Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
1
APPARATUS AND SYSTEM FOR CLASSIFYING AND
CONTROL ACCESS TO INFORMATION
TECHNICAL FIELD OF THE INVENTION
THIS INVENTION relates to apparatus and system for classifying information
on communications network and in particular but not limited to apparatus and
system for classifying content servers and for selectively controlling access
to
classified content servers.
BACKGROUND OF THE INVENTION
The phenomenon growth of information technology has allowed many
people to have access to diverse information on communications networks. The
Internet in particular allows fetching of information from any cooperating
computers or content servers located in different parts of the world by simply
clicking references to the information. As the number of accessible computers
or
content servers and the amount of information over the communications network
grow daily it becomes increasingly difficult to classify them manually.
Known systems for controlling the types of information accessible on a
network rely on comparing a requested destination with those on pre-determined
Access Control Lists (ACL) or on word matching to determine whether to allow
or
deny access. This approach can be applied at the client node prior to
requesting the
information or on any suitably intelligent network device capable of
intercepting
the request or subsequent reply prior to it reaching the requester. For
example, in
the case of an Internet browser running on a PC or work station, a request is
made
for an Internet resource such as a web site. A software program for monitoring
such
requests on the PC can be configured to scan a pre-determined list of site
addresses
for a match. If found, access to the site may be denied and a suitable message
is
then displayed informing the user that access is denied. Alternatively, the
request
may be allowed to proceed, but as data are received from the site they are
scanned
for checking a match with one or more sets of pre-determined words, word
fragments or phrases. If a match is found the site is not displayed on the
computer
but instead there is shown a suitable message. Typically, this type of control
software is installed on a PC or work station which does not have particularly
strict
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
2
access privileges. The control software can be easily removed, disabled or
otherwise circumvented and thereby defeating the control system.
A network device capable of intercepting the request or reply to a request,
such as a proxy server, may perform similar actions using the same methods of
web
site matching. This is usually maintained by a network administrator with
strict
access rights. Also, a network requiring clients to connect through the
network
device in order to access the network can have its content control enforced.
This
allows content control of multiple clients from one central point.
While these known systems do provide some access control abilities, there
are several disadvantages. A system based on word or phrase matching can only
match text and it therefore would allow access to undesired information
comprising
graphic images. Also, a single word may match a broad range of sites with
quite
different classes of information. As an example, when the word "sex" is used
to
match pornographic sites the system would also block access to other sites
providing non offensive information such as articles on biology.
A system based on an access control list of prohibited sites is much more
selective. Access can only be denied when attempting to access the sites which
are
included in the lists. While a suitably large list could bar access to a great
deal of
undesirable information it is difficult to keep up to date due to the rapid
increase
in the number of new sites and removal of sites.
The above systems also do not lend themselves to adaptation to other
network protocols and services such as interactive chat, streaming video,
email or
encrypted data streams. Extending to different languages also poses a problem
for
globalisation of these systems.
OBIECT OF THE INVENTION
An object of the present invention is to alleviate or to reduce to a certain
degree one or more of the above disadvantages.
Another object of the present invention is provide an apparatus/system for
classifying user profiles.
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
3
SUMMARY OF THE INVENTION
In one aspect therefor the present invention resides in an apparatus for
classifying information on communications network. The apparatus comprises
means for obtaining one or more transmission characteristics of information on
a
path of said communications network, and analysing means for predicting a
classification of said information based on said one or more transmission
characteristics.
In a second aspect therefor the present invention resides in an apparatus for
classifying content servers which are accessible on a communications network.
The
apparatus comprises means for obtaining one or more transmission
characteristics
of information provided by any of said content servers on a path of said
communications network, and analysing means for predicting a classification of
said
information based on said one or more transmission characteristics.
In a third aspect therefor the present invention resides in a computer
program for classifying information which is accessible on a communications
network. The program comprises means for obtaining one or more transmission
characteristics of information on a path of said communications network, and
analysing means for predicting a classification of said information based on
said one
or more transmission characteristics.
In a fourth aspect therefor the present invention resides in a computer
program for classifying content servers which are accessible on a
communications
network. The apparatus comprises means for obtaining one or more transmission
characteristics of information provided by any of said content servers on a
path of
said communications network, analysing means for predicting a classification
of
said information based on said one or more transmission characteristics.
In a fifth aspect therefor the present invention resides in an
apparatus/computer program for classifying user profiles of users accessing
information or content servers on a communications network. The
apparatus/computer program comprises means for obtaining one or more
transmission characteristics of information or information provided by any one
of
said content servers on a path of said communications network, analysing means
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
4
for predicting a classification of said information or said one content server
based
on said one or more transmission characteristics, and means for classifying
user
profile in accordance with the predicted classification.
The above invention may also comprise means for storing said one or more
transmission characteristics
Typically said one or more transmission characteristics include any one or
more of network protocol, date and time stamps, size of transmission
activities (text
and image), content type of transmission activities, pattern seen within the
content
of the transmission and any other characteristic that can be employed for
predicting
classifications.
In preference said one or more transmission characteristics are obtained from
network packets or fragments thereof.
It is also preferred that the analysing means includes profiling means for
providing profiles of interactions based on said one or more transmission
characteristics. Typically said profiling means is arranged to process said
one or
more transmission characteristics for providing any one or more of frequency
of
interaction, duration of interaction, duration of absence of interaction,
patterns of
transmission, average number of http links within an object of related sites,
average
number of like sites visited within a time frame, and statistics from said
other
characteristics, for forming interaction profiles. The analysing means can
then use
the profiles for predicting classifications.
The invention may have a knowledge base of predetermined profiles, and
the analysing means is adapted to predict a classification based on a
comparison
between the profile of information to be classified and predetermined
profiles.
Advantageously the invention may have means for updating the knowledge
base so that the classification prediction may be enhanced fol lowing
classifications.
In order that the present invention can be more readily understood and be
put into practical effect reference will now be made to the accompanying
drawings
which illustrate one preferred embodiment of the invention and wherein:
BRIEF DESCRIPTION OF THE DRAWING
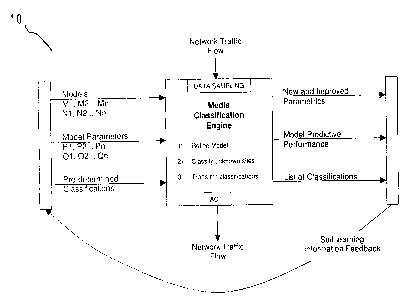
Figure 1 is a schematic diagram of the apparatus according to the invention;
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
Figure 2 is a table of selected data of captured packets of a search engine
using the apparatus shown in Figure 1;
Figure 3 is a partial table of selected data of captured packets of a news web
site using the apparatus shown in Figure 1;
5 Figure 4 is a table of selected data of captured packets of an entertainment
web site using the apparatus shown in Figure 1;
Figure 5 is a table of selected data of captured packets of the web site of an
e-commerce merchant using the apparatus shown in Figure 1;
Figure 6 is a table of selected data of captured packets of the web site of
another e-commerce merchant using the apparatus shown in Figure 1;
Figure 7 is a table of selected data of captured packets of a pornography web
site using the apparatus shown in Figure 1;
Figure 8 is a table of selected data of captured packets of another
pornography web site using the apparatus shown in Figure 1;
Figure 9 is a table of model N1 results using the apparatus shown in Figure
1;
Figure 10 is a table of model N2 results using the apparatus shown in Figure
1;
Figure 11 is a table of model N3 results using the apparatus shown in Figure
1; and
Figure 12 is a table of classification prediction confidence levels using the
apparatus shown in Figure 1.
DESCRIPTION OF THE PREFERRED EMBODIMENT
Referring initially to Figure 1 there is shown an apparatus 10 for classifying
media or information flowing through a path of a communications network which
in this case is the Internet.
As can be seen, network traffic passing through the apparatus 10 is captured
and analysed for providing statistics relating to interactions between two or
more
terminals (not shown). The captured traffic is first checked against a list of
predetermined classifications to determine if it is known or unknown.
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
6
When the captured traffic is of an unknown classification, various models
(to be described more fully below) are applied to the data set in the captured
traffic
in order to predict the content classification. The models use parameters
derived
from a knowledge base of previously classified data sets and fitness with
these
parameters to determine the classification of the content of the newly
captured
traffic. Thus, the web site sending the captured traffic is now classified and
is added
to the list of known classifications.
It should be noted that the embodiment of the apparatus 10 as described
herein is for an analysis of transmission traffic using the HTTP protocol. The
apparatus 10 according to the present invention is not restricted to HTTP, and
is easily adaptable to analyse data carried within any networks using any
known
protocol. Examples of the protocols include FTP, SMTP, NNTP, etc.
Following classification the captured data set is stored in the knowledge
base. As the knowledge base expands, more data are used for the model
parameters. This refines the apparatus and results in improved predictive
performance.
The sites that are deemed to include undesirable information are added to
Access control lists (ACLs). The ACLs are used control the flow of content
information between terminals. E.g. Undesired content information can be
prevented from travelling further through the network by simply not forwarding
it,
or by replacing it, or by intercepting the request for such content
information and
modifying its destination.
Classification of traffic from content servers are relatively static. On the
other
hand, user terminals that interact with these content servers are variable and
their
classifications are considered transient classifications.
Whereas classifications of content servers form a model of the style of
content residing on the server, transient classifications form a model of
style of
content being viewed by a user terminal, or content consumer. This in effect
forms
a behaviour profile of such a consumer. This profile can be used to tailor the
content information to suit the consumer.
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
7
As mentioned earlier the apparatus 10 captures a set of observed data
relating to a network interaction event, and provides a set of results
indicating the
classification of a resource or personality residing at each network node
involved
in the interaction. This is accomplished by applying various statistical
models to a
profile, and testing this against results obtained from profiles of known
classifications. In this example of the invention this process is represented
by the
following formulas:
x is an unknown profile to be classified;
Profiles p1,p2,p3...pn are of known classifications;
Models M1,M2,M3...Mn are available to operate on these profiles; and
C1,C2,C3...Cn are profile classifications.
The population of a profile of classification C1, may be defined by the
population of M1 (p). M1 (x) may be tested against the true population using
any of
the standard statistical hypothesis methods.
A pre-determined set of media terminals of a classification are modelled by
various models M1, M2 .. Mn. Each model consists of an approach and a set of
parameter, e.g linear regression, gradient and point of interception, so that
for a
single classification M1 (p1,p2 .. pn), M2(ql,q2 .. qn) .. Mn(r1,r2 .. rn) are
used to
model the population from the classification. The models may be based on
mathematical structures, or arbitrary rules.
The models are continually refined as more network traffic passes through
the apparatus 10, thereby increasing the population space from which the
classifications are computed.
A terminal may be permanently or transitionally defined in relation to a
classification. A transitionally defined terminal may move between
classifications
based on the fitness of the observed traffic to the models of the various
classifications.
Figures 2 to 8 are tables of selected data of traffic for testing the profile
of
data during a network interaction with a content server to determine if it
contains
media content of a pornographic nature. Assumption is made that profiles for
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
8
content servers contain a variable which is the average size of graphical
images
served.
A nor mai distribution or similar non-deterministic probability distribution
is
then used to test the hypothesis that the profile belongs to a population
classified
as pornographic. In this example, the population of the classification may be
defined by the population of N(a,b) where N is the image size and a and b are
the
mean and variance respectively, based on a normal distribution. The average
and
standard deviation derived from the observed samples is tested against the
true
population using standard statistical hypothesis methods.
In some cases this approach may be broadened to encompass analysis of
variance methods with multiple dependant variables, to model the
characteristics
of a site. Traditional ANOVA or regressive techniques may be applied to model
the
media content.
A variety of traditional deterministic and non-deterministic models may be
applied to determine the hypothesis of profile classification. These may be
changed
or upgraded continually depending on the level of predictive power found. The
functionality of models used is not limited to, but can include simple rules-
of-
thumb, deterministic and non-deterministic probability models, or arbitrary
calculations.
The choice of model is primarily dictated by the predictive power of that
model against the population in question.
Figures 2 through 8 show examples of basic data set that can be gathered by
observing network traffic of a typical interaction between a client browser
and a
web server.
Figures 9 to 11 illustrate a simple classification model. This model looks at
the size, content and relationships of objects being transmitted by a content
server.
The outcome of this model is to determine if the media being transmitted has
pornographic content.
Classification: pornographic
Standard Model:
N 1 (a,b)
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
9
Where N 1 is the image size, a and b are the mean and variance respectively,
based
on a normal distribution.
N2(c,d)
Where N2 is the ratio of text to graphics, c and d are the total size of the
text and
graphic objects respectively.
N3(e)
Where N3 is the count of word patterns matched from a list of pre-determined
words, and a is the text of an object.
Observed Samples are given in the tables shown in Figures 2 to 8.
For model N1 shown in Figure 9, there is applied the normal distribution
hypothesis test to the observed samples deriving the results.
The result shows confidence to the 93% and 87% level for sites 6 and 7
respectively, that the sites belong to a population of pornographic sites. The
other
samples give much lower confidence levels.
For model N2 shown in Figure 10, a simple rule is used to test if the ratio is
below a pre-determined threshold. The results show that sites 2, 4, 6 and 7
are
within the threshold rating.
For Model N3 shown in Figure 11, a simple rule is used to test if the
number of words matching a list of patterns, exceeds a pre-determined
threshold.
The results show that sites 6 and 7 exceed the threshold.
A weighting formula is then applied to derive a final result as shown in
Figure 12.
Therefore, using this example model, the apparatus 10 would predict that
sites 6 and 7 are probably serving media with pornographic content, whereas
sites
1 through 5 probably are not.
The attached appendix shows an example of the set of rules, constants and
formulas which determineaconfidence prediction based on logistic regression.
The
rules are defined using "Submodel" and "Model" components to define individial
data points, and aggregated data points. These are then referred to in the
"ProbabilityAnalyser" equations which use standard predictive formulas.
CA 02363574 2001-08-31
WO 00/52598 PCT/AU00/00158
Whilst the above has been given by way of illustrative example of the
present invention many variations and modifications thereto will be apparent
to
those skilled in the art without departing from the broad ambit and scope of
the
invention as herein set forth.