Note: Descriptions are shown in the official language in which they were submitted.
CA 02564798 2007-05-15
SYSTEMS AND METHODS FOR ANALYZING AUDIO COMPONENTS OF
COMMUNICATIONS
BACKGROUND
[0001] It is desirable in many situations to record communications, such as
telephone
calls. This is particularly so in a contact center in which many agents may be
handling
hundreds of telephone calls each every day. Recording of these telephone calls
can allow
for quality assessment of agents, improvement of agent skills and/or dispute
resolution,
for example.
[0002] In this regard, it is becoming more commonplace for recordings of
telephone
communications to be reduced to transcript form. However, the number of
individual
words within each telephone call is such that storing each word as a record in
a relational
database is impractical for large contact centers handling millions of calls
per annum.
SUMMARY
[0003] In this regard, systems and methods for analyzing audio components of
communications are provided. An embodiment of such a system comprises an audio
analyzer operative to: receive information corresponding to an audio component
of a
communication session; generate text from the information; and integrate the
text with
additional information corresponding to the communication session, the
additional
information being integrated in a textual format.
[0004] An embodiment of a method comprises: receiving information
corresponding to
an audio component of a communication session; generating text from the
information;
1
CA 02564798 2007-05-15
and integrating the text with additional information corresponding to the
communication
session, the additional information being integrated in a textual format.
[0005] Other systems, methods, features, and advantages of this disclosure
will be or
become apparent to one with skill in the art upon examination of the following
drawings
and detailed description. It is intended that all such additional systems,
methods, features,
and advantages be included within this description and be within the scope of
the present
disclosure.
BRIEF DESCRIPTION
[0006] Many aspects of the disclosure can be better understood with reference
to the
following drawings. The components in the drawings are not necessarily to
scale,
emphasis instead being placed upon clearly illustrating the principles of the
present
disclosure. Moreover, in the drawings, like reference numerals designate
corresponding
parts throughout the several views. While several embodiments are described in
connection with these drawings, there is no intent to limit the disclosure to
the
embodiment or embodiments disclosed herein. On the contrary, the intent is to
cover all
alternatives, modifications, and equivalents.
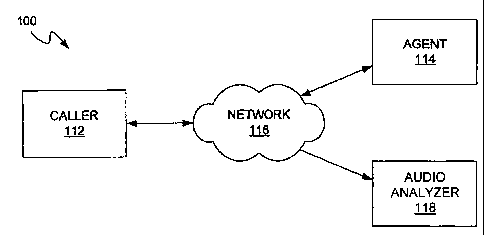
[0007] FIG. 1 is a schematic diagram illustrating an embodiment of a system
for
analyzing audio components of communications.
[0008] FIG. 2 is a flowchart illustrating functionality (or methods steps)
that can be
preformed by the embodiment of the system for analyzing audio components of
communication of FIG. 1.
2
. . . . .. . .. . . . .. . . . . . I . .. . .. . . .
CA 02564798 2007-05-15
[0009] FIG. 3 is a schematic diagram illustrating another embodiment of a
system for
analyzing audio components of communications.
[0010] FIG. 4 is a diagram depicting an embodiment of a textual representation
of an
audio component of a communication.
[0011] FIG. 5 is a diagram depicting another embodiment of a textual
representation of
an audio component of a communication.
[0012] FIG. 6 is a diagram depicting an embodiment of a call flow
representation of a
communication.
[0013] FIG. 7 is a schematic diagram illustrating an embodiment of voice
analyzer that is
implemented by a computer.
DETAILED DESCRIPTION
[0014] Systems and methods for analyzing audio components of communications
are
provided. In this regard, several exemplary embodiments will be described in
which
various aspects of audio components of conununications are analyzed. By way of
example, in some embodiments, the audio component of a communication, e.g., a
telephone call, is converted to a textual format such as a transcript.
Additional
information, such as amplitude assessments of the communication, is associated
with the
textual format. Notably, such additional information also can be textual,
thereby resulting
in a data file that uses less memory than if the audio component were stored
as audio and
appended with the additional information. Moreover, since the data file uses a
textual
format, text-based indexing and searching can be readily accommodated.
3
CA 02564798 2007-05-15
[0015] The textual representation of the dialog and surrounding telephony
experience
occupies much less space per hour of telephone call than the audio recording
of the call
itself and hence can be accommodated within a recording system for marginal
additional
storage cost. The infrastructure of the recording system makes it easy to
manage, access,
secure and archive the content along with the audio to which it relates.
[0016] In some embodiments, this approach allows a single repository and
search
mechanism to search across both contacts that originated as text (e.g., email
and web chat)
and those originating as speech (e.g., telephone calls). This potentially
enables a user to
view their entire customer contact through a single mechanism.
[0017] In this regard, FIG. 1 is a schematic diagram illustrating an
embodiment of a
system for analyzing audio components of communications. As shown in FIG. 1,
system
100 incorporates an audio analyzer 118 that is configured to analyze audio
components of
communications. In FIG. 1, the audio component is associated with a
communication
session that is occurring between a caller 112 and an agent 114 via a
communication
network 116. In this embodiment, the agent is associated with a contact center
that
comprises numerous agents for interacting with customers, e.g., caller 112.
[0018] One should also note that network 116 can include one or more different
networks
and/or types of networks. As a nonlimiting, example, communications network
116 can
include a Wide Area Network (WAN), the Internet, and/or a Local Area Network
(LAN).
[0019] In operation, the audio analyzer of FIG. 1 performs various functions
(or method
steps) as depicted in the flowchart of FIG. 2. As shown in FIG. 2, the
functions include
receiving information corresponding to an audio component of a communication
session
(block 210). In block 212, text is generated from the information. Then, in
block 214,
4
CA 02564798 2007-05-15
the text is integrated with additional information corresponding to the
communication
session, with the additional information being integrated in a textual format.
By way of
example, in some embodiments, the text with additional information is stored
as a text
document.
[0020] It should be noted that a communication such as a telephone call may
last from a
few seconds to a few hours and, therefore, may include from one to several
thousand
words - and several tens of thousands of phonemes (i.e., meaning laden sounds
that form
spoken words). Thus, in some embodiments, for each word or phoneme, the audio
analyzer identifies one or more of the following: the time or offset within
the
communication at which each word/phoneme started; the time or offset within
the
communication at which each word/phoneme ended; and the confidence level with
which
each word/phoneme was identified. In this regard, some embodiments can
identify not
only the "best guess" word/phoneme but the "N-best" guesses.
[0021] FIG. 3 is a schematic diagram illustrating another embodiment of a
system for
analyzing audio components of communications. As shown in FIG. 3, system 300
incorporates an audio analyzer 310 that is configured to analyze audio
components of
communications. In FIG. 3, the audio component is associated with a
communication
session that is occurring and/or has occurred between a caller 312 and an
agent 314 via a
communication network 316. Notably, in this embodiment, at least some of the
information corresponding to the communication session is provided to the
audio
analyzer by a recorder 318 that is used to record at least a portion of the
communication
session. Thus, when the communication is facilitated by the use of Internet
Protocol (IP)
packets, the recorder can be an IP recorder. It should also be noted that
depending on the
CA 02564798 2007-05-15
type of information that is to be received by an audio analyzer, one or more
of various
other components may be involved in providing information in addition to or in
lieu of a
recorder.
[0022] As shown in the embodiment of FIG. 3, audio analyzer 310 incorporates a
speech
recognition engine 322, a phonetic analyzer 324, an amplitude analyzer 326 and
a call flow
analyzer 328. It should be noted that in other embodiments, an audio analyzer
may
incorporate fewer than all of the components 322, 324, 326 and 328 and/or all
of the
corresponding functions.
[0023] With respect to the speech recognition engine 322, the speech
recognition engine,
which can be a large vocabulary type, generates a textual transcript (e.g.,
transcript 332)
of at least a portion of an audio component of a communication session. Once
so
generated, the transcript can be stored as a text document.
[0024] In some embodiments, such a transcript can incorporate interruptions
from the
other party (e.g., "uh-huh" feedback) within the text of the active speaker.
Schemes that
can be used for implementing such a feature include but are not limited to:
encapsulation
within characters that do not form part of the active speaker text (e.g., "<uh-
huh>" or "Juh-
huhl"); a marker character that indicates the location of the interjection
without indicating
the actual utterance (e.g., "~"); the interjection may be inserted within a
word or at the
next/previous word boundary; and/or the interjection may be surrounded by
space or other
whitespace (arbitrary) characters so as not to be considered as concatenated
to the
previous/next word.
[0025] The phonetic analyzer 324 generates a phonetic representation of at
least a portion
of the audio component of the communication session as a text document. This
can be
6
. . . .. . . . . . . ... ... . .. . .. . .. .. . . . . .
CA 02564798 2007-05-15
accomplished using standard symbols for speech or an alternate mapping of
phoneme to
character. In some embodiments, a space character can be used to indicate a
pause. In a
refinement, the duration of pauses may be indicated by multiple space
characters, e.g. one
space per second.
[0026] The amplitude analyzer 326 generates a textual representation of the
audio
component. In particular, the textual representation includes an
identification of which
party is speaking at any time during the communication, and an indication of
the
amplitude of the speech at each time. By way of example, FIG. 4 depicts a
textual
representation of an audio component of a communication. Specifically, the
embodiment
of FIG. 4 is a one character per second representation of a call recorded in
stereo. This
embodiment corresponds to a call in which an agent ("a") greeted the customer
for four
seconds using normal voice levels (designated by the use of the lower case
letter). After a
one second pause, indicated by a single space character, the customer ("c")
responded at
normal levels for three seconds then spoke at a high level (e.g., shouted) for
three seconds
(designated by the use of the upper case letters). After a four second pause,
indicated by
the use of four space characters, the agent responded for 13 seconds at normal
levels.
Then, after a one second pause, indicated by a single space character, the
agent spoke for
nine seconds, during which the customer interjected twice briefly (designated
by the "b"
for both speaking at normal levels). After another one second pause, an
extended verbal
exchange between the agent and customer takes place that is generally broke
into a twelve
second portion and a ten second portion. Notably, the lack of pauses in this
section and
the use of capital letters appears to indicate an argument between the
customer and the
agent.
7
CA 02564798 2007-05-15
[0027] During the twelve second portion, the customer responded at high levels
during
which the agent interjected two times (designated by the "B"), first for five
seconds and
then for three seconds. Then, during the ten second portion, the agent was
able to speak
for one second at a normal level, after which the customer interjected at high
levels for
two seconds, following another one second during which the agent was able to
speak at a
normal level. After that, both the agent and the customer spoke simultaneously
for one
second, during which at least one of them was speaking at a high level
(presumably the
customer), and then the customer alone spoke at high levels for five seconds.
[0028] An alternative representation, which does not use a fixed number of
characters per
second of audio, is depicted in FIG. 5. In FIG. 5, the same communication
session that
was used to generate the text in FIG. 4 has been used for generating this
text. In
particular, each component in this representation is a combination of a
character for who
was talking and a number designating the number of seconds of speaking by that
person.
By way of example, "a4" indicates that the agent was speaking at less than a
high level
for four seconds.
[0029] As in the embodiment of FIG. 4, a lower case letter designates speaking
at less
than a high level and a capital letter designates speaking at a high level.
Note that one
benefit of using upper and lowercase letters for designating various features
allows for
case sensitive searching. Thus, when interested in speech of a high level,
case sensitive
searching for upper case letters can be used. Whereas, in contrast, if the
amplitude level
is not relevant to a particular search, case insensitive searching can be
performed.
8
. . .. ..... . .. . . . .... ... . . . . I .. ... .. ......... . . . . . . ..
. . . ...
CA 02564798 2007-05-15
[0030] Clearly, various other characters could be used in addition to or
instead of those
characters used in the embodiments of FIGs. 4 and 5. For instance, the letter
"f' could be
used to indicate feedback in the audio component.
[0031] In a further refinement, more than the three amplitude levels (e.g.,
silence, normal,
high) may be identified with different characters being used to indicate each.
[0032] With respect to the call flow analyzer 328, this analyzer generates a
textual
representation of the communication from a call flow perspective. That is, the
call flow
analyzer generates text corresponding to the events occurring during the
communication,
such as time spent ringing, hold times, and talking times. By way of example,
FIG. 6
depicts an embodiment of a textual representation of the same communication
that was
used to generate the text outputs depicted in FIGs. 4 and 5.
[0033] As shown in FIG. 6, this representation indicates that the
communication involved
ringing for 15 seconds ("R15"), talking for 61 seconds ("T61"), on-hold for
the following
35 seconds ("H35") and then terminated with caller abandonment ("A"). Clearly,
various
other characters could be used in addition to or instead of those characters
used in the
embodiment of FIG. 6 and/or various other events could be represented. For
instance, the
letter "X" could be used to indicate a transfer and the letter "H" can be used
to indicate
that an agent hung up the call.
[0034] In those embodiments in which an annotation of time is maintained, time
approximation techniques such as banding can be used to facilitate easier
clustering of the
information. For example, it may be desirable to summarize the
talk/listen/silence
fragments rather than provide a fixed number of characters per second rate. In
one
implementation of banding, for example, any silence less than 1 second could
be
9
CA 02564798 2007-05-15
represented as "sO," a 1 to 2 second delay as "sl," and a 2 to 5 second delay
as "s3," in
increasing bands. Notably, the banding for periods of speaking may be
different from those
of silence and/or hold. For example, hold of 0 to 15 seconds may be considered
insignificant and classified as "HO" but when there is speaking, there is a
potentially
significant difference between many 2 second sentences and a flowing, 10
second sentence.
Hence the breadth of the talk bands could be narrower at the low end but
broader at the high
end. For instance, any continuous period of speaking above 1 minute without
letting the
customer speak may be considered unacceptable and rare enough that additional
banding
above 1 minute is not necessary.
[0035] Based on the foregoing examples, it should be understood that an
embodiment of
a voice analyzer can be configured to generate text documents that include
various
formats of information pertaining to communications. In some embodiments, such
a
document may include a combination of one or more of the formats of
information
indicated above to produce a richly annotated record of a communication. This
can be
achieved in a number of ways. By way of example, such information could be
interleaved
or can be segmented so that information of like type is grouped together.
Notably each such
text document can include an attribute that identifies the document type(s),
e.g., transcript,
phonetic transcript and/or talk/listen pattern.
[0036] Additionally or alternatively, at least some of the information can be
provided as
html tags that are associated with a text document. By way of example, the
following html
tag could be associated with one or more of the document types described above
with
respect to FIGs. 4- 6, "<telephony state=ringing duration-15 /><telephony
CA 02564798 2007-05-15
state=connected><talklisten speaker=agent duration=4.5 volume=normal>Thank you
for
calling Widgets Inc</talklisten> .... </telephony>."
[0037] Note also the timestamps embedded in the html above. These could be at
the
talk/listen fragment level, individual word level or every second, on nearest
word
boundary so as to allow positioning within the call to the nearest second, for
example.
[0038] In some embodiments, the voice analyzer can determine the time offset
within the
call of one or more words/phonemes by the insertion of whitespace characters,
e.g., tab
characters. In such an implementation, a tab can be inserted once each second,
for example,
between words. This allows the offset of any word, and the duration of any
pause to be
determined to within 1 second accuracy. This is adequate for retrieving the
appropriate
section of audio from a call as typically a short lead-in to the specific
word/phrase is played
to give the user some context within which the word/phrase of interest has
meaning. It
should be noted that the mechanism for determining any time offset may, in
some
embodiments, be in addition to any mechanism used for determining segment or
event
timing.
[0039] In some embodiments, the generated text documents are provided to
indexing and
search algorithms. In some embodiments, the same indexing and search
algorithms can be
used across the document types because there is little to no overlap between
the "tokens" in
the different categories of documents. Thus, a search can be constructed using
words,
phonemes or talk/listen patterns or a combination thereof. The results will be
largely
unaffected by the presence of tokens from other two domains and a single
search across a
mixed set of text documents can be performed.
11
CA 02564798 2007-05-15
[0040] In some embodiments, the text documents are loaded into a text search
engine,
such as Lucene, information about which can be located at the World Wide Web
address
of apache.org, which generates indexes that allow for rapid searching for
words, phrases
and patterns of text as would be done on web-site content.
[0041] In this regard, any such indexing process could be modified so that at
least some
of the information is excluded from the indexing. By way of example, if a text
document
is stored as a composite transcript, telephony events and talk/listen pattern,
the latter two
may be excluded in the same way that embedded html tags are typically excluded
from
normal text indexing of web documents. In fact, if these subsidiary
annotations are
embedded as html tags, these tags can be excluded automatically through normal
operation by a standard html ingestion parser.
[0042] Additionally or alternatively, an ingestion process can be modified so
that rather
than offset into the text in characters, the offset in seconds of each word is
stored. By
way of example, the offsets can be deduced from the number of tab characters
processed
to date if these are used to indicate one second intervals as above.
[0043] In some embodiments, a search engine's handling of proximity searches
can be
modified such that "A within T seconds of B" can optionally mean "by the same
speaker"
or "by different speakers."
[0044] Further, in some embodiments, modified stemming algorithms can be used
to
stem phonetic strings by stripping the phonetic equivalents of "..ing", "..ed"
etc. rather
than the normal English language text stemming algorithm.
[0045] Bayesian clustering algorithms can be applied in some embodiments to
the text
documents to identify phrases of multiple words and/or phonemes that occur
frequently.
12
CA 02564798 2007-05-15
These text documents (and hence the calls/call fragments they represent) can
be grouped
into clusters that show common characteristics.
[0046] A further refinement proactively highlights the emergence of new
clusters and the
common phrases that are being identified within them. The user may then review
some
examples of these and determine the significance, or otherwise, of the new
clusters.
[0047] As a further refinement, a text document generated by a voice analyzer
can be
incorporated along with call attributes (e.g., AIVI, AgentID and Skill). In
some of these
embodiments, the information can be provided in an xml file. This information
can be
stored, archived and/or secured alongside the recorded audio or in
complementary
locations.
[0048] As should be noted, the aforementioned exemplary embodiments tend to
leverage
the highly scalable and efficient text indexing and search engines that the
have been
developed to search the millions of documents on the web. This can allow
businesses to
search through the content of millions of calls without impacting their
existing relational
databases that typically hold the metadata associated with these calls.
[0049] FIG. 7 is a schematic diagram illustrating an embodiment of voice
analyzer that is
implemented by a computer. Generally, in terms of hardware architecture, audio
analyzer
700 includes a processor 702, memory 704, and one or more input and/or output
(I/O)
devices interface(s) 706 that are communicatively coupled via a local
interface 708. The
local interface 708 can include, for example but not limited to, one or more
buses or other
wired or wireless connections. The local interface may have additional
elements, which
are omitted for simplicity, such as controllers, buffers (caches), drivers,
repeaters, and
receivers to enable communications.
13
CA 02564798 2007-05-15
[0050] Further, the local interface may include address, control, and/or data
connections
to enable appropriate communications among the aforementioned components. The
processor may be a hardware device for executing software, particularly
software stored
in memory.
[0051] The memory can include any one or combination of volatile memory
elements
(e.g., random access memory (RAM, such as DRAM, SRAM, SDRAM, etc.)) and
nonvolatile memory elements (e.g., ROM, hard drive, tape, CDROM, etc.).
Moreover,
the memory may incorporate electronic, magnetic, optical, and/or other types
of storage
media. Note that the memory can have a distributed architecture, where various
components are situated remote from one another, but can be accessed by the
processor.
Additionally, the memory includes an operating system 710, as well as
instructions
associated with a speech recognition engine 712, a phonetic analyzer 714, an
amplitude
analyzer 716 and a call flow analyzer 718. Exemplary embodiments of each of
which are
described above.
[0052] It should be noted that embodiments of one or more of the systems
described
herein could be used to perform an aspect of speech analytics (i.e., the
analysis of
recorded speech or real-time speech), which can be used to perform a variety
of functions,
such as automated call evaluation, call scoring, quality monitoring, quality
assessment
and compliance/adherence. By way of example, speech analytics can be used to
compare
a recorded interaction to a script (e.g., a script that the agent was to use
during the
interaction). In other words, speech analytics can be used to measure how well
agents
adhere to scripts, identify which agents are "good" sales people and which
ones need
additional training. As such, speech analytics can be used to find agents who
do not
14
CA 02564798 2007-05-15
adhere to scripts. Yet in another example, speech analytics can measure script
effectiveness, identify which scripts are effective and which are not, and
find, for
example, the section of a script that displeases or upsets customers (e.g.,
based on
emotion detection). As another example, compliance with various policies can
be
determined. Such may be in the case of, for example, the collections industry
where it is
a highly regulated business and agents must abide by many rules. The speech
analytics of
the present disclosure may identify when agents are not adhering to their
scripts and
guidelines. This can potentially improve collection effectiveness and reduce
corporate
liability and risk.
[0053] In this regard, various types of recording components can be used to
facilitate
speech analytics. Specifically, such recording components can perform one or
more
various functions such as receiving, capturing, intercepting and tapping of
data. This can
involve the use of active and/or passive recording techniques, as well as the
recording of
voice and/or screen data.
[0054] It should be noted that speech analytics can be used in conjunction
with such
screen data (e.g., screen data captured from an agent's workstation/PC) for
evaluation,
scoring, analysis, adherence and compliance purposes, for example. Such
integrated
functionalities improve the effectiveness and efficiency of, for example,
quality assurance
programs. For example, the integrated function can help companies to locate
appropriate
calls (and related screen interactions) for quality monitoring and evaluation.
This type of
"precision" monitoring improves the effectiveness and productivity of quality
assurance
programs.
CA 02564798 2007-05-15
[0055] Another aspect that can be accomplished involves fraud detection. In
this regard,
various manners can be used to determine the identity of a particular speaker.
In some
embodiments, speech analytics can be used independently and/or in combination
with
other techniques for performing fraud detection. Specifically, some
embodiments can
involve identification of a speaker (e.g., a customer) and correlating this
identification
with other information to determine whether a fraudulent claim for example is
being
made. If such potential fraud is identified, some embodiments can provide an
alert. For
example, the speech analytics of the present disclosure may identify the
emotions of
callers. The identified emotions can be used in conjunction with identifying
specific
concepts to help companies spot either agents or callers/customers who are
involved in
fraudulent activities. Referring back to the collections example outlined
above, by using
emotion and concept detection, companies can identify which customers are
attempting to
mislead collectors into believing that they are going to pay. The earlier the
company is
aware of a problem account, the more recourse options they will have. Thus,
the speech
analytics of the present disclosure can function as an early warning system to
reduce
losses.
[0056] Additionally, included in this disclosure are embodiments of integrated
workforce
optimization platforms. At least one embodiment of an integrated workforce
optimization platform integrates: (1) Quality Monitoring/Call Recording -
voice of the
customer; the complete customer experience across multimedia touch points; (2)
Workforce Management - strategic forecasting and scheduling that drives
efficiency and
adherence, aids in planning, and helps facilitate optimum staffing and service
levels; (3)
Performance Management - key performance indicators (KPIs) and scorecards that
16
CA 02564798 2007-05-15
analyze and help identify synergies, opportunities and improvement areas; (4)
e-Learning
- training, new information and protocol disseminated to staff, leveraging
best practice
customer interactions and delivering learning to support development; and/or
(5)
Analytics - deliver insights from customer interactions to drive business
performance. By
way of example, the integrated workforce optimization process and system can
include
planning and establishing goals - from both an enterprise and center
perspective - to
ensure alignment and objectives that complement and support one another. Such
planning may be complemented with forecasting and scheduling of the workforce
to
ensure optimum service levels. Recording and measuring performance may also be
utilized, leveraging quality monitoring/call recording to assess service
quality and the
customer experience.
[0057] One should note that the flowcharts included herein show the
architecture,
functionality, and/or operation of a possible implementation of software. In
this regard,
each block can be interpreted to represent a module, segment, or portion of
code, which
comprises one or more executable instructions for implementing the specified
logical
function(s). It should also be noted that in some alternative implementations,
the
functions noted in the blocks may occur out of the order. For example, two
blocks shown
in succession may in fact be executed substantially concurrently or the blocks
may
sometimes be executed in the reverse order, depending upon the functionality
involved.
[0058] One should note that any of the programs listed herein, which can
include an
ordered listing of executable instructions for implementing logical functions
(such as
depicted in the flowcharts), can be embodied in any computer-readable medium
for use
by or in connection with an instruction execution system, apparatus, or
device, such as a
17
CA 02564798 2007-05-15
computer-based system, processor-containing system, or other system that can
fetch the
instructions from the instruction execution system, apparatus, or device and
execute the
instructions. In the context of this document, a "computer-readable medium"
can be any
means that can contain, store, communicate, propagate, or transport the
program for use
by or in connection with the instruction execution system, apparatus, or
device. The
computer readable medium can be, for example but not limited to, an
electronic,
magnetic, optical, electromagnetic, infrared, or semiconductor system,
apparatus, or
device. More specific examples (a nonexhaustive list) of the computer-readable
medium
could include an electrical connection (electronic) having one or more wires,
a portable
computer diskette (magnetic), a random access memory (RAM) (electronic), a
read-only
memory (ROM) (electronic), an erasable programmable read-only memory (EPROM or
Flash memory) (electronic), an optical fiber (optical), and a portable compact
disc read-
only memory (CDROM) (optical). In addition, the scope of the certain
embodiments of
this disclosure can include embodying the functionality described in logic
embodied in
hardware or software-configured mediums.
[0059] It should be emphasized that the above-described embodiments are merely
possible examples of implementations, merely set forth for a clear
understanding of the
principles of this disclosure. Many variations and modifications may be made
to the
above-described embodiment(s) without departing substantially from the spirit
and
principles of the disclosure. All such modifications and variations are
intended to be
included herein within the scope of this disclosure.
18