Note: Descriptions are shown in the official language in which they were submitted.
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
MEDICAL DECISION SUPPORT SYSTEM
CROSS-REFERENCE TO RELATED APPLICATIONS
The instant application claims benefit of the following: U.S. Provisional
Application Serial
No. 62/838,270 filed on 24 April 2019, and U.S. Provisional Application Serial
No. 62/838,296
filed on 24 April 2019, each of which is incorporated herein by reference in
its entirety.
BRIEF DESCRIPTION OF THE DRAWINGS
In the accompanying drawings:
FIG. 1 illustrates a block diagram of a coronary-artery-disease detection
system;
FIG. 2 illustrates a first aspect of a data recording module and a first
aspect of an associated
docking system, in accordance with a first aspect of the coronary-artery-
disease detection system
illustrated in FIG. 1;
FIG. 3 illustrates a fragmentary view of a human thorax and associated
prospective
locations of auscultatory sound sensors at associated right, sternum and left,
second, third, fourth
and fifth, inter-costal spaces, left posterior locations at the second and
third inter-costal spaces,
and locations proximate to the heart apex;
FIG. 4 illustrates a second aspect of a data recording module and a second
aspect of an
associated docking system, in accordance with a second aspect of the coronary-
artery-disease
detection system illustrated in FIG. 1;
FIG. 5a illustrates an auscultatory sound sensor coupled to the skin of a test-
subject, by
bonding via associated adhesive layers or surfaces on both sides of an
adhesive interface;
FIGS. 5b and Sc each illustrate an auscultatory sound sensor that is detached,
and therefore
fully decoupled, from the skin of a test-subject, wherein FIG. 5b illustrates
the associated adhesive
interface detached from the skin of the test-subject, and FIG. Sc illustrates
the associated adhesive
interface detached from the auscultatory sound sensor;
FIGS. 5d through 5g each illustrate an auscultatory sound sensor that is
partially coupled
to, but debonded from, the skin of a test-subject;
FIG. 6 illustrates a test-subject reclined on a surface, with their torso
inclined while
capturing auscultatory sound signals from a plurality of auscultatory sound
sensors attached to the
thorax of the test-subject;
FIG. 7 illustrates a flowchart of a first aspect of an associated auscultatory-
sound-sensing
process that incorporates a process for detecting a decoupling of the
associated auscultatory sound
sensors from the skin of the thorax of a test-subject being diagnosed for a
prospective abnormal
cardiovascular condition, wherein the decoupling-detection process occurs
after each block of
breath-held auscultatory sound time-series data is acquired, and is based upon
scaled time-series
data and responsive to an associated pre-determined debond-detection
threshold;
-1-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 8 illustrates a flowchart of a first aspect of a process for acquiring
auscultatory sound
signals from the associated auscultatory sound sensors coupled to the skin of
the thorax of the test-
subject being diagnosed for a prospective abnormal cardiovascular condition;
FIG. 9 illustrates a plurality of six blocks of breath-held, auscultatory-
sound-sensor time-
series data recorded from an auscultatory sound sensor coupled to the skin of
the thorax of a test-
subject being diagnosed for a prospective abnormal cardiovascular condition;
FIGS. 10a-10f respectively illustrate a simulation of successively recorded
blocks of
breath-held, sensor time-series data illustrated in FIG. 9, each illustrated
with an expanded time
scale, wherein FIGS. 10a-10e illustrates a condition for which the
auscultatory sound sensor is
coupled to the skin of the test-subject, and FIG. 10f illustrates a condition
for which the
auscultatory sound sensor is decoupled from the skin of the test-subject;
FIG. 11 illustrates a flowchart of a process for determining a scale factor
used to scale
auscultatory-sound-sensor time-series data, the latter of which is analyzed to
detect whether or not
the associated auscultatory sound sensor is decoupled from the skin of the
test-subject, wherein
the scale factor provides for directly determining if the associated
auscultatory sound sensor is
detached from the skin of the test-subject;
FIGS. 12a-12f respectively illustrate time-series of the absolute values of
the
corresponding time-series data illustrated in FIGS. 10a-10f, further
illustrating a division of the
block of breath-held, sensor time-series data into a plurality of associated
data segments, with each
data segment of sufficient width to nominally include sound from a single
heartbeat, and with the
peak values in each data segment marked, wherein FIGS. 12a-12e illustrates a
condition for which
the auscultatory sound sensor is coupled to the skin of the test-subject, and
FIG. 12f illustrates a
condition for which the auscultatory sound sensor is decoupled from the skin
of the test-subject;
FIG. 13 illustrates an accelerometer on the thorax of a test-subject during a
respiration
cycle of the test-subject;
FIG. 14 illustrates a breath-hold detection process;
FIG. 15 illustrates a flowchart of a first aspect of a process for detecting
whether or not an
auscultatory sound sensor is debonded from the skin of a test-subject;
FIG. 16 illustrates an organization of data from an auscultatory sound sensor
recorded by
an auscultatory coronary-artery-disease detection system from a test subject;
FIG. 17 illustrates a flowchart of a noise detection process;
FIG. 18 illustrates a flowchart of a process for generating a matched noise
filter;
FIG. 19 illustrates a flowchart of a process for evaluating the noise content
in a spectral
signal of an auscultatory sound signal;
-2-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 20 illustrates a flowchart of a process for logging results from the
noise-evaluation
process of FIG. 19;
FIG. 21 illustrates a block diagram of a process for preprocessing and
screening
auscultatory sound signals;
FIG. 22a illustrates a process for pre-processing auscultatory sound signals
from
auscultatory sound-or-vibration sensors;
FIG. 22b illustrates a process for pre-processing electrographic signals from
an ECG
sensor;
FIG. 23 illustrates a process for segmenting auscultatory sound signals from
auscultatory
sound-or-vibration sensors, by heart cycle based upon an electrographic signal
from an ECG
sensor, and by heat phase based upon the auscultatory sound signals;
FIG. 24 illustrates an auscultatory sound signal from an auscultatory sound-or-
vibration
sensor;
FIG. 25 illustrates a corresponding electrographic signal from an ECG sensor,
in
correspondence with the auscultatory sound signal illustrated in FIG. 24;
FIG. 26 illustrates a process for identifying heart-cycle boundaries in an
electrographic
signal from an ECG sensor;
FIG. 27 illustrates a first process for generating an envelope of a signal,
which is called
from the process illustrated in FIG. 26;
FIG. 28 illustrates an envelope, and associated peaks, of a portion of the
electrographic
signal illustrated in FIG. 25, generated in accordance with the process
illustrated in FIGS. 26 and
27;
FIG. 29 illustrates a first aspect of a process for validating the peaks of an
electrographic
signal, which is called from the process illustrated in FIG. 26;
FIG. 30 illustrates a plot of the auscultatory sound signal illustrated in
FIG. 24 together
with plot of an envelope of the corresponding electrographic signal
illustrated in FIGS. 25 and
28;
FIG. 31 illustrates a plot of the auscultatory sound signal illustrated in
FIG. 24, but over a
relatively greater total period of time, with the auscultatory sound signal
segmented based upon
the peaks of the envelope of the associated electrographic signal, and
presented as a beat stack,
each illustrating a corresponding associated heart beat;
FIG. 32 illustrates a second process for generating an envelope of a signal,
which is called
from the process illustrated in FIG. 23;
FIG. 33 illustrates a rectified auscultatory sound signal and an associate
envelope thereof
determined in accordance with the process illustrated in FIG. 32;
-3-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 34 illustrates a plot of the auscultatory sound signal that is shown
rectified in FIG.
33, together with plots of the associated quadratic models of the associated
envelopes in proximity
to the associated Si and S2 heart sounds, illustrating time-points associated
with zero-amplitude
roots of the associated quadratic models that are used to locate associated
heart phases;
FIG. 35 illustrates the auscultatory sound signal beat stack illustrated in
FIG. 31, together
with indicia showing the locations of the roots of the quadratic models
associated with the Si and
S2 heart sounds that are used to locate associated heart phases, with the
auscultatory sound signals
of the beat stack aligned with one another based upon the mean values of the
roots of the S2 heart
sounds;
FIG. 36 illustrates a process for identifying outliers in a diastole region of
an auscultatory
sound signal;
FIG. 37 illustrates a flow chart of a process for selecting valid heart cycles
and analyzing
the results therefrom;
FIG. 38 illustrates a portion an auscultatory sound signal during diastole,
and also
illustrates associated noise power thresholds;
FIG. 39a illustrates an auscultatory sound signal for a plurality of heart
cycles;
FIG. 39b illustrates the auscultatory sound signal for the plurality of heart
cycles illustrated
in FIG. 39a, with the heart cycles aligned with respect to the mean times of
the S2 heart sound;
FIG. 40a illustrates the auscultatory sound signal for a plurality of heart
cycles illustrated
in FIG. 39b, including indications of the start of the S2 heart sound and the
end of diastole;
FIG. 40b illustrates portions of the auscultatory sound signal during diastole
for the
plurality of heart cycles illustrated in FIG. 40a, with the heart cycles
temporally normalized and
resampled;
FIG. 41 illustrates a cross-correlation process;
FIG. 42 illustrates a image of a plurality of localized cross-correlation
signals associated
with auscultatory sound signals from a plurality of heart cycles;
FIG. 43 illustrates a time-frequency analysis based on a continuous wavelet
transform of
an auscultatory sound signal during diastole;
FIG. 44 illustrates a process for detecting coronary artery disease from
features of cross-
correlation images generated from analysis of auscultatory sound signals
during diastole for a
plurality of heart cycles, incorporating a Convolution Neural Network (CNN)
classifier with a
single convolution layer;
FIG. 45 illustrates a display of results in a heart/arteries view and textual
view;
FIG. 46a illustrates a displace of a Receiver Operating Characteristic (ROC)
curve;
-4-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 46b illustrates line graph display of true positives, true negatives,
false negatives, and
false positives;
FIG. 47 illustrates a display of a Heartbeat View comprising a graphical plot
of the systolic
and diastolic intervals of each heartbeat captured;
FIG. 48 illustrated a display of a Stacked Heartbeat View;
FIG. 49 illustrates a Bruit Identification View in a Line Graphs with
Underfill mode,
FIG. 50 illustrates a display of a Bruit Identification View in a Spectrogram
mode;
FIG. 51 illustrates a display of a Bruit Analysis View;
FIG. 52 illustrates a comparison of a current test with a previous test, using
the Bruit
Identification View, Spectrogram mode, to confirm success of PCI;
FIG. 53 illustrates a comparison of a current test with a previous test, using
the Bruit
Identification View, Line Graph with Underfill mode, to confirm success of
PCI;
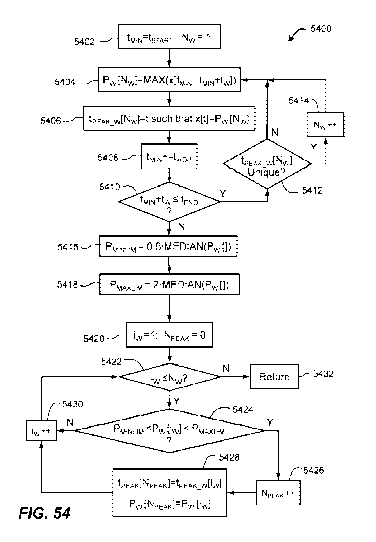
FIG. 54 illustrates a second aspect of a process for detecting R-peaks in an
electrographic
signal;
FIG. 55 illustrates an envelope, and associated peaks, of a portion of the
electrographic
signal that includes noise and other signal components to be ignored;
FIG. 56 illustrates a second aspect of a process for validating the peaks of
an electrographic
signal, which is called from the process illustrated in FIG. 26, following the
second aspect process
for detecting R-peaks in an electrographic signal, illustrated in FIG. 26;
FIG. 57 illustrates a three-level Discrete Wavelet Transformation (DWT)
process;
FIG. 58 illustrates the effective filter spectra associated with the outputs
of the three-level
Discrete Wavelet Transformation process illustrated in FIG. 57;
FIG. 59 illustrates a scaling function of a Daubechies 4 (db4) wavelet family;
FIG. 60 illustrates a wavelet function of a Daubechies 4 (db4) wavelet family;
FIG. 61 illustrates a kernel discrete wavelet transformation process;
FIG. 62 illustrates a three-level Wavelet Packet Transformation (WPT) process;
FIG. 63 illustrates the effective filter spectra associated with the outputs
of the three-level
Discrete Wavelet Transformation process illustrated in FIG. 62;
FIG. 64 illustrates a high-pass filtered auscultatory sound signal for a
single heart cycle
from a high-pass filter having a 30 Hz cut-off frequency;
FIG. 65 illustrates a Wavelet Packet Transformation energy map for the high-
pass filtered
auscultatory sound signal illustrated in FIG. 64, with either decomposition
levels;
FIG. 66 illustrates a selected basis of frequency bins from the Wavelet Packet
Transformation energy map illustrated in FIG. 64, selected using Shannon
entropy as a cost
function;
-5-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 67 illustrates a Support Vector Machine classifier trained to distinguish
two-class
data samples with respect to an associated highest-margin hyperplane;
FIG. 68 illustrates a feed-forward artificial neural network for binary
classification;
FIG. 69 illustrates a geometric construction that provides for determining a
projected
transverse location of an acoustic source with respect to a plane containing
three auscultatory
sound sensors;
FIG. 70 illustrates various phases of a heart cycle in relation to an
electrographic signal;
FIG. 71 illustrates the 51, S2, S3 and S4 phases of a heart cycle in relation
to an
electrographic signal; and
FIG. 72 illustrates a second embodiment of a Convolution Neural Network (CNN).
DESCRIPTION OF EMBODIMENT(S)
Referring to FIGS. 1 and 2, an auscultatory coronary-artery-disease detection
system
10 incorporates at least one auscultatory sound sensor 12 that is operatively
coupled to a
recording module 13 running at least a first portion 14.1 of a Data Recording
Application
(DRA) 14, 14.1 on a first specialized computer or electronic system comprising
a first computer
processor or FPGA (Field Programmable Gate Array) 15 and first memory 17
powered by
a first power supply 19, which provides for recording and preprocessing
auscultatory sound
signals 16 from the at least one auscultatory sound sensor 12. For example, in
one set of
embodiments, the at least one auscultatory sound sensor 12 comprises a first
group 12' of three
auscultatory sound sensors 12, 121', 122', 123' physically interconnected end-
to-end with one
another, and physically and electrically interconnected with a first wireless
transceiver 18; and a
second group 12" of three auscultatory sound sensors 12, 121", 122", 123"
physically
interconnected end-to-end with one another, and physically and electrically
interconnected with
the first wireless transceiver 18, with both groups 12', 12" of auscultatory
sound sensors
placed on the skin of the thorax 20 of a test-subject 22, in acoustic
communication therewith.
Referring also to FIG. 3, the placement of the first group of auscultatory
sound sensors 12' in
FIG. 1 is illustrated with the respective associated auscultatory sound
sensors 12, 121', 122', 123'
in substantial alignment with the corresponding respective third R3, fourth R4
and fifth R5,
inter-costal spaces on the right side 20R of the thorax 20, and the placement
of the second group
of auscultatory sound sensors 12" in FIG. 1 is illustrated with the respective
associated
auscultatory sound sensors 12, 121", 122", 123" in substantial alignment with
the corresponding
respective third L3, fourth L4 and fifth L5, inter-costal spaces on the left
side 201' of the thorax
20. Prospective sensor locations R2-R5, S2-S5, and L2-L5 illustrated in FIG. 3
respectively refer
to the second R2 through fifth R5 inter-costal spaces on the right side 20R of
the thorax 20,
the second S2 through fifth S5 inter-costal spaces at the center/sternum 20s
of the thorax 20,
-6-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
and the second L2 through fifth L5 inter-costal spaces on the left side 201'
of the thorax 20.
Furthermore, prospective left-side posterior sensor locations LP2 and LP3
illustrated in FIG. 3
respectively refer to at the second LP2 and third LP3 intercostal spaces
locations on the
posterior of the thorax 20. Yet further, prospective sensor locations HA-1 and
HA-2 are
proximate to the apex of the heart, either on the anterior or the posterior of
the thorax 20. For
example, in one set of embodiments, The auscultatory sound sensors 12, 121',
122', 123", 121",
122", 123" are located at the second S2, L2, third S3, L3 and fourth S4, L4
inter-costal spaces
at the sternum S2-S4 and left-side L2-L4 of the thorax 20.
As used herein, the term "auscultatory sound" is intended to mean a sound
originating
.. from inside a human or animal organism as a result of the biological
functioning thereof, for
example, as might be generated by action of the heart, lungs, other organs, or
the associated
vascular system; and is not intended to be limited to a particular range of
frequencies -- for
example, not limited to a range of frequencies or sound intensities that would
be audible to a human
ear, -- but could include frequencies above, below, and in the audible range,
and sound intensities
that are too faint to be audible to a human ear. Furthermore, the term
"auscultatory-sound sensor"
is intended to mean a sound sensor that provides for transducing auscultatory
sounds into a
corresponding electrical or optical signal that can be subsequently processed.
The auscultatory sound sensors 12, 121', 122', 123' , 121", 122", 123" provide
for
transducing the associated sounds received thereby into corresponding
auscultatory sound
signals 16 that are preprocessed and recorded by an associated hardware-based
signal
conditioning/preprocessing and recording subsystem 25, then communicated to
the first
wireless transceiver 18, and then wirelessly transmitted thereby to an
associated second wireless
transceiver 26 of an associated wireless interface 26' of an associated
docking system 27,
possibly running a second portion 14.2 of the Data Recording Application (DRA)
14, 14.2 on
.. a corresponding second specialized computer or electronic system comprising
an associated
second computer processor or FPGA (Field Programmable Gate Array) 28 and
second
memory 30, both of which are powered by an associated second power supply 32,
which together
provide for recording and preprocessing the associated auscultatory sound
signals 16 from the
auscultatory sound sensors 12, 121', 122', i2', 121", 122", 123".
For example, in accordance with one set of embodiments, the hardware-based
signal
conditioning/preprocessing and recording subsystem 25 includes an amplifier --
either of fixed
or programmable gain, -- a filter and an analog-to-digital converter (ADC).
For example, in one
set of embodiments, the analog-to-digital converter (ADC) is a /6-bit analog-
to-digital converter
(ADC) that converts a -2.25 to +2.25 volt input to a corresponding digital
value of¨ 32, 768 to +
.. 32, 767. Furthermore, in accordance with one set of embodiments of the
amplifier, the amplifier
-7-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
gain is programmable to one of sixteen different levels respectively
identified as levels 0 to 15,
with corresponding, respective gain values of 88, 249, 411, 571, 733, 894,
1055, 1216, 1382, 1543,
1705, 1865, 2027, 2188, 2350 and 2510, respectively for one set of
embodiments. In accordance
with another set of embodiments of the amplifier, the amplifier gain is fixed
at the lowest above
value, i.e., for this example, 88, so as to provide for avoiding the relative
degradation of the
associated signal-to-noise ratio (SNR) that naturally occurs with the
relatively high gain levels of
the programmable-gain set of embodiments.
It should be understood that the associated processes of the Data Recording
Application
(DRA) 14 could be implemented either in software-controlled hardware,
hardware, or a
to .. combination of the two.
For example, in one set of embodiments, either or both the recording module 13
or
docking system 27 may be constructed and operated in accordance with the
disclosure of U.S.
Provisional Application No. 62/575,364 filed on 20 October 2017, entitled
CORONARY
ARTERY DISEASE DETECTION SYSTEM, or International Application No.
PCT/US2018/056832 filed on 22 October 2018, entitled CORONARY ARTERY DISEASE
DETECTION SIGNAL PROCESSING SYSTEM AND METHOD, each of which is incorporated
by reference in its entirety. Furthermore, in accordance with one set of
embodiments, the
auscultatory coronary-artery-disease detection system 10 may further
incorporate an ECG
sensor 34, for example, in one set of embodiments, an ECG sensor 34'
comprising a pair of
.. electrodes incorporated in a corresponding pair of auscultatory sound
sensors 12, wherein the
signal from the ECG sensor 34' is also preprocessed and recorded by a
corresponding different
signal channel of the same hardware-based signal conditioning/preprocessing
and recording
subsystem 25 of the recording module 13 that is used to preprocess the signals
from the one or
more auscultatory sound sensors 12. Alternatively, the ECG sensor 34 may
comprise a separate
set of a pair or plurality of electrodes that are coupled to the skin of the
test subject, for example,
in one set of embodiments, a pair of signal electrodes 35, 35+/- in
cooperation with a ground
electrode 35 , wherein, referring to FIG. 3 (illustrating the locations of the
electrodes 35, 35+/-,
350), in accordance with one non-limiting embodiment, the signal electrodes
35, 35+/- span the
heart from diametrically-opposed quadrants of the torso 44, and the ground
electrode 35 is
located in a different quadrant, orthogonally displaced from a midpoint of a
baseline connecting
the signal electrodes 35, 35+/-. Alternatively the signal electrodes 35, 35+/-
could span across the
top of the top of the thorax 20, or at any pair of locations commonly used for
conventional ECG
tests. Furthermore, in one set of embodiments, the recording module 13 and
docking system 27
may each incorporate a corresponding respective USB interface 36.1, 36.2 to
provide for
transferring corresponding auscultatory sound signals 16 and or an
electrographic signal 37 -
-8-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
from an associated ECG sensor 34, 34' -- from the recording module 13 to the
docking system
27, for example, rather than relying upon the first 18 and second 26 wireless
transceivers of an
associated wireless interface 26'. Further alternatively, either instead of,
or in addition to, the
wireless interface 26' or the USB interface 36.1, 36.2, data may be
transferred from the
recording module 13 to the docking system 27 via a portable memory element,
for example,
either an SD memory card or a Micro SD memory card.
The functionality of the Data Recording Application (DRA) 14 is distributed
across the
recording module 13 and the docking system 27. For example, referring to FIG.
2, in accordance
with a first aspect 10' of an auscultatory coronary-artery-disease detection
system 10, 10', the
Data Recording Application (DRA) 14 spans across the recording module 13 and
the docking
system 27, with a first portion 14.1 comprising the hardware-based signal
conditioning/preprocessing and recording subsystem 25 operative on the
recording module
13, and a remaining second portion 14.2 operative on the docking system 27.
Alternatively, as
another example, referring to FIG. 4, in accordance with a second aspect 10"
of an auscultatory
coronary-artery-disease detection system 10, 10", the Data Recording
Application (DRA) 14
is operative entirely on the recording module 13.
The auscultatory sound sensor 12 provides for sensing sound signals that
emanate from
within the thorax 20 of the test-subject 22 responsive to the operation of the
test-subject's heart,
and the resulting flow of blood through the arteries and veins, wherein an
associated build-up of
deposits therewithin can cause turbulence in the associated blood flow that
can generate associated
cardiovascular-condition-specific sounds, the latter of which can be detected
by a sufficiently-
sensitive auscultatory sound sensor 12 that is acoustically coupled to the
skin 38 of the thorax
20 of the test-subject 22. For some cardiovascular-conditions associated with,
or predictive of, a
cardiovascular disease, the sound level of these cardiovascular-condition-
specific sounds can be
below a level that would be detectable by a human using a conventional
stethoscope. However,
these sound levels are susceptible to detection by sufficiently sensitive
auscultatory sound sensor
12 that is sufficiently acoustically coupled to the skin 38 of the thorax 20
of the test-subject 22.
For example, in one of embodiments, the auscultatory sound sensor 12 may be
constructed in
accordance with the teachings of U.S. Provisional Application No. 62/568,155
filed on 04
October 2017, entitled AUSCULTATORY SOUND SENSOR, or International Application
No. PCT/US2018/054471 filed on 04 October 2018, entitled AUSCULTATORY SOUND-OR-
VIBRATION SENSOR, each of which is incorporated by reference in its entirety.
Furthermore,
in another set of embodiments, the auscultatory sound sensor 12 may be
constructed in
accordance with the teachings of U.S. Pat. Nos. 6,050,950, 6,053,872 or
6,179,783, which are
incorporated herein by reference.
-9-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring also to FIG. 5a, the auscultatory sound sensors 12, 121', 122', 12',
121", 122",
123" are acoustically coupled to the skin 38 of the thorax 20 of the test-
subject 22 via an acoustic
interface 40, for example, via a hydrogel layer 40', that also functions as an
associated adhesive
interface 42 that is attached to the associated auscultatory sound sensor 12,
121', 122', 12', 121",
122", 123" with a first adhesive layer 42.1, for example, either a first
surface 40.1' of the
hydrogel layer 40' or a first layer of double-sided tape 42.1' on a first side
of the
acoustic/adhesive interface 40,42, and that is attached to the skin 38 of the
thorax 20 of the test-
subject 22 with a second adhesive layer 42.2, for example, either a second
surface 40.2' of the
hydrogel layer 40' or a second layer of double-sided tape 42.2' on the
opposing, second side of
the acoustic/adhesive interface 40, 42. When fully coupled - as illustrated in
FIG. 5a, -- the
auscultatory sound sensor 12, 121', 122', 123' , 121", 122", 123" is fully
attached to the
acoustic/adhesive interface 40, 42 via the first adhesive layer 42.1, 42.1',
40.1', and the
acoustic/adhesive interface 40, 42 is fully attached to the skin 38 of the
thorax 20 of the test-
subject 22 via the second adhesive layer 42.2, 42.2', 40.2', so that sound
signals from within the
thorax 20 of the test-subject 22 can propagate otherwise unimpeded to the
auscultatory sound
sensor 12, 121', 122', 12', 121", 122", 123", thereby providing for a maximum
achievable level of
the corresponding associated auscultatory sound signals 16, and thereby
improving the prospect
of detecting an associated abnormal cardiovascular condition - if present -
therefrom. Referring
to FIGS. 5b and Sc - with the acoustic/adhesive interface 40, 42 respectively
detached from the
skin 38 or detached from the auscultatory sound sensor 12, respectively, -- if
the auscultatory
sound sensor 12, 121', 122', 12', 121", 122", 123" is completely detached from
the skin 38 of the
thorax 20 of the test-subject 22, and thereby fully decoupled therefrom, the
resulting
auscultatory sound sensor 12, 121', 122', 123' , 121", 122", 123" would be
substantially non-
responsive to sound signals from within the thorax 20 of the test-subject 22.
Referring to FIGS.
5d to 5g, if the auscultatory sound sensor 12, 121', 122', 12', 121", 122",
123" is partially attached
to the skin 38 of the thorax 20 of the test-subject 22, and thereby partially
decoupled therefrom
- i.e., in a condition referred to herein as being debonded therefrom -- the
resulting auscultatory
sound sensor 12, 121', 122', 12', 121", 122", 123" would be only partially
responsive to sound
signals from within the thorax 20 of the test-subject 22, but not sufficiently
responsive to provide
for an associated auscultatory sound signal 16 of sufficient amplitude to
provide for reliably
detecting a prospective associated abnormal cardiovascular condition. More
particularly, FIGS.
5d and 5e respectively illustrate an acoustic/adhesive interface 40, 42
partially detached from
skin 38, and an acoustic/adhesive interface 40,42 partially detached from an
auscultatory sound
sensor 12, respectively. Furthermore, FIG. 5f illustrates an auscultatory
sound sensor 12
attached to a wrinkled acoustic/adhesive interface 40, 42, and FIG. 5g
illustrates an
-10-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
acoustic/adhesive interface 40, 42 attached to wrinkled skin 38. In
anticipation of prospective
problems with nature of the attachment of the acoustic/adhesive interface 40,
42, the Data
Recording Application (DRA) 14 is provided with a means - described more fully
hereinbelow
-- for detecting if one or more auscultatory sound sensors 12, 121', 122',
12', 121", 122", 123" is,
or are, either detached or debonded from the skin 38 of the thorax 20 of the
test-subject 22, so as
to provide for excluding data from auscultatory sound sensors 12, 121', 122',
12', 121", 122",
123" that are either detached or debonded, from the skin 38 of the thorax 20
of the test-subject
22 from being used to diagnose a prospective abnormal cardiovascular
condition.
Generally, the adhesive interface 42 could comprise either a hydrogel layer
40', for
example, P-DERMO Hydrogel; a silicone material, for example, a P-DERMO
Silicone Gel
Adhesive; an acrylic material, for example, a P-DERMO Acrylic Adhesive; a
rubber material; a
synthetic rubber material; a hydrocolloid material; or a double-sided tape,
for example, with either
rubber, acrylic or silicone adhesives.
Referring to FIG. 6, it has been found that the quality of the auscultatory
sounds acquired
from a test-subject 34 can be improved if the torso 44 of the test-subject 34
is inclined, for
example, in one set of embodiments, at an inclination angle 0 of about 30
degrees above
horizontal -- but generally, as close to upright (i.e. 9=90 degrees) as can be
accommodated by the
associated adhesive interface(s) 42 of the associated auscultatory sound
sensors 12, 121', 122',
12', 121", 122", 123" -- which imposes a transverse component of gravitational
force on each of
the auscultatory sound sensors 12, 121', 122', 123' , 121", 122", 123" that is
resisted by the
associated adhesive interface(s) 42.
Referring to FIGS. 7-15, in accordance with a first aspect 700, an
auscultatory-sound-
sensing process 700 provides for first determining a scale factor SF from an
initially-acquired
block of auscultatory-sound-sensor time-series data S, and initially
determining from the scale
factor SF whether one or more of the auscultatory sound sensors 12, 121',
122', 12', 121", 122",
123" is detached from the skin 38 of the thorax 20 of the test-subject 22,
wherein when multiplied
by the scale factor SF, the values of the associated auscultatory-sound-sensor
time-series data
S are nominally within a range that is a predetermined percentage of the
dynamic range of the
associated data acquisition system (for example, that provides /6-bit signed
digital values). If
there is no detachment, the first aspect 700, the auscultatory-sound-sensing
process 700
provides for acquiring successive blocks of auscultatory-sound-sensor time-
series data S while
the test-subject 22 is holding their breath, and determining from each block
of auscultatory-
sound-sensor time-series data S - using an associated predetermined debond-
detection threshold
- whether or not one or more auscultatory sound sensors 12, 121', 122', 12',
121", 122", 123" is
debonded from the skin 38 of the thorax 20 of the test-subject 22, or whether
there is excessive
-11-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
noise in the auscultatory-sound-sensor time-series data S. The auscultatory-
sensor time-
series data S is rejected if excessive noise is detected, and the test is
aborted if one or more
auscultatory sound sensors 12, 121', 122', 12', 121", 122", 123" has become
decoupled from the
skin 38 of the thorax 20.
More particularly, referring to FIG. 7, the first aspect 700 of the
auscultatory-sound-
sensing process 700 commences with step (702) by initializing a data-block
counter i to a value
of zero, and then, in step (704), acquiring a block of Ns contiguous samples
of auscultatory-
sound-sensor time-series data S in accordance with a first aspect 800 of a
data acquisition
process 800. This initially-acquired data is then used to determine the scale
factor SF that is used
to determine whether or not one or more auscultatory sound sensors 12, 121',
122', 12', 121",
122", 123" is/are detached from the skin 38 of the thorax 20 of the test-
subject 22, and then
subsequently to scale subsequent blocks of time-series data S. The initial
block of auscultatory-
sound-sensor time-series data S may be acquired either with, or without, the
test-subject 22
holding their breath, but typically with the test-subject 22 allowed to breath
normally -- for their
comfort and convenience. The number of samples Ns to be acquired is given by
the product of an
acquisition period 5i in seconds, times a sampling frequency Fs in Hz. For
example, in one set
of embodiments, in step (704), the initially-acquired block of auscultatory-
sound-sensor time-
series data S typically contains 10 seconds of data, which at a sampling
frequency Fs of 24 KHz,
results in Ns = 5 i*Fs = 240,000 samples.
More particularly, referring to FIG. 8, the data acquisition process 800
commences with
step (802) by pre-filtering the electronic signal from the associated
auscultatory sound sensor
12, 121', 122', 12', 121", 122", 123" with an analog anti-aliasing filter, for
example, an analog
second-order band-pass filter having a pass band in the range of 3 Hz to 2.5
KHz, for which the
upper-cutoff frequency is sufficiently below the sampling frequency (i.e. no
more than half) so as
to prevent high frequency components in the signal being sampled from
appearing as low
frequency components of the sampled signal, i.e. so as to prevent aliasing.
Following step (802),
if, in step (804), the test-subject 22 need not necessarily hold their breath
¨ as is the case for the
initially-acquired block of auscultatory-sound-sensor time-series data S, --
then, in step (806),
the pre-filtered auscultatory sound signal 16 is sampled at the sampling
frequency Fs and
converted to digital form by the associated analog-to-digital (ADC) converter.
Then, from step
(808), the auscultatory sound signal 16 continues to be sampled in step (806)
until Ns samples
of the block of auscultatory-sound-sensor time-series data S have been
acquired, after which,
in step (810), the Ns samples of auscultatory-sound-sensor time-series data S
are returned to
step (704) of the auscultatory-sound-sensing process 700. For example, FIGS. 9
and 10a each
-12-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
illustrate a first block of auscultatory-sound-sensor time-series data S of
duration go that was
recorded from one of the auscultatory sound sensors 12, 121', 122', 12', 121",
122", 123".
Referring again to FIG. 7, following step (704), in step (706), the scale
factor SF is
determined from the initially-acquired block of auscultatory-sound-sensor time-
series data S,
in accordance with an associated scale-factor-determination process 1100. More
particularly,
referring to FIGS. 11 and 12a, the scale-factor-determination process 1100
commences with
step (1102), wherein the block of auscultatory-sound-sensor time-series data S
is divided into
a plurality of data segments 46, for example, each of the same data-segment
duration SD that
nominally spans a single heartbeat, for example, about one second. For
example, in FIG. 12a, the
SO = 10 second block of auscultatory-sound-sensor time-series data S is
divided into Nseg = 10
data segments 46, each of SD =one second duration. FIG. 12a illustrates a time
series ISI
containing the absolute values of the auscultatory-sound-sensor time-series
data S illustrated in
FIG. 10a. As indicated by X's in FIG. 12a, for each data segment 46, m
spanning the range
k=kmiN(m) to k=kmAx(m) of the auscultatory-sound-sensor time-series data S(k),
the
corresponding maximum absolute value of the auscultatory-sound-sensor time-
series data S(k)
is determined, as given by:
Smm = Max (IS (1) (1)
km,3, (m).kmAx. (n)
Then, in step (1104), the median of these maximum values is determined, as
given by
median(SimAz (2)
Finally, in step (1106), the scale factor SF is determined, as given by:
SF = DR,-P (3)
median(Sm4x
15m5Nseg
wherein DRo-p is the nominal zero-to-peak dynamic range of the auscultatory-
sound-sensor
time-series data S after scaling, i.e. after multiplying the acquired values
by the scale factor SF.
For example, in one set of embodiments, the nominal zero-to-peak dynamic range
is set to be about
80 percent - more broadly, but not limiting, 80 percent plus or minus 15
percent -- of the zero-to-
peak range of the associated analog-to-digital converter-- for example, in one
set of embodiments,
a 16-bit signed analog-to-digital converter used to digitize the auscultatory-
sound-sensor time-
series data S in step (806). In one set of embodiments, the scale factor SF is
integer-valued that,
for an attached and bonded auscultatory sound sensor 12, 121', 122', 12',
121", 122", 123", ranges
in value between 1 and 28.
If one or more of the associated auscultatory sound sensors 12, 121', 122',
12', 121",
122", 123" is detached from the skin 38 of the thorax 20 of the test-subject
22, then the associated
-13-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
level of the auscultatory sound signals 16 will be low - for example, at a
noise level - resulting
in a relatively large associated scale factor SF from step (1106).
Accordingly, if, in step (1108),
the scale factor SF is in excess of an associated threshold SFmAx, then the
Data Recording
Application (DRA) 14 is aborted in step (1110), and the operator 48 is alerted
that the one or
more auscultatory sound sensors 12, 121', 122', 12', 121", 122", 123" is/are
detached, so that this
can be remedied. For example, in one set of embodiments, the value of the
threshold SFmAx is
28 for the above-described fixed-gain embodiment, i.e. for which the
associated amplifier has a
fixed gain of 88, feeding a /6-bit analog-to-digital converter (ADC) that
provides for converting
a +/- 5 volt input signal to +/- 32,767. Otherwise, from step (1108), if the
value of the scale factor
SF does not exceed the associated threshold SFmAx, in step (1112), the scale
factor SF is returned
to step (706) for use in scaling subsequently-recorded breath-held
auscultatory sound signals
16.1.
Referring again to FIG. 7, following step (706), in step (708), the value of
the data-block
counter i is incremented, so as to point to the next block of auscultatory-
sound-sensor time-
series data S to be recorded. If, while this next block is recorded, the
auscultatory sound sensors
12, 121', 122', 12', 121", 122", 123" remain attached and bonded to the skin
38 of the thorax 20
of the test-subject 22, and the associated breath-held auscultatory sound
signals 16.1 are not
corrupted by excessive noise, then this next block of auscultatory-sound-
sensor time-series data
S will then be subsequently used to detect a prospective abnormal
cardiovascular condition
therefrom. The auscultatory sound signals 16 used to detect prospective
abnormal
cardiovascular conditions are recorded while the test-subject 22 holds their
breath, the latter to
prevent the resulting cardiovascular-based auscultatory sound signals 16 from
being
overwhelmed by breathing-related sounds that are substantially louder than
cardiovascular-based
sounds, thereby providing for improving the associated signal-to-noise ratio
of the cardiovascular-
based auscultatory sound signals 16.
Accordingly, in step (710), a next block of Ns contiguous samples of
auscultatory-sound-
sensor time-series data S is acquired over an acquisition period Si in
accordance with a first
aspect 800 of a data acquisition process 800, during which time the test-
subject 22 is instructed
to hold their breath. For example, in one set of embodiments, the nominal
acquisition period gi
is 10 seconds - but at least 5 seconds, -- which, at a sampling frequency Fs
of 24 KHz, results in
Ns = Si *Fs = 240,000 samples.
More particularly, referring again to FIG. 8, the data acquisition process 800
commences
with step (802) by pre-filtering the electronic signal from the associated
auscultatory sound
sensor 12, 121', 122', 123 , 121", 122", 123" with the above-described analog
anti-aliasing filter.
Then, from step (804), because breath-held data is to be acquired, in step
(812), the test-subject
-14-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
22 is instructed by the operator 48 to hold their breath. In step (814), if
the operator 48 observes
that the test-subject 22 is compliant in holding their breath, or,
additionally or alternatively, if this
is confirmed by a below-described breath-hold detection process 1400, then
upon manual
initiation by the operator 48, in step (816), a sample counter j is
initialized to a value of one,
and, in step (818), the next sample of pre-filtered auscultatory sound signal
16 is sampled at the
sampling frequency Fs and converted to digital form by an associated analog-to-
digital (ADC)
converter. This process continues until either Ns = (51 *Fs samples have been
acquired, or the test-
subject 22 resumes breathing. More particularly, in step (820), if one or more
addition samples
remain to be acquired, and if the operator 48 continues to observe that the
test-subject 22 is
holding their breath, or, additionally or alternatively, if this is confirmed
by a below-described
breath-hold detection process 1400, then, in step (822) the sample counter j
is incremented, and
the next sample is acquired in step (818). Otherwise, from step (820), if
either all Ns = Si *Fs
samples have been acquired, or if either the operator 48 observes that the
test-subject 22 has
resumed breathing, or, additionally or alternatively, if this is confirmed by
a below-described
breath-hold detection process 1400, or, if the test-subject 22 indicates by
their own separate
manual switch input that they will resume breathing, then, in step (824), the
data acquisition
process 800 terminates, and the block of breath-held auscultatory-sound-sensor
time-series
data S containing Ns =j samples is returned to step (710). In one set of
embodiments, if, following
step (814), the test-subject 22 is not holding their breath, the pre-filtered
auscultatory sound
.. signals 16 are also separately-recorded while waiting for the test-subject
22 to hold their breath,
or resume doing so. In practice, the auscultatory sound signals 16 typically
continue to be
recorded between breath-held segments, that latter of which are identified by
associated recorded
start and stop times with respect to the associated continuous recording.
Referring also to FIG. 13, alternatively, or additionally, in step (814), the
auscultatory
coronary-artery-disease detection system 10 may further incorporate an
accelerometer 50
operatively coupled to the thorax 20 of the test-subject 22 to provide an
associated acceleration
signal responsive to the motion of the thorax 20. With the test-subject 22
lying on their back at
an inclined angle, for example, at about 30 degrees above horizontal, for
example, as illustrated in
FIG. 4 of U.S. Provisional Application No. 62/568,155 filed on 04 October
2017, entitled
AUSCULTATORY SOUND SENSOR, which has been incorporated by reference herein in
its
entirety, the associated acceleration signal ¨ operatively coupled to
recording module 13 and
possibly transmitted to the docking system 27 --- may be twice integrated
either in recording
module 13 or the docking system 27 to generate a measure of the peak-to-peak
displacement of
the thorax 20, which if greater than a threshold would be indicative of
breathing by the test-
.. subject 22.
-15-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
More particularly, referring also to FIG. 14, for an auscultatory coronary-
artery-disease
detection system 10 incorporating an accelerometer 50 operatively coupled to
the thorax 20 of
the test-subject 22, an acceleration signal 52 therefrom may alternatively or
additionally be
processed by an associated breath-hold detection process 1400 to provide for
automatically
determining ¨ for example, in step (814) of the data acquisition process 800
illustrated in FIG.
8 ¨ whether or not the test-subject 22 is breathing, responsive to the
determination, from the
acceleration signal 52, of a peak-to-peak displacement of the thorax 20 of the
test-subject 22.
More particularly, beginning with, and in, step (1402), the respective
previous/initial values of
thorax displacement Yo and thorax velocity Vo, respectively, are each
initialized to values of
zero; a sample counter i is initialized to an initial value, for example,
zero; the respective
minimum YMIN and maximum YmAx values of thorax displacement are each set equal
to the
(initial) value of thorax displacement Yo; the values of the sample counter
imiN and imAx at
which the corresponding minimum YMIN and maximum YmAx values of thorax
displacement
occur are set equal to the initial value of the sample counter i; and a
BreathingFlag is set to
indicate that the test-subject 22 is breathing. Then, in step (1404), the
current sample of thorax
acceleration A is acquired. Then, in step (1406), if the sample counter i is
equal to the initial
value, i.e. i == 0, then, in step (1408), the previous value of thorax
acceleration Ao (i.e. initially,
the initial value thereof) is set equal to the value of the current sample of
thorax acceleration A,
i.e. Ao== A, and then, in step (1410), the sample counter i is incremented,
after which the breath-
hold detection process 1400 repeats with step (1404).
Otherwise, from step (1406), if the current sample of thorax acceleration A is
not the
first sample, then, in step (1412), the current value of thorax velocity V is
calculated by
integrating the previous Ao and current A measurements of thorax acceleration,
for example,
using a trapezoidal rule, as follows:
V ¨(4+A) 2 __ =dt+V (4)
wherein dt is the time period between samples, i.e. dt=1/Fs. Then, in step
(1414), the current
value of thorax displacement Y is calculated by integrating the above-
calculated previous Vo
and current V values of thorax velocity, for example, again using a
trapezoidal rule, as follows:
Y ¨ + dt+Y (5)
2
Then, in step (1416), the respective previous values of thorax acceleration
Ao, thorax
displacement Yo and thorax velocity Vo are respectively set equal to the
corresponding current
values of thorax acceleration A, thorax velocity V and thorax displacement Y,
respectively,
that will each be used in subsequent iterations of steps (1412) and (1414).
-16-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Then, in step (1418), if the current value of thorax displacement Y is greater
than then
current maximum value of thorax displacement YmAx ¨ for example, as would
result during a
phase of chest expansion by the test-subject 22, -- then, in step (1420), the
current maximum
value of thorax displacement YmAx is set equal to the current value of thorax
displacement Y
and the corresponding value of the sample counter MAXi associated therewith
is set to the current
value of the sample counter i. Otherwise, from step (1418) ¨ for example, as
would result from
other than a phase of chest expansion by the test-subject 22, -- if, in step
(1422), the amount by
which the current value of the sample counter i exceeds the value of the
sample counter imAx
associated with the maximum value of thorax displacement YmAx is not equal to
a threshold
value A (the relevance of which is described more fully hereinbelow), then in
step (1424), if the
current value of thorax displacement Y is less than then current minimum value
of thorax
displacement YMIN¨ for example, as would result during a phase of chest
contraction by the test-
subject 22, -- then, in step (1426), the current minimum value of thorax
displacement YMIN is
set equal to the current value of thorax displacement Y and the corresponding
value of the
sample counter infiN associated therewith is set to the current value of the
sample counter i. From
either steps (1420) or (1426), in step (1428), if the amount by which the
current maximum value
of thorax displacement YmAx is greater the current minimum value of thorax
displacement
YMIN meets or exceeds a displacement threshold A YmAx, then, in step (1430),
the BreathingFlag
is set to indicate that the test-subject 22 is breathing, after which, in step
(1410), the sample
counter i is incremented, after which the breath-hold detection process 1400
repeats with step
(1404). Similarly, from step (1428), if the displacement threshold LlYmAx is
not exceeded, in
step (1410), the sample counter i is incremented, after which the breath-hold
detection process
1400 repeats with step (1404). Further similarly, from step (1424) ¨ for
example, as would result
from other than a phase of chest contraction by the test-subject 22, --if, in
step (1432), the amount
by which the current value of the sample counter i exceeds the value of the
sample counter inHAT
associated with the minimum value of thorax displacement YMIN is not equal to
the threshold
value A, in step (1410), the sample counter i is incremented, after which the
breath-hold
detection process 1400 repeats with step (1404).
If, from step (1432), the amount by which the current value of the sample
counter i
exceeds the value of the sample counter inHN associated with the minimum value
of thorax
displacement Limy is equal to the threshold value A-- following a minimum
chest contraction of
the test-subject 22, in anticipation of subsequent chest expansion, wherein
the threshold value
A is greater than or equal to one, -- then, in step (1434), the peak-to-peak
thorax displacement
AY is calculated as the difference between the current maximum YmAx and
minimum YMIN
values of thorax displacement, and, in step (1436), the maximum value of
thorax displacement
-17-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
YmAx is set equal to the current value of thorax displacement Y. and the value
of the sample
counter imAx at which the corresponding maximum value of thorax displacement
YmAx occurred
is set equal to the current value of the sample counter i, in anticipation of
subsequently increasing
magnitudes of the current value of thorax displacement Y to be tracked in
steps (1418) and
(1420).
Similarly, if, from step (1422), the amount by which the current value of the
sample
counter i exceeds the value of the sample counter MAXi
associated with the maximum value of
thorax displacement YmAx is equal to the threshold value A -- following a
maximum chest
expansion of the test-subject 22, in anticipation of subsequent chest
contraction, wherein the
threshold value A is greater than or equal to one, -- then, in step (1438),
the peak-to-peak thorax
displacement AY is calculated as the difference between the current maximum
YmAx and
minimum YMIN values of thorax displacement, and, in step (1440), the minimum
value of
thorax displacement Limy is set equal to the current value of thorax
displacement Y. and the
value of the sample counter iMIN at which the corresponding minimum value of
thorax
displacement Y3HAT occurred is set equal to the current value of the sample
counter i, in
anticipation of subsequently decreasing magnitudes of the current value of
thorax displacement
Y to be tracked in steps (1424) and (1426).
Accordingly, the threshold value A, provides for a delay to assure that a most-
recent
extremum of displacement has been reached, either the current maximum YmAx or
minimum
YMIN values of thorax displacement, before calculating the associated peak-to-
peak thorax
displacement AY
From either steps (1436) or (1440), in step (1442), if the amount of the peak-
to-peak
thorax displacement AY calculated in steps (1434) or (1438), respectively,
meets or exceeds the
displacement threshold tlYmAx, then, in step (1444), the BreathingFlag is set
to indicate that the
test-subject 22 is breathing. Otherwise, from step (1442), if the amount of
the peak-to-peak
thorax displacement AY calculated in steps (1434) or (1438), respectively,
does not exceed the
displacement threshold tlYmAx, then, in step (1446), the BreathingFlag is
reset to indicate that
the test-subject 22 is not breathing. Following either step (1444) or (1446),
in step (1410), the
sample counter i is incremented, after which the breath-hold detection process
1400 repeats
with step (1404).
Referring again to FIG. 7, in step (712), a corresponding block of scaled
auscultatory-
sound-sensor time-series data g is calculated by multiplying the acquired
block of auscultatory-
sound-sensor time-series data S by the scale factor SF, and in step (714), the
scaled
auscultatory-sound-sensor time-series data g is analyzed by an associated
debond detection
-18-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
process 1500 to determine whether or not any of the auscultatory sound sensors
12, 121', 122',
12', 121", 122", 123" was debonded from skin 38 of the thorax 20 of the test-
subject 22 during
the associated data acquisition process 800.
More particularly, referring to FIG. 15, the debond detection process 1500
commences
with step (1502) by initializing a sample counter j to a value of one, and
initializing a threshold
counter TC to a value of zero, wherein the threshold counter TC is a count of
the number of
contiguous successive samples for which the value of the scaled auscultatory-
sound-sensor
time-series data g is less than an associated predetermined debond-detection
threshold DT For
example, in one set of embodiments, the debond-detection threshold DT is set
to a value that is
if) about 20% of the achievable maximum value of the output from the analog-
to-digital converter
(ADC). Then, in step (1504), if the absolute value of the sample of scaled
auscultatory-sound-
sensor time-series data g, i.e. Ig (j)I, is less than the predetermined debond-
detection threshold
DT (or, alternatively, if I SF*S(j)I < DT, thereby precluding a need to
separately calculate and store
scaled auscultatory-sound-sensor time-series data g), then in step (1506), the
threshold
counter TC is incremented, after which, in step (1508), if the value of the
threshold counter TC
does not exceed the number of samples in ND successive data segments 46, i.e.
TC < ND*(5D*Fs,
and in step (1510), if the sample counter j does not exceed the number of
samples Ns in the block
of scaled auscultatory-sound-sensor time-series data g, then, in step (1512),
the sample
counter j is incremented, and the process continues again with step (1504).
Otherwise, from step
(1504), if the absolute value of the current sample of scaled auscultatory-
sound-sensor time-
series data g, i.e. Ig (j)I, is not less than the predetermined debond-
detection threshold DT -
indicating that the auscultatory sound sensor 12, 121', 122', 12', 121", 122",
123" is not debonded
from the skin 38 of the thorax 20 of the test-subject 22, -- then, in step
(1514), the threshold
counter TC is reset to a value of zero and the process continues with step
(1510). Otherwise, from
step (1510), if the sample counter j exceeds the number of samples Ns in the
block of scaled
auscultatory-sound-sensor time-series data g or auscultatory-sound-sensor time-
series data
S -- indicating that the entire block of scaled auscultatory-sound-sensor time-
series data g or
auscultatory-sound-sensor time-series data S has been screened, -- then the
debond detection
process 1500 is terminated with step (1516) by returning an indication to step
(714) of the
auscultatory-sound-sensing process 700 that the associated auscultatory sound
sensor 12, 12v,
122', 12', 121", 122", 123" is not debonded from the skin 38 of the thorax 20
of the test-subject
22. Otherwise, from step (1508), if the value of the threshold counter TC
exceeds the number
of samples in ND successive data segments 46, then the debond detection
process 1500 is
terminated with step (1518) by returning an indication to step (714) of the
auscultatory-sound-
sensing process 700 that the associated auscultatory sound sensor 12, 12v,
122', 12', 121", 122",
-19-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
123" is debonded from the skin 38 of the thorax 20 of the test-subject 22. For
example, in one
set of embodiments, the value of ND is equal to 4, and the value of SD is
equal to 1 second.
Returning to FIG. 7, in step (716), if, from step (714), the debond detection
process 1500
detected that the associated auscultatory sound sensor 12, 121', 122', 12',
121", 122", 123" was
debonded while acquiring the block of auscultatory-sound-sensor time-series
data S, then the
Data Recording Application (DRA) 14 is aborted in step (718), and the operator
48 is alerted
that one or more auscultatory sound sensors 12, 121', 122', 12', 121", 122",
123" are debonded,
so that this can be remedied. Otherwise, if, from step (714), the debond
detection process 1500
did not detect that the associated auscultatory sound sensor 12, 121', 122',
12', 121", 122", 123"
1() was debonded while acquiring the block of auscultatory-sound-sensor
time-series data S, then,
in step (720), if sufficient noise-screened data has not been gathered - for
example, in one set of
embodiments, a total duration of at least 65 seconds of recorded data, -- then
the auscultatory-
sound-sensing process 700 continues with step (708).
In step (724), an associated noise detection (i.e. noise-screening) process -
operating on
either the block of scaled auscultatory-sound-sensor time-series data g, or
the block of
auscultatory-sensor time-series data S, in parallel with the debond detection
process 1500 -
provides for detecting if the block of auscultatory-sound-sensor time-series
data S has been
corrupted by excessive noise, and if so, from step (726), that block of
auscultatory-sound-sensor
time-series data S is ignored, and the auscultatory-sound-sensing process 700
continues by
repeating step (710) to acquire a new block of auscultatory-sound-sensor time-
series data S.
Otherwise, from step (726), if the block auscultatory-sound-sensor time-series
data S has not
been corrupted by excessive noise, the process continues with the above-
described step (720).
From step (720), if sufficient noise-screened data has been gathered for which
the
associated one or more auscultatory sound sensors 12, 121', 122', 12', 121",
122", 123" were not
debonded from the skin 38 of the thorax 20 of the test-subject 22 - for
example, in one set of
embodiments, a total duration of at least 65 seconds of recorded data, --then,
in step (722), at least
the composite set of blocks of breath-held auscultatory-sound-sensor time-
series data S
acquired in step (710) are subsequently analyzed by an associated Data
Analysis Application
(DAA) 54 operative on the docking system 27 - as illustrated in FIGS. 2 and 3 -
- so as to provide
.. for detecting an abnormal cardiovascular condition of the test-subject 22.
In addition to recording
the segments of breath-held data, alternatively, all data may be recorded and
provided to the Data
Analysis Application (DAA) 54, along with an associated index that provides
for identifying the
corresponding associated breath-held portions thereof for which the associated
auscultatory
sound sensors 12, 121', 122', 12', 121", 122", 123" were neither detached nor
debonded from the
skin 38 of the thorax 20 of the test-subject 22, nor corrupted by noise.
-20-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIGS. 9 and 10a-10f illustrate a simulation of six blocks of breath-held
auscultatory-
sound-sensor time-series data S recorded in accordance with the first aspect
700 of
auscultatory-sound-sensing process 700, with respective durations of Si, 82,
83, 54, 55, and 86
during which time periods the test-subject 22 was holding their breath,
separated by periods
Lii, 42, 43, 4, and 45 of normal breathing, wherein FIGS. 10a-10e illustrate
breath-held
auscultatory sound signals 16.1, 16.1' from a normally-bonded auscultatory
sound sensor 12,
12v, 122', 12', 121", 122", 123" as illustrated in FIG. 5a, and FIG. 10f
illustrates a breath-held
auscultatory sound signal 16.1, 16.1" from a debonded auscultatory sound
sensor 12, 12v,
122', 12', 121", 122", 123", for example, as illustrated in any of FIGS. 5d-
5g, for example, as
might be caused by excessive hair between the adhesive interface 40 and the
auscultatory sound
sensor 12, poor placement of the auscultatory sound sensor 12 on the thorax 20
of the test-
subject 22, poor angular orientation of the auscultatory sound sensor 12
relative to the surface
of the skin 38, or wrinkled adhesive interface 40 between the auscultatory
sound sensor 12 and
the skin 38, For purposes of simplicity of illustration, FIGS. 10b-10e are
identical to FIG. 10a.
However, it should be understood that typically the amplitude of the
auscultatory sound signals
16, 16.1 varies from heartbeat to heartbeat, and from one breath-held segment
to another.
Alternatively, one or more of the auscultatory-sound-sensing process 700, the
data
acquisition process 800, the scale-factor-determination process 1300, or the
de-bond detection
process 1500 could be implemented with corresponding alternative processes
disclosed in U.S.
Application Serial No. 16/136,015 filed on 19 September 2018 - with particular
reference to
FIGS. 16 through 22 - which is incorporated by reference herein in its
entirety.
Referring to FIG. 16, in one set of embodiments, all the data is recorded
throughout the
duration of the test, including segments both with and without breathing, and
a set of index pointers
are used to identify locations of associated events, for example, index
pointer arrays loll and [1
to store the sample locations at the beginning and end of breath-held data
segments of the
corresponding sampled auscultatory sound data 5"111 from the mth auscultatory
sound sensor
12, and later-used index pointer arrays isill and is2[1 to store the sample
locations of the 51 sound
at the beginning of each heart cycle, and the S2 sound at the beginning of
diastole respectively,
wherein in FIG. 16, the symbol "B" is used to indicate a period of breathing,
the symbol "H" is
used to indicate a period of breath-holding, and the symbol "D" is used to
indicate a period of
diastole. A status array Status [m, k] indicates the measurement status of the
lith breath-held data
segment of the mth auscultatory sound signal 16, i.e. the sampled auscultatory
sound data Sin()
from the mth auscultatory sound sensor 12. Accordingly, step (728) -- that
provides for ignoring
data -- may be implemented by setting the corresponding value of the status
array Status(m, k)
to a value of IGNORE.
-21-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring to FIGS. 17-20, a noise detection process 1700 called from step
(724) provides
for determining whether or not a particular segment of breath-held
auscultatory sound signal
16.1 is corrupted by excessive noise, and if so, provides for flagging that
segment as being
excessively noisy so as to be prospectively excluded from subsequent
processing. Generally the
noise detection process 1700 generates, in step (1714), frequency-domain noise
filters FH[]
responsive to cross-correlations of frequency spectra of pairs of adjacent
auscultatory sound
sensors 12. Accordingly, sensor-index pointers ml[p] and m2[p] provide for
identifying the
associated auscultatory sound sensors 12, ml [p], m2[p] of each pair, the
latter of which is
identified by a pair pointer p. For each pair of adjacent auscultatory sound
sensors 12 in a set
of adjacent pairs -- selected by sensor-index pointers ml[p] and m2[p] in
steps (1706) and
(1710), respectively, wherein the pair pointer p is initialized to 1 in step
(1704) -- the noise
detection process 1700 generates, in step (1714), a frequency-domain noise
filter FH[] by cross-
correlating, in step (1802), the frequency spectra FSAI] and FSB1] --
generated in steps (1708)
and (1712) -- of each associated breath-held auscultatory sound signal 16.1:
5A11 and 51311,
wherein the values of the frequency-domain noise filter FH[] are generated by
normalizing the
frequency spectra of the cross-correlation function to a range of 0 to 1 in
step (1804), then
subtracting these values from unity, and then setting resulting values that
are less than a noise floor
to the value of the noise floor in step (1806). Accordingly, when used to
multiply the frequency
spectra FSAI] and FSB1] in step (1904) as called from steps (1718) and (1720)
for frequency
.. spectra FSAI] and FSB1], respectively, the frequency-domain noise filter
FH[] provides for
attenuating the components of the breath-held auscultatory sound signal 16.1:
SA[] and SB[]
that are correlated with one another. Accordingly, the operation of step
(1904) provides for a
matched filtering process to accentuate the underlying noise in the associated
breath-held
auscultatory sound signal 16.1: SA[] or SB[] by attenuating frequency-
component portions
thereof that are correlated with a corresponding breath-held auscultatory
sound signal 16.1:
SB[] or SA[] from the other auscultatory sound sensor 12, ml [p], m2[p] of the
pair.
Furthermore, in step (1904), the product of the frequency-domain noise filter
FH[] with either
of the frequency spectra FSAI] or FSB1] is inverse Fourier transformed back to
the corresponding
time domain noise signal SN[]. Then, in steps (1908) through (1918), a
plurality of NFFT-point
short-time Fourier transform (STFT) arrays are generated, for example, with
NFFT=1024, with
each overlapped with respect on one another by a half width, i.e. NFFT /2,
after which the associated
average spectral power array FX[] in dB is calculated in step (1920). Then,
the average powers
PLOW, PMID, PHIGH in three respective frequency ranges 20 Hz to 200 Hz, 200 Hz
to 800 Hz, and
800 Hz to 1,500 Hz, respectively, is calculated in steps (1922), (1924) and
(1926), respectively,
wherein each average power PLOW, PMID, PHIGH is compared with a corresponding
threshold --
-22-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
for example, in one set of embodiments, -20 dB, -50 dB and -30 dB,
respectively ¨ in step (1928).
The corresponding breath-held auscultatory sound signal 16.1: SA[] or SB[] is
then flagged in
step (1930) as being noisy if any of the associated noise power thresholds are
exceeded. Referring
to FIG. 20, if one auscultatory sound sensor 12 exceeds the noise threshold in
a given kth breath-
held segment of breath-held sampled auscultatory sound data Sm[io[k]: ii[k]],
that
auscultatory sound sensor 12, m is flagged in step (2008) as being noisy so as
to later be ignored
for that kth breath-held segment. If a particular auscultatory sound sensor
12, m exceeds the
noise threshold for more than one breath-held segment of breath-held sampled
auscultatory
sound data Sm[io[k]: ii[k]], then that auscultatory sound sensor 12, m is
flagged in step (2016)
as being bad. For each breath-held segment k of data, the process of steps
(1706) through (1722)
repeats for each of NPAIRS pairs of adjacent auscultatory sound sensors. For
example, referring
to FIG. 3, in one set of embodiments, there are three pairs of adjacent
auscultatory sound sensors,
i.e. NPAIRS=3, as follows: for p=1, the auscultatory sound sensors 12 at the
left and sternum
second intercostal spaces L2, S2; for p=2, the auscultatory sound sensors 12
at the left and
sternum third intercostal spaces L3, S3; and for p=3, the auscultatory sound
sensors at the left
and sternum fourth intercostal spaces L4, S4. The process of steps (1704)
through (1726) is
repeated until all the breath-held segments k of data have been processed.
More particularly, referring to FIG. 17, the noise detection process 1700
commences with
step (1702) by initializing a breath-held-segment pointer k to a value of 1,
so as to provide for
pointing to the first breath-held segment of data. Generally, the breath-held-
segment pointer
k provides for pointing to the lith breath-held segment of data, of duration 8
k, extending between
sample locations io[k] and iillq, as illustrated in FIG. 16. Then, in step
(1704), the pair pointer
p is initialized to a value of 1, and a noise counter NNOISY is initialed to a
value of 0. Then, in step
(1706), the kth breath-held segment of breath-held sampled auscultatory sound
data
.. SmliPl[io[k]: ii[k]] is selected as the sampled auscultatory sound data
SAL] of the first
auscultatory sound sensor 12, ml [p] of the pair p, and in step (1708) the
Fourier Transform of
the sampled auscultatory sound data SAL] is calculated as FSAI] = FFT(SAID.
Similar, then, in
step (1710), the kth breath-held segment of breath-held sampled auscultatory
sound data
[k]] is selected as the sampled auscultatory sound data 5B11 of the second
auscultatory sound sensor 12, m2[p] of the pair p, and in step (1712) the
Fourier Transform of
the sampled auscultatory sound data 5A11 is calculated as FSBI] = FFT(SB[]).
Then, in step (1714), the frequency-domain noise filter FH[] generated by a
matched-
noise-filter generation process 1800 that -- referring also to FIG. 18 --
commences in step (1802)
with the cross correlation of the frequency spectra FSA1], FSB1] of the
sampled auscultatory
sound data 5A11, 5B11 of the first ml[p] and second m2[p] auscultatory sound
sensors 12 of the
-23-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
pair p, wherein the resulting cross-correlation is stored in array FH[] and
then normalized to a
range of 0 to 1 in step (1804), and then inverted in step (1806), wherein each
element of the
normalized array FH[] is subtracted from 1, and if the result is less than a
noise floor, is set to
the value of the noise floor NoiseFloor. Then, in step (1808), the resulting
frequency-domain
noise filter FH[] is returned and subsequently used in steps (1716) and (1718)
of the noise
detection process 1700 to evaluate the noise in the frequency spectra FSA1],
FSB1] of the
sampled auscultatory sound data SAL], SBI] of the first ml[p] and second m2[p]
auscultatory
sound sensors 12 of the pair p, respectively, in accordance with an associated
noise-content-
evaluation process 1900, the latter of which is called from step (1716) to
evaluate the noise
content of the frequency spectrum FSAI] of the sampled auscultatory sound data
SAL] of the
first auscultatory sound sensor 12, ml [p] of the pair p, and which is called
from step (1718) to
evaluate the noise content of the frequency spectrum FSB1] of the sampled
auscultatory sound
data SBI] of the second auscultatory sound sensor 12, m2 [p] of the pair p.
Referring to FIG. 19, the noise-content-evaluation process 1900 commences in
step
(1902) with receipt of the index m of the associated auscultatory sound sensor
12, m, the
associated frequency spectrum FS[] of the associated auscultatory sound sensor
12, m, and the
associated frequency-domain noise filter FH[]. Then, in step (1904), the time
domain noise
signal SN[] ¨ containing a total of NPTS data points, i.e. the number of data
points in the breath-
held sampled auscultatory sound data Smflo[k]: [k]] -- is given by the inverse
Fourier
Transform of the product of the associated frequency spectrum FS[] with the
associated
frequency-domain noise filter FH[], corresponding to a time-domain cross-
correlation of the
corresponding associated time-domain signals. Then, in step (1906), each of
the NFFT summation
data points of a frequency-domain summation array FXSUM[] is initialized to
zero, as is an
associated summation counter Nsum, wherein the number of summation data points
NFFT is a
power of 2, for example, 1024, and substantially less than the total number of
data points NPTS
in the time domain noise signal SN[]. Then, in step (1908), an index jmiN --
to the first sample
of an NFFT-point window of samples to be analyzed from the time domain noise
signal SN[] ¨ is
initialized to a value of 1. Then, in step (1910), an index jmAx -- to the
last sample of the NFFT-
point window of samples to be analyzed from the time domain noise signal SN[]
¨ is set to the
value of jmix + NFFT- 1. Then, in step (1912), if the end of the time domain
noise signal SN[]
has not been reached, then, in step (1914), the square of values ¨ i.e.
corresponding to noise power
-- of an NFFT-point Fourier Transform of the data from the NFFT-point window
of samples of the
time domain noise signal SN[] over the range of samples SN[jmiN] to SNUmAx],
is added to the
frequency-domain summation array FXSUM[]. Then, in step (1916), the summation
counter
Nsum is incremented, and in step (1918), the index jmiN is incremented by half
the width of the
-24-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
NFFT-point window, i.e. by a value of NFFT /2, so as the provide for the next
NFFT-point window
to be analyzed to overlap the current NFFT-point window by half the window
width. The above
noise-content-evaluation process 1900 repeats beginning with step (1910),
until, in step (1912),
the index imAx exceeds the end of the time domain noise signal SN[], after
which, in step (1920),
each of the values of the frequency-domain summation array FXSUM[] is divided
by the value
of the summation counter Nsum so as to calculate an associated average noise
power FX[].
Then, in steps (1922), (1924) and (1926), respectively, the noise power is
summed in three
different corresponding respective frequency ranges, for example, 20 Hz to 200
Hz, 200 Hz to
800 Hz, and 800 Hz to 1,500 Hz, respectively, to give three corresponding
respective power
levels, PLOW, PAID) and PHIGH, respectively. Then, in step (1928), if any of
the power levels,
PLOW, PMID or PHIGH exceeds a corresponding respective power threshold value
ThresholdLow,
Thresholdmip or ThresholdifiGH, then, in step (1930), the noise threshold is
considered to have
been exceed for the particular auscultatory sound sensor 12, m and the
particular associated
segment k of breath-held sampled auscultatory sound data Sill [k]: [k]] is
flagged with a
corresponding indication of an associated status in an associated NoiseStatus
flag. Otherwise,
from step (1928), if none of the power levels, PLOW, PMID or PHIGH exceeds the
corresponding
respective power threshold value ThresholdLow, Thresholdmip or ThresholdifiGH,
then, in step
(1932), the noise threshold is considered to have not been exceed for the
particular auscultatory
sound sensor 12, m and the particular associated segment of breath-held
sampled auscultatory
sound data Sill [k]: i1 1k]] is flagged with a corresponding indication of
the associated status in
the NoiseStatus flag. The results from either steps (1930) or (1932) are then
logged by an
associated results-logging process 2000, which is called from step (1934).
Referring to FIG. 20, the results-logging process 2000 commences with receipt
in step
(2002) of the index m of the associated auscultatory sound sensor 12, m and
the associated
NoiseStatus flag. If, in step (2004), the NoiseStatus flag indicates a noisy
auscultatory sound
sensor 12, m, then, in step (2006), the noise counter NNOISY is incremented,
and, in step (2008),
the corresponding element of the status array Status [m, k] for the associated
auscultatory sound
sensor 12, m and breath-held segment k is updated to activate an associate
Noisy flag, so as to
indicate the associated auscultatory sound sensor 12, m being noisy for the
associated breath-
held segment k. Then, in step (2010), if the value of the noise counter NNOISY
is greater than 1,
then, in step (2012), the corresponding elements of the status array Status
[m, k] for each of the
auscultatory sound sensors 12, m is updated to activate the Ignore flag, so as
to provide for
ignoring each of the auscultatory sound sensors 12, m for the associated
breath-held segment
k. Then, or otherwise from step (2010), in step (2014), if the Noisy flag of
the status array
Status [m, k] is activated for at least NFAIL breath-held segments k for the
associated
-25-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
auscultatory sound sensor 12, m, then, in step (2016), status array Status [m]
for the associated
auscultatory sound sensor 12, m is updated to activate the Bad flag for the
associated
auscultatory sound sensor 12, m, so as to indicate that the associated
auscultatory sound sensor
12, m is bad. Then, or otherwise from either step (2004) or step (2014), the
results-logging
process 2000 terminates by returning to the noise detection process 1700.
More particularly, referring again to FIG. 17, in step (1720), if all of the
pairs of adjacent
auscultatory sound sensors 12 have not been processed, then, in step (1722),
the pair pointer p
is incremented, and the noise detection process 1700 is repeated for the next
pair of auscultatory
sound sensors 12, ml [p], m2 [p], beginning with step (1706) for the same
breath-held segment
k. Otherwise, from step (1720), if in step (1724), additional segments of
breath-held sampled
auscultatory sound data Sm[io[k]: ii [k]] remain to be processed, then, in
step (1726), the breath-
held-segment pointer k is incremented, and the noise detection process 1700 is
repeated
beginning with step (1704) for the next segment of breath-held sampled
auscultatory sound
data Sm[io[k]: ii[k]]. Otherwise, from step (1724), the noise detection
process 1700 terminates
with step (1728).
Referring again to FIG. 1, in accordance with one set of embodiments, the
results from the
docking system 27 may be transferred to a server computer system 56, for
example, for
subsequent transfer to an external data storage or processing system 58, for
example, to provide
for either viewing or analyzing the results at a remote location. Referring
again to FIGS. 2 and
4, in one set of embodiments, the composite set of blocks of breath-held
auscultatory-sound-
sensor time-series data S are screened prior to analysis by the associated
Data Analysis
Application (DAA) 54, for example, by first segmenting the set of blocks of
breath-held
auscultatory-sound-sensor time-series data S by heart cycle with an associated
segmentation
process 60, and then validating the associated heart cycle data with an
associated heart cycle
validation process 62, for example, to provide for additional screening for
heart-phase associated
noise.
Referring to FIG. 21, an auscultatory sound signal preprocessing and screening
process 2100 provides for preprocessing breath-held auscultatory sound signals
16.1 and an
associated electrographic signal 37 from an ECG sensor 34, 34', for example,
as acquired, for
example, in accordance with the above-described auscultatory-sound-sensing
process 700, with
concurrent recording of an associated electrographic signal 37 from an ECG
sensor 34, 34'. In
accordance with one embodiment as illustrated, in step (2102) a good beat
counter GB is
initialized to zero, and a segment counter ksEG is initialized to a value of
1, wherein the good
beat counter GB provides a count of the number of heart cycles for which the
associated breath-
held sampled auscultatory sound data S[] is not corrupted by either outliers
or noise during
-26-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
diastole, and the segment counter ksEG is the value of the breath-held-segment
pointer k for the
current block B of breath-held sampled auscultatory sound data S[].
Then, from step (2104), referring to FIG. 22a, a segment of breath-held
auscultatory
sound signals 16.1 is acquired and preprocessed by an associated auscultatory
sound signal
acquisition and filtering process 2200, wherein, in step (2202), for each
auscultatory sound
sensor 12, in step (2204), a block of data of associated breath-held
auscultatory sound signals
16.1 is acquired, for example, in accordance with the auscultatory-sound-
sensing process 700,
or as an associated segment k of a previously acquired and recorded breath-
held sampled
auscultatory sound data Sm[io[k]: ii[k] for the mth auscultatory sound sensor
12. With data
.. recorded at a sampling frequency Fs of 24 kHz, and for portions of the
spectrum of the breath-
held auscultatory sound signals 16.1 of interest related to coronary artery
disease limited to a
few hundred Hertz ¨ i.e. without significant acoustic energy above 500 Hz --
the sampling rate
may be reduced to 2 kHz. Accordingly, in step (2206), the breath-held
auscultatory sound
signal 16.1 is filtered by a fourth order Type II Chebyshev filter low-pass
filter having a cut-
off frequency of 500 Hz to avoid aliasing, and then, in step (2208), decimated
to a 2 kHz sampling
rate using a phase invariant method that also involves low-pass filtering, so
as to generate
corresponding filtered-decimated breath-held sampled auscultatory sound signal
64.
The breath-held auscultatory sound signal 16.1 in some cases can include very
low
frequency ¨ for example, around 10 Hz -- vibrations that are believed to be
associated with
movements of the entire auscultatory sound sensor 12 stimulated by chest
motion. Considering
the sensor housing as an inertial mass under a tangential component of
gravitational force attached
to elastic surface, it is possible to initiate sensor vibration by small
surface displacements. Such
vibrations can be amplified by resonance characteristics of the tissue-sensor
interface. Depending
on the Q-factor of tissue-sensor system, vibrations may decay very slowly,
extending well into
diastolic interval of heart beat, contaminating the signal of interest with
relatively large amplitude
unwanted interference. The net effect of such interference is an unstable
signal baseline and
distortion of the actual underlying heart sounds. Potential sources of noise
relevant to digitized
acquisition of acoustic signals include: electric circuit thermal noise,
quantization noise from the
A/D converter, electro-magnetic interference, power line 60 Hz interference
and acoustic noises
relevant to human physiology and the environment where recording is done
(ambient noise).
Generally thermal noise power and AID converter quantization noise are very
low for the
bandwidth of interest and may be significant only for the signals with
amplitude in microvolt
region. Furthermore, recording artifacts may significantly reduce visibility
of the signal of interest
since these artifacts may have relatively high amplitude and may overlap in
spectral content. These
artifacts are due to uncontrolled patient movements, signals related to
respiration, and sensor
-27-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
vibrations produced by the associated oscillating mass of the auscultatory
sound sensor 12
coupled to the elastic skin tissue surface (cardio seismographic waves). The
latter type of artifact
may be caused by the inertial mass of the sensor housing and can be relatively
high in amplitude
due to resonance properties of the sensor-tissue interface. Although the
frequency of such
vibrations is relatively low (around 10 Hz), the associated relatively high
amplitude thereof can
result in an unstable signal baseline, which complicates the detection of
target signals.
However cardiac activity may also produce low frequency signals ¨ for example,
as a result
of contraction of heart muscle, or as a result of valvular sounds --that may
have valuable diagnostic
information. In some situations, the spectrum of the artifacts may overlap
with the acoustic
spectrum of cardiac signals such as myocardium vibrations. Therefore, it can
be beneficial to
reduce baseline instability so as to provide for recording primarily acoustic
signals originating
from the cardiac cycle.
In accordance with one set of embodiments, these very low frequency artifacts
may be
rejected by using additional signal filtering to suppress the associated
characteristic vibration
frequencies, for example, using a software-implement high-pass filter 66
having a 3 dB cut-off
frequency above 10 Hz, for example, as provided for by a Savitzky-Golay-based
high-pass filter
66', wherein, in step (2210), the filtered-decimated breath-held sampled
auscultatory sound
signal 66 is smoothed by a Savitzky-Golay (SG) smoothing filter 68 to generate
a smoothed
breath-held sampled auscultatory sound signal 70, the latter of which, in step
(2212), is
subtracted from the filtered-decimated breath-held sampled auscultatory sound
signal 64 to
then generate the corresponding resulting high-pass-filtered breath-held
sampled auscultatory
sound signal 72 having a relatively-higher signal-to-noise ratio (SNR), but
without significant
distortion of the original filtered-decimated breath-held sampled auscultatory
sound signal
64.
The digital Savitzky-Golay smoothing filter 68 is useful for stabilizing
baseline
wandering (for example, as may be exhibited in ECG signals) and provides for
removing the low-
frequency signal components without causing significant ringing artifacts. The
Savitzky-Golay
smoothing filter 68 employs a least squares approximation of a windowed signal
using a
polynomial function. The associated parameters of the Savitzky-Golay smoothing
filter 68
.. include the window size M in samples that defines the associated cut-off
frequency, and the
polynomial degree N used for the approximation. The associated roll-off range
is fairly wide and
the cut-off frequency is somewhat arbitrary. For example, for the Savitzky-
Golay smoothing
filter 68 used in step (2210), the associated window size M ¨ expressed in
terms of window time
duration tw ¨ is in the range of 8 milliseconds to 100 milliseconds, with N=3.
For example, a
window time duration tw = 8 milliseconds provides a cut-off frequency of
approximately 100
-28-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Hz, and a window time duration tw = 25 milliseconds, provides for passing
signal frequencies
above 40 Hz through the Savitzky-Golay-based high-pass filter 66'.
The Savitzky-Golay smoothing filter 68 is defined by a least-squares fit of
windowed
original samples, with an Nth degree polynomial,
y(n) =la knk (6)
k=0
so as to minimize the associated error function, E:
m N \ 2
E =knk x[n] (7)
n=-111 \k=0
wherein the total window width is 2M+1 samples. The associated short-time
window sliding
through entire time series fits the data with a smooth curve. The frequency
response of the
Savitzky-Golay smoothing filter 68 depends strongly on the window size M and
polynomial
order N. The normalized effective cut-off frequency of the Savitzky-Golay
smoothing filter 68
is empirically given as follows, wherein fc = Ws/7t, for which (psis the
radian sampling frequency:
N + 1
(8)
fc = 3.2M ¨ 4.6
Following the high-pass filter 66, 66' of steps (2210) and (2212), from step
(2214), the
auscultatory sound signal acquisition and filtering process 2200 is repeated
beginning with
step (2202) for each of the auscultatory sound sensors 12, after which, from
step (2216), the
resulting blocks of high-pass-filtered breath-held sampled auscultatory sound
signals 72 -- for
each of the auscultatory sound sensors 12-- are returned to step (2104).
Then, also from step (2104), referring to FIG. 22b, a corresponding segment of
a
concurrent electrograhic signal 37 is acquired and preprocessed by an
associated electrographic
signal acquisition and filtering process 2200', wherein, in step (2204'), a
block of
electrographic data 74 of the corresponding electrographic signal 37 from the
ECG sensor 34,
34' ¨ in correspondence with the blocks of high-pass-filtered breath-held
sampled auscultatory
sound signals 72 returned by the above-described auscultatory sound signal
acquisition and
filtering process 2200 ¨ is acquired, for example, in accordance with the
above-described data
acquisition process 800, or as an associated segment k of previously acquired
and recorded
electrographic data 74. Then, in step (2206'), and as explained more fully
herein below, the
electrographic data 74 is filtered by a fourth order Type II Chebyshev filter
low-pass filter
having a cut-off frequency of 40 Hz, and then, in step (2208'), is decimated
by a factor often, so
as to generate corresponding filtered-decimated electrographic signal 76,
which, in step (2216'),
is returned to step (2104).
-29-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring again to FIG. 21, in step (2106), the high-pass-filtered breath-held
sampled
auscultatory sound signals 72, or alternatively, the breath-held auscultatory
sound signals
16.1, are segmented to identify the starting and ending points of each heart
cycle, and to identify
the starting and ending points of each associated diastole region or phase,
thereof
In accordance with a first aspect, this may be accomplished using the breath-
held
auscultatory sound signals 16.1 -- or the corresponding associated high-pass-
filtered breath-
held sampled auscultatory sound signals 72 ¨ alone, without relying upon the
associated
electrograhic signal 37 from the ECG sensor 34, 34', or upon the corresponding
associated
filtered-decimated electrographic signal 76, for example, in accordance with
the following
to portions of the disclosure and drawings of U.S. Patent No. 9,364,184:
Abstract, FIGS. 1-50, Col.
1, Line 1 through Col. 3, line 59 (indicated), Col. 5, line 1 through Col. 34,
line 55 (indicated), and
the claims, which are incorporated herein by reference.
However, in accordance with a second aspect, the electrographic signal 37 from
the ECG
sensor 34, 34', and particularly, the corresponding associated filtered-
decimated electrographic
signal 76 responsive thereto, provides an effective basis for segmenting the
breath-held
auscultatory sound signals 16.1, 72 by heart cycle, after which the high-pass-
filtered breath-
held sampled auscultatory sound signal 72 may then be used to locate the
associated dominant
Si and S2 heart sounds that provide for locating the associated heart phases
of systole and diastole,
data from the latter of which provides for detecting coronary artery disease
responsive to
information in the breath-held auscultatory sound signals 16.1, 72.
Referring also to FIG. 23, in accordance with the second aspect, a heart-cycle
segmentation and heart-phase identification process 2300 is called from step
(2106) of the
auscultatory sound signal preprocessing and screening process 2100 to locate
the heart cycles
responsive to the filtered-decimated electrographic signal 76, to then segment
the high-pass-
filtered breath-held sampled auscultatory sound signal 72 by heart cycle
responsive thereto,
and to then identify the region of diastole within each heart cycle (and
implicitly, to therefor also
identify the remaining region of systole) from an analysis of the high-pass-
filtered breath-held
sampled auscultatory sound signal 72 alone.
The normal human cardiac cycle consists of four major intervals associated
with different
phases of heart dynamics that generate associated audible sounds: 1) the first
sound (Si) is
produced by closing of mitral and tricuspid valves at the beginning of heart
contraction, 2) during
the following systolic interval, the heart contracts and pushes blood from
ventricle to the rest of
the body, 3) the second sound (S2) is produced by the closing of aortic and
pulmonary valves and
4) during the following diastolic interval, the heart is relaxed and the
ventricles are filled with
oxygenated blood.
-30-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring to FIGS. 24 and 25, respectively illustrating a breath-held
auscultatory sound
signal 16.1, 72 and a corresponding electrographic signal 37, 76 associated
with six heartbeats,
each QRS complex 78 illustrated in FIG. 25 is generated by an associated
ventricular
depolarization that precedes cardiac contraction. The Si heart sound resulting
from the closing of
mitral and tricuspid valves is observed immediately after R-peak , and the S2
heart sound resulting
from the closing of aortic and pulmonary valves is observed at the end of T-
wave of the ECG
cycle. This relative timing of the heart sounds Si, S2 and the QRS complex 78
of the associated
electrographic signal 37, 76 provides for using the electrographic signal 37
to locate the
beginning and end of each heart cycle without relying upon the breath-held
auscultatory sound
signal 16.1, 72 to do so. For each heartbeat, the Si heart sound -- marking
the start of systole ¨
follows shortly after the R-peak, and the S2 heart sound ¨ marking the end of
systole and the
beginning of diastole ¨ follows thereafter, with diastole continuing until the
next R-peak.
Although the QRS complex 78 is the most prominent feature, the electrographic
signal
37, 76 may be distorted by low frequency baseline wandering, motion artefacts
and power line
interference. To stabilize the baseline, a Savitzky-Golay-based high-pass
filter 66' ¨ similar to
that used in steps (2210/2212) when filtering the breath-held auscultatory
sound signal 16.1 --
may be used to cancel low-frequency drift, for example, prior to the
subsequent low-pass filtering,
in step (2206'), by the fourth order Type II Chebyshev filter low-pass filter,
for example,
having a 40 Hz cut-off frequency, and/or prior to decimation of the sampling
by factor of 10 in
step (2208'), which together provide for both reducing high frequency noise
and emphasizing
QRS complexes 78.
More particularly, referring again to FIG. 23, and also referring to FIG. 26,
the heart-
cycle segmentation and heart-phase identification process 2300 commences in
step (2302) by
calling an electrographic segmentation process 2600 that provides for
identifying the locations
of the R-peaks. More particularly, in step (2602), a block of electrographic
data x[] is received,
and, in step (2604), normalized so as to have a maximum absolute value of
unity. Then, referring
also to FIGS. 27 and 28, from step (2606), beginning with step (2702) of an
associated first
envelope generation process 2700, the block of filtered-normalized
electrographic data x[] is
used to generate an associated electrographic envelope waveform 80, Fs[] that
emphasizes the
R-peaks of the filtered-normalized electrographic data x[], wherein, for each
value of index k
-- set in step (2702) -- the corresponding value of the electrographic
envelope waveform 80,
Fs[k] is set in step (2704) responsive to a sum of values within a sliding
window containing a
subset of Nw points, as follows:
1 Nw
Fs (t(k))=--(x(k +))4 ln(X(k +))4
(9)
AT,
-31-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Equation (9) is similar to a Shannon energy function, but with the associated
discrete signal
values raised to the fourth power ¨ rather than a second power -- to emphasize
difference between
R-peaks 80' and baseline noise. The value of the electrographic envelope
waveform 80, Fs[] is
calculated for each of the NPTS values of index k until, in step (2706), all
points have been
calculated, after which, in step (2708), the electrographic envelope waveform
80, Fs [] is returned
to step (2606) of the electrographic segmentation process 2600.
Returning to FIG. 26, in step (2608), in accordance with a first aspect, the
peaks of the
electrographic envelope waveform 80, Fs[] are located, for example, by finding
indices k for
which the associated value of the electrographic envelope waveform 80, Fs [k]
is a local
maximum exceeding a fixed, predetermined threshold. For example, FIG. 28
illustrates the
electrographic envelope waveform 80, Fs[] and associated R-peaks 80' thereof,
for a portion of
a 10-second recording of a filtered-decimated electrographic signal 76.
The electrographic segmentation process 2600 for finding R-peaks is quite
simple and
stable when signal-to-noise ratio (SNR) of recording is sufficiently high.
Otherwise, when the
electrographic data 74 is excessively noisy, additional signal processing such
as discrete wavelet
decomposition may be used to further enhance R-peaks and facilitate QRS
detection. Occasional
relatively high amplitude transients due to patient movements or ambient
interference may produce
false peaks unrelated to QRS complex, and therefore complicate segmentation.
Referring to FIG. 29, in step (2610), the R-peaks 80' of the electrographic
envelope
waveform 80, Fs[] are then validated by a peak validation process 2900, both
with respect to
temporal location ¨ i.e. relative spacing -- and magnitude ¨ i.e. deviation
from a median value, --
so as to verify that the detected R-peaks 80' correspond to R-peaks 80' rather
than noise. More
particularly, in step (2902), for each of the detected R-peaks 80', in step
(2904), if the difference
in temporal locations of each pair of R-peaks 80' is less than a time
threshold Tmllv, or if, in step
(2906), the difference between the magnitude P(tpEAK(i)) of each R-peak 80'and
the median
value of the magnitudes of all R-peaks 80' is greater than a magnitude
threshold VmAx, then, in
step (2908), a status indicator associated with the R-peak 80' being tested is
set to IGNORE, in
order to prevent the associated R-peak 80' from being used for subsequent
segmentation of the
breath-held auscultatory sound signal 16.1, 72. Otherwise, from step (2910),
the peak
validation process 2900 terminates in step (2912) and returns to step (2612)
of the
electrographic segmentation process 2600, which, in turn, returns the peak
locations tpEAK1] to
step (2302) of the heart-cycle segmentation and heart-phase identification
process 2300,
wherein valid R-peaks 80' satisfy both of the following conditions:
(10)
and
-32-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
(t pEAK (i)) median
(13)17mAx (11)
wherein tpEAK(i) is the time of the ith R-peak 80' and P(tpEAK(i)) is the
corresponding magnitude
of the R-peak 80'.
Referring again to FIG. 26, alternatively, in accordance with a second aspect,
the R-peaks
80' of the electrographic envelope waveform 80, Fs[] are located in step
(2608) by an associated
R-peak detection process 5400 that provides for discriminating valid R-peaks
80' from noise or
other anomalies. Referring to FIGS. 54 and 55, the R-peak detection process
5400 determines
the peak values and associated samples times of the electrographic envelope
waveform 80, Fs[]
within a plurality of samples window 81, each of window width tw, and each
offset from one
another with an associated hop period hwy.. More particularly, the R-peak
detection process
5400 commences with step (5402) by setting a window start time tmiN to point
to the beginning
of the electrographic envelope waveform 80, Fs [], and by initializing a
window counter Nw to
a value of 1. Then, in step (5404), the maximum value of the electrographic
envelope waveform
80, Fs[] is determined within the sample window 81 extending between sample
times twirl and
tiwiN + tw, and stored in element PwINw] of window-peak array Pw[], wherein,
for example, the
window width tw is sufficiently wide to span a single heart cycle, for
example, with tw equal to
about 1.5 seconds. Then, in step (5406), the corresponding sample time at
which the associated
peak value occurred is stored as a corresponding element tpEAK wiNwl of an
associated window-
peak-time array tpEAx_w[]. Then, in step (5408), the window start time tmiN is
incremented by
the hop size hwy., and, in step (5410), if the prospective end twirl + tw of
the prospective next
sample window 81 is before the end tEND of the electrographic envelope
waveform 80, Fs[],
then, in step (5412), if the most-recently detected R-peak 80' is unique,
then, in step (5414), the
window counter Nw is incremented. Then, or otherwise directly from step
(5412), the R-peak
detection process 5400 repeats beginning with step (5404). For example, in one
set of
embodiments, the hop size hwp is set to half the shortest heart cycle, but no
less than 0.3 second,
or a corresponding fraction of the window width tw, although it should be
understood that the
particular values of the window width tw and hop size tDop are not limiting.
Although depending
upon the window width tw and hop size hwy., different sample windows 81 may
potentially span
the same R-peak 80', step (5412) provides for ensuring that each of the R-
peaks 80' in the
window-peak array Pw[] are unique, and that the associated sample times in the
window-peak
array Pwll are in monotonically increasing order.
Then, from step (5410) following R-peak detection within the last sample
window 81, in
step (5416), a minimum peak-threshold PMINLIM is set equal to about 60 percent
of the median
-33-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
amplitude of the R-peaks 80' within the window-peak array Pw[], and, in step
(5418), a
maximum peak-threshold PMAXLIM is set equal to twice the median amplitude of
the R-peaks
80' within the window-peak array Pw[]. Then, in steps (5420) through (5430), R-
peaks 80'
that are outside those limits are ignored, so as to provide for ignoring noise
or other spurious signal
components. More particularly, beginning in step (5420), a second window
counter iw -- that
provides pointing to the above-detected unique R-peaks 80' -- is initialized
to a value of /, and a
peak counter NPEAK -- that provides for counting the number of R-peak 80'
within the above-
determined amplitude thresholds -- is initialized to a value of 0. Then, in
step (5422), if the value
of the second window counter iw is less than the number of windows Nw
determined above in
steps (5402) through (5414), then, in step (5424), if the magnitude of the
currently-pointed-to R-
peaks 80', i.e. Pw[iw], is greater than the minimum peak-threshold PMINLIM and
less than the
maximum peak-threshold PMAXLIM - indicating a potentially valid R-peak 80' ¨
then, in step
(5226), the peak counter NPEAK is incremented, and the corresponding magnitude
and time of the
associated R-peak 80', i.e. Pw[iw] and tPEAK OW], are stored as respective
values in in a
corresponding peak array PINpEAK] and peak-time array tPEAKINPEAK]
(alternatively, the
window-peak array Pwl] and the window-peak-time array tpEAK_w[] could be
reused in place
for storing these values). For example, referring again to FIG. 55, step
(5424) provides for
ignoring occurrences of noise and a noise or spurious signal -- the magnitudes
of each of which
are less than the minimum peak-threshold PMINLIM, -- and provides for ignoring
the example of
a false R-peak 80' that resulted from electro-static discharge (ESD), and
which exceeded the
maximum peak-threshold PMAXLIM. Then, in step (5430), the second window
counter iw is
incremented to point to the next entry of the window-peak-time array tPEAK
WI], and the R-peak
detection process 5400 repeats with step (5422). If, from step (5422), all
entries of the have been
processed, then, in step (5432), the process returns control to step (2608) of
the electrographic
segmentation process 2600.
Referring again to FIG. 26, following step (2608) and completion of the
associated second
aspect R-peak detection process 5400, a second aspect of a peak validation
process 5600
provides for validating the R-peaks 80' detected by the second aspect R-peak
detection process
5400. More particularly, referring also to FIG. 56, in steps (5602) through
(5608), the associated
heart-cycle period DT [ipEAK] between each pair of temporally-adjacent R-peaks
80' is calculated
in step (5604), indexed by a second peak counter 'PEAK that is initialized to
a value of 1 in step
(5602) and incremented in step (5608) so long as, in step (5606), the value
thereof is less then
NpEAK-1 that had been determined in steps (5424) and (5426) of the second
aspect R-peak
detection process 5400. Then, in step (5610), a minimum heart-cycle-period-
threshold
DTmiNum is set to 0.3 seconds (corresponding to a heart rate of 200 BPM).
Then, in step (5612),
-34-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
a corresponding heart-rate HR[] array is calculated from the heart-cycle
period DT[] array,
wherein each element of the former is given by the inverse of the
corresponding element of the
latter, after which the median heart-rate HRmEDIAN is determined a the median
of the values of
the elements of the heart-rate array HR[]. Then, in step (5618) a status
STATUS [] array to
initially indicate that each R-peak 80' associated with the heart-rate array
HR[] is "OK", and
the second peak counter 'PEAK that is initialized to a value of 1. Then, if,
in step (5618), the
heart-cycle period DT[ipEAK] is not greater than the minimum heart-cycle-
period-threshold
DTmiNum, or, in following step (5620), the heart-rate HR[] is not both greater
than 60 percent
of the median heart-rate HRMEDIAN AND less than 140 percent of the median
heart-rate
.. HRmEDIAN, then, in step (5622) the STATUS IipEAK] of the corresponding R-
peak 80' is set to
"IGNORE". Then, or otherwise from steps (5618) and (5620), if, in step (5624),
all R-peaks 80'
have not been processed, then, in step (5626), the second peak counter 'PEAK
is incremented, and
the second aspect peak validation process 5600 repeats with step (5618).
Otherwise, from step
(5628), the process returns control to step (2610) of the electrographic
segmentation process
2600.
Referring again to FIG. 23, in step (2304), for each auscultatory sound sensor
12, in
step (2306), the associated high-pass-filtered breath-held sampled
auscultatory sound signal
72 thereof is segmented based upon the locations of the associated R-peaks 80'
in the
corresponding filtered-decimated electrographic signal 76. For example, FIG.
30 illustrates a
correspondence between the breath-held auscultatory sound signal 16.1, 72 and
the
corresponding electrographic envelope waveform 80, Fs[], wherein the locations
of the R-peaks
80' in the latter are used to segment the former by heart cycle. Furthermore,
FIG. 31 illustrates a
stack of segments of the high-pass-filtered breath-held sampled auscultatory
sound signal 72,
each segment corresponding to a different corresponding heart cycle 82, 82.1,
82.2, 82.3, 82.4,
82.5, 82.6, 82.7, 82.8, 82.9 -- each resulting from a single corresponding
heart beat -- within the
corresponding continuous high-pass-filtered breath-held sampled auscultatory
sound signal
72 illustrated in FIG. 30.
The exact location of the first Si and second S2 heart sounds produced by the
respective
closing of atrioventricular and semilunar valves is somewhat ambiguous, and
can be particularly
difficult to locate in situations when the associated breath-held auscultatory
sound signals 16.1
are recorded in an environment with relatively high level ambient noise, or if
there are associated
heart murmurs resulting from turbulent blood flow. However, even under
relatively-poor
recording conditions, the first Si and second S2 heart sounds of the cardiac
cycle remain the
most prominent acoustic features.
-35-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring again to FIG. 23, following segmentation of the high-pass-filtered
breath-held
sampled auscultatory sound signal 72 into corresponding resulting associated
heart-cycle
segments in step (2306) -- each comprising one heart cycle 82, resulting from
a single
corresponding heart beat, ¨ beginning with step (2308), for each of the heart
cycles 82 located in
step (2306), in step (2310) a Shannon energy envelope is generated from the
corresponding
associated portion of the high-pass-filtered breath-held sampled auscultatory
sound signal 72
in accordance with a corresponding second envelope generation process 3200,
which is similar
to the above-described first envelope generation process 2700 except for the
associated envelope
function. More particularly, referring to FIG. 32, beginning with step (3202)
of the second
envelope generation process 3200, for the lith of NSAMPLES samples of a block
of high-pass-
filtered breath-held sampled auscultatory sound data 72, s[] of the
corresponding associated
heart cycles 82, a corresponding value of an associated acoustic envelope
waveform 84, Es 1k]
is generated in step (3204), responsive to a sum of values within a short-time
sliding window ¨
with different windows overlapping one another -- containing a subset of Nw
points, as follows in
accordance with a canonical Shannon energy function Es[k] that provides a
measure of the
energy of the underlying high-pass-filtered breath-held sampled auscultatory
sound signal 72,
s[]:
1 NH'
Es (t(k))= (s(k + i))2 in (S (k i))2
(12)
The value of the acoustic envelope waveform 84, Es 1k] is calculated for each
of the NSAN1PLES
values of index k until, in step (3206), all points have been calculated,
after which, in step (3208),
the acoustic envelope waveform 84, Es[k] is returned to step (2310) of the
heart-cycle
segmentation and heart-phase identification process 2300.
For envelope generation by each of the first 2700 and second 3200 envelope
generation
processes illustrated in FIGS. 27 and 32, the associated signal x[], s[], from
which the
corresponding envelope Fs [], Es I] is generated, is zero-padded at the
beginning and at the end with
(Nw ¨ 1)/2 zeros, assuming Nw is an odd integer, wherein the first data point
in the padded signal
x[], s[] would then begin at index 1+(Nw ¨ 1)/2. After that, sliding window
with size Nw and
stride = 1 is used to compute windowed values of the associated envelope
function, so as to
provide for generating a time-series of the same length as the associated
signal x[], s[], without a
time shift relative thereto.
Referring again to FIG. 23, in step (2312), the acoustic envelope waveform 84,
Es1k]
generated in step (2310) is smoothed to reduce local fluctuations therein, for
example using either
a moving average filter, or a Savitzky-Golay smoothing filter 68, for example,
with an associated
window size of tw = 8.3 milliseconds.
-36-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
FIG. 33 illustrates an example of an acoustic envelope waveform 84, Es[] in
correspondence with a rectified version 86 (i.e. containing an absolute value)
of the associated
high-pass-filtered breath-held sampled auscultatory sound data 72, s[] from
which the
acoustic envelope waveform 84, Es[k] was generated, wherein the respective
envelope peaks
88Si, 8.-62
a associated with the corresponding Si and S2 heart sounds can be
readily identified in
the acoustic envelope waveform 84, Es[].
Referring again to FIG. 23, in step (2314), the locations of the envelope
peaks 88s1, 88s2
associated with the corresponding Si and S2 heart sounds are identified using
an adaptive
threshold method that iteratively adjusts an associated threshold value down
from a maximum
value until the two most prominent envelope peaks 88s1, 88s2 emerge within the
associated heart
cycle 82, above the a particular threshold limit. Referring also to FIG. 34,
the final position of
envelope peaks 88s1, 88s2 associated with the corresponding Si and S2 heart
sounds is found as
the apex of a local quadratic model 90.1, 90.2 of the acoustic envelope
waveform 84, Es[], as
described more fully hereinbelow. Adaptive thresholding provides for
accommodating substantial
variation in the relative magnitude of the envelope peaks 88s1, 88s2 that
might occur either from
one heart beat to another, from one patient to another, or from one recording
site to another.
Then, in step (2316), the locations of the envelope peaks 88s1, 88s2
associated with the
corresponding Si and S2 heart sounds are validated using a normalized acoustic
envelope
waveform 84, Es[], i.e. normalized to a range of 0 and /, and the associated
local quadratic
models 90.1, 90.2 thereof, in accordance with a minimum-time-spacing criteria
used to remove or
ignore spurious transient peaks unrelated to heart sounds, similar to equation
10 above that is
associated with step (2904) of the above-described peak validation process
2900 used to validate
the electrographic envelope waveform 80, Fs[1.
Then, in step (2318), the acoustic envelope waveform 84, Es[] is searched
relative to the
associated indices ksiyEAK, liS2_PEAK -- respectively associated with the
corresponding respective
envelope peaks 88s1, 88S2 -- to find adjacent data points therein, -- i.e.
having associated indices
-- for which the corresponding values of the acoustic envelope waveform 84,
Es(ksi_), Es(ksi+), Es(lis2_), Es(k52+) are each about 5 percent down, i.e. 95
percent of, the
corresponding values Es(lisi_pEAK), Es(ksz_pEAK) of the associated envelope
peaks 88", 8852.
Then, in step (2320), respective local quadratic models ES1(k), 90.1' and
ES2(k), 90.2'
are fitted - for example, by least-squares approximation -- to the three
points associated with each
of the corresponding respective envelope peaks 88", 88s2 as follows:
ES1(k) =Quadratic Fit ( Iksi-, Es(ksi-)1, Iksi_pEAK, Es(ksi_pEAK)1, {ksi+,
Es(ksi+)} ) (13a)
ES2(k) =Quadratic Fit ( Iks2-, Es(ks2-)1, kS2_PEAK, Es(ks2_pEAK)1, {ks2+,
Es(ks2+)} ) (13b)
-37-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Then, referring again to FIG. 34, in step (2322), the respective pairs of
roots (lisi_sTART,
lisi_END) and (kS2_START, liS2_END) of the local quadratic models ES1(k),
90.1' and ES2(k), 90.2'
are solved, such that ES1(liSl_START) = ES1(liSl_END) =0 and ES2(kS2_START) =
ES2(liS2_END) =0,
wherein kSl_START < liSl_PEAK< kSl_END and liS2_START < liS2_PEAK< kS2_END.
Referring to FIGS. 70 and 71, in addition to the Si and S2 sounds, S3, S4 or
S5 sounds
may be present in the heart cycles 82 for some test-subjects 22. The purpose
of identifying Si,
S2, S3, S4, and S5 regions is to help extract or derive useful features (such
as Indicators that
correlate highly with the existence of coronary artery disease (CAD)) from
heart sounds. In turn,
these features can be used in direct detection and machine learning for
discriminating CAD
to patients from non-CAD patients. The prerequisite of many feature
extractions is to correctly
identify the Si and S2 sounds.
The S3, S4, and S5 sounds do not appear for every patient. But each may
indicate one or
more cardiac conditions, such as, CAD, Aortic Insufficiency, Aortic Stenosis,
Luminal
Irregularities, and Mitral Regurgitation. The regions within diastole during
which the S3 and S5
sounds may occur are located relative to the diastasis region of diastole,
which is a relative rest
period of the heart during mid-to-late diastole, during which period the heart
motion is minimal.
The region during which the S4 sound may occur is located relative to the R-
peak 80' at the end
of the heart cycle 82 and the beginning of the next heart cycle 82.
The starting point of the diastasis region is determined using what is
referred to as the
.. Weissler or Stuber formula for the period of delay DT -- in milliseconds --
from an R-peak 80' to
the starting point of the diastasis region, given by the following:
DTms = (ATõ ins ¨350) = 0.3 +350
wherein ATR-R is the time interval in milliseconds between R-peaks 80'. In one
set of
embodiments, this is approximately the ending point for the region most likely
to include S3, i.e.
the S3 region. Accordingly, the starting point for the S3 region is determined
by advancing relative
to the starting point of diastasis ¨ or, equivalently, the end point of the S3
region -- by a time
interval ATs3. For example, in this set of embodiments, the time interval
commences at about 100
milliseconds prior to the starting point of diastasis and ends at the starting
point of diastasis. In
another set of embodiments, the time interval of the S3 region is taken to
extend from about 60
milliseconds prior, to 60 milliseconds after, the starting point of diastasis.
The S3 swing is
calculated by subdividing the S3 region of the associated breath-held
auscultatory sound signal
16.1, for example, band-pass-filtered breath-held sampled auscultatory sound
data s[] having
a pass-band in the range of 20, 25, or 30 Hz to 40 or 50 Hzõ into a series of
¨ i.e. one or more --
time intervals, and calculating or determining one or more of the difference
between the maximum
-38-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
and minimum amplitude values -- i.e. maximum amplitude ¨ minimum amplitude, --
the minimum
amplitude, and the maximum amplitude, for each interval in the S3 region.
In addition to the above time-domain analysis, the associated breath-held
auscultatory
sound signal 16.1 is also analyzed in the frequency domain using a Short-Time
Fourier Transform
.. (STFT), for example, in one set of embodiments, having a 1 Hz frequency
resolution and a 0.0025
second time resolution -- but generally, using frequency and time resolutions
that may be
empirically adjusted to improve detection and discrimination ¨ in cooperation
with an associate
windowing method, for example, using Chebyshev windowing on a sliding window
that is moved
along the S3 region of the breath-held auscultatory sound signal 16.1. The
frequency-domain
features for each heart beat are generated by calculating the mean and median
of each of the
windows of the STFT.
The S3 swing values and frequency-domain features are saved for further
calculations
and/or for use as an input to one or more of the below-described
classification processes. In view
of there being relatively few patients that clearly exhibit an S3 sound, an
unsupervised clustering
.. method is applied on all the generated features to classify heart beats
into two clusters that
respectively include "with S3" and "without S3" heart beats. S3 is analyzed on
a beat-by-beat
basis. Given the S3 is not an intermittent signal, one strategy is to analyze
all heart beats from a
given patient, and if S3 appears in more than one third of all the heart
beats, that patient would be
identified as having S3. There are some patients who exhibit a low-ejection
fraction ratio (e.g. an
ejection fraction (E. F.) lower than 35%) that are highly likely to have S3.
However some of these
patients have CAD, and some have other types of cardiac arrhythmia. Once the
unsupervised
clustering is applied followed by voting among all beats belonging to one
patient, if those patients
are found in the cluster "with S3", this would provide for validating that the
clustering matches
reality.
The S4 region is located in a final portion of diastole, starting at the P
wave on the ECG
signal. However, in anticipation of a prospective absence of the P wave in
some ECG recordings,
an approximate starting point for the S4 region may be used, for example, a
time interval of ATs4,
for example, from /0 to 20 percent of the period of the heart cycle 82, for
example, about 100 to
200 milliseconds in a / second duration heart cycle 82, in advance of the R-
peak 80' at the end
of the heart cycle 82, or equivalently, in advance of the beginning of the Si
sound of the next
heart cycle 82. The S4 region of the associated breath-held auscultatory sound
signal 16.1, e.g.
the band-pass-filtered breath-held sampled auscultatory sound data s[] having
a pass-band in
the range of 20, 25, or 30 Hz to 40 or 50 Hz, is subdivided into a series of
intervals and the
associated S4 swing within each interval is calculated as the absolute value
of the difference
between maximum and minimum amplitude magnitudes of the raw or high-pass-
filtered data
-39-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
within that interval in the S4 region. The S4 swing is calculated separately
for audible (above 20
Hz) and inaudible (below 20 Hz) frequency ranges, for which the configurations
of the associated
signal filters are specific to the particular frequency range. Generally, the
minimum and maximum
values of the signal will depend upon the associated frequency range of the
associated signal, and
the type of filter used to generate the filtered signal.
The S2 swing is also similarly calculated over the associated S2 region, in
addition to
calculating the S4 swing as described hereinabove. The ratio of the S4 swing
to S2 swing provides
a measure of the likelihood that a patient exhibits an S4 sound, with that
likelihood increasing with
increasing value of the S4-to-S2 swing ratio. For example, FIG. 71 illustrates
a heartbeat for
which the S4-to-S2 swing ratio has a value of 0.49 for the illustrated channel
1 of the band-pass-
filtered breath-held sampled auscultatory sound data s[].
The S2 and S4 swing values, and/or the S4-to-S2 swing ratio, are saved for
further
calculations and/or for use as an input to one or more of the below-described
classification
processes. In accordance with one approach, the mean value of the S4-to-S2
swing ratio is
calculated for an entire population of patients, beat by beat, and then the
median of S4-to-S2 swing
ratio is taken across all beats of each patient. For those patients for which
the S4-to-S2 swing ratio
is greater than the associated mean value of the S4-to-S2 swing ratio are
identified as having an
S4 sound for purposes of training the associated below-described classifier,
from which an
associated threshold value is determined that ¨ in combination with other
factors -- provides for
.. discriminating patients with CAD from patients without CAD, after which the
threshold value of
the S4-to-S2 swing ratio is then applied to the associated test set.
The S5 region is identified as the end of the S3 region to the start of the S4
region.
Accordingly, the starting point is determined using the above-described
Weissler or Stuber
formula. As mentioned, this is approximately the ending point for the S3
region. The ending point
of the S5 region is located at the beginning of a time interval of ATS4, for
example, about 100
milliseconds, in advance of the R-peak 80' at the end of the heart cycle 82,
or equivalently, in
advance of the beginning of the Si sound of the next heart cycle 82. The S5
swing is calculated
by subdividing the S5 region of the associated breath-held auscultatory sound
signal 16.1, e.g.
the band-pass-filtered breath-held sampled auscultatory sound data s[] having
a pass-band in
the range of 20, 25, or 30 Hz to 40 or 50 Hz, into a series of intervals and
calculating the absolute
value of maximum amplitude ¨ minimum amplitude for each interval in the S5
region. The S5
swing values may be saved for further calculations and/or for use as an input
to one or more of the
below-described classification processes.
If, in step (2324), all heart cycles 82 in the high-pass-filtered breath-held
sampled
auscultatory sound signal 72 have not been processed, then the heart-cycle
segmentation and
-40-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
heart-phase identification process 2300 is repeated beginning with step (2308)
for the next heart
cycle 82. Otherwise, from step (2326), if all auscultatory sound sensors 12
have not been
processed, then the heart-cycle segmentation and heart-phase identification
process 2300 is
repeated beginning with step (2304) for the next auscultatory sound sensor 12.
Otherwise, from
step (2326), in step (2328), the heart-cycle segmentation and heart-phase
identification
process 2300 returns either the mean values ksi, lis2 of the corresponding
root locations
{ksi_sTART, ks2_ENDI associated with the corresponding Si
and S2 heart
sounds, or the corresponding mean values tsi, ts2 of the associated times,
i.e. ft(lisi_sTART),
t(kst_END)}, ft(lis2_sTART), t(lis2_END)}, for each of the heart cycles 82 in
each of the high-pass-
filtered breath-held sampled auscultatory sound signals 72 from each of the
associated
auscultatory sound sensors 12.
Referring to FIG. 35, segmented high-pass-filtered breath-held sampled
auscultatory
sound data 72, s[] from each of the heart cycles 82, 82.1, 82.2, 82.3, 82.4,
82.5, 82.6, 82.7, 82.8,
82.9 may be synchronized with respect to the mean time ts2 associated with the
S2 heart sound
of each heart cycle 82, 82.1, 82.2, 82.3, 82.4, 82.5, 82.6, 82.7, 82.8, 82.9,
as illustrated in FIG.
35, or alternatively, may be synchronized with respect to the mean time tsi
associated with the Si
heart sound of each heart cycle 82, 82.1, 82.2, 82.3, 82.4, 82.5, 82.6, 82.7,
82.8, 82.9, wherein
the region of diastole extends from the time associated with the second root
lis2_END , i.e. t(lis2_END),
associated with the S2 heart sound, to the end of the associated heart cycle
82, 82.1, 82.2, 82.3,
82.4, 82.5, 82.6, 82.7, 82.8, 82.9.
Referring again to FIG. 21, either the breath-held auscultatory sound signal
16.1, or the
corresponding high-pass-filtered breath-held sampled auscultatory sound signal
72, is first
analyzed within each region of diastole for each heart cycle 82 identified in
step (2106/2300), and
for auscultatory sound sensor 12, m to identify any outliers, and to detect,
for selected pairs of
auscultatory sound sensor 12, excessive noise. More particularly, beginning
with step (2107), a
heart-cycle pointer kBEAT is first initialized to a value of 1, after which,
via step (2108), for each
heart cycle 82 and for each auscultatory sound sensor 12, m, in step (2110),
each region of
diastole of either the breath-held auscultatory sound signal 16.1, or the
corresponding high-
pass-filtered breath-held sampled auscultatory sound signal 72, i.e. extending
between
samples isilksEG, kBEATJ and isilksEG, kBEAT+// is checked for outliers, e.g.
random spikes, using
a beat outlier detection process 3600, wherein the heart-cycle pointer kBEAT
points to the
particular heart cycle 82 within the selected breath-held segment ksEG, and
iSilkSEG, kBEATJ
corresponds to the kS2_END of the associated heart cycle 82 at the beginning
of diastole, and
isilksEG, kBEAT-Fd corresponds to the end of diastole of that heart cycle 82,
and the beginning of
the systole for the next heart cycle 82. Referring to FIG. 36, the beat
outlier detection process
-41-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
3600 commences in step (3602) with receipt of the identifier m of the
auscultatory sound sensor
12, the associated sampled auscultatory sound data Sm[], the segment counter
ksEG, and the
heart-cycle pointer kBEAT. Then, in steps (3604) and (3606), a standard-
deviation counter
kSTDDEV is initialized to a value of 1, and an index jmiN is set equal to
is2IksEG, kBEAT], the location
of the beginning of diastole in the sampled auscultatory sound data Sm 11,
respectively. Then,
steps (3608) through (3616) provides for repetitively calculating, in step
(3612), a standard
deviation STD[kSTDDEV] of the sample values SmUmiN : jmAx] in a plurality of
windows of
NWINDOW samples, each window shifted by one sample with respect to the next in
steps (3614) and
(3616) --that increment kSTDDEV and jMIN, respectively, -- resulting in a
standard deviation array
STD[] containing kSTDDEV standard deviation values, wherein, in step (3608),
jmAx = jmiN
NwEvDow -1. For example, in one set of embodiments, NWINDOW is equal to 128.
Then, in step
(3618), the standard deviation array STD[] is rank ordered, and the median
value thereof,
MedianSTD, is used in step (3620) to calculate a standard deviation
compactness metric
STDDEVCM, as follows:
STDDEVCM =Alax(D[1)¨medianStd
medianStd ¨Min(D[1)
(14)
Then, in step (3622), if the standard deviation compactness metric STDDEVCM
exceeds a
threshold, for example, in one set of embodiments, equal to 6, but generally
between 1 and 10, the
particular region of diastole for the particular breath-held segment from the
particular
auscultatory sound sensor 12, m, is flagged as an outlier in step (3624).
Then, or otherwise from
step (3622), in step (3626), the process returns to step (2110) of the
auscultatory sound signal
preprocessing and screening process 2100.
Referring again to FIG. 21, then, in step (2112) of the auscultatory sound
signal
screening process 2100, if an outlier was detected in step (3622) and flagged
in step (3624) of
the beat outlier detection process 3600, then in step (2120), if the end of
the breath-held segment
has not been reached, i.e. if kBEAT < NBEATOSEG), then the auscultatory sound
signal
preprocessing and screening process 2100 repeats beginning with step (2108)
for the next heart
cycle 82.
Otherwise, from step (2112), referring again to FIGS. 17-20, the above-
described noise
detection process 1700 may be called from step (2114) to provide for
determining whether or not
a particular region of diastole for a particular heart cycle 82 of either the
breath-held
auscultatory sound signal 16.1, or the corresponding high-pass-filtered breath-
held sampled
auscultatory sound signal 72, is corrupted by excessive noise, and if so,
provides for flagging
that region of diastole as being excessively noisy so as to be prospectively
excluded from
-42-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
subsequent processing, wherein above references to breath-held auscultatory
sound signal 16.1
in the description of the associated noise detection process 1700 should be
interpreted as referring
to the corresponding region of diastole, i.e. between samples isziksEG, kBEAT]
and isi IksEG,
kBEAT+1] for the kBEATth heart cycle 82 of segment ksEG of either the breath-
held auscultatory
sound signal 16.1, or the corresponding high-pass-filtered breath-held sampled
auscultatory
sound signal 72, and references to the breath-held segment k in the associated
noise detection
process 1700 ¨ which in this case would not be incremented in step (1726),
with kmAx=k in step
(1724), -- should be interpreted as referring to a corresponding particular
heart cycle 82 associated
with the particular region of diastole, wherein the noise detection process
1700 would terminate
with step (1934) of the associated noise-content-evaluation process 1900.
Then, returning to the step (2116) of the auscultatory sound signal screening
process
2100, if a noise threshold was exceeded in step (1930) of the noise-content-
evaluation process
1900, in step (2120), if the end of the breath-held segment has not been
reached, i.e. if kBEAT <
NBEATOSEG), then the process repeats beginning with step (2108) for the next
heart cycle.
Otherwise, from step (2116), the good beat counter GB is incremented in step
(2118) before
continuing with step (2120) and proceeding therefrom as described hereinabove.
Otherwise, from
step (2120) if the end of the breath-held segment has been reached, in step
(2122), if a threshold
number of valid heart cycles has not been recorded, the process repeats with
step (2104) after
incrementing the segment counter ksEG in step (2123). Otherwise, the recording
process ends
with step (2124).
Accordingly, each breath-holding interval B, ksEG of either the breath-held
auscultatory
sound signal 16.1, or the corresponding high-pass-filtered breath-held sampled
auscultatory
sound signal 72 is segmented into individual heart beats 82 (i.e. heart cycles
82, wherein
reference to heart beats 82 is also intended as a short-hand reference to the
associated breath-held
sampled auscultatory sound data S[]) and the diastolic interval D is analyzed
to determine the
associated noise level to provide for quality control of the associated breath-
held sampled
auscultatory sound data S[], so as to provide for signal components thereof
associated with
coronary artery disease (CAD) to be detectable therefrom. Quality control of
the recorded signals
provides for detecting weak signals that may indicate health problems but can
otherwise be
blocked by strong noise or unwanted interference. The present method is
developed for
quantitative control of signal quality and can be deployed in the recording
module 13 for real-
time quality monitoring or can be used at the post recording stage to extract
only low-noise heart
beats 82 that satisfy specific quality condition.
Referring to FIG. 37, a second aspect of an auscultatory sound signal
preprocessing and
.. screening process 3700 -- also referred to as a beat selection algorithm,
as was the first aspect
-43-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
auscultatory sound signal preprocessing and screening process 2100 -- provides
for collecting
heart beats 82 that have diastolic noise level below the specific mean noise
power level
threshold Po. As described hereinabove, the associated auscultatory-sound-
sensing process 700
proceeds through sequential acquisition of heart sound intervals with duration
between 5 and 15
sec (for example, breath-holding intervals B). In step (3702), the sampled
auscultatory sound
data Sm[], the identifier m of the associated auscultatory sound sensor 12,
and the associated
segment counter lisEG are received, and, in step 3704), the corresponding
recorded data block is
passed through the heart-cycle segmentation and heart-phase identification
process 2300 that
identifies the beginning and the end of each heart beat 82 using synchronized
ECG recording or
another signal processing code that identifies timing of the first (Si) and
second (S2) heart sounds,
as described hereinabove. The second aspect auscultatory sound signal
preprocessing and
screening process 3700 input parameters also include the mean noise power
level threshold Po
and the required number NG3HAT of high quality heart beats 82. In step (3706),
a good beat
counter GB is initialized to a value of 0. Following the heart-cycle
segmentation and heart-
phase identification process 2300, a two-dimensional array of heart beats 82
is created, for
example, as illustrated in FIGS. 31 and 35. The heart-cycle segmentation and
heart-phase
identification process 2300 also identifies timing of diastolic interval D of
each heart beat 82.
Beginning with the selection of the first heart cycle 82 in step (3708), in
step (3710), the breath-
held sampled auscultatory sound data S[] is normalized with respect to
absolute value of the S2
peak, and, in accordance with a first aspect, in step (3712), the mean noise
power P is computed
within a time window T. The time-window T, is slid along the diastole D with
the 50% overlap
to compute an array of localized signal power P[]. After the power P[iw] of
the sampled
auscultatory sound data Sm[] is calculated within each time-window T, indexed
by index iw,
the maximum power PmAx of diastole D is determined i.e. as given by the
maximum of the array
of localized signal power P[], and, in step (3714), is compared against the
mean noise power
level threshold Po, the latter of which in one set of embodiments, for
example, has a value of ¨20
dB. A noise power level P Iiw] in one of the time-windows T, greater than the
mean noise power
level threshold Po may indicate either excessive noise or presence of a large
amplitude transient
outlier.
Referring to FIG. 38, in accordance with a second aspect of heart-beat quality
assessment
procedure, the quality test consists of two stages designed to detect high
amplitude transient spikes
and noisy beats with broad-band spectrum. The quality tests are performed on
the diastolic portion
of the heart cycle 82, which is the region of primary interest for CAD
detection. Nonstationary
signals can be analyzed using a relatively short time sliding time-window T,,
for example, in one
set of embodiments, with T, = 30 ms (Nõ, = 120 samples at fs = 4 kHz), which
is slid across
-44-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
diastole, with each time-window T, advanced in time with respect to the
previous time-window
T, by a stride period. In one set of embodiments, the stride period is equal
to the duration of the
time-window T,, so that adjacent time-windows T, abut one another without
overlap. The total
number of time-windows T, (i.e. sub-segments) in diastole, without overlap, is
given by Ns =
N/Nõ, where N is the total number of samples during diastolic, and Nõ, is the
number of samples
in each time-window T.
The variance within each time-window T, ¨ used to detect any outliers therein
¨ is
computed as:
2 1 VAC
(15)
AT), k_1
wherein xik and yx are respectively the km sample and the mean value, of the
ith time-window T,,
respectively. The local signal power of the ith time-window T,, is given by:
p = 2 (16)
An outlier power threshold Pum is determined by adding 6 dB to the median
value of Pi for all
time-windows T,, and in step (3714), if the value of Pi exceeds PLim for any
time-window T,,
then, in step (3720), the current heart cycle 82 is ignored.
If none of the time-windows T, include an outlier, then the mean power of
diastole is
given by:
1 Ns
P ¨ (17)
AT _1
The associated noise power threshold PTh is defined with respect to the 2-byte
AID converter range,
So that:
(7-
PTh = 'ADC .1 (18)
wherein Th is a predetermined threshold, for example, -50 dB, and PADc is the
power associated
with the maiximum signed range of a 2-byte AID converter, i.e. (32767)2.
Accordingly, if, in step
(3714), the mean diastole power Pm exceeds the noise power threshold PTh,
then, in step (3720),
the current heart cycle 82 is ignored.
If, from step (3714), the diastolic signal power exceeds the mean noise power
level
threshold Po, then, in step (3720), the associated heart beat 82 is labeled as
noisy beat and is not
counted in the overall tally of heart beats 82. Otherwise, from step (3714),
the good beat counter
GB in step (3716), and if, in step (3718), if the number of good heart beats
82, i.e. the value of
the good beat counter GB, is less than the required number NGyHAT of high
quality heart beats
82, then the second aspect auscultatory sound signal preprocessing and
screening process
3700 repeats with step (3708) for the next heart cycle 82. In one set of
embodiments, if the
-45-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
required number of high quality heart beats 82 is not reached within a
reasonable period of time,
then the user is informed that recording is excessively noisy so that
additional actions can be
performed to improve signal quality.
Following the acquisition of a sufficient number of sufficiently-low-noise
heart beats 82,
following step (3718), the sampled auscultatory sound data Sm[] is further
preprocessed to
emphasize acoustic signals in diastole D and extract signal specific features
that can be used for
disease classification. For example, in step (3722), the mean position of the
peak of the S2 heart
sound ¨ for example, the above-described mean value ts2 -- is determined for
each heart beats
82, after which the heart beats 82 are synchronized with respect thereto, for
example, as illustrated
in FIGS. 39a and 39b, which respectively illustrate a stack of heart beats 82
before and after
this S2 alignment, wherein the synchronization of the heart beats 82 with
respect to the S2 heart
sound helps to locate an acoustic signature that might be present in a
majority of the heart beats
82 and that is coherent between or amongst different heart beats 82.
Then, in step (3724), the heart beats 82 are normalized with respect to time
so as to
compensate for a variation in heart-beat rate amongst the heart beats 82, and
to compensate for a
resulting associated variation in the temporal length of the associated
diastolic intervals. Generally,
heart-beat rate is always changing and typically never remains the same over a
recording period
of several minutes, which if not compensated, can interfere with the
identification of specific signal
features in diastole D, for example, when using the below-described cross-
correlation method.
Although heart-beat segmentation alone provides for aligning heart-beat
starting points, variations
in the heart-beat rate can cause remaining features of the heart cycle 82 to
become shifted and out
of sync ¨ i.e. offset -- with respect to each other. However, such offsets can
be removed if the
associated heat beats 82 are first transformed to common normalized time scale
t/T*, where T* is
the fixed time interval, for example, the duration of the slowest heart beat
82, followed by beat
resampling and interpolation so as to provide for normalizing the original
signal at a new sampling
rate, for example, as illustrated in FIGS. 40a and 40b that respectively
illustrate stacks of heart
beats 82 before and after such a time normalization, wherein FIG. 40a
illustrates complete heart
cycles 82, and FIG. 40b illustrates only the temporally-normalized diastolic
portions D thereof
Referring again to FIG. 37, in step (3730), a final stage of signal pre-
processing provides
for extracting acoustic features from the recorded heart beats 82. There are
numerous options that
can be applied to feature extraction which typically involves certain
transformation of raw data to
low-dimensional or sparse representation that uniquely characterizes the given
recording.
Alternatively, the raw data can be transformed in a set of images and some
image recognition
algorithm like convolutional neural net can be employed for automatic feature
selection. For
example, in accordance with one set of embodiments, referring to FIG. 41, a
local cross-
-46-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
correlation (CC) of multiple heart beats 82 provides for identifying a
relatively high-pitch signal
component in the diastolic phase of the heart cycle 82 occurring in multiple
heart beats 82, which
can be result from turbulent blood flow, wherein pairs of heart beats 82 of a
2-D stack of heart
beats 82 ¨ each segmented from the above-described high-pass-filtered breath-
held sampled
auscultatory sound data 72, s[] ¨are cross-correlated with one another by
computing an
associated set of cross-correlation functions Rxixj for each pair of heart
beats 82, xi[], x[]. This
computation is made using a sliding short-time window with Nw samples (for
example, typically
128) which is advanced in time one sample per each iteration of the cross-
correlation computation.
The cross-correlation is computed without time lag, resulting in an array --
of the same size as that
of the original signals -- that is given by:
1 N-
Rxx, (n) = x (n + k) = x (n + k) (19)
Nix k=1
The cross-correlation assigned to each beat is given by an average of cross-
correslations thereof
with the remaining Nb - 1 heat beats 82:
1 Nb-1
R (n) ¨ ,
x , x
(Nb ¨1) R(n)
(20)
wherein xi and xj are the diastolic high-pass-filtered breath-held sampled
auscultatory sound
data 72, s[] of two distinct heart beats 82, and Nb is the total number of
heart beats 82 in the 2-
D stack. Following computation of all possible pairs of heart beats 82, an Nb
x/Vt cross-correlation
matrix is obtained and displayed as a 2D image, wherein Nt is the number of
time samples in each
heart beat 82. A similar signal pattern during diastole that is present in
majority of heart beats
82 will produce a localized cross-correlation peak in diastole. Accordingly,
cross-correlation peaks
associated with a micro-bruit signal occurring at approximately at the same
temporal location
within the diastole interval from one heart beat 82 to another will produce
distinct bands across
the image within the same temporal region of each heart beat 82, for example,
as illustrated in
FIG. 42, which illustrates an image of the cross-correlation function Rxi as a
function of n
(corresponding to time) for each heart beat 82, with different heart beats 82
at different ordinate
positions, wherein the value of the cross-correlation function is indicated by
the color of the
associated pixels. The cross-correlation operation provides for emphasizing
signal features that are
coherent within the current time window, and provides for suppressing
uncorrelated noise, thereby
providing for increasing the associated signal-to-noise ratio.
Alternatively, or additionally, acoustic features in diastolic interval of
heart beat 82 can
be visualized using continuous wavelet transform (CWT). The wavelet transform
processing is
similar to the short-time cross-correlation but instead of cross-correlating
signals from different
-47-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
heart beats 82, the signal of interest is correlated using a wavelet function
with limited support to
facilitate temporal selectivity.
X (a,b) = ¨ b
¨ dt
(21)
11/2
a a
wherein the associated mother wavelet w is a continuous function in time and
frequency domains.
The wavelet family is typically chosen empirically using specifics of the
signal under
consideration. The family of Morlet wavelets appears as an appropriate choice
for analysis of heart
sounds. Output of the wavelet transform is a two-dimensional time-frequency
representation of
signal power 1X(a,b)12 defined in terms of scaling and shift parameters. An
example of a wavelet
transform ¨ using a 6th order Morlet wavelet -- is illustrated in FIG. 43,
where the associated
.. corresponding original color map represents distribution of the signal
power in a time-frequency
plane, with normalized time-shift ¨ as a function of b -- as the abscissa, and
frequency as the
ordinate, with frequency fin Hertz given as follows:
f ¨ 27. a
(21a)
wherein w is the wavelet order, for example, w=6 for a 6th order Morlet
wavelet, and the results
plotted in FIG. 43 are the result of a cumulative processing of the diastolic
portions of a plurality
of heart cycles. For the purpose of signal classification, the wavelet
representation can be reduced
further by dividing the time axis into discrete intervals and computing
overall signal power within
such interval and specific frequency bandwidth. For example, in one
embodiment, the wavelet
image may be subdivided in time intervals of 200 milliseconds and two
frequency bands of 10 Hz
- 40 Hz and 40 Hz ¨100 Hz. The resulting output vector of the signal power
within the associated
intervals of time and frequency can be used as an input to a neural network
classifier.
Generally, step (3730) of the second aspect auscultatory sound signal
preprocessing
and screening process 3700 ¨ which may also be used in cooperation with the
above-described
first aspect auscultatory sound signal preprocessing and screening process
2100 --
incorporates one or more feature extraction algorithms which identify
significant signal parameters
that can be linked to coronary artery disease (CAD) and which can be used for
training a machine
learning algorithm for automatic CAD detection. Furthermore, if auscultatory
sound signals 16
are recorded at a relatively high sampling rate (for example, at a 4 kHz
sampling rate), each heart
beat 82 might contain over 4000 samples per each of six channels. Such large
amount of highly
correlated variables makes the usage of the raw waveform for classification
very difficult without
additional signal processing to reduce the dimensionality of the problem. Such
dimensionality
reduction can be achieved by use of an appropriate feature extraction
algorithm that identifies a
reduced set of parameters that are related to CAD. Mathematically, the feature
extraction
-48-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
procedure provides a mapping of the high-dimensional raw data into the low-
dimensional feature
space with adequate inter-class separation. For example, standard
dimensionality reduction
routines such as singular value decomposition (SVD) or principal component
analysis (PCA) may
be used to decompose raw data onto orthonormal basis and to provide for
selecting relevant
features with minimal loss of information. The time domain signal itself can
be transformed prior
to feature extraction to emphasize unique features thereof For example,
frequency domain
representation by Fourier transform can be advantageous for feature extraction
if the signal
contains discrete set of characteristic frequencies. The performance of a
signal classifier can be
dramatically improved by excluding a large number of irrelevant features from
analysis. In
accordance with one aspect, the signal classification problem begins with a
mapping from the
original high-dimensional space (size N) to a feature space (size p
N), followed by a mapping
of the feature space to an m-dimensional space, wherein the dimension m is
equal to the number
of classes. For example, for a binary classification problem-- e.g. CAD or no
CAD, -- m=2.
In accordance with one set of embodiments, step (3730) of the second aspect
auscultatory
sound signal preprocessing and screening process 3700 employs a wavelet packet
transformation (WPT) for sparse representation of heart sounds in time-
frequency domain,
followed by a custom designed binary classifier. Several standard classifier
algorithms can be
trained using reduced feature set, and to provide for binary classification of
the associated heart
sounds-- useable either individually or in combination, -- including, but not
limited to, a support
vector machine (SVM), a fully-connected artificial neural network (ANN), or a
convolution neural
network (CNN) applied to two-dimensional time-frequency images.
Referring to FIGS. 57-66, a wavelet packet transformation (WPT) processing
stage
provides for reducing dimensionality by converting raw time-domain
auscultatory sound signals
16 into a time-frequency basis using discrete wavelet transform (DWT),
followed by elimination
of associated components that do not provide significant contribution to the
original signal or do
not provide substantial contrast between two classes of interest. For example,
referring to FIG. 57,
in one set of embodiments of discrete wavelet decomposition, an initial
(input) signal x[n] is passed
through a series of stages at which low-pass and high-pass filter functions
(quadrature mirror
filters) are applied to obtain approximation a3(k) and detail d3(k)
coefficients at the fh level of
decomposition. This procedure is repeated recursively at the subsequent steps
with the only
approximation coefficients used as an input, The coefficients generated at
each indicated level of
filtering provide the corresponding amplitude of the initial signal x[n] after
filtering by a filter
having a corresponding bandpass filter response characteristic illustrated in
FIG. 58.
Referring to FIGS. 59 and 60, In accordance with one set of embodiments, the
discrete
wavelet transform (DWT) is implemented using a Daubechies wavelet family, for
example, a
-49-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Daubechies 4 (db4) wavelet family, for which the associated scaling function 9
-- having low-
pass filter coefficients ho through h7 -- is illustrated in FIG. 59, and for
which the associated
wavelet function if -- having high-pass filter coefficients go through g7 ¨ is
illustrated in FIG. 60.
Referring to FIGS. 57 and 61, at each node 92 of the discrete wavelet
transform (DWT),
an input time series wj,k/l/ from decomposition level j is transformed into
two output time series
at decomposition level j+1, i.e. wj-F/,20 and wj+1,2k-F1[lJ, each containing
half the number of
samples as in the input time series, and mutually-exclusive halves of the
frequency content of the
input time series, wherein the transformation to generate the wj-F1,2k-F1[//
lower-half bin of frequency
content is given by the transformation 61.1g¨>61.2g illustrated in FIG. 61 and
in equation 22
below, and the transformation to generate the wj-F/,20 upper-half bin of
frequency content is given
by the transformation 61.1h¨>61.2h illustrated in FIG. 61 and equation 23
below, wherein k
designates an associated frequency bin for the associated decomposition level
j.
The filter functions are designed to provide for energy conservation and
lossless
reconstruction of the original signal from the set of transformed time series
wjjfil from a particular
decomposition level j. These properties along with smoothness requirements
define the family of
scaling and wavelet functions used for decomposition. The resulting set of
K=23 distinct frequency
bands at each decomposition level j, together with the corresponding
associated transformed time
series wj,k/1]. can be used for analysis and feature extraction, instead of
relying upon the
corresponding original raw signal x[n].
The wavelet packet transformation (WPT) is generalization of the standard
multi-level
DWT decomposition, wherein both approximation and detail coefficients are
decomposed using
quadrature mirror filters, for example, as described in M. Wickerhauser,
"Lectures on Wavelet
Packet Algorithms", http://citeseerx.ist.psu.edu, which is incorporated herein
by reference. FIG.
62 illustrates a wavelet packet transformation (WPT) at decomposition level
j=3, and FIG. 63
illustrates the bandpass frequency responses associated with each of the
outputs thereof
Analytically, the wavelet packet transformation (WPT) decomposition can be
described by the
following recursive expressions:
j+1,2k+1[1] = -.5 = 1m gmw,,k [2.1 ¨m] (22)
m=i
Wi +1,2k [1] = NE = Ihmw [2 .1 ¨ ml (23)
m=i
where go, is the coefficient of the scaling function and hm is the coefficient
of the wavelet function,
k is the index of the associated frequency bin at decomposition level j, and /
is the index of the
associated time series array associated with the particular frequency bin k.
-50-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
The wavelet packet transformation (WPT) provides a benefit of sparse signal
representation similar to the discrete wavelet transformation (DWT), but also
provides better
resolution of frequency components by decomposing the detail part of discrete
wavelet
transformation (DWT), which results in the sub-band structure illustrated in
FIG. 63. The
maximum decomposition level j for a given signal depends on the signal length
and the trade-off
between desired time and frequency resolutions. The resulting tree-like
structure of wavelet packet
transformation (WPT) bases ¨ each base corresponding to a particular frequency
bin k at a
particular decomposition level j -- provides a highly redundant representation
of the original signal
x[n], which limits the amount of dimensionality reduction. However, heart
sounds have
characteristic properties that can be well described by a relatively small
number of wavelet packet
transformation (WPT) bases and a substantial amount of irrelevant information
can be discarded.
For example, in one set of embodiments, the WPT tree nodes with highest energy
concentration
are retained for further analysis and classification. For example, FIG. 65
illustrates a wavelet
packet transformation (WPT) energy map of the high-pass-filtered breath-held
sampled
auscultatory sound signal 72 for the heart cycle 82 illustrated in FIG. 64,
generated by an 8-
level wavelet packet transformation (WPT) using a Daubechies 4 (db4) wavelet
family, wherein
the individual nodes 92 ¨ or associate bases or frequency bins -- are outlined
with rectangular
boundaries in the image, and each frequency bin is color coded to indicated
the total energy EA of
the km node at ther decomposition level, which is computed using wavelet
packet transformation
(WPT) coefficients wja as follows:
E =11,v ,k2 [11 (24)
For each decomposition level j, the total energy from all frequency bins is
the same, i.e.
ETotal = E1,k is the same value regardless of decomposition level j. (25)
The wavelet packet transformation (WPT) energy map of FIG. 65 illustrates that
most of
the signal energy is concentrated in the relatively low frequency bands, and
that only the levels 7
and 8 of decomposition show the fine structure of the energy distribution.
Accordingly, this
example shows that most of the wavelet packet transformation (WPT) nodes 92
can be ignored
without significant loss of information. A formal approach to the selection of
the best bases ¨that
relies on Shannon entropy as a cost function computed for each node in the
tree --is described by
H. Saito and R. Coifman in the following documents that are incorporated
herein by reference: N.
Saito, R. R. Coffman, "On local feature extraction for signal classification",
http s ://www. math. ucdavi s . edu/ ¨saito/publications/saito iciam95. pdf,
and N. S aito, R. R.
Coffman, "Local discriminant bases and their applications", J. Math. Imaging
and Vision, 5, 337-
358 (1995). For example, traversing the wavelet packet transformation (WPT)
tree from the leaf
-51-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
level up (i.e. highest to lowest decomposition level j), children nodes with
the combined entropy
lower than that of the parent node will be retained as the most relevant for a
given signal, for
example, as illustrated in FIG. 66 for the wavelet packet transformation (WPT)
energy map
illustrated in FIG. 65, wherein the Shannon entropy is given by:
/j,k = p j,,,[1]= log (p j,,,[1]) (26)
and p1,k[1]= [2/1 . (27)
wi,k [Li
The Wavelet Packet Transform (WPT) provides a redundant representation of
actual signal
using the discrete wavelet transform with various decomposition levels that
provide higher
frequency resolution (in terms of filter banks) at the expense of reduced time
resolution. The WPT
of the signal can be described by a set of coefficient wj(k, 1), where j is
the decomposition level, k
is the filter bank index and 1 is the coefficient index within filter bank. An
example of WPT
decomposition is shown in FIG. 65 where each cell outlines positions of filter
bank for each level
and intensity is related to the signal energy from equation 24. It can be seen
that energy
distribution withing specific frequency bands becomes apparent at high
decomposition levels ( j >
6). Although, the color of the high frequency cells is dark blue, the values
of the associated WPT
coefficients is not zero.
The entire WPT energy map is highly redundant and not well suited in its raw
form for
signal classification. Instead, only those cell that uniquely characterize a
given signal are kept
while ignoring remaining cells. This can be accomplished using the best WPT
basis selection
algorithm which employs entropy WPT coefficients as a metric of the filter
bank (cell) importance.
This algorithm runs from leave cells up along the decomposition tree and
selects parent cell whose
entropy is less compared to the sum of the two children cells. An example of
best basis selection
applied to the WPT map in FIG. 65 is shown in FIG. 66. Values the best basis
would generally
not coincide with the energy map shown in FIG. 65 because entropy and energy
differ from one
another,
In FIG. 65, the total energy of a particular cell is represented by the
intensity thereof FIG.
65 illustrates that most of the energy is concentrated in the relatively-lower
frequency bands. The
cells of FIG. 66 ¨ for which intensity is inversely related to entropy ¨ are
considered to be a
signature of a given signal, and do not overlap with the corresponding cells
of FIG. 65, the latter
of which is representative of energy. None of the cells below the highlighted
(children) cells in
FIG. 66 are selected because they exhibit high entropy.
The wavelet packet transformation (WPT) energy map and the associated best
basis
selection can be used to reduce dimensionality of the heart beat
classification problem by analyzing
-52-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
the signal represented by transformed time series wj,kfi/ and rejecting
information irrelevant for
the classification task. The wavelet packet transformation (WPT) is one of a
variety of signal
processing techniques that can be used for extraction of important parameters
or features suitable
for prediction of CAD. The very basic set of features may include typical
metrics of raw signals
(amplitude, timing, spectral power and other) that can be derived from
segmented heart beats.
However, such hand-crafted feature set may not be optimal for current problem
of CAD
classification. Regardless of which method is used for feature extraction, the
output of this data
processing stage is a vector ofp elements with p <<N, where Nis the size of
raw signals. The
feature vector can be represented either as a 1-D array of p elements or as a
2-D matrix for a
classification algorithm operating on image information. There are several
powerful classification
algorithms that can be trained for disease detection using recorded heart
sounds and the extracted
feature vector. These algorithms include support vector machine (SVM), feed-
forward artificial
neural network (ANN) and convolutional neural network (CNN), which is
particularly suitable for
2-D image classification.
Referring to FIG. 67, a support vector machine (SVM) is a powerful supervised
machine
leaning algorithm frequently used for data classification problems, which has
several useful
properties and can operate reliably on a small data sets with poor class
separation. In case of
linearly separable data, the SVM classifier will create decision hyperplane in
feature space with
highest separation between two classes using training data set. For example,
FIG. 67 illustrates
a trained SVM classifier and decision boundary for a two-dimensional feature
space with two
classes. The support vectors are circled, and the highest margin hyperplane is
shown by the solid
straight line. When separation between classes is less then perfect, the
tolerance of SVM algorithm
to data misclassification can be tuned by adjusting an associated C parameter
during training. In
more complicated situations, a nonlinear decision boundary can be created
using a kernel function
to project data into higher dimensions and apply SVM algorithm to modified
data.
The SVM algorithm can be used as a CAD classifier with data recorded by the
Data
Recording Application (DRA) 14, 14.1. Prior to sending data to SVM algorithm,
recordings are
processed by beat segmentation and feature extraction stages, to produce a
feature vector for each
test-subject 22, by preprocessing of n available recordings and extracting p
features, with each
channel data then transformed into an n xp feature matrix. The feature vector
extracted from the
segmented beats can be either a set of custom selected metrics (amplitude,
timing of specific
segment, energy, statistic parameters, sample entropy and others) or a subset
of wavelet packet
transformation (WPT) coefficients associated with the signal region of
interest. If the resulting
number of features p is still relatively high, a principal component analysis
(PCA) procedure can
be applied to identify a subset of features with highest variance and
eliminate correlating features.
-53-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
After all preprocessing steps and data normalization, the feature matrix is
split into testing and
training sets with ratio 1 to 4 respectively. The training set is used to
train SVM and optimize
classifier hyper-parameters, while the testing set is used to evaluate
classifier performance with
unseen data. Computer code that provides for implementing a SVM classifier is
available in
several open source packages for Python and R programming languages, for
example, the sklearn
machine learning package in Python.
Referring to FIG. 68, a feed-forward artificial neural network (ANN) provides
an
alternative option for classification of auscultatory sound signals 16
following preprocessing and
feature extraction stages. An artificial neuron is a nonlinear processing
element withp inputs and
lit a nonlinear activation function that generates an activation output.
Assuming x0) is a feature
vector which is sent to the p inputs of each neuron, then the associated
activation output of ith
neuron is computed as:
(
ci, = g j = x +b,
(28)
wherein wij is the weight matrix that defines connection strength of ith
neuron tor input, bi is the
neuron bias and g(z = wTx + b) is the associated nonlinear activation
function. The specific form
of the activation function g is chosen at the design stage, wherein commonly
used functions include
sigmoid, hyperbolic tan and rectified linear unit (ReLu). The network of
interconnected neurons
constitutes the artificial neural network (ANN), which can be capable of
modeling relatively
complicated relationships between the input vector and target class variables
by adjusting weights
and biases during training stage.
Properties of a specific artificial neural network (ANN) implementation are
defined at the
design stage and include: 1) number of hidden layers, 2) number of neurons per
hidden layer, 2)
type of activation function, 3) learning rate and 4) regularization method to
prevent overfitting.
For example, in one set of embodiments, the artificial neural network (ANN) is
implemented using
the open source TensorFlow deep learning framework, which provides for setting
each of these
parameters. The neuron connection strength is defined by the weight matrix wij
for each layer
which is adjusted during network training and a cost function evaluated at
each training epoch
using available truth labels. The artificial neural network (ANN) training is
accomplished by a
standard back-propagation algorithm using a cross-entropy cost function. The
network design
specifics are determined by the available data since a network with multiple
hidden layers (deep
ANN) can be very powerful but also is prone to overfitting when a small data
set is used.
Therefore, the specific artificial neural network (ANN) architecture is
developed on a trail-and-
error basis, dependent upon the available data and the size of feature vector.
In one set of
embodiments, output layer of the artificial neural network (ANN) for a binary
classifier is
-54-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
implemented as the softmax function with two-element vector [1, 01 for CAD
positive and [0, 11
for CAD negative case.
For example, in one set of embodiments, the features used as inputs to either
an ANN
classifier or a SVM classifier are selected from the following: length (time
duration) of: Si, systole,
S2, and diastole; ECG RR peak duration; amplitudes of Si, systole, S2, and
diastole; ratios of
corresponding amplitudes; and energy of spectral bands associated with Si,
systole, S2 and
diastole. Other features such statistics (mean, variance, skewness and
kurtosis) of the parameter
distributions can also be used as features for input to either an ANN
classifier or a SVM classifier.
Referring to FIG. 44, in one set of embodiments, a convolutional neural
network is
ft) employed to analyze cross-correlation images of acoustic signals in
order to provide for
automating the process of acoustic feature extraction. The network input
consists of the three-
dimensional array of cross-correlation data recorded from the left or right
positions on the thorax
20 of the test-subject 22, and combined into a single array, for example,
representing three
individual channels associated with three different auscultatory sound sensors
12. The
convolutional neural network (CNN) comprises several convolutional layers that
each use a 5x5
kernel array to scan input data to build a structure of acoustic features with
increasing complexity.
Neuron activation uses rectified linear unit (ReLU) nonlinearity to produce
output data. The final
stage of the network classifier is a fully connected neural net with an
additional clinical information
(age, gender, blood pressure, etc.) merged with the acoustic features
identified by CNN. The
network output is a two-node layer implementing binary classification via
softmax function
applied to the incoming data. The CNN classifier is trained using 80% of all
available data with
binary CAD labels (Yes = 1 and No = 0). The remaining 20% of data is randomly
selected to test
the classifier performance. Reported performance metrics include prediction
accuracy, sensitivity,
specificity, negative prediction value and positive prediction value. New
patient data are classified
by passing through the same pre-processing stages and feeding the computed
cross-correlation
image to CNN classifier.
Convolutional neural networks (CNN) have proved to be very efficient for
prediction and
classification problems especially with large scale problems involving images.
The typical size of
input image data can be quite large, which makes application of standard feed
forward networks
either impractical or even impossible due to huge number of parameters to be
trained.
Convolutional neural networks (CNN) accommodate the size of the problem by
weight sharing
within small number of neurons comprising a receptive field that is scanned
over the 2-D input.
One benefit of using a convolutional neural network (CNN) for machine learning
problems to the
ability thereof to learn important features directly from data, so as to
provide for bypassing the
feature extraction stage that is used by support vector machine (SVM) and feed-
forward artificial
-55-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
neural network (ANN) classifiers. A typical convolutional neural network (CNN
structure consists
of one or more convolution and pooling layers that build a hierarchical
structure of features with
increasing complexity. Following convolution and max pooling, the extracted
features are fed to
a fully connected network at the final stage of convolutional neural network
(CNN) classifier. For
.. example, FIG. 44 illustrates a convolutional neural network (CNN)
architecture incorporating a
single convolution layer. Each cell of the max pool contains the maximum value
of a
corresponding array of cells in the corresponding convolution layer.
The receptive field is a relatively small 2-D array of neurons (for example, 5
x 5) that is
scanned across the input image while performing an associated cross-
correlation operation. A
to relatively small number of connected neurons provides for a relatively
small number of
corresponding weights to be adjusted. The max polling operation provides for
reducing the size
of the input to the associated fully-connected neural network by selecting
pixels with maximum
intensity from the associated convolution layer. Similar convolution and max
polling operations
can be performed multiple times to extract the most significant features
before submitting to an
associated fully-connected neural network for classification. Although a
convolutional neural
network (CNN) can be trained to recognize complicated patterns in 2-D data
sets, this typically
requires large amount of data for efficient generalization and to avoid
overfitting. The
convolutional neural network (CNN) classifier can be applied either directly
to the auscultatory
sound signals 16 (or filtered versions thereof), or to corresponding 2-D
images generated
therefrom, for example, using either a continuous wavelet transform or an
associated
decomposition thereof by wavelet packet transformation (WPT) . For example, in
cooperation
with the extraction of features using wavelet packet transformation ( WPT),
the coefficients off
level of decomposition can be transformed into a matrix with dimensions (N/2)
x 2.1, where N is
the size of the time domain signal. Such 2-D data can be used train the
convolutional neural
network (CNN) classifier in order to find any patterns associated with CAD.
This type of network
is more complicated than a standard feed-forward artificial neural network
(ANN), and utilizes
more hyperparameters to be tuned to achieve optimal performance. In addition
to parameters
applicable to an artificial neural network (ANN), the convolutional neural
network (CNN) design
includes specification of the number of convolution layers, the size of
receptive fields (kernel size),
number of channels processed simultaneously, filter properties,
regularization. After finalization
of its design, the convolutional neural network (CNN) can be trained using a
training data set and
then evaluated using an unseen test data set. For example, for one set of
embodiments, the open-
source TensorFlow flexible deep learning toolkit and API ¨ which provide for
building high-
performance neural networks for variety of applications ¨ have been used to
design and train the
convolutional neural network (CNN) for detecting CAD.
-56-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Referring to FIG. 72, a second embodiment of a convolutional neural network
(CNN)
incorporates a plurality of convolution stages (Cony-1, Conv-2, Conv-3, Conv-4
and Conv-5) that
are interspersed with corresponding associated MaxPool stages, wherein the
output of the final
max pooling stage is fed into a first fully-connected neural network (FC1)
with 128 neurons, the
output of which is fed into a second fully-connected neural network (FC2) with
64 neurons, the
output of which is processed by a SoftMax output operation given by:
out, ¨ (29)
ez' +e z2
where zi = wuxj + b, bi is a bias term, and repeated indexes imply summation.
The result of the
classification (CAD/No CAD) is defined by the highest value of output outi.
The input to the convolutional neural network (CNN) is a series of either
FIGS, 41/42-sytle
convolution images, or a series of FIG. 43-sytle CWT transform images, with
one image for each
of the six different auscultatory sound sensor 12, with each image, for
example, given by a 100
by 200 array of pixels.
Each of the convolution stages (Cony-1, Conv-2, Conv-3, Conv-4 and Conv-5)
provides
for convolving the array of input elements (or pixels) with an either 3x3 or
5x5 kernel or weight
array, which is scanned across the input image with a stride if one pixel. If
zero padding is used,,
a single kernel generates one feature map with the size as the original image,
but 2D convolution
applied as follows:
y(ti,,n,) =I Ix(k1,k2).w(n1¨k1,n2¨k2) (30)
k, k2
where x(kl, k2) is the input image, and w is the kernel matrix. To extract a
variety of features,
each convolution layer has multiple kernels that are applied to the input
image. For example, in
FIG. 72, each convolution stages (Cony-1, Conv-2, Conv-3, Conv-4 and Conv-5)
is designated as
P x MxN K=LxL, wherein P is the number of different kernels that are applied,
MxN is the
dimension of the associated image, and LxL is the dimension of the associated
kernel matrix. If
zero padding is not used, the dimension of the output from the convolution
stages (Cony-1, Cony-
2, Conv-3, Conv-4 and Conv-5) is reduced by (L-1). Following convolution, the
max pooling
layer is applied which is a simple mask 2x2 scanned across feature maps. At
each position only
one pixel with highest magnitude is selected which is essentially a decimation
operation that
reduces the size of feature map by 2 while selecting brightest pixels.
It should be understood that the CNN, ANN and SVM classifiers each provide an
independent means of classifying the associated input features in order to
determine whether or
not CAD is likely. These are alternative classification algorithms and a
decision as to which one
to use is typically based on their respective performance, for example,
prediction accuracy.
-57-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
Alternatively, the different algorithms could be combined to make a single
prediction, for example,
using either a voting scheme or a weighted sum of likelihoods.
The auscultatory coronary-artery-disease detection system 10 can present
various
views of the acoustic data (both unprocessed and processed) that was captured
during the test for
review by a clinician. By reviewing different visualizations of the test
results, the clinician may
strengthen his case for a particular diagnosis, either in agreement with or
disagreement with the
result produced by the system. Additionally, particular visualizations may
help reassure the patient
that the diagnosis is the correct one.
Referring to FIG. 45, the system presents heart/arteries view comprising a
graphical
tt) representation of the heart and coronary artery tree, highlighting the
data in accordance with a
Textual View. By selecting any of the occlusions, the clinician is presented
with the option to
highlight the blockage in either: a Stacked Heartbeat View; a Bruit
Identification View (either
mode); a Bruit Analysis View; or a Receiver Operating Characteristic Curve.
For example, FIG.
45 illustrates test results showing severity of obstructions and zonal
location of each obstruction
within coronary artery tree. The tree diagram also indicates which arteries
are critical, and which
are not, with associated color coding in accordance with the amount of
occlusion, for example,
with the illustrated region of 50 occlusion highlighted in a reddish hue, and
the region of 30%
occlusion highlighted in a yellowish hue.
In accordance with the Textual View, the system presents, in a textual manner,
the system's
interpretation of the acoustic data, including: whether or not the patient has
a clinical level of CAD;
the count of obstructions detected, for each obstruction: the location (zone)
of the obstruction; the
percentage occlusion of the obstruction; or the type of blockage (soft plaque,
hard plaque). For
each of the items in the view listed above, the system provides for presenting
an associated
confidence level, which indicates how confident the system is of each specific
element of
information presented, or, based on the patient's demographic data (age, sex,
BMI, medical and
family history), the percentage of other patients who have a similar count,
severity, and position
of obstructions. From this view, the clinician may switch to any other view
listed in this document
for more information.
Referring to FIG. 46a, the system presents a Receiver Operating Characteristic
(ROC)
curve to highlight the system's CAD detection algorithm sensitivity as a
function of its false
positive rate (1-specificity). The graph's attributes will be as is standard
for ROC curves ¨ vertical
axis representing sensitivity, horizontal axis representing the false positive
rate, with a 45-degree
dotted line representing a "coin flip" test (AUC = 0.5).
On this graph, the system will plot the ROC curve and calculate the Area Under
the Curve
(AUC) based on the patient's demographics, and the system's clinical trial
results. The coordinate
-58-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
that corresponds to the current positivity criterion will be highlighted. The
clinician will be able
to display a modified graph if he commands the system to exclude specific
parts of the patient's
demographic data. The graph may or may not contain gridlines and/or data
points defining the
ROC curve, and it may or may not fill in the AUC.
Alternatively, referring to FIG. 46b, the data may be visualized as a line
graph (with or
without underfill), where true positives, true negatives, false negatives, and
false positives are
displayed, with a line indicating the currently-used cutoff value.
Referring to FIGS. 47 through 53, the system provides for visualizing the
acoustic data
resulting from an analysis of the breath-held auscultatory sound signals 16.1
from the
auscultatory sound sensors 12.
Referring to FIG. 47, the system presents a heartbeat view comprising a
graphical plot of
the systolic and diastolic intervals of each heartbeat captured. The
horizontal axis of the graph
represents captured heartbeats. This representation is a subset of the
acoustic capture time, as
some acoustic data acquired is discarded (poor quality, etc.) during the
system's analysis process.
The duration of the 51 and S2 sounds are also highlighted on this axis.
Generally the vertical axis may comprise acoustic data captured from each of
the system's
sensors ¨ both acoustic and ECG. A correlation procedure is performed to
ensure that the data
captured from each of the system's sensors is aligned to one another. Because
the initial display
of this view may contain many dozens of heartbeats, the clinician has the
option to highlight a
subset of the data on the horizontal axis, and command the system to zoom into
the selected
section. In this way, the clinician can perform a deeper analysis on one or
more sections of the
acoustic capture data as he so chooses, and explore any discrepancies between
the data captured
by the ECG and acoustic sensors for any particular heartbeat. For example,
FIG. 47 illustrates an
example of the Heartbeat View wherein the acoustic view has been limited by
the clinician to
Sensor#3 only, and zoomed in to see only 2 heartbeats, with the ECG data also
displayed.
Referring to FIG. 48, in accordance with a Stacked Heartbeat View, the system
presents a
graphical plot of the systolic and diastolic intervals of each heartbeat
captured. The horizontal
axis of the graph represents time (in seconds or milliseconds) from the
beginning of the systolic
interval to the end of the diastolic interval. The duration of the 51 and S2
sounds are highlighted
on this axis. The vertical axis is comprised of the acoustic data captured for
each of the heartbeats,
in either ascending or descending order of capture, where each heartbeat is
itself a graph, with a
vertical axis representing intensity. A correlation procedure is performed to
ensure that the start
of the systolic interval for each heartbeat is aligned on x-axis=0. For each
heartbeat, the system
highlights any unexpected acoustic signals captured, as such signals may be an
indication of an
obstruction or other cardiac condition. For example, in FIG. 48, unexpected
acoustic signals are
-59-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
highlighted in red. The clinician has the option to highlight a subset of the
data on the horizontal
axis, and command the system to zoom into the selected section. In this way,
the clinician can
perform a deeper analysis on one or more sections of the acoustic capture data
as he so chooses,
especially so that he may explore more deeply any unexpected acoustic signals.
Referring to FIG. 49, in accordance with a Bruit Identification View in a Line
Graphs
with Underfill mode, the system presents a graphical plot of unexpected
acoustic signals captured
during the diastolic interval by means of a line graph with underfill. The
horizontal axis of the
graph represents time (in seconds or milliseconds) from the beginning of the
diastolic interval to
the end of the diastolic interval. The duration of the S2 sound is also
highlighted on this axis. The
to
vertical axis is comprised of the acoustic data captured for each of the
heartbeats, in either
ascending or descending order of capture, where each heartbeat is itself a
graph, with a vertical
axis representing intensity. A correlation procedure is performed to ensure
that the start of the
diastolic interval for each heartbeat is aligned on x-axis=0. An underfill is
used to visually
highlight deviation from the baseline.
For each heartbeat diastole displayed, the system highlights any unexpected
acoustic
signals captured, as such signals may be an indication of an obstruction or
other cardiac condition.
Such signals are highlighted by the height of the line graph, which represents
intensity. These
highlighted areas on the graph allow a clinician to distinguish low-energy
noise (which may or
may not be a sign of non-obstructive CAD) from high-energy noise (which is a
likely indicator of
obstructive CAD). In this view, it is also easy for a clinician to understand
the correlation (across
heartbeats) of noise, as well as the number and timing of correlated instances
of noise (which may
indicate the number and location of blockages, respectively). For example, the
data illustrated in
FIG. 49 exhibits relatively high intensity noise in many heartbeats at
approximately t=0.05
seconds into diastole.
The clinician has the option to highlight a subset of the data on the
horizontal axis, and
command the system to zoom into the selected section. In this way, the
clinician can perform a
deeper analysis on one or more sections of the acoustic capture data as he so
chooses, especially
so that he may explore more deeply any unexpected acoustic signals.
Referring to FIG. 50, in accordance with a Bruit Identification View in a
Spectrogram
mode, the system presents a graphical plot of unexpected acoustic signals
captured during the
diastolic interval by means of a spectrogram. The horizontal axis of the graph
represents time (in
seconds or milliseconds) from the beginning of the diastolic interval to the
end of the diastolic
interval. The duration of the S2 sound is also highlighted on this axis. The
vertical axis is
comprised of the acoustic data captured for each of the heartbeats, in either
ascending or
-60-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
descending order of capture. A correlation procedure is performed to ensure
that the start of the
diastolic interval for each heartbeat is aligned on x-axis=0.
For each diastole displayed, the system highlights any unexpected acoustic
signals
captured, as such signals may be an indication of an obstruction or other
cardiac condition. Such
highlighted areas indicate the intensity of the unexpected signal. Highlights
are in the form of
color, which indicate varying intensity of the signal. This view could
alternatively be represented
in monochrome as a contour plot. For example, the data illustrated in FIG. 50
exhibits relatively
high intensity noise in many heartbeats at approximately t=0.05 seconds into
diastole.
These highlighted areas on the graph allow a clinician to distinguish low-
energy noise
(which may or may not be a sign of non-obstructive coronary artery disease
(CAD() from high-
energy noise (which is a likely indicator of obstructive CAD). In this view,
it is also easy for a
clinician to understand the correlation (across heartbeats) of noise, as well
as the number and
timing of correlated instances of noise (which may indicate the number and
location of blockages,
respectively).
The clinician has the option to highlight a subset of the data on the
horizontal axis, and
command the system to zoom into the selected section. In this way, the
clinician can perform a
deeper analysis on one or more sections of the acoustic capture data as he so
chooses, especially
so that he may explore more deeply any unexpected acoustic signals.
Referring to FIG. 51, in accordance with a Bruit Analysis View, the system
presents a
graphical time/frequency plot of unexpected acoustic signals captured. The
horizontal axis of the
graph represents time (in seconds or milliseconds) from the beginning of the
systolic interval to
the end of the diastolic interval. The duration of the Si and S2 sounds are
highlighted on this axis.
The vertical axis represents the frequency (in Hz or kHz) of any unexpected
acoustic signals,
averaged from all captured data. For each unexpected acoustic signal captured,
the color on the
graph represents the intensity of that signal. Alternatively, the graph could
be represented in
monochrome as a contour plot.
These highlighted areas on the graph allow a clinician to distinguish low-
energy noise
(which may or may not be a sign of non-obstructive CAD) from high-energy noise
(which is a
likely indicator of obstructive CAD). It is also easy for a clinician to
understand the frequency of
high-energy noise, as well as the timing of this noise ¨ this is important as
different cardiac
conditions may be defined by specific frequencies and timings of noise. For
example, the data
illustrated in FIG. 51 exhibits relatively high intensity noises at
approximately 1=0.25, 0.75 and
0.8 seconds into the heartbeat.
The system provides a User Interface, and associated navigation, is designed
for use on
tablets and smartphones, and thus uses common touch-screen user interface
paradigms. For
-61-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
example, two fingers moving apart from one another can be used to zoom in to
any area on any
graph, and two fingers moving together can be used to zoom out. A single
finger can be used to
highlight any areas on the horizontal axis, and the graph can be zoomed in to
that highlighted area
by touching a button.
Touching any area of the graph provides information to the user (either in a
pop-up window
or beside/below the graph) on the values of the horizontal and vertical axes
at that point, as well
as the "height" information of that point if available (e.g. in the Matrix
View). For example, in
Stacked Heartbeat View, touching on an individual heartbeat would cause the
system to provide
the heartbeat number, the maximum intensity of that heartbeat (and the time on
the horizontal axis
at which the maximum intensity occurs), and the time on the horizontal axis
corresponding to the
touch. In the case of the Matrix View, touching on any area of the graph would
cause the system
to provide the frequency, time, and intensity corresponding to the coordinate
on the graph that was
touched.
For use with a mouse, the user interface paradigms are similar, except with
zoom. In this
case, zoom can be accomplished through a common desktop/laptop user interface
paradigm, such
as dedicated zoom in/out buttons in the UI, or mouse wheel scrolling.
For some of these graphs, it is possible to restrict the display of data to
some subset of the
acoustic sensors (for example, as illustrated in FIG. 47), to combine acoustic
data from all sensors
(the default mode), or to display data from each sensor individually. This may
be helpful to
clinicians who want to spatially localize any unexpected acoustic signals.
This capability is
relevant to the Stacked Heartbeat View, the Bruit Identification View (both
modes), and the Bruit
Analysis View.
The following features of sound propagation with the body provide for the
localization of
acoustic sources based upon the relative strengths of the associated acoustic
signals from different
auscultatory sound sensors 12. First, any sound feature that originates from
the heart, acts as a
single source for all auscultatory sound sensors 12. For example, the
characteristic sound that
the heart makes, dub-blub, acts like two sounds coming from two separate
locations. Second, for
practical purposes, sound travels fast enough in the body that all
auscultatory sound sensors 12
would effectively receive each sound individually at substantially the same
time. Third, the farther
a sound's origin is from an auscultatory sound sensor 12, the weaker that
sound will be when
received by that auscultatory sound sensor 12. This is due to the sound energy
being dissipated
as it travels through the body. In view of these features, using the relative
signal strengths from
different auscultatory sound sensors 12, the location of the sound source can
be triangulated from
the locations of the auscultatory sound sensors 12 with the three largest
signal strengths,
weighted by the relative strengths of those signals, with the resulting
calculated location of the
-62-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
sound source being relatively closer to auscultatory sound sensors 12 with
relatively stronger
signals than to auscultatory sound sensors 12 with relatively weaker signals.
More particularly, referring to FIG. 69, in accordance with one method of
localizing the
sound source 94 of an auscultatory sound signal 16 based upon associated
respective signal
strengths Pl, P2 and P3 of respective first 12.1, second 12.2 and third 12.3
auscultatory sound
sensors that are assumed to be located in Cartesian space on an X-Y plane 96
at respective
predetermined sensor locations (Xl, Y1), (X2, Y2) and (X3, Y3), at Z=0.
Assuming that the
distance from each of the auscultatory sound sensors 12.1, 12.2, 12.3 is
inversely related to the
corresponding associated signal strengths Pl, P2 and P3, the corresponding
lengths Al, A2, A3
of corresponding edges El, E2, E3 of an associated tetrahedral solid 98 are
assumed to be
inversely related to the corresponding associated signal strength Pl, P2, P3
of the auscultatory
sound sensors 12.1, 12.2, 12.3 located at a corresponding vertices V1, V2, V3
of the tetrahedral
solid 98 to which the corresponding edge El, E2, E3 is connected. Other than
being sufficiently
long to meet at a fourth vertex V4 of the tetrahedral solid 98 at location (X,
Y, Z), the lengths
Al, A2, A3 of the edges El, E2, E3 are otherwise arbitrary, although
relatively shorter lengths
provide for less geometric dilution of precision (GDOP) of the ultimate
determination of the
lateral, (X, Y) location of the fourth vertex V4 than to relatively longer
lengths. In view of the
lateral (X, Y) location of the sound source 94 on the X-Y plane 96 being the
same as the lateral
(X, Y) location of the fourth vertex V4, the lateral (X, Y) location of the
sound source 94 may
be determined by solving the following system of three equations in three
unknowns (X, Y, Z) for
the location (X, Y, Z) of the fourth vertex V4:
(X ¨X1)2 +(Y ¨Y1)2 +Z2 = Al2 (31)
(X ¨X2)2 +(Y ¨Y2)2 +Z2 =A22 (32)
(X ¨X3)2 +(Y ¨Y3)2 +z2 =A32 (33)
Following the solution of equations 31-33, the resulting lateral (X, Y)
location of the
sound source 94 may then be displayed, for example, as a location on a
silhouette of a torso, or
transformed to a corresponding location on the image of the heart illustrated
in FIG. 45.
For some of these graphs, it is possible for the user to directly compare the
results of the
current test with one or more previous tests. This can be done by simply
placing the graphs side-
by-side (for example, as illustrated in FIGS. 52 and 53), or by overlaying
them on-top of one
other, with some variable transparency or color variation so that the
clinician can distinguish data
from one test versus another. In the case where the graphs are placed on top
of one another, the
system could fade in to one graph and out from the other slowly, repeatedly in
a loop (almost like
a video file), so that the clinician can easily see the differences in the
processed data between one
-63-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
test and the other. Alternatively, if the graphs are placed on top of one
another, a subtraction
operation could be performed to highlight only the differences between the two
graphs (e.g. red
for increase in noise from previous test result, green for decrease). For
example, FIG. 52 illustrates
a comparison of a current test with a previous test, using the Bruit
Identification View,
Spectrogram mode, to confirm success of PCI. Similarly, as another example,
FIG. 53 illustrates
a comparison of a current test with a previous test, using the Bruit
Identification View, Line Graph
with Underfill mode, to confirm success of PCI.
The ability to compare the current test with a previous test is critical to
the clinicians
understanding of the progression of a particular cardiovascular condition
(either worsening, or
improved as in the case of a PCI procedure). This capability is relevant to
the Stacked Heartbeat
View, the Bruit Identification View (both modes), and the Bruit Analysis View.
The graphs may be rendered locally or remotely (server-based) or both,
depending on the
capabilities desired by the clinician and the organization to which he
belongs. In most use cases
(tablet, phone, desktop, or laptop), the graph rendering will be done locally,
either through a web-
browser (full or embedded) on the client, or through a graphics library
optimized for each specific
supported client platform.
In other cases, the rendering may be done on the server side ¨ graphs may be
generated
and exported to JPEG (or other similar) format so that they can be emailed or
sent via instant
message to interested parties.
While specific embodiments have been described in detail in the foregoing
detailed
description and illustrated in the accompanying drawings, those with ordinary
skill in the art will
appreciate that various modifications and alternatives to those details could
be developed in light
of the overall teachings of the disclosure. It should be understood, that any
reference herein to the
term "or" is intended to mean an "inclusive or" or what is also known as a
"logical OR", wherein
when used as a logic statement, the expression "A or B" is true if either A or
B is true, or if both
A and B are true, and when used as a list of elements, the expression "A, B or
C" is intended to
include all combinations of the elements recited in the expression, for
example, any of the elements
selected from the group consisting of A, B, C, (A, B), (A, C), (B, C), and (A,
B, C); and so on if
additional elements are listed. Furthermore, it should also be understood that
the indefinite articles
"a" or "an", and the corresponding associated definite articles "the' or
"said", are each intended to
mean one or more unless otherwise stated, implied, or physically impossible.
Yet further, it should
be understood that the expressions "at least one of A and B, etc.", "at least
one of A or B, etc.",
"selected from A and B, etc." and "selected from A or B, etc." are each
intended to mean either
any recited element individually or any combination of two or more elements,
for example, any of
the elements from the group consisting of "A", "B", and "A AND B together",
etc. Yet further, it
-64-
CA 03137910 2021-10-22
WO 2020/219991 PCT/US2020/029970
should be understood that the expressions "one of A and B, etc." and "one of A
or B, etc." are each
intended to mean any of the recited elements individually alone, for example,
either A alone or B
alone, etc., but not A AND B together. Furthermore, it should also be
understood that unless
indicated otherwise or unless physically impossible, that the above-described
embodiments and
aspects can be used in combination with one another and are not mutually
exclusive. Accordingly,
the particular arrangements disclosed are meant to be illustrative only and
not limiting as to the
scope of the invention, which is to be given the full breadth of the appended
claims, and any and
all equivalents thereof
What is claimed is:
-65-