Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02282999 2002-10-31
CA9-1999-040 1
METHOD AND APPARATUS FOR CROSS-NODE SHARING OF INSTRUCTIONS IN
A MULTIPLE NODE RELATIONAL DATABASE MANAGEMENT SYSTEM
ENVIRONMENT
FIELD OF THE INVENTION
This invention relates to database management systems, and has particular
application to
relational database management systems (RDBMS) and more particularly to a
method and
apparatus for efficiently sharing of instructions, such as cached dynamic SQL
statements between
applications connected at different nodes in a multiple node database while
maintaining cache
and application integrity across the nodes.
BACKGROUND OF THE INVENTION
Structured Query Language (SQL) is the database access language most commonly
used to
access relational databases (such as the DB2 product sold by IBM Corporation)
in an open,
heterogeneous environment. Although this disclosure refers to the DB2
relational database
product sold by IBM, individuals skilled in the art will recognize that the
caching of database
access statements is applicable to any relational database management system
(RDBMS).
Within this specification including the claims, the following terms will be
used:
Access Plan An access plan is the methods) chosen by the SQL Compiler to
satisfy an
application request as stated in the form of an SQL statement.
Agent A process used by a RDBMS to provide services for an application
request.
Node A node is a physical entity (eg. a processor and memory) that is used to
process application requests to the RDBMS and contains some or all of the
database. A serial version of the RDBMS contains at most 1 node, while a
parallel version of the RDBMS can contain 1 or more nodes.
CA 02282999 2002-10-31
CA9-1999-040 2
Section A section contains all the information required by the RDBMS to
execute
the chosen access plan for an SQL statement. A section is the compiled
version of the access plan chosen by the SQL compiler.
Coordinator node: The coordinator node refers to the node at which an
application issues SQL queries to the database.
Subordinate node: Subordinate nodes are all the nodes, aside from the
coordinator node, on which processing of a given SQL
request must be run.
Catalogue node: The catalogue node is the single node in the database
system which contains the system catalogues. These
catalogues contain meta-data about each of the table and
SQL objects in the system and the relationships between
them.
There are two basic types of SQL statements, static and dynamic. In using
static SQL the
user embeds SQL requests for data in an application program. An SQL
precompiler removes
these statements from the application program and replaces them with function
calls whose
parameters indicate a specific section entry for the package corresponding to
the current source
file. The removed SQL statement is then sent to the database management system
for
compilation. Compiling (also known as preparing) a SQL statement is the
process by which the
database management system SQL compiler chooses and builds an access plan to
efficiently
resolve the SQL statement. The access plan is saved in its executable format,
a section, in the
system catalogues.
CA 02282999 2002-10-31
CA9-1999-040 3
The parsing of the statement and building of the access plan can be relatively
long and
complicated. Compilation of static SQL improves run time performance by
building the access
plan before the application is executed.
Dynamic SQL is SQL issued by an application that is not compiled until the
time the
application issues the query; and is often used for ad hoc SQL requests. For
example, in a
database used to track sales of individual products, a dynamic SQL query may
be invoked to list
the top ten products sold, by sales region. Depending upon the nature of a
dynamic SQL request,
the time required to parse it and create an access plan to satisfy the user
request can be
significant. Furthermore, if the dynamic SQL request is repeated later in the
application by the
same agent or perhaps by a different agent, a new access plan must be created
in each instance.
Thus, the creation of an identical access plan may often have to be repeated,
thereby impacting
performance of the application.
In such a scenario, each of the nodes involved in processing the query must
have a copy
of the "section" in order that the query runs completely. Including all the
data from all the nodes.
As a basic solution to this requirement, the dynamic SQL statement is compiled
at the node
where the application is running. The resulting section is then sent or
"shipped" to the remote
nodes. At each of the nodes "agents" on behalf of the application can then
execute the query
using the shipped section. Similarly, applications that are running on other
nodes of the database
that issue dynamic SQL, require the SQL to be compiled on the resulting
section be shipped to all
of the remote nodes that are involved in the transaction.
Given the potentially high cost of compilation and of SQL sections, it is
desirable to
avoid repeated compilation of the identical dynamic SQL request, and reply on
previously
compiled sections.
SUMMARY OF THE INVENTION
In accordance with another aspect of the present invention there is provided a
database
system comprising
a) a plurality of nodes
b) a plurality of databases stored on the nodes; and
CA 02282999 2002-10-31
CA9-1999-040 4
c) a global dynamic SQL statement cache stored on at least one node; the
global
dynamic SQL cache being accessible to a plurality of applications in the
database system.
In accordance with the present invention there is also provided a method of
maintaining
cache and application integrity across a relational database system comprising
a plurality of
nodes and a plurality of databases shared on the nodes, the method comprising
the steps of: (a)
providing for at least some of the databases, a global cache including
information to enable
agents to access the databases; (b) originating a request through a
coordinating node, the
coordinating node sending information on the dynamic SQL request to be
executed to remote
nodes: (c) having each remote node receive the request and check the global
cache on the
respective remote node for a current copy of the dynamic SQL entry; and (d) if
the remote node
does not have the current entry, the remote node requesting the coordination
node to send the
current version of the dynamic SQL entry and its section (e) having the global
dynamic SQL
cache be accessible for applications that are running at any node in the
database system so that an
application is able to re-use a cached copy of a previously inserted dynamic
SQL entry and its
section regardless of the node at which it was originally compiled.
Various aspects of the invention provide a data processing system, a method,
and
software for operating it where the data processing system includes a number
of interconnected
nodes. At least one data partition resides on one of the nodes, and one or
more tables reside in a
data partition. One of the nodes has a catalogue containing metadata
describing tables and other
objects and relationships therebetween in the data processing system. There is
a global
instruction cache at each node having a statement portion storing instruction
statements and
associated executables; each of the executable is designed for a particular
environment; the
instruction cache includes a dependency portion which lists objects and links
them to the
corresponding executable entries that depend on the objects; the instruction
cache includes a
shipped variation portion, each entry of the shipped variation portion refers
to one executable
entry and identifies the node from which the statement associated with the
executable was
originally shipped and the identification of such executable in the node from
which it was
originally shipped. The cache includes an invalidations in progress portion,
each entry of the
invalidations in progress portion refers to an object entry in the dependency
portion.
CA 02282999 2002-10-31
CA9-1999-040 5
In a further aspect of the invention in a data processing system a catalogue
node has a
catalogue containing metadata describing tables and other SQL objects and
relationships
therebetween in the data processing system; wherein the SQL objects may
include tables views
of tables, aliases of tables, functions, and user defined types among others;
a global SQL
instruction cache at each node having a statement portion storing dynamic SQL
statements and
associated executables; each executable being designed for a particular
environment; the SQL
cache includes a dependency portion which lists SQL objects and links them to
the corresponding
executable entries that depend on the objects; the SQL cache includes a
shipped variation
portion, each entry of the shipped variation portion refers to one executable
entry and identifies
the node at which the SQL statement associated with the executable was
originally compiled and
identification of such executable in the node at which it was compiled; the
SQL cache includes
an invalidations in progress portion, each entry of the invalidations in
progress portion refers to
an object entry in the dependency portion.
In yet a further aspect of the invention the data processing system the global
SQL
instruction cache includes a statement entry which includes:
SQL instruction statement text and a list of associated environment entries;
each environment entry includes a description of the environment and a list of
variations,
each the variation includes: an identification number; the executable itself;
a list of required
privileges; a reference available to the entry in the shipped variation list
portion of the cache.
Another aspect of the invention provides a method of executing an SQL request
issued by
an application from a node (a coordinator node) comprising: searching in a
global SQL cache at
the coordinator node for an executable that is associated with an SQL
statement and environment
corresponding to the SQL request; if the executable is not found in the global
cache then the
database management system compiles the SQL request at the coordinator node
then inserts an
executable entry into the global cache at the coordinator node; searching at
the coordinator node
in the global SQL cache for an SQL statement entry, the text of which matches
the text of the
SQL request; if the entry is not present at the coordinator node, inserting,
by the database
management system, a new SQL statement entry, the text of which matches the
SQL request; if
the entry is present then the database management system searches for
environment entries
CA 02282999 2002-10-31
CA9-1999-040 6
associated with the SQL statement entry for an environment entry that matches
the environment
for which the SQL request was issued; if the entry is not present then the
database management
system inserts into the cache a new environment entry matching the environment
of the SQL
request; the database management system searches for a variation entry
comprising a valid
executable corresponding to the SQL request, which includes the SQL statement
and
environment entry, and, if a valid executable is not found then the database
management system
compiles the SQL request, refernng to the appropriate environment, into an
executable (a set of
one or more executable instructions) to carry out the SQL request; inserting
into a variation entry
the compiled executable, including a list of required privileges, a list of
dependent objects, an
identification number of the variation entry, and identification of the
validity of the entry; and,
for each object in the list of dependent objects searching in the dependency
portion of the global
SQL cache for an object entry with a matching object name and object type, and
if it does not
exist in the cache, inserting a new entry.
The invention also provides for a data processing system having a plurality of
nodes at
which processing may be performed, a method of identifying an executable
comprising
identifying the executable by node identification and entry identification
associated with the first
node of the data processing system that shipped the executable to any other
node in the data
processing system.
Preferably the executable is identified by node and entry identification
associated with the
first node of the data processing system that compiled and shipped the
executable to any other
node in the data processing system.
Another aspect of the invention provides a method of indexing data and
instructions for
storage and retrieval for a mufti-node data processing system comprising:
storing identification of the data and instructions in a list wherein the data
and
instructions are identified by node identification and entry identification
associated with the first
node that shipped the data and instructions to any other node.
Preferably the node list comprises an entry portion and a lookup portion
wherein:
the entry portion stores the following:
SQL statements;
CA 02282999 2002-10-31
CA9-1999-040 7
executables;
environment parameters;
entry identification for that entry in the list; and,
wherein the lookup portion includes the following:
the entry identification;
the identification of the node that first shipped or compiled the executable;
entry identification of the executable at the node that first shipped or
compiled the executable.
In still another aspect of the invention which may be used in a data base
system, having a
plurality of interconnected nodes, managed by a database management system,
each of the nodes
having an unique identification, the nodes being capable of storing or
processing information,
each node having a cache, the cache having a statement portion and a shipped
variation portion;
the statement portion of the cache at each node for storing SQL statements,
executables
associated with the SQL statements, and environments with which the
executables are associated,
wherein the executables are each identified by an unique entry identification;
the shipped variation portion (list) for storing identification entries for
the executables
including:
identification (ID number) of the executable which corresponds to the
identification (ID
number) of the associated entry in the statement portion of the cache;
the node identification (ID number) of the node from which the executable was
originally
shipped from or compiled; and,
the identification (ID number) of the executable at the node from which the
executable
was first shipped;
a method of executing a data processing request from a node (the coordinator
node) in a
manner adapted to avoid redundant shipping of executables comprising:
finding a suitable executable for carrying out the request by:
CA 02282999 2002-10-31
CA9-1999-040 8
searching the statement portion of the cache at the coordinating node for an
executable
that is associated matching the request and environment in which the request
was issued; and,
if the matching statement and environment were not found in the statement
portion of the
cache of the coordinating node, then compiling the request and inserting the
request into the
cache;
sending a request to all other nodes of the data base management system that
are
necessary to process the request (subordinate nodes of the coordinating node)
wherein the request
to all other such nodes includes: the identification of the coordinator node
and the entry
identification of the executable, and if there is a entry in the shipped
variation list associated with
the executable on the coordinator node cache then the database management
system also ships
identification of the node and entry.
In yet another aspect the invention provides for use in a database system
having a
plurality of nodes, and being managed by a database management system, each
node having a
storage cache for indexing and storing instructions including statements,
executables and
environment information, a method of executing a request by an application at
a first node
wherein the application identifies the executable that is desired to be
executed, searches at the
first node for the executable, and, if the executable is not found at the node
compiling the
executable, then, using identification of the node by the node and entry
identification of the
executable on the node from which it was first shipped or compiled, requesting
execution by all
other nodes required for executing the executable;
the other nodes searching in their respective caches by the node and entry
identification of
the executable assigned by the node from which it was initially shipped or
compiled; and,
if the executable is found at each the other node executing it at each node at
which it is
found; and,
if it is not found at one or more of the other nodes requesting that the
executable be
shipped from the first node to the nodes where the executable was not found;
and, then executing
the executable at each of the other nodes receiving it.
CA 02282999 2002-10-31
CA9-1999-040 9
Another aspect of the invention also provides a method of performing data
processing in
a mufti-node data processing system by sharing dynamic compiled (SQL)
executable data
processing statements between nodes of the data processing system comprising:
identifying each compiled SQL statement with a (numerical) identifier;
at a node receiving statements (a receiving node) storing a list of statements
received at
the receiving node listing the originating node and identifier for each of the
received statements;
upon receiving a request for processing with a specified statement having the
receiving
node check its list of statements received for the specified statement by its
originating node and
identifier;
comparing the identification of the specified statement with the statements in
the list of
the receiving node, and if a match is found then accessing the statement
stored at the receiving
node;
if a match is not found, having the receiving node request the specified
statement from
another node, and when it is received then loading it into its local cache;
having the receiving node update its list of statements;
executing the statement at the receiving node.
In another aspect the invention provides a method for use in a data base
management
system having a plurality of interconnected nodes, each of the nodes having an
unique
identification, the nodes being capable of storing or processing information,
one of the nodes comprising a catalogue node having metadata describing tables
and
other SQL objects and relationships between them in the data processing
system;
each node having a cache, the cache having a statement portion and a
dependency
portion;
the statement portion of the cache at each node for storing SQL statements,
executables
associated with the SQL statements, and environments with which the
executables are associated,
wherein the executables are each identified by an unique entry identification;
the dependency portion for storing object entries for the SQL objects
including:
CA 02282999 2002-10-31
CA9-1999-040 10
identification of the object which corresponds to the object name and object
type;
a list of entries refernng to executable entries in the statement portion of
the cache whose
execution relies on the definition and existence of the object;
a method of updating entries in the cache at each node when object definition
entries in
the catalogue are changed comprising:
updating the catalogue node by removing all invalid entries and broadcasting
instructions
to other known nodes of system to remove invalid entries from their respective
caches, by:
making a first broadcast of instructions to the nodes to secure entries in the
dependency
portion of each cache by first:
finding an object entry associated with the object that is being changed in
the dependency
portion of the cache;
if such an object entry in the dependency portion of the cache is not found,
inserting a
new object entry;
securing the object entry in the dependency portion of caches of the other
nodes; marking
1 S all the executables currently listed as being associated with the object
as invalid;
reporting to the database management system at the catalog node that the
object entry in
each of the caches have been marked as secured;
examining any executable newly arnving in a cache of a node and determining if
it
depends on an object that has been secured, and if so, marking it as invalid;
making a second broadcast from the catalog node to all known nodes to:
mark all entries in the caches which are dependent on a secured object or an
invalid
object as being invalid; and,
removing the secured marking of all secured objects;
removing all invalid entries and objects.
In a further aspect of the immediately above method entries are updated in the
cache at
each node when a node is added to the database comprising:
CA 02282999 2002-10-31
CA9-1999-040 11
when a new node is added to the database system, sending from the catalogue
node a list
of all secured objects to the new node;
at the new node, for all the objects in the list of the objects secured at the
catalog node,
creating and securing a new object entry in the dependency portion of the
cache of the new node;
at the new node, examining any executable newly arriving in the cache of the
new node
and determining if the executable depends on an object that has been secured,
and if so, marking
it as invalid.
A further aspect of the invention provides a computer program product
comprising
computer readable storage for storing statements or instructions for use in
execution in a
computer in accordance with one or more aspects of the invention described
above.
BRIEF DESCRIPTION OF THE DRAWINGS
Fig. 1 depicts a mufti-node database management system.
Fig. 2 depicts a dynamic SQL cache.
Fig. 3 depicts the structure of the dynamics SQL portion of a global cache.
Fig. 4 depicts the basic unit of the dependency portion of a dynamic SQL
cache.
Fig. 5 depicts the shipped variation portion of a dynamic SQL cache.
Fig. 6 depicts the invalidation in progress portion of the cache.
Figs. 7a, 7b, 7c depict a flow chart illustrating an embodiment of the present
invention for
executing SQL requests in a mufti-node environment.
Figs. 8a, 8b, 8c depict a flow chart for mufti-node database management system
accordance with an embodiment of the present invention.
Fig. 9 depicts a flow chart of anew node registering with a database
management system
in accordance with the invention.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENT
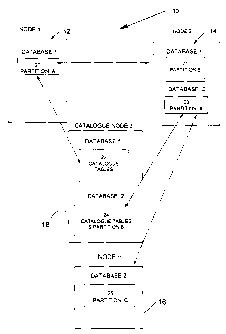
Figure 1 is a conceptual diagram of a Relational Database Management System
(RDBMS) 10. The RDBMS of 10 of Figure 1 illustrates only one of many
configurations
CA 02282999 2002-10-31
CA9-1999-040 12
available in an RDBMS and is intended only to show a networked system that may
utilize the
present invention. In the configuration as shown, RDBMS 10 contains a
plurality of nodes ( 12,
14, 16, 18). Each node (12, 14, 16, 18) may contain a partition or all of a
database. In the
example of Figure 1, the RDBMS has two databases, although any number of
databases can be
provided, the content of which is partitioned among the plurality of nodes.
The first of these
databases is divided into a partition 20 and a partition 21. The catalogue 22
for this first database
is stored on catalogue node 18. The catalogue 22 contains tables in which
resides all the
"meta-data" such as the structure, tables, packages and functions relating to
the first database.
The second database is divided into partitions 23, 24 and 25. Note that in the
illustrated
example, the partition 24 of the second database also contains the catalogue
tables for the second
database. Thus, a catalogue node 18 may contain data as well as catalogue
tables. Catalogue
tables are per database and can be located at different nodes for different
databases. This means
that the term "catalogue node" is relative per database, i.e. the catalogue
could reside on any
node.
The Global Cache
The global cache acts as a repository for package and section information for
static SQL
and statement and section information for dynamic SQL as detailed below.
In this disclosure, we discuss the method and apparatus for the dynamic SQL
cache only.
In the preferred embodiment, the global cache is kept at the database level,
and is
accessible to all agents for a database at a particular node of the database
(physical or logical). It
is allocated from the same memory set as other database-level entities, such
as the lock list or
buffer pool; it is created when the database is initialized, and it remains
active until the database
is shut down. The global cache acts like a "public" library for all the agents
using the database at
a given node. Agents simply copy the package information and the modifiable
portions of the
sections (e.g. buffers and flags).
CA 02282999 2002-10-31
CA9-1999-040 13
Refernng to Figure 2, the dynamic SQL portion 40 of the global cache is
subdivided into
four portions: the statement portion 41, the dependency portion 42, the
shipped variation portion
43 invalidations in progress list portion 44. The statement portion 41, also
known more
generally as the entry portion of the cache contains SQL statement entries 62
(see Figure 3)
which contain the text of the cached dynamic SQL statements as well as the
different sections
compiled for each SQL statement. The statement portion 41 of the dynamic cache
40 is used to
support application requests to prepare the dynamic SQL statement 64 (see
Figure 3) and obtain
an executable section. The dependency portion 42 of the dynamic cache 40
contains entries for
all the objects upon which the cached dynamic SQL sections are dependent. This
information is
used to support cached object invalidation due to data definition language
statements and other
database activities. The shipped variation portion 43, also known as the
lookup portion of the
cache is a list used to lookup entries that have been shipped from other nodes
of the database
system. The invalidations in progress portion 44, contains a list of objects
that are currently being
modified in the database management system.
Referring to Figure 3, the primary structure of the dynamic SQL portion 40 of
the global
cache is based upon the unique text for a given SQL statement 64, which is
stored within SQL
statement entry 62. A SQL statement entry 62 contains characteristic
information about the SQL
statement 64 that is determined once the first occurrence of the statement
text 64 is compiled.
This information is invariant since the statement text 64 is constant and
these characteristics are
inherent in the statement text 64 itself, independent of the environment in
which it was compiled.
The compilation environment 66 contains information on the environment used to
generate or compile the section. The compilation environment 66 contains all
information not
already contained in the catalogue tables, that influence or control an access
plan created by the
SQL compiler, and thus the section.
Below each compilation environment 66 are stored individual units known as
"variations"
68. A variation 68 represents a unique section for the statement text 64,
where the uniqueness is
CA 02282999 2002-10-31
CA9-1999-040 14
specified by the compilation environment 66 used to generate the section. The
compilation
environment 66 encompasses all those elements that affect the nature and
result of the section
generated by the SQL compiler for a dynamic SQL statement (e.g., special
registers, relevant
package compilation defaults, use of default qualifiers, use of function path,
etc.). Note that since
S privileges do not affect the actual section generated, only whether it is
allowed to be executed,
the prerequisite privileges for a dynamic SQL statement 64 are irrelevant to
the compilation
environment 66. In the preferred embodiment, privileges are not part of the
compilation
environment 66.
A variation 68 is simply the representation of the fact that two applications
issuing the
same dynamic SQL statement 64 in the same context with the exact same
compilation
environment 66 should generate the exact same section, although the results of
execution may
differ due to actions within the individual units of work. For example, two
applications using the
same section for SELECT C1 FROM T1 may return different results if the first
application has
inserted some rows into T 1 but not committed its changes. The first
application will get the row
returned by the section, but the second application may not.
In addition to the identifying compilation environment, each variation 68
under a
statement entry 62 and compilation environment 66 also contains: the required
privileges list of
privileges needed to execute the section, the dependency list for the section
and the section
generated for the specified compilation environment, and a pointer (reference)
to an entry in the
shipped list. The dependency list refers to those objects and entities in the
catalogue tables
required, either directly or indirectly, by the section for a variation 68.
The dependency list is also
used to determine whether the section is no longer valid when an object on the
dependency list is
dropped; if the variation 68 is in use at the time, the drop request is
rejected. When a section is
no longer valid, the variation 68 becomes an invalid variation 70 and must be
regenerated.
Details of the dependency list and its use to invalidate dynamic SQL sections
is discussed below
in the description of Figure 4. The major difference between dependencies and
privileges is that
CA 02282999 2002-10-31
CA9-1999-040 1 S
the loss of privileges does not result in any variation 68 being marked as an
invalid variation 70
since, as noted previously, privileges do not affect the contents of the
section. Since a variation
68 represents a dynamic SQL statement, and dynamic SQL always reflects the
current
environment, other actions such as issuing the RUNSTATS command against a
table or creating
a new User Defined Function (UDF) can cause a variation to be marked invalid.
Each dynamic SQL statement entry 62 may have one or more compilation
environments
66, but each compilation environment 66 may contain only one valid variation
68. An invalid
variation 70 will be flushed from the cache during cache space management. For
example, an
ALTER TABLE statement can cause a variation 68 to become an invalid variation
70 in the
dynamic cache 44 and will eventually be flushed from the dynamic cache 44.
The variation entry includes a pointer or reference to an entry in the shipped
variation list,
if such an entry exists.
Referring now to Figure 4, the basic unit of the dependency portion 42 of the
dynamic
SQL cache 40 is the object 72. An object 72 represents a database object upon
which a dynamic
SQL variation 68 is dependent. Each object 72 is associated with one or more
variations 68.
Each object 72 in the dependency portion 42 of the global cache is distinct
and only one
occurrence of the object 72 may appear at any one time. To facilitate access,
each object 72 is
associated with a specific object type anchor point 74 by hashing the
qualified object name 76 to
a unique anchor point 74. Once associated with an anchor point 74, the object
72 is inserted into
the list of objects 78 off that anchor point 74 in alphabetical order based on
the object name 76
followed by the qualifier. Anchor points 74 are type specific (i.e. an alias
anchor point only holds
aliases) and only objects 72 of the type represented by the anchor point 74
are to be found off that
anchor point 74. In the present embodiment, this includes objects of types:
view, alias, index,
User Defined Functions (UDF), table, structured types, summary tables,
hierarchies, pagesizes,
summary tables and hierarchical tales. In addition, a field is kept for each
object, indicating
whether the entry is secured.
An essential characteristic of a dynamic SQL statement is that the running of
it should
reflects the current database environment as if it were compiled for everytime
the query were
CA 02282999 2002-10-31
CA9-1999-040 l 6
issued; the dynamic SQL cache 44 does not alter this characteristic. If an
environment change
affects a dynamic SQL section, the variation 68 for that section will become
an invalid variation
70. When invalidating a dynamic SQL variation 68 due to a change in a
dependent object, the
name of the affected object 76 is hashed to obtain the appropriate anchor
point 74 for the same
object type. The list of objects 78 is then scanned to find a matching object
72. Once a matching
object 72 is found, the list of dependent variations below that object is
scanned and an attempt is
made to invalidate them in the statement portion of the cache.
Referring to Figure 5, the shipped variation portion 43 of the cache is
comprised of a list
of zero or more "shipped" entries 102. Each shipped variation entry 102 refers
to only one
variation entry in the statement portion of the cache. The entry is identified
by "original node"
identification, that is it includes the node # at which the variation
originally was compiled and
shipped, as well as the variation ID at that node at which the variation was
compiled. This
original node information is used for lookup purposes. The shipped variation
entry also includes
the ID of the variation in that node's global SQL cache, so that once a match
is found in the
shipped variations list based on the original node information, the entry then
refers to the actual
local entry in the current node's cache. Note that the original node
information does not
necessarily correspond with the node, and variation ID corresponding to the
coordinating node
that actually shipped the query.
Referring to Figure 6, the "invalidations in progress" portion 44 of the cache
is comprised
of zero or more entries 130. Each entry indicates an object that is in the
process of being
dropped, altered, or otherwise causing invalidation.
This object refers to an entry in the dependency portion of the cache. For the
catalog
node, entries are added to this list when an attempt to modify the definition
of a specific object is
made. At other nodes entries are only added at node startup/registration time
as noted in the
description of node startup.
Mufti-node execution and cross-node sharing
Referring to Figures 7a, 7b, 7c, there is depicted a flowchart or a method for
executing
SQL in a mufti-node environment is described. In this method, it is ensured
that the SQL request
CA 02282999 2002-10-31
CA9-1999-040 17
is carried out by the database management system on behalf of the application
on all the nodes
relevant to that query. As well the method of lookup and identification of the
appropriate
variation entry on the subordinate node is optimized for an environment where
identical SQL
requests are issued by applications at many different nodes of the
application. By appropriately
labeling the shipped variation entry with the node number and the id of the
variation at which the
section was originally compiled, needless duplication of entries is eliminated
and communication
costs are greatly reduced.
The method as noted in the diagram is as follows. An application issues a
request to
execute an SQL statement that is received by the database manager at the
coordinator node.
Searching for a match based on the SQL statement and environment of the
application request, a
search is made in the statement portion 41 of the dynamic SQL cache 40 at the
coordinator node.
If a match is not found, a new variation entry is inserted appropriately into
the statement portion
of the cache at that node. At this point the variation entry, identified by an
id unique to the
coordinator node, is in place; this variation entry includes the section
(executable) that is to be
executed at this node and a number of subordinate nodes. An 'identifying'
request is sent to the
subordinate nodes) to execute the section from an appropriate variation entry
in the subordinator
node that matches the variation entry at the coordinator. To do this, the
request identifies the
appropriate entry by the following information:
- local node identification comprising the coordinator node id and the
variation id at the
coordinator node and
- original node identification, which comprises the node at which this
variation entry was
originally compiled and shipped from and the variation id at that original
node. The original node
identification is derived from the shipped variation entry associated with the
local variation id. If
the variation does not have a shipped variation id (which would be the case if
this variation is
new and the section was just compiled; it also would be the case if this node
has always been a
coordinator node with respect to this SQL request and never a subordinate
node), then the
original node identification is set to be identical to the coordinator node
identification.
At the subordinate nodes, this request to run the section of the variation
identified as
indicated is received by the DBMS. The shipped variation lookup list is
searched to find an entry
CA 02282999 2002-10-31
CA9-1999-040 18
that matches the original node identification indicated above. If a match is
found in that list
based on the original node identification, then it refers to a variation in
the statement (entry)
portion from the cache, the section of which can then be used to run the query
at that node.
If the a matching shipped variation entry is not found based on the original
node
identification, then the DBMS creates a new shipped variation entry in the
shipped variation list,
whose original identification is as supplied in the request. At this point
this shipped variation
entry does not correspond to a variation entry in the cache. The DBMS then
determines if the
original node number identified in the request matches the node number of the
current
subordinate node. If it is, then, since this current subordinate node is the
original node, then we
search the statement portion of the cache for the original node variation id.
If this id is found
(which is not necessarily the case; it may have been removed from the cache at
this node by this
time), then the desired variation has been found and the new shipped variation
entry created
above is set to be associated with (pointing to) this variation.
However if the current subordinate node is not the same as the original node -
or if they
are the same, but the original variation entry was found to no longer exist in
the cache, then the
DBMS needs to request that this variation entry be 'shipped' from the
coordinator node. (Note,
it cannot assume that it can request from the original node to find the entry
as the entry is not
guaranteed to be in the original node's statement portion of the cache;
however since the
coordinator node originated the request, we know that it is guaranteed to have
the entry still
present in its cache). Thus a new 'ship' request is sent back to the
coordinator node (as
determined from the local node identification part of the first identifying
request), requesting that
that node send back the full information associated with its local variation,
whose identification
number is sent to the coordinator node as the 'local' variation id. This
request is received at the
coordinator node, which then finds the id of the variation specified and sends
back all the
relevant information (including the statement text, the environment entry, and
all other
information associated with the variation including the section (executable).
At the subordinate
node, this information is received and then, based on the statement and
environment information,
a new variation and its companion entries are placed in the statement portion
of the cache (as
well as any associated dependency entries in the dependency portion of the
cache). The newly
CA 02282999 2002-10-31
CA9-1999-040 19
created shipped variation entry (which indicates the original node information
of this variation)
in the shipped variation portion of the cache is then associated with (pointed
to) with this new
variation in the statement portion of the cache.
By having the shipped variation list lookup based on the "original node ID" we
allow
S much more efficient cross node sharing.
The alternate, prior art solution can be summarized, via example as follows:
Application A connected at node 1 inserts or finds an existing variation entry
for the
executable version of the dynamic SQL at the SQL cache at node 1. It has a
unique id, say
NNN.1. It sends a request to relevant nodes to execute validation NNN.1 from
node 1. At each
of these other nodes, a lookup is performed in its shipped variation list to
determine if there is an
entry for NNN.1 from node 1 that has already been shipped to this node. If
not, it requests that
node 1 ships that NNN.1 entry information to the current node; once shipped an
executable entry
for the original text is inserted into the cache at that node as well as an
entry in the shipped list
indicating that the new entry has been shipped as NNN.1 from node 1. As long
as that entry is in
the cache this entry in the shipped list ensures that anyone who issues the
same text associated
with entry NNN.1 at node 1 will also be able to have the SQL run on its behalf
at other nodes
without additional shipping.
In an environment where cross-node sharing is allowed, we find that this
scheme by itself,
while providing for a solution that works, will involve extra shipping of
dynamic SQL entries.
Consider the following three nodes of a multi-node database, in which
different applications
connected at each of the nodes issue the same dynamic SQL text: "INSERT into
t1 values 1*",
and where t1 is a table whose partitioning includes nodes l, 2 and 3. In this
case application A
connects to the database at node 1, application B at node 2, and application C
at node 3, and
chronological execution at all 3 nodes proceeds down the diagram.
* The "values" entry "1" was merely chosen as an example.
CA 02282999 2002-10-31
CA9-1999-040 20
Node 1 Node 2 Node 3
A: application issues "INSERT
into t1 values 1 *",
The statement gets compiled and a :
Receives a request to execute
dynamic SQL executable is ~.1 ~m node
1. Cannot find
inserted into the cache for this an A~ Receives a request
entry in the shi to execute NNN.1
ed list
so it
pp from node 1. Cannot find
, an entry in the
variation, with variation ID = pulls
the entry for NNN.1 from
NNN. l . Sends out a request to node shipped list, so it pulls
1. This new entry is the entry for NNN.1
other nodes to execute NNN.1 inserted from node 1. This new
into the cache on node 2 entry is inserted into
from node 1 with unique id = MMM.2. the cache on node 3 with
A unique id = SSS.3.
shipped list entry is also added A shipped list entry
is also added indicating
indicating that this new entry was that this new entry was
brought as NNN.1
brought as NNN.1 from node 1. from node 1.
Application B: issues "INSERT
into t 1 values An entry for this
statement is found in the cache
(MMM.2). Sends a request to
other nodes to execute MMM.2
from node 2.
B: receives a request to execute B: receives a request
to execute MMM.2
MMM.2 from node 2. Cannot from node 2. Cannot fmd
an entry in the
find an entry in the shipped list, so shipped list, so it pulls
the entry for MMM.2
it pulls the entry for MMM.2 from Applicationfrom node 2. This new
B: issues INSERT entry is inserted into
node 2. This new entry is inserted ~to the cache as QQQ.3 and
t1 values 1 *". An entry for a shipped list entry
into the cache as LLL.1 and a his statementis added indicating that
is found in the this new entry came
shipped list entry is added cache (MMM.2).from MMM.2 from node
Sends a request 2. The existing
indicating that this new entry came entry (SSS.3) that matches
to other nodes to execute the same
from MMM.2 from node 2. The MMM.2 from statement text is marked
node 2. as not current.
existing entry (NNN.I) that
matches the same statement text is C: Application issues:
marked as not current. "INSERT into t1 value
1 *".
An entry for this statement
is found
in the cache (QQQ.3).
Sends a
request to other nodes
to execute
C: receives a request to execute
QQQ.3 from node 3.
QQQ.3 from node 3. Cannot find C: receives
a request to execute
an entry in the shipped list, so it
QQQ.3 from node 3. Cannot find
pulls the entry for QQQ.3 from an entry
in the shipped list, so it
node 3. This new entry is inserted pulls
the entry for QQQ.3 from
into the cache as UUU.1 and a node 3.
This new entry is
shipped list entry is added inserted
into the cache as TTT.2
indicating that this new entry came
and a shipped list entry is added
from QQQ.3 from node 3. The indicating
that this new entry
existing entry (LLL.1) that came from
QQQ.3 from node 3.
matches the same statement text is The
existing entry (MMM.2) that
marked as not current. matches the same.
CA 02282999 2002-10-31
CA9-1999-040 21
It can be seen in this prior art implementation that when an attempt is made
to share the
cached dynamic SQL that has been shipped from another node we end up
needlessly pulling
extra copies of what is already in the cache to other nodes. This causes extra
demands on the
networks, poorer performance and extra demands on the memory of the nodes' SQL
caches.
Note that this needless shipping back and forth of the same SQL entry can
continue if
applications at each of the nodes continue to issue that same SQL text.
To solve this performance/resource problem, the identification of the dynamic
SQL entry
in the shipping process is based on original node information, which
corresponds to the
identification of the entry at node where the request was originally compiled
and shipped from.
It is this compiled-at node information that is used to maintain and search
the shipped list. The
node at where the SQL is issued will send a request to all other nodes
indicating not only which
entry from the current node to execute, but also the node where the SQL was
originally compiled.
Further details can be seen in the revised flow of the previous scenario,
where the same SQL
request is issued in order from node 1, node 2 and node 3.:
CA 02282999 2002-10-31
CA9-1999-040 22
Node 1 Node 2 Node 3
A: Application issues "INSERT
into t1 values 1 *".
The statement gets compiled and a
dynamic SQL executable is A; Receives a request to execute A: Receives a
request to execute
inserted into the cache for this ~,1 from node 1 which was NNN.1 from node 1
which was
statement, with unique ID = originally compiled as NNN.1 from originally
compiled as NNN.1 from
NNN. I. Sends out a request to node 1. Cannot find an entry in the node I.
Cannot find an entry in the
other nodes to execute NNN.1 shi ed list, so it ulls the ent for shi
from node 1, originally compiled pp p ry pped list, so it pulls the entry for
as NNN.1 at node 1. ~~ 1 from node 1. This new NNN.1 from node 1. This new
entry is
entry is inserted into the cache on inserted into the cache on node 2 with
node 2 with unique id = MMM.2. A unique id = SSS.3. A shipped list entry
shipped list entry is also added is also added indicating that this new
indicating that this new entry was entry was originally compiled as
originally compiled as NNN.1 from NNN.1 from node 1.
node 1.
B: Application issues "INSERT into
t1 values 1 *".
B: receives a requestAn entry for this B: receives a request
to execute statement is found to execute
MMM.2 from node in the cache (MMM.2).MMM.2 from node 2 that
2 that was Sends a was
originally compiledrequest to other nodesoriginally compiled
as NNN.1 at to execute as NNN.1 at node
node 1. Since this MMM.2 from node 2, 1. An entry is found
is node 1, which was in the ship list
NNN.1 is found to originally compiled corresponding to an
exist, so the as NNN.1 from original
MMM.2 entry will node 1. compilation of NNN.
not have to be l at node 1, so the
pulled from node MMM.2 entry will not
2. have to be
pulled from node 2.
C: Application issues "INSERT into t1
values 1 *".
An entry for this statement is found in
the cache (SSS.3).
Sends a request to
C: receives a request other nodes to execute
to execute SSS.3 from
SSS.3 from node C: receives a requestnode 3 that was originally
3 that was to execute compiled as
originally compiledSSS.3 from node 3 NNN.1 at node 1.
as NNN.1 at that was
node 1. Since this originally compiled
is node 1, as NNN.1 at
NNN.1 is found to node 1. An entry is
exist, so the found in the
SSS.3 entry will ship list corresponding
not have to be to an original
pulled from node compilation ofNNN.I
3. at node 1, so
the SSS.3 entry will
not have to be
pulled from node 3.
CA 02282999 2002-10-31
CA9-1999-040 23
Thus, by organizing the search in the shipped variation list based on the id
and the node
of the entry where it was first compiled, we are able to avoid needless
shipping of entries and
needless insertion of entries. In this example this method has changed the
shipping situation: in
which there are 3 insertions of entries on node 1 (one a compile, and two from
shipping), 2
insertions of shipped entries on node 2, and 2 insertions of shipped entries
on node 3 with the
original scheme; with the proposed method each node has only one entry
inserted, which implies
an increase in performance by reducing the network traffic and the programming
steps required
to ship and entry from node to node and then insert it at the new node. By
this identification
schema, space usage in the cache is also reduced.
The Partic~ating Nodes List and Node Startup
In order to minimize network traffic and to allow for the ignoring of nodes
that are either
down or have not connected to a particular database, a list of participating
nodes for a database is
built and maintained on the catalogue node. A participating node is a node
which is active,
1 S connected to the database and has registered in the participating nodes
list at the database
catalogue node.
The list of participating nodes is used to define which nodes must be informed
when a
communication bulletin (described hereinbelow) is to be broadcast for a
database. The
information is broadcast to all nodes in the list of participating nodes other
than the current one
(catalogue node) by the agent wishing to send the information. Before any
broadcast, the
broadcasting agent must acquire the latch for the list of participating nodes
to prevent any new
nodes from being added. Processing for the cache at the catalogue node is
handled by the
broadcasting agent.
Invalidating_dynamic SOL
Certain actions affecting the definition of objects can render a variation and
its associate
section (executable) invalid. That is, it should not be executed, otherwise
internal system errors
could occur. As an example, if the statement "SELECT * SNOWBELL.TI" is
complied and
CA 02282999 2002-10-31
CA9-1999-040 24
inserted into the cache, then the action "DROP TABLE SNOWBELL.TI" must ensure
that all
variations in the cache, including the one for the statement above, are not
being executed, and are
marked as invalid, to prevent further execution.
In a mufti-node environment, the request to invalidate based on an object
drop/modification must be broadcast to all nodes from the catalogue node, in
such a way that it is
ensured that there are no variations that depend on the object on any other
node that are still
considered valid on any node.
The prior art for modifying objects involved sending a single broadcast from
the catalog
node to all nodes in the system. At each of the nodes in the system, the
dependency portion 42 of
the dynamic cache 40 is searched for an entry that matches the object name and
object type of the
object being modified. If an entry is found, then all the variations in the
statement portion of the
cache, that are referred to by this object entry in the dependency portion of
the cache are marked
as invalid. This proves to be adequate in a database management system that
does not allow
sharing. In that case a lookup in the statement portion of cache to match an
SQL request will not
be considered successful if it is found that the entry was in fact originally
compiled at another
node. However when the system allows sharing, there are situations in which,
due to the timing
of invalidation broadcasts and concurrent shipping of variations that may be
happening on the
system, a shipped variation may end up on one of the nodes caches that should
be marked as
invalid but in fact manages to remain marked as valid. If a new application
issuing the same SQL
on the shipped-to finds the entry in the cache, and sharing is allowed, it
will use an invalid entry
which could cause DBMS system failures. For illustrative purposes, on such a
scenario is
indicated in the 3 node table as follows (where chronological execution at all
3 nodes proceeds
down the diagram; consider node 0 to be the catalog node).
CA 02282999 2002-10-31
CA9-1999-040 25
Node 0 Node 1 Node 2
A: Application A issues:
"INSERT
into Tl values 1,2,3";B; Receives request
a matching entry to invalidate all
is not found in node SQL dependent on T1
1's cache, so it is and finds no
compiled and executableobject entry in dependency
inserted into portion of
cache at node 1 with the cache; nothing to
ID=xx. This invalidate
B: "DROP table T1" executable is executed
sends on this node
request to all nodesand a request is sent A: receives request
to invalidate to node 2 to to execute xx from
all SQL dependent execute ID=xx from node 1 and ships a copy
on T1 node 1 over from node
1 and inserts into cache
at node 2 the
B: Receives request entry for "INSERT into
to invalidate all Tl values
SQL dependent on T 1,2,3". Executes and
1 - has to wait informs Node 1
behind application that it has done. The
A to finish entry for this
executing the INSERT statement remains in
on all nodes the cache
before entry xx is
removed
A: receives notice that node 2 has
completed executing the request,
completes executing and frees up the
xx entry in the cache to be deleted C: Application C issues: "INSERT into
T 1 values 1,2,3". An entry for this is
B: now that A has finished, it deletes found in the cache from when app A
the xx entry for the INSERT shipped it over from node 1. However
this entry refers to a dropped table and
should not be valid. Danger!!!
B: Receives notice that all nodes
have finished
invalidating and drops the table
CA 02282999 2002-10-31
CA9- I 999-040 26
It can be seen in this example that with respect to the application executing,
the broadcast
event reached the subordinate node before the variation entry had been shipped
from the
coordinator node, thus not finding an entry in the dependency portion 42 of
the cache. A valid
entry ends up at the subordinate node, and then if an application at that node
later tries to 'share'
that entry it would find an entry that looks to be valid.
Invalidating Method - two phase broadcast:
Figures 8a, 8b, 8c describe the general method for a mufti-node invalidation
that ensures
that entries that should be invalid do not end up at any subordinate node, in
which case sharing
would then allow a new application at that node to run from an invalid
variation and its section.
Refernng to Figure 8a, in this method, two separate broadcast occurs, the
second of
which does not complete until the first has completed successfully on all
nodes. We consider
generally a request originating at a node that is not necessarily the catalog
node, to modify (in the
example in the figure - drop) an object. This request, since it involves a
change in the definition
of the object which is maintained in the catalog tables at the catalog node,
is forwarded to the
catalog node to control. At the catalog node, the request is received to
modify/drop a specific
object. When this happens a new entry is added to the invalidations in
progress portion 44 of the
cache (iip list in Figure 8) , which indicates the object type, object name,
as well as a unique
identifier. (The purpose of this entry in the invalidations in progress list
is discussed in the
context of a modified node startup algorithm below). Then phase 1 is executed
at the catalog
node and then a broadcast is issued to all nodes to execute phase 1 of the
invalidation. Phase 1
(Figure 7a, 7b, or 7c) does not involve the active marking of variations
invalid. Instead it is
performed to ensure that newly shipped variations that are dependent on the
object that is being
modified to immediately be marked invalid when being placed in the shipped-to
node's cache.
At each node in phase 1, this is done by searching in the dependency portion
of the cache for an
object entry that matches the object type and object name of the object being
modified or
dropped. If an entry does not exist, a new entry is created. At this entry the
object is marked as
'secured'. Once marked as secured, any new insertions of variations shipped
from other nodes
CA 02282999 2002-10-31
CA9-1999-040 27
that attempt to insert a dependency entry (for the newly shipped variation)
for the object being
modified/dropped will note that the entry is secured, and will immediately
mark the variation
entry as invalid. Once the object entry in the dependency portion 42 of the
cache is marked as
secured, phase 1 is complete and control returns to the catalog node.
Once all nodes have been completed before phase 2, the DBMS then executes
phase 2 of
the invalidation - first locally at the catalog node, and then a broadcast
request is sent to all nodes
to execute phase 2 of invalidation for modifying/dropping a specific object.
In phase 2 (Figure 7c), a search is performed in the dependency portion of the
cache for
the object that matches the name and the type of the object being modified.
(This object entry
should have already marked as 'secured' during the first phase). Once this
object has been
located, all dependent variations, the list of which is maintained at the
object entry, are marked as
invalid in the statement portion of the cache. The invalidations in progress
list is then searched
for a matching object name and type. If one exists, it is dropped. Once this
has completed, the
object entry in the dependency portion of the cache is then marked as not
secured, and the second
phase is complete. When the catalogue node is informed of the success of all
second phases from
all nodes, the object definition modification can then proceed.
In this phase 2 algorithm, the first phase has thus insured that the second
phase can occur
without regard for new shipping of variations that may occur while the second
phase takes place,
and thus ensures that all variations that should be marked as invalid are
marked as invalid at all
nodes of the system.
However this phase 2 algorithm alone still does not ensure that the
invalidation is
completely impervious to improperly marked variations. This is because the
broadcast events
only occur from the catalog node to all nodes that the catalog node
recognizes; and those are only
the nodes that have been registered (as described above). However, not all
nodes of a system
need to be active all the time, thus it is possible to have a new node start
up and be added to the
list of registered node in between the first two phases of the invalidation.
In this case, the first
phase which secured the objects until the second phase would not be performed
at that node, thus
re-opening the possibility that shipping a variation may end up missing the
invalidation process
CA 02282999 2002-10-31
CA9-1999-040 28
and ending up on a shipped-to node marked as valid when it should be invalid.
This scenario is
illustrated by example in the following example, where for simplicity we have
assumed that the
"drop table" request is issued at node 0, which is the catalog:
CA 02282999 2002-10-31
CA9-1999-040 29
Node 0 - catalogue Node 1 Node 2
node
A: Application issues: ** NODE INACTIVE ***
"INSERT into TI
values 1,2,3"; compiled** NODE INACTIVE ***
and executable
B: Application issuesinserted into cache ** NODE INACTIVE ***
"DROP table at node 1 with ID=xx.
T1". The DBMS sends This executable is executed** NODE INACTIVE ***
phase 1 of on this node
invalidation requestand a request is sent ** NODE INACTIVE ***
to all nodes to to node 2 to execute
invalidate all SQL ID=xx from node I ** NODE INACTIVE ***
dependent on
Tl. At this point ** NODE INACTIVE ***
it only recognizes
node 1 as a node B: Receives Phase I ** NODE INACTIVE ***
to broadcast to, invalidation
since node 2 is inactive.received from node 0. Node starts up to handle
No new SQL new
dependent on T I will application request
be allowed on this
Node 2 is registerednode. ** NODE INACTIVE ***
at catalogue
node ** NODE INACTIVE ***
** NODE INACTIVE ***
B: phase 2 of invalidation ** NODE INACTIVE ***
sent to
all nodes. It now ** NODE INACTIVE ***
recognizes node
and node 2 as nodes
to send a
broadcast to B: Receives phase 2
invalidation
Request from node 0.
However no
object entry for TI
is found.
B: Receives Phase 2 A: receives request
invalidation request to execute xx from
from node O.request node 1. This starts
to invalidate all up the node. A copy
SQL dependent on T1 of xx is shipped over
- has to wait from node 1 and
behind application A inserts into cache at
to finish executing node 2 the entry for
the INSERT on all nodes"INSERT into T1 values
before it can 1,2,3".
remove entry xx Executes and informs
Node 1 that it has
done.
A: receives notice that
node 2 has
B: Receives notice completed, frees up
that all nodes the xx entry in the
have finished invalidatingcache for deletion.
and
drops the table
B: now that A has finished, it deletes the
entry for the INSERT C: "INSERT into T1 values 1,2,3". An
entry for this is found in the cache from
when app A shipped it over from node 1
and seems to be valid. Danger! ! !
CA 02282999 2002-10-31
CA9-1999-040 30
In the example the 'securing' aspect of phase 1 of invalidation is missed by
the node that
has just started up. In order to ensure that the securing can occur on this
node without the benefit
of the first phase of the invalidation, the node registering process is
enhanced whereby when a
new node registering is made aware of invalidations that are in progress. This
is described in
Figure 9. When a new node starts up, it sends a request to the catalog node to
register itself as a
'participating node'. The catalog node adds this node to its list of
participating nodes, and then
sends to this new node the list of all the current invalidations in progress
entries from the
invalidations in progress portion of the cache. The new node receives this
list, and sets up on its
node's cache and invalidations in progress list. For each of the entries
therein, (each of which
indicate the object name and type of an object being modified) a new entry in
the dependency is
created for that object and the object is secured as it would have been if
phase 1 of the
invalidation were to have been received on that node. Note that this algorithm
relies on some of
the elements described already for the phase 2 invalidation in Figure 8, that
is, the catalog node
adds a new entry to the invalidations in progress list before even executing
phase 1; also at the
end of phase 2 every node examines the invalidations in progress for a
matching entry for the
object being modified - if found the entry is deleted.
In this way the new node when starting up has mimicked phase 1 of the
invalidation by
securing object entries to ensure new shipped insertions in the statement
portion of the cache are
aware whether they need to be marked invalid.
Pseudocode
The pseudocode listed below when read in combination with the description
above and
the drawings should assist those skilled in the art in appreciating the
present invention.
Part I
Modules A-C are the pseudo code associated with running an SQL request/query
in a multi-node
environment.
CA 02282999 2002-10-31
CA9-1999-040 31
Accompanying Figure 7 a-c.
Module A) Psuedocode for SQL request: coordinator node - part I):
The following code is run by the DBMS coordinator agent on behalf of an
application
that issues an SQL request against a database:
1 ) search statement part of dynamic SQL cache for matching statement entry
2) if (matching statement entry not found)
2.1 ) Create new statement entry containing the statement text of the SQL
request issued
by application
2.2) Insert new statement entry into statement part of the cache
2) end if
3) search statement entry for a matching environment entry
4) if (matching environment entry not found)
4.1) Create new environment entry containing environment in which the SQL
request was
issued
4.2) Insert new environment entry into cache as an environment of the matching
statement
4) end if
5) search environment entry for a variation entry with a valid executable
6) if (valid variation entry not found)
6.1) Compile SQL request (supplying the statement, environment)
6.2) Create new variation entry containing:
6.2.1 ) compiled section (executable)
6.2.2) privilege information
6.2.3) dependent objects
6.2.4) new variation id unique to this (coordinator) node's cache.
6.3) Insert new variation entry into cache as a valid variation of the
matching environment.
6.3.1) For each dependent object in dependency list (step 6.2.3)
CA 02282999 2002-10-31
CA9-1999-040 32
6.3.1.2) Search in dependency portion of cache for a matching object entry
(matching that
in 6.3.1)
6.3.1.3) If (matching object entry not found)
6.3.1.3.1) Create new object entry in the dependency portion of the cache
identifying the object (in 6.3.1)
6.3.1.3.2) Insert new object entry into cache
6.3.1.3) end if
6.3.1.4) Create new dependent variation entry identifying the variation (6.2)
6.3.1.5) Insert new dependent variation entry into dependency portion of cache
as a
dependent variation entry of the object entry
6.3 .1 ) end for
6) end if (at this point the desired variation exists in the cache with a
unique id)
7) Determine from the section/executable which nodes are the subordinate nodes
8) if (variation entry has a entry in the shipped variation list)
8.1 ) original node id = original node id in the shipped variation list entry
8.2) original variation id = original variation id in the shipped variation
list entry
8) else
8.3) original node id = current (coordinator) node
8.4) original variation id = id of variation at current (coordinator) node (6)
8) end if
9) Send request to all subordinate nodes to run a section from a variation
identified by:
- local node id = current (coordinator) node
local variation id = id of variation at current (coordinator) node (6)
- original node id (step 8)
- original variation id (step 8)
10) Executes from the section in the variation at the coordinator
11 ) Wait for execution from all subordinate nodes to complete, and results
received from all
nodes.
CA 02282999 2002-10-31
CA9-1999-040 33
12) Return result to application
13) exit
Note steps 1-10 are in the first column of Figure 7a), steps 11-13 are in the
first column of figure
7c).
Module B) Psuedocode for SQL request coordinator node - part II).
The following logic is run by the another DBMS agent at the coordinator node
as a response to a
subordinate node request to ship a variation from the coordinator node over to
that subordinate
node (Module C, step 3.5.1):
1 ) request is received from subordinate node to ship a variation of a
particular id
2) statement part of cache is searched for a variation of the requested id ( 1
) (will be found)
3) package together into one 'delivery', the variation entry with all its sub-
components, the parent
environment entry of that variation, and the parent statement entry of the
variation and
environment
4) send the delivery back to requesting subordinate node
5) exit.
All steps of B) are on the first column of Figure 7b) at coordinator node.
Module C) Psuedocode for SQL request at subordinate node.
The following logic is run a DBMS agent on the subordinate node in response to
a request of step
9) in module A to execute a specific variation's section:
1 ) request received from coordinator node to all subordinate nodes to run a
section from a
variation identified by:
- local node id - this is coordinator node id
- local variation id - this is the variation entry id at the coordinator
- original node id
CA 02282999 2002-10-31
CA9-1999-040 34
- original variation id
2) Search shipped variation portion of dynamic cache for entry matching the
original node id,
original variation id
3) if (matching shipped variation entry found)
3.1 ) The variation entry in the statement part of the cache that is
associated the shipped entry
is the desired variation whose section is to be run.
3) else
3.2) create new shipped variation entry with original node id and original
variation id as
supplied ( 1 )
3.3) insert new shipped variation entry in the shipped variation portion of
cache (currently not
associated with any variation in local (subordinate) cache
3.4) if the original node id (step 1 ) same as the current (subordinate)
node's id
3.4.1) Search for the original node variation id in the current (subordinate
node's cache)
3.4.2) if variation entry is found in the cache with a matching id as the
original node
variation id
3.4.3) Associate the new shipped variation entry (3.2) with the matching
variation
(3.4.2). This is the desired section to be run.
3.4) end if
3.5) If the new shipped variation is still not associated with any local
variation entry
3.5.1 ) Send request to coordinator node (as identified as local node id in
step 1 ) to ship
local variation id ( 1 ). (This request is handled at the coordinator node by
Module B)
3.5.2) Receive variation information, as well as matching statement and
environment
entry from coordinator node
3.5.3) Create and insert new variation entry (and if necessary statement,
environment
entries) in statement portion of local cache
The steps for inserting the new variation are similar to steps 2-6 in Module A
with the
following exceptions:
CA 02282999 2002-10-31
CA9-1999-040 35
3.5.3.1 ) If a matching statement/environment entry already exists and a valid
variation
for that statement/environment is already present in the cache (Module A, step
6), that
variation is marked as invalid; a new variation entry is always inserted
3.5.3.2) The variation is not compiled at the local node (as in Module A step
6.1 ),
rather the variation info obtained from the shipment from the coordinator node
is used
to fill in the new var; this includes info in Module A, 6.2.1, 6.2.2, 6.2.3.
(the section,
the privileges information and the dependency information). The variation id,
however is a new variation id for this variation, chosen to be unique at the
subordinate
node.
3.5.3.3) When inserting entries in the dependency portion of the subordinate
node's
cache (Module A, steps 6.3.1 ) an additional check is performed (which would
take
place after 6.3.1.5 in the Module A)
3.5.3.3.1) If object entry is marked as secured, then mark the new variation
entry
as invalid
3.5.4) Associate created shipped variation entry (3.2) with newly created
variation (3.5.3).
This is the variation with the required section/executable.
3) end if
4) run from section from the indicated variation
5) send results back to coordinator node (received in Module A) step 11 )
6) exit
Note all of Module C is in the second column of Figures 7b and 7c.
Part 2
Modules D) - I) are associated with Invalidation logic in a multi-node system.
Module D) Pseudocode for Invalidation - Coordinator node.
CA 02282999 2002-10-31
CA9-1999-040 36
1) Request received from an application to change the definition of an SQL
object or to drop the
object itself.
2) If the coordinator node is the catalog node
2.1 ) Execute Module E)
2) else
2.2) Request is send to the catalog node to execute the request
2.3) Waits for reply from catalog node
2) end if
3) Returns result of execution at the catalog node to the application
4) exit;
The following code is run by the DBMS coordinator agent on behalf of an
application that issues
a request to change the definition (or drop the existence) of an SQL object:
Note all of Module D is in the first column of Figure 8a.
Module E) Pseudocode for Invalidation - Catalog node
The following logic is run a DBMS agent on the catalog node in response to a
request from the
coordinator node to change the definition of an SQL object:
1) Request received from the coordinator to drop or modify the definition of
an SQL object
2) Add an entry to the invalidations in progress list identifying the object
name and object type
3) execute Phase 1 of the invalidation (Module F) at this (catalog) node,
specifying the object
name and object type in question (1)
4) Broadcast request to all other known nodes to execute Phase 1 (Module F) of
the invalidation
5) Wait for response from all other known nodes
6) If (confirmation received from all nodes that phase 1 is successful)
6.1 ) Execute phase 2 of the invalidation (Module G) at this (catalog) node,
specifying the
object name and object type in question (1)
CA 02282999 2002-10-31
CA9-1999-040 37
6.2) Broadcast request to all other known nodes to execute Phase 2 (Module G)
of the
invalidation. (Note all the known nodes may not be the same list of known
nodes as in the
Phase 1 broadcast in 4)).
6.2) Wait for response from all other known nodes
6) end if
7) If phase 1 and phase 2 are successful
7.1) drop the object or modify the object in the catalogs as requested
8) Return success/fail information to coordinating node
Note all of Module E is in the second column of Figure 8a.
Module F) Pseudocode for Invalidation - Phase 1 at all nodes
1) Request received from catalog node to execute phase 1 of invalidation for
an object, identified
by its name, and object type
2) Search dependency portion of cache for an object entry that matches the
name, type identified
in 1)
3) If object entry does not exists in the dependency portion of the cache
3.1) Create an object entry with the name, type identification from 1 )
3) end if
3) Denote in the object entry that the entry has been secured.
4) Send success/fail information back to catalog node
5) exit;
Note all of Module F is in Figure 8b.
Module G) Psuedocode for Invalidation - Phase 2 at all nodes.
1) Request received from catalog node to execute phase 2 of invalidation for
an object, identified
by its name, and object type
CA 02282999 2002-10-31
CA9-1999-040 3 8
2) Search object entry in dependency portion of cache that matches the name,
type identified in
1)
3) If object entry exists in the dependency portion of the cache
3.1) For all dependent variation entry listed for the object entry in the
dependency portion of
the cache
3.1.1 ) find the variation entry in the statement portion of the cache
(variation is indicated
in the dependent variation entry).
3.1.2) Wait until no other DBMS agents operating on this node is using the
variation
3.1.3) Mark the variation entry as invalid
3.1 ) end for
3.2) Denote in the object entry that the entry is no longer secured
3.3) Search the invalidations in progress portion of the cache for an entry
matching the object
name, object type indicated in 1)
3.4) If matching entry is found
3.5) Delete the invalidations in progress entry
3.4) end if
3) end if
4) exit
Note all of Module G is in Figure 8b.
Module H) Psuedocode for node start up logic - New node
The following code is run by an agent of the DBMS at the new node starting up
before it acts on
any other requests. Any request is received at the new node that until the
point is currently
inactive; in order to allow the node to activate the following is performed:
I) A request is sent to the catalog node to register this new node. (Module I
at the catalog node)
2) The reply from the catalog node is received together with a list of
invalidations in progress
3) All entries of invalidations in progress received are created identically
at the new node
CA 02282999 2002-10-31
CA9-1999-040 39
4) For all entries in the invalidations in progress list
4.1) add a new object entry in the dependency portion of the cache with the
object name, type
matching that indicated in the invalidations in progress entry
4.2) Denote in the object entry that the entry has been secured.
4) end for
5) exit
Note all of Module H is in the second column of Figure 9.