Note: Descriptions are shown in the official language in which they were submitted.
1 METHOD AND SYSTEM FOR GENERATING ASPECTS ASSOCIATED WITH A FUTURE
2 EVENT FOR A SUBJECT
3 TECHNICAL FIELD
4 [0001] The following relates generally to data processing, and more
specifically, to a method
and system for generating aspects associated with a future event for a
subject.
6 BACKGROUND
7 [0002] Predicting aspects of a future event can generally be undertaken
where there is
8 sufficient historical data to provide a sufficiently accurate prediction.
For example, for retailers,
9 they may rely on extensive customer and product data to better understand
customer behaviour
and predict future purchases (events) of items (aspects) by the customer
(subject). However,
11 this prediction can provide insufficiently accurate predictions for new
subjects or infrequent
12 events in the historical data; for example, for new or infrequent
customers for which historical
13 transaction data is limited.
14 SUMMARY
[0003] In an aspect, there is provided a method for generating at least one
aspect associated
16 with a future event for a subject using historical data, the historical
data comprising a plurality of
17 aspects associated with historical events, the method executed on at
least one processing unit,
18 the method comprising: receiving the historical data; determining a
subject embedding using a
19 recurrent neural network (RNN), input to the RNN comprises historical
events of the subject
from the historical data, each historical event comprising by an aspect
embedding, the RNN
21 trained using aspects associated with events of similar subjects from
the historical data;
22 generating at least one aspect of the future event for the subject using
a generative adversarial
23 network (GAN), input to the GAN comprises the subject embedding, the GAN
trained with
24 subject embeddings determined using the RNN for other subjects in the
historical data; and
outputting the at least one generated aspect.
26 [0004] In a particular case of the method, the aspect embedding
comprises at least one of a
27 moniker of the aspect and a description of the aspect.
28 [0005] In another case of the method, the RNN comprises a long short
term memory (LSTM)
29 model trained using a multi-task optimization approach.
1
CA 3059904 2019-10-24
1 [0006] In yet another case of the method, the multi-task optimization
approach comprises a
2 plurality of prediction tasks, the LSTM randomly sampling which of the
prediction tasks to
3 predict for each training step.
4 [0007] In yet another case of the method, the prediction tasks comprise:
predicting whether the
aspect is a last aspect to be predicted in a compilation of aspects;
predicting a grouping or
6 category of the aspect; and predicting an attribute associated with the
aspect.
7 [0008] In yet another case of the method, the GAN comprises a generator
and a discriminator
8 collectively performing a min-max game.
9 [0009] In yet another case of the method, the discriminator maximizes an
expected score of
real aspects and minimizes a score of generated aspects, and wherein the
generator maximizes
11 a likelihood that the generated aspect is plausible, where plausibility
is determined by the output
12 of the discriminator.
13 [0010] In yet another case of the method, the similarity of subjects is
determined using a
14 distance metric on the subject embedding.
[0011] In yet another case of the method, the method further comprising
generating further
16 aspects for subsequent future events by iterating the determining of the
subject embedding and
17 the generating of the at least one aspect, using the previously
determined subject embeddings
18 and generated aspects as part of the historical data.
19 [0012] In yet another case of the method, aspects are organized into
compilations of aspects
that are associated with each of the events in the historical data and the
future event.
21 [0013] In another aspect, there is provided a system for generating at
least one aspect
22 associated with a future event for a subject using historical data, the
historical data comprising a
23 plurality of aspects associated with historical events, the system
comprising one or more
24 processors in communication with a data storage, the one or more
processors configurable to
execute: a data acquisition module to receive the historical data; an RNN
module to determine a
26 subject embedding using a recurrent neural network (RNN), input to the
RNN comprises
27 historical events of the subject from the historical data, each
historical event comprising by an
28 aspect embedding, the RNN trained using aspects associated with events
of similar subjects
29 from the historical data; and a GAN module to generate at least one
aspect of the future event
for the subject using a generative adversarial network (GAN), input to the GAN
comprises the
31 subject embedding, the GAN trained with subject embeddings determined
using the RNN for
32 other subjects in the historical data, and output the at least one
generated aspect.
2
CA 3059904 2019-10-24
1 [0014] In a particular case of the system, the aspect embedding comprises
at least one of a
2 moniker of the aspect and a description of the aspect.
3 [0015] In another case of the system, the RNN comprises a long short term
memory (LSTM)
4 model trained using a multi-task optimization approach.
[0016] In yet another case of the system, the multi-task optimization approach
comprises a
6 plurality of prediction tasks, the LSTM randomly sampling which of the
prediction tasks to
7 predict for each training step.
8 [0017] In yet another case of the system, the prediction tasks comprise:
predicting whether the
9 aspect is a last aspect to be predicted in a compilation of aspects;
predicting a grouping or
category of the aspect; and predicting an attribute associated with the
aspect.
11 [0018] In yet another case of the system, the GAN comprises a generator
and a discriminator
12 collectively performing a min-max game.
13 [0019] In yet another case of the system, the discriminator maximizes an
expected score of real
14 aspects and minimizes a score of generated aspects, and wherein the
generator maximizes a
likelihood that the generated aspect is plausible, where plausibility is
determined by the output
16 of the discriminator.
17 [0020] In yet another case of the system, the similarity of subjects is
determined using a
18 distance metric on the subject embedding.
19 [0021] In yet another case of the system, the one or more processors
further configurable to
execute a pipeline module to generate further aspects for subsequent future
events by iterating
21 the determining of the subject embedding by the RNN module and the
generating of the at least
22 one aspect by the GAN module, using the previously determined subject
embeddings and
23 generated aspects as part of the historical data.
24 [0022] In yet another case of the system, aspects are organized into
compilations of aspects
that are associated with each of the events in the historical data and the
future event.
26 [0023] These and other embodiments are contemplated and described
herein. It will be
27 appreciated that the foregoing summary sets out representative aspects
of systems and
28 methods to assist skilled readers in understanding the following
detailed description.
29 BRIEF DESCRIPTION OF THE DRAWINGS
3
CA 3059904 2019-10-24
1 [0024] The features of the invention will become more apparent in the
following detailed
2 description in which reference is made to the appended drawings wherein:
3 [0025] FIG. 1 is a schematic diagram of a system for generating at least
one aspect associated
4 with a future event for a subject using historical data, in accordance
with an embodiment;
[0026] FIG. 2 is a flowchart of a method for generating at least one aspect
associated with a
6 future event for a subject using historical data, in accordance with an
embodiment;
7 [0027] FIG. 3 is a diagrammatic example of embedding subjects via multi-
task learning, in
8 accordance with the system of FIG. 1;
9 [0028] FIG. 4 is a diagrammatic example of basket sequence generation for
a retail datasets
example, in accordance with the system of FIG. 1;
11 [0029] FIG. 5 is a visualization of product embeddings in a 2D space for
the a retail datasets
12 example of FIG. 4;
13 [0030] FIG. 6 is a histogram plot comparing the frequency distributions
of categories between
14 baskets generated using the system of FIG. 1 and real baskets for an
example experiment;
[0031] FIG. 7 is a histogram plot comparing the frequency distributions of
brands between
16 baskets generated using the system of FIG. 1 and real baskets for the
example experiment of
17 FIG. 6;
18 [0032] FIG. 8 is a histogram plot comparing the frequency distributions
of prices between
19 baskets generated using the system of FIG. 1 and real baskets for the
example experiment of
FIG. 6;
21 [0033] FIG. 9 is a histogram plot comparing the frequency distributions
of basket sizes between
22 baskets generated using the system of FIG. 1 and real baskets for the
example experiment of
23 FIG. 6;
24 [0034] FIG. 10 is a plot of a percentage of the top-k most common real
sequential patterns that
are also found in the generated data as k varies from 1 to 1000 for the
example experiment of
26 FIG. 6;
27 [0035] FIG. 11 shows scatter plots for basket representations as bags-of-
products vectors at a
28 category level, projected using t-SNE, for the example experiment of
FIG. 6; and
29 [0036] FIG. 12 shows scatter plots for basket representations as bags-of-
products vectors at a
category level, projected using PCA, for the example experiment of FIG. 6.
4
CA 3059904 2019-10-24
I DETAILED DESCRIPTION
2 [0037] Embodiments will now be described with reference to the figures.
For simplicity and
3 clarity of illustration, where considered appropriate, reference numerals
may be repeated
4 among the Figures to indicate corresponding or analogous elements. In
addition, numerous
specific details are set forth in order to provide a thorough understanding of
the embodiments
6 described herein. However, it will be understood by those of ordinary
skill in the art that the
7 embodiments described herein may be practiced without these specific
details. In other
8 instances, well-known methods, procedures and components have not been
described in detail
9 so as not to obscure the embodiments described herein. Also, the
description is not to be
considered as limiting the scope of the embodiments described herein.
11 [0038] Various terms used throughout the present description may be read
and understood as
12 follows, unless the context indicates otherwise: "or" as used throughout
is inclusive, as though
13 written "and/or"; singular articles and pronouns as used throughout
include their plural forms,
14 and vice versa; similarly, gendered pronouns include their counterpart
pronouns so that
pronouns should not be understood as limiting anything described herein to
use,
16 implementation, performance, etc. by a single gender; "exemplary" should
be understood as
17 "illustrative" or "exemplifying" and not necessarily as "preferred" over
other embodiments.
18 Further definitions for terms may be set out herein; these may apply to
prior and subsequent
19 instances of those terms, as will be understood from a reading of the
present description.
[0039] Any module, unit, component, server, computer, terminal, engine or
device exemplified
21 herein that executes instructions may include or otherwise have access
to computer readable
22 media such as storage media, computer storage media, or data storage
devices (removable
23 and/or non-removable) such as, for example, magnetic disks, optical
disks, or tape. Computer
24 storage media may include volatile and non-volatile, removable and non-
removable media
implemented in any method or technology for storage of information, such as
computer
26 readable instructions, data structures, program modules, or other data.
Examples of computer
27 storage media include RAM, ROM, EEPROM, flash memory or other memory
technology, CD-
28 ROM, digital versatile disks (DVD) or other optical storage, magnetic
cassettes, magnetic tape,
29 magnetic disk storage or other magnetic storage devices, or any other
medium which can be
used to store the desired information and which can be accessed by an
application, module, or
31 both. Any such computer storage media may be part of the device or
accessible or connectable
32 thereto. Further, unless the context clearly indicates otherwise, any
processor or controller set
33 out herein may be implemented as a singular processor or as a plurality
of processors. The
5
CA 3059904 2019-10-24
1 plurality of processors may be arrayed or distributed, and any processing
function referred to
2 herein may be carried out by one or by a plurality of processors, even
though a single processor
3 may be exemplified. Any method, application or module herein described
may be implemented
4 using computer readable/executable instructions that may be stored or
otherwise held by such
computer readable media and executed by the one or more processors.
6 [0040] The following relates generally to data processing, and more
specifically, to a method
7 and system for generating aspects associated with a future event for a
subject.
8 [0041] For the sake of clarity of illustration, the following disclosure
generally refers to the
9 implementation of the present embodiments with respect to retail
datasets; however, it is
appreciated that the embodiments described herein can be used for any suitable
application of
11 where input data augmentation is required. In the retail datasets
example, future events are
12 future purchases of one or more items and the subject is a given
customer.
13 [0042] In a further example, the embodiments described herein could be
used to predict utility
14 consumption of a household (as the purchaser) across electricity,
internet, gas, hydro etc. (as
the products). The "basket" could be the quantity of these things over a fixed
time period, such
16 as a month. The system could generate new populations of data for people
and their behaviour.
17 [0043] In a further example, the embodiments described herein could be
used to predict airline
18 flight planning data. The historical data could include consumer flyers
(as the purchaser) and
19 their flights (as the products). In this case, the basket could include
the flight, including the
number of passengers, upgrades, etc. The system could then predict flight
purchasing patterns
21 over time for certain trained populations
22 [0044] In a further example, the embodiments described herein could be
used to predict
23 hospital services utilization. The historical data could include
patients (as the purchaser) utilizing
24 different medications and/or services (as the products) while at a
hospital. The basket of
products could be what services and/or medications the patients use, on a
daily basis, during
26 their stay. Their pathology could be the contextual information about
each patient which is
27 analogous to the demographics described herein in the retail datasets
example.
28 [0045] In the retail datasets example, retailers often collect, store,
and utilize massive amounts
29 of consumer behaviour data through their customer tracking efforts, such
as their customer
loyalty programs. Sources such as customer-level transactional data, customer
profiles, and
31 product attributes allow the retailer to better service their customers
by utilizing data mining
32 techniques for customer relationship management (CRM) and direct
marketing systems. Better
6
CA 3059904 2019-10-24
I data mining techniques for CRM databases can allow retailers to
understand their customers
2 more effectively, leading to increased loyalty, better service and
ultimately increased sales.
3 [0046] Modelling customer behaviour is a complex problem with many
facets, such problems
4 being typical for modelling with incomplete datasets. For example, a
retailer's loyalty data
provides a censored view into a customer's behaviour because it only shows the
transactions
6 for that retailer, leading to noisy observations. In addition, the
sequential nature of consumer
7 purchases adds additional complexity as changes in behaviour and long-
term dependencies
8 should be taken into account. Additionally, in many cases, a large number
of customers
9 multiplied by a large catalog of products results in a vast amount of
transactional data, but can
be simultaneously very sparse at the level of individual customers.
11 [0047] There are indirect approaches to modelling customer behaviour for
specific tasks. For
12 example, techniques that utilize customer-level transactional data such
as customer lifetime
13 value, recommendations, and incremental sales, can formulate these tasks
as supervised
14 learning problems. There are other direct approaches to modelling
customer behaviour through
the use of simulators. For example, using customer marketing simulators to
understand decision
16 support and understand how behavioural phenomena affect consumer
decisions. Other
17 simulator approaches simulate direct marketing activities to find an
ideal marketing policy to
18 maximize a pre-defined reward over time. However, these techniques are
focused on
19 generating an optimal marketing policy and generally do not generate
realistic simulations of
customer transactional data.
21 [0048] Some approaches to generating modelling can learn realistic
distributions from the data
22 in different contexts. For example, in one approach, realistic orders
from an e-commerce
23 dataset can be generated. While in this approach the model can learn
complex relationships
24 between customers and products to generate realistic simulations of
customer orders, it does
not consider an important aspect of how customer behaviour changes over time.
26 [0049] Some approaches for learning a representation of customers from
their transactional
27 data borrow inspiration from natural language processing (NLP) by
embedding customers into a
28 common vector space based of their transaction sequences. For instance,
learning the
29 embeddings by adapting the paragraph vector-distributed bag-of-words or
the n-skip-gram
models. The underlying idea behind these approaches is that by solving an
intermediate task
31 such as predicting the next word in a sentence or the next item a
customer will purchase, the
32 system can learn features that have good predictive power and are
meaningful for a wide
7
CA 3059904 2019-10-24
I variety of tasks. However, this approach alone does not learn the
sequential behavior of a
2 customer because it only looks locally at adjacent transactions.
3 [0050] Other approaches can use collaborative filtering to predict a
customer's preference for
4 -- items; although such approaches usually do not directly predict a
customer's next purchase.
-- Such approaches can mimic a recurrent neural network (RNN) by feeding
historical transaction
6 data as input to a neural network which predicts the next item. However,
similarly to the above,
7 this approach alone does not learn the sequential behavior of a customer
because it only looks
8 -- locally at adjacent transactions. For collaborative filtering in
particular, generally there is not
9 even a prediction of the next item, but rather there is a reliance on an
unsupervised clustering-
like technique in order to find products the customer will "like".
11 [0051] In the retail datasets example, a customer's state with respect
to a given retailer (i.e., the
12 types of products they are interested in and the amount of money they
are willing to spend)
13 -- evolves overtime. In marketing research, some agent-based approaches
have been used in
14 building simple simulations of how customers interact and make
decisions. Data mining and
machine learning approaches can be used to model a customer's state in the
context of direct
16 marketing activities. Some approaches model the problem in the
reinforcement learning
17 framework attempting to learn the optimal marketing policy to maximize
rewards over time.
18 These approaches use various techniques to represent and simulate the
customer's state over
19 time. However, these approaches do not use the customer's state to
generate its future orders,
but rather consider it more narrowly in the context of the defined reward.
Other approaches
21 generate plausible customer e-commerce orders for a given product using
a Generative
22 Adversarial Network (GAN). Given a product embedding, some approaches
generate a tuple
23 containing a product embedding, customer embedding, price, and date of
purchases, which
24 summarizes a typical order. This approach using a GAN can provide
insights into product
demand, customer preferences, price estimation and seasonal variations by
simulating what are
26 likely potential orders. However, such approach only generates orders
and does not directly
27 model customer behaviour over time.
28 [0052] In embodiments of the present disclosure, approaches are provided
to learn distribution
29 of subject-level aspects of future events over time from a subject-level
dataset of past events; in
the retail datasets example, learning a distribution of customer-level aspects
of customer orders
31 of products over time from a customer-level dataset of retail
transactions. These approaches
32 can generate samples of both subjects and traces of aspects associated
with their events over
33 time. Advantageously, this allows the system to essentially generate new
subject-level event
8
CA 3059904 2019-10-24
1 datasets that match the distributional properties of the historical data.
Advantageously, this
2 allows for further applications. For instance, in the retail datasets
example, generating a
3 distribution of likely products to be purchased by an individual customer
to derive insights, or by
4 providing external researchers with access to generated data for a
dataset that otherwise would
be restricted due to privacy concerns.
6 [0053] In an embodiment of the present disclosure, an approach is
provided that generates
7 subject-level event data using a combination of Generative Adversarial
Networks (GAN) and
8 Recurrent Neural Network (RNN). An RNN is trained to generate a subject
embedding by using
9 a multi-task learning approach. The inputs to the RNN are embeddings of
one or more aspects
of a future event derived from textual descriptions of the aspects. This
allows the system to
11 describe the subject state given previous events associated with the
subject and/or similar
12 subjects. Values for aspects of a future event are determined based on
historical values for
13 such aspect of similar subjects. A GAN, trained by conditioning on a
subject embedding at a
14 current time, is used to predict a value for an aspect of a future event
for a given subject. In
some cases, the future event can have a compilation of aspects associated with
it. In this case,
16 the prediction is repeated until all values of aspects associated with
the future event are
17 determined. Advantageously, this provides a prediction for multiple
aspects of a single subject-
18 level event. In some cases, the predicted aspect values can be fed back
into the RNN to
19 generate a prediction for a subsequent event associated with the subject
by then repeating the
above steps. While some of the present embodiments describe using an RNN, it
is understood
21 that any suitable sequential dependency (time series) model can be used;
for example,
22 Bayesian structural time series, ARIMA models, and the like. While some
of the present
23 embodiments describe using a GAN, it is understood that any suitable
generative model can be
24 used; for example, variational auto encoders, convolutional-based neural
networks, probabilistic
graph networks, and the like.
26 [0054] In general, "embedding" as used herein means encoding a discrete
variable (e.g.
27 products) into a real-valued vector. In an example, if there are 100,000
products, it may not be
28 scalable to put this many one-hot binary variables into a model.
However, the 100,000 products
29 can be "embedded" into a smaller (e.g. 100) dimensional real-valued
vector; which is much
more computationally efficient. Generally, the system tries to ensure that
each product is
31 placed in a reasonable location in the 100-Dimesional vector space. In a
particular case, the
32 system can use similarities between products to achieve a global optimum
of placement. One
33 way to compute similarity is using textual descriptions; where similar
descriptions mean they will
9
CA 3059904 2019-10-24
1 be closer together in the vector space and vice versa. Other cases can
use other information
2 for placement, such as using basket information; items that appear in the
same "context" (other
3 items in the basket) will be similar to each other and should be placed
closer together in the
4 vector space.
[0055] In the present embodiments, the GAN generates a new data point by
sampling from a
6 random distribution (in some cases, a multi-variate Gaussian
distribution) and then putting it
7 through a neural network to generate the data point. In some cases, the
GAN can be
8 conditioned by having an additional input to this process that sets the
"context" of how the GAN
9 should interpret the sample of the random distribution. During training,
each training sample
should provide this additional context and then the system should be able to
generate new data
11 points from the context. In the retail datasets example, the GAN can be
conditioned based on
12 the customer embedding at the current time.
13 [0056] The present inventors conducted example experiments to
demonstrate the effectiveness
14 of the present embodiments using several qualitative and quantitative
metrics. The example
experiments show that the generator can reproduce the relative frequencies of
various product
16 features including types, brands, and prices to within a 5% difference.
The example experiments
17 also show that the generated data retains all of the strongest
associations between products in
18 the real data set. The example experiments also show that most of the
real and generated
19 baskets are indistinguishable, with a classifier trained to separate the
two being able to achieve
an accuracy of only 63% at the category level.
21 [0057] Referring now to FIG. 1, a system 100 for generating aspects
associated with a future
22 event for a subject, in accordance with an embodiment, is shown. In this
embodiment, the
23 system 100 is run on a server. In further embodiments, the system 100
can be run on any other
24 computing device; for example, a desktop computer, a laptop computer, a
smartphone, a tablet
computer, a mobile device, a smartwatch, or the like.
26 [0058] In some embodiments, the components of the system 100 are stored
by and executed
27 on a single computer system. In other embodiments, the components of the
system 100 are
28 distributed among two or more computer systems that may be locally or
globally distributed.
29 [0059] FIG. 1 shows various physical and logical components of an
embodiment of the system
100. As shown, the system 100 has a number of physical and logical components,
including a
31 central processing unit ("CPU") 102 (comprising one or more processors),
random access
32 memory ("RAM") 104, an input interface 106, an output interface 108, a
network interface 110,
CA 3059904 2019-10-24
1 non-volatile storage 112, and a local bus 114 enabling CPU 102 to
communicate with the other
2 components. CPU 102 executes an operating system, and various modules, as
described below
3 in greater detail. RAM 104 provides relatively responsive volatile
storage to CPU 102. The input
4 1nterface106 enables an administrator or user to provide input via an
input device, for example a
keyboard and mouse. The output interface 108 outputs information to output
devices, such as a
6 display and/or speakers. The network interface 110 permits communication
with other systems,
7 such as other computing devices and servers remotely located from the
system 100, such as for
8 a typical cloud-based access model. Non-volatile storage 112 stores the
operating system and
9 programs, including computer-executable instructions for implementing the
operating system
and modules, as well as any data used by these services. Additional stored
data, as described
11 below, can be stored in a database 116. During operation of the system
100, the operating
12 system, the modules, and the related data may be retrieved from the non-
volatile storage 112
13 and placed in RAM 104 to facilitate execution.
14 [0060] In an embodiment, the system 100 further includes a data
acquisition module 118, a
GAN module 120, an RNN module 122, and a pipeline module 124. In some cases,
the
16 modules 118, 120, 122, 124 can be executed on the CPU 110. In further
cases, some of the
17 functions of the modules 118, 120, 122, 124 can be executed on a server,
on cloud computing
18 resources, or other devices. In some cases, some or all of the functions
of any of the modules
19 118, 120, 122, 124 can be run on other modules.
[0061] Forecasting is the process of obtaining a future value for a subject
using historical data.
21 Machine learning techniques, as described herein, can use the historical
data in order to train
22 their models and thus produce reasonably accurate forecasts when
queried.
23 [0062] Generative adversarial networks (GANs) are a class of generative
models aimed at
24 learning a distribution. This approach was founded on the game
theoretical concept of two-
player zero-sum games, wherein two players each try to maximize their own
utility at the
26 expense of the other player's utility. By formulating the distribution
learning problem as such a
27 game, a GAN can be trained to learn good strategies for each player. A
generator G aims to
28 produce realistic samples from this distribution while a discriminator D
tries to differentiate fake
29 samples from real samples. By alternating optimization steps between the
two components, the
generator ultimately learns the distribution of the real data.
31 [0063] The generator network G: Z X is a mapping from a high-dimensional
noise space Z =
32 Raz to the input space X on which a target distribution fx is defined.
The generator's task
33 consists of fitting the underlying distribution of observed data fx as
closely as possible. The
11
CA 3059904 2019-10-24
I discriminator network D: X ¨> ll n [0,1] scores each input with the
probability that it belongs to
2 the real data distribution fx rather than the generator G. The GAN
optimization minimizes the
3 Jensen-Shannon divergence (JS) between the real and generated
distributions. In some cases,
4 the JS metric can be replaced by the Wasserstein-1 or Earth-Mover
divergence. The system
100 can use a customized version of this approach, the Wasserstein GAN (WGAN)
with a
6 gradient penalty. The objective of such approach is given by:
7 minmax E [D (x)] + IE [¨D(x)] + p(A), (1)
G D x- f x (x) x-G(z)
8 where p (A) = A(IIV gl)(2)11 ¨ 1)2, 2 = Ex + (1 ¨ E)G(Z), E¨Uniform(0,1),
and Z¨ fz(z). Setting
9 A = 0 recovers the original WGAN objective
[0064] Embodiments of the system 100 can use the pipeline module 124 that
executes a
11 pipeline comprising a GAN model executed by the GAN module 120 and an
RNN model
12 executed by the RNN module 122, which are intertwined in a sequence of
aspect prediction
13 (also referred to as generation) and subject state updating. The GAN
module 120 can train a
14 GAN model to generate a compilation of aspects of a future event (also
referred to as a basket)
conditioned on a time-sensitive subject representation. The RNN module 122 can
train an RNN
16 model, for example a Long Short Term Memory (LSTM) model, using a
sequential nature of the
17 subject's state as it interacts with the various aspects. Each of these
modules can use uses
18 semantic embeddings of the subjects and the aspects for representational
purposes, as defined
19 herein.
[0065] To capture semantic relationships between aspects of the event that
exist independently
21 of subject interactions, the system 100 can learn aspect representations
based on their
22 associated textual descriptions. For example, a corpus can be created
comprising a sentence
23 for each aspect as a concatenation of the aspect's moniker and
description. In some cases,
24 preprocessing can be applied to remove stopwords and other irrelevant
tokens. In the example
experiments of the retail datasets example, described herein, an example
corpus can contain
26 11,443 products (as the aspect) that are transacted (as the future
event), which has a
27 vocabulary size of 21,894 words. In this example, each transaction can
comprise purchasing
28 multiple products in a basket (as the compilation). In some cases, a
word2vec skipgram model
29 can be trained on this corpus; for example, using a context window size
of 5 and an embedding
dimensionality of 128. In some cases, each aspect representation can be
defined as an
31 arithmetic mean of the word embeddings in the aspect's moniker and
description; particularly,
32 since sums of word vectors can produce semantically meaningful vectors.
12
CA 3059904 2019-10-24
1 [0066] To characterize subjects by their past patterns, the RNN module
122 can learn subject
2 embedding representations from historical data. For example, in the
retail datasets example,
3 customers can be characterized by their purchase habits by learning
customer embedding
4 representations from the customer's transactional data. The RNN module
122 can provide the
LSTM model, as input, a sequence of events for a given subject, where each
event is defined by
6 an aspect embedding and, in some cases, a time of the event. For example,
in the retail
7 datasets example, the input can comprise a sequence of transactions for a
given customer,
8 where each transaction is defined by an item embedding and the week of
purchase. The LSTM
9 model can be trained to learn the subject's sequential patterns via a
multi-task optimization
approach. In an embodiment, the output of the LSTM model is fed as inputs one
or more
11 prediction tasks that are representative of a customer to track their
behaviour. In an example,
12 the inputs could be at least one of the following three prediction
tasks:
13 1) Predicting whether an aspect is a last aspect to be predicted in a
compilation of aspects
14 by performing binary classification on each item;
2) Predicting a grouping or category of the next aspect, where the grouping or
category
16 associates two or more aspects together (in the retail datasets example,
predicting a
17 product category for the next product that will be purchased); and
18 3) Predicting an attribute associated with the next aspect (in the
retail datasets example,
19 predicting the price of the next product that will be purchased).
[0067] In the present embodiments, the LSTM can be trained to learn the
customer's sequential
21 patterns via a multi-task optimization procedure. When training the LSTM
(or other RNN), in
22 general cases, there is a single loss/objective function. In this way,
it is given one training data
23 point and it updates the neural network weights by back propagation.
However, with a "multi-
24 task optimization", there may be many different problems, and for each
problem, there may be
different training data points. The training procedure can use the same neural
network (with
26 various modifications to outputs and loss functions) and applies the
training data points in
27 sequence to train it. In this way, the neural network is learning to
generalize across the
28 problems. This is advantageous for the present embodiments because it is
generally desirable
29 for the RNN to learn a general data distribution.
[0068] In an embodiment, the RNN module 122 trains the LSTM model so as to
maximize the
31 performance of all three prediction tasks by randomly and uniformly
sampling a single task in
32 each step and optimizing for this task. After convergence, the hidden
state of the LSTM model
13
CA 3059904 2019-10-24
1 can be used to characterize a subject's patterns (for example, a
customer's purchasing habits),
2 and thus a subject's state. Thus, subjects with similar patterns will be
closer together in the
3 resulting embedding space. FIG. 3 diagrammatically illustrates an example
of a process of
4 learning this embedding. Embedding subjects via multi-task learning with
an LSTM model,
where the input is the sequence of aspects associated with events of a subject
over time in the
6 historical data. After convergence, the hidden state of the LSTM model
can be used to
7 characterize a subject's state.
8 [0069] In order for the network to accurately predict the one or more
prediction tasks, it is useful
9 for the network to have some internal representation of what the subject
is at that stage (based
on all their events up to that point). If the network is accurately predicting
the prediction tasks,
11 then the system can advantageously use its internal representation as a
proxy for the subject's
12 state; an "embedding" into a high dimensional real vector space.
13 [0070] In an embodiment, to learn aspect distributions, the GAN module
120 can use a
14 conditional Wasserstein GAN. In an optimization process, the GAN module
120 can use a
discriminator and a generator in a min-max game. In this game, the
discriminator aims to
16 maximize the following loss function:
max E [D (x (h, w)] + E [¨D(xl(h, w)] + A(I1V2D(il(h, w)I
- 1)2
17 D x- f x (x) x-G(z1(kw)) (2)
18 where A is a penalty coefficient, I = Ex + (1 ¨ e)G (z I (h, w)) , and
E¨Uniform(0,1). The first term
19 is the expected score (which can be thought of as likelihood) of seeing
an aspect x being
associated with a given subject in a given timeframe (for example, an item
being purchased by
21 a given customer in a given week (h, w)). The second term is the score
of seeing another
22 aspect z being associated with the same subject in the same timeframe
(for example, another
23 item also being purchased by that same customer and in the same week (h,
w)). Taken
24 together, these first two terms encourage the discriminator to maximize
the expected score of
the real aspects x f x (x) given context (h, w) and minimize the score of the
generated aspects
26 x¨G(z1(h, w)) . The third term the above equation is a regularization
penalty to ensure that D
27 satisfies the 1-Lipschitz conditions.
28 [0071] The generator is trained to minimize the following loss function:
29 max E [D (x I (h, w)] (3)
G x-G(z1(h,w))
14
CA 3059904 2019-10-24
1 [0072] The objective aims to maximize the likelihood that the generated
aspect x¨G(z1(h,w)) is
2 plausible given the context (h, w), where plausibility is determined by
the discriminator
3 D(xl(h,w)). With successive steps of optimization, the CAN module 120
obtains a G which can
4 generate samples that are more similar to a real data distribution.
[0073] While the generator learned from Equation (3) can yield realistic
product embeddings, in
6 some cases the CAN module 120 may obtain specific instances from a
database P = tPir-i of
7 known aspects. This can be useful, for instance in the retail datasets
example, to obtain a
8 product recommendation for customer h at week W. Given a generated
product embedding
9 G(z1(h,w)), this can be accomplished by computing the closest aspect from
the database
according to the L2 distance metric: p = argminpiEP I I G (z1(11, w)) ¨ p1ll3.
In further cases, other
11 distance metrics can be used, such as cosine distance.
12 [0074] The pipeline module 124 develops a pipeline to generate a
sequence for compilations of
13 aspects that will likely be associated with a subject over consecutive
timeframes; for instance, in
14 the retail dataset example, a sequence of baskets of items that a
customer will likely purchase
over several consecutive weeks. The pipeline module 124 incorporates the
aspect generator G
16 to produce individual aspects in the compilation as well as the RNN
module to model the
17 evolution of a subject's state over a sequence of compilations.
18 [0075] Given a new subject with an event history B1, B2, ...,B1, where
each Bi denotes a
19 compilation of aspects for a given timeframe Wi and i 1, the pipeline
module 124 generates a
compilation B1+1 for a subsequent timeframe. The pipeline module 124 extracts
the subject
21 embedding at timeframe w1, denoted hi, by passing the event sequence
through the hidden
22 state of the LSTM model. The pipeline module 124 finds the k most
similar subjects from a
23 historical database of known subjects by, for example, determining L2
distance from hi. Similar
24 to retrieving known aspects from a historical database, as described
herein. The pipeline
module 124 determines the number of aspects to generate for the given subject
in a given
26 timeframe w1. To determine this value, the pipeline module 124 uniformly
samples from
27 compilation sizes of the compilations associated with the k most similar
subjects to retrieve the
28 number of aspects to generate, ni. From the most similar subjects, the
pipeline module 124 can
29 get a list of all the associated basket sizes; which forms a
distribution, from 1 to max basket
size, from which the pipeline module 124 can sample. The CAN module 120 can
use the
31 generator network to generate ni aspects via the generator, G (hi, mit).
CA 3059904 2019-10-24
1 [0076] In some cases, the above approach can be extended to generate
additional compilations
2 by the RNN module 122 by feeding Eit+i back into the LSTM model, whose
hidden state is
3 updated as if the subject had been associated with event Bi+1. The
updated subject
4 representation hi+i can once again be used to estimate a compilation size
ni+1 and fed into the
generator G(hi+i,wi+i) which yields a compilation of aspects for the given
timeframe wt+1. This
6 cycle can be iterated multiple times to generate compilation sequences of
arbitrary length. An
7 example of the approach for compilation generation for the retail
datasets example is illustrated
8 by PSEUDO-CODE 1 and illustrated in FIG. 4. Note that all values in the
PSEUDO-CODE 1
9 example are also indexed by the customer index c; where the symbol Bg is
used to denote the
entire history of customer c.
11 PSEUDO-CODE 1
12 Input: LSTM L, generator G, set of historical basket sequences for each
customer
13 [B6)=1, hyperparameter k, number of weeks W
14 for c = 1, C do
Compute initial customer embedding hg via L(Bg)
16 for w = 1, W do
17 Sample n via k-nearest customers of K,
18 Generate basket Bf of 74, products from G(h,w)
19 Update the customer embedding with the LSTM:
hfõ,1 = L (Btcy, hfv).
21 end for
22 end for
23
24 [0077] In this manner, the system 100 can efficiently and effectively
augment a new subject's
event history by predicting their future events for an arbitrary amount of
time. In this way, a
26 subject's embedding representation evolves as future events arrive, and
therefore might share
27 some common properties with other subjects through their event
experiences. The system 100
28 can derive insights from this generated data by learning a better
characterization of the subject's
29 likely events into the future.
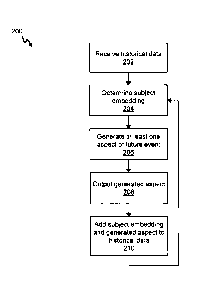
[0078] Turning to Figure 2, a flowchart for a method 200 for generating
aspects associated with
31 a future event for a subject, according to an embodiment, is shown. The
generating the aspects
32 is based on historical data, for example, as stored in the database 116
or as otherwise received.
16
CA 3059904 2019-10-24
I The historical data comprising a plurality of aspects associated with
historical events for the
2 subject and/or other subjects.
3 [0079] At block 202, the data acquisition module 118 receives the
historical data comprising the
4 plurality of aspects from the input interface 106, the network interface
110, or the non-volatile
storage 112.
6 [0080] At block 204, the RNN module 122 determines a subject embedding
using a recurrent
7 neural network (RNN). Input to the RNN comprises historical events of the
subject from the
8 historical data, each historical event comprising by an aspect embedding.
The RNN is trained
9 using aspects associated with events of similar subjects from the
historical data.
[0081] At block 206, the GAN module 120 generates at least one aspect of the
future event for
11 the subject using a generative adversarial network (GAN). Input to the
GAN comprises the
12 subject embedding. The GAN is trained with subject embeddings determined
using the RNN for
13 other subjects in the historical data.
14 [0082] At block 208, the GAN module 120, via the output interface 108,
the network interface
110, or the non-volatile storage 112, outputs the at least one generated
aspect.
16 [0083] At block 210, in some cases, the pipeline module 124 adds the
previously determined
17 subject embeddings and generated aspects as part of the historical data.
The pipeline module
18 124 then generates further aspects for subsequent future events (block
208) by iterating the
19 determining of the subject embedding by the RNN module (block 204) and
the generating of the
at least one aspect by the GAN module (block 208).
21 [0084] The present inventors empirically demonstrated the efficacy of
the present embodiments
22 via example experiments. For the retail datasets example, the example
experiments compared
23 the compilation data generated by the present embodiments to real
collected customer data.
24 Evaluation was first performed with respect to the distributions of key
metrics aggregated over
the entire data sets, including product categories, brands, prices, and basket
sizes. Association
26 rules that exist between products in both data sets were compared. The
separability between
27 the real and generated baskets with multiple different basket
representations was evaluated.
28 [0085] The present embodiments were evaluated using a data set from an
industrial retailer,
29 which consisted of 742,686 transactions over a period of 5 weeks during
the summer of 2016.
This data is composed of 174,301 customer baskets with an average size of 4.08
items and
31 price of $12.2. A total of 7,722 distinct products and 66,000 distinct
customers exist across all
32 baskets.
17
CA 3059904 2019-10-24
1 [0086] FIG. 5 shows an example of product embedding representations for
the example
2 experiments extracted from textual descriptions, as described herein,
projected into a 2-
3 dimensional space using a t-SNE algorithm. Products were classified into
functional categories
4 such as Hair Styling, Eye Care, and the like. Products from the same
category tended to be
clustered close together, which reflects the semantic relationships between
such products. At a
6 higher level, it was observed that similar product categories also occur
in close proximity to one
7 another; for example, the categories of Hair Mass, Hair Styling and Hair
Designer are mapped
8 to adjacent clusters, as are the categories of Female Fine Frag and Male
Fine Frag. These
9 proximities help basket generation which directly generates product
embeddings, while specific
products are obtained based on their proximity to other products in the
embedding space. As
11 the GAN produces a product embedding (real-valued vector) as its output,
this output has to be
12 mapped to an actual product by determining the closest product to the
vector. If the products
13 were randomly placed in the vector space, the system might inadvertently
map this embedding
14 to a strange product. Advantageously, for the present embodiments,
similar products are
grouped together in the vector space, thus the probability of mapping to a
desirable product is
16 significantly higher.
17 [0087] The RNN module 122 trained the LSTM model on the above data set
with multi-task
18 optimization, as described herein, for 25 epochs. For each customer, an
embedding was
19 obtained from the LSTM hidden state after passing through all of that
customer's transactions.
These embeddings were then used by the GAN module 120 to train the conditional
GAN model.
21 The GAN was trained for 100 epochs using an Adam optimizer with
hyperparameter values of
22 a = 0.5 and f = 0.9. The discriminator was comprised of two hidden
layers of 256 units each
23 with ReLU activation functions, with the exception of the last layer
which was free of activation
24 functions. The generator used the same architecture except for the last
layer which had a tanh
activation function. During training, the discriminator was prioritized by
applying five update
26 steps for each update step to the generator. This helped the
discriminator converge faster so as
27 to better guide the generator. Once the LSTM and GAN were trained, the
pipeline module 124
28 performed basket sequence generation. For each customer, 5 weeks of
baskets were
29 generated following the approach described herein.
[0088] FIGS. 6, 7, 8, and 9 compare the frequency distributions of the
categories, brand, prices,
31 and basket sizes, respectively, between the baskets generated using the
present embodiments
32 and the real baskets. For the brand, the histogram plots were restricted
for clarity to include only
33 the top 30 most frequent brands. Additional metrics are provided in
TABLE 1, comparing
18
CA 3059904 2019-10-24
1 averages of the baskets for the real and generated data, and TABLE 2,
showing standard
2 deviation discrepancies between the real and generated data for various
criterion. It was
3 observed that the present embodiments could substantially replicate the
ground-truth
4 distribution. This is particularly evidenced by TABLE 2, which indicates
that the highest absolute
difference in frequency of generated brands is 5.6%. The lowest discrepancy
occurs for the
6 category feature, where the maximum deviation is 3.2% in the generated
products. In addition,
7 the generated basket size averages 3.85 items versus 4.08 for the real
data which is a
8 difference of approximately 5%. The generated item prices are an average
of $3.1 versus $3.4
9 for the real data (a 10% difference). This demonstrated that the present
embodiments could
mimic the aggregated statistics of the real data to a substantial degree. Note
that it should not
11 be expected that the two distributions are to match exactly because the
system 100 was
12 projecting each customer's purchases into the future, which necessarily
will not have the same
13 distributive properties.
14 TABLE 1
Real Generated
Transactions Transactions
Average basket size 4.08 3.85
Average basket price $3.1 $3.4
16 TABLE 2
Criterion Max absolute
deviation (in %)
Category 3.2%
Brand 5.6%
Price 5.2%
Basket size
(only applies for 4.1%
basket size 5 20)
17
18 [0089] Sequential pattern mining (SPM) is a technique to discover
statistically relevant
19 subsequences from a sequence of sets ordered by time. One frequent
application of SPM is in
retail transactions where one wishes to determine subsequences of items across
baskets
21 customers have bought overtime. For example, given an set of baskets a
customer has
19
CA 3059904 2019-10-24
I purchased ordered by time: {milk, bread), {cereal, cheese), {bread,
oatmeal, butter), one
2 sequential pattern a system can derive is: {milk}, {bread, butter)
because {milk} in the first
3 basket comes before {bread, butter) in the last basket. A pattern is
typically measured by its
4 support, which is defined as the number of customers containing the
pattern as a subsequence.
For the example experiments, sequential pattern mining was performed on the
real and
6 generated datasets via a sequential frequent pattern mining (SFPM)
library using a minimum
7 support of 1% of the total number of customers. FIG. 10 plots a
percentage of the top-k most
8 common real sequential patterns that are also found in the generated data
as k varies from 1 to
9 1000. Here items were defined at either the category or subcategory
level, so that two products
were considered equivalent if they belonged to the same functional grouping.
As shown, for the
11 category-level, it was possible to recover 98% of the top-100 patterns,
while at the subcategory
12 level, it was possible to recover 63%. This demonstrated that the
present embodiments were
13 generating plausible sequences of baskets for customers because most of
the real sequential
14 patterns showed up in the generated data. TABLE 3 shows examples of the
top sequential
patterns of length 2 and 3 from the real data at the subcategory level that
also appeared in the
16 generated transactional data. The two right columns show the support for
both the real and
17 generated datasets, which is normalized by dividing by the total number
of customers.
18 TABLE 3
Generated
Sequence Real support
support
Hemorrhoid relief, Skin treatment & dressings 0.045 0.098
Skin treatment & dressings, Female fine frag 0.029 0.100
Facial moisturizers, Skin treatment & dressings 0.028 0.075
Shower products, Female fine frag 0.028 0.056
Hemorrhoid relief, Female fine frag 0.028 0.093
Skin treatment & dressings, Facial moisturizers 0.027 0.076
Skin treatment & dressings, Preg test & ovulation 0.027 0.082
Shower products, Skin treatment & dressings 0.026 0.056
Hemorrhoid relief, Preg test & ovulation 0.026 0.075
Female fine frag, Preg test & ovulation 0.025 0.081
Facial moisturizers, Hemorrhoid relief 0.025 0.069
Skin treatment & dressings, Skin treatment & dressings, 0.007 0.014
Hemorrhoid relief
19
CA 3059904 2019-10-24
1 [0090] Association rules are a way to discover patterns, associations or
correlations, between
2 items from transactional data T. Such rules typically take the form of X
Y, where X is a set of
3 antecedent items and Y is a set of consequent items. A common example of
such product
4 relations is that a morning breakfast is usually bought together with
milk, or that potato chips are
often bought with beer. Thus, association rules can serve to guide product
recommendations
6 when it is given that a customer has bought the antecedent items. In the
example experiments,
7 it was determined that the present embodiments preserved these
associations. Each
8 association rule can be characterized by the metrics of support,
confidence and the lift. The
9 support measures how frequently an item set X appears in a transactional
data: Tr:
Ifx: x E Tr A X c x}I
Supp(X) =
11 [0091] The confidence is the likelihood that item set Y is bought given
that X is bought:
Supp(X U Y)
12 Conf (X Y) = ________
Supp(X)
13 where X u Y represents the union of item sets X and Y.
14 [0092] The lift measures the magnitude of the dependency between item
sets X and Y:
Supp(X u Y)
Lif t(X Y) = Supp(X) x Supp(Y)
16 [0093] A lift value strictly greater than 1 indicates high correlation
between X and Y while a
17 value of 1 means Y is unlikely to be bought if X is bought.
18 [0094] TABLE 4 compares association rules between the generated
transactional data with
19 ones from the real data.
TABLE 4
Confidence Lift
Antecedent Consequent
Real Generated Real Generated
Shower
Bar soap 0.71 0.14 8.69 1.86
products
Shower
Bar soap 0.51 0.10 8.69 1.86
products
Facial Skin treatment
0.37 0.21 3.28 1.27
moisturizers & dressings
21
CA 3059904 2019-10-24
Skin treatment
Blonding 0.34 0.24 3.08 1.50
& dressings
Facial Hemorrhoid
0.34 0.19 3.25 1.24
moisturizers relief
Hemorrhoid Skin treatment 0.33 0.20 2.98 1.23
relief & dressings
Skin treatment Hemorrhoid
0.31 0.23 2.98 1.54
& dressings relief
1
2 [0095] In TABLE 4, item sets were defined at the product category level,
so that two items were
3 considered equivalent if they belong to the same functional category.
This choice reflects the
4 intuition that a real customer's purchase decisions are influenced
primarily by an item's purpose
or function rather than its specific serial number, which is usually
uncorrelated with that of other
6 items in the customer's basket. The table presents the top rules with a
support of at least 0.01,
7 ordered by confidence score along with their confidence and lift for each
of the real and
8 generated data points. TABLE 4 shows that all of the strongest
associations in the real data also
9 exist in the generated data.
[0096] The example experiments also directly compared the generated and real
baskets by the
11 items they contained. For each basket of products Bi = pia vector
representation vi was
12 defined using a bag-of-products scheme. Where P is the set of all known
products and vi is a
13 IP I-dimensional vector with 4i) = 1 if pi E Bi or vP) = 0 otherwise. P
can be defined at various
14 levels of precision such as the product serial number, the brand, or the
category. At the
category level, for instance, two products would be considered equivalent and
correspond to the
16 same index] if they belong to the same category. The resulting vectors
were then projected into
17 two dimensions using t-SNE for visualization purposes. The distributions
of the real and
18 generated data are plotted in FIG. 11. For an alternative viewpoint,
FIG. 12 plots basket
19 representations as bags-of-products vectors at the category level
projected using Principal
Component Analysis (PCA). These plots qualitatively indicate that the
distributions match
21 substantially closely.
22 [0097] The example experiments further analyzed the observations
quantitatively by training a
23 classifier to distinguish between points from the two distributions. By
measuring the prediction
24 accuracy of this classifier, an estimate of the degree of separability
between the data sets was
obtained. For the example experiments, a subset of the generated points was
randomly
26 sampled such that the number of real and generated points were equal.
This way, a perfectly
22
CA 3059904 2019-10-24
1 indistinguishable generated data set should yield a classification
accuracy of 50%. It should be
2 noted that this classification task is fundamentally unlike that which is
performed by the
3 discriminator during the GAN training, as the latter generally operates
on the embedding
4 representation of a single product while the former generally operates on
the bag-of-items
representation of a basket. The results are given in TABLE 5 using a logistic
regression
6 classifier. Each row corresponds to a different level of granularity in
the definition of the bag-of-
7 products representation, with category 1 being the finest-grained and
stock keeping unit (sku)
8 being the most coarse-grained. As shown, the classifier performs
substantially poorly at the
9 category levels, meaning that the generated baskets of categories are
substantially plausible.
TABLE 5
Classification
Basket Representation
Accuracy
Bag-of-items category 1 0.634
Bag-of-items category 2 0.663
Basket embedding sku-level 0.704
11
12 [0098] Accordingly, the example experiments illustrate that the present
embodiments were able
13 to generate sequences of realistic customer orders for customer-level
transactional data. After
14 learning the customer embeddings with the LSTM model, an item basket was
generated
conditioned on the customer embedding, using the generator from the GAN model.
The
16 generated basket of items was fed back into the LSTM model to generate a
new customer
17 embedding and the above steps were repeated. Advantageously, the present
embodiments
18 were able to substantially replicate statistics of the real data
distribution (category, brand, price
19 and basket size). Additionally, the example experiments verified that
common associations exist
between products in the generated and real data, and that the generated orders
were difficult to
21 distinguish from the real orders.
22 [0099] Although the invention has been described with reference to
certain specific
23 embodiments, various modifications thereof will be apparent to those
skilled in the art without
24 departing from the spirit and scope of the invention as outlined in the
claims appended hereto.
23
CA 3059904 2019-10-24