a second embodiment of the invention wherein a task
schedule
dynamically manages multiple parallel speech recognition paths.
DETAILED DESCRIPTION OF EMBODIMENTS OF THE INVENTION
[0024] Referring to Fig. 1 A there is shown a typical example of speech
recognition
according to the prior art, which is typically deployed within an environment
of
networking with high power microprocessor access. Shown are several user entry
formats
for speech, such as a dictation machine at a user's desk 101, a portable
dictation machine
102, a PABX telephone 103 and a dedicated online computer access point 104.
All of
these in the embodiment shown being interfaceable to a LAN network 161, which
for
example operate via TCP/IP protocols.
[0025] As shown the dedicated online computer access point 104 can provide
direct
real-time transfer but with multiple users and complex language transcription
can become
overloaded. The dictation machine 101, portable dictation machine 102, and
PABX
telephone 103 are connected to the LAN network 161 for transfer of digitized
speech files
to either the dedicated online computer access point 104 or to remote
transcription
servers 130.
[0026] Interconnection of the LAN network 161 being either via a direct LAN
connection 163 or through the World Wide Web 162. In the case of World Wide
Web
connection 162 the digitized speech is firstly transmitted via the remote
connection
system 120 to the remote transcription servers 130. As shown the array of a
second LAN
network 164 interconnects remote transcription servers 130.
[0027] A typical requirement of a software application loaded onto either the
dedicated
online recognition system 104 or the remote transcription servers is that they
be
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
configured with high-end processors and large memory. For example the
recommended
minimum system configuration for "Dragon NaturallySpeaking"TM, just to create
emails,
surf the web and send instant messages, is a minimum 500MHz processor, 256MB
RAM,
and a minimum of 500MB non-volatile memory.
[0028] Fig. 1 B illustrates a typical example of an audio music player of
current art
which would benefit from the provision of speech recognition. Here, a user 180
is using a
portable multimedia player 170 to listen to an audio recording stored within
the memory
of the device. A typical portable multimedia player 170 today is available
with memory
options ranging from 512MB at the cheapest end, through to 60GB at the high-
end.
However, within all of these memory options the core microprocessor is still a
low-speed
unit such as the 80MHz or 90MHz ARMTM processor within the AppleTM iPODTM. As
such it would be evident that these are not today systems geared to mapping a
speech
recognition solution into the feature set despite the ability of a 60GB RAM
device to hold
approximately 15,000 songs. This is an immense amount of scrolling to find a
single
song.
[0029] Fig. 1 C shows a typical user configuration for such a portable
multimedia player
170 wherein the user 180 has the player held within a band 190 on their arm
for use
during jogging, cycling or another exercise activity. It would therefore be
evident that as
commonly deployed the user is unable to select songs using the normal physical
entry
elements integrated within the portable multimedia player 170 as they are
either covered
by the band 190 or the screen is inaccessible with the portable multimedia
player 170
within the band 190. Such devices today weigh less than 50g and are in an
extremely
competitive and price sensitive market such that whilst speech recognition has
immense
user advantages the manufacturers will seek to implement this only when costs
are
extremely low. Typical prior art solutions such as outlined in Fig. 1 A are
incompatible
with this advantageous migration of speech recognition onto mobile platforms
where the
language requirements are for a large vocabulary, the user will typically be
in noisy
environments, their voice will change for example from rest at starting
exercise to that
during exercise, and multiple users might access the same portable multimedia
player.
6
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
[0030] Fig. 2 illustrates a typical prior solution using a dedicated
peripheral to provide
speech recognition. Shown is a dedicated peripheral processor 200, which is
intended to
provide off-loading of the speech recognition from a microprocessor within a
device.
Shown is a microphone 220 which receives the users speech and provides the
analog
signal to a pre-amplifier and gain control circuit 201 which provides a
conditioning of the
circuit so that the analog signal is within a predetermined acceptable range
for the
subsequent analog-to-digital conversion performed by the ADC block 202. Such
conditioning providing for maximum dynamic range of sampling.
100311 The digitally sampled signal is then passed through appropriate digital
filtering
203 before being coupled to the core general-purpose microprocessor (RSC) 250,
which
performs the bulk of the processing. As shown the RSC is externally coupled by
databus
213 to the device requiring speech recognition, not shown for clarity. The RSC
also
having a second databus 214 which is connected internally within the dedicated
peripheral microprocessor 200 to a vector accelerator circuit 215 as well as
facilitating
additional external processing support with the external aspect of the databus
214.
[0032] In order to perform the speech recognition the RSC 250 is electrically
coupled
to ROM 217 and SRAM 216, which contain user defined vocabulary, language
information and other aspects of the software required for the RSC 250. The
ROM 217
and SRAM 216 also being electrically connected to the vector accelerator
circuit 215,
which provides for specific mathematical functions within the speech
recognition, which
are best, further offloaded from the RSC 250.
[00331 The RSC 250 is also electrically coupled to the pre-amplifier and gain
control
circuit 201 directly to provide an audio-wakeup trigger from the audio-wakeup
circuit
212 in the event the RSC 250 has gone into standby mode and then a user
speaks. Further
the RSC 250 provides control signals back to the pre-amplifier and gain
control circuit
201 via the automatic gain control circuit 211.
[0034] Additionally the dedicated peripheral processor 200 contains timing
circuits 205
and low battery detection circuit 208. Such solutions today typically operate
at sampling
rates of 1 kHz such that the audio signal is broken into l Oms elements, which
are then
7
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
digitized giving sampling rates typically of 8kb/s. A typical prior art
embodiment of this
form has retail pricing comparable to the portable multimedia devices it is
intended for,
providing a significant cost barrier to their deployment, as do their slow
speed of
recognition, serial processing and limited vocabulary without large and
expensive
dedicated memory.
100351 Fig. 3 illustrates a prior art solution using multiple processors
associated with
pre-determined lexical trees to provide some acceleration to speech
recognition. Shown is
a speech recognition circuit 300, which has provided at input port 302 a
digital audio
stream, representing the speech to be recognized. Also provided at a second
input port
301 is a control word addressing a language model processor 315 within the
speech
recognition circuit 300. The language model processor 315 in response to the
control
word present at the second input port 301 extracts the appropriate language
set from the
language model memory 305.
[0036] The extracted words are then provided from the language model processor
315
to the multiple lexical tree processors 330. Each lexical tree processor 330
therein being a
number of unique word initial states based upon a closed set of phonemes, the
phonemes
varying according to the langauge model processor 315 state. Each lexical tree
processor
330 is arranged in conjunction with one of a plurality of acoustic model
memories 335
which provide the phoneme patterns to be matched within the specific lexical
tree groups.
[0037] The digitized speech entered into the speech recognition circuit 300 at
the input
port 302 is initially coupled to a feature vector buffer 302a before being
sent to the array
of lexical tree processors 330 for processing. Each lexical tree processor 330
is then
coupled to the results memory 325 such that a satisfactory match between the
input
digitized speech and one of the word states of a lexical tree processor is
then stored
within memory. Additionally the results memory 325 can arbitrate based upon
multiple
phoneme based hits within the lexical tree processors 330. The results memory
325 also
provides the matched word to the output 303 of the speech recognition circuit.
[0038] Upon obtaining a match the results memory 325 communicates with a
search
controller 320 which controls the lexical tree processors 330 and the feature
vector buffer
8
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
302a such that a new word is entered into the lexical tree processors for
matching. The
search controller 320 is additionally coupled to a program and data memory
which
provides control instructions according to the state of the speech recognition
circuit 300.
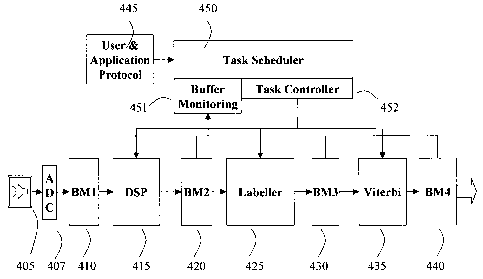
[0039] Fig. 4 illustrates a first embodiment of the invention wherein a task
scheduler
manages the loading across the speech recognition elements. Shown is an input
microphone 405 which is electrically coupled to an analog-to-digital converter
(ADC)
407 which provides a digitized representation of the audio signal to a first
buffer memory
410 which stores the digitized representation of the of the audio signal until
it is fed
forward to a digital signal processing circuit 415 which performs functions
including, but
not limited to noise reduction, segmentation, bias adjustment, gain control,
amplification
and filtering. The output of the digital signal processing circuit 415 is then
fed to the
second buffer memory 420 where the processed audio signal is stored pending
forwarding to the labeler circuit 425.
[0040] Labeler circuit 425 upon receiving the processed audio signal
undertakes a first
stage identification of the forwarded process audio segment, the first stage
identification
being one of many possible approaches including forward prediction based upon
previous
identified phoneme or word, consonant or vowel classification based upon
spectral
content, priority tagging and phoneme position within processed audio signal.
The output
of the labeler circuit 425 is fed forward to a third buffer memory 430 for
storage pending
request to forward from the third buffer memory 430 to the Viterbi decoder
435.
[0041] The Viterbi decoder 435 in the embodiment shown operating using a
Viterbi
algorithm, namely a dynamic programming algorithm for finding the most likely
sequence of a set of possible hiddent states. Commonly the Viterbi decoder
will operate
in the context of hidden Markov models (HMM). Typically, the Viterbi decoder
operating upon an algorithm for solving HMM makes a number of assumptions.
These
can include, but are not limited to, the observed events and hidden events are
in a
sequence, the sequence corresponds to time, the sequences need to be aligned,
and that an
observed event needs to correspond to exactly one hidden event. Additionally
the
computing may make the assumption that the most likely hidden sequence up to a
certain
9
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
point t must depend only on the observed event at point t, and the most likely
sequence at
point t - 1. These assumptions would all be satisfied in a first-order hidden
Markov
model.
[0042] The output of the Viterbi decoder 435 is fed forward to a fourth buffer
memory
440 prior to being fed forward, the feed forward being to a results memory,
additional
pattern recognition circuitry or a variety of other circuitry options. In
respect of
sequencing the overall process a task controller 452 is in communication with
at least the
digital signal processor 415, labeler circuit 425 and Viterbi decoder 435 in
respect of
determining their activities within a given time period of the overall
function.
[0043] The task controller 452 is also in communication with the buffer memory
monitoring circuit 451. The buffer monitoring circuit providing a status of
the buffer
memory circuits 410, 420, 430 and 440 such that the task controller 452 can
make
balancing decisions based upon the loading of the buffer memory circuits 410,
420, 430
and 440 in relation to the status of operations within the digital signal
processor 415,
labeler circuit 425 and Viterbi decoder 435. Both the task controller 452 and
buffer
memory monitoring circuit 451 are in communication with a master task
scheduler 450
which can provide for example, process overrides, buffer memory wiping of
stored audio
signals, re-prioritization of tasks or re-segmentation of the digitized audio
signals.
[0044] The task scheduler 450 is shown in communication with a user and
language
protocol circuit 445 which provides input to the task scheduler, which can
adjust the
operation of the overall speech recognition process based upon a wide range of
potential
events including the user, who is bilingual and generally speaking English
swaps to
French for a phrase or term having no simple English equivalent, the user
changes from a
mother to her daughter with a resulting shift in phoneme construction and
common
vocabulary use, or the user switches from choosing audio files on their
portable electronic
device to entering a voice message for forwarding to a user via the portable
electronic
devices wireless network interconnection.
[0045] It would be evident that many other embodiments and applications of the
invention are possible without departing from the scope of the invention. The
task
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
scheduler 450 can additionally provide a variety of additional functions
including, but not
limited to, shutting down one or more circuit elements based upon presence or
absence of
digitized audio signal to process, dynamically adjusting the memory space for
the buffer
memory circuits, adjusting clock signal distribution to the multiple circuits
to either
reduce buffered memory usage or reduce power consumption, and terminating
processes
to process a different digitized audio signal segment prior to reprocessing
the terminated
segment at a later point in time.
[0046] Advantageously the first buffer memory 410 might be connected directly
to an
alternate source of audio other than the microphone such as voicemail for
transcription or
display to a deaf or hard-of-hearing user for example. Equally the digital
signal processor
might receive directly a digitized signal stream thereby eliminating the need
for
digitization and memory buffering to simply proceed with segmentation and
prioritization
of the information, for example.
[0047] Fig. 5 illustrates a second embodiment of the invention wherein a task
schedule dynamically manages multiple parallel speech recognition paths. Shown
is an
input microphone 505 which is electrically coupled to an analog-to-digital
converter
(ADC) 507 which provides a digitized representation of the audio signal to a
first buffer
memory 510 which stores the digitized representation of the of the audio
signal until it is
fed forward to a digital signal processing circuit 515 which performs
functions including,
but not limited to noise reduction, segmentation, bias adjustment, gain
control,
amplification and filtering. The output of the digital signal processing
circuit 515 is then
fed to the second buffer memory 520 where the processed audio signal is stored
pending
forwarding to one of the plurality of labeler circuits 525 to 527.
[0048] Each of the labeler circuits 525 to 527 upon receiving the processed
audio signal
undertakes a first stage identification of the forwarded process audio
segment. The task
controller 552 determining which of the labeler circuits 525 to 527 to use for
processing
either upon a first come first served basis or other alternative sequencing
rules. The first
stage identification being one of many possible approaches including forward
prediction
based upon previous identified phoneme or word, consonant or vowel
classification based
11
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
upon spectral content, priority tagging and phoneme position within processed
audio
signal. The output of the labeler circuits 525 to 527 is then fed forward to a
third buffer
memory 530 for storage pending request to forward from the third buffer memory
530 to
one of the Viterbi decoders 535 to 537. Whilst the second and third buffer
memories 520
and 530 are shown as single blocks it would evident that alternate
arrangements are
possible wherein the buffer memory is also segmented according to a
predetermined or
dynamic rule such that the overall processing speed and power consumption of
the
speech recognition circuitry is optimized.
[0049] The Viterbi decoders 535 to 537 in the embodiment shown operating using
a
Viterbi algorithm, namely a dynamic programming algortim for finding the most
likely
sequence of a set of possible hidden states. Commonly the Viterbi decoder will
operate in
the context of hidden Markov models (HMM). Typically, the Viterbi decoder
operating
upon an algorithm for solving HMM makes a number of assumptions. These can
include,
but are not limited to, the observed events and hidden events are in a
sequence, the
sequence corresponds to time, the sequences need to be aligned, and that an
observed
event needs to correspond to exactly one hidden event. Additionally the
computing may
make the assumption that the most likely hidden sequence up to a certain point
t must
depend only on the observed event at point t, and the most likely sequence at
point t - 1.
These assumptions would all be satisfied in a first-order hidden Markov model.
Alternatively different Viterbi decoders 535 to 537 could be configured with
different
models and prioritised based upon a variety of different rules.
[0050] The output of the Viterbi decoders 535 to 537 is fed forward to a
plurality of
fourth buffer memories 540 to 542 on a one-to-one basis prior to being fed
forward, the
feed forward including a variety of functions including into a results memory,
additional
pattern recognition circuitry or a variety of other circuitry options. In
respect of
sequencing the overall process a task controller 552 is in communication with
at least the
digital signal processor 515, labeler circuits 525 to 527, and Viterbi
decoders 535 to 537
in respect of determining their activities within a given time period of the
overall
function.
12
CA 02558279 2006-08-31
Doc. No. 297-02 CA Patent
[0051] The task controller 552 is also in communication with the buffer memory
monitoring circuit 551. The buffer monitoring circuit providing a status of
the first,
second and third buffer memory circuits 510, 520, 530, and the plurality of
fourth buffer
memory circuits 540 to 542. As such these allow the task controller 552 to
make
balancing decisions based upon the loading of the buffer memory circuits 510,
520, 530
and 540 to 542 in relation to the status of operations within the digital
signal processor
515, labeler circuits 525 to 527, and Viterbi decoders 535 to 537. Both the
task controller
552 and buffer memory monitoring circuit 551 are in communication with a
master task
scheduler 550 which can provide for example, process overrides, buffer memory
wiping
of stored audio signals, re-prioritization of tasks or re-segmentation of the
digitized audio
signals.
[0052] The task scheduler 550 is shown in communication with a user and
language
protocol circuit 545, which provides input to the task scheduler, which can
adjust the
operation of the overall speech recognition process based upon a wide range of
potential
events.
[0053] It would be evident that the embodiment as shown can be adjusted in
many
ways to balance a variety of tradeoffs such as memory usage, power
consumption,
processor usage, speed of recognition, and accuracy of recognition for example
without
departing from the spirit of the invention. It would also be advantageous in
some
scenarios to vary the relative ratios of the different functional blocks
either physically
using hardware or by portioning using firmware. Additionally the dynamic
provision of
the number of each function block can be advantageous where speech recognition
may
shift substantially from say single user recognition for audio file playing
through to
transcribing a two-way communication.
[0054] Numerous other embodiments may be envisaged without departing from the
spirit or scope of the invention.
13