Note: Descriptions are shown in the official language in which they were submitted.
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
METHOD AND SYSTEM FOR INTEGRATING WEB-BASED SYSTEMS WITH
LOCAL DOCUMENT PROCESSING APPLICATIONS
FIELD OF THE INVENTION
[0001] The present invention relates generally to natural language
processing,
information retrieval and more particularly to determining relevancy of terms
within
documents in the context of searching for authority, such as legal authority,
and in facilitating
the generation of documents, such as legal briefs. The invention relates to
determine how
relevant or important terms or aspects are to documents and in particular to
the content of that
document. Also, the invention relates to processes, software and systems for
use in delivery
of services related to the legal, corporate, and other professional sectors
and more particularly
delivery of such services in connection with a subscriber's work function,
e.g., preparing
documents in a word processing environment and application. The invention
relates to a
system that presents searching functions to users, such as subscribers to a
professional
services related service, processes search terms and applies search syntax
across document
databases, and displays search results generated in response to the search
function and
processing.
BACKGROUND OF THE INVENTION
[0002] With the advents of the printing press, typeset, typewriting
machines,
computer-implemented word processing and mass data storage, the amount of
information
generated by mankind has risen dramatically and with an ever quickening pace.
As a result
there is a continuing and growing need to collect and store, identify, track,
classify and
catalogue for retrieval and distribution this growing sea of information.
[0003] In many areas and industries, including the financial and legal
sectors and
areas of technology, for example, there are content and enhanced experience
providers, such
as The Thomson Reuters Corporation. Such providers identify, collect, analyze
and process
key data for use in generating content, such as law related reports, articles,
etc., for
consumption by professionals and others involved in the respective industries,
e.g., lawyers.
Providers in the various sectors and industries continually look for products
and services to
provide subscribers, clients and other customers and for ways to distinguish
their firms over
the competition. Such providers strive to create and provide enhance tools,
including search
1
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
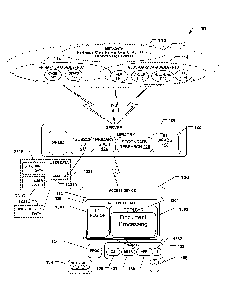
and ranking tools, to enable clients to more efficiently and effectively
process information
and make informed decisions.
[0004] In particular, for example, judges and lawyers within the
American legal
system, as well as many others across the globe, are continually researching
an ever-
expanding body of legislation and judicial opinions to assist them
understanding and
resolving new or potential disputes. To facilitate this research, companies,
such as West
Publishing Company of St. Paul, Minn. (doing business as Thomson West),
collect legal
statutes, judicial opinions, law articles, and other legal and non-legal
materials and make
these available electronically over a computer network, through the Westlaw
online research
system. (Westlaw is a trademark licensed to Thomson West.) At least one
problem the
present inventors recognized with this powerful system as well as other online
research
systems is that their valuable functionality is highly segregated from the
functionality of other
computer applications. For instance, legal researchers typically use results
of their online
legal research as part of a larger process of producing documents, such as
legal briefs and
memorandum. However, systems, such as the Westlaw system, are typically
functionally
separated from popular word processing applications, such as Microsoft Word or
Corel
WordPerfect, that are used for creating these documents.
[0005] For example, with advancements in technology and sophisticated
approaches
to searching across vast amounts of data and documents, e.g., database of
issued court
decisions, law review articles, statutes and laws, regulations, etc.,
professionals and other
users increasingly rely on mathematical models and algorithms in making
professional and
business determinations. In addition, there are known tools, such as word
processing
applications, e.g., Corel's WordPerfect and Microsoft's Word , and systems
available to
professionals and others for preparing work product, such as legal briefs,
court decisions, etc.
There are also known systems, e.g., Thomson Reuter's Knowledge Management,
that allow
users to automatically access Information Service Provider (ISP) networks or
websites, such
as over the Internet, and that perform functions based on text included in a
document being
created or edited on a word processing system. For example, if a legal brief
or memorandum
includes citations to legal authority, such as case law or statutes, the
user's system can
interface with an ISP's service to check proper citation form and to check on
the status of the
relied on authority to confirm that the statute has not been revised or
repealed or that a case
has not been reversed or otherwise called into question. Systems may include
an applet or
2
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
application executing locally on the user's computer that interfaces with the
ISP network-
based system.
[0006] Although adds-ons such as West BriefToolsTm software and
WestCiteLink
software are available to identify, mark, verify, tabulate, link, and/or
indicate status of legal
citations in word processor documents, their functionality is isolated to
legal citations. This
means that for other types of legal informational needs users must leave the
context of the
word processing application to execute searches via browsers or other search
tools and then
cut and paste information from their browsers or other search interfaces into
the documents.
Moreover, the inventors recognized that conventional techniques for expanding
the
functionality of word processing applications using customized add-ons
requires adding fully
customized software to the computer hosting the word processing application.
This approach,
however, is inefficient an information services company, such as Thomson
Reuters, wants to
offer a growing set of add-ons, such as West BriefTools and WestCiteLink
software, to its
customers.
[0007] In one known system, Thomson Reuter's Knowledge Management, an
application
runs locally at a user's computer or access device that is operating a word
processor application
and automatically, such as by a user manipulating via a user interface screen,
accesses the ISP
service over a network connection, e.g., the Internet. The ISP then applies
one or more search
engines across one or more databases to retrieve documents in response to
terms identified in the
user-created document or user defined queries or search terms. The search
engine(s) compare the
terms that appear in the document (e.g., "summary judgment") to arrive at a
set of one or more
documents within a database or network of databases for presenting to the
user. The system may
also perform a series of enhanced functions to rank or otherwise score or
present the documents
to the user. The system may use functions such as Term Frequency-Inverse
Document Frequency
(TFIDF) in comparing terms appearing in a document against a collection of
documents.
[0008] Although existing ISP search engines (SE) can be used to search
for non-standard
terms and strings, because they are limited to case law a single layer search
is often ineffective or
at least less effective when dealing with such terms. For instance, existing
ISP SEs are likely to
find zero or few relevant cases on an issue represented in non-standard form
or terms. The
known systems suffer from the disadvantage of being less effective when
dealing with
uncommon or non-standard terms or expression and, therefore, fail to identify
and present
documents, e.g., case law, that would otherwise being helpful and of interest
as being related to
the uncommon or non-standard terms used by the user in the user-created
document.
3
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0 00 9] Moreover, legal professionals in the US and abroad are often
involved in
litigation, arbitration, mediation, administrative proceedings and other
evidentiary processes
wherein large amounts of information is collected. For instance, in a
litigation there are often
numerous depositions in which thousands and thousands of pages of recorded,
videotaped,
and transcribed testimony is collected. It is a constant need in the legal
community to most
efficiently and effectively track, edit, search and otherwise access and use
such voluminous
materials and information for use in providing legal services. For instance,
an attorney
preparing for trial often desires to prepare and outline for interrogating a
witness. The
attorney and/or paralegal typically pours through the deposition transcripts
and videotapes
associated not only with the witness being deposed but others to identify
areas of questioning
and past and potential responses. In addition to testimony, the attorney must
consider and
attempt to identify, collect and incorporate into the witness outline a vast
collection of
pleadings, documents, exhibits, etc., for planning and for fast and effective
reference and
possible display at and during trial. For instance, where an attorney is
questioning a witness
at trial it is a recognized need to be able to reference the past testimony of
the witness and
others to good effect and to quickly locate and present, such as by overhead
projector, video
screen, Elmo and other means, documents as exhibits to assist in the
questioning and
presentation of evidence to a jury or other fact-finder.
[0010] In addition, there is a need in the legal community to be able
to quickly
reference research, including case law, controlling or relevant to a
particular issue that is the
subject of questioning at trial or deposition or the subject of presentation,
such as to an
appellate court, administrative body, or otherwise. The legal professional is
concerned with
researching an ever-expanding body of legislation and judicial opinions and in
tracking and
associating such research to issues related to disputes to assist them
understanding and
resolving new or potential disputes. To facilitate this research, Information
Service Provider
(ISP) concerns, such as West Publishing Company of St. Paul, Minn. (a Thomson
Reuters
business), collect legal statutes, judicial opinions, law articles, and other
legal and non-legal
materials and make these available electronically over a computer network,
e.g., the
Westlaw online research system. (Westlaw is a trademark of Thomson Reuters
West.) At
least one problem the present inventors recognized with this powerful system
as well as other
online research systems is that ISP's valuable functionality, while highly
effective in
researching and preparing legal documents, is not as readily available to a
legal professional
involved in real time activities, such as depositions and taking witnesses at
trial.
4
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0011] West provides a service called LiveNote that provides to users:
live feed of a
transcript, audio and video directly on the attorney's or user's computer;
streaming live
transcript, audio and video feed off-site to remote participants; effective
management of
transcripts and related evidence in a case; performing sophisticated full-text
searches across
.. transcripts in a case to quickly retrieve critical testimony; highlight,
annotate and analyze all
transcripts; view hyperlinked exhibits; create dynamic reports on keywords,
issues,
annotations and exhibit lists that will automatically update as a case
evolves; quickly prepare
PowerPoint slides of transcript text synced with video to present at trial,
hearings, or
meetings; shared cases over a network so multiple team members can work
simultaneously,
or save a project locally and synchronize your work to the network case at a
later time;
control of a deposition or hearing, integrating innovative technology with
realtime resources;
and enables swift, efficient and secure online collaboration at various
locations.
[0012] West LiveNote may also be used in an online fashion, e.g.,
LiveNote Web, to
provide users additional access and functionality. Remote Access Server (RAS)
is an
additional online type service similar to LiveNote Web. Typically, LiveNote
Web and RAS,
as well as other such systems, allow users with subscriptions to login to a
case over the World
Wide Web. After logging in, users may download case information, including
transcripts and
documents, to their computers and work from a web-based or local application,
such as West
LiveNote.
[0013] The present inventors recognized a need to provide information
consumers
relational and event information about entities, such as companies, persons,
cities, that are
mentioned in electronic documents. For example, documents, such as news feeds,
SEC
(Securities and Exchange Commission) filings or scientific articles, may
indicate that
Company A merged with Company B, that Lawyer C moved to Firm D, or that the
interaction of protein E with protein F produces result G.
[0014] However, automatically discerning the relational and event
information about
these entities is difficult and time consuming even with state-of-the art
computing equipment,
because an event description can be found in a single sentence or spread out
over a
paragraph, a document or an entire collection of documents.
5
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
SUMMARY OF THE INVENTION
[0015] To address this and/or other needs, the present inventors
devised, among other
things, systems, methods, and software that allow users to readily access
additional
informational resources, such as online legal research tools, while using
other applications,
such as word processors. The invention is directed to providing a seamless
user experience in
connecting functions between word processing applications and ISP searching
and research
services. The invention provides an additional layer of searching over the
prior art and an
enhanced searching capability to ascertain and present documents responsive to
text or terms
appearing in a user's working document that may not match perfectly or neatly
in the manner
generally presented in relevant case law, statutes and the like. Often the
situation arises
where a user uses loose terms or expression or may not know the exact term of
art or phrase
or legal standard that applies in researching or writing about a particular
issue.
[0016] The invention may be used in connection with searching based on
known
terms but is particularly powerful when a user uses terms not traditionally
used in connection
with an issue or a subject, e.g., "everyone agrees to the underlying events"
as opposed to "no
genuine issue of material fact" in the context of summary judgment
proceedings. The
invention provides the enhanced feature of searching not only primary sources,
e.g., case law
and statute databases, but also searches secondary sources of collections or
sets of referencing
texts to identify and present case law relevant to an issue being researched.
"Referencing text
documents" included in Reference Text Collections or Sets (RTC or RTS), e.g.,
ALR, are
documents that are not part of the body of law or direct legal authority but
that do cite to case
law, statutes, regulations and other legal authorities. The invention
processes the search
criteria to yield a responsive set of referencing text documents from the RTC
based on a user
search request or query, such as may be highlighted or otherwise derived from
a working
document operating in a word processor application by the user. The responsive
set of
referencing text documents are identified by matching search terms or criteria
with text
appearing in the referencing text documents that is associated with case law
cited in the
referencing text documents.
[0017] The system identifies those citations related to the highlighted or
search terms
found in the referencing text documents to yield a set of "referencing text
results", which is a
set of case law cited in the referencing text documents. Accordingly, the
invention generates
a set of search results comprised of two sets of case law for presenting to a
user on a subject
6
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
of interest. The first set of case law is generated by performing the search
on the primary
case law database and the second set of case law is generated based on the
citations contained
in the set of referencing text documents that relates to the user search
request. In this manner,
the invention provides a seamless integration of searching functions and
database resources
from the word processor environment that includes not only primary case law
but also
secondary sources of non-case law. Accordingly, when searching from the word
processing
environment for terms or highlighted statement contained within a working
document, the
invention provides an additional layer of searching in addition to traditional
ISP systems and
provides an enhanced way of searching for responsive legal authority based on
terms not
traditionally used and that appear in secondary sources, e.g., ALR. The system
provides
searching in both the primary and the secondary sources and presents
responsive case law
from the primary source and case law that is cited in responsive referencing
text documents.
In addition, the system may rank, together or separately, the two sets of case
law, the primary
search results from the primary database of case law and the set of
referencing text results.
The system may also reduce, such as through a de-duplication process, the set
of search
results or the component search results. The system may display to the user
the respective
responsive search results either combined or separated. The set or search
results are then
available for user examination and may be incorporated into the working
document.
[0018] One exemplary computer-implemented system provides an add-on
software
framework that integrates into a host word processing application on a client
access device.
In essence the invention provides a web-based control of or interaction with
desktop
applications. The add-on software framework allows users to select from one or
more web
applications on a web server, with each of the web application capable of
controlling
operation of the host word processing application (via appropriate APIs and an
embedded
browser control with framework). The web applications facilitate access to
information from
the information-retrieval services and incorporation of the information in the
document or in
metadata associated with the document. The invention further provides an
enhanced
experience by providing a system that automatically or semi-automatically
derives
information associated with user documents in a word processing environment
not only to
access an ISP collection of search tools and documents but also utilize
secondary source of
documents, e.g., ALR, AmJur, Headnotes, law review articles, in confirming
legal authority
and in presenting argument in work product, such as legal briefs and
decisions.
7
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0019] In a first embodiment, the invention provides a computer
useable medium
having a set of executable code for enabling electronic communications between
a word
processing program of a client access device and an information services
provider system
(ISP). The set of executable code comprises the following sets of computer
program code
executable by the processor. A first set of computer program code for
operatively connecting
to the word processing program. A second set of computer program code for
operatively
connecting to the information services provider system. A third set of
computer program code
for accepting a user search request initiated by a user of the word processing
program.
A fourth set of computer program code for transmitting the user search request
to the
information services provider system. A fifth set of computer program code for
receiving a
set of search results, the set of search results comprising a set of
referencing text results. A
sixth set of computer program code for displaying within the word processing
program at
least a portion of the set of referencing text results. In addition, the third
set of computer
program code may comprise code for identifying a highlighted portion of text
within the
word processing program. Also the word processing program may be either
Microsoft Word
or Corel WordPerfect. Also, the set of referencing text results preferably
comprises case law
and the set of search results comprises a primary set of case law results
derived from an ISP
case law database. In addition, the computer useable medium may further
comprise a
computer program code for combining the set of referencing text results and
the primary set
of case law results. The computer useable medium may comprise a memory within
the
information services provider system and further comprise a seventh set of
computer program
code for receiving from the ISP the first set of computer program code, the
second set of
computer program code, the third set of computer program code, the fourth set
of computer
program code, the fifth set of computer program code, and the sixth set of
computer program
code at the client access device; and an eighth set of computer program code
for installing at
the client access device the first set of computer program code, the second
set of computer
program code, the third set of computer program code, the fourth set of
computer program
code, the fifth set of computer program code, and the sixth set of computer
program code on
the client access device.
[0020] In a second embodiment, the invention provides a computer-
implemented
method for enabling electronic communications between a word processing
program
operating on a client access device and a computer-based information services
provider
system (ISP). The method comprises the following steps of operatively
connecting to a word
8
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
processing program operating on a client access device; operatively connecting
to an ISP;
accepting a user search request initiated by a user of the word processing
program;
transmitting the user search request to the ISP; receiving a set of search
results, the set of
search results comprising a set of referencing text results; and receiving for
display within a
user interface of the word processing program at least a portion of the set of
referencing text
results. In addition, the step of accepting a user search request may comprise
identifying a
highlighted portion of text within a document associated with the word
processing program.
The method may further comprise receiving from the ISP a set of computer
program code at
the client access device, the set of computer program code adapted to execute
on the client
access device to perform in whole or in part the steps of (a)-(f); and
installing the set of
computer program code on the client access device.
[0021] In yet a third embodiment, the invention provides a client
access, such as a
computer. The device includes: a processor adapted to execute code; a memory
for storing
executable code; a word processing program executed by the processor; means
for
establishing electronic communications with an information services provider
system (ISP)
having a first database having a primary set of documents; a first set of
computer program
code for operatively connecting to the word processing program; a second set
of computer
program code for operatively connecting to the information services provider
system; a third
set of computer program code for accepting a user search request initiated by
a user of the
word processing program; a fourth set of computer program code for
transmitting the user
search request to the information services provider system; a fifth set of
computer program
code for receiving a set of search results, the set of search results
comprising a set of
referencing text results; and a sixth set of computer program code for
receiving for display
within a user interface of the word processing program at least a portion of
the set of
referencing text results. In one manner, the device displays within a user
interface of the word
processing program at least a subset of the primary set of documents and at
least a portion of
the set of referencing text results. Moreover, the displayed sets may be
ranked with respect to
relevancy to data associated with the user search request at least a portion
of one or both of
the primary set of documents and the set of referencing text results. Also,
the referencing text
results may comprise case law derived from case citations contained in non-
case law
referencing text documents identified in a database other than the first
database.
[0022] In yet another embodiment the present invention provides a
network-based,
computer-implemented information services provider system (ISP) having a set
of executable
9
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
code for enabling data exchange with a word processing program remotely
operating on a
client access device, the system comprising: a processor adapted to execute
code; a memory
for storing executable code; a first database accessible by the processor and
having stored
therein a primary set of documents; a first set of computer program code
adapted to
operatively connect to the word processing program; a second set of computer
program code
adapted to receive search data associated with a user search request initiated
by a user of the
word processing program; a third set of computer program code adapted to
generate a set of
search results, the set of search results comprising a set of primary search
results from the
first database and a set of referencing text results derived from a database
other than the first
database; and a fourth set of computer program code adapted to transmit for
display within a
user interface of the word processing program at least a portion of the set of
search results
including at least a portion of the set of referencing text results.
[0023] Moreover, the present inventors further devised, among other
things, systems
and methods for named-entity tagging, resolving and event and relationship
extraction. This
.. further present invention addresses above discussed needs as well as others
by incorporating,
linking or otherwise accessing the vast amounts of documents, testimony and
data collected
over the course of a litigation or other proceeding as well as harnessing the
research resources
of an ISP for use in outlining and presenting and eliciting testimony and
evidence, such as at
trial. For example, with advancements in technology and sophisticated
approaches to
.. searching across vast amounts of data and documents, e.g., database of
evidence, testimony,
documents, case law, statutes and laws, regulations, etc., professionals and
other users
increasingly rely on Information Service Provider (ISP) networks or websites,
such as over
the Internet, and that perform functions based on text included in a document
being created or
edited on a Word processing system. For example, in preparing an outline for
deposition or
trial a legal professional may utilize a word processor application or
component and
highlight, tag, insert links or references to video, insert links or
references to documents,
insert links or references to case law, briefs or pleadings, etc., in
preparing such documents.
ISPs may provide an applet or application executing locally on the user's
computer that
interfaces with the ISP network-based system and that may be used separate and
standalone.
For example, at trial a legal team may have onsite a database(s) of documents,
testimony,
videotape, exhibits, etc., in electronic form. Also onsite, the team may have
one or more
computers connected to display technology to present information, documents,
videotape,
etc., accessible from the database.
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0024] In one embodiment, the present invention provides an Outline
feature for use
in a computer/software-based Litigation Support System ("LSS"), such as
Thomson Reuters
Corporation's West LiveNote and West Case Notebook software-based products.
The outline
feature operates within the LSS to allow users to make outlines of cases and
to perform other
.. enhanced functions. Although discussed in terms of certain proprietary
systems, it is
understood that the invention is not limited to such proprietary
implementations and applies
to any suitable LSS system and broadly to such professional services provider
systems. For
instance, West Case Notebook is a software program that helps attorneys keep
all case-related
documents in one place while they perform all the necessary parts of
litigation. Built on
West's LiveNote platform, West Case Notebook easily integrates with Westlaw.
Any
research done on Westlaw can be moved into a Case Notebook file, where users
can
annotate, search and report on the research and other documents.
[0025] West Case Notebook provides the following user enhancements:
organize case
documents, pleadings, legal research and information about "characters", i.e.,
individuals or
organizations connected to the case; classify case documents, research and
information by
annotating notes and pre-defined, color-coded issues; export Westlaw research
with
comments, issue tags KeyCite status and live links directly into a Case
Notebook file; receive
realtime feed at depositions or court and leave with a usable electronic
transcript saved into a
legal team's case file; locate information quickly with summary reports on
specific issues or
data, and with flexible full text searching targeted to particular data sets
such as specific
transcripts or documents; organize sub-sets of documents and information using
data groups;
and remote access to case file.
[0026] West Case Notebook, as well as other such systems, organizes
all essential
case information in a centralized electronic database. This allows a legal
team to enter and
share key facts, documents, main characters, evidence, pleadings, legal
research and more.
Case Notebook users are able to easily search for and find "characters", i.e.,
the names of
major participants in cases or are people involved in cases, and associated
information, e.g.,
"character information." These "characters" may be directly input into the
system or may be
derived or "found" by the system in processing documents such as transcripts,
case law, etc.
The system "tags" or "pins" or otherwise associates references with the
characters and
provides tools that allow users to research the names or "characters" for a
variety of purposes.
[0027] More particularly, the system of the further present invention
creates and
inserts "Character Smart Tags" or "Smart Tags" for associating characters with
documents,
11
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
exhibits, testimony, outline information, etc., e.g., metadata. The names of
characters input
into or found by the system, such as appearing in transcripts, documents, and
pleadings, are
marked, such as by underlining, highlighting, etc., for perception and action
by the user. For
instance, a user right-clicking an underlined name will open a context menu.
The underlines
are referred to as Character Smart Tags or simply Smart Tags. For purposes of
this
explanation and meaning of the invention, the term "document" should be given
a broad
meaning to include all of the above mentioned items in whatever form and
including
"redacted documents" and further including a collection or corpus of
documents.
[0028] The further present invention provides character maintenance
functionality
based on software or program code (Entity Maintenance Module ¨ EMM) that, in
one
implementation, is embedded in an LSS, e.g., West LiveNote Case Notebook, and
will
recognize the names of people (referred to as characters) involved in a
specific case. The
character maintenance of EMM aspect of the LSS will search for names in the
properties of
documents, pleadings, and transcripts. It will search the text of transcripts
and perform a
character recognition process, such as by use of Adobe Acrobat or similar
technology, to
"OCR" the documents and pleadings, and list the primary name in, for example,
a Character
Display pane. EMM, working within an LSS, e.g., West LiveNote Case Notebook,
will
underline the primary names and their variants (referred to as aliases). Users
will be able to
access Smart Tag context menus for more information about the character,
including data on
Westlaw. Users will also have the option to turn off automated Character Smart
Tag creation
and create Smart Tags manually. The system may use any of a variety of xML-
based rules or
constructs or other suitable schemas or formats in encoding documents or
files.
[0029] The LSS may be integrated with or incorporate other services
to enhance and
leverage reporting and legal videography litigation functions. For example,
West Case
LiveNote is the legal industry's benchmark for transcript and evidence
management and may
be used in conjunction with reporting services, such as West Court Reporting
Services. Such
integrated systems may include or interface with word processing or other
software for text
editing. The invention allows users to insert copied text from transcripts,
copied text from
documents and pleadings, annotation text, questions and answers from
transcripts, and
electronic outlines. The outline feature may be implemented as a software-
based add-on to an
- existing subscription-based service or product. For example, a
"Transcript Summary" feature
may be an add-on to Case Notebook subscribers that allows users to type
summaries for
specific lines of transcripts.
12
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0030] An exemplary system includes an entity tagger, an entity
resolver, a text
segment classifier, and a relationship extractor. The entity tagger receives
an input text
segment, and tags named entities with the segment as being a person, company,
or place. In
response, the entity resolver accesses an authority files, and associates the
persons and
companies named in the text segment with specific entries in the authority
files. The text
segment classifier determines whether the entity tagged and resolved text
segment includes a
relationship event, such as job-change event or merger and acquisition. For a
text segment
that includes the relationship event, the relationship extractor determines
the role of named
entities in the text segment within the event. For example, the extractor
determines for a
merger and acquisition event, which named company was the acquirer and which
was
acquired.
[0031] In a first embodiment the further present invention provides a
computer-
implemented method comprising: accessing a preexisting entity list; analyzing
a first
document to detect an entity, the entity comprising a person, place, or
organization, the first
document being associated with a current legal event; resolving the entity
with the
preexisting entity list and: if the entity is not present in the preexisting
entity list, adding the
entity to the preexisting entity list and generating a first set of
relationship data associated
with the relationship between the first document and the entity; or if the
entity is present in
the preexisting entity list, generating a first set of relationship data
associated with a
relationship between the first document and the entity; repeating the
resolving step for each
distinct entity detected in the first document; and storing the first set of
relationship data. The
method further characterized by the detected entity is one of the group
consisting of attorney
names, judge names, courts, names of parties to a lawsuit, expert names,
witness names, and
law firm names. The method further characterized by the first set of
relationship data includes
a first set of location data representing one or more locations in the first
document in which
the entity appears.
[0032] In a second embodiment, the further present invention provides
a computer-
implemented method comprising: accessing a preexisting entity list; analyzing
a first
document to detect an entity, the entity comprising a person, place, or
organization, the first
document being associated with a current legal event; resolving the detected
entity with the
preexisting entity list and, if the detected entity is not present in the
preexisting entity list,
generating a list of new entities; generating respective sets of relationship
data representing a
relationship between the first document and each respective detected entity;
repeating the
13
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
resolving step for each distinct entity detected in the first document and
adding each distinct
entity not present in the preexisting entity list to the list of new entities;
and storing the
respective sets of relationship data. The method further characterized by
displaying a user
interface adapted to allow a user to select and/or deselect one or more of the
new entities.
[0033] In a third embodiment, the further invention provides a computer
useable
medium having a set of executable code for enabling electronic communications
between a
Word processing program of a client access device and an information services
provider
system (ISP), the set of executable code comprising: a first set of computer
program code
adapted to access a preexisting entity list; a second set of computer program
code adapted to
.. analyze a first document to detect an entity, the entity comprising a
person, place, or
organization, the first document being associated with a current legal event;
a third set of
computer program code adapted to resolve the entity with the preexisting
entity list and: if the
entity is not present in the preexisting entity list, adding the entity to the
preexisting entity list
and generating a first set of relationship data associated with the
relationship between the first
document and the entity; or if the entity is present in the preexisting entity
list, generating a
first set of relationship data associated with a relationship between the
first document and the
entity; a fourth set of computer program code adapted to repeat the resolving
step for each
distinct entity detected in the first document; and a fifth set of computer
program code
adapted to store the first set of relationship data. The computer useable
medium further
characterized by a sixth set of computer program code adapted to generate
smart tags based
on the first set of relationship data, whereby subsequent display of the first
document
includes displaying a set of smart tags at a set of locations in the first
document associated
with the entity. The computer useable medium further characterized by a
seventh set of
computer program code adapted to generate, in response to a report request, a
signal based
upon the set of smart tags; and an eight set of computer program code adapted
to generate a
computer display associated with the signal.
[0034] In a fourth embodiment, the further invention provides a
computer-
implemented method comprising: analyzing a first document to detect entities
appearing in
the document, the first document being associated with an event; detecting a
first entity in
.. the first document; generating a first set of relationship data
representing a relationship
between the first document and the detected first entity; comparing the
detected first entity
with a set of entity data derived from an existing authority database of known
entities; and
14
updating the authority database of known entities including storing the first
set of
relationship data.
[0034a] In accordance with an aspect of the present invention there
is provided a
computer useable medium storing statements and instructions, which when
executed by one
or more processors, causes the one or more processors to enable electronic
communications
between a word processing program of a client access device and an information
services
provider system (ISP), by performing a method comprising:
(a) operatively connecting to the word processing program;
(b) operatively connecting to the information services provider system;
(c) accepting a user search request initiated by a user of the word processing
program;
(d) transmitting the user search request to the information services provider
system;
(e) deriving a set of pseudo documents from a set of secondary documents,
each pseudo document in the set of pseudo documents representing a version of
a secondary
document from the set of secondary documents and comprising a set of
identified citations
and a set of text segments from said secondary document in the set of
secondary documents,
each text segment in the set of text segments being associated with and
immediately
preceding a corresponding identification citation from the set of identified
citations;
(f) receiving a set of search results, the set of search results comprising a
primary set of case law search results and a secondary set of non-case law
search results, the
primary set of case law search results comprising a first set of case
documents, the secondary
set of non-case law search results comprising a referencing text document set,
the referencing
text document set comprising a case law citation set, the case law citation
set comprising one
or more citations from the set of identified citations in the set of pseudo
documents and used
to derive a set of referencing text results, and wherein the set of
referencing text results
comprises a second set of case documents used to supplement the primary set of
case law
search results; and
(g) displaying within the word processing program at least a portion of the
second set of case documents from the set of referencing text results.
[0034b[ In accordance with a further aspect of the present invention
there is provided a
computer-implemented method for enabling electronic communications between a
word
processing program operating on a client access device and a computer-based
information
services provider system (ISP), the method comprising:
(a) operatively connecting to a word processing program operating on a client
- 15 -
CA 2807494 2018-11-07
access device;
(b) operatively connecting to an ISP;
(c) accepting a user search request initiated by a user of the word processing
program;
(d) transmitting the user search request to the ISP;
(e) receiving a set of search results, the set of search results comprising a
primary set of case law search results and a secondary set of non-case law
search results, the
primary set of case law search results comprising a first set of case
documents, the secondary
set of non-case law search results comprising a referencing text document set,
the referencing
text document set comprising a set of pseudo documents derived from a set of
secondary
documents, each pseudo document in the set of pseudo documents representing a
version of a
secondary document from the set of secondary documents and comprising a set of
identified
citations and a set of text segments from said secondary document in the set
of secondary
documents, each text segment in the set of text segments being associated with
and
immediately preceding a corresponding identification citation from the set of
identified
citations, the referencing text document set comprising a case law citation
set, the case law
citation set used to derive a set of referencing text results, and wherein the
set of referencing
text results comprises a second set of case documents used to supplement the
primary set of
case law search results; and
(1) receiving for display within a user interface of the word processing
program
at least a portion of the second set of case documents from the set of
referencing text results.
10034c1 In accordance with a further aspect of the present invention
there is provided a
client access device comprising:
a processor adapted to execute code;
a memory for storing executable code;
a word processing program executed by the processor;
a database comprising a set of pseudo documents derived from a set of
secondary
documents, each pseudo document in the set of pseudo documents representing a
version of a
secondary document from the set of secondary documents and comprising a set of
identified
citations and a set of text segments from said secondary document in the set
of secondary
documents, each text segment in the set of text segments being associated with
and
immediately preceding a corresponding identification citation from the set of
identified
citations;
means for establishing electronic communications with an information services
provider system (ISP) having a first database having a primary set of
documents;
- 15a -
CA 2807494 2018-11-07
a first set of computer program code for operatively connecting to the word
processing
program;
a second set of computer program code for operatively connecting to the
information services provider system;
a third set of computer program code for accepting a user search request
initiated by a user of the word processing program;
a fourth set of computer program code for transmitting data derived from the
user search request to the information services provider system;
a fifth set of computer program code for receiving a set of search results,
the set
of search results comprising a primary set of case law search results and a
secondary set of
non-case law search results, the primary set of case law search results
comprising a first set of
case documents, the secondary set of non-case law search results comprising a
referencing
text document set, the referencing text document set comprising a case law
citation set, the
case law citation set comprising one or more citations from the set of
identified citations in
the set of pseudo documents and used to derive a set of referencing text
results, and wherein
the set of referencing text results comprises a second set of case documents
used to
supplement the primary set of case law search results; and
a sixth set of computer program code for receiving for display within a user
interface of the word processing program at least a portion of the second set
of case
documents from the set of referencing text results.
10034d1 In accordance with a further aspect of the present invention
there is provided a
network-based, computer-implemented information services provider system (1SP)
having a
set of executable code for enabling data exchange with a word processing
program remotely
operating on a client access device, the system comprising:
a processor adapted to execute code;
a memory for storing executable code;
a first database accessible by the processor and having stored therein a
primary
set of documents;
a second database accessible by the processor and having stored therein set of
pseudo documents derived from a set of secondary documents, each pseudo
document in the
set of pseudo documents representing a version of a secondary document from
the set of
secondary documents and comprising a set of identified citations and a set of
text segments
from said secondary document in the set of secondary documents, each text
segment in the
set of text segments being associated with and immediately preceding a
corresponding
identification citation from the set of identified citations;
- 15b -
CA 2807494 2018-11-07
a first set of computer program code adapted to operatively connect to the
word
processing program;
a second set of computer program code adapted to receive search data
associated with a user search request initiated by a user of the word
processing program;
a third set of computer program code adapted to generate a set of search
results,
the set of search results comprising a set of primary case law search results
from the first
database and a set of secondary non-case law search results comprising a
referencing text
document set derived from the second database, the referencing text document
set
comprising a case law citation set, the case law citation set comprising one
or more citations
from the set of identified citations in the set of pseudo documents and used
to derive a set of
referencing text results, and wherein the set of referencing text results
comprises a second set
of case documents used to supplement the set of primary case law search
results; and
a fourth set of computer program code adapted to transmit for display within a
user interface of the word processing program at least a portion of the set of
search results
including at least a portion of the second set of case documents from the set
of referencing
text results.
BRIEF DESCRIPTION OF THE DRAWINGS
100351 In order to facilitate a full understanding of the present
invention, reference is
now made to the accompanying drawings, in which like elements are referenced
with like
numerals. These drawings should not be construed as limiting the present
invention, but are
intended to be exemplary and for reference.
100361 Figure 1 is a first schematic diagram illustrating an
exemplary computer-based
system for implementing the present invention;
(0037] Figure 2 is a second schematic diagram illustrating an
exemplary computer-
based system for implementing the present invention;
100381 Figure 3 is a search flow diagram illustrating an exemplary
method of
implementing the present invention;
100391 Figure 4 is a flow diagram illustrating a database and document
accessing
aspect of the present invention;
100401 Figure 5 is a schematic diagram of a hardware configuration
of a processor-
based system for implementing the present invention;
100411 Figure 6 is a workflow associated with processing the
Drafting Assistant
aspect of the present invention;
100421 Figures 7A-7C represent a logon and access aspect in
conjunction with the
present invention;
- 15c -
CA 2807494 2018-11-07
100431 Figures 7D represents a matter control aspect in conjunction
with the present
invention;
100441 Figure 8 is a workflow for determining compatibility of
applications and
controls in conjunction with the present invention;
100451 Figures 9A-9I3 are screen shots representing IIT controls
aspect in conjunction
with the present invention;
100461 Figure 10 is a workflow for selecting controls in conjunction
with the present
invention;
- 15d -
CA 2807494 2018-11-07
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[0047] Figure 11 is a screen shot associated with a user-selected
control in
conjunction with the present invention;
[0048] Figure 12-14B are workflows for accessing documents and
templates and
importing documents in conjunction with the present invention;
[0049] Figure 15 is a screen shot representing a control and search and
import aspect
of the present invention;
[0050] Figures 16 and 17 are a workflow and screen shot illustrating a
user selected
ISP search aspect of the present invention;
[0051] Figures 18 through 20 are a workflow and screen shots
illustrating a user
selected ISP search and results aspect of the present invention;
[0052] Figures 21A through 26 are a workflow and screen shots
illustrating the
Locate Authority UI and search aspect of the present invention; and
[0053] Figures 27A-27D illustrate a series of screen shots
illustrating a search results
screen resulting from processing the present invention.
[0054] Figure 28 is a block and flow diagram of an exemplary system for
named-
entity tagging, resolving and event extraction, which corresponds to one or
more
embodiments of the present invention.
[0055] Figure 29 is a diagram illustrating guided sequence decoding
for named-entity
tagging which corresponds to one or more embodiments of the present invention.
[0056] Figure 30 is a block diagram of an exemplary named-entity tagging,
resolution, and event extraction system corresponding to one or more
embodiments of the
present invention.
[0057] Figure 31 is a flow chart of an exemplary method of named-
entity tagging and
resolution and event extraction corresponding to one or more embodiments of
the present
invention.
[0058] Figure 32 is a flow chart of another exemplary method of named-
entity
tagging and resolution corresponding to one or more embodiments of the present
invention.
[0059] Figures 33-46 illustrate a series of screen shots associated
with the user
interface aspects and control aspects and display aspects corresponding to one
or more
.. embodiments of the present invention.
16
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
DETAILED DESCRIPTION OF THE INVENTION
[0060] The present invention will now be described in more detail with
reference to
exemplary embodiments as shown in the accompanying drawings. While the present
invention is described herein with reference to the exemplary embodiments, it
should be
understood that the present invention is not limited to such exemplary
embodiments. Those
possessing ordinary skill in the art and having access to the teachings herein
will recognize
additional implementations, modifications, and embodiments, as well as other
applications
for use of the invention, which are fully contemplated herein as within the
scope of the
present invention as disclosed and claimed herein, and with respect to which
the present
invention could be of significant utility.
[0061] The present invention provides, among other things, software
platform
components that enable an application to perform several functions without
leaving the
document and the host application. Essentially, the document could become a
software
platform. These functions include for example extracting key context
indicators such as
document type (memo, pleading, agreement etc), jurisdiction and governing law
(Orange
County, New York etc.) and storing them, for example, in a data structure
logically
associated with the user and/or the document. In some embodiments, a document
identifier is
also stored to uniquely associate the document with the user. Some embodiments
store the
data as metadata linked to the document; others within subscriber data for an
online legal
research service (or a professional information research service.) The system
also presents
relevant content options to users based on the context of the document being
drafted. For
example the system may include functionality that automatically extracts
jurisdiction,
document type and title from the document and allows searching similar content
on WestLaw
or WestLaw Business. The system may include the functionality of extract key
legal entities
from the document and using this information to enhance the document by adding
relevant
content. The system may automatically extract judge and party names, link
automatically to
profiles, extract and validate, KeyCite (KC) Flags (West BriefTools, West
Knowledge
Management (West KM)), and provide guidance on citation format (West
CiteAdvisor). The
system allows users to use predefined Litigation and Transactional workflows
to track
progress. This process is described in more detail below in the context of
exemplary
embodiments.
17
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Exemplary Document Processing and Information Retrieval System
[0062] Figure 1 shows an exemplary Integrated System 100 comprising an
online
information-retrieval (or legal research) system adapted to integrate with a
client-operated
document processing system. In this exemplary embodiment, System 100 includes
at least
one web server that can automatically control one or more aspects of an
augmented
document-processing application on a client access device. The document-
processing
application, for example, the Microsoft word application, is augmented with an
add-on
framework that integrates into the graphical user interface of the application
and includes a
browser control that can access one or more web-based applications and allow
macro-type
scripts of the web-based applications or services control the document
processing application.
System 100 includes one or more databases 110, one or more servers 120, and
one or more
access devices 130.
[0063] Databases 110 includes a set of primary databases (PDC) 112, a
set of
secondary databases (RTC) 114, and a set of metadata databases 116. Primary
databases 112,
in the exemplary embodiment, include a case law database 1121 and a statute
database(s)
1122, which respectively include judicial opinions and statutes from one or
more local, state,
federal, and/or international jurisdictions. Secondary databases 114, which
contain legal
documents of secondary legal authority or more generally authorities
subordinate to those
offered by judicial or legislative authority in the primary database, includes
an ALR
(American Law Reports) database, 1141, an AMJUR database 1142, a West Key
Number
(KNUM) Classification database 1143, and a law review (LREV) database 1144.
Metadata
databases 116 include, for instance, case law and statutory citation
relationships, KeyCite
data, depth of treatment data, quotation data, headnote assignment data, and
ResultsPlus
secondary source recommendation data. Other embodiments may include non-legal
databases that include financial, scientific, or health-care information.
Still other
embodiments provide public or private databases, such as those made available
through
WESTLAW, INFOTRAC, and more generally any open web or Internet content. Also,
in
some embodiments, primary and secondary connote the order of presentation of
search
results and not necessarily the authority or credibility of the search
results.
[0064] Databases 110, which take the exemplary form of one or more
electronic,
magnetic, or optical data-storage devices, include or are otherwise associated
with respective
indices (not shown). Each of the indices includes terms and phrases in
association with
corresponding document addresses, identifiers, and other conventional
information.
18
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Databases 110 are coupled or couplable via a wireless or wireline
communications network,
such as a local-, wide-, private-, or virtual-private network, to server 120.
[0065] Server 120, which is generally representative of one or more
servers for
serving data in the form of webpages or other markup language forms with
associated
applets, ActiveX controls, remote-invocation objects, or other related
software and data
structures to service clients of various "thicknesses." More particularly,
server 120 includes a
processor module 121, a memory module 122, a subscriber database 123, a
primary search
module 124, metadata research module 125, and a user-interface module 126.
[0066] Processor module 121 includes one or more local or distributed
processors,
controllers, or virtual machines. In the exemplary embodiment, processor
module 121
assumes any convenient or desirable form.
[0067] Memory module 122, which takes the exemplary form of one or
more
electronic, magnetic, or optical data-storage devices, stores subscriber
database 123, primary
search module 124, secondary search module 125, and user-interface module 126.
[0068] Subscriber database 123 includes subscriber-related data for
controlling,
administering, and managing pay-as-you-go or subscription-based access of
databases 110.
In the exemplary embodiment, subscriber database 123 includes one or more user
preference
(or more generally user) data structures. In the exemplary embodiment, one or
more aspects
of the user data structure relate to user customization of various search and
interface options.
To this end, some embodiments include user profile information such
jurisdiction of
practice, area of practice, and position within a firm.
[0069] Primary search module 124 includes one or more search engines
and related
user- interface components, for receiving and processing user queries against
one or more of
databases 110. In the exemplary embodiment, one or more search engines
associated with
search module 124 provide Boolean, tf-idf, natural-language search
capabilities.
[0070] Secondary module 125 includes one or more search engines for
receiving and
processing queries against one or more of databases 114. Some embodiments
charge a
separate or additional fee for searching and/or accessing documents from the
secondary
databases.
[0071] Information-integration-tools (IIT) framework module 126 (or
software
framework or platform) includes machine readable and/or executable instruction
sets for
wholly or partly defining software and related user interfaces having one or
more portions
19
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
thereof that integrate or cooperate with one or more document-processing
applications.
Exemplary document-processing (or document-authoring or -editing) applications
include
word processing applications, email applications, presentation applications,
and spreadsheet
applications. (More about the module 126 is described below.) In the exemplary
embodiment,
these applications would be hosted on one or more accesses devices, such as
access device
130.
[0072] The invention may also include a metadata research module that
includes one
or more search engines for receiving and processing queries against metadata
databases 116
and aggregating, scoring, and filtering, recommending, and presenting results.
In the
exemplary embodiment, the metadata module includes one or more feature vector
builders
and learning machines to implement the functionality described herein. Some
embodiments
charge a separate or additional fee for accessing documents from the second
database. Also
included may be a user-interface module that includes machine readable and/or
executable
instruction sets for wholly or partly defining web-based user interfaces over
a wireless or
wireline communications network on one or more accesses devices, such as
access device
130.
[0073] Access device 130 is generally representative of one or more
access devices.
In the exemplary embodiment, access device 130 takes the form of a personal
computer,
workstation, personal digital assistant, mobile telephone, or any other device
capable of
providing an effective user interface with a server or database. Specifically,
access device
130 includes a processor module 131 one or more processors (or processing
circuits) 131, a
memory 132, a display 133, a keyboard 134, and a graphical pointer or selector
135.
[0074] Processor module 131 includes one or more processors,
processing circuits, or
controllers. In the exemplary embodiment, processor module 131 takes any
convenient or
desirable form. Coupled to processor module 131 is memory 132.
[0075] Memory 132 stores code (machine-readable or executable
instructions) for an
operating system 136, a browser 137, document processing software 138. (In the
exemplary
embodiment, memory 132 also includes document management software and time and
billing
system software not shown in the FIG. 1. In some embodiments, this software
may be hosted
on a separate server.) In the exemplary embodiment, operating system 136 takes
the form of a
version of the Microsoft Windows operating system, and browser 137 takes the
form of a
version of Microsoft Internet Explorer. Operating system 136 and browser 137
not only
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
receive inputs from keyboard 134 and selector 135, but also support rendering
of graphical
user interfaces on display 133. In the exemplary embodiment, document
processing software
138 includes one or more word processing applications, e.g., Microsoft Word
processing
software, Powerpoint presentation software, Excel spreadsheet software, and
Outlook email
software. Document processing software is shown integrated with information-
integration
tools 1381, which may be, for example, downloaded from server 120 via a wired
or wireless
communication link established with, for example, an ISP. Upon launching of
the document
processing software an integrated document-processing and information-
retrieval graphical-
user interface 139 is defined in memory 132 and rendered on display 133. Upon
rendering,
interface 139 presents data in association with one or more interactive
control features (or
user-interface elements). In the exemplary embodiment, each of these control
features takes
the form of a hyperlink or other browser-compatible command input. User
selection of some
control features results in retrieval and display of at least a portion of the
corresponding
document within a region of interface 139. Although FIG. 1 shows regions as
being
simultaneously displayed, some embodiments present them at separate times.
[0076] More particularly, interface 139 includes document-processing
tool bar region
1391, document-processing (editing and display) region 1392, and integrated
information
region(s) 1393. In the exemplary embodiment, region 1393 includes control and
display
elements for external content and services, such as a listing of one, two, or
more web apps (or
locally supported apps) provided by server 120 and databases 110, specifically
the web apps
and framework components of module 126. Region 1393 includes control and
display
elements for metadata content related to completing a task related to
authoring a document
loaded into document-processing (active editing) window 1392. For example,
region 1393
may list contact data regarding all persons, such as law-firm and client
personnel, opposing
legal counsel and court personnel, and witnesses associated with a legal case
for which the
loaded document is being prepared. Such entities and persons are referred to
herein
interchangeably as "entity", "person", "company", and "named entity". In some
embodiments, region 1393 includes specific workflow information and control
elements
related to the user who launched the document-processing application and/or
generic
workflow information accessible via the user. In some embodiment, the user may
select a
workflow step or task within region 1393 and initiate update of the content or
available tools
and services of module 126.
21
CA 02807494 2013-02-05
WO 2012/033511 PCT/US2011/001391
[0077] Also, in the exemplary embodiment, the information integration
tools include
local desktop tools, such as Brieffools, CiteLink, DealProof, LiveNote, local
server tools and
services, such as West km knowledge management system, ES, and Elite
accounting, and
remote tools and services, such as KeyCite and other Thomson Reuters or third-
party tools
and services. These tools are made available through an exemplary software
platform or
framework of module 126. As discussed in more detail below, one or more
portions of tools,
APIs and software are downloaded and installed as an add-on or add-in
framework and set of
associated APIs to host application 138. An Information Services Provider
(ISP), such as
Thomson Reuters West, provides a Litigation Support System (LSS) that is
software-based,
such as West Case Notebook, and that includes functionality operating at one
or both of
server 120 and client access device 130. FIG. 2, discussed below, shows
another exemplary
embodiment of the overall system.
[0078] In the exemplary embodiment the framework generally allows for
building
applications that operate in a user desktop workflow scenario. The exemplary
framework or
platform can be broken down into the following layers or silos. Hooks:
Mechanism in the
host application, such as a toolbar button in MS Word word processing
application to invoke
the container. Container: The area, such as a command bar object in MS Word
application,
where the feature applications are hosted. Applications: Feature applications
that support a
specific set of features. Service Blocks: Infrastructure pieces that feature
applications can
leverage.
[0079] A hook, in the exemplary embodiment, is designed as a mechanism
for users
to open the container from a host application. The hook loads itself inside
that host
application and then loads the container. A hook also introduces a uniform way
to see the
content. The hook, through the use of application programming interfaces
(APIs), provides a
way to get at, extract, and/or insert data of the particular opened document
within the host
application. A host application could be any Microsoft desktop application,
WordPerfect,
Adobe Professional, or a web browser (e.g., Internet Explorer, Netscape,
FireFox, etc.). In
one example, the host application is Microsoft Word. The exemplary embodiment
provides
single add-in for all supported Word versions. One way of achieving this
support is to add an
.. abstraction layer based on the use of reflection into the version specific
library to allow the
=
same code to work for all versions of Word. The abstraction layer is based on
the most recent -
version, and falls back on earlier supported method calls if needed. It also
fails gracefully
when the functionality is missing in the Word version. Additionally, the layer
implements
22
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
changes to add-in to determine the correct version specific library to load
and all method calls
to Word object model using reflection.
[0080] For host application integration of the software platform, many
interfaces
provide support for including a hook that assists the host application to
provide the user
interface (UI) real-estate for the container as well as providing the
integration mechanism
itself. The U1 real-estate is an area on the screen set aside for the
container and a toolbar
button. The host application is responsible for creating this space and
creating an instance of
Forms.DynamicContainer. Generally a window is created as the parent of the
DynamicContainer. Additionally, the host is responsible for providing the
ability to resize the
area for the DynamicContainer.
[0081] The software platform is a managed .Net product with the Common
Language
Runtime (CLR) at the core and is loaded into the host process. CLR is a
platform for software
development that provides services by consuming metadata. In one embodiment,
the software
platform provides support and help for creating unmanaged host integrations
using
C++/COM. From a COM based language, the CLRLoader can be used to load the CLR
into
process, and invoke a designated managed class in a separate assembly to
bridge into
managed code and the rest of the add-in implementation. The CLRLoader is a COM
object
that can be created using standard COM methods (CoCreateInstance( )etc). It
provides an
interface that starts the CLR, and can load a managed class from an assembly
with
information provided in a configuration file. The managed class that is
created by the
CLRLoader must be given the HostShim Attribute and the user must define a
method called
"Configure" that returns a void and has a single "object" parameter. The
software platform
host application should implement the interface. Additionally, all the
interfaces defined in the
project, file document.cs are implemented on a set of classes to provide
access to the
document content of the host application.
[0082] In some exemplary embodiments, the container is designed to
host feature
application features and functions. However, some embodiments host the feature
application
itself. Hosted within the container is a browser control or mini embedded
browser. The
browser control does application user interface (UI) rendering and script
execution. An
exemplary browser control is Internet Explorer but any web browser or
equivalent would be
acceptable as well. U1 rendering refers to displaying the user interface of
the feature
application within the container. The feature application IA's are developed
using html and
Cascading Style Sheets (CSS) but some embodiments use other browser based
technologies,
23
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
such as ASP.Net pages, Silverlight applications, Adobe Flash applications,
etc. Much of the
functionality of the feature applications is implemented in the JavaScript
programming
language. Embedded in the browser control is a JavaScript execution engine
that reads the
script and performs the requested operations defined in the JavaScript
program.
[0083] Feature applications are designed with intent of reusing the
software platform
and functionality. They are developed independently but may be dependent on
the software
platform components. For example, one app inserts and updates flags. Assuming
the software
platform already has a communication service block and diagnostics service
block (service
blocks described in further detail below), the communication service block
could be used to
gather flag information and the diagnostics service block could be used to add
tracing and
logging into the application as well as add exception handling into the
application.
[0084] Another example feature application provides linking to
referenced
documents. This feature application relies on Office Integration to provide a
handle to the
document in focus within Word. The application should also include the ability
to select
referenced documents for analysis. An assuming once again a diagnostics
service block exists
with the software platform, the diagnostics service block could be used to add
tracing and
logging into the application as well as add exception handling into the
application.
[0085] There are a wide variety of ways to develop an application that
can be hosted
within the software platform container. At a minimum in the exemplary
embodiment, the user
needs to provide an XML feature file that informs the software platform where
the HTML
page for the UI resides and the HTML UI itself. The Features XML file is a
simple XML
document that contains the URL for the main UI for a given
feature/application. It consists of
a root element ", a single child element " whose content is the URL of the
HTML User
Interface of the application. This features XML file is deployed to the user's
desktop. The UI
can take the form of a static HTML page or other web application language. The
inclusion of
a script tag for the inject.cs script file facilitates access to the desktop
injected items of the
Host and ServiceLocator. The ServiceLocator is used to create instances of
other Desktop
Services by name. The UI location is constrained by the container, and thus
influences design
of the UI.
[0086] If the application needs to access content from within the software
platform
host application, the exemplary embodiment references the two JavaScript files
(inject.cs and
Load.cs) that are a part of the software platform main web package. JavaScript
interacts with
24
the desktop services provided. This gives access to a JavaScript reference to
the "host" object
as well as the locator" ServiceLocator object. Finally, if the application
provides a desktop
service, the service implementation (See Software Platform Exemplary Service
Practices
section) is provided in an installable package.
[0087] Feature applications call service blocks which are designed
with the intent of
reusability and expose the services of those feature applications. In other
words, the
purpose of service blocks is to supply local reusable components to a feature
application.
The functionality can be accessed via JavaScript and/or by referencing the
necessary .net
assemblies. Examples of application building platform components that can be
leveraged
are
more fully detailed and set forth in U.S. Published Application Publ. No.
2010/0115401.
[0088] In one embodiment of operating a system using the present
invention, an add-
on framework is installed and one or more tools or APIs on server 120 are
loaded onto one or
more client devices 130. In the exemplary embodiment, this entails a user
directing a browser
in a client access device, such as access device 130, to internet-protocol
(IP) address for an
online information-retrieval system, such as the Westlaw system and then
logging onto the
system using a username and/or password. Successful login results in a web-
based interface
being output from server 120, stored in memory 132, and displayed by client
access device
130. The interface includes an option for initiating download of information
integration
software with corresponding toolbar plug-ins for one or more applications. If
the download
option is initiated, download administration software ensures that the client
access device is
compatible with the information integration software and detects which
document-processing
applications on the access device are compatible with the information
integration software.
With user approval, the appropriate software is downloaded and installed on
the client device.
In one alternative, an intermediary "firm" network server may receive one or
more of the
framework, tools, APIs, and add-on software for loading onto one or more
client devices 130
using internal processes.
[0089] Once installed in whatever fashion, a user may then be
presented an online
tools interface in context with a document-processing application. In the
exemplary
embodiment, this entails a user launching and opening or creating a document
using one
or more of the following independent applications: Microsoft Word word
processing
application, Corel WordPerfect word processing application, Internet Explorer
browser
application, Adobe Acrobat desktop publishing application, and Microsoft
Outlook email
CA 2807494 2017-11-15
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
application. As used herein "word processor" and "word processing application"
refers
broadly to "document processors" and "document processing applications" and
the use of
"word" and "document" should be given broad meaning in the context of units of
communication and include such forms as electronic mail and other discrete
forms of
.. electronic communications or containers of information. Add-on software for
one or more of
these applications is simultaneous invoked, which in turn results in
presentation of the add-on
menu. The add-on menu includes a listing of web services or application and/or
locally
hosted tools or services. A user selects via the tools interface, such as
manually via a pointing
device. Once selected the selected tool, or more precisely its associated
instructions, is
executed. In the exemplary embodiment, this entails communicating with
corresponding
instructions or web application on server 120, which in turn may provide
dynamic scripting
and control of the host word processing application using one or more APIs
stored on the host
application as part of the add-on framework.
[0090] For example, the user launches the host application (i.e.
Microsoft Word,
WordPerfect, etc.) to work on a document, e.g., legal brief or memorandum. A
Word
processor Software Framework (WSF) interface includes code, add-on or module
that may be
loaded as an add-on to the host application, e.g., App 138. This will load the
WSF Document
API, the WSF Application Container, initialize the installed Application List,
and create the
Ul elements (Ribbons, toolbars, menu items, etc.). The user opens a document
and selects
the desired WSF Application from a list of applications presented via the
integrated Ul
elements. WSF displays the application within the WSF Container and navigates
the
embedded browser to the applications base URL (server 120, appropriate portion
of IIT
module 126). WSF applications can be installed and run as: Local HTA (i.e.,
locally installed
HTML, JS, CSS, etc.); Enterprise web application (intranet or extranet); or
Internet web
application, for example. WSF injects the WSF Document API references into the
JavaScript
execution engine for access from the applications JavaScript. The document in
display (active
edit window of host application, such as a word processing application)
preserves the context
of the application in WSF (i.e., each document has its own instance of WSF
which can be
customized based on user preferences).
[0091] The WSF JavaScript execution engine allows the application code to
run. The
application can use the WSF API's to access the contents of the opened host
(i.e., Microsoft
Word, WordPerfect, etc.) Document, including modifications to these documents.
The WSF
API's exposed to the client include but are not limited to: collection of Open
Documents,
26
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
including API methods for accessing Document specific data; collections of
Paragraphs,
Footnotes, Endnotes, Tables of Authority, hyperlinks, images and many other
document
content objects within a specific open document; and the ability to create a
Location object to
represent a given textual location within the document.
[0092] The WSF API methods that are called by the application in turn will
call
methods exposed by the Host application (ex. Microsoft Word). The manner in
which these
calls are done is Host application specific and dependent on facilities
exposed by the Host
application. The WSF manages the mappings between its own API and the
functionality
exposed by the Host. Additionally, the application can use native browser
capabilities and
other WSF functionality to communicate with web services available locally on
the host
machine, at enterprise (intranet or extranet), or the over the Internet.
[0093] Figure 2 illustrates another representation of an exemplary
system 200 for
carrying out the herein described processes that are carried out in
conjunction with the
combination of hardware and software and communications networking. In this
example,
system 200 provides a framework for searching, retrieving, analyzing, and
ranking claims
and/or patent documents as well as a system for monitoring user subscription
rights and
access and for downloading tools and software associated with providing
enhanced services
to subscribed users. System 200 may be used in conjunction with a system 204
offering of an
information or professional services provider (ISP), e.g., West Services Inc.,
a part of
Thomson Reuters Corporation, and include an Information Integration and Tools
Framework
and Applications module 126, as described hereinabove. Further, in this
example, system
200 includes a Central Network Server/Database Facility 201 comprising a
Network Server
202, a Database of documents, e.g., published court decisions, statutes, etc.,
203, an
Information/Document Retrieval System 205 having as components a Search Engine
209, a
Feature Extraction module 206, a Ranking module 207 and a Learning Module 208.
The
Central Facility 201 may be accessed by remote users 210, such as via a
network 226, e.g.,
Internet. Aspects of the system 200 may be enabled using any combination of
Internet or
(World Wide) WEB-based, desktop-based, or application WEB-enabled components.
The
remote user system 210 in this example includes a GUI interface operated via a
computer
211, such as a PC computer or the like, that may comprise a typical
combination of hardware
= and software including, as shown in respect to computer 211, system
memory 212, operating
system 214, application programs 216, graphical user interface (GUI) 218,
processor 220, and
storage 222 which may contain electronic information 224 such as electronic
documents.
27
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
The methods and systems of the present invention, described in detail
hereafter, may be
employed in providing remote users access to a searchable database. In
particular, remote
users may search a document database using search queries based on patent
claims to retrieve
and view patent documents of interest. Because the volume of documents is
quite high, the
invention provides scoring and ranking processes that facilitate an efficient
and highly
effective, and much improved, searching and retrieving operation. Client side
application
software may be stored on machine-readable medium and comprising instructions
executed,
for example, by the processor 220 of computer 211, and presentation of web-
based interface
screens facilitate the interaction between user system 210 and central system
211. The
operating system 214 should be suitable for use with the system 201 and
browser
functionality described herein, for example, Microsoft Windows Vista
(business, enterprise
and ultimate editions), Windows 7, or Windows XP Professional with appropriate
service
packs. The system may require the remote user or client machines to be
compatible with
minimum threshold levels of processing capabilities, e.g., Intel Pentium III,
speed, e.g., 500
MHz, minimal memory levels and other parameters.
[0094] The configurations thus described are ones of many and are not
limiting as to
the invention. Central system 201 may include a network of servers, computers
and
databases, such as over a LAN, WLAN, Ethernet, token ring, FDDI ring or other
communications network infrastructure. Any of several suitable communication
links are
available, such as one or a combination of wireless, LAN, WLAN, ISDN, X.25,
DSL, and
ATM type networks, for example. Software to perform functions associated with
system 201
may include self-contained applications within a desktop or server or network
environment
and may utilize local databases, such as SQL 2005 or above or SQL Express, IBM
DB2 or
other suitable database, to store documents, collections, and data associated
with processing
such information. In the exemplary embodiments the various databases may be a
relational
database. In the case of relational databases, various tables of data are
created and data is
inserted into, and/or selected from, these tables using SQL, or some other
database-query
language known in the art. In the case of a database using tables and SQL, a
database
application such as, for example, MySQLTM, SQLServerTm, Oracle 8ITM, 1OGTM, or
some
other suitable database application may be used to manage the data. These
tables may be
organized into an RDS or Object Relational Data Schema (ORDS), as is known in
the art.
[0095] Now with reference to Figure 5, an exemplary representation of
a machine in
the example form of a computer system 500 within which a set of instructions
may be
28
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
executed to cause the machine to perform any one or more of the methodologies
discussed
herein. In particular, the system 500, and variations of this, may be used to
implement the
/system/modules/interfaces. In alternative embodiments, the machine operates
as a
standalone device or may be connected (e.g., networked) to other machines. In
a networked
deployment, the machine may operate in the capacity of a server or a client
machine in
server-client network environment, or as a peer machine in a peer-to-peer (or
distributed)
network environment. The machine may comprise a server computer, a client
computer, a
personal computer (PC), a network router, switch or bridge, or any machine
capable of
executing a set of instructions (sequential or otherwise) that specify actions
to be taken by
that machine. Further, while only a single machine is illustrated, the term
"machine" shall
also be taken to include any collection of machines that individually or
jointly execute a set
(or multiple sets) of instructions to perform any one or more of the
methodologies discussed
herein.
[0096] The example computer system 500 includes a processor 502 (e.g.,
a central
processing unit (CPU), a graphics processing unit (GPU), or both), a main
memory 504 and a
static memory 506, which communicate with each other via a bus 508. The
computer system
500 may further include a video display unit 510, a keyboard or other input
device 512, a
cursor control device 514 (e.g., a mouse), a storage unit 516 (e.g., hard-disk
drive), a signal
generation device 518, and a network interface device 520.
[0097] The storage unit 516 includes a machine-readable medium 522 on which
is
stored one or more sets of instructions (e.g., software 524) embodying any one
or more of the
methodologies or functions illustrated herein. The software 524 may also
reside, completely
or at least partially, within the main memory 504 and/or within the processor
502 during
execution thereof by the computer system 500, the main memory 504 and the
processor 502
also constituting machine-readable media. The software 524 may further be
transmitted or
received over a network 526 via the network interface device 520.
[0098] While the machine-readable medium 522 is shown in an example
embodiment
to be a single medium, the term "machine-readable medium" should be taken to
include a
single medium or multiple media (e.g., a centralized or distributed database,
and/or associated
caches and servers) that store the one or more sets of instructions. The term
"machine-
readable medium" shall also be taken to include any medium that is capable of
storing,
encoding or carrying a set of instructions for execution by the machine and
that cause the
machine to perform any one or more of the methodologies of the present
invention. The term
29
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
"machine-readable medium" shall accordingly be taken to include, but not be
limited to,
solid-state memories, optical and magnetic media, and carrier wave signals.
Exemplary Methods of Operating
[0099] The invention may be used in connection with searching based on
known
.. terms but is particularly powerful when a user uses terms not traditionally
used in connection
with an issue or a subject, e.g., "everyone agrees to the underlying events"
as opposed to "no
genuine issue of material fact" in the context of summary judgment
proceedings. The
invention provides the enhanced feature of searching not only primary sources
(Fig. 1 ¨
Primary DBs 112), e.g., case law and statute databases, but also searching
secondary sources
of collections or sets of referencing texts (Fig. 1 ¨ Secondary DBs 114). The
resulting set of
referencing text documents yielded by the second layer of searching is then
used to identify
and present primary source case law relevant to an issue being researched. In
this manner the
invention provides an added layer of searching within a wholly separate and
distinct body of
reference documents or texts and then uses that secondary source search to
further search
primary source databases to thereby enriching and enhancing the set of primary
source
documents ultimately provided to the user. When used in conjunction with
ranking, scoring
and other helpful techniques, the invention enhances the effectiveness of the
overall system
performance.
[0 01 00] "Referencing text documents" included in Reference Text
Collections or Sets
(RTC or RTS), e.g., ALR, are documents that are not part of the body of law or
direct legal
authority but that do cite to case law, statutes, regulations and other legal
authorities. The
invention processes the search criteria to yield a responsive set of
referencing text documents
from the RTC based on a user search request or query, such as may be
highlighted or
otherwise derived from a working document operating in a word processor
application by the
user. The responsive set of referencing text documents are identified by
matching search
terms or criteria with text appearing in the referencing text documents that
is associated with
case law cited in the referencing text documents.
[00101] The system identifies those citations related to the
highlighted or search terms
found in the referencing text documents to yield a set of "referencing text
results", which is a
set of case law cited in the referencing text documents. Accordingly, the
invention generates
a set of search results comprised of two sets of case law for presenting to a
user on a subject
of interest. The first set of case law is generated by performing the search
on the primary
case law database and the second set of case law is generated based on the
citations contained
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
in the set of referencing text documents that relates to the user search
request. In this manner,
the invention provides a seamless integration of searching functions and
database resources
from the word processor environment that includes not only primary case law
but also
secondary sources of non-case law. Accordingly, when searching from the word
processing
.. environment for terms or highlighted statement contained within a working
document, the
invention provides an additional layer of searching in addition to traditional
ISP systems and
provides an enhanced way of searching for responsive legal authority based on
terms not
traditionally used and that appear in secondary sources, e.g., ALR. The system
provides
searching in both the primary and the secondary sources and presents
responsive case law
from the primary source and case law that is cited in responsive referencing
text documents.
In addition, the system may rank, together or separately, the two sets of case
law, the primary
search results from the primary database of case law and the set of
referencing text results.
The system may also reduce, such as through a de-duplication process, the set
of search
results or the component search results. The system may display to the user
the respective
responsive search results either combined or separated. The set or search
results are then
available for user examination and may be incorporated into the working
document.
[00102] In one exemplary method of operation, and with reference to the
flow of
Figure 3, the following processes are performed. Initially, at step 302, a
user highlights text
within a word processing application. At step 304 the system uses the
highlighted text as a
query, or to derive a query, to search a primary document collection/database,
e.g., Primary
DB 112 of Fig. 1. At step 306, the system uses this same information to search
a reference
text collection/database, e.g., RTC 114 of Fig. 1. Optionally, text may be
normalized before
it is used a search query. In particular, the Novus search API may do some
standard
normalization before executing the search. The query may be identical for each
search and
can be run simultaneously. At step 308, the system aggregates, ranks, and/or
re-ranks the
search results, either separately or in the aggregate. In addition, the system
may invoke
enhanced functions of IPS services such as de-duplicating process to further
refine the search
results. The queries may both be "natural language searches" using the same
Novus search
APIs. The searches may be metadata restricted, for example, to specify
jurisdiction. The
processes of steps 304-308 may be performed in part outside the user
experience, including:
receiving a ranked set of results for the document collection search;
receiving a ranked set of
results for the reference text collection search; re-ranking the aggregated
results. At step 310,
the system returns for display via a user interface a set of results to a user
(optionally displays
31
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
only primary documents, e.g., cases, from the PDC 112 and/or display
separately a list of
secondary or Reference Text documents from the RTC 114). At step 312, the user
performs,
such as via GUI, further operations to incorporate aspects of the search into
the user
document opened in the word processing application, e.g., 139/1392 of Figure
1.
[00103] In one manner, re-ranking involves taking aggregated results and
applying a
statistical model to re-rank the results. The re-ranking algorithm receives
search result lists
from both searches. The lists are filtered by jurisdiction and other criteria.
Also, for instance,
"writ denied" cases from the referencing text collection may be filtered out
before being sent
to the re-ranking algorithm. Note that the aggregated set of results could
have duplicate cases
with different rankings; usually take the higher ranked case. For example,
Case A could have
been found in Primary Document Collection, e.g., 112, and is ranked #1; Case A
could also
be found in Reference Text Collection, e.g., 114, and is ranked #2. In this
scenario Case A
from the PDC collection would be used and the Case A from Reference Text
Collection will
be discarded before the statistical model is run. Return a list to the U1
(User Interface, e.g.,
139/1393) of some or all search result Document GUIDs along with which source
that Doc
GUID came from (i.e., PDC Collection or RTC - Reference Text Collection). In
ranking
responsive documents, the source, e.g., primary or secondary, may be used to
differentiate the
results presented to the user. For instance, in one pane the results from the
ISP or primary
source may be listed, ranked or not, and in a second pane the results from the
secondary
source, e.g., referencing texts from sources such as ALR, AmJur, etc., may be
presented. A
variety of search functions may be performed on either or both sets,
separately or
collectively, in determining a set or sub-set of documents from the primary
and secondary
sources to present to the user.
[00104] With respect to the document collections, the collections may
be arrived at by
Natural Language search on cases. Could be an all cases search with filter
available at any
time afterward but before it gets to the user. Alternatively it could be a
specific case search of
only certain jurisdictions, court levels. For instance, about 100 cases may be
passed through
to be re-ranked. The number of cases returned for ranking or presenting may be
limited.
[00105] With respect to the Reference Text Collection (RTC) associated
with
secondary sources or databases, and the exemplary structure of Figure 4, the
system may be
structured so that the Reference Text Collection contains "Pseudo Documents"
and operates
as follows. Each Case has a Pseudo Document within the RTC collection. Pseudo
Documents contain references, citations and GUID for the case, e.g., a
litigation maintained
32
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
in a Litigation Support System (LSS), such as West Case Notebook. Reference:
pre-
determined amount of text that supports the proposition that the case is being
cited for. With
respect to initially populating the RTC collection with Pseudo Documents,
search for
citations within the briefs and case databases. Once a citation is found,
collect pre-determined
amount of text immediately preceding the citation (every citation is one
reference). The
system associates the reference and related citation to a Case ID/Doc GUID.
The system
concatenates new references onto existing GUID if there is one or it creates a
pseudo
document if the GUID has not been seen before. Concatenating occurs on to an
existing
Pseudo Document. The system stores Pseudo Documents within the RTC collection
if, for
example, they have a pre-defined number or more references, e.g., 10. If they
do not have the
requisite number of references then the system stores the Pseudo Documents in
a separate
collection. If the references in the separate collection become greater than,
for example, 10
for a pseudo document then the pseudo document is moved to the RTC collection.
Also, the
system may be configured to truncate Pseudo Documents at a set number or
threshold, e.g.,
500 references. Limiting the number may be especially necessary where Pseudo
Documents
for very highly cited cases contain so many words that nearly any search terms
would return
those documents. The language may be too broad. In one manner, as new cites
are added to
Pseudo Documents, only the most recent 500 cites (or citations) may be
included. In other
words, when the 5015 cite is added, the 15 (earliest) cite will roll off and
the Pseudo
Document will be back at 500 cites. In addition, metadata about the case
(jurisdiction, court
level) may be accessed to help in the re-ranking of aggregated search results
but can also be
helpful if the UI decides to filter by the metadata right before displaying
the results to the
user. In the diagram of Figure 4, D4 implies three bits of information in the
Pseudo
Document. However, the Pseudo Document may be a structured document with, for
example, the following fields:
1. Case GUID
2. Metadata
a. Case jurisdiction
b. Case court level
3. Citing document A and its referencing text
4. Citing document B and its referencing text
5. Citing document C and its referencing text
...
n. Citing document X and its referencing text
33
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00106] All referencing text for the case is effectively concatenated
together as a single
paragraph as far as the natural language search is concerned. To allow the UI
to be able to
display the referencing text for a given reference (the best matching
reference, usually), the
system may be configured to add "padding" in between each chunk of referencing
text (fields
3, 4, 5, and n) above. This is because the search engine, e.g., West's Novus
platform, may be
configured to return the text surrounding only the best matching portion of
the Pseudo
Document.
[00107] For example, say the user's query happens to return the Pseudo
Document
above. The search engine, e.g., Novus, may also identify which is the best
matching portion
within the document, and may flag the text surrounding the best matching
portion. For
instance, if the referencing text for citing document B matches the user's
query the best.
Because of the padding, the best matching text returned will only be for
citing document B.
The referencing text around documents A and C are just too "far" away from the
best
matching portion due to the padding. This approach may be used to facilitate
the UI usage of
the documents returned from referencing text search. The padding has no effect
on the search
itself, as the search doesn't recognize the padding ¨ it's only used to
determine which text to
return as the best matching portion with no pollution from adjacent
referencing text.
[00108] Figures 6 and 7A-7C illustrates methods of installation and
updating of
software platform in association with the present invention. Generally, one
way for the user
to deploy a software platform is to access a download site containing a base
package for an
application that includes a software platform built on a .NET framework and
COM
technology, a feature application, and, optionally, an updater. The user
downloads this
package and deploys the software platform along with the feature application
and possibly
the updater. Another option is to download and deploy the individual
components separately
in install order of the .NET framework, software platform, a feature
application. The updater
can be installed anytime after the software platform is installed. In the
exemplary
embodiment, the updater and the software platform are independent of each
other.
[00109] Generally, there are five exemplary methods for how to update
the software
distribution: direct from the provider's software platform server (on-site
distribution server)--
Updater directly; from remote provider's server (remote distribution server
located within
- user's firewall)--Updater directly; user manually kicks off update process
direct from provider
server (on-site distribution server), user snapshots the changes to create
his/her own
installation package; manually get a copy of the software to install on a test
workstation.
34
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Once o.k. on the test or base image, it is pushed out via SMS or another
distribution package;
and user wants the list of changed and files for the update and creates
his/her SMS package
from the documentation.
[00110] Figures 7D and 10 illustrate an exemplary manner of handling
matter control
in the context of the exemplary implementation of the invention. In the
examples discussed
below, the "matter" refers to a particular litigation or other legal
proceeding for which a file
or working area is set up on an LSS, for instance on Case Notebook. In this
example, the
LSS may include a set of existing template or genericized document types to
assist the user in
preparing documents of the sort commonly associated with a broad range of
litigated issues.
For example, the documents may include genericized, or previously prepared,
Pleadings,
Motions, and Memoranda (PM&M). In particular, the documents may include the
following
Motions: Alter Judgment; Certify Class; Compel; Compel Arbitration; Compel
Discovery;
Consolidate; Declare a Mistrial; Directed Verdict; Dismiss; Dismiss for Lack
of Jurisdiction;
Limine; Intervene; Joinder; Judgment Notwithstanding the Verdict; Judgment as
a Matter of
Law; Judgment on Partial Findings; Judgment on the Pleadings; Judgment Under
Rule 54(b);
New Trial; Partial Summary Judgment; Permanent Injunction; Preliminary
Injunction;
Protective Order; Remand; Set Aside Judgment; Set Aside Verdict; Stay
Discovery; Strike;
Summary Judgment; Temporary Restraining Order; and Vacate. The set of
genericized
documents may also include the following documents: Trial Brief; Pleadings;
Complaints;
Answers and Counterclaims; and Briefs. The User shall have the ability to
access
Templates/Model documents and to access matter-specific Transcripts,
Documents, Pleadings
and Research. Also, the User can generate the following reports: annotations;
issues; full text
search; key facts; and case.
[00111] The portion of the LSS that facilitates integration of the word
processing host
application and a research and litigation support features may be called a
"Drafting
Assistant." The workflow of Figure 9 and corresponding screen shots of Figures
9A and 9B,
illustrates a manner in which a user opens a word processing application. The
LIT aspect of
the invention, as described above, has been loaded and resides at the client
access device,
e.g., computer, 130 and presents to the user via a GUI control options, which
may be
presented in any of a number of acceptable ways including via toolbar, ribbon,
container,
dialog boxes, etc. Figure 9A illustrates a GUI presenting control options via
a ribbon. Figure
9B illustrates control options appearing in a container. The user selects from
the user
interface a control and the system launches the control selected. Exemplary
controls include:
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
locate authority; check formatting; ISP/Westlaw search; Import documents; and
Preferences,
for example. If the User selects Locate Authority, the system launches the
Locate Authority
feature. If the User selects Check Formatting, the system launches the Rules
Based
Validation engine. If the User selects Westlaw Search, the system launches the
Westlaw
Search process. If the User selects Import Document, the system launches the
process to add
documents to Templates/Model Documents.
[00112] Figure 12 illustrates a screen shot in which a user has opened
a word processor
for editing a document shown in the right-hand pane (corresponds to 1392
region of UI 139
of Figure 1) and within left-hand panes the user has access to ISP solution
functionality
(corresponds to 1393 region of UI 139 of Figure 1). In this instance, the user
has selected
Transcripts and is presented with a list of available transcripts to open
including opening into
Case Notebook.
[00113] Figures 13 and 14A and 14B, illustrate workflows for importing
files and
folders into the LSS including browsing capabilities. The Drafting Assistant
System includes
an organizational group labeled "Templates/Model Documents" for storing
documents not
originating in Case Notebook. Users will have access to Templates/Model
Documents even
if they do not subscribe to Case Notebook. Folders and Content contained
within
Templates/Model Documents will be the same regardless of which matter a User
has
selected, or even if a User has not selected a matter from Case Notebook. The
default folders
for Templates/Model Documents are as follows: Model Documents, Language, West
Templates. Where a firm makes networked materials available via Repository
functionality,
Users shall have both personal and firm folders and documents. Default firm
folders are as
follows: Model Documents, Language, West Templates. In a network environment,
default
personal folders are as follows: Model Documents, Language. All folders and
content
contained within Templates/Model Documents will be stored locally on the
User's computer
- either hard drive or network drive. All Users will have the ability to
perform functions on
network documents and folders.
[00114] Users may access Import by: clicking on Import Documents in the
Ribbon in
Word 2007; clicking on the Import Documents button in the Toolbar in earlier
versions of
Word and WordPerfect; selecting Import Document from the pulldown menu in the
Container; or context-sensitive right-click menu. With reference to Figure 15,
If Import is
accessed via the Ribbon/Toobar/Pulldown, the User can select from the
following options:
36
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Search and Import Local/Network Content; Import Current Document; or Import
Selected
Text. Access can also be via the Toolbar, Container, or dialog.
[00115] Figures 16-20 relate to a user performing searching functions
outside the word
processing application but within the context and UI 139 of the combined
experience. Figure
16 describes the process by which a user selects a function, e.g., ISP search
¨ in this example
West Solutions, Westlaw Search. The user may be presented with a logon screen
to access
the ISP search services ancUor content. This may depend on an existing
subscription to the
individual or at the firm level. Preferences associate with the user's account
with the ISP
may also be implemented. The user experience with respect to the ISP aspect is
preferably
viewed as seamless and consistent within the host word processing application.
Figure 18
illustrates an exemplary workflow associated with a user selecting the "Locate
Briefs or
Motions" link in the Westlaw Search pane of Figure 17 and is self-explanatory.
Figures 19
and 20 illustrate Urs, and in particular the HT region 1393 of UI 139 of
Figure 1, associated
with inputting KeyRules search criteria, Figure 19, and displaying search
results, Figure 20.
[00116] Figures 21 through 27 relate to a user's ability to highlight
sections of text
from an open document in the word processing application and to perform a
search based on
the present invention to return useful search results for use in preparing the
working
document, including incorporating excerpts from the researched authority.
Figures 21A and
21B illustrate a workflow in which a user highlights a section of text in the
word document,
e.g., document open in right-pane region 1392 of UI 139, in order to search on
the terms of
interest in the search IIT region 1393 of UI 139. The flow as represented in
the figures
explains the process. Figure 22 is a workflow that illustrates the process for
a user to, after
performing a search using the information integrated tools and resources
available in region
1393, select text from the document/authority displayed in region 1393 for
"copying and
pasting" into the word processor document in region 1392. Figure 23
illustrates a UI
presented to the user in IIT region 1393 and Figure 24 illustrates a UI
screen, UI 139,
presented to a user for performing the process described above and in
connection with
Figures 21A-21B. The User shall have the ability to identify text in the
document being
drafted which may require citation to legal authority. The User shall have the
ability to mark
authority to visibly flag text requiring authority so that the User or the
System can return later
to provide the appropriate citation. The User shall have the ability at any
time during drafting
to launch a process that will use a Westlaw query to suggest legal authority
for text flagged as
requiring authority.
37
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00117] In this example, the user has highlighted the text "Because
unions are
inevitably required to represent employees with conflicting interests,
judicial review of union
action must be highly deferential" from the word processing document in the
right-hand
region 1392. The drafting assistant component of the system presents the user
with "Mark to
Locate Authority" tool to delineate the text to be searched for finding
authority, e.g., case law
or statutes stored in PDC 112. Figure 24 shows the highlighted text as having
the search
delineated by the markers "STARTAUTHORITY" and "ENDAUTHORITY." A second text
excerpt is also shown as having been marked. From the search dialog box in the
viewing
pane, the User shall have the ability to go to the next set of authority
markers without
performing a search by selecting the Next button. The user may then enter
additional search
criteria in the IIT region 1393 of UI 139, e.g., "Authority Type" (case law,
secondary
sources, statutes, and administrative codes) as well as "Date" and
"Jurisdiction" criteria and
restrictions. The user may then click on the 'Begin Locate Authority Search"
button to
launch a search within the 1SP. Figures 27A-27D illustrate the resulting
search results
screens associated with the Locate Authority process.
Exemplary Named-Entity Tagging and Resolution System
[00118] Figure 28 shows an exemplary named entity tagging and resolving
system
2100. In addition to processors 2101 and a memory 2102, system 2100 includes
an entity
tagger 2110, an entity resolver 2120, and authority files 2130. (Tagger 2110,
resolver 2120,
and authority files 2130 are implemented using machine-readable data and/or
machine-
executable instructions stored on memory 2102, which may take a variety of
consolidated
and/or distributed forms.
[00119] Entity tagger 2110, which receives textual input in the form of
documents or
other text segments, such as a sentence 2109, includes a tokenizer 2111, a
zoner 2112, and a
statistical tagger 2113.
[00120] Tokenizer 2111 processes and classifies sections of a string of
input
characters, such as sentence 2109. The process of tokenization is used to
split the sentence or
other text segment into word tokens. The resulting tokens are output to zoner
2112.
[00121] Zoner 2112 locates parts of the text that need to be processed
for tagging,
using patterns or rules. For example, the zoner may isolate portions of the
document or text
having proper names. After that determination, the parts of the text that need
to be processed
further are passed to statistical sequence tagger 2113.
38
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00122] Statistical sequence tagger 2113 (or decoder) uses one or more
unambiguous
name lists (lookup tables) 2114 and rules 2115 to tag the text within sentence
2109 as
company, person, or place or as a non-name. The rules and lists are regarded
herein as high-
precision classifiers.
[00123] Exemplary pattern rules can be implemented using regex+Java, Jape
rules
within GATE, ANTLR, and so forth. A sample rule for illustration dictates that
"if a
sequence of words is capitalized and ends with "Inc." then it is tagged as a
company or
organization. The rules are developed by a human (for example, a researcher)
and encoded in
a rule formalism or directly in a procedural programming language. These rules
tag an entity
in the text when the preconditions of the rule are satisfied.
[00124] Exemplary name lists identify companies, such as Microsoft,
Google, AT&T,
Medtronics, Xerox; places, such as Minneapolis, Fort Dodge, Des Moines, Hong
Kong; and
drugs, such as Vioxx, Viagra, Aspirin, Penicillin. In the exemplary
embodiment, the lists are
produced offline and made available during runtime. To produce the list, a
large corpus of
documents, for example, a set of news stories, is passed through a statistical
model ancUor
various rules (for example, a CRF model) to determine if the name is
considered
unambiguous. Exemplary rules for creating the lists include: 1) being listed
in a common
noun dictionary; and 2) being used as company name more than ninety percent of
the time the
name is mentioned in a corpus. The lookup tagger also finds systematic
variants of the
names to add to the unambiguous list. In addition, the lookup tagger guides
and forces partial
solutions. Using this list assists the statistical model (the sequence tagger)
by immediately
pinning that exact name without having to make any statistical determinations.
[00125] Examples of statistical sequence classifiers include linear
chain conditional
random field (CRF) classifiers, which provide both accuracy and speed.
Integrating such
high precision classifiers with the statistical sequence labeling approach
entails first
modifying the feature set of the original statistical model by including
features corresponding
to the labels assigned by the high-precision classifiers, in effect turning
"on" the appropriate
label features depending on the label assigned by the external classifier.
Second, at run time,
a Viterbi decoder (or a decoder similar in function) is constrained to respect
the partially
labeled or tagged sequences assigned by the high- precision classifiers.
[00126] This form of guided decoding provides several benefits. First,
the speed of the
decoding is enhanced, because the search space is constrained by the
pretagging. Second,
39
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
results are more consistent, because three sources of knowledge are taken
account: the lists,
the rules, and trained decoder statistical model. The third benefit is an ease
of customization
that stems from an elimination of a need to retrain the decoder if new rules
and list items are
added.
[00127] Figure 29 is a conceptual diagram showing how a text segment
"Microsoft on
Monday announced a" is pretagged and how this pretagging (or pinning)
constrains the
possible tags or labeling options that a decoder, such as Viterbi decoder, has
to process. In the
Figure, the term Microsoft is tagged or pinned as a company based on its
inclusion in a list of
company names; the term Monday is marked as "out" based on its inclusion of a
list of terms
that should always be marked as "out"; and the term "on" is marked as out
based on a rule
that it should be marked as "out", if it is followed by an term that is marked
as "out" in this
case the term "Monday."
[00128] In the exemplary embodiment, the statistical sequence tagger
calculates the
probability of a sequence of tags given the input text. The parameters of the
model are
estimated from a corpus of training data, that is, text where a human has
annotated all entity
mentions or occurrences. (Unannotated text may also be used to improve the
estimation of
the parameters.) The statistical model then assembles training data, develops
a feature set and
utilizes rules for pinning. Pinning is a specific way to use a statistical
model to tag a
sequence of characters and to integrate many different types of information
and methods into
the tagging process.
[00129] The statistical model locates the character offset positions
(that is, beginning
and end) in the document for each named entity. The document is a sequence of
characters;
therefore, the character offset positions are determined. For example, within
the sentence
"Hank's Hardware, Inc. has a sale going on right now," the piece of text
"Hank's Hardware,
Inc." has an offset position of (0, 20). The sequence of characters has a
beginning point and
an ending point; however the path in between those points varies.
[00130] After the character offset positions are located, information
about the entity is
identified through the use of features. This information ranges from general
information (that
is, determining text is last name) to specific information (e.g., unique
identifier). The
exemplary embodiment uses the features discussed below, but other embodiments
use other
types and numbers amounts of features:
= Regular expressions: contains an uppercase letter, last char is a dot,
Acronym format,
contains a digit, punctuation
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
= Single word lists: last names, job titles, loc words, etc.
= Multi-word lists: country names, country capitals, universities, company
names, state
names, etc.
= Combination features: title@-1 AND (firstname OR last)
= Copy features: copies features from one token to neighboring tokens, for
example, the
token two to the left of me is capitalized (Cap@-2)
= The word itself features: "was" has the feature was@O
= First-sentence features: copy features from 1st sentence words to others
= Abbreviation feature: copy features of name to mentions of abbr.
[00131] The features computation does not calculate features for
isolated pinned
tokens. The computations combine hashes, combine tries, and combine regular
expressions.
Features are only computed when necessary (for example punctuation tokens are
not in any
hashes so do not look them up). Once the model has been trained, the Viterbi
algorithm (or
an algorithm similar in function) is used to efficiently find the most
probable sequence of tags
given the input and the trained model. After the algorithm determines the most
probable
sequence of tags, the text, such as tagged sentence 2119, where the entities
are located is
passed to a resolver, such as entity resolver 2120.
[00132] Entity resolver 2120 provides additional information on an
entity by matching
an identifier for an external object within authority files 2130 to which the
entity refers. The
resolver in the exemplary embodiment uses rules instead of a statistical model
to resolve
named entities. In the exemplary embodiment, the external object is a company
authority file
containing unique identifiers. The exemplary embodiment also resolves person
names.
[00133] The exemplary resolver uses three types of rules to link names
in text to
authority file entries: rules for massaging the authority file entries, rules
for normalizing the
input text, and rules for using prior links to influence future links. Other
embodiments
include integrating the statistical model and resolver.
[00134] This list along with the original text is the input to an
entity resolver module.
The entity resolver module takes these tagged entities and decides which
element in an
authority file the tagged entity refers. In the exemplary embodiment,
authority file 130 is a
database of information about entities. For example an authority file entry
for Swatch might
have an address for the company, a standard name such as Swatch Ltd., the name
of the
current CEO, and a stock exchange ticker symbol. Each authority file entry has
a unique
identity. In the previous example a unique id could be, ID:345428 , "Swatch
Ltd." , Nicholas
G. Hayek Jr. , UHRN.S. The goal of the resolver is to determine which entry in
the authority
file matches corresponds a name mention in text. For example, it should figure
out the
41
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Swatch Group refers to entity ID:345428. Of course, resolving names like
Swatch is
relatively easy in comparison to a name like Acme. However, even for names
like Swatch, a
number of related but different companies may be possible referents. What
follows is a
heuristic resolver algorithm used in the exemplary embodiment:
Heuristic Resolver Algorithm for Companies
Iterate through entities tagged by the CRF:
If entity tagged as ORG:
If a "do not resolve" ORG (i.e., stock exchange abbreviations):
set ID attribute to "NOTRESOLVED"
Else:
If entity in the company authority file,
set ID attribute to company ID
Else:
set ID attribute to "NOTRESOLVED"
Iterate through NOTRESOLVED entities:
If E is a left-anchored substring of a resolved company:
set ID attribute to already resolved company substring match ID,
change the tag kind to ORG, if necessary
If E is an acronym of an already-resolved company:
set ID attribute to already resolved non-acronym company ID,
change the tag kind to ORG, if necessary
[00135] Note that the exemplary entity tagger and variations thereof is
not only useful
for named entity tagging. Many important data mining tasks can be framed as
sequence
labeling. In addition, there are many problems for which high precision (but
low recall)
extemal classifiers are available that may have been trained on a separate
training set.
Exemplary Event and Relationship Extraction System
[00136] Figure 30 shows an exemplary system 2300 which builds onto the
components of system 2100 with a classifier 2310 and a template extractor
2320, which are
shown as part of memory 2102, and understood to be implemented using machine-
readable
and machine-executable instructions.
[00137] Classifier 2310, which accepts tagged and resolved text such as
sentence 2129
from resolver 2120, identifies sentences that contain extractable relationship
information
pertaining to a specific relationship class. For example, if one is interested
in the hiring
relationship where the relationship is hire(firm, person), the filter (or
classifier) 2312
identifies sentence (1.1) as belonging to the class of sentences containing a
hiring or job-
change event and sentence (1.2) as not belonging to the class.
42
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
(1.1) John Williams has joined the firm of Skadden & Arps as an associate.
(1.2) John Williams runs the billing department at Skadden & Arps.
[00138] The exemplary embodiment implements classifier 2310 as a binary
classifier.
In the exemplary embodiment, building this binary classifier for relationship
extraction
entails:
1) Extracting articles from a target database;
2) Splitting sentences in all articles and loading to a single file;
3) Tagging and resolving types of entities relevant to a relationship type
that occur
within each sentence;
4) Selecting from set of sentences all sentences that have the minimal number
of
tagged entities needed to form a relationship of interest.
This means for example that at least one person name and one law firm name
must be
specified in a sentence for it to contain a job change event. Sentences
containing
requisite number of tagged entity types are called candidate sentences; 5)
Identifying
500 positive instances from the candidate set and 500 negative instances. A
sentence
in the candidate set that actually contains a relationship of interest is
called a positive
instance. A sentence in the candidate set that does not contain a relationship
of
interest is called a negative instance. All sentences within the candidate set
are either
positive or negative instances. These sampled instances should be
representative of
their respective sets and should be found as efficiently as possible;
6) Creating classifier that combines selected features with selected training
methods.
Exemplary training methods include naive bayes and Support Vector Machine
(SVM.) Exemplary features include co-occurring terms and syntax trees
connecting
relationship entities; and
7) Testing the classification of randomly selected sentences from candidate
pool.
After testing the exemplary embodiment evaluates first hundred sentences
classified
as positive (for example, job change event containing) and first hundred
classified as
negative, computing precision and recall and saving evaluated sentences as
gold data
for future testing.
[00139] A range of filters that are either document-dependent filters or
complex
relation detection filters based on machine learning algorithms are developed
and tools that
easily retarget new document types. The structure of a document type provides
very reliable
clues on where the sought after information can be found. Ideally, the filter
is flexible and
43
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
automatically detects promising areas in a document. For example, a filter
that includes a
machine learning tool (for example Weka) that detects promising areas and
produces
pipelines that can be changed according to the relevant features needed for
the task.
[00140] Depending on the requirements, different levels of co-reference
resolution can
be implemented. In some domains, no co-reference resolution is used. Other
situations use a
relatively simple set of rules for co-reference resolution, based on recent
mentions in the text
and identifiable attributes (i.e., gender, plurality, etc.) of the interested
named entities. For
example, in the job change event, almost all co-reference issues are solved by
simply
referring backward to the most recent mention of the matching entity type
(that is, law firm or
lawyer name).
[00141] Template extractor 2320 extracts event templates from
positively classified
sentences, such as sentence 2319, from classifier 2310. In the exemplary
embodiment,
extracting templates from sentences involves identifying the name entities
participating in the
relationship and linking them together so that their respective roles in the
relationship are
identified. A parser is utilized to identify noun phrase chunks and to supply
a full syntactic
parse of the sentence.
[00142] In the exemplary embodiment, implementing extractor 2320
entails:
1) Create gold data by taking positive example sentences from classification
phase
and manually generating appropriate template records. The user is
automatically
presented with all possible templates which could be generated from the
sentence and
asking the user to select the one that is correct;
2) Take 400 sentences from gold data set for training data and develop
extraction
programs based on one or more of the following technologies: association
rules,
chunk kernel based on chunks, CRF, and tree kernel based on syntactic
structure;
3) Test solutions on 100 held out test samples;
4) Combine classifier with extractor to test precision using unseen data.
For instance, a sentence containing a job change event is one that describes
an
attorney joining a law firm or other organization in a professional capacity.
The
target corpora from which job change events are extracted are legal newspaper
databases. The minimal number of tagged entities which qualify a sentence for
inclusion in the candidate set is one lawyer name and one legal organization
name.
One way to efficiently collect positive and negative training instances is to
stratify
samplings. This can be done by sorting the sentences according to the head
word of
44
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
the verb phrase that connects a person with a law firm in the sentence. Then
collect all
head verbs that occur at least five times under a single bucket. After
collection, select
five example sentences from each bucket randomly and mark them as either
positive
or negative examples. For each bucket that yields only positive examples, add
all
remaining instances to the positive example pool. And for each bucket that
yields only
negative examples, add all examples to the negative examples group. If there
are less
than 500 positive examples or less than 500 negative examples, manually score
randomly selected sentences until 500 examples of each time are identified.
The job
change event extractor moves identified entities from a positively classified
job
change event sentence into a structured template record. The template record
identifies the roles the named entities and tagged phrases play in the event.
The template below (which also represents a data structure) is in reference to
sentence 1.1
above.
Role Value Entity ID
Attorney John Williams A23456
Firm Skadden & Arps F56748
Position Associate P234
[00143] In another embodiment, classifier 2310 determines whether tagged
and
resolves sentences (or more generally text segments) from entity resolver 2120
include a
merger and acquisitions event, that is, an event in which one company merges
with or
acquires another company. The target corpora for extracting merger and
acquisition events
are financial news wire articles. The minimal number of tagged entities which
qualifies a
sentence for inclusion in the candidate set is two company names. To help
collect training
data, utilize structured records from merger and acquisitions database on
Westlaw
information-retrieval system (or other suitable information-retrieval system)
to identify
merger and acquisition events that have taken place in the recent past.
[00144] To efficiently identify positive training instances from the
candidate set, find
sentences that contain the names of entities that match these records and were
published
during the time frame over which the merging event took place. To identify
negative
instances, select sentences that contain companies are known to not have been
involved in a
merger or acquisition. The merger and acquisition (M & A) event extractor
moves identified
entities from a positively classified M & A change event sentence into a
structured template
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
record. The template record identifies the roles the named entities and tagged
phrases play in
the event.
[00145] Another embodiment classifies and extracts net income
announcement events
in sentences. A net income announcement event occurs when a company announces
it has
expected or actualized net income over a specific time frame. The target
corpora for extract
merger and acquisition events are financial news wire articles. The minimal
number of tagged
entities which qualifies a sentence for inclusion in the candidate set is one
company name and
the phrase "net income" or the word "profit". To efficiently find positive
instances, extract
net income information from SEC documents for particular companies and find
positive
candidates when the named company in the sentence and the dollar amount or
percentage
increase in profit for a time period line up with information from an SEC
document.
Negative instances are found when the data for a particular company does not
line up with
SEC filings. The net income announcement event extractor moves identified
entities from a
positively classified net income announcement event sentence into a structured
template
record. The template record identifies the roles the named entities and tagged
phrases play in
the event.
[00146] An additional embodiment of the present invention includes a
tool that
generates sentence paraphrases starting from the seed templates provided by a
user. The tool
takes sentences that indicate an event with high precision with the actual
entities replaced by
their generic types. The sentence is searched for in a corpus and the actual
entity identities are
obtained. Then other sentences are located with the same entities in the
corpus (perhaps in a
narrow time window) which saves as paraphrases for the initial sentence. This
step can now
be repeated with the newly acquired sentences. The sentences can be ordered
according to
frequencies of component phrases and manually checked to generate gold data.
[00147] Various assumptions are incorporated in the exemplary embodiment.
One
main assumption is that the identity of the entities is usually independent of
the way of
talking about an event or relationship. Another assumption is that the
extraction of sentences
deemed paraphrases based upon the equality of constituent entities and time
window is
relatively error-free. The precision of this latter filtering step is improved
by having other
checks such as on the cosine similarity between the documents in which the two
sentences
are found, similarity of titles of the documents etc. This approach entails
the following:
1) Providing a large corpus of documents preferably having the property that
several
documents talking about the same event or relationship from different authors
are
46
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
easy to find. One example is a time-stamped news corpus from different news
sources, where the same event is likely to be covered by different sources;
2) Using a named entity recognizer to tag the entities in the corpus with
reasonable
accuracy. Cleary the set of entities that need to be covered by the NER (named-
entity
resolver) depends upon the extraction problem;
3) Providing an indexer for efficient search and retrieval from the corpus;
4) Providing a human generated list of high-precision sentences with the
entities
replaced by wild-cards. For example, for MA, a human might provide a rule
"ORG1
acquired ORG2" means this is an MA sentence with ORG1 being the buyer and
ORG2 being the target.
[00148] Another embodiment entails extraction of information from
tables found in
text. An SVM classifier (or another classifier similar in function)
distinguishes tables from
non-tables. Tables that are only used for formatting reasons are identified as
non-tables. In
addition, tables are classified as tables of interest, such as background,
compensation, etc.
The feature set comprises text before and after the tables as well as n-grams
of the text in the
table. The tables of interest are then processed according to the following:
1) label/value detection. The table has to be partitioned in the labels and
the values.
For the exemplary table below, the system determines that the money amounts
are values and
the rest are labels;
2) label grouping. Some labels are grouped together. For example, Eric Schmidt
and
his current position are one label. On the other hand, a table that contains a
year and a list of
term names (i.e. Winter, Spring, Fall) are not grouped together;
3) abstract table derivation. A derived Cartesian coordinate system leads to
the
notation that defines every value accordingly. [Name and Principal
Position.Eric Schmidt
Chairman of the Executive Committee and Chief Executive Officer.Year.2005,
Annual
Compensation.Salary($)]=1;
4) relation extraction. Given the abstract table representation, the desired
relations are
derived. The compensation relation, for example, is filled with: NAME: Eric
Schmidt;
COMPENSATION TYPE: salary; AMOUNT: 1; CURRENCY: $. Finally, an interpreter for
the tables of interest is created. The input to the interpreter is a table and
the output is a list of
relations represented by the table.
Name and PrincipalPosition Year Annual Compensation
Salary($) Bonus(S) other Annual Compensation(S)
47
CA 02807494 2013-02-05
WO 2012/033511 PCT/US2011/001391
Eric Schmidt 2005 1 1,630 24,741
Chairman of the Executive 2004 81,432 1,556 0
Committee and Chief
Executive Officer
Exemplary Methods of Operating
a Named-Entity Tagging, Resolution and Event and Relationship Extraction
System
[00149] Figure 31 shows a flow chart 2400 of an exemplary method of
operating a
named entity tagging, resolution, and event extraction system, such as system
2300 in Figure
30. Flow chart 2400 includes blocks 2410-2460, which are arranged and
described serially.
However, other embodiments also provide different functional partitions or
blocks to achieve
analogous results.
[00150] Block 2410 entails breaking the extracted text into tokens.
Execution
proceeds at block 2420.
[00151] Block 2420 entails locating parts of the extracted text that
need to be
processed. In the exemplary embodiment, this entails use of zoner 2112 to
locate candidate
sentences for processing. Execution then advances to block 2430.
[00152] Block 2430 entails finding the named entities within the
processed parts of
extracted text. Then the entities of interest in the candidate sentences are
tagged. Candidate
sentences are sentences from target corpus that might contain a relationship
of interest. For
example, one embodiment identifies text segments that indicate job-change
events; another
identifies segments that indicate merger and acquisition activity; a yet
another identifies
segments that may indicate corporate income announcements. Execution continues
at block
440.
[00153] Block 2440 entails resolving the named entities. Each entity is
attached to a
unique ID that maps the entity to a unique real world object, such as an entry
in an authority
file. Execution then advances to block 2450.
[00154] Block 2450 classifies the candidate sentences. The candidate
sentences are
classified into two sets: those that contain the relationship of interest and
those that do not.
For example, one embodiment identifies text segments that indicate job-change
events;
another identifies segments that indicate merger and acquisition activity; a
yet another
48
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
identifies segments that may indicate corporate income announcements. When the
text is
classified, executes advances to block 2460.
[00155] Block 2460 entails extracting the relationship of interest
using a template.
More specifically, this entails extracting entities from text containing the
relationship and
place the entities in a relationship template that properly defines the
relationship between the
entities. When the template is completed, the extracted data may be stored in
a database but
it may also involve more complex operations such as representing the data
according a time
line or mapping it to an index.
[00156] Some embodiments of the present invention are implemented using
a number
of pipelines that add annotations to text documents, each component receiving
the output of
one or more prior components. These implementations use the Unstructured
Information
Management Architecture (UIMA) framework and ingest plain text and decomposes
the text
into components. Each component implements interfaces defined by the framework
and
provide self-describing metadata via XML descriptor files. The framework
manages these
components and the data flow between them. Components are written in Java or
C++; the
data that flows between components is designed for efficient mapping between
these
languages. UIMA additionally provides a subsystem that manages the exchange
between
different modules in the processing pipeline. The Common Analysis System (CAS)
holds the
representation of the structured information Text Analysis Engines (TAEs) add
to the
unstructured data. The TAEs receive results from other UIMA components and
produce new
results that are added to the CAS. At the end of the processing pipeline, all
results stored in
the CAS can be extracted from there by the invoking application (for example,
database
population) via a CAS consumer. Primitive TAEs (for example, tokenizer,
sentence splitter)
can be bundled into an aggregate TAE. Other embodiments use alternatives to
the
UIMA.framework.
[0015T] With reference to Figure 32, in another exemplary
implementation the
invention operates as follows. A character analysis and processing procedure
2500 begins at
step 2502 with the LSS/EMM initialized with a set or list of existing
character names and the
associated alias names of those characters. The LSS will construct this list
from its relational
database (RDB). Next, at step 2504, the system initiates processing by passing
EMM the
contents of a document. At step 2506, EMM then finds characters in the
document and
generates a set of characters for passing to the LSS. These may be characters
from the
original list or new characters. At step 2508, EMM returns to LSS a set or
list of found
49
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
characters which may be new or existing characters or aliases. At step 2510,
EMM also
returns a set or list of document location information that represent
locations or where in the
document each character was found. For instance, the locations may comprise
page, line, and
start and end positions within the document. At step 2512 LSS takes the
returned character
list or set and updates its relational database (RDB). This process may
include adding new
characters and updating existing ones. Also, existing characters may be
updated with new
aliases. Optionally, EMM may also identify and collect address, contact and
other
information associated with a character found in a document and return a set
of such
information to LSS. LSS may then update address, contact or other information
associated
with a character. At step 2514 LSS then takes the location set or list,
translates it to the
internal document location representation and stores in a relational table for
that document.
At step 516, the end user can access for viewing and further action the
updated character set
or list in the LSS interface. At step 518, the end user can also access for
viewing and further
action smart tags in the document associated with characters involved in an
event, e.g., a
litigation.
[00158] More particularly, the Character Recognition Process performed
by the EMM
of the LSS system operates as follows. The LSS integrates with a component,
EMM, to
recognize "characters," e.g., persons, entities, company names, that appear
within part or all
of a document, e.g., within the text or body of a document. This process may
be performed
across a set of documents. For instance, in the legal context, decisions
rendered in cases
result in published opinions, orders or other documents that are of interest
to legal
professionals. LSS systems provide searching functions to enable users, such
as attorneys, to
search, identify and examine documents of interest. For instance, an attorney
may be
interested in reviewing decisions rendered by a certain court, judge or other
entity. An LSS
.. may maintain an existing relational DB of character or entity records
associated with a
collection of case law. The present invention may be used, for instance on a
periodic basis as
decisions are rendered and published, to update the RDB to further associate
published
decisions with existing characters, such as judges, attorneys, parties, etc.
Upon detecting a
"new" character, the present invention may be used to allow the LSS to create
a new
character record. The LSS, for instance, may be an integrated solution, such
as West's
LiveNote and Case Notebook solutions, and may include centralized components,
such as
web-servers and databases, and may involve localized applications that are
downloaded and
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
stored locally such as at a client computer or server. For instance, Case
Notebook stores data
in "Cases" and each case can contain many documents in various formats.
[00159] In one implementation of the present invention, the EMM
provides an xml
based messaging system for inter-process communication between EMM and LSS.
LSS
starts the EMM executable as desired or on a periodic scheduled basis or as
when needed to
process a set of documents to recognize characters and/or maintain the RDB.
The LSS opens
a named pipe to communicate with that process. Essentially, LSS sends xml,
receives a
response, then sends more xml, etc. The following is an exemplary EMM
Communication
Process:
(1) LSS starts a session with EMM.
(2) LSS sends EMM a set or list of characters. This character list or set is
used for all
content in the session. Characters have a name, and they can also have a list
of aliases
or nicknames, e.g., one alias for the name "David" is "Dave."
Pidgin XML:
<Characters>
<Character Name="John Smith" Metadata>
<Alias Name="John" I>
<Alias Name="Mr. Smith" I>
</Character>
<Character Name="Thomson Reuters" Metadata>
</character>
</Characters>
Actual XML
<EMMInput>
<Instruction Method="LoadCharacterList" I>
<A11Characters>
<AcceptedCharacters>
<Character ID="1" Type="Individual"
<Name Full="Copperfield David" Last="David" First="Copperfield"
</Name>
<Business Name="" Streetl=" 5treet2=" Street3=" City="
State=" Postal="" Country=" Email=" Phone="" Cell="" Fax="/>
<Home Streetl="" Street2=" Street3=" City=" State=" Postal="
Country=" Email="" Phone=" Cell=""/>
</Character>
<Character ID="2" Type="Individual"
<Name Full= "John Creakle" Last="Creakle" First="John"
<Alias Name="Creakle"/>
</Name>
<Business Name=" Streetl="" Street2=" Street3=" City="
State=" Postal="" Country=" Email=" Phone=" Cell=" Fax="/>
<Home Streetl=" Street2="" Street3="" City=" State=" Postal="
Country=" Email="" Phone="" Cell="/>
</Character>
<Character ID="3" Type="Individual"
<Name Full="William Nell" Last="Mell" First="William"
<Alias Name="Mell"/>
</Name>
<Business Name=" Streetl=" Street2=" Street3=" City="
State=" Postal="" Country="" Email=" Phone=" Cell=" Fax="/>
51
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
<Home Streetl="" Street2="" Street3="" City="" State="" Postal=""
Country="" Email="" Phone="" Cell=""/>
</Character>
<Character ID="4" Type="Organization"
<Name Full="Salem House" Last="" First="">
</Name>
<Business Name="Salem House" Streetl="" Street2="" Street3=""
City="" State="" Postal="" Country="" Email="" Phone="" Cell=""
Fax=" '/->
<Home Streetl="" 5treet2=" Street3="" City="" State="" Postal=""
Country="" Email="" Phone="" Cell=""/>
</Character>
</AcceptedCharacters>
</AllCharacters>
</EMMInput>
(3) LSS then sends a set of documents or content, e.g., each document or
content may be
sent one item at a time. A process translates the document's internal
coordinate
system into a coordinate system configured in the EM.M. (For example,
transcripts are
stored with document locations specified by a page, a line and a position on
that line.
Word Processing files (RTF, Word, etc.) are stored with document locations
specified
by an offset position from the start of the file. Image locations are
specified by a page
along with a rectangle on that page (i.e., an x,y origin and a width and
height). The
EMM document location may be the same as the transcript document location.)
Pidgin XML:
<Document ID="0">
<page Num="0"
<Line Num="0"
The Quick Brown Fox jumped
</Line>
<Line Num="1"
over John Smith.
</Line>
</Page>
</Document
Actual XML
<EMMInput>
<Instruction Method="Annotate_Conservative" Args="I>
<EMMMetadata>
<Document IsOCR="false" Type="Transcript"
</Document>
</EMMMetadata>
<InputFile>
<Page Index="0"
<Line Index="0">I HAD led this life about a month, when the man
with the wooden leg began to stump</Line>
<Line Index="1">about</Line>
<Line Index="2">with a mop and a bucket of water, from which I
inferred that preparations were making</Line>
<Line Index="3">to</Line>
<Line Index="4">receive Mr. Creakle and the boys. I was not
mistaken; for the mop came into the</Line>
<Line Index="5">schoolroom</Line>
<Line Index="6">before long, and turned out Mr. Mell and me, who
lived where we could, and got on how</Line>
<Line Index="7">we</Line>
52
CA 02807494 2013-02-05
WO 2011933511
PCT/US2011/001391
<Line Index="8">could, for some days, during which we were always
in the way of two or three young</Line>
<Line Index="9">women,</Line>
<Line Index="10">who had rarely shown themselves before, and were
so continually in the midst of dust</Line>
<Line Index="11">that</Line>
<Line Index="12">I sneezed almost as much as if Salem House had
been a great snuff-box.</Line>
<Line Index="13">One day I was informed by Mr. Mell that Mr.
Creakle would be home that evening. In the</Line>
<Line Index="14">evening, after tea, I heard that he was come.
Before bedtime, I was fetched by the man</Line>
<Line Index="15">with the wooden leg to appear before him.</Line>
<Line Index="16">Mr. Creakle's part of the house was a good
deal more comfortable than ours, and he had</Line>
<Line Index="17">a snug bit of garden that looked pleasant after
the dusty playground, which was such a</Line>
<Line Index="18">desert in miniature, that I thought no one but a
camel, or a dromedary, could have felt</Line>
<Line Index="19">at home in it. It seemed to me a bold thing even
to take notice that the passage</Line>
<Line Index="20">looked comfortable, as I went on my way,
trembling, to Mr. Creakle's presence: which</Line>
<Line Index="21">so abashed me, when I was ushered into it, that I
hardly saw Mrs. Creakle or Miss</Line>
<Line Index="22">Creakle (who were both there, in the parlour), or
anything but Mr. Creakle, a stout</Line>
<Line Index="23">gentleman with a bunch of watch-chain and seals,
in an arm-chair, with a tumbler and</Line>
<Line Index="24">bottle beside him.</Line>
<Line Index="25"></Line>
<Line Index="26">'So!' said Mr. Creakle. 'This is
the young gentleman whose teeth are to be filed!</Line>
<Line Index="27">Turn him round.'</Line>
<Line Index="28">The wooden-legged man turned me about so as to
exhibit the placard; and having afforded</Line>
<Line Index="29">time for a full survey of it, turned me about
again, with my face to Mr. Creakle, and</Line>
<Line Index="30">posted himself at Mr. Creakle's side. Mr.
Creakle's face was fiery, and his eyes were</Line>
<Line Index="31">small, and deep in his head; he had thick veins in
his forehead, a little nose, and a</Line>
<Line Index="32">large chin. He was bald on the top of his head;
and had some thin wet-looking hair that</Line>
<Line Index="33"></Line>
<Line Index="34">was just turning grey, brushed across each temple,
so that the two sides interlaced on</Line>
<Line Index="35">his forehead. But the circumstance about him which
impressed me most, was, that he had</Line>
<Line Index="36">no voice, but spoke in a whisper. The exertion
this cost him, or the consciousness of</Line>
<Line Index="37">talking in that feeble way, made his angry face so
much more angry, and his thick veins</Line>
<Line Index="38">so much thicker, when he spoke, that I am not
surprised, on looking back, at this</Line>
<Line Index="39">peculiarity striking me as his chief one.
'Now,' said Mr. Creakle. 'What's the
report</Line>
<Line Index="40">of this boy?'</Line>
<Line Index="41">'There's nothing against him yet,'
returned the man with the wooden leg. 'There has</Line>
53
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
<Line Index="42">been</Line>
<Line Index="43">no opportunity.'</Line>
<Line Index="44">I thought Mr. Creakle was disappointed. I thought
Mrs. and Miss Creakle (at whom I now</Line>
<Line Index="45">glanced for the first time, and who were, both,
thin and quiet) were not disappointed.</Line>
<Line Index="46"></Line>
<Line Index="47">'Come here, sir!' said Mr. Creakle,
beckoning to me.</Line>
<Line Index="48"></Line>
<Line Index="49">'Come here!' said the man with the
wooden leg, repeating the gesture.</Line>
<Line Index="50"></Line>
<Line Index="51">'I have the happiness of knowing your father-
in-law,' whispered Mr. Creakle, taking me</Line>
<Line Index="52">by the ear; 'and a worthy man he is, and a
man of a strong character. He knows me, and</Line>
<Line Index="53">I know him. Do YOU know me? Hey?' said Mr.
Creakle, pinching my ear with ferocious</Line>
<Line Index="54">playfulness.</Line>
</Page>
</InputFile>
</EMMInput>
(4) EMM then processes the document to identify characters. The EMM may
idetnify
characters both from the existing list (derived from the LSS RDB), and it may
also
identify new characters that do not correspond to any character records
maintained by
the LSS. EMM sends to the LSS a set or list of new characters, along with a
set or list
of location information representing where in the document each character can
be
found. LSS then merges the returned character list with the cases character
set
maintained at the RDB ¨ this may also be referred to as an authority DB.
Optionally,
the EMM may simply return to the LSS a complete list of characters identified
in the
set of documents and the functionality of determining duplication within the
returned
character set vis-à-vis the existing or authority character set.
Pidgin XML:
<Characters>
<Character Name="John Smith" Metadata>
<Alias Name="John" />
<Alias Name="Mr. Smith" I>
<AliasLocation Page="0" Line="1" Position="5"
</Character>
<Character Name="Thomson Reuters" Metadata>
</Character>
<Character Name="Quick Brown Fox" Metadata>
</Character>
</Characters>
Actual XML
<EMMOutput>
<Error Code="0" Description=""/>
<FoundCharacters>
<OtherCharacters>
</OtherCharacters>
<AcceptedCharacters>
<Character ID="3"
Type="Individual" >
54
CA 02807494 2013-02-05
VVC) 20114133511
PCT/US2011/001391
<Name Full="William Mell" Last="Mell" First="William"
<Alias Name="Mell"/>
</Name>
<Business Name="" Streetl="" Street2="" Street3="" City="" State=""
Postal="" Country="" Email="" Phone="" Cell=" Fax=""/>
<Home Streetl="" Street2=" Street3="" City="" State="" Postal=""
Country="" Email="" Phone=" Cell="/>
</Character>
<Character ID="2"
Type="Individual" >
<Name Full="John Creakle" Last="Creakle" First="John"
<Alias Name="Creakle"/>
</Name>
<Business Name="" Streetl="" Street2="" Street3="" City=" State=""
Postal="" Country="" Email="" Phone="" Cell="" Fax=""/>
<Home Streetl="" Street2=" Street3=" City=" State="" Postal=""
Country=" Email="" Phone="" Cell=""/>
</Character>
</AcceptedCharacters>
</FoundCharacters>
<FoundLinks>
<Link CharacterID="2" BeginPage="0" BeginLine="4" BegPos="12"
EndPage="0" EndLine="4" EndPos="19" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="3" BeginPage="0" BeginLine="6" BegPos="32"
EndPage="0" EndLine="6" EndPos="36" Confidence="Mell"
Status="RESOLVED"I>
<Link CharacterID="4" BeginPage="0" BeginLine="12" BegPos="31"
EndPage="0" EndLine="12" EndPos="42" Confidence="Salem House"
Status="RESOLVED"/>
<Link CharacterID="3" BeginPage="0" BeginLine="13" BegPos="30"
EndPage="0" EndLine="13" EndPos="34" Confidence="Mell"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="13" BegPos="44"
EndPage="0" EndLine="13" EndPos="51" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="16" BegPos="4"
EndPage="0" EndLine="16" EndPos="11" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="20" BegPos="59"
EndPage="0" EndLine="20" EndPos="66" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="21" BegPos="66"
EndPage="0" EndLine="21" EndPos="73" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="22" BegPos="0"
EndPage="0" EndLine="22" EndPos="7" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="22" BegPos="67"
EndPage="0" EndLine="22" EndPos="74" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="26" BegPos="15"
EndPage="0" EndLine="26" EndPos="22" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="29" BegPos="73"
EndPage="0" EndLine="29" EndPos="80" Confidence="Creakle"
Status="RESOLVED"I>
<Link CharacterID="2" BeginPage="0" BeginLine="30" BegPos="22"
EndPage="0" EndLine="30" EndPos="29" Confidence="Creakle"
Status="RESOLVED"/>
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
<Link CharacterID="2" BeginPage="0" BeginLine="30" BegPos="42"
EndPage="0" EndLine="30" EndPos="49" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="39" BegPos="58"
EndPage="0" EndLine="39" EndPos="65" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="44" BegPos="14"
= EndPage="0" EndLine="44" EndPos="21" Confidence="Creakle"
Status="RESOLVED"I>
<Link CharacterID="2" BeginPage="0" BeginLine="44" BegPos="64"
EndPage="0" EndLine="44" EndPos="71" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="47" BegPos="27"
EndPage="0" EndLine="47" EndPos="34" Confidence="Creakle"
Status="RESOLVED"/>
<Link CharacterID="2" BeginPage="0" BeginLine="51" BegPos="68"
EndPage="0" EndLine="51" EndPos="75" Confidence="Creakle"
Status="RESOLVED"I>
<Link CharacterID="2" BeginPage="0" BeginLine="53" BegPos="43"
EndPage="0" EndLine="53" EndPos="50" Confidence="Creakle"
Status="RESOLVED"/>
</FoundLinks>
</EMMOutput>
(5) LSS repeats steps (3) and (4) until it has no more documents to scan. It
then shuts
down the EMM process.
[00160] The LSS may also include code to transform LSS-related content
coordinate
systems into the EMM coordinate system. For instance, where the LSS integrates
or
functions in conjunction with other applications, e.g., Microsoft Word, Corel
WordPerfect,
then a module may be provided to transform Word Processing coordinates into
EMM
coordinates. Word Processing files have coordinates that are stored as a
single number,
which is a character offset from the beginning of the file. These are
transformed into EMM
coordinates by "walking down" the document. Every 75 characters the process
walks forward
to the end of a word. For each such instance the process recognizes this 75+
character string
as a line. For every 25 lines, the process adds those lines to a page. Note
that in the context of
translating coordinates the reference to "character" is not to an entity or
name, as used
elsewhere in this specification, but rather to individual discrete, base units
of linguistic
expression. For example, the single "character" "David" comprises five
characters.
[00161] The LSS may also include code to transform LSS-related Image
coordinates
into EMM coordinates. Images have words located in rectangles on pages. To
transform
these rectangles into lines, the LSS leverages the fact that its OCR engine
lists words in the
traditional English order (i.e., it starts from the top left, moves right, and
then back to the left
when the line is ended). Accordingly, the process runs down the list of
rectangles. If they
coordinates of the word do not overlap with the previous word (which would
indicate a move
56
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
to the next line), or if the x coordinates are less than the previous
rectangle (which would
indicate a carriage return equivalent), then the process starts a new line.
[00162] With reference to Figure 33, the system allows the user to
modify the Options
which control the following operations via user interfaces 2602 and 2604.
"Update Character
Smart Tags" 2606 controls smart tagging names of persons and companies in the
data.
Assigning a "confidence" level to control how precise the Entity Tagger
behaves in
determining whether a word is a name is controlled via "Confidence level"
2608.
"Automatically Creates Characters from Full Text" 2610 controls whether names
of persons
and organizations are automatically added to the user-displayed Characters
table when the
Entity Tagger tags them in the FULL TEXT data imported and stored in the LSS,
for
example in West Case Notebook. "Automatically Creates Characters from
Properties" 2612
controls whether names of persons and organizations are automatically added to
the user-
displayed Characters table when the user manually enters the name into a
specific metadata
property, e.g. Deponent Name. If the box is selected or "checked" then the EMM
automatically adds any new entities or names identified when running the EMM
on the
selected document.
[00163] The user may optionally de-select the checkbox appearing
beneath the heading
"Automatically Creates Characters from Full Text." When de-selected, the EMM
does not
automatically display new names in the Characters table when the Character
Recognition
software tags words in the full text of data imported into the system. The EMM
software still
tag names, however they will be stored in a side table, for example, for the
user to analyze at
a later time, and potentially add them to the main Characters table. This may
be a default
setting.
[00164] In the exemplary manner of operation illustrated, and with
reference to Figure
34, the user clicks the Import New Document button and selects "Document (from
File)"
2702. The user navigates to the location of the document(s) (see the Open
dialog box at
Figure 41) which they wish to import. The selected document, e.g.,
memorandum13.doc, is
imported into the LSS and the EMM Character Recognition process runs on the
words
indexed from the target document. After the EMM Character Recognition process
is
completed, the user does not see some of the entity names of persons and
organizations
"smart-tagged" in the data, unless the user has already manually entered that
name into the
LSS.
57
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00165] With reference to Figures 35-37, the user selects from the
"New" tab drop-
down the "Characters (from Smart Tags)" 2802 option. This option displays the
side table
referenced above, Figure 36, and allows the user to analyze the names the EMM
has tagged
and to choose which entities/names to add to the user-displayed Characters
table of Figure
33. The side table, Figure 36, allows the user to analyze the names tagged by
the EMM
process and to choose which to add to the user-displayed Characters table. In
the example
illustrated in Figure 36, the user has selected all entity names to be added,
which may be a
default. Accordingly, when next viewing the Character list or table 1000, as
illustrated in
Figure 37, all of the "new" entities found by the EMM are included in the
master entity list or
table. This main user-display Characters table 3000 now displays all of the
characters or
entities previously loaded onto the list as well as the new entities from the
subsequently run
EMM process on the selected document ¨ memorandum13.doc. The user will now see
the
"Smart Tag" link markup in the full text data stored within the LSS. In
addition, and
optionally, the options box 3002 allows the user to run, for example, a
Characters report for
the new entities and Profile the new entities on a separate part of the LSS or
using an outside
or separate professional services system, e.g., Westlaw. The LSS may include a
"onePass"
type user authorization feature that permits seamless integration and flow to
some or all of
additional research or other tools and systems. A user may also be presented
with a typical
"login" screen to access the outside or separate service or tool.
[00166] For instance, the user may select the entity "Apache Nitrogen
Products, Inc."
3006 and select "Profile on Westlaw" to display a further option box 3004 from
which the
user may select "Person & Company Library" feature. Figure 38 shows a screen,
following
any required login process, for performing this added service of a search for
the selected
entity using the selected resource. Figure 39 illustrates a series of reports
resulting from the
additional search. These search results may also be brought into the LSS
system for use in
performing professional services. For example, the results may include
documents relating to
a case and/or entity of interest to the user and may be incorporated into a
documents
database, may be processed for smart tagging, may be excerpted for deposition
outline, etc.
The processes described above may now be performed on any imported document
from the
.. outside or added service.
[00167] With reference to the example of Figure 40, the user clicks the
New Character
button and is presented with a dialog 3300 within which the user can manually
create a new
58
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
Character "Frank Ermis" 3302. The user clicks OK and the name Frank Ermis is
added to the
user-displayed Characters table, as also reflected in the "Characters" drop
down 3306.
[00168] With reference to Figure 41, the user clicks the import New
Document button
and the Data Import Wizard dialog appears. The user navigates, such as by
clicking on the
"Load File" button or by right-clicking the mouse, to launch a dialog box 3406
for navigating
to the location of the document(s) which they wish to import. In this example,
the user has
selected document "memorandum7.doc." These are merely exemplary of the many
ways the
LSS may be configured to allow a user to access documents for performing the
EMM
Character Recognition and smart tagging operation of the present invention and
is not
limiting as to the scope of the invention.
[00169] The document 3500 (memorandum7.doc) is then imported into the
LSS, e.g.,
West Case Notebook, and the EMM Character Recognition process runs on the
words
indexed from the target document.
[00170] In this example, the name Frank Ermis was found in the full
text of this
.. document, and was "Smart Tagged." The user now has right-click options
associated with
this Smart Tagged name as described above in regards to Figures 37-39. In
addition, because
the Options were set to automatically display new names in the user-displayed
Characters
table when the EMM Character Recognition software tags identified entities,
new Characters
were added to the table automatically.
[00171] The user also has right-click options associated with this Smart
Tagged name,
appearing in the Characters table. In this example, the user chooses the
Characters Report
3502 right-click option for Frank Ermis. As shown in Figure 44, the Characters
Report runs
and returns the reference to Frank Ermis's name in the full text of the
document currently
stored in the LSS. The user may then click the link to the document titled
"memorandum7"
to view the full document referencing the name Frank Ermis. The LSS retrieves
the full
document referencing the name Frank Ermis, highlighting the reference. This is
useful when
the user wants to quickly see the thousands of references to a Character of
the litigation
appearing across potentially thousands of documents stored in the LSS.
[00172] With reference to Figures 45-46, the user double-clicks the
entity listing
"Enron North America Corp." 3802 to view the Properties dialog 3804 of the
user-displayed
Characters table1800. The "Details" tab of the dialog 3804 is presented, but
the user may
click on the "Aliases" tab to add alias information for the "Enron North
America Corp"
59
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
entity. Upon selecting the Aliases tab, the user is presented with the Aliases
screen 3900,
including the "Other Aliases & Characters" table 3902 on the right side of the
dialog box.
This table or list 3902 displays a list of entities displayed in the
Characters table, as well as
the entities tagged in the data by the EMM Character Recognition software.
[00173] The user can use this list to verify that variations of an entity
name are
properly associated to the name displayed in the Characters table. In this
example, the user
has selected "Enron North America" from the list on the right side, with the
intent to add it to
the list on the left side 3904 and thus become a variation of the name. Doing
this means the
Characters report will return results for "Enron North America" in addition to
the main listed
variation "Enron North America, Corp."
Appendix
Exemplary Extraction of Information From Tables Found In Text
[00174] For the exemplary embodiment, we downloaded hundreds of
documents from
Edgar database (EDGAR) and annotated 150 of them for training and evaluation.
We
converted the documents into XHTML using Tidy (Raggett ) before annotating
them.
Annual Compensation Lang-Teem All Other
Name and Principal Position Other Annual ComPino- Comlousa-
Fiscal Salary(S) Bontis(S)(1) tCiompensa- tiopontizaZ isoxa2)
Year (5)
John T. Chambers 2005 350.000 1,300,000 0 1.500.000 8,977
President. Chief Executive 2004 1 1,900,000 0 0 0
Officer and Director 2003 1 0 0 4.000.000 0
Mario Mazzola 2005 447,120 557,737 0 600,000 7.424
Former Senior Vice President. 2004 464,317 666,850 0
600,000 5.726
Chief Development Officer (3-) 2003 447,120 764,897 0
500.000 2,905
Charles H. Giancarlo
Table 3: A compensation table
[00175] Our information extraction system for genuine tables involve
the following:
1. table classification
2. label row and column classification
3. table structure recognition
4. table understanding
[00176] Step 1, which is implemented to maintain efficiency, entails
identifying tables
that have a reasonable chance of containing the desired relation before deep
analysis are
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
applied. The tables containing the desired information are quickly identified
using relation-
specific classifiers based on supervised machine learning. In Step 2, we
distinguish between
label column and label rows from values inside those tables. This time, the
same supervised
machine learning approach is used, but the training data is different from
those in Step 1. In
Step 3, after those label rows and label column are identified, an elaborate
procedure is
applied to these complex tables to ensure that semantically coherent labels
are not separated
into multiple cells, or multiple distinct labels are not squashed into a cell.
The goal here is to
associate each value with their labels in the same column and the same row.
The result of the
Step 3 is a list of attribute-value pairs. In Step 4, a rule-based inference
module goes through
each attribute-value pairs and identify the desirable ones to populate the
officers and directors
database.
[00177] Before providing the details of those steps, we will first
describe the
annotation for performing the supervised learning employed in both Step 1 and
Step 2.
[00178] Annotation Requirements: In the early stage of the project, we
originally
categorized tables containing desired information based on the overall
information conveyed
in each table, such as "officer compensation" or "director committee
assignment". We
annotate tables with the desired relations directly. In SEC filings, the
relation "name+title"
might appear in various categories of tables, which makes the original table
categories
ineffective. In addition, there are too many variations of tables in this
domain which makes
defining an effective closed set of categories difficult. For example, Table 3
is a
compensation table, but it also contains job title information.
[00179] To make our system more robust against lexical variations and
table
variations, we employed supervised machine learning in Step 1 and Step 2. As
we know in
supervised learning, one of the most challenging and time-consuming tasks is
to obtain the
labeled examples. To make our approach reusable across different domains, we
developed a
scheme that minimizes the human annotation effort needed.
[00180] For the tables containing the desired information, the
exemplary embodiment
uses the following annotations:
I. isGenuine: a flag indicates that this is a genuine table or a non-genuine
table.
2. relations: the relations that a table contain, such as "name+title",
"name+age",
name+year+salary" or "name+year+bonus", or a combination of them.
61
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
3. isContinuous: a flag indicates that if this table is a continuation of the
previous
genuine table.
4. lastLabelRow: the row number of the last label row.
5. lastLabelColumn: the column number of the last label column associated with
each
relation.
6. valueColumn: the number of the column that contains the desired values for
each
relation.
[00181] The specified relations are used as training instances to build
models for Step
1. The information lastLabelRow and lastLabelColumn are used to build models
to classify
rows and column as labels rows or columns in Step 2. In our guideline to
annotators, we
specifically ask them to annotate the column number of the last label column
for each
relation. The need for such fine-grained annotation is best illustrated using
an example. In
Table 3, for relation "name+title", the last label column is 1, the column
"name and principal
position". But for relation "name+year+bonus", the last label column is 3,
"fiscal year". For
extracting multiple relations in a table, these relations might share the same
last label column,
but this is not always the case. As a result, there is a need to annotate the
associated label
column for each relation separately. The flag isContinuous indicates if the
current table is a
continuation of the previous table. If it is, the current table can "borrow"
the boxhead from
previous table since such information is missing. We eliminate tables marked
with
"isContinuous" flag during training, but kept those table during evaluation.
The annotation
valueColumn can be used for automatic evaluation in the future.
[00182] There are few rare instances where the default arrangement of
boxhead and
stub, as shown in Table 3, are swapped in the corpus. Currently in our
annotation, we simply
don't supply "valueColumn" for the relations since they don't apply. For table
classification
and table understanding tasks, this is not of much an issue, but the above
annotation scheme
would need to be further modified to capture such difference.
[00183] Table classification: Much of past work in table classification
focused on
distinguishing between genuine and non-genuine tables (Wang & Hu 2002). For
information
extraction, we need to go a step further. We also need to know if a table
contains the desired
information before we perform expensive operations on it. To identify tables
that contain
desired relations, we employed LIBSVM (Chang & Lin 2001), a well-known
implementation
of support vector machine. Based on the annotated tables, a separate model is
trained for each
62
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
desired relation. In SEC domain, a table might contain multiple relations.
Exemplary features
include:
= top 1000 words inside tables in the corpus, and top 200 words in text
preceding the
tables. These thresholds are based on experiments using LIBSVM 5-fold cross
validation. A stop word list was used. =
= number of words in tables that are label words
= number of cells containing single word
= number of cells containing numbers
= maximum cell string size
= number of names
= number of label words in the first row
[00184] We built a model for each desired relations. Because
"name+year+salary" and
"name+year+bonus" cooccur 100% of the time in the annotated corpus, the same
classifier
was for both relations. In this domain, the number of negative instances is
significantly
larger than positive instances ( 3building an accurate model. We suspected
that having both
signature tables and tables containing background information in sentences
format create
significant overlap between positive and negative instances. To address this,
we only use a
subset of negative instances for training (75% of our training instance are
negative instances).
We also trained a separate module for distinguish between a genuine and non-
genuine tables
based on annotated data. This second model is relation independent. The
feature set is similar
to the feature set mentioned above.
[00185] To identify which words are likely to be names, we downloaded
the list of
names from (U.S. Census Bureau). The list of names is further filtered by
removing the
common words, such as "white", "cook", or "president", based on a English word
list
(Atkinson August 2004). At our disposal, we also have a list of common title
words. We
intentionally do not use such information in this paper to make our result
more generalizable
to other domains.
[00186] We can imagine using such information would significantly
improve the
precision and recall for extracting relation "name+title".
[00187] Label row and column classification: Based on the annotated data,
LIBSVM
is again used to classify which rows belong to boxhead and which columns
belong to stub.
The training data for the models are words in the desired tables that were
manually identified
63
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
as box-head and stubs by using lastLabelRow and lastLabelColumn features.
Other features
used include the frequency of label words, the frequency of name words, and
frequency of
numbers.
[00188] For each relation, the exemplary embodiment uses a different
label column
classifier, since the lastColumnLabel might differ between different
relations, as explained in
the Annotation Section.
[00189] Table structure recognition: Because tables in the SEC filings
are somewhat
complex and formatted for visual purpose, a significant amount of effort is
needed to
normalize the table to facilitate later operations. Once label rows and
columns are identified,
several normalization operations are carried out:
1. create duplicate cells based on rowspan and columnspan
2. merge cells into coherent label cells
3. identify subheadings
4. split specific column based on conjoin marker, such as "and" or parenthesis
(before
last label column)
5. split cells containing multiple labels, such as years "2005, 2006, 2007"
[00190] Step 1 specifically addresses the issue with the use of
columnspan and
rowspan in HTML table, as have been done in (Chen, Tsai, & Tsai 2000). In
Table 3, without
copying the original labels into spanning cells, the label "annual
compensation" would not be
attached to the value "1,300,000" using just the HTML specification. By doing
this step, we
only need to associate all the labels in the box-head in that particular
column to the value and
ignore other columns.
[00191] In Step 2, we use certain layout information, such as
underline, empty line, or
background color, to determine when a label is really complete. In SEC
filings, there are
many instances where a label is broken up into multiple cells in the boxhead
or stub. In those
cases, we want to recreate the semantically meaningful labels to facilitate
later relation
extraction ¨ a process that is heavily dependent on the quality of the labels
attached to the
values. For example, in Table 3, based on the separate in row 5, cells "John
T. Chambers",
"President, Chief Executive", and "Officer and Director" are merged into one
cell, with line
break marker (#) inserted into the original position. The new cell is "John T.
Chambers#President, Chief Executive#Officer and Director", and it is stored in
cell on row
2, and copied to cells on row 3 and 4.
64
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00192] In Step 4, heuristic rules were applied to identify subheader.
For example, if
there is no value in the whole row except for the first label cell, then that
label cell is
classified as subheader. The subheader label is assigned as part of the label
to every cell
below it until a new subheader label cell is encountered.
[00193] Step 5 splits certain columns into multiple columns to ensure that
a value cell
does not contain multiple values. For example, in Table 3, the first cell in
first column is
"name and principal position". The system detects the word "and" and split the
column into
two columns, "name" and "principal position", and do similar operations to all
the cells in the
original column. Remember in Step 3, cell on row 2 is the result of merge 3
cells, with line
break markers between the string in the original cells. By default, we use the
first line break
marker to break the merged cell into two cells. After this transformation, we
have "John T.
Chambers" and "President, Chief..." that corresponding to "name" and
"principal position".
This type of operation is not only limited to "and", but also to certain
parenthesis,
"Nondirector Executive Officer (Age as of February 28, 2006)". Such cells are
broken into
two, and so are the other cells in the same column.
[00194] Step 6 deals with repeated sequences in last label column. In
Table 3, we are
fortunate that all the cells under "fiscal year" contains only 1 value. There
are instances in our
corpus that such information is represented inside the same cell with line
break between each
value. In such cases, there are no lines between these values, and the
resulting table looks
cleaner and thus visually more pleasing. It is certainly incorrect to assign
all 3 years "2005,
2004, 2003" to the cell containing bonus information "1,300,000". To address
this, our
system performs repeated sequence detection on all last label columns. If a
sequence pattern,
which doesn't always have to be exactly the same, is detected, the repeated
sequence are
broken into multiple cells so that each cell can be assigned to the associated
value correctly.
[00195] Transforming a normalized table to Wang's representation (Wang
1996) is a
trivial process. Given a value cell at (r,c), all the label cells in column
(c) and row (r) are its
associated labels. In addition, the labels in stub might also have additional
associated labels in
the boxhead, and those should be associated with the value cell also. For
example, the value
"1,300,000" will have following 4 associated labels: [annual
compensationIbonus($)(1)],
[fiscal yearI2005], [principal positionlpresident, chief executive officer and
director],
[namelJohn T. Chambers]. The characters "I" inside those associate labels
indicate
hierarchical relation between the labels. For tables with subheading, the
subheading labels
have already been inserted into all the associated labels in the stubs
earlier.
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00196] Table understanding: Similar to (Gatterbauer et al. 2007), we
consider IE
from Wang's model requires further intelligent processing. To populate
database based on
Wang's representation, a rule-based system is used. We specifically look for
certain patterns,
such as "name", "title" or "position" in the associated labels in order to
populate the "name-
title" relation. For different relations, a different set of patterns is used.
It's important to
perform error analysis at this stage to detect ineffective patterns. For
example, several tables
with "name-title" information used the phrase "nondirector executive officer"
instead of the
label for "name". Clearly, we can apply supervised machine learning to make
the process
more robust. In our annotation, we have asked the annotators to identify the
columns that
contains the information we want in valueColumn. Such information might be
used to train
our table understanding module in the future.
[00197] The following procedures can be used to tailor our approach to
a new
application or domain:
= Collect a corpus and annotate the tables with the desired information as
described in
the Annotation section.
= Modify features to take advantage of knowledge in the new domain.
= Train all the classifiers. Depending on the size of the corpus, different
thresholds can
be specified to minimize the size of the vocabulary, which is used as
features. This
training process can be automated.
= Modify table normalization to take advantage of domain knowledge. For
example,
in SEC domain, separating the label cell "name and title" is applied in order
to simply
later relation extraction operations.
= Modify relation extraction rules. Different relations are signaled by
different words
in the labels. Currently, we manually specify these rules.
This process is designed to maximize precision and recall while minimizing the
annotation
effort. Each component can be modified to take advantage of the domain
specific information
to improve its performance.
Conclusion
[00198] The embodiments described above are intended only to illustrate
and teach
one or more ways of practicing or implementing the present invention, not to
restrict its
breadth or scope. The actual scope of the invention, which embraces all ways
of practicing or
implementing the teachings of the invention, is defined only by the issued
claims and their
equivalents.
66
CA 02807494 2013-02-05
WO 2012/033511
PCT/US2011/001391
[00199] In implementation, the inventive concepts may be automatically
or semi-
automatically, i.e., with some degree of human intervention, performed. Also,
the present
invention is not to be limited in scope by the specific embodiments described
herein. It is
fully contemplated that other various embodiments of and modifications to the
present
invention, in addition to those described herein, will become apparent to
those of ordinary
skill in the art from the foregoing description and accompanying drawings.
Thus, such other
embodiments and modifications are intended to fall within the scope of the
following
appended claims. Further, although the present invention has been described
herein in the
context of particular embodiments and implementations and applications and in
particular
environments, those of ordinary skill in the art will appreciate that its
usefulness is not limited
thereto and that the present invention can be beneficially applied in any
number of ways and
environments for any number of purposes. Accordingly, the claims set forth
below should be
construed in view of the full breadth and spirit of the present invention as
disclosed herein.
67