Note: Descriptions are shown in the official language in which they were submitted.
CA 03165582 2022-06-21
DATA PROCESSING METHOD AND SYSTEM BASED ON SIMILARITY MODEL
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the field of big data analysis
technology, and more
particularly to a data processing method and a data processing system based on
a
similarity model.
Description of Related Art
[0002] Being one of the kernel viewpoints in the network marketing conception
with attitude,
precision marketing is based on precision positioning, and relies on the
modern
information technical means, big data technology in particular, to create a
customized
customer communication service system, to enhance efficiencies of
communication and
service by the enterprise with respect to customers, and to reduce operational
cost.
Winning over and converting are two principal processes of internet operation,
of which
winning over means to promulgate internet products, expose brands, and develop
new
users of the products. Converting means to convert low consumption value users
of
internet products to high value users, namely to promote consumption behaviors
of users
in the internet products, and to enhance operational achievements of the
enterprise.
[0003] Means for winning over and converting in the state of the art are
mostly based on blind
advertising promotion, but it has been found in practice that, since target
users are
indefinite, what the large input in advertisement brings about is only a
limited number of
users won over and converted, whereby there is an obvious contradiction
between the
advertisement cost as input and the conversion rate as acquired, thus exposing
the
deficiencies of high cost and low efficiency in the state of the art where
users are won
1
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
over and converted through the mode of blind advertising promotion.
SUMMARY OF THE INVENTION
[0004] An objective of the present invention it is to provide a data
processing method and a data
processing system based on a similarity model, employs data processing
technical means
based on a similarity model, and can effectively enhance the conversion rate
of customers
with decreased cost.
[0005] In order to achieve the above objective, according to one aspect, the
present invention
provides a data processing method based on a similarity model, the method
comprises:
[0006] collecting plural pieces of customer data, wherein the customer data
are positive-sample
data or negative-sample data;
[0007] extracting continuous label data from each piece of customer data,
subjecting the same
data to binning transformation to thereafter correspondingly obtain plural
groups of
discrete label data;
[0008] sequentially performing similarity distance calculation on a discrete
factor in each group
of discrete label data, and simultaneously screening out plural groups of new
discrete
label data consisting of prominently contributive discrete factors;
[0009] employing a random forest algorithm and a gradient boosting decision
tree algorithm to
respectively perform weight calculation on discrete factors in the new
discrete label data,
and obtaining weight results of plural groups of discrete factors after
weighted summation;
[0010] employing a Manhattan distance algorithm to calculate a final
similarity distance between
each piece of customer data and the positive-sample data on the basis of the
weight results
of the various groups of discrete factors and similarity distances of the
various discrete
factors; and
[0011] screening out any potential customer according to the final similarity
distances.
[0012] Preferably, the step of extracting continuous label data from each
piece of customer data,
2
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
subjecting the same data to binning transformation to thereafter
correspondingly obtain
plural groups of discrete label data includes:
[0013] performing label feature extraction on each piece of customer data, and
obtaining plural
groups of continuous label initial data;
[0014] performing data cleaning with respect to the various groups of
continuous label initial
data, and retaining continuous label data after having removed any invalid
label feature
therefrom; and
[0015] employing an optimum binning strategy to perform optimum binning
processing on the
various pieces of continuous label data respectively, and correspondingly
obtaining plural
groups of discrete label data, wherein each group of discrete label data
includes plural
label features discrete from one another.
[0016] Preferably, the step of performing data cleaning with respect to the
various groups of
continuous label initial data, and retaining continuous label data after
having removed
any invalid label feature therefrom includes:
[0017] cleaning and filtering invalid label features in the various groups of
continuous label
initial data sequentially in accordance with a missing rate filter condition,
a tantile filter
condition, and a proportion of categories filter condition of the label data,
and
correspondingly obtaining plural groups of continuous label data.
[0018] Preferably, the step of sequentially performing similarity distance
calculation on a
discrete factor in each group of discrete label data, and simultaneously
screening out
plural groups of new discrete label data consisting of prominently
contributive discrete
factors includes:
[0019] employing an evidence weight algorithm to perform similarity distance
calculation on
variables of various discrete factors in one group of discrete label data;
[0020] calculating an IV value to which each discrete factor corresponds
through an information
value formula, and screening out discrete factors with high value degrees on
the basis of
sizes of the IV values;
3
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0021] employing a Lasso regression algorithm to screen discrete factors with
high identification
degrees out of the discrete factors with high value degrees;
[0022] employing a ridge regression algorithm to further screen discrete
factors with prominent
importance out of the discrete factors with high identification degrees, and
constituting
plural groups of new discrete label data consisting of prominently
contributive discrete
factors; and
[0023] respectively invoking other groups of discrete label data to repeat the
above calculating
steps, and correspondingly obtaining plural groups of new discrete label data.
[0024] Preferably, the step of employing a random forest algorithm and a
gradient boosting
decision tree algorithm to respectively perform weight calculation on discrete
factors in
the new discrete label data, and obtaining weight results of plural groups of
discrete
factors after weighted summation includes:
[0025] selecting data in a positive sample as a target variable, taking the
discrete factor in each
piece of discrete label data as a dependent variable, and employing the random
forest
algorithm to calculate importance indices of various variables of the discrete
factors in
the various pieces of discrete label data;
[0026] selecting data in a positive sample as a target variable, taking the
discrete factor in each
piece of discrete label data as a dependent variable, and employing the
gradient boosting
decision tree algorithm to calculate importance indices of various variables
of the discrete
factors in the various pieces of discrete label data; and
[0027] performing weighted assignment on the importance indices of the various
variables of the
discrete factors obtained by employing the random forest algorithm and on the
importance indices of the various variables of the discrete factors obtained
by employing
the gradient boosting decision tree algorithm in the same piece of discrete
label data, and
thereafter performing summation to obtain weight results of plural groups of
discrete
factors.
[0028] Preferably, the step of employing a Manhattan distance algorithm to
calculate a final
4
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
similarity distance between each piece of customer data and the positive-
sample data on
the basis of the weight results of the various groups of discrete factors and
similarity
distances of the various discrete factors includes:
[0029] multiplying the weight results of the various groups of discrete
factors with the similarity
distances of the various discrete factors, and calculating a similarity
distance between
each discrete factor in the customer data and the positive-sample data; and
[0030] employing the Manhattan distance algorithm to summate the similarity
distances of all
discrete factors in each piece of customer data, and obtaining a final
similarity distance
between each piece of customer data and the positive-sample data.
[0031] Exemplarily, the step of screening out any potential customer according
to the final
similarity distances includes:
[0032] reversely arranging the final similarity distances according to value
sizes, screening out
top-ranking N pieces of customer data and marking the same as potential
customers.
[0033] In comparison with prior-art technology, the marketing method based on
a similarity
model provided by the present invention achieves the following advantageous
effects:
[0034] In the data processing method based on a similarity model provided by
the present
invention, plural pieces of customer data are collected to construct a
dataset, the dataset
contains positive-sample data of converted customers and negative-sample data
of not
converted customers, the label data of each piece of customer data in the
dataset is
thereafter correspondingly output to obtain plural groups of continuous label
data, at this
time, in order to verify each label feature in the continuous label data,
namely the
prominence of contribution of each discrete factor to the model, it is further
needed to
employ a binning transformation method to subject the various groups of
continuous label
data respectively to discrete processing, and to correspondingly obtain plural
groups of
discrete label data, in which one discrete factor in the discrete label data
represents one
label feature, and by performing similarity distance calculation on the
discrete factors in
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
each group of discrete label data, it is realized to score the various
discrete factors, for
instance, the smaller the value of the calculation result of a discrete factor
is, this indicates
the closer will be the discrete factor to the contribution degree of the
positive-sample data,
otherwise it indicates the farther will be the discrete factor to the
contribution degree of
the positive-sample data, until similarity distance calculations on the
discrete factors in
the various groups of discrete label data have been completed, obviously
invalid discrete
factors are eliminated from the various groups of discrete label data to form
plural groups
of prominently contributive discrete label data, the random forest algorithm
and the
gradient boosting decision tree algorithm are thereafter respectively employed
to
calculate importance indices of variables of various discrete factors in each
group of
discrete label data, weighted summation is performed on the calculation
results of the two
algorithms to thereafter obtain weight results of the discrete factors, and
the Manhattan
distance algorithm is finally employed to calculate a final similarity
distance between
each piece of customer data and the positive-sample data on the basis of the
weight results
of the various groups of discrete factors and similarity distances of the
various discrete
factors, to realize value estimation of each piece of customer data. As easily
understandable, the smaller the final similarity distance is, the closer will
be to the
positive-sample data, and the higher will be the value of such customers, in
other words,
they are more likely to be converted to converted customers; to the contrary,
the larger
the final similarity distance is, the farther will be to the positive-sample
data, and the
lower will be the value of such customers, in other words, they are less
likely to be
converted to converted customers, till now, it is possible to screen out
potential customers
that meet the requirement according to the final similarity distance of each
customer, and
to hence carry out precision marketing on them.
[0035] Seen as such, the present invention brings about the following
technical effects to winning
over and converting of platform businesses:
[0036] Through the design of customer value degree appraising function, it is
made possible to
provide marketing activities of platforms with customer data support; relative
to the blind
6
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
advertising promotion in the state of the art, the present invention markedly
reduces
promotion cost of marketing activities at the same time of enhancing
conversion rate of
customers, and guarantees effects of the marketing activities.
[0037] Use of the similarity model can pertinently calculate the final
similarity distance of each
piece of customer data in accordance with label features in different customer
data, hence
appraise the value degree of each piece of customer data, and accurately
screen out
potential high-value customers.
[0038] According to another aspect, the present invention provides a data
processing system
based on a similarity model, the system is applied in the data processing
method based
on a similarity model as recited in the foregoing technical solution, and the
system
comprises:
[0039] an information collecting unit, for collecting plural pieces of
customer data, wherein the
customer data are positive-sample data or negative-sample data;
[0040] a binning transforming unit, for extracting continuous label data from
each piece of
customer data, subjecting the same data to binning transformation to
thereafter
correspondingly obtain plural groups of discrete label data;
[0041] a label screening unit, for sequentially performing similarity distance
calculation on a
discrete factor in each group of discrete label data, and simultaneously
screening out
plural groups of new discrete label data consisting of prominently
contributive discrete
factors;
[0042] a weight calculating unit, for employing a random forest algorithm and
a gradient
boosting decision tree algorithm to respectively perform weight calculation on
discrete
factors in the new discrete label data, and obtaining weight results of plural
groups of
discrete factors after weighted summation;
[0043] a similarity distance calculating unit, for employing a Manhattan
distance algorithm to
calculate a final similarity distance between each piece of customer data and
the positive-
sample data on the basis of the weight results of the various groups of
discrete factors and
similarity distances of the various discrete factors; and
7
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0044] a marketing unit, for screening out any potential customer according to
the final similarity
distances.
[0045] Preferably, the binning transforming unit includes:
[0046] an initial data extracting module, for performing label feature
extraction on each piece of
customer data, and obtaining plural groups of continuous label initial data;
[0047] a data cleaning module, for performing data cleaning with respect to
the various groups
of continuous label initial data, and retaining continuous label data after
having removed
any invalid label feature therefrom; and
[0048] a binning processing module, for employing an optimum binning strategy
to perform
optimum binning processing on the various pieces of continuous label data
respectively,
and correspondingly obtaining plural groups of discrete label data, wherein
each group
of discrete label data includes plural label features discrete from one
another.
[0049] Preferably, the label screening unit includes:
[0050] an evidence weight algorithm module, for employing an evidence weight
algorithm to
perform similarity distance calculation on variables of various discrete
factors in one
group of discrete label data;
[0051] an information value calculating module, for calculating an IV value to
which each
discrete factor corresponds through an information value formula, and
screening out
discrete factors with high value degrees on the basis of sizes of the IV
values;
[0052] a Lasso regression algorithm module, for employing a Lasso regression
algorithm to
screen discrete factors with high identification degrees out of the discrete
factors with
high value degrees; and
[0053] a ridge regression algorithm module, for employing a ridge regression
algorithm to
further screen discrete factors with prominent importance out of the discrete
factors with
high identification degrees, and constituting plural groups of new discrete
label data
consisting of prominently contributive discrete factors.
8
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0054] Preferably, the weight calculating unit includes:
[0055] a random forest algorithm module, for selecting data in a positive
sample as a target
variable, taking the discrete factor in each piece of discrete label data as a
dependent
variable, and employing a random forest algorithm to calculate importance
indices of
various variables of the discrete factors in the various pieces of discrete
label data;
[0056] a gradient boosting decision tree algorithm module, for selecting data
in a positive sample
as a target variable, taking the discrete factor in each piece of discrete
label data as a
dependent variable, and employing a gradient boosting decision tree algorithm
to
calculate importance indices of various variables of the discrete factors in
the various
pieces of discrete label data; and
[0057] a weighted assignment module, for performing weighted assignment on the
importance
indices of the various variables of the discrete factors obtained by employing
the random
forest algorithm and on the importance indices of the various variables of the
discrete
factors obtained by employing the gradient boosting decision tree algorithm in
the same
piece of discrete label data, and thereafter performing summation to obtain
weight results
of plural groups of discrete factors.
[0058] Preferably, the similarity distance calculating unit includes:
[0059] a label feature similarity distance module, for multiplying the weight
results of the various
groups of discrete factors with the similarity distances of the various
discrete factors, and
calculating a similarity distance between each discrete factor in the customer
data and the
positive-sample data; and
[0060] a customer data similarity distance module, for employing the Manhattan
distance
algorithm to summate the similarity distances of all discrete factors in each
piece of
customer data, and obtaining a final similarity distance between each piece of
customer
data and the positive-sample data.
[0061] In comparison with prior-art technology, the advantageous effects
achieved by the data
processing system based on a similarity model provided by the present
invention are
9
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
identical with the advantageous effects achievable by the data processing
method based
on a similarity modal provided by the foregoing technical solution, so these
are not
redundantly described in this context.
BRIEF DESCRIPTION OF THE DRAWINGS
[0062] The drawings described here are meant to provide further understanding
of the present
invention, and constitute part of the present invention. The exemplary
embodiments of
the present invention and the descriptions thereof are meant to explain the
present
invention, rather than to restrict the present invention. In the drawings:
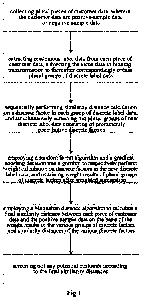
[0063] Fig. 1 is a flowchart schematically illustrating a data processing
method based on a
similarity model in Embodiment 1 of the present invention;
[0064] Fig. 2 is an exemplary view illustrating customer data in Fig. 1; and
[0065] Fig. 3 is a block diagram illustrating the structure of a data
processing system based on a
similarity model in Embodiment 2 of the present invention.
[0066] Reference numerals:
[0067] 1 ¨ information collecting unit 2 ¨ binning transforming unit
[0068] 3 ¨ label screening unit 4 ¨ weight calculating unit
[0069] 5 ¨ similarity distance calculating unit 6 ¨ marketing unit
[0070] 21 ¨ initial data extracting module 22¨ data cleaning module
[0071] 23 ¨ binning processing module 31 ¨ evidence weight algorithm
module
[0072] 32 ¨ information value calculating module 33 ¨ Lasso regression
algorithm module
[0073] 34 ¨ ridge regression algorithm module 41 ¨ random forest algorithm
module
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0074] 42 ¨ gradient boosting decision tree 43 ¨ weighted assignment module
algorithm module
[0075] 51 ¨ weighted assignment module 52
¨ customer data similarity distance
module
DETAILED DESCRIPTION OF THE INVENTION
[0076] To make more lucid and clear the objectives, features and advantages of
the present
invention, the technical solutions in the embodiments of the present invention
are clearly
and comprehensively described below with reference to the accompanying
drawings in
the embodiments of the present invention. Apparently, the embodiments as
described are
merely partial, rather than the entire, embodiments of the present invention.
All other
embodiments obtainable by persons ordinarily skilled in the art on the basis
of the
embodiments in the present invention without spending creative effort shall
all fall within
the protection scope of the present invention.
[0077] Embodiment 1
[0078] Fig. 1 is a flowchart schematically illustrating a data processing
method based on a
similarity model in Embodiment 1 of the present invention. Please refer to
Fig. 1, the data
processing method based on a similarity model provided by this embodiment
comprises:
[0079] collecting plural pieces of customer data, wherein the customer data
are positive-sample
data or negative-sample data; extracting continuous label data from each piece
of
customer data, subjecting the same data to binning transformation to
thereafter
correspondingly obtain plural groups of discrete label data; sequentially
performing
similarity distance calculation on a discrete factor in each group of discrete
label data,
and simultaneously screening out plural groups of new discrete label data
consisting of
prominently contributive discrete factors; employing a random forest algorithm
and a
gradient boosting decision tree algorithm to respectively perform weight
calculation on
11
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
discrete factors in the new discrete label data, and obtaining weight results
of plural
groups of discrete factors after weighted summation; employing a Manhattan
distance
algorithm to calculate a final similarity distance between each piece of
customer data and
the positive-sample data on the basis of the weight results of the various
groups of discrete
factors and similarity distances of the various discrete factors; and
screening out any
potential customer according to the final similarity distances.
[0080] In the data processing method based on a similarity model provided by
this embodiment,
plural pieces of customer data are collected to construct a dataset, the
dataset contains
positive-sample data of converted customers and negative-sample data of not
converted
customers, the label data of each piece of customer data in the dataset is
thereafter
correspondingly output to obtain plural groups of continuous label data, at
this time, in
order to verify each label feature in the continuous label data, namely the
prominence of
contribution of each discrete factor to the model, it is further needed to
employ a binning
transformation method to subject the various groups of continuous label data
respectively
to discrete processing, and to correspondingly obtain plural groups of
discrete label data,
in which one discrete factor in the discrete label data represents one label
feature, and by
performing similarity distance calculation on the discrete factors in each
group of discrete
label data, it is realized to score the various discrete factors, for
instance, the smaller the
value of the calculation result of a discrete factor is, this indicates the
closer will be the
discrete factor to the contribution degree of the positive-sample data,
otherwise it
indicates the farther will be the discrete factor to the contribution degree
of the positive-
sample data, until similarity distance calculations on the discrete factors in
the various
groups of discrete label data have been completed, obviously invalid discrete
factors are
eliminated from the various groups of discrete label data to form plural
groups of
prominently contributive discrete label data, the random forest algorithm and
the gradient
boosting decision tree algorithm are thereafter respectively employed to
calculate
importance indices of variables of various discrete factors in each group of
discrete label
data, weighted summation is performed on the calculation results of the two
algorithms
12
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
to thereafter obtain weight results of the discrete factors, and the Manhattan
distance
algorithm is finally employed to calculate a final similarity distance between
each piece
of customer data and the positive-sample data on the basis of the weight
results of the
various groups of discrete factors and similarity distances of the various
discrete factors,
to realize value estimation of each piece of customer data. As easily
understandable, the
smaller the final similarity distance is, the closer will be to the positive-
sample data, and
the higher will be the value of such customers, in other words, they are more
likely to be
converted to converted customers; to the contrary, the larger the final
similarity distance
is, the farther will be to the positive-sample data, and the lower will be the
value of such
customers, in other words, they are less likely to be converted to converted
customers, till
now, it is possible to screen out potential customers that meet the
requirement according
to the final similarity distance of each customer, and to hence carry out
precision
marketing on them.
[0081] Seen as such, this embodiment brings about the following technical
effects to winning
over and converting of platform businesses:
[0082] 1. Through the design of customer value degree appraising function, it
is made possible
to provide marketing activities of platforms with customer data support;
relative to the
blind advertising promotion in the state of the art, this embodiment markedly
reduces
promotion cost of marketing activities at the same time of enhancing
conversion rate of
customers, and guarantees effects of the marketing activities.
[0083] 2. Use of the similarity model can pertinently calculate the final
similarity distance of
each piece of customer data in accordance with label features in different
customer data,
hence appraise the value degree of each piece of customer data, and accurately
screen out
potential high-value customers.
[0084] To facilitate comprehension, please refer to Fig. 2, financial platform
financing is taken
for example for description, customer data can be collected from a database of
the
financial platform, in which positive-sample data means data of quality
customers who
13
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
have bought financing products, while negative-sample data means data of
common
customers who have not bought any financing product; during the process of
collecting
positive-sample data and negative-sample data, a timeline point is firstly
selected, and a
period of time after the timeline point is then taken as a performance period,
data of
customers who have bought financing products within the performance period is
defined
as positive-sample data, and data of customers who have not bought any
financing
product within the performance period is defined as negative-sample data, more
specifically, the positive-sample data and the negative-sample data both
contain
identification feature attribute discrete factors, such as account numbers of
Yihubao,
member genders, and member birth dates, etc., historical consumption behavior
attribute
discrete factors, such as latest shopping payment dates, latest water fee
recharging dates,
and latest electricity fee recharging dates, etc., member assets status
attribute discrete
factors, such as recent subscription amounts at Change Treasure, recent
subscription
amounts for funds, and subscription amounts for periodical financing, etc.,
and online
behavior trajectory attribute discrete factors, such as numbers of in-depth
financing pages
accessed by members, numbers of in-depth crowd-funding pages accessed by
members,
and numbers of in-depth insurance pages accessed by members, etc.
[0085] The method of extracting continuous label data from each piece of
customer data,
subjecting the same data to binning transformation to thereafter
correspondingly obtain
plural groups of discrete label data in the foregoing embodiment includes:
[0086] performing label feature extraction on each piece of customer data, and
obtaining plural
groups of continuous label initial data; performing data cleaning with respect
to the
various groups of continuous label initial data, and retaining continuous
label data after
having removed any invalid label feature therefrom; employing an optimum
binning
strategy to perform optimum binning processing on the various pieces of
continuous label
data respectively, and correspondingly obtaining plural groups of discrete
label data,
wherein each group of discrete label data includes plural label features
discrete from one
another.
14
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0087] Specifically, the method of performing data cleaning with respect to
the various groups
of continuous label initial data, and retaining continuous label data after
having removed
any invalid label feature therefrom includes: cleaning and filtering invalid
label features
in the various groups of continuous label initial data sequentially in
accordance with a
missing rate filter condition, a tantile filter condition, and a proportion of
categories filter
condition of the label data, and correspondingly obtaining plural groups of
continuous
label data.
[0088] During the process of specific implementation, the entire label
features in the various
groups of continuous label initial data are firstly counted, and label
features that do not
satisfy the missing rate filter condition are then cleaned away from the label
features, for
instance, the missing rate filter condition can be so set that label features
with missing
rate exceeding 90% are to be cleaned away, afterwards label features that do
not satisfy
the tantile filter condition are then cleaned away from the remaining label
features, for
instance, the tantile filter condition can be so set that label features with
tantile being
smaller than or equal to 0.1 are to be cleaned away, thereafter label features
that do not
satisfy the missing rate filter condition are again cleaned away from the
remaining label
features, and continuous label data is finally output; the above steps are
repeated to
perform data cleaning with respect to the various groups of continuous label
initial data
respectively, and plural groups of continuous label data can be
correspondingly obtained.
This embodiment makes it possible to remove invalid label features through the
data
cleaning steps, whereby it is avoided that noises as occur should reduce the
precision of
the model.
[0089] Moreover, the method of employing an optimum binning strategy to
perform optimum
binning processing on the various pieces of continuous label data
respectively, and
correspondingly obtaining plural groups of discrete label data includes the
following:
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0090] The optimum binning strategy is employed with respect to the continuous
label data, i.e.,
the attribute of the positive-sample data or the negative-sample data is used
as a
dependent variable, each continuous variable (label feature) serves as an
independent
variable, and a conditional inference tree algorithm is employed to discretize
the
continuous variables; it is firstly supposed that all independent variables
and dependent
variables are independent, chi-square independence test is subsequently
carried out
thereon, independent variables with P value being smaller than a set threshold
are
screened out, and split points are finally selected from each screened
independent variable
through displacement detection, whereby is achieved the objective of
discretizing the
continuous variables and finally forming discrete label data. As should be
stressed, use of
the optimum binning strategy to discretize continuous variables pertains to
technical
means frequently employed in this field of technology, so this is not
redundantly
described in this embodiment.
[0091] Specifically, the method of sequentially performing similarity distance
calculation on a
discrete factor in each group of discrete label data, and simultaneously
screening out
plural groups of new discrete label data consisting of prominently
contributive discrete
factors in the foregoing embodiment includes:
[0092] employing an evidence weight algorithm to perform similarity distance
calculation on
variables of various discrete factors in one group of discrete label data;
calculating an IV
value to which each discrete factor corresponds through an information value
formula,
and screening out discrete factors with high value degrees on the basis of
sizes of the IV
values; employing a Lasso regression algorithm to screen discrete factors with
high
identification degrees out of the discrete factors with high value degrees;
employing a
ridge regression algorithm to further screen discrete factors with prominent
importance
out of the discrete factors with high identification degrees, and constituting
plural groups
of new discrete label data consisting of prominently contributive discrete
factors; and
respectively invoking other groups of discrete label data to repeat the above
calculating
steps, and correspondingly obtaining plural groups of new discrete label data.
16
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0093] During specific implementation, the evidence weight algorithm in this
embodiment
indicates a WOE algorithm, the use of which can score the variables of various
discrete
factors in the discrete label data, the smaller the score of a variable of the
discrete factor
is, this indicates the higher will be its contribution to the positive sample,
and it is further
needed, after the variables of the discrete factors have been scored, to
normalize them to
form similarity distance WOE, in which i expresses the ith discrete factor
(label feature),
I expresses the jth variable (the variable here can also be understood as a
classification) in
the ith discrete factor, and the variable is a further definitive description
of the discrete
factor, for instance, when the discrete factor is member gender, it can be
further defined
to be classified into two types, the first type is male, and the second type
is female;
alternatively, when the discrete factor is date, such as the latest shopping
payment date,
its further definition can be classified according to time lengths from a
timeline point, the
first type is within 10 days therefrom, the second type is within 30 days
therefrom, and
the third type is out of 30 days therefrom; when the discrete factor is
numeral, such as the
recent subscription amount at Change Treasure, its further definition can be
classified
according to a numerical gradient, for instance, the first type is within an
amount of 5,000
Yuans RMB, the second type is within an amount of 50,000 Yuans RMB, and the
third
type is outside an amount of 50,000 Yuans RMB, the result of WOEy is in the
range of
[0,1] on completion of calculation. In practical operation, the number of
classifications
can be specifically set according to actual circumstances, and this embodiment
makes no
redundant description thereto. In addition, the evidence weight algorithm is
an existing
algorithm in this field of technology, however, in order to facilitate
comprehension,
specific formulae are given in this embodiment for explanation thereof:
#0ii #0,i
(p01 #cliT = 41
WOEii = In _____________ ,, In ____ In __
p if # 1 i j #00,
[0094] iT\#l1.
[0095] where WOEy expresses the score of the jth variable in the ith discrete
factor, pOu expresses
the probability of the jth variable in the ith discrete factor being a
negative sample, ply
17
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
expresses the probability of the jth variable in the ith discrete factor being
a positive sample,
#0y expresses the number of the jth variable in the ith discrete factor being
negative
samples, #0,T expresses the total number of variables that are negative
samples in the ith
discrete factor, My expresses the number of the jth variable in the ith
discrete factor being
positive samples, and #LT expresses the total number of variables of the ith
variable being
positive samples.
[0096] After the similarity distance of each discrete factor has been
calculated, it is needed to
further calculate the IV (information value) value of each discrete factor,
and the IV value
calculation formula is as follows:
IV =1()0 u -ply) * = -
WOE
[0097]
[0098] where n expresses the total number of variables in discrete factor i,
and j expresses the jth
variable in discrete factor i.
[0099] After the IV value of each discrete factor has been completed, the
Lasso regression
algorithm is then employed to calculate identification degrees of the various
label features,
and discrete factors with high identification degrees are screened out
therefrom;
optionally, the screening condition of identification degrees is to screen out
the minimum
X, that satisfies the condition, and to retain discrete factors that satisfy
the minimum X, to
form a variable set. Subsequently the ridge regression algorithm is then
employed to
screen out discrete factors with prominent importance from the variable set,
and the
screening condition of identification degrees is to screen out discrete
factors with P value
<0.1; through the aforementioned three rounds of screening, prominently
contributive
discrete label data are finally retained, and the discrete factors remaining
at this time can
be generally classified into three large types, which are, respectively,
customers' own
attributes, customer accessing behaviors, and customer transaction behaviors.
As is
understandable, X, is a Lagrange operator representing a coefficient of a
first-order model
18
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
norm penalty term in the Lasso regression algorithm.
[0100] As should be noted, both the Lasso regression algorithm and the ridge
regression
algorithm are regression algorithms frequently employed by persons skilled in
this field
of technology, and their specific formulae are not redundantly described in
this context.
[0101] Preferably, the method of employing a random forest algorithm and a
gradient boosting
decision tree algorithm to respectively perform weight calculation on discrete
factors in
the new discrete label data, and obtaining weight results of plural groups of
discrete
factors after weighted summation in the foregoing embodiment includes:
[0102] selecting data in a positive sample as a target variable, taking the
discrete factor in each
piece of discrete label data as a dependent variable, and employing the random
forest
algorithm to calculate importance indices of various variables of the discrete
factors in
the various pieces of discrete label data; selecting data in a positive sample
as a target
variable, taking the discrete factor in each piece of discrete label data as a
dependent
variable, and employing the gradient boosting decision tree algorithm to
calculate
importance indices of various variables of the discrete factors in the various
pieces of
discrete label data; and performing weighted assignment on the importance
indices of the
various variables of the discrete factors obtained by employing the random
forest
algorithm and on the importance indices of the various variables of the
discrete factors
obtained by employing the gradient boosting decision tree algorithm in the
same piece of
discrete label data, and thereafter summating the same data to obtain weight
results of
plural groups of discrete factors.
[0103] During specific implementation, the random forest algorithm is employed
to classify
discrete factors in each group of discrete label data, and to obtain
importance indices (Wrfl,
Wrf2, = .. Wrfn) to which various variables of each discrete factor
correspond, the gradient
boosting decision tree (GBDT) algorithm is further employed at the same time
to classify
discrete factors in each group of discrete label data, and to obtain
importance indices
19
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
(WGBDT1, WGBDT2, = = = WGBDTn) to which various variables of each discrete
factor
correspond, and weighted assignment is thereafter performed on the same
discrete label
data; preferably, 0.3 is weighted-assigned to the importance indices obtained
by
employing the random forest algorithm, 0.7 is weighted-assigned to the
importance
indices obtained by employing the gradient boosting decision tree algorithm,
and weight
results (W
, 1, W2,..., W) ¨0.3*(Wrfl, Wrf2,= = =, Wrfn)+0.7*(WGBDT1,
WGBDT2, WGBDTn)
of the various variables of the discrete factor can be obtained after
summation. The
random forest algorithm and the gradient boosting decision tree algorithm are
both
algorithmic formulae frequently employed by persons skilled in this field of
technology,
and are hence not redundantly described in this embodiment.
[0104] Moreover, the method of employing a Manhattan distance algorithm to
calculate a final
similarity distance between each piece of customer data and the positive-
sample data on
the basis of the weight results of the various groups of discrete factors and
similarity
distances of the various discrete factors in the foregoing embodiment
includes:
[0105] multiplying the weight results of the various groups of discrete
factors with the similarity
distances of the various discrete factors, and calculating a similarity
distance between
each discrete factor in the customer data and the positive-sample data; and
employing the
Manhattan distance algorithm to summate the similarity distances of all
discrete factors
in each piece of customer data, and obtaining a final similarity distance
between each
piece of customer data and the positive-sample data.
[0106] During specific implementation, the final weights (Wi, W2, ... Wn) of
the various
variables in each discrete factor are multiplied with the score WOE,J of the
WOE of the
various variables in the discrete factor (Wi*W0Ey) to obtain the similarity
distance
between the customer and the positive sample on a single discrete factor. The
Manhattan
distance algorithm is thereafter employed to summate the similarity distances
of all
discrete factors in each piece of customer data, to obtain a final similarity
distance
between each piece of customer data and the positive-sample data. The
Manhattan
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
distance algorithm formula is as follows:
distance =
[0107] j =
[0108] The n expresses the number of discrete factors in the discrete label
data, I, expresses the
value of the jth classification of the corresponding ith discrete factor in
the positive-sample
data, in which I, represents an indicator matrix valuated as 0 or 1, for
instance, when the
ith discrete factor (such as gender) of a male member user is valuated as j
(male), the
corresponding Iy (Igender, male) is valuated as 1, and other variables (such
as Igender, female) on
the ith discrete factor are valuated as 0.
[0109] Specifically, the method of screening out any potential customer
according to the final
similarity distances in the foregoing embodiment includes: reversely arranging
the final
similarity distances according to value sizes, screening out top-ranking N
pieces of
customer data and marking the same as potential customers. Preferably, N is
valuated as
5,000, 5,000 customers with the least final similarity distances are then
searched for and
marked as "potential quality customers", and precision marketing is thereafter
performed
thereon, so as to entice them to purchase products of the platform.
[0110] Embodiment 2
[0111] Please refer to Fig. 1 and Fig. 3, this embodiment provides a data
processing system based
on a similarity model, the system comprises:
[0112] an information collecting unit 1, for collecting plural pieces of
customer data, wherein
the customer data are positive-sample data or negative-sample data;
[0113] a binning transforming unit 2, for extracting continuous label data
from each piece of
customer data, subjecting the same data to binning transformation to
thereafter
correspondingly obtain plural groups of discrete label data;
[0114] a label screening unit 3, for sequentially performing similarity
distance calculation on a
21
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
discrete factor in each group of discrete label data, and simultaneously
screening out
plural groups of new discrete label data consisting of prominently
contributive discrete
factors;
[0115] a weight calculating unit 4, for employing a random forest algorithm
and a gradient
boosting decision tree algorithm to respectively perform weight calculation on
discrete
factors in the new discrete label data, and obtaining weight results of plural
groups of
discrete factors after weighted summation;
[0116] a similarity distance calculating unit 5, for employing a Manhattan
distance algorithm to
calculate a final similarity distance between each piece of customer data and
the positive-
sample data on the basis of the weight results of the various groups of
discrete factors and
similarity distances of the various discrete factors; and
[0117] a marketing unit 6, for screening out any potential customer according
to the final
similarity distances.
[0118] Specifically, the binning transforming unit 2 includes:
[0119] an initial data extracting module 21, for performing label feature
extraction on each piece
of customer data, and obtaining plural groups of continuous label initial
data;
[0120] a data cleaning module 22, for performing data cleaning with respect to
the various groups
of continuous label initial data, and retaining continuous label data after
having removed
any invalid label feature therefrom; and
[0121] a binning processing module 23, for employing an optimum binning
strategy to perform
optimum binning processing on the various pieces of continuous label data
respectively,
and correspondingly obtaining plural groups of discrete label data, wherein
each group
of discrete label data includes plural label features discrete from one
another.
[0122] Specifically, the label screening unit 3 includes:
[0123] an evidence weight algorithm module 31, for employing an evidence
weight algorithm to
perform similarity distance calculation on variables of various discrete
factors in one
group of discrete label data;
22
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0124] an information value calculating module 32, for calculating an IV value
to which each
discrete factor corresponds through an information value formula, and
screening out
discrete factors with high value degrees on the basis of sizes of the IV
values;
[0125] a Lasso regression algorithm module 33, for employing a Lasso
regression algorithm to
screen discrete factors with high identification degrees out of the discrete
factors with
high value degrees; and
[0126] a ridge regression algorithm module 34, for employing a ridge
regression algorithm to
further screen discrete factors with prominent importance out of the discrete
factors with
high identification degrees, and constituting plural groups of new discrete
label data
consisting of prominently contributive discrete factors.
[0127] Specifically, the weight calculating unit 4 includes:
[0128] a random forest algorithm module 41, for selecting data in a positive
sample as a target
variable, taking the discrete factor in each piece of discrete label data as a
dependent
variable, and employing a random forest algorithm to calculate importance
indices of
various variables of the discrete factors in the various pieces of discrete
label data;
[0129] a gradient boosting decision tree algorithm module 42, for selecting
data in a positive
sample as a target variable, taking the discrete factor in each piece of
discrete label data
as a dependent variable, and employing a gradient boosting decision tree
algorithm to
calculate importance indices of various variables of the discrete factors in
the various
pieces of discrete label data; and
[0130] a weighted assignment module 43, for performing weighted assignment on
the
importance indices of the various variables of the discrete factors obtained
by employing
the random forest algorithm and on the importance indices of the various
variables of the
discrete factors obtained by employing the gradient boosting decision tree
algorithm in
the same piece of discrete label data, and thereafter performing summation to
obtain
weight results of plural groups of discrete factors.
[0131] Specifically, the similarity distance calculating unit 5 includes:
23
Date Recue/Date Received 2022-06-21
CA 03165582 2022-06-21
[0132] a label feature similarity distance module 51, for multiplying the
weight results of the
various groups of discrete factors with the similarity distances of the
various discrete
factors, and calculating a similarity distance between each discrete factor in
the customer
data and the positive-sample data; and
[0133] a customer data similarity distance module 52, for employing the
Manhattan distance
algorithm to summate the similarity distances of all discrete factors in each
piece of
customer data, and obtaining a final similarity distance between each piece of
customer
data and the positive-sample data.
[0134] In comparison with prior-art technology, the advantageous effects
achieved by the data
processing system based on a similarity model provided by this embodiment of
the
present invention are identical with the advantageous effects achievable by
the data
processing method based on a similarity modal provided by the foregoing
Embodiment
1, so these are not redundantly described in this context.
[0135] As understandable to persons ordinarily skilled in the art, the entire
or partial steps
realizing the method of the present invention can be completed via a program
that
instructs relevant hardware, the program can be stored in a computer-readable
storage
medium, and subsumes the various steps of the method in the foregoing
embodiment
when it is executed, while the storage medium can be an ROM/RAM, a magnetic
disk,
an optical disk, or a memory card, etc.
[0136] What the above describes is merely directed to specific modes of
execution of the present
invention, but the protection scope of the present invention is not restricted
thereby. Any
change or replacement easily conceivable to persons skilled in the art within
the technical
range disclosed by the present invention shall be covered by the protection
scope of the
present invention. Accordingly, the protection scope of the present invention
shall be
based on the protection scope as claimed in the Claims.
24
Date Recue/Date Received 2022-06-21