Note: Descriptions are shown in the official language in which they were submitted.
CA 03166784 2022-07-04
HUMAN-MACHINE INTERACTIVE SPEECH RECOGNIZING METHOD AND
SYSTEM FOR INTELLIGENT DEVICES
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the technical field of speech
recognition, and more
particularly to a human-machine interactive speech recognizing method and
system for
an intelligent device.
Description of Related Art
[0002] With the development of the internet technology, there come into being
more and more
intelligent devices that employ speeches for human-machine interaction.
Currently
available speech interactive systems include Siri, Xiaomi, Cortana, Avatar
Framework,
and Duer, etc. As compared with the traditional human-machine interaction
based on
manual input, speech human-machine interaction exhibits characteristics of
conveniency,
high efficiency, and broad range of application scenarios. During the process
of speech
recognition, intent recognition and slot filling techniques are keys to
ensuring the
accuracy of speech recognition results.
[0003] As regards intent recognition, it can be abstracted as a classification
problem, and a
classifier represented by means of CNN + knowledge is then employed to train
an intent
recognition model, in which is further introduced semantic representation of
knowledge
to enhance the generalization capability of the presentation layer in addition
to word-
embedding for speech questions of users, but it has been found in practical
application
that such a model is defective in terms of slot information filling deviation,
whereby
accuracy of the intent recognition model is adversely affected. As regards
slot filling, its
1
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
essence is to formalize a sentence sequence to a marked sequence, and there
are many
frequently used methods to mark sequences, such as the hidden Markov model or
the
conditional random field model, but these slot filling models cannot satisfy
practical
application requirements under specific application scenarios, due to
ambiguities of slots
existent under different semantic intents caused by the lack of contextual
information.
Seen as such, trainings of the two models are independently carried out in the
state of the
art, and there is no combined optimization of the intent recognition task and
the slot filling
task, so that the finally trained models are problematic in terms of low
recognition
accuracy in the aspect of speech recognition, and user experience is lowered.
SUMMARY OF THE INVENTION
[0004] The objective of the present invention is to provide a human-machine
interactive speech
recognizing method and system for an intelligent device, to enhance accuracy
of speech
recognition by jointly optimizing and training intent recognition and slot
filling.
[0005] To achieve the above objective, according to one aspect, the present
invention provides a
human-machine interactive speech recognizing method for an intelligent device,
the
method comprising:
[0006] subjecting a speech question of a user to a term-segmenting process to
obtain an original
term sequence, and vectorizing the original term sequence through an embedding
process;
[0007] calculating a hidden state vector hi and a slot context vector cis of
each term segmentation
vector, and weighting the hidden state vector hi and the slot context vector
cis to thereafter
obtain a slot label model y ;
[0008] calculating a hidden state vector hT and an intent context vector cf of
the vectorized
original term sequence, and weighting the hidden state vector hT and the
intent context
vector cf to thereafter obtain an intent prediction model y';
[0009] employing a slot gate g to join the slot context vector cis and the
intent context vector cf,
and generating a transformed representation of the slot label model yis
through the slot
2
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
gate g; and
[0010] jointly optimizing the intent prediction model yi and the transformed
slot label model yis
to construct a target function, and performing intent recognition on the
speech question
of the user based on the target function.
[0011] Preferably, the step of subjecting a speech question of a user to a
term-segmenting process
to obtain an original term sequence, and vectorizing the original term
sequence through
an embedding process includes:
[0012] receiving the speech question of the user and transforming the speech
question to a
recognizable text, and employing a tokenizer to term-segment the recognizable
text and
obtain the original term sequence; and
[0013] subjecting the original term sequence to a word embedding process, and
realizing a vector
representation of each segmented term in the original term sequence.
[0014] Preferably, the step of calculating a hidden state vector hi and a slot
context vector cis of
each term segmentation vector, and weighting the hidden state vector hi and
the slot
context vector cis to thereafter obtain a slot label model yis includes:
[0015] employing a bidirectional LSTM network to encode each term segmentation
vector, and
outputting the hidden state vector hi corresponding to each term segmentation
vector;
[0016] calculating the slot context vector cis, to which each term
segmentation vector
corresponds, through formula ciS = , wherein a
represents an attention
weight of a slot, its calculation formula is a11 = ¨ exp (ei k)
Texp (eij)
, e ¨ o-(Whsehj), where
represents a slot activation function, and WL represents a slot weight matrix;
and
[0017] constructing a slot label model yiS = softmax (Whse(hi +cis) ) based on
the hidden
state vector hi and the slot context vector cis.
[0018] Further, the step of calculating a hidden state vector hT and an intent
context vector cf of
the vectorized original term sequence, and weighting the hidden state vector
hT and the
3
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
intent context vector cf to thereafter obtain an intent prediction model yi
includes:
[0019] employing a hidden unit in the bidirectional LSTM network to encode the
vectorized
original term sequence, and obtaining the hidden state vector hT;
[0020] calculating the intent context vector cf of the original term sequence
through formula
c1 = EaJhT, wherein ai represents an attention weight of an intent, its
calculation
formula is al. ¨ Texp (e1)
e ¨ o- ' hT
) , where a' represents an intent activation
k=lexp (e k)'
function, and Ku, represents an intent weight matrix; and
[0021] constructing an intent prediction model 371 = so ftmax(Wilu,(hT + cl))
based on the
hidden state vector hT and the intent context vector cf.
[0022] Preferably, the step of employing a slot gate g to join the slot
context vector cis and the
intent context vector cf, and generating a transformed representation of the
slot label
model yis through the slot gate g includes:
[0023] formally representing the slot gate g as g= v = tanh (cr + W = c') ,
wherein v
represents a weight vector obtained by training, and W represents a weight
matrix
obtained by training; and
[0024] formally representing the transformation of the slot label model yis
through the slot gate
g as:
[0025] y = so ftmax(W hse(hi + c g)).
[0026] Optionally, the target function constructed by jointly optimizing the
intent prediction
model yi and the transformed slot label model yis is:
[0027] p(ys , 3711X) = p(y1 IX) {I p(yiclX) , wherein p(ys , 371 IX)
represents a conditional
probability for outputting slot filling and intent prediction at a given
original term
sequence, where X is the vectorized original term sequence.
[0028] Preferably, the step of performing intent recognition on the speech
question of the user
based on the target function includes:
4
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
[0029] sequentially obtaining intent conditional probabilities, to which the
various segmented
terms in the original term sequence correspond, through the target function;
and
[0030] screening therefrom a segmented term with the maximum probability value
and
recognizing the segmented term as the intent of the speech question of the
user.
[0031] In comparison with prior-art technology, the human-machine interactive
speech
recognizing method for an intelligent device provided by the present invention
achieves
the following advantageous effects.
[0032] In the human-machine interactive speech recognizing method for an
intelligent device
provided by the present invention, the speech question of the user as obtained
is firstly
transformed to a recognizable text, a term segmenting process is carried out
on the basis
of the recognizable text to generate an original term sequence, which is then
subjected to
a word embedding process to realize vector representation, thereafter, a slot
label model
yis and an intent prediction model yi are respectively constructed on the
basis of the
vectorized original term sequence, wherein the step of constructing the slot
label model
yis is to calculate a hidden state vector h, and a slot context vector c15 of
each term
segmentation vector, and weight the hidden state vector hi and the slot
context vector os
to thereafter obtain the slot label model yis, while the step of constructing
the intent
prediction model yi is to calculate a hidden state vector hT and an intent
context vector cf
of the original term sequence, and weight the hidden state vector hT and the
intent context
vector cf to thereafter obtain the intent prediction model j/; seen as such,
in order to fuse
the intent prediction model)/ with the slot label model yis, a decoder layer
is additionally
added to the existing encoder-decoder framework to construct the intent
prediction model
y', join the slot context vector c15 and the intent context vector c' by
introducing a slot gate
g, finally jointly optimize the intent prediction model yl and the transformed
slot label
model yis to obtain a target function, employ the target function to
sequentially obtain
intent conditional probabilities, to which the various segmented terms in the
original term
sequence correspond, and screen therefrom a segmented term with the maximum
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
probability value and recognize it as the intent of the speech question of the
user, so as to
ensure accuracy of speech recognition.
[0033] According to another aspect, the present invention provides a human-
machine interactive
speech recognizing system for an intelligent device, wherein the system is
applied to the
human-machine interactive speech recognizing method for an intelligent device
as recited
in the foregoing technical solution, and the system comprises:
[0034] a term segmentation processing unit, for subjecting a speech question
of a user to a term-
segmenting process to obtain an original term sequence, and vectorizing the
original term
sequence through an embedding process;
[0035] a first calculating unit, for calculating a hidden state vector hi and
a slot context vector cis
of each term segmentation vector, and weighting the hidden state vector hi and
the slot
context vector cis to thereafter obtain a slot label model yis;
[0036] a second calculating unit, for calculating a hidden state vector hT and
an intent context
vector cf of the vectorized original term sequence, and weighting the hidden
state vector
hT and the intent context vector cf to thereafter obtain an intent prediction
model yi;
[0037] a model transforming unit, for employing a slot gate g to join the slot
context vector cis
and the intent context vector cf, and generating a transformed representation
of the slot
label model yis through the slot gate g; and
[0038] a joint optimization unit, for jointly optimizing the intent prediction
model yl and the
transformed slot label model yis to construct a target function, and
performing intent
recognition on the speech question of the user based on the target function.
[0039] Preferably, the term segmentation processing unit includes:
[0040] a term-segmenting module, for receiving the speech question of the user
and transforming
the speech question to a recognizable text, and employing a tokenizer to term-
segment
the recognizable text and obtain the original term sequence; and
[0041] an embedding processing module, for subjecting the original term
sequence to a word
embedding process, and realizing a vector representation of each segmented
term in the
6
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
original term sequence.
[0042] Preferably, the first calculating unit includes:
[0043] a hidden state calculating module, for employing a bidirectional LSTM
network to encode
each term segmentation vector, and outputting the hidden state vector hi
corresponding to
each term segmentation vector;
[0044] a slot context calculating module, for calculating the slot context
vector cis, to which each
term segmentation vector corresponds, through formula c = Eah1, wherein ais:j
represents an attention weight of a slot, its calculation formula is ___ =
Texp (e
Ek=i exP (ei,k)'
e = o-(Whsehj), where a represents a slot activation function, and WL
represents a
slot weight matrix; and
[0045] a slot label model module, for constructing a slot label model yic =
so f tmax (14a(hi + cis) ) based on the hidden state vector hi and the slot
context
vector cis.
[0046] As compared with prior-art technology, the advantageous effects
achieved by the human-
machine interactive speech recognizing system for an intelligent device
provided by the
present invention are identical with the advantageous effects achievable by
the human-
machine interactive speech recognizing method for an intelligent device
provided by the
foregoing technical solution, so these are not redundantly described in this
context.
BRIEF DESCRIPTION OF THE DRAWINGS
[0047] The drawings described here are meant to provide further understanding
of the present
invention, and constitute part of the present invention. The exemplary
embodiments of
the present invention and the descriptions thereof are meant to explain the
present
invention, rather than to restrict the present invention. In the drawings:
7
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
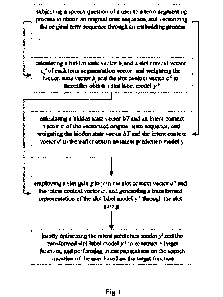
[0048] Fig. 1 is a flowchart schematically illustrating the human-machine
interactive speech
recognizing method for an intelligent device in Embodiment 1 of the present
invention;
[0049] Fig. 2 is an exemplary view illustrating encoder-decoder fusing model
in Embodiment 1
of the present invention;
[0050] Fig. 3 is an exemplary view illustrating the slot gate g in Fig. 2; and
[0051] Fig. 4 is a block diagram illustrating the structure of the human-
machine interactive
speech recognizing system for an intelligent device in Embodiment 2 of the
present
invention.
[0052] Reference numerals:
[0053] 1 ¨ term segmentation processing unit
[0054] 3 ¨ second calculating unit
[0055] 5 ¨joint optimization unit
2¨ first calculating unit
4¨ model transforming unit
8
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
DETAILED DESCRIPTION OF THE INVENTION
[0056] To make more lucid and clear the objectives, features and advantages of
the present
invention, the technical solutions in the embodiments of the present invention
are clearly
and comprehensively described below with reference to the accompanying
drawings in
the embodiments of the present invention. Apparently, the embodiments as
described are
merely partial, rather than the entire, embodiments of the present invention.
All other
embodiments obtainable by persons ordinarily skilled in the art on the basis
of the
embodiments in the present invention without spending creative effort shall
all fall within
the protection scope of the present invention.
[0057] Embodiment 1
[0058] Fig. 1 is a flowchart schematically illustrating the human-machine
interactive speech
recognizing method for an intelligent device in Embodiment 1 of the present
invention.
Referring to Fig. 1, the human-machine interactive speech recognizing method
for an
intelligent device provided by this embodiment comprises:
[0059] subjecting a speech question of a user to a term-segmenting process to
obtain an original
term sequence, and vectorizing the original term sequence through an embedding
process;
calculating a hidden state vector hi and a slot context vector cis of each
term segmentation
vector, and weighting the hidden state vector hi and the slot context vector
cis to thereafter
obtain a slot label model yis; calculating a hidden state vector hT and an
intent context
vector cf of the vectorized original term sequence, and weighting the hidden
state vector
hT and the intent context vector cf to thereafter obtain an intent prediction
model yi;
employing a slot gate g to join the slot context vector cis and the intent
context vector cf,
and generating a transformed representation of the slot label model yis
through the slot
gate g; and jointly optimizing the intent prediction model./ and the
transformed slot label
model yis to construct a target function, and performing intent recognition on
the speech
9
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
question of the user based on the target function.
[0060] In the human-machine interactive speech recognizing method for an
intelligent device
provided by this embodiment, the speech question of the user as obtained is
firstly
transformed to a recognizable text, a term segmenting process is carried out
on the basis
of the recognizable text to generate an original term sequence, which is then
subjected to
a word embedding process to realize vector representation, thereafter, a slot
label model
yis and an intent prediction model yi are respectively constructed on the
basis of the
vectorized original term sequence, wherein the step of constructing the slot
label model
yis is to calculate a hidden state vector h, and a slot context vector cis of
each term
segmentation vector, and weight the hidden state vector hi and the slot
context vector cis
to thereafter obtain the slot label model yis, while the step of constructing
the intent
prediction model yi is to calculate a hidden state vector hT and an intent
context vector cf
of the original term sequence, and weight the hidden state vector hT and the
intent context
vector cf to thereafter obtain the intent prediction model yl; as shown in
Fig. 2, in order to
fuse the intent prediction model yi with the slot label model yis, a decoder
layer is
additionally added to the existing encoder-decoder framework to construct the
intent
prediction model
join the slot context vector cis and the intent context vector cf by
introducing a slot gate g, finally jointly optimize the intent prediction
model yl and the
transformed slot label model yis to obtain a target function, employ the
target function to
sequentially obtain intent conditional probabilities, to which the various
segmented terms
in the original term sequence correspond, and subsequently screen therefrom a
segmented
term with the maximum probability value and recognize it as the intent of the
speech
question of the user, so as to ensure accuracy of speech recognition.
[0061] Specifically, the step of subjecting a speech question of a user to a
term-segmenting
process to obtain an original term sequence, and vectorizing the original term
sequence
through an embedding process in the foregoing embodiment includes:
[0062] receiving the speech question of the user and transforming the speech
question to a
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
recognizable text, and employing a tokenizer to term-segment the recognizable
text and
obtain the original term sequence; and subjecting the original term sequence
to a word
embedding process, and realizing a vector representation of each segmented
term in the
original term sequence.
[0063] As should be noted, the step of calculating a hidden state vector hi
and a slot context
vector cis of each term segmentation vector, and weighting the hidden state
vector hi and
the slot context vector cis to thereafter obtain a slot label model yis in the
foregoing
embodiment includes:
[0064] employing a bidirectional LSTM network to encode each term segmentation
vector, and
outputting the hidden state vector hi corresponding to each term segmentation
vector;
calculating the slot context vector cis, to which each term segmentation
vector
corresponds, through formula c = ,
wherein a represents an attention
exp (ei j) s
weight of a slot, its calculation formula is = = _______________________ e
= o-(Whehj), where
exp
a represents a slot activation function, and WL represents a slot weight
matrix; and
constructing a slot label model y;s. = softmax (WL(hi +cis) ) based on the
hidden
state vector hi and the slot context vector cis.
[0065] During specific implementation, after plural term segmentation vectors
have been input
to the bidirectional LSTM network, hidden state vectors hi can be
correspondingly output
on a one-by-one basis, as regards formula c = E of
the slot context vector, where
represents the attention weight of the slot, i represents the ith term
segmentation
vector, and j represents the jth element in the ith term segmentation vector.
Specifically,
the calculation formula of the attention weight of the slot is cO. ¨ Texp (e
, e = =
exp (ei,k)
o-(Wilhj), where T represents the total number of elements in the term
segmentation
vector, and K represents the Kth element in T. In addition, as regards slot
activation
function a and slot weight matrix W,, these can be derived on the basis of
vector
11
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
matrix training of the original term sequence, and the specific training
processes are
conventional technical means frequently employed in this technical field, so
these are not
redundantly described in this embodiment.
[0066] The step of calculating a hidden state vector hT and an intent context
vector cf of the
vectorized original term sequence, and weighting the hidden state vector hT
and the intent
context vector cf to thereafter obtain an intent prediction model yi in the
foregoing
embodiment includes:
[0067] employing a hidden unit in the bidirectional LSTM network to encode the
vectorized
original term sequence, and obtaining the hidden state vector hT; calculating
the intent
context vector cf of the original term sequence through formula c1 = EaJhT,
wherein
aJ represents an attention weight of an intent, its calculation formula is aJ
¨ Texp (ei)
Ek,, exp (e k)'
ei = o-' (Wifi,hT) , where a' represents an intent activation function, and
Wif,
represents an intent weight matrix; and constructing an intent prediction
model 37' =
so f tmax (14/11,õ(hT + c')) based on the hidden state vector hT and the
intent context
vector c.f.
[0068] During the process of specific implementation, the method of training
the intent
prediction model yi is the same as the method of training the slot label model
yis, and the
difference rests in the fact that the hidden state vector hT can be obtained
merely by means
of a hidden unit in the bidirectional LSTM network, after one-dimensional
transformation
of the vector matrix, formula cd = E ct. hT is subsequently invoked to
calculate the
intent context vector cf of the original term sequence, where ct.; represents
an attention
weight of an intent, its calculation formula is ct" = Texp (e1)
e- = (K.", hT) ,
Ek,, exp (e k)
wherein a' represents an intent activation function, and Ku, represents an
intent
weight matrix; as regards the intent activation function a' and the intent
weight matrix
Wkõ, these can be derived on the basis of processed one-dimensional vector
training, the
12
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
specific training processes are conventional technical means frequently
employed in this
technical field, so these are not redundantly described in this embodiment.
[0069] Moreover, the step of employing a slot gate g to join the slot context
vector cis and the
intent context vector cf, and generating a transformed representation of the
slot label
model yis through the slot gate g in the foregoing embodiment includes:
[0070] formally representing the slot gate g as g= v = tanh (cis. + W = c') ,
wherein v
represents a weight vector obtained by training, and W represents a weight
matrix
obtained by training; and formally representing the transformation of the slot
label model
yis through the slot gate g as yis. = so ftmax (WL (hi + c g)). Fig. 3 shows a
structure
model of the slot gate g.
[0071] Preferably, the target function constructed by jointly optimizing the
intent prediction
model yi and the transformed slot label model yis in the foregoing embodiment
is:
[0072] p(ys y' po ,
polispo wherein p (ys, y11X) represents a conditional
probability for outputting slot filling and intent prediction at a given
original term
sequence, where X represents the vectorized original term sequence. After
expansion,
P (ys ,Y1 IX) = P(371 IX) Fr P(YiclX) = P(371 ixi,' xT)
P(Yis. 'xi, = = = xT) , where xi
represents the ith term segmentation vector, and T represents the total number
of term
segmentation vectors. Through calculation of the target function can be
obtained intent
probability values of the various term segmentation vectors, and a segmented
term with
the maximum probability value is screened out of the various term segmentation
vectors
and recognized as the intent of the speech question of the user.
[0073] Embodiment 2
[0074] Referring to Fig. 1 and Fig. 4, this embodiment provides a human-
machine interactive
speech recognizing system for an intelligent device, the system comprising:
13
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
[0075] a term segmentation processing unit 1, for subjecting a speech question
of a user to a
term-segmenting process to obtain an original term sequence, and vectorizing
the original
term sequence through an embedding process;
[0076] a first calculating unit 2, for calculating a hidden state vector hi
and a slot context vector
cis of each term segmentation vector, and weighting the hidden state vector hi
and the slot
context vector cis to thereafter obtain a slot label model yis;
[0077] a second calculating unit 3, for calculating a hidden state vector hT
and an intent context
vector ef of the vectorized original term sequence, and weighting the hidden
state vector
hT and the intent context vector cf to thereafter obtain an intent prediction
model yl;
[0078] a model transforming unit 4, for employing a slot gate g to join the
slot context vector cis
and the intent context vector cf, and generating a transformed representation
of the slot
label model yis through the slot gate g; and
[0079] a joint optimization unit 5, for jointly optimizing the intent
prediction model yl and the
transformed slot label model yis to construct a target function, and
performing intent
recognition on the speech question of the user based on the target function.
Specifically,
the term segmentation processing unit includes:
[0080] a term-segmenting module, for receiving the speech question of the user
and transforming
the speech question to a recognizable text, and employing a tokenizer to term-
segment
the recognizable text and obtain the original term sequence; and
[0081] an embedding processing module, for subjecting the original term
sequence to a word
embedding process, and realizing a vector representation of each segmented
term in the
original term sequence.
[0082] Specifically, the first calculating unit includes:
[0083] a hidden state calculating module, for employing a bidirectional LSTM
network to encode
each term segmentation vector, and outputting the hidden state vector hi
corresponding to
each term segmentation vector;
[0084] a slot context calculating module, for calculating the slot context
vector cis, to which each
term segmentation vector corresponds, through formula c = Eahj, wherein ais:j
14
Date Regue/Date Received 2022-07-04
CA 03166784 2022-07-04
exp (e ii)
represents an attention weight of a slot, its calculation formula is c0../ =
exp
cid = o-(Whsehj), where a represents a slot activation function, and WL
represents a
slot weight matrix; and
[0085] a slot label model module, for constructing a slot label model yis =
softmax (W, (hi +cis) ) based on the hidden state vector hi and the slot
context
vector cis.
[0086] As compared with prior-art technology, the advantageous effects
achieved by the human-
machine interactive speech recognizing system for an intelligent device
provided by this
embodiment of the present invention are identical with the advantageous
effects
achievable by the human-machine interactive speech recognizing method for an
intelligent device provided by the foregoing Embodiment 1, so these are not
redundantly
described in this context.
[0087] As understandable to persons ordinarily skilled in the art, realization
of the entire or
partial steps in the method of the present invention can be completed via a
program that
instructs relevant hardware, the program can be stored in a computer-readable
storage
medium, and subsumes the various steps of the method in the foregoing
embodiment
when it is executed, wherein the storage medium can be an ROM/RAM, a magnetic
disk,
an optical disk, or a memory card, etc.
[0088] What the above describes is merely directed to specific modes of
execution of the present
invention, but the protection scope of the present invention is not restricted
thereby. Any
change or replacement easily conceivable to persons skilled in the art within
the technical
range disclosed by the present invention shall be covered by the protection
scope of the
present invention. Accordingly, the protection scope of the present invention
shall be
based on the protection scope as claimed in the Claims.
Date Regue/Date Received 2022-07-04