Note: Descriptions are shown in the official language in which they were submitted.
CA 02810457 2013-03-25
1 SYSTEM AND METHOD FOR APPLYING A CONVOLUTIONAL NEURAL NETWORK TO
2 SPEECH RECOGNITION
3 .. TECHNICAL FIELD
4 [0001] The following relates generally to convolutional neural
networks and more specifically to
applying a convolutional neural network to speech recognition.
6 BACKGROUND
7 [0002] Systems for automatic speech recognition (ASR) are generally
challenged with the wide
8 range of speaking, channel, and environmental conditions that humans can
generally handle well. The
9 conditions may, for example, include ambient noise, speaker variability,
accents, dialects and language
differences. Other variations may also be present in a particular speech
pattern.
11 [0003] These types of acoustic variations have been found to be
challenging to most ASR systems
12 .. that use Hidden Markov Models (HMMs) to model the sequential structure
of speech signals, where each
13 HMM state uses a Gaussian Mixture model (GMM) to model short-time
spectral representation of speech
14 signal. Better acoustic models should be able to model a variety of
acoustic variations in speech signals
more effectively to achieve robustness against various speaking and
environmental conditions.
16 [0004] More recently, deep neural networks have been proposed to
replace GMM as the basic
17 acoustic models for HMM-based speech recognition systems and it has been
demonstrated that neural
18 .. network (NN)-based acoustic models can achieve competitive recognition
performance in some difficult
19 large vocabulary continuous speech recognition (LVCSR) tasks. One
advantage of NNs is the distributed
representations of input features (i.e., many neurons are active
simultaneously to represent input features)
21 that generally makes them more efficient than GMMs. This property allows
NNs to model a diversity of
22 speaking styles and background conditions with typically much less
training data because NNs can share
23 similar portions of the input space to train some hidden units but keep
other units sensitive to a subset of
24 the input features that are significant to recognition. However, these NNs
can be computationally
.. expensive to implement.
26 [0005] It is an object of the following to obviate or mitigate at
least one of the foregoing issues.
27 SUMMARY
28 [0006] In one aspect, a method for applying a convolutional neural
network to a speech signal to
29 .. mitigate acoustic variation in speech is provided, the convolutional
neural network comprising at least
one processor, the method comprising: (a) obtaining an acoustic signal
comprising speech; (b)
31 preprocessing the acoustic signal to: (i) transform the acoustic signal
to its frequency domain
1
CA 02810457 2013-03-25
1 representation; and (ii) divide the frequency domain representation into
a plurality of frequency bands; (c)
2 providing the plurality of frequency bands to a convolution layer of the
convolutional neural network, the
3 convolution layer comprising a plurality of convolution units each
receiving input from at least one of the
4 frequency bands; and (d) providing the output of the convolution layer to
a pooling layer of the
convolutional neural network, the pooling layer comprising a plurality of
pooling units each receiving
6 input from at least one of the convolution units, the output of the
pooling layer being a representation of
7 the acoustic signal mitigating acoustic variation.
8 [0007] In another aspect, a system for mitigating acoustic
variation in speech is provided, the system
9 comprising a convolutional neural network, the convolutional neural
network comprising at least one pair
of: (a) a convolution layer comprising a plurality of convolution units each
receiving input from at least
11 one frequency band of an acoustic signal comprising speech; (b) a
pooling layer comprising a plurality of
12 pooling units each receiving input from at least one of the
convolutional units, the output of the pooling
13 layer being a representation of the acoustic signal mitigating acoustic
variation.
14 DESCRIPTION OF THE DRAWINGS
[0008] The features will become more apparent in the following detailed
description in which
16 reference is made to the appended drawings wherein:
17 [0009] FIG. 1 is an architecture diagram of a convolutional neural
network applied to speech
18 recognition;
19 [0010] FIG. 2 is a flowchart of a method for applying a
convolutional neural network to speech
recognition;
21 [0011] FIG. 3 is a block diagram of an exemplary convolutional
neural network with full weight
22 sharing applied to an acoustic signal; and
23 [0012] FIG. 4 is a block diagram of an exemplary convolutional
neural network with limited weight
24 sharing applied to an acoustic signal.
DETAILED DESCRIPTION
26 [0013] Embodiments will now be described with reference to the
figures. It will be appreciated that
27 for simplicity and clarity of illustration, where considered
appropriate, reference numerals may be
28 repeated among the figures to indicate corresponding or analogous
elements. In addition, numerous
29 specific details are set forth in order to provide a thorough
understanding of the embodiments described
herein. However, it will be understood by those of ordinary skill in the art
that the embodiments described
31 herein may be practiced without these specific details. In other
instances, well-known methods,
2
CA 02810457 2013-03-25
1 procedures and components have not been described in detail so as not to
obscure the embodiments
2 described herein. Also, the description is not to be considered as
limiting the scope of the embodiments
3 described herein.
4 [0014] It will also be appreciated that any module, engine, unit,
application, component, server,
computer, terminal or device exemplified herein that executes instructions may
include or otherwise have
6 access to computer readable media such as storage media, computer storage
media, or data storage
7 devices (removable and/or non-removable) such as, for example, magnetic
disks, optical disks, or tape.
8 Computer storage media may include volatile and non-volatile, removable
and non-removable media
9 implemented in any method or technology for storage of information, such
as computer readable
instructions, data structures, program modules, or other data. Examples of
computer storage media
11 include RAM, ROM, EEPROM, flash memory or other memory technology, CD-
ROM, digital versatile
12 disks (DVD) or other optical storage, magnetic cassettes, magnetic tape,
magnetic disk storage or other
13 magnetic storage devices, or any other medium which can be used to store
the desired information and
14 which
can be accessed by an application, module, or both. Any such computer storage
media may be part =
of the device or accessible or connectable thereto. Any application, module or
engine herein described
16 may be implemented using computer readable/executable instructions that
may be stored or otherwise
17 held by such computer readable media.
18 [00I5] It has been found that acoustic variation can be mitigated
by processing an acoustic signal
19 comprising speech along both time and frequency axes. By applying the
CNN convolution and pooling
operations along the frequency axis, substantial invariance to small shifts
along the frequency axis can be
21 achieved to normalize acoustic variation.
22 [0016] A CNN as described herein applies local filtering and
pooling along the frequency axis to
23 normalize speaker variance and enforce locality of features to enable an
increase in speaker independent
24 speech recognition performance. The CNN comprises at least one pair of
layers comprising a convolution
layer, comprising a plurality of convolution units, and a pooling layer,
comprising a plurality of pooling
26 units, to normalize spectral variations of speech signals. The spectral
variations may comprise various
27 speaking and environmental conditions, including, for example, channel
noise, colored background,
28 speaker variability, accents, dialects and language differences.
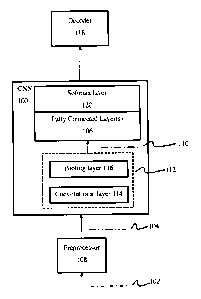
29 [0017] Referring now to Fig. 1, a system for applying a
convolutional neural network (CNN) to
speech recognition is shown. The CNN (100) may be applied to speech
recognition within the framework
31 of a hybrid NN-HMM architecture. That is, the CNN (100) may be applied
to an obtained or observed
32 acoustic signal comprising speech (102) with the output of the pooling
layer feeding a fully connected
33 hidden NN layer (106), with better speech features (110) having
increased robustness to speaker and
3
CA 02810457 2013-03-25
1 noise variations. The CNN (100) is operable to analyze spectro-temporal
patches of the acoustic signal,
2 providing the HMM component with a signal representation that may be
characterized by increased
3 robust to variances in speaker and noise conditions. The HMM component
may comprise a decoding unit
4 (decoder) (118), which may be applied to the output of the CNN to output
a sequence of labels that were
recognized. It will be appreciated that the decoder may alternatively operate
relative to another state-
6 based model, rather than an HMM, to output a label sequence.
7 [0018] A preprocessing unit (preprocessor) (108) computes speech
features that are suitable for the
8 CNN (100). These features are computed from the acoustic signal (102)
prior to inputting the frequency
9 domain representation of the signal (104) to the CNN (100). The
preprocessor (108) may therefore
generate, for each of a plurality of signal frames (in the time domain), a
frequency domain representation
11 of the obtained acoustic signal (102) and divide this representation
into a plurality of bands (shown in Fig.
12 3) which are input to the CNN (100), where a band refers to a particular
frequency range that is
13 represented by a vector of features either in the input or other CNN
layers' units. Alternatively, rather
14 than the preprocessor (108) dividing the frequency domain representation
into a plurality of bands, the
CNN may comprise a set of filters enabling each convolution unit of the bottom
layer to operate on
16 particular bands.
17 [0019] The CNN comprises at least one pair of layers (112), each
pair comprising a convolution
18 layer (114) and pooling layer (116). The convolution layer (114) applies
a set of kernels, each one of the
19 kernels processing one or more bands of the layer input. Each kernel
produces a learnable weight vector.
The pooling layer (116) comprises one or more pooling layer units, each one of
the pooling layer units
21 applying a pooling function to one or more convolution unit kernel
outputs computed at different bands
22 using a pooling function. The pooling function may be an average or a
maximum function or any other
23 function that aggregates multiple values into a single value. Top fully
connected layers may be applied to
24 combine pooling layer units from the topmost pooling layer. A final
softmax layer may fmally be applied
to combine the outputs of the fully connected layer using softmax functions.
26 [0020] The CNN is applied along the frequency axis of the observed
speech signal, while the
27 variability along the time axis of the speech signal may be normalized
by application of a HMM
28 component. The dependency between adjacent speech frames may be utilised
by the application of a long
29 time context window that feeds as input to the CNN.
[0021] The output of the CNN may be the probability P (s V Ot) that the
frame at time t belongs to
31 an HMM state s. Generally, in an example, t may be on the order of tens
of milliseconds or some other
32 period suitable for the HMM. A decoder may be applied over the signal in
the time domain to match the
4
CA 02810457 2013-03-25
1 states to speech based on the probabilities P, where the best fit may be
used to output a sequence of
2 labels.
3 [0022] As previously mentioned, it has been found that speech
signals typically exhibit locality
4 characteristics along the frequency axis. Thus, different phonemes many
have energy concentrations in
different local bands along the frequency axis. For example, voiced phonemes
have a number of formants
6 appearing at different frequencies. The preprocessor generates frequency
representations of the signal to
7 enable the CNN to distinguish phonemes based upon the local energy
patterns. As a result, kernels
8 provided by the CNN that operate on different bands of local frequency
regions may represent these local
9 structures, and may represent combinations of these local structures
along the whole frequency axis to
enable the CNN to recognize output labels. The locality of processing within
these kernels further enables
11 robustness against ambient noises, particularly where noises are only
concentrated in parts of the
12 spectrum. In this situation, kernels that process bands in relatively
cleaner parts of the spectrum can still
13 detect speech features well, in order to compensate for the ambiguity of
noisy parts of the spectrum.
14 [0023] The CNN described herein is capable of modeling these local
frequency structures by
enabling each dimension of each vector computed by each kernel of the
convolution layer to operate upon
16 features representing a limited bandwidth (the receptive field of the
respective dimension of the kernel
17 output vector) of the complete speech spectrum. To achieve this, the
preprocessor (108) may be operable
18 to represent the observed signal in a frequency scale that can be
divided into a number of local bands. The
19 frequency scale may, therefore, comprise any of linear spectrum, Mel-
scale spectrum, filter-bank features
or any other locality preserving features.
21 [0024] Referring now to Figs. 2 and 3, the preprocessor (108)
obtains the acoustic signal, at block
22 200, and generates a speech signal v (300) by transforming, in block
202, the observed speech signal for a
23 particular context window (i.e., a plurality of frames) to its frequency
domain representation.
24 [0025] In block 204, the preprocessor then divides v into a
plurality of B bands, i.e., v =
[v1v2... vB], where vb is the feature vector representing band b. The feature
vector vb may include
26 speech spectral features (s), delta (as) and acceleration (A2s)
parameters from local band b of all feature
27 frames within the current context window, where the window comprises c
frames, as follows:
A2s(0,s(t+i),As(r+1.), A2s(t+1), s(t+c),As(t+c), A2s(t+c)1
Vb = [S(t), As (t),
28 [0026] In block 206, the speech signal v, for each particular
context window, is each individually
29 input to the convolution layer (302) which operates upon each window of
the speech signal v. Activations
of the convolution layer (302) are divided into K bands where each band
contains J different kernel
31 activations. The number of bands K in the convolution layer output may
be equal to the number of input
5
CA 02810457 2013-03-25
1 bands by adding extra bands with zero values before and after the actual
input bands. Each band
2 activation may be denoted as hk =h
[ -k,1 - h
k,2. = = hkj]. The convolution layer activations can be computed
3 as a convolution-like operation of each kernel on the lower layer bands
followed by a non-linear
4 activation function:
(P s
hic,i = 0 Z / Wjd,,p12b+k_im -I- aj
p=1 6=1
where 9(x) is the activation function, s is the kernel size in the number of
input bands, P is the size of vb ,
6 Wimm is the weight element representing the pth component of the bth band
of the jth filter kernel. In full
7 weight sharing, all of the K bands share the same set of filter kernels
as shown in the previous equation.
8 [0027] This convolution layer comprises K bands where each band
comprises Junits. The
9 convolution layer may be considered similar to a standard NN layer where
all nodes of the hidden layer
are grouped into bands and each node receives inputs only from bands of the
lower layer. Moreover,
11 weights and biases for the jth node of each band may be shared among
different hidden convolution layer
12 bands. Note that in Fig. 3, weights represented by the same line style
may be shared among all
13 convolution layer bands.
14 [0028] As previously mentioned, speech spectrum includes many local
structures and these local
structures are distributed over a range of the frequency axis, where each
local structure typically appears
16 to center around one particular frequency that can vary within a limited
range. For example, central
17 frequencies of formants for the same phoneme may vary within a limited
range and typically differ
18 between different speakers and sometimes between different utterances
from the same speaker.
19 [0029] A pooling layer may be operable to mitigate the foregoing
variability. In block 208, a pooling
layer is applied to the output of the convolution layer. The pooling layer
activations may be divided into
21 Mbands. Each band of the pooling layer receives input from r convolution
layer neighbouring bands to
22 generate Jvalues corresponding to the convolution Jkernels. The jth
value represents the result of the
23 pooling function on the corresponding activations of the jth convolution
kernel along the r bands of the
24 convolution layer, as shown in Fig. 3. The pooling layer may generate a
lower resolution version of the
convolution layer by applying this pooling operation every n convolution layer
bands, where n is the sub-
26 sampling factor. As a result, a smaller number of bands may be obtained
in the pooling layer that provide
27 lower frequency resolution features that may contain more useful
information that may be further
28 processed by higher layers in the CNN hierarchy.
6
CA 02810457 2013-03-25
1 [0030] The activations of the mth band of the pooling layer may be
denoted as
2 Pm = [Pm,i Pan,2 Pm,11T. Each activation may be computed as:
r f
Pm,]
k=1
3 where r may be referred to as pooling size n may be smaller than r to
have some overlap between
4 adjacent pooling bands. p is the pooling function. Examples of this
pooling function are the maximum,
sum, and average but may be any summary function that can compute a single
value from an arbitrary set
6 of values, or it may be learned. The example shown in Fig. 3 has a
pooling layer with a sub-sampling
7 factor of 2 and a pooling size of 3.
8 [0031] Referring now to Fig. 4, an exemplary CNN with limited weight
sharing is shown. In a
9 standard CNN, a full weight sharing scheme is used where the local filter
weights are tied and shared for
all positions or bands within the whole input space, as in Fig. 3. In this
case, computation of all filters'
11 activations may be a convolution of the filter weights and the input
signals.
12 [0032] In speech signals, however, different local patterns appear
at different frequencies. Therefore,
13 it may be more effective to have a limited weight sharing scheme. In a
limited weight sharing scheme,
14 weight sharing is limited to those local filters that are close to one
another and are pooled together in the
pooling layer. This weight sharing strategy is depicted in Fig. 4, where one
set of kernels weights is used
16 for each pooling band. For example, in Fig. 4, W(1) represents the
weights matrix shared between bands
17 1-41), q=), and 141), where 1111) receives input from bands 1-4 in input
layer, ie receives input from
18 bands 2-5, and so on.
19 [0033] As a result, the convolution layer may be divided into a
number of convolution sections,
where all convolution bands in each section are pooled together into one
pooling layer band and are
21 computed by convolving section kernels with a small number of the input
layer bands. In this case, the
22 pooling layer activations may be computed as:
=
k=1
23 with
(P s-1
hrd) = II im(Tri)
'W,TI'mxn+b+km + a jcm)
p=1 b=1
24 where 147) is the activation of the jth kernel of the mth section of the
convolution layer applied at the kth
band position. In this context, n may be referred to as a band shift in the
pooling layer.
7
CA 02810457 2013-03-25
1 [0034] It should be understood that the full weight sharing
implementation as described herein is
2 distinct from the limited weight sharing implementation described
earlier. In the case of full weight
3 sharing, the sets of weights in different bands are configured to be the
same. However, this configuration
4 does not constrain the choice of value for M, the number of bands into
which the pooling layer activations
may be divided. In the case of limited weight sharing as described above,
however, the sets of weights in
6 different bands are configured to be the same when the convolution layer
consists of only one convolution
7 section and, thus, when there is only a single pooling band for the
entire corresponding convolution layer.
8 In a general case, there may be multiple convolution sections, and there
may be a different number of
9 bands into which the pooling layer activations of each section may be
divided.
[0035] This type of limited weight sharing may be applied only in the
topmost convolution layer
11 because the filters in different bands are not related and cannot be
convoluted and pooled afterwards.
12 [0036] In another aspect, the CNN may comprise one or more pairs of
convolution and pooling
13 layers, where the lowest layers process a small number of input
frequency bands independently to
14 generate higher level representation with lower frequency resolution.
The number of bands may decrease
in higher layers. The input to each convolution layer may be padded to ensure
that the first and last input
16 bands are processed by a suitable number of kernels in the convolution
layer. For example, each input
17 may be padded by adding a number of dummy bands before and after the
first and last bands,
18 respectively, so that the number of bands is consistent between the
original input and convolution layers.
19 [0037] In embodiments, the top layers of the CNN are fully connected
to combine different local
structures extracted in the lower layers for the final recognition.
21 [0038] In block 210, the output from the pooling layer is fed to a
number of fully connected hidden
22 layers. The posterior probabilities of output labels may be computed
using a top softmax layer (120). The
23 CNN may process each input speech utterance by generating all output
label probabilities for each frame.
24 In block 212, a decoder, such as a Vitetbi decoder for example, may then
be applied to obtain the
sequence of labels corresponding to the input utterance.
26 [0039] In the training stage, the CNN may, for example, be estimated
using a back-propagation
27 technique to minimize cross entropy of targets and output layer
activations. The training targets may be
28 obtained from forced alignments generated from a trained HMM component.
29 [0040] In exemplary embodiments, in feature extraction, speech may
be analyzed using, for
example, a 25-ms frame length multiplied by a Hamming function with a 10-ms
fixed frame rate. The
31 speech feature vector may be generated by Fourier-transform-based filter-
banks, which may include, for
32 example, 40 coefficients distributed on a Mel-scale and energy, along
with their first and second temporal
8
AppIn no. CA2,810,457
Agent ref: 103-005CAP
Amendment dated 2017/08/14
I derivatives. All speech data may be normalized by averaging over all
training cases so that each
2 coefficient or first derivative or second derivative all has zero mean and
unit variance. An n-gram
3 language model may be applied in decoding to generate the output label
sequence.
4 I 00411 in exemplary embodiments, for network training, a learning
rate, annealing and early
stopping strategics may be applied. The NN input layer may include a context
window of IS frames, for
6 example. The input of the CNN may be divided into 40 bands, for example.
In this example, each band
7 may include one of the 40 filter-bank coefficients along the 15 frames
context window including their
8 first and second derivatives. Moreover, all bands of the first
convolution layer may receive the energy as
9 an extra input because it may not be suitable to treat it as a frequency
band. Moreover the inputs of
.. convolution layers may be padded as previously mentioned. Exemplary pooling
sizes may be from 1 to 8,
11 .. for example. Around 80 to 97 filters may be provided per band, for
example.
12 1,0042,1 Although the above has been described with reference to
certain specific embodiments,
13 various modifications thereof will be apparent to those skilled in the
art without departing from the scope
14 of the claims appended hereto.
9
CA 2810457 2017-08-14