Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
MULTI-DIMENSIONAL DATA CUBE GENERATION METHOD, DEVICE AND
SYSTEM
Technical Field
[0001] The present invention relates to the technical field of the big data
processing, in
particular to a method, a device, and a system for generating multi-dimension
data cubes.
Background
[0002] A multi-dimensional data cube (Cube) is a data set constructed based on
the facts and
dimensions, so as to satisfy the customer requirements of conducting data
query and analyzing
from various aspects at multiple levels. In general, the Cube is a data set
for the same service
topic. The current techniques use the Cube for data analysis in online
analyzing processing
(OLAP) engines, storing indices and results by pre-computation technologies to
achieve high
query efficiency. Based on the current technology, the OLAP engines do not
have the capability
to manage the Cubes. Consequently, the dimension combinations of the Cubes
require manual
inputs or statement inputs as conditions. However the forementioned methods
are defined in a
customizable manner by technical personnel according to different service
scenarios. If the Cube
is generated by the forementioned method and applied in OLAP engines, the
following problems
will be emerged:
[0003] 1. The low quality of the Cube manually created by users, with
dimension loss, time
granularity mismatching, and low Cube hit rate;
[0004] 2. The manually created Cube by users lacks universality and leads to
lowered calling
rate of a portion of the Cube; and
[0005] 3. Without comprehensive procedures for constructing the Cube, the
manually created
Cube by users are not capable for scheduling and data complementing.
Summary
[0006] In order to solve the current technical problems, the present invention
provides a
method, a device, and a system for generating multi-dimension data cubes,
comprising:
1
Date Recue/Date Received 2021-09-24
[0007] From the first perspective, a multi-dimensional data cube generation
method is
provided, comprising:
[0008] collecting query data from an analytical engine including model
information, dimension
information, metric information, and time granularity associated with the
described query;
[0009] statistically analyzing the mentioned query data to determine
construction information
for a multi-dimensional data cube, including recommending models, recommending
dimension
combinations, recommending metrices, and recommending time granularity; and
[0010] generating the multi-dimensional data cube according to the mentioned
construction
information.
[0011] In particular, the described query data is statistically analyzed to
determine construction
information of the multi-dimensional data cube, comprising:
[0012] according to the described model information associated with the
described query,
counting model calling volumes within a pre-set time period, to identify
models satisfying the
model calling volume conditions as the described recommending models;
[0013] according to the described dimension information associated with the
described query,
counting both dimension combination calling volume of the recommending models
within the
pre-set time period and responding time of the dimension combinations, to
identify the
dimension combinations satisfying the dimension calling conditions and
responding time
conditions as the described recommending dimension combinations;
[0014] identifying the time granularity of the described recommending
dimension
combinations as the described recommending time granularity; and
[0015] identifying the metric fields in the models as the recommending
metrices.
[0016] In particular, the described method of generating the multi-dimensional
data cube
according to the mentioned construction information comprises:
[0017] calling an analytical engine according to the described construction
information, and
determining the storage information and creating interface of the described
multi-dimensional
data cube in the described analytical engine, to complete the generation the
described multi-
dimensional data cube.
[0018] In particular, the determination of recommending dimension combination
is determined
comprises:
2
Date Recue/Date Received 2021-09-24
[0019] according to the number of recommending dimension combinations,
expanding the
described recommending dimension combinations by joining dimension
combinations; and/or
[0020] complementing the described recommending dimension combinations
according to
dimension tables.
[0021] In particular, the determination of construction information comprises:
[0022] calculating return values of the described construction information.
The mentioned
return value is calculated by summing the products of the calling volume and
the mean
responding time of the non-optimized dimension combinations covered by the
described
recommending dimension combinations.
[0023] In particular, the determination of construction information also
includes calculating the
similarity amongst each described recommending dimension combination from the
described
construction information.
[0024] In particular, after generating the described multi-dimensional data
cubes, the described
method also includes:
[0025] assigning an intermediate table obtained based on the fact table and
the dimension table
into the described multi-dimensional data cube, to perform data complementing
of the described
multi-dimensional data cube and scheduling of the described multi-dimension
data cube.
[0026] In particular, after generating the described multi-dimensional data
cubes, the described
method also includes:
[0027] counting the hit rate of the described multi-dimensional data cubes
within the pre-set
time period, wherein the hit rate is the ratio of calling volume of the
described multi-dimensional
data cubes and the calling volume of the models.
[0028] From the second perspective, a multi-dimensional data cube generation
device is
provided, comprising:
[0029] a data collecting module, configured to collect the query data in the
analytical engine
including model information, dimension information, metric information, and
time granularity
associated with the described query;
[0030] a construction information determination module, configured to
statistically analyze the
mentioned query data to determine construction information for a multi-
dimensional data cube,
including recommending models, recommending dimension combinations,
recommending
metrices, and recommending time granularity; and
3
Date Recue/Date Received 2021-09-24
[0031] a generating module, configured to generate the multi-dimensional data
cube according
to the mentioned construction information.
[0032] In particular, the construction information determination module
comprises:
[0033] a recommending model determination module, configured to count the
model calling
volume within a pre-set time period according to the described model
information associated
with the described query, to identify the models satisfying the model calling
volume conditions
as the described recommending models.
[0034] A recommending dimension combination determination module, configured
to count
both the dimension combination calling volume of the recommending models
within the pre-set
time period and the responding time of the dimension combinations according to
the described
dimension information associated with the described query, to identify the
dimension
combinations satisfying dimension calling conditions and responding time
conditions as the
described recommending dimension combinations.
[0035] A recommending time granularity determination module, configured to
identify the
time granularity of the described recommending dimension combinations as the
described
recommending time granularity.
[0036] A recommending metrices determination module, configured to identify
the metric
fields in the models as the recommending metrices.
[0037] In particular, the generating module is configured to call an
analytical engine according
to the described construction information, and determine storage information
and creating
interface of the described multi-dimensional data cube in the described
analytical engine, to
complete the generation the described multi-dimensional data cube.
[0038] In particular, the recommending dimension combination determination
module also
includes:
[0039] a dimension combination expanding module, configured to expand the
recommending
dimension combinations by joining dimension combinations according to the
number of
recommending dimension combinations.
[0040] A dimension combination complementing module, configured to complement
recommending dimension combinations according to the dimension tables.
[0041] In particular, the construction information determination module also
includes:
4
Date Recue/Date Received 2021-09-24
[0042] a return value computing module, configured to calculate return values
of the described
construction information, wherein the mentioned return value is calculated by
summing the
products of the calling volume and the mean responding time of the non-
optimized dimension
combinations covered by the described recommending dimension combinations.
[0043] In particular, the construction information determination module also
includes:
[0044] a similarity determination module, configured to calculate the
similarity amongst each
described recommending dimension combination from the described construction
information.
[0045] In particular, the device of the present invention also includes:
[0046] a data complementing module, configured to assign an intermediate table
obtained
based on the fact table and the dimension table into the described multi-
dimensional data cube, to
perform data complementing of the described multi-dimensional data cube.
[0047] A scheduling module, configured to assign an intermediate table
obtained based on the
fact table and the dimension table into the described multi-dimensional data
cube, to perform
scheduling of the described multi-dimension data cube.
[0048] In particular, the device of the present invention also includes:
[0049] a hit rate computing module, configured to count the hit rate of the
described multi-
dimensional data cubes within the pre-set time period, where the hit rate is
the ratio of calling
volume of the described multi-dimensional data cubes and the calling volume of
the models.
[0050] From the third perspective, a computer system is provided, comprising:
[0051] one or more processors; and
[0052] a storage medium related to the described one or more processors,
configured to store
the program commands, when the described program commands are executed by the
described
one or more processors, any of the forementioned methods in the first
perspective are performed.
[0053] The technical strategies in the present invention result in the
benefits of:
[0054] 1. The technical strategies provided in the present invention allows
the automatic Cube
generation, to solve the problems of possible dimension loss, time granularity
mismatching, and
low Cube hit rate in the manually created Cube;
[0055] 2. The technical strategies provided in the present of the automatic
Cube generation
allows the Cube to include multiple dimension combinations, consequently to
improve
universality and calling rate of the Cube; and
Date Recue/Date Received 2021-09-24
[0056] 3. The technical strategies provided in the present with the
comprehensive automatic
Cube generation procedures allows the automatic Cube data complementing and
scheduling.
Brief description of the drawings
[0057] In order to make the technical strategies of the present invention
clearer, the accompany
drawings for the present invention will be briefly introduced below.
Obviously, the following
drawings in the descriptions are only a portion of embodiments of the present
invention. Those
skilled in the art are able to generate other configurations according to the
provided drawings
without requiring any creative works.
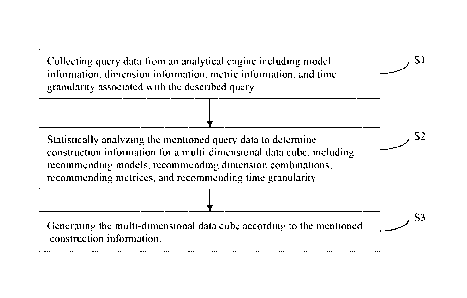
[0058] Fig. 1 is a flow diagram of the multi-dimensional data cube generation
method in an
embodiment of the present invention.
[0059] Fig. 2 is a structure diagram of the multi-dimensional data cube
generation device in an
embodiment of the present invention.
[0060] Fig. 3 is an internal structure diagram of the computer system of the
multi-dimensional
data cube generation in an embodiment of the present invention.
Detailed descriptions
[0061] In order to make the objective, the technical scheme, and the
advantages of the present
invention clearer, the present invention will be explained further in detail
precisely below with
references to the accompany drawings. Obviously, the embodiments described
below are only a
portion of embodiments of the present invention and cannot represent all
possible embodiments.
Based on the embodiments in the present invention, the other applications by
those skilled in the
art without any creative works are falling within the scope of the present
invention.
[0062] The described OLAP engine in the background introduction is based on a
fast-analyzing
technique of sheared multi-dimensional data, allowing users to observe the
data from different
aspects by the multi-dimensional database technique and supporting complex
analyzing
operations. By emphasizing the decision support for administrative personnel,
the complex big
data query requests by technical personnel can be performed fast and flexibly,
then the query
results are displayed in a clear and precise manner to assist the decision
making. Common
6
Date Recue/Date Received 2021-09-24
technical selections by OLAP engines includes Druid and PostgreSQL. Druid
engine is a real-
time processing engine for chronological data, sorting the indices in the
chronological order and
routes the indices during the query according to the timeline. PostgreSQL is a
versatile and open-
source object-relational database management system. By supporting MMP
scaffold, the
complex SQL analysis can be performed quickly over the large data sets.
However, neither Druid
engines nor PostgreSQL engines are capable for Cube management. The query
analysis feature
of the mentioned Druid engines or PostgreSQL engines requires manually created
dimension
combinations by users according to service scenarios, causing the problems of
low hit rat, lack of
universality of the Cube, and not being schedulable and complementable.
[0063] In order to solve the forementioned technical problems, the present
invention provides a
method, a device, and a system for generating multi-dimension data cubes,
comprising:
[0064] A multi-dimensional data cube generation method shown in Fig. 1
comprises:
[0065] 51:collecting query data from an analytical engine including model
information,
dimension information, metric information, and time granularity associated
with the described
query;
[0066] The mentioned analytical engines mainly imply OLAP engines, while the
other data
analyzing engines are applicable.
[0067] The query data is classified into two types, wherein one type is
calling query data, and
the other type is circuit-breaker query data. The calling query data is the
data information from
the analytical engine, allowed to execute the query analyzing request without
permissions for
intercepting the data query, including model information, dimension
information, metric
information, and time granularity. Furthermore, the mentioned calling query
data also includes
the data routed back to the source Cube (the source Cube implies the Cubes
manually created by
users), responding time, marks for success or failure, marks for whether
hitting the cache, etc.
The circuit-breaker query data is the data information intercepted by the
analytical engine,
allowed to intercept the data query without permissions for executing the
query analyzing
request, due to a large amount of data associated with executing the query
analyzing request,
including model information, dimension information, metric information, and
time granularity.
Furthermore, the mentioned circuit-breaker query data also includes circuit-
breaker warning
messages.
7
Date Recue/Date Received 2021-09-24
[0068] The forementioned model information includes model notations, model
serial numbers,
model and calling volume. The dimension information primarily implies the
dimension
combinations and the corresponding calling volume, wherein the dimension
combinations may
include analytical dimension, filtering dimension, sorting dimension, self-
filters of the indices,
etc. The metric information primarily implies the metric fields and the
corresponding calling
volume, including metric functions. The time granularity is the time range of
the query, for
example, in days, months, quarters, or years. A time granularity of a day
represents data within
one day, and so forth.
[0069] To clarify, the forementioned dimension is the non-quantitative data
for the aspects of
observing data in the data table. Taking sale data as an example, the sale of
each product type
can be determined and the sale of each product can also be determined, wherein
the "product
type" and "product" are defined as dimensions, individually.
[0070] The metrices are the quantitative data in the data table, such as
sales, amounts sold, etc.
The metric functions are used to compute the metrices, such as max, sum, min,
etc.
[0071] A model comprises the dimensions and the metrices. A fact table and one
or more sets
of dimension tables are combined in a certain manner to construct a model. The
fact table is the
table to store the metric values and external keys of the dimension table. All
the data in the
analytical engine is obtained from the fact tables. The dimension tables
provide descriptions of
the dimensions, wherein one or more dimension tables may associated with a
single dimension.
In detail, the matching modes of dimensions and dimension table can be star
shape, snow-flask
shape, fact constellation, etc. The star shape matching mode implies that one
dimension
corresponds to one dimension table. The snow-flask shape matching mode implies
that one
dimension corresponds to multiple dimension tables. The models are the sources
of fields for the
Cube, wherein the fields of a finally constructed Cube is a subset of the
model fields.
[0072] S2: statistically analyzing the mentioned query data to determine
construction
information for a multi-dimensional data cube, including recommending models,
recommending
dimension combinations, recommending metrices, and recommending time
granularity.
[0073] The forementioned recommending model is obtained based on the counting
results from
the model information in step Si. The recommending dimension combinations are
obtained by
the counting results from the dimension information in step Si. The
recommending metrices are
obtained based on the models.
8
Date Recue/Date Received 2021-09-24
[0074] To clarify, step S2 requires a separate analysis of the calling query
data and the circuit-
breaker query data due to much less data calling volume for circuit-breaker
query data than the
data calling volume for calling query data. If the calling query data and
circuit-breaker query
data are mixed for an analysis, the circuit-breaker query data will be
filtered out. To separate the
analysis of the calling query data and the circuit-breaker query data, the
Cube is used for a large
data-volume query analysis, wherein the large data-volume query analysis is
not achievable by
the previous OLAP engines using model query data. Consequently, less query
data is associated
due to a subset of the model fields involved in the Cube fields. As a result,
the query becomes
more specific, preventing the problem of circuit breaker mechanism in the OLAP
engines due to
a large data volume.
[0075] In an embodiment of the present invention, step S2 comprises:
[0076] S21: according to the described model information associated with the
described query,
counting model calling volumes within a pre-set time period, to identify
models satisfying the
model calling volume conditions as the described recommending models.
[0077] S22: according to the described dimension information associated with
the described
query, counting both dimension combination calling volume of the recommending
models within
the pre-set time period and responding time of the dimension combinations, to
identify the
dimension combinations satisfying the dimension calling conditions and
responding time
conditions as the described recommending dimension combinations.
[0078] S23: identifying the time granularity of the described recommending
dimension
combinations as the described recommending time granularity.
[0079] S24: identifying the metric fields in the models as the recommending
metrices.
[0080] The forementioned step S21 is used to detect the models with relatively
large calling
volume. Besides the models satisfying the model calling volume conditions, the
mandatory
models can also be added as the recommending models. In detail, the calling
volumes of the
models in the pre-set time period are counted and sorted according to the
model calling volume
conditions. Step S22 is used to select the dimension combinations with large
calling volume
from the large calling volume models, to be identified as the recommending
dimension
combinations. In detail, the calling volumes of the dimension combinations in
the pre-set time
period are counted and sorted, and synchronously the responding time of the
dimension
combinations in the pre-set time period are counted and sorted. The obtained
recommending
9
Date Recue/Date Received 2021-09-24
dimension combinations are required to satisfy both the dimension-combination
calling volume
conditions and the dimension-combination responding time conditions. By steps
S21 ¨ S23, the
recommending models, recommending dimension combinations, recommending time
granularity
are obtained, to yield observing aspects for the data. Then, by step S24, the
metric fields in the
models are exported as the recommending fields, to generate the final
construction information,
including recommending models, recommending dimension combinations,
recommending
metrices, and recommending time granularity. The change of the dimension
combination
numbers in the Cube can cause the change of the data amount geometrically in
the Cube, while
the change of the number of metrices in the Cube does not affect the data
amount in the Cube
significantly. As a result, in an embodiment of the present invention, in
order to ensure versatility
of service data in the Cube, step S24 extracts the metric fields in the models
as the
recommending metrices.
[0081] The cube construction information of the calling query data and the
cube construction
information of the circuit-breaker query data are obtained by step S2. Then
the constructed
multi-dimensional data cube comprises the Cube of the calling query data and
the Cube of the
circuit-breaker query data.
[0082] In an embodiment of the present invention, step S22 also includes the
optimization of
the recommending dimension combinations. In particular:
[0083] S221: according to the number of recommending dimension combinations,
expanding
the described recommending dimension combinations by joining dimension
combinations.
[0084] S222: complementing the described recommending dimension combinations
according
to dimension tables.
[0085] The forementioned step S222 is used to balance the calculation
resources. In detail, an
arbitrary combination is applied with a smaller number of recommending
dimension
combinations, while a pair-wise combination is applied with a greater number
of recommending
dimension combinations.
[0086] In terms of the arbitrary combination, for example, only one
recommending dimension
combination is obtained: [district, city company, retailer store, product
type, brand], and the
results of the arbitrary combinations include:
[0087] district, city company
[0088] district, retailer store
Date Recue/Date Received 2021-09-24
[0089] district, product type
[0090] district, brand
[0091] city company, retailer store
[0092] ...
[0093] district, city company, retailer store
[0094] district, city company, product type
[0095] district, city company, brand
[0096] ...
[0097] district, city company, retailer store, product type
[0098] district, city company, retailer store, brand
[0099] ...
[0100] district, city company, retailer store, product type, brand
[0101] In terms of the pair-wise combination, for example, three recommending
dimension
combinations are obtained, wherein the first dimension combination is
[district, city company,
retailer store]; the second dimension combination is [district, city company,
product type]; and,
the third dimension combination is [product type, brand]. The results of the
pair-wise
combinations include:
[0102] district, city company, retailer store, product type
[0103] district, city company, retailer store, product type, brand
[0104] district, city company, product type, brand
[0105] Step S222 is used for further complementing the dimension combinations,
particularly
includes two complementing methods of the dimension level complementing method
and the
derived dimension method.
[0106] An example of the dimension level complementing method:
[0107] recommending dimension combination contains the dimension of brand,
then the upper-
level dimension in the model is automatically complemented in the
forementioned
recommending dimension combination, wherein the record volume remains the same
to satisfy
more scenarios.
[0108] An example of the derived dimension method:
[0109] recommending dimension combination contains the dimension of retailer
store, then the
store opening time and closing time in the dimension table of the retailer
store in the model are
11
Date Recue/Date Received 2021-09-24
automatically complemented in the recommending dimension combination, wherein
the record
volume still remains the same.
[0110] In an embodiment of the present invention, the optimization of the
recommending
dimension combinations also includes elimination of the existing recommending
dimension
combinations. With the current technology, OLAP engines may carry the Cubes
that are
manually created by users. As a result, the repeated recommending dimension
combinations of
the existing Cube dimension combinations are required to be eliminated to
prevent duplications.
In particular,
[0111] S233: comparing the existing recommending dimension combinations and
deleting the
recommending dimension combinations repetitive to the existing recommending
dimension
combinations.
[0112] In an embodiment of the present invention, step S2 also includes:
[0113] S25: calculating return values of the described construction
information. The mentioned
return value is calculated by summing the products of the calling volume and
the mean
responding time of the non-optimized dimension combinations covered by the
described
recommending dimension combinations.
[0114] The formula for the described return value calculation is:
[0115] return value = SUM (mean responding time of the non-optimized dimension
combinations covered by the described recommending dimension combinations x
calling
volume)
[0116] For example:
[0117] The recommending time granularity is the granularity of a day, and the
recommending
dimension combination is [district, city company, retailer store].
[0118] The non-optimized recommending time granularity is a granularity of the
day. The non-
optimized the recommending dimension combination 1 is [district]. The calling
time is 100
times, and the mean responding time is 200 ms.
[0119] The non-optimized recommending time granularity is the granularity of a
day. The non-
optimized the recommending dimension combination 2 is [city company]. The
calling time is
150 times, and the mean responding time is 250 ms.
[0120] Hence, the return value of the recommending dimension combination = the
calling time
of the non-optimized the recommending dimension combination 1 x mean
responding time +
12
Date Recue/Date Received 2021-09-24
the calling time of the non-optimized the recommending dimension combination 2
x mean
responding time = 100 x 200 + 150 x 250 = 57500.
[0121] In an embodiment of the present invention, step S2 also includes:
[0122] S26: estimating the data volume of the Cube constructed by the
construction
information. In particular, the data volume is the estimated data volume of
the Cube constructed
by the construction information according to the number of dimension
combinations.
[0123] In an embodiment of the present invention, step S2 also includes:
[0124] S27: calculating the similarity amongst each described recommending
dimension
combination from the described construction information.
[0125] The forementioned step S26 also includes:
[0126] sorting the construction information in descending order according to
the return values,
and selecting the sorted construction information that satisfying the return
value conditions; and
[0127] calculating similarity amongst each described recommending dimension
combination
from the described construction information
[0128] The calculation of similarity can adopt the method of Jaccard, and the
computation
principles are:
[0129] giving two sets, A and B, and defining Jaccard constant as the size of
the intersection of
A and B divided by the size of the union set of A and B, shown in the
equation:
[0130] KA, B) = lAnBI
1A1+1B1-1AnBI
[0131] In particular, when the set A and set B are both empty sets, J(A, B) is
defined as 1.
[0132] For example:
[0133] the construction information of the Cube 1 has the recommending
dimension
combination of {district, city company, retailer store format} . The
construction information of
the Cube 2 has the recommending dimension combination of {district, city
company, retailer
store, product type} . Hence, J(Cube 1, Cube 2) = 2/5.
[0134] For different recommending time granularities of the construction
information, the
similarity is defined as 0.
[0135] To clarify, in order to avoid filtering out the Cube construction
information for the
circuit-breaker query data when calculating the similarity, it is necessary to
separate the
computation of the similarity amongst the Cube construction information for
the calling query
13
Date Recue/Date Received 2021-09-24
data and the computation of the similarity amongst the Cube construction
information for the
circuit-breaker query data.
[0136] As a result of steps S21 ¨ S27, each Cube construction information
comprises seven
components: recommending models, recommending time granularity, recommending
dimension
combinations, recommending metrices, data volume, return values, and
similarities to the other
Cube construction information. In particular, the data volume, return values,
and similarities are
the measurements for the Cubes to be constructed. The technical personnel
determine the value
of the Cubes according to the forementioned values, and conduct manual
intervention
accordingly.
[0137] S3: constructing the multi-dimensional data cubes according to the
construction
information.
[0138] The forementioned multi-dimensional data cubes are used to determine
the storage
information and creating interface of the described multi-dimensional data
cube in the described
analytical engine.
[0139] Therefore, in an embodiment of the present invention, the step S3
includes:
[0140] calling the analytical engine according to the described construction
information, and
determining the storage information and creating interface of the described
multi-dimensional
data cube in the described analytical engine, to complete the generation the
described multi-
dimensional data cube.
[0141] For example, the Cube automatically inherits the associated information
from the
source model, such as storage medium and affiliate cluster. In other words, if
the model is
planned to be stored in the Druid, then the Cube of the described model is
automatically initiated.
If the source model for the Cube is stored in the Druid, then the Cube is
constructed by creating
json of construction data source and calling the rest ports of the Druid. If
the source model for
the Cube is stored in PostgreSQL, then the PG table is constructed by jdbc. In
the meanwhile, in
order to support the resource control and manual intervention for Cube
construction from certain
models, the Cube construction of the mentioned certain models are first
manually screened then
proceeds to the Cube construction.
[0142] In an embodiment, the multi-dimensional data cube construction method
provided in
the present invention also includes:
14
Date Recue/Date Received 2021-09-24
[0143] S4: assigning an intermediate table obtained based on the fact table
and the dimension
table into the described multi-dimensional data cube, to perform data
complementing of the
described multi-dimensional data cube and scheduling of the described multi-
dimension data
cube.
[0144] The forementioned data complementing process assigns the history data
of the model
into the Cube. The scheduling assigns the data in the current and future time
period of the model
into the Cube. The data complementing and scheduling adopt the same input
method. The
forementioned intermediate table is the model generated by expanding and
combining the fact
table and the dimension table. For example,
[0145] for the Cube data complementing:
[0146] after the Cube construction, the Cube data complementing is
automatically initiated for
all data within the model life span. The process of data complementing is
based on the offline
computation platform. First, the fact table and dimension table are expanded
by Left join
method, and the expanded intermediate table is assigned into the Cube. The
Cube data generation
rules comprise:
[0147] if the Cube is stored in the Druid, by calling the rest ports of the
Druid via spark-druid,
assigning a Post request to the Druid mater node, initiating the Hadoop Index
Job of the Druid
reading the data from the Hadoop cluster and assigning the data into the
Druid.
[0148] If the Cube is stored in the PG, assigning the data into PG via the
spark-jdbc port. The
Cube data generation rules comprise:
[0149] in case of the Cube containing the following construction information:
[0150] the time granularity of the day,
[0151] the dimension combination field of district, city company, product type
and brand, and
[0152] the metric combination field of number (sum as the aggregate function),
and amount of
money (sum as the aggregate function),
[0153] then the Cube data generates schematic SQL as following:
[0154] SELECT
[0155] DATE FORMAT (time, `Day'),
[0156] district
[0157] city company,
[0158] product type,
Date Recue/Date Received 2021-09-24
[0159] brand,
[0160] SUM(number) AS number,
[0161] SUM(amount of money) AS amount of money
[0162] FROM
[0163] expanding the intermediate table
[0164] WHERE time >= T ¨2
[0165] AND time <= T ¨ 1
[0166] GROUP BY DATE FORMAT (time, `Day'),
[0167] district
[0168] city company,
[0169] product type,
[0170] brand
[0171] the Cube scheduling:
[0172] after the cube construction, automatically registering the cube
scheduling task, and
automatically initiating the Cube data complementing according to the
registration frequency,
wherein the Cube computation scheduling is performed at certain frequency. The
process begins
with expansion according to the fact table and the dimension table, followed
by the assignment
of all the Cube data in the models by the expanded intermediate table. The
scheduling and the
data complementing adopts the same input rules.
[0173] In an embodiment, the multi-dimensional data cube construction method
provided in
the present invention also includes:
[0174] S5: calculating the hit rate of the multi-dimensional data cube in the
pre-set time period,
where the hit rate is the ratio of calling volume of the described multi-
dimensional data cubes
and the calling volume of the models.
[0175] The forementioned step S5 is used to estimate the precision of
constructed multi-
dimensional data cubes, wherein a higher hit rate indicates a more precise
multi-dimensional data
cubes.
[0176] In an embodiment based on the forementioned hit rate, multi-dimensional
data cube
construction method provided in the present invention also includes:
[0177] acquiring the calling volumes of the multi-dimensional data cubes
within the pre-set
time period; and
16
Date Recue/Date Received 2021-09-24
[0178] deleting the multi-dimensional data cubes with the calling volumes less
than the calling
volume threshold and the hit rate less than the hit rate threshold within the
described pre-set time
period.
[0179] The forementioned method is the eliminating mechanism for the multi-
dimensional data
cubes to ensure the constructed multi-dimensional data cubes satisfying the
query analyzing
request. When the Cube is deleted and the Cube is store in the Druid, then the
REST port of the
Druid is called to delete the described Cube;
[0180] if the Cube is stored in the PG, then the Cube is deleted via jdbc; and
[0181] after acquiring the Cube mark, where if the current Cube is marked as
an important
Cube, the Cube will not be automatically deleted and will be processed with
manual intervention
based on the daily Cube hit rate.
[0182] As shown in Fig. 2, based on the multi-dimensional data cube
construction method
provided in the present invention, a multi-dimensional data cube construction
device is provided
in the present invention, comprising
[0183] a data collecting module 201, configured to collect the query data in
the analytical
engine including model information, dimension information, metric information,
and time
granularity associated with the described query.
[0184] A construction information determination module 202, configured to
statistically
analyze the mentioned query data to determine construction information for a
multi-dimensional
data cube, including recommending models, recommending dimension combinations,
recommending metrices, and recommending time granularity.
[0185] In an embodiment of the present invention, the construction information
determination
module 202 comprises:
[0186] a recommending model determination module, configured to count the
model calling
volume within a pre-set time period according to the described model
information associated
with the described query, to identify the models satisfying the model calling
volume conditions
as the described recommending models.
[0187] A recommending dimension combination determination module, configured
to count
both the dimension combination calling volume of the recommending models
within the pre-set
time period and the responding time of the dimension combinations according to
the described
dimension information associated with the described query, to identify the
dimension
17
Date Recue/Date Received 2021-09-24
combinations satisfying dimension calling conditions and responding time
conditions as the
described recommending dimension combinations.
[0188] A recommending time granularity determination module, configured to
identify the
time granularity of the described recommending dimension combinations as the
described
recommending time granularity.
[0189] A recommending metrices determination module, configured to identify
the metric
fields in the models as the recommending metrices.
[0190] In an embodiment of the present invention, the recommending dimension
combination
determination module comprises:
[0191] a dimension combination expanding module, configured to expand the
recommending
dimension combinations by joining dimension combinations according to the
number of
recommending dimension combinations.
[0192] A dimension combination complementing module, configured to provide
complementary information for the recommending dimension combinations
according to the
dimension tables.
[0193] In an embodiment of the present invention, the recommending dimension
combination
determination module also provides the optimization of the recommending
dimension
combination, Comprising:
[0194] A dimension combination de-duplicating model, configured to compare the
existing
recommending dimension combinations, and deleting the recommending dimension
combinations repetitive to the existing recommending dimension combinations.
[0195] In an embodiment of the present invention, the construction information
determination
module 202 also includes:
[0196] a return value computing module, configured to calculate return values
of the described
construction information. The mentioned return value is calculated by summing
the products of
the calling volume and the mean responding time of the non-optimized dimension
combinations
covered by the described recommending dimension combinations.
[0197] In an embodiment of the present invention, the construction information
determination
module 202 also includes:
[0198] a data volume computation module, configured to estimate the data
volume of the Cube
constructed by the construction information. In particular, the data volume is
the estimated data
18
Date Recue/Date Received 2021-09-24
volume of the Cube constructed by the construction information according to
the number of
dimension combinations.
[0199] In an embodiment of the present invention, the construction information
determination
module 202 also includes:
[0200] a similarity determination module, configured to calculate the
similarity amongst each
described recommending dimension combination from the described construction
information,
and particularly configured to:
[0201] sort the construction information in descending order according to the
return values,
and selecting the sorted construction information that satisfying the return
value conditions; and
[0202] calculate similarity amongst each described recommending dimension
combination
from the described construction information.
[0203] In particular, the calculation of similarity can adopt the method of
Jaccard.
[0204] A generating module 203, configured to generate the multi-dimensional
data cube
according to the mentioned construction information, and particularly
configured to:
[0205] call the analytical engine according to the described construction
information, and
determine storage information and create interface of the described multi-
dimensional data cube
in the described analytical engine, to complete the generation the described
multi-dimensional
data cube
[0206] The multi-dimensional data cube construction device provided in the
present invention
also includes:
[0207] a data complementing module, configured to assign an intermediate table
obtained
based on the fact table and the dimension table into the described multi-
dimensional data cube, to
perform data complementing of the described multi-dimensional data cube.
[0208] A scheduling module, configured to assign an intermediate table
obtained based on the
fact table and the dimension table into the described multi-dimensional data
cube, to perform
scheduling of the described multi-dimension data cube.
[0209] The multi-dimensional data cube construction device provided in the
present invention
also includes:
[0210] a hit rate computing module, configured to count the hit rate of the
described multi-
dimensional data cubes within the pre-set time period, where the hit rate is
the ratio of calling
volume of the described multi-dimensional data cubes and the calling volume of
the models.
19
Date Recue/Date Received 2021-09-24
[0211] The multi-dimensional data cube construction device provided in the
present invention
also includes:
[0212] an eliminating module, configured to delete the multi-dimensional data
cubes with the
calling volumes less than the calling volume threshold and the hit rate less
than the hit rate
threshold within the described pre-set time period.
[0213] Based on the forementioned methods and embodiments, a multi-dimensional
data cube
construction computer system is provided in the present invention, comprising:
[0214] one or more processors; and
[0215] a storage medium related to the described one or more processors,
configured to store
the program commands. When the described program commands are executed by the
described
one or more processors, any of the forementioned methods in the first
perspective are performed.
[0216] In particular, a schematic of the computer system structure is shown in
Fig. 3,
comprising a processor 310, a video display adaptor 311, a disk driver 312, an
input/output
connection port 313, an internet connection port 314, and a memory 320. The
forementioned
processor 310, video display adaptor 311, disk driver 312, input/output
connection port 313, and
internet connection port 314 are connected and communicated via the system bus
control.
[0217] In particular, the processor 310 can adopt a universal CPU (central
processing unit), a
microprocessor, an ASIC (application specific integrated circuit) or the use
of one or more
integrated circuits. The processor is used for executing associated programmes
to achieve the
technical strategies provided in the present invention.
[0218] The memory 320 can adopt a read-only memory (ROM), a random access
memory
(RAM), a static memory, a dynamic memory, etc. The memory 320 is used to store
the operating
system 321 for controlling the electronic apparatus 300, and the basic input
output system
(BIOS) 322 for controlling the low-level operations of the electronic
apparatus 300. In the
meanwhile, the memory can also store the internet browser 324, data storage
management
system 324, the device label information processing system 325, etc. The
described device label
information processing system 325 can be a program to achieve the
forementioned methods and
procedures in the present invention. In summary, when the technical strategies
are performed via
software or hardware, the codes for associated programs are stored in the
memory 320, then
called and executed by the processor 310.
Date Recue/Date Received 2021-09-24
[0219] The input/output connection port 313 is used to connect with the
input/output modules
for information input and output. The input/output modules can be used as
components that are
installed in the devices (not included in the drawings), or can be externally
connected to the
devices to provide the described functionalities. In particular, the input
devices may include
keyboards, mouse, touch screens, microphones, various types of sensors, etc.
The output devices
may include monitors, speakers, vibrators, signal lights, etc.
[0220] The internet connection port 314 is used to connect with a
communication module (not
included in the drawings), to achieve the communication and interaction
between the described
device and other equipment. In particular, the communication module may be
connected by wire
connection (such as USB cables or internet cables), or wireless connection
(such as mobile data,
WIFI, Bluetooth, etc.)
[0221] The system bus control 330 include a path to transfer data across each
component of the
device (such as the processor 310, the video display adaptor 311, the disk
driver 312, the
input/output connection port 313, the internet connection port 314 and the
memory 320).
[0222] Besides, the described electronic device 300 can access the collection
condition
information from the collection condition information database 341 via a
virtual resource object,
so as for conditional statements and other purposes.
[0223] To clarify, although the schematic of the forementioned device only
includes the
processor 310, the video display adaptor 311, the disk driver 312, the
input/output connection
port 313, the internet connection port 314, the memory 320 and the system bus
control 330, the
practical applications may include the other necessary components to achieve
successful
operations. It is comprehensible for those skilled in the art that the
structure of the device may
comprise of less components than that in the drawings, to achieve successful
operations.
[0224] By the forementioned descriptions of the applications and embodiments,
those skilled in
the art can understand that the present invention can be achieve by
combination of software and
necessary hardware platforms. Based on this concept, the present invention is
considered as
providing the technical benefits in the means of software products. The
mentioned computer
software products are be stored in the storage media such as ROM/RAM, magnetic
disks,
compact disks, etc. The mentioned computer software products also include
using several
commands to have a computer device (such as a personal computer, a server, or
a network
21
Date Recue/Date Received 2021-09-24
device) to perform portions of the methods described in each or some of the
embodiments in the
present invention.
[0225] The embodiments in the description of the present invention are
explained step-by-step.
The similar contents can be referred amongst the embodiments, while the
differences amongst
the embodiments are emphasized. In particular, the system and the
corresponding embodiments
have similar contents to the method embodiments. Hence, the system and the
corresponding
embodiments are described concisely, and the related contents can be referred
to the method
embodiments. The described system and system embodiments are for demonstration
only, where
the components that are described separately can be physically separated or
not. The components
shown in individual units can be physical units or not. In other words, the
mentioned components
can be at a single location or distributed onto multiple network units. All or
portions of the
modules can be used to achieve the purposes of embodiments of the present
invention based on
the practical scenarios. Those skilled in the art can understand and apply the
associated strategies
without creative works.
[0226] The technical strategies in the present invention result in the
benefits of:
[0227] 1. The technical strategies provided in the present invention allows
the automatic Cube
generation, to solve the problems of possible dimension loss, time granularity
mismatching, and
low Cube hit rate in the manually created Cube;
[0228] 2. The technical strategies provided in the present of the automatic
Cube generation
allows the Cube to include multiple dimension combinations, consequently to
improve
universality and calling rate of the Cube; and
[0229] 3. The technical strategies provided in the present with the
comprehensive automatic
Cube generation procedures allows the automatic Cube data complementing and
scheduling.
[0230] The described technical strategies can be adopted by all possible
combinations to
generate possible embodiments of the present invention, and will not be
discussed in further
detail.
[0231] The forementioned contents of preferred embodiments of the present
invention shall not
limit the applications of the present invention. Therefore, all alternations,
modifications,
equivalence, improvements of the present invention fall within the scope of
the present
invention.
22
Date Recue/Date Received 2021-09-24