Note: Descriptions are shown in the official language in which they were submitted.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
1
PROCEDE D'ADAPTATION DE DONNEES DANS UN SYSTEME DE
TRANSMISSION DE DONNEES ET SYSTEME ASSOCIE
La présente invention concerne un système et un procédé
d'adaptation de données dans le cadre d'une transmission de données entre
un émetteur et un récepteur qui ne partagent pas la même définition
syntaxique de ces données.
L'invention s'applique notamment dans le cadre de systèmes
communiquant composés d'applications logicielles qui échangent des
messages entre elles.
Une application logicielle connectée à un réseau de communication
hétérogène communique dans la plupart des cas avec une autre application
distante par l'intermédiaire de messages contenant des données. Ces
messages peuvent avoir la même nature sémantique, c'est-à-dire véhiculer
le même contenu, mais présenter une syntaxe ou un schéma de la structure
des données différents. Par exemple, un message qui définit une adresse
postale peut être généré par une première application sous la forme d'une
seule structure de données contenant les champs suivants: un entier
spécifiant un numéro de rue, un énumérateur spécifiant un type de rue , une
chaine de caractères spécifiant un nom de rue, un entier spécifiant un code
postal, une chaine de caractères spécifiant une ville et une chaine de
caractères spécifiant un pays. Ce même message définissant la même
adresse postale peut être généré par une seconde application avec une
syntaxe différente, par exemple une première structure de données indiquant
la ville et contenant le code postal, le nom de la ville et le nom du pays
sous
forme de chaines de caractères et une seconde structure de données
indiquant la rue et contenant son numéro, son type et son nom spécifiés
sous forme de chaines de caractères. Dans cet exemple, les contenus
sémantiques des deux messages sont identiques mais leur syntaxe est
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
2
différente ce qui engendre des problèmes d'interopérabilité entre les
applications.
Le problème que cherche à résoudre la présente invention est
notamment de permettre l'échange de données entre plusieurs applications
sans pour autant qu'elles ne partagent le même schéma de données ou la
même syntaxe.
Les solutions connues à ce problème sont de plusieurs types. Tout
d'abord l'interopérabilité peut être gérée par une première transformation du
1o format du message d'origine vers un format pivot puis une seconde
transformation du format pivot vers le format du message cible. Cette
solution présente l'inconvénient d'engendrer un temps de calcul long. De
plus l'écriture de ces deux transformations est laissée à la charge des
fournisseurs des applications cliente et serveur puisqu'ils sont les seuls à
maîtriser les formats d'origine et cible respectivement. Cela engendre un
travail supplémentaire qu'ils doivent prendre en compte lors du
développement de leurs applications.
De plus il est possible de perdre des informations en passant par un
format intermédiaire pivot.
D'autres solutions sont basées sur l'utilisation de lexiques permettant
de calculer une transformation du format du message d'origine vers le format
du message cible en essayant d'établir des correspondances entre les
éléments des messages et leurs structures de données. L'utilisation de
lexiques n'est cependant pas suffisante car elle ne permet pas d'assurer une
correspondance exacte entre deux termes dans tous les cas, par exemple
les formes abrégées d'un terme ne sont pas prises en compte par un lexique.
L'invention propose, afin de résoudre le problème précédemment
introduit, un procédé d'adaptation de données permettant de transformer
3o dynamiquement un format de données non hiérarchique origine vers un
format de données structuré utilisé par une cible avec laquelle on cherche à
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
3
communiquer. L'expression format de données non hiérarchique fait
référence à un ensemble de données de types divers mises bout à bout afin
de former un message sans structure particulière.
Le procédé et le système selon l'invention prennent appui sur l'utilisation
d'une base de connaissances ou ontologie dans laquelle sont définis un
ensemble de concepts sémantiques.
L'invention présente notamment les avantages suivants, l'utilisation
d'une ontologie comme base de connaissance commune permet d'être plus
1o complet qu'un lexique grâce notamment aux relations qui existent entre deux
concepts sémantiques tel que, par exemple, la relation d'équivalence. De
plus, l'abandon du format pivot permet de réduire significativement le temps
de calcul.
L'invention a pour objet un système d'adaptation de données comprenant
au moins un émetteur exécutant au moins une application appelante et un
récepteur exécutant au moins une application appelée, les émetteurs et
récepteurs étant interconnectés via un réseau de communication, ladite
application appelante générant des messages à destination de ladite
application appelée, lesdits messages étant structurés selon une première
syntaxe SA, ladite application appelée étant adaptée à recevoir des
messages structurés selon une seconde syntaxe SB, ledit système étant
caractérisé en ce qu'il comporte une base de connaissances ontologique et
un annuaire de services communs aux émetteurs et récepteurs, ledit
système d'adaptation comportant en outre un module de traduction connecté
à ladite base et audit annuaire adapté à effectuer une traduction directe
desdits messages selon la seconde syntaxe SB.
Dans une variante de réalisation de l'invention ladite base de
connaissances ontologique définit un ensemble de spécifications
sémantiques des données échangées entre les émetteurs et les récepteurs
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
4
dudit système, lesdites spécifications étant formalisées par des concepts
sémantiques liés entre eux par des relations de dépendance, ledit module de
traduction étant adapté à exploiter le contenu de ladite base afin de faire
correspondre les spécifications sémantiques du message structuré selon la
syntaxe SA avec celles du message structuré selon la syntaxe SB de façon à
ce que lesdits messages présentent le même contenu sémantique.
Dans une variante de réalisation de l'invention le module de traduction
est, en plus, adapté à exploiter les relations entre concepts sémantiques
définis dans la base de connaissance ontologique pour élargir les recherches
1o de correspondance entre les spécifications sémantiques des messages
structurés selon deux syntaxes SA, SB différentes.
Dans une variante de réalisation de l'invention l'annuaire de services
contient l'ensemble des syntaxes SA, SB associées aux applications
exécutées par les émetteurs et récepteurs dudit système.
Dans une variante de réalisation de l'invention la syntaxe SA de
l'application appelante est définie comme l'enchainement d'un ensemble de
données sans structure particulière ni ordre spécifique.
Dans une variante de réalisation de l'invention les spécifications
sémantiques contenues dans la base de connaissance ontologique sont
définies à l'aide du langage de définition Resource Description
Framework ou du langage de définition Web Ontology Language
Dans une variante de réalisation de l'invention les syntaxes SA, SB
contenues dans l'annuaire de services sont définies à l'aide du langage de
description IDL Interface Description Language ou du langage de
description XSD XML Schema Description ou encore par un diagramme
défini en langage UML Unified Modelling Language .
Dans une variante de réalisation de l'invention ledit module de traduction
est propre à chaque émetteur ou est commun à l'ensemble des applications
exécutées par les émetteurs et récepteurs dudit système et centralisé dans
un bus logiciel.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
L'invention a également pour objet un procédé d'adaptation de données
dans un système comprenant au moins un émetteur exécutant au moins une
application appelante et un récepteur exécutant au moins une application
appelée, les émetteurs et récepteurs étant interconnectés via un réseau de
5 communication, ladite application appelante générant au moins un message
à destination de ladite application appelée, ledit message étant structuré
selon une première syntaxe SA, ladite application appelée étant adaptée à
recevoir au moins un message structuré selon une seconde syntaxe SB, ledit
procédé étant caractérisé en ce qu'il comprend au moins les étapes
1o suivantes :
- une étape d'association dudit message avec un identifiant de
l'application appelée destinataire dudit message,
> une étape de détermination de la syntaxe SB associée à
l'application appelée à partir de son identifiant,
- une étape de traduction directe dudit message dans un format
adapté à la syntaxe SB mais ayant le même contenu
sémantique que le message initial, à partir de la
correspondance entre les spécifications sémantiques de la
syntaxe SA et celles de la syntaxe SB ,
- une étape de transmission dudit message transformé à
l'application appelée via ledit réseau de communication.
D'autres caractéristiques apparaîtront à la lecture de la description
détaillée
donnée à titre d'exemple et non limitative qui suit faite en regard de dessins
annexés qui représentent :
La figure 1 un schéma illustrant un mode de réalisation du système
d'adaptation de données selon l'invention,
La figure 2 un schéma illustrant les étapes mises en oeuvre lors de la
transmission d'un message de données source vers une cible ayant un
schéma de structure de données propre,
Les figures 3, 4 et 5 des exemples de réalisation de l'invention.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
6
La figure 1 représente un exemple de réalisation du système
d'adaptation de données selon l'invention.
Des émetteurs de données 101,102 et des récepteurs de données
111,112,113 sont connectés ensemble à travers un réseau de
communication 150. Ces émetteurs et récepteurs sont, par exemple, des
terminaux informatiques qui peuvent endosser à la fois la fonction d'émetteur
et de récepteur ou uniquement l'un des deux. Chaque émetteur 101,102
exécute au moins une application appelante 131,132 qui échange des
1o messages 181,182 avec une application appelée 141,142,143 exécutée sur
des terminaux récepteurs de données 111,112,113. Ces messages
comportent un ensemble de données représentées selon une syntaxe
particulière SA, c'est-à-dire une structure de présentation de leur contenu
ainsi qu'un type associé à chacune des données. Cette syntaxe est propre à
chaque application appelante 131,132. De façon similaire, une application
appelée 141,142,143 possède également une syntaxe particulière SB pour la
représentation des messages de données qu'elle utilise. Les deux syntaxes
appelantes SA et appelées SB peuvent être différentes, ce qui pose le
problème de l'interopérabilité lors de l'échange de messages entre deux
applications.
Pour permettre à chaque application appelante 131,132 d'adapter la syntaxe
des messages qu'elle souhaite transmettre à celle de l'application appelée
141,142,143 , chaque terminal émetteur 101,102 exécute en plus un module
de traduction 120 dont la fonction est de traduire le message à envoyer dans
la syntaxe SB de l'application appelée. Ce module de traduction 120 est, par
exemple, une bibliothèque locale et propre à chaque application 131,132
mais peut également être partagée par plusieurs applications, dans ce
dernier cas, le module de traduction 120 est centralisé dans un bus logiciel
qui est utilisé, notamment, pour faire communiquer plusieurs systèmes qui ne
sont pas interopérables, par exemple car ils n'utilisent pas les mêmes
protocoles de communication.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
7
Le module de traduction 120 est, en outre, connecté à une base de
connaissances ontologique 160 ainsi qu'à un annuaire de services 170.
L'annuaire de services 170 englobe l'ensemble des définitions de syntaxes,
également appelées interfaces, de messages utilisées par toutes les
applications ou services 131,132,141,142,143 participantes. A cet effet,
chaque nouvelle application qui s'enregistre dans le système selon
l'invention doit communiquer à l'annuaire de services 170 la syntaxe qu'elle
utilise. La syntaxe peut être définie à l'aide de langages de descriptions
connus tels que IDL ( Interface Description Language ), XSD ( XML
1o Schema Description ) ou par un diagramme UML ( Unified Modelling
Language ).
La base de connaissances ontologique ou ontologie 160 contient
l'ensemble des spécifications sémantiques nécessaires à l'explicitation d'un
domaine de connaissance. Des exemples de tels domaines de connaissance
sont la santé, les applications de sécurité ou l'administration électronique.
L'ontologie 160 comporte, pour chaque domaine de connaissances qu'elle
traite, un modèle de données comprenant un ensemble de concepts liés les
uns aux autres par des relations sémantiques. Ces relations sont définies,
par exemple, à l'aide d'un langage de spécification sémantique tel que RDF
( Resource Description Framework ) ou OWL ( Web Ontology
Language ). Chaque concept correspond à une spécification sémantique et
peut également comporter une ou plusieurs instances, c'est-à-dire des
éléments appartenant à ce concept. Le terme spécification sémantique
définit l'ensemble des informations associées à une donnée qui permettent
d'en préciser le sens dans les contours d'un domaine particulier. Il s'agit de
métadonnées qui permettent d'expliciter de manière la plus précise possible
le contenu d'une donnée. L'ontologie 160 est, par exemple, développée par
des experts oeuvrant dans les domaines concernés par les applications
131,132,141,142,143, puis standardisée de manière à pouvoir être partagée
par l'ensemble des applications participantes. Une ontologie 160 diffère
notamment d'une base de données classique en ce qu'elle permet de
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
8
raisonner sur des concepts. Une ontologie, associée par exemple à un
moteur d'inférence, permet de façon automatisée la création
de nouvelles relations entre les concepts par déduction sur les
définitions des relations initiales entre concepts.
L'ontologie 160 et l'annuaire de services 170 sont, préférablement,
centralisées et accessibles par les terminaux émetteurs et récepteurs
101,102,111,112,113 à travers le réseau 150. Dans un autre mode de
réalisation du système selon l'invention, l'ontologie 160 et l'annuaire de
services 170 peuvent être dupliqués sur chaque terminal si celui-ci possède
les ressources suffisantes en termes de mémoire disponible pour stocker les
deux bases 160,170. Ce mode de réalisation a pour avantage d'éviter les
échanges de données à travers le réseau 150 entre les applications, la base
ontologique 160 et l'annuaire de services 170. Cela implique alors une mise
en place d'un système de synchronisation des bases de connaissances 160
entre elles ainsi que des annuaires de services 170 entre eux.
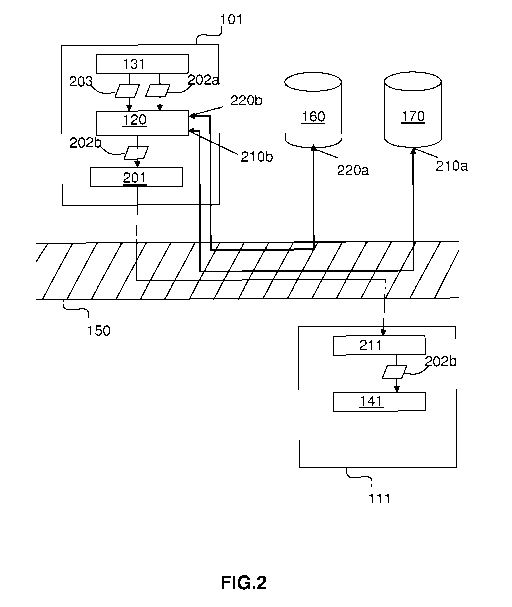
La figure 2 illustre les étapes mises en oeuvre par l'invention pour
adapter la syntaxe des messages transmis d'une application appelante 131
vers une application appelée 141
L'application 131 exécutée sur le terminal 101 cherche à transmettre un
message 202a de données à une application distante 141 avec laquelle elle
communique par l'intermédiaire du réseau 150. La transmission d'un
message 202a se fait, par exemple, lors de l'appel par l'application 131 d'une
fonction exécutée par l'application 141 appelée distante. L'application
appelante 131 transmet le message 202a avec une syntaxe SA spécifique au
module de traduction 120 ou dans un format non hiérarchique directement.
Cette syntaxe SA est par exemple définie à l'aide du langage de balisage
extensible XML ( Extensible Markup Language ). Elle transmet également
un moyen 203 d'identifier l'application appelée 141. Ce moyen 203 est, par
exemple, l'adresse du terminal récepteur 111 sur le réseau 150 associé à un
identifiant du service fourni par l'application appelée 141.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
9
Dans une variante de réalisation pour laquelle le module de traduction
120 est centralisé dans un bus logiciel auquel sont connectées toutes les
applications participantes, l'application appelante 131 transmet au bus
logiciel un identifiant du service avec lequel elle souhaite dialoguer et le
bus
logiciel se charge de déterminer l'adresse du terminal récepteur 111 qui
héberge ce service.
Dans un premier temps, le module de traduction 120 transforme le
message 202a afin de lui donner une structure simple avec un seul niveau
de profondeur, c'est-à-dire que l'ensemble des éléments composant ce
1o message sont mis bout à bout sans ordre spécifique afin d'obtenir une
structure de données non hiérarchique. Cette transformation est optionnelle
au sens où l'application appelante 131 peut transmettre directement le
message 202a avec un format non hiérarchique.
Dans un second temps, le module de traduction 120 envoi une
requête 210a pour interroger l'annuaire de services 170 en lui communiquant
l'identifiant 203 afin de connaître la syntaxe SB qu'utilise l'application
appelée
141. L'annuaire de services 170 lui transmet 210b alors la syntaxe SB
requise afin de générer le squelette du format du message 202b adapté à
être interprété par l'application appelée 141. Cette syntaxe SB utilise, par
exemple, différents niveaux de profondeur et des types de données divers
pour structurer les éléments d'un message. Tous les éléments définis par les
syntaxes utilisées par les applications participantes 101,111 sont spécifiés
sémantiquement et tous les concepts sémantiques proviennent de l'ontologie
160 qui est partagée par toutes les applications 101,111.
Dans une variante de réalisation, l'application appelante 131 communique
directement avec l'annuaire de services 170 afin de récupérer la syntaxe SB
de l'application appelée 141 et communique ensuite cette syntaxe au module
de traduction 120.
Dans un troisième temps, le module de traduction 120 envoie une
requête 220a à la base de connaissances ontologique 160 afin que celle-ci
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
lui transmette 220b les concepts sémantiques associés aux éléments qui
forment le contenu du message de données 202a. A partir de ces concepts
sémantiques, le module de traduction 120 établit une correspondance entre
les spécifications sémantiques des données du message initial 202a et celles
5 associées à la syntaxe SB. Le module de traduction génère alors les
éléments du message 202b qui ont la même interprétation sémantique mais
qui sont structurés selon la syntaxe SB qui permet à l'application appelée 141
de traiter ce message. Une fois généré, le message 202b est transmis à une
infrastructure de transmission 201 qui transmet le message à l'application
1o distante 141 via l'intermédiaire d'une infrastructure de réception 211.
Dans une variante de réalisation de l'invention, dans le cas où il n'est
pas possible de trouver une correspondance directe entre les concepts
sémantiques de l'application appelante et ceux de l'application appelée, le
module de traduction 120 utilise les relations entre concepts sémantiques
présents dans la base de connaissances 160 pour élargir les recherches de
correspondance.
La figure 3 schématise l'exploitation d'une ontologie comprenant
plusieurs concepts reliés par des relations lors de l'adaptation selon
l'invention de données structurées selon un premier format vers un second
format.
L'ontologie considérée contient plusieurs concepts servants à spécifier
sémantiquement un client à partir de plusieurs attributs. L'ontologie
comprend notamment les concepts de personne 301 et de client 302 reliés
entre eux par la relation est un 311. Les concepts de personne 301 ou de
client 302 sont reliés par des relations de composition ou d'agrégation aux
concepts de nom de famille 303, de prénom 304, d'âge 305 et de sport 306.
Le message d'entrée 321 du procédé d'adaptation selon l'invention est par
exemple écrit en langage XML et contient un certain nombre de données
permettant d'identifier un client particulier. Le contenu sémantique de ce
message 321 correspond à la personne Martin Dupont dont l'âge est 18 ans
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
11
et le sport pratiqué est la natation. Ce message 321 présente un format de
donnée non hiérarchique, c'est-à-dire que les sujets nom, prénom, âge et
sport sont listés successivement sans structure particulière, ils sont de plus
spécifiés en langue française.
Le format du message 323 de sortie du procédé est différent d'une part car
les champs spécifiés dans ce message sont rédigés en anglais et une
séparation structurelle est effectuée entre les champs firstname
(traduction anglaise de prénom) et surname (traduction anglaise de nom
de famille) qui définissent un premier niveau de spécification sémantique du
1o contenu de ce message et d'autres champs tels l'âge du client qui sont
rangés dans une structure étiquetée other_info . Enfin la structure globale
du message se rapporte au concept de client 303 alors que celle du
message d'entrée 321 se rapporte au concept de personne 301.
Le procédé selon l'invention opère une transformation 322 du message
d'entrée 321 vers le message de sortie 323 dont les contenus sémantiques
sont identiques en exploitant les relations entre concepts de l'ontologie. Les
données sont réarrangées dans le bon ordre et en respectant la structure
cible. Le procédé exploite la relation sémantique est un 311 entre les
concepts personne 301 et client 303 afin d'effectuer une correspondance
entre les champs de données de même contenu sémantique des deux
messages 321, 323. Enfin les données non utilisées, par exemple celles
correspondant au sport 306 ne sont pas prises en compte dans le message
de sortie 323.
La figure 4 schématise un deuxième exemple illustrant le procédé
selon l'invention. La même ontologie est considérée en y ajoutant le concept
de nom complet 401 qui est relié aux concepts de nom de famille 308 et de
prénom 304 par l'intermédiaire de la relation sémantique est composé de
411.
CA 02763289 2011-11-23
WO 2010/136408 PCT/EP2010/057069
12
Le message d'entrée 421 comprend le nom de famille 303 de la personne,
dans l'exemple Dupont et son prénom 304 Martin. La structure du message
de sortie 423 présente un seul champ de donnée associé au concept 401
nom complet qui regroupe le nom et le prénom en une seule donnée.
Dans ce cas la transformation 422 opérée exploite à la fois la relation 311
est un et la relation 411 est composé de afin générer la donnée
composée Martin Dupont dans le message de sortie 423.
La figure 5 schématise un troisième exemple illustrant le procédé
1o selon l'invention. Le message d'entrée 521 contient la définition
sémantique
de plusieurs personnes 301, à savoir Martin Dupont et Jean Dubois. Le
procédé selon l'invention permet de définir un ensemble d'éléments non
ordonnés qui ne seront pas dissociés lors de l'adaptation de données. Cette
notion est notamment nécessaire pour la gestion des types tels qu'une liste,
un tableau, une collection. Cette notion permet, tout en exploitant les
relations sémantiques 311,411 entre concepts de l'ontologie, de ne pas
dissocier deux données initialement associées tels le nom et le prénom d'une
personne. Ainsi le procédé selon l'invention génère 522 un message de
sortie 523 contenant les noms composés Jean Dubois et Martin Dupont et
non pas Jean Dupont et Martin Dubois comme cela serait possible si aucune
notion d'ensemble ordonnés n'était spécifiée.