Note: Descriptions are shown in the official language in which they were submitted.
METHOD AND APPARATUS FOR CLICKHOUSE-BASED CROWD SELECTION
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the technical field of big data, and
more particularly to
a method and apparatus for Clickhouse-based crowd selection.
Description of Related Art
[0002] Currently, precise selection of crowd from massive internet data is
critical to successful
placement of advertising information. Usually, this can be achieved by tagging
user
characteristic behaviors, using the obtained tags as criteria to screen the
target crowd, and
placing real-time advertisement. Since advertising campaigns are usually
audience specific,
criteria used for screening different crowds are highly diverse.
[0003] Conventionally, off-line compute engines such as Elasticsearch and
spark are used to
determine this selection. However, as the business side has increasingly
demanding
requirements for computation performance in terms of crowd packages, these
existing
compute engines are becoming incompetent to satisfy users when it comes to
quasi real-time
performance. Besides, the data volume of selection criteria has now reached a
scale of
hundreds of millions, making data pulling extremely time-consuming, and this
is adverse to
business needs.
SUMMARY OF THE INVENTION
[0004] The objective of the present invention is to provide a method and an
apparatus for
Clickhouse-based crowd selection, which provide the business side with fast
and efficient
computation of crowd packages.
1
Date recue / Date received 202 1-1 1-26
[0005] To achieve the foregoing objective, in a first aspect, the present
invention provides a
method for Clickhouse-based crowd selection, which comprises:
[0006] configurating tag information to create spark tasks, and introducing
original-table data
of tags into a CH table of a Clickhouse engine according to configured
information items;
[0007] partitioning the CH table into aggregation tables of different types on
the basis of feature
types of tag values;
[0008] acquiring query tags from a user to generate sql query criteria, and
converting the sql
query criteria into Clickhouse query clauses; and
[0009] executing the Clickhouse query clauses parallelly by means of
multithreading, acquiring
query detail data from the aggregation tables of the corresponding types,
storing the detail
data into a Hive table, and obtaining crowd selection query results.
[0010] Preferably, the step of configurating tag information to create spark
tasks, and
introducing original-table data of tags into a CH table of a Clickhouse engine
according to
configured information items comprises:
[0011] configurating the tag information through a visual interface of a
business system,
wherein the tag information includes three kinds of configuration information
items and the
corresponding tag original-table data, wherein the three kinds of
configuration information
items are tag codes, tag names, and tag values; and
[0012] automatically creating spark tasks to process the tag original-table
data, and introducing
the tag original-table data into the CH table in the Clickhouse engine in
formats of tag codes,
tag names, and tag values.
[0013] More preferably, the step of based on feature types of tag values,
partitioning the CH
table into aggregation tables of different types comprises:
[0014] dividing the feature types of the tag values into an int type, a double
type, a string type,
and a date type; and
[0015] according to the feature types of the tag values in the tag original-
table data, partitioning
2
Date recue / Date received 202 1-1 1-26
the CH table correspondingly into an it-type tag-value aggregation table, a
double-type tag-
value aggregation table, a string-type tag-value aggregation table, and a date-
type tag-value
aggregation table.
[0016] Further, after the step of partitioning the CH table into aggregation
tables of different
types on the basis of feature types of tag values, the method further
comprises:
[0017] distributing the aggregation tables across nodes of the Clickhouse
engine, for
performing distributed query.
[0018] Preferably, the step of acquiring query tags from a user to generate
sql query criteria,
and converting the sql query criteria into Clickhouse query clauses comprises:
[0019] selecting the query tags through the visual interface of the business
system to form the
sql query criteria, and sending the sql query criteria to kafka; and
[0020] consuming sql query criteria data, receiving drop tables through
SparkStreaming tasks,
and converting the sql query criteria into the Clickhouse query clauses.
[0021] Preferably, the step of executing the Clickhouse query clauses
parallelly by means of
multithreading, acquiring query detail data from the aggregation tables of the
corresponding
types, storing the detail data into a Hive table, and obtaining crowd
selection query results
comprises:
[0022] using the Spark tasks to execute the Clickhouse query clauses
parallelly by means of
multithreading, while acquiring detail data from the corresponding aggregation
tables and
storing the detail data into the Hive table, so as to obtain the crowd
selection query results
through computation.
[0023] Preferably, after the step of executing the Clickhouse query clauses
parallelly by means
of multithreading, acquiring query detail data from the aggregation tables of
the
corresponding types, storing the detail data into a Hive table, and obtaining
crowd selection
query results, the method further comprises:
3
Date recue / Date received 202 1-1 1-26
[0024] storing the detail data of the Hive table into redis, for the business
system to use
according to business needs.
[0025] As compared to the prior art, the method for Clickhouse-based crowd
selection of the
present invention has the following beneficial effects:
[0026] With the disclosed method for Clickhouse-based crowd selection, a user
is enabled to
configure tag information through a back end of a business system and create
spark tasks.
Then the user can introduce original-table data of tags into a CH table of a
Clickhouse engine
according to configured information items. Afterward, according to feature
types of tag
values, a CH table in a Clickhouse engine can be partitioned into different
types of
aggregation table. Subsequently, the user can provide query tags to generate
sql query criteria.
The criteria are then converted into Clickhouse query clauses. By means of
multithreading,
the Clickhouse query clauses are executed parallelly. Query detail data are
acquired from
aggregation tables of the corresponding types, and stored into a Hive table,
so that crowd
selection query results can be obtained.
[0027] It is thus clear that the present invention uses a concept of
Clickhouse + Spark
computation to introduce the computation process for criteria of tag
combinations into a
Clickhouse engine, and use the combination of the Spark compute engine and the
Clickhouse
compute engine to generate the crowd package, thereby shortening the time
required by
computation of detail data satisfying the criteria of tag combinations from
minutes to seconds.
[0028] In a second aspect, the present invention provides an apparatus for
Clickhouse-based
crowd selection, which is applicable to the method for Clickhouse-based crowd
selection of
the foregoing technical scheme. The apparatus comprises:
[0029] a configuring unit, for configurating tag information to create spark
tasks, and
introducing original-table data of tags into a CH table of a Clickhouse engine
according to
configured information items;
[0030] a table-partitioning unit, for partitioning the CH table into
aggregation tables of different
4
Date recue / Date received 202 1-1 1-26
types on the basis of feature types of tag values;
[0031] a query unit, for acquiring query tags from a user to generate sql
query criteria, and
converting the sql query criteria into Clickhouse query clauses; and
[0032] a processing unit, for executing the Clickhouse query clauses
parallelly by means of
multithreading, acquiring query detail data from the aggregation tables of the
corresponding
types, storing the detail data into a Hive table, and obtaining crowd
selection query results.
[0033] Preferably, the table-partitioning unit is for dividing the feature
types of the tag values
into an int type, a double type, a string type, and a date type, according to
the feature types
of the tag values in the tag original-table data, partitioning the CH table
correspondingly into
an it-type tag-value aggregation table, a double-type tag-value aggregation
table, a string-
type tag-value aggregation table, and a date-type tag-value aggregation table.
[0034] As compared to the prior art, the disclosed apparatus for Clickhouse-
based crowd
selection provides beneficial effects that are similar to those provided by
the disclosed
method for Clickhouse-based crowd selection as enumerated above, and thus no
repetitions
are made herein.
[0035] In a third aspect, the present invention provides a computer-readable
storage medium,
storing thereon a computer program. When the computer program is executed by a
processor,
it implements the steps of the method for Clickhouse-based crowd selection as
described
previously.
[0036] As compared to the prior art, the disclosed computer-readable storage
medium provides
beneficial effects that are similar to those provided by the disclosed method
for Clickhouse-
based crowd selection as enumerated above, and thus no repetitions are made
herein.
BRIEF DESCRIPTION OF THE DRAWINGS
[0037] The accompanying drawings are provided herein for better understanding
of the present
invention and form a part of this disclosure. The illustrative embodiments and
their
Date recue / Date received 202 1-1 1-26
descriptions are for explaining the present invention and by no means form any
improper
limitation to the present invention, wherein:
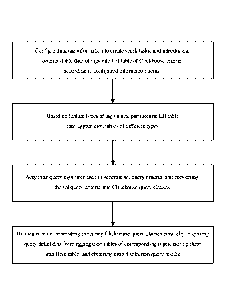
[0038] FIG. 1 is a flowchart of the method for Clickhouse-based crowd
selection of one
embodiment of the present invention;
[0039] FIG. 2 is a schematic drawing illustrating that a CH table is
partitioned into four types
of aggregation tables according to an embodiment of the present invention; and
[0040] FIG. 3 is another flowchart of the method for Clickhouse-based crowd
selection of the
embodiment of the present invention.
DETAILED DESCRIPTION OF THE INVENTION
[0041] To make the foregoing objectives, features, and advantages of the
present invention
clearer and more understandable, the following description will be directed to
some
embodiments as depicted in the accompanying drawings to detail the technical
schemes
disclosed in these embodiments. It is, however, to be understood that the
embodiments
referred herein are only a part of all possible embodiments and thus not
exhaustive. Based on
the embodiments of the present invention, all the other embodiments can be
conceived
without creative labor by people of ordinary skill in the art, and all these
and other
embodiments shall be embraced in the scope of the present invention.
Embodiment 1
[0042] Referring to FIG. 1 through FIG. 3, the present embodiment provides a
method for
Clickhouse-based crowd selection that comprises:
[0043] configurating tag information to create spark tasks, and introducing
original-table data
of tags into a CH table of a Clickhouse engine according to configured
information items;
partitioning the CH table into aggregation tables of different types on the
basis of feature
types of tag values; acquiring query tags from a user to generate sql query
criteria, and
converting the sql query criteria into Clickhouse query clauses; and by means
of
multithreading executing the Clickhouse query clauses parallelly, acquiring
query detail data
from the aggregation tables of the corresponding types, storing the detail
data into a Hive
6
Date recue / Date received 202 1-1 1-26
table, and obtaining crowd selection query results.
[0044] With the disclosed method for Clickhouse-based crowd selection, a user
is enabled to
configure tag information through a back end of a business system and create
spark tasks.
Then the user can introduce original-table data of tags into a CH table of a
Clickhouse engine
according to configured information items. Afterward, according to feature
types of tag
values, a CH table in a Clickhouse engine can be partitioned into different
types of
aggregation table. Subsequently, the user can provide query tags to generate
sql query criteria.
The criteria are then converted into Clickhouse query clauses. By means of
multithreading,
the Clickhouse query clauses are executed parallelly. Query detail data are
acquired from
aggregation tables of the corresponding types, and stored into a Hive table,
so that crowd
selection query results can be obtained.
[0045] It is thus clear that the present invention uses a concept of
Clickhouse + Spark
computation to introduce the computation process for criteria of tag
combinations into a
Clickhouse engine, and use the combination of the Spark compute engine and the
Clickhouse
compute engine to generate the crowd package, thereby shortening the time
required by
computation of detail data satisfying the criteria of tag combinations from
minutes to seconds.
[0046] In the foregoing embodiment, the step of configurating tag information
to create spark
tasks, and introducing original-table data of tags into a CH table of a
Clickhouse engine
according to configured information items comprises:
[0047] configurating the tag information through a visual interface of a
business system,
wherein the tag information includes three kinds of configuration information
items and the
corresponding tag original-table data, wherein the three kinds of
configuration information
items are tag codes, tag names, and tag values; and automatically creating
spark tasks to
process the tag original-table data, and introducing the tag original-table
data into the CH
table in the Clickhouse engine in formats of tag codes, tag names, and tag
values.
7
Date recue / Date received 202 1-1 1-26
[0048] In a particular implementation, the information items may include three
types, namely
tag codes, tag names, and tag values. For instance, if it is desired to know
preferences of male
members about some merchandise item, the tag code, tag name, and tag value of
the
information items are set as labelname, labelvalue, and userid, respectively.
Then the tag
original-table data are introduced into the CH table in the formats of the
foregoing
information items. For an example where one of the entries of the CH table is
labelname =A,
then labelvalue =male(1), userid=[1,2,3,4].
[0049] As a further example, in order to query a crowd package of 18-year-old
male members,
a user may, through the back end of the business system, visually configure a
tag A=gender
(labelname=A, labelvalue=1 representing male), and a tag B= age (labelname=B,
labelvalue=18), so as to obtain the sql query criteria of "age=18 && gender
=male." Then,
data of male members and data of 18-year-old members are acquired from the
corresponding
aggregation tables. These data are assembled and computed before fed back to
the user as the
query results for crowd selection.
[0050] In the foregoing embodiment, the step of based on feature types of tag
values,
partitioning the CH table into aggregation tables of different types
comprises:
[0051] dividing the feature types of the tag values into an int type, a double
type, a string type,
and a date type; and according to the feature types of the tag values in the
tag original-table
data, partitioning the CH table correspondingly into an it-type tag-value
aggregation table,
a double-type tag-value aggregation table, a string-type tag-value aggregation
table, and a
date-type tag-value aggregation table.
[0052] As shown in FIG. 2, in a particular implementation, through the back
end of the business
system, the commonly used tag values are divided into four types, namely the
int type, the
double type, the string type, and the date type, so as to satisfy diverse
business needs about
query criteria. Then according to the feature types of the tag values in the
tag original-table
data, the CH table can correspondingly be partitioned into the it-type tag-
value aggregation
8
Date recue / Date received 202 1-1 1-26
table, the double-type tag-value aggregation table, the string-type tag-value
aggregation table,
and the date-type tag-value aggregation table. This is to say that all the tag
values in the int-
type tag-value aggregation table are of the int type, and all the tag values
in the double-type
tag-value aggregation table are of the double type, and so on.
[0053] For example, for checking the access count, the relevant tag values are
obviously of the
int type, and the conditional operators for crowd package data are count
days>= '15' and
count days<'30'. In other words, it is to query for the access count generated
between the
date of 15 and the date of 30.
[0054] For example, for checking the coordinate locations of users, the
relevant tag values are
obviously of the double type. This type is suitable for queries of coordinate
locations, and
helps select a member crowd in a certain latitude-longitude coordinate range.
[0055] For example, for checking member levels of users, the relevant tag
values are obviously
of the string type. This type is favorable to precise query matching.
[0056] For example, for checking access dates of users, the relevant tag
values are obviously of
the date type. This type is suitable for comparison of dates, such as criteria
for crowd
packages like a first-for-purchase time later than a certain date.
[0057] To satisfy business needs, in the present embodiment, four types of CH
aggregation
tables are introduced, with the following table structures:
Field Type Description
labelname String Tag Code
labelvalue String/Int64/double/Date Tag Value
uv AggregateFunction(groupBitmap, Bitmap generated from
unique
UInt64) aggregation function numbers of members
9
Date recue / Date received 202 1-1 1-26
[0058] As can be seen, all labelname fields are of the String type. This is
usually used to express
a tag code. The labelvalue fields may be of the String type, the Int type, the
double type, or
the Date type, usually for expressing a tag value. uv is usually used to
express a tag name.
[0059] With the four types of aggregation tables, data can be acquired from
corresponding types
of CH aggregation tables according to business needs automatically for
subsequent
computation, thereby significantly improving computation performance of the
system.
[0060] For example, for tags related to the number of days users sleep for,
the criteria are
described as users sleeping for more than a certain number of days or fewer
than a certain
number of days, i.e., count days>= '15' and count days<'30'. The aggregation
tables of the
Int type are correspondingly selected for data acquiring and to support data
operators.
[0061] In the foregoing embodiment, after the step of partitioning the CH
table into aggregation
tables of different types on the basis of feature types of tag values, the
method further
comprises: distributing the aggregation tables across nodes of the Clickhouse
engine, for
performing distributed query.
[0062] In a particular implementation, since the aggregation tables are local
tables distributed
across nodes of the Clickhouse engine, a distributed table directing to the
aggregation tables
at the nodes may be used to realize distributed query computation. As
demonstrated in tests,
when tag data were introduced into a Clickhouse engine from an original table
(such as
HDFS), the standalone performance was 1 million/sec, showing linear expansion
in terms of
performance. It was also found through actual measurement that 50 billion data
could be
introduced into the CH table in one hour. The measurement was performed in a
Clickhouse
cluster environment, with the following machine configuration: 32 cores, 256G,
4T drive,
using a cluster of 6 machines.
Date recue / Date received 202 1-1 1-26
[0063] In the foregoing embodiment, the step of acquiring query tags from a
user to generate
sql query criteria, and converting the sql query criteria into Clickhouse
query clauses
comprises:
[0064] selecting the query tags through the visual interface of the business
system to form the
sql query criteria, and sending the sql query criteria to kafka; and consuming
sql query criteria
data, receiving drop tables through SparkStreaming tasks, and converting the
sql query
criteria into the Clickhouse query clauses.
[0065] In the foregoing embodiment, the step of executing the Clickhouse query
clauses
parallelly by means of multithreading, acquiring query detail data from the
aggregation tables
of the corresponding types, storing the detail data into a Hive table, and
obtaining crowd
selection query results comprises:
[0066] using the Spark tasks to execute the Clickhouse query clauses
parallelly by means of
multithreading, while acquiring detail data from the corresponding aggregation
tables and
storing the detail data into the Hive table, so as to obtain the crowd
selection query results
through computation.
[0067] In the foregoing embodiment, after the step of executing the Clickhouse
query clauses
parallelly by means of multithreading, acquiring query detail data from the
aggregation tables
of the corresponding types, storing the detail data into a Hive table, and
obtaining crowd
selection query results, the method further comprises:
[0068] storing the detail data of the Hive table into redis, for the business
system to use
according to business needs.
[0069] Referring to FIG. 3, for easy understanding, an example is used to
explain the scheme
as discussed in the foregoing embodiment:
[0070] A user may select query tags through the page of the business system to
generate sql
query criteria and send them to kafka. SparkStreaming consumes the
corresponding kafka
data and converts sql into Clickhouse query clauses that are then stored into
Mysql. Spark
11
Date recue / Date received 202 1-1 1-26
tasks read Clickhouse query clauses from Mysql. Afterward, by means of
multithreading, the
Clickhouse query clauses are executed parallelly to query detail data from the
CH aggregation
tables corresponding to the distributed nodes. The detail data are then stored
into a Hive table
for the business system to query and use, thereby outputting crowd selection
query results.
In addition, the detail data in the hive table may be transferred to redis
according to business
needs, so as to provide the business system with other query services.
[0071] To sum up, the present embodiment has the following innovations:
1. The present invention uses a concept of Clickhouse + Spark
computation to introduce
the computation process for criteria of tag combinations into a Clickhouse
engine,
and use the combination of the Spark compute engine and the Clickhouse compute
engine to generate the crowd package, thereby shortening the time required by
computation of detail data satisfying the criteria of tag combinations from
minutes to
seconds.
2. Addition or removal of tags can be visually configured through the back end
of the
business system, thereby eliminating hassles about complicated operations for
adding
or removing tags.
3. The present invention leverages the benefits of Clickhouse to solve issues
about
aggregation performance related to large volume of data, thereby providing
better
user experience.
4. The present invention saves hardware resources. According to early-stage
assessment,
Clickhouse only needs half of the hardware computation resources required by
elasticsearch. As to storage capacity, for identical data, one Clickhouse
machine is
equivalent to 27 elasticsearch machines.
Embodiment 2
[0072] The present embodiment provides a Clickhouse-based crowd selection
apparatus, which
comprises:
[0073] a configuring unit, for configurating tag information to create spark
tasks, and
12
Date recue / Date received 202 1-1 1-26
introducing original-table data of tags into a CH table of a Clickhouse engine
according to
configured information items;
[0074] a table-partitioning unit, for based on feature types of tag values,
partitioning the CH
table into aggregation tables of different types;
[0075] a query unit, for acquiring query tags from a user to generate sql
query criteria, and
converting the sql query criteria into Clickhouse query clauses; and
[0076] a processing unit, for executing the Clickhouse query clauses
parallelly by means of
multithreading, acquiring query detail data from the aggregation tables of the
corresponding
types, storing the detail data into a Hive table, and obtaining crowd
selection query results.
[0077] Preferably, the table-partitioning unit is for dividing the feature
types of the tag values
into an int type, a double type, a string type, and a date type, according to
the feature types
of the tag values in the tag original-table data, partitioning the CH table
correspondingly into
an it-type tag-value aggregation table, a double-type tag-value aggregation
table, a string-
type tag-value aggregation table, and a date-type tag-value aggregation table.
[0078] As compared to the prior art, the disclosed apparatus for Clickhouse-
based crowd
selection provides beneficial effects that are similar to those provided by
the method for
Clickhouse-based crowd selection as enumerated above, and thus no repetitions
are made
herein.
Embodiment 3
[0079] The present embodiment provides a computer-readable storage medium,
storing thereon
a computer program. When the computer program is executed by a processor, it
implements
the steps of the method for Clickhouse-based crowd selection as described
previously.
[0080] As compared to the prior art, the disclosed computer-readable storage
medium provides
beneficial effects that are similar to those provided by the disclose method
as enumerated
above, and thus no repetitions are made herein.
13
Date recue / Date received 202 1-1 1-26
[0081] As will be appreciated by people of ordinary skill in the art,
implementation of all or a
part of the steps of the method of the present invention as described
previously may be
realized by having a program instruct related hardware components. The program
may be
stored in a computer-readable storage medium, and the program is about
performing the
individual steps of the methods described in the foregoing embodiments. The
storage medium
may be a ROM/RAM, a magnetic disk, an optical disk, a memory card or the like.
[0082] The present invention has been described with reference to the
preferred embodiments
and it is understood that the embodiments are not intended to limit the scope
of the present
invention. Moreover, as the contents disclosed herein should be readily
understood and can
be implemented by a person skilled in the art, all equivalent changes or
modifications which
do not depart from the concept of the present invention should be encompassed
by the
appended claims. Hence, the scope of the present invention shall only be
defined by the
appended claims.
14
Date recue / Date received 202 1-1 1-26