Note: Descriptions are shown in the official language in which they were submitted.
1 30~774
The present lnvention rel~tes to ~n ~pparatus
and methodforiden~ngh~dwnt~ncha~rs.
Since trade between Non-En~116h p~akln~
countrles and Western countrleæ has lncreasea
dramatlcally, the lmportance ~f oommun~cations has
lncreased. For ~xample, ln the past when correspondln~
between En~l$sh and Chlnese speak~ng countrles, e
docum~nt written ln Engli6h that was received ~n C~na
would f~r~tly be forwarded to a government tr~nslatlon
centre. ~he ~cument would then be translated and
transcrlbed by hand lnto Chlnese ~n~ flnally dellvere~
to the ~ddrassee cf the document. When a response to
the translated document was prepared, the response would
be translated from Chinese lnto Engllsh ~t the
government transl atl on centre and forwarded to the
En~llsh correspondent. However, a problem existed in
that the use of translators to transcrlbe the documents
from Engllsh to Chlnese and v~ce versa added a
~lgnificant delay in the communlcatlons process.
To overcome these difflcultles, a typewrlter
devlce has been developed havlng keys representlng the
ldeographlc char~cter~ of the Chlnese language. ~hls
devlce allows ~ard coples of documents wrltten ln
Chinese to b- produced by hlrlng an operator skilled ln
the Chlne~e l~ngua~e and oapable of us$ng the
typewrlter. ~owever, a problem xlsts ln that ~ lar~e
number of keys are required on the typewrit~r devlce
slnce the Chlne~e language lncludes ~ore t~an 50,000
~lfferent ldeogr~p~ic c~ar~cters. Improvements to thls
type of ~evlce have b~sn introduced to r~duc- the number
of keys r-quired by u~ing functlon koys, howevar, the
above-mentloned problom ~tlll ~x18t6. Furth~r~ore,
another problom exlst~ when uslng the typewrlt~s d~vlces
$n that extenslve tralnlng $~ r~qulrod for the operators
-- 1 --
.~ .
7 7 4
to learn how to use ade~uately the kayboard devlce, a
process which is e~pensive and time oonsumlng.
To overcome the problems encountered when
using the keyboard devices, ~n ideographic character
detection appara~us has been developed for receiving and
ident$fying handwritten ideographic characters. The
apparatus requires that the ideographic character be
written on an input device and that the wrltten
characters be formed from predetermined fundamental
strokes or primitives which are typical strokes used by
everyone who writes ln the ideographic language. After
an ideographic character has been entered into the
apparatus, the apparatus examines the primitives forming
the entered ideographic character and compares the
entered primitives with the contents of a look-up table.
The look-up table stores a plurality of variations of
each of the predetermined primitives to accommodate
variations in user's handwritlng. Due to the large
number of variations of each prlmitive stored in the
table, the primitives forming the character are usually
determined by the device. The table also stores the
sets of primitives used to form each of the characters
in the ideo~raphic language. If the set primitives
forming the entered character corresponds with one of
the sets of primitives in the look-up table, an output
code associated with the set of primitives i8 generated
- snd conveyed to an output device. This allows a hard
copy image of the entered ldeographic character to be
formed. However, a problem exlsts in that due to the
large number of variatlons of each primitive stored in
the table, the processing speed of the apparatu~ is
greatly reduced making it unsultable for real-tlme
appl$cations.
1 30q774
Moreover, the number of predetermlned
fundament~l stro~es or pr~mltives u~ed ln thl~ app~rstu6
has typically boen chosen to be flve or 1~8 or twenty
or more. By uslng only ~lve ~undamental pri~ltlve~ ln
the fiub-set to ~or~ ~very ldeogr~phlc character ln the
language, n problem exi~ts ln that a large number of
different ldeographlc character~ are formed from the
identical set of pr~mitives even though the ldeographic
character~ are un~que ~n appearance. ~hls results ln
the decreased ablllty cf the apparatus to distingu~sh
between different ldeographic characters.
~o attempt to overcome thls problem, twenty or
more distlnct prlmltives h~ve been $ncluded in the sub-
set. However, the same problem ~till exi~ts ln that
dlf~erent ldeograph~c character~ Are still formed from
- the ldentical series of prlmitives although the
occurrence of a set of primi~ves representing moré
than one ideographlc character 1~ reduced. However, by
lncreaslng the number of prlmltives ln the ~ub-~et,
anether problem exi~ts ln that the processing tlme of
the apparatus is further lncreased.
Furthermore, stlll yet another problem oxlsts
ln that typlcally these devlces are capable of detecting
characters written $n one language ~nd do not permlt
multl-language character detectlon. Accordingly, there
is a need for an improved char~cter recognitlon
apparatus.
It 18 therefore an obJect of the pr~ent
invention to ~bviate or mltlgate the above
dl6advantages.
According to one aspect of the present invention there is
provlded a character reccgnitlQn apparatus for
- 3 -
4~
~ 30~77~
identifying a handwritten character formed from at least one primitive, said character
and said primitives being members of pIedetermined sets, said apparatus comprising:
input means for receiving successively and in an order determined by
pre-defined rules, each of the handwritten primitives forming said handwritten
character, said input means generating input signals for each of said handwritten
primitives;
processing means receiving said input signals for each of said
primitives, said processing means converting the input signals generated for each
primitive into data representing a series of generally horizontal, vertical and diagonal
vectors and comparing said data with stored information therein, said processingmeans generating a primitive code for each of the prirnitives forming said handwritten
character when said data are detected as being equivalent to stored information
associated with a single primitive;
first differentiation means in communication with said processing means
and performing discriminatory tests on said data when said are detected as beingequivalent to stored inforrnation associated with a plurality of primitives to determine
the primitive associated with said data to permit said processing means to determine
said primitive code, the series of primitive codes generated by said processing means
forming a character code;
storage means storing a character code and an associated output code
for each of the characters in said predetermined set;
comparing means comparing said character code generated for said
handwritten character with said character codes in said storage means to identify said
entered handwritten character;
second differentiation means examining said input signals generated for
each of said handw~itten primitives and performing discriminatory tests thereon when
said character code generated for said handwritten character is equivalent to a
character code in said storage means associated with a plurality of output codes to
identify the output code associated with said handwritten character; and
output means in communication with said comparing means and said
second differentiation means and generating a reproduction of said handwritten
character upon identification of the output code associated with the handwritten character.
-3a-
According to another aspect of the present invention there is provided a
character recognition apparatus for identifying a handwritten character of a t 1 3 0 ~ 7 7 4
predetermined set of characters formed from at least one primitive selected from a
predetermined set of primitives illustrated in Figure 3 with said primitives forming
said handwritten character being written in an order determined by pre-defined rules,
said apparatus comprising:
input means for receiving successively and in accordance with said pre-
defined rules each of the primitives forming said handwritten character and generating
input signals for each of said received primitives;
processing means receiving said input signals and identifying each of
said primitives received by said input means, said processing means generating acharacter code representing said handwritten character upon identification of said
primitives forming said handwritten character;
storage means for storing a character code and an associated output
code for each of the characters in said predetermined set;
comparing means for comparing said character code generated for said
handwritten character with said character codes in said storage means to identify said
handwr~tten character; and
output means in communication with sa~d comparing means and
gènerating a reproduction of said handwritten character upon the identification thereof
by said companng means.
Methods of recognizing handwritten characters are also provided.
Proferably, the apparatus further lncludes
dlf~erentlatlon means xamlnlng sald input cign~ls
generated for esch of 6nld prlm~tlve~ and performlng
operatlons thereon, when aald charncter code ls
equlval0nt to a charact~r code assoeiate~ wlth a
plurallty o~ output codes to ldentlfy tho output oode
assoclated wlth sald chsr~cter
Pr-forably the apparatus ~6 ~rov~ with
~ubst~tution means for ~el-ct$ng the ~aract-r ~ode
tored ln the torago ~e~ns h~vlng th~ bl~ho~t
probab~ y of ~elng ~qul~al~nt to the ~ar-eter oode
~enerated ~or ~he ontered e~aractsr, when the lnput
- 4 -
1 3~9774
character code i6 not equlvalent ~o ~ny of the character
codes ~tored ln the ~tor~ge ~aans. It i~ o preferred
that the output means ccmprises at least one ~avlce
c~sen form the group comprlEing ~ printer, ~u~lo
S ~yntheslzer or video di6play tarmlnal to all~w a
r~productlon of the r~celved ideographlc ~haracter to be
~ormed or an audio reproduction of the ldeographic
~haracter to be produced.
Preferably, the charecter recogn~tlon
apparatus 18 capable of racognizlng char~cters wrltten
in all ideographic lsnguages, upper c4se Engllgh
language characters, anB Russlan characters.
It 1~ also desirsble that the predetermlned
~et of fundamental prlmltlves i8 chosen to comprl~e 20
unique prlmltives, the various comblnat~ons of wh~ch
will ~orm ~ubstantially ~11 characters ln a plur~llty of
dlfferent languages, whllst decreasln~ the occurrence of
different characters being formed from the same set
of prlmitlves. Thus, the use of twenty ~$stinct
prl~ltlves decreases the occurrence of enter0d
characters being repre~ented character codes whlch are
equivalent to a character code associated wlth more than
one lnternatiQnal output code. Thls of courfie,
increases the probability of detecting the correct
ldeographlc character.
An ombodiment of the present inventlon wlll
now be descrlbed, by way of xample only, wlth reference
to the accompanylng drawlngs ln w~lch:
Flgure 1 1~ a functional block dlagram of an
apparatus for identifying handwritten characters;
Flgure 2 1~ ~n illu~tration of an l~eographlc
3~ character;
~2
1 3u 7774
Flgura 3 are lllustrutions of the fundamental
prlmltlves u~ed ln the ~evice Illu~trated ln ~lyure 1:
Flgures 4a to 4c 16 an illu6tratlon o~ the
Dethod of ~onming the character ~hown ln Fl~ure 2 from
the primitives ~h~wn ln ~lgure 3:
F~gure 5 18 a more dethlled fu~ctlonal block
dia~ram of the device lllustrated ln Flgure 1:
Pigure 6 i8 a detalled fun~tional block
d~agram of a portlon of the devlce lllustrated in ~l~ure
1;
Flgure 7 i6 an lllustratlon of a codlng method
used in the devlce illustrated ln Flgure l:
Flgures 8a and Bb ~re lllustrations of entered
fundamental ~trokes:
Flgures 9a and 9b are illustration6 of stlll
more ldeograp~lc eharacters:
Flgure 10 i6 an lllu6tratlon of a proba~illty
matrlx used in the devlce lllu6trated ln Flgure 1:
Flgure ll i6 An lllu~trfltlon of ~n Engll6h
character; and
Flgure 12 i8 an illustration of more English
characters.
Referring to Figure 1, an apparatus lO for
ldentlfying handwrltten character6 18 chown. The
apparatus lO comprise~ an lnput devlce 12 connected to a
data processor 14. The $nput devlce 12 recelves the
handwrltten char~cter and convert6 the character lnto a
~eries of clgnal6 that are convayed to the ~ata
proce~sor ~4. The data proce~sor 14 procefi~e~ the
recelved ~lgnal6 ln order to detect the char~ctor
ent~red on the lnput device 12. An output ~evlGo 16 16
also connected to the data processor 14 and receives from it an
lnternational ASCII output ¢ode ropresontln~ the
handwr~tten char~ct~r that ~8 F~Ge~Ved by the lnput
B
1 3~q77~
devlce 12. ~his sllow~ 8 reproduct~on of the
~an~wrltten character to be generated.
~he ~pparetus 10 1~ operable ln number ~f
modes, oac~ ~ode of whlch sllows handwrltton çharActers
of a dlfferent language to be reco~nlzed and reproduced.
Selection means lB are provlded to allow a user to
~elect the l~nguage ln whic~ the appar~tus 10 15 to
operate. Thus, the proces~lng means 14 ls responsive to
the selectlon means lB and 16 partltloned lnto ~ectlons
14a, 14b,..., 14n 80 that approprlate lnformstlon for
each language 16 ~eparately ~tore~ and ~ccesslble
depending Dn the mode selected by the ~electlon means
18.
~or ~implicity, the appar~tus 8~0wn ln Figure
1 wlll be described when the proce~slng means 14 is
conditioned to detect ldeogrsphlc characters, although
lt s~ould be rsallzed that char~cters ln other langusges
can be detected ln a ~lmllar mnnner by condltioning the
selectlon means 18 to a different mode.
Referrlng to Flgure 2, an ldeograph$c
character IC ls shown. As can be ceen, the l~eographlc
character IC ls formed from a number of fundamental
strokes or prlmltlves, the ~rlmltives belng labelled as
Prl to Pr3 respectivoly. The prlmltlves Prl to Pr3 are
fundamental ~tro~es usod when wrltlng in the ldeographlc
language.
~he wrltlng ~rder of the ~equence of trokes
for ideographic characters is mainly based on logic,
officlency, experlenoe cnd natural hu~n ~blt6.
Acoordlng to ~overal rosearch flndlngs, ther- x~t
number ~f bas~c ~ules when wr$t~n~ ~eo~r~phlc
characters ~nd they are as follows:
- 7 -
,~
1 ~3~J774
up - down
left - rlght
out - in
horizontal - vertlcal
left slant ~ rlght slant
flrst enter - last close.
Each Chinese character may employ one or more
of the above rules ln the formation of the eharaeter.
Examples of basic stroke sequenees of ldeographie
characters are illustrated in Table 1 hereinbelow:
TABLE 1
U P _ ... o _ = ht~ r~l -t
` ~;w~ _ ~ ~ ~"~ ~ - t
~r~ ~ J`~Slr~N~ ~ / `
20_ ~ S ~ ~ - R\c~ *,
~'r .~E~ ~ J~- f~ f~ _E3 n
,~ ~q - n ~ ~ -/~s~s~ l ~ n ~ ~
To decrease the number of prlmitives that a
user must be requlred to wrlte when forming an
ideographie eharaeter and to reduee the amount of data
that has to be processed by the processor 14, fifteen of
the twenty prlmitives Prh to PrO illustrated in Pigure 3
are used by the apparatus lO. The fifteen primltives
Pr~ to PrO are members of the set of fundamental strokes
typically used in the formation of ldeographlc
eharacters. This sub~et of primitives ls ehosen since
all of the ideographie eharaeters in the various
languages ean be formed from various eombinations of the
-- 8 --
1 3Q?774
primitives Pr~ to PrO. The primitives Prp to Prt ~re
used with some of the primitives Pr. to PrO when-the
apparatus ls operatlng to detect characters wrltten in
another language as will be described.
Referrlng now to Figure 5, the apparatus 10 ls
better lllustrated. The input device 12 comprlses an
on-line digitizer tablet 20 having a stylus 20a. The
ideographic character to be recognized is writtsn on the
tablet 20 with the stylus 20a. ~his causes a serles of
cartesian co-ordinate data point signals PNo to PNN to
be generated for each of the primitives Pra to PrO
entered that form the ideographic character IC. The
upper case "N" of the data point signal refers to the
order in which the primitive was entered when forming
the character IC while the subscript "N" refers to the
number of the sampled point along the primitiveO The
data point signals are then conveyed to the data
processor 14.
2a
A memory 22 is located in the data processor
14 and is connected to the digitizer tablet 20. The
memory 22 receives the raw cartesian co-ordinate data
point signals and stores them prior to processing. A
pre-processor 24 receives a copy of the cartesian co-
ordinate data point signals PNo to PNN for each entered
primitive and processes the data to remove redundant and
spurious data. The pre-processed cartesian co-ordinate
data signals are conveyed from the pre-processor 24 to a
feature extractlon section 26 which converts the
cartesian co-ordinate data point signais for each of the
entered primitives Pr lnto a vector code and a ~erles of
scalars.
The vector code and series of ~calars
generated by the feature extraction ~actlon 26 ars
_ g _
1 7i~ 77~
applied to a primitive detectlon section 28 which
compares the vector code generated for each entered
primitive Pr, to PrO form~ng the character IC wlth the
contents of a look-up table or dictionary. Thls Qllow~
the process~r 14 to detact whether the entered
primitives are members Of the fifteen primitlves Pr. to
Pr~. When an entered primltive Pr results in the
formation of a vector code equivalent to a vector code
associated with only one of the fifteen primitives
stored in the primitive detection section 28, a
primitive code a to o is generated and conveyed to a
memory 30. This procsss ls performed for each vector
code representing each primitive Pr forming the entered
ideographic character IC. Thus, a series of primitive
codes or a character code is generated for the entered
character which represents the ideographic character IC.
However, if a vector code generated for an entered
primitive Pr is equivalent to a vector code associated
with more than one of the flfteen primitives Pr~ to PrO,
the detection section 28 performs tests on the series of
scalars assoclated with the generated vector code to
detect the correct entered primltive.
The generated character code is conveyed ~rom
the memory 30 to a character detecti~n section 32 and
compared with the contents of a second look-up table or
dlctionary. Sectlon 32 stores the character code
representlng each of the ideographlc characters ln the
language. The stored character codes are based on the
requirement that the ldeographic characters are formed
from a combination of the fifteen primitives lllustrated
in Figure 3 and that the characters sre entered on the
tablet 20 ln an order as determined by the previously
mentioned rules. Slnce the previously mentioned rules
ars generally used when writlng in an ldeogrsphic
language, character codes which can represent
-- 10 --
7 7 ~
lde~gr~phic chara~ters, but are f~rme~ from ~rlmltiv~
en~r~ ~ ~ ~t order ~e omitt~ ~om ~e
look-up tQble.
When the char~cter c~de gener~te~ for the
~ntered lde~r~phlc char~cter IC ~ oqulvalent to a
character code ~ound in the c~ar~cter ~etection sectlon
32, ~n ~ss3ciBted output co~e or lnternotlonal ASCII
output code ls outputt~d to ~ m~mory 34. Nowever, lf
t~e character code 1B qulvalent to ~ character code
representing more than one ldeo~r~phlc char~cter, the
character detectl~n sect~on 32 performs oper~tlon~ on
the raw carteslan co-ordlnate data polnt ~iynals stored
ln the memory 22 to determine the correct ldeographic
character IC that the character code represents.
~his allows the correct lnternational ASCII code to be
outputted to the memory 34.
A cubstltution and corroctlon means 36 1~ also
2D provlded and examines the entered oharacter code when it
i8 not equ~valent to a charact7er code ctored in the
character detection section 32. The substitution means
36 substitut~s for the entered character code, the most
probable character code that the entered character code
was cuppose~ to represent and convey~ lt b~ck to the
chara_ter detection section 32 wherein the above-
mentloned pr~cess 1~ performed.
The internatlon~l ASCII code representlng the
ldeograph~c c~ar~Gtes IC Etore~ $n the ~emory 34 i~
~pplied to the output devlce or devics~ 16 whlch
typlcal~y lnclude ~ vldeo ~l~pl~y ter~lnal (VD~ 16a,
prlnter 16b and/or a vl~eo cynthe~izer 16c wh~roin an
audio and/or visual r productlon of the 1~20graphlc
char~cter ~C ~an be fsr~ed.
.a
1 33~77~
Referring to Flgure 6, the proc~sslng means 14
ls better lllustrated. ~he pre-pr~cessor 24 comprises a
comparator 24a and a memory 24b whlch functlon in a
manner to be desc~ibed to ellminate redundant and
S ~purious cartesian co-ordinate ~ata point ~lgnals. The
feature extraction section 26 includes a second
comparator 26a and a loo~-up table or dict~onary 26b
which function to generate vectors for ad~acent
cartesian co-ord~nate data point slgnals forming each
primitive Pr. A memory 26c receives the vectors and in
turn conveys the vectors to a third comparator 26d. The
comparator 26d examines the vectors and removes
redundant information to form a serles of unit vectors
or a vector code for each primitive Pr and a series of
scalars. The scalars represent the length of each unit
vector in the vector code generated for each primitive.
The vector code and series of scalars generated for each
primitlve Pr are conveyed to a memory 26e and stored
prior to being conveyed to the primltlve detectlon
section 28.
The primitive detection section 28 includes a
fourth comparator 28a connected to a second look-up
table or dictionary 28b. The table 28b stores a list of
predetermined vector codes and a prlmitive code for each
primitive Pr~ to PrO. The vector codes represent one or
more of the fifteen primitives Pr~ to PrO. The
primitive detection section 28 also comprises a memory
28c which holds the scalars generated for each vector
code and a test section 28d. The test section 28d
performs operations on the series of scalars lf the
vector code associated therewith is eguivalent to a
vector code ~hich represents more than one of the
fifteen primitives. This allows the correct prlmitive
to be determined. When the vector code for each of the
entered primitives Pr is located in the dictionary 28b,
- 12 -
~ 39~'~7~
the primitive code a to o assoclated therewith is
applled to the memory 30.
The ~eries of primitive codes or character
code generated for the sntered ldeographlc character IC
is conveyed to the character datection section 32 which
oomprises ~ fifth comparator 32a and a third lo~k-up
table or dictionary 32b. ~he dictionary 32b stores a
list o~ the character codes forming each of the
ideographic characters ln the language and an associated
international output code. The Comparator 32a and the
dictionary 32b function to detect wh~ther the character
code representing the entered ideographic character IC
is equivalent to a character code representing one or
more of the ideographic characters. The character
detection section 32 also lncludes a differentiator 32c
which performs tests on the raw cartesian co-ordinate
data point signals if the character code is equivalent
to a character code whlch represents more than one
ideographic character. This allows the correct
ideographic character to be detected. When the correct
ideo~raphic character has been identified, the
international ASCII code associated therewith is
conveyed to the memory 34 and in turn to the output
device 16.
As mentioned previously, when the character
code ls not e~uivalent to a character code found in the
dictionary 32b, the ~ubstitution and correction means 36
ls used. The substltution section 36 lncludes a
probablllty matrlx 36a, a sixth comparator 36b and a
memory 36c which collectively function to determine the
most probable character code that the character code
generated for the entered ldeographic character ~C was
supposed to be. ~hls lncreases the probabillty of
- 13 -
1 3~ ',77~
detecting the ideographic chnracter IC entered on the
di~itlzer tablet 20.
When ~n ldeogr~phic character IC 18 to be
entered lnto the apparatus 10 vla the digitlzer tablet
20, the stylus 20a ls placed on the tablet 20 ~nd each
of the prlmitl~es Pr formlng the ldeographlc character
IC ls drawn æeparately. AS dercrlbed herelnabove, the
primitives used to form the ideo~raphic character IC
must be substantially equlvalent to one of the fifteen
primitives Pr~ to Prg. However, this limitation does
not pose many problems since each of the fifteen
primitlves are fundamental strokes used by substantially
everyone who is capable of writing in an ideographic
language. Furthermore, the primitives Pr~ to PrO are
chosen to reduce the number of entered characters that
generate the 8ame character code when inputted into the
apparatus 10 and to simplify processing ln sectlon 14.
After ~ primitive Pr has been entered, the ~tylus 20a is
removed from the tablet 20 for a predetermined len~th of
time. This results ln 8 time-out signal belng generated
which allows the data processor 14 to recognlze that the
prlmitive Pr has been completely entered. Thereafter,
the next prlmitive forming the character is entered and
a time-out slgnal 18 generated. Thls process contlnues
until eaoh primitive formin~ the character has been
entered into the apparatus 10.
As the stylus 20a ls moved across the tablet
20 to form a primitive Pr, a series of cartesian co-
ordinate data point signals are generated. The data
processor 14 samples the cartesian co-ordinate data
polnt signals generated for each primitive at a sampllng
rate of approximately 100 samples per second snd stores
the ~ampled co-ordlnate data Bignals ln the memory 22.
The ~ampled data for each primitive i8 continuously
- 14 -
1 3.,~77~
~tored ln ~eparate registers until the data processor 14
recelves a time-out signal signifying tha~ the complete
prlmltive has been entered. While the next prlmitlve
Pr2 is being formed on the tablet ~0, the sampled
cartesian co-ordinate data point signals are separately
stored in different registers in the memory 22 until the
next time-out signal ls detected by the processor 14.
This process continues until each primitive forming the
ideographic character has been entered and the cartesian
co-ordinate data signals generated therefor have been
stored separately in the memory 22. To indicate to the
data processor 14 that the entire ideographic character
IC has been entered, an end-of-character (EOC) key
located on the tablet must be depressed. This prevents
further data entered on the tablet 20 from corrupting
the data associated with previously entered ideographic
character.
Since a digitizer tablet 20 is used, temporal
and irregular noise occurs during the sampling process
due to miscoupling of the 8tylus 20a and the digitizer
tablet surface 20. Furthermore, ~mall amplitude noise
occurs due to uneven movements in the operator's hand
which introduces discrepancies between the sampled
cartesian co-ordinate data point signals and the desired
cartesian co-ordinate data point signals. Also, the
slow movement of the stylus 20a across the diyitizer
tablet surface 20a with respect to the sampling rate of
the processor 14 introduces a large number of redundant
data point signals which ln turn requires a large amount
of storage space and lncreases the processing time of
the apparatus 10. Thus, as mentloned previously, the
pre-processor 24 ls usad to reduce the redundant and
spurious data.
- 15 -
1 3G9774
To perform this functlon, a copy of the
sampled ca~teslan co-ordinate data point slgnals ls
applled to the comparator 24a. ~o reduce the noise
caused by the lnadvertent decoupllng of th~ 8tylu8 20a
and the digltizer tablet 20, the sampled cartesian co-
ordinate data point slgnalg are separately analyzed. If
any sampled cartesian co-ordinate data point signal is
detected as having a set of co-ordinates extending
beyond the boundary of the digitizer tablet 20, the
cartesian co-ord$nate data point signal ls deleted.
Secondly, to reduce the amount of redundant data and
hence, to lncrease the processing speed of the apparatus
10, the first two cartesian co-ordinate data point
signals are compared ln the comparator 24a. If the
distance between the two cartesian co-ordinate data
point signals is less than a predetermined threshold
value, the second sampled data point signal is deleted
and the distance between the first and the third sampled
cartesian co-ordinate data point signals is examlned.
This process continues until the distance between two
data point signals is greater than the threshold value.
When, the distance ls greater than the threshold value,
the first data point slgnal is conveyed to the memory
24b and the other data point signal is compared with the
next preceding data point signal.
Furthermore, if the distance between the two
cartesian co-ordinate data point slgnals is greater than
a 6econd predetermined threshold value, the second
cartesian co-ordinate data point signal ls compared with
the third data point slgnal. If the distance between
the second and third data point ~ignals i~ larger than
the second threshold value~ the second data point signal
is assumed to have been generated due to an lnadvertent
mi8coupling o~ the ~tylu8 20a ~nd the tablet 20 ~nd is
deleted. However, if the distance between the second
- 16 -
1 ~09774
data point ~ignal and the thlrd data point s$gnal 18
less than the second threshold value, the flrst data
polnt signal is assumed to have been generated
lnadvertently snd ls deleted. Thls process ls performed
on the ~amp~ed cartesian co-ordlnate data polnt signals
for each of the entered prlmltlves forming the entered
character and hence, reduces the ~mount of data that
requires processing.
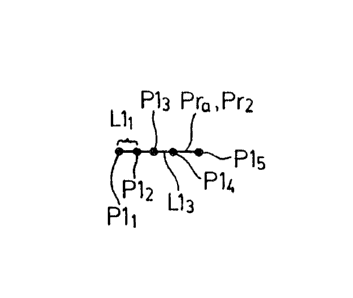
For example, lf the lde~graphic character IC
illustrated in Figure 2 is entered lnto the apparatus
10, the primitives Prl to Pr3 forming the character IC
are entered on the tablet 20 separately. The data
processor 14 samples the cartesian co-ordinate data
generated by the tablet 20 for the first primltlve Prl
and stores the sampled cartesian co-ordinate data point
signals Pll to Pl5 in the memory 22 as chown ln Figures
4a to 4c. Similarly, the processor 14 samples the
cartesian co-ordlnate data polnt signals P21 to P28 and
P31 to P38 generated for the next two prlmltives Pr2 and
Pr3 respectlvely and stores the sampled cartesian co-
ordinate data point signals in the memory 22.
Following this, the cartesian co-ordinate data
point signals are conveyed separately to the pre-
processor 24 wherein they are stored ln the comparator
24a. Firstly, the sampled cartesian co-ordinate data
polnt slgnal Pll for the flrst primitive Prl ls compared
wlth the outer boundary carteslan co-ordlnates of the
dlgitizer tablet 20. If the ~ampled data polnt signal
ls detected as being outslde the boundary of the tablet
20, lt ls deleted. Secondly, each of the remaining data
point 6ignals Pl2 to Pl5 are compared wlth the previous
data polnt slgnal Pll. For example, lf the dlstance
between the data points Pl2 and Pll is less than a
predetermlned value, the data point ~lgnal Pl2 is
- 17 -
1 30~774
deleted and the data point slgnals Pl3 ls compared w$th
the data pelnt signal Pl,. If the distance between the
dat~ polnt slgnals Pl3 and Pll i~ greater than the
thre~hold value, the dat~ point ~ignal Pll 18 stor~d ln
the memory 24b and the above-mentioned process is
recommenced examinlng the data point slgnals P13 and
Pl~. This process is performed for each data point
signal ~ampled for the first primitlve Prl until the co-
ordinate data representing the inputted primltive Prl
has been reduced. Thls process is also performed on the
sampled cartes~an co-ordinate data polnt signals for
each of the other entered primltlve6 Pr2 and Pr3 and
thus, the memory 24b stores the reduced cartesian co-
ordinate data point slgnals for each of the entered
primitives.
When the spurious and redundant sampled
cartesian co-ordinate data point signals for each
entered primitive have been removed, the resultant data
polnt slgnals are conveyed from the memory 24b to the
feature extraction section 26.
In the feature extraction section 26, the
cartesian co-ordinate data point signals for each
entered primitlve are converted lnto a vector code and
series of scalars in order to simplify the process of
detecting the prlmitives that were entered on the tablet
20. However, prior to forming the vector code and
scalars for the entered primltive, the carteslan co-
ordinate data is examined to detect whether it has been
reduced to a single palr of co-ordinstes by the pre-
processor 24. This occurs if the primitive Pr. ls
entsred on the tablet 20. If this primltive 18
detected, the primitive code e is outputted to the
memory wlthout requiring any further processlng. The
feature extraction section 26 implements the use of a
- 18
1 3 '~J q77 ~
modified Freeman c~ding system FC whlch ls illustrated
~ n Figure 7 when forming the vector codes and scalars to
determlne the ~ther primitlves. The Freaman cod~ng
~ystem allows a ~ries of cartesian co-ordinate data
point gignals (PO, Pl, -- P1 ~ P1~1 ) wher~ P0 ls
equal t~ (X0~ Y0) and P1 is equal to (Xi, Y1), to be
converted lnto a ~eries of unit vectors, each vector of
which has an associated length. The unit vectors are
formed by comparing a line drawn between ad;acent
cartesian co-ordinate data point signals Pi and Pi~l
wlth one of the eight Freeman unit vectors FVl to FV8 in
the Freeman code FC.
However, due to angles lntroduced into the
shape of the entered primitlves on the digitizer tablet
20, a tolerance ls requlred to allow a llne formed
between a pair of cartesian co-ordinate data polnt
signals Pi and P~l that 18 not colncldent wlth a
Freeman unit vector FVN to be asslgned to the correct
Freeman unit vector. To accommodate these drawlng
variations of the entered primltives, the Freeman coding
system FC uses a 20 tolerance for each of the Freeman
unlt vectors PVN and thus, allows any llne formed
between a palr of cartesian co-ordinate data polnt
slgnals P, and Pi~1 falllng wlthin one of the boundarles
Al to AB to be assigned to the proper Freeman unit
vector FVN assoclated with that boundary.
To generate the Freeman unit vector FVN for
each line formed between each ad~acent carteslan co-
ordinate data polnt slgnals for each o the prlmitives,
the pre-processed carteslan co-ordlnate data polnt
slgnals are conveyed to the comparator 26a. In the
comparator 26a, ad~acent cartesian co-ordlnate data
point signals are examined and a llne is formed
therebetween. To reduce the errors introduced in the
-- 19 --
l ~'f~774
sampled carteslan co-ordlnate data-due to lnadvertent
movement of the 8tylus 20a by the operator, the-length
of the llne formed between each sd~acent data polnt
81gnal 18 compared with a threshold value. If the
length is less than that of the predetermined threshold
length, the second data polnt signal 18 assumed to be
the result of a ~purlous hand movement by the operator
and ls thus deleted. This process ensures that a
horizontal line drawn by an operator with a slight
undesired non-horizontal portion will be flltered to
produce data representlng the deslred horlzontal llne.
After the removal of lnadvertent data point
slgnals, lines are formed between the remaining ad~acent
data point signals and compared with the modified
Freeman code FC. If the llne fall,s within one of the
tolerance boundarles Al to A8, the Freeman unlt vector
FVl to FV8 ssYoclated therewlth i8 conveyed to the
memory 26c. If the line formed between two carteslan
co-ordinate data polnt slgnals falls within one of the
lnvalid boundarles Xl to X8 ln the Freeman code FC, the
second cartesian co-ordinate data point signal is
replaced by the next preceding cartesian co-ordlnate
data polnt signal and a new line 18 formed therebetween.
Similarly, the new line ls compared with the Freeman
code FC once agaln to detect lf the llne lies wlthln one
of the valid boundarles Al to A8. If the resultant llne
falls wlthln a valld boundary Ah, the Freeman unlt
vector FVN assoclated with the boundury Ah 18 conveyed
to the memory 26c. However, lf a ~alld Freeman unlt
vector 18 not detected, the second data point signal of
the palr is replaced by the next precedlng data polnt
and the same process 18 repeated. If a line falllng ln
a valid boundary AN 18 still not detected after
fiubstltuting each of the remalnlng carteslan co-ordinate
data points generated for the entered primitive, the
- 20 -
1 ~5~774
cartesian co-ordinates ~re represented by an lnvalld
Freeman unit vector U' and the lnvalid Freeman vector is
conveyed to the memory 26c.
Thus, a serles of Freeman unit vectors FVi to
FVN or U' are formed for each of the entered prlmltlves
and are stored separately ln the memory 26c. The ser~es
of unit vectors are then separately conveyed to the
comparator 26d. The comparator 26d compares each unit
vector FVi ~1 with the previous unit vector FVi ~nd if
they are equivalent, a scalar count is incremented for
that unit vector and the unit vector FVi~l is deleted.
This process is performed on the unit vectors ~enerated
for each of the entered primitives Pr. This operation
results ln the formation of 8 reduced series of unit
vectors or a vector code for each entered primitive
forming the character, each vector code of which has an
associated series of scalars, which represent the length
of each of the unit vectors ln the vector code.
For example, if the ldeographlc IC illustrated
ln Figures 1 and 4 is entered lnto the apparatus 10, the
comparator 26a flrstly examlnes the cartesian co-
ordinate data points associated with the first primitive
Prl and forms the llnes Lll to Ll~ between each ad~acent
data polnt Pll to Pl5 respectlvely. The llnes Lll to
Ll4 are then compared with the Freeman code FC and the
associated Freeman vectors FVl to FVN are assigned to
the lines. Thus, the primltlve Prl formed from
carteslan co-ordinate data points Pll to Pls and
ger.erating lines Lll to Ll~ as lllustrated in Figure 4
is assigned the Freeman vectors FV3, FV3, FV3, FV3 since
each of the lines Lll to Ll~ falls wlthin ths boundary
A3 (assuming that the length of each of the llnes ~ 8
abovs the threshold value).
- 21 -
1 309~7~
With each of the vector6 generated for the
primitive Prl, the ~eries of vectors are oonveyed to the
memory 26c nnd stored thereln. The above descrlbed
process 1B then performed on the carteslsn co-ordlnate
data points assoc~ated wlth the primltlve~ Pr2 and Pr3
and resultant vector~ formed therefor are al80 conveyed
to the memory 26c. Following this, the Freeman vectors
for each primitive Pr ~re conveyed to the comparator
26d. Thereafter, ad~acent Freeman vectors generated for
oach primitive sre compared. If adJacent vectorfi are
ldentlcal, one of the vectors is deleted and the scalar
count therefor ls lncremented. The results from the
comparator 26d are then conveyed to the memory 26e.
For example, when the primitive Prl shown in
Figure 4a is processed to form the 8eries of Freeman
vectors FV3, FV3, FV3, FV3, the comparator 26d reduces
the series of vectors to the vector code FV3 having a
scalar of 4. If, for example, a primitive was ~ntered
and a series of Freeman vectors equal to FV3, FV3, FV3,
FV4, FV4, FV4, FV5, FV5, FV3 was generated therefor, the
series of unit vectors would be reduced to the vector
code FV3, FV4, FV5, FV3, and a series of scalars equal
to 3, 3, 2, 1 would be generated.
From the memory 26e, the vector code and
associated series of scalars for each primitive forming
the entered character are conveyed to the primitive
detection section 28. The vector codes are applied to
the comparator 28a and the series of scalar are stored
in the memory 28c. The vector codes received by the
comparator 28a are compared with the vector codes ~tored
in the primitive dictionary 28b. The dictionary 28b is
partitioned into slxteen prlmitive code sectlons, the
first fifteen sections of which are uniquely associated
with one of the fifteen primitives Pr~ to PrO and ~tore
- 22 -
1 3`~q77~
vector code~ unlquely asxoclated with that prlmitlve.
The 81xteenth ~ectlon holds am~iguous vector codes whlch
can repre~ent more than one of the prlmltlves. The
slxteenth sectlon also holds unlque test lnformatlon for
each ambiguous vector code to allow the correct entered
primitives to be determlned.
If the vector code for an entered primitlve
equivalent to a vector code found in one of the first
flfteen sections of the dictionary 28b, the primitlve
code a to ~ assoclated therewith is conveyed to the
memory 30. This process ls performed for each of the
vector codes generated for each prlmitive formlng the
entered character. Thus, a serles of primltive codes or
a character code ls generated, the character code of
whlch represents the ldeographlc character entered on
the digltizer tablet 20.
However, when a vector code generated for one
of the primitives is compared with the contents of the
dictionary 28b and lt ls equlvalent to a vector code
stored ln the slxteenth section, the test information
associated with the amblguous vector code is applied to
the test section 28d. The test sectlon 28d receives the
test lnformatlon and examlnes lt to determine which
vector code ls being exam$ned. Thereafter, the test
8ection 28d receives the series of scalars associated
with the examined veotor oode and performs operatlons
thereon, the operations of which are determined by the
unique test lnformation. The results of the tests are
conveyed back to the dictionary 28b which in turn
selects the correct primitive code that represents the
entered prlmitive. The serles of scalars provlde
suitQble information to di3crlminate between each
ambiguous vector code Qlnce although the veCtor codes
- 23 -
1 3G~774
are ambiguous, the value of each scalar ln the ~erles
are typlcally very different.
For example, lf the prlmltlve Pr.' lllustrated
~n F$gure 8a was entered on th~ tablet 20, Q vector code
equivalent to FVl, FV2, FVI would be generated.
However, the v~ctor code would be detected ln the
~xteenth ~ection of the dictionary 28b since this
vector code ~s also u~ed to represent the primitive Prb
lllustrated in Figure 8b. Although the vector codes for
the two primltives are identical, the series of scalars
associated therewith are very different. As ca~ be seen
the series of scalars associated with the primitive Pra
would be 3, 1, 3 whilst the series of scalars assoclated
with primitive Prb would be 1, 5, 1. Thus, by comparing
the relative lengths between the first two scalars ln
the series, the correct primitlve code can be
determined.
If the vector code being compared w~th the
contents of the dictionary 28b is not equivalent to a
vector code located therein, the vector code i8 asslgned
an unidentified primitive code U which is similarly
applied to the memory 30. Thus, the output of the
primitive detection section 28 comprises a series of
primitive codes or a charaater code, which represents
the lnputted ideographic character IC.
The character code stored ln the memorv 30 is
applied to the character code recoynition section 32 and
received by the comparator 32a. The comparator 32a
compares the character code with the contents of the
character dlctionary 32b generated for the entered
character. As mentioned prevlously, the dictlonary 32b
stores a character code for each of the posslble
ideographic characters in the language along with lts
- 24 -
I ~ ' 7 7~
correspondlng lnternatlonal ASCII output code. The
$ntsrnational ASCII output code ls used interna~ionally
to represent the ldeographic character. Since a number
of ldeographic characters are ~ormed from the same
primitlves entered ln the same order, some ideographic
characters have identical character codes although the
relative positions betwaen the entered prlmitives are
very different. To allow the apparatus 10 to detect the
proper ideographic character when an ambiguous character
code is received, the character dictionary 32b also
contains test information uniquely associated with each
amblguous character code.
When a character code is received from the
memory 30, it ls compared wlth the contents of the
dictlonary 32b via comparator 32a. If received
character code is equivalent to a character code found
in the dictionary 32b that is uniquely associated with
only one $deographic character, the lnternational ASCII
output code assoc$ated therewith is outputted from the
dictionary 32b and stored in the memory 34. However,
when the character code generated for the entered
ideographic character ls equivalent to an ambiguous
character code that 18 assoclated with more than one
ideographic character, the unlque test lnformatlon
associated therewith is applied to the character
dlfferentiator 32c.
Upon receptlon of the test lnformatlon, the
dlfferentiator 32c retrieves the unprocessed cartesian
co-ordinate data from the memory 22 and performs
operatlons thereon as determined by the test lnformation
in order to determine the international ASCII output
code that represents the lnputted ldeographlc character.
When performing the test operatlons, the unprocessed
cartesian co-ordlnate data points are used as opposed to
- 25 -
1 3 ,~774
the series of scalars formed therefor, 61nce the
unprocessed carteslan co ordinate data contains -
lnformatlon regardlng the relative posltlon of each of
the entered primitlves. When the correct lnt0rnational
ASCII output code ha~ been determlned, lt 18 slmilsrly
conveyed to the memory 34.
For example, lf the ideographic character
illustrated in ~igure l was entered into the apparatus,
a character code equal to "aba" would be generated and
compared with the contents of the dlctionary 32b.
However, the character code would be detected as being
ambiguous since the ideographic characters IC2 and IC3
shown in Figures 9a and 9b respectively are also
represented by the same character code "aba". ~he
unique test information associated with the character
code "aba" would be applied to the differentiator 32c,
along with the unprocessed carteslan co-ordinate data
from the memory 22. For this example, the test
information would cause the differentiator 32c to
examine the posltion of the second prlmltlve Pr2 wlth
respect to the first prlmltlve Prl to determlne lf the
second prlmitive Pr2 passes through the first primltlve
Prl. If the result of thls test was negative, the
dlfferentiator 32c would acknowledge that the entered
ideographic character IC is not equivalent to
ideographic character IC2 slnce this feature is not
present in the character IC2. To dlstinguish between
the ideographlc character IC and IC3, the thlrd
prlmltive Pr3 is compared wlth the flrst primitlve Pr
formlng the entered ldeographic character IC and the
relative sizes therebetween are examined. ~he result of
this test enables the differentistor 32c to select the
correct international ASCII output code since the
primitive Prl is smaller than the primitive Pr3. The
dictionary 32b receives the results generated by the
- 26 -
~ ~ r! ~3 7 7 ~
differentiator 32c ~nd the correct lnternational ASCII
output eode ls conveyed to the memory 34.
After the lnternational ASCI~ output code has
S been determlned and 6tored in the memory 34, lt ean be
applled to output devices such as a printer 16a, a VDT
terminal 16b or an audio synthesizer 16c in order to
produce an image of the inputted $deographie eharacter.
However, if the character code is formed from
a eries o$ primltive codes wherein one or more of the
primitives have been asslgned unidentifled primitive
codes U or lf the charaeter eode is not equivalent to
any of the character eodes found in the eharacter
dictionary 32b, the eharacter code is applied to the
substitution and correetion section ~6. The
~ubstitution and correetion seetion 36 lncludes the
probabillty matrix 36a, which is in the form of a
sixteen row by flfteen eolumn array of registers 36.'.
As shown ln Flgure lO, each row of the matrix is
associated wlth one of the posslble slxteen primltive
eodes a to o ineluding the unldentifled prlmltive eode U
and eaeh of the eolumns of the matrix ls assoelated wlth
one of the flfteen pO8S~ ble prlmitive eodes ~ to o.
Eaeh of the re~lsters 36~' holds a number representing
the probablllty that the prlmltive eode of the row eould
be mistaken for the primltlve eode of the eolumn.
Thus, the probabillty values ~tored ln the
re~i6ters along the left to right dlagonal of the matrix
36a all have values of l sinee the probablllty that a
prlmlt~ve eode will be deteeted as itself is hlgh. The
probablllty of two very dlssimilar primitives belng
mi~taken for one another 1~ highly lmprobable and thus,
the probabillty values ~tored in e register ~ssoeiated
with two dissimllar primitivss ls typleally zero. For
- 27 -
7 7 4
example, looking at the flrst row of the matrlx 36a
whlch is sssociated with the prlmitlve Pr,, the -
probablllty that the prlmitlve Pr~ could actually be
mistaken for primltlve Prc ls 0.0 8~ nce these prlmitlves
are very dlfferent ln the manner in whlch they are
formed. Primltives which have some similarltles to
other primitives are asslgned probabillty values ranging
from 0.1 to 0.9, depending on the number of similarities
therebetween.
When a character code ls recelved ln the
comparator 36b havlng at least one unldentified
prlmitive code U thereln, the probabilities in the row
associated with the primitive code U are examined. When
the highest probability value ln the row ls detected,
the prlmitive code of the column is used to replace the
unidentified primitive code U. The resultant character
code is conveyed back to the comparator 32a snd ls
compared with the contents of the character dictionary
32b to detect if the resultant character code ls
equlvalent to a character code found therein. If the
resultant character code 18 equlvalent to a character
code ln the dictionary, the lnternational ASCII output
code ls retrieved from the dlctlonary 32b and conveyed
to the memory 34 wherein lt ls stored. If the resultant
lnput character code is equlvalent to an ambiguous
character code, tests are performed on the carteslan co-
ordinate data stored ln the memory 22 ln the same manner
as prevlously described to determine the correct
international ASCII output cpde.
However, lf the resultant character code is
not equivalent to a character code found ln the
dictionary 32b or lf the originally entered ~haracter
code does not correspond wlth a char3cter c~de found ln
the dictlonary 32b, a second substitution is performed.
- 28 -
3 ~ ,! i 7 7 4
When one of the above cases occurs, the character code
ls conveyed to the comparator 36b and examined to
identlfy the number of primitive codes formlng the
character code. Following this, each character code ln
the character dictlonary 32b formed from the same number
of primitlve codes i5 conveyed to the comparator 36b and
compared with the unidentlfled character code. Durlng
this comparison, the number of differences between the
primitive codes forming each of the character codes and
the primitive codes forming the unidentlfled character
code are examined. If the number of differences
detected between the character code and the unldentif$ed
character code ls greater than a thr~shold value, the
character code is discarded.
However, every character code hav~ng a smaller
number of differences than the threshold value ls noted
and the lnternatlonal ASCII output code associated
therewith is ~tored ln the memory 36c. The order of the
lnternational output code~ stored in the memory 36c ls
chosen so that the first international ASCII output code
ln the memory i8 associated wlth the character code most
similar to the unidentified character code. The
international output codes stored in the memory 36c are
then retrleved from the memory 36c and conveyed to the
VDT terminal, thereby displaying to the user each of the
ideographlc characters that are most likely to be
equivalent to the entered ideographlc character. The
user may then choose the ldeographic character
corresponding to the ideographic character that was
entered lnto the apparatus lO via suitable edit~ng
software. If the substitution section 36 doe~ not
produce the desired ideographlc character, editlng
programs can be u~ed to retrieve the correct
international ASCII output code from the dlctionary 32b.
- 29 -
1 3c,,77a~
The ldeographic character signals ~tored in
the memory 34 can be coupled to the printer 16a to allow
a reproduction of the inputted ldeographic character to
be generated. Furthermore, the character signals can be
conveyed to the VDT screen 16b to allow the user to view
the characters that has been 0ntered lnto the apparatus
10. The apparatus lO ls also capable of functlonlng
with known ~diting programs to allow the user to change
the ideographic character signals stored in the memory
34.
When the apparatus lO ls conditioned in one of
the other modes so that the apparatus functions to
recognize characters o~ a different language, the same
set of primitives shown in Figure 3 are used to form the
characterq. It should be apparent that the primitives
shown in Figure 3 are particularly useful in forming
ideographic and upper case English language characters
since all of the characters in these languages can be
formed from these primitives. However, lt should be
appreclated that other primitives may have to be added
so that all of the aharacters in all languages can be
formed, however, this will be rare slnce the twenty
primitives should be capable of formlng substantially
all of the characters in every language.
As mentloned prevlously, the dictionarles in
the processor 14 are partitioned with each partition
holding the various primltive codes, character codes and
ASCII output codes for each upper case character in the
other languages. The upper case characters are stored
in the apparatus ~lnce these characters are typically
written ln the same manner and order by everyone versed
ln the languaga. The various sectlons ln the processor
also include test information to allow different
- 30 -
1 3Q~77~
characters whlch gen~rate the 6ame character code to be
recognized.
For languages which use ~trokes slmllar to
pr$mitives Prp to Pr~ when formlng the characters
therein, the primltive detectlon and prlmltive code
determination is performed ln the same manner previously
described using the Freeman coding except when one of
the primitives Prp to Prt are entered on the tablet 20.
Accordlngly, When a primitive ls entered on the tablet
20, the feature extraction section 26 examlnes the
tangents of the lines formed between the sampled points
along the primitive to determine the degree of curvature
of the prlmltive (le. 180, 270, 360) prior to using
the Freeman Coding.
If the primitive is detected as having a
curvature of substantially 270 or 360, the primltlve
code s or t assoclated wlth the entered prlmitlve Pr. or
prt i8 lmmedlately determined wlthout further
processing. If the curvature of the primltlve ls
detected as belng approxlmately 180, the starting and
ending co-ordinate data signals of the primitive are
examlned along wlth the dlrection of the tangents (ie.
clockwlse or counter-clockwise) This allows the
primitives Prp to Prr to be differentiated without
requiring further processing. Other wise if the entered
primitive is not detected as having a substantlally
constant gradient when examinlng the tangents, the pre-
processed co-ordinate data signals are processed using
the Freeman coding to determine the correct primltive
code.
For example, referring to Figure 11, lf the
apparatus ls conditioned to recognlze Engllsh language
characters and the character "M" i5 entered on the
- 31 -
1 3iJ9774
tablet 20, the primitives Prb, PrO, Prc and Prb are u6ed
to form the character. These prlmltlves sre processed
by the feature extractlon sectlon 26 and the prlmltlve
detection section ln the same manner previou~ly
descr~bed. Accordingly, a character code equal to
~bgcb" would be generated. The associated ASCII output
code would outputted ~ince this code is only associated
with the character "M" ln the English language.
If for example, the English characters "D" and
"P" were entered on the tablet 20 as shown in Figure 12,
the character code generated for each character would be
"bq" since the primitives forming both characters are
Prb and Prq. Thus, if one of these characters is
entered, test informatlon stored ln the character
dictionary is used in a ~imilar manner to that
previously described and the length of the primitive Prb
and the length between the starting snd ending points of
primitive Prq are examined. This allows the two
characters to be differentiated even though the
character codes generated for the two characters are the
same.
With respect to other languages such as
German, French etc. the method of detecting the
handwritten characters is the same although the
apparatus must be condltioned to the appropriate mode
via means 18. This is even necessary for languages like
German ,French and Engllsh wherein the characters
forming the language are the same since the ASCII output
codes therefor are different. The substitution matrix
can also be used for each of the other languages
although it ls not necescary due to the small number of
characters used in non-ideographic languages.
1 3l~iq77~
Also, when the apparatus 10 i8 conditioned to
detect upper characters of B language, the devlae ls
also included wlth software for outputtlng the ASCII
code for the lower case eguivalent of the detected upper
case character lf desired. Although the lower case
letters can be detected in a similar manner to the upper
case letters, lower case letters are typically written
differently by lndivlduals thereby making the detection
process more difficult and reguiring more memory space
to permit detection of the character in the many
possible ways that it can be written.
The present apparatus has been employed in an
IBM PC XT personal computer manufactured by
International Business Machines provided with a 20 Mb
hard disk which functions to store the information for
the dictionaries. To perform the identification
processes described hereinabove, the computer is
supplied with the approprlate software which allows the
input cartesian co-ordinate data point signals to be
processed in the above-mentloned manner. Since a large
amount of data is stored in the dictionary 32b, ie.
character codes and associated international output
codes for approximately 50,000 different ideographic
characters, a B-tree algorithm which is well known in
the art ls used to lncrease the speed of the detection
between the character code generated for the inputted
ideographic and the character codes stored therein.
Although the B-tree algorithm increases processing
speed, it also increases memory reguirementæ, 6ince
indexing flles are requlred.
The present apparatus 10 can also be
manufactured on a ~mall lntegrated circuit board capable
of belng coupled to Q conventlonal per~onal computer,
the board of which i8 provided ROM components to store
- 33 -
1 3r9774
the various dlctionary content6 and a microprocessor
including approprlate 80ftware to perform the data
processing functions.
Thus, the present apparatus provides the
advantages of being able to dlstinguish between
characters wh~ch are formed from the same primlt$ves
entered in the same order. This decreases the
occurrences of an operator havin~ to halt data entry
operations in order to choose the correct ideographic
character. Moreover, the substitution means further
decreases the above-mentioned occurrence since allowing
the present apparatus to choose a dlfferent character
code that is most similar to the entered character code,
if the input character is not found ln the apparatus 10.
Furthermore, since the apparatus can be generated using
software or manufactured using hardware components, the
apparatus ls versatile and can be used in various
environments.
The present device also provides further
advantages in that the manner ln which the entered
strokes are processed in the apparatus, allows the
strokes to be wrltten substantially anywhere on the
tablet surface except for the small number of characters
which generate an ambiguous character code. Also, the
processlng used prior to the determlnation the
primit~ves forming the character allows the entered
characters to be determlned irrelevant of the length of
the entered primitives except for a few exceptions.
Furthermore, the simply approach and processing allows
handwritten characters ln substantially all languages to
be recognized ~ulckly thereby allowing the devlce to be
used in real-time appllcatlons.
- 34 -
~, 3~S774
It should be ~pparent to one skilled in the
art that the pre6ent devlce can be ~odlfled to detect
any lnputted character provlded the approprlate
informatlon regardlng the character to be detected is
stored in the dictionaries located therein.
- 35 -