Note: Descriptions are shown in the official language in which they were submitted.
METHODS AND SYSTEMS FOR IMPLEMENTING DEEP SPIKING NEURAL NETWORKS
Field Of The Invention
[0001] The system and methods described herein are generally directed to
computing using
single or multi-layer spiking neural networks. The methods described here are
specifically directed
at learning efficient, accurate implementations of feedforward or recur- rent
deep networks using
temporally discontinuous nodes (i.e., 'spiking neurons').
Background
[0002] Deep artificial neural networks (ANNs) have recently been very
successful at solving
image categorization problems. Early successes with the Mixed National
Institute of Standards and
Technology (MNIST) database were expanded to the more difficult but similarly
sized Canadian
Institute for Advanced Research 10 category (CIFAR-10) dataset and Street-view
house numbers
(SVHN) dataset. More recently, many groups have achieved better results on
these small datasets as
well as success on larger datasets. This work culminated with the application
of deep neural
networks to ImageNet (see A. Krizhevsky, I. Sutskever, and G. Hinton, Imagenet
classification with
deep convolutional neural networks, in Advances in Neural Information
Processing Systems, 2012),
a very large and challenging dataset.
[0003] The relative success of deep ANNs in general¨and convolutional
neural networks in
particular¨on these datasets have put them well ahead of other methods in
terms of image
categorization by machines. Given that deep ANNs are approaching human
performance on some
datasets (or even passing it, for example on MNIST) suggests that these models
may be able to
shed light on how the human visual system solves these same tasks.
[0004] There has recently been considerable effort to take deep ANNs and
make them more
biologically plausible by introducing neural "spiking", such that connected
nodes in the network
transmit information via instantaneous single bits (spikes), rather than
transmitting real-valued
signals. While one goal of this work is to better understand the brain by
trying to reverse engineer
it, another goal is to build energy-efficient neuromorphic systems that use a
similar communication
1
Date recue / Date received 2021-12-16
method for image categorization. Previous approaches to implementing deep
networks with spiking
neurons rely on assuming that the neural spiking is generated by an integrate-
and-fire neuron. This
is a simple, non-biologically plausible model that is seldom implemented in
neuromorphic hardware.
Some previous approaches assume you have more than one spiking neurons per
node in the deep
network being implemented. A system that is able to be employed with a wider
variety of dynamic
spiking neural models would be more flexible. A system that is able to use a
single spiking neuron
per deep network node would be more efficient. Such a design could provide
more efficient
implementations of a wider variety of deep neural networks and allow a wider
range of hardware
implementations.
Summary
[0005] In a first aspect, some embodiments of the invention provide a
method for designing a
system for implementing single or multilayer spiking neural network
computations based on
statically trained networks. The method includes defining any node response
function that exhibits
brief temporal nonlinearities for representing state, i.e., 'neural spikes'.
This response function is
dynamic because the nonlinearity is temporal. A static response function is
one which maps
directly from an input state to an output state without dynamics being
considered (e.g., a sigmoid).
The method also includes defining a static version of the dynamic node
response function and
employing the static version of the response function to train a neural
network using any available
training method, resulting in neural connection weights. It is then possible
to use those connection
weights in a dynamically implemented spiking neural network to compute the
function trained for.
[0006] In some cases, the initial couplings and connection weights are
determined using a
neural compiler.
[0007] In a second aspect, some embodiments of the invention provide a
system for pattern
classification, data representation, or signal processing in spiking neural
networks. The system
includes one or more input layers presenting a vector of 1 or greater
dimensions, as well as zero
or more intermediate layers coupled via weight matrices to at least one of the
input, other
intermediate, or output layers and one or more output layers generating a
vector representation
of the data presented at the input layer. Each layer comprises a plurality of
nonlinear components,
2
Date recue / Date received 2021-12-16
wherein each nonlinear component is configured to generate temporally brief
outputs at each
moment in time in response to the input (i.e., a 'spike') and is coupled to
the output module by
at least one weighted coupling. The output from each nonlinear component is
weighted bythe
connection weights of the corresponding weighted couplings and the weighted
outputs are
provided to the output module to form the output modifier. The output from
each nonlinear
component may be filtered by a connection filter between that component and
others it is
connected to. The connection weights are determined using methods of the first
aspect.
[0008] In some cases, the input to the system is either discrete or
continuous in time and/or
space.
[0009] In some cases, the input to the system can be scalar or a
multidimensional vector.
Brief Description of the Drawings
[00010] A preferred embodiment of the present invention will now be specified
in detail with
reference to the drawings.
[00011] FIG. 1 is a block diagram of layers and nonlinear spiking elements
in accordance with an
example embodiment.
[00012] FIG. 2 is a diagram of the process involved in applying the method.
[00013] FIG. 3 is a diagram of the process involved in applying several of
the variations of the
method described herein.
[00014] FIG. 4 is an illustration of a plot showing leaky integrate-and-
fire (LIF) and soft LIF
response functions as well as their derivatives.
[00015] FIG. 5 is an illustration of a plot showing variability in filtered
spike trains versus input
current for the LIF neuron.
3
Date recue / Date received 2021-12-16
Description of Exemplary Embodiments
[00016] Herein, numerous specific details are set forth in order to provide
a thorough
understanding of the exemplary embodiments described. However, it will be
understood by those
of ordinary skill in the art that the embodiments described herein may be
practiced without
these specific details. In other instances, well-known methods, procedures and
components have
not been described in detail so as not to obscure the embodiments generally
described herein.
Furthermore, this description is not to be considered as limiting the scope of
the embodiments
described herein in any way, but rather as merely describing the
implementation of various
embodiments as presented here for illustration.
[00017] The embodiments of the systems and methods described herein may be
implemented
in hardware or software, or a combination of both. These embodiments may be
implemented in
computer programs executing on programmable computers, each computer including
at least one
processor, a data storage system (including volatile memory or non-volatile
memory or other data
storage elements or a combination thereof), and at least one communication
interface. In certain
embodiments, the computer may be a digital or any analogue computer.
[00018] Program code is applied to input data to perform the functions
described herein and
to generate output information. The output information is applied to one or
more output devices,
in known fashion.
[00019] Each program may be implemented in a high level procedural or
object oriented
programming or scripting language, or both, to communicate with a computer
system. However,
alternatively the programs may be implemented in assembly or machine language,
if desired. The
language may be a compiled or interpreted language. Each such computer program
may be stored
on a storage media or a device (e.g., read-only memory (ROM), magnetic disk,
optical disc),
readable by a general or special purpose programmable computer, for
configuring and operating
the computer when the storage media or device is read by the computer to
perform the procedures
described herein. Embodiments of the system may also be considered to be
implemented as a
non-transitory computer-readable storage medium, configured with a computer
program, where
the storage medium so configured causes a computer to operate in a specific
and predefined
4
Date recue / Date received 2021-12-16
manner to perform the functions described herein.
[00020] Furthermore, the systems and methods of the described embodiments are
capable of
being distributed in a computer program product including a physical,
nontransitory computer
readable medium that bears computer usable instructions for one or more
processors. The
medium may be provided in various forms, including one or more diskettes,
compact disks, tapes,
chips, magnetic and electronic storage media, and the like. Non-transitory
computer-readable
media comprise all computer-readable media, with the exception being a
transitory, propagating
signal. The term non-transitory is not intended to exclude computer readable
media such as a
volatile memory or random access memory (RAM), where the data stored thereon
is only
temporarily stored. The computer useable instructions may also be in various
forms, including
compiled and non-compiled code.
[00021] It should also be noted that, as used herein, the wording and/or is
intended to represent
an inclusive-or. That is, X and/or Y is intended to mean X or Y or both, for
example. As a further
example, X, Y, and/or Z is intended to mean X or Y or Z or any combination
thereof.
[00022] Embodiments described herein generally relate to a system and
method for designing
and implementing a shallow or deep feedforward or recurrent spiking neural
network. Such a
system can be efficiently implemented on a wide variety of distributed systems
that include a large
number of nonlinear components whose individual outputs can be combined
together to
implement certain aspects of the system as will be described more fully herein
below.
[00023] Examples of nonlinear components that can be used in various
embodiments described
herein include simulated/artificial neurons, field-programmable gate arrays
(FPGAs), graphics
processing units (GPUs), and other parallel computing systems. Components of
the system may also
be implemented using a variety of standard techniques such as by using
microcontrollers. Also note
the systems described herein can be implemented in various forms including
software simulations,
hardware, or anyneuronal fabric. Examples of mediums that can be used to
implement the system
designs described herein include Neurogrid (see S. Choudhary, S. Sloan, S.
Fok, A. Neckar, Eric,
Trautmann, P. Gao, T. Stewart, C. Eliasmith, and K. Boahen, Silicon neurons
that compute, in
International Conference on Artificial Neural Networks, 2012, pp. 12128.),
Spinnaker (see M. Khan,
Date recue / Date received 2021-12-16
D. Lester, L. Plana, A. Rast, X. Jin, E. Painkras, and S. Furber, SpiNNaker:
Mapping neural networks
onto a massively-parallel chip multiprocessor. IEEE, Jun. 2008.), open
computing language (OpenCL),
and TrueNorth (see P. Merolla, J. V. Arthur, R. Alvarez-Icaza, A. S. Cassidy,
J. Sawada, F. Akopyan, B. L.
Jackson, N. Imam, C. Guo, Y. Nakamura, B. Brezzo, I. Vo, S. K. Esser, R.
Appuswamy, Taba, A. Amir, M.
D. Flickner, W. P. Risk, R. Manohar, and D. S. Modha, Artificial brains. A
million spiking-neuron
integrated circuit with a scalable communication network and interface.
Science (New York, N.Y.),
vol. 345, no. 6197, pp. 66873, Aug. 2014.). As used herein the term 'neuron'
refers to spiking
neurons, continuous rate neurons, or components of any arbitrary high-
dimensional, nonlinear,
distributed systems.
[00024] To generate such systems we train a network employing static response
functions on
images using traditional deep learning techniques; we call this the static
network. We then take the
parameters (weights and biases) from the static network and use them to
connect spiking neurons,
forming the dynamic network (or spiking network). The challenge is to train
the static network in
such a way that a) it can be transferred into a spiking network, and b) the
classification error of
the dynamic network is as close to that of the static network as possible
(i.e., the conversion to
a dynamic network introduces as little performance error as possible).
[00025]
FIG. 1 shows the general architecture of these networks. Each layer (100)
consists of
several nodes (102) that can be either spiking or non-spiking. The overall
network structure can be
quite varied, with layers connecting within or back to themselves (recurrent
networks), or to other
layers earlier or later than them in the network. Networks that connect only
in one direction are
called feedforward networks. Connections between layers may also be quite
varied, including full
connectivity, local connectivity, convolutional connectivity, or any other
connectivity pattern.
Regardless of the topology, the network takes some form of vector input (101)
which it converts
via its weighted, connected components to a different vector output (103),
possibly changing the
dimensionality. This figure represents the basic structure of both
convolutional and non-
convolutional networks. In the case of convolutional networks, there is extra
structure imposed on
the topology of the connections between layers. Convolutional networks have
excellent
performance on many machine learning tasks. Consequently, we use this kind of
network in our
example embodiment.
6
Date recue / Date received 2021-12-16
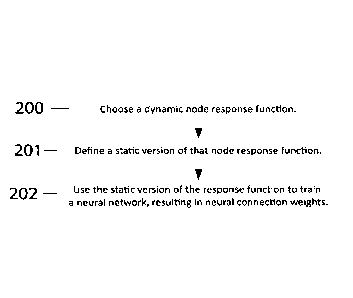
[00026] We describe here a method for designing a system for implementing
single or multi-
layer, feedforward or recurrent spiking neural network computations, depicted
in FIG. 2 and in more
detail in FIG. 3. The first step in the method consists in defining any node
response function that
exhibits brief temporal nonlinearities for representing state overtime, i.e.,
'spikes' (200). There are
a wide variety of example nonlinearities in the literature, including the
Hodgkin-Huxley (HH) neuron,
the Fitzhugh-Nagumo neuron, the exponential, quadratic, adaptive, or standard
leaky integrate-
and-fire (LIF) neuron, the integrate-and-fire neuron, the Wilson neuron, the
lzhichevich neuron,
among others. Various hardware implementations of these and other
nonlinearities have also been
proposed, for generating spike-like outputs. In addition, for certain
embodiments a synapse model
can be chosen (300) when smoothing and/or training with noise. There are a
wide variety of synapse
models in the literature, including exponential decay, the alpha-synapse, and
conductance-based
models.
[00027] The second step consists in determining a static version of that node
response function
(201). The methods used can depend on the dynamic model (303). For example,
the standard LIF
neuron has a closed form static description. In contrast, the adaptive LIF
will require
approximation of its temporally varying response function via weighted
averaging or a similar
method. Similarly, numerical simulation methods can be used to determine
static approximations
of more complex neuron models, like the HH model. Additionally, such static
models may have a
discontinuous, high, or unbounded derivative, which must be smoothed (304). We
provide an
example smoothing method below, and discuss a variety of smoothing and noise
modeling
methods. Smoothing typically requires choosing a synapse model. These should
be chosen to match
that used in the final dynamic simulation if one is to be performed.
[00028] The
third step consists in employing the static version of the response function
to train
a neural network using any available training method, resulting in neural
connection weights (202).
The method for training is not restricted (306). In our example embodiment, we
focus on recent
state-of-the-art methods, including convolutional networks and denoising
autoencoders. However,
any standard method for training ANNs may be employed, including supervised,
unsupervised, or
reinforcement learning.
[00029] With this method, the connection weights determined in step three can
be used in a
7
Date recue / Date received 2021-12-16
dynamically implemented spiking neural network to compute the function trained
for (310). This
consists in running the dynamic neural model, where each neuron is connected
to others by the
synaptic dynamics weighted by the connection weights determined during ANN
training. As shown
in the example embodiment, this set of steps allows for good performance on
the original task in
the spiking network.
[00030] In this method, smoothing of the static nonlinearity can be
performed using equation 4,
an analytic smoothing function, or numerical filtering (305). This is often
necessary if the derivative
of the static response function is high or unbounded. Any of these methods
will allow an
approximation that will have a usable derivative for the purposes of employing
standard learning
methods. Application of smoothing can vary depending on how well training is
progressing (308-
309). The amount of smoothing can be reduced during training so that less
error is introduced when
converting to the dynamic response function (309).
[00031] In this method, the initial couplings and connection weights can be
determined in any
of a number of ways, including by using a neural compiler, like the methods of
the Neural
Engineering Framework (NEF). It is more common to use random weights, which
will also often
result in useful network.
[00032] In this method it is possible to introduce an adaptive rule that
fine tunes the weights
initially determined using this method. There are a wide variety of such rules
that work in spiking
neural networks, including spike-timing-dependent plasticity (STDP) rules,
such as the prescribed
error sensitivity (PES) rule (see T. Bekolay, Learning in large scale spiking
neural networks, Masters,
University of Waterloo, 2011.). These rules can be applied at any point during
the simulation of the
dynamic network.
[00033] This method can often be enhanced by training with noise that, at
least in part,
accounts for variability introduced by neural spiking (301-302). In our
example embodiment, we
demonstrate that training with noise on neuron outputs improved the
performance of the spiking
network. In that case, our additive Gaussian noise is a rough approximation of
the variability that
the spiking network will encounter. Using these same methods we can include
training with noise
that is more representative of the variability seen in spiking networks, to
accommodate both the
8
Date recue / Date received 2021-12-16
non-Gaussian statistics at any particular input current, and the changing
statistics across input
currents.
[00034]
This method can be integrated with additional nonlinearities (e.g. computing
the max
function) or linearities (e.g., computing average pooling) in the network. In
our example
embodiment we demonstrate including additional linearities. Similar methods
can be used to model
nonlinearities as well. Using approximation to an arbitrary function (e.g,.
max pooling) by
introducing a network topology into the spiking neurons (e.g., lateral
inhibition) and simulating the
effects of that topology on the input/output mapping provided by that group of
neurons, for a
wide range of static inputs to the neurons is one example. This static
input/output mapping can
then be used during the standard training of the static network to approximate
thatcomputation.
Example
[00035] We base our example network off that of Krizhevsky et al., which
achieved 11% error on
the CIFAR-10 dataset (a larger variant of the model won the ImageNet 2012
competition). The
original network consists of five layers: two generalized convolutional
layers, followed by two
locally-connected non-convolutional layers, followed by a fully-connected
softmax classifier. A
generalized convolutional layer consists of a set of convolutional weights
followed by a neural
nonlinearity, then a pooling layer, and finally a local response normalization
layer. The locally-
connected non-convolutional layers are also followed by a neural nonlinearity.
In the case of the
original network, the nonlinearity is a rectified linear (ReLU) function, and
both pooling layers
perform overlapping max-pooling. Code for the original network and details of
the network
architecture and training can be found at https://code.google.com/p/ cuda-
convnet2/.
[00036] Past work has not demonstrated how to make static networks
transferable to spiking
neurons in general. The methods described herein address this problem. Some of
these
modifications simplify the network topology, but the central modifications
relate to matching a
dynamic neuron response function to a static one to allow effective training.
In this example
embodiment, we begin with topological changes to simplify the network being
trained. These
simplifications are not crucial to the invention, and are used here only for
demonstration. First, we
remove the local response normalization layers. This computation would likely
require some sort of
9
Date recue / Date received 2021-12-16
lateral connections between neurons, but for this demonstration we will allow
the resulting network
to remain feed-forward. However, the methods described will work for recurrent
networks.
[00037] Second, we changed the pooling layers from max pooling to average
pooling. Again,
computing max pooling would likely require lateral connections between
neurons. Average pooling,
on the other hand, allows the network to remain feedforward, since it is
simply a weighted sum.
[00038] While not demonstrated here, some embodiments can generate an
approximation to
an arbitrary function (e.g,. max pooling) by introducing a network topology
into the spiking neurons
(e.g., lateral inhibition) and simulating the effects of that topology on the
input/output mapping
provided by that group of neurons, for a wide range of static inputs to the
neurons. This static
input/output mapping can then be used during the standard training of the
static network to
approximate that computation.
[00039] The central modification being introduced here is using leaky
integrate-and-fire
neurons in place of standard non spiking ReLU units. In addition, we discuss
training with noise as
it plays an important role in getting good quality results.
[00040] Our network uses a modified leaky integrate-and-fire (LIF) neuron
nonlinearity instead of
the rectified linear nonlinearity. Past work has kept the rectified linear non-
linearity for the static
network and substituted in the spiking integrate-and-fire (IF) neuron model in
the dynamic
network (see Y.Cao, Y. Chen, and D. Khosla, Spiking Deep Convolutional Neural
Networks for Energy-
Efficient Object Recognition, International Journal of Computer Vision, vol.
113, no. 1, pp. 5466,
Nov. 2014. and P. U. Diehl, D. Neil, J. Binas, M. Cook, S.-C. Liu, and M.
Pfeiffer, Fast-Classifying, High-
Accuracy Spiking Deep Networks Through Weight and Threshold Balancing, in IEEE
International
Joint Conference on Neural Networks (IJCNN), 2015.), since the static firing
curve of the IF neuron
model is a rectified line. This approach attempts to remove the dynamics of
the neuron from having
an effect on the network, rather than accounting for it during training.
Often, very high firing rates
are chosen, effectively making the dynamic model identical to the static
model.
[00041] Our motivations for using the LIF neuron model are that a) it is
more biologically realistic
than the IF neuron model because IF models lack absolute and relative
refractory periods, lack
saturation effects, lack membrane time constant effects, and employ other
simplifications, and b) it
Date recue / Date received 2021-12-16
demonstrates that alternative models can be used in such networks. The LIF
model is a canonical
neural model that has been shown to be the reduction of a wide variety of
complex conductance
models. More generally, the methods applied here are transferable to any other
spiking neuron
model, and can be used to train a network for the idiosyncratic neuron types
employed by some
neuromorphic hardware. This includes neurons whose dynamic response functions
are time-
varying (e.g. adapting neurons), as long as a static approximation can be
generated. We provide an
example method here for generating such an approximation for LIF neurons. The
method we
demonstrate, as well as statistical modeling of dynamic responses, regression
fitting methods,
analytic reduction or other forms of generating static solutions for dynamic
systems can be
employed.
[00042] The LIF neuron dynamics are given by the equation
(//1(t)
t) + JO )
/ ( 1 )
dt
1 until another spike occurs.
[00044] Given a constant input current./ (t) =j, we can solve Equation 1
for the time it takes the
voltage to rise from zero to one, and thereby find the steady-state firing
rate
=
r(j)
v 1
t i ] . .
ref ¨ TRc 10g(I i ) J > Vth
otherwise . (2)
{:
11
Date recue / Date received 2021-12-16
[00045] Theoretically, we should be able to train a deep neural network using
Equation 2 as the
static nonlinearity and make a reasonable approximation of the network in
spiking neurons,
assuming that the spiking network has a synaptic filter that sufficiently
smooths a spike train to
give a good approximation of the firing rate. The LIF steady state firing rate
has the particular
problem that the derivative approaches infinity as] 0+, which causes problems
when employing
backpropagation. To address this, we add smoothing to the LIF rate equation.
[00046] Equation 2 can be rewritten as
r(j) ff=--- Tc f 11 TRc lOg (1 11 ___________
-1
[r VthT 7 , )1
PO - vth ) (3)
[00047] where p(x) = max(x, 0). If we replace this hard maximum with a softer
maximum pi(x) =
log(1 + ex), then the LIF neuron loses its hard threshold and the derivative
becomes bounded.
Further, we can use the substitution
P2 (x) ¨ -./ tog 1 + exhr
[ (4)
[00048] to allow us control over the amount of smoothing, wherep2(x)
max(x,O)as y 0. FIG. 4
shows the result of this substitution, comparing the LIF and soft LIF response
functions. The left
panel shows the response functions themselves. The LIF function (400) has a
hard threshold at] =
Vth = 1; the soft LIF function (410) smooths this threshold. The right panel
shows the derivatives
of the response functions. The hard LIF function (401) has a discontinuous and
unbounded
derivative at j = 1; the soft LIF function has a continuous bounded derivative
(411), making it
amenable to use in backpropagation, the most common method used for training
deep networks.
Training with Noise
12
Date recue / Date received 2021-12-16
[00049] Training neural networks with various types of noise on the inputs
is not a new idea.
However, its application in the case of spiking networks will be shown to be
important, and hence
is included in our description of the current invention as it is a unique
application in this context.
[00050] In the past, denoising autoencoders have been successfully applied
to datasets like
MNIST, learning more robust solutions with lower generalization error than
their non-noisy
counterparts.
[00051] In a spiking neural network, the neuron receiving spikes in a
connection (called the post-
synaptic neuron) actually receives a filtered version of each spike. This
filtered spike is called a
post-synaptic current (or potential), and the shape of this signal is
determined by the combined
dynamics of the pre-synaptic neuron (e.g. how much neurotransmitter is
released) and the post-
synaptic neuron (e.g. how many ion channels are activated by the
neurotransmitter and how they
affect the current going into the neuron). The post-synaptic current dynamics
can be characterized
relatively well as a linear system with the impulse response given by the a-
function:
itI1 (5)
's
[00052] Note, however, that the methods described herein do not depend on
there being a low-
order linear system description available, as in this case. These methods will
work for a wide variety
of higher order and nonlinear filters.
[00053] The filtered spike train can be viewed as an estimate of the neuron
activity. For example,
if the neuron is firing regularly at 200 Hz, filtering spike train will result
in a signal fluctuating around
200 Hz. We can view the neuron output as being 200 Hz, with some additional
"noise" around this
value. By training our static network with some random noise added to the
output of each neuron
for each training example, we can simulate the effects of using spikes on the
signal received by the
post-synaptic neuron.
13
Date recue / Date received 2021-12-16
[00054] FIG. 5 shows how the variability of filtered spike trains depends
on input current for the
LIF neuron. Variability in filtered spike trains versus input current for the
LIF neuron (rRc = 0.02, rref
= 0.004) can be seen here. The solid line (500) shows the mean of the filtered
spike train (which
matches the analytical rate of Equation 2), the 'x'-points (501) show the
median, the solid error
bars (503) show the 25th and 75th percentiles, and the dotted error bars (502)
show the minimum
and maximum. The spike train was filtered with an a-filter (Equation 5) with
rs = 0.003 s. (Note that
this is different than the rs = 0.005 used in simulation, to better display
the variation.)
[00055] Since the impulse response of the a-filter has an integral of one,
the mean of the filtered
spike trains is equal to the analytical rate of Equation 2. However, the
statistics of the filtered signal
vary significantly across the range of input currents. Just above the firing
threshold, the distribution
is skewed towards higher firing rates (i.e. the median is below the mean),
since spikes are infrequent
so the filtered signal has time to return to near zero between spikes. At
higher input currents, on
the other hand, the distribution is skewed towards lower firing rates (i.e.
the median is above the
mean). In spite of this, we used a Gaussian distribution to generate the
additive noise during
training, for simplicity. Note, however, that the noise distribution can be of
other forms, and will be
more effective the more similar the distribution form is to the observed
noise.
[00056] We found the average standard deviation to be approximately a = 10
across all positive
input currents for an a-filter with rs = 0.005. The final steady-state soft
LIF curve used in training is
given by
- ¨1
Vt h
r(j) = Tref + T Re lo g(1 + + i(j) (6)
P(3 ¨ Voi)
where
G(0, cr) )13 > Vth
rgi) (7)
0 otherwise
mid p(.) is given by EquLtion 4
14
Date recue / Date received 2021-12-16
Conversion to a Spiking Network
t
[00057] Finally, we convert the trained static network to a dynamic spiking
network. The
parameters in the spiking network (i.e. weights and biases) are all identical
to that of the static
network. The convolution operation also remains the same, since convolution
can be rewritten as
simple connection weights (synapses) wij between pre-synaptic neuron land post-
synaptic neuron
J.
[00058] Similarly, the average pooling operation can be written as a simple
connection weight
matrix, and this matrix can be multiplied by the convolutional weight matrix
of the following layer
to get direct connection weights between neurons. For computational
efficiency, we actually
compute the convolution and pooling separately.
[00059] Given the methods described above, for this embodiment, the only
component of the
network that actually changes, when moving from the static to the dynamic
network, is the
neurons themselves. The most significant change is that we replace the soft
LIF rate model
(Equation 6) with the LIF spiking model (Equation 1). We also remove the
additive Gaussian noise
used in training. There are, however, a plurality of ways that the change from
the static to dynamic
network may be achieved. One is using the same neuron model as described here.
Another
embodiment may use a different dynamic and static model (i.e., models
generated from different
neuron models), as long as they are sufficiently similar to compute the
function trained for. Another
embodiment would be to use more than one dynamic neuron to approximate the
static function
used during training.
[00060] When generating the dynamic network post-synaptic filters are also
included in this
example embodiment, which filter the incoming spikes before passing the
resulting currents to the
LIF neuron equation. It is not essential to add these filters. As stated
previously, we use the a-filter
for our synapse model, since it has both strong biological support, and
removes a significant portion
of the high-frequency variation produced by spikes. We pick the decay time
constant rs = 5 ms,
typical for excitatory AMPA receptors in the brain.
Date recue / Date received 2021-12-16
Results
[00061] We tested our network on the CIFAR-10 dataset. This dataset is
composed of 60000 32
x 32 pixel labelled images from ten categories. We used the first 50000 images
for training and the
last 10000 for testing, and augmented the dataset by taking random 24x24
patches from the tra ining
images and then testing on the center patches from the testing images. This
methodology is similar
to Krizhevsky et al., except that they also used multiview testing where the
classifier output is the
average output of the classifier run on nine random patches from each testing
image (increasing the
accuracy by about 2%).
[00062] Table 1 shows the effect of each modification on the network
classification error. Our
original static network based on the methods of Krizhevsky et al. achieved
14.63% error, which is
higher than the 11% achieved by the original paper since a) we are not using
multiview testing, and
b) we used a shorter training time (160 epochs versus 520 epochs).
[00063] Rows 1-5 in Table 1 show that each successive modification to make the
network
amenable to running in spiking neurons adds about 1-2% more error. Despite the
fact that training
with noise adds additional error to the static network, rows 6-8 of the table
show that in the
spiking network, training with noise pays off, though training with too much
noise is not
advantageous. Specifically, though training with a = 20 versus a= 10 decreased
the error introduced
when switching to spiking neurons ( 1% versus 2%), training with a = 20 versus
a = 10 introduced an
additional 2.5% error to the static network, making the final spiking network
perform worse. In the
interest of time, these spiking networks were all run on the same 1000-image
random subset of
the testing data. The last two rows of the table show the network with the
optimal amount of noise
(a = 10) trained for additional epochs (a total of 520 as opposed to 160), and
run on the entire test
set. Our spiking network achieves an error of 17.05% on the full CIFAR-10 test
set, which is the best
published result of a spiking network on this dataset.
16
Date recue / Date received 2021-12-16
# Modification CIFAR-10 error
0 Original static network based on Krizhevskv etal. 14.63%
1 Above minus local contrast normalization .. 15.27%
2 Above minus max pooling 17.20%
3 Above with soft LIF 18.92%
4 Above with training noise (a= 10) 19.74%
Above with training noise (a= 20) 22.22%
6 Network 3 (o-= 0) in spiking neurons lc 1 cv,a
7 Network 4(a= 10) in spiking neurons li 70i, a
8 Network 5 (a= 20) in spiking neurons lq loi,C/
9 Network 4 (a= 10) with additional training epochs16.01%
Network 9 (a = 10) in spiking neurons 17.05%
a Results from the same random 1000-image subset of the testing set.
Table 1 Effects of successive modifications to CIFAR-10 error. We first show
the original static (non-
spiking) network based on Krizhevsky et al. Modifications 1-5 are cumulative,
which each one
applied in addition to the previous ones. Rows 6-8 show the results of running
static networks 3-5
in spiking neurons, respectively. Row 9 shows the best architecture for
spiking implementation,
Network 4, trained for additional epochs, and row 10 shows this highly-trained
network in spiking
neurons. This is the best spiking-network result on CIFAR-10 to date.
[00064] Comparing spiking networks is difficult, since the results depend
highly on the
characteristics of the neurons used. For example, neurons with very high
firing rates, when filtered,
will result in spiking networks that behave almost identically to their static
counterparts. Using
neurons with lower firing rates have much more variability in their filtered
spike trains, resulting in
noisier and less accurate dynamic networks. Nevertheless, we find it
worthwhile to compare our
results with those of Cao et al., who achieved 22.57% error on the CIFAR-10
dataset (as far as we
know, the only other spiking network with published results on CIFAR-10). The
fact that we achieved
better results suggests that LIF neuron spiking networks can be trained to
state-of-the-art
accuracy and that adding noise during training helps improve accuracy.
[00065] Most spiking deep networks to date have been tested on the MNIST
dataset. The MNIST
dataset is composed of 70000 labelled hand-written digits, with 60000 used for
training and 10000
reserved for testing. While this dataset is quickly becoming obsolete as deep
networks become
more and more powerful, it is only recently that spiking networks are
beginning to achieve human-
level accuracy on the dataset.
17
Date recue / Date received 2021-12-16
Source MNIST error
Brader et al. 3.5% (1.3% misclassified. 2.2% not classified) (IF)
Eliasmith et al. 6% (LIF)
Neftci et al. 8.1% (LIF)
O'Connor et al. 2.52% (sigmoid-binary), 5.91% (LIF)
Garbin et al. 1.7% (IF)
Diehl et al. 1 qA0/.. a 11P1
Our network 1.63% (LIF)
aTheir best result for a non-convolutional network.
Table 2 Comparison of our network to the best published results for spiking
networks on MNIST
(see J. M. Broder, W. Senn, and S. Fusi, Learning real-world stimuli in a
neural network with spike-
driven synaptic dynamics, Neural Computation, vol. 19, pp. 28812912, 2007 AND
C. Eliasmith, T. C.
Stewart, X. Choo, T. Bekolay, T. DeWolf, C. Tang, and D. Rasmussen, A Large-
Scale Model of the
Functioning Brain, Science, vol. 338, no. 6111, pp. 1202 1205, Nov. 2012 AND
E. Neftci, S. Das, B.
Pedroni, K. Kreutz-Delgado, and G. Cauwenberghs, Event-driven contrastive
divergence forspiking
neuromorphic systems, Frontiers in Neuroscience, vol. 7, no. 272, 2013 AND P.
Connor, D.
Neil, S.-C. Liu, T. Delbruck, and M. Pfeiffer, Real-time classification and
sensor fusion with a
spiking deep belief network, Frontiers in Neuroscience, vol. 7, Jan. 2013 AND
D. Garbin, 0.
Bichler, E. Vianello, Q. Rafhay, C. Gamrat, L. Perniola, G. Ghibaudo, and B.
DeSalvo, Variability-
tolerant convolutional neural network for pattern recognition applications
based on OxRAM
synapses, in IEEE International Electron Devices Meeting (IEDM), 2014, pp.
28.4.128.4.4). Our
network performs on par with state-of-the-art results, demonstrating that
state-of-the-art spiking
networks can be trained with LIF neurons.
[00066] We trained an example network on the MNIST dataset. This network used
layer-wise
pretraining of non-convolutional denoising autoencoders, stacked and trained
as a classifier. This
network had two hidden layers of 500 and 200 nodes each, and was trained on
the unaugmented
dataset. Despite the significant differences between this network and the
network used on the
CIFAR-10 dataset, both networks use spiking LIF neurons and are trained with
noise to minimize
the error caused by the filtered spike train variation. Table 2 shows a
comparison between our
network and the best published results on MNIST. Our network significantly
outperforms the best
results using LIF neurons, and is on par with those of IF neurons. This
demonstrates that state-
of-the-art networks can be trained with LIF neurons.
18
Date recue / Date received 2021-12-16
[00067] These example results demonstrate that the methods described in this
invention allow
us to train accurate deep convolutional networks for image classification
using more biologically
accurate leaky integrate-and-fire (LIF) neurons, as opposed to the traditional
rectified-linear or
sigmoid neurons. Such a network can be run in spiking neurons, and training
with noise decreases
the amount of error introduced when running in spiking versus rate neurons.
[00068] The methods described that employ smoothing the neuron response
function is
applicable to neuron types other than the LIF neuron. Many other neuron types
have discontinuous
response functions (e.g. the FitzHugh-Nagumo neuron), and our smoothing method
allows such
neurons to be used in deep convolutional networks. We found that there was
very little error
introduced by switching from the soft response function to the hard response
function with LIF
neurons for the amount of smoothing that we used. However, for neurons with
harsh discontinuities
that require more smoothing, it may be possible to slowly relax the smoothing
over the course of
the training so that, by the end of the training, the smooth response function
is arbitrarily close
to the hard response function.
[00069] Our example networks also demonstrate that training with noise on
neuron outputs can
decrease the error introduced when transitioning to spiking neurons. Training
with noise on neuron
outputs improved the performance of the spiking network considerably (the
error decreased by
3.4%). This is because noise on the output of the neuron simulates the
variability that a spiking
network encounters when filtering a spike train. There is a tradeoff between
too little training noise,
where the resultant dynamic network is not robust enough against spiking
variability, and too much
noise, where the accuracy of the static network is decreased. Since the
variability produced by
spiking neurons is not Gaussian (FIG. 5), our additive Gaussian noise is a
rough approximation of the
variability that the spiking network will encounter. Using these same methods
we can include
training with noise that is more representative of the variability seen in
spiking networks, to
accommodate both the non-Gaussian statistics at any particular input current,
and the changing
statistics across input currents.
[00070] Our example networks perform favourably with other spiking networks,
achieving the
best published result for a spiking network on CIFAR-10, and the best result
for a LIF neuron spiking
network on MN 1ST.
19
Date recue / Date received 2021-12-16
[00071]
Similar methods that extend those explicitly tested here can be used to
include max-
pooling and local contrast normalization layers in spiking networks. Computing
these functions in
spiking networks can exploit the methods like those described by Eliasmith and
Anderson (see C.
Eliasmith and C. H. Anderson, Neural Engineering: Computation, Representation,
and Dynamics in
Neurobiological Systems. Cambridge, MA: MIT Press, 2003). Networks could also
be trained offline
as described here and then fine-tuned online using a spike-timing-dependent
plasticity (STDP) rule,
such as the prescribed error sensitivity (PES) rule (see T. Bekolay), to help
further reduce errors
associated with converting from rate-based to spike-based networks, while
avoiding difficulties
with training a network in spiking neurons from scratch.
[00072] The aforementioned embodiments have been described by way of example
only. The
invention is not to be considered limiting by these examples and is defined by
the claims that now
follow.
Date recue / Date received 2021-12-16