Note: Descriptions are shown in the official language in which they were submitted.
CA 02774513 2012-04-17
=
Method
INTRODUCTION
The present invention relates to a method and system for cleaning water,
typically extracted from a subterranean formation, to remove hydrocarbon
therefrom,
wherein an external diluent, e.g. liquid hydrocarbon, is added to the water.
The
invention also relates to a method for separating a mixture comprising
hydrocarbon and
water wherein the separated water is cleaned by the method herein described.
BACKGROUND TO THE INVENTION
Heavy hydrocarbons, e.g. bitumen, represent a huge natural source of the
world's total potential reserves of oil and specialist methods have been
developed for
recovering such hydrocarbons. A number of these methods utilise steam to
mobilise
the hydrocarbon, e.g. steam assisted gravity drainage (SAGD), hot solvent
extraction,
VAPEX, ISC and cyclic steam stimulation (CSS).
The mobilised hydrocarbon recovered at the surface by these methods is in the
form of a mixture with water from condensed steam and formation water. A
diluent is
usually added to this mixture to reduce its viscosity. The diluent used is
generally a
lighter hydrocarbon such as naphtha, a light crude oil, a gas condensate or
synthetic
crude. The dilution of the mobilised hydrocarbon/water mixture with a diluent
typically
reduces its overall API to about 20 degrees enabling it to be pumped to a
processing
plant.
In the plant the hydrocarbon/water mixture is generally treated to separate
the
hydrocarbon from the produced water. Ideally the water that is obtained from
this
separation process is recycled by using it for the generation of further steam
in a steam
generator. Usually, however, the water must first be cleaned or purified to
render it
suitable for feeding to a steam generator, e.g. a once through steam generator
(OTSG). Otherwise the oil, organics, minerals and inorganic salts present in
the water
precipitate out to form deposits that stick to the heat surfaces of the boiler
in a process
often referred to as "fouling". The deposits form a thermal barrier on the
heat surfaces
and increase the temperature of the surfaces which ultimately reduces the
strength of
their material and their service lifetime. The deposits also reduce the heat
transfer to
water to generate steam thus reducing the quantity and quality of the steam
subsequently produced by the steam generator. Boilers generally need to be
taken out
of operation at regular intervals for cleaning and maintenance to remove
deposits
31443582-1-kgordon
CA 02774513 2012-04-17
2
created by fouling. The higher the degree of fouling the shorter the
operational periods
between cleaning and maintenance are.
To minimise the amount of fouling that occurs in a steam generator, e.g. an
OTSG, various different methods are employed to treat water recovered from
hydrocarbon production prior to recycling it for steam generation. In the
commercial
process operated today, the hydrocarbon/water mixture to which diluent is
usually
added is generally separated in a bulk separator to yield a
hydrocarbon/diluent fraction
and a water fraction. Emulsion breakers are usually added to improve the
separation
process. The water fraction is generally cooled and then sent to a skim tank,
gas
floatation tank and/or oil removal filter wherein further hydrocarbon
impurities are
removed. Flocculants and/or coagulants may optionally be added during these
latter
stages. Further chemical treatments to reduce water hardness and silica
content are
often carried out on the resulting water prior to its pumping to a boiler.
There are, however, drawbacks associated with this process. Although the
water finally produced by the process meets the current requirements for use
in steam
generators, e.g. <50 ppm wt hydrocarbon, it still causes some fouling in the
generators
and they must regularly be taken out of service for cleaning and maintenance.
The
coolers used in the processing of the water fraction are also prone to
fouling. The
water that enters the coolers, namely the water obtained from the initial bulk
separation, still tends to contain at least 0.01 %wt hydrocarbon and could
potentially
contain up to about 4 %wt hydrocarbon, and as a result fouling occurs.
Relatively high
amounts of chemicals such as emulsion breakers, flocculants and coagulants
also
need to be added to, e.g. the separator, skim tank and flotation tank, to
improve the
separation processes. The use of such chemicals is, however, expensive.
Attempts have been made to improve the above-described process to increase
the purity of the water recycled for steam generation. A number of attempts
have
focussed on improving the separation that occurs in the bulk separator, i.e.
on the initial
separation of the hydrocarbon and water mixture extracted from a formation.
W02010/004266 discloses a method wherein a lipophilic liquefied gas is
injected into a
mixture comprising gas, hydrocarbon, water and solids to be separated by a
separator.
The lipophilic liquefied gas is preferably a gas condensate and is preferably
introduced
into the separator in an aqueous carrier.
EP-A-1,783,101 discloses a related method wherein a C1.8 hydrocarbon is
injected into a water, oil and gas mixture in an oil/water separator. In the
method of
EP-A-1,783,101 water is separated from oil and gas in a first separator and
the
31443582-1-kgordon
CA 02774513 2012-04-17
3
resulting water fraction which still comprises some oil and gas is led to a
liquid-
liquid/gas separator. A condensed C1_8 hydrocarbon is added into this
separator. The
C1_8 hydrocarbon becomes substantially gaseous due to the release of pressure.
This
is said to lead to a more efficient separation of oil/gas from water. It is
thought that the
C1.8 hydrocarbon fluid absorbs the oil in the water and that the gas bubbles
of fluid
enhance the separation. It is therefore essential that the C1.8 hydrocarbon
fluid
converts to gaseous form in the separator. In the separator the mixture is
separated
into a water fraction and an oil/gas fraction. The oil/gas fraction is then
separated into
a light fraction, which includes the added C1_8 hydrocarbon, and a heavy
fraction. The
light fraction is subsequently condensed in a condensation vessel and the C1-8
hydrocarbon is obtained therefrom. It is then pressurised by a pump and
recycled for
injection into the separator.
W001/58813 discloses a different method which targets separation of oil
soluble components such as naphthalene and phenantrene (NPD), polyaromatic
hydrocarbons (PAH) and benzene/toluene/ethyl benzene/xylene (BTEX), rather
than
dispersed oil. In the method of W001/58813 a liquid condensate is separated
from the
extracted oil that has a lower concentration of water soluble oil components
than the
water phase and is then injected into the water phase. Since the liquid
condensate has
a lower concentration of oil soluble components mass transfer occurs from the
water to
the condensate. The mass transfer is optimised by injecting the liquid
condensate
through a nozzle to produce a fine distribution having a maximum surface area
and
therefore contact area with the water. The liquid condensate, along with the
oil soluble
components that have transferred into it, are then separated from the water in
a
separator such as a hydrocyclone.
The method disclosed in W001/58813 does, however, have some
disadvantages. First W001/58813 highlights the importance of choosing the
correct
liquid condensate for use in the extraction process. W001/58813 therefore
advocates
the inclusion of a device such as a rectifier or fractionater to ensure that a
condensate
with the required low concentrations of NPD, PAH and BTEX can be obtained.
Alternatively stripping, adsorption or absorption equipment may be employed to
remove NPD, PAH and BTEX from condensates. In all cases, however, there is
need
to include additional equipment specifically for producing suitable liquid
condensate for
use in the extraction process as well as for piping to route the liquid
condensate to the
separated water. Second, as noted by W001/58814, the temperature of the
condensate obtained from the, e.g. rectifier or fractionation column, is often
lower than
31443582-1-kgordon
CA 02774513 2012-04-17
4
that of the separated water to which it is to be added therefore the risk of
gas being
formed is high. As a result, W001/58814 advocates the inclusion of a heat
exchanger
in the liquid condensate line prior to the point at which it is mixed with
water. A means
to remove any gas produced in the heat exchanger must then also be provided.
A need therefore exists for an alternative method for cleaning separated water
that utilises conventional equipment and is straightforward to put into
practice.
Methods requiring the use of fewer specialist chemicals such as emulsion
breakers,
flocculants and coagulants are particularly attractive. Naturally methods that
yield
water of high purity that reduces steam generator and cooler fouling are
especially
attractive.
It has now been discovered that a method of cleaning separated water wherein
an external diluent is added thereto is highly advantageous. Since the diluent
is added
to the water after the separation stage in a bulk separator, conventional
separation
equipment may be used for the bulk separation. The presence of the external
diluent
during subsequent cleaning steps wherein hydrocarbon is removed from the
separated
water, however, improves the purity of the final water obtained. The use of an
external
diluent to perform this function is highly beneficial. The external diluent is
readily
available at the plant, therefore its use avoids the need to include any
equipment in the
plant specifically for the production and transport of diluent. A further
significant
advantage is that the external diluent can be recycled with hydrocarbon
without any
need to carry out a separation.
SUMMARY OF INVENTION
Viewed from a first aspect, the present invention provides a method of
cleaning
water to remove hydrocarbon therefrom comprising:
(i) adding an external diluent to said water; and
(ii) removing said hydrocarbon together with said diluent from said water.
Viewed from a further aspect, the present invention provides a method of
separating a mixture comprising hydrocarbon and water wherein said method
comprises:
(i) separating said mixture in a separator to produce separated hydrocarbon
and
separated water; and
(ii) cleaning said separated water by a method as hereinbefore described.
Viewed from a still further aspect, the present invention provides a system
for
cleaning water to remove hydrocarbon therefrom comprising:
31443582-1-kgordon
CA 02774513 2012-04-17
(a) a means for adding an external diluent to water separated in a bulk
separator; and
(b) a means for removing hydrocarbon together with said diluent from said
water and
comprising an outlet for water,
wherein said means for adding an external diluent comprises at least one inlet
for said
5 external diluent in between said bulk separator and said means for
removing
hydrocarbon from said water.
Preferred systems further comprise a cooler. Further preferred systems
comprise a dispersing device for dispersing said external diluent in said
water.
Preferred methods and system remove dispersed and/or dissolved hydrocarbon
from the water.
DESCRIPTION OF THE INVENTION
As used herein the term external diluent refers to a diluent that is produced
or
supplied from outside, or independently to, the methods of the invention. More
specifically an external diluent is not produced or supplied from the
hydrocarbon
extracted from the formation in combination with the water being cleaned.
Preferably
the diluent is a liquid hydrocarbon.
In the methods of the present invention water is cleaned or purified. More
specifically the amount of hydrocarbon present in the water is reduced.
Hydrocarbon
may also be completely removed from water in the methods of the invention.
The water cleaned in the methods of the present invention is preferably water
separated from a hydrocarbon and water mixture, particularly mixtures
extracted from a
subterranean formation, e.g. an oil well. A number of methods used to extract
mixtures
utilise steam, e.g. SAGD, CSS, hot solvent extraction, VAPEX, 1SC and
combinations
thereof. The method of the present invention is particularly useful for
cleaning water
separated from a hydrocarbon and water mixture extracted by steam based
methods
since the cleaned water can then be recycled for further steam generation.
SAGD is
the most commonly used extraction process commercially. Preferably therefore
the
water cleaned is water separated from a hydrocarbon and water mixture
extracted from
a hydrocarbon formation using SAGD.
When a hydrocarbon and water mixture is extracted from a formation, it
generally undergoes a bulk separation in a bulk separator wherein hydrocarbon,
water,
gas and solids are separated. The cleaning methods of the present invention
are
preferably carried out on the separated water obtained from this bulk
separation in a
bulk separator.
31443582-1-kgordon
CA 02774513 2012-04-17
6
The water cleaned in the methods of the invention predominantly comprises
water. Preferably at least 90 % by weight, more preferably at least 95 % by
weight, yet
more preferably at least 97 % by weight, still more preferably at least 98 %
by weight,
e.g. at least 99 % by weight of the water cleaned is water. The maximum
concentration of water may be, for example, 99.9 % by weight.
In the methods of the present invention the water cleaned may comprise up to 5
%wt hydrocarbon. The amount of hydrocarbon present in the water may be, for
example, 0.0002 to 5 %wt. More typically, however, the water cleaned in the
method
of the invention comprises 0.01 to 3 % wt hydrocarbon, more preferably 0.015
to 1 %
wt hydrocarbon, still more preferably 0.02 to 0.1 A wt hydrocarbon, e.g.
about 0.025 to
0.05 % wt hydrocarbon. Amounts up to 3 or 4 %wt of hydrocarbon can, however,
be
present. This occurs, for instance, when there is a problem such as the
presence of an
unstable emulsion in the bulk separation process.
The hydrocarbon present in the water is generally a mixture of different types
of
hydrocarbon having a range of molecular weights. The hydrocarbon present in
the
water may be dispersed therein or dissolved therein. The method of the present
invention is, however, aimed at removal of hydrocarbon dispersed in the water.
Preferably therefore the hydrocarbon present in the water is not water
soluble.
As mentioned above, the methods of the present invention are particularly
useful for cleaning water produced by steam assisted extraction methods. Such
methods are typically used for extraction of heavy hydrocarbons. Thus in many
cases
the hydrocarbon present in the water to be cleaned will comprise heavy
hydrocarbon.
Heavy hydrocarbons are often characterised by their API gravity. A heavy
hydrocarbon
preferably has an API gravity of less than about 20 , preferably less than
about 150
,
more preferably less than 12 , still more preferably less than 10 , e.g. less
than 8 .
Generally a heavy hydrocarbon has an API of about 5 to about 150, more
preferably
from about 6 to about 12 , still more preferably about 7 to about 12 , e.g.
about 7.5-
9 .
A key step in the method of the present invention is that an external diluent,
especially an external hydrocarbon diluent, is added to the water to be
cleaned. The
external diluent used in the method of the invention is preferably a liquid.
By a liquid is
meant herein that the diluent is in liquid form at 20 C and at atmospheric
pressure.
Still more preferably the external diluent is in liquid form throughout the
method of the
invention. Preferably therefore the diluent does not undergo an evaporation
and/or
compression process.
31443582-1-kgordon
CA 02774513 2012-04-17
7
Preferably the external diluent has a boiling point in the range 30 to 130 C
and
more preferably 50 to 95 C. Preferably the external diluent has a density in
the range
700-900 kg/m3 and more preferably 725-850 kg/m3. Preferably the external
diluent has
a flash point in the range -10 to -50 C. Preferably the external diluent is
completely
stable in the water and does not cause, e.g. precipitation of asphaltenes.
The external diluent added to the water in the methods of the invention is
preferably a hydrocarbon diluent. Preferred external hydrocarbon diluents
comprise a
mixture of C6-30 hydrocarbons, particularly C10-28 hydrocarbons and more
preferably
C12+ hydrocarbons. External diluents comprising longer hydrocarbons, e.g. C6+
or Clo+
are preferred since they are less likely to cause flashing when they are added
to the
water. Preferred diluents have an API of 20-80 , more preferably 30-70 .
Preferred external diluents comprise aromatic hydrocarbons. These
hydrocarbons are generally better at removing hydrocarbon impurities than
aliphatic
hydrocarbons. Preferably the concentration of BTEX in the external diluent is
in the
range 0 to 3 wt% and more preferably 0.5 to 2 wt%.
Representative examples of suitable external diluents include naphtha, light
crude oil or gas oils, synthetic oil, gas condensates and mixtures thereof.
External
diluent comprising naptha, light crude oil or gas oil and synthetic oil are
generally
preferred. External diluent may, for example, comprise 0-100 %wt naptha, 0-70
%wt
light crude oil or gas oil, 0-25% gas condensates, 0-3 %wt butane and 0-3 %wt
BTEX.
Particularly preferably the external diluent added to the water is the same
diluent that is added to the hydrocarbon and water mixture after it has been
extracted
from the subterranean formation and prior to a bulk separation. As described
in more
detail below, this facilitates the recycling of the external diluent and the
capture of the
hydrocarbon and avoids the need for any separation equipment.
The addition of external diluent, especially external hydrocarbon diluent, to
the
water to be cleaned is counter intuitive since the objective of the method is
to remove
hydrocarbon. It has been found, however, that the addition of external diluent
after the
bulk separation is completed has a number of beneficial effects. First it
improves the
removal of further hydrocarbon, especially heavy hydrocarbon, from water in
subsequent steps, e.g. by skimming in a skim tank. Second, in addition to
removing
dispersed hydrocarbon, it improves removal of dissolved hydrocarbon. Third it
may
reduce the amount of specialty chemicals that need to be used in the cleaning
process.
Fourth it increases the overall purity of the cleaned water by increasing the
amount of
31443582-1-kgordon
CA 02774513 2012-04-17
8
hydrocarbon, especially heavy hydrocarbon, removed therefrom, thus
facilitating
recycling of the cleaned or purified water to a steam generator.
The amount of diluent added to the water to be cleaned varies and depends, for
example, on the level of separation achieved in the bulk separator, the nature
of the
hydrocarbon impurities and the level of purity that the final water must
achieve.
Typically, however, the amount of diluent added is 0.05-10 %wt, more
preferably 0.1 to
5 %wt and still more preferably 0.5 to 1.5 %wt, e.g. about 0.75 %wt based on
the total
weight of the water to be cleaned (including any impurities such as
hydrocarbon
present therein). The diluent is preferably added to the water in neat form,
i.e. in the
absence of a carrier.
An advantage of the method of the invention is that the diluent may be added
to
the water to be cleaned over a wide range of temperatures, e.g. in the range 0
to 160
C. In preferred methods of the invention, however, the water is cooled to a
temperature of 80-140 C and more preferably 90-130 C. Cooling of the water
is
preferably carried out in at least one heat exchanger. Still more preferably
the water is
cooled in a plurality of heat exchangers connected in series and/or parallel.
In some
preferred methods the water is cooled prior to removing hydrocarbon (e.g.
after bulk
separation). In other preferred methods the water is cooled after a first step
of
removing hydrocarbon. When the latter approach is used, preferably a further
hydrocarbon removal step follows cooling (i.e. cooling occurs in between
hydrocarbon
removal steps).
In some preferred methods of the invention the external diluent is added to
the
water to be cleaned prior to cooling (e.g. after it is obtained by separation
in the bulk
separator and prior to cooling). In this case the temperature of the water may
be in the
range 100-160 C and more preferably 120-145 C when the diluent is added. In
other
preferred methods the external diluent is added to the water after cooling but
prior to
removal of hydrocarbon therein. In this case the temperature of the water may
be in
the range 80-140 C and more preferably 90-130 C. The addition of external
diluent to
the water prior cooling is advantageous as may decrease the level of fouling
in the
coolers. Otherwise the decrease in temperature that occurs in the coolers
tends to
result in the precipitation of previously dispersed or dissolved components
from the
water.
The pressure of the water at the point of addition of external diluent may be
in
the range 0-20 barg and more preferably 3-10 barg. Preferably the pressure of
the
water is similar to the operational pressure of the bulk separator from which
the water
31443582-1-kgordon
CA 02774513 2012-04-17
9
is obtained. Adjustments may, however, be made to the pressure of the water in
order
to keep the water and/or diluent in liquid form.
The amount of external diluent added to the water is so small that the
temperature and pressure of the diluent has little influence on the
temperature and
pressure of the resulting mixture. Prior to the addition the external diluent
is preferably
stored in a tank on site. An advantage of the use of an external diluent is
that it has a
wide window of operation. In other words the external diluent can effectively
be used in
a wide range of temperature and pressure conditions. Preferably the
temperature of
the external diluent in its storage tank and therefore just prior to addition
to water is in
the range -15 to 25 C and more preferably -20 to 20 C. Preferably the
external
diluent is stored in its storage tank and therefore just prior to addition to
water at
atmospheric pressure. To facilitate addition it may be pumped, therefore the
pressure
of the diluent at the point of addition may be up to 100 kPa.
The addition of the external diluent to water is preferably carried out by
adding
diluent into the line transporting the water to the cooler and/or the means
for removing
hydrocarbon therefrom. This may be achieved, for example, by the use of a
suitable
inlet valve. Preferably a controlled dosing system is used. The resulting
diluent-
containing water is preferably forced through a dispersing device, e.g.
valves, nozzles
or mixers, to distribute the external diluent throughout the water. The
addition of
external diluent in this way is advantageous in that the water and diluent are
thoroughly
mixed and contact between the diluent and hydrocarbon present in the water is
achieved. Often a pressure drop, e.g. of up to 0.5 bar, occurs during the
dispersing
process.
In a preferred method of the present invention, the hydrocarbon and external
diluent present in the water to be cleaned are removed together in a
separator. Any
conventional separator may be used, e.g. a cyclone, gravity separator, skim
tank,
flotation tank (e.g. a gas flotation tank) or oil removal filter. The method
of the present
invention may comprise one or more cleaning steps, e.g. two, three or four
cleaning
steps. When multiple cleaning steps are used, each step may be carried out in
the
same or different types of separator. Preferably, however, the method of the
invention
comprises one or two cleaning steps and still more preferably one cleaning
step.
In a preferred method the hydrocarbon and external diluent are removed
together in a skim tank. The majority of external diluent added to the water
is removed
in this process. Any conventional skim tank may be used. Such tanks are
commercially available. In the skim tank the hydrocarbon and the majority of
added
31443582-1-kgordon
CA 02774513 2012-04-17
diluent are captured by the skimming material. The external diluent will
generally have
a significantly lower density than the hydrocarbon present in the water and as
a result
will float to the surface much faster than, e.g. heavy hydrocarbon droplets.
The fast
floating diluent droplets also capture heavy hydrocarbon droplets and
transport them to
5 the top of the tank. The conditions in the skim tank are those
conventionally used.
Preferably the temperature is 70 to 95 C. Preferably the pressure is
atmospheric
pressure.
In another preferred method the hydrocarbon and diluent are removed together
in a flotation tank. The majority of external diluent added to the water is
removed in
10 this process. Any conventional flotation tank, e.g. gas flotation tank,
may be used.
Such tanks are commercially available. In the flotation tank the hydrocarbon
and the
majority of added diluent are captured. The external diluent may improve the
performance of the flotation tank because the diluent mixed into the
hydrocarbon
droplets will start forming bubbles inside oil droplets and thereby induce
strong
buoyancy thereto. The hydrocarbon and external diluent floating on the surface
of the
water can then be removed. The conditions in the flotation tank are those
conventionally used. Preferably the temperature is 70 to 95 C. Preferably the
pressure is atmospheric pressure.
In a further preferred method the hydrocarbon and external diluent are removed
together in a separator, e.g. gravity separator or cyclone. The majority of
the external
diluent added to the water is removed in this process. Any conventional
separator may
be used and such separators are commercially available.
The water obtained from the first cleaning step, e.g. after gravity
separation,
skimming or flotation, preferably comprises 0-20 ppm wt hydrocarbon and more
preferably 0-10 ppm wt hydrocarbon. In some methods, the water may be suitable
for
recycling to a steam generator. Often, however, the water is treated to remove
dissolved organics and/or inorganics prior to recycling to a steam generator.
Other preferred methods comprise the further step of removing hydrocarbon
present in the water obtained in the first cleaning step in a further
separator, skim tank,
flotation tank or oil removal filter. In one preferred method the first
cleaning step is in a
skim tank and the second cleaning step is in a flotation tank. In another
preferred
method the first cleaning step is in a separator and the second cleaning step
is in a
skim tank.
The water obtained from the second cleaning step, e.g. the flotation tank
preferably comprises 0-20 ppm wt hydrocarbon and more preferably 0-10 ppm wt
31443582-1-kgordon
CA 02774513 2012-04-17
11
hydrocarbon. As above, in some methods, the water may be suitable for
recycling to a
steam generator. Often, however, the water is treated to remove dissolved
organics
and/or inorganics prior to recycling to a steam generator.
Other methods, however, comprise the further step of removing hydrocarbon
present in the water obtained in the second cleaning step in a further
separator, skim
tank, flotation tank or oil removal filter. Preferably an oil removal filter
is used. After
filtration the resulting water preferably comprises 0-5 ppm wt hydrocarbon and
more
preferably 0-1 ppm wt hydrocarbon.
A preferred method of the invention comprises cooling the water, removing the
hydrocarbon together with the external diluent from cooled water in a skim
tank,
flotation tank and/or oil removal filter, preferably connected in series.
Another preferred
method comprises removing hydrocarbon together with external diluent from the
water,
cooling the resulting water and removing further hydrocarbon and diluent from
the
cooled water.
The hydrocarbon and external diluent removed from the water, e.g. in a
separator, skim tank, flotation tank and/or oil removal filter, are preferably
recycled,
particularly preferably without separation. Preferably the hydrocarbon and
external
diluent removed from the water are recycled to a separator (e.g. a bulk
separator used
to produce the water to be cleaned) and/or to a hydrocarbon treater. An
advantage of
the method of the present invention is that the hydrocarbon and external
diluent
removed during cleaning does not need to be separated and instead can be
recycled
together. This benefit arises from the fact that the external diluent used to
enhance the
removal of hydrocarbon from the water is an external diluent which is
preferably similar,
or still more preferably identical, to the diluent used to decrease the
viscosity of the
hydrocarbon and water mixture extracted from a hydrocarbon formation. The
hydrocarbon separated in the bulk separation will therefore comprise similar
or identical
diluent, hence the recycling of the hydrocarbon and diluent removed from the
water to
the separator and/or treater does not add anything new to be separated
downstream,
e.g. at the treater. This significantly simplifies recycling of the external
diluent and
avoids any need for an additional separation steps or equipment to regenerate
diluent.
Preferably the method of the present invention yields water that meets the
requirements with respect to dispersed hydrocarbon for use in a steam
generator, e.g.
OTSG, in terms of its hydrocarbon content. Preferably the method of the
invention
yields water comprising 0 to 50 ppm wt dispersed hydrocarbon, still more
preferably 0
to 25 ppm wt dispersed hydrocarbon and especially 0 to 10 ppm wt dispersed
31443582-1-kgordon
CA 02774513 2012-04-17
12
hydrocarbon, e.g. 0 to 5 ppm wt dispersed hydrocarbon. Preferably the water
obtained
is recycled to a steam boiler to generate steam, e.g. for SAGD. Preferably the
water
obtained is sent to a water treatment facility prior to recycling to a steam
boiler.
The water produced by the method of the invention may comprise dissolved
organic components, e.g. PAH, NPD and BTEX. Preferred processes of the
invention
further comprise a step of removing dissolved organic components. Similarly
the water
produced by the method of the invention may comprise dissolved inorganic
components, e.g. salts, silica. Preferred processes of the invention further
comprise a
step of removing dissolved inorganic components. Conventional processes that
are
well know to the skilled man may be used, e.g. warm lime softening, media
filtration
and ion exchangers (WAC).
The method of cleaning water according to the present invention may be
incorporated into a method of separating a mixture comprising hydrocarbon and
water.
As mentioned above, the hydrocarbon produced at the surface of a formation by
extraction, e.g. using steam, comprises water. The amount of water present in
the
hydrocarbon and water mixture is highly variable and depends, for example, on
the
type of formation, the type of recovery operation being carried out, the
quality of the
steam injected into the formation and the length of time for which the
operation has
been carried out. The amount of water present in the hydrocarbon and water
mixture
may be, for example, 30-90% by volume. Correspondingly the amount of
hydrocarbon
present in the hydrocarbon and water mixture is variable and may be, for
example, 70-
10% by volume.
When the hydrocarbon and water mixture is extracted from the subterranean
formation, despite its mobilisation by steam, it is typically still viscous
and therefore
difficult to pump. Preferably therefore a diluent is added to the mixture
comprising
hydrocarbon and water prior to separation in a bulk separator. Preferably the
diluent
added is similar or identical to the external diluent added during the
cleaning method.
Preferably therefore the diluent is as described above in relation to the
cleaning
method.
The diluent may be added to the mixture comprising hydrocarbon and water
prior to its entry to the bulk separator or may be added to the bulk
separator.
Preferably, however, the diluent is added to the mixture prior to its entry to
the bulk
separator, e.g. shortly after the mixture is brought to the surface of the
formation from
which it is extracted. This improves the pumpability and separability of the
mixture.
The addition of the diluent is preferably carried out by adding diluent into
the line
31443582-1-kgordon
CA 02774513 2012-04-17
13
transporting the mixture of hydrocarbon and water to the separator. This may
be
achieved, for example, by the use of a suitable inlet valve.
The bulk separator used to carry out the bulk separation on the hydrocarbon
and water mixture may be any conventional separator, e.g. a gravity separator,
a
cyclone separator or a vortex separator. Preferably, however, the separator is
a gravity
separator. The
separator optionally includes means for separation of gas from the
mixture. The separator optionally includes means for separation of solids from
the
mixture. The separator is operated under conditions that are conventional in
the art.
The separator may be operated in a continuous, semi-continuous or batchwise
manner.
In the bulk separator the hydrocarbon and water mixture is separated to yield
separated hydrocarbon and separated water. The mixture is fed into the bulk
separator
and allowed to separate out to a gas phase, a hydrocarbon phase, a water phase
and
a solids phase in vertically descending order. Optionally chemicals such as
emulsion
breakers may be added to the separator to improve the separation. The
separated
hydrocarbon predominantly comprises hydrocarbon. Preferably at least 75 % by
volume, more preferably at least 85 % by volume and still more preferably at
least 95
% by volume of the separated hydrocarbon is hydrocarbon.
The separated hydrocarbon is preferably removed from the bulk separator via a
hydrocarbon outlet. The majority of the diluent added to the mixture prior to
its entry
into the bulk separator will be present in this separated hydrocarbon.
Preferably the
separated hydrocarbon is transported to a treater for processing.
The separated water is preferably cleaned by the method as hereinbefore
described.
An advantage of the methods of the present invention is that it can be carried
out using conventional equipment, i.e. conventional separators, coolers, skim
tanks,
floatation tanks, filters etc. Such equipment is all commercially available.
The only
modifications required to carry out the method of the present invention is
that an inlet
for external diluent and optionally a dispersing device be provided in the
system prior to
the means for removing hydrocarbon from the water. Such an inlet can
conveniently
be provided in the form of a suitable valve in the line transporting the water
to be
cleaned. Preferred systems comprise a means for dispersing the external
diluent in the
water, e.g. valves, nozzles or mixers etc. Valves are generally preferred.
Suitable
valves, nozzles and mixers are commercially available.
31443582-1-kgordon
CA 02774513 2012-04-17
14
Preferred systems of the invention further comprise a cooler comprising an
inlet
for water and an outlet for cooled water. In preferred systems of the present
invention,
the cooler is at least one heat exchanger. In particularly preferred systems,
a plurality
of heat exchangers are present, preferably connected in series and/or
parallel.
Suitable heat exchangers are commercially available.
In further preferred systems the means for removing hydrocarbon from the
water is a conventional separator, e.g. a separator (e.g. gravity separator or
cyclone),
skim tank, a flotation tank and/or oil removal filter. Preferred systems
comprise at
least two of a separator (e.g. gravity separator or cyclone), a skim tank, a
flotation tank
and/or an oil removal filter. Particularly preferred systems comprise a skim
tank and a
flotation tank or a separator (e.g. gravity separator) and a skim tank. The
system
preferably comprises an outlet for water that is fluidly connected, directly
or indirectly,
to the water supply tank of a steam generator.
In some preferred systems the cooler is in between the bulk separator and the
means for removing hydrocarbon. In this case the cooler is fluidly connected
to a water
outlet of a bulk separator and comprises a cooled water outlet fluidly
connected to the
means for removing hydrocarbon. In other preferred systems, the cooler is
after the
means for removing hydrocarbon. In this case the water outlet of the means for
removing hydrocarbon is fluidly connected to the water inlet of said cooler.
Preferably
the outlet of the cooler is fluidly connected to a second means for removing
hydrocarbon.
The inlet for external diluent is after the bulk separator. The inlet for
external
diluent may be prior to or after the cooler. Preferably it is before the
cooler. When the
means for removing hydrocarbon is before the cooler, the inlet for diluent is
preferably
prior to the means for removing hydrocarbon, i.e. in between the bulk
separator the
means for removing hydrocarbon.
In one preferred system of the invention, particularly a system wherein a
cooler
is in between the bulk separator and the means for removing hydrocarbon, the
means
for removing hydrocarbon is a skim tank or flotation tank, particularly a skim
tank,
fluidly connected to the cooled water outlet of the cooler and comprising an
outlet for
water. Such systems optionally further comprise a flotation tank fluidly
connected to
the outlet for water of said means for removing hydrocarbon from the water and
comprising an outlet for water. Such systems further optionally comprise an
oil
removal filter fluidly connected to the outlet for water of the means for
removing
hydrocarbon or the flotation tank and comprising an outlet for further
purified water.
31443582-1-kgordon
CA 02774513 2012-04-17
Still more preferably the outlet for water and/or further purified water is
fluidly
connected to a water treatment system feeding the water supply tank of a steam
generator.
In other preferred systems of the invention, particularly a system wherein a
5 cooler is after the means for removing hydrocarbon, the means for
removing
hydrocarbon is a separator, e.g. gravity separator or cyclone. Such systems
optionally
further comprise a skim tank, a flotation tank and/or an oil filter removal
fluidly
connected to said cooled water outlet of said cooler. It is preferable in some
systems
to remove dispersed or dissolved hydrocarbon and external diluent in a first
means for
10 removing hydrocarbon, e.g. a separator, and then cool the mixture prior
to removing
further dispersed or dissolved hydrocarbon and external diluent. The cooling
process
affects the equilibria in action in the mixture and, e.g. causes more
hydrocarbon to
come out of solution into dispersion and reduces the solubility of the
dissolved
hydrocarbon.
15 The means for removing hydrocarbon from the cooled water, e.g. the
separator,
skim tank, flotation tank and/or oil removal filter, preferably further
comprises an outlet
for hydrocarbon and external diluent that is fluidly connected to the bulk
separator
and/or treater (both described below). This enables the hydrocarbon and
external
diluent removed to be recycled through the process.
Further preferred systems of the invention enable a hydrocarbon and water
mixture to be separated as well as cleaned. Such systems further comprise a
bulk
separator, preferably a bulk gravity separator, a bulk cyclone separator or a
vortex
separator, especially a bulk gravity separator. The bulk separator comprises
an inlet
for a mixture comprising hydrocarbon and water, an outlet for hydrocarbon and
an
outlet for water. The bulk separator optionally includes means for separation
of gas
from the mixture. The bulk separator optionally includes means for separation
of solids
from the mixture. Suitable bulk separators for use in the invention are
commercially
available.
Preferred systems of the present invention further comprise a treater fluidly
connected to the hydrocarbon outlet of the separator and comprising an outlet
for
treated hydrocarbon.
DETAILED DESCRIPTION OF PREFERRED EMBODIMENTS OF THE INVENTION
The invention will now be described with reference to the following non-
limiting
Figures and examples wherein:
31443582-1-kgordon
CA 02774513 2012-04-17
16
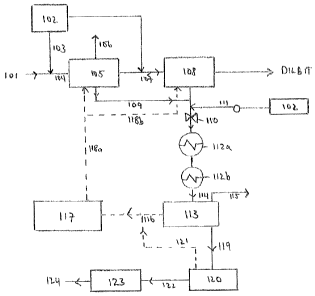
Figure 1 shows a schematic of a method and system for cleaning water
according to the present invention;
Figure 2 shows a schematic of another method and system for cleaning water
according to the invention;
Figure 3 shows a schematic of a further method and system for cleaning water
according to the invention. In Figures 1-3 the method of cleaning begins with
separated water 109. The additional steps involved in a method of separating a
hydrocarbon and water mixture comprising the cleaning method of the invention
is
described in relation to 101-108;
Figure 4 shows a schematic of the experimental set up used to test the method
of the invention; and
Figure 5 shows the effect of addition of external diluent on the removal of
hydrocarbon from simulated separated water.
Referring to Figure 1, a mixture 101 is extracted from an oil well which
comprises hydrocarbon, water, gas and solids. External diluent
102 is generally
added via line 103 to mixture 101 to lower its viscosity and improve its
ability to be
pumped and separated. The diluent is preferably a liquid. The mixture 101
further
comprising diluent 102 is led via line 104 to a bulk separator 105 wherein an
initial
separation of the mixture into a separated hydrocarbon, a separated water and
gas is
carried out. This bulk separator 105 may be any conventional three-phase
separator
known in the art, e.g. a gravity separator or a cyclone separator. Any gas
present is
removed via line 106.
The separated hydrocarbon is led via line 107 to a treater 108. Most of the
diluent 102 added is present in the separated hydrocarbon. Further external
diluent
102 is optionally added to the separated hydrocarbon in line 107. The
treater
produces dilbit (diluted bitumen).
The separated water is led via line 109 to at least one cooler 112a. Prior to
its
entry to cooler 112a, external diluent 102 is added to the separated water via
line 111.
The separated water comprising external diluent is then passed through a
dispersing
device 110. As shown in Figure 1 this may be a valve that disperses the
external
diluent throughout the water. Preferably the external diluent 102 is identical
to the
external diluent added to the original mixture 101 extracted from the well.
Optionally
the cooled water comprising external diluent 102 passes through a further
cooler 112b.
The cooled water comprising external diluent is then led to skim tank 113 via
line 114.
31443582-1-kgordon
CA 02774513 2012-04-17
17
In the skim tank 113 the water is cleaned by removing the hydrocarbon and
external diluent. Any gas generated in the process is removed via line 115.
The
external diluent improves the cleaning process by coalescing with the
dispersed
hydrocarbon thereby generating larger droplets. The external diluent will also
generally
have a lower density than the dispersed hydrocarbon therefore the coalesced
droplets
generally also float better than the droplets solely comprising hydrocarbon.
The
hydrocarbon and diluent droplets are collected by the skimming media and leave
the
skim tank via line 116. As shown the hydrocarbon and external diluent may be
recycled together via slop tank 117 to the treater 108 via line 118b and/or to
separator
105 via line 118a. A significant advantage of the method of the present
invention is
therefore that the external diluent 102 used is already on site and is, in a
sense, simply
"borrowed" from the hydrocarbon treating processes.
The water is led via line 119 to a gas floatation tank 120 wherein further
hydrocarbon and external diluent are removed. Again the external diluent
improves the
cleaning process by dissolved gas flotation and continued coalescence with the
dispersed hydrocarbon to form larger droplets having a lower density than the
dispersed hydrocarbon droplets that are easier to remove. The hydrocarbon and
external diluent are recycled via line 121 to line 116 from where it is
eventually returned
to separator 105 and treater 108.
The water is led via line 122 to an oil removal filter 123. The water 124
obtained therefrom preferably meets the specification required for use in a
steam
generator. If necessary, however, the water may undergo further treatments,
for
example, to remove inorganic components. Preferably it is not necessary to
remove
any further dissolved organics from the water. The water 124 is stored for
future use in
steam generation.
Referring to Figure 2, it shows a similar method and system to that of Figure
1
except that the separated water 109 is cooled in heat exchangers 112a, 112b
prior to
addition of external diluent 102 via line 111. Otherwise the method and system
are the
same. The water in line 119 may optionally be further cleaned in a flotation
tank and/or
oil removal filter as described in relation to Figure 1.
Referring to Figure 3, the method and system shown therein comprises gravity
separator 150. Thus the separated water 109 to which external diluent 102 has
already been added as described above in relation to Figure 1, is transported
into
separator 150 and separation occurs. Any gas produced in the process is
removed via
line 151. The separated hydrocarbon and external diluent is removed via line
152 and
31443582-1-kgordon
CA 02774513 2012-04-17
18
is recycled to the bulk separator 105. Although not shown it could
alternatively or
additionally be recycled to the treater 108. The presence of the external
diluent 102 in
the separator 150 improves the separation process.
The separated water 153 is transported to coolers 112a, 112b. The cooled
water is then led to skim tank 113 via line 114. In the skim tank 113 the
water is
cleaned by removing the hydrocarbon and external diluent present. Although a
significant proportion of the hydrocarbon and external diluent is removed in
the
separator 150, the cooling process reduces the solubility of hydrocarbon in
the water
and more dispersed and less soluble hydrocarbon results.
The water 124 produced by the skim tank preferably meets the specification
required for use in a steam generator. If necessary, however, the water may
undergo
further treatments, for example, to remove inorganic components. Preferably it
is not
necessary to remove any further dissolved organics from the water. The water
124 is
led by line 119 to storage for future use in steam generation.
The method of the present invention at least provides the following
advantages:
= The method introduces an external diluent during transportation of the
water to
be cleaned from the bulk separator to the means for removing hydrocarbon,
e.g. skim tank or separator. The only modification needed to the system to
carry out the method is the addition of one or more valves on the
transportation
line to enable the addition of external diluent and optionally dispersing
means
(e.g. valves or nozzles) to disperse the diluent throughout the water.
= The method allows for removal of both dispersed and dissolved
hydrocarbons.
= The external diluent used is a liquid, rather than a condensed gas.
Consequently there is no need for separation equipment, e.g. fractionating
column or rectifier, or compression equipment to facilitate recycling of the
external diluent.
= The external diluent used is preferably the same diluent added to the
hydrocarbon mixture obtained from the oil well to reduce its density and
viscosity. This is highly beneficial. The diluent is readily available on site
and it
opens up the possibility of recycling the diluent to various stages of the
process
without separation from the hydrocarbon. For instance, the hydrocarbon and
diluent may be recycled to the separator or to the treater. A huge advantage
is
gained by the fact that the hydrocarbon and diluent do not need to be
separated
to enable recycling to occur.
31443582-1-kgordon
CA 02774513 2012-04-17
19
= Since the external diluent used in the method is the same as that added
to the
crude hydrocarbon mixture obtained from the well, no instability issues due to
incompatibility of the hydrocarbon and the diluent is expected.
= The method may utilise one three-phase separator in a conventional manner
and does not therefore require any modification to the separator or the
addition
of extra equipment.
= The method allows for efficient removal of hydrocarbons without the
presence
of conventional water treatment chemicals
EXAMPLES
A series of experimental laboratory tests have been performed in the "water
rig"
in Statoil Porsgrunn. The objective of the testing was to demonstrate
efficient
hydrocarbon removal by dispersing a diluent (OSN) into water simulating water
produced by SAGD. Batch sample testing has been performed in the water rig,
giving
a 5-30 fold improvement of oil removal with 1% diluent compared to the same
process
without diluent, depending on the oil droplet size. The conclusion of the
tests
performed is that the results indicate a significant improvement of de-oiling
efficiency in
SAGD produced water.
The batch sample testing was done according to the schematic in figure 4. A
water tank (3 m3) heated to 80 C and applying diluted seawater to 3500, mg/L
TDS
functioned as a water reservoir. A pump from a loop close to the oil addition
point
gives a flow of approximately 150 L/min through the system. Leismer dilbit was
dosed
into the water stream as the hydrocarbon to be removed and exposed to a short
pressure drop across a ball valve to control the droplet size (8-25 pm). The
external
diluent (OSN) was added in a 0.2, 0.5 and 1.0% of total volume ratio and was
intermixed with the oil containing stream across a second valve (S2) with a
given
pressure drop. Batch samples of the water stream were then sampled in 2L pyrex
bottles with a given settling time (0-60 minutes). The pyrex bottles simulates
the skim
tank in the cleaning process. After a given settling time, the water samples
were tapped
from the bottom of the pyrex bottle and analyzed. During the settling process,
the
pyrex bottles were kept warm in a heating cabinet at 70 C. The results are
shown in
Figure 5.
As Figure 5 shows, the hydrocarbon removal is most efficient for the largest
droplets, which is logical with reference to Stoke's law, where the larger oil
droplets (25
pm) have a larger rising velocity than the smaller ones (8.5 pm). The effect
of adding
31443582-1-kgordon
CA 02774513 2012-04-17
external diluent has a strong positive impact, which increases with increased
amount of
added diluent up to 1%. When adding 1% external diluent, the extraction and
separation of hydrocarbon from the water phase happens much more quickly than
with
no or lower diluent concentrations.
5
31443582-1-kgordon