Note: Descriptions are shown in the official language in which they were submitted.
TEXT PROCESSING METHOD AND DEVICE AND COMPUTER-READABLE
STORAGE MEDIUM
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the technical field of computer
information processing,
and more particularly to a text processing method and corresponding device and
computer-
readable storage medium.
Description of Related Art
[0002] In online borrowing businesses at present, there often occur
circumstances in which
outlaws make illegal profits through borrowing platforms from a whole
industrial chain
including fabricating false information, tampering with equipments,
manipulating scripts,
and taking advantage of technical loopholes to evade surveillance systems and
risk-control
engines.
[0003] It has been found after previously introducing collection records of
collection systems
that abnormally overdue clients would mention such suspiciously latent
aggregation
circumstances in the collection process as "the loan was manipulated through a
middleman"
and "via an agency introduced by a friend", etc., it is therefore currently
common to make
data exploration to certain degrees on to-be-collected users in the after-loan
link to judge
whether the to-be-collected users exhibit aggregation features, and the
specific means
employed is to identify these suspicious patterns during processes of
sessions.
[0004] However, when identifying and screening operations are made on sessions
during
collection processes, it is usually impossible to carry out scenario
restorations for the massive
1
Date Regue/Date Received 2022-08-10
quantity of text data because it is impossible to cover the entire keywords by
manual check,
so that hitting rates are rendered relatively low, the keywords are few, and
it is made
impossible to enlarge the exploration range according to corpora.
SUMMARY OF THE INVENTION
[0005] It is an objective of the present invention to provide a text
processing method and
corresponding device and computer-readable storage medium enabling precise
identification
as to whether a collected object is a suspiciously illegal borrowing object
according to call
records.
[0006] To achieve the above objective, the present invention employs the
following technical
solutions. According to the first aspect, the present invention provides a
text processing
method that comprises:
[0007] obtaining a session content text;
[0008] classifying the session content text to obtain a target session content
text to which a
target object corresponds; and
[0009] identifying the target session content text, on the basis of a
preconstructed classification
model and the session content text, to mark the target object.
[0010] In a preferred mode of execution, the step of obtaining a session
content text includes:
[0011] obtaining a session content text generated by conversion on the basis
of a call record,
wherein the session content text includes a session object number and session
sentence fields
to which the object number corresponds.
[0012] In a preferred mode of execution, the step of classifying the session
content text to obtain
a target session content text to which a target object corresponds includes:
[0013] identifying a target session object number on the basis of the session
sentence fields and
obtaining a target session sentence field to which the target session object
number
2
Date Regue/Date Received 2022-08-10
corresponds, wherein the target session content text includes the target
session sentence field.
[0014] In a preferred mode of execution, the step of identifying a target
session object number
on the basis of the session sentence fields and obtaining a target session
sentence field to
which the target session object number corresponds includes:
[0015] identifying a first preset field in the session sentence fields;
[0016] marking the session object number, to which the session sentence fields
that contain the
first preset field correspond, as a reference session object number, wherein
the session
sentence fields to which the reference session object number corresponds
constitute a
reference session content text; and wherein
[0017] the remaining part in the session sentence fields other than the
reference session content
text is the target session sentence field, and the session object number to
which the target
session sentence field corresponds is the target session object number.
[0018] In a preferred mode of execution, the step of identifying the target
session content text,
on the basis of a preconstructed classification model and the session content
text, to mark the
target object includes:
[0019] obtaining a target identification label and a target field to which the
target identification
label corresponds on the basis of the preconstructed classification model and
the target
session sentence field;
[0020] judging whether the target identification label is correct on the basis
of the reference
session content text and the target session content text;
[0021] if yes, marking the target session object number with the target
identification label;
[0022] if not, updating the target identification label and marking the target
session object
number with the updated target identification label.
[0023] In a preferred mode of execution, the step of judging whether the
target identification
label is correct on the basis of the reference session content text and the
target session content
text includes:
3
Date Regue/Date Received 2022-08-10
[0024] judging whether a session sentence field adjacent to the target field
in the reference
session content text contains a second preset field;
[0025] if yes, indicating that the target identification label is correct;
[0026] if not, judging whether the target identification label is correct on
the basis of the target
session content text.
[0027] In a preferred mode of execution, the step of judging whether the
target identification
label is correct on the basis of the target session content text includes:
[0028] obtaining probability distribution of each preset identification label
on the basis of the
classification model and the target session sentence field;
[0029] judging whether standard deviation of the probability distribution is
greater than a preset
threshold;
[0030] if yes, updating the target identification label with the preset
identification label having
the maximum probability value;
[0031] if not, calculating a probability value, to which each preset
identification label
corresponds, on the basis of the target session sentence field and a
previously counted
probability value of conversion from a current dialogue intent type to a
dialogue type of the
next round, and choosing the preset identification label, to which the
probability value having
the maximum value corresponds, to update the target identification label.
[0032] In a preferred mode of execution, prior to the step of identifying the
target session
content text, on the basis of a preconstructed classification model and the
session content text,
to mark the target object, the method further comprises:
[0033] rectifying the target session content text on the basis of a
preconstructed rectification
database.
[0034] According to the second aspect, the present invention provides a text
processing device
that comprises:
[0035] an obtaining module, for obtaining a session content text;
4
Date Regue/Date Received 2022-08-10
[0036] a classifying module, for classifying the session content text to
obtain a target session
content text to which a target object corresponds; and
[0037] an identifying and marking module, for identifying the target session
content text, on
the basis of a preconstructed classification model and the session content
text, to mark the
target object.
[0038] According to the third aspect, the present invention provides a
computer-readable
storage medium storing thereon a computer program that performs steps of any
text
processing method provided by the first aspect when it is executed by a
processor.
[0039] Advantages of the present invention are as follows. Provided are a text
processing
method and corresponding device and computer-readable storage medium, wherein
the text
processing method comprises: obtaining a session content text; classifying the
session
content text to obtain a target session content text to which a target object
corresponds; and
identifying the target session content text, on the basis of a preconstructed
classification
model and the session content text, to mark the target object, whereby
collected objects and
their session content are differentiated according to the session contents,
and the session
content of the collected object is then identified, judged and marked
according to the
preconstructed classification model in combination with specific content of
the dialogue, so
as to quickly and efficiently judge whether the collected object is a
suspiciously illegal
borrowing object.
BRIEF DESCRIPTION OF THE DRAWINGS
[0040] To more clearly describe the technical solutions in the embodiments of
the present
application or the prior-art technology, drawings required to illustrate the
embodiments will
be briefly introduced below. Apparently, the drawings introduced below are
merely directed
to some embodiments of the present application, while persons ordinarily
skilled in the art
may further acquire other drawings on the basis of these drawings without
spending creative
Date Regue/Date Received 2022-08-10
effort in the process.
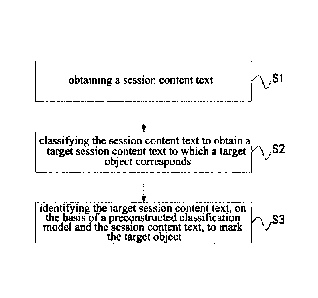
[0041] Fig. 1 is a flowchart illustrating the text processing method provided
by Embodiment 1
of the present invention;
[0042] Fig. 2 is a view illustrating the content of the session content text
in Embodiment 1 of
the present invention;
[0043] Fig. 3 is a flowchart illustrating judgement as to whether the target
identification label
is correct on the basis of the target session content text in the text
processing method provided
by Embodiment 1 of the present invention;
[0044] Fig. 4 is a view presenting a storage table generated in the text
processing method
provided by Embodiment 1 of the present invention; and
[0045] Fig. 5 is a view illustrating the structure of the text processing
device provided by
Embodiment 2 of the present invention.
DETAILED DESCRIPTION OF THE INVENTION
[0046] The technical solutions in the embodiments of the present application
will be clearly and
comprehensively described below with reference to the accompanying drawings in
the
embodiments of the present application. Apparently, the embodiments as
described are
merely partial, rather than the entire, embodiments of the present
application. Any other
embodiments makeable by persons ordinarily skilled in the art on the basis of
the
embodiments in the present application without creative effort shall all fall
within the
protection scope of the present application.
[0047] As noted in the Description of Related Art, when an abnormally overdue
borrowing user
6
Date Regue/Date Received 2022-08-10
is urged for collection by a collector, key sentences often appear in the
dialogue, wherein
manual mode is currently employed to screen the key sentences from the
collection session
record to identify whether the overdue borrowing user is abnormal, but due to
restrictions of
progress and precision by manual check, it is impossible to quickly and
accurately determine
the abnormal identification of the overdue borrowing user.
[0048] To address the above problem, the present application introduces the
NLP (Natural
Language Processing) technology to process collection dialogue contents,
constructs a text
classification model to extract therefrom target session sentences containing
specific labels,
identifies user identifications accurately from user patterns, obtains key
sentence fields to
obtain more evidence to facilitate feedback of circumstances concerning
intervention of
intermediaries in the after-loan link, further digs for suspicious aggregation
of intermediaries
out of hit user groups, and makes it easy for subsequent tracking change
tendencies of
overdue borrowing users of different classifications to facilitate early
warning at the same
time.
[0049] Embodiment 1: this embodiment provides a text processing method, with
reference to
Fig. 1, the method comprises the following steps.
[0050] Si - obtaining a session content text.
[0051] In a preferred mode of execution, this step includes:
[0052] obtaining a session content text generated by conversion on the basis
of a call record,
wherein the session content text includes a session object number and session
sentence fields
to which the object number corresponds.
[0053] Preferably, the session content text obtained in this embodiment is
generated through
conversion from a quality-inspected call record.
7
Date Regue/Date Received 2022-08-10
[0054] Since there are usually two dialoging parties in a call record, to
facilitate subsequent
differentiated processing, besides session content text generated by
conversion from speeches,
the session content text further includes each session object number, more
specifically, before
the session content text of each sentence of dialogue, there is the session
object number of
this sentence of dialogue. Of course, the session content text can further
include the duration
or a time node identifier of each sentence of dialogue, to which no
restriction is made in this
embodiment.
[0055] S2 - classifying the session content text to obtain a target session
content text to which
a target object corresponds.
[0056] In a preferred mode of execution, this step includes:
[0057] identifying a target session object number on the basis of the session
sentence fields and
obtaining a target session sentence field to which the target session object
number
corresponds, wherein the target session content text includes the target
session sentence field.
[0058] More preferably, this step specifically includes the following.
[0059] S21 - identifying a first preset field in the session sentence fields.
[0060] The first preset field is an identifier field capable of performing
identification judgment.
[0061] S22 - marking the session object number, to which the session sentence
fields that
contain the first preset field correspond, as a reference session object
number, wherein the
session sentence fields to which the reference session object number
corresponds constitute
a reference session content text; and
[0062] wherein the remaining part in the session sentence fields other than
the reference session
content text is the target session sentence field, and the session object
number to which the
target session sentence field corresponds is the target session object number.
8
Date Regue/Date Received 2022-08-10
[0063] Specifically, when telephone collection is made by a collector,
greeting will be made
after the telephone has been connected, for example, "Mr. x" or "Madam X",
accordingly,
the "Mr." and "Madam" are set as first preset fields, by identifying the "Mr."
or "Madam"
field in the session sentence fields, it can be judged that the session object
number to which
the session sentence fields containing this field correspond is the collector
number, namely a
reference session object number, and all session sentence fields to which this
reference
session object number corresponds constitute a reference session content text.
More
preferably, by identifying the first preset field in a preset number of the
first session sentence
fields in the session sentence fields, it is judged that the session object
number to which the
session sentence fields containing this field correspond is the reference
session object number.
The number of the other party in the dialogue is the borrowing user number,
namely a target
object number, and the session sentence fields to which the target object
number corresponds
constitute borrower session content, namely a target session content text.
[0064] Exemplarily, "1" and "2" represents the collector and the borrowing
user, respectively,
and the role of the collector is identified through "Mr." or "Madam"
information contained
in the first ten sentences of the dialogue. As shown in Fig. 2, number "1"
represents the
collector, number "2" represents the borrowing user, by identifying the "Mr."
field it is
determined that the session object number "1" to which the session sentence
fields containing
the "Mr." field correspond is the collector number, namely the reference
session object
number, and all session sentence fields to which the session object number "1"
corresponds
constitute the reference session content text. The remaining session sentence
fields other than
the reference session content text in the session sentence fields are target
session sentence
fields, and all target session sentence fields constitute the session content
text of the target
object, namely the borrowing user, that is to say, all session sentence fields
to which session
object number "2" corresponds constitute the session content text of the
target object.
Sentences corresponding to "1" serve as collector patterns, and sentences
corresponding to
"2" serve as user patterns.
9
Date Regue/Date Received 2022-08-10
[0065] In a preferred mode of execution, after S2 and prior to S3, the method
further comprises:
[0066] SA - rectifying the target session content text on the basis of a
preconstructed
rectification database.
[0067] Specifically, asr (accent speech recognition) is inferior in the
recognition effect when
faced with regional dialects, session content texts generated by conversion
contain erroneous
fields, and the introduction of a text rectifying function greatly helps
enhance the
classification effect. The preconstructed rectification database is a black
industry rectification
knowledge base constructed on basis of previously collected collection
contents and via a
finance knowledge base; exemplarily, the preconstructed rectification database
is a black
industry rectification knowledge base constructed on basis of previously
collected one
hundred thousand pieces of collection contents and via a finance knowledge
base. The black
industry rectification knowledge base has types 2-gram, 3-gram, and 4-gram,
with formats
shown below: the 2-gram corresponds to "Mr.: T!'ft, _____________________
tEIF1 (all Chinese
homophones of the Chinese pronunciation of 'MC)", the 3-gram corresponds to
"no problem:
(all Chinese homophones of the Chinese pronunciation of 'no problem')",
and the 4-gram corresponds to "financial management: itAft fl 914 )3", ft] 914
, fl 914
(all Chinese homophones with antecedent modifiers of the Chinese pronunciation
of
'financial management')"; if erroneous terms are matched in a sentence, these
terms are
replaced with the corresponding correct terms.
[0068] S3 - identifying the target session content text, on the basis of a
preconstructed
classification model and the session content text, to mark the target object.
[0069] In a preferred mode of execution, this step includes the following.
[0070] S31 - obtaining a target identification label and a target field to
which the target
identification label corresponds on the basis of the preconstructed
classification model and
Date Regue/Date Received 2022-08-10
the target session sentence field.
[0071] Specifically, the preconstructed classification model's functions are
to identify a pattern
of the borrowing user, namely the target field, and to assign the target field
to the
corresponding preset identification label type.
[0072] The preconstructed classification model is obtained through the
following method:
[0073] constructing a machine-learning model;
[0074] employing a corpus training set to train the machine-learning model and
obtain a
preconstructed classification model, wherein the corpus training set includes
corpora with
previously well-marked identification labels, there are altogether 1090 pieces
of corpora, and
the previously marked identification labels include whether being the given
person,
identification acquaintance, identification negation, identification
questioning, and others;
[0075] constructing a rule classification model, for identifying a label
"commissioned to
intermediary" ¨ this is so because the label "commissioned to intermediary"
has very few
data, with which it is difficult to train the machine-learning model; the
preconstructed
classification model includes the aforementioned well-trained machine-learning
model and
rule classification model. The machine-learning model can be any of a
MultinomialNB,
LogisticRegression, RandomForestClassifier, SVM, and Fasttext models, and the
classification precision rates of the various models are as shown in the
following Table. The
Fasttext classification model is preferentially selected in this embodiment.
[0076]
LogisticRegression MultinomialNB RandomForestClassifier SVM Fasttext
0.7996 0.7990 0.5368
0.8083 0.8152
[0077] After a target session sentence has been input into the preconstructed
classification
model, the preconstructed classification model outputs a corresponding target
identification
label and a target field to which the identification label corresponds.
11
Date Regue/Date Received 2022-08-10
[0078] Exemplarily, the five pieces of target session sentences to which the
target session object
number, namely number "2", as obtained in the foregoing step corresponds are
sent into the
text classifier piece by piece, sentences corresponding to intents as "whether
being the given
person", "identification acquaintance", "identification negation",
"identification questioning"
and "commissioned to intermediary" are identified, sentences of the type
"others" are filtered
away, a target identification label of "identification confirmation" is
obtained via
classification, and target fields corresponding thereto are ["I say to you",
"go, of course", "no
money, I've told you so", "um, um"'
[0079] S32 - judging whether the target identification label is correct on the
basis of the
reference session content text and the target session content text;
[0080] if yes, entering step S33; if not, entering step S34.
[0081] As can be seen from the target field to which the target identification
label corresponds
as obtained through the classification model, there are many erroneous data in
the classified
target fields, because the classification model merely classifies single
sentences so it tends
easily to generate classification errors, it is required at this time to
combine with contextual
information and to make use of contextual patterns of the borrowing user and
the collector to
verify whether the target identification label obtained by the classification
model is correct.
[0082] In a preferred mode of execution, this step includes the following.
[0083] S321 - judging whether a session sentence field adjacent to the target
field in the
reference session content text contains a second preset field.
[0084] If yes, the target identification label is correct; if not, step S322
is entered.
[0085] Specifically, the second preset field is a keyword for identification
query, and keywords
for identification query include "Mr.", "Madam", "Hi", "How are you", etc., by
identifying
12
Date Regue/Date Received 2022-08-10
whether a session sentence field adjacent to the target field in the reference
session content
text contains a second preset field, namely identifying whether a collector
session sentence
adjacent to the target field contains such a field as "Mr." or "Madam" or "Hi"
or "How are
you", it is judged whether the target identification label is correct. More
preferably, it is
judged whether the two rounds of session sentence fields both before and after
the target field
in the reference session content text contain the second preset field, namely
to judge whether
the collector session sentences in two rounds of sessions both before and
after the target field
contain such a field as "Mr." or "Madam" or "Hi" or "How are you", if yes,
then the target
identification label is correct.
[0086] Exemplarily, most circumstances of identification confirmation rest in
the opening
patterns, and target fields to which the label "identification confirmation"
corresponds are ["I
say to you", "go, of course", "no money, I've told you so", "um, um"].
Firstly, the session
sentence fields before the target field "I say to you" in the reference
session content text
contain the second preset field "Mr.", the following session sentence fields
contain "Suning",
and both the antecedent and the following session sentence fields contain
keywords for
identification query, namely second preset fields, then the number of the
target session object
is correspondingly recorded as 2, it is confirmed that the target
identification label is correct,
and the target field "I say to you" is stored in an identification
confirmation list. The
confidence value to which the target field "go, of course" is 1, the target
identification label
is correct, and is also stored in the identification confirmation list. The
session sentence fields
"Why has this not been processed yet" and "I have been told, when have I been
told" before
the target field "no money, I've told you so" in the reference session content
text do not
contain any keyword for identification query, namely any second preset field,
then the
confidence value to which the target field corresponds is 0, so "no money,
I've told you so"
is not stored in the identification confirmation list, by the same token, "um,
um" should also
be removed.
[0087] S322 ¨judging whether the target identification label is correct on the
basis of the target
13
Date Regue/Date Received 2022-08-10
session content text.
[0088] If no second preset field is identified from the reference session text
in step S321, this
indicates that the collector session sentence fields contextually do not
contain any key
information, but sometimes the user pattern actually contains the intent of
classification, and
it is required at this time to make use of the user contextual pattern to
confirm the target
identification label.
[0089] Specifically, this step includes the following.
[0090] S3221 - obtaining probability distribution of each preset
identification label on the basis
of the classification model and the target session sentence field.
[0091] Specifically, after the target session sentence field has entered the
classification model,
it is possible to output the probability value of each preset type, namely the
probability value
of each preset identification label.
[0092] S3222 -judging whether standard deviation of the probability
distribution is greater than
a preset threshold.
[0093] If yes, step S3223 is entered, if not, step 3224 is entered.
[0094] Specifically, if the probability value of the identification label with
the maximum
probability value as output from the classification model is by far greater
than the
probabilities of other identification labels, i.e., the standard deviation of
the probability value
is relatively large, it can then be considered that the identification label
with the maximum
probability value is reliable. Exemplarily, a standard deviation threshold is
set as 0.2. Of the
target session sentence field "I am that", probability distributions output
from the
classification model are 80% for "identification confirmation", 5% for
"identification
14
Date Regue/Date Received 2022-08-10
acquaintance", 5% for "identification negation", 5% for "identification
questioning", and 5%
for "others", and the standard deviation of the probability is 0.3, then the
identification label
"identification confirmation" is reliable. If the predicted probability
distributions are
relatively close to one another, i.e., the standard deviation is smaller than
0.2, this then means
that the classification model cannot determine several intent identification
labels with close
probabilities with respect to the given sentence, and this circumstance is
usually due to the
fact that the sentence lacks key information for the classification model to
make decisive
judgment. At this time, foregoing session sentence fields of the user are
required to help judge
the current intent, and the process enters step S3224.
[0095] S3223 ¨ updating the target identification label with the preset
identification label
having the maximum probability value.
[0096] S3224 - calculating a probability value to which each preset
identification label
corresponds on the basis of the target session sentence field and a
probability value of
conversion from a current dialogue intent type to a dialogue type of the next
round as
previously counted, and choosing the preset identification label to which the
probability value
having the maximum value corresponds to update the target identification
label.
[0097] Specifically, the probability value of conversion from a current
dialogue intent type to a
dialogue type of the next round as previously counted is obtained through the
following
method: firstly, dialogue transfer probabilities are counted on the basis of
identification label
results marked with great quantities of collection dialogues, a dialogue
transfer probability is
the probability value of converting from the dialogue intent type of the
current round to the
dialogue type of the next round. For instance, the current user pattern intent
type is
"identification negation", the transfer probability for the dialogue of the
next round to
correspond to "identification acquaintance" is 0.6, the probability to
correspond to
"identification confirmation" is 0.2, the probability to correspond to
"identification negation"
is 0.15, and the probability to correspond to "identification questioning" is
0.05; intent
Date Regue/Date Received 2022-08-10
transfer probability values are as shown in the following table:
[0098]
Identification Identification Identification Identification Others
Confirmation Negation Acquaintance Questioning
Identification 0.2 0.1 0.1 0.15 0.45
Confirmation
Identification 0.1 0.3 0.2 0.2 0.2
Negation
Identification 0.2 0.2 0.3 0.1 0.2
Acquaintance
Identification 0.1 0.25 0.25 0.1 0.3
Questioning
Others 0.15 0.1 0.15 0.1 0.5
[0099] Black industry collection corpora involve many circumstances of
multiple rounds of
dialogues, effective information contained in the previous round of dialogue
might be
insufficient, multiple rounds of user dialogue information are added to the
classification
model here and an identification label to which the target session sentence
field of each round
of dialogue corresponds is output. Suppose that the probability value for the
first i round of
identification label to be transferred to the current identification label is
pi, the probability of
the current identification label is q, a; represents the ith round transfer
probability weight, the
farther the current sentence is distanced, the smaller will be the cu value,
the current
identification label probability value pfinal is n
f inal = ai
* pi *q, the final probability
is usually calculated in accordance with the intent values of three rounds of
user dialogues,
let ai=0.5, a2=0.33, and a3=0.17, the identification label with the highest
probability value
is found out, and the target identification label is updated with this
identification label.
[0100] S33 ¨ marking the target session object number with the identification
label.
[0101] Specifically, the type label ["identification confirmation"' is written
in the
category type field to mark the object session object number. More preferably,
the two
sentences "I say to you" and "go, of course" as well as their corresponding
label
16
Date Regue/Date Received 2022-08-10
"identification confirmation" are written in the category field.
[0102] S34 ¨ updating the identification label and marking the target session
object number
with the updated target identification label.
[0103] More preferably, the method further comprises:
[0104] S4 ¨ generating a storage table on the basis of the session content
text, the target
identification label and the target field.
[0105] Preferably, the storage table further includes therein call record IDs
and confidence
values in step S321, and the storage table is of the hive format. The text
processing method
provided by this embodiment comprises obtaining a session content text;
classifying the
session content text to obtain a target session content text to which a target
object corresponds;
and identifying the target session content text, on the basis of a
preconstructed classification
model and the session content text, to mark the target object, whereby
collected objects and
their session content are differentiated according to the session contents,
and the session
content of the collected object is then identified, judged, and marked
according to the
preconstructed classification model in combination with specific content of
the dialogue, so
as to quickly and highly effectively judge whether the collected object is a
suspiciously illegal
borrowing object.
[0106] Embodiment 2: this embodiment provides a text processing device, as
shown in Fig. 5,
the device comprises:
[0107] an obtaining module 51, for obtaining a session content text;
[0108] a classifying module 52, for classifying the session content text to
obtain a target session
content text to which a target object corresponds; and
[0109] an identifying and marking module 53, for identifying the target
session content text, on
the basis of a preconstructed classification model and the session content
text, to mark the
target object.
17
Date Regue/Date Received 2022-08-10
[0110] In a preferred mode of execution, the obtaining module 51 is employed
for obtaining a
session content text generated by conversion on the basis of a call record,
wherein the session
content text includes a session object number and session sentence fields to
which the object
number corresponds.
[0111] More preferably, the classifying module 52 is employed for:
[0112] identifying a target session object number on the basis of the session
sentence fields and
obtaining a target session sentence field to which the target session object
number
corresponds, wherein the target session content text includes the target
session sentence field.
[0113] More preferably, the classifying module 52 includes:
[0114] an identifying submodule 521, for identifying a first preset field in
the session sentence
fields;
[0115] a classifying submodule 522, for marking the session object number, to
which the
session sentence fields that contain the first preset field correspond, as a
reference session
object number, wherein the session sentence fields to which the reference
session object
number corresponds constitute a reference session content text; and
[0116] wherein the remaining part in the session sentence fields other than
the reference session
content text is the target session sentence field, and the session object
number to which the
target session sentence field corresponds is the target session object number.
[0117] More preferably, the identifying and marking module 53 includes:
[0118] an obtaining submodule 531, for obtaining a target identification label
and a target field
to which the target identification label corresponds on the basis of the
preconstructed
classification model and the target session sentence field;
[0119] a judging submodule 532, for judging whether the target identification
label is correct
on the basis of the reference session content text and the target session
content text;
[0120] an marking submodule 533, for marking the target session object number
with the target
18
Date Regue/Date Received 2022-08-10
identification label when the judging submodule 532 judges that the target
identification label
is correct on the basis of the reference session content text and the target
session content text;
and
[0121] a label updating submodule 534, for updating the target identification
label and marking
the target session object number with the updated target identification label
when the judging
submodule 532 judges that the target identification label is not correct on
the basis of the
reference session content text and the target session content text.
[0122] More preferably, the judging submodule 533 includes:
[0123] a first judging unit 5331, for judging whether a session sentence field
adjacent to the
target field in the reference session content text contains a second preset
field; and
[0124] a second judging unit 5332, for judging whether the target
identification label is correct
on the basis of the target session content text.
[0125] More preferably, the second judging unit 5332 includes:
[0126] an obtaining subunit 53321, for obtaining probability distribution of
each preset
identification label on the basis of the classification model and the target
session sentence
field;
[0127] a judging subunit 53322, for judging whether standard deviation of the
probability
distribution is greater than a preset threshold;
[0128] if yes, the label updating submodule 534 updates the target
identification label with the
preset identification label having the maximum probability value; and
[0129] a calculating and choosing subunit 53323, for calculating a probability
value to which
each preset identification label corresponds on the basis of the target
session sentence field
and a probability value of conversion from a current dialogue intent type to a
dialogue type
of the next round as previously counted, and choosing the preset
identification label to which
the probability value having the maximum value corresponds, at which time the
label
updating submodule 534 updates the target identification label with the preset
identification
label to which the probability value having the maximum value corresponds.
19
Date Regue/Date Received 2022-08-10
[0130] In a preferred mode of execution, the device further comprises:
[0131] a rectifying module 54, for rectifying the target session content text
on the basis of a
preconstructed rectification database before the identifying and marking
module 53 identifies
the target session content text, on the basis of a preconstructed
classification model and the
session content text, to mark the target object.
[0132] The text processing device provided by this embodiment is employed for
executing the
text processing method provided by Embodiment 1, and the advantageous effects
achieved
thereby are identical with the advantageous effects achievable by the text
processing method
provided by Embodiment 1, so these are not redundantly described in this
context.
[0133] As should be noted, when the text processing device provided by this
embodiment
executes a text processing method, it is merely exemplarily explained by being
divided into
the aforementioned various functional modules, whereas it is possible, in
actual application,
to assign the above functions to different functional modules for completion
according to
requirements, that is to say, the internal structure of the device is
classified into different
functional modules to complete the entire or partial functions as described
above. In addition,
since the text processing device provided by this embodiment pertains to the
same conception
as the text processing method, see the method embodiment for its specific
implementation
process, while no repetition is redundantly made in this context.
[0134] Embodiment 3: this embodiment provides a computer-readable storage
medium that
stores a computer program thereon, and the computer program realizes any of
the following
steps when it is executed by a processor:
[0135] obtaining a session content text;
[0136] classifying the session content text to obtain a target session content
text to which a
target object corresponds; and
[0137] identifying the target session content text, on the basis of a
preconstructed classification
Date Regue/Date Received 2022-08-10
model and the session content text, to mark the target object.
[0138] The computer-readable storage medium provided by this embodiment is
employed for
processing and executing the steps of the text processing method provided by
Embodiment
1, and the advantageous effects achieved thereby are identical with the
advantageous effects
achievable by the text processing method provided by Embodiment 1, so these
are not
redundantly described in this context.
[0139] As understandable to persons ordinarily skilled in the art, the entire
or partial steps
realizing the foregoing embodiments can be completed via hardware, or via a
program that
instructs relevant hardware, wherein the program can be stored in a computer-
readable
storage medium, and the storage medium can be, but is not limited to be, a
read-only memory,
a magnetic disk, or an optical disk.
[0140] Of course, the foregoing embodiments are merely meant to explain
technical conception
and characteristics of the present invention, and aim to enable technicians
familiar with the
technology to learn of and implement the contents of the present invention,
but the protection
scope of the present invention should not be restricted thereby. Any
modification made in
accordance with the spiritual essence of the main technical solution of the
present invention
shall be covered by the protection scope of the present invention.
21
Date Regue/Date Received 2022-08-10