Note: Descriptions are shown in the official language in which they were submitted.
WO 92/08203 2 ~ 9 ~ 7 Q ~ PCl`/US91/03624
HANDWRITTEN DIGIT RECOGNmON APPARA~US & METHOD
Technical Field of the Invention
The technical field of the present invention
relates to optical character recognition and more
5 particularly recognition of handwritten digits.
Bac~ound o~ the InvQntion
TherQ are many instances where it would be useful
or desirable to provide a computer readable form of a
document not available in a compatible computer readable
10 form. Normally it is the case that the document is not
available in machine readable form because the document was
handwritten or typewritten and thus no computer readable
form exists, or because the computer readable form is not
available. In some instances there is a "foreign"
15 document, i.e. an existing computer readable form but the
document was produced on an incompatible computer system.
In some instances, such as facsimile transmission, a simple
optical scan of the document can produce the required form.
In most instances the form most useful for later use and
20 decision making is a separate indication of each character
of the document.
The field of optical character recognition deals
with the problem of separating and indicating printed or
written characters. In optical character recognition, the
25 document is scanned in some fashion to produce a electrical
image of the marks of the document. This image of the
2 ~
W092/08203 PCT/US91/03624
-- 2
marks is analyzed by computer to produce an indication of
each character of the document. It is within the current
state of the art to produce relatively error free
indication of many typewritten and printed documents. The
5 best systems of the prior art are capable of properly
distinguishing a number of differing typa fonts~
On the other hand, unconstrained handwritten
characters have not been succassfully located and
recogni2ed by present optical systems~ The problem of
10 properly reading unconstrained handwritten characters is
difficult because of the great variability of the
characters. One person may not write the same character
exactly the same every time. The variability between
different persons writing the same character is even
15 greater than the variability of a single person. In
addition to the variability of the characters themselves,
handwritten text is often not cleanly executed. Thus
characters may overlap horizontally. Loops and descenders
may overlap vertically. Two characters may be connected
20 together, strokes of one character may be disconnected from
other strokes of the same character. Further, the
individual written lines may be on a slant or have an
irregular profile. The different parts of the handwriting
may also differ in size. Thus recognition of handwritten
25 characters is a difficult task.
An example of a field where recognition of
handwritten characters would be very valuable is in mail
sorting. Each piece of mail must be classified by
destination address. Currently, a large volume of
~W092/08203 2 ~ 3 ~ 7 0 ~ PCT/US91/03624
typewritten and printed mail is read and sorted using prior
art optical character recognition techniques. Presently,
approximately 15% of current U.S~ mail that is hand
addressed. Present technology uses automated conveyer
5 systems to present these pieces of mail, one at a time, to
an operator who ViQWS the address and enters a code for the
destination. This is the most labor intensive, slowest and
consequently most expensi~e part of the entire mail sorting
operation.
Furthermore, it is expensive to misidentify a ZIP
code and send the piece of mail to the wrong post of~ice.
Once the mail is forwarded to the receiving post office,
the receiving post office recognizes that there is no
matching address or addressee in that ZIP code. The mail
15 must then be resorted and redirected to the proper post
office. Because of the high expense associated with
misdirected mail, it is more desirable to have an automated
system reject a piece of mail if the system cannot
determine the ZIP code with an extremely high degree of
20 accuracy. The rejected pieces of mail can then be hand
sorted at the sending station or other measures can be
taken to eliminate or reduce the cost of the misdelivery.
Sorting of handwritten mail is an area having a
unique set of characteristics. First, due to the problem
25 of user acceptance it is not feasible to place further
constraints on the address. Thus address lines or
individual character boxes, which would be useful in
regularizing the recognition task, are ruled out. on the
other hand, therè already exists a relatively constrained
2 Q Q'~ ;3 '~
W092t08203 PCT/US91/03624
- 4 -
portion of the current address. The ZIP code employed in
a majority of handwritten destination addresses provides
all the information needed for the primary sorting
operation~ Most handwritten ZIP codes are formatted with
5 5 digits while some handwritten ZIP codes use the longer 9
digit ZIP code. This information is relativel~ constrained
because the 2IP code consists o~ only 5 or 9 digits~ In
addition thQ ZIP code is usua~ly located at the end of the
last line of the destination address or sometimes is by
l0 itself on the last line.
Various systems have been devised to recognize
handwritten digits. However, many of these systems assume
that the digits are already located and isolated and the
problem is only to determine which numeral the handwritten
15 digit represents. Often these systems require the digits
to be written inside individual boxes.
In order for a computer to analyze and recognize
the handwritten numerals in a hand-written ZIP code in an
address block typically appearing on an envelope, the group
20 of numerals comprising the ZIP code must first be
successfully located as a group.
Even though the above mentioned constraints on
the ZIP code in the form of number of digits and location
exist, previous attempts to locate the ZIP code have
25 encountered problems. The same problems that exist in
general for successful recognition of handwriting also pose
problems for locating the ZIP code. Previous attempts to
count lines of a handwritten address block have been
W092/08203 ~ Q . ~ 7 0 ~ PCT/US91/03624
stymied by loops, descenders, line slant or other line
irregularities.
What is needed is a highly reliable system to
correctly locate the ZIP code in an address block before
5 analysis of the digits of the ZIP code.
Sum~y of the I~venti~n
In accordance with one aspect of the invention,
a computer system is designed to locate a 2IP code from an
digitized address block. The address block can be derived
lO ~rom an addressed envelope, postcard or other label through
optical scanning. The digitized address block is comprised
of pixels arranged in a matrix. Preferably the digital
address block is binary with pixels either being part of
the foreground image or part of the background.
The computer system includes a mechanism for
computing horizontal distances between sequential but
separated pixels of the foreground image that are in the
same row. The computer system subsequently compiles and
determines a first significant peak in occurrences of
20 distances which is designated as the interstroke distance.
In the foreseen application, the foreground image
represents character strokes of the address block. The
strokes are arranged into words based on the interstroke
distance.
The words are then formatted into groupings, i.e.
blocks. The interline vertical connections between
different lines of the address block are broken via
horizontal erosion of the strokes. The word blocks are
r~
WO 92/08203 PCI`/US91/03624
then skeletonized down to a horizontal skeleton. A
subsystem dilates the resulting horizontal skeleton
vertically into boxes with each box having a uniform height
and then dilates the boxes horizontally such that boxes
5 overlapping in the horizontal direction are merged together
to form line images. The line images are labeled (i.e.,
numbered~ uni~uely from the top of the image, to produce
line numbers. Another subsystem then determines each line
imaye's medial axis and superimposes the line-numbered
10 medial axis onto the original digiti2ed address block.
Desirably, the computer system then bleeds the
line number label from each medial axis to identify all
strokes connected to the medial axis. Strokes that are
connected to two horizontal axes are divided to either the
15 line above or the line below. ~he mechanism identifies
foreground image pixels not connected to any medial axis
and excludes these pixels from a subsequent line count.
The desired last line that is large enough to contain a ZIP
code is then selected and possible wording splits of the
20 last line are determined from interstroke distances and the
identified foreground imaye pixels that do not touch any
medial axis~ One wording split is selected and a word from
the split is identified as the ZIP code location.
Preferably a mechanism for creating a bounding
~5 box of the digitized address block is provided and
operations are directed to only pixels within the bounding
box to reduce the computer operating time. Furthermore,
the pixels within the bounding box are down sampled further
W092/08203 2 ~ ~ ~ 7 Q ~ PCT/US9t/03624
reducing computer time while still rendering the needed
calculations and processing.
Preferably the computer system incorporates a
parallel processing system. Computational time is hence
5 reduced to acceptable levels while the expense of a
sufficiently powerful general computer is avoided.
In accordance with a broader aspect of the
invention, the invention relates to a computer system and
m~thod for locating a predetermined group o~ pixels within
10 a larger selection of pixels forming character images
derived from handwriting or machine printing characters.
The computer system calculates horizontal distances between
separated foreground image pixels in the same row to
determine a first peak of distance lengths that is labeled
15 the interstroke distance~ The computer system separates
the address block image into separate line images using the
interstroke distances to form blocks, erodes the blocks
horizontally to break interline strokes, skeletonizes the
blocks, and subsequently dilates the skeletonized blocks to
20 form lines of the handwritten image. A group of pixels in
a particular line is then selected by use of the
interstroke distances and identified foreground pixels that
do not have a connection to any medial axis of any
respective line.
25 Brief Description of the Drawings
Reference now is made to the accompanying
drawings in which:
W092/08203 2 ~ 3 ~ 7 0 ~ PCT/US9~/03624 ^~
! ` - 8 -
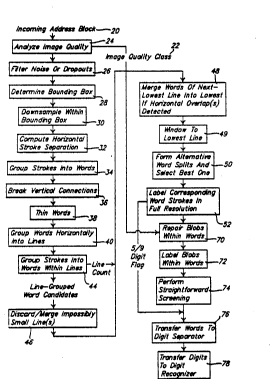
FIGURE 1 illustrates, in flow chart form, the
process of ZIP code location employed in the preferred
embodiment of the present invention;
FIGURE 2 schematically illustrates a sample
5 address block and its bounding box;
FIGURE 3 is an enlargad viet~ of the address block
in the bounding box schematically illustrating the
horizontal distances between two sequantial but separated
pixels o~ the ~oreground image:
FIGURE 4 schematically illustrates t~e arranging
o~ strokes into word blocks based upon the interstroke
distance shown in FIGURE 3;
FIGURE 5 schematically shows the breaking of the
descenders and vertical connections between the lines and
15 the formation of convex hulls:
FIGURE 6 schematically illustrates
skeletonization of the convex hulls;
FIGURE 7 illustrates the vertically dilated word
box areas dilated horizontally into lines and the formed
20 medial axis of each line;
FIGURE 8 illustrates superimposing the medial
axis of each line shown in FIGURE 7 onto the original
bounded down-sampled address block shown in FIGURE 2 and
bleeding the characters from the medial axes;
FIGURE 9 illustrates a selection of the last line
as determined by the previous steps;
FIGURE 10 discloses one selected splitting of
words;
~V092/08203 2 ~ 9 ~ 7 0 ~ PCT/US91/03624
FIGURE 11 discloses an alternative selected
splitting of words;
FIGURE 12 discloses a preferred selected word
chosen for the ZIP code;
FIGURE 13 discloses a 2IP code correlating to the
word being chosen in FIGURE 12;
FIGURE 14 discloses in block diagram form the
morphological computer employed in the preferred embodiment
of the present invention; and
FIGUR~ 15 illustrates in block diagram form one
of the neighborhood processing stages of the morphological
computer illustrated in FIGURE 14.
Detailed ~escription of the Preferred Embodiment
A ZIP code location system of the present
lS invention implementing the method illustrated in Figure 1
is capable of locating a ZIP code within an address block.
Figures 2-13 provide an exemplary illustration of the steps
diagrammed in Figure 1 and reference will be made to this
example as the description of Figure 1 proceeds.
The handwritten fictional sample shown in figure
2 illustxates several problems that may occur in a
handwritten address. The handwritten sample is only an
example and it should be understood that the same below
descxibed method is equally applicable to other
25 handwritings that can be quite distinctive and very
different from the one shown.
The shown example has several common problems
that posed problems for various prior art systems. The "J"
W092/08203 2 ~ 9 `~ 7 0 ~ PCT/US91/03624 ~i
-- 10 --
in the "John~ in the first line extends below the medial
axis in the second line. Furthermore, the "P" in the
middle initial actually is connected to the "n" in the line
below. The "S" and the "t" in the middle line extend below
5 the top of the ZIP code in the line below~ The lower part
of the "S" is furthermore connected ~ith the extendex of
the ~irst "0" in the ZI~ code. The second "NY" is angled
such that the top of the "NY" is vertically located above
the bottom o~ the "S,`' "t," and the "r" in the word
10 "Street'` in the line above. The word ~Main~ is positioned
signi~icantly higher with regard to the word "Street'` such
that this line of the address is significantly wavy. The
letters also vary in size, e.g., compare the two capital
"M's." Furthermore, the letters have extra loops, e.g.,
15 the "M" in "Main," the initial "P" and the first "O" in the
ZIP code. Furthermore, the strokes are relatively jagged
and the ZIP code is unevenly separated by the intrusion of
the '`t" and the wider spacing between the second "0'` and
the "7.`'
A digitized address block 21 as shown in Figure
2 forms input 20 into the system. The block 21 can
originally be obtained from an optical scan or can be
previously digitized and stored on disk or other computer
storage techni~ues. The address block 21 is inputted in
25 digitized form in an array of pixels that are horizontally
and vertically spaced into rows and columns. The address
block pixels can have background states or image states.
The image states can be the state of thinned components,
end points, junctions and "flesh," i.e., the part of the
` `W092/08203 2 0 ~ ~ 7 Q ~ PCT/US91/03624
-- 11 --
image removed during thinning. The address block 21 is
first analyzed for its quality (step 24) which includes
noise, dropouts, broken strokes and other image processing
defects which can effect analysis of the image. The
5 defects are than quantified and the image is then
classified as a certain quality 22. The incoming address
bloc~ ~1 then has noise and dropouts filtered (step 26) to
the e~tent desired. A bounding box 23 as shown in Figure
2 is then determined ~step 28). A bounding box is
10 determined by the most left and right, and the uppermost
and lowermost extent of the strokes of the image as shown
by example in Figure 2. The image is then down-sampled
within the bounding box 23 as indicated by step 30. The
bounding box is formed and downsampled to reduce computer
15 time. The address block 21 then has horizontal stroke
separation computed (step 32) as schematically shown in
Figure 3. The horizontal spacing between two sequential
but separated and horizontally aligned is computed. The
~pacing between different sequential but separated are
20 illustrated by spaces 25, 27, 29 and 31 of differing
lengths. Common printing and handwriting provides that
there is a common range of spacing between most adjacent
vertical strokes as indicated by the stroke distances
labeled 31. Significantly smaller gap distances occur less
25 often than stroke distance 31. Distances approximately
equal to the gap distance 25 between horizontally adjacent
image words occur less often than smaller stroke distances.
In addition, horizontal gaps that are slightly greater than
the stroke distance 31 decrease in number such that the
W092/08203 2 ~ 9 ~ 7 Q ~ PCT/US91/03624
- 12 -
computer can calcùlate a first peak of stroke distances
approximately equal to distance 31 which are labeled an
interstroke distance.
With the calculated interstroke distance 31 for
5 address block 21 as a guide, the strokes are then arranged
into words (step 34). The words 35 are determined from
the interstroke distances 31 and the wider distances 25 and
29 in Figure 3. The result of the grouping step 3~ is
shown in Figure 4. Blocks 35 schematically represent the
10 groupings of each word. The vertical stroke connections
between the lines are then broken (step 36) via horizontal
dilation and subsequent horizontal erosion of the
characters where thin descenders and long extenders 37 of
characters are eliminated. The elimination of descenders
15 and extenders 37 break the connections between the two
adjacent address lines~
Each block of words 35 then is completely
separated and these group blocks 35 ar`e then formed into
convex hulls 33 about the eroded image. The hulls 33 are
20 then skeletonized as shown in step 38 into skeletal
segments 39 as shown in Figure 6. As shown in step 40, the
blocks 35 are then further grouped horizontally into
address lines. This is accomplished by dilating the
skeletonized segments 39 vertically from the skeletal
25 segments 39 to form boxed areas 41 of uniform vertical
thickness~ As shown in Figure 7, the boxed areas 41 are
then dilated horizontally such that any horizontal overlap
of one area 41 with an adjacent area 41 is filled in as
indicated in areas 43.
W092/08203 ~ 7 ~ ~ PCT/US91/03624
- 13 -
The next step 44 is to label strokes according to
line number. This is accomplished by determining a medial
axis 4S for each line 1, 2 and 3 shown in Figure 7 and
superimposing the line-numbered medial axis 45 onto the
5 original down-sampled image of the address block 21 as
shown in Figure 8~ A line number bleeding process based on
connectivity is per~ormed. The bleeding process starts at
the line-numbered medial axis. Any lettering that is
directly connected to the medial axis or any stroke that is
10 conn~cted to a stroke that is in turn touching the medial
axis will be identified as belonging to that medial axis of
either lines 1, 2 or 3. For example, the descender of the
`'t" in the word "street," even though it is below the top
of the "0" and the top of the "7" of the third line will be
15 identified as part of the second line. The "r" in "Nr.,"
even though situated below the ~edial axis 44 will be
identified as part of the first line since it is connected
to the "M" and the line number bleeding will occur from the
"M" into the "r."
The bleeding also helps define letters of two
different lines that are connected to each other. The
extender for the "P" in the middle initial and the extender
of the "n" in "Main" are connected as are and the "S" in
the word "Street" and the "0" in the third line are
25 connected. These characters are divided apart by the
bleeding of the respective letters. The bleeding of the
different lines meet at points 51. By definition any
image pixel above point 51 is identified with the upper
character and any image pixel below the point 51 is
W092/08203 2 ~ 3 ~/, n ~ PCT/US91/03624 `
- 14 -
identified with the lower character. The period 53 and
comma 55 are not connected to any axis and are therefor be
left unlabeled and designated as punctuation marks.
Based on the bleeding, the punctuation, and the
5 interstroke distances, the strokes are grouped into words
within the lines shown in step 44. We no~ have line
yrouped word candidates. Step 46 now either discards
impossibly small lines or merges the small lines together
as indicated in step 48 if there is a hori~ontal overlap
10 detected between these lines. The last or lowest line 57
as indicated in Figure 9 is selected as shown in step 49.
The last line however does not include the lowest extension
of the "t" in "Street`' in the line above nor will it
include any of the part of the first "0" above the point
15 51.
The last line 57 is split into words as shown in
step 50. Fiqure 10 indicates a splitting into three words
with "NY" before the punctuation mark 55 forming one word
59, the second "NY" forming a word 61 after the punctuation
20 mark 55 and before the relatively large gap 27 as shown in
Figure 3. The "10073" forms a third word 63. Alternative
splits are also performed as shown in Figure 11. The
alternate four-word splitting has the "loo" in one word
labeled 65 and the "73" is in a second word labeled 67.
25 ~he split is a result of the slightly larger distances
between the second "0" and the "7." However, due to other
constraints, for example, the size of the word 67 being too
small for a ZIP code in and of itself based on interstroke
distances, the word split shown in Figure lo is preferred
~V092/08203 ~3 ~ r~) Q ~ PCT/US91/03624
- 15 -
over the word split shown in Figure 11. The word 63 is
then selected as being the location of the ZIP code and as
shown in Figure 12.
Step 52 provides that the corresponding
5 characters 69 for word 63 are shown in full resolution as
illustrated in Figure 13. Based upon the class of the
image ~uality as indicated in step 22, noise, blobs and
dropouts within the word 63 are repaired as indicated in
step 70. The blobs and noise are labeled in step 72 and
10 the image pixels in word 63 are shown on a sc~een in step
74. The ZIP code is then transferred to a digit separator
in step 76 in which the group of ZI~ code digits can then
be segmented, and the digits are then analyzed recognized
by step 78 with a digit recognizer. If per chance a 9
15 digit ZIP code is used, the 9 digit ZIP code is detected
and the digit separator then determines 9 digits rather
than 5 digits.
The computer system used with the ZIP code
location process is preferably a morphological type
20 computer which is pre~erably constructed in accordance with
U.S. Patent No. 4,167,728 issued September 11, 1979 to
Sternberg and entitled `'Aùtomatic Image Processor" and is
commercially known by the mark "Cytocomputer." The
teachings of U.S. Patent No. 4,167,728 are incorporated
25 herein by reference. Briefly, the construction is
described in conjunction with Figures 14 and 15. The
overall construction of the morphological computer 70 is
illustrated in Figure 14 and the construction of a single
W092/08203 ~ 7 a~ PCT/US91/03624
neighborhood processing stage 80 is illustrated in Figure
15.
In general, the morphological computer 70
includes of a pipeline of a plurality of neighborhood
5 processing stages 80, 8~...84. The first neighborhood
processing stage 80 receives as its input a data stream
corresponding to individual pixels of a binary image as the
incoming address block in a raster scan fashion. The image
of the incoming address block includes data corresponding
10 to individual pixels arranged in a plurality of rows and
columns. The raster scan data stream consists of pixels
in order starting with the top row of the left-most pixel
to the right-most pixel, followed by the next row in left
to right order followed by each succeeding row in similar
15 fashion.
The neighborhood processing stage 80 in turn
produces an output stream of data also corresponding to
individual pixels of a transformed image in a raster scan
sequence. Each pixel of this output data stream
20 corresponds to a particular pixel of the input data stream.
the neighborhood processing stage 80 forms each pixel of
the output data stream based upon the value of the
corresponding input pixel and the values of the 8
neighboring pixels. Thus, each pixel of the output data
25 stream corresponds to the neighborhood of a corresponding
input pixel. The output of each neighborhood processing
stage 80,82... is supplied to the input of the next
following stage. The output of the last neighboring
`` W O 92/08203 2 f~ 9 ~ 7 0 ~ PC~r/US91/03624
processing stage 84 forms the output of the morphological
computer 70.
The particular transformation or neighborhood
operation performed by each neighborhood processing stage
5 80,82 ..~ 84 is controlled by transformation controller
90~ Each neighborhood processing stage 80,~2...84 has a
unique digital address. The transformation controller 90
specifies a particular address on addrass line 92 and then
spQcifies a command corresponding to a particular
10 transformation on command line 94. The neighborhood
processing stage 80,82... 84 having the specified address
stores the command. Each stage then performs the
transformation corresponding to its last received command.
Figure 15 illustrates in further detail the
15 construction of an exemplary neighborhood processing stage
80. The neighborhood processing stage 80 operates in
conjunction with the delay line formed of pixel elements
100-108 and shift register delay lines llo and 112. Pixel
elements 100-108 are each capable of storing the bits
20 corresponding to the data of a single pixel of the input
image.
An eight bit or sixteen bit pixel in most
foreseeable uses would suffice since standard dilation and
skelètonization need to define each pixel in one of five
25 states; background, thinned components, end points,
junctions, and "flesh." Shift register delay lines 110 and
112 have a length equal to three less than the number of
pixels within each line of the image. The length of the
shift register delay lines 110 and 112 are selected to
W092/0~203 2a 9~ PCT/US91/03624 ` ``
- 18 -
ensure that pixel elements 100, 103 and 106 store data
corresponding to pixels vertically adjacent in the input
image. Likewise, the data and pixel elements 101, 104, 107
correspond to vertically adjacent pixels and the data in
5 pixel elements 102, 105, 108 correspond to vertically
adjacent pixels.
Pixel data is supplied in raster scan ~ashion to
the input o~ the neighborhood processing stage 80. The
pixel is first stored in pixel element 100. Upon receipt
10 of the following pixel, the pixel stored in pixel element
100 is shifted to the pixel element 101 and the new pixel
is stored in pixel element 100. Receipt of the next pixel
shifts the first pixel to pixel element 102, the second
pixel to pixel element 101 and the just received pixel
15 stored in pixel element 100. This process of shifting data
along the delay line continues in the direction of the
arrows appearing in Figure 15. Once the pixel reaches
pixel element 108, it is discarded upon receipt of the next
pixel.
The neighborhood processing stage 80 operates by
presenting appropriate pixel data to combination circuit
114. Note that once the shift delay lines 112 and 110 are
filled, pixel elements 100-108 store a 3 x 3 matrix of
pixel elements which are adjacent in the original image.
25 If pixel element 104 represents the center pixel, then
pixel elements 100, 101, 102, 103, 105, 106, 107, 108
represent the eight immediately adjacent pixels. This
combination circuit 114 forms some combination of the nine
pixels. Such combinations could take many forms. The
2 ~ 3 ~ rt ~ ~
`~.V092/08203 PCT/US91/03624
-- 19 --
pixel output data may have more or fewer bits than the
input data depending on the combination formed. It is also
feasible that combination circuit 114 may form comparisons
between one or more of the pi~els or between a pixel and a
5 constant received from transformation controller so. The
essential point is that combination circuit 114 forms an
output pixel from some combination of the pixels stored in
the pixel elements 100-108.
The advantage of the arrangement of Figures 14
1~ and 15 for image operations is apparent. Each neighborhood
processing stage 80,82 ... 84 forms a neighborhood
operation on the received image data as fast as that data
can be recalled from memory. Each stage requires only a
fixed delay related to the line length of the image before
15 it` is producing a corresponding output pixel stream at the
same rate as it receives pixels. Dozens, hundreds or even
thousands of these neighborhood processing stages can be
disposed in the chain. ~hile each neighborhood processing
stage performs only a relatively simple function, the
20 provision of long chains of such stages enables extensive
image operations within a short time frame. As known from
the above description, location of the ZIP code does
require a complex and extensive computation due to the
number of problems that are inherent in handwritten ZIP
25 codes such as descenders, slanted lines, and jagged lines,
irregular spacings, broken strokes, interconnected
characters and lines and ink blots and other image noise.
The hardware system such as the one described is needed to
provide the computational capacity to work on a typical
W092/08203 2 0 9 ll 7 Q g PCT/US91/03624
- 20 -
handwritten address block to locate the ZIP code within
that block.
Variations and modifications of the present
invention are possible without departing from the scope and
5 spirit of the invention as defined in the appended claims.