Note: Descriptions are shown in the official language in which they were submitted.
-
~ 336208
AN ADAPTIVE THRESHOLD VOICED DETECTOR
Technical Field
This invention relates to determining whether or not speech contains a
fi~nd~m.ont~l frequency which is commonly referred to as the unvoiced/voiced
decision. More particularly, the unvoiced/voiced decision is made by a two stage5 voiced detector with the final threshold values being adaptively calculated for the
speech environllRIlt utilizing statistical techniques.
Background and Problem
In low bit rate voice coders, degradation of voice quality is often due
to inaccurate voicing decisions. The difficulty in correctly making these voicing
10 decisions lies in the fact that no single speech parameter or classifier can reliably
distinguish voiced speech from unvoiced speech. In order to make the voice
decision, it is known in the art to combine multiple speech classifiers in the form
of a weighted sum. This method is commonly called discrimin~nt analysis. Such
a method is illustrated in D. P. Prezas, et al., "Fast and Accurate Pitch Detection
15 Using Pattern Recognition and Adaptive Time-Domain Analysis," Proc. IEEE Int.Conf. Acoust., Speech and Signal Proc., Vol. 1, pp. 109-112, April 1986. As
described in that article, a frame of speech is declared voice if a weighted sum of
cl~sifiers is greater than a specified threshold, and unvoiced otherwise. The
weights and threshold are chosen to maximize pe.rw~ ce on a training set of
20 speech where the voicing of each frame is known.
A problem associated with the fixed weighted sum method is that it
does not p~.rOl,l, well when the speech envin~nmellt changes. The reason is thatthe threshold is ~etermined from the training set which is dirf~ ;nt from speechsubject to background noise, non-linear distortion, and filtering
One method for adapting the threshold value to changing speech
en~ nlllent is disclosed in the paper of H. ~s~nein, et al., "Implementation of
the Gold-Rabiner Pitch Detector in a Real Time Environment Using an Improved
Voicing Detector," EEE Transactions on Acoustic, Speech and Signal
Processing, 1986, Tokyo, Vol. ASSP-33, No. 1, pp. 319-320. This paper discloses
30 an empirical method which compares three dirr~,re.-t paldll~ete.~ against
independent thresholds associated with these pa,allle~ and on the basis of each
comparison either incl~lllenls or decrements by one an adaptive threshold value.The three pa,dllle~ utilized are energy of the signal, first reflection coefficient,
1 336208
and zero-crossing count. For example, if the energy of the speech signal is lessthan a predefined energy level, the adaptive threshold is incremented. On the other
hand, if the energy of the speech signal is greater than another predefined energy
level, the adaptive threshold is decremented by one. After the adaptive threshold
5 has been calculated, it is subtracted from an output of an elementary pitch detector.
If the results of the subtraction yield a positive number, the speech frame is
declared voice; otherwise, the speech frame is declared on unvoice. The problem
with the disclosed method is that the parameters themselves are not used in the
elementary pitch detector. Hence, the adjustment of the adaptive threshold is
10 ad hoc and is not directly linked to the physical phenomena from which it is
calculated. In addition, the threshold cannot adapt to rapidly ch~nging speech
environments.
Solution
In accordance with one aspect of the invention there is provided an
15 apparatus for detecting the presence of a fundamental frequency in frames of
speech, comprising: means responsive to a set of classifiers defining speech
attributes of one of said frames of speech for generating a general value indicating
said presence of said fundamental frequency; means responsive to said general
value for calculating a set of statistical parameters; means for calculating a
20 threshold value in response to said set of said parameters; means for calculating a
weight value in response to said set of said parameters; means for communicatingsaid weight value and said threshold value to said means for calculating said set of
parameters to be used for calculating another set of parameters for another one of
said frames of speech; and means responsive to said weight value and said
25 threshold value and the calculated set of statistical parameters for determining said
presence of said fundamental frequency in said present one of said frames of
speech.
In accordance with another aspect of the invention there is provided a
method for detecting the presence of a fundamental frequency in frames of speech30 comprising the steps of: generating a general value in response to a set of
classifiers defining speech attributes of one of said frames of speech to indicate
,
-- -2a- 1 336208
!
said presence of said fundamental frequency; calculating a set of statistical
parameters in response to said general value; and deterrnining said presence of said
fundamental frequency in said one of said frames; said step of determining
comprises the steps of calculating a threshold value in response to said set of said
5 parameters; calculating a weight value in response to said set of said parameters;
and communicating said weight value and said threshold value to said means for
calculating said set of parameters to be used for calculating another set of
parameters for another one of said frames of speech.
Advantageously, in response to speech attributes of the present and past
10 speech frames, the mean for unvoiced frames is calculated by calculating the
probability that the present speech frame is unvoiced, calculating the overall
probability that any frame will be unvoiced, and calculating the probability that the
present speech frame is voiced. The mean of the unvoiced speech frames is then
calculated in response to the probability that the present speech frame is unvoiced
15 and the overall probability. In addition, the mean of the voiced speech frame is
calculated in response to the probability that the present speech frame is voiced and
the overall probability. Advantageously, the calculations of probabilities are
performed ~ltili7.ing a maximum likelihood statistical operation.
,~
3 1 3 3 6 2 0 8
Advantageously, the generation of the general value is performed
utilizing a discriminant analysis procedure, and the speech attributes are speech
classifiers.
Advantageously, the decision regions are de_ned by the mean of the
5 unvoiced and voiced speech frames and a weight and threshold value generated in
response to the general values of past and present frames and the means of the
voiced and unvoiced frames.
The method for detecting the presence of a fun~l~m~nt~l frequency in
speech frames compri~es the steps of: generating a general value in response to a
10 set of cl~sifiers ~lefining speech attributes of a present speech frame to indic~t~
the presence of the filn~1~ment~1 frequency, calculating a set of statistical
pa~ letel~ in response to the general value, and determining the presence of thefilnd~ment~l frequency in response to the general value and the calculated set of
statistical pal~lRt~ . The step of generating the general value is p~,lrolllled
15 utilizing a discrimin~nt analysis procedure. Further, the step of dele ..~ ing the
filnfl~mt~nt~l frequency comprises the step of calculating a weight and a threshold
value in response to the set of parameters.
Brief Description of the Drawin~
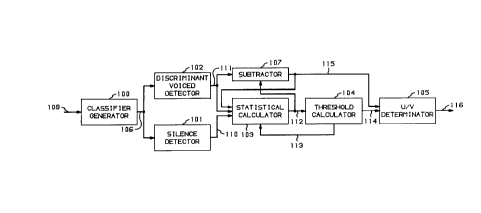
FIG. 1 illusllales, in block diagram form, the present invention; and
FIGS. 2 and 3 illustrate, in greater detail, certain functions pelrc~llcd
by the voiced detection appa~alus of FIG. 1.
Detailed Description
FIG. 1 illustrates an appalalus for pclr IlllPillg the unvoiced/voiced
decision operation by _rst l1tili7ing a ~i~crimin~nt voiced detector to process voice
25 classifiers in order to generate a rliscrimin~nt variable or general variable. The
latter variable is st~ti~tic~lly analyzed to make the voicing decision. The
statistical analysis adapts the threshold utilized in m~king the unvoiced/voiceddecision so as to give reliable pelrollllance in a variety of voice enviro~
Consider now the overall operation of the al~a dlus illustrated in
30 FIG. 1. Cl~csifier gcnclalol 100 is responsive to each frame of voice to generate
classifiers which advantageously may be the log of the speech energy, the log ofthe LPC gain, the log area ratio of the first reflection coefficient, and the squared
correlation coefficient of two speech segments one frame long which are offset by
one pitch period. The calculation of these classifiers involves digitally sampling
35 analog speech, forming frames of the digital samples, and processing those frames
- 4 - l 3 3 6 2 0 ~
and is well known in the art. Generator 100 transmits the classifiers to silencedetector 101 and discriminant voiced detector 102 via path 106. Discrimin~nt
voiced detector 102 is responsive to the classifiers received via path 106 to
calculate the discrimin~nt value, x. Detector 102 pclrOllllS that calculation by5 solving the equation: x = c'y+d. Advantageously, "c" is a vector comprising the
weights, "y" is a vector comprising the classifiers, and "d" is a scalar representing
a threshold value. Advantageously, the components of vector c are inih~li7~-i asfollows: coll~ol-ent corresponding to log of the speech energy equals 0.3918606,colllpol1ellt cwl~ onding to log of the LPC gain equals -0.0520902, colllponent
corresponding to log area ratio of the first reflection coefficient equals 0.5637082,
and component corresponding to squared correlation coefficient equals 1.361249;
and d initially equals -8.36454. After calculating the value of the discrimin~ntvariable x, the detector 102 transmits this value via path 111 to statistical
calculator 103 and subtracter 107.
Silence detector 101 is responsive to the cl~csifiers tr~nsmittçd via
path 106 to determine whether speech is actually present on the data being
received on path 109 by classifier generator 100. The intlic~tion of the presence
of speech is tr~n~mitted via path 110 to statistical calculator 103 by silence
detector 101.
For each frame of speech, detector 102 generates and transmits the
discrimin~nt value x via path 111. St~tistic~l calculator 103 m~int~in~ an average
of the ~ çrimin~nt values received via path 111 by averaging in the fli.~crimin~nt
value for the present, non-silence frame with the ~liscrimin~nt values for previous
non-silence frames. St~ti~tic~l calculator 103 is also responsive to the signal
25 received via path 110 to calculate the overall probability that any frame is
unvoiced and the probability that any frame is voiced. In addition, st~ti~tic~l
calculator 103 calculates the statisdcal value that the discrimin~nt value for the
present frame would have if the frame was unvoiced and the statistical value that
the discrimin~nt value for the present frame would have if the frame was voiced.30 Advantageously, that st~tistic~l value may be the mean. The calculations
p~lrcllllcd by calculator 103 are not only based on the present frame but on
previous frames as well. St~ti~ti-~l calculator 103 performs these calculations not
only on the basis of the discrimin~nt value received for the present frame via
path 106 and the average of the classifiers but also on the basis of a weight and a
35 threshold value defining whether a frame is unvoiced or voiced received via
-
1 336208
path 113 from threshold calculator 104.
Calculator 104 is responsive to the probabilities and statistical values
of the classifiers for the present frame as generated by calculator 103 and received
via path 112 to recalculate the values used as weight value a, and threshold value
S b for the present frame. Then, these new values of a and b are tr~nsmitted back
to st~tisti-~l calculator 103 via path 113.
Calculator 104 transmits the weight, threshold, and statistical values
via path 114 to U/V determin:ltor 105. The latter detector is responsive to the
inîo~ ation transmitted via paths 114 and 115 to determine whether or not the
10 frame is unvoiced or voiced and tO LI~lSll~it this decision via path 116.
Consider now in greater detail the operations of blocks 103, 104, 105,
and 107 illustrated in FIG. 1. Statistical calculator 103 implements an improvedEM algoliLhm similar to that suggested in the article by N. E. Day entitled
~F.stim~ting the Col~onenls of a Mixture of Normal Distributions", Biometrika,
15 Vol. 56, No. 3, pp. 463-474, 1969. Utilizing the concept of a decaying average,
calculator 103 calculates the average for the discrimin~nt values for the present
and previous frames by calculating following equations 1, 2, and 3:
n=n+l if n<2000 (1)
z = l/n (2)
Xn = (1--z) Xn--l + zxn (3)
Xn is the discrimin~nt value for the present frame and is received from
detector 102 via path 111, and n is the number of frames that have been processed
up to 2000. z represents the decaying average coefflcient, and Xn represents the
-
- 6 - l 3 3 6 2 0 8
average of the discrimin~nt values for the present and past frames. Statistical
calculator 103 is responsive to receipt of the z, xn and Xn values to calculate the
variance value, T, by first calculating the second moment of Xn, Qn, as follows:
Qn = (l~z)Qn-l + zxn (4)
S After Qn has been calculated, T is calculated as follows:
T = Qn--Xn (S)
The mean is subtracted from the discrimin~nt value of the present frame as
follows:
xn = xn -- Xn (6)
10 Next, calculator 103 determines the probability that the frame represented by the
present value xn is unvoiced by solving equation 7 shown below:
P(ulx ) 1 (7)
After solving equation 7, c~lcul~tor 103 determines the probability that the
discrimin~nt value represents a voiced frame by solving the following:
P(vlxn) = 1--P(ulxn) . (8)
-
7 l 336208
Next, calculator 103 determines the overall probability that any frame will be
unvoiced by solving equation 9 for Pn:
Pn = (1--z) Pn-l + z P(u I xn) . (9)
After determining the probability that a frame will be unvoiced,
S calculator 103 determines two values, u and v, which give the mean values of
discrimin~nt value for both unvoiced and voiced type frames. Value u, statistical
average unvoiced value, contains the mean discrimin~nt value if a frarne is
unvoiced, and value v, st~ti~ti-~l average voiced value, gives the mean
discrimin~nt value if a frame is voiced. Value u for the present frame is solved10 by calculating equation 10, and value v is determined for the present frame by
calculating equationlll as follows:
Un = (1--z) Un_l + Z Xn P(ulxn)lpn--ZXn (10)
Vn = ( 1--Z) Vn_l + Z Xn P(v I Xn) / ( 1--Pn) --ZXn ( 1 1 )
Calculator 103 now co...n~ ic~tes the u, v, and T values, and probability Pn to
15 threshold calculator 104 via path 112.
Calculator 104 is responsive to this info~ alion to calculate new
values for a and b. These new values are then tr~n~mitte~l back to statistical
calculator 103 via path 113. This allows rapid adaptations to changing
enviro~ e -l~. If n is greater than advantageously 99, values a and b are
20 calculated as follows. Value a is determined by solving the following equa~ion:
a = rl (vn--un) (12)
1--Pn(l--pn) I--1 (un--Vn)2
- 8- 1 3362G8
Value b is determined by solving the following equation:
b =--2 a(un+vn) + log[(l-pn)/pn ] (13)
After calculating equations 12 and 13, calculator 104 transmits values a, u, and v
to block lOS via path 114.
Determinator 105 is responsive to this tr~n~mitte~ fc.~ ation to
decide whether the present frame is voiced or unvoiced. If the value a is positive,
then, a frame is declared voiced if the following equation is true:
axn--a(un+vn)/2 > 0; (14)
or if the value a is negative, then, a frame is declared voiced if the following10 equation is true:
axn--a(un+vn)/2 < 0 . (15)
Equation 14 can also be expressed as:
axn + b--log[(l -Pn) /Pn] >
Equation lS can also be expressed as:
axn + b--log[(l--Pn)/Pn] < -
-
9 1 3362G8
If the previous conditions are not met, determinator 105 declares the frame
unvoiced.
In flow chart form, FIGS. 2 and 3 illustrate, in greater detail, the
operations performed by the apparatus of FIG. 1. Block 200 implements
5 block 101 of FIG. 1. Blocks 202 through 218 implement statistical
calculator 103. Block 222 implements threshold calculator 104, and blocks 226
through 239 implement block 105 of FIG. 1. Subtracter 107 is implemented by
both block 208 and block 224. Block 202 calculates the value which represents
the average of the discrimin~nt value for the present frame and all previous
10 frames. Block 200 determines whether speech is present in the present frame; and
if speech is not present in the present frame, the mean for the discrimin~nt value
is subtracted from the present discrimin~nt value by block 224 before control istransferred to decision block 226.
However, if speech is present in the present frame, then the statistical
15 and weight calculations are pelrwmed by blocks 202 through 222. First, the
average value is found in block 202. Second, the second moment value is
calculated in block 206. The latter value along with the mean value X for the
present and past frames is then utilized to calculate the variance, T, also in
block 206. The mean X is then subtracted from the discrimin~nt value xn in
20 block 208.
Block 210 calculates the probability that the present frame is unvoiced
by utilizing the present weight value a, the present threshold value b, and the
discrimin~nt value for the present frame, xn. After calculating the probability that
the present frame is unvoiced, the probability that the present frame is voiced is
25 calculated by block 212. Then, the overall probability, Pn, that any frame will be
unvoiced is calculated by block 214.
Blocks 216 and 218 calculate two values: u and v. The value u
represents the st~tictin~l average value that the discrimin~nt value would have if
the frame were unvoiced. Whereas, value v l~ipl~_sents the st~tisti~l average value
30 that the discrimin~nt value would have if the frame were voiced. The actual
discrimin~nt values for the present and previous frames are clu~ ,d around either
value u or value v. The discr~min~nt values for the previous and present frames
are clustered around value u if these frames had been found to be unvoiced;
otherwise, the previous values are clustered around value v. Block 222 then
35 calculates a new weight value a and a new threshold value b. The values a and b
- lO- 1 336208
are used in the next sequential frame by the prece~ling blocks in FIG. 2.
Blocks 226 through 239 implement U/V determinator 105 of FIG. 1.
Block 226 determines whether the value a for the present frame is greater than
zero. If this condition is true, then decision block 228 is executed. The latterS decision block determines whether the test for voiced or unvoiced is met. If the
frame is found to be voiced in decision block 228, then the frame is so marked as
voiced by block 230 otherwise the frame is marked as unvoiced by block 232. If
the value a is less than zero for the present frame, blocks 234 through 238 are
executed and function in a similar manner to blocks 228 through 232.
It is to be understood that the afore-described embodiment is merely
illustrative of the principles of the invention and that other arrangements may be
devised by those skilled in the art without departing from the spirit and the scope
of the invention.