Note: Descriptions are shown in the official language in which they were submitted.
W09l/02347 ~ PCT/US90/03990
2~3723 ~ ~
A M~TIIOD AND ~PPAR~TUS FOR
nAN~1A~.r AND SP~ R R~COGNITION
Field of_the Inventio~
The present invention defines a method and
apparatus for recognizing aspects o~ sound. More
spccific~lly, the lnventlon allows recoynition by
pre-storing a histogram of occurrences of spectral
vectors of all the aspects and building an
occurrence table of these spectral vectors for each
known aspect. Pattern recogntion is used to
recognize the closest match to this occurrence table
to recognize the aspect. -
Backaround of the Invention
There are many applications where it is
desirable to determine an aspect of spoken sounds.
This aspect may include identifying a language
being spoken, identifying a particular speaker,
identifying a device, such as a helicopter or
airplane and a type of the device, and identifying a
; radar signature, ~or instance. For instance, a user
may have a tape recording of information, which the `~
user needs to understand. If this information is in
a foreign language, it may be required to be
translated. However, without knowing what language
the information is in, it will be difficult ~or the
user to choose a proper translator.
Similarly, it may be useful, when
processing tape recordings, to determine who is the
speaker at any particular time. This will be
especially useful in making transcripts of a
recorded conversation, when it may be difficult to
determine who is speaking and at what time.
It is well known that all language is made
up of certain phonetic sounds. The English
: :............ . , : . :............ . . . .
WO91/02~7 PCT/US90/0399~
2~637~3
language, for example, has thirty-eight phonetic
sounds that make up every single word. In a~erage
English continuous speech, there are approximately
ten phonetic sounds which are uttered every second.
Other languages are composed of other phonetic
sounds.
Prior techniques for recognizing languages
have attempted to identify a number of these
phonetic sounds. When a determined number of
phonetic sounds are identified, a match to the
particular language which has these phonetic sounds
is esta~lished. However, this technique takes a
long time to determine the proper language, and may
allow errors in the language determination.
The inventor of the present invention has
recognized that one reason for this is certain
phonetic sounds are found in more than one language.
Therefore, it would take a very long time to
recognize any particular language, as many of the
phonetic sounds, some of which are infrequently
uttered, will have to be recognized before a
positive language match can be determined.
The present invention makes use of this
property of languages in a new way which is
independent of the actual phonetic sounds which are
being uttered.
,~ . .
Su~mary of the_Invention
The present invention obviates al} these
problems which have existed in the prior art by
providing a new technique for recognizing aspects of
sound. According to the present invention, these
aspects can include identifying a language being
"
: ~ . , . ,. , :
:. .. .~ , , ................. :, , ,, ~.
~.: . -:., - . . ~ - .. . .
WO91/02~7 ~ 8 6 3 7 2 3 PC~/US90/03990
., ' . ,`'
spoken, identifying a particular speaker, a device,
a radar signature, or any other aspect. Identifying
the language being spoken will be used herein as an
example. One aspect of the invention creates energy
distribution diagrams for known speech. In the
preferred embodiment, this is done by using an
initial learning phase, during which histograms for
each of the languages to be recogniz d are formed.
This learning phase uses a two pass process.
The preferred embodiment uses a two pass
learning technique described below. A first pass
enters a numb~r of samples of speech, and each of ~ -
these samples of speech are continually processe~
At each predetermined instant of time, each sample
of speech is Fast Fourier ~ransformed (FFT) to
create a spectrum showing frequency content of the
speech at that instant of time ~a spectral vector).
This frequency content represents a sound at a
particular instant. The ~requency content is
compared with frequency contents which have been
stored. If the current spectral vector is close
enough to a preYiously stored spectral vector, a
weighted average between the two is formed, and a
weight indicating frequency of a current is
incremented. If the current value is not similar to
one which has been previously stored, it is stored
with an initial weight of "1".
The end result of this first pass is a
plurality of frequency spectrums for the language,
for each of a plurality of instants of time, and
numbers of occurrences of each of these frequency
spectru~. The most COmmQr frequency spectrum, as
determined fro~ those with a highest number of
:.
, . :
.: :: - .:, .
.:., : -
WO~1/02~7 PCT/US90/03990
2n~3723
occurrences, are determined for each language to
form a basis set for the language. Each of these
frequency spectrum for each of the languages are
grouped together to form a composite basis set.
This composite basis set therefore includes the most
commonl~ occurring freq~ency spectrum for each of
the many languages which can be reco~nized.
A second pass then puts a sample of
sounds, which may be the same sounds or different
sounds than the previously obtained sounds, through
the Fast Fourier Transform to again obtain frequency
spectrums. The obtained frequency spectrums are -
compared against all of the pre-stored frequency
spectra in the composite basis set, and a closest
match is determined. A number of occurrences of
each frequency spectra in the composite basis set is
maintained.
For each known language sent through the
second pass, therefore, a number of occurrences of
each of the frequency spectrum for each of the
languages is obtained. This information is used to
form a histogram between the various spectrum of the
CQmpoSite basis set and the number of occurrences of
each of the frequency spectrum~
This histogram is used during the
recognition phase to determine a closest fit between
an unknown language which is currently being spoken
and one of the known languages which has been
represented in terms of histograms during the
learning phase. The unknown language is Fast
Fourier Transformed at the instants of time as in
the }earning phase to form frequency spectrum
information which is compared against the composite
:. ~ .: . .... . ~ ;
WO9l/02~7 PCT/US90/03990
2~3723
.... ' ~ ~
,
basis set used in the second pass of the learning
phas~. A histogram is formed from the number of
occurrences of each element of the composite ~asis
set. This histogram of the unknown language is
compared against all of the histograms for all of ~
the known languages, and a closest fit is ~-
determined. ~ -
By using inter-language dependency in
forming the known histograms and the unknown
histogram, the possibility of error and the speed of
convergence of a proper result is maximized. The
inter-language dependencies come from the composite
basis set including the most common spectrum
distributions from each of the languages to be
determined and not just from the one particular
language. In addition, the use of spectral
distributions at predetermined instants of time
ensure that all phonetic sounds, and not just those
which are the easiest to recognized using machine
recognition, enter into the recognition process. ,
Brief Descri~tion of the Drawinas
These and other objects will now be
described in detail with reference to the
accompanying drawings, in which:
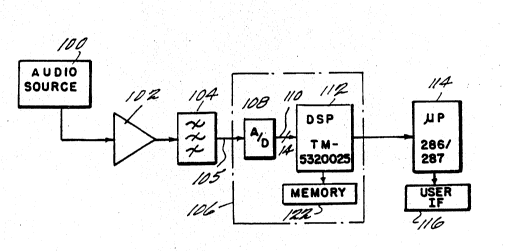
FIGURE 1 shows a block diagram of the
hardware used according to the present invention;
FIGURES 2A and 2B respectively show
summary flowcharts of the learning and recogni~ion
phases of the present invention;
FIGURE 3 shows a flowchart used by the
first pass of the learning of the present invention,
in which the cvmpoaite basis vector set is formed;
-
wo~l/02347 PCT/US90/039gO
2~3~23
FIGURE 4 shows a flowchart of the second
pass of the learning operation of the present
invention in which the histograms for each of
plur~lity of languages are formed;
FIGURE 5 shows the recognit:ion phase of
the present invention in which an unknown language
to be determined is compared against the pre-stored
references;
FIGURE 6 shows a summary flowchart using
the concepts of FIGURES 3-5 but applied to speaker
identification; and
- FIGURE 7A-7C show representative
histograms for English, Russian, and Chinese.
.
Desc~iption of the Preferred Embodiment
A preferred embodiment of the invention
will now be described in detail with reference to
the accompanying drawings.
FIGURE 1 shows an overview of the hardware
configuration of the recognition system of the
present invention. The initial data comes from an
audio source 100 which can be a tape recorder, a
radio, a radar device , a microphone or any other
source of sound. The information is first amplified
by a~plifier 102, and then is band pass filtered by
band pass filter 104. Band pass filter 104 limits
the pass band of the filter to telephone bandwidths,
approximately 90 Hz to 3800 Hz. This is necessary
' to prevent the so-called aliasing or frequency
folding in the sampling process. It would be
understood by those of skill in the art that the
- aliasing filter may not be necessary for other than
: speech appli*ations. ~he band pass iiltered sig*al
: .
: ~
'~`.'.' ' ~ ` . '' '' ' ' ' ' : .
~: ~ . , .
WO91/02347 2 ~ ~ 3 7 2 3 PCT/US90/03990
. . .
105 is coupled to first processor 106. First
processor 106 includes an A-D convert:er 108 which
digitizes the band pass filtered sounds 105 at 8 kHz
to produce a 14 bit signal llo. The digitized
signal 110 is coupled to a digital signal processor
112 which processes the language recognition
according to the invention as will be described
later with reference to the flowcharts.
User interface is accomplished using a
82286-82287 microprocessor pair which is coupled to
a user interface 116.
-The actual operation of the present
invention is controlled by the signal processor 112,
which in this embodiment is a TI TMS320C25. The
code for the C25 in this embodiment was written in
TI assembler language and assembled using a TI
XASM25 assembler. This code will be described in
detail herein.
The first embodiment of the invention
recognizes a language which is being spoken, from
among a plurality of languages. The language
recognition system of the present invention
typically operates using pre-stored language
recognition information. The general operation of
the system is shown by the flowcharts of FIGURE 2.
FIGURE 2A begins at step 200 with a
learning ~ode which is done off line. In the ;~
learning mode, a known language is entered at step
202. This known language is converted into bacis
vectors or a set of representative sounds at step
204. The basis vectors are combined into a
composite basis vector, and a histogram of
, . ~ ,. , . : . .
WO9l/02347 PCT/US90/03990
7 ~ ~
occurances of the elements of the COTnpOSite basis
vector is created at step 206.
- FIGURE 2B shows the recognition mode which
is the mode normally operatlng in digital signal
processor 1}2. FIGURE ~B begins with step 220, in
which the unknown language is entered at step 222.
At step 223, the unknown language is compared with
the basis vector to build a histogram. Euclidean
distance to each of the basis vectors in the
composite basis vector is determined at step 224 to
recognize a language.
This summary will be elucidated throughout
this specification.
The learning mode, summarized shown in
1~ FIGURE 2A, is a mode in which the reference basis
vectors and histograms, used to recognize the spoken
language, is created. Once these vectors are
created, they are user-transparent, and are stored
in memory 122. Depending on the amount of memory
available, many different basis vectors may be
created and stored. For instance, different basis
vectors can be created for all known languages, as
~ well as all known dialects of all known languages.
; Alternately, only the most common ones may be
created, if desired. The technique used to create
the basis vectors will now be described in detail.
This technique uses a two pass system of learnïng.
In summary, the first pass determines all possible
spectral contents of all languages, and the second
pass determines the occurrences of each of these
spectral contents.
FIGURE 3 shows the first pass of the
learning mode of the present invention.
.
.. ~; - . .
: , . ~
wo9l/02~7 PCT/US90/03990
2~3723
, . ~ 1 .; ,
. i. .;
The learning mode exposes the computer
system to a known language such that the computer
system, using the unique technique of the present
invention, can produce the basis vectors used for
later recognition of this known language. Using
pattern recognition parlance, this is doing a
"future selection". The technique of the present
invention arranges these features in a sequence and
uses them in a process called vector quantization
lo which will be described herein.
The first pass of the embodiment of the
; present invention creates a first bank of -
information for each language. The first pass uses ?
at least five speakers, each of which speak ~or at
least five minutes. A better distribution may be
obtained by using five male and five female
speakers. However, the actual number of speakers
and time of speaking can obviously be changed
without changing the present invention.
The data is entered into the system at
step 300 where the A-D converter 108 digitizes the
sounds every 16 ~s (8 kHz). A 128 point butterfly
; Fast Fourier Transform (FFT) is done after 128
samples are taken. This equivalently creates
information which represents the energy in each of a
plurality of frequency cells. The 128 point FFT
results in sixty-four indications of energy, each
indicating an energy in one spectral range. Each of
these numbers is represented in the computer by a
word, and each of the sixty-four words represent the
energy in one of the cells. The cells are evenly
spaced from 0 to 3800 hertz, and therefore are each
separated by appro~imately 60 Hz. There~ore, th~
W09~/02~7 PCT/US9n/03990
2~3~3 :
sixty-four numbers represent energy in 60 hPrtz
cells over the spectral range extending from 0 to
3800 Hz.
The 128 point FFT gives us 64 numbers
representing these 64 cells. Therefore, for
instance, cell 1 covers from o through approximately
60 hertz tthis should always be zero due to the
bandpass filtering below 90 hertz). Cell 2 covers
approximately 60 through approximate}y 120 hertz.
... Cell 64 covers approximately 3740 through 3800
hertz. Each of the cells is represented by two 8-
bit bytes or one computer word. The 64 word array
therefore represents a spectral analysis of the
entered sound at a snapshot of time. The 64 computer
words, taken as a whole, are called the SPECTRA
vector. At any given time, this vector represents
the energy distribution of the spoken sound.
Therefore, for each period of time, the
process gives us 64 words of data. This data is
then stored in an array called SPECTRA, which has 64
memory locations. Since this information is also
obtained every period of time, the array in which it
is stored must also have a second dimension for
holding the information obtained at each period of
time.
If the amount of memory available was
unlimited, all of the data could simply be stored as
it is obtained, in the array SPECTRA at location i
~where i has been initialized to l) and be
incremented at each 16 x 128 milliseconds to produce
an array of data for later processing. However, for ~ -
a five-minute processing sequence, this would -
produce i = {(5 speakers) (5 min) (60 sec/min)
.~ ~ .. . . . .
. .
WO9l/023~7 PCT/US90/~3990
20~3723
11
(8000 samples/sec) ~64 spectra/sample-speaker) (1
word/location-spectra)}/ (128 samples/location),
which would require storage of about six million
words of information (12 megabytes). While this is
attainable, it would require expensiva hardware, the
preferred embodiment of the present invention
processes the data as it is taken in to thereby
minimize the amount of data storage which needs to
be done. In order to do this, the present
information must be compared with all previously
stored information.
- This is done by setting up a loop at step
304 from 1 to the current point (i-l). During the
first pass, no comparisons are made. Therefore, the
information is stored in the array SPECTRA at
position i (here 1) at step 350. However, for all
other passes besides the first pass, the loop set up
at step 304 is executed.
First, at step 306, the contents of the
array SPECTRA at position n is obtained. While step
306 shows the value (N!64), it should be understood
that this is shorthand for SPECTRA (1,1-64), and is
intended to denote the contents of the entire
SPECT~A vector from position 1 through position 64.
Once SPECTRA (N,64) is obtained, the current values
are compared with this st~red SPECTRA (N,64) using a ;~
dot product technique. This dot product technique
will be described in detail later on. To summarize, `
however, the dot product produces an angle
indicative of a vector difference between the vector
formed by the current values and the vector formed
by SPEC~A (N,64), which is from 0 to 90. This
:~ .
: ,
~09l/02347 PCT/US9~03990
12
embadiment considers the two vectors to be similar
if the angle of difference is than 2.5.
If the angle i5 less than 2.5O, as
determined at step 310, the vectors ,are considered
similar, and a weighted average is calculated at
step 312. An array o~ wei~hts is stored as WEIGHT
(N) in which the number of values which have been
weighted in the array SPECTRA at position n is
maintained. This value WEIGHT (N) is obtained and
lo stored in a first temporary position Tl. The value
of the array SPECTRA (N,64) at position N is
multiplied by Tl (the number of values making up the
weighted value) and maintained at a second temporary
position T2. A third temporary position T3 gets the
value of the weighted SPECTRA value in position,
added T2 to the current values, to produce a new
weighted value in position T3. The value WEIGHT (N)
is then incremented to indicate one additional value
, stored in SPECTRA (N,64), and the new weighted
average value of SPECTRA (N,64) is stored in the
proper position by dividing the value of T3 by the
incremented weight. `
A flag is also set to 0 indicating that
the current value has been stored, and the loop is
ended in any appropriate way, depending upon the
programming language which is being used.
If the result at step 310 is no, (the
angle is not less than 2.5), the loop is
incremented to the next N value at step 314. This
is done until the last N value has been tested and
therefore all of the values of SPECTRA array have
; been tested.
,' ~' ' ` ' ` : ' :
W091fO2347 PCT/US90/03990
2~63723
a
13
If the angle is greater than 2.50 for all
values already stored at the end of the loop, this
means that no previously stored value is
sufficiently c10s2 to the current values to do a
weighted average, and the current values therefore
need to be stored as a new value. Therefore, step
350 is executed in which the current values are
stored in the array SPECTRA (I,64) at position I. ;
step 354 sets WEIGHT (I) of the weight matrix to l,
lo indicating that o~e value is stored in position i of
SPECTRA. The value i (the pointer) is then
incremented at step 356, and control then passes to
position A ln FIGURE 3. Position A returns to step
300 where another sound is digitized. ;~
The loop is ended either by an external
timer interrupt, or by the operator. A typic~l pass
of information would be five minutes of information
for five different speakers of each sex. This
creates a set of features from the five speakers
which indicates average spectral distributions of '
sound across these five people.
The concept of dot product is well known
in the field of pattern recognition, but will be -
described herein for convenience. Each set of ~4 ; :
values obtained from the FFT can be considered as a
vector having magnitude and direction (in 64
dimensions). To multiply one vector by another ~-
vector, we obtain the following situation shown with
reference to formula 1:
-> ->
A B = ¦A¦ 1~1 COS e ........................ : ~
where ¦A¦ and ¦B¦ are magnitudes of the vectors. ~ ~
.~ :
~ .
-: . , ,.,, . . - . . .. . :
'.,.. , ~' ..... .. :......... ' ~ . ' ~: . . ''
::~: .,
. .. . . . .
WO9l/023~7 PCT/US90/03990
2~3723 14
The deslred end rPsult of the dot product is the
~; value of the angle e which is the correlation angle
between the two vectors. Conceptua].ly, this angle
indicates tne similarity in directions between the
two vectors.
In order to calculate the dot product of
the two vectors including the 64 bits of information
that we have for each, we must calculate the
relation:
-> -> 64
A ~ B = ~ A(i) ~ B(i) (2)
64
. ¦A¦ = ~S~ where S~ - ~ A(i) ~ A(i)
i = 1
¦B¦ - ~S3 where S = ~ 4B(i) B(i)
1 = 1
Substituting between formula ~1) and
formula B allows us to solve for e as
~64 -> ->
e ~ arc C05 ¦~ A(i)~B(i) ¦
(3)
11-1 1 '.`'
l"S^ ' ~S5 ~ .
~"' ',
,
.
'
' '. : ' ~ ` . ., ,: , ' ., ' :
: : : : ' : ' ,:. , ' : ' '
W O 91/02347 PC~r/US90~03990
~37~3
. ~ . . , `. -
Therefore, if the two vectors are
identical, the val~e e is equal to o~ and cos e is
equal to 1. If the two vectors are completely
opposite, the opposite identity is established. The
dot product technique takes advantage of the ~act
that there are two ways of computing the dot product ~ -
using formulas Nos. 1 and 2. This enables
comparison between the two vectors.
After pass 1 is completed, a number of
basis vectors are obtained, and each one has a
weight which indicates the number of the occurrences
; - of that vector. The basis vectors created, along
with the weights, are further processed in pass 2. ~
It is understood that pass 1 should be ~ -`
processed in real time, to minimize the amount of
memory used. However, with an unlimited storage,
both pass 1 and pass 2 could be performed as a
single sample i9 taken. Alternately, with a
sufficient amount of processor capability, both pass
1 and pass 2 could simultaneously be processed while
the data is being obtained. ~
The pass 2 operation creates a histogram ~ -
using information from the basis sets which have `
already been created in pass 1. This histogram ~-~
represents the frequency of occurrence for each
basis sound for each language or speaker. The key
point of the present invention is that the histogram
which is created, is an occurrence vector of each
basis set among all basis sets for all languages to
be recognized, and does not represent the basis
sounds themselves. This will be described in detail
with reference to FIGURE 4 which represents the pass
2 technique.
,
~:,''', ' ' . . '., ' ; :., ~ - :
:, :. ::. . . .: :., .:, , . :~ : . -. -. .
WO91/02347 P~T/US90/03990
.
2~637'~
16
What i5 obtained at the end of pass 1 is
an average of the spectral content of all
occurrences of the sounds which have been detected
in the language, and the weight (number of times of
occurrence) for each spectrum. Each spectrum
represents one basis vector, and each basis vector
has a weight dependent on its frequ~ency of
occurrence.
At the end of pass 1, we therefore have
enough information to prepare a histogram between
the different basis vectors in the language and the
frequency of occurrence of each of these basis
vectors. This would be sufficient to prepare a
histogram which would enable the dif~erent languages
to be recognized. However, pass 2 adds additional
inter-language dependency to this technique which
enables the recognition process to converge ~aster.
Pass 2 can be conceptually explained as
~ollows. Each language, as discussed above,
consists of a number of phonetic sounds which are
common to the language. By~determining the
frequency of occurrence of these phonetic sounds,
the language could be recognized. However different
languages share common phonetic sounds.
To give an example, phonetic sound x may
be common to English, French and German. It may
even have a relatively high frequency of occurrence
in all three languages. Phonetic sound y may also
be common to English, French and German, but may
have a high freguency of occurrence in the English
language. In the other languages, phonetic sound y
; may have a low frequency of occurrence. Another
problem with prior recognitlon systems is that some
:: . .
WO91/02347 2 ~ 3 7 2 ~CT/~S90/03990
phonetic sounds are sub-vocalized, and therefore
hard to recognize. The inv~ntor of the present
inv~ntion has recognized that the inter-language
dependencies ~that ls, phonetic sounds which are
co~mon to multiple languages) enable ready
recognition of the various languages. The inventor
has also recognized that spectral distributions
- calculated at all times obviate the problem of
difficulty of detecting sub-vocalized sounds.
Pass 2 calculates the histograms by uslng
alI the values determined in pass l for all
languages, to add inter-language dependencies
between the various languages.
Pass 2 begins at step 400, where the
composite basis set CBASIS is created. Step 400
gets the x most common SPECTRA values (those with
the highest weights) for each of y languages to be
recognized and stores this in the CBASIS array. In
this embodiment, the preferred value of x is 15.
If, for example, there are ten languages to be
recognized, this yields lS0 x 64 entries in the
array CBASIS.
Each of these lS0 entries ~x by y) -
represents a basis vector which has been found as
having a high occurrence in one of the languages to
be recognized. Each of these basis vectors which
has a high frequency of occurrence in one language.
By using each basis vector in each of the languages
to be recognized, the inter-language dependencies of
the various sounds (SPECTRA ~64)) in each of the
; languages can be determined, not just those
languages in which the values occur.
. . . ~ ~ -.
. .
: . :
-: .: : . . ~ :, .
. . .
WO91/02347 PCT/US90/03990
2~37~ ~
18
step 402 begins the second pass in which
new sounds from the language to be recognized are
obtained. These sounds are digitized and fast
Fourier transformed in the samP way as steps 300 and
302 of FIGURE 3.
The next step for each sound which is
entered is to form the histogram for each known
language. To do this, a ~or loop is set up between
steps 404 and 406, which increments between 1 and
lo (x*y) (which is all of the various basis vectors).
Within this loop, each element of the composite
vector array CBASIS is compared with the current
SPECTRA which has bee~ obtained at step 410. The
comparison is actually a comparison measuring ~sing `
euclidian distance, comparing the incoming SPECTRA
(64) with each vector in the composite basis set
CBASIS (n,64). Step 412 determines if this distance `
is less than 20,000. This value has been
empirically determined as sufficiently close to
represent a "hit". I~ the value is less than
20,000, the value is compared against a previous ~;
lowest answer which has been previously stored. ;--
Those of ordinary skill in the art would understand
that a very large "previous answer" is initially
stored as an initial value. I~ the current answer
is greater than the previous answer, flow passes to
step 406 which increments the loop, without changing
the current stored minimum. If the answer at step
412 is less than 20,000, and the answer at 414 is
less than the previous answer, that means that this
pass of the loop has received a lower answer than
any previous pass of the loop. Accordingly, the
current answer becomes the previous answer at step
.: : ~ . ~ . . . . . .
WO91/02~7 PCT/US90/03990
2~6~23
416, and the current count of the closest match,
whlch is kept in a temporary location Tl becomes N ;
(the current loop count). The loop is then
incremented a~ain at step 406.
The temporary location Tl keeps the number :
of the lowest answer, and thereSore the closest
match. Accordingly, as long as any occurrences of j~ -
the answer less than 20,000 have been determined at ~ ;
step 412, the histogram address of T1 is incremented
at step 420.
Therefore, the histogram array or vect~r
is successively incremented through its different
values as the loop is executed. Each of the -~
di~ferent values of the histogram represent one
specific sound or SPECTRA, among the set of sounds
or SPECTRA making up each of the most common
spectral distributions of each of the known
~; languages. The effect is to find an average
distribution for the particular language. This
average distribution also includes the effect of
inter-language dependency.
Pass 2 therefore provides us with a
histogram in which each of a plurality of sounds or
SPECTRA from each of the languages are plotted to
show their number of occurrences. These reference
histograms are used during the recognition phase,
~ which will be described in detail with reference to
i~ FIGURE 5.
The FIGURE 5 ~lowchart shows the steps
used by the present invention to recognize one of
the plurality of languages, and therefore is the one
that is normally executed by the hardware assembly
shown in FIGURE 1. The learning modes will - ~;
.
:::: - . . - - ,
WO~1/02~7 PCT/US90/03~gO
2~63~23
typically hav~ been done prior to the final
operation and are therefore are transparent to the
user. During the recognition mode, :it is assumed
that histograms for each of the languages of
interest have therefore been previou~;ly produced.
The objective of the recognition mode is
to find the histogram vector, among t:he set of known
histogram vectors, which is closest t:o the hi~togram
vector crsated for the unknown language. This is
done by determining the euclidian distances with the
known language histogram vectors. If the nearest
euclidian distance is sufficiently close, this is
assumed to be a match, and therefore indicates a
recognition.
For purposes of explanation, the euclidian
distance will now be described. So-called euclidian
distance is the distance between two vector points
in ~ree space. Using the terminology that
, i _> _~
A = A(64) B = B(64), then
:' :
(5)
_>_> 1 64 r
; 25 E. Distance ~A-B)= ¦ ~ l(A(i) - B(i)¦' ~
This is essentially the old c2 = a' + b' --
from euclidian geometry, expanded into 64 dimensions
to meet the 64 SPECT~A values. The numbers for Ai
and Bi can vary from 0 to 16383 (2'' for the 14 bit
A-~). A distance match of 20,000 is empirically
deter~ined for these 2'' bits. It is understood that
for different numbers of bits, those of the ordinary
'
wosl/o2~7 PCT/US90/03~9a
2~3723
21
~ skill in the art could and would be expected to find ~,~
- different empiriGal values. ~:
FIGUR~ S, showing the recognition phase,
will now be explained.
Step 500 is the initial step of the -~
recognition phase, and could equally well be a part
of the preformed data. Step 500 firs;t loads the
composite basis array CBASIS where the array has xy
elements: the x most common SPEGTRA values for each `
of the y languages to be recognized. Step 500 also
loads y histograms, and using the CBASIS array and
the y hlstograms forms a reference array. This
reference array has a correlation between each of
the y histograms, each of the xy SPECTRA in each o~
the histograms, and the values of the xy SPECTRA.
; Step 502 gets the sounds o~ the lanyuage
to be analyzèd and digitizes and FFTs these sounds,
similar to the way this is done in steps 300 and 302
of FIGURE 3. Step 504 compares the input sounds
against silence. This is done according to the
, present invention by taking the sum of all of the
SPECTRA cells, and adding these up. If all of these
sounds add up to fourty or less, the SPECTRA is
labeled as silence and is appropriately ignored. If
the SPECTR~ is determined not to be silence in step
504, a histogram for the language to be analyzed is
created at step 506. This histogram is created in
the same way as the histogram created in steps
404-420 of FIGURE 4, using all of the spectral
categories for all of the languages to be analyzed.
This histogram is created for 3 seconds in order to
form an initial histogram.
.~,
;: : : . - . .
.: . ,.. ~. : ~ .. , ~ ,
w09l/023~7 PCT/US~/03990
2~)b~7~
22
Step 508 compares the histogram for the
language to be anaiyzed to all elements of the
reference array 1 through y where y is the number of
languages being analyzed. This comparison yields a
euclidian distance for each of the values 1 through
y. Step 510 determines the minimum among these
euclidian distances and determines if this minimum
- is less than 20,000. If the minimum distance is not
less than 20,000, step 512 updates the histogram for
the language to be analyzed, and returns control to
step 508 to redo the test. At this point, we assume
that the analysis has not "converged". However, if
the result is positive at step 510, and the minimum
distance is less than 20,000, then the minimum
distance language is determined to be the proper one
at step 512 thus ending the recognition phase.
Therefore, it can be said that if the
computed distance of the unknown versus the
re~erence is the minimum between all the references
and less than a user-chosen limit (here empirically
determined to be 20,000), then we can say the
unknown language has been recognized to be this
minimum.
Because of the inter-language dependencies ~ `
which have been added into the histogram categories,
the present invention enables a quicker
determination of a proper language. Although a
phonetic sound ~ay be present in two or more
languages, typically this phonetic sound will sound
slightly different in different languages. By
taking the SPECTRA distribution of this phonetic
sound, and dete~mining the minimum Euclidean
distance, the closest possible fit is determined.
.
.
- , : . .- : . :
`" ~ ' - ' '"' . ';,'~' , ' .` ..
W091/02347 PCT/US90tO3990
2~3723 ..
23
; Therefore, even if there are many similar sounds,
the closest one will be chosen, thereby choosing the
proper language even when the sounds are simil~r for
- different languages. This enables the recognition
to converge faster.
An additional nuance of the system
averages all the language histograms and creates a
null language. This null language is loaded as one
o~ the y histograms. Whenever the system recognizes
this null language as being the closest match, this
; is determined as a rejection of the language.
A second embodiment of the invention ,
operates similar to the first embodiment, but the
aspect to be determined is optimized for speaker
identification, as compared with language
identification~ Language identification identifies
the language which is being spoken. Speaker
identification identifies the specific speaker who
is speaking the language. The techniques and
concepts are ~uch the same as the first embodiment.
This second embodiment is shown in the fIowchart of
FIGU2E 6 in somewhat summary form. Step 600 ~
executes pass l for each of the speakers to be -
recognized. Each speaker is ex2cuted for five
minutes, or for some other user selectable amount of
time. This creates a set of basis vectors for each
of the z speakers to be recognized. The pass 2
sy tem is executed at step 602 where the x most
common SPECTRA values for each of the z speakers to
be recognized is ~irst determined to form CBASIS, or
composite basis vector just as in pass 2 shown in
FIGURE 4. Step 604 then executes the rest of pass 2
with the only exception that step 412 in FIGURE 4 is
.
., . - -. . . :
. . . . .
, ~, . . .
W09l/02~7 PCT/US90/03990
2~3723
24
replaced with a comparison with 15,000 as khe
euclidian distance instead of the comparison with
20,000. This is because the match for speaker
recognition is required to be closer than the
necessary match ~or language recognition. At the
end of step 604, the histograms for each of the
speakers to be analyzed has been formed. Step 606
; begins the recognize phasel and exec:utes all
elements of the recognize flowchart of FIGURE 5 with
the exception of step 510 in which the value to be
compared with is 15,000.
- The system i-s operated by use of a
plurality of user friendly menus which enable the
user to perform various functions. The main menu
allows the user to choose between building new basis
sets, looking at previously stored language
histograms, or entering the recognized language's
menu. Some sub-menus allow changing the rate of
sampling, the number of points of FFT
transformation, and the different ways in which the
data is being distributed.
A sample set of reference histograms for
English, Chinese, and Russian are shown in FIGURE S
7A-7C. These histograms show the sound indicated by
numbers on the x axis, and show the number of
occurrences on the y axis. These examples use only
approximately 68 different sounds as the possible
sounds, but it is understood that many more than
these are po~sible to be used.
; 30 Many modifications in the above program
and technique are possible. For instance, as stated
above, it would be quite feasible to operate the
entire learning phase in a single pass, assuming
.,, , ... ...... - . .. , . .. - ... :
::-:.: . . - ::: .: . ~ - . . .: . - . : . : . . . ::; :
: .: : . ~ ~ ,. . . . ..
.. ~ : . .. . ~ ,: .
:'' ~ ' '' ' ~. , , .. :
WO91/02347 PCT/US90/03990
2~3~23
. , :: .
that sufficient proce~sing speed and power and
sufficient memory were available. This would
obviate the need for two different entries of data.
Of course, the various empirical values which have
been described herein could be modified by users.
In addition, any number of languages could be used
by this system, and limited only by the amount of
available memory space.
In addition, other aspects of sound could
be determined besides speaker identification and
language identification including identification of
dialects, possible area of origin of the speaker,
and many other applications are possible. In
addition, this technique could be used to identify a
type of aircraft from its sound, c- by converting a
radar trace to sound, a radar signa~ure could be
identified. Of course, these examples are not
limiting, and many other uses for the aspect
recognition of the present invention.
All of these modi~ications are intended to
be encompas~ed within the following claim~.
., .
.
,'. ' ~` '' ' ' ' ' ~ :
:
.. ~