Note: Descriptions are shown in the official language in which they were submitted.
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
METHOD AND APPARATUS FOR GENERATING STANDARD
DOCUMENT IDENTIFIERS FROM CONTENT REFERENCES
BACKGROUND
[0001] This invention relates to digital rights display and methods and
apparatus
for determining reuse rights for content to which multiple licenses and
subscriptions
apply. Works, or "content", created by an author is generally subject to legal
restrictions
on reuse. For example, most content is protected by copyright. In order to
conform to
copyright law, content users often obtain content reuse licenses. A content
reuse
license is actually a "bundle" of rights, including rights to present the
content in different
formats, rights to reproduce the content in different formats, rights to
produce derivative
works, etc. Thus, depending on a particular reuse, a specific license to that
reuse may
have to be obtained.
[0002] Many organizations use content for a variety of purposes, including
research and knowledge work. These organizations obtain that content through
many
channels, including purchasing content directly from publishers and purchasing
content
via subscriptions from subscription resellers. Subscriptions generally include
some
reuse rights that are conveyed to the subscriber. A given subscription service
will
generally try to offer a standard set of rights across its subscriptions, but
large
customers will often negotiate with the service to purchase additional rights.
Thus,
reuse rights may vary from subscription to subscription and the reuse rights
available for
a particular subscription may vary even across publications within that
subscription. In
addition, the reuse rights conveyed in these subscriptions often overlap with
other rights
and licenses purchased from license clearinghouses, or from other sources.
[0003] Many knowledge workers attempt to determine which rights are available
for particular content before using that content in order to avoid infringing
legitimate
rights of rightsholders. However, at present, determining what reuse rights an
organization has for any given publication is a time-consuming, manual
procedure,
generally requiring a librarian or legal counsel to review in advance of the
use, all
license agreements obtained from content providers and purchased from other
sources
which may pertain to the content and its reuse. The difficulty of this
determination
means that sometimes an organization will overspend to purchase rights for
which it
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
already has paid. Alternatively, knowledge workers may run the risk of
infringing a
reuse right for which they believe that the organization has a license, but
which, in
actuality, the organization does not.
[0004] One of the problems in determining which rights apply to a given
publication is connecting the publication to one or more agreements that
convey rights
so that the correct agreement can be examined to determine what rights are
available to
an organization. One prior art method for performing this connection is to
embed a
special "tag" in the publication. When the publication is later opened, for
example, for
examination, the tag can be activated to direct the user to a specific
location, such as a
web site, where rights agreements are located. While this arrangement is
effective, it
requires each publication to contain the special tag. While this might be
feasible for
newly published publication, it would be prohibitive to re-publish older
publications with
the special tag. Thus, this system would not work with many existing
publications.
[0005] Often a user trying to locate publication rights has only a publication
universal resource locator or URL associated with a publication. The primary
purpose
of such a URL is to indicate where on a network, such as the Internet, a copy
of the
publication can be located. Thus, the URL typically does not directly identify
the
publication itself. However, many URLs contain information that is useful in
identifying
the publication. Unfortunately, there is no current standard URL configuration
so that
such useful information may be located in various places within the URL
depending on
the publisher or clearinghouse. Further, the useful information may be coded
in various
ways. Therefore, it may be difficult to extract the information from a
particular URL.
[0006] In still other cases, even the URL is not available. For example, only
basic information such as the publication title, author, the work in which the
publication
is contained and the year of publication or some combination of the
aforementioned
information may appear in the text of a webpage that the worker is viewing.
Alternatively, a publication that the worker is viewing may contain a
reference to another
web page, such as an abstract or a bibliographic page that contains the
aforementioned
information. Since each webpage may have a different and unique format, it is
difficult
to determine even where on a particular page to look for the information
necessary to
identify the rights that are available (called content "metadata").
2
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
SUMMARY
[0007] In accordance with the principles of the invention, the domain name of
the website in which a knowledge worker is working is sent to a rights advisor
website.
The rights advisor website uses the domain name to obtain a parser program
that is
specific to the domain. The parser program is then sent back to the browser on
which
the knowledge worker is viewing information and extracts content metadata from
the
website in which the knowledge worker is working. The extracted content
metadata is
returned to the rights advisor website and used to determine rights associated
with the
publications.
[0008] In one embodiment, the parser program extracts content metadata from
the webpage displayed in the browser.
[0009] In another embodiment, the parser program navigates from the webpage
that is being displayed in the browser to another webpage that contains
content
metadata and extracts the content metadata from that other page.
[0010] In still another embodiment, content metadata, such as a publication
title,
that is returned to the rights advisor website via the parser is "normalized"
to obtain a
standard identifier that is, in turn, used to determine rights for the
content.
[0011] In yet another embodiment, when a URL is associated with content, the
rights advisor website attempts to locate a standard identifier for the
content using that
URL simultaneously with attempts to obtain a parser program that is specific
to the
website domain and which can look for information associated with the content
on the
webpage.
BRIEF DESCRIPTION OF THE DRAWINGS
[0012] Figure 1 is a block schematic diagram illustrating in a high level form
the
basic architecture of the inventive rights location system.
[0013] Figure 2 is a table array in a database for storing bookmarklet script
information.
[0014] Figure 3 is a typical screen display presented by a conventional search
engine in a web browser.
3
CA 02735215 2011-02-24
WO 2010/024811 PCT/1JS2008/074579
[0015] Figure 4 is a typical display of content located by the search engine
when the keywords "nature methods" have been entered into the text box. This
figure
shows the hyperlinks to a rights advisor web page.
[0016] Figure 5 is a flowchart showing the steps in an illustrative process
for
determining and resolving rights for a requested type of use.
[0017] Figure 6 is a block schematic diagram illustrating the components of an
agreement.
[0018] Figure 7 is a block schematic diagram illustrating the components in a
publication identifier location apparatus.
lo [0019] Figures 8A and 8B, when placed together, form a flowchart showing
the
steps in an illustrative process for locating a publication identifier which
process is
performed by the apparatus shown in Figure 7.
[0020] Figure 9 is a table array in a database for storing URL parsers and
metadata parsing scripts.
[0021] Figure 10 is a screen shot of a journal web page with an International
Standard Serial Number (ISSN) identifier embedded in the page.
[0022] Figure 11 is the HTML code used to display the web page shown in
Figure 10 in a conventional web browser illustrating how such a web page could
be
parsed to retrieve the identifier.
DETAILED DESCRIPTION
[0023] Figure 1 is a block schematic diagram illustrating one embodiment 100
constructed in accordance with the principles of the present invention. In
some cases, a
customer can use a conventional search engine in a web browser 102 to search
for
content and to display that content in the display area 103. The web browser
102 has
been modified by downloading a small executable program called a "bookmarklet"
that
causes the browser to interact with a "rights advisor" web server in
accordance with the
principles of the invention. Such a program might, for example, be a
Javascript
program, which is specific to a particular URL domain or to a set of URL
domains.
[0024] Figure 2 illustrates a set of database tables 200 for storing script
text
corresponding to various bookmarklet scripts. These tables include a URL base
key
4
CA 02735215 2011-02-24
WO 2010/024811
PCT/1JS2008/074579
table 204 which specifies URL map keys, each of which identifies a set of URLs
to
which a particular bookmarklet script applies. Each record of the latter table
includes a
URL map key identifier (URL_MAPKEY_ID), a name for the map key
(URL_MAPKEY_BASE) and an identifier specifying a particular bookmarklet text
that
applies to that map key (BOOKMARKLET_SCRIPT_ID). The URL domains that are
members of each domain map are specified in the URL Domain Table 206. The URL
domain table 206 contains records, each of which includes a URL domain
identifier
(URL_DOMAIN_ID), a map key identifier specifying the domain map to which the
domain belongs (URL_MAPKEY_ID), the domain name (URL_DOMAIN), a URL
configuration file (URL_CONFIG_XML), a primary parser identifier
(URL_PRIMARY_PARSER) and an identifier for an associated bookmarklet script
(BOOKMARKLET_SCRIPT_ID). If a bookmarklet script is specified for a particular
domain, it overrides any script specified for a domain map to which that
domain
belongs.
[0025] The bookmarklet scripts are identified in the Bookmarklet Script Table
208. Each record of table 208 contains a script identifier (SCRIPT_ID), a key
to select a
particular script (SELECT_KEY), an indication whether the script is enabled,
and
various timing and retry parameters used in determining how the script is
downloaded
and executed. The actual script text is stored in the Versioned Text Table
210. This
latter table contains records, each of which, in turn, includes a text
identifier
(VTEXT_ID), a text type (VTEXT_TYPE_ID), a revision number (REVISION_NUM) and
the actual text (CONTENT). The text table stores both script text and URL
configurations as indicated by the type field. If a script is modified, its
record is not
overwritten. Instead, a new record in inserted into the text table. This
allows review of
previous script versions and rollback, if necessary.
[0026] Figure 3 shows a typical screen display presented by such a search
engine. The web browser 300 includes a search field 302 that, in turn,
includes a text
box 304 for receiving a search phrase and a command button 306 for initiating
a search
for publications whose text includes the search phrase. The web browser 300
has been
modified to include a small executable program called a "bookmarklet" that
causes the
5
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
browser to interact with a "rights advisor" program in accordance with the
principles of
the invention.
[0027] Figure 4 shows a typical display of content located by the search
engine
when the keywords "nature methods" have been entered into the text box 404 in
the
search field 402 of the browser 400 and the command button 406 has been
selected.
The search results are shown as a plurality of rows 408-418 in the list box
407. Each
row includes information concerning an article located in the search. The
search engine
illustrated in Figure 4 displays information including the article title, the
publisher and a
standard identifying number associated with the publication that contains the
article.
[0028] Each article has associated with it a hyperlink generated by the
bookmarklet that enables a user to locate and display rights associated with
that article.
For example, row 408 includes a hyperlink 420 that enables a user to locate
and display
rights for the "Nature Methods" article displayed in that row. Similarly, rows
410-418
have hyperlinks 422-430 for locating and viewing rights associated with the
articles
displayed in those rows.
[0029] In other cases, a URL associated with an article may not refer to the
publisher or the containing publication. For example, the user might be
examining the
full text of a document containing a URL that points to a different portion of
the
document or to a bibliography containing text information that identifies the
publisher
and publication. Alternatively, the full text page of the document may not
contain any
URLs. Instead, text identifying the publication and publisher or URLs pointing
to the
publication and publisher may be located on another web page, for example a
bibliographic page or an initial document information page. The locations and
format of
the information are generally specific to a particular domain or web site and,
in some
cases, only the URL of the website, containing the domain may be all that is
available.
However, in accordance with the principles of the present invention, an
article can be
identified by parsing a URL or by searching for article identification
information
embedded in other textual information on a web page. Further, the URL parsing
mechanism and text search can be tailored on a per-domain basis so that
different
formats can be accommodated.
6
CA 02735215 2016-07-26
[0030] Returning to Figure 1, when a hyperlink is selected, the bookmarklet
104
causes the web browser 102 to access a rights advisor web page 108 hosted by a
server in a rights clearinghouse location. When the web page 108 is accessed,
the
bookmarklet generates a unique bookmarklet key which is used to identify the
member
and a "session" during which rights for the displayed article will be
retrieved and
displayed. The bookmarklet also sends any available information regarding the
article to
the rights advisor web page 108. The rights advisor web page 108 uses the
article
information to try and located rights associated with the article. In
addition, in
accordance with the inventive principles, the web server that displays the
rights advisor
web page also searches the web site from which the article is displayed in
order to
attempt to locate additional information concerning the article.
[0031] The process performed by the rights advisor web page 108 to locate and
resolves rights is set forth in Figure 5. This process begins with step 500
and proceeds
to step 502 where the rights advisor web page 108 receives article
information, the
organization member context and a desired type of use from the bookmarklet
104.
Rights that are available for an organization are defined by agreements that
are stored in
the rights database 112. Rights database 112 is arranged as a plurality of
tables where
rights are stored in a table separate from the content identifiers. Such a
database is
described in detail in U.S. Patent No. 5,991,876. In particular, the rights
database 112
contains information regarding agreements.
[0032] An agreement is any construct under which an organization obtains or
expresses rights related to secondary use of content. Such agreements could
include a
copyright license for an entire collection of publications obtained from a
rights
clearinghouse. An example of such an agreement is an annual copyright license
obtained from the Copyright Clearance Center. Agreements may also be made
directly
with a publisher, such as the Pharmaceutical Documentation Ring agreement made
with
the publisher Elsevier. Another type of agreement could be made with other
Reproductive Rights Organizations such as a contract with the Copyright
Licensing
Agency in the United Kingdom. Agreements can also be obtained from various
content
aggregators. Such an agreement might be a Factiva license. Agreements can also
be
7
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
implied by statutory law, for example, Swiss law allows Swiss companies to
share
content without royalties. Still other agreements may involve company policy.
[0033] In step 504, the rights advisor 108 accesses the rights database as
indicated schematically by arrow 114 and retrieves all agreements that apply
to the
organization. The components of an agreement 600 as represented in the rights
database 112 are shown in Figure 6. These components include boundaries 602,
titles
included 610, rights 620 and terms 621. Boundaries 602 specify the member
context,
or various constraints, an organization member must meet in order to be
covered by the
agreement and are defined by three variables: country, location and
organization
defined attributes. The country variable has values corresponding to global
nationalities, such as United States or France. The location variable has
values that
correspond to various site location of the organization, such as the Waltham
site or the
Wilmington site. The organization defined variable may have any values that
determine, within that organization, whether the agreement applies to a member
of that
organization. For example, the variable may specify that a member of the
organization
must be part of the marketing department or part of the research and
development
department, etc. to be covered by the agreement. The country, location and
organization defined variables may be assigned the value "any" which indicates
that the
agreement would apply to any member context which meets the other boundary
variables. For example, the organization defined variable may be assigned a
value of
"any." In this case the agreement would apply to any member who meets the
country
and location boundary variables.
[0034] An agreement 600 also includes a designation 610 of the publications or
titles that it covers. The agreement 600 may apply to collections 612, which
are any
grouping of publications. For example, an agreement may apply to all the
titles that are
included in an EBSCO subscription package. This would be considered a "public"
collection; the titles included are defined by the information provider and
are standard
for all purchasers of the package. Another alternative would be a "private"
collection.
For example, an organization may create an "a la carte" subscription from a
provider
like EBSCO. The agreement 600 may also apply to separate publications 616 in
addition to, or as an alternative to, collections 612.
8
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
[0035] The third component of an agreement is the rights 620 associated with
the agreement. Each right is associated with a specific type of use. In order
to
standardize agreements, a set of distinct rights are predefined. In the
discussion below,
a set of distinct types of use have been predefined for publications. However,
the set of
predefined rights could include more or less distinct rights as would be
understood by
those skilled in the art. For example, an illustrative set of predefined
rights could
include (1) emailing a copy of the publication to a member of the
organization, (2)
emailing a copy of the publication to a person who is not a member of the
organization,
(3) storing a copy of the publication on a local hard drive, (4) storing a
copy of the
publication on a shared network drive, (5) scan and then email a copy of the
publication
to a member of the organization, (6) scan and then email a copy of the
publication to a
person who is not a member of the organization, (7) photocopy publication and
share
with a member of the organization, (8) photocopy publication and share with a
person
who is not a member of the organization, (9) share a printed copy of the
publication with
a member of the organization, (10) share a printed copy of the publication
with a person
who is not a member of the organization, (11) share a copy of the publication
using
Lotus Notes', (12) upload a copy of the publication to an Internet site, (13)
post a copy
of the publication for advertising purposes and (14) upload a copy of the
publication to
an electronic paper (soft billboard.) Customers can define their own type of
use, but
these custom use types must map to one of the fourteen predefined use types.
[0036] Rights may be associated with each type of use. In addition, rights can
be specified for the agreement 600 as indicated schematically by arrow 622,
for a
collection covered by the agreement as indicated schematically by arrow 624 or
for
individual publications within that collection as indicated schematically by
arrow 626.
Rights can also be assigned to separate publications that are covered
individually by
the agreement as indicated schematically by arrow 628.
[0037] Terms 621 may also be associated with each agreement. Terms include
rights holder terms, contract terms that cannot be expressed programmatically
as a
right, certain statutory laws, such as Swiss law allowing publication sharing
with other
Swiss employees and company policies. Terms may be assigned at the
publication,
collection and agreement levels. In general, terms associated with rights are
tagged as
9
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
-
"Restrictive" or "Nonrestrictive". The "Restrictive" tag indicates that the
associated right
(such as a right to photocopy a publication) is limited by the text of the
terms (for
example, a restrictive term might be "only internal distribution is allowed").
The
"Nonrestrictive" tag indicates the terms do not limit the applicability of the
right, perhaps
because they extend the scope of the permitted activity (for example,
nonrestrictive
terms might include "There are no restrictions on the distribution of
photocopies of this
content").
[0038] Returning to Figure 5, in step 506, the rights advisor accesses a
metadata database 122 as indicated schematically by arrow 120, and attempts to
obtain
a standard number for the publication containing the article for which the
member has
requested rights information in order to determine whether any of the
retrieved
agreements are applicable to that publication. In accordance with the
principles of the
invention, the rights advisor tries to lookup the publication using two
separate methods
that are performed in parallel.
[0039] In accordance with the first method, the rights advisor uses
information
that it receives from the member's browser to attempt to lookup the
publication. If this
information includes the article title and recognized standard identifying
numbers, such
as an ISSN or an ISBN number for the publication, then a lookup of the
publication may
be possible using just this information. However, in some cases, only the URL
of the
article may be available. Article URLs are often arbitrary, and by themselves
provide no
consistent means to determine whether a given article belongs to a publication
with a
recognized standard identifier. Thus, the rights advisor web page 108 attempts
to map,
or translate, the URL into a standard identifier, where such an identifier is
available.
Using this standard identifier, the rights advisor web page 108 can then
access the
metadata database 122 to obtain a standard number that identifies the
publication. This
standard number can be applied to the retrieved agreements for the
organization to
determine which agreements apply to the specified publication.
[0040] URL mapping performed by the rights advisor relies on a variety of URL
parsers, each of which uses a parsing algorithm, and a supporting database of
URL
formats 118. In particular, the rights advisor program 108 has a set of rules
for
determining which parsers are applicable to a particular URL and a set of
parsers that
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
are each able to separate a particular URL into web-site specific identifiers
useful for the
URL mapping task. Once these specific identifiers have been obtained, they are
applied, as schematically indicated by arrow 116, to a database 118 of rules
for
translating the web-site specific identifiers into standard identifiers such
as ISSN or
ISBN identifiers. Once the standard identifiers have been obtained, they are
applied, as
indicated schematically by arrow 114 to a database 112 that is keyed by the
standard
identifiers for publications. This database 112 enumerates publication titles
and the
rights under which the publications can be used.
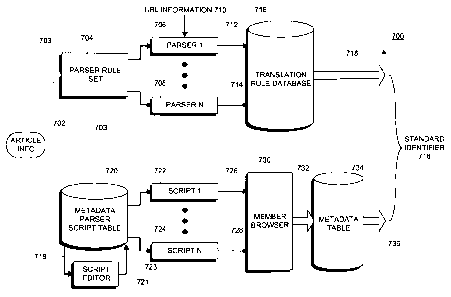
[0041] Apparatus 700 for obtaining a standard identifier from article
information
is illustrated in Figure 7 and the steps in the lookup process are illustrated
in Figures 8A
and 8B. The lookup process begins in step 800 and proceeds to step 802 where
information 702 concerning the displayed article is received from the member
web
browser 102. In step 804, an attempt is made by the web server to lookup the
corresponding publication in a metadata table 734 (as schematically indicated
by arrow
703) using information, such as a title or any standard numbers present in the
information received from the browser. If this attempt is successful, as
determined in
step 806, a standard identifier is returned as indicated schematically by
arrow 736 and
the process proceeds, via off-page connectors 822 and 828 to finish in step
848.
[0042] Alternatively, if the attempt is not successful, then the process
proceeds
to step 808 where the domain name is saved by the web server using, for
example, a
store and forward dispatcher. This storage operation triggers two processes
that
operate in parallel and attempt to locate the standard identifier for the
applicable
publication. The first process is set forth in steps 810, 814, 818, 824, 830
and 834. The
second process is illustrated by steps 812, 816, 820, 832, 836, 840 and 842.
[0043] In step 810 of the first process and, as indicated by arrow 703, the
URL
of the website that is being viewed in the member's browser is used to query a
set of
parser rules 704 to determine the most applicable URL parser as well as
configuration
settings to determine how parsers will be used in the cases that the rules
identify. In
particular, the stored domain name in the URL is matched against the set of
parser
rules to select rules that apply to that domain. In turn, the selected rules
are then used
to select and configure the parsers.
11
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
[0044] Figure 9 shows an illustrative embodiment 900 for the parser rule set
704. In this embodiment, the parser rule set is implemented as a set of
relational
database tables 902, 904, 906, 910 and 912. Each content provider is provided
in the
content provider table 902 with a record containing a unique identifier
(CONTENT_PROVIDER_ID) and a name (CONTENT_PROVIDER_NAME). A content
provider may be associated with one or more Internet domains via the Content
Provider
Domain table 904. Table 904 contains one or more records for each content
provider
and each record contains a domain identifier (CONTENT_PROVIDER_DOMAIN_ID), a
domain name (CONTENT_PROVIDER_DOMAIN), a reference to the content provider
(CONTENT_PROVIDER_ID) and a precedence level (PRECEDENCE_LEVEL) that
indicates, if there are a plurality of domains, which domain should be
examined first.
The table also includes a URL segment map identifier (URL_SEGMENT_MAP_ID) and
URL parser identifier (URL_PARSER_ID) for each domain. The URL segment map
identifier identifies a record in the URL Segment Map table 912 which contains
data
indicating the structure of the URL, which can consist of three segments
(URL_SEGMENT_1, URL_SEGMENT_2 and URL_SEGMENT_3). In some cases, a
standard publication number or a publication identifier may be directly
associated with a
domain name. If this is the case, these identifiers are stored in the URL
segment map
(STD_NO and PUB_ID).
[0045] If publication identifiers are cannot be directly associated with the
domain name, then a URL parser is associated with the content provider domain
via a
reference to the URL Parser table 906. Table 906 includes a parser identifier
(URL_PARSER_ID) and a parser name (URL_PARSER_NAME) and an indication
whether the particular parser is enabled. A further table 910 (the URL Parser
Param
table) contains parameters that are used with a particular parser.
[0046] Returning to Figure 7, after selecting a parser rule set based on the
domain name in the URL, one of a set of parsers, of which parsers 706 and 708
are
shown, identified in the selected rule is used, in step 814, to parse the URL
and
generate the data field values. A parser consists of the instructions for
extracting from a
URL the data fields necessary to use translation rules to determine a standard
identifier.
One such set of data fields includes three members: the key base, the journal
key and
12
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
the publication date. The key base specifies a context in which the derived
identifier is
meaningful; in other words, a particular publisher may give all of the
publications on its
web site unique, proprietary numbers, and use this numbering system in the
URLs for
the articles on its web site. The key base in this case can be any string that
specifies
the publisher's web site, such as 'PUB 1 '; the journal key is then the
publisher's own
proprietary identifier.
[0047] Parsers, such as parsers 706-708, are defined to extract data in
particular formats. For instance, many publishers follow an informal
convention in which
the URL for an article contains the concatenation of a unique string
identifying the
publication with four numeric digits signifying the year and month of
publication of the
article. A variety of well-known parsing techniques can be used to locate this
string and
split it into the desired components. Once a parser is created to extract this
concatenated string from a URL and split the string into its two useful
components, the
parser can be configured with parser rules, such as those set forth above, to
perform
the same task for URLs of any publisher that follows this convention. Any
selected
parsing technology must be able to implement at least the following
capabilities: within a
given string, locate a specified prefix string; extract characters following
the prefix string
until a specified suffix string is located; and split an extracted string into
multiple
substrings according to simple format specifications. Conventional UNIX- or
Perl-like
regular expressions are easily capable of performing these parsing and
extraction tasks.
In general new parser rules and parsers can be added to support new URL
formats. A
more detailed discussion of parsers and their construction is contained in
U.S. Patent
Application Serial No. 11/733,423 filed on April 10, 2007 by C. Howard, J.
Arbo and V.
Shetty and entitled "Method and Apparatus for Converting a Document Universal
Resource Locator to a Standard Document Identifier." This disclosure of this
application
is hereby included herein in its entirety by reference.
[0048] The process then proceeds, via off-page connectors 818 and 824 to step
830, where the extracted data field values are presented to the translation
rule database
714 as indicated schematically by arrows 710 and 712. The translation database
includes a plurality of entries, each entry constituting a translation rule
that, in turn,
includes at least three fields: the key base, the journal key and the standard
identifier
13
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
and may include other fields, such as date fields. The key base and journal
keys are
used as key fields. If the data field values presented to the translation rule
database
match these fields, the associated standard identifier is returned.
[0049] Since the journal key is internal data for a particular publisher,
there is
no guarantee that journal keys will be unique outside the context of a
particular website
or website subset. The key base provides a mechanism for ensuring that the
journal
keys can be mapped accurately to standard identifiers, such as an ISSN. If, in
step
834, it is determined that such a standard identifier results from the
database query,
then the URL mapping process proceeds to step 836 where an attempt is made to
lookup the publication using the standard identifier. If the publication is
found, as
determined in step 840, the process finishes in step 848.
[0050] The second process for obtaining a standard identifier for a
publication
begins in step 812. As previously mentioned, this process is initiated when a
domain
name is stored (in step 808) and proceeds in parallel with the aforementioned
URL
parsing process. In step 812, a script, called a metadata parser, which is
specific to the
domain, is retrieved from the URL mapping database 118. Illustratively, this
script might
be a Javascript. As shown in Figure 9 metadata parser scripts are stored in a
metadata
parser table 908. Each record in this table includes a parser identifier
(METADATA_PARSER_ID), a domain key (SELECT_KEY), an indication whether the
script is enabled, the script text (SCRIPT_TEXT) and several timing entries
that control
the timeout interval and retry policies for script execution. Each script can
also be
disabled for a particular customer by making an entry into the
METADATA_CUST_DISABLED table 914. The URL of the web page is used as the
domain key to access the table 914 and retrieve script text that is specific
to that
domain.
[0051] The retrieved script text is downloaded to the member's browser and
appended to the bookmarklet script already running in the browser using the
timing and
retry numbers stored with the script. When activated, the script text parses
the HTML
code of one or more web pages on the current web site and attempts to locate
additional data concerning the desired publication, again using the timing and
retry
information stored with the script. For example, such a script may parse the
HTML
14
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
code of the web page that the member is currently viewing. Alternatively, the
script may
navigate from one page to another web page and then parse the HTML code on the
second web page. Illustratively, this might occur in situations where the
member is
viewing a full-text version of an article, but publication information for
that article is
available on a different web page that displays publication abstracts.
[0052] The scripts are typically designed by a human operator who visits the
web site, notes the location of the additional information and then writes the
script to
retrieve the information. An operator can generate scripts from "scratch"
using the
general workflow of the site for extracting content identifiers as the
functional boundary,
but in most cases, operators will begin with an existing metadata parser
script. Scripts
designed to process similar types of publications are typically similar in
construction so
that each publication type has a template script that can be modified for a
specific
domain. For example, template scripts might be designed for trade journals,
news
articles, patents and press releases or other sites which have similar page
layouts and
types, or from which similar metadata will be extracted or which have similar
site
structures. Alternatively, an operator may decide to use an existing script if
the content
or documents to be parsed are a similar type and structure or contain the same
kind of
metadata, such as an author's name or the year in a copyright notice. For
example, a
copyright notice appears in most Web pages in the footer, at the bottom of the
page. A
typical format is "Copyright @ 2006 copyright holder name." Because the format
and
the data captured are similar, a system user can modify an existing script to
perform the
same function on a different Web site or page set.
[0053] A template or existing script can be selected by an operator based on
the URL of the web site as schematically illustrated by arrow 719 in Figure 7.
Then, the
operator would typically log onto the web site with a temporary account, note
the
location of the relevant information and modify the template script to
navigate to that
location. This modification is performed by applying the existing script to a
script editor
721 to generate a new script 723 which is them stored in the metadata script
parser
table 720. Illustratively, a template script for a trade journal could skip
over the first one
thousand bytes of the HTML code in order to avoid header information and then
parse
the remaining HTML script with parsers similar to those discussed above for
URLs.
CA 02735215 2011-02-24
WO 2010/024811
PCT/US2008/074579
[0054] Generally, the scripts are site specific. For example, a web page made
up of HTML code and other formatting elements will require a different parser
than a
page coded in PDF (Portable Document Format). However, a web page with a
similarly-located standard identifier, such as an ISBN (International Standard
Book
Number), an ISSN (International Standard Serial Number), or a DOI (Digital
Object
Identifier) may be used by many sites and services for a particular kind of
work (e.g.,
books, journals or research articles).
[0055] For example, Figure 10 is a screen shot of an illustrative web page
from
a website of the publisher Elsevier which contains an ISSN (0304-4203)
identifying the
journal "Marine Chemistry" embedded in the web page text. Figure 11 shows the
HTML
code which causes the web page display shown in Figure 10 to be generated in a
conventional web browser. In order to parse the HTML code shown in Figure 11,
the
parser steps through the DOM (Document Object Model) to pick out the document
identifier, (ISSN, DOI, etc.) The DOM provides a hierarchical structure of the
web page
along with values, allowing a program to search and step through a fixed
format to
gather the information required. Consistency of format is important, but with
the page
information returned by the DOM, a program can, for example, query for the
<span> tag
where the class equals, for example, "journalinformation" and then use various
conventional methods, such as regular expression matching, to extract the
standard
number from the block of returned text.
[0056] The following is an example of a metadata parser script which is
constructed in accordance with the principles of the invention. This script is
written in
the JavaScript language.
1 ----------------------------------------------------------------- //
2 // METADATA PARSER SCRIPT for @DOMAINMASK@ PARSES CURRENT DOCUMENT
3 ----------------------------------------------------------------- //
4
5 var PARSERMASK="@PARSERMASK@";
6
7 var PROTOCOL='http://';
8
9 ----------------------------------------------------------------- //
10 // PICKUP KEY, DOMAIN, and ORIGINALURL
11 /-
12
13 var KEY='@BOOKMARKLETKEY@';
16
CA 02735215 2011-02-24
WO 2011024811
PCT/US2008/074579
14 var DOMAIN='@HREFDOMAIN@';
15 var ORIGINALURL='@ORIGINALURL@';
16
17 // -----------------------------------------------------------------
18 // PICKUP ACTION will be either 'parse' or null
19 // -----------------------------------------------------------------
21 var ACTION=@ACTION@;
22
23 // -----------------------------------------------------------------
24 // FIELDS TO BE IDENTIFIED
/-
26
27 var MDATA TITLE = "&title=";
28 var MDATA¨ISSN="&stdno=";
29 var MDATAIRESET = "&reset=true";
var MDATA_KEY = "&key=" + KEY;
31
32 var FINDARGUMENTS="FINDARGUMENTS:";
33 var PROTOARGUMENTS="PROTOCOL=" + PROTOCOL;
34 var RESULTS=";
36 // -----------------------------------------------------------------
37 // verifyProtocol - verify if it is http or https
38 /-
39
function verifyProtocol() {
41
42 var regexInstance;
43 var ignoreCase =
44 var regexString =
var searchString = document.location.href;
46 var foundValue=null;
47 var position=1;
48
49 if ( ignoreCase == "i" ) {
regexInstance = new RegExp(regexString, ignoreCase);
51 } else 1
52 regexInstance = new RegExp(regexString);
53
54
//PROTOARGUMENTS += "verifyProtocol: ";
56 //PROTOARGUMENTS += " Pattern=" + regexInstance.source;
57 //PROTOARGUMENTS += ";Position=" + position;
58 //PROTOARGUMENTS += ";IgnoreCase=" + regexInstance.ignoreCase;
59 //PROTOARGUMENTS += ";SearchString=" + searchString + "\n";
61 var matchAttempt = regexInstance.exec( searchString );
62
63 PROTOARGUMENTS = "PROTOCOL=";
64
if ( matchAttempt != null ) {
66
67 foundValue = matchAttempt [position];
68
69 if ( foundValue!= null && foundValue.length == 0 ) {
foundValue=null;
17
CA 02735215 2011-02-24
VM) 201111024811
PCT/US2008/074579
71 PROTOARGUMENTS += PROTOCOL;
72 } else 1
73 PROTOCOL = foundValue;
74 PROTOARGUMENTS += " Reset to " + PROTOCOL;
76 } else
77
78 PROTOARGUMENTS += PROTOCOL;
79
81
82 return PROTOCOL;
83 }
84
// -----------------------------------------------------------------
86 // findRegexValue - find issn and title
87 // -----------------------------------------------------------------
88
89 function findRegexValue ( regexString, searchString, ignoreCase,
position )
{
91
92 FINDARGUMENTS += "\n";
93 var foundValue=null;
94 var regexInstance;
if ( ignoreCase ==
96 regexInstance = new RegExp(regexString, ignoreCase);
97 } else {
98 regexInstance = new RegExp(regexString);
99
100 FINDARGUMENTS += "\nPattern=" + regexInstance.source;
101 FINDARGUMENTS += "\nPosition=" + position;
102 FINDARGUMENTS += "\nIgnoreCase=" + regexInstance.ignoreCase;
103
104 var matchAttempt = regexInstance.exec( searchString );
105
106 if ( matchAttempt != null ) 1
107
108 foundValue = matchAttempt [position];
109
110 FINDARGUMENTS += "\nFound=" + foundValue;
111
112
113
114 return foundValue;
115
116 }
117
118
119 /-
120 // findMetadata - find issn and title
121 --------------------------------------------------------------- //
122
123 function findPubInformation( html ){
124
125 RESULTS = "\nResults Reported to Rightsphere:" + "\n";
126 var ignoreCaseTrueFlag="i";
127
18
CA 02735215 2011-02-24
VM) 2010/024811 PCT/US2008/074579
128 var gotIssn = false;
129 var issn=null;
130
131 if ( !gotIssn )
132 var regexISSNOnline = "(?:<td.*>)(\\d[0-9,-
133 ]*\\d)(?:\\s*\\(Print\\)\\s*)(\\d[0-9,-
]*\\d)(?:\\s*\\(Online\\)</td>)";
134 issn = findRegexValue(regexISSNOnline,html,ignoreCaseTrueFlag,2);
135 if ( issn != null ) 1
136 MDATA ISSN += issn;
137 RESULTS += "\n\tOnline ISSN: " + issn;
138 gotIssn=true;
139
140 1
141
142 if ( !gotIssn ) {
143 var regexISBNOnline =
144 z1) (?: \ \ s* \ \ (Print \ \ ) \ \ s*) ( \ \d{4}- \ \ d{ 3 } [0-9,a-
z,A-
145 z] (?: \ \ s*\ \ (online\ \ )</td>) ";
146 issn = findRegexValue(regexISBNOnline,html,ignoreCaseTrueFlag,2);
147 if ( issn != null ) 1
148 MDATA ISSN += issn;
149 RESULTS += "\n\tOnline ISBN: " + issn;
150 gotIssn=true;
151 1
152
153
154 if ( !gotIssn ) {
155 var regexISSNPrint = "(?:<td.*>)(\\d[0-9,-
156 ]*\\d)(7:\\s*\\(Print\\)\\s*)(\\d[0-9,-
]*\\d)(?:\\s*\\(Online\\)</td>)";
157 issn = findRegexValue(regexISSNPrint,html,ignoreCaseTrueFlag,1);
158 if ( issn != null ) 1
159 MDATA ISSN += issn;
160 RESULTS += "\n\tPrint ISSN: " + issn;
161 gotIssn=true;
162 1
163
164
165 if ( !gotIssn )
166 var regexISBNPrint = "(?:<td.*>)(\\d{4}-\\d{3}[0-9,a-z,A-
167 Z]) (?:\\s*\\ (Print\\)\\s*) (\\d{4}-\\d{3}
168 Z] ) (?: \ \ s* \ \ (Online \ \ )</td>) ";
169 issn = findRegexValue(regexISBNPrint,html,ignoreCaseTrueFlag,1);
170 if ( issn != null )
171 MDATA ISSN += issn;
172 RESULT'S += "\n\tPrint ISBN: " + issn;
173 gotIssn=true;
174
175 1
176
177 //<td class="labelName">ISSN</td><td class="labelValue">0895-
4852</td>
178
179 if ( !gotIssn ) {
180 var regexISSNalone = "<td.*>ISSN</td>\\s*<td.*>\\s*(\\d{4}-?\\d{31[0-
181 9,a-z,A-Z])";
182 issn = findRegexValue(regexISSNalone,html,ignoreCaseTrueFlag,1);
183 if ( issn != null )
184 MDATA_ISSN += issn;
19
CA 02735215 2011-02-24
VM3 2010/024811
PCT/US2008/074579
185 RESULTS += "\n\tISSN: " + issn;
186 gotIssn=true;
187
188 1
189
190 var title=null;
191 var gotTitie=false;
192
193 if ( !gotTitle ) {
194 var titleREGEX = "<div
195 class=\\\"?MPReader Content
PrimitiveHeadingControlName\\\"?>\\s*([^<]*)";
196 title = finaRegexValue(tit1eREGEX,html,ignoreCaseTrueFlag,1);
197 if ( title != null ) 1
198
199 MDATA TITLE += encodeURIComponent(title);
200 RESULTS += "\n\tTitle: " + title;
201 gotTitle=true;
202 1
203
204
205 // -------------------------------------------------------
206 // Store ISSN Information to Rightsphere
207 // -------------------------------------------------------
208
209 var d = document.getElementsByTagName("html")[0];
210 if(d!=null){
211 s=d.appendChild(document.createElement(!scriptI));
212 s.id=inaples'+KEY;
213 s.language=ljavascript';
214 void(s.src=1@webapp.baseURL@/dispatcher?type=ra&target=store' +
215 MDATA_RESET + MDATA_KEY + MDATA_ISSN + MDATA_TITLE)
216 1
217 1
218
219 /-
220 // resetContentPage - display any debugging info and resets page
221 // following completion of data store
222 // ----------------------------------------------------------------
223
224 function resetContentPage(){
225
226 /-
227 // Display results in a debugging alert
228 /-
229
230 if ( ALLOWDEBUG == true ) {
231 if ( DEBUG != null ) {
232 var debugResults = "PARSERMASK="+PARSERMASK;
233 debugResults += "\nKEY="+KEY;
234 debugResults += "\n"+PROTOARGUMENTS;
235 debugResults += " DOMAIN="+DOMAIN;
236 debugResults += " ORIGINALURL="+ORIGINALURL;
237 debugResults += "\nACTION="+ACTION+"\n";
238 debugResults += "\n"+FINDARGUMENTS;
239 debugResults += "\n"+RESULTS;
240 alert (debugResults);
241 1
CA 02735215 2011-02-24
WO 2010/024811
PCT/US2008/074579
242
243
244 /-
245 // refresh the user's window MUST BE LAST STATEMENT EXECUTED!!
246 // ---------------------------------------------------
247
248 refreshUserWindow();
249
250
251
252 // ----------------------------------------------------------------
253 // Execute the findPubInformation procedure
254 /-
255
256 if ( ACTION == 'parse' ) {
257
258 verifyProtocol();
259 findPubInformation ( document .getElementsByTagName ("html") [0]
.innerHTML
260 );
261
262
[0057] In this example, the code at lines 1-35 defines various variables that
are
used in the following subroutines. The code at lines 36-84 defines a
subroutine that
determines whether the protocol of the web page under examination is http or
https.
The code at lines 85-118 defines a subroutine that searches a text string for
the
occurrence of another text string. The code at lines 119-204 uses the search
function
defined in lines 85-118 to sequentially search the web page html code for
predetermined character patterns that indicate the presence of the publication
standard
identifier and document title. Lines 205-218 define a sub routine that stores
the
metadata information retrieved from the web page html code to the bookmarklet
data
storage. The code at lines 219-243 displays debugging information and rests
the web
page following the metadata storage operation. The code at lines 244-251
refreshes
the user's display window and the code at lines 252-262 executes the parsing
subroutines.
[0058] In some cases the metadata is not contained on a Web page which is
initially displayed, but only on a preceding page or on a page that requires
user
interaction with the Web site. Therefore, some metadata parser scripts can
perform the
functions necessary to navigate the client browser up or down in the browsing
history
before extracting metadata. When creating scripts for new sites that require
controlling
21
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
the browser location, the system user may begin generating a new metadata
parser
script from an existing one that contains this functionality.
[0059] In step 816, the script is executed in the member's browser and parses
the HTML code to locate relevant publication information. This information can
include,
for example, the publication title and standard publication numbers, such as
an ISSN or
an ISBN number. The process then proceeds, via off-page connectors 820 and
826, to
step 832, where any information extracted from the website is stored using the
bookmarklet key as a retrieval key. Storage of the information is necessary at
this point
because the first process may still be proceeding.
[0060] If, in step 834, the first process determines that a publication
identifier
could not be located by parsing the publication URL or, in step 840, that an
attempt to
lookup the publication with the located identifier failed, then the process
proceeds to
step 838 where a determination is made whether any publication information has
been
stored in step 832 by accessing storage with the aforementioned bookmarklet
key. If no
publication information is located, the process proceeds to step 846 where a
search
web page is displayed that allows the member to perform a manual search for
the
publication information, and the process then finishes in step 848.
[0061] Alternatively, if in step 838, it is determined that stored information
obtained by the second process is located with the bookmarklet key, then an
attempt is
made in step 842 to lookup the publication using the stored information.
Before such a
lookup attempt is made, the information may be pre-processed into a standard
format in
order to simplify the lookup process. For example, certain standard
information may be
may be removed, including HTML tags, spaces, foreign language characters and
common articles. Then, the standard form is used to perform a lookup attempt.
The
lookup attempt itself may proceed in several stages. First, the lookup process
tries to
use any standard publication numbers and titles found to generate a
"fingerprint" in
order to lookup the publication. If that attempt fails, the process uses just
the standard
number looking at alternate ID numbers. If the publication is still not found,
the lookup
process will use the title alone and look for a matching fingerprint.
[0062] If the publication is found, as determined in step 844, then the
publication identifier is returned in step 848. Alternatively, if the
publication is not found,
22
CA 02735215 2011-02-24
WO 2010/024811 PCT/US2008/074579
as determined in step 844, the aforementioned search web page is displayed
that
allows the member to perform a manual search for the standard publication
identifier,
and the process then finishes in step 848.
[0063] Returning to Figure 5, in step 506, once the standard publication
identifier has been obtained using one of the methods described above, the
process
proceeds to step 508 where the rights advisor web server uses that identifier
to
determine all retrieved agreements that apply to the identified publication.
Next, in step
510, a determination is made of all agreements that fit the member context.
This
determination is made by examining the boundaries of each agreement and then
determining whether that agreement covers the member country and location and
that
the member meets any organization defined attributes.
[0064] In step 512 the best right for the type of use requested is determined.
The process then finishes in step 514.
[0065] The process of determining the best right as set forth in step 512
involves examining each agreement that applies to the publication and meets
the
member context in order to determine the most appropriate right for the
specified type of
use that is included in the agreement. In performing this examination, each
agreement
is examined from the "bottom up." That is, more specific rights supersede more
general
rights. Thus, an agreement is first examined to determine whether a right for
the type of
use requested has been assigned directly to the specified publication, either
by itself or
to the publication as contained in a collection. If such a right is found it
is the right used
for that agreement. If no such right has been assigned to the publication, the
agreement is next checked to determine whether a right for requested type of
use has
been assigned to a collection that includes the specified publication. If so,
it is the right
that is used for that publication. If no such right is found, then the
agreement is checked
to determine whether a right for the type of use has been assigned at the
agreement
level. If so, that right is used for the agreement.
[0066] Then, the most applicable rights from all agreements are collected and
ordered. In particular, rights are placed into a specific best to worst order
based on the
type of right and whether any terms are associated with the right. For
purposes of
resolution, rights with terms tagged as "Nonrestrictive" are treated as rights
without
23
CA 02735215 2011-02-24
WO 2010/024811
PCT/US2008/074579
terms - that is, at the highest level of applicability. The order of rights
from best
applicability to worst applicability is (1) right to use granted with no
associated terms, (2)
right to use granted with associated restrictive terms, (3) rights available
for purchase
under a pre-authorized contract, (4) rights available for purchase, but rights
holder must
be contacted with more information, (5) rights available for purchase, but
must be
special ordered, (6) contact librarian to determine rights and (7) no rights
available. If a
right cannot be determined it is treated as (6) above.
[0067] After the available rights have been collected and ordered, a
determination is made whether the ordering yields one "clear winner." That is,
one
agreement includes a right that is more applicable than rights included in all
other
agreements. If so, this "clear winner" is used to determine the rights and
terms for the
requested type of use. These rights and terms are then displayed to the member
in the
rights advisor web page.
[0068] If no "clear winner" exists, then a "tie" exists between two or more
agreements. Ties among two or more rights can take several forms. For example,
a tie
between two or more rights without terms indicates that identical rights are
available
from two different agreements. Since the rights are identical and
indistinguishable, one
agreement is selected by a variety of techniques (for example, arbitrarily)
and the rights
and terms of that agreement are displayed.
[0069] Alternatively, a tie between two or more rights with terms results in
the
display of all such rights together with the terms, so that the end user can
make an
informed judgment as to the permissibility of the requested activity. Another
example is
a tie between two or more rights with "Purchase" status. Such a tie results in
the
display of a list of the purchase information or capability for all such
rights. In another
embodiment, once a publication has been selected, the "best" rights which are
available
for various types of use are determined and presented to the member
simultaneously.
[0070] Once the rights have been displayed on the rights advisor web page, the
process finishes in step 514.
[0071] A software implementation of the above-described embodiment may
comprise a series of computer instructions either fixed on a tangible medium,
such as a
computer readable media, for example, a diskette, a CD-ROM, a ROM, or a fixed
disk,
24
CA 02735215 2016-07-26
or transmittable to a computer system for storage thereon via a modem or other
interface device over a transmission path. The transmission path either may be
tangible
lines, including but not limited to, optical or analog communications lines,
or may be
implemented with wireless techniques, including but not limited to microwave,
infrared or
other transmission techniques. The transmission path may also be the Internet.
The
series of computer instructions embodies all or part of the functionality
previously
described herein with respect to the invention. Those skilled in the art will
appreciate
that such computer instructions can be written in a number of programming
languages
for use with many computer architectures or operating systems. Further, such
instructions maybe stored using any memory technology, present or future,
including
but not limited to, semiconductor, magnetic, optical or other memory devices,
or
transmitted using any communications technology, present or future, including
but not
limited to optical, infrared, microwave, or other transmission technologies.
It is
contemplated that such a computer program product may be distributed as a
removable
medium with accompanying printed or electronic documentation, e.g., shrink
wrapped
software, pre-loaded with a computer system, e.g., on system ROM or fixed
disk, or
distributed from a server or electronic bulletin board over a network, e.g.,
the Internet or
World Wide Web.
[0072] An exemplary embodiment of the invention has been disclosed; however,
various changes and modifications can be made which will achieve some of the
advantages of the invention. For example, it will be obvious to those
reasonably skilled
in the art that, in other implementations, process operations different from
those shown
may be performed.
[0073] What is claimed is: