Note: Descriptions are shown in the official language in which they were submitted.
CA 02465584 2004-04-29
SYSTEM AND METHOD OF FORMULATING QUERIES IN RELATIONAL
DATABASES
Field of the Invention
The present invention concerns database analysis and more particularly
methods for improving query formulation based on model and metadata
information
describing data stored in relational database systems.
Background of the Invention
Large data sets are now commonly used in business organizations. In fact, so
much data has been gathered that responding to even a simple question about
the data
has become a challenge. The modern information revolution is creating huge
data
stores that, instead of offering increased productivity and new opportunities,
are
threatening to drown the users in a flood of information. Tapping into large
databases
for even simple browsing can result in an explosion of irrelevant and
unimportant
facts. Even people who do not 'own' large databases face the overload problem
when
accessing databases on the Internet. A large challenge now facing the database
community is how to sift through these databases to find useful information.
Existing database management systems (DBMS) perform the steps of reliably
storing data and retrieving the data using a data access language, such as
Structured
Query Language (SQL). One major use of database technology is to help
individuals
and organizations make decisions and generate reports based on the data
contained in
the database.
In these databases it is usual to relate data in various tables using joins
that
allow the data to be accessed in different ways. The manner of performing such
joins
is well understood, but in the increasingly complex data being analyzed, there
are
several opportunities for information to be misinterpreted. For example, one
such
mechanism results in the double counting of data. In these more complex data
environments, it is well known to use modeling software applications to
provide a
convenient mechanism to relate the data in ways that make most sense to the
users.
Such modeling applications are intended to minimize the knowledge required of
a
user to make appropriate queries of the data. However, in some cases, the very
nature
and complexity of the data and its structure has meant that the user is
required to have
CA 02465584 2004-04-29
considerable knowledge of the actual structure of the data. What is needed is
away to
reduce this requirement.
Summary of the Invention
The invention provides a methodology to automatically derive the
relationships between tables and columns within tables so that problems such
as those
that result in double counting of information are avoided. The invention also
provides
for a process that is largely automated and therefore less error-prone.
In one aspect the invention comprises a method for creating a report in a
computer-based business intelligence system, the method comprising the steps
of
defining a model based on an existing database including at least two query
subjects,
each query subject comprising at least one fact query item and one primary key
query
item, generating a hierarchy of query items in query subjects within the
model,
introducing a further fact into one of the query subjects, accepting an input
request
from a user to define the contents of the report, determining an expression to
extract
data from the database to fulfill the input request, decomposing the
expression into
subqueries to prevent multiple-counting of data in ambiguously defined by
using the
further fact to determine that such decomposition is required, accessing the
data using
the subqueries and producing the report.
Brief Description of Drawings
The invention wilt be explained with reference to the following drawings.
Figure 1 shows a typical configuration in which embodiments of the invention
may be deployed.
Figure 2 illustrates a situation where embodiments of the invention can be
used.
Figure 3 shows the effect of introducing an embodiment of the invention.
Figure 4 shows a further example where an embodiment of the invention is
introduced.
Figure 5 gives an outline flowchart of an embodiment of the invention.
Detailed Description of Embodiments of the Invention
Embodiments of the invention are used in a general purpose client-server
database system framework suitable for a business intelligence system. Figure
1
shows a typical configuration in which such embodiments may be conveniently
2
CA 02465584 2004-04-29
deployed. This configuration includes a network 400 that permits clients 410
to
communicate with a server 420 having a database or data warehouse 430
attached.
Other configurations would be suitable, including those where the client and
server
functions are not separate, and those where more than one database is used,
and those
in which the databases are remote from the server and accessed over a network.
In the following description a number of terms are introduced. The first of
these is a "query subject", which is used to model a table in a relational
data source.
The second is a "query item", which represents a column of a table in the
relational
data source.
Modelers are experts in defining transforms between databases and the derived
data stored in data warehouses. They also provide the necessary tools to
permit users
and report authors to access the resultant data. The modeler is expected to
properly
define the functional dependency between query items in a query subject
(referred to
as capturing the determinants of a query subject). Within a query subject, a
determinant is a set of query items whose values describe, identify, limit, or
otherwise
determine the values of one or more other query items within the query
subject. Each
query subject has at least one determinant, namely, the one or more query
itemsthat
make up the primary key. Previous solutions to the problem have usually
involved the
modeler manually defining levels, thereby organizing them into hierarchies. In
these
hierarchies, each level contains one or more "key query items", and one or
more
properties. However, performing this task can be tedious and error-prone. It
is
therefore one objective of this invention to reduce the level of effort
required by the
modeler so that the definition of the hieranrhy is dealt with invisibly, and
does not
impact the modeler at all.
In systems employing embodiments of the invention, the modeler produces a
model that can be adapted and run by a report author. The resultant model
content is
accessed by a query engine in which information obtained by parsing the query
and
by examining the model is used to produce valid SQL (or an equivalent data
manipulation language), based on a specified query. This resultant SQL code is
ultimately used to produce a report, that report being data extracted from the
database
and formatted as required by the end-user.
Dimension information is dynamically generated based on the joins (also
referred to as associations or relationships) between the query subject (which
are
somewhat analogous to a table) under examination and other related query
subjects.
3
CA 02465584 2004-04-29
In addition, information stored in unique indices is used to determine if some
combination of query items uniquely identifies a row in the query subject. In
addition,
information about unique indices is used to detect the presence of
determinants.
It should be noted that the "introduction" of an extra query subject as
described in the various embodiments of the invention does not necessarily
mean that
new data are added to the database, (or even to the derived database where one
is
used). In many cases, the data will already exist, with the required
relationship. As
used here "introduction" should therefore be taken to mean that embodiments
ofthe
invention "take advantage" of these data and their relationship to data of
interest -
previously ignored - in determining the relationship interdependence of the
data. (This
might be considered as deriving the metadata- that which describes the data-
from
context.)
The following rules are used in the computation of the dimensional
information:
1. for a given query subject (QS1) compute a unique set of determinants { D }
The set of query items of the Primary Key and each set of query items of each
of
the unique Indices define a determinant.
2. a determinant is related to a set of query items { QI }
3. a subset of { QI } called { QI } s may be used in the relationship with
another
query subject (QS2) , since it is a subset it is known that the data from QS2
potentially relates to multiple rows of QS 1, thus the potential for multiple
counting is detected.
4. a further subset o~ { QI } s called { QI } ss may be related to yet another
query
subject (QS3) ;
5. The number of rows related to these query item sets is
{QI}>{QI} s>{QI} ss
6. Each set of query items forms a level.
7. A set of levels is organized in a hierarchy. The highest level has the
fewest query
items and each lower level has more query items, each higher level having a
set of
query items that is a subset of its immediate lower level.
8. Multiple hierarchies for a query subject are computed for non-overlapping
determinants.
As an illustration of the rules, given:
4
CA 02465584 2004-04-29
QS 1 With
Determ inants
D I as { QI A, QI B, QI C }
D2 as { QI D }
Relationship
R1 using QI D
R2 using QI A, QI B, QI C
R3 using QI A, QI B
Based on R1 a hierarchy with a single level is computed
H1
--> L1:{QI D}
Based on R2 and R3 a hierarchy with two levels is computed
H2
- - > L2 : { QI A, QI B }
- -> L3 : { QI A, QI B, QI C }
The invention and its utility are most conveniently described with reference
to
simple examples in which a user wishes to produce reports containing measures
totaled by various periods - monthly, quarterly, annually. First, the
situation is
described in which miscounting occurs. Next, manual changes that would
eliminate
the problem are described. Finally, the necessary changes to implement an
embodiment of the invention are described, giving the sample code snippets
that
result from the query engine once the embodiments are utilized.
The code snippets that follow are of modeling 'code' or pseudo-code.
Comments within the code are shown by: /* <comment text> * /
The first example describes the data as shown in Figure 2 assuming that the
embodiment of the invention is not applied. Figure 2 is a simple entity
relationship
(ER) diagram, showing two fact tables, or query subjects, namely Calendar,
100, and
Quotas, 110, having a 1- n relationship, 130, linking Year, Quarter in each
table.
Definition of CALENDAR query subject (table):
/*It contains the following query items.*/
MONTHID ( Primary key of the query subject (table) )
YEAR
5
CA 02465584 2004-04-29
QUARTER
MONTH
Definition of QUOTAS query subject(table):
/* It contains the following query items */
YEAR
QUARTER
PRODUCTNUMBER
SALESSTAFFCODE
QUOTA /* this is a measure/quantity */
CALENDAR (1:1) --- (1:n) QUOTAS on
(CALENDAR.YEAR = QUOTAS.YEAR and
CALENDAR. QUARTER = QUOTAS. QUARTER)
/*The data has n--n relationship. Though for
reporting purposes it is modeled as a 1--n
relationship./
It is desired to build a report including columns for:
Year
Month
Quota across all Products for each Year and Month
and including an overall total of the Quota column, i.e. the grand-total
Without using dimensional information the following code will be generated:
select
rrTllrr . rrC/1rr "YEAR1",
"TO"."C1" "MONTH1",
"TO"."C2" "QUOTA",
sum("TO"."C2") over() "QUOTA1"
from
select
"CALENDAR"."YEAR" "CO",
6
CA 02465584 2004-04-29
"CALENDAR"."MONTH" "C1",
sum("QUOTAS"."QUOTA") "C2"
f r om
"STARQEQC"."CALENDAR" "CALENDAR",
S "STARQEQC"."QUOTAS" "QUOTAS"
whe re
"CALENDAR"."YEAR" _ "QUOTAS"."YEAR" and
"CALENDAR"."QUARTER" _ "QUOTAS"."QUARTER"
group by
"CALENDAR"."YEAR",
"CALENDAR"."MONTH"
"TO"
The resultant table is:
Year Month Quota (for
quarter)
2 0 0 01 12,140,000
0
2000 02 12,140,000
2 0 0 0 3 12,140,000
0
2000 04 7,500,000
2000 05 7,500,000
2 0 0 0 6 7,500,000
0
2 0 0 0 7 7,685,000
0
2 0 0 0 8 7,685,000
0
2 0 0 0 9 7,685,000
0
2 0 0 10 8,025,000
0
2 0 0 11 8,025,000
0
2 0 0 12 8,025,000
0
106,050,000
7
CA 02465584 2004-04-29
As can be seen, the above code results in accumulating the entries that are
reported at each month, although these entries actually belong to each
quarter. The
overall total of 106,050,000 is thus inflated 3 times and is useless!
Of course, when dimensional information is supplied manually, the problem of
double (or multiple) counting is solved. The following code snippets show one
possible solution using a manual method.
This first code snippet defines that YEAR QUARTER 'contains' MONTHID
as a lower, or finer, level of granularity. Now when the previous report is
run, the
query engine has the information that defines the requested item
[CALENDAR].[MONTH] as being from a lower level than the items that are used in
the relationship between the CALENDAR and QUOTAS query subjects.
Dimension Information for CALENDAR query subject
Hierarchy (H1)
Level (Year and Quarter):
Key: [YEAR], [QUARTER]
Level (Month)
Key: [MONTHID]
Property: [MONTH]
Using the resultant hierarchy, the following code snippet, which respects the
different granularities in the dimension quay subject, is generated by the
Query
Engine:
select
coalesce("D2"."YEAR1", "D3"."YEAR1") "YEAR1",
"D3"."MONTH1" "MONTH1",
"D2"."QUOTA" "QUOTA",
min("D2"."QUOTA1") over () "QUOTA1"
from
select distinct
"CALENDAR"."YEAR" "YEAR1",
"CALENDAR"."MONTH" "MONTH1"
from
"STARQEQC"."CALENDAR" "CALENDAR"
CA 02465584 2004-04-29
"D3"
full outer join
select
"TO"."CO" "YEAR1",
"TO"."C1" "QUOTA",
sum("TO"."C1") over () "QUOTA1"
from
select
"CALENDAR"."YEAR1" "CO",
sum("QUOTAS"."QUOTA") "C1"
from
select distinct
"CALENDAR"."YEAR" "YEAR1",
"CALENDAR"."QUARTER" "QUARTER"
from
"STARQEQC"."CALENDAR" "CALENDAR"
) "CALENDAR",
"STARQEQC"."QUOTAS" "QUOTAS"
where
"CALENDAR"."YEAR1" = "QUOTAS"."YEAR"
and "CALENDAR"."QUARTER" _
"QUOTAS"."QUARTER"
group by
"CALENDAR"."YEAR1"
"TO"
"D2" on "D3"."YEAR1" _ "D2"."YEAR1"
The resultant (correct) table is:
9
CA 02465584 2004-04-29
Year Month Quota (for
quarter
)
2 0 0 01 12,140,000
0
2 0 0 0 2 12,140,
0 000
2 0 0 0 3 12,140,000
0
2000 04 7,500,000
2000 05 7,500,000
2 0 0 0 6 7,500,000
0
2000 07 7,685,000
2 0 0 0 8 7,685,000
0
2 0 0 0 9 7,685,000
0
2 0 0 10 8,025,000
0
2 0 0 11 8,025,000
0
2 0 0 12 8,025,000
0
35,350,000
In the following, a first preferred embodiment of the invention is described
that prevents this "double counting" error. This obviates the necessity of the
modeler
making manual changes. The algorithm of the embodiment computes the
dimensional
or hierarchical information that was stated previously, based on existing
information
in the model. In the provided example the following are known:
~ the relationship is based on two query items
~ the cardinality of the relationships can be used to determine that the
CALENDAR query subject has a lower number of rows than the
QUOTAS query subject.
~ the relationship is not based on all the key query items of the
CALENDAR query subject.
The above would lead to the following dimensional information:
Hierarchies:
H 1
L 1
Keys: Unique
H 2
L 2
L 1
CA 02465584 2004-04-29
K 0->MONTHID
Props:
3->MONTH
Keys:
K 1->YEAR
K 2->QUARTER
Keys: Unique
K 0->MONTHID
Props:
3->MONTH
The introduction of a further fact (such as SALES by MONTHID means that
the query engine can see two fact query subjects.
This algorithm leads to a different result when additional information is
provided as shown in the entity relationship (ER) diagram of Figure 3. Here a
further
fact table or query subject , namely SALES, 240, is introduced, which has a 1
to n
relationship, 250, to the CALENDAR fact table, 100. Based on the additional
information, more details of the dimensional information of the CALENDAR query
subject can be computed.
Based on the additional query subject SALES and its relationship to the
CALENDAR query subject, the hierarchical information is computed as:
CALENDAR (1:1) --- (1:n) QUOTAS on
(CALENDAR.YEAR = QUOTAS.YEAR and
CALENDAR. QUARTER = QUOTAS. QUARTER).
CALENDAR (1:1) --- (1:n) SALES on (MONTHID)
The generated dimensional information is the same as for the immediately
preceding case.
The query for the report previously defined now becomes:
select
coalesce("D2"."YEAR1", "D3"."YEAR1") "YEAR1",
"D3"."MONTH1" "MONTH1",
11
CA 02465584 2004-04-29
"DZ"."QUOTA" "QUOTA",
min("D2"."QUOTA1") over () "QUOTA1"
from
(
select distinct
"CALENDAR"."YEAR" "YEAR1",
"CALENDAR"."MONTH" "MONTHl"
from
"STARQEQC"."CALENDAR" "CALENDAR"
) "D3"
full outer join
select
"TO"."CO" "YEAR1",
i5 "TO"."C1" "QUOTA",
sum("TO"."C1") over () "QUOTA1"
from
select
"CALENDAR"."YEAR1" "CO",
sum("QUOTAS"."QUOTA") "C1"
f rom
select distinct
"CALENDAR"."YEAR" "YEAR1",
"CALENDAR"."QUARTER" "QUARTER"
f rom
"STARQEQC"."CALENDAR" "CALENDAR"
"CALENDAR",
"STARQEQC"."QUOTAS" "QUOTAS"
where
"CALENDAR"."YEAR1" _ "QUOTAS"."YEAR"
and "CALENDAR"."QUARTER" _
"QUOTAS"."QUARTER"
12
CA 02465584 2004-04-29
group by "CALENDAR"."YEAR1"
"TO"
"D2" on "D3"."YEAR1" _ "D2"."YEAR1"
As in the manually adjusted case, double (or multiple) counting does not
occur.
A further embodiment provides for the situation where CALENDAR does not
have dimensional information. In this situation, further information is
introduced as
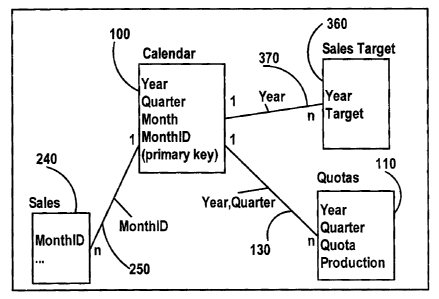
shown in the Figure 4, in which the query subject SALESTARGET, 360, is added.
This additional query subject SALESTARGET, 360, is also related, 370, to the
query
subject CALENDAR, but only through the single query item YEAR.
Here the model is defined as:
j1: CALENDAR (1:1) --- (1:n) QUOTAS
on (CALENDAR.YEAR = QUOTAS.YEAR and
CALENDAR. QUARTER = QUOTAS. QUARTER).
IS /* Note that the real data has N--N
relationship! */
j2: CALENDAR (1:1) ----(l: n) SALES
on (CALENDAR.MONTHID = SALES.MONTHID)
j3: CALENDAR (1:1)----(1:n) SALESTARGET
on (CALENDAR. YEAR = SALESTARGET.YEAR).
/* The real data has N--N relationship! */
The embodiments of the invention first determine:
1. Does the query subject have a primary key (a set of one or more columns
that uniquely identify a record) and at least a one~o-many relationship to
another
query subject, which is not defined on the primary key?
And then the following step is performed:
2. For each not-on-PrimaryKey one-to-many relationship, fetch and sort the
query items used in the relationship.
Embodiments of the invention use this information to determine that
[CALENDAR].[YEAR] is at a higher level in the defined hierarchy than
[CALENDAR].[QUARTER]. Thus the following dimensional information is
computed:
13
CA 02465584 2004-04-29
[YEAR] (j3)
[YEAR], [QUARTER] (j1)
The following hierarchy is then generated:
Hierarchies:
H 1
L 1
Keys: Unique
K 0->MONTHID
Props:
3->MONTH
H 2
L 3
Keys:
K 1->YEAR
L 2
Keys:
K 2->QUARTER
L 1
Keys: Unique
K 0->MONTHID
Props:
3->MONTH
Other embodiments take advantage of the fact that the dynamically computed
information can be used as a first iteration for modeling the dimensional
information
of a query subject. The modeler can then further refine the computed
information,
thus allowing generation of more efficient queries.
One embodiment is described with reference to Figure 5. Any required
processing that precedes and follows this process is not described since it is
well
known and understood. The processing starts 510 by the input of a query 520,
and the
query subjects defined by the query are computed 520. The related dimensional
query
subjects are determined 540, and each is assessed to determine whether
sufficient
dimensional information is available 550. If not the missing information is
computed
560 and the query subject again assessed to determine whether sufficient
dimensional
14
CA 02465584 2004-04-29
information is available 550. When there is sufficient dimensional
information, the
data base query is formulated using sub-queries 570, and the process ends.
Embodiments of the present invention may be implemented by any hardware,
software or a combination of hardware and software capable of the above-
described
functions. The entire or a part of the software code may be stored in a
computer
readable memory for use in a general purpose computer.
15