Note: Descriptions are shown in the official language in which they were submitted.
CA 02776701 2012-05-07
1%0 02/064631
PCT/IJS02/00198
TiR TASTE RECEPTORS AND GENES ENCODING SAME
Background of the Invention
Field of the Invention
[0002] The invention relates to newly identified mammalian chemosensory G
protein-coupled receptors, to family of such receptors, and to the genes and
cDNA
encoding said receptors. More particularly, the invention relates to newly
identified mammalian chemosensory G protein-coupled receptors active in taste
signaling, to a family of such receptors, to the genes and cDNA encoding said
receptors, and to methods of using such receptors, genes, and cDNA in the
analysis and discovery of taste modulators. The invention provides in
particular a
DNA sequence encoding a novel human taste receptor identified infra as TI R2
and the corresponding receptor polypeptide.
Description of the Related Art
[0003] The taste system provides sensory information about the chemical
composition of the external world. Mammals are believed to have at least
five basic taste modalities: sweet, bitter, sour, salty, and umami. See,
e.g., Kawamura et at., Introduction to Umami: A Basic Taste (1987); Kinnamon
et
at., Ann. Rev. Physiol., 54:715-31 (1992); Lindemann, Physiol. Rev., 76:718-66
(1996); Stewart et al., Am. J. Physiol., 272:1-26(1997). Each
taste modality is thought to be mediated by a distinct protein receptor or
receptors that are expressed in taste receptor cells on the surface of the
= tongue (Lindemann, Physol. Rev. 76:718-716 (1996)). The taste receptors
that recognize bitter, sweet, and umami taste stimuli belong to the
= G-protein-coupled receptor (GPCR) superfamily (Hoon et at., Cell 96:451
(1999); Adler et at., Cell 100:693 (2000)). (Other taste modalities are
believed to be mediated by ion channels.)
[0004] G protein-coupled receptors mediate many other physiological
1
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
functions, such as endocrine function, exocrine function, heart rate,
lipolysis, and carbohydrate metabolism. The biochemical analysis and
molecular cloning of a number of such receptors has revealed many basic
principles regarding the function of these receptors. For example, United
States Patent No. 5,691,188 describes how upon a ligand binding to a GPCR,
the receptor undergoes a conformational change leading to activation of a
heterotrimeric G protein by promoting the displacement of bound GDP by GTP on
the surface of the Ga subunit and subsequent dissociation of the Ga
subunit from the Gb and Gg subunits. The free Ga subunits and Gbg complexes
activate downstream elements of a variety of signal transduction pathways.
[0005] Complete or partial sequences of numerous human and other eukaryotic
chemosensory receptors are currently known. See, e.g., Pilpel, Y. and Lancet,
D.,
Protein Science, 8:969-977 (1999); Mombaerts, P., Annu. Rev. Neurosci., 22:487-
50 (1999). See also, EP0867508A2, US 5874243, WO 92/17585, WO 95/18140,
WO 97/17444, WO 99/67282. Because of the complexity of ligand-receptor
interactions, and more particularly taste stimulus-receptor interactions,
information
about ligand-receptor recognition is lacking.
[0006] The identification and characterization of the GPCRs that function
as sweet and umami taste receptors could allow for new methods of discovery of
new taste stimuli_ For example, the availability of receptors could
permit the screening for receptor modulators. Such compounds would modulate
taste and could be useful in the food industry to improve the taste of a
variety of
consumer products; e.g., improving the palatability of
low-calorie beverages through the development of new artificial sweeteners.
[0007] In
part, the present invention addresses the need for better
understanding of the interactions between chemosensory receptors and chemical
stimuli. The
present invention also provides, among other things, novel
chemosensory receptors, and methods for utilizing such receptors, and the
genes
a cDNAs encoding such receptors, to identify molecules that can be used to
modulate chemosensory transduction, such as taste sensation.
Summary of the Invention
[0008] The invention relates to a new family of G protein-coupled receptors,
and
to the genes and cDNAs encoding said receptors. The receptors are thought to
2
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
be primarily involved in sweet taste transduction, but can be involved in
transducing signals from other taste modalities as well.
[0009] The invention provides methods for representing the perception of taste
and/or for predicting the perception of taste in a mammal, including in a
human.
Preferably, such methods may be performed by using the receptors and genes
encoding said receptors disclosed herein.
[0010] Toward that end, it is an object of the invention to provide a new
family of
mammalian G protein-coupled receptors, herein referred to as TI Rs, active in
.
taste perception. It is another object of the invention to provide fragments
and
variants of such Ti Rs that retain taste stimulus-binding activity.
[0011] It is yet another object of the invention to provide nucleic acid
sequences
or molecules that encode such TI Rs, fragments, or variants thereof.
[0012] It is still another object of the invention to provide expression
vectors
which include nucleic acid sequences that encode such Ti Rs, or fragments or
variants thereof, which are operably linked to at least one regulatory
sequence
such as a promoter, enhancer, or other sequence involved in positive or
negative
gene transcription and/or translation.
[0013] it is still another object of the invention to provide human or non-
human
cells tat functionally express at least one of such Ti Rs, or fragments or
variants
thereof.
[0014] It is still another object of the invention to provide T1R fusion
proteins or
polypeptides which include at least a fragment of at least one of such Ti Rs.
[0015] It is another object of the invention to provide an isolated nucleic
acid
molecule encoding a T1R polypeptide comprising a nucleic acid sequence that is
at least 50%, preferably 75%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical
to a nucleic acid sequence selected from the group consisting of: SEQ ID NOS:
1,
2, 3, 9, 11, 13, 15, 16, 20, and conservatively modified variants thereof.
[0016] It is a further object of the invention to provide an isolated nucleic
acid
molecule comprising a nucleic acid sequence that encodes a polypeptide having
an amino acid sequence at least 35 to 50%, and preferably 60%, 75%, 85%, 90%,
95%, 96%, 97%, 98%, or 99% identical to an amino acid sequence selected from
the group consisting of: SEQ ID NOS: 4, 10, 12, 14, 17, 21, and conservatively
modified variants thereof, wherein the fragment is at least 20, preferably 40,
60,
3
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
80, 100, 150, 200, or 250 amino acids in length. Optionally, the fragment can
be
an antigenic fragment which binds to an anti-TiR antibody.
[0017] It is still a further object of the invention to provide an isolated
polypeptide
comprising a variant of said fragment, wherein there is a variation in at most
10,
preferably 5, 4, 3, 2, or 1 amino acid _residues.
[0018] It is still another object of the invention to provide agonists or
antagonists
of such Ti Rs, or fragments or variants thereof.
[0019] It is yet another object of the invention to provide methods for
representing the perception of taste and/or for predicting the perception of
taste in
a mammal, including in a human. Preferably, such methods may be performed by
using the Ti Rs, or fragments or variants thereof, and genes encoding such Ti
Rs,
or fragments or variants thereof, disclosed herein.
[0020] It is yet another object of the invention to provide novel molecules or
combinations of molecules which elicit a predetermined taste perception in a
mammal. Such molecules or compositions can be generated by determining a
value of taste perception in a mammal for a known molecule or combinations of
molecules; determining a value of taste perception in a mammal for one or more
unknown molecules or combinations of molecules; comparing the value of taste
perception in a mammal for one or more unknown compositions to the value of
taste perception in a mammal for one or more known compositions; selecting a
molecule or combination of molecules that elicits a predetermined taste
perception
in a mammal; and combining two or more unknown molecules or combinations of
molecules to form a molecule or combination of molecules that elicits a
predetermined taste perception in a mammal. The combining step yields a single
molecule or a combination of molecules that elicits a predetermined taste
perception in a mammal.
[0021] It is still a further object of the invention to provide a method of
screening
one or more compounds for the presence of a taste detectable by a mammal,
comprising: a step of contacting said one or more compounds with at least one
of
the disclosed Ti Rs, fragments or variants thereof, preferably wherein the
mammal
is a human.
[0022] It is another object of the invention to provided a method for
simulating a
taste, comprising the steps of: for each of a plurality of Ti Rs, or fragments
of
4
CA 02776701 2012-05-07
WO 02/064631 PCTIUS02/00198
variants thereof disclosed herein, preferably human Ti Rs, ascertaining the
extent
to which the T1R interacts with the taste stimulus; and combining a plurality
of
compounds, each having a previously ascertained interaction with one or more
of
the Ti Rs, in amounts that together provide a receptor-stimulation profile
that
mimics the profile for the taste. Interaction of a taste stimulus with a T1R
can be
determined using any of the binding or reporter assays described herein. The
plurality of compounds may then be combined to form a mixture. If desired, one
or more of the plurality of the compounds can be combined covalently. The
combined compounds substantially stimulate at least 50%, 60%, 70%, 75%, 80%
or 90% or all of the receptors that are substantially stimulated by the taste
stimulus.
[0023] In yet another aspect of the invention, a method is provided wherein a
plurality of standard compounds are tested against a plurality of T1Rs, or
fragments or variants thereof, to ascertain the extent to which the Ti Rs each
interact with each standard compound, thereby generating a receptor
stimulation
profile for each standard compound. These receptor stimulation profiles may
then
be stored in a relational database on a data storage medium. The method may
further comprise providing a desired receptor-stimulation profile for a taste;
comparino the desired receptor stimulation profile to the relational database;
and
ascertaining one or more combinations of standard compounds that most closely
match the desired receptor-stimulation profile. The method may further
comprise
combining standard compounds in one or more of the ascertained combinations to
simulate the taste.
[0024] It is a further object of the invention to provide a method for
representing
taste perception of a particular taste stimulus in a mammal, comprising the
steps
of: providing values X1 to Xr, representative of the quantitative stimulation
of each
of n Ti Rs of said vertebrate, where n is greater than or equal to 2; and
generating
from said values a quantitative representation of taste perception. The T1Rs
may
be an taste receptor disclosed herein, or fragments or variants thereof, the
representation may constitutes a point or a volume in n-dimensional space, may
constitutes a graph or a spectrum, and may constitutes a matrix of
quantitative
representations. Also, the providing step may comprise contacting a plurality
of
recombinantly-produced Ti Rs, or fragments or variants thereof, with a test
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
composition and quantitatively measuring the interaction of said composition
with
said receptors.
[0025] It is yet another object of the invention to provide a method for
predicting
the taste perception in a mammal generated by one or more molecules or
combinations of molecules yielding unknown taste perception in a mammal,
comprising the steps of: providing values X, to Xn representative of the
quantitative
stimulation of each of n TI Rs of said vertebrate, where n is greater than or
equal
to 2; for one or more molecules or combinations of molecules yielding known
taste
perception in a mammal; and generating from said values a quantitative
representation of taste perception in a mammal for the one or more molecules
or
combinations of molecules yielding known taste perception in a mammal,
providing values Xi to XT, representative of the quantitative stimulation of
each of n
Ti Rs of said vertebrate, where n is greater than or equal to 2; for one or
more
molecules or combinations of molecules yielding unknown taste perception in a
mammal; and generating from said values a quantitative representation of taste
perception in a mammal for the one or more molecules or combinations of
molecules yielding unknown taste perception in a mammal, and predicting the
taste perception in a mammal generated by one or more molecules or
combinations of molecules yielding unknown taste perception in a mammal by
comparing the quantitative representation of taste perception in a mammal for
the
one or more molecules or combinations of molecules yielding unknown taste
perception in a mammal to the quantitative representation of taste perception
in a
mammal for the one or more molecules or combinations of molecules yielding
known taste perception in a mammal. The Ti Rs used in this method may include
a taste receptor, or fragment or variant thereof, disclosed herein.
Detailed Description of the Figures
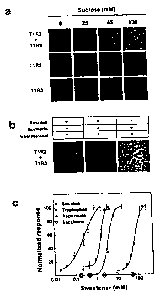
[0026] Figures la-1c present functional data for the human T1R2/T1R3
receptor. Intracellular calcium responses of HEK cells stably expressing Ga15
that are transiently transfected with human Ti R2, Ti R3, and T1R2/T1R3 to
various concentrations of sucrose are shown in Figure la. Each panel
corresponds to approximately 1000 confluent, transfected, and calcium-dye-
loaded cells. Inhibition of T1R2/T1R3 activity by the sweet-taste inhibitor
gurmarin
is shown in Figure lb. T1R2/T1R3 dose responses to four sweeteners and
6
i
CA 02776701 2012-05-07
WO 02/064631
PCT/I1S02/00198
correlated psychophysical detection thresholds (X-axis circles) are shown in
Figure 1c.
[00271 Figure 2 presents functional data for the rat Ti1R2/1-1R3 receptor.
Human
T1R2fT1R3 and rat T1R2fT1R3 (as well as mixed rat/human receptors) responses
to 350 mM sucrose, and 15 mM aspartame.
Rat Ti R2111R3 does not respond to aspartame or monellin, which are
not palatable to rodents (data not shown).
[0028] Figures 3a-3c present functional data for the human T1R2fT1R3
receptor. Intracellular calcium responses of HEK cells stably expressing Gal 5
that are transiently transfected with human T1R1, T1R3, and T1R1fT1R3 to
various concentrations of L-glutamate are shown in Figure 3a. Potentiation of
the
T1R1/T1R3 response by IMP is shown in Figure 3b. T1R1fT1R3 dose responses
to L-glutamate and L-glutamate plus 0.2 mM IMP and correlated psychophysical
detection thresholds (X-axis circles) are shown in Figure 3c.
[0029] Figures 4a-4b present immunofluorescence and FACS experiments that
demonstrate that fusing the PDZIP peptide (SEQ ID No: 1) to human Ti R2
enhanced its expression on the surface of HEK cells.
[0030] Figure 5 presents automated fluorescence imaging data for cell lines
that
stably e;=press Ga15 and human T1R1fT1R3. L-glutamate dose responses were
determined in the presence of 0.5 mM IMP.
[00311 Figure 6 presents automated fluorescence imaging data for cell lines
that
stably express Gal 5 and human T1R2/T1R3. Sucrose, D-tryptophan, saccharin,
and aspartame dose responses are shown for on stable cell line.
Detailed Description of the Invention
[0032] The invention thus provides isolated nucleic acid molecules encoding
taste-cell-specific G protein-coupled receptors ("GPCR"), and the polypeptides
they encode. These nucleic acid molecules and the polypeptides that they
= encode are members of the T1R family of taste-cell-specific GPCRs.
Members of
the T1R family of taste-cell-specific GPCRs are identified in Hoon etal.,
Cell,
= 96:541-551 (1999), WO 00/06592, and WO 00/06593.
More particularly, the invention provides nucleic acids encoding a novel
family of taste-cell-specific GPCRs. These nucleic acids and the receptors
7
i
CA 02776701 2012-05-07
WO 02/064631 PCTIUS02/00198
that they encode are referred to as members of the "Ti R" family of
taste-cell-specific GPCRs. In particular embodiments of the invention, the
T1R family members include human T1 R1, Ti R2, and Ti R3. As described supra,
different TiR combinations likely mediate sweet and umami taste.
Further, it is believed that TiR family members may act in combination with
other
T1R family members, other taste-cell-specific GPCRs, or a combination thereof,
to
thereby effect chemosensory taste transduction. For instance, it is believed
that
T1 R1 and Ti R3 maybe coexressed within the same taste receptor cell type, and
the two receptors may physically interact to form a heterodimeric taste
receptor.
Alternatively, T1 R1 and Ti R3 may both independently bind to the same type of
ligand, and their combined binding may result in a specific perceived taste
sensation.
[0033] These nucleic acids provide valuable probes for the identification of
taste
cells, as the nucleic acids are specifically expressed in taste cells. For
example,
probes for T1R polypeptides and proteins can be used to identify taste cells
present in foliate, circumvallate, and fungiform Papillae, as well as taste
cells
present in the geschmackstreifen, oral cavity, gastrointestinal epithelium,
and
epiglottis. They may also serve as tools for the generation of taste
topographic
maps that elucidate the relationship between the taste cells of the tongue and
taste sensory neurons leading to taste centers in the brain. In particular,
methods
of detecting Ti Rs can be used to identify taste cells sensitive to sweet
taste
stimuli or other specific modalities of taste stimuli. Furthermore, the
nucleic acids
and the proteins they encode can be used as probes to dissect taste-induced
behaviors. Also, chromosome localization of the genes encoding human TI Rs
can be used to identify diseases, mutations, and traits caused by and
associated
with TiR family members.
[0034] The nucleic acids encoding the T1R proteins and polypeptides of the
invention can be isolated from a variety of sources, genetically engineered,
amplified, synthesized, and/or expressed recombinantly according to the
methods
disclosed in WO 00/035374.
[0035] The invention also provides methods of screening for modulators, e.g.,
activators, inhibitors, stimulators, enhancers, agonists, and antagonists, of
these
8
I i
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
novel taste-cell-specific GPCRs. Such modulators of taste transduction are
useful
for pharmacological, chemical, and genetic modulation of taste signaling
pathways. These methods of screening can be used to identify high affinity
agonists and antagonists of taste cell activity. These modulatory compounds
can
then be used in the food and pharmaceutical industries to customize taste,
e.g., to
modulate the sweet tastes of foods or drugs.
[0036] Thus, the invention provides assays for detecting and characterizing
taste modulation, wherein T1R family members act as direct or indirect
reporter
molecules of the effect of modulators on taste transduction. GPCRs can be used
in assays to, e.g., measure changes in ligand binding, ion concentration,
membrane potential, current flow, ion flux, transcription, signal
transduction,
receptor-ligand interactions, second messenger concentrations, in vitro, in
vivo,
and ex vivo. In one embodiment, members of the T1R family can be used as
indirect reporters via attachment to a second reporter molecule such as green
fluorescent protein (see, e.g., Mistili & Spector, Nature Biotechnology,
15:961-964
(1997)). In another embodiment, T1R family members may be recombinantly
expressed in cells, and modulation of taste transduction via GPCR activity may
be
assayed by measuring changes in Ca2+ levels and other intracellular messages
such as cAMP, cGMP, or IP3.
[0037] In certain embodiments, a domain of a T1R polypeptide, e.g., an
extracellular, transmembrane, or intracellular domain, is fused to a
heterologous
polypeptide, thereby forming a chimeric polypeptide, e.g., a chimeric
polypeptide
with GPCR activity. Such chimeric polypeptides are useful, e.g., in assays to
identify ligands, agonists, antagonists, or other modulators of a T1R
polypeptide.
In addition, such chimeric polypeptides are useful to create novel taste
receptors
with novel ligand binding specificity, modes of regulation, signal
transduction
pathways, or other such properties, or to create novel taste receptors with
novel
combinations of ligand binding specificity, modes of regulation, signal
transduction
pathways, etc.
[0038] In one embodiment, a T1R polypeptide is expressed in a eukaryotic cell
as a chimeric receptor with a heterologous, chaperone sequence that
facilitates
plasma membrane trafficking, or maturation and targeting through the secretory
pathway. The optional heterologous sequence may be a rhodopsin sequence,
9
i
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
such as an N-terminal fragment of a rhodopsin. Such chimeric T1R receptors can
be expressed in any eukaryotic cell, such as HEK-293 cells. Preferably, the
cells
comprise a G protein, e.g., Ga15 or Ga16 or another type of promiscuous G
protein capable of pairing a wide range of chemosensory GPCRs to an
intracellular signaling pathway or to a signaling protein such as
phospholipase C.
Alternatively, the cells may express a chimeric or variant G protein that is
selected
based on its ability to couple with TiRs to produce a functional T1R taste
receptor. Examples of variant G proteins which are especially preferred
include
the G protein variants disclosed in U.S. Patent No. 6,818,747 and the chimeric
Ga15 variants.
These applications disclose G protein variants that have been shown to couple
better
with Ti Rs than Gal 5, a well known promiscuous G protein. Activation of such
chimeric receptors in such cells can be detected using any standard method,
such
as by detecting changes in intracellular calcium by detecting FURA-2 dependent
fluorescence in the cell. If preferred host cells do not express an
appropriate G
protein, they may be transfected with a gene encoding a promiscuous G protein
such as those described in WO 2002/036622.
[0039] Methods of assaying for modulators of taste transduction include in
vitro
ligand-binding assays using: T1R polypeptides, portions thereof, i.e., the
extracellular domain, transmembrane region, or combinations thereof, or
chimeric
proteins comprising one or more domains of a T1R family member; oocyte or
tissue culture cells expressing T1R polypeptides, fragments, or fusion
proteins;
phosphorylation and dephosphorylation of T1R family members; G protein binding
to GPCRs; ligand-binding assays; voltage, membrane potential and conductance
changes; ion flux assays; changes in intracellular second messengers such as
cGMP, CAMP and inositol triphosphate; changes in intracellular calcium levels;
and neurotransmitter release.
[0040] Further, the invention provides methods of detecting T1R nucleic acid
and protein expression, allowing investigation of taste transduction
regulation and
specific identification of taste receptor cells. T1R family members also
provide
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
useful nucleic acid probes for paternity and forensic investigations. T1R
genes
are also useful as a nucleic acid probes for identifying taste receptor cells,
such as
foliate, fungiform, circumvallate, geschmackstreifen, and epiglottis taste
receptor
cells. T1R receptors can also be used to generate monoclonal and polyclonal
= antibodies useful for identifying taste receptor cells. Taste receptor
cells can be
identified using techniques such as reverse transcription and amplification of
mRNA, isolation of total RNA or poly A+ RNA, northern blotting, dot blotting,
in situ
hybridization, RNase protection, Si digestion, probing DNA microchip arrays,
western blots, and the like.
[0041] Functionally, the T1R polypeptides comprise a family of related seven
transmembrane G protein-coupled receptors, which are believed to be involved
in
taste transduction and may interact with a G protein to mediate taste signal
transduction (see, e.g., Fong, Cell Signal, 8:217 (1996); Baldwin, Cum Opin.
Cell
Biol., 6:180 (1994)). Structurally, the nucleotide sequences of T1R family
members may encode related polypeptides comprising an extracellular domain,
seven transmembrane domains, and a cytoplasmic domain. Related T1R family
genes from other species share at least about 50%, and optionally 60%, 70%,
80%, or 90%, nucleotide sequence identity over a region of at least about 50
nucleotides in length, optionally 100, 200, 500, or more nucleotides in length
to
SEQ ID NOS: 1, 2, 3, 9, 11, 13, 15, 16, 20, or conservatively modified
variants
thereof, or encode polypeptides sharing at least about 35 to 50%, and
optionally
60%, 70%, 80%, or 90%, amino acid sequence identity over an amino acid region
at least about 25 amino acids in length, optionally 50-to 100 amino acids in
length
to SEQ ID NOS: 4õ10, 12, 14, 17, 21, or conservatively modified variants
thereof.
[0042] Several consensus amino acid sequences or domains have also been
identified that are characteristic of T1R family members. For example, TiR
family
members typically comprise a sequence having at least about 50%, optionally
55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95-99%, or higher, identity to T1R
consensus sequences 1 and 2 (SEQ ID NOs 18 and 19, respectively). These
conserved domains thus can be used to identify members of the T1R family, by
identity, specific hybridization or amplification, or specific binding by
antibodies
raised against a domain. Such T1R consensus sequences have the following
amino acid sequences:
11
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
T1R Family Consensus Sequence 1: (SEQ ID NO: 18)
(TR)C(FL)(RQP)R(RT)(SPV)(VERKT)FL(AE)(WL)(RHG)E
TiR Family Consensus Sequence 2: (SEQ ID NO: 19)
(LQ)P(EGT)(NRC)YN(RE)A(RK)(CGF)(VLI)T(FL)(AS)(ML)
[0043] These consensus sequences are inclusive of those found in the T1R
polypeptides described herein, but T1R family members from other organisms
may be expected to comprise consensus sequences having about 75% identity or
more to the inclusive consensus sequences described specifically herein.
[0044] Specific regions of the T1R nucleotide and amino acid sequences may
be used to identify polymorphic variants, interspecies homologs, and alleles
of
T1R family members. This identification can be made in vitro, e.g., under
stringent hybridization conditions or PCR (e.g., using primers encoding the
T1R
consensus sequences identified above), or by using the sequence information in
a
computer system for comparison with other nucleotide sequences. Different
alleles of T1R genes within a single species population will also be useful in
determining whether differences in allelic sequences correlate to differences
in
taste perception between members of the population. Classical PCR-type
amplification and cloning techniques are useful for isolating orthologs, for
example, where degenerate primers are sufficient for detecting related genes
across species, which typically have a higher level of relative identity than
paralogous members of the T1R family within a single species.
[0045] For instance, degenerate primers SAP077 (SEQ. ID NO. 5) and
SAP0079 (SEQ. ID NO. 6) can be used can be used to amplify and clone T1R3
genes from different mammalian genomes. In contrast, genes within a single
species that are related to Ti R3 are best identified using sequence pattern
recognition software to look for related sequences. Typically, identification
of
polymorphic variants and alleles of T1R family members can be made by
comparing an amino acid sequence of about 25 amino acids or more, e.g., 50-100
amino acids. Amino acid identity of approximately at least 35 to 50%, and
optionally 60%, 70%, 75%, 80%, 85%, 90%, 95-99%, or above typically
demonstrates that a protein is a polymorphic variant, interspecies homolog, or
allele of a TiR family member. Sequence comparison can be performed using
12
CA 02776701 2012-05-07
WO 02/064631 PCTIUS02/00198
any of the sequence comparison algorithms discussed below. Antibodies that
bind specifically to T1R polypeptides or a conserved region thereof can also
be
used to identify alleles, interspecies homologs, and polymorphic variants.
[0046] Polymorphic variants, interspecies homologs, and alleles of T1R genes
can be confirmed by examining taste-cell-specific expression of the putative
T1R
polypeptide. Typically, T1R polypeptides having an amino acid sequence
disclosed herein can be used as a positive control in comparison to the
putative
T1R polypeptide to demonstrate the identification of a polymorphic variant or
allele
of the T1R family member. The polymorphic variants, alleles, and interspecies
homologs are expected to retain the seven transmembrane structure of a G
protein-coupled receptor. For further detail, see WO 00/06592, which discloses
related TiR family members, GPCR-B3s.
GPCR-B3
receptors are referred to herein as rT1R1 and mT1R1. Additionally, see WO
00/06593, which also discloses related T1R family members, GPCR-B4s.
GPCR-B4 receptors are referred to herein as rT1R2 and
mT1R2.
[0047] Nuclt.otide and amino acid sequence information for T1R family
members may also be used to construct models of taste-cell-specific
polypeptides
in a computer system. These models can be subsequently used to identify
compounds that can activate or inhibit T1R receptor proteins. Such compounds
that modulate the activity of T1R family members can then be used to
investigate
the role of T1R genes and receptors in taste transduction.
[0048] The present invention also provides assays, preferably high throughput
assays, to identify molecules that interact with and/or modulate a T1R
polypeptide.
In numerous assays, a particular domain of a T1R family member is used, e.g.,
an
extracellular, transmembrane, or intracellular domain or region. In numerous
embodiments, an extracellular domain, transmembrane region or combination
thereof may be bound to a solid substrate, and used, e.g., to isolate ligands,
agonists, antagonists, or any other molecules that can bind to and/or modulate
the
activity of a T1R polypeptide.
13
CA 02776701 2012-05-07
WO (12/064631 PCT/US02/00198
[0049] In one aspect of the invention, a new human GPCR gene of the T1R
family, termed hTIR3, is provided. The hT1R3 gene was identified from the
human genome sequence database including the HTGS division of GenBank.
The nucleotide and conceptually translated amino acid sequence for hT1R3 are
provided in SEQ. ID NOS 1-4. The hT1R3 receptor was identified in the
partially
sequenced BAC genomic clone RP5-89003 (database accession number
AL139287) by virtue of its sequence similarity to the candidate rat taste
receptor
rT1R1 (accession number AF127389). By reference, the pairwise identity
between the predicted hT1R3 and rT1R1 protein sequences is approximately
34%. Sequence comparisons with additional members of the GPCR Family C
(which includes the calcium-sensing receptors, putative V2R pheromone
receptors, GABA-B receptors, fish taste receptors, and metabotropic glutamate
receptors) indicate that hT1R3 is likely to belong to the Family C subgroup
defined
by T1 R1 and a second rat candidate taste receptor (rT1R2, accession number
AF127390).
[0050] The invention also provides the human ortholog, termed hT1R1, of a rat
taste receptor, designated rT1R1. The gene products of rT1R1 and hT1R1 are
approximately 74% identical. The mouse gene, mT1R1 has been reported, see
Hoon et al., Cell, 96:541-551 (2000), and maps to a chromosomal interval
homologous to the interval containing hT1R1. The nucleotide and conceptually-
translated hT1R1 sequences are described herein as SEQ. ID NOS 15 and 16,
respectively.
[0051] While not wishing to be bound to any particular theory, the T1R family
of
receptors is predicted to be involved in sweet taste transduction by virtue of
the
linkage of mTIR3 to the Sac locus, a locus on the distal end of chromosome
four
that influences sweet taste. Human Ti R3 has also been reported to localize to
1p36.2-1p36.33, a region that displays conserved synteny with the mouse
interval
containing Sac and T1 R1. However, T1R type receptors may mediate other taste
modalities, such as bitter, umami, sour and salty.
[0052] Various conservative mutations and substitutions are envisioned to be
within the scope of the invention. For instance, it would be within the level
of skill
in the art to perform amino acid substitutions using known protocols of
recombinant gene technology including PCR, gene cloning, site-directed
14
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
mutagenesis of cDNA, transfection of host cells, and in-vitro transcription.
The
variants could then be screened for taste-cell-specific GPCR functional
activity.
A. Identification and Characterization of T1R Polypeptides
[0053] The amino acid sequences of the TiR proteins and polypeptides of the
invention can be identified by putative translation of the coding nucleic acid
sequences. These various amino acid sequences and the coding nucleic acid
sequences may be compared to one another or to other sequences according to a
number of methods.
[0054] For example, in sequence comparison, typically one sequence acts as a
reference sequence, to which test sequences are compared. When using a
sequence comparison algorithm, test and reference sequences are entered into a
computer, subsequence coordinates are designated, if necessary, and sequence
algorithm program parameters are designated. Default program parameters can
be used, as described below for the BLASTN and BLASTP programs, or
alternative parameters can be designated. The sequence comparison algorithm
then calculates the percent sequence identities for the test sequences
relative to
the reference sequence, based on the program parameters.
[0055] A "comparison window," as used herein, includes reference to a segment
of any one of the number of contiguous positions selected from the group
consisting of from 2010 600, usually about 50 to about 200, more usually about
100 to about 150 in which a sequence may be compared to a reference sequence
of the same number of contiguous positions after the two sequences are
optimally
aligned. Methods of alignment of sequences for comparison are well known in
the
art. Optimal alignment of sequences for comparison can be conducted, e.g., by
the local homology algorithm of Smith & Waterman, Adv. App!. Math. 2:482
(1981), by the homology alignment algorithm of Needleman & Wunsch, J Mot
Biol. 48:443 (1970), by the search for similarity method of Pearson & Lipman,
Proc. Natl. Acad Sci. USA 85:2444 (1988), by computerized implementations of
these algorithms (GAP, BESTFIT, FASTA, and TFASTA in the Wisconsin
Genetics Software Package, Genetics Computer Group, 575 Science Dr.,
Madison, WI), or by manual alignment and visual inspection (see, e.g., Current
Protocols in Molecular Biology (Ausubel et al., eds. 1995 supplement)).
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0056] A preferred example of an algorithm that is suitable for determining
percent sequence identity and sequence similarity are the BLAST and BLAST 2.0
algorithms, which are described in Altschul et a/., Nuc. Acids Res. 25:3389-
3402
(1977) and Altschul eta!, J Mol. Biol. 215:403-410 (1990), respectively.
Software
for performing BLAST analyses is publicly available through the National
Center
for Biotechnology Information. This algorithm
involves first identifying high scoring sequence pairs (HSPs) by identifying
short
words of length W in the query sequence, which either match or satisfy some
positive-valued threshold score T when aligned with a word of the same length
in
a database sequence. T is referred to as the neighborhood word score threshold
(Altschul et al., Altschul etal., Nuc. Acids Res. 25:3389-3402 (1977) and
Altschul
etal., J Mol. Biol. 215:403-410 (1990)). These initial neighborhood word hits
act
as seeds for initiating searches to find longer HSPs containing them. The word
hits are extended in both directions along each sequence for as far as the
cumulative alignment score can be increased. Cumulative scores are calculated
using, for nucleotide sequences, the parameters M (reward score for a pair of
matching residues; always > 0) and N (penalty score for mismatching residues;
always <0). For amino acid sequences, a scoring matrix is used to calculate
the
cumulative score. Extension of the word hits in each direction are halted
when:
the cumulative alignment score falls off by the quantity X from its maximum
achieved value; the cumulative score goes to zero or below, due to the
accumulation of one or more negative-scoring residue alignments; or the end of
either sequence is reached. The BLAST algorithm parameters W, T, and X
determine the sensitivity and speed of the alignment. The BLASTN program (for
nucleotide sequences) uses as defaults a wordlength (W) of 11, an expectation
(E) or 10, M=5, N=-4 and a comparison of both strands. For amino acid
sequences, the BLASTP program uses as defaults a wordlength of 3, and
expectation (E) of 10, and the BLOSUM62 scoring matrix (see Henikoff &
Henikoff, Proc. Natl. Acad Sci. USA 89:10915 (1989)) alignments (B) of 50,
expectation (E) of 10, M=5, N=-4, and a comparison of both strands.
[0057] Another example of a useful algorithm is PILEUP. PILEUP creates a
multiple sequence alignment from a group of related sequences using
progressive, pairvvise alignments to show relationship and percent sequence
16
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
identity. It also plots a so-called "tree" or "dendogram" showing the
clustering
relationships used to create the alignment (see, e.g., Figure 2). PILEUP uses
a
simplification of the progressive alignment method of Feng & Doolittle, J Mol.
Evol.
35:351-360 (1987). The method used is similar to the method described by
Higgins & Sharp, CABIOS 5:151-153 (1989). The program can align up to 300
sequences, each of a maximum length of 5,000 nucleotides or amino acids. The
multiple alignment procedure begins with the pairwise alignment of the two
most
similar sequences, producing a cluster of two aligned sequences. This cluster
is
then aligned to the next most related sequence or cluster of aligned
sequences.
Two clusters of sequences are aligned by a simple extension of the pairwise
alignment of two individual sequences. The final alignment is achieved by a
series of progressive, pairwise alignments. The program is run by designating
specific sequences and their amino acid or nucleotide coordinates for regions
of
sequence comparison and by designating the program parameters. Using
PILEUP, a reference sequence is compared to other test sequences to determine
the percent sequence identity relationship using the following parameters:
default
gap weight (3.00), default gap length weight (0.10), and weighted end gaps.
PILEUP can be obtained from the GCG sequence analysis software package,
e.g., version 7.0 (Devereaux etal., Nuc. Acids Res. 12:387-395 (1984) encoded
by the genes were derived by conceptual translation of the corresponding open
reading franies. Comparison of these protein sequences to all known proteins
in
the public sequence databases using BLASTP algorithm revealed their strong
homology to the members of the T1R family, each of the T1R family sequences
having at least about 35 to 50%, and preferably at least 55%, at least 60%, at
least 65%, and most preferably at least 70%, amino acid identity to at least
one
known member of the family.
B. Definitions
[0058] As used herein, the following terms have the meanings ascribed to them
unless specified otherwise.
[0059] "Taste cells" include neuroepithelial cells that are organized into
groups
to form taste buds of the tongue, e.g., foliate, fungiform, and circumvallate
cells
(see, e.g., Roper et al., Ann. Rev. Neurosci. 12:329-353 (1989)). Taste cells
are
17
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
also found in the palate and other tissues, such as the esophagus and the
stomach.
[0060] "Ti R" refers to one or more members of a family of G protein-coupled
receptors that are expressed in taste cells such as foliate, fungiform, and
circumvallate cells, as well as cells of the palate, and esophagus (see, e.g.,
Hoon
etal., Cell, 96:541-551 (1999)).
Members of this family are also referred to as GPCR-B3 and TR1 in WO 00/06592
as well as GPCR-B4 and TR2 in WO 00/06593. GPCR-B3 is also herein referred
to as rT1R1, and GPCR-B4 is referred to as ill R2. Taste receptor cells can
also
be identified on the basis of morphology (see, e.g., Roper, supra), or by the
expression of proteins specifically expressed in taste cells. TiR family
members
may have the ability to act as receptors for sweet taste transduction, or to
distinguish between various other taste modalities.
[0061] "T1R" nucleic acids encode a family of GPCRs with seven
transmembrane regions that have "G protein-coupled receptor activity," e.g.,
they
may bind to G proteins in response to extracellular stimuli and promote
production
of second messengers such as IP3, cAMP, cGMP, and Ca2+ via stimulation of
enzymes such as phospholipase C and adenylate cyclase (for a description of
the
structure and function of GPCRs, see, e.g., Fong, supra, and Baldwin, supra).
A
single taste cell may contain many distinct T1R polypeptides.
[0062] The term "Ti R" family therefore refers to polymorphic variants,
alleles,
mutants, and interspecies homologs that: (1) have at least about 35 to 50%
amino
acid sequence identity, optionally about 60, 75, 80, 85, 90, 95, 96, 97, 98,
or 99%
amino acid sequence identity to SEQ ID NOS: 4, 10, 12, 14, 17, or 21 over a
window of about 25 amino acids, optionally 50-100 amino acids; (2)
specifically
bind to antibodies raised against an immunogen comprising an amino acid
sequence selected from the group consisting of SEQ ID NOS: 4, 10, 12, 14, 17,
21 and conservatively modified variants thereof; (3) are encoded by a nucleic
acid
molecule which specifically hybridize (with a size of at least about 100,
optionally
at least about 500-1000 nucleotides) under stringent hybridization conditions
to a
sequence selected from the group consisting of SEQ ID NOS: 1, 2, 3, 9, 11, 13,
15, 16, 20, and conservatively modified variants thereof; (4) comprise a
sequence
at least about 35 to 50% identical to an amino acid sequence selected from the
18
a a
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
group consisting of SEQ ID NOS: 4, 10, 12, 14, 17, or 21; or (5) are amplified
by
primers that specifically hybridize under stringent hybridization conditions
to the
same sequence as degenerate primer sets encoding SEQ ID NOS: 7, 8, and
conservatively modified variants thereof.
[0063] Topologically, certain chemosensory GPCRs have an "N-terminal
domain;" "extracellular domains;" "transmembrane domains" comprising seven
transmembrane regions, and corresponding cytoplasmic, and extracellular loops;
"cytoplasmic domains," and a "C-terminal domain" (see, e.g., Hoon et al.,
Cell,
96:541-551 (1999); Buck & Axel, Cell, 65:175-187 (1991)). These domains can
be structurally identified using methods known to those of skill in the art,
such as
sequence analysis programs that identify hydrophobic and hydrophilic domains
(see, e.g., Stryer, Biochemistry, (3rd ed. 1988); see also any of a number of
Internet based sequence analysis programs).
Such domains are useful for making chimeric proteins
and for in vitro assays of the invention, e.g., ligand-binding assays.
[0064] "Extracellular domains" therefore refers to the domains of T1R
polypeptides that protrude from the cellular membrane and are exposed to the
extracellular face of the cell. Such domains generally include the "N terminal
domain" that is expced to the extracellular face of the cell, and optionally
can
include portions of the extracellular loops of the transmembrane domain that
are 2
exposed to the extracellular face of the cell, i.e., the loops between
transmembrane regions 2 and 3, between transmembrane regions 4 and 5, and
between transmembrane regions 6 and 7.
[0065] The "N terminal domain" region starts at the N-terminus and extends to
a
region close to the start of the transmembrane domain. More particularly, in
one
embodiment of the invention, this domain starts at the N-terminus and ends
approximately at the conserved glutamic acid at amino acid position 563 plus
or
minus approximately 20 amino acid. These extracellular domains are useful for
in
vitro ligand-binding assays, both soluble and solid phase. In addition,
= transmembrane regions, described below, can also bind ligand either in
combination with the extracellular domain, and are therefore also useful for
in vitro
ligand-binding assays.
19
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0066] "Transmembrane domain," which comprises the seven "transmembrane
regions," refers to the domain of T1R polypeptides that lies within the plasma
membrane, and may also include the corresponding cytoplasmic (intracellular)
and extracellular loops. In one embodiment, this region corresponds to the
domain of TiR family members which starts approximately at the conserved
glutamic acid residue at amino acid position 563 plus or minus 20 amino acids
and
ends approximately at the conserved tyrosine amino acid residue at position
812
plus or minus approximately 10 amino acids. The seven transmembrane regions
and extracellular and cytoplasmic loops can be identified using standard
methods,
as described in Kyte & Doolittle, J. MoL Biol., 157:105-32 (1982)), or in
Stryer,
supra.
[0067] "Cytoplasmic domains" refers to the domains of TiR polypeptides that
face the inside of the cell, e.g., the "C terminal domain" and the
intracellular loops
of the transmembrane domain, e.g., the intracellular loop between
transmembrane
regions 1 and 2, the intracellular loop between transmembrane regions 3 and 4,
and the intracellular loop between transmembrane regions 5 and 6. "C terminal
domain" refers to the region that spans the end of the last transmembrane
domain
and the C-terminus of the protein, and which is normally located within the
cytoplasm. In one embodiment, this region starts at the conserved tyrosine
amino
acid residue at position 812 plus or minus approximately 10 amino acids and
continues to the C-terminus of the polypeptide.
[0068] The term "ligand-binding region" or "ligand-binding domain" refers to
sequences derived from a chemosensory receptor, particularly a taste receptor,
that substantially incorporates at least the extracellular domain of the
receptor. In
one embodiment, the extracellular domain of the ligand-binding region may
include the N-terminal domain and, optionally, portions of the transmembrane
domain, such as the extracellular loops of the transmembrane domain. The
ligand-binding region may be capable of binding a ligand, and more
particularly, a
taste stimulus.
[0069] The phrase "functional effects" in the context of assays for testing
compounds that modulate T1R family member mediated taste transduction
includes the determination of any parameter that is indirectly or directly
under the
influence of the receptor, e.g., functional, physical and chemical effects. It
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
includes ligand binding, changes in ion flux, membrane potential, current
flow,
transcription, G protein binding, GPCR phosphorylation or dephosphorylation,
signal transduction, receptor-ligand interactions, second messenger
concentrations (e.g., cAMP, cGMP, IP3, or intracellular Ca2+), in vitro, in
vivo, and
ex vivo and also includes other physiologic effects such increases or
decreases of
neurotransmitter or hormone release.
[0070] By "determining the functional effect" in the context of assays is
meant
assays for a compound that increases or decreases a parameter that is
indirectly
or directly under the influence of a TiR family member, e.g., functional,
physical
and chemical effects. Such functional effects can be measured by any means
known to those skilled in the art, e.g., changes in spectroscopic
characteristics
(e.g., fluorescence, absorbance, refractive index), hydrodynamic (e.g.,
shape),
chromatographic, or solubility properties, patch clamping, voltage-sensitive
dyes,
whole cell currents, radioisotope efflux, inducible markers, oocyte T1R gene
expression; tissue culture cell T1R expression; transcriptional activation of
T1R
genes; ligand-binding assays; voltage, membrane potential and conductance
changes; ion flux assays; changes in intracellular second messengers such as
cAMP, cGMP, and inositol triphosphate (IP3); changes in intracellular calcium
levels; neurotransmtter release, and the like.
[0071] "Inhibitors," "activators," and "modulators" of T1R genes or proteins
are
used interchangeably to refer to inhibitory, activating, or modulating
molecules
identified using in vitro and in vivo assays for taste transduction, e.g.,
ligands,
agonists, antagonists, and their homologs and mimetics. Inhibitors are
compounds that, e.g., bind to, partially or totally block stimulation,
decrease,
prevent, delay activation, inactivate, desensitize, or down regulate taste
transduction, e.g., antagonists. Activators are compounds that, e.g., bind to,
stimulate, increase, open, activate, facilitate, enhance activation,
sensitize, or up
regulate taste transduction, e.g., agonists. Modulators include compounds
that,
e.g., alter the interaction of a receptor with: extracellular proteins that
bind
activators or inhibitor (e.g., ebnerin and other members of the hydrophobic
carrier
family); G proteins; kinases (e.g., homologs of rhodopsin kinase and beta
adrenergic receptor kinases that are involved in deactivation and
desensitization
of a receptor); and arrestins, which also deactivate and desensitize
receptors.
21
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
Modulators can include genetically modified versions of T1R family members,
e.g.,
with altered activity, as well as naturally occurring and synthetic ligands,
antagonists, agonists, small chemical molecules and the like. Such assays for
inhibitors and activators include, e.g., expressing T1R family members in
cells or
cell membranes, applying putative modulator compounds, in the presence or
absence of taste stimuli, e.g., sweet taste stimuli, and then determining the
functional effects on taste transduction, as described above. Samples or
assays
comprising T1R family members that are treated with a potential activator,
inhibitor, or modulator are compared to control samples without the inhibitor,
activator, or modulator to examine the extent of modulation. Control samples
(untreated with modulators) are assigned a relative T1R activity value of
100%.
Inhibition of a T1R is achieved when the T1R activity value relative to the
control is
about 80%, optionally 50% or 25-0%. Activation of a T1R is achieved when the
T1R activity value relative to the control is 110%, optionally 150%,
optionally 200-
500%, or 1000-3000% higher.
[0072] The terms "purified," "substantially purified," and "isolated" as used
herein
refer to the state of being free of other, dissimilar compounds with which the
compound of the invention is normally associated in its natural state, so that
the
"purified," "substantially purified," and "isolated" subject comprises at
least 0.5%,
1%, 5%, 10%, or 20%, and most preferably at least 50% or 75% of the mass, by
weight, of a given sample. In one preferred embodiment, these terms refer to
the
compound of the invention comprising at least 95% of the mass, by weight, of a
given sample. As used herein, the terms "purified," "substantially purified,"
and
"isolated" "isolated," when referring to a nucleic acid or protein, of nucleic
acids or
proteins, also refers to a state of purification or concentration different
than that
which occurs naturally in the mammalian, especially human, body. Any degree of
purification or concentration greater than that which occurs naturally in the
mammalian, especially human, body, including (I )the purification from other
associated structures or compounds or (2) the association with structures or
compounds to which it is not normally associated in the mammalian, especially
human, body, are within the meaning of "isolated." The nucleic acid or protein
or
classes of nucleic acids or proteins, described herein, may be isolated, or
otherwise associated with structures or compounds to which they are not
normally
22
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
associated in nature, according to a variety of methods and processes known to
those of skill in the art.
[0073] As used herein, the term "isolated," when referring to a nucleic acid
or
polypeptide refers to a state of purification or concentration different than
that
which occurs naturally in the mammalian, especially human, body. Any degree of
purification or concentration greater than that which occurs naturally in the
body,
including (1) the purification from other naturally-occurring associated
structures or
compounds, or (2) the association with structures or compounds to which it is
not
normally associated in the body are within the meaning of "isolated" as used
herein. The nucleic acids or polypeptides described herein may be isolated or
otherwise associated with structures or compounds to which they are not
normally
associated in nature, according to a variety of methods and processed known to
those of skill in the art.
[0074] As used herein, the terms "amplifying" and "amplification" refer to the
use
of any suitable amplification methodology for generating or detecting
recombinant
or naturally expressed nucleic acid, as described in detail, below. For
example,
the invention provides methods and reagents (e.g., specific degenerate
oligonucleotide primer pairs) for amplifying (e.g., by polymerase chain
reaction,
PCR) naturally expresnd (e.g., genomic or mRNA) or recombinant (e.g., cDNA)
nucleic acids of the invention (e.g., taste stimulus-binding sequences of the
invention) in vivo or in vitro.
[0075] The term "7- transmembrane receptor" means a polypeptide belonging to
a superfamily of transmembrane proteins that have seven domains that span the
plasma membrane seven times (thus, the seven domains are called
"transmembrane" or "TM" domains TM Ito TM VII). The families of olfactory and
certain taste receptors each belong to this super-family. 7-transmembrane
receptor polypeptides have similar and characteristic primary, secondary and
tertiary structures, as discussed in further detail below.
[0076] The term "library" means a preparation that is a mixture of different
nucleic acid or polypeptide molecules, such as the library of recombinantly
generated chemosensory, particularly taste receptor ligand-binding domains
generated by amplification of nucleic acid with degenerate primer pairs, or an
isolated collection of vectors that incorporate the amplified ligand-binding
23
CA 02776701 2012-05-07
WO 02/06-1631 PCT/US02/00198
domains, or a mixture of cells each randomly transfected with at least one
vector
encoding an taste receptor.
[0077] The term "nucleic acid" or "nucleic acid sequence" refers to a deoxy-
ribonucleotide or ribonucleotide oligonucleotide in either single- or double
stranded form. The term encompasses nucleic acids, i.e., oligonucleotides,
containing known analogs of natural nucleotides. The term also encompasses
nucleic-acid-like structures with synthetic backbones (see e.g.,
Oligonucleotides
and Analogues, a Practical Approach, ed. F. Eckstein, Oxford Univ. Press
(1991);
Antisense Strategies, Annals of the N.Y. Academy of Sciences, Vol. 600, Eds.
Baserga etal. (NYAS 1992); Milligan J. Med. Chem. 36:1923-1937 (1993);
Antisense Research and Applications (1993, CRC Press), WO 97/03211; WO
96/39154; Mata, ToxicoL App!. PharmacoL 144:189-197 (1997); Strauss-Soukup,
Biochemistry 36:8692-8698 (1997); Samstag, Antisense Nucleic Acid Drug Dev,
6:153-156 (1996)).
[0078] Unless otherwise indicated, a particular nucleic acid sequence also
implicitly encompasses conservatively modified variants thereof (e.g.,
degenerate
codon substitutions) and complementary sequences, as well as the sequence
explicitly indicated. Specifically, degenerate codon substitutions may be
achieved
by generating, e.g., sequences in which the third position of one or more
selected
codons is substituted with mixed-base and/or deoxyinosine residues (Batzer et
al.,
Nucleic Acid Res., 19:5081 (1991); Ohtsuka at al., J. Biol. Chem., 260:2605-
2608
(1985); Rossolini etal., Mol. Cell. Probes, 8:91-98 (1994)). The term nucleic
acid
is used interchangeably with gene, cDNA, mRNA, oligonucleotide, and
polynucleotide.
[0079] The terms "polypeptide," "peptide" and "protein" are used
interchangeably herein to refer to a polymer of amino acid residues. The terms
apply to amino acid polymers in which one or more amino acid residue is an
artificial chemical mimetic of a corresponding naturally occurring amino acid,
as
well as to naturally occurring amino acid polymers and non-naturally occurring
amino acid polymer.
[0080] The term "plasma membrane translocation domain" or simply
"translocation domain" means a polypeptide domain that, when incorporated into
the amino terminus of a polypeptide coding sequence, can with great efficiency
24
i
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
"chaperone" or "translocate" the hybrid ("fusion") protein to the cell plasma
membrane. For instance, a "translocation domain" may be derived from the amino
terminus of the bovine rhodopsin receptor polypeptide, a 7-transmembrane
receptor. However, rhodopsin from any mammal may be used, as can other
translocation facilitating sequences. Thus, the translocation domain is
particularly
efficient in translocating 7-transmembrane fusion proteins to the plasma
membrane, and a protein (e.g., a taste receptor polypeptide) comprising an
amino
terminal translocating domain will be transported to the plasma membrane more
efficiently than without the domain. However, if the N-terminal domain of the
polypeptide is active in binding, the use of other translocation domains may
be
preferred.
[00811 The "translocation domain," "ligand-binding domain", and chimeric
receptors compositions described herein also include "analogs," or
"conservative
variants" and "mimetics" ("peptidomimetics") with structures and activity that
substantially correspond to the exemplary sequences. Thus, the terms
"conservative variant" or "analog" or "mimetic" refer to a polypeptide which
has a
modified amino acid sequence, such that the change(s) do not substantially
alter
the polypeptide's (the conservative variant's) structure and/or activity, as
defined
herein. These include conservatively modified variations of an amino acid
sequence, i.e., amino acid substitutions, additions or deletions of those
residues
that are not critical for protein activity, or substitution of amino acids
with residues
having similar properties (e.g., acidic, basic, positively or negatively
charged, polar
or non-polar, etc.) such that the substitutions of even critical amino acids
does not
substantially alter structure and/or activity.
[0082] More particularly, "conservatively modified variants" applies to both
amino acid and nucleic acid sequences. With respect to particular nucleic acid
sequences, conservatively modified variants refers to those nucleic acids
which
= encode identical or essentially identical amino acid sequences, or where
the
nucleic acid does not encode an amino acid sequence, to essentially identical
sequences. Because of the degeneracy of the genetic code, a large number of
functionally identical nucleic acids encode any given protein.
[0083] For instance, the codons GCA, GCC, GCG and GCU all encode the
amino acid alanine. Thus, at every position where an alanine is specified by a
i
=
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
codon, the codon can be altered to any of the corresponding codons described
without altering the encoded polypeptide.
[0084] Such nucleic acid variations are "silent variations," which are one
species
of conservatively modified variations. Every nucleic acid sequence herein
which
encodes a polypeptide also describes every possible silent variation of the
nucleic
acid. One of skill will recognize that each codon in a nucleic acid (except
AUG,
which is ordinarily the only codon for methionine, and TGG, which is
ordinarily the
only codon for tryptophan) can be modified to yield a functionally identical
molecule. Accordingly, each silent variation of a nucleic acid which encodes a
polypeptide is implicit in each described sequence.
[0085] Conservative substitution tables providing functionally similar amino
acids
are well known in the art. For example, one exemplary guideline to select
conservative substitutions includes (original residue followed by exemplary
substitution): ala/gly or ser; arg/lys, asn/gln or his; asp/glu; cys/ser;
gln/asn;
gly/asp; gly/ala or pro; his/asn or gin; ile/leu or val; leu/ile or val;
lys/arg or gin or
glu; met/leu or tyr or lie; phe/met or leu or tyr; ser/thr; thr/ser; trp/tyr;
tyr/trp or phe;
vat/lie or leu. An alternative exemplary guideline uses the following six
groups,
each containing amino acids that are conservative substitutions for one
another:
1) Alanine (A), Serine (S), Threonine (T); 2) Aspartic acid (D), Glutamic acid
(E);
3) Asparagine (N), Glutamine (Q); 4) Arginine (R), Lysine (I); 5) lsoleucine
Leucine (L), Methionine (M), Valine (V); and 6) Phenylalanine (F), Tyrosine
(Y),
Tryptophan (W); (see also, e.g., Creighton, Proteins, W .H. Freeman and
Company (1984); Schultz and Schimer, Principles of Protein Structure, Springer-
Vilag (1979)). One of skill in the art will appreciate that the above-
identified
substitutions are not the only possible conservative substitutions. For
example,
for some purposes, one may regard all charged amino acids as conservative
substitutions for each other whether they are positive or negative. In
addition,
individual substitutions, deletions or additions that alter, add or delete a
single
amino acid or a small percentage of amino acids in an encoded sequence can
also be considered "conservatively modified variations."
[0086] The terms "mimetic" and "peptidomimetic" refer to a synthetic chemical
compound that has substantially the same structural and/or functional
characteristics of the polypeptides, e.g., translocation domains, ligand-
binding
26
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
domains, or chimeric receptors of the invention. The mimetic can be either
entirely composed of synthetic, non-natural analogs of amino acids, or may be
a
chimeric molecule of partly natural peptide amino acids and partly non-natural
analogs of amino acids. The mimetic can also incorporate any amount of natural
amino acid conservative substitutions as long as such substitutions also do
not
substantially alter the mimetic's structure and/or activity.
[0087] As with polypeptides of the invention which are conservative variants,
routine experimentation will determine whether a mimetic is within the scope
of the
invention, i.e., that its structure and/or function is not substantially
altered.
Polypeptide mimetic compositions can contain any combination of non-natural
structural components, which are typically from three structural groups: a)
residue
linkage groups other than the natural amide bond ("peptide bond") linkages; b)
non-natural residues in place of naturally occurring amino acid residues; or
c)
residues which induce secondary structural mimicry, i.e., to induce or
stabilize a
secondary structure, e.g., a beta turn, gamma turn, beta sheet, alpha helix
conformation, and the like. A polypeptide can be characterized as a mimetic
when
all or some of its residues are joined by chemical means other than natural
peptide bonds. Individual peptidomimetic residues can be joined by peptide
bonds, other chemical bends or coupling means, such as, e.g., glutaraldehyde,
N-
hydroxysuccinimide esters, bifunctional maleimides, N,N'-
dicyclohexylcarbodiimide
(DCC) or N,N'-diisopropylcarbodiimide (D1C). Linking groups that can be an
alternative to the traditional amide bond ("peptide bond") linkages include,
e.g.,
ketomethylene (e.g., -C(=0)-CH2- for -C(=0)-NH-), aminomethylene (CH2-NH),
ethylene, olefin (CH=CH), ether (CH2-0), thioether (CH2-S), tetrazole (CN14),
thiazole, retroamide, thioamide, or ester (see, e.g., Spatola, Chemistry and
Biochemistry of Amino Acids, Peptides and Proteins, Vol. 7, pp 267-357,
"Peptide
Backbone Modifications," Marcell Dekker, NY (1983)). A polypeptide can also be
characterized as a mimetic by containing all or some non-natural residues in
place
of naturally occurring amino acid residues; non-natural residues are well
described
in the scientific and patent literature.
[0088] A "label" or a "detectable moiety" is a composition detectable by
spectroscopic, photochemical, biochemical, immunochemical, or chemical means.
For example, useful labels include 32P, fluorescent dyes, electron-dense
reagents,
27
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
enzymes (e.g., as commonly used in an ELISA), biotin, digoxigenin, or haptens
and proteins which can be made detectable, e.g., by incorporating a radiolabel
into the peptide or used to detect antibodies specifically reactive with the
peptide.
[0089] A "labeled nucleic acid probe or oligonucleotide" is one that is bound,
either covalently, through a linker or a chemical bond, or noncovalently,
through
ionic, van der Weals, electrostatic, or hydrogen bonds to a label such that
the
presence of the probe may be detected by detecting the presence of the label
bound to the probe.
[0090] As used herein a "nucleic acid probe or oligonucleotide" is defined as
a
nucleic acid capable of binding to a target nucleic acid of complementary
sequence through one or more types of chemical bonds, usually through
complementary base pairing, usually through hydrogen bond formation. As used
herein, a probe may include natural (i.e., A, G, C, or T) or modified bases
(7-deazaguanosine, inosine, etc.). In addition, the bases in a probe may be
joined
by a linkage other than a phosphodiester bond, so long as it does not
interfere
with hybridization. Thus, for example, probes may be peptide nucleic acids in
which the constituent bases are joined by peptide bonds rather than
phosphodiester linkages. It will be understood by one of skill in the art that
probes
may bind target sequences lacking complete complementarity with the probe
sequence depending upon the stringency of the hybridization conditions. The
probes are optionally directly labeled as with isotopes, chromophores,
lumiphores,
chromogens, or indirectly labeled such as with biotin to which a streptavidin
complex may later bind. By assaying for the presence or absence of the probe,
one can detect the presence or absence of the select sequence or subsequence.
[0091] The term "heterologous" when used with reference to portions of a
nucleic acid indicates that the nucleic acid comprises two or more
subsequences
that are not found in the same relationship to each other in nature. For
instance,
the nucleic acid is typically recombinantly produced, having two or more
sequences from unrelated genes arranged to make a new functional nucleic acid,
e.g., a promoter from one source and a coding region from another source.
Similarly, a heterologous protein indicates that the protein comprises two or
more
subsequences that are not found in the same relationship to each other in
nature
(e.g., a fusion protein).
28
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0092] A "promoter" is defined as an array of nucleic acid sequences that
direct
transcription of a nucleic acid. As used herein, a promoter includes necessary
nucleic acid sequences near the start site of transcription, such as, in the
case of
a polymerase II type promoter, a TATA element. A promoter also optionally
includes distal enhancer or repressor elements, which can be located as much
as
several thousand base pairs from the start site of transcription. A
"constitutive"
promoter is a promoter that is active under most environmental and
developmental conditions. An "inducible" promoter is a promoter that is active
under environmental or developmental regulation. The term "operably linked"
refers to a functional linkage between a nucleic acid expression control
sequence
(such as a promoter, or array of transcription factor binding sites) and a
second
nucleic acid sequence, wherein the expression control sequence directs
transcription of the nucleic acid corresponding to the second sequence.
[0093] As used herein, "recombinant" refers to a polynucleotide synthesized or
otherwise manipulated in vitro (e.g., "recombinant polynucleotide"), to
methods of
using recombinant polynucleotides to produce gene products in cells or other
biological systems, or to a polypeptide ("recombinant protein") encoded by a
recombinant polynucleotide. "Recombinant means" also encompass the ligation
of nucleic acids having varic,is coding regions or domains or promoter
sequences
from different sources into an expression cassette or vector for expression
of, e.g.,
inducible or constitutive expression of a fusion protein comprising a
translocation
domain of the invention and a nucleic acid sequence amplified using a primer
of
the invention.
[0094] The phrase "selectively (or specifically) hybridizes to" refers to the
binding, duplexing, or hybridizing of a molecule only to a particular
nucleotide
sequence under stringent hybridization conditions when that sequence is
present
in a complex mixture (e.g., total cellular or library DNA or RNA).
[0095] The phrase "stringent hybridization conditions" refers to conditions
under
which a probe will hybridize to its target subsequence, typically in a complex
mixture of nucleic acid, but to no other sequences. Stringent conditions are
sequence-dependent and will be different in different circumstances. Longer
sequences hybridize specifically at higher temperatures. An extensive guide to
the hybridization of nucleic acids is found in Tijssen, Techniques in
Biochemistry
29
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
and Molecular Biology¨Hybridisation with Nucleic Probes, "Overview of
principles
of hybridization and the strategy of nucleic acid assays" (1993). Generally,
stringent conditions are selected to be about 5-10 C lower than the thermal
melting point (Tm) for the specific sequence at a defined ionic strength pH.
The
Tm is the temperature (under defined ionic strength, pH, and nucleic
concentration) at which 50% of the probes complementary to the target
hybridize
to the target sequence at equilibrium (as the target sequences are present in
excess, at Tm, 50% of the probes are occupied at equilibrium). Stringent
conditions will be those in which the salt concentration is less than about
1.0 M
sodium ion, typically about 0.01 to 1.0 M sodium ion concentration (or other
salts)
at pH 7.0 to 8.3 and the temperature is at least about 30 C for short probes
(e.g.,
to 50 nucleotides) and at least about 60 C for long probes (e.g., greater
than
50 nucleotides). Stringent conditions may also be achieved with the addition
of
destabilizing agents such as formamide. For selective or specific
hybridization, a
positive signal is at least two times background, optionally 10 times
background
hybridization. Exemplary stringent hybridization conditions can be as
following:
50% formamide, Sx SSC, and 1% SDS, incubating at 42 C, or, Sx SSC, 1% SDS,
incubating at 65 C, with wash in 0.2x SSC, and 0.1 % SDS at 65 C. Such
hybridizations and wash steps can be carried out for, e.g., 1, 2, 5, 10, 15,
30, 60;
or more minutes.
[0096] Nucleic acids that do not hybridize to each other under stringent
conditions are still substantially related if the polypeptides which they
encode are
substantially related. This occurs, for example, when a copy of a nucleic acid
is
created using the maximum codon degeneracy permitted by the genetic code. In
such cases, the nucleic acids typically hybridize under moderately stringent
hybridization conditions. Exemplary "moderately stringent hybridization
conditions"
include a hybridization in a buffer of 40% formamide, 1 M NaCI, 1% SDS at 37
C,
and a wash in 1X SSC at 45 C. Such hybridizations and wash steps can be
carried out for, e.g., 1, 2, 5, 10, 15, 30, 60, or more minutes. A positive
hybridization is at least twice background. Those of ordinary skill will
readily
recognize that alternative hybridization and wash conditions can be utilized
to
provide conditions of similar stringency.
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0097] "Antibody" refers to a polypeptide comprising a framework region from
an
immunoglobulin gene or fragments thereof that specifically binds and
recognizes
an antigen. The recognized immunoglobulin genes include the kappa, lambda,
alpha, gamma, delta, epsilon, and mu constant region genes, as well as the
myriad immunoglobulin variable region genes. Light chains are classified as
either
kappa or lambda. Heavy chains are classified as gamma, mu, alpha, delta, or
epsilon, which in turn define the immunoglobulin classes, IgG, IgM, IgA, IgD
and
IgE, respectively.
[0098] An exemplary immunoglobulin (antibody) structural unit comprises a
tetramer. Each tetramer is composed of two identical pairs of polypeptide
chains,
each pair having one "light" (about 25 kDa) and one "heavy" chain (about 50-70
kDa). The N-terminus of each chain defines a variable region of about 100 to
110
or more amino acids primarily responsible for antigen recognition. The terms
variable light chain (VL) and variable heavy chain (VH) refer to these light
and
heavy chains respectively.
[0099] A "chimeric antibody" is an antibody molecule in which (a) the constant
region, or a portion thereof, is altered, replaced or exchanged so that the
antigen
binding site (variable region) is linked to a constant region of a different
or altered
class, effector function and/or species, or an entirely different molecule
which
confers new properties to the chimeric antibody, e.g., an enzyme, toxin,
hormone,
growth factor, drug, eic.; or (b) the variable region, or a portion thereof,
is altered,
replaced or exchanged with a variable region having a different or altered
antigen
specificity.
[0100] An "anti-Ti R" antibody is an antibody or antibody fragment that
specifically binds a polypeptide encoded by a T1R gene, cDNA, or a subsequence
thereof.
[0101] The term "immunoassay" is an assay that uses an antibody to
specifically
bind an antigen. The immunoassay is characterized by the use of specific
binding
properties of a particular antibody to isolate, target, and/or quantify the
antigen.
[0102] The phrase "specifically (or selectively) binds" to an antibody or,
"specifically (or selectively) immunoreactive with," when referring to a
protein or
peptide, refers to a binding reaction that is determinative of the presence of
the
protein in a heterogeneous population of proteins and other biologics. Thus,
31
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
under designated immunoassay conditions, the specified antibodies bind to a
particular protein at least two times the background and do not substantially
bind
in a significant amount to other proteins present in the sample. Specific
binding to
an antibody under such conditions may require an antibody that is selected for
its
specificity for a particular protein. For example, polyclonal antibodies
raised to a
T1R family member from specific species such as rat, mouse, or human can be
selected to obtain only those polyclonal antibodies that are specifically
immunoreactive with the T1R polypeptide or an immunogenic portion thereof and
not with other proteins, except for orthologs or polymorphic variants and
alleles of
the T1R polypeptide. This selection may be achieved by subtracting out
antibodies that cross-react with T1R molecules from other species or other T1R
molecules. Antibodies can also be selected that recognize only T1R GPCR family
members but not GPCRs from other families. A variety of immunoassay formats
may be used to select antibodies specifically immunoreactive with a particular
protein. For example, solid-phase ELISA immunoassays are routinely used to
select antibodies specifically immunoreactive with a protein (see, e.g.,
Harlow &
Lane, Antibodies, A Laboratory Manual, (1988), for a description of
immunoassay
formats and conditions that can be used to determine specific
immunoreactivity).
Typically a specific or selective reaction will be at least twice background
signal or
noise and more typically more than 10 to 100 times background.
[0103] The phrase "selectively associates with" refers to the ability of a
nucleic
acid to "selectively hybridize" with another as defined above, or the ability
of an
antibody to "selectively (or specifically) bind to a protein, as defined
above.
[0104] The term "expression vector" refers to any recombinant expression
system for the purpose of expressing a nucleic acid sequence of the invention
in
vitro or in vivo, constitutively or inducibly, in any cell, including
prokaryotic, yeast,
fungal, plant, insect or mammalian cell. The term includes linear or circular
expression systems. The term includes expression systems that remain episomal
or integrate into the host cell genome. The expression systems can have the
ability to self-replicate or not, i.e., drive only transient expression in a
cell. The
term includes recombinant expression "cassettes which contain only the minimum
elements needed for transcription of the recombinant nucleic acid.
32
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0105] By "host cell" is meant a cell that contains an expression vector and
supports the replication or expression of the expression vector. Host cells
may be
prokaryotic cells such as E. coli, or eukaryotic cells such as yeast, insect,
amphibian, or mammalian cells such as CHO, HeLa, HEK-293, and the like, e.g.,
cultured cells, explants, and cells in vivo.
A. Isolation and Expression of T1R Polypeptides
[0106] Isolation and expression of the Ti Rs, or fragments or variants
thereof, of
the invention can be performed as described below. PCR primers can be used for
the amplification of nucleic acids encoding taste receptor ligand-binding
regions,
and libraries of these nucleic acids can optionally be generated. Individual
expression vectors or libraries of expression vectors can then be used to
infect or
transfect host cells for the functional expression of these nucleic acids or
libraries.
These genes and vectors can be made and expressed in vitro or in vivo. One of
skill will recognize that desired phenotypes for altering and controlling
nucleic acid
expression can be obtained by modulating the expression or activity of the
genes
and nucleic acids (e.g., promoters, enhancers and the like) within the vectors
of
the invention. Any of the known methods described for increasing or decreasing
expression or activity can be used. The invention can be practiced in
conjunction
with any method or protocol kr,-)wn in the art, which are well described in
the
scientific and patent literature.
[0107] The nucleic acid sequences of the invention and other nucleic acids
used
to practice this invention, whether RNA, cDNA, genomic DNA, vectors, viruses
or
hybrids thereof, may be isolated from a variety of sources, genetically
engineered,
amplified, and/or expressed recombinantly. Any recombinant expression system
can be used, including, in addition to mammalian cells, e.g., bacterial,
yeast,
insect, or plant systems.
[0108] Alternatively, these nucleic acids can be synthesized in vitro by well-
known chemical synthesis techniques, as described in, e.g., Carruthers, Cold
Spring Harbor Symp. Quant. Biol. 47:411-418 (1982); Adams, Am. Chem. Soc.
105:661 (1983); Belousov, Nucleic Acids Res. 25:3440-3444 (1997); Frenkel,
Free
Radic. Biol. Med. 19:373-380 (1995); Blommers, Biochemistry 33:7886-7896
(1994); Narang, Meth. Enzymol. 68:90 (1979); Brown, Meth. Enzymol. 68:109
(1979); Beaucage, Tetra. Lett. 22:1859 (1981); U.S. Patent No. 4,458,066.
33
CA 02776701 2012-05-07
1
WO 02/064631 PCT/US02/00198
Double-stranded DNA fragments may then be obtained either by synthesizing the
complementary strand and annealing the strands together under appropriate
conditions, or by adding the complementary strand using DNA polymerase with an
appropriate primer sequence..
[0109] Techniques for the manipulation of nucleic acids, such as, for example,
for generating mutations in sequences, subcloning, labeling probes,
sequencing,
hybridization and the like are well described in the scientific and patent
literature.
See, e.g., Sambrook, ed., Molecular Cloning: a Laboratory manual (2nd ed.),
Vols.
1-3, Cold Spring Harbor Laboratory (1989); Current Protocols in Molecular
Biology, Ausubel, ed. John Wiley & Sons, Inc., New York (1997); Laboratory
Techniques in Biochemistry and Molecular Biology: Hybridization With Nucleic
Acid Probes, Part I, Theory and Nucleic Acid Preparation, Tijssen, ed.
Elsevier,
N.Y. (1993).
[0110] Nucleic acids, vectors, capsids, polypeptides, and the like can be
analyzed and quantified by any of a number of general means well known to
those
of skill in the art. These include, e.g., analytical biochemical methods such
as
NMR, spectrophotometry, radiography, electrophoresis, capillary
electrophoresis,
high performance liquid chromatography (HPLC), thin layer chromatography
(TLC), and hyperdiffusion chromatography, various immunological methods, e.g.,
fluid or gel precipitin reactions, immunodiffusion, immunoelectrophoresis,
radioimmunoassays (RIAs), enzyme-linked immunosorbent assays (ELISAs),
immuno-fluorescent assays, Southern analysis, Northern analysis, dot-blot
analysis, gel electrophoresis (e.g., SDS-PAGE), RT-PCR, quantitative PCR,
other
nucleic acid or target or signal amplification methods, radiolabeling,
scintillation
counting, and affinity chromatography.
[0111] Oligonucleotide primers may be used to amplify nucleic acid fragments
encoding taste receptor ligand-binding regions. The nucleic acids described
herein can also be cloned or measured quantitatively using amplification
techniques. Amplification methods are also well known in the art, and include,
e.g., polymerase chain reaction, PCR (PCR Protocols, a Guide to Methods and
Applications, ed. Innis. Academic Press, N.Y. (1990) and PCR Strategies, ed.
Innis, Academic Press, Inc., N.Y. (1995), ligase chain reaction (LCR) (see,
e.g.,
Wu, Genomics 4:560 (1989); Landegren, Science 241:1077,(1988); Barringer,
34
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
Gene 89:117 (1990)); transcription amplification (see, e.g., Kwoh, Proc. Natl.
Acad. Sci. USA 86:1173 (1989)); and, self-sustained sequence replication (see,
e.g., Guatelli, Proc. Natl. Acad. Sci. USA 87:1874 (1990)); Q Beta replicase
amplification (see, e.g., Smith, J. Clin. Microbic!. 35:1477-1491 (1997));
automated Q-beta replicase amplification assay (see, e.g., Burg, MoL CelL
Probes
10:257-271 (1996)) and other RNA polymerase mediated techniques (e.g.,
NASBA, Cangene, Mississauga, Ontario); see also Berger, Methods Enzymol.
152:307-316 (1987); Sambrook; Ausubel; U.S. Patent Nos. 4,683,195 and
4,683,202; Sooknanan, Biotechnology 13:563-564 (1995). The primers can be
designed to retain the original sequence of the "donor" 7-membrane receptor.
Alternatively, the primers can encode amino acid residues that are
conservative
substitutions (e.g., hydrophobic for hydrophobic residue, see above
discussion) or
functionally benign substitutions (e.g., do not prevent plasma membrane
insertion,
cause cleavage by peptidase, cause abnormal folding of receptor, and the
like).
Once amplified, the nucleic acids, either individually or as libraries, may be
cloned
according to methods known in the art, if desired, into any of a variety of
vectors
using routine molecular biological methods; methods for cloning in vitro
amplified
nucleic acids are described, e.g., U.S. Pat. No. 5,426,039.
[0112] The primer pairs may be designed to selectively amplify ligand-binding
regions of the T1R family members. These regions may vary for different
ligands
or taste stimuli. Thus, what may be a minimal binding region for one taste
stimulus, may be too limiting for a second taste stimulus. Accordingly, ligand-
binding regions of different sizes comprising different extracellular domain
structures may be amplified.
[0113] Paradigms to design degenerate primer pairs are well known in the art.
For example, a COnsensus-DEgenerate Hybrid Oligonucleotide Primer
(CODEHOP) strategy computer program is accessible on the internet,
and is directly linked from the BlockMaker
=
multiple sequence alignment site for hybrid primer prediction beginning with a
set
of related protein sequences, as known taste receptor ligand-binding regions
(see,
e.g., Rose, Nucleic Acids Res. 26:1628-1635 (1998); Singh, Biotechniques
24:318-319 (1998)).
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0114] Means to synthesize oligonucleotide primer pairs are well known in the
art. "Natural" base pairs or synthetic base pairs can be used. For example,
use of
artificial nucleobases offers a versatile approach to manipulate primer
sequence
and generate a more complex mixture of amplification products. Various
families
of artificial nucleobases are capable of assuming multiple hydrogen bonding
orientations through internal bond rotations to provide a means for degenerate
molecular recognition. Incorporation of these analogs into a single position
of a
PCR primer allows for generation of a complex library of amplification
products.
See, e.g., Hoops, Nucleic Acids Res. 25:4866-4871 (1997). Nonpolar molecules
can also be used to mimic the shape of natural DNA bases. A non-hydrogen-
bonding shape mimic for adenine can replicate efficiently and selectively
against a
nonpolar shape mimic for thymine (see, e.g., Morales, Nat. Struct. Biol. 5:950-
954
(1998)). For example, two degenerate bases can be the pyrimidine base 6H, 8H-
3,4-dihydropyrimido[4,5-c][1,21oxazin-7-one or the purine base N6-methoxy-2,6-
diaminopurine (see, e.g., Hill, Proc. Natl. Acad. Sc!. USA 95:4258-4263
(1998)).
Exemplary degenerate primers of the invention incorporate the nucleobase
analog
5'-Dimethoxytrityl-N-benzoy1-2'-deoxy-Cytidine,3'-[(2-cyanoethyl)-(N,N-
diisopropyl)]-phosphoramidite (the term "P" in the sequences, see above). This
pyrimidine analog hydrogen bonds with purines, including A and G residues.
[0115] Polymorphic variants, alleles, and interspecies homologs that are
substantially identical to a taste receptor disclosed herein can be isolated
using
the nucleic acid probes described above. Alternatively, expression libraries
can
be used to clone T1R polypeptides and polymorphic variants, alleles, and
interspecies homologs thereof, by detecting expressed homologs immunologically
with antisera or purified antibodies made against a T1R polypeptide, which
also
recognize and selectively bind to the T1R homolog.
[0116] Nucleic acids that encode ligand-binding regions of taste receptors may
be generated by amplification (e.g., PCR) of appropriate nucleic acid
sequences
using degenerate primer pairs. The amplified nucleic acid can be genomic DNA
from any cell or tissue or mRNA or cDNA derived from taste receptor-expressing
cells.
[0117] In one embodiment, hybrid protein-coding sequences comprising nucleic
acids encoding TI Rs fused to a translocation sequences may be constructed.
36
I i
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
Also provided are hybrid Ti Rs comprising the translocation motifs and taste
stimulus-binding domains of other families of chemosensory receptors,
particularly
taste receptors. These nucleic acid sequences can be operably linked to
transcriptional or translational control elements, e.g., transcription and
translation
initiation sequences, promoters and enhancers, transcription and translation
terminators, polyadenylation sequences, and other sequences useful for
transcribing DNA into RNA. In construction of recombinant expression
cassettes,
vectors, and transgenics, a promoter fragment can be employed to direct
expression of the desired nucleic acid in all desired cells or tissues.
[0118] In another embodiment, fusion proteins may include C-terminal or N-
terminal translocation sequences. Further, fusion proteins can comprise
additional elements, e.g., for protein detection, purification, or other
applications.
Detection and purification facilitating domains include, e.g., metal chelating
peptides such as polyhistidine tracts, histidine-tryptophan modules, or other
domains that allow purification on immobilized metals; maltose binding
protein;
protein A domains that allow purification on immobilized immunogiobulin; or
the
domain utilized in the FLAGS extension/affinity purification system (Immunex
Corp, Seattle WA).
[0119] The inclusion of a cleavoble linker sequences such as Factor Xa (see,
e.g., Ottavi, Biochimie 80:289-293 (1998)), subtilisin protease recognition
motif
(see, e.g., Polyak, Protein Eng. 10:615-619 (1997)); enterokinase (Invitrogen,
San
Diego, CA), and the like, between the translocation domain (for efficient
plasma
membrane expression) and the rest of the newly translated polypeptide may be
useful to facilitate purification. For example, one construct can include a
polypeptide encoding a nucleic acid sequence linked to six histidine residues
followed by a thioredoxin, an enterokinase cleavage site (see, e.g., Williams,
Biochemistry 34:1787-1797 (1995)), and an C-terminal translocation domain. The
histidine residues facilitate detection and purification while the
enterokinase
cleavage site provides a means for purifying the desired protein(s) from the
remainder of the fusion protein. Technology pertaining to vectors encoding
fusion
proteins and application of fusion proteins are well described in the
scientific and
patent literature, see, e.g., Kroll, DNA Cell. Biol. 12:441-53 (1993).
37
CA 02776701 2012-05-07
_
WO 02/964631 PCT/US02/00198
[0120] Expression vectors, either as individual expression vectors or as
libraries
of expression vectors, comprising the ligand-binding domain encoding sequences
may be introduced into a genome or into the cytoplasm or a nucleus of a cell
and
expressed by a variety of conventional techniques, well described in the
scientific
and patent literature. See, e.g., Roberts, Nature 328:731 (1987); Berger
supra;
Schneider, Protein Expr. Purif. 6435:10 (1995); Sambrook; Tijssen; Ausubel.
Product information from manufacturers of biological reagents and experimental
equipment also provide information regarding known biological methods. The
vectors can be isolated from natural sources, obtained from such sources as
ATCC or GenBank libraries, or prepared by synthetic or recombinant methods.
[0121] The nucleic acids can be expressed in expression cassettes, vectors or
viruses which are stably or transiently expressed in cells (e.g., episomal
expression systems). Selection markers can be incorporated into expression
cassettes and vectors to confer a selectable phenotype on transformed cells
and
sequences. For example, selection markers can code for episomal maintenance
and replication such that integration into the host genome is not required.
For
example, the marker may encode antibiotic resistance (e.g., chloramphenicol,
kanamycin, G418, bleomycin, hygromycin) or herbicide resistance (e.g.,
chlorosulfuron or Basta) to permit selection of those cells transformed with
the
desired DNA sequences (see, e.g., Blondelet-Rouault, Gene 190:315-317 (1997);
Aubrecht, J. Pharmacol. Exp. Ther. 281:992-997 (1997)). Because selectable
marker genes conferring resistance to substrates like neomycin or hygromycin
can
only be utilized in tissue culture, chemoresistance genes are also used as
selectable markers in vitro and in vivo.
[0122] A chimeric nucleic acid sequence may encode a T1R ligand-binding
domain within any 7-transmembrane polypeptide. Because 7-transmembrane
receptor polypeptides have similar primary sequences and secondary and
tertiary
structures, structural domains (e.g., extracellular domain, TM domains,
cytoplasmic domain, etc.) can be readily identified by sequence analysis. For
example, homology modeling, Fourier analysis and helical periodicity detection
can identify and characterize the seven domains with a 7-transmembrane
receptor
sequence. Fast Fourier Transform (FFT) algorithms can be used to assess the
dominant periods that characterize profiles of the hydrophobicity and
variability of
38
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
analyzed sequences. Periodicity detection enhancement and alpha helical
periodicity index can be done as by, e.g., Donnelly, Protein Sci. 2:55-70
(1993).
Other alignment and modeling algorithms are well known in the art, see, e.g.,
Peitsch, Receptors Channels 4:161-164 (1996); Kyle & Doolittle, J. Md. Bio.,
157:105-132 (1982); Cronet, Protein Eng. 6:59-64 (1993) (homology and
"discover modeling").
[0123] The present invention also includes not only the DNA and proteins
having the specified nucleic and amino acid sequences, but also DNA fragments,
particularly fragments of, e.g., 40, 60, 80, 100, 150, 200, or 250
nucleotides, or
more, as well as protein fragments of, e.g., 10, 20, 30, 50, 70, 100, or 150
amino
acids, or more. Optionally, the nucleic acid fragments can encode an antigenic
polypeptide which is capable of binding to an antibody raised against a T1R
family
member. Further, a protein fragment of the invention can optionally be an
antigenic fragment which is capable of binding to an antibody raised against a
T1R family member.
[0124] Also contemplated are chimeric proteins, comprising at least 10, 20,
30,
50, 70, 100, or 150 amino acids, or more, of one of at least one of the T1R
polypeptides described herein, coupled to additional amino acids representing
all
or part of another GPCR, preferably a member of the 7 transmembrane
superfamily. These chimeras can be made from the instant receptors and
another:
GPCR, or they can be made by combining two or more of the present receptors.
In one embodiment, one portion of the chimera corresponds torn or is derived
from the extracellular domain of a T1R polypeptide of the invention. In
another
embodiment, one portion of the chimera corresponds to, or is derived from the
extracellular domain and one or more of the transmembrane domains of a T1R
polypeptide described herein, and the remaining portion or portions can come
from another GPCR. Chimeric receptors are well known in the art, and the
techniques for creating them and the selection and boundaries of domains or
fragments of G protein-coupled receptors for incorporation therein are also
well
known. Thus, this knowledge of those skilled in the art can readily be used to
create such chimeric receptors. The use of such chimeric receptors can
provide,
for example, a taste selectivity characteristic of one of the receptors
specifically
39
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
disclosed herein, coupled with the signal transduction characteristics of
another
receptor, such as a well known receptor used in prior art assay systems.
[0125] For example, a domain such as a ligand-binding domain, an extracellular
domain, a transmembrane domain, a transmembrane domain, a cytoplasmic
domain, an N-terminal domain, a C-terminal domain, or any combination thereof,
can be covalently linked to a heterologous protein. For instance, an T1R
extracellular domain can be linked to a heterologous GPCR transmembrane
domain, or a heterologous GPCR extracellular domain can be linked to a T1R
transmembrane domain. Other heterologous proteins of choice can include, e.g.,
green fluorescent protein, 8-gal, glutamtate receptor, and the rhodopsin
presequence.
[0126] Also within the scope of the invention are host cells for expressing
the
TI Rs, fragments, or variants of the invention. To obtain high levels of
expression
of a cloned gene or nucleic acid, such as cDNAs encoding the Ti Rs, fragments,
or variants of the invention, one of skill typically subclones the nucleic
acid
sequence of interest into an expression vector that contains a strong promoter
to
direct transcription, a transcription/translation terminator, and if for a
nucleic acid
encoding a protein, a ribosome binding site for translational initiation.
Suitable
bacterial promoters are well known in the art and described, e.g., in Sambrook
et
a/. However, bacterial or eukaryotic expression systems can be used.
[0127] Any of the well known procedures for introducing foreign nucleotide
sequences into host cells may be used. These include the use of calcium
phosphate transfection, polybrene, protoplast fusion, electroporation,
liposomes,
microinjection, plasma vectors, viral vectors and any of the other well known
methods for introducing cloned genomic DNA, cDNA, synthetic DNA or other
foreign genetic material into a host cell (see, e.g., Sambrook et al.) It is
only
necessary that the particular genetic engineering procedure used be capable of
successfully introducing at lest one nucleic acid molecule into the host cell
capable of expressing the Ti R, fragment, or variant of interest.
[0128] After the expression vector is introduced into the cells, the
transfected
cells are cultured under conditions favoring expression of the receptor,
fragment,
or variant of interest, which is then recovered from the culture using
standard
techniques. Examples of such techniques are well known in the art. See, e.g.,
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
WO 00/06593.
B. Detection of T1R polypeptides
[0129] In addition to the detection of T1R genes and gene expression using
nucleic acid hybridization technology, one can also use immunoassays to detect
Ti Rs, e.g., to identify taste receptor cells, and variants of T1R family
members.
Immunoassays can be used to qualitatively or quantitatively analyze the TI Rs.
A
general overview of the applicable technology can be found in Harlow & Lane,
Antibodies: A Laboratory Manual (1988).
1. Antibodies to T1R family members
[0130] Methods of producing polyclonal and monoclonal antibodies that react
specifically with a T1R family member are known to those of skill in the art
(see,
e.g., Coligan, Current Protocols in Immunology (1991); Harlow & Lane, supra;
Goding, Monoclonal Antibodies: Principles and Practice (2d ed. 1986); and
Kohler
& Milstein, Nature, 256:495-497 (1975)). Such techniques include antibody
preparation by selection of antibodies from libraries of recombinant
antibodies in
phage or similar vectors, as well as preparation of polyclonal and monoclonal
antibodies by immunizing rabbits or mice (see, e.g., Huse et aL, Science,
246:1275-1281 (1989); Ward et al., Nature, 341:544-546 (1989)).
[0131] A number of T1R-comprising immunogens may be used to produce
antibodies specifically reactive with a T1R family member. For example, a
recombinant T1R polypeptide, or an antigenic fragment thereof, can be isolated
as
described herein. Suitable antigenic regions include, e.g., the consensus
sequences that are used to identify members of the T1R family. Recombinant
proteins can be expressed in eukaryotic or prokaryotic cells as described
above,
and purified as generally described above. Recombinant protein is the
preferred
immunogen for the production of monoclonal or polyclonal antibodies.
Alternatively, a synthetic peptide derived from the sequences disclosed herein
and
conjugated to a carrier protein can be used an immunogen. Naturally occurring
protein may also be used either in pure or impure form. The product is then
injected into an animal capable of producing antibodies. Either monoclonal or
polyclonal antibodies may be generated, for subsequent use in immunoassays to
measure the protein.
41
CA 02776701 2012-05-07
WO 02/064631 PCPUS02/00198
[0132] Methods of production of polyclonal antibodies are known to those of
skill
in the art. For example, an inbred strain of mice (e.g., BALB/C mice) or
rabbits is
immunized with the protein using a standard adjuvant, such as Freund's
adjuvant,
and a standard immunization protocol. The animal's immune response to the
immunogen preparation is monitored by taking test bleeds and determining the
titer of reactivity to the Ti R. When appropriately high titers of antibody to
the
immunogen are obtained, blood is collected from the animal and antisera are
prepared. Further fractionation of the antisera to enrich for antibodies
reactive to
the protein can be done if desired (see Harlow & Lane, supra).
[0133] Monoclonal antibodies may be obtained by various techniques familiar to
those skilled in the art. Briefly, spleen cells from an animal immunized with
a
desired antigen may be immortalized, commonly by fusion with a myeloma cell
(see Kohler & Milstein, Eur. J. ImmunoL, 6:511-519 (1976)). Alternative
methods
of immortalization include transformation with Epstein Barr Virus, oncogenes,
or
retroviruses, or other methods well known in the art. Colonies arising from
single
immortalized cells are screened for production of antibodies of the desired
specificity and affinity for the antigen, and yield of the monoclonal
antibodies
produced by such cells may be enhanced by various techniques, including
injection into the peritoneal cavity of a vertebrate host. Alternatively, one
may
isolate DNA sequences which encode a monoclonal antibody or a binding
fragment thereof by screening a DNA library from human B cells according to
the
general protocol outlined by Huse et aL, Science, 246:1275-1281 (1989).
[0134] Monoclonal antibodies and polyclonal sera are collected and titered
against the immunogen protein in an immunoassay, for example, a solid phase
immunoassay with the immunogen immobilized on a solid support. Typically,
polyclonal antisera with a titer of 104 or greater are selected and tested for
their
cross reactivity against non-TiR polypeptides, or even other T1R family
members
or other related proteins from other organisms, using a competitive binding
immunoassay. Specific polyclonal antisera and monoclonal antibodies will
usually
bind with a Kd of at least about 0.1 mM, more usually at least about 1 pM,
optionally at least about 0.1 p.M or better, and optionally 0.01 pM or better.
[0135] Once T1R family member specific antibodies are available, individual
TiR proteins and protein fragments can be detected by a variety of immunoassay
42
CA 02776701 2012-05-07
WO 021064631
PCT/US02/00198
=
methods. For a review of immunological and immunoassay procedures, see
Basic and Clinical Immunology (Stites & Terr eds., 7th ed. 1991). Moreover,
the
immunoassays of the present invention can be performed in any of several
configurations, which are reviewed extensively in Enzyme Immunoassay (Maggio,
ed., 1980); and Harlow & Lane, supra.
2. Immunological binding assays
[0136] T1R proteins, fragments, and variants can be detected and/or quantified
using any of a number of well recognized immunological binding assays (see,
e.g.,
U.S. Patents 4,366,241; 4,376,110; 4,517,288; and 4,837,168). For a review of
the general immunoassays, see also Methods in Cell Biology: Antibodies in Cell
Biology, volume 37 (Asai, ed. 1993); Basic and Clinical Immunology (Stites &
Terr,
eds., 7th ed. 1991). Immunological binding assays (or immunoassays) typically
use an antibody that specifically binds to a protein or antigen of choice (in
this
case a T1R family member or an antigenic subsequence thereof). The antibody
(e.g., anti-Ti R) may be produced by any of a number of means well known to
those of skill in the art and as described above.
[0137] Immunoassays also often use a labeling agent to specifically bind to
and
label the complex formed by the antibody and antigen. The labeling agent may
itself be one of the moieties comprising the antibody/antigen complex. Thus,
the
labeling agent may be a labeled T1R polypeptide or a labeled anti-TiR
antibody.
Alternatively, the labeling agent may be a third moiety, such a secondary
antibody,
that specifically binds to the antibodyfT1R complex (a secondary antibody is
typically specific to antibodies of the species from which the first antibody
is
derived). Other proteins capable of specifically binding immunoglobulin
constant
regions, such as protein A or protein G may also be used as the label agent.
These proteins exhibit a strong non-immunogenic reactivity with immunoglobulin
constant regions from a variety of species (see, e.g., Kronval et al., J.
Immunol.,
111:1401-1406 (1973); Akerstrom et al., J. ImmunO I., 135:2589-2542 (1985)).
The labeling agent can be modified with a detectable moiety, such as biotin,
to
which another molecule can specifically bind, such as streptavidin. A variety
of
detectable moieties are well known to those skilled in the art.
[0138] Throughout the assays, incubation and/or washing steps may be
required after each combination of reagents. Incubation steps can vary from
about
43
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
seconds to several hours, optionally from about 5 minutes to about 24 hours.
However, the incubation time will depend upon the assay format, antigen,
volume
of solution, concentrations, and the like. Usually, the assays will be carried
out at
ambient temperature, although they can be conducted over a range of
temperatures, such as 10 C to 40 C.
a. Non-competitive assay formats
[0139] Immunoassays for detecting a T1R polypeptide in a sample may be
either competitive or noncompetitive. Noncompetitive immunoassays are assays
in which the amount of antigen is directly measured. In one preferred
"sandwich"
assay, for example, the anti-TIR antibodies can be bound directly to a solid
substrate on which they are immobilized. These immobilized antibodies then
capture the T1R polypeptide present in the test sample. The T1R polypeptide is
thus immobilized is then bound by a labeling agent, such as a second T1R
antibody bearing a label. Alternatively, the second antibody may lack a label,
but
it may, in turn, be bound by a labeled third antibody specific to antibodies
of the
species from which the second antibody is derived. The second or third
antibody
is typically modified with a detectable moiety, such as biotin, to which
another
molecule specifically binds, e.g., streptavidin, to provide a detectable
moiety.
b. Competitive assay formats
[0140] In competitive assays, the amount of T1R polypeptide present in the
sample is measured indirectly by measuring the amount of a known, added
(exogenous) T1R polypeptide displaced (competed away) from an anti-TIR
antibody by the unknown T1R polypeptide present in a sample. In one
competitive assay, a known amount of T1R polypeptide is added to a sample and
the sample is then contacted with an antibody that specifically binds to the
Ti R.
The amount of exogenous T1R polypeptide bound to the antibody is inversely
proportional to the concentration of T1R polypeptide present in the sample. In
a
particularly preferred embodiment, the antibody is immobilized on a solid
substrate. The amount of T1R polypeptide bound to the antibody may be
determined either by measuring the amount of T1R polypeptide present in a
T1R/antibody complex, or alternatively by measuring the amount of remaining
uncomplexed protein. The amount of T1R polypeptide may be detected by
providing a labeled T1R molecule.
44
CA 02776701 2012-05-07
WO 02/06-1631 PCT/US02/00198
[0141] A hapten inhibition assay is another preferred competitive assay. In
this
assay the known T1R polypeptide is immobilized on a solid substrate. A known
amount of anti-TiR antibody is added to the sample, and the sample is then
contacted with the immobilized TI R. The amount of anti-TiR antibody bound to
the known immobilized T1R polypeptide is inversely proportional to the amount
of
T1R polypeptide present in the sample. Again, the amount of immobilized
antibody may be detected by detecting either the immobilized fraction of
antibody
or the fraction of the antibody that remains in solution. Detection may be
direct
where the antibody is labeled or indirect by the subsequent addition of a
labeled
moiety that specifically binds to the antibody as described above.
c. Cross-reactivity determinations
[0142] Immunoassays in the competitive binding format can also be used for
cross-reactivity determinations. For example, a protein at least partially
encoded
by the nucleic acid sequences disclosed herein can be immobilized to a solid
support. Proteins (e.g., T1R polypeptides and homologs) are added to the assay
that compete for binding of the antisera to the immobilized antigen. The
ability of
the added proteins to compete for binding of the antisera to the immobilized
protein is compared to the ability of the T1R polypeptide encoded by the
nucleic
acid sequences disclosed herein to compete with itself. The percent cross-
reactivity for the above proteins is calculated, using standard calculations.
Those
antisera with less than 10% cross-reactivity with each of the added proteins
listed
above are selected and pooled. The cross-reacting antibodies are optionally
removed from the pooled antisera by immunoabsorption with the added
considered proteins, e.g., distantly related homologs. In addition, peptides
comprising amino acid sequences representing conserved motifs that are used to
identify members of the T1R family can be used in cross-reactivity
determinations.
[0143] The immunoabsorbed and pooled antisera are then used in a competitive
binding immunoassay as described above to compare a second protein, thought
to be perhaps an allele or polymorphic variant of a T1R family member, to the
immunogen protein (i.e., T1R polypeptide encoded by the nucleic acid sequences
disclosed herein). In order to make this comparison, the two proteins are each
assayed at a wide range of concentrations and the amount of each protein
required to inhibit 50% of the binding of the antisera to the immobilized
protein is
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
determined. If the amount of the second protein required to inhibit 50% of
binding
is less than 10 times the amount of the protein encoded by nucleic acid
sequences disclosed herein required to inhibit 50% of binding, then the second
protein is said to specifically bind to the polyclonal antibodies generated to
a T1R
immunogen.
[0144] Antibodies raised against T1R conserved motifs can also be used to
prepare antibodies that specifically bind only to GPCRs of the TI R family,
but not
to GPCRs from other families.
[0145] Polyclonal antibodies that specifically bind to a particular member of
the
T1R family can be made by subtracting out cross-reactive antibodies using
other
TI R family members. Species-specific polyclonal antibodies can be made in a
similar way. For example, antibodies specific to human TI RI can be made by,
subtracting out antibodies that are cross-reactive with orthologous sequences,
e.g., rat TI RI or mouse TI RI.
d. Other assay formats
[0146] Western blot (immunoblot) analysis is used to detect and quantify the
presence of T1R polypeptide in the sample. The technique generally comprises
separating sample proteins by gel electrophoresis on the basis of molecular
weight, transferring the separated proteins to a suitable solid support, (such
as a
nitrocellulose filter, a nylon filter, or derivatized nylon filter), and
incubating the
sample with the antibodies that specifically bind the T1R polypeptide. The
anti-TIR polypeptide antibodies specifically bind to the T1R polypeptide on
the
solid support. These antibodies may be directly labeled or alternatively may
be
subsequently detected using labeled antibodies (e.g., labeled sheep anti-mouse
antibodies) that specifically bind to the anti-TiR antibodies.
[0147] Other, assay formats include liposome immunoassays (LIA), which use
liposomes designed to bind specific molecules (e.g., antibodies) and release
encapsulated reagents or markers. The released chemicals are then detected
according to standard techniques (see Monroe etal., Amer. Clin. Prod. Rev.,
5:34-41 (1986)).
e. Reduction of non-specific binding
[0148] One of skill in the art will appreciate that it is often desirable to
minimize
non-specific binding in immunoassays. Particularly, where the assay involves
an
46
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
antigen or antibody immobilized on a solid substrate it is desirable to
minimize the
amount of non-specific binding to the substrate. Means of reducing such
non-specific binding are well known to those of skill in the art. Typically,
this
technique involves coating the substrate with a proteinaceous composition. In
particular, protein compositions such as bovine serum albumin (BSA), nonfat
powdered milk, and gelatin are widely used with powdered milk being most
preferred.
f. Labels
[0149] The particular label or detectable group used in the assay is not a
critical
aspect of the invention, as long as it does not significantly interfere with
the
specific binding of the antibody used in the assay. The detectable group can
be
any material having a detectable physical or chemical property. Such
detectable
labels have been well developed in the field of immunoassays and, in general,
most any label useful in such methods can be applied to the present invention.
Thus, a label is any composition detectable by spectroscopic, photochemical,
biochemical, immunochemical, electrical, optical, or chemical means. Useful
labels in the present invention include magnetic beads (e.g., DYNABEADSTM),
fluorescent dyes (e.g., fluorescein isothiocyanate, Texas red, rhodamine, and
the
like), radiolabels (e.g., 3H, 1251, 3sS, 14C, or 32P), enzymes (e.g.,
horseradish
peroxidase, alkaline phosphatase and others commonly used in an ELISA), and
colorimetric labels such as colloidai gold or colored glass or plastic beads
(e.g.,
polystyrene, polypropylene, latex, etc.).
[0150] The label may be coupled directly or indirectly to the desired
component
of the assay according to methods well known in the art. As indicated above, a
wide variety of labels may be used, with the choice of label depending on
sensitivity required, ease of conjugation with the compound, stability
requirements,
available instrumentation, and disposal provisions.
[0151] Non-radioactive labels are often attached by indirect means. Generally,
a ligand molecule (e.g., biotin) is covalently bound to the molecule. The
ligand
then binds to another molecules (e.g., streptavidin) molecule, which is either
inherently detectable or covalently bound to a signal system, such as a
detectable
enzyme, a fluorescent compound, or a chemiluminescent compound. The ligands
47
i
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
and their targets can be used in any suitable combination with antibodies that
recognize a T1R polypeptide, or secondary antibodies that recognize anti-Ti R.
[0152] The molecules can also be conjugated directly to signal generating
compounds, e.g., by conjugation with an enzyme or fluorophore. Enzymes of
interest as labels will primarily be hydrolases, particularly phosphatases,
esterases
and glycosidases, or oxidotases, particularly peroxidases. Fluorescent
compounds include fluorescein and its derivatives, rhodamine and its
derivatives,
dansyl, umbelliferone, etc. Chemiluminescent compounds include luciferin, and
2,3-dihydrophthalazinediones, e.g., luminol. For a review of various labeling
or
signal producing systems that may be used, see U.S. Patent No. 4,391,904.
[0153] Means of detecting labels are well known to those of skill in the art.
Thus, for example, where the label is a radioactive label, means for detection
include a scintillation counter or photographic film as in autoradiography.
Where
the label is a fluorescent label, it may be detected by exciting the
fluorochrome
with the appropriate wavelength of light and detecting the resulting
fluorescence.
The fluorescence may be detected visually, by means of photographic film, by
the
use of electronic detectors such as charge-coupled devices (CCDs) or
photomultipliers and the like. Similarly, enzymatic labels may be detected by
providing the appropriate substrates for the enzyme and detecting the
resulting
reaction product. Finally simple colorimetric labels may be detected simply by
observing the color associated with the label. Thus, in various dipstick
assays,
conjugated gold often appears pink, while various conjugated beads appear the
color of the bead.
[0154] Some assay formats do not require the use of labeled components. For
instance, agglutination assays can be used to detect the presence of the
target
antibodies. In this case, antigen-coated particles are agglutinated by samples
comprising the target antibodies. In this format, none of the components need
be
labeled and the presence of the target antibody is detected by simple visual
inspection.
C. Detection of Modulators
[0155] Compositions and methods for determining whether a test compound
specifically binds to a chemosensory receptor of the invention, both in vitro
and in
vivo, are described below. Many aspects of cell physiology can be monitored to
48
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
assess the effect of ligand binding to a T1R polypeptide of the invention.
These
assays may be performed on intact cells expressing a chemosensory receptor, on
permeabilized cells, or on membrane fractions produced by standard methods.
[0156] Taste receptors bind taste stimuli and initiate the transduction of
chemical stimuli into electrical signals. An activated or inhibited G protein
will in
turn alter the properties of target enzymes, channels, and other effector
proteins.
Some examples are the activation of cGMP phosphodiesterase by transducin in
the visual system, adenylate cyclase by the stimulatory G protein,
phospholipase
C by Gq and other cognate G proteins, and modulation of diverse channels by Gi
and other G proteins. Downstream consequences can also be examined such as
generation of diacyl glycerol and IP3 by phospholipase C, and in turn, for
calcium
mobilization by IP3.
[0157] The T1R proteins or polypeptides of the assay will typically be
selected
from a polypeptide having a sequence of SEQ ID NOS: 4, 10, 12, 14, 17, 21 or
fragments or conservatively modified variants thereof. Optionally, the
fragments
and variants can be antigenic fragments and variants which bind to an anti-TiR
antibody.
[0158] Alternatively, the T1R proteins or polypeptides of the assay can be
derived from a eukaryote host cell and can include an amino acid subsequence
having amino acid sequence identity to SEQ ID NOS: 4, 10, 12, 14, 17, 21, or
fragments or conservatively modified variants thereof. Generally, the amino
acid
sequence identity will be at least 35 to 50%, or optionally 75%, 85%, 90%,
95%,
96%, 97%, 98%, or 99%. Optionally, the T1R proteins or polypeptides of the
assays can comprise a domain of a T1R protein, such as an extracellular
domain,
transmembrane region, transmembrane domain, cytoplasmic domain, ligand-
binding domain, and the like. Further, as described above, the T1R protein or
a
domain thereof can be covalently linked to a heterologous protein to create a
chimeric protein used in the assays described herein.
[0159] Modulators of T1R receptor activity are tested using T1R proteins or
polypeptides as described above, either recombinant or naturally occurring.
The
T1R proteins or polypeptides can be isolated, expressed in a cell, expressed
in a
membrane derived from a cell, expressed in tissue or in an animal, either
recombinant or naturally occurring. For example, tongue slices, dissociated
cells
49
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
from a tongue, transformed cells, or membranes can be used. Modulation can be
tested using one of the in vitro or in vivo assays described herein.
1. In vitro bindin_q assays
[0160] Taste transduction can also be examined in vitro with soluble or solid
state reactions, using a T1R polypeptide of the invention. In a particular
embodiment, a T1R ligand-binding domain can be used in vitro in soluble or
solid
state reactions to assay for ligand binding.
[0161] For instance, the T1R N-terminal domain is predicted to be involved in
ligand binding. More particularly, the TI Rs belong to a GPCR sub-family that
is
characterized by large, approximately 600 amino acid, extracellular N-terminal
segments. These N-terminal segments are thought to form, at least in part, the
ligand-binding domains, and are therefore useful in biochemical assays to
identify
T1R agonists and antagonists. The ligand-binding domain may also contain
additional portions of the extracellular domain, such as the extracellular
loops of
the transmembrane domain. Similar assays have been used with other GPCRs
that are related to the T1Rs, such as the metabotropic glutamate receptors
(see,
e.g., Han and Hampson, J. Biol. Chem. 274:10008-10013 (1999)). These assays
might involve displacing a radioactively or fluorescently labeled ligand,
measuring
changes in intrinsic fluorescence or changes in proteolytic susceptibility,
etc.
[0162] Ligand binding to a T1R polypeptide of the invention can be tested in
solution, in a bilayer membrane, optionally attached to a solid phase, in a
lipid
monolayer, or in vesicles. Binding of a modulator can be tested using, e.g.,
changes in spectroscopic characteristics (e.g., fluorescence, absorbance,
refractive index) hydrodynamic (e.g., shape), chromatographic, or solubility
properties. Preferred binding assays of the invention are biochemical binding
assays that use recombinant soluble N-terminal T1R domains.
[0163] Receptor-G protein interactions can also be examined. For example,
binding of the G protein to the receptor, or its release from the receptor can
be
examined. More particularly, in the absence of GTP, an activator will lead to
the
formation of a tight complex of a G protein (all three subunits) with the
receptor.
This complex can be detected in a variety of ways, as noted above. Such an
assay can be modified to search for inhibitors, e.g., by adding an activator
to the
receptor and G protein in the absence of GTP, which form a tight complex, and
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
then screen for inhibitors by looking at dissociation of the receptor-G
protein
complex. In the presence of GTP, release of the alpha subunit of the G protein
from the other two G protein subunits serves as a criterion of activation. An
activated or inhibited G protein will in turn alter the properties of target
enzymes,
channels, and other effector proteins.
[0164] In another embodiment of the invention, a GTPyS assay may be used.
As described above, upon activation of a GPCR, the Ga subunit of the G protein
complex is stimulated to exchange bound GDP for GTP. Ligand-mediated
stimulation of G protein exchange activity can be measured in a biochemical
assay measuring the binding of added radioactively-labeled GTPy35S to the G
protein in the presence of a putative ligand. Typically, membranes containing
the
chemosensory receptor of interest are mixed with a complex of G proteins.
Potential inhibitors and/or activators and GTPyS are added to the assay, and
binding of GTPyS to the G protein is measured. Binding can be measured by
liquid scintillation counting or by any other means known in the art,
including
scintillation proximity assays (SPA). In other assays formats, fluorescently-
labeled
GTPyS can be utilized.
2. Fluorescence Polarization Assays
[0165] In another embodiment, Fluorescbnce Polarization ("FP") based assays
may be used to detect and monitor ligand binding. Fluorescence polarization is
a
versatile laboratory technique for measuring equilibrium binding, nucleic acid
hybridization, and enzymatic activity. Fluorescence polarization assays are
homogeneous in that they do not require a separation step such as
centrifugation,
filtration, chromatography, precipitation, or electrophoresis. These assays
are
done in real time, directly in solution and do not require an immobilized
phase.
Polarization values can be measured repeatedly and after the addition of
reagents
since measuring the polarization is rapid and does not destroy the sample.
Generally, this technique can be used to measure polarization values of
fluorophores from low picomolar to micromolar levels. This section describes
how
fluorescence polarization can be used in a simple and quantitative way to
measure the binding of ligands to the T1R polypeptides of the invention.
[0166] When a fluorescently labeled molecule is excited with plane polarized
light, it emits light that has a degree of polarization that is inversely
proportional to
51
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
its molecular rotation. Large fluorescently labeled molecules remain
relatively
stationary during the excited state (4 nanoseconds in the case of fluorescein)
and
the polarization of the light remains relatively constant between excitation
and
emission. Small fluorescently labeled molecules rotate rapidly during the
excited
=
state and the polarization changes significantly between excitation and
emission.
Therefore, small molecules have low polarization values and large molecules
have
high polarization values. For example, a single-stranded fluorescein-labeled
oligonucleotide has a relatively low polarization value but when it is
hybridized to a
complementary strand, it has a higher polarization value. When using FP to
detect and monitor taste stimulus-binding which may activate or inhibit the
chernosensory receptors of the invention, fluorescence-labeled taste stimuli
or
auto-fluorescent taste stimuli may be used.
[0167] Fluorescence polarization (P) is defined as:
P 1nt1-1 -
Int u + Int
Where n is the intensity of the emission light parallel to the excitation
light plane
and Intl is the intensity of the emission light perpendicular to the
excitation light
plane. P, being a ratio of light intensities, is a dimensionless number. For
example, the Beacon 0 and Beacon 2000 TM System may be used in connection
with these assays. Such systems typically express polarization in
millipolarization
units (1 Polarization Unit =1000 mP Units).
[0168] The relationship between molecular rotation and size is described by
the
Perrin equation and the reader is referred to Jolley, M. E. (1991) in Journal
of
Analytical Toxicology, pp. 236-240, which gives a thorough explanation of this
equation. Summarily, the Perrin equation states that polarization is directly
proportional to the rotational relaxation time, the time that it takes a
molecule to
rotate through an angle of approximately 68.5 Rotational relaxation time is
related
to viscosity (1), absolute temperature (T), molecular volume (V), and the gas
constant (R) by the following equation:
Rotational Relaxation Time = ¨377V
RI'
[0169] The rotational relaxation time is small 1 nanosecond) for small
molecules (e.g. fluorescein) and large 100 nanoseconds) for large molecules
52
I I
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
(e.g. immunoglobulins). If viscosity and temperature are held constant,
rotational
relaxation time, and therefore polarization, is directly related to the
molecular
volume. Changes in molecular volume may be due to interactions with other
molecules, dissociation, polymerization, degradation, hybridization, or
conformational changes of the fluorescently labeled molecule. For example,
fluorescence polarization has been used to measure enzymatic cleavage of large
fluorescein labeled polymers by proteases, DNases, and RNases. It also has
been used to measure equilibrium binding for protein/protein interactions,
antibody/antigen binding, and protein/DNA binding.
3. Solid state and soluble high throughput assays
[0170] In yet another embodiment, the invention provides soluble assays using
a T1R polypeptide; or a cell or tissue expressing an T1R polypeptide. In
another
embodiment, the invention provides solid phase based in vitro assays in a high
throughput format, where the T1R polypeptide, or cell or tissue expressing the
T1R polypeptide is attached to a solid phase substrate.
[0171] In the high throughput assays of the invention, it is possible to
screen up
to several thousand different modulators or ligands in a single day. In
particular,
each well of a microtiter plate can be used to run a separate assay against a
selected potential modulator, or, if concentratien or incubation time effects
are to
be observed, every 5-10 wells can test a single modulator. Thus, a single
standard microtiter plate can assay about 100 (e.g., 96) modulators. If 1536
well
plates are used, then a single plate can easily assay from about 1000 to about
1500 different compounds. It is also possible to assay multiple compounds in
each plate well. It is possible to assay several different plates per day;
assay
screens for up to about 6,000-20,000 different compounds is possible using the
integrated systems of the invention. More recently, microfluidic approaches to
reagent manipulation have been developed.
[0172] The molecule of interest can be bound to the solid state component,
directly or indirectly, via covalent or non-covalent linkage, e.g., via a tag.
The tag
can be any of a variety of components. In general, a molecule which binds the
tag
(a tag binder) is fixed to a solid support, and the tagged molecule of
interest (e.g.,
the taste transduction molecule of interest) is attached to the solid support
by
interaction of the tag and the tag binder.
53
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0173] A number of tags and tag binders can be used, based upon known
molecular interactions well described in the literature. For example, where a
tag
has a natural binder, for example, biotin, protein A, or protein G, it can be
used in
conjunction with appropriate tag binders (avidin, streptavidin, neutravidin,
the Fc
region of an immunoglobulin, etc.). Antibodies to molecules with natural
binders
such as biotin are also widely available and appropriate tag binders (see,
SIGMA
lmmunochemicals 1998 catalogue SIGMA, St. Louis MO).
[0174] Similarly, any haptenic or antigenic compound can be used in
combination with an appropriate antibody to form a tag/tag binder pair.
Thousands of specific antibodies are commercially available and many
additional
antibodies are described in the literature. For example, in one common
configuration, the tag is a first antibody and the tag binder is a second
antibody
which recognizes the first antibody. In addition to antibody-antigen
interactions,
receptor-ligand interactions are also appropriate as tag and tag-binder pairs.
For
example, agonists and antagonists of cell membrane receptors (e.g., cell
receptor-ligand interactions such as transferrin, c-kit, viral receptor
ligands,
cytokine receptors, chemokine receptors, interleukin receptors, immunoglobulin
receptors and antibodies, the cadherein family, the integrin family, the
selectin
family, and the like; see, e.g., Pigott & Power, The Adhesion Molecule Facts
Book
1(1993)). Similarly, toxins and venoms, viral epitopes, hormones (e.g.,
opiates,
steroids, etc.), intracellular receptors (e.g., which mediate the effects of
various
small ligands, including steroids, thyroid hormone, retinoids and vitamin D;
peptides), drugs, lectins, sugars, nucleic acids (both linear and cyclic
polymer
configurations), oligosaccharides, proteins, phospholipids and antibodies can
all
interact with various cell receptors.
[0175] Synthetic polymers, such as polyurethanes, polyesters, polycarbonates,
.
polyureas, polyamides, polyethyleneimines, polyarylene sulfides,
polysiloxanes,
polyimides, and polyacetates can also form an appropriate tag or tag binder.
Many other tag/tag binder pairs are also useful in assay systems described
herein,
as would be apparent to one of skill upon review of this disclosure.
[0176] Common linkers such as peptides, polyethers, and the like can also
serve as tags, and include polypeptide sequences, such as poly gly sequences
of
between about 5 and 200 amino acids. Such flexible linkers are known to
persons
54
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
of skill in the art. For example, poly(ethelyne glycol) linkers are available
from
Shearwater Polymers, Inc. Huntsville, Alabama. These linkers optionally have
amide linkages, sulfhydryl linkages, or heterofunctional linkages.
[0177] Tag binders are fixed to solid substrates using any of a variety of
methods currently available. Solid substrates are commonly derivatized or
functionalized by exposing all or a portion of the substrate to a chemical
reagent
which fixes a chemical group to the surface which is reactive with a portion
of the
tag binder. For example, groups which are suitable for attachment to a longer
chain portion would include amines, hydroxyl, thiol, and carboxyl groups.
Aminoalkylsilanes and hydroxyalkylsilanes can be used to functionalize a
variety
of surfaces, such as glass surfaces. The construction of such solid phase
biopolymer arrays is well described in the literature. See, e.g., Merrifield,
J. Am.
Chem. Soc., 85:2149-2154 (1963) (describing solid phase synthesis of, e.g.,
peptides); Geysen etal., J. Immun. Meth., 102:259-274 (1987) (describing
synthesis of solid phase components on pins); Frank & Doring, Tetrahedron,
44:60316040 (1988) (describing synthesis of various peptide sequences on
cellulose disks); Fodor etal., Science, 251:767-777 (1991); Sheldon et al.,
Clinical
Chemistry, 39(4):718-719 (1993); and Kozal et al., Nature Medicine,
2(7):753759
(1996) (all describing arrays of biopolymers fixed to solid substrates). =
Non-chemical approaches for fixing tag binders to substrates include other
common methods, such as heat, cross-linking by UV radiation, and the like.
4. Computer-based assays
[0178] Yet another assay for compounds that modulate T1R potypeptide activity
involves computer assisted compound design, in which a computer system is used
to generate a three-dimensional structure of an T1R polypeptide based on the
structural information encoded by its amino acid sequence. The input amino
acid
sequence interacts directly and actively with a preestablished algorithm in a
computer program to yield secondary, tertiary, and quaternary structural
models of
the protein. The models of the protein structure are then examined to identify
regions of the structure that have the ability to bind, e.g., ligands. These
regions
are then used to identify ligands that bind to the protein.
[0179] The three-dimensional structural model of the protein is generated by
entering protein amino acid sequences of at least 10 amino acid residues or
55
=
I
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
corresponding nucleic acid sequences encoding a T1R polypeptide into the
computer system. The nucleotide sequence encoding the TiR polypeptide, or the
amino acid sequence thereof, can be any sequence disclosed herein, and
conservatively modified versions thereof.
[0180] The amino acid sequence represents the primary sequence or
subsequence of the protein, which encodes the structural information of the
protein. At least 10 residues of the amino acid sequence (or a nucleotide
sequence encoding 10 amino acids) are entered into the computer system from
computer keyboards, computer readable substrates that include, but are not
limited to, electronic storage media (e.g., magnetic diskettes, tapes,
cartridges,
and chips), optical media (e.g., CD ROM), information distributed by internet
sites,
and by RAM. The three-dimensi9nal structural model of the protein is then
generated by the interaction of the amino acid sequence and the computer
system, using software known to those of skill in the art.
[0181] The amino acid sequence represents a primary structure that encodes
the information necessary to form the secondary, tertiary and quaternary
structure
of the protein of interest. The software looks at certain parameters encoded
by
the primary sequence to generate the structural model. These parameters are
referred to as "energy terms," and primarily include electrostatic potentials,
hydrophobic potentials, solvent accessible surfaces, and hydrogen bonding.
Secondary energy terms include van der Waals potentials. Biological molecules
form the structures that minimize the energy terms in a cumulative fashion.
The
computer program is therefore using these terms encoded by the primary
structure or amino acid sequence to create the secondary structural model.
[0182] The tertiary structure of the protein encoded by the secondary
structure
is then formed on the basis of the energy terms of the secondary structure.
The
user at this point can enter additional variables such as whether the protein
is
membrane bound or soluble, its location in the body, and its cellular
location, e.g.,
cytoplasmic, surface, or nuclear. These variables along with the energy terms
of
the secondary structure are used to form the model of the tertiary structure.
In
modeling the tertiary structure, the computer program matches hydrophobic
faces
of secondary structure with like, and hydrophilic faces of secondary structure
with
like.
56
i
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
[0183] Once the structure has been generated, potential ligand-binding regions
are identified by the computer system. Three-dimensional structures for
potential
ligands are generated by entering amino acid or nucleotide sequences or
chemical formulas of compounds, as described above. The three-dimensional
structure of the potential ligand is then compared to that of the TiR
polypeptide to
identify ligands that bind to the protein. Binding affinity between the
protein and
ligands is determined using energy terms to determine which ligands have an
enhanced probability of binding to the protein.
[0184] Computer systems are also used to screen for mutations, polymorphic
variants, alleles, and interspecies homologs of T1R genes. Such mutations can
be associated with disease states or genetic traits. As described above,
GeneChipTM and related technology can also be used to screen for mutations,
polymorphic variants, alleles, and interspecies homologs. Once the variants
are
identified, diagnostic assays can be used to identify patients having such
mutated
genes. Identification of the mutated TiR genes involves receiving input of a
first
nucleic acid or amino acid sequence of a T1R gene, or conservatively modified
versions thereof. The sequence is entered into the computer system as
described
above. The first nucleic acid or amino acid sequence is then compared to a
second nucleic acid or amino acid sequence thal has substantial identity to
the
first sequence. The second sequence is entered into the computer system in the
manner described above. Once the first and second sequences are compared,
nucleotide or amino acid differences between the sequences are identified.
Such
sequences can represent allelic differences in various T1R genes, and
mutations
associated with disease states and genetic traits.
5. Cell-based binding assays
[0185] In one embodiment, a T1R protein or polypeptide is expressed in a
eukaryotic cell as a chimeric receptor with a heterologous, chaperone sequence
= that facilitates its maturation and targeting through the secretory
pathway. Such
chimeric T1R polypeptides can be expressed in any eukaryotic cell, such as
HEK-293 cells. Preferably, the cells comprise a functional G protein, e.g.,
GaI5,
that is capable of coupling the chimeric receptor to an intracellular
signaling
pathway or to a signaling protein such as phospholipase C. Activation of such
chimeric receptors in such cells can be detected using any standard method,
such
57
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
as by detecting changes in intracellular calcium by detecting FURA-2 dependent
fluorescence in the cell.
[0186] Activated GPCR receptors become substrates for kinases that
phosphorylate the C-terminal tail of the receptor (and possibly other sites as
well).
Thus, activators will promote the transfer of 32P from gamma-labeled GTP to
the
receptor, which can be assayed with a scintillation counter. The
phosphorylation
of the C-terminal tail will promote the binding of arrestin-like proteins and
will
interfere with the binding of G proteins. The kinase/arrestin pathway plays a
key
role in the desensitization of many GPCR receptors. For example, compounds
that modulate the duration a taste receptor stays active would be useful as a
means of prolonging a desired taste or cutting off an unpleasant one. For a
general review of GPCR signal transduction and methods of assaying signal
transduction, see, e.g., Methods in Enzymology, vols. 237 and 238 (1994) and
volume 96(1983); Bourne etal., Nature, 10:349:117-27 (1991); Bourne etal.,
Nature, 348:125-32 (1990); Pitcher et al., Annu. Rev. Biochem., 67:653-92
(1998).
[0187] T1R modulation may be assayed by comparing the response of a T1R
polypeptide treated with a putative T1R modulator to the response of an
untreated
control sample. Such putative T1R modulators can include taste stimuli that
either
inhibit or activate T1R polypeptide activity. In one embodiment, control
samples
(untreated with activators or inhibitors) are assigned a relative T1R activity
value
of 100. Inhibition of a T1R polypeptide is achieved when the T1R activity
value
relative to the control is about 90%, optionally 50%, optionally 25-0%.
Activation
of a T1R polypeptide is achieved when the T1R activity value relative to the
control is 110%, optionally 150%, 200-500%, or 1000-2000%.
[0188] Changes in ion flux may be assessed by determining changes in ionic
polarization (i.e., electrical potential) of the cell or membrane expressing a
T1R
polypeptide. One means to determine changes in cellular polarization is by
measuring changes in current (thereby measuring changes in polarization) with
voltage-clamp and patch-clamp techniques (see, e.g., the "cell-attached" mode,
the "inside-out" mode, and the "whole cell" mode, e.g., Ackerman etal., New
Engl.
J Med., 336:1575-1595 (1997)). Whole cell currents are conveniently determined
using the standard. Other known assays include: radiolabeled ion flux assays
and
fluorescence assays using voltage-sensitive dyes (see, e.g., Vestergarrd-
Bogind
58
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
etal., J. Membrane Biol., 88:67-75 (1988); Gonzales & Tsien, Chem. Biol.,
4:269-
277 (1997); Daniel etal., J. Pharmacol. Meth., 25:185-193 (1991); Holevinsky
et
al., J. Membrane Biology, 137:59-70 (1994)). Generally, the compounds to be
tested are present in the range from 1 pM to 100 mM.
[0189] The effects of the test compounds upon the function of the polypeptides
can be measured by examining any of the parameters described above. Any
suitable physiological change that affects GPCR activity can be used to assess
the influence of a test compound on the polypeptides of this invention. When
the
functional consequences are determined using intact cells or animals, one can
also measure a variety of effects such as transmitter release, hormone
release,
transcriptional changes to both known and uncharacterized genetic markers
(e.g.,
northern blots), changes in cell metabolism such as cell growth or pH changes,
and changes in intracellular second messengers such as Ca2+, IP3, cGMP, or
cAMP.
[0190] Preferred assays for GPCRs include cells that are loaded with ion or
voltage sensitive dyes to report receptor activity. Assays for determining
activity of
such receptors can also use known agonists and antagonists for other G protein-
coupled receptors as negative or positive controls to assess activity of
tested
compounds. In assays for identifying modulatory compounds (e.g., agonists,
antagonists), changes in the level of ions in the cytoplasm or membrane
voltage
will be monitored using an ion sensitive or membrane voltage fluorescent
indicator, respectively. Among the ion-sensitive indicators and voltage probes
that
may be employed are those disclosed in the Molecular Probes 1997 Catalog. For
G protein-coupled receptors, promiscuous G proteins such as Gal5 and Gal 6
can be used in the assay of choice (Wilkie et al., Proc. Nat'l Acad. Sc.,
88:10049-10053 (1991)). Such promiscuous G proteins allow coupling of a wide
range of receptors.
[0191] Receptor activation typically initiates subsequent intracellular
events,
e.g., increases in second messengers such as IP3, which releases intracellular
stores of calcium ions. Activation of some G protein-coupled receptors
stimulates
the formation of inositol triphosphate (IP3) through phospholipase C-mediated
hydrolysis of phosphatidylinositol (Berridge & Irvine, Nature, 312:315-21
(1984)).
1P3 in turn stimulates the release of intracellular calcium ion stores. Thus,
a
59
CA 02776701 2012-05-07
_
WO 02/064631 PCT/US02/00198
change in cytoplasmic calcium ion levels, or a change in second messenger
levels
such as IP3 can be used to assess G protein-coupled receptor function. Cells
expressing such G protein-coupled receptors may exhibit increased cytoplasmic
calcium levels as a result of contribution from both intracellular stores and
via
activation of ion channels, in which case it may be desirable although not
necessary to conduct such assays in calcium-free buffer, optionally
supplemented
with a chelating agent such as EGTA, to distinguish fluorescence response
resulting from calcium release from internal stores.
[0192] Other assays can involve determining the activity of receptors which,
when activated, result in a change in the level of intracellular cyclic
nucleotides,
e.g., cAMP or cGMP, by activating or inhibiting enzymes such as adenylate
cyclase. There are cyclic nucleotide-gated ion channels, e.g., rod
photoreceptor
cell channels and olfactory neuron channels that are permeable to cations upon
activation by binding of cAMP or cGMP (see, e.g., Altenhofen et al., Proc.
Nat'l
Acad. Sc., 88:9868-9872 (1991) and Dhallan etal., Nature, 347:184-187 (1990)).
In cases where activation of the receptor results in a decrease in cyclic
nucleotide
levels, it may be preferable to expose the cells to agents that increase
intracellular
cyclic nucleotide levels, e.g., forskolin, prior to adding a receptor-
activating
compound to the cells in the assay. Cells for this type of assay can be made
by
co-transfection of a host cell with DNA encoding a cyclic nucleotide-crated
ion
channel, GPCR phosphatase and DNA encoding a receptor (e.g., certain
glutamate receptors, muscarinic acetylcholine receptors, dopamine receptors,
serotonin receptors, and the like), which, when activated, causes a change in
cyclic nucleotide levels in the cytoplasm.
[0193] In a preferred embodiment, T1R polypeptide activity is measured by
expressing a T1R gene in a heterologous cell with a promiscuous G protein that
links the receptor to a phospholipase C signal transduction pathway (see
Offermanns & Simon, J. Biol. Chem., 270:15175-15180 (1995)). Optionally the
cell line is HEK-293 (which does not naturally express T1R genes) and the
promiscuous G protein is Gal5 (Offermanns & Simon, supra). Modulation of taste
transduction is assayed by measuring changes in intracellular Ca2+ levels,
which
change in response to modulation of the T1R signal transduction pathway via
administration of a molecule that associates with a T1R polypeptide. Changes
in
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
Ca2+ levels are optionally measured using fluorescent Ca2+ indicator dyes and
fluorometric imaging.
[0194] In one embodiment, the changes in intracellular cAMP or cGMP can be
measured using immunoassays. The method described in Offermanns & Simon,
J. Bio. Chem., 270:15175-15180 (1995), may be used to determine the level of
cAMP. Also, the method described in Felley-Bosco et aL, Am. J. Resp. Cell and
MoL Biol., 11:159-164 (1994), may be used to determine the level of cGMP.
Further, an assay kit for measuring cAMP and/or cGMP is described in U.S.
Patent 4,115,538,
[0195] In another embodiment, phosphatidyl inositol (PI) hydrolysis can be
analyzed according to U.S. Patent 5,436,128.
Briefly, the assay involves labeling of cells with 3H-myoinositol for 48 or
more hrs.
The labeled cells are treated with a test compound for one hour. The treated
cells
are lysed and extracted in chloroform-methanol-water after which the inositol
phosphates were separated by ion exchange chromatography and quantified by
scintillation counting. Fold stimulation is determined by calculating the
ratio of
cpm in the presence of agonist, to cpm in the presence of buffer control.
Likewise, fold inhibition is determined by calculating the ratio of cpm in the
presence of antagonist, to cpm in the presence of L.Jffer control (which may
or
may not contain an agonist).
[0196] In another embodiment, transcription levels can be measured to assess
the effects of a test compound on signal transduction. A host cell containing
a
T1R polypeptide of interest is contacted with a test compound for a sufficient
time
to effect any interactions, and then the level of gene expression is measured.
The =
amount of time to effect such interactions may be empirically determined, such
as
by running a time course and measuring the level of transcription as a
function of
time. The amount of transcription may be measured by using any method known
to those of skill in the art to be suitable. For example, mRNA expression of
the
protein of interest may be detected using northern blots or their polypeptide
products may be identified using immunoassays. Alternatively, transcription
based assays using reporter gene may be used as described in U.S. Patent
5,436,128, The reporter genes can be, e.g.,
chloramphenicol acetyltransferase, luciferase, `3-galactosidase and alkaline
61
i
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
phosphatase. Furthermore, the protein of interest can be used as an indirect
reporter via attachment to a second reporter such as green fluorescent protein
(see, e.g., Mistili & Spector, Nature Biotechnology, 15:961-964 (1997)).
[0197] The amount of transcription is then compared to the amount of
transcription in either the same cell in the absence of the test compound, or
it may
be compared with the amount of transcription in a substantially identical cell
that
lacks the T1R polypeptide of interest. A substantially identical cell may be
derived
from the same cells from which the recombinant cell was prepared but which had
not been modified by introduction of heterologous DNA. Any difference in the
amount of transcription indicates that the test compound has in some manner
altered the activity of the T1R polypeptide of interest.
6. Transcienic non-human animals expressing
chemosensory receptors
[0198] Non-human animals expressing one or more chemosensory receptor
sequences of the invention, can also be used for receptor assays. Such
expression can be used to determine whether a test compound specifically binds
to a mammalian taste transmembrane receptor polypeptide in vivo by contacting
a
non-human animal stably or transiently transfected with a nucleic acid
encoding a
chemosensory receptor or ligand-binding region thereof with a test compound
and
determining whether the animal reacts to the test compound by specifically
binding to the receptor polypeptide.
[0199] Animals transfected or infected with the vectors of the invention are
particularly useful for assays to identify and characterize taste
stimuli/ligands that
can bind to a specific or sets of receptors. Such vector-infected animals
expressing human chemosensory receptor sequences can be used for in vivo
screening of taste stimuli and their effect on, e.g., cell physiology (e.g.,
on taste
neurons), on the CNS, or behavior.
[0200] Means to infect/express the nucleic acids and vectors, either
individually
or as libraries, are well known in the art. A variety of individual cell,
organ, or
whole animal parameters can be measured by a variety of means. The T1R
sequences of the invention can be for example expressed in animal taste
tissues
by delivery with an infecting agent, e.g., adenovirus expression vector.
62
I
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0201] The endogenous chemosensory receptor genes can remain functional
and wild-type (native) activity can still be present. In other situations,
where it is
desirable that all chemosensory receptor activity is by the introduced
exogenous
hybrid receptor, use of a knockout line is preferred. Methods for the
construction
of non-human transgenic animals, particularly transgenic mice, and the
selection
and preparation of recombinant constructs for generating transformed cells are
well known in the art.
[0202] Construction of a "knockout" cell and animal is based on the premise
that
the level of expression of a particular gene in a mammalian cell can be
decreased
or completely abrogated by introducing into the genome a new DNA sequence
that serves to interrupt some portion of the DNA sequence of the gene to be
suppressed. Also, "gene trap insertion" can be used to disrupt a host gene,
and
mouse embryonic stem (ES) cells can be used to produce knockout transgenic
animals (see, e.g., Holzschu, Transgenic Res 6:97-106 (1997)). The insertion
of
the exogenous is typically by homologous recombination between complementary
nucleic acid sequences. The exogenous sequence is some portion of the target
gene to be modified, such as exonic, intronic or transcriptional regulatory
sequences, or any genomic sequence which is able to affect the level of the
target
gene's expression; or a combination thereof. Gene tai jeting via homologous
recombination in pluripotential embryonic stem cells allows one to modify
precisely
the genomic sequence of interest. Any technique can be used to create, screen
for, propagate, a knockout animal, e.g., see Bijvoet, Hum. MoL Genet. 7:53-62
(1998); Moreadith, J. MoL Med. 75:208-216 (1997); Tojo, Cytotechnology 19:161-
165 (1995); Mudgett, Methods Mol. Biol. 48:167-184 (1995); Longo, Transgenic
Res. 6:321-328 (1997); U.S. Patents Nos. 5,616,491; 5,464,764; 5,631,153;
5,487,992; 5,627,059; 5,272,071; WO 91/09955; W093/09222; WO 96/29411;
WO 95/31560; WO 91/12650.
[0203] The nucleic acids of the invention can also be used as reagents to
produce "knockout" human cells and their progeny. Likewise, the nucleic acids
of
the invention can also be used as reagents to produce "knock-ins" in mice. The
human or rat T1R gene sequences can replace the orthologous TiR in the mouse
genome. In this way, a mouse expressing a human or rat T1R is produced. This
63
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
mouse can then be used to analyze the function of human or rat TI Rs, and to
identify ligands for such Ti Rs.
D. Modulators
[0204] The compounds tested as modulators of a T1R family member can be
any small chemical compound, or a biological entity, such as a protein, sugar,
nucleic acid or lipid. Alternatively, modulators can be genetically altered
versions
of a T1R gene. Typically, test compounds will be small chemical molecules and
peptides. Essentially any chemical compound can be used as a potential
modulator or ligand in the assays of the invention, although most often
compounds can be dissolved in aqueous or organic (especially DMSO-based)
solutions are used. The assays are designed to screen large chemical libraries
by
automating the assay steps and providing compounds from any convenient source
to assays, which are typically run in parallel (e.g., in microtiter formats on
microtiter plates in robotic assays). It will be appreciated that there are
many
suppliers of chemical compounds, including Sigma (St. Louis, MO), Aldrich (St.
Louis, MO), Sigma-Aldrich (St. Louis, MO), Fluka Chemika-Biochemica Analytika
(Buchs, Switzerland) and the like.
[0205] In one preferred embodiment, high throughput screening methods
involve providing a combinatorial chemical or peptide library containing a
large
number of potential therapeutic compounds (potential modulator or ligand
compounds). Such "combinatorial chemical libraries" or "ligand libraries" are
then
screened in one or more assays, as described herein, to identify those library
members (particular chemical species or subclasses) that display a desired
characteristic activity. The compounds thus identified can serve as
conventional
"lead compounds" or can themselves be used as potential or actual
therapeutics.
[0206] A combinatorial chemical library is a collection of diverse chemical
compounds generated by either chemical synthesis or biological synthesis, by
combining a number of chemical "building blocks" such as reagents. For
example,
a linear combinatorial chemical library such as a polypeptide library is
formed by
combining a set of chemical building blocks (amino acids) in every possible
way
for a given compound length (i.e., the number of amino acids in a polypeptide
compound). Millions of chemical compounds can be synthesized through such
combinatorial mixing of chemical building blocks.
64
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0207] Preparation and screening of combinatorial chemical libraries is well
known to those of skill in the art. Such combinatorial chemical libraries
include,
but are not limited to, peptide libraries (see, e.g., U.S. Patent 5,010,175,
Furka,
mt. J. Pept. Prot. Res., 37:487-493 (1991) and Houghton etal., Nature, 354:84-
88
(1991)). Other chemistries for generating chemical diversity libraries can
also be
used. Such chemistries include, but are not limited to: peptoids (e.g., PCT
Publication No. WO 91/19735), encoded peptides (e.g., PCT Publication WO
93/20242), random bio-oligomers (e.g., PCT Publication No. WO 92/00091),
benzodiazepines (e.g., U.S. Pat. No. 5,288,514), diversomers such as
hydantoins,
benzodiazepines and dipeptides (Hobbs et al., Proc. Nat. Acad. Sci.,
90:6909-6913 (1993)), vinylogous polypeptides (Hagihara etal., J. Amer. Chem.
Soc., 114:6568 (1992)), nonpeptidal peptidomimetics with glucose scaffolding
(Hirschmann et al., J. Amer. Chem. Soc., 114:9217-9218 (1992)), analogous
organic syntheses of small compound libraries (Chen et al., J. Amer. Chem.
Soc.,
116:2661(1994)), oligocarbamates (Cho et al., Science, 261:1303 (1993)),
peptidyl phosphonates (Campbell et al., J. Org. Chem., 59:658 (1994)), nucleic
acid libraries (Ausubel, Berger and Sambrook, all supra), peptide nucleic acid
libraries (U.S. Patent 5,539,083), antibody libraries (Vaughn et al., Nature
Biotechnology, 14(3):309-314 (1996) and WO 97/0027, carbohydrate
libraries (Liang etal., Science, 274:1520-1522 (1996) and U.S. Patent
5,593,853),
small organic molecule libraries (benzodiazepines, Baum, C&EN, Jan 18, page 33
(1993); thiazolidinones and metathiazanones, U.S. Patent 5,549,974;
pynrolidines,
U.S. Patents 5,525,735 and 5,519,134; morpholino compounds, U.S. Patent
5,506,337; benzodiazepines, U.S. Patent No. 5,288,514, and the like).
[0208] Devices for the preparation of combinatorial libraries are commercially
available (see, e.g., 357 MPS, 390 MPS (Advanced Chem Tech, Louisville KY),
Symphony (Rainin, Woburn, MA), 433A (Applied Biosystems, Foster City, CA),
9050 Plus (Millipore, Bedford, MA)). In addition, numerous combinatorial
libraries
are themselves commercially available (see, e.g., ComGenex, Princeton, NJ;
Tripos, Inc., St. Louis, MO; 3D Pharmaceuticals, Exton, PA; Martek
Biosciences;
Columbia, MD; etc.).
[0209] In one aspect of the invention, the T1R modulators can be used in any
food product, confectionery, pharmaceutical composition, or ingredient thereof
to
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
thereby modulate the taste of the product, composition, or ingredient in a
desired
manner. For instance, T1R modulators which enhance sweet taste sensation can
be added to sweeten a product or composition, while T1R modulators which block
undesirable taste sensations can be added to improve the taste of a product or
composition.
E. Methods for Representing and Predicting the Perception of
Taste
[0210] The invention also preferably provides methods for representing the
perception of taste and/or for predicting the perception of taste in a mammal,
including in a human. Preferably, such methods may be performed by using the
receptors and genes encoding said T1R polypeptides disclosed herein.
[0211] Also contemplated as within the invention, is a method of screening one
or more compounds for the presence of a taste detectable by a mammal,
comprising; contacting said one or more compounds with the disclosed
receptors,
preferably wherein the mammal is a human. Also contemplated as within the
invention, is a method for representing taste perception of a particular taste
in a
mammal, comprising the steps of: providing values X1 to Xn representative of
the
quantitative stimulation of each of n chemosensory receptors of said
vertebrate,
where n is greater than or equal to 2; and generating from said values a
quantitative representation of taste perception. The chemosensory receptors
may
be a chemosensory receptor disclosed herein, the representation may
constitutes
a point or a volume in n-dimensional space, may constitutes a graph or a
spectrum, and may constitutes a matrix of quantitative representations. Also,
the
providing step may comprise contacting a plurality of recombinantly-produced
chemosensory receptors with a test composition and quantitatively measuring
the
interaction of said composition with said receptors.
[0212] Also contemplated as within the invention, is a method for predicting
the
taste perception in a mammal generated by one or more molecules or
combinations of molecules yielding unknown taste perception in a mammal,
comprising the steps of: providing values X1 to Xi-, representative of the
quantitative
stimulation of each of n chemosensory receptors of said vertebrate, where n is
greater than or equal to 2, for one or more molecules or combinations of
molecules yielding known taste perception in a mammal; and generating from
said
66
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
values a quantitative representation of taste perception in a mammal for the
one
or more molecules or combinations of molecules yielding known taste perception
in a mammal, providing values X, to Xn representative of the quantitative
stimulation of each of n chemosensory receptors of said vertebrate, where n is
greater than or equal to 2, for one or more molecules or combinations of
molecules yielding unknown taste perception in a mammal; and generating from
said values a quantitative representation of taste perception in a mammal for
the
one or more molecules or combinations of molecules yielding unknown taste
perception in a mammal, and predicting the taste perception in a mammal
generated by one or more molecules or combinations of molecules yielding
unknown taste perception in a mammal by comparing the quantitative
representation of taste perception in a mammal for the one or more molecules
or
combinations of molecules yielding unknown taste perception in a mammal to the
quantitative representation of taste perception in a mammal for the one or
more
molecules or combinations of molecules yielding known taste perception in a
mammal. The chemosensory receptors used in this method may include a
chemosensory receptor disclosed herein.
[0213] In another embodiment, novel molecules or combinations of molecules
are generated which elicit a predetermined taste perception in a mammal by
determining a value of taste perception in a mammal for a known molecule or
combinations of molecules as described above; determining a value of taste
perception in a mammal for one or more unknown molecules or combinations of
molecules as described above; comparing the value of taste perception in a
mammal for one or more unknown compositions to the value of taste perception
in
a mammal for one or more known compositions; selecting a molecule or
combination of molecules that elicits a predetermined taste perception in a
mammal; and combining two or more unknown molecules or combinations of
molecules to form a molecule or combination of molecules that elicits a
predetermined taste perception in a mammal. The combining step yields a single
molecule or a combination of molecules that elicits a predetermined taste
perception in a mammal.
[0214] In another embodiment of the invention, there is provided a method for
simulating a taste, comprising the steps of: for each of a plurality of cloned
67
CA 02776701 2012-05-07
W0021064631 PC171192/00198
chemosensory receptors, preferably human receptors, ascertaining the extent to
which the receptor interacts with the taste stimulus; and combining a
plurality of
compounds, each having a previously-ascertained interaction with one or more
of
the receptors, in amounts that together provide a receptor-stimulation profile
that
mimics the profile for the taste stimulus. Interaction of a taste stimulus
with a .
chemosensory receptor can be determined using any of the binding or reporter
assays described herein. The plurality of compounds may then be combined to
form a mixture. If desired, one or more of the plurality of the compounds can
be
combined covalently. The combined compounds substantially stimulate at least
75%, 80%, or 90% of the receptors that are substantially stimulated by the
taste
stimulus.
[0215] In another preferred embodiment of the invention, a plurality of
standard
compounds are tested against a plurality of chemosensory receptors to
ascertain
the extent to which the receptors each interact with each standard compound,
thereby generating a receptor stimulation profile for each standard compound.
These receptor stimulation profiles may then be stored in a relational
database on
a data storage medium. The method may further comprise providing a desired
receptor-stimulation profile for a taste; comparing the desired receptor
stimulation
profile to the relational database; and ascertaining one or more combinations
of
standard compounds that most closely match the desired receptor-stimulation
profile. The method may further comprise combining standard compounds in one
or more of the ascertained combinations to simulate the taste.
F. Kits
[0216] TiR genes and their homologs are useful tools for identifying
chemosensory receptor cells, for forensics and paternity determinations, and
for
examining taste transduction. T1R family member-specific reagents that
specifically hybridize to T1R nucleic acids, such as T1R probes and primers,
and
T1R specific reagents that specifically bind to a TiR polypeptide, e.g., T1R
antibodies are used to examine taste cell expression and taste transduction
regulation.
[0217] Nucleic acid assays for the presence of DNA and RNA for a T1R family
member in a sample include numerous techniques are known to those skilled in
the art, such as southern analysis, northern analysis, dot blots, RNase
protection,
68
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
=
S1 analysis, amplification techniques such as PCR, and in situ hybridization.
In in
situ hybridization, for example, the target nucleic acid is liberated from its
cellular
surroundings in such as to be available for hybridization within the cell
while
preserving the cellular morphology for subsequent interpretation and analysis.
The following articles provide an overview of the art of in situ
hybridization: Singer
et al., Biotechniques, 4:230250 (1986); Haase et aL, Methods in Virology, vol.
VII,
pp. 189-226 (1984); and Nucleic Acid Hybridization: A Practical Approach
(Names
et al., eds. 1987). In addition, a T1R polypeptide can be detected with the
various
immunoassay techniques described above. The test sample is typically compared
to both a positive control (e.g., a sample expressing a recombinant T1R
polypeptide) and a negative control.
[0218] The present invention also provides for kits for screening for
modulators
of T1R family members. Such kits can be prepared from readily available
materials and reagents. For example, such kits can comprise any one or more of
the following materials: T1R nucleic acids or proteins, reaction tubes, and
instructions for testing T1R activity. Optionally, the kit contains a
biologically
active T1R receptor. A wide variety of kits and components can be prepared
according to the present invention, depending upon the intended user of the
kit
and the particular needs of the user.
EXAMPLES
[0219] In the protein sequences presented herein, the one-letter code X or Xaa
refers to any of the twenty common amino acid residues. In the DNA sequences
presented herein, the one letter codes N or n refers to any of the of the four
common nucleotide bases, A, T, C, or G.
EXAMPLE 1 ¨ hT1R3
[0220] The hT1R3 genomic DNA is provided below as SEQ ID NO 1 and SEQ
ID NO 2 with predicted coding sequences (cds) shown in boldface. The break
between the 5' and 3' contigs is shown as elipses (' ................... ').
The hT1R3 predicted
cds are described in SEQ ID NO 3. Finally, a preferred, predicted hT1R3 amino
acid sequence is provided as SEQ ID NO 4, using the one-letter code for the
amino acids.
69
CA 02776701 2012-05-07
- =
WO 02/064631 PCT/US02/00198
hT1R3 qenomic DNA -5' contiq (SEQ ID NO 1)
AGCCTGGCAGTG GCCTCAGGCAGAGTCTGACGCGCACAAACTTTCAGGCCC
AGGAAGCGAGGACACCACTGGG GCCCCAGGGTGTGGCAAGTGAGGATGGC
AAG GGTTTTGCTAAACAAATCCTCTGCCCGCTCCCCGCCCCGGGCTCACTCC
AT GTGAGGCCCCAGTCG GGGCAGCCACCTGCCGTGCCTGTTG GAAGTTGCC
TCTGCCATGCTGGGCCCTGCTGTCCTGGGCCTCAGCCTCTGGGCTCTCCTG
CACCCTGGGACGGGGGCCCCATTGTGCCTGICACAGCAACTTAGGATGAAG
GGGGACTACGTGCTGGGGGGGCTGTTCCCCCTGGGCGAGGCCGAGGAGGC
TGGCCTCCGCAGCCGGACACGGCCCAGCAGCCCTGTGTGCACCAGGTACA
GAGGTGGGACGGCCTG G GTCGGG GTCAGGGTGACCAGGTCTGGGGTGCTC
CTGAGCTGGGGCCGAG GTGGCCATCTGCGGTTCTGTGTGGCCCCAGGTTCT
CCTCAAACGGCCTGCTCTGGGCACTGGCCATGAAAATGGCCGTGGAGGAGA
TCAACAACAAGTCGGATCTGCTGCCCGGGCTGCGCCTGGGCTACGACCTCT
TTGATACGTGCTCGGAGCCTGTGGTGGCCATGAAGCCCAGCCTCATGTTCCT
GGCCAAGGCAGGCAGCCGCGACATCGCCGCCTACTGCAACTACACGCAGTA
CCAGCCCC GTGT GCTGGCTGTCATCGGGCCCCACTCGTCAGAGCTCGCCAT
GGTCACCGGCAAGTTCTTCAGCTTCTTCCTCATGCCCCAGTGGGGCGCCCC
CCACCATCACCCACCCCCAACCAACCCCTGCCCCGTGGGAGCCCCTTGTGT
CAGGAGAATGC (SEQ ID NO: 1)
hT1R3 cienomic DNA 3' contig (SEQ ID NO 2)
.......... TACATGCACCCCACCCAGCCCTGCCCTGGGAGCCCTGTGTCAG
AAGATGCTCTTGGCCTTGCAGGTCAGCTACGGTGCTAGCATGGAGCTGCTG
AGCGCCCGGGAGACCTTCCCCTCCTTCTTCCGCACCGTGCCCAGCGACCGT
GTGCAGCTGACGGCCGCCGCGGAGCTGCTGCAGGAGTTCGGCTGGAACTG
GGTGGCCGCCCTGGGCAGCGACGACGAGTACGGCCGGCAGGGCCTGAGC
ATCTTCTCGGCCCTGGCCGCGGCACGCGGCATCTGCATCGCGCACGAGGG
CCTG GTGCCGCTGCCCCGTGCCGATGACTCGCGGCTGGGGAAGGTGCAGG
ACGTCCTGCACCAGGTGAACCAGAG CAGCGTGCAGGTGGTGCTGCTGTTCG
CCTCCGTGCACGCCGCCCACGCCCTCTTCAACTACAGCATCAGCAGCAGGC
TCTCGCCCAAGGTGTGGGTGGCCAGCGAGGCCTGGCTGACCTCTGACCTGG
TCATGGGGCTGCCCGGCATGGCCCAGATGGGCACGGTGCTIGGCTTCCTCC
AGAGGGGTGCCCAGCTGCACGAGTTCCCCCAGTACGTGAAGACGCACCTG
GCCCTGGCCACCGACCCGGCCTTCTGCTCTGCCCTGGGCGAGAGGGAGCA
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
GGGTCTGGAGGAGGACGTGGTGGGCCAGCGCTGCCCGCAGTGTGACTGCA
TCACGCTGCAGAACGTGAGCGCAGGGCTAAATCACCACCAGACGTTCTCTG
TCTACGCAGCTGTGTATAGCGTGGCCCAGGCCCTGCACAACACTCTTCAGTG
CAACGCCTCAGGCTGCCCCGCGCAGGACCCCGTGAAGCCCTGGCAGGTGA
GCCCGGGAGATGGGGGTGTGCTGTCCTCTGCATGTGCCCAGGCCACCAGG
CACGGCCACCACGCCTGAGCTGGAGGTGGCTGGCGGCTCAGCCCCGTCCC
CCGCCCGCAGCTCCTGGAGAACATGTACAACCTGACCTTCCACGTGGGCGG
GCTGCCGCTGCGGTTCGACAGCAGCGGAAACGTGGACATGGAGTACGACCT
GAAGCTGTGGGTGTGGCAGGGCTCAGTGCCCAGGCTCCACGACGTGGGCA
GGTTCAACGGCAGCCTCAGGACAGAGCGCCTGAAGATCCGCTGGCACACGT
CTGACAACCAGGTGAGGTGAGGGTGGGTGTGCCAGGCGTGCCCGTGGTAG
CCCCCGCGGCAGGGCGCAGCCTGGGGGTGGGGGCCGTTCCAGTCTCCCGT
GGGCATGCCCAGCCGAGCAGAGCCAGACCCCAGGCCTGTGCGCAGAAGCC
CGTGTCCCGGTGCTCGCGGCAGTGCCAGGAGGGCCAGGTGCGCCGGGTCA
AGGGGTTCCACTCCTGCTGCTACGACTGIGTGGACTGCGAGGCGGGCAGCT
ACCGGCAAAACCCAGGTGAGCCGCCTTCCCGGCAGGCGGGGGTGGGAACG
CAGCAGGGGAGGGTCCTGCCAAGTCCTGACTCTGAGACCAGAGCCCACAGG
GTACAAGACGAACACCCAGCGCCCTTCTCCTCTCTCACAGACGACATCGCCT
GCACCTTTTGTGGCCAGGATGAGTGGTCCCCGGAGCGAAGCACACGCTGCT
TCCGCCGCAGGTCTCGGTTCCTGGCATGGGGCGAGCCGGCTGTGCTGCTGC
TGCTCCTGCTGCTGAGCCTGGCGCTGGGCCTTGTGCTGGCTGCTTTGGGGC
TGTTCGTTCACCATCGGGACAGCCCACTGGITCAGGCCTCGGGGGGGCCCC
TGGCCTGCTTTGGCCTGGTGTGCCTGGGCCIGGTCTGCCTCAGCGTCCTCC
TGTTCCCTGGCCAGCCCAGCCCTGCCCGATGCCTGGCCCAGCAGCCCTTGT
CCCACCTCCCGCTCACGGGCTGCCTGAGCACACTCTTCCTGCAGGCGGCCG
AGATCTICGTGGAGTCAGAACTGCCTCTGAGCTGGGCAGACCGGCTGAGTG
GCTGCCTGCGGGGGCCCTGGGCCTGGCTGGTGGTGCTGCTGGCCATGCTG
GTGGAGGTCGCACTGTGCACCTGGTACCTGGTGGCCTTCCCGCCGGAGGTG
GTGACGGACTGGCACATGCTGCCCACGGAGGCGCTGGTGCACTGCCGCAC
ACGCTCCTGGGTCAGCTTCGGCCTAGCGCACGCCACCAATGCCACGCTGGC
CTTTCTCTGCTTCCTGGGCACTTTCCTGGTGCGGAGCCAGCCGGGCTGCTAC
AACCGTGCCCGTGGCCTCACCTTTGCCATGCTGGCCTACTTCATCACCTGGG
TCTCCTTTGTGCCCCTCCTGGCCAATGTGCAGGTGGTCCTCAGGCCCGCCGT
71
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
GCAGATGGGCGCCCTCCTGCTCTGTGTCCTGGGCATCCTGGCTGCCTTCCA
CCTGCCCAGGTGTTACCTGCTCATGCGGCAGCCAGGGCTCAACACCCCCGA
GTTCTTCCTGGGAGGGGGCCCTGGGGATGCCCAAGGCCAGAATGACGGGA
ACACAGGAAATCAGGGGAAACATGAGTGACCCAACCCTGTGATCTCAGCCC
CGGTGAACCCAGACTTAGCTGCGATCCCCCCCAAGCCAGCAATGACCCGTG
TCTCGCTACAGAGACCCTCCCGCTCTAGGTTCTGACCCCAGGTTGTCTCCTG
ACCCTGACCCCACAGTGAGCCCTAGGCCTGGAGCACGTGGACACCCCTGTG
ACCATC (SEQ ID NO 2)
hT1R3 full-length genomic DNA (SEQ ID NO 20)
AGCCTGGCAGTGGCCTCAGGCAGAGTCTGACGCGCACAAACTTTCAGGCCC
AGGAAGCGAGGACACCACTGGGGCCCCAGGGTGTGGCAAGTGAGGATGGC
AAGGGTTTTGCTAAACAAATCCTCTGCCCGCTCCCCGCCCCGGGCTCACTCC
ATGTGAGGCCCCAGTCGGGGCAGCCACCTGCCGTGCCTGTTGGAAGTTGCC
TCTGCCATGCTGGGCCCTGCTGTCCTGGGCCTCAGCCTCTGGGCTCTCCTG
CACCCTGGGACGGGGGCCCCATTGTGCCTGTCACAGCAACTTAGGATGAAG
GGGGACTACGTGCTGGGGGGGCTGTTCCCCCTGGGCGAGGCCGAGGAGGC
TGGCCTCCGCAGCCGGACACGGCCCAGCAGCCCTGTGTGCACCAGGTACA
GAGGT GG GACGGCCTGGGTCGGGGTCAGGGTGACCAGGTCTGGGGTGCTC
CTGAGCTGGGGCCGAGGTGGCCATCTGCGGTTCTGTGTGGCCCCAGGTTCT
CCTCAAACGGCCTGCTCTGGGCACTGGCCATGAAAATGGCCGTGGAGGAGA
TCAACAACAAGTCGGATCTGCTGCCCGGGCTGCGCCTGGGCTACGACCTCT
TTGATACGTGCTCGGAGCCTGTGGIGGCCATGAAGCCCAGCCTCATGITCCT
GGCCAAGGCAGGCAGCCGCGACATCGCCGCCTACTGCAACTACACGCAGTA
CCAGCCCCGTGTGCTGGCTGTCATCGGGCCCCACTCGTCAGAGCTCGCCAT
GGTCACCGGCAAGTICTTCAGCTTCTTCCTCATGCCCCAGIGGGGCGCCCC
CCACCATCACCCACCCCCAACCAACCCCTGCCCCGTGGGAGCCCCTTGTGT
CAGGAGAATGCTACATGCACCCCACCCAGCCCTGCCCTGG GAGCCCTGTGT
CAGAAGATGCTCTTGGCCTTGCAGGTCAGCTACGGTGCTAGCATGGAGCTG
CTGAGCGCCCGGGAGACCTTCCCCTCCTTCTTCCGCACCGTGCCCAGCGAC
CGTGTGCAGCTGACGGCCGCCGCGGAGCTGCTGCAGGAGTTCGGCTGGAA
CTGGGTGGCCGCCCTGGGCAGCGACGACGAGTACGGCCGGCAGGGCCTGA
GCATCTTCTCGGCCCTGGCCGCGGCACGCGGCATCTGCATCGCGCACGAG
GGCCTGGTGCCGCTGCCCCGTGCCGATGACTCGCGGCTGGGGAAGGTGCA
72
CA 02776701 2012-05-07
WO 02/064631 P CT/U SO 2/00198
GGACGTCCTGCACCAGGTGAACCAGAGCAGCGTGCAGGTGGTGCTGCTGTT
CGCCTCCGTGCACGCCGCCCACGCCCTCTICAACTACAGCATCAGCAGCAG
GCTCTCGCCCAAGGTGTGGGTGGCCAGCGAGGCCTGGCTGACCTCTGACCT
GGTCATGGGGCTGCCCGGCATGGCCCAGATGGGCACGGTGCTTGGCTTCCT
CCAGAGGGGTGCCCAGCTGCACGAGTTCCCCCAGTACGTGAAGACGCACCT
GGCCCTGGCCACCGACCCGGCCTTCTGCTCTGCCCTGGGCGAGAGGGAGC
AGGGTCTGGAGGAGGACGTGGTGGGCCAGCGCTGCCCGCAGTGTGACTGC
ATCACGCTGCAGAACGTGAGCGCAGGGCTAAATCACCACCAGACGTTCTCT
GTCTACGCAGCTGTGTATAGCGTGGCCCAGGCCCTGCACAACACTCTTCAGT
GCAACGCCTCAGGCTGCCCCGCGCAGGACCCCGTGAAGCCCTGGCAGGTG
AGCCCGGGAGATGGGGGTGTGCTGTCCTCTGCATGTGCCCAGGCCACCAG
GCACGGCCACCACGCCTGAGCTGGAGGTGGCTGGCGGCTCAGCCCCGTCC
CCCGCCCGCAGCTCCTGGAGAACATGTACAACCTGACCTTCCACGTGGGCG
GGCTGCCGCTGCGGTTCGACAGCAGCGGAAACGTGGACATGGAGTACGAC
CTGAAGCTGTGGGTGTGGCAGGGCTCAGTGCCCAGGCTCCACGACGTGGG
CAGGTTCAACGGCAGCCTCAGGACAGAGCGCCTGAAGATCCGCTGGCACAC
GTCTGACAACCAGGTGAGGTGAGGGTGGGTGTGCCAGGCGTGCCCGTGGT
AGCCCCCGCGGCAGGGCGCAGCCTGGGGGTGGGGGCCGTTCCAGTCTCCC
GTGGGCATGCCCAGCCGAGCAGAGCCAGACCCCAGGCCTGTGCGCAGAAG
CCCGTGTCCCGGTGCTCGCGGCAGTGCCAGGAGGGCCAGGTGCGCCGGGT
CAAGGGGTTCCACTCCTGCTGCTACGACTGTGTGGACTGCGAGGCGGGCAG
CTACCGGCAAAACCCAGGTGAGCCGCCITCCCGGCAGGCGGGGGTGGGAA
CGCAGCAGGGGAGGGTCCTGCCAAGTCCTGACTCTGAGACCAGAGCCCACA
GGGTACAAGACGAACACCCAGCGCCCTTCTCCTCTCTCACAGACGACATCG
CCTGCACCTTTTGIGGCCAGGATGAGTGGTCCCCGGAGCGAAGCACACGCT
GCTTCCGCCGCAGGTCTCGGTTCCTGGCATGGGGCGAGCCGGCTGTGCTGC
TGCTGCTCCTGCTGCTGAGCCTGGCGCTGGGCCTTGTGCTGGCTGCTTTGG
GGCTGTTCGTTCACCATCGGGACAGCCCACTGGTTCAGGCCTCGGGGGGGC
CCCTGGCCTGCTTTGGCCTGGTGTGCCTGGGCCTGGTCTGCCTCAGCGTCC
TCCTGTTCCCTGGCCAGCCCAGCCCTGCCCGATGCCTGGCCCAGCAGCCCT
TGTCCCACCTCCCGCTCACGGGCTGCCTGAGCACACTCTTCCTGCAGGCGG
CCGAGATCTTCGIGGAGTCAGAACTGCCTCTGAGCTGGGCAGACCGGCTGA
GTGGCTGCCTGCGGGGGCCCTGGGCCTGGCTGGTGGTGCTGCTGGCCATG
73
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
CTGGTGGAGGTCGCACTGTGCACCTGGTACCTGGTGGCCTTCCCGCCGGAG
GTGGTGACGGACTGGCACATGCTGCCCACGGAGGCGCTGGTGCACTGCCG
CACACGCTCCIGGGICAGCTTCGGCCTAGCGCACGCCACCAATGCCACGCT
G GCCTTTCTCTGCTTCCTGGGCACTTTCCTGGTGCGGAGCCAGCCG GGCTG
CTACAACCGTGCCCGTGGCCTCACCTTTGCCATGCTGGCCTACTTCATCACC
TGGGTCTCCTTTGTGCCCCTCCTGGCCAATGTGCAGGIGGICCTCAGGCCC
GCCGTGCAGATGGGCGCCCTCCTGCTCTGTGTCCTGGGCATCCTGGCTGCC
TTCCACCTGCCCAGGTGTTACCTGCTCATGCGGCAGCCAGGGCTCAACACC
CCCGAGTICTTCCTGGGAGGGGGCCCTGGGGATGCCCAAGGCCAGAATGA
CGGGAACACAGGAAATCAG GG GAAACATGAGTGACCCAACCCTGTGATCTC
AGCCCCGGTGAACCCAGACTTAGCTGCGATCCCCCCCAAGCCAGCAATGAC
CCGTGTCTCGCTACAGAGACCCTCCCGCTCTAGGTTCTGACCCCAGGTTGTC
TCCTGACCCTGACCCCACAGTGAGCCCTAGGCCTGGAGCACGTGGACACCC
CTGTGACCATC (SEQ ID NO 20)
hT1R3 predicted cds (SEQ ID NO 3)
ATGCTGGGCCCTGCTGTCCTGGGCCTCAGCCTCTGGGCTCTCCTGCACCCT
GGGACGG GGGCCCCATTGTGCCTGTCACAGCAACTTAGGATGAAGGGGGAC
TACGTGCTGGGGGGGCTGTTCCCCCTGGGCGAGGCCGAGGAGGCTGGCCT
CCGCAGCCGGACACGGCCCAGCAGCCCTGTGTGCACCAGGTTCTCCTCAAA
C GG CCTG CTCTG GGCACTG G CCATGAAAATG GCCGTG GAG GAGATCAACAA
CAAGTCGGATCTGCTGCCCGGGCTGCGCCTGGGCTACGACCTCTTTGATAC
GTGCTCGGAGCCTGTGGTGGCCATGAAGCCCAGCCTCATGTTCCTGGCCAA
G GCAGGCAGCCGCGACATCGCCGCCTACTG CAACTACACGCAGTACCAGCC
CCGTGTGCTGGCTGTCATCGGGCCCCACTCGTCAGAGCTCGCCATGGTCAC
CGGCAAGTTCTTCAGCTTCTTCCTCATGCCCCAGGTCAGCTACGGTGCTAGC
ATGGAGCTGCTGAGCGCCCGG GAGACCTTCCCCTCCTTCTTCCGCACCGTG
CCCAGCGACCGTGTGCAGCTGACGGCCGCCGCGGAGCTGCTGCAGGAGTT
CGGCTGGAACTGGGTGGCCGCCCTGGGCAGCGACGACGAGTACGGCCGGC
AGG GCCTGAGCATCTTCTCGGCCCTGGCCG CGGCACG CGGCATCTGCATCG
CGCACGAGGGCCTGGTGCCGCTGCCCCGTGCCGATGACTCGCGGCTGGGG
AAGGTGCAGGACGTCCTGCACCAGGTGAACCAGAGCAGCGTGCAGGTGGTG
CTGCTGTTCGCCTCCGTGCACGCCGCCCACGCCCTCTTCAACTACAGCATCA
GCAGCAGGCTCTCGCCCAAGGTGTGGGTG GCCAGCGAGGCCTGGCTGACC
74
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
TCTGACCTGGTCATGGGGCTGCCCGGCATGGCCCAGATGGGCACGGTGCTT
GGCTTCCTCCAGAGGGGTGCCCAGCTGCACGAGTTCCCCCAGTACGTGAAG
ACGCACCTGGCCCTGGCCACCGACCCGGCCTTCTGCTCTGCCCTGGGCGAG
AGGGAGCAGGGTCTGGAGGAGGACGTGGTGGGCCAGCGCTGCCCGCAGTG
TGACTGCATCACGCTGCAGAACGTGAGCGCAGGGCTAAATCACCACCAGAC
GTTCTCTGTCTACGCAGCTGTGTATAGCGTGGCCCAGGCCCTGCACAACACT
CTTCAGTGCAACGCCTCAGGCTGCCCCGCGCAGGACCCCGTGAAGCCCTGG
CAGCTCCTGGAGAACATGTACAACCTGACCTTCCACGTGGGCGGGCTGCCG
CTGCGGTTCGACAGCAGCGGAAACGTGGACATGGAGTACGACCTGAAGCTG
TGGGTGTGGCAGGGCTCAGTGCCCAGGCTCCACGACGTGGGCAGGTTCAAC
GGCAGCCTCAGGACAGAGCGCCTGAAGATCCGCTGGCACACGTCTGACAAC
CAGAAGCCCGTGTCCCGGTGCTCGCGGCAGTGCCAGGAGGGCCAGGTGCG
CCGGGTCAAGGGGTTCCACTCCTGCTGCTACGACTGTGTGGACTGCGAGGC
GGGCAGCTACCGGCAAAACCCAGACGACATCGCCTGCACCTTTTGTGGCCA
GGATGAGTGGTCCCCGGAGCGAAGCACACGCTGCTTCCGCCGCAGGTCTCG
GTTCCTGGCATGGGGCGAGCCGGCTGTGCTGCTGCTGCTCCTGCTGCTGAG
CCTGGCGCTGGGCCTTGTGCTGGCTGCTTTGGGGCTGTTCGTTCACCATCG
GGACAGCCCACTGGTTCAGGCCTCGGGGGGGCCCCTGGCCTGCTTTGGCC
TGGTGTGCCTGGGCCTGGTCTGCCTCAGCGTCCTCCTGTTCCCTGGCCAGC
CCAGCCCTGCCCGATGCCTGGCCCAGCAGCCCTTGTCCCACCTCCCGCTCA
CGGGCTGCCTGAGCACACTCTTCCTGCAGGCGGCCGAGATCTTCGTGGAGT
CAGAACTGCCTCTGAGCTGGGCAGACCGGCTGAGTGGCTGCCTGCGGGGG
CCCTGGGCCTGGCTGGTGGTGCTGCTGGCCATGCTGGTGGAGGTCGCACT
GTGCACCIGGTACCTGGIGGCCTTCCCGCCGGAGGTGGTGACGGACTGGCA
CATGCTGCCCACGGAGGCGCTGGTGCACTGCCGCACACGCTCCTGGGTCAG
CTICGGCCTAGCGCACGCCACCAATGCCACGCTGGCCTTTCTCTGCTTCCTG
GGCACTTTCCTGGTGCGGAGCCAGCCGGGCTGCTACAACCGTGCCCGTGGC
CTCACCTTTGCCATGCTGGCCTACTTCATCACCIGGGTCTCCTTTGTGCCCC
TCCTGGCCAATGTGCAGGTGGTCCTCAGGCCCGCCGTGCAGATGGGCGCCC
TCCTGCTCTGTGTCCTGGGCATCCTGGCTGCCTTCCACCTGCCCAGGTGTTA
CCTGCTCATGCGGCAGCCAGGGCTCAACACCCCCGAGTTCTTCCTGGGAGG
GGGCCCTGGGGATGCCCAAGGCCAGAATGACGGGAACACAGGAAATCAGG
GGAAACATGAGTGA (SEQ ID NO 3)
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
hrl R3 conceptual translation (SEQ ID NO 4)
MLGPAVLGLSLWALLHPGTGAPLCLSQQLRMKGDYVLGGLFPLGEAEEAGLRS
RTRPSSPVCTRFSSNGLLWALAMKMAVEEINNKSDLLPGLRLGYDLFDTCSEPV
VAMKPSLMFLAKAGSRDIAAYCNYTQYQPRVLAVIGPHSSELAMVTGKFFSFFLM
PQVSYGASMELLSARETFPSFFRTVPSDRVQLTAAAELLQEFGWNWVAALGSD
DEYGRQGLSIFSALAAARGICIAHEGLVPLPRADDSRLGKVQDVLHQVNQSSVQ
VVLLFASVHAAHALFNYSISSRLSPKVWVASEAWLTSDLVMGLPGMAQMGTVLG
FLQRGAQLHEFPQYVKTHLALATDPAFCSALGEREQGLEEDVVGQRCPQCDCIT
LQNVSAGLNHHQTFSVYAAVYSVAQALHNTLQCNASGCPAQDPVKPWQLLENM
YNLTFHVGGLPLRFDSSGNVDMEYDLKLWVWQGSVPRLHDVGRFNGSLRTERL
KIRW HTSDNQKPVSRCSRQCQEGQVRRVKGFHSCCYDCVDCEAGSYRQNPDD
IACTFCGQDEWSPERSTRCFRRRSRFLAWGEPAVLLLLLLLSLALGLVLAALGLF
VHHRDSPLVQASGGPLACFGLVCLGLVCLSVLLFPGQPSPARCLAQQPLSHLPL
TGCLSTLFLQAAEIFVESELPLSWADRLSGCLRGPWAWLVVLLAMLVEVALCTW
YLVAFPPEVVTDWHMLPTEALVHCRTRSWVSFGLAHATNATLAFLCFLGTFLVR
SQPGCYNRARGLTFAMLAYFITWVSFVPLLANVQVVLRPAVQMGALLLCVLGILA
AFHLPRCYLLMRQPGLNTPEFFLGGGPGDAQGQNDGNTGNQGKHE (SEQ ID
N04)
EXAMPLE 2¨ rT1R3 and mT1R3
[0221] Segments of the rat and mouse Ti R3 genes were isolated by PCR
amplification from genomic DNA using degenerate primers based on the human
Ti R3 sequence. The degenerate primers SAP077 (5'-
CGNTTYYTNGCNIGGGGNGARCC-3'; SEQ ID NO 5) and SAP079 (5'-
CGNGCNCGRTTRTARCANCCNGG-3'; SEQ ID NO 6) are complementary to
human TI R3 residues RFLAWGEPA (corresponding to SEQ ID NO 7) and
PGCYNRAR (corresponding to SEQ ID NO 8), respectively. The PCR products
were cloned and sequenced. Plasmid SAV115 carries a cloned segment of the
mouse TI R3 gene, and SAV118 carries a segment of the rat gene. These
sequences, shown below, clearly represent the rodent counterparts of human
Ti R3, since the mouse segment is 74% identical to the corresponding segment
of
human Ti R3, and the rat segment is 80% identical to the corresponding segment
of human Ti R3. The mouse and rat segments are 88% identical. No other
database sequences are more than 40% identical to these TI R3 segments.
76
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
SAV115 mouse TI R3 segment in sense orientation (sequence
corresponding to degenerate primer removed) (SEQ ID NO 91
GTGCTGTCACTCCTCCTGCTGCTTTGCCTGGTGCTGGGTCTAGCACTGGCTG
CTCTGGGGCTCTCTGTCCACCACTGG GACAGCCCTCTTGTCCAGGCCTCAG
GCGGCTCACAGTTCTGCTTTGG CCTGATCTGCCTAGGCCTCTTCTGCCTCAG
TGTCCTTCTGITCCCAGGACGGCCAAGCTCTGCCAGCTGCCTTGCACAACAA
CCAATGGCTCACCTCCCTCTCACAGGCTGCCTGAGCACACTCTTCCTGCAAG
CAGCTGAGACCTTTGTGGAGTCTGAGCTGCCACTGAGCTGGGCAAACTGGC
TATGCAGCTACCTTCGGGACTCTGG CCTGCTAGTGGTACTGTTGGCCACTTT
TGTGGAGGCAGCACTATGTGCCTGGTATTTGACCGCTTCACCAGAAGTGGTG
ACAGACTGGTCAGTGCTGCCCACAGAGGTACTGGAGCACTGCCACGTGCGT
TCCTGGGTCAACCTGGGCTTGGTGCACATCACCAATGCAATGGTAGCTTTTC
TCTGCTTTCTGGGCACTTTCCTGGTACAAGACCAG (SEQ ID NO 9)
mT1 R3 segment, conceptual translation (SEQ ID NO 10)
VLSLUILCLVLGLALAALGLSVHHWDSPLVQASGGSQ FCFGLI CLGLFCLSVLLF
PGRPSSASCLAQQPMAHLPLTGCLSTLFLQAAETFVESELPLSWANWLCSYLRD
SG LLVVLLATFVEAALCAWYLTASPEVVTDWSVLPTEVLEH CHVRSWVNLGLVH
ITNAMVAFLCFLGTFLVQDQ (SEQ ID NO 10)
SAV118 rat TI R3 segment in sense orientation (sequence
corresponding to degenerate primer removedi (SEQ ID NO 11)
GTGCTGTCACTTCTCCTGCTGCTTTGCCTGGTGCTGGGCCTGACACTGGCTG
CCCTGGGGCTCTTTGTCCACTACTGGGACAGCCCTCTTGTTCAGGCCTCAGG
TGGGTCACTGTTCTGCTTTGGCCTGATCTGCCTAGGCCTCTTCTGCCTCAGT
GTCCTTCTGTTCCCAGGACGACCACGaCTGCCAGCTGCCTTGCCCAACAAC
CAATGGCTCACCTCCCTCTCACAGGCTGCCTGAGCACACTCTTCCTGCAAGC
AGCCGAGATCTTTGTG GAGTCTGAGCTGCCACTGAGTTGGGCAAACTGGCT
CTGCAGCTACCTTCGGGGCCCCTGGGCTTGGCTGGTGGTACTGCTGGCCAC
= TCTTGTGGAGGCTGCACTATGTGCCTGGTACTTGATGGCMCCCTCCAGAG
GTGGTGACAGATTGGCAGGTGCTGCCCACGGAGGTACTGGAACACTG CC GC
ATG CGTTCCTGG GTCAGCCTGGGCTTGGTGCACATCACCAATGCAGGGGTA
GCTTTCCTCTGCTTTCTGGGCACTTTCCTGGTACAAAGCCAG (SEQ ID NO 11)
77
CA 02776701 2012-05-07
Th\
WO 02/064631 PCT/US02/00198
rT1R3 segment, conceptual translation (SEQ ID NO 12)
VLSLLLLLCLVLG LTLAALGLFVHYVV DSPLVQASGGSLFCFGLICLGLFCLSVLLFP
G RPRSASCLAQQPMAHLPLTGCLSTLFLQAAE I FVESELPLSWANWLCSYLRGP
WAW LVVLLATLVEAALCAWYLMAF PPEVVTDWQVLPTEVLEH CRM RSWVSLGL
VHITNAGVAFLCFLGTFLVQSQ (SEQ ID NO 12)
EXAMPLE 3 ¨ Cloning of rT1R3
[0222] The mT1R3 and rT1R3 fragments identified above as SEQ ID NOs 9 and
11 were used to screen a rat taste tissue-derived cDNA library. One positive
clone was sequenced and found to contain the full-length rT1R3 sequence
presented below as SEQ ID NO 13. Sequence comparison to the mT1R3 and
rT1R3 partial sequences and to the full-length hT1R3 sequence established that
this cDNA represents the rat counterpart to hT1R3. For example, the pairwise
amino acid identity between rT1R3 and hT1R3 is approximately 72%, whereas the
most related annotated sequence in public DNA sequence data banks is only
approximately 33% identical to rT1R3.
rT1R3 predicted cds (SEQ. ID NO. 131
ATGCCGGGTTTGGCTATCTTGGG CCTCAGTCTGGCTGCTTTCCTGGAGCTTG
GGATG GG GTCCTCTTTGTGTCTGTCACAGCAATTCAAGGCACAAGGGGACTA
TATATTGGGTGGACTATTTCCCCTGGGCACAACTGAGGAGGCCACTCTCAAC
CAGAGAACACAGCCCAACGGCATCCTATGTACCAGGTTCTCGCCCCTTGGTT
TGTTCCTGGCCATGGCTATGAAGATGGCTGTAGAGGAGATCAACAATGGATC
TGCCTTGCTCCCTGGGCTGCGACTGGGCTATGACCTGTTTGACACATGCTCA
GAGCCAGTGGTCACCATGAAGCCCAGCCTCATGTICATGGCCAAGGIGGGA
AGTCAAAGCATTGCTGCCTACTGCAACTACACACAGTACCAACCCCGTGTGC
TGGCTGTCATTGGTCCCCACTCATCAGAGCTTGCCCTCATTACAGGCAAGTT
CTTCAGCTTCTTCCTCATGCCACAGGTCAGCTATAGTGCCAGCATGGATCGG
CTAAGTGAC CGG GAAACATTTCCATCCTTCTTCCGCACAGTG CCCAGTGACC
GGGTGCAG CTGCAGGCCGTTGTGACACTGTTGCAGAATTTCAGCTGGAACT
GGGTGGCTGCCTTAGGTAGTGATGATGACTATG GCCGGGAAGGTCTGAGCA
TC __ F I I I CTGGTCTGGCCAACTCACGAGGTATCTGCATTGCACACGAGGGCCT
GGTGCCACAACATGACACTAGTGGCCAACAATTGGGCAAGGTGGTGGATGT
GCTACGCCAAGTGAACCAAAGCAAAGTACAGGTGGTGGTGCTGTTTGCATCT
GCCCGTGCTGTCTACTCCCTTTTTAGCTACAGCATCCTTCATGACCTCTCACC
78
CA 02776701 2012-05-07
WO 02/064631
PCT/US02/00198
CAAGGTATG GGTGGCCAGTGAGTCCTG GCTGACCTCTGACCTGGTCATGAC
ACTTCCCAATATTGCCCGTGTGG G CACTGTTCTTGGGTTTCTGCAGCGCG GT
GCCCTACTGCCTGAAI i FI ______________ CCCATTATGTGGAGACTCGCCTTGCCCTAGCTG
CTGACCCAACATTCTGTGCCTCCCTGAAAGCTGAGTTGGATCTGGAG GAG C G
= CGTGATGGGGCCACGCTGTTCACAATGTGACTACATCATGCTACAGAACCTG
TCATCTGGG CTGATGCAGAACCTATCAG CTGGGCAGTTGCACCACCAAATAT
TTG CAACCTATGCAGCTGTGTACAG TGTGGCTCAGGCCCTTCACAACACCCT
G CAGTGCAATGTCTCACATTG C CACACATCAGAG C CTGTTCAAC C CTGGCA.G
CT C CTG GAGAACATGTACAATATGAGTTTCCG TGCTCGAGACTTGACACTGC
AGTTTG ATG C CAAAGGG AGTGTAGACATG GAATATGACCTGAAGATGTGGGT
GTGGCAGAGCCCTACACCTGTACTACATACTGTAGGCACCTTCAACGGCACC
CTTCAGCTGCAGCACTCGAAAATGTATTGGCCAGGCAACCAGGTG CCAGTCT
CCCAGTGCTCCCGGCAGTGCAAAGATGGCCAGGTGCGCAGAGTAAAGGGCT
TTCATTCCTGCTGCTATGACTGTGTGGACTGCAAGGCAGGGAGCTACCGGAA
GCATCCAGATGACTTCACCTGTACTCCATGTGG CAAGGAT CAGTGGT C C C CA
GAAAAAAGCACAACCTGCTTACCTCGCAGGCCCAAGTTTCTGGCTTGGGGG
GAGCCAGCTGTGCTGTCACTTCTCCTGCTG CTTTG CCTGGTGCTGGGCCTGA
CACTGGCTGCCCTGGGGCTCTTTGTCCACTACTGGGACAGCCCTCTTGTTCA
GGC CTCAGGTGGGTCACTGTTCTGCTTTG GCCTGATCT GC CTAGG CCTCTTC
TGCCTCAGTGTCCTTCTGTTCCCAGGACGACCACGCTCTGCCAGCTGCCTTG
CC CAACAAC CAATGGCTCACCTCC CTCTCACAG GCTGCCTGAGCACACTCTT
CCTGCAAGCAGCCGAGATCTTTGTGGAGTCTGAGCTGCCACTGAGTTGGGC
AAACTGGCTCTGCAGCTACCTTCGG GGCCCCTGG G CTTGGCTGGTGGTACT
GCT G G CCACTCTTGTG GAGG CTGCACTATGTG CCTGGTACTTGATG G CTTTC
CCTCCAGAGGTGGTGACAGATTGGCAGGTGCTGCCCACGGAGGTACTGGAA
CACTGCCG CATGCGTTCCTGGGTCAGCCTGGGCTTGGTGCACATCAC CAAT
GCAGTGTTAGCTTTCCTCTGCTTTCTGGGCACTTTCCTGGTACAGAGCCAGC
= CT G GTC GCTATAACCGTGCC C GTG G CCTCACCTTC GCCATG CTAGCTTATTT
CATCATCTG G GTCT CTTTTGTGCCC CTCCTG GCTAATGTGCAGGTGGCCTAC
= CAGCCAGCTGTGCAGATGGGTGCTATCTTATTCTGTGCCCTGGGCATCCTGG
CCACCTTCCACCTGCCCAAATGCTATGTACTTCTGTGGCTG CCAGAGCTCAA
CAC C CAG GAGTTCTTCCTG G G AAGGAGC C C CAAG GAAG CATCAGATGGGAA
TAGTGGTAGTAGTGAGGCAACTCGGGGACACAGTGAATGA (SEQ ID NO 13)
79
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
rT1R3 conceptual translation (SEC). ID NO. 14)
MPGLAILGLSLAAFLELGMGSSLCLSQQFKAQGDYI LGGLF PLGTTEEATLNQRT
QPNGILCTRFSPLGLFLAMAMKMAVEEINNGSALLPGLRLGYDLFDTCSEPVVTM
KPSLMFMAKVGSQSIAAYCNYTQYQPRVLAVIGPHSSELALITGKFFSFFLMPQV
SYSASMDRLSDRETFPSFFRTVPSDRVQLQAVVTLLQNFSWNWVAALGSDDDY
GREGLSIFSGLANSRGICIAHEGLVPQHDTSGQQLGKVVDVLRQVNQSKVQVVV
LFASARAVYSLFSYS I LH DLSPKVWVASESWLTSDLVMTLPNIARVGTVLGFLQR
GALLPEFSHYVETRLALAADPTFCASLKAELDLE ERVMG PRCSQCDYI MLQNLSS
GLMQNLSAGQLHHQ1FATYAAVYSVAQALHNTLQCNVSHCHTSEPVQPWQLLE
NMYNMSFRARDLTLQFDAKGSVDMEYDLKMWVWQSPTPVLHTVGTFNGTLQL
QHSKMYWPGNQVPVSQCSRQCKDGQVRRVKGFHSCCYDCVDCKAGSYRKHP
DDFTCTPCGKDOWSPEKSTTCLPRRPKFLAWGEPAVLSLLLLLCLVLGLTLAAL
GLFVHYWDSPLVQASGGSLFCFGLICLGLFCLSVLLFPGRPRSASCLAQQPMAH
LPLTGCLSTLFLQAAEIFVESELPLSWANW LCSYLRG PWAWLVVLLATLVEAALC
AWYLMAFPPEVVTDWQVLPTEVLEHCRMRSWVSLGLVHITNAVLAFLCFLGTFL
VQSQPGRYNRARGLTFAMLAYFI IWVSFVPLLANVQVAYQPAVQMGAI LFCALG I
LATFHLPKCYVLLWLPELNTQEFFLGRSPKEASDGNSGSSEATRGHSE (SEQ ID
NO 14)
EXAMPLE 4¨ Expression of mT1R3
[0223] The above described mouse Ti R3 fragment contained in SAV115 was
PCR amplified using M13 forward and M13 reverse primers and then gel purified.
The Ti R3 DNA template was placed into an in vitro transcription labeling
reaction
where Digoxigenin labeled UTP was incorporated into an antisense cRNA probe.
This probe was hybridized to adult mouse taste tissue containing cicumvallate
papillae. The Ti R3 in situ hybridization and detection were performed
following
the protocol of Schaeren-Wiemers et al., Histochemistry, 100:431-400 (1993).
Briefly, fresh frozen mouse tongue was sectioned at 14 urn and prepared for
hybridization. 200 ng/mL of the antisense Digoxigenin Ti R3 probe was
hybridized
for 14 hours at 72 C. Posthybridization consisted of a 0.2xSSC wash at 72 C.
Digoxigenin detection was accomplished by incubation with 1:5000 dilution of
anti-
DIG Alkaline Phosphatase antibody followed by a 12-hour reaction of the
phosphatase in NBT/BCIP.
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
EXAMPLE 5¨ hT1Ri
[0224] The human ortholog (Database accession no. AL159177) of a rat taste
receptor, designated rT1R1, is provided below as SEQ ID NO 15. Predicted cds
are indicated in bold and some intronic sequence intervals are denoted as runs
of
N. The nucleotide and conceptually-translated hT1R1 sequences are also
described herein as SEQ ID NO 16 and 17, respectively
hT1R1 genomic DNA (SEQ ID NO 15)
GAGAATCTCGCGAGATCCCGTCGGTCCGCCCCGCTGCCCTCCCAGCTGCCG
AAAAGAGGGGCCTCCGAGCCGCCGGCGCCCTCTGCCGGCAACCTCCGGAA
GCACACTAGGAGGTTCCAGCCGATCTGGTCGAGGGGCTCCACGGAGGACTC
CATTTACGTTACGCAAATTCCCTACCCCAGCCGGCCGGAGAGAGAAAGCCAG
AAACCTCGCGACCAGCCATGGGCCACCTCTCCGGAAAAACACCGGGATATTT
____ CTCCTGCAGAAAAAGCTITAGGATTGGCAGTTTAAACAAAACATGTCT
ATTTGCATAC CTTCG GTTTG CATG CATTTGTTTCGAAGTGAG CAACCCTGG GT
AACAAGGCGAAAGTATATGACAATTTGCTCAGAATCTTAATGTCAGAAAACTG
GAGACTGGGGCAGGGGGGTGTCGACTCAAAGCTGTGTCTCATTTAGTAAACT
GAGGCCCAGGTAAAAAGTTCTGAAACCTCGCAACACCCGGAGAAATTGTGTT
CCAGCCTCCCACCTCGCCCCAAAATGCCAGAGCTCCTTTTCTAAGCCAGGTG
AAGTCACAGAG CGTG GACAGAACCCACAACCGTCCAGAGGAAGGGTCACTG
GGTGCCACCTGGTTTGCATCTGTGCCTTCGTCCTGCCCAGTTCCTGAGTGGG
ACCGCAGGCCCGGAATGTCAAGGCAAACAGTCCTGCTTCAGCCACTGGGCT
CCAGTCCCACCCCTTTTGGGGGCCTGAAGTTAGGAAGCATCCGGCAGCTGC
CTTCTATTTAAGCAACTGGCCTCCTTAGAGGCCACTCCTTGGCCATGCCAGG
CGCGGGCATCTGGCCAGCATGCTGCTCTGCACGGCTCGCCTGGTCGGCCTG
CAGCTTCTCATTTCCTGCTGCTGGGCCTTTGCCTGCCATAGCACGGAGTCTT
CTCCTGACTTCACCCTCC CCG GAGATTACCTCCTGGCAGGCCTGTTCCCTCT
CCATTCTGGCTGTCTGCAGGTGAGGCACAGACCCGAGGTGACCCTGTGTGA
CAGGTGAGTGAGG GGCCAGCAGAGCCACACTTAGTGGGACCCCTGGCTATA
G GGCCCCTCTGG CTGCCATCCTCCAAACAGGACCTTGCCTCTGCCTTTGCCC
CTTGAACTGTCCCCAGGCCTTGTTCATCAATCCACTTGCCACCTAAGTGCTG
GCTAGACCTTCCTAGACACTTCGGCCAGTTTCCAATTATTTCACCCTTGCTGT
TAGAATGTNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
81
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
NNNNNNNAATTCCTTAAACTAAATTTCTCACTITCTCTCTCTCTCTGGAAAACA
CTGACTAATGTAGCAGGTTTCTCTGCTCCAGGACTTCAGGACC ________________ ii iCGATc3
CTAATAAGTTTCTCCATCAGGGCCAGCTTGTTCCTCCTACTGAGCTTGAGAG
CCCTTGTTGAAGTTGTGGTTTGGGGGACTGGACCGATGACCTCAAAGGTTCC
CTTTGCTCCCAAGCCTCAGAGTCTAGGAGGCCAGAGGGTCTCAGCAGGCCT
TTGTCCTTCTCAGCTGTCTCTTACTGGCTITCTCCACAGGTCTTGTAGCTICA
ATGAGCATGGCTACCACCTCTTCCAGGCTATGCGGCTTGGGGTTGAGGAGA
TAAACAACTCCACGGCCCTGCTGCCCAACATCACCCTGGGGTACCAGCTGT
ATGATGTGTGTTCTGACTCTGCCAATGTGTATGCCACGCTGAGAGTGCTCTC
CCTGCCAGGGCAACACCACATAGAGCTCCAAGGAGACCTTCTCCACTATTCC
CCTACGGTGCTGGCAGTGATTGGGCCTGACAGCACCAACCGTGCTGCCACC
ACAGCCGCCCTGCTGAGCCCTTTCCTGGTGCCCATGGTAAGCTGGAGCCTC
AGACCTTTGCCCATCTCCCITCAGGCAAGTCTGGGNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNGCCACCATGCCCGGCTA
________ GTA Iti I __ AGTAGAGACGGGGTTTCACCGTGTTAGCCAGGCTGGT
CGCAAACTCCTAACCTCGTGATCCACCCACCTCGGCCTCCCAATGTGCTGGG
ATTACAGGTGTGAGCCACTGCACCCGGCCATAATGTATTAATATAATAAAATA
ATTATACAACTCACCATAATGTAGAATCAGTGGGAGCCCTGAGCTTGTTTICC
TACAACTAGATGGTCCCATCTGGGGGTGATGGGAGACAGTGACAGATCATCA
GACATTAGATTCTCATAAGTAGCGTGCAACCCAGATCCCTCGCATGTGCAGT
TCACAGTAGGGTTCAAGCTCCTACAAGAATCTGATGCTGCTGCTGATCTGAC
AGGAGGGGAGCAGCTGTAAATACAGATGAAGCT1CGCTTACTCACCAGCTGC
TCACCTCCTCCTGTGAGGCCCGGTTCCTAACAGGCCACTGACCTAACTTCTG
CCCTGACCTACACATGCTTCTCTTCTTCCTTGCAAACTGCCTCCAGTGGAAGT
CCCTGAAGGTCCCCAAACACACGGGACTATTICACTCCTATGCAGGTTTTGT
CTCCTTTGCTTGGAATGCATCCCCTCACCCCTTGTCCCCAGGCAGATTCCCA
CCCCTCCCCCAGAACCTGCCCCAGTGGAGCCTTCGCAGGTGATTTGTCAGTT
TCACAGGCTGAGGGGTGCTCTCCTGGTCTCCCCGGCTCCCTGTATCCCCAC
ACCCAGCACAGGGCCAGGCACTGGGGGGGCCTTCAGTGGAGACTGAAATG
GCTGAACGGGACCTCCCATAGATTAGCTATGCGGCCAGCAGCGAGACGCTC
AGCGTGAAGCGGCAGTATCCCTCTITCCTGCGCACCATCCCCAATGACAAGT
ACCAGGTGGAGACCATGGTGCTGCTGCTGCAGAAGTTC GGGTGGACCTGGA
TCTCTCTGGTTGGCAGCAGTGACGACTATGGGCAGCTAGGGGTGCAGGCAC
82
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
TGGAGAACCAGGCCACTGGTCAGGGGATCTGCATTGCTTTCAAGGACATCAT
GCCCTTCTCTGCCCAGGTGGGCGATGAGAGGATGCAGTGCCTCATGCGCCA
CCTGGCCCAGGCCGGGGCCACCGTCGTGGTTGTTTTTTCCAGCCGGCAGTT
GGCCAGGGIGTTTTTCGAGTCCGTGGTGCTGACCAACCTGACTGGCAAGGT
GTGGGTCGCCTCAGAAGCCTGGGCCCTCTCCAGGCACATCACTGGGGTGCC
CGGGATCCAGCGCATTGGGATGGTGCTGGGCGTGGCCATCCAGAAGAGGG
CTGTCCCTGGCCTGAAGGCGTTTGAAGAAGCCTATGCCCGGGCAGACAAGA
AGGCCCCTAGGCCTTGCCACAAGGGCTCCTGGTGCAGCAGCAATCAGCTCT
GCAGAGAATGCCAAGCTTTCATGGCACACACGATGCCCAAGCTCAAAGCCTT
CTCCATGAGTTCTGCCTACAACGCATACCGGGCTGTGTATGCGGTGGCCCAT
GGCCTCCACCAGCTCCTGGGCTGTGCCTCTGGAGCTTGTTCCAGGGGCCGA
GTCTACCCCTGGCAGGTAAGAGAGCCCACCCCAGCACCTCCTGTCAGGGAG
AACAGCCAATCCTGAGATGAGCAGAGTGGG CACTCTCCGGTCACTCTAAATG
CCAAGGGGGATAAATGCCACTAACTTGAGGTTITTTGITTTG ____________________________ I 1 I
1 G 1 1 1 I GT
11111 _________________________________________________________________
GAGACAGTCTGGCTCTGTCACCCAGGCTGCAGTGTAGTGATGCGATC
TCGGCTCTCTGCAACTTCCACCTCCTG GGTTCAAGTGATTCTCTTGCCTCGG
CCTCCTGAGTAGCTGGGATTACAGGCACCCACCACCATGCCTGGATAATITT
TC II __ ill f111111 I VI 1 1 _________________________________________
GAGATAGAGTCTCGCTCTGTTGCCCAGGCTGGA
ATGCAGTGGTGCGATCTTGGCTCACTGTGAGCTCCGCCTCCCAGGTTCACTC
CATTCCCCTGCCTCAGCCTCCCAAGTAGGTGGGACTACGGGCGCCCGCCAC
CACGCCCAGCTAA 11111It1 _________________________________________________
GTATTTTGAGTAGAGACGGGGITTCACCATGT
TAGCCAGGATGGTCTCAATCTCCTGACCTTGTCATCCGCCCACCTCGTCCTC
CCAAAGTGCTGGGATTACAGGCGTGAGCCACCGCACCCGGCCTAA __________________________ 1 1 1
1 I GT
Ai III! AGTAGAGATGGGGTTTCACCATGTTGGCCAGGCTGGTCTCGAACTC
CTGGCATCAAGTGATCCTCCTGCTTCGGCCTCCCAAAGTGCTGGGATTACAG
GCATTAGCTCTCTTCTCTTAGACAGATCTTTCTCTCTGATCCTTGCCTTCTCTC
ACCCACTGTGTCTTGGAAGTGTCAAGTGATAAGATCCAGGGCTAAAACTGTC
TGTAAAGGAGTGTTTGTTAGAGGCCTCCTCTCAGGAGGTTGGTGGGGAAGAT
TGAGGGGCTTCCTAAGAAGGAAGGGACGAGACCTTCCTGATGGGCTGAAAC
CACCAGGACGGAAACCCAGGAAGGCCCCAGGCCCTTGCTTCTGGGACCATG
TGGGTCTGTGCTGTCTGTGGTGGCTTCATGATACGCGTTICTTTCAGCTITTG
GAGCAGATCCACAAGGTGCATTTCCTICTACACAAGGACACTGTGGCGTTTA
ATGACAACAGAGATCCCCTCAGTAGCTATAACATAATTGCCTGGGACTGGAA
83
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
TGGACCCAAGTGGACCTTCACGGTCCTCGGTTCCTCCACATGGTCTCCAGTT
CAGCTAAACATAAATGAGACCAAAATCCAGTGGCACGGAAAGGACAACCAG
GTAATGGGGATGTGGCTACTCACCATGTAACTGGCTTATGGGCAACCTAGAG
CCTGGGGGTGATGCTGACACAGTGTACAGGGAGCAGGAGGGGGGCCCCAG
GGGTCCAGCTGCCACCACTCTACCCATCCTGGCCAGGGAAGCAGGGAAGAC
ACTCCGTAGGCGAGTGTGCAGATGCCCTGGGGCGGAAGTTCACACGACCAG
GGGCCCTGCCCTGGGAGTGAGCCCTGAGGGCAGATGCACAGAGATTCTGTT
TTCTGTTCCACATGTGAGCTGTCCTTTGACTTGGGCCCCTACGTGTGGCCCC
TCTGGCTTCTTACAGGTGCCTAAGTCTGTGTGTTCCAGCGACTGTCTTGAAG
GGCACCAGCGAGTGGTTACGGGTTTCCATCACTGCTGCTITGAGTGIGTGCC
CTGTGGGGCTGGGACCTTCCTCAACAAGAGTGGTGAGTGGGCAATGGAGCA
GGCGAGCTACCCAGCACTCCCGGGGGCTGCACGGTGGAGGGAGGGCCTCC
CTTGGGCCCCATGTGCCCTGCCCCAGAACCAAGGCCCAGTCACTGGGCTGC
CAGTTAGCTTCAGGTTGGAGGACACCTGCTACCAGACAGAATTCTGATCAAG
AGAATCAGCCACTGGGTGCGGTGGCTCATGCCTGTAATCCCAGCACTTTGG
GAGGCTGAGGCGGGTGGATCACTTGAGGTCGGGAGTTCGAGACCAGCCTG
GCCAACATGGTGAAACCCCATCTCTACCAAAAATATAAAAAATTAGCTGGGTG
TGGTGGCGCGTGCCTGTAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGAA
TCACTTGAACCCAGGAGGCGGAGGTTGCAGTGAGCCAAGATGCATTCCAGC
CTGGACCACAAAGCGAGAATTCGTCCCCCCAAAAAAAGAAAGGAGGCCGGG
CGCGGTGGCTCACACCTGTAATCCCAGCACTTTGGGAGGCCGAGGTGGGTG
GATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGACCAACATGGTGAAACC
CCATCTCTACTAAAAATACAAAAAAAGTTAGCCGGGCGTTGTGGCGTGTGCC
TGTAATTCCAGCTACTCGGGAGGCTGAGGCAGGAGAATTGCTTGAACCCGG
GAGGCGGAGGTTGCAGTGAGCCAAGATTGCACCATTGCACTCCAGCCTGGG
CGACAAGAGAAAAACTCTGTCTCAAAAAAAAAGAAAGAAAGAAAGAATTAGCC
AACTGAAAGCCTTAGACTGAGGTGTGTCCTCTGTTAGAGAGCTGTCATCACA
=
ACTCCTACAAAAGCAGTCGTATCCTGAATTCAACCTCTTTCTCTAAATGAATAT
AGCTATTGTTCCCTTTGTGCCCTCTTGTCCTACTGICCCTTCTGTTGCCCATG
CCAAAGACAGCTAGCTCCTTGAACAGCTIGGCCTGAATACAGATACTAGCGT
GICTGCAGCAGAGAAAAAAACAGCATTCCCCATCCAGAAATGCAAGGICAAG
AACAGGAGCAAATTAGGTAGCTAAGGACTCAGGTCCTTAGTTGGTGTCCAG
GGGCCACATTCTTTCCTTTCACCATCTCTGTAGGGACAGGAATACTTCCCTTC
84
CA 02776701 2012-05-07
W002/064631 PCT/US02/00198
TGTCCTCAGAGGGTCAGGACTCAGAGAAACCACAGAGCAGCAGCTCAGGAA
AGTGGTTCATGGAAATGCTGGCAAGAGAGAGGGGTTACAATGCCCTCCCTTG
GGAGCAGGCTGCTCCCATCAGATCGTAACCTCTCTGGTATGTGGGCAGAGC
TACCAGGTTAAGGTCCTCCCTAGGGTTTGCAAAACCCTCATGGGATCATGAG
CCATACAGAACCGACCTGTGIGTCTCCAGAGTCTGTAATTAACACAGGCATTT
TGAGGAAATGCGTGGCCTCAGGCCCCACTCCCGGCTACCCCCATCCCACTA
TGCCTAGTATAGTCTAGCTGCCCTGGTACAATTCTCCCAGTATCTTGCAGGC
CCCTATTTCCTATTCCTACTCTGCTCATCTGGCTCTCAGGAACCITCTTGGCC
TTCCCTTTCAGACCTCTACAGATGCCAGCCTTGTGGGAAAGAAGAGTGGGCA
CCTGAGGGAAGCCAGACCTGCTTCCCGCGCACTGTGGTGTTTTTGGCTTTGC
GTGAGCACACCTCTTGGGTGCTGCTGGCAGCTAACACGCTGCTGCTGCTGC
TGCTGCTTGGGACTGCTGGCCTGTTTGCCTGGCACCTAGACACCCCTGTGGT
GAGGTCAGCAGGGGGCCGCCTGTGCTTTCTTATGCTGGGCTCCCTGGCAGC
AGGTAGTGGCAGCCICTATGGCTTCITTGGGGAACCCACAAGGCCTGCGTG
CTTGCTACGCCAGGCCCTCITTGCCCTTGGTTTCACCATCTTCCTGTCCTGCC
TGACAGTTCGCTCATTCCAACTAATCATCATCTTCAAGTT7TCCACCAAGGTA
CCTACATTCTACCACGCCTGGGTCCAAAACCACGGTGCTGGCCTGTTTGTGA
TGATCAGCTCAGCGGCCCAGCTGCTTATCTGTCTAACTIGGCTGGTGGTGTG
GACCCCACTGCCTGCTAGGGAATACCAGCGCTTCCCCCATCTGGTGATGCTT
GAGTGCACAGAGACCAACTCCCTGGGCTTCATACTGGCCTTCCTCTACAATG
GCCTCCTCTCCATCAGTGCCTTTGCCTGCAGCTACCTGGGTAAGGACTTG CC
AGAGAACTACAACGAGGCCAAATGTGTCACCTTCAGCCTGCTCTICAACTTC
GTGTCCTGGATCGCCTTCTTCACCACGGCCAGCGTCTACGACGGCAAGTAC
CTGCCTGCGGCCAACATGATGGCTGGGCTGAGCAGCCTGAGCAGCGGCTTC
GGTGGGTATTTTCTGCCTAAGTGCTACGTGATCCTCTGCCGCCCAGACCTCA
ACAGCACAGAGCACTTCCAG GCCTCCATTCAGGACTACACGAGGCGCTGCG
GCTCCACCTGACCAGTGGGTCAGCAGGCACGGCTGGCAGCCTTCTCTGCCC
TGAGGGTCGAAGGTCGAGCAGGCCGGGGGTGTCCGGGAGGTCTTTGGGCA
TCGCGGTCTGGGGTTGGGACGTGTAAGCGCCTGGGAGAGCCTAGACCAGG
CTCCGGGCTGCCAATAAAGAAGTGAAATGCGTATCTGGICTCCTGTCGTGGG
AGAGTGTGAGGTGTAACGGATTCAAGTCTGAACCCAGAGCCTGGAAAAGGC
TGACCGCCCAGATTGACGTTGCTAGGCAACTCCGGAGGCGGGCCCAGCGCC
AAAAGAACAGGGCGAGGCGTCGTCCCCGCATCCCATTGGCCGTTCTCTGCG
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
GGGCCCCGCCCTCGGGGGCCGGAGCTAGAAGCTCTACG CTTCCGAGGCGC
ACCTCCTGGCCTGCACGCTTTGACGT (SEQ ID NO 15)
hT1R1 predicted cds iSEQ ID NO 16)
ATGCTGCTCTGCACGGCTCGCCTGGTCGGCCTGCAGCTTCTCATTTCCTGCT
=
GCTGGGCCTTTGCCTGCCATAGCACGGAGTCTTCTCCTGACTTCACCCTCCC
CGGAGATTACCTCCTGGCAGGCCTGTTCCCTCTCCATTCTGGCTGTCTGCAG
GTGAGGCACAGACCCGAGGTGACCCTGTGTGACAGGTCTTGTAGCTTCAAT
GAGCATGGCTACCACCTCTTCCAGGCTATGCGGCTTGGGGTTGAGGAGATA
AACAACTCCACGGCCCTGCTGCCCAACATCACCCTGGGGTACCAGCTGTATG
ATGTGTGTTCTGACTCTGCCAATGTGTATGCCACGCTGAGAGTGCTCTCCCT
GCCAGGGCAACACCACATAGAGCTCCAAGGAGACCTTCTCCACTATTCCCCT
ACGGTGCTGGCAGTGATTGGGCCTGACAGCACCAACCGTGCTGCCACCACA
GCCGCCCTGCTGAGCCCTTTCCTGGTGCCCATGATTAGCTATGCGGCCAGC
AGCGAGACGCTCAGCGTGAAGCGGCAGTATCCCTCTTTCCTGCGCACCATC
CCCAATGACAAGTACCAGGTGGAGACCATGGTGCTGCTGCTGCAGAAGTTC
GGGTGGACCTGGATCTCTCTGGTTGGCAG CAGTGACGACTATGGGCAGCTA
GGGGTGCAGGCACTGGAGAACCAGGCCACTGGTCAGGGGATCTGCATTG CT
TTCAAGGACATCATGCCCTTCTCTGCCCAGGTGGGCGATGAGAGGATGCAG
TGCCTCATGCGCCACCTGGCCCAGGCCGGGGCCACCGTCGTGGTTG ________________________
TCCAGCCGGCAGTTGGCCAGGGTG ______________________________________________ I I I
I I CGAGTCCGTGGTGCTGACCAAC
CTGACTG GCAAGGTGTGGGTCGCCTCAGAAGCCTGGGCCCTCTCCAGGCAC
ATCACTGGGGTGCCCGGGATCCAGCGCATTGGGATGGTGCTGGGCGTGGC
CATCCAGAAGAGGGCTGTCCCTGGCCTGAAGGCGTTTGAAGAAGCCTATGC
CCGGGCAGACAAGAAGGCCCCTAGGCCITGCCACAAGGGCTCCTGGTGCAG
CAGCAATCAGCTCTGCAGAGAATGCCAAGCTTTCATGGCACACACGATGCCC
AAGCTCAAAGCCTTCTCCATGAGTTCTGCCTACAACGCATACCGGGCTGTGT
ATGCGGTGGCCCATGGCCTCCACCAGCTCCTGGGCTGTGCCTCTGGAGCTT
GTTCCAGGGGCCGAGTCTACCCCTGGCAGCTTTTGGAGCAGATCCACAAGG
TGCATTTCCTTCTACACAAGGACACTGTGGCGTTTAATGACAACAGAGATCCC
CTCAGTAGCTATAACATAATTGCCTGGGACTGGAATG GACCCAAGTGGACCT
TCACGGTCCTCGGTTCCTCCACATGGTCTCCAGTTCAGCTAAACATAAATGA
GACCAAAATCCAGTGGCACGGAAAGGACAACCAG GTGCCTAAGTCTGTGTG
TTCCAGCGACTGTCTTGAAGGGCACCAGCGAGTGGTTACGGGTTTCCATCAC
1
CA 02776701 2012-05-07
WO 02/064631
PCTTLIS02/00198
TGCTGCTTTGAGTGTGTGCCCTGTGGGGCTGGGACCTTCCTCAACAAGAGT
GACCTCTACAGATGCCAGCCTTGTGGGAAAGAAGAGTGGGCACCTGAGGGA
AGCCAGACCTGCTTCCCGCGCACTGTGGTGT I I I I
___________________________________________ GGCTTTGCGTGAGCACA
CCTCTTGGGTGCTGCTGGCAGCTAACACGCTGCTGCTGCTGCTGCTGCTTG
GGACTGCTGGCCTGTTTGCCTGGCACCTAGACACCCCTGTG GTGAGGTCAG
CAGGGGGCCGCCTGTGCTTTCTTATGCTGGGCTCCCTGGCAGCAGGTAGTG
GCAGCCTCTATGGCTTCTTTGGGGAACCCACAAGGCCTGCGTGCTTGCTAC
GCCAGGCCCTCTTTGCCCTTGGTTTCACCATCTTCCTGTCCTGCCTGACAGT
TCGCTCATTCCAACTAATCATCATCTTCAAG
___________________________________________________ I I I CCACCAAGGTACCTACATT
CTACCACGCCTGGGTCCAAAACCACGGTGCTGGCCTGTTTGTGATGATCAGC
TCAGCGGCCCAGCTGCTTATCTGTCTAACTTGGCTGGTGGTGTGGACCCCAC
TGCCTG CTAG GGAATACCAG CG CTTCCCCCATCTGGTGATG CTTGAGTG CAC
AGAGACCAACTCCCTGGGCTTCATACTGGCCTTCCTCTACAATGGCCTCCTC
TCCATCAGTGC CTTTG CCTGCAG CTAC CTGG GTAAGGACTTGCCAGAGAACT
ACAACGAGGCCAAATGTGTCACCTTCAGCCTGCTCTTCAACTTCGTGTCCTG
GATCGCCTTCTTCACCACGGCCAGCGTCTACGACGGCAAGTACCTGCCTGC
GGCCAACATGATGGCTGGGCTGAGCAGCCTGAGCAGCGGCTTCGGTGGGTA
II
_______________________________________________________________________________
_ t I CTGCCTAAGTGCTACGTGATCCTCTGCCGCCCAGACCTCAACAGCACA
GAGCACTTCCAGGCCTCCATTCAGGACTACACGAGGCGCTGCGGCTCCACC
TGA (SEQ ID NO 16)
hT1R1 conceptual translation (SEQ ID NO 17)
MUCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRH
RPEVTLCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSA
NVYATLRVLSLPGQHH I ELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPM
I SYAASSETLSVKRQYPSF LRTI PNDKYQVETMVLLLQKFGWTW ISLVGSSDDYG
QLGVQALENQATGQG I CIAFKDI MP FSAQVGDERMQCLMRH LAQAGATVVVVFS
S RQLARVF F ESVVLTNLTGKVWVAS EAWALS RH ITGVPG IQRIGMVLGVAIQKRA
VPGLKAF EEAYARADKKAPRPCHKGSWCSSNQLCRECQAFMAHTMPKLKAFS
=
MSSAYNAYRAVYAVAHGLHQLLGCASGACSRGRVYPWQLLEQIHKVHFLLHKD
TVAFN DN RDPLSSYN I IAWDW NG PKWTFTVLGSSTVVSPVQLN I NETKIQW HGK
DNQVPKSVCSSDCLEGHQRVVTGFHHCCFECVPCGAGTFLNKSDLYRCQPCG
KEEWAP EG SQTCFPRTVVFLALREHTSWVLLAANTLLLLLLLGTAGLFAWHLDT
PVVRSAGGRLCFLMLGSLAAGSGSLYGFFGEPTRPACLLRQALFALGFTIFLSCL
87
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
TVRSFQLIII FKFSTKVPTFYHAWVQNHGAGLFVMISSAAQLLICLTWLVVWTPLP
AREYQRFPHLVMLECTETNSLGFILAFLYNGLLSISAFACSYLGKDLPENYNEAKC
VTFSLLFNFVSWIAFFTTASVYDGKYLPAANMMAGLSSLSSGFGGYFLPKCYVIL
CRPDLNSTEHFQASIQDYTRRCGST (SEQ ID NO 17)
EXAMPLE 6¨ hT1R2
=
[0225] The predicted cds of the human ortholog of a rat taste receptor,
designated hT1R2, is provided below as SEQ ID NO 23. The conceptually-
translated hT1R2 sequences is also described herein as SEQ ID NO 21.
According to the present invention, the first two coding exons of hT1R2 were
identified within a PAC by Southern blot. Exon 1 was isolated within a
BamHI/Bg111 fragment that was identified in the Southern experiment, and exon
2
was isolated within a PCR product that spans exon 1 to exon 3. Comparison of
the first two coding exons to the hT1R2 sequence established that the two
exons
encode the N-terminus of the human counterpart to rT1R2. For example, the
painovise amino acid identity between the hT1R2 N-terminal sequence coded by
the two exons and corresponding regions of rT1R2 is approximately 72%,
whereas the most related annotated sequence in public DNA sequence data
banks is only approximately 48% identical to hT1R2.
hT1R2 predicted cds (SEQ ID NO 23)
ATGGGGCCCAGGGCAAAGACCATCTGCTCCCTGITCTTCCTCCTATGGGTCC
TGGCTGAGCCGGCTGAGAACTCGGACTTCTACCTGCCTGGGGATTACCTCC
TGGGTGGCCTCTTCTCCCTCCATGCCAACiesTGAAGGGCATTGTTCACCTTAA
CTICCTGCAGGTGCCCATGTGCAAGGAGTATGAAGTGAAGGTGATAGGCTAC
AACCTCATGCAGGCCATGCGCTTCGCGGTGGAGGAGATCAACAATGACAGC
AGCCTGCTGCCTGGTGTGCTGCTGGGCTATGAGATCGTGGATGTGTGCTAC
ATCTCCAACAATGTCCAGCCGGIGCTCTACTTCCTGGCACACGAGGACAACC
TCCITCCCATCCAAGAGGACTACAGTAACTACATTTCCCGTGTGGTGGCTGT
CATTGGCCCTGACAACTCCGAGTCTGTCATGACTGTGGCCAACTTCCTCTCC
CTATTTCTCCTTCCACAGATCACCTACAGCGCCATCAGCGATGAGCTGCGAG
ACAAGGTGCGCTTCCCGGCTTTGCTGCGTACCACACCCAGCGCCGACCACC
ACGTCGAGGCCATGGTGCAGCTGATGCTGCACTTCCGCTGGAACTGGATCA
TTGTGCTGGTGAGCAGCGACACCTATGGCCGCGACAATGGCCAGCTGCTTG
GCGAGCGCGTGGCCCGGCGCGACATCTGCATCGCCTTCCAGGAGACGCTG
88
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
CCCACACTGCAGCCCAACCAGAACATGACGTCAGAGGAGCGCCAGCGCCTG
GTGACCATTGTGGACAAGCTGCAGCAGAGCACAGCGCGCGTCGTG GTCGTG
TTCTCGCCCGACCTGACCCTGTACCACTTCTTCAATGAGGTGCTGCGCCAGA
ACTTCACGGGCGCCGTGTGGATCGCCTCCGAGTCCTGGGCCATCGACCCGG
TCCTGCACAACCTCACGGAGCTGGG CCACTTG GGCACCTTCCTGGGCATCA
CCATCCAGAGCGTGCCCATCCCGGGCTTCAGTGAGTTCCGCGAGTGGGGCC
CACAGGCTGGGCCGCCACCCCTCAGCAGGACCAGCCAGAGCTATACCTGCA
ACCAGGAGTGCGACAACTGCCTGAACGCCACCTTGTCCTTCAACACCATTCT
CAGGCTCTCTGGGGAGCGTGTCGTCTACAGCGTGTACTCTGCGGTCTATGC
TGTGGCCCATGCCCTGCACAGCCTCCTCGGCTGTGACAAAAGCACCTGCAC
CAAGAGGGTGGTCTACCCCTGGCAGCTGCTTGAGGAGATCTGGAAGGTCAA
CTTCACTCTCCTGGACCACCAAATCTTCTTCGACCCGCAAGGGGACGTGGCT
CTGCACTTGGAGATTGTCCAGTGGCAATGGGACCGGAGCCAGAATCCCTTC
CAGAGCGTCGCCTCCTACTACCCCCTGCAGCGACAGCTGAAGAACATCCAA
GACATCTCCTGGCACACCGTCAACAACACGATCCCTATGTCCATGTGTTCCA
AGAGGTGCCAGTCAGGGCAAAAGAAGAAGCCTGTGGGCATCCACGTCTGCT
GCTTCGAGTGCATCGACTGCCTTCCCGGCACCTTCCTCAACCACACTGAAGA
TGAATATGAATGCCAGGCCTGCCCGAATAACGAGTGGTCCTACCAGAGTGAG
ACCTCCTGCTTCAAGCGGCAGCTGGTCTTCCTGGAATGGCATGAGGCACCC
ACCATCGCTGTGGCCCTGCTGGCCGCCCTGGGCTTCCTCAGCACCCTGGCC
ATCCTGGTGATATTCTGGAGGCACTTCCAGACACCCATAGTTCGCTCGGCTG
GGGGCCCCATGTGCTTCCTGATGCTGACACTGCTGCTGGTGGCATACATGG
TGGTCCCGGTGTACGTGGGGCCGCCCAAGGTCTCCACCTGCCTCTGCCGCC
AGGCCCTCTTTCCCCTCTGCTICACAATTTGCATCTCCTGTATCGCCGTGCGT
TCTTTCCAGATCGTCTGCGCCTTCAAGATGGCCAGCCGCTTCCCACGCGCCT
ACAGCTACTG GGTCCG CTACCAGGGGCCCTACGTCTCTATGGCATTTATCAC
GGTACTCAAAATGGICATTGIGGTAATTGGCATGCTGGCCACGGGCCTCAGT
CCCACCACCCGTACTGACCCCGATGACCCCAAGATCACAATTGTCTCCTGTA
ACCCCAACTACCGCAACAGCCTGCTGTTCAACACCAGCCTGGACCTGCTGCT
CTCAGTGGTGGGTTTCAGCTTCGCCTACATGGGCAAAGAGCTGCCCACCAAC
TACAACGAGGCCAAGTTCATCACCCTCAGCATGACCTTCTATTTCACCTCATC
CGTCTCCCTCTGCACCTTCATGTCTGCCTACAGCGGGGTGCTGGTCACCATC
GTGGACCTCTTGGTCACTGTGCTCAACCTCCTGGCCATCAGCCTGG GCTACT
89
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
TCGGCCCCAAGTGCTACATGATCCTCTTCTACCCGGAGCGCAACACGCCCG
CCTACTTCAACAGCATGATCCAGGGCTACACCATGAGGAGGGACTAG (SEQ
ID NO. 23 )
hT1R2 conceptual translation ISEQ ID NO 21)
MGPRAKTICSLFFLLWVLAEPAENSDFYLPGDYLLGGLFSLHANMKGIVHLNFLQ
=
VPMCKEYEVKVIGYNLMQAMRFAVEEINNDSSLLPGVLLGYEIVDVCYISNNVQP
VLYFLAHEDNLLPIQEDYSNYISRVVAVIGPDNSESVMTVANFLSLFLLPQITYSAI
SDELRDKVRFPALLRTTPSADHHVEAMVQLMLHFRWNWIIVLVSSDTYGRDNGQ
LLGERVARRDICIAFQETLPTLQPNQNMTSEERQRLVTIVDKLQQSTARVVVVFS
PDLTLYHFFNEVLRQNFTGAVWIASESWAIDPVLHNLTELGHLGTFLGITIQSVPIP
GFSEFREWGPQAGPPPLSRTSQSYTCNQECDNCLNATLSFNTILRLSGERVVYS
VYSAVYAVAHALHSLLGCDKSTCTKRVVYPWQLLEEIWKVNFTLLDHQIFFDPQG
DVALHLEIVQWQWDRSQNPFQSVASYYPLQRQLKNIQDISWHTVNNTIPMSMC
SKRCQSGQKKKPVGIHVCCFECIDCLPGTFLNHTEDEYECQACPNNEWSYQSE
TSCFKRQLVFLEW HEAPTIAVALLAALGFLSTLAILVIFWRHFQTPIVRSAGGPMC
FLMLTLLLVAYMVVPVYVGPPKVSTCLCRQALFPLCFTICISCIAVRSFQIVCAFKM
ASRFPRAYSYWVRYQGPYVSMAFITVLKMVIVVIGMLATGLSPTTRTDPDDPKITI
VSCNPNYRNSLLFNTSLDLLLSVVGFSFAYMGKELPTNYNEAKFITLSMTFYFTSS
VSLCTFMSAYSGVLVTIVDLLVTVLNLLAISLGYFGPKCYMILFYPERNTPAYFNS
MIQGYTMRRD (SEQ ID NO. 21)
Example 7
Methods for Neter l000us Expression of Ti Rs in Heterologous Cells
[0226] An HEK-293 derivative (Chandrashekar et at, Cell 100(6): 703-11
(2000)), which stably expresses Gal 5, was grown and maintained at 37 C in
Dulbecco's Modified Eagle Medium (DMEM, Gibco BRL) supplemented with 10%
FBS, MEM non-essential amino acids (Gibco BRL), and 3 g/mlblasticidin. For
calcium-imaging experiments, cells were first seeded onto 24-well tissue-
culture
plates (approximately 0.1 million cells per well), and transfected by
lipofection with
Mirus TransIt-293 (PanVera). To minimize glutamate-induced and glucose-
induced desensitization, supplemented DMEM was replaced with low-glucose
DMEM/GlutaMAX (Gibco BRL) approximately 24 hours after transfection. 24 hours
later, cells were loaded with the calcium dye Fluo-4 (Molecular Probes), 3 M
in
Dulbecco's PBS buffer (DPBS, GibcoBRL), for 1.5 hours at room temperature.
CA 02776701 2012-05-07
1
WO 02/064631
PCT/US02/00198
After replacement with 2500 DPBS, stimulation was performed at room
temperature by addition of 200111 DPBS supplemented with taste stimuli.
Calcium
mobilization was monitored on a Axiovertm S100 TV microscope (Zeiss) using
Imaging Workbench 4.0 software (Axon). T1R1fT1R3 and T1R2/T1R3 responses
were strikingly transient ¨ calcium increases rarely persisted longer than 15
seconds ¨ and asynchronous. The number of responding cells was thus relatively
constant over time; therefore, cell responses were quantitated by manually
counting the number of responding cells at a fixed time point, typically 30
seconds
after stimulus addition.
Example 8
Human T1R2/T1R3 functions as a sweet taste receptor
[0227] HEK cells stably expressing Gal 5 were transiently transfected with
human T1R2, T1R3 and T1R2fT1R3, and assayed for increases in intracellular
calcium in response to increasing concentrations of sucrose (Figure 1(a)).
Also,
T1R2/T1R3 dose responses were determined for several sweet taste stimuli
(Figure 1(b)). The maximal percentage of responding cells was different for
different sweeteners, ranging from 10-30%. For clarity, dose responses were
normalized to the maximal percentage of responding cells. The values in Figure
1
represent the mean + s.e. of four independent responses. X-axis circles mark
psychophysical detection thresholds determined by taste testing. Gurmarin (50-
full dilution of a filtered 10g/1 Gymnema sylvestre aqueous extract) inhibited
the
response of T1R2fT1R3 to 250 mM sucrose, but not the response of endogenous
/32-adrenergic receptor to 20 irM isoproterenol (Figure 1(b)). Figure 1(c)
contains
the normalized response of T1R2fT1R3 co-expressing cell lines to different
sweeteners(sucrose, aspartame, tryptophan and saccharin)
EXAMPLE 9
Rat T1R2fT1R3 also functions as a sweet taste receptor
= [0228] HEK cells stably expressing Gal 5 were transiently transfected
with
hT1R2/hT1R3, rT1R2/rT1R3, hT1R2/rT1R3, and rT1R2/hT1R3. These
transfected cells were then assayed for increased intracellular calcium in
response
to 350 mM sucrose, 25 mM tryptophan, 15 mM aspartame, and 0.05 of monellin.
The results with sucrose and aspartame are contained in Figure 2 and indicate
91
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
that rT1R2/rT1R3 also functions as a sweet taste receptor. Also, these results
suggest that TI R2 may control T1R2/T1R3 ligand specificity.
EXAMPLE 10
Human T1R1/T1R3 functions as umami taste receptors
=
[0229] HEK cells stably expressing Gal 5 were transiently transfected with
human T1R1, T1R3 and T1R1/T1R3 and assayed for increases in intracellular
calcium in response to increasing concentrations of glutamate (Figure 3(a) and
0.5
mM glutamate), 0.2 mM IMP, and 0.5 mM glutamate plus 0.2 mM IMP (Figure
3(b)). Human T1R1rri R3 dose responses were determined for glutamate in the
presence and absence of 0.2 mM IMP (Figure 3(c)). The maximal percentages of
responding cells was approximately 5% for glutamate and approximately 10% for
glutamate plus IMP. For clarity, does responses are normalized to the maximal
percentage of responding cells. The values represent the mean + s.e. of four
independent responses. X-axis circles mark taste detection thresholds
determined by taste testing.
EXAMPLE 11
PDZIP as an Export Sequence
[0230] The six residue PDZIP sequence (SVSTVV (SEQ ID NO:22)) was fused
to the C-terminus of hT1R2 and the chimeric receptor (i.e. hT1R2-PDZIP) was
transfected into an HEK-293 host cell. The surface expression of hT1R2 was
then
monitored using immunofluorescence and FACS scanning data. As shown in
Figures 6A and 6B, the inclusion of the PDZIP sequence increased the surface
expression of hT1R2-PDZIP relative to hT1R2.
PKZ1P Sequence
SVS1VV (SEQ ID NO:22)
[0231] More specifically, Figure 4A shows an immunofluorescence staining of
myc-tagged hT1R2 demonstrating that PDZIP significantly increases the amount
=
of hT1R2 protein on the plasma membrane. Figure 46 shows FAGS analysis data
demonstrating the same result.¨ Cells expressing myc-tagged hT1R2 are
indicated by the dotted line and cells expressing myc-tagged hT1R2-PDZIP are
indicated by the solid line.
92
CA 02776701 2012-05-07
WO 02/064631
PCTTUS02/00198
Example 12
Generation of Cell Lines that Stably Co-Express T1R1/T1R3 or T1R2/T1R3
[0232] Human cell lines that stably co-express human T1R2/T1R3 or human
T1R1fT1R3 were generated by transfecting linearized PEAK10-derived (Edge
=
Biosystems) vectors containing pCDNA 3.1/ZEO-derived (lnvitrogen) vectors
respectively containing hT1R1 or hT1R2 expression construct (plasmid SAV2485
for TI RI, SAV2486 for Ti R2) and hT1R3 (plasmid S)(V550 for TI R3) into a Gam
expressing cell line. Specifically, T1R2/T1R3 stable cell lines were produced
by
co-transfecting linearized SAV2486 and SXV550 into Aurora Bioscience's HEK-
293 cell line that stably expresses Ga15. T1R1/T1R3 stable cell lines were
produced by co-transfecting linearized SAV2485 and SXV550 into the same HEK-
293 cell line that stably expresses Ga15. Following SAV2485/SCV550 and
SAV2486/SXV550 transfections, puromycin-resistant and zeocin-resistant
colonies were selected, expanded, and tested by calcium imaging for responses
to sweet or umami taste stimuli. Cells were selected in 0.0005 mg/ml puromycin
(CALBIOCHEM) and 0.1 mg/ml zeocin (Invitrogen) at 37 C in low-glucose DMEM
supplemented with GlutaMAX, 10% dialyzed FBS, and 0.003 mg/ml blasticidin.
Resistant colonies were expanded, and their responses to sweet taste stimuli
evaluated by Fluorescence microscopy. For automated fluorimetric imaging on
VIPR-II instrumentation (Aurora Biosciences), T1R2fT1R3 stable cells were
first
seeded onto 96-well plates (approximately 15,000 cells per well). Twenty-four
hours later, cells were loaded with the calcium dye fluo-3-AM (Molecular
Probes),
0.005 mM in PBS, for one hour at room temperature. After replacement with 70
ml
PBS, stimulation was performed at room temperature by addition of 70 ml PBS
supplemented with taste stimuli. Fluorescence (480 nm excitation and 535 nm
emission) responses from 20 to 30 seconds following compound addition were
averaged, corrected for background fluorescence measured prior to compound
= addition, and normalized to the response to 0.001 mM ionomycin
(CALBIOCHEM), a calcium ionophore.
[0233] It was then observed that when these cell lines were contacted with
sweet or umami, that for active clones typically 80-100% of cells responded to
taste stimuli. Unexpectedly, the magnitude of individual cell responses was
markedly larger than that of transiently transfected cells.
93
CA 02776701 2012-05-07
WO 02/064631 PCT/US02/00198
[0234] Based on this observation, the inventors tested the activity of TiR
stable
cell lines by automated fluorescence imaging using Aurora Bioscience's VIPR
instrumentation as described above. The responses of two T1R1fT1R3 and one
T1R2/T1R3 cell line are shown in Figure 5 and Figure 6 respectively.
=
[0235] Remarkably, the combination of increased numbers of responding cells
and increased response magnitudes resulted in a greater than 10-fold increase
in
activity relative to transiently transfected cells. (By way of comparison, the
percent
ionomycin response for cells transiently transfected with T1R2/T1 R3 was
approximately 5% under optimal conditions.) Moreover, dose responses obtained
for stably expressed human T1R2fT1R3 and T1R1fT1R3 correlated with human
taste detection thresholds. The robust T1R activity of these stable cell lines
suggests that they are well suited for use in high-throughput screening of
chemical
libraries in order to identify compounds, e.g. small molecules, that modulate
the
sweet or umami taste receptor and which therefore modulate, enhance, block or
mimic sweet or umami taste.
[0236] = While the foregoing detailed description has described several
embodiments of the present invention, it is to be understood that the above
description is illustrative only and not limiting of the disclosed invention.
The
invention is to be limited only by the claims which follow.
94