Note: Descriptions are shown in the official language in which they were submitted.
`~ 20811~8
Patent Appllcation of
Hanavi M. Hirsh
for
APPARATUS AND METHOD POR CONTINUOUS SPEEC~ RECOGNITION
8ackground -- Fleld of Invention
Thi8 invention relate~ to apparatus and methods for the recognition of
continuous speech in which an operator ~nteracts with the ~ystem.
Summary of Invention
My invention i9 an improved method for continuous speech recognition in
which an operator sends the system signals to explicitly mark the divisions
between spoken words. The utterance segments delimited by the signals are
analyzed in parallel, using prosodic data as well as conventional spectral
data, with different processing strategies being employed for segments of
different length.
Background -- Descriptlon of Prior Art
The most general form of the challenging problem of automatic continuous
speech recognition ~CSR) mlght be stated as follows: analyze by automatic mean~
utterances in the form of connected word~ taken from a normal range of
vocabulary spoken in conver~ational tones and rhythm by a normal range of
people in normal environments, and transform the utterances into Pquivalent
orthographic form, i.e. a spelled-out representation of the word~ which were
spoken .
In connected speech, a human li~tener can recognize a particular word that
is spoken at a different pitch or with a diff~rent intonation or ~tress
pattern, whether it i~ spoken loudly or ~oftly, quickly or slowly, even if ~ome
~mall parts of the word have been left out, are distorted, or are obscured by
noise. The ultimate goal of ef~orts in the field of Automatic speeah
recognition is to develop a system wlth thl~ level of tolerance for variability
in the speech signal.
`" 208~88
Despite the fact that there are numerouo inotanceo where voice entry of
speech into a computer would be preferred to the uoe of a keyboard, and deopite
the fact that many exampleo of an automatic CSR oyotem are known to the art,
none hao had wide ~ucceoo in the marketplace. The different CSR oyotemo
currently available ouffer from being inadequate ln one or more of the
following areas: response time, eaoe of uoe, flexlbility in terms of size of
vocabulary or variety of speakers accomodated, ratio of benefits gained
compared to system cost, and suitabillty for use ln a normal working
environment.
Although no satiofactory solution to the general problem of CSR has been
demonotrated, when meaJured by the numbor and sophistication of the well
eotabliohed computational techniquea uoed by researchers in thio field speech
recognition muot be con~idered to be a highly developod art. Theoe technique~
are employed in aopecto of the recognition proceoo which include signal
normalizatlon, utterance oegmentation, feature extractlon, and feature matching
with reference data.
e Appendix to thio invention dlsclooure descrlbeo the hardware elemento of
a conventional CSR ao well ao the analytical steps typically therein employed.
e preoent invention repreoento an improvement over exioting oyotemo in the
area of utterance oegmentation. Any CSR implementatlon that uses the improved
_ thod wlll draw on the large choico of well-developed computational strategies
that are already known to thooe f d liar with the art.
Exampleo of recent prior art which are repreoentative of speech recognitlon
oystemo which rely on conventional utterance oegmentation techniqueo are
deocribed~ln U.S. Pat. Noo. 4,949,382 Griggs and 5,025,471 Scott et al.
Analytical techniqueo known to the art wbich can be effectively employed in
combination witb the novel utterance segmentation technique of the present
invention are deocribed in Speech Analyolo, Syntheolo and Perception, Flanagan,
1972, IEEE Symposium on Speech Recognltion, Erman ~ed.), 1974, and Speech
Recognitlon by Machine, Ainoworth, 1988.
Problems Aosociated With a ~Bottom-up" Approach
Becauoo it i~ virtually impoooiblo for convontional CSR syotemo to idontify,
at the outoot of the procooo, lntervalo of tho uttoranc~ otr-am whlch repreoent
word-length data, complex analytlcal methodo are flrot uood to ldentlfy the
`` 2081 188
component phonological units by the error-prone processes of extraction and
labeling. Only after those processes have been completed can word-length
utterance segments be hypothesized by concatenating strlngs of phonological
units. Even then, it is quite likely that a hypothesized 3egment does not
contain the word to be recognized.
In the "bottom up" approach of conventional systems, the initial
discrimination process, which focusses exclusively on the basic phonological
units, is nece~sarily carried out in a sequential manner. In contrast, a
system that works, from the outset, on word-length segments can process all of
the words in a sentence in parallel. Limiting a CSR system to ~equential
processing during the most computationally expensive part of the whole process
is a very serious constraint at a time when very powerful multiprogra~ming
microcomputers are available at low cost. Multiproce3sor microcomputers
systems and massively parallel processing machines which use standard
components are also increasingly avallable, with their co~ts steadily dropping,
making applications which could benefit from their exceptional parallel
processing power increasingly affordable. A system that is constrained to
perform seguential processing, as is the cuse for conventional CSR systems,
cannot gain significant benefit from the newly available hardware.
Advantages of My Invention Over Existing Systems
No CSR that claims to be capable of functioning as a speech-to-text
transcriber has proven to have the performance capabilities and affordable
price that would lead to its gaining recognition in the marketplace. All of
the CSR systems heretofore known suffer from a number of specific disadvantages
which follow primarily from difficulties a~sociated with the steps leading to
the segmentation of utterances into words. In summary, those disadvantages are:
(a) Because a CSR system must contend with the inherent variability of normal
speech, it is highly likely that some errors will arise in the initial
analytical processes of phonological unit extraction and labeling.
(b) Because the process of identifying a phonological unit is influenced by the
state of the preceding one, errors arising from both extraction and
labeling will tend to propagate, making correct identification of the
succeeding unit more difficult and uncertain.
2081188
(c) The degree of uncertainty inherent in the identiflcation of indlvidual
phonological unit~ will be multiplied when those unit~ are concatenated
into strings for word-level matching with lexical entries.
(d~ Bottom-up approaches cannot avail themselves of word-level and sentence-
level data, such as the characteristic~ of stres~, intonation, and the
relative duration of words and syllables, known collectively as prosodics,
before a great amount of other proces~ing has been done.
(e) Tbe sequential processing methods of conventional CSR system3 cannot take
full advantage of the immense proce~sing power of multiprogramming and
parallel processing microcomputers.
This invention relates to a method for continuous speech recognition
comprising the step of marklng the divisions between ~poken words or syllabic
segment~ of such words by generating a signal that coincides in time
sub~tantially with the divi~ions between the words or segments. It also
relates to an apparatus for continuous speech recognition compris~ng
signal-sending means for marking the divisions between spoken word~ or yllabic
segments of such word~. Accordingly, several advantages of the present
invention are that:
(a) ~y invention incorporates a method of determining robust and effective
distinguishing characteristic~ of word-length utterance ~egment~ that i8
not totally dependent on a highly accurate extraction and labeling of
phonological units;
(b) my invention determines di~tinguishing characteri~tics for utterance
segments, with the ~uccess of that determination being substantially
independent of the outcome of a ~imilar proces~ which ~a~ been applled to
preceding ~egments;
(c) ~y invention aoes not totally depend on sped fic phonological units being
concatenated into a string before matching cun be attempted with lexical
entrie3;
(d) my invention can u~e prosodic and other data relating to word-length
segments as part of a pattern-matching proces~ with similar data associated
with entsie~ in the system lexicon lndependently of and prior to any
lexical entry pattern matching which uses phonological unit data; and
2081~.88
(e) my invention can take full advantage of the proca~sing power of
multiprogramming and parallel processing computers by maklng it pos~ible
for the analyqis of a number of dlfferent word-length utterance segments to
take place simultaneously.
Further advantages of the apparatus and method for continuous speech
recognit~on and understanding of my invention are: It can, at an early stage in
processing, make use of prosodic patterns in multi-word segments of the
utterance as a whole, such as phrases and sentences; it can select processing
strategies which are appropriate for each word-length segment according to the
number of syllables in the segment; it is easy to u~e, even by the physically
handicapped; it doas not require expensive, purpose-built hardware for it~
realization; it facilitates the production of well articulated and readily
recognized utterances by requiring the speaker to explicitly indicate divisions
between words; it can be used remotely via telephone; lt can be part of a
real-time ~ystem for speech transcription; it can be part of a computer-
assisted translation system $or use at conferences and by travelers; and it can
be part of ~ystems which are designed to aid communication with the bllnd and
the hearing-impaired. Still further ob~ects and advantages will become
apparent from a consideration of the ensuing description and drawings.
Drawing Figures
In the drawings, which lllu~trate dlagrammatically the general form of prior
art and the preferred embodiments of the invention,
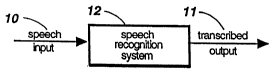
Flgs lA and lB show blcck diagram ab~tractlon~ of conventional CSR systems
and of the present invention to indicate tbe nature of the inputs and outputs,
Figs 2A and 2B show block diagram abstractions of a conventional CSR ~ystem
and of the present invention in which each employ a confirmation and correction
process controlled interactively by the operator,
Figs 3A and 3B show block diagrams depicting the hardware components of a
conventional CSR and of the preferred embodiment of the invention,
Fig 4 shows the relationship between the elements which~link acoustic data
to recognized words, according to most CSR sy~tems,
Fig 5 shows the ~equence of processing steps that comprise the operation of
a conventional CSR system,
Fig 6A shows the sequence of off-line processing step~ that comprise the
system preparation proces~es of the invention, and
Fig 6B shows the ~equence of on-line proces~ing steps that comprise the
operation of the preferred embodiment of the invention.
20811~8
Reference Numerals ln Drawlng-
Inputs and outputs On-llne processes
10 speech input 12 speech recognitlon
Il speech transcrlptlon output 16 conflrmatlon and correctlon
14 word-marker slgnal 23 acoustlc data collectlon
20 conflrmatlon-ana-correctlon and preparatlon
lnput 25 output presentatlon
30 dlgltal data stream 45 slgnal normallzation
90 warning ~ignal output 47 phonological unit extraction
49 phonologlcal unit labelllng
Data storage contents 51 trlal segment synthesls
34 ~ets of acoustic data 53 pattern matching
36 algorlthm-based programs 58 word-boundary detectlon
38 reference tables 59 nolse detectlon and exclslon
40 system lexicon 60 word end-polnt determlnatlon
42 knowledge-base rules 62 contiguous ~unction boundary
determlnation
Har~ are eloments 64 word recognitlon
18 ~lgnal-sending devlce 66 segment classlficatlon
22 dlgltal computer 68 phrase analysls
24 data store 70 sentence analysls
26~ mlcrophone ~ 72 syntactlc analysl~
28 ~band-pass fllter bank 74 semantlc analysls
32~ analog-to-dlgltal-converslon 76 pragmatlc analysls
module 78 prosodic analysis
34~ vldeo dlsplay unlt 80 lntonation analysls
82 system monltor
Off-line proc-sses 84 class 'A' analy3is
42 system preparatlon 86 class 'B' analysls
44 lesicon compllatlon 88 class 'C' analysls
46 reference table compllatlon 92 manner class determinatlon
48 word relation compilation
50 lexicon adaptatlon
52 operator tralnlng
54 speaker verlflcatlon
56 system-to-speaker adaptatlon
2081188
Descriptlon - Figs 1, 2, and 6
Unlike the conventional CSR system shown in Fig lA which has a single input,
a typical embodiments of my invention, as shown in Fig lB, has two input
signals: a speech input 10 and a word-marker signal 14 sent by the operator.
Fig 2B shows my invention in an embodiment in which the system operator
confirm~ and corrects the recognizea words by mean~ of a conf~rmation and
correction process 16. In contrast with a conventional two-input embodiment of
an interactive system, a~ shown in Fig 2A, Fig 2B ~hows three inputs: speech
input 10; signal 14 from the operator that is received by the system prior to a
speech recognition process 12; and a conirmation and correction input 20 which
is received from the operator after speech recognition process 12.
Fig 3B shows the functional elements which comprise the preferred embodiment
of the invention of the type shown in Fig 2B. All hardware elements are
similar to those which comprise a conventional CSR system with the exception of
an operator-actuated signal-sending device 18 which sends word-marker ~ignals
14 to digital computer 22. Speech input 10 is received by microphone 26 whose
output iA an analog signal directed to a band-pass filter bank 28. The output
of filter-bank 28 is a set of band-limited analog signals of different central
frequencies which cover the most significant range of the original spectrum.
The analog signals are transformed by an analog-to-digital conversion module 32
into a digital data ~tream 30 that is directed to digital computer 22 which
stores the data in the form of a time-sliced data set 34 for each frequency
band, with each data element being associated with the time when it is
received. In parallel with it~ receiving o~ data stream 30, computer 22
receives marker signals 14 indicating the divisions between words, as sent by
signal-sending device 18.
In an implementation of ~y ~peech recognition system in which speech is
conveyed to the system by telephone from a remote location, the embodiment will
differ from Fig 3B only in that signal-sending device 18 is designed to
generate a tone or a click which is picked up by microphone 26, which, in a
remote location embodiment, is the mlcrophone built into the telephone
handset. A purpose-built telephone for that application would have the
signal-sending device generate an electrical analog signal which is added to
the signal sent by the handset microphone 26.
-- 2081188
Although those skilled in the art will recognize that slgnal-sendlng device
24 could take many dlfferent forms, the preferred embodiment of the lnventlon
for local speech lnput appllcations uses a two-button mouse. Such a devlce 18
commonly avallable, is inexpenslve, and is speclfically designed to send
signals to a computer.
The preferred use of the device is to tap alternatlvely on the buttons wlth
the index and middle fingers, timing each tap with the beginning of each word.
If only one finger is used on a single button, some operators will experlence
difficulty keeping up with rapid speech. Other methods of marking the
divisions between words, such as timing tbe signal to coincide with the end of
each word, or sending one signal before and one signal after each word, were
found to be less satisfactory than the preferred method. In some applications,
an alternative use of the signal-sending device would have the operator mark
the breaks between syllables rather than between words.
The processing steps which co~pri~e the functioning of the preferred
embodiment of the invention are set out in block diagram form in Figs 6A and
6B. Fig 6A illuotrateo the functioning of off-line processes which are
employed to prepare the system for recognition use. The ~ystem preparation
processes include:
(a) a lexicon compilation 44 process and a reference table
compilation process 46 which prepare, respectively, a
system lesicon 40 and reference tables 38 which reside
- in a data store 24 with a ouite of programs 36;
(b) a word relation proceso 46;
(c) an operator training process 52; and
: ~ ,
(d) a speaker verification proceos 54.
Prior to using the system for a recognition oeosion, a Jpeaker will uJe a
system-to-opeaker adaptation proceos 56. On a regular basis, a lexicon
adaptation proceso 50 is run to update oyotem lexicon 40 with data ln the form
of admi~sible word entri-o, word rolations, and pronunciation varianto, baoed
on the experience gained by th- oyotom durlng th- moot rocent recognltion
seooions.
2081188
Fig 6B sets out, ln block diagram form, the saguence of processing ~tep~
which are employed by the preferred embodiment of my CS~ system during a
recognition ~es~ion. The preferred method comprises:
(a) a word-boundary detection procesa 58 which calls on it~
servant tasks, a word-endpoint determination procesa
60, a contiguous-boundary determination process 62, and
a noi~e detection and excision process 59;
(b) a sentence analysis process 70;
(c) a phrase analysis process 68;
(d) a segment classification process 66;
(e) an intonation analysis process 80; and
(d) a word recognition process 64.
Separate copies of word recognition process 64 run in different partitiona,
one for each utterance ~egment, under the control of a syatem monitor procea~
82. System monitor process 82 will cau~e a warning signal 90 to be generated
in the event that speech production is about to exceed the capacity of the
~ystem.
Each process 64 will employ servant tasks according to need, with those
tasks comprising: a class 'A' analysis proce~s 84, a class 'B' analysis process
86; and a class 'C' analysis procesY 88. The class-speciflc analysis proces~es
84, 85, and 88 will call on their servant tasks, as needed, which comprise:
(a) a syntactic analysls process 72;
(b) a se~antic analysis task 74;
(c) a prosodic analy~is task 78; and
(d) a pragmatic analysis task 76.
The servant tasks can draw on a set of knowledge ba~e rulefl 42.
2081188
Operatlon - Fig~ 6A and 6B
The operation of the preferred embodiment lncludes the followlng gen~rlc
processes:
(a) ~ystem preparation;
(b) operator training;
(c) ~y~tem-to-speaker adaptation;
(d) word recognition; and
(e) word confirmation and correction.
(a) System Preparation
~ efore it can be used, the reference data which is the basis of effecting
the recognition of utterances must be entered and structured. This includes
varlous reference tables 38 compiled by reference table compilatlon process 46,
which relate~ acoustlc data to di~tlnctive features, and system lexicon 40,
compiled by lexicon compilatlon process 44, which lists all admissible words
together with various characteristics for each entry. A number of different
speakers, representative of the expected user population in terms of accent and
manner of speaking, train the ~ystem by reading sufficient known text to
provide for the requisite variety of phonological unit templates, which may be
combined into "blurred" templates, against which unknown utterances will be
matched. For applications in which a largc number of very different speakers
are expected to use the syYtem, many training speakers are required. They are
sometimes usefully divided into classe~ according to their manner of speech,
e.g. male native speaker~, female native speakars, male Hispanic speakers,
female ~ispanic speakers, etc. Representative templates are gathered for each
class.
(b) Operator Training
Each operator who will be using the system must be trained in the use of
signal-sending device 18, and the ~ystem must know something of thelr
characteristic use of device 18.- Indlvidual~ wlll enter the click marking the
start of a word in a particular way, with the actual time of the click
deviating form the start of the word by a characteristic delay. W~th this
information being available to the system, more accurate word boundary marking
can be achieved. Interactive operator training process 52, which give~
real-time feed-back to the operator concerning tbi~ delay, quickly helps the
operator develop the knack of sendlng the marker signal at the right time and
leads to more consistent and accurate word marks.
208il88
For a population that includes a number of very divergent speaklng styles,
each speaker who uses the system wlll speak a tralnlng text as part o~ speaker
veriflcatlon process 54 to determlne whlch speaker class he or she falls into,
and whether this speaker ~xhibits speech peculiarlties which deviate
signlficantly from the expected pattern. Some of those devlations from the
norms used in developlng acoustlc reference tables 38 can be allowed for by
employing adaptation parameters which can be differently set for each speaker.
(c) System-to-speaker Adaptatlon
The speech of an individual will vary from day to day. Even on the same
day, a particular speaker may speak in a dlfferent manner ~ust after having a
coffee and donut in the morning compared to a session with the recognition
system that ~akes place after a large lunch that includes wine and a martini.
To adapt the system for such variatlons, particularly the prosodic ones which
relate to ~peech rhythm, syllabic streofl, and intonation, a very brief known
sign-on text is read at the start of each session as part of a sy~tem-to-
speaker adaptatlon process 56. Parameters related to speaking manner can thus
be set, based on the way that the known text is read.
~d) Word Recognition
The operator of my CSR system explicltly declares the start of each word by
alternatively pressing the right and left buttons of signal-senaing device 18,
using the index finger and the middle finger of the dominant hand. The time
that each word-marker signal is received by the digital computer 22 is stored
in a file after it has been ad~usted by the speaker's characteristic delay
factor which ha~ been establi~hed during operator training process 52. The
utterance segment delimited by each pair of signals thus contains a single
word, and the digital data for that sogment, which is stored in a set of data
elements, each of which can be de~criptive of, say, lOO~sec-long time sllces,
can readily be extracted. The data is then grouped together in time frames
which may, for coDputational convenience, each be 25.6ms in duration 80 that
each frame will contain 256 data elements.
Signal 14 ~ent by the operator will only give an approximate indication of
the break between word~. Analytical technique~ omployed by a word boundary
detection process 58 to pin down the break position pr-ci~ely will ~tart
looking in the time fra~e in whlch the word-marker slgnal falls. If no
deflnltive br-ak ldentlflcatlon can be found there, the ad~ac-nt time frames
2081 188
will be examined. Extraneous productions of noise, such as throat-clearing or
breathing sounds, will typically occur after a word is spoken and before the
next signal ~ 9 sent. Noise productions are recognized and excised by a noise
excision process 59, which uses techniques chosen from among those developed
for this purpo~e which are well known to those skilled in the art.
Where clear gaps between ad~acent sounds occur, a word end-point
determination process 60 is used which i3 similar to that used in isolated word
or discrete utterance recognition. When there i5 no clear break, a different
method, a contiguous ~uncture boundary determination process 62, which is
closely related to that used in isolated word recognition to determlne syllabic
breaks, i8 used. Such algorithms or methods are well-known to thos2 skilled in
the art and exist in many specialized versionq. The choice of an optimal
boundary detection instrument depends on the specific pair of phonological
units which must be divided.
In normal continuous speech ~ome word breaks will not be readily
discernible. ~he terminal sound of one word will be confused by and merge into
the initial sound of the adjacent word because of coarticulation and clipping.
When the operator of my CSR system is also the speaker, the use of
signal-sending device 18 leads to a ~uch more precise articulation of each
word, with more definite breaks between words, even without any conscious
effort to do 80 being made by the speaker-operator.
Once the utterance stream has been divided into word-length segments, the
speech recognition problem is reduced, substantially, to one of isolated word
recognition. There are many methods well known to those skilled in the art
which deal effectively with what is generally recognized a~ being a much easier
problem than continuous speech recognition. In most such applications,
however, the size of the vocabulary is, at most, a few hundred word3. In the
pre~ent CSR system, the words in the lexicon can be expected to number in the
thousands. The task of di~criminating between words in ~y CSR s,/3tem, however,can also draw on syntactic and semantic constraints. Many methods of doing 80,
including expert systems and network models, are well known to those skilled in
the art.
To deal effectively with a large vocabulary, the ~ystem depicted in Fig 5B
2081188
includes a segment classification proce~s 66 which counts the number of
~yllables in each word-length utterance segment. It employs techniques well
known to tho3e skilled in the art which can identify syllabic breaks with a
high level of reliability.
The word-length segment~ are divided into three classes:
Claas 'A': one-syllable words
Class '8': two-~yllable words
Class 'C': three-or-more-syllable wordY
A different analytical strategy will then be applied to each class of
segment, as the problem is quite different for the different classes. A major
shortcoming of the many heretofore known CSR systems 18 that one set of
techniques must bo universally applied. With any conventional approach that
performs a sequential analysis of phonological units, the system cannot know
what size word is being dealt with until it has been recognized.
My CSR system enables the most efficient recognition strategy to be used for
each utterance segment, one that will make use of the most appropriate
dlstinctive charactoristics in each case. A hlerarchical ordering of
parameters and successive hypothesize-and-test iterations will enable the
process to converge to a recognized word in as few steps a~ possible. Although
each parameter, in itself, is liable to be unreliable as a fine discriminator,
the application of a series of constraints will quickly bring the number of
possible word candidates down to a single best choice.
Computer 22 keeps a record of the time that each word-marker ~ignal 14 is
received. The start of each signal marks the creation of a new in~tantiation
of word-recognition process 64. mu~ a separate process 64 runs for each
~egment of the utterance, with all segments boing analyzed simultaneously.
Each process 64 will omploy techniques which are appropriate to the class, as
- dotermined above, of the utterance sogment that is being proce~sed. Thi~ i8
done by calling the appropriate ~ervant proceos, clas~ 'A' analysis process 84,
class 'B' analysis proce~s 86, or class 'C' analysis process 88; which aro
describcd below.
-- 2081188
The way that computer resources are allocated to the dlfferent concurrently
executing processes depends on the type of computer system used. A multlpro-
gramming environment wlll have each process share the same processor, running
in different memory partitlons ln a tlme-sharing mode. A multlprocessor system
wlll dlvide the processes ~mong the lndependent processors. The system 18
deolgned to process sentenco-long utterances whlch have a maximum duratlon and
maxlmum number of words that depend~ on the maln memory capaclty and proces31ng
speed of the computer that 18 employed. The system wlll, lf pos31ble, slmulta-
neously run an independent process for each word ln the sentence. In parallel
with the word analysis processes, phrase-analy~ls process 68 and sentence-
analysis process 70 are running. As well as, syntactic-analysls process 72,
semantic-analysis process 74, and, in some applications, pragmatic-analysls
process 76, act a~ servant processeY which can be brought lnto play by the
multlple concurrent word-recognltlon processe~ 64. These processes consult the
syntactlc, semantic, and pragmatlc knowledge ba~e~. A~ each word-recognition
process 64 terminates, the re~ults of the analysls are passed to sentence-
analy~ls process 70 and the next copy of word-analysls process 64 can run ln
the freed partltion to process the next word-length segment to be processed.
Warnlng signal 90 asks the speaker to pause if the system processlng capaclty
is about to be exceeded, us detected by system-monltor process 82. In ~uch
cases, a sentence fragment will be processed.
Class 'A' Analysis Process
In normal speech, more than 50% of the words are drawn from a small sub-set
of the overall vocabulary. All of tho~e 300 or 80 common words have one or two
syllables, and 75~ of those are monosyllablc. This means that a strategy that
tries to identlfy single-~yllable utterances ln contlnuous speech would do well
to flrst look for a match from among the most common words.
.
Each admlssible word 18 assoclated wlth a ~volume" ln lexicon 40 whose
hierarchlcal arrangement of volumes determines the order of consultatlon. The
structure of the lexlcon 18 context-dependent. If the appllcatlon relates to
travel, next ln sequence after the volume contalning hlgh-frequency ~tandard
vocabulary i9 a volume containlng a ~et of ~pecialized words uoed ln the
context of travel. The speclallzed vocabulary would be dlfferent lf the
context 18, for ln~tance, an archltectural ~peclflcatlon. Subsequent volumes
contaln words of decrea~ing fr-quency. The fact that a word 1~ recognl~ed more
14
2081188
frequently by the system than expected wlll lead to its belng promoted to the
appropriate volume.
Words other than thosa found in the high frequency standard vocabulary
volume are associated with other laxical entries which appear most often with
them in the same phrase. This aspect of the lexicon is compiled by m~ans of
word-relation process 48 that extracts such in$ormation from many samples of
text pertaining to a certain context that are entered as part of lexicon
compilation process 44. The system "learns" more about such connections
between words as it is used, by means of lexicon-adaptation process S0.
Another parameter which can help distinguish one word from another is the
duration of the spoken word. A monosyllabic word such as "bit" may be quite
similar, acoustically, to "beet", but the latter is significantly longer in
duration. A duration value, based on a standard rate of speech produc:tion,
e.g. the normal number of stressed syllables per minute, is stored for each
word in the lexicon.
The computation of values for the prosodic parameters which characterize
significant di~tinctive non-~pectral features of an utterance segment,
including parameters related to syllable stress, syllable duration, ~yllable
intonation, and segment overall duration, are handled by a prosodic analysis
process 78.
If a useful comparison is to be made between a lexical entry's duration and
the duration of an unknown utterance segment, two levels of normalization can
first be considered.
The first is the average speaking rate of the person who~e speech i~ to be
recognized. He or ~he will speak a known text before the recognition proce3s
begins during system-to-speaker adaptation process 56. This enables the sy~tem
to be adapted to the speech of that particular speaker by means of special
parameters which compensate for any deviations from the system's standard
values, including the rate of speech production.
A second normalization relates to the particular phrase being annlyzed. Thc
phrase in question i~ She sequence of words falllng wlthin a continuous
2~8il88
intonation contour that includes the word ln question. A comparlson of the
average interval between ~tressed syllables for that phrase a8 computed by
phrase analysis process 68, ln comparlson with the overall average for the
speaker, will yield a second factor. Both factors would be applied to the
measured duration of an utterance segment before that value is used to make a
comparison with the value for words in the lexlcon.
Stress is another characteristic that can help distinguish one monosyllabic
word from another one that iY acoustically similar. For instance, while
differences between the sound~ of "of" and "off" can be difficult to
distinguish, "of" will u~ually be unstressed while "off" will li~ely be
stressea. As 18 the case for duratlon, stress 1~ a relatlve measure that only
yields a meaningful comparison when it is applied to two word~ in the same
phrase.
~ ecause a monosyllabic word, in comparison with a long word, contains a
relatively small number of di~tingulshing features, all the significant nuances
~ of it~ features mu~t be employed to ensure a level of redundancy that is
; sufficient to the reliable recognition of the word from the often imperfect
data which is obtainable in situations outside of the laboratory. A reflection
of this concern is the careful analysis of spectral data that i~ required for
; nosy}labic words. a Class 'A' analysis proces~ ~4 therefore employ~ precise
and unambiguouo phonological units: demi-~yllables and affixeo.
Normally occurring spectral varlants for the words in the lexicon are
handled by associating them with dlfferent classes of speakers who participated
ln reference table compilatlon process 46 which resulted ln the compilatlon of
` the acoustic reference data stored in the system tables. Variations which
result from interactlons wlth ad~acent words are handled by malntaining a
plurality of templates for the same word, or by the appllcatlon of phonologlcal
~: rules.
A speaker's characterlstic pronunciation 18 ascertalned durlng speaker
verification process 54. Although some adaptation parameters will be set as a
consequence, the ma~or adaptation i~ accompllshed by placing the speaker ln a
particular clas~ificatlon.
2081188
Class 'B' Analysis Process
Two-syllable words can be dlvided lnto 16 differont classlfleatlons based on
each syllable belng elther lony or short and stressed or unotressed. In some
instances, the intonation pattern of a word, l.e. the change ln fundamental
frequency between the two syllables, ean help diserlmlnate between dlfferent
word candidate~. The consideration of this pattern must be done in the context
of the overall intonation pattern of the phrase. Inton~tion analysis process
80 mea~ures thls characteristic when required. A word's characteristic
intonational contour may change according to its syntactlcal role. An example
of this pattern i8 the word, "German". It is high-low as a noun, but becomes
low-low when used as an ad~ectlve, as ln "German shepherd". Such a distinction
ean be helpful ln determinlng the syntactical role played by a word in a
particular context.
Class 'C' Analysis Process
As the number of syllables ln a word-length utteranee segment lnereases, the
prosodle characterlstlcs of syllabic stress and duration ln comblnatlon wlth
the normalized total utterance duration, become increasingly determinant. The
simplest parameter is word duration. A stress pattern can usually be detected
by syllabie variations in total energy. Some speaker~ wlll eharacteristically
raise the piteh of the emphasized syllable instead of the lntensity. Sueh an
idio~yncrasy can be deteeted by ehanges in the fundamental frequeney whieh are
not oxplained by the overall intonational eontour of the phrase. A notation
that~uses eapltal letter~ for stre~sed syllables ean deserlbe the duration-
trQ charaeter of the word, "redundant", a~ short-LONG-short and of
Hlndustrlous" as short-LONG-short-long. A database representatlon of the same
lnformation reguires only two blts per syllable.
::
In utteranee segments of this elas~, it is suffieient to limit a first
analysi~ of speetral data to a determination of the manner elasses of eaeb
sound in the utteranee, e.g. a grouping of sounds by the manner in whieh they
are produeed. The form of elassification used eonsists of: vowels, plosive~,
frieatives, nasals, glides, affrieatos, ~ilenee, and others. The manner elas~
determination is aeeompllshed by a mannor elass determinatlon proce~s 92. Each
Class'C' entry in the lexicon wlll be charactorlzed by the sound~ it contains
in terms of manner classes. ~hls will avoid tho computationally more oxpensive
and inherently more orror-prono proeo~s of analyzing tho utteranee into
speeific phonologieal units.
2081188
The lexicon also includes strings of symbols representing finer resolution
phonological units, such as demi-syllables, for long as well as short word~ ln
the lexicon. The~e reference strings are used, on an exception basis, for the
purpose~ of disambiguating word candidates when the computationally simpler
techniques fail to discriminate between them. In such cases, the utterance
segment must be analyzed into comparable units.
(e) Word confirmation and correction
As they are recognized, each word is added to the sequence of recognized
words which are displayed on the computer terminal. At the end of every
sentence, the operator uses signal-sending device 18 to send an acceptance or a
rejection signal to the system in response to the single highlighted word on
the screen, as each word in the sentence i8 highlighted in turn.
In the case of a rejected word, the operator can choose the correct one from
a list of alternative candidate woras which are displayed as soon as the
re~ection signal has been received. If the correct word is not on the list,
the operator has the choice of either speaking the word again or spelling the
word out by means of the computer terminal keyboard. Signal-~ending device 18
is also used during confirmation and correction proce~s 16 to indicate desired
hyphens, punctuation, and capitalization.
Ramifications
The CSR system of Shis invention can form the basis of a voice-actuated
typewriter with the operator being, for instance, a keyboard-~hy executive.
Letters and documents, including those of a confidential naturs, can be created
without the delay and inconvenience of an intermediate dlctation process and
without having to use the services of a skilled typist~
The same CSR system could be used by a relatively unskilled operator to
transcribe pre-recorded speech or speech whlch is being received from a remote
location via telephone. Another application would use ~y CSR system to
transcribe prewritten text, such as a hand-written document, which is not
amenable to optical character recognition. This would be particularly valuable
for research pro~ects which deal with voluminous archival material.
My CSR system can also be operated cooperativ01y by two people, one who
18
2081188
marks the words and a second who uses a separate terminal and slgnal-sendlng
device to effect the confirmatlon and correction of the orthographlc output.
Such a configuration will make possible the production of transcription~ of
ongoing conversational speech in real time. Thls could be most useful for
conferences ln which speakers, such as those particlpating ln a discussion or
debate, do not speak from prepared texts. Transcrlptlons of th- conference
sesslon would bo avallable for dl~trlbuelon a few mlnutes after lts closing.
The output from such a conference transcription system could be directed to
a computer-aided translation ~ystem run by a third operator. The syntactlc and
semantic analyses already performed by the CSR system for its own purposes
would be avallable to the translatlon system that needs such informatlon to
prepare an accurate ver~ion of the speaker's words in the socond language.
The output from the above translation system could be dlrected to a large
dlgltlzed text dlsplay un~t that 18 vlslble to all partlclpants in the
conference, lncluding those who do not understand the speaker, as is commonly
done for subtltles of forelgn language fllms shown ln fllm festivals.
A varlant would see the same-language transcrlption of the speaker's words
~di~played on a large dlgltlzed dlsplay, even ln slngle-language conferences,
for the~`ben-flt of those partlclpants who are hearlng lmpalred.
The same orthographlc output from a slmultaneous translatlon ~ystem based on
my CSR ~ystem can bo transformod lnto ~peech ln the second language by means of
a convontional text-to-spooch proce~s. Tho translation would then be made
avallable to conference partlclpants, almost ln real tlme, vla FM transmission
to headsets. Such FM recelvers are commonly used by conventional simultaneous
traDslatlon servlces whlch requlre the efforts of hlghly skilled and exponsive
lnterpretors. The same ~ystem 18 useful, even when the translation is also
dlsplayed on a larg- dlgitized display, for the bonefit of participants who are
~- visually impalred.
A portable version of the above translation system could be used by a single
operator, with slower response time. Someone would use such an automatic
translator to communicate whllo traveling ln a forelgn country ln a way that i~
much more graceful than tho common thumblng and ~tumbllng through a phraso book.
2081188
The CSR system of my lnvention could be used remotely, by someone who want~
to enter contlnuous speech lnto a system vla telephone. Complex database
inquirles could be made in thls way, wlth the deslred ln$ormatlon belng given
to the caller ln voice-response fashion by means of a text-to-speech system.
In this circumstance, the operator uoes a variation of the signal-sendlng
device that has been descrlbed as being a standard computer mouse ln the
preferred embodiment. For remote appllcations, a two-button finger-actuated
portable dev~ce that sends an analog slgnal through the telephone handset
microphone could be employed. A slmpler device would be in the form of two
finger-size sleeves wlth hard protuberances at their ends whlch are worn over
the index and mlddle fingers of the domlnant hand. Wlth this device, the
speaker can tap directly on the hand~et to generate high-frequency clicks at
the onset of each spoken word. The word-marking clicks will be conveyed by the
handset microphone and telephone connection together with the ~poken words to
~the CSR system.
Conclu~ion~, Further Ramiflcatlon~, and Scope
Accordlngly, the reader wlll see that the method and apparatus of this
inventlon, ln which an lndlcation of the locatlon of the start of words ln
contlnuous speech iB expllcltly glven to a speech recognltlon ~ystem by the
operator by means of a commonly avallable slgnal-sendlng devlce, greatly
facllltates the t~sk of analyzlng the utt-rance. Powerful analytlc technlques
whlch make use of varlous parameters derlved from word-length utterance
segment~ can be applled from the outset. An utterance that lncludes the words
r-cognize speech~ repre~ents a difflcult problem to conYentional CSR systems,
as acoustic, syntactic, and semantlc analyses can easily lead to "wreck a nice
beach~. A CSR system that use~ the improved segmentation technique of my
in ntlon will greatly reduce the number of such ambiguiti-s.
In the case of polysyllablc words, only an approximate classlflcatlon of
sounds ln the utterance segment 18 requlred, as easlly computed prosodic
parameters are very effectlve dlscrimlnatory lnstruments for long wordY. This
substantlally reduces the time-consumlng computation that 18 lnherent ln
conventlonal systems, and make~ use of parameters whlch are more robu~t than
those which are available to conventional CSR ~ystem~.
~ 2081188
In the case of shorter words, prosodic data contribute additional orthogonal
parameters to help differentiate between word candidates propooed by parameters
derived from acoustic data. A capital advantage conferred by the pre~ent
invention which i~ applicable to words of any length in an utterance 18 that
the analysis of different word-length utteranceo can be undertaken si~ultan-
eously, by means of readily available multiprogramming and multlprocessor
computers. This brings the beneflt of a dramatlc increase in recognition speed
in comparison with the results obtainable by conventional techniques, which
cannot make efficient use of such computer hardware, making real-time
continuous speech recognition possible using low-cost equip~ent.
Current workers in the art make use of connectionist moaels, ~ncluding
artificial neural nets, to deal with the uncertaintieo in the network of
posolbilltieo that ties together computed parasetero, dlstlnctlve features,
phonologlcal units, and words. CSR oyotems based on such modelo can also
benefit from the use of the utterance oegmentation techniques of my invention.
Furthermore, the use of the signal-sending device by an operator who also i9
the-speaker will, without any consciouo effort on the operator's part to do 80,
lead to speech production that io better articulated and which exhibits clearly
defined word boundarieo in the acouotic data. Thio phenomenon can be verified
by the reader by the sisple expodient of tapping on a table alternatively with
th- indes and middle fingero of the dominant hand as the wordo of this
disclooure are read out loud. The reader will find that after very little
practlce the marking of the onoet of wordo can be accomplished accurately,
without adveroely affecting the fluency of speech.
Althouyh the deocription above contalns many specificities, these should not
be construed as li~iting the scope of the invention but as merely provlding
illuotrations of oome of the preoently preferred embodiments of this
invention. For example, oignal-sending device 18 can be foot-operated in~tead
of hand-operated, and the device may be actuated by any type of switch known to
the owitch-making art. This can include, but is not limited to, electrostatic
owitches, acoustically-opsrated owitcheo, and switches operated by the
interruption of radiant energy. The proceosing stepo ohown, which, without
exception, uoe algorithms well known to thooe okill-d in the art, can be
employed in arrangemento which are very different from that uoed in the example
20~1~88
given, while still taking full advantage of the word-marking information
~upplied by the ~ignal-sending device. Alternative configurations could use
special hardware, such as connectionist machines, including artificial neural
network computers, and fuzzy logic circuits which can handle the great
variability wh~ch i8 a characteristic of speech.
Thus the scope of ths invention should be determined by the appended claims
and their legal equivalents, rather than by the examples given.