Note: Descriptions are shown in the official language in which they were submitted.
WO 94/29795 . PCT/US94/06321
-~~6 5 910
TEXT TR-ANsUfM
A METHOD FOR PROVIDING J!A_R_TTY IN A RAID SiJE-SYST'EM
1IJSING A NON-VOLATILE MEMORY
F3ACKGROLJND OF THE INVENTION
r
1. FIELD OF THIE INVENTTON
The present invention is related to the field of error correction
techniques for an array of disks.
2 BACKGROUI~fD ART'
A computer system typically requires large amounts of secondary
memory, such as a disk drive, to store information (e.g. data and/or
application programs). Prior art computer systems often use a single
"Winchester" style hard disk drive to provide permanent storage of large
amounts of data. As the performance of computers and associated processors
has increased, the need for disk drives of larger capacity, and capable of
high
speed data transfer rates, has increased. To keep pace, changes and
improvements in dis)r, drive performance have been made. For example, data
and track density increases, media improvements, and a greater number of
heads and disks in a single disk drive have resulted in higher data transfer
rates.
A disadvantage of using a single disk drive to provide secondary storage
is the expense of repl.acing the drive when greater capacity or performance is
required. Another disadvantage is the lack of redundancy or back up to a
single disk drive. When a single disk drive is damaged, inoperable, or
replaced, the system i.s shut down.
SIJBSTITUTE SHEET (RULE 26)
CA 02165910 2004-05-27
77761-6
-2-
One prior art attempt to reduce or eliminate the above disadvantages of
single disk drive systems is to use a plurality of drives coupled together in
parallel. Data is broken into chunks that may be accessed simultaneously from
multiple drives in parallel, or sequentially from a single drive of the
plurality
of drives. One such system of combining disk drives in parallel is known as
"redundant array of inexpensive disks" (RAID). A RAID system provides the
same storage capacity as a larger single disk drive system, but at a lower
cost.
Similarly, high data transfer rates can be achieved due to the parallelism of
the
array.
RAID systems allow incremental increases in storage capacity through
the addition of additional disk drives to the array. When a disk crashes in
the
RAID system, it may be replaced without shutting down the entire system.
Data on a crashed disk may be recovered using error correction techniques.
RAID Arravs
RAID has six disk array configurations referred to as RAID level 0
through RAID level5. Each RAID level has advantages and disadvantages. In
the present discussion, only RAID levels 4 and 5 are described. However, a
detailed description of the different RAID levels is disclosed by Patterson,
et al.
in A Case for Redundant Arrays of Inexpensive Disks (RAID), ACM SIGMOD
Conference, June 1988.
RAID systems provide techniques for protecting against disk failure.
Although RAID encompasses a number of different formats (as indicated
above), a common feature is that a disk (or several disks) stores parity
information for data stored in the array of disks. A RAID level 4 system
stores
WO 94179795 PCTIUS9"'16321
2165910
-3-
all the parity inform,ation ori a single parity disk, whereas a RAID level 5
system stores parity blocks throughout the RAID array according to a known
pattern. In the case of a disk failure, the parity information stored in the
RAID
subsystem allows the lost data from a failed disk to be recalculated.
Figure 1 is a block diagram illustrating a prior art system implementing
RAID level 4. The system comprises N+1 disks 112-118 coupled to a computer
system, or host computer, by communication channel 130. In the example,
data is stored on each hard disk in 4 KByte (KB) blocks or segments. Disk 112
is
the Parity disk for the system, while disks 114-118 are Data disks 0 through N-
i.
RAID level 4 uses disk "striping" that distributes blocks of data across all
the
disks in an array as shown in Figure 1. A stripe is a group of data blocks
where
each block is stored cin a separate disk of the N disks along with an
associated
parity block on a single parity disk. In Figure 1, first and second stripes
140 and
142 are indicated by clotted lines. The first stripe 140 comprises Parity 0
block
and data blocks 0 to N-1. In the example shown, a first data block 0 is stored
on
disk 114 of the N+1 disk array. The second data block 1 is stored on disk 116,
and so on. Finally, data block N-1 is stored on disk 118. Parity is computed
for
stripe 140 using well-known techniques and is stored as Parity block 0 on disk
112. Similarly, stripe 142 comprising N data blocks is stored as data block N
on
disk 114, data block N+i on ciisk 116, and data block 2N-1 on disk 118. Parity
is
computed for the 4 stripe 142. and stored as parity block 1 on disk 112.
As shown in Fiigure 1, RAID level 4 adds an extra parity disk drive
containing error-correcting information for each stripe in the system. If an
error occurs in the system, the RAID array must use all of the drives in the
array to correct the etror in the system. RAID level 4 performs adequately
WO 94/29795 2 1r C p1O PCTIUS94/06321
-4-
when reading small pieces of data. However, a RAID level 4 array always uses
the dedicated parity drive when it writes data into the array.
RAID level 5 eLrray systems also record parity information. However, it
does not keep all of the parity sectors on a single drive. RAID level 5
rotates
the position of the parity blocks through the available disks in the disk
array of
N+1 disk. Thus, RAID level. 5 systems improve on RAID 4 performance by
spreading parity data across the N+1 disk drives in rotation, one block at a
time. For the first set of blocks, the parity block might be stored on the
first
drive. For the seconci set of 'blocks, it would be stored on the second disk
drive.
This is repeated so that each set has a parity block, but not all of the
parity
information is stored on a single disk drive. In RAID level 5 systems, because
no single disk holds all of the parity information for a group of blocks, it
is
often possible to wrilte to several different drives in the array at one
instant.
Thus, both reads and writes are performed more quickly on RAID level 5
systems than RAID 4: array.
Figure 2 is a block diagram illustrating a prior art system implementing
RAID level S. The system comprises N+1 disks 212-218 coupled to a computer
system or host computer 120 by communication channel 130. In stripe 240,
parity block 0 is stored on the first disk 212. Data block 0 is stored on the
second
disk 214, data block 1. is stored on the third disk 216, and so on. Finally,
data
block N-1 is stored oin disk 218. In stripe 212, data block N is stored on the
first
disk 212. The second. parity iblock 1 is stored on the second disk 214. Data
block
N+1 is stored on disk 216, and so on. Finally, data block 2N-1 is stored on
disk
218. In M-1 stripe 244, data block MN-N is stored on the first disk 212. Data
block MN-N+1 is stored on ithe second disk 214. Data block MN-N+2 is stored
on the third disk 216, and sc- on. Finally, parity block M-1 is stored on the
nth
Wo 94/29795 PCT1US9,'i321
2165910
-5-
disk 218. Thus, Figure 2 illtistrates that RAID level 5 systems store the same
parity information as RAID level 4 systems, however, RAID level 5 systems
rotate the positions cif the parity blocks through the available disks 212-
218.
In RAID level 5, parity is distributed across the array of disks. This leads
to multiple seeks across the disk. It also inhibits simple increases to the
size of
the RAID array since a fixed number of disks must be added to the system due
to parity requirements.
The prior art systems for implementing RAID levels 4 and 5 have
several disadvantages. The first disadvantage is that, after a system failure,
the
parity information for each stripe is inconsistent with the data blocks stored
on
the other disks in the stripe. This requires the parity for the entire RAID
array
to be recalculated. The parity is recomputed entirely because there is no
method for knowing which ;parity blocks are incorrect. Thus, all the parity
blocks in the RAID array must be recalculated. Recalculating parity for the
entire RAID array is highly time consuming since all of the data stored in the
RAID array must be iread. For example, reading an entire 2 GB disk at
maxiunum speed takes 15 to 20 minutes to complete. However, since few
computer systems are able to read very many disks in parallel at maximum
speed, recalculating parity for a RAID array takes even longer.
One technique for hiding the time required to recompute parity for the
RAID array is to allo=w access to the RAID array immediately, and recalculate
parity for the system while it is on-line. However, this technique suffers two
problems. The first problein is that, while recomputing parity, blocks having
inconsistent parity ai-e not protected from further corruption. During this
time, a disk failure in the RA.ID array results in permanently lost data in
the
WO 94/29795 PCT/US94r06321
-6- 2165910
system. The second ;probleni with this prior art technique is that RAID
subsystems perform poorly while calculating parity. This occurs due to the
time delays created by a plurality of input/output (I/O) operations imposed to
recompute parity.
The second disadvantage of the prior art systems involves writes to the
RAID array during a period when a disk is not functioning. Because a RAID
subsystem can recalculate data on a malfunctioning disk using parity
information, the RAID subsystem allows data to continue being read even
though the disk is malfunctioning. Further, many RAID systems allow writes
to continue although a disk is malfunctioning. This is disadvantageous since
writing to a broken RAID array can corrupt data in the case of a system
failure.
For example, a systein failure occurs when an operating system using the
RAID. array crashes cir when a power for the system fails or is interrupted
otherwise. Prior art :RAID subsystems do not provide protection for this
sequence of events.
CA 02165910 2004-05-27
77761-6
7
SUMMARY OF THE INVENTION
The present invention is a method for providing error
correction for an array of disks using non-volatile random
access memory (NV-RAM).
Non-volatile RAM is used to increase the speed of
RAID recovery from disk error(s). This is accomplished by
keeping a list of all disk blocks for which the parity is
possibly inconsistent. Such a list of disk blocks is smaller
than the total number of parity blocks in the RAID subsystem.
The total number of parity blocks in the RAID subsystem is
typically in the range of hundreds of thousands of parity
blocks. Knowledge of the number of parity blocks that are
possibly inconsistent makes it possible to fix only those few
blocks, identified in the list, in a significantly smaller
amount of time than is possible in the prior art. The present
invention also provides a technique of protecting against
simultaneous system failure and a broken disk and of safely
writing to a RAID subsystem with one broken disk.
In accordance with an aspect of the present
invention, there is provided a method for providing parity
correction for a RAID array in a computer system after a system
failure, including steps of: maintaining information in non-
volatile memory about stripes having possibly inconsistent
parity during routine operation of the computer system; afte:r
said system failure, identifying stripes in response to said
information; and for each said stripe so identified, correcting
said possibly inconsistent parity; wherein when updating data
that is destined for said stripes, said step of maintaining
includes reading into said non-volatile memory one or more
blocks of said stripes from said array.
In accordance with another aspect of the present
invention, there is provided an apparatus for providing parity
CA 02165910 2004-05-27
77761-6
7a
correction for a RAID array in a computer system after a system
failure, said apparatus includes: a maintenance mechanism
configured to maintain information in non-volatile memory about
stripes having possibly inconsistent parity during routine
operation of the computer system; an identification mechanism
configured to identify stripes in response to said information,
said identification apparatus activated in response to check. on
reboot after a system failure; a correction mechanism
configured to correct said possibly inconsistent parity for
each of said stripes identified by said identification
mechanism; wherein when updating data that is destined for said
stripes, said maintenance mechanism reads into said non-
volatile memory one or more blocks of said stripes from said
array.
In accordance with yet another aspect of the present
invention, there is provided a computer program product,
including: a computer usable storage medium having computer
readable code embodied therein for causing a computer to
provide parity correction for a RAID array in a computer system
after a system failure, said computer readable code includes:
computer readable program code configured to cause said
computer to maintain information in non-volatile memory about
stripes having possibly inconsistent parity during routine
operation of the computer system; computer readable program
code configured to cause said computer to identify stripes in
response to said information, activated in response to check on
reboot after a system failure; computer readable program code
configured to cause said computer to correct said possibly
inconsistent parity for each of said stripes identified by said
computer readable program code configured to cause said
computer to identify. stripes; wherein when updating data that
is destined for said stripes, maintaining said information
CA 02165910 2004-05-27
77761-6
7b
includes reading into said non-volatile memory one or more
blocks of said stripes from said array.
In accordance with yet another aspect of the present
invention, there is provided a computer program product,
including: a computer data signal embodied in a carrier wave
having computer readable code embodied therein for causing a
computer to provide parity correction for a RAID array in a
computer system after a system failure, said computer readable
code includes: computer readable program code configured to
cause said computer to maintain information in non-volatile
memory about stripes having possibly inconsistent parity during
routine operation of the computer system; computer readable
program code configured to cause said computer to identify
stripes in response to said information, activated in response
to check on reboot after a system failure; computer readable
program code configured to cause said computer to correct said
possibly inconsistent parity for each of said stripes
identified by said computer readable program code configured to
cause said computer to identify stripes; wherein when updating
data that is destined for said stripes, maintaining said
information includes reading into said non-volatile memory one
or more blocks of said stripes from said array.
In accordance with yet another aspect of the present
invention, there is provided a method for maintaining a
consistent file system, wherein said file system is stored in
stripes of blocks in a RAID array, that allows for recovery of
the file system to a consistent state after a disk failure and
a system failure occur prior to successful completion of
writing new data to one or more blocks of a stripe of said RAID
array, said disk failure rendering a block of said stripe in
said RAID array unreadable, comprising the steps of: prior to
writing new data to one or more blocks of a stripe in said R.AID
array, reading said one or more blocks of said stripe to obtain
CA 02165910 2004-05-27
77761-6
7c
prior data stored in said one or more blocks of said stripe,
said prior data stored in said stripe storage means comprising
a prior parity value read from a parity block of said stripe
and prior data read from one or more data blocks of said
stripe; storing said prior data stored in said one or more
blocks of said stripe in non-volatile stripe storage means;
initiating the writing of said new data to said one or more
blocks of said stripe; and if said writing of said new data to
said one or more blocks of said stripe in said RAID array is,
successfully completed, clearing said prior data from said one
or more blocks of said stripe from said stripe storage means;
otherwise, performing the steps of: after a failure has
occurred, checking said stripe storage means to determine
whether said stripe storage means contains any prior data for
any stripe; when said stripe storage means contains prior data
for any stripe, performing the steps of: determining whether
said block of said stripe in said RAID array rendered
unreadable by said disk failure is one of said data blocks of
said stripe in said RAID array for which prior data has been
stored in said stripe storage means; if said block of said
stripe in said RAID array rendered unreadable by said disk
failure is one of said data blocks of said stripe in said RAID
array for which prior data has been stored in said stripe
storage means, performing the steps of: reading data from each
remaining readable data block of said stripe in said RAID array
other than said data block rendered unreadable by said disk
failure; recomputing a parity value for said stripe based on
said prior data stored in said stripe storage means for said
data block rendered unreadable by said disk failure and on said
data read from said each remaining readable data block of said
stripe; and writing said recomputed parity value for said
stripe to said parity block of said stripe in said RAID array.
CA 02165910 2004-05-27
77761-6
7d
In accordance with yet another aspect of the present
invention, there is provided a method for maintaining a
consistent file system, wherein said file system is stored in
stripe of blocks in a RAID array, that allows for recovery of
the file system to a consistent state after disk failure and
system failure occur prior to completion of writing new data to
one or more blocks of a stripe of said RAID array, said disk
failure rendering a block of said stripe in said RAID array
unreadable, comprising the steps of: prior to writing new data
to one or more blocks of a stripe in said RAID array, reading
said one or more blocks of said stripe to obtain prior data
stored in said one or more blocks of said stripe, said prior
data stored in said stripe storage means comprising a prior
parity value read from a parity block of said stripe and prior
data read from one or more data blocks of said stripe; storing
said prior data stored in said one or more blocks of said
stripe in non-volatile stripe storage means; initiating the
writing of said new data to said one or more blocks of said
stripe; and if said writing of said new data to said one more
blocks of said stripe in said RAID array is successfully
completed, clearing said prior data from said one or more
blocks of said stripe from said stripe storage means;
otherwise, performing the steps of: after a failure has
occurred, checking said stripe storage means to determine
whether said stripe storage means contains any prior data for
any stripe; when said stripe storage means contains prior data
for any stripe, performing the steps of: determining whether
said block of said stripe in said RAID array rendered
unreadable by said disk failure is one of said data blocks of
said stripe in said RAID array other than said one or more data
blocks for which prior data has been stored in said stripe
storage means; if said block of said stripe in said RAID array
rendered unreadable by said disk failure is one of said data
blocks of said stripe in said RAID array other than said one or
CA 02165910 2004-05-27
77761-6
7e
more data blocks for which prior data has been stored in said
stripe storage means, performing the steps of: reading data
from each remaining readable data block of said stripe in said
RAID array other than said one or more data blocks of said
stripe for which prior data has been stored in said stripe
storage means; computing data for said data block rendered
unreadable by said disk failure based on said data read from
said each remaining data block of said stripe in said RAID
array other than said one or more data blocks of said RAID
array for which prior data has been stored in said stripe
storage means and on said prior data or said one or more data
blocks of said stripe and said prior parity value for said
parity block of said stripe stored in said stripe storage
means; reading data from said data blocks of said stripe in
said RAID array for which prior data has been stored in said
stripe storage means; recomputing a new parity value based on
said computed data for said data block rendered unreadable by
said disk failure, said data read from said data blocks of said
stripe in said RAID array for which prior data has been stored
in said stripe storage means; and said data read from said each
remaining readable data block of said stripe in said RAID array
other than said one or more data blocks for which prior data
has been stored in said stripe storage means; and writing said
new parity value for said stripe to said parity block of said
stripe in said RAID array.
In accordance with yet another aspect of the present
invention, there is provided a method for maintaining a
consistent file system, wherein said file system is stored in
stripes of blocks in a RAID array, that allows for recovery of
the file system to a consistent state after disk failure and
system failure occur prior to completion of writing new data to
one or more blocks of a stripe of said RAID array, said disk
failure rendering a block of said stripe in said RAID array
CA 02165910 2004-05-27
77761-6
7f
unreadable, comprising the steps of: prior to writing new data
to one or more blocks of a stripe in said RAID array, reading
said one or more blocks of said stripe to obtain prior data
stored in said one or more blocks of said stripe, said prior
data stored in said stripe storage means comprising a prior
parity value read from a parity block of said stripe and prior
data read from one or more data blocks of said stripe; storing
said prior data stored in said one or more blocks of said
stripe in non-volatile stripe storage means; initiating the
writing of said new data to said one or more blocks of said
stripe; and if said writing of said new data to said one or
more blocks of said stripe in said RAID array is successfully
completed, clearing said prior data from said one or more
blocks of said stripe from said stripe storage means;
otherwise, performing the steps of: after a failure has
occurred, checking said stripe storage means to determine
whether said stripe storage means contains any prior data for
any stripe; when said stripe storage means contains prior data
for any stripe, performing the steps of: determining whether
said block of said stripe in said RAID array rendered
unreadable by said disk failure is one of said data blocks of
said stripe in said RAID array other than said one or more data
blocks for which prior data has been stored in said stripe
storage means; if said block of said stripe in said RAID array
rendered unreadable by said disk failure is one of said data
blocks of said stripe in said RAID array other than said one or
more data blocks for which prior data has been stored in said
stripe storage means, writing said prior data for said one or
more data blocks of said stripe and said prior parity value
stored in said stripe storage means to said stripe in said RAID
array.
In accordance with yet another aspect of the present
invention, there is provided a method for maintaining a
CA 02165910 2004-05-27
77761-6
7g
consistent file system, wherein said file system is stored in
stripes of blocks of a RAID array, that allows for recovery of
the file system to a consistent state after a disk failure and
a system failure occur prior to successful completion of
writing new data to one or more blocks of a stripe of said RAID
array, said disk failure rendering a block of said stripe in
said RAID array unreadable, comprising the steps of: prior to
writing new data to one or more blocks of a stripe in said RAID
array, reading any other blocks of said stripe in said RAID
array other than said one or more blocks to which new data is
to be written to obtain prior data stored in said other blocks
of said stripe; storing said prior data stored in said other
blocks of said stripe in non-volatile stripe storage means;
initiating the writing of said new data to said one or more
blocks of said stripe in said RAID array; and if said writing
of said new data to said one or more blocks of said stripe is
successfully completed, clearing said prior data from said
other blocks of said stripe from said stripe storage means;
otherwise performing the steps of: after a failure has
occurred, checking said stripe storage means to determine
whether said stripe storage means contains any prior data for
any stripe; when said stripe storage means contains prior data
for any stripe, performing the steps of: determining whether
said block of said stripe in said RAID array rendered
unreadable by said disk failure is one of said data blocks of
said stripe in said RAID array for which prior data has been
stored in said stripe storage means; if said block of said
stripe in said RAID array rendered unreadable by said disk
failure is one of said data blocks of said stripe in said RAID
array for which prior data has been stored in said stripe
storage means, performing the steps of: reading data from each
remaining readable data block of said stripe in said RAID array
other than said data block rendered unreadable by said disk
failure; recomputing a new parity value for said stripe based
CA 02165910 2004-05-27
77761-6
7h
upon said data read from said each remaining readable data
block of said stripe in said RAID array and said prior data
stored in said stripe storage means for said data block
rendered unreadable by said disk failure; and writing said riew
parity value for said stripe to a parity block of said stripe
in said RAID array.
In accordance with yet another aspect of the present
invention, there is provided a method for operating a file
system that provides protection against corruption of the file
system upon writing new data to the file system after a disk
failure has rendered unreadable a data block in a stripe of
RAID array wherein the file system is stored, and that allows
recovery of the file system to a consistent state when a system
failure occurs prior to all of said new data being successfully
written and comprising the steps of: prior to writing new data
to one or more blocks of said stripe, reading all readable
blocks of said stripe in said RAID array; computing data for
said unreadable block based upon said readable blocks; storing
said computed data in non-volatile stripe storage means;
initiating the writing of said new data to said one or more
blocks of said stripe in said RAID array; and if said writing
of said new data to said one or more blocks of said stripe is
successfully completed, clearing said computed data from said
stripe storage means; otherwise, performing the steps of: after
said system failure has occurred, checking said stripe storage
means to determine whether said stripe storage means contains
any computed data for any unreadable data block of any stripe;
when said stripe storage means containing computed data for an
unreadable data block of a stripe, performing the steps of:
reading data from each readable data block of said stripe
failure in said RAID array other than said data block rendered
unreadable by said disk; recomputing a parity value for said
stripe based on said computed data for said unreadable data
CA 02165910 2004-05-27
77761-6
7i
blocks of said stripe stored in said stripe storage means and
said data read from said remaining readable data blocks in said
stripe in said RAID array; and writing said recomputed parity
value for said stripe to a parity block of said stripe in said
RAID array.
WO 94/29795 2165 g 10 PCT/US9" '-~321
-8-
BRIEF DESCRIPTION OF THE DR.AWINGS
Figure 1 is a bl.ock diagram of a prior art RAID level 4 subsystem;
Figure 2 is a block diagram of a prior art RAID level 5 subsystem;
Figures 3A-3C are prior art diagrams illustrating recomputation of data
stored in a "stripe";
Figures 4A-4B are prior art timing diagrams for parity corruption on
system failure;
Figure 5 is a timing diagram of the present invention for preventing
data corruption on occurrence of a write to a malfunctioning disk;
Figure 6 is aprior art timing diagram illustrating data corruption on a
write with a broken disk;
Figures 7A-7B are timing diagrams of the present invention for
preventing data corruption cin a write with a broken disk;
Figure 8 is a diagram illustrating the present invention.
Figure 9 is a prior art timing diagram illustrating data corruption for
simultaneous system and disk failures;
Figures 1OA-1CC are tiinming diagrams of the present invention
preventing data comiption for simultaneous system and disk faiiures; and,
PCT/US9a In6321
WO 94/29795 2165910
-9-
Figures 11A-11C are flow diagrams of the present invention illustrating
the process of recovery.
Figures 12A-12C are timing diagrams for parity by recalculation.
WO 94129795 PCTIUS9,' '"4321
2165910
-10-
DETAILED DESC TION OF THE PRESENT INVENTION
A method and apparatus for providing error correction for an array of
disks using non-vola-tile random access memory (NV-RAM) is described. In
the following description, niunerous specific details, such as number and
nature of disks, disk block si.es, etc., are described in detail in order to
provide
a more thorough description of the present invention. It will be apparent,
however, to one skilled in the art, that the present invention may be
practiced
without these, specific details. In other instances, well-known features have
not been described in detail so as not to unnecessarily obscure the present
invention.
In particular, nnany examples consider the case where only one block in
a stripe is being updated, but the techniques described apply equally well to
multi-block updates.
The present invention provides a technique for: reducing the time
required for recalculating parity after a system failure; and, preventing
corruption of data in a RAID array when data is written to a malfunctioning
disk and the system crashes. The present invention uses non-volatile RAM to
reduce these problems. A description of the prior art and its corresponding
disadvantages follow;s. The ciisadvantages of the prior art are described for:
parity corruption on ia system failure; data corruption on write with broken
disk; and, data corruption with simultaneous system and disk failures.
PC"T/US9e "321
WO 94129795 2165910
-11-
Recomputine Lost Data 'th RAID
Parity is computed by Exclusive-ORing the data blocks stored in a stripe.
The parity value computed from the N data blocks is recorded in the parity
block of the stripe. When data from any single block is lost (i.e., due to a
disk
failure), the lost data for the disk is recalculated by Exdusive-ORing the
remaining blocks in the stripe. In general, whenever a data block in a stripe
is
modified, parity must be recomputed for the stripe. When updating a stripe by
writing all N data blocks, parity can be computed without reading any data
from disk and parity and data can be written together, in just one I/O cycle.
Thus, writing to all N data blocks in a stripe requires a minimum amount of
time. When writing a single data block to disk, parity-by-subtraction is used
(described below). One I/O cycle is required to read the old data and parity,
and
a second I/O cyde is required to write the new date and parity. Because the
spindles of the disks irn the RAID array are not synchronized, the writes do
not
generally occur at exactly the same time. In some cases, the parity block will
reach the disk first, anci in other cases, one of the data blocks will reach
the disk
first. The techniques described here do not depend on the order in which
blocks reach the disk.
Another alternative for disks having non-synchronized spindles is for
parity to be computed first and the parity block written to disk before a data
block(s) is written to disk. Each data block on a disk in the RAID array
stores 4
KB of data. In the follciwing discussion, the data in each 4 KB block is
viewed
as a single, large integer (64 K-bits long). Thus, the drawings depict integer
values for information stored in the parity and data disk blocks. This
convention is used for illustration only in order to simplify the drawings.
WO 94129795 PCTIUS9-' " ,321
21 65910
-12-
Figure 3A is a diagram illustrating a prior art RAID level 4 subsystem,
where N = 3, comprising four disks, 330-336. In the diagram, disk 330 is the
parity disk. Disks 332-336 are data disks. The diagram illustrates a stripe
320
contained on the disks 330-336 in the RAID array. Disk block 330A is a parity
block containing the i nteger =value 12. Disk blocks 332A-336A are data blocks
of
the stripe 320, respeclively. lData blocks 332A-336A contain data values of 4,
7
and 1, respectively. Data for each block 332A-336A in a single stripe 320 is
represented as an integer. Parity for stripe 320 is represented as the sum of
data
values stored in data blocks 332A-336A. Parity block 330A contains the value
12 (i.e., 4+7+1). Figure 3A is a drawing that is merely one example of an
error
correction technique using parity. The parity value is the Exdusive-OR of the
data blocks 332A-336A, but the mathematical properties of addition match
those of the Exdusive-OR function. Therefore, addition is used in Figure 3A.
Figure 3B is a timing diagram of activity on the stripe 320 illustrated in
Figure 3A. The table has headings of Parity, Data 0, Data 1 and Data 2. The
values 12, 4, 7 and 1 are illustrated under the corresponding table headings.
Figure 3B is a-table illustrating a stripe having a lost data block at time
TB. As illustrated in Figure 3B, stripe 320 contains lost data in data block 1
from data disk 334 of' Figure 3A. This is illustrated in the table by a
question
mark enclosed in a box under the data 1 heading. At time TA, parity, data 0
and data 2 have values of 12,, 4 and 1, respectively. The data on disk 334 for
data block 1 can be recalculated in real time as follows:
Datal=Parity-DataO-Data2=12-4-1=7, (1)
PCT/US9e '- '321
WC194i29795 2165910
-13-
where data block 1 is computed using the parity block, data block 0 and data
block 2. Thus, the data value 7 stored in data block 1 of disk 334 shown in
Figure 3A can be recomputeci at time TC. In Figure 3B, at time TC, the value 7
that has been recompiited for data block 1, is indicated by being enclosed
within
parentheses. In subsequent figures, recomputed values are represented using
parentheses. That is, the parentheses indicate data for a broken disk as
computed by the pariity and data on the other disks.
As shown in Figure 3B, data on a broken disk can be recomputed using
the parity disk and the remaining disks in the disk array. The broken disk 334
of Figure 3A can eventually be replaced and the old contents of the disk can
be
recalculated and written to a new disk. Figure 3C is a block diagram of the
RAID subsystem containing a new data 1 disk 338. As shown in Figure 3E,
stripe 320 has values of 12, 4, 7 and 1 for parity, data 0, new data 1 and
data 2.
These values are stored in parity block 330A and data blocks 332A, 338A and
336A. Thus, a new disk 338 replaces broken disk 334 of the RAID system, and
the data value stored ;previously in data block 334A of disk 334 can be
computed as shown above and stored in data block 338A of replacement disk
338.
When new data is written to a data block, the parity block is also
updated. Parity is easily computed, as described above, when all data blocks
in
a stripe are being upolated at once. When this occurs, the new value for
parity
is recalculated from the information being written to the disks. The new
parity
and data blocks are then written to disk. When only some of the data blocks in
a stripe are modified, updatizig the parity block is more difficult since more
I/O
operations are required. There are two methods for updating parity in this
case: parity update by subtraction; and, parity update by recalculation.
WO 94/29795 2165910 PCTIUS9e '321
-14-
For example, when a single data block is written, the RAID system can
update parity by subtraction. The RAID system reads the parity block and the
block to be overwritten. It first subtracts the old data value from the parity
value, adds the new data value of the data block to the intermediate parity
value, and then writes both the new parity and data blocks to disk.
For recalculaticin of parity, the RAID system first reads the other N-1
data blocks in the stripe. After reading the N-1 data blocks, the RAID system
recalculates parity from scratch using the modified data block and the N-1
data
blocks from disk. Once parity is recalculated, the new parity and data blocks
are
written to disk.
Both the subtricEion and recalculation technique for updating parity can
be generalized to situations ivhere more than one data block is being written
to
the same stripe. For subtraction, the parity blocks and the current contents
of
all data blocks that are about to be overwritten are first read from disk. For
recalculation, the cun-ent contents of all data blocks that are not about to
be
overwritten are first read from disk. The instance where all N data blocks in
the stripe are written simultaneously is a degenerate case of parity by
recalculation. All data blocks that are not being written are first read from
disk,
but in this instance, there are no such blocks.
How Strives Become Incons,stent During System Failure
An inconsistent stripe comprises a parity block that does not contain the
Exclusive-OR of aIl other blocks in the stripe. A stripe becomes inconsistent
when a system failure occurs while some of the writes for an update have been
WO 94/29795 2165 91O PCT/US9e '321
-15-
completed but others have not. For example, when a first data block is being
overwritten. As previously clescribed, the parity block for the stripe is
recomputed and overwritten as well as the data block. When the system fails
after one of the data blocks has been written to disk, but not the other, then
the
stripe becomes inconsistent.
A stripe can ortly become inconsistent when it is being updated. Thus,
the number of potentially inconsistent stripes at any instant is limited to
the
number of stripes that are being updated. For this reason, the present
invention maintains a list in NV-RAM comprising all the stripes that are
currently being updaited. Since only these stripes can potentially be
corrupted,
parity is recalculated after a system failure for only the stripes stored in
the list
in NV-RAM. This greatly reduces the total amount of time required for
recalculating parity after a system failure in comparison to the prior art
methods, described previously, that take much longer.
Parity Corruption On A System Failure In The Prior Art
In the following diagrams, the value indicated within parentheses for a
malfunctioning data disk is not an actual value stored on disk. Instead, it is
a
calculated value retained in memory for the broken disk in the RAID array.
Figure 4A is a prior art diagram illustrating a system crash while
changing values are written to disks 330-336 of Figure 3A. The diagram is for
the case where the da.ta blocic reaches the disk before the parity block. As
indicated in Figure 4A, time is increasing in a downward direction. At time
TA, the parity block has a value of 12 and data blocks 0 to 2 have values of
4, 7,
and 1, respectively. At time TB, a new value of 2 is written (indicated by a
box
PCT/US94 321
WG 94/29795 2165 910
-16 around the value 2) to data block 0, thereby replacing the value of 4 that
is
stored in data block 0 at time TA. The other values stored in data blocks 1
and 2
do not change. When operaling normally, the prior art writes a new parity
value of 10 (indicated by a box) at time TC to the parity disk as indicated
under
the parity heading. This updates the parity block for the write to data block
0 at
time TB. The new value of 10 for parity at time TC is computed from the
values of 2, 7, and 1 of data blocks 0 to 2, respectively. Thus, the timing
diagram in Figure 4A illustrates a prior art RAID subsystem in the case where
the data block reaches, disk before the parity block.
When a systemL failure occurs between time TB and TC in Figure 4A,
parity is corrupted for the stripe. The timing diagram shows that a new data
value of 2 is written to data disk 0 at time TB before recomputed parity for
the
stripe is updated. Thus, when the RAID subsystem subsequently restarts, the
parity disk has the olci value of 12 (indicated by an underline) instead of
the
correct value of 10. This occurs since the stripe was not updated before the
system failure occurre.d. The parity for the stripe is now corrupted since:
Parity=DataO+Data1+Data2=2+7+1=10:;f- 12. (2)
Similarly, Figtu-e 4B is another prior art diagram illustrating a system
crash while changing values are written to disks 330-336 of Figure 3A. The
diagram is for the case where the parity block reaches disk before the data
block.
At time TA, the parity block has a value of 12 and data blocks 0 to 2 have
values
of 4, 7, and 1, respectively. At time TB, a new value of 10 is written
(indicated
by a box around the value 2) to the parity block, thereby replacing the value
of
12 that is stored in the parity 'block at time TA. The data values stored in
data
blocks 0-2 do not change. The new value of 10 for parity at time TB is
--WO 94/29795 - 2 j b 5910 PCTIUS91 321
-17-
computed from the viclues of 7 and 1 for data blocks 1 and 2, respectively,
and
the new value of 2 for data block 0. When operating normally, the prior art
writes the new data value of :2 (indicated by a box) at time TC to the data
disk 0
as indicated under the Data 0 heading. This updates the data block 0 in
accordance with the write to the parity block at time TB. Thus, the timing
diagram in Figure 4A illustrates a prior art RAID subsystem in the case where
the parity block reaches disk before the data block.
When a systerrL failure occurs between time TB and TC in Figure 4B,
parity is corrupted fo:r the stripe. The timing diagram shows that the new
parity value of 10 is -oiritten to the parity disk at time TB before data
block 0 of
the stripe is updated. Thus, when the RAID subsystem subsequently restarts,
data disk 0 has the old value of 4 (indicated by an underline) instead of the
correct value of 2. This occurs because the stripe was not updated before the
system failure occurred. The, parity for the stripe is now corrupted since:
Parity=Data0+Datal+Data2=4+7+1=12-A 10. (3)
Figures 4A-4B ;illustrate two cases of writing new data to a data block and
updating the parity disk where the spindles of the disks in the RAID array are
not synchronized. The first case shown in Figure 4A illustrates a new data
value reaching the data disk first, and then subsequently updating the parity
value on the parity disk. The second case illustrated in Figure 4B illustrates
parity reaching disk first followed by the data update. For Figures 4A and 4B,
when the system fails between times TB and TC, corruption of the file system
occurs. If the system fails after time TB in Figures 4A and 4B, then the
parity
values illustrated are not correct for the system. In the case of the system
illustrated in Figure 4EA., the :new data values have a sum of 10, which is
equal
PCTIUS9 5321
WO 94/29795 2165910
-18-
to the values of 2, 7 and 1. However, the parity value at time TB indicates a
value of 12. Thus, the parity value stored on the parity disk does not equal
the
new parity value for ithe data values stored on data disk 0-2. Similarly, if a
failure occurs after thne TB for the second system illustrated in Figure 4B,
the
data disks 0-1 have viilues of 4, 7 and 1, respectively. The parity value for
these
data blocks is equal tc> 12. However, parity in this system is first updated
before
writing the new data value to disk, therefore, the parity stored on the parity
disk at time TB is equal to 10. Thus, subsequent to time TB, the parity stored
on
the parity disk does nLot equal the parity value for the data blocks since the
new
data was not updated. before the system failed.
In the prior art, after a system fails, parity is recalculated for all of the
stripes on occurrence of a system restart. This method of recalculating parity
after a failure for all stripes irequires intensive calculations, and
therefore, is
very slow. The present invention is a method for recalculating parity after a
system failure. The system rnaintains a list of stripes having writes in
progress
in non-volatile RAM. Upon restarting after a system failure, just the list of
stripes with writes in progress that are stored in non-volatile RAM are
recalculated.
Data Corruption On Write With Broken Disk In The Prior Art
When writing to a RAID array that has a malfunctioning or broken disk,
data corruption occurs during system failure. Figure 6 is a prior art diagram
illustrating data corruption for a malfunctioning disk when a system failure
occurs where the data disk is updated for the new data value before parity is
written to disk. In Figure 6, data disk 1 is shown to be malfunctioning by
indicating values within parentheses under the Data 1 heading. At time TA,
WO 94/29795 2165 g1a PCT/US94' <321
-19-
the parity disk has a value of 12. Prior to time TA when data disk 1
malfunctions, the parity disk value is equal to the sum of data disks 0 to 2
having values of 4, 7imd 1, respectively. The value of 7 for data block 1 at
time
TA is enclosed within parentheses. This value does not represent a value
stored on data disk 1, but instead is computed from the
parity block and data 'blocks 0 and 2 of the stripe as follows:
DataO=Parity.- Data 1 - Data2 = 12-4-1 = 7. (4)
At time TB, a new value of 2 is written to data disk 0 (indicated by
enclosing 2 within a box). At: time TB, parity has not been updated for the
new
value of 2 written to data dis'k 0 and has a value of 12. Thus, the computed
value for data block 1 is 9 instead of 7. This is indicated in Figure 6 by
enclosing the value 9 within parentheses for data disk 1 at time TB.
When operating normally at time TC, the parity block is updated to 10
due to the value of 2written to data block 0 at time TB. The new value of 10
for parity at time TC is indicated within a rectangle. For a parity value of
10,
the correct value of 7 for data block 1 is indicated within parentheses. As
indicated in the Figure 6, because data disk 1 is broken, the data stored in
data
block 1 is calculated based on the other blocks in the disk array. After the
first
write at time TB for data block 0, the computed value of data block 1 is
incorrect. The value of 9 for data block 1 is incorrect until the second write
for
parity at time Tc is ccimpleted.
When a systemL failure occurs between times TB and TC, writing to a
RAID array that has a malfunctioning or broken disk corrupts data in the
stripe. As shown in Figure 6 for the prior art, parity is not updated and
WO 94/29795 2r659 10 PCT/US9 M1
-20-
therefore has a value: of 12 (indicated by an underline). Thus, the computed
value for data block '1 of the stripe is incorrect and the stripe is corrupted
as
follows:
Data1= Parity-DataO-Data2=12-2-1=9#7. (5)
Similar corruption of data occurs for the case where parity reaches disk
before data does.
Data Corruption With Simultaneous System And Disk Failures
RAID systems are most likely to experience a disk failure when a system
failure occurs due to power interruption. Commonly, a large, transient
voltage spike occurring aftei- power interruption damages a disk. Thus, it is
possible for a stripe t:o be coirrupted by simultaneous system and disk
failures.
Figure 9 is a prior art diagram illustrating simultaneous system and disk
failures where the data disk is updated for a new data value before parity is
written to disk. At time TA, the parity disk has a value of 12 and data disks
0-2
have values of 4, 7, and 1, respectively. At time TB, a new value of 2 is
written
to data disk 0 (indicated by a box). At time TB, parity is not updated for the
new
value of 2 written to data disk 0 and has a value of 12. When a system failure
occurs between times TB anci TC, the value of disk 1 is corrupted. This occurs
due to simultaneous system and disk failures between times TB and T.
At time TC, parity is not updated due to the system failure and therefore
has a value of 12 instead of 7Ø Further, data disk 1 is corrupted due to the
disk
WO 94/29795 2 165 Q~ 0 PCT/US94 '321
-21- 7
failure. The computed value of 9 for data block 1 is incorrect. It is computed
incorrectly for data disk 1 using the corrupt parity value as follows:
Data1= Parity - Data 0 - Data 2 = 12 - 2 - 1 = 9:A 7. (7)
Data is similarly corrupted for the case where parity reaches disk before
data.
Overview Of The Present Invention
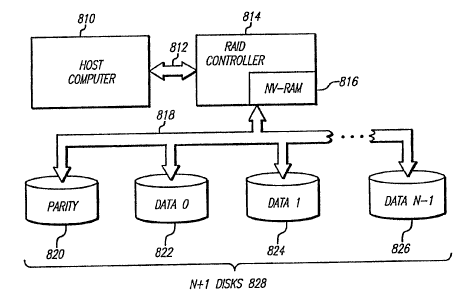
Figure 8 is a diagram illustrating the present invention for providing
error correction using NV-RAM for a RAID system comprising host computer
810, RAID controller 814 inchiding NV-RAM 816, and N+1 disks 820-826. Host
computer 810 is coupled to RAID controller 814 by a first communications
channe1812. RAID ccintroller 814 comprises NV-RAM 816 for storing stripes
of the RAID array 828 that are possibly in an inconsistent state. RAID
controller 814 is couplied to the N+1 disks 820-826 of the RAID array 828 by a
second communications channel 818. The RAID array 828 comprises parity
disk 820 and N data diisks 822-826, respectively.
NV-RAM 816 is used to increase the speed of RAID recovery after a
system failure by maintaining a list of all parity blocks stored on parity
disk 820
that are potentially inc:onsistent. Typically, this list of blocks is small.
It may be
several orders of magnitude smaller than the total number of parity blocks in
the RAID array 828. F'or exaniple, a RAID array 828 may comprise hundreds of
thousands of parity blocks while the potentially inconsistent blocks may
number only several hundred or less. Knowledge of the few parity blocks that
WO 94/29795 2165910 PCTIUS94' 121
-22-
are potentially inconsiistent facilitates rapid recalculation of parity, since
only
those parity blocks have to be: restored.
The present invention also uses NV-RAM 816 to safely write data to a
RAID array 828 having a broicen disk without corrupting data due to a system
failure. Data that can be corrupted is copied into NV-RAM 816 before a
potentially corrupting operation is performed. After a system failure, the
data
stored in NV-RAM 816 is use!d to recover the RAID array 828 into a consistent
state.
Figures 11A-C are flow diagrams illustrating the steps performed by the
present invention. Referring first to Figure 11A, a boot operation is
executed.
At decision block 11011 a check is made to determine if the system has just
failed. If decision block returns true, the system proceeds to step 1102
(Figure
11B) and executes a recovery process. If decision block returns false, the
system
proceeds to step 1103 (Figure 11C) for normal operation.
Referring now ito Figure 11B, a flow diagram of recovery after system
failure is illustrated. At decision block 1104 a check is made to determine if
there are any remaining stripes specified in the list of dirty stripes in NV-
RAM. If decision block 1104 returns false, the system proceeds to a return
step.
If decision block 1104 returns true, the system proceeds to step 1105.
At step 1105, the stripe number is obtained. At step 1106, the data blocks
of the identified stripe required to recompute parity are read. Parity is
recomputed for the stripe at step 1107. At step 1108, the new parity block for
the stripe is written. 'I'he system then returns to decision block 1104.
WO 94129795 2+ 657 t O PCT/US94'" '321
-23-
Normal operation is iTlustrated in Figure 11C. At step 1109, all blocks
required to update a stripe are read. At step 1110 a new parity for the stripe
is
computed using the riew data. The stripe number of that stripe is written to
the list of dirty stripes in NV=-RAM at step 1111. At step 1112, the disk
blocks
required to update the stripe are written to disk. At step 1113 the number of
the stripe is removed from the list of dirty stripes in NV-RAM.
Pari orrup 'on For ASy tem Failure Using NV-RAM
Figure 5 is a diagram illustrating the present invention for preventing
corruption of parity using NV-RAM. The timing diagram is described with
reference to Figures 11A-C. :Figure 5 is a timing diagram for the present
invention illustrating a system crash while changing values are written to
disks 330-336 of Figure 3A. 7['he diagram is for the case where parity is
computed for a new data value and the data is written to disk prior to
updating
the parity block. At time TA, the parity block has a value of 12 and data
blocks 0
to 2 have values of 4, 7, and 1, respectively. At time TA, step 1109 of Figure
11 C
for the present invenition is performed where blocks necessary to update the
stripe are read into mLemory. The system performs step 1110 where a new
parity value is computed dependent upon the new data value(s). At time TB,
step 1111 of Figure 17[C is performed where the stripe number is written to
NV-RAM.
At time TC, in step 1112, the new data value of 2 is written (indicated by
a box around the value 2) to data block 0, thereby replacing the value of 4
that
is stored in data block 0 at time TB. The other values stored in data blocks 1
and 2 do not change. First, consider the normal case where the system does
not fail. The present invention writes a new parity value of 10 (indicated by
a
Wl) 94l29795 PCT/US9 '1321
2165910
-24-
box under the parity heading) at time TD in step 1112. This updates the parity
block for the write to data block 0 at time TC. At time TE, in step 1113, the
stripe number in NV-RAM is cleared. Thus, the stripe comprising the blocks
for the parity disk and data ciisks 0-2 have values of 10, 2, 7, and 1,
respectively.
Next, consider the ruse when the system does fail between time ti and tp
(between steps 1111 and 1113). The system reboots, and begins execution at
START in Figure 11 A.
In decision block 1101, at time TD, when a system fault occurs, decision
block 1101 returns true (Yes). The stripe has a value of 12 (indicated by an
underline) for parity and values for data disks 0-2 of 2, 7, and 1,
respectively.
As illustrated in Figure 5 for time Tc, parity is corrupted after a system
failure
since:
Parity=DataO+Datal+Data2=2+7+1=10#12. (9)
However, the stripe can be recovered to a consistent state. NV-RAM includes
an indication of the stripes that are candidates for recovery, i.e. a list of
stripes
that are being updated. Everything but the parity value is available on disk
(the "2" having been written to disk at time TC). The data values for the
stripe
are read from disk and a new parity value of 10 is calculated.
Parity=DataO+Datal+Data2=2+7+1=10. (10)
Thus, the newly calctilated parity value of 10 is written to the parity disk
in
step 1108 at time TD, and the stripe is no longer corrupt.
2165910
-25-
The following is an example of pseudo code that
describes the operation of Figure 11C:
(1) Read all disk blocks required to update stripe.
(2) Ca:Lculate new parity contents.
(3) Add stripe # for stripe being written to NV-RAM
dirty stripe list.
(4) Wr:Lte all disk blocks required to update
stripe.
(5) Rernove stripe # for stripe just written from
NV-=RAM dirty stripe list.
After a systern failure, a part of the start-up
procedure of Figure 11B can be described by the following
pseudo code:
for (al]. stripes specified in the NV-RAM dirty
stripe ]. ist )
{
(1) Read all data blocks in the stripe.
(2) Recompute the parity block for the stripe.
(3) Write the new parity block for the stripe.
}
Thus, the present invention prevents parity corruption after a
system failure by using NV-RAM.
Parity Corruption Detection with a Bitmap Instead of a List
The previous section describes a technique in which
a list of potentieilly corrupted stripes is kept in NV-RAM so
that on reboot after acsystem failure, only the stripes in the
list need to have their parity blocks recalculated. An
74906-4
2165910
-25a-
alternate embodimi=nt of the present invention uses a bitmap in
NV-RAM to indicatia the potentially corrupted stripes whose
parity blocks must be recalculated after a system failure.
74906-4
Wp 94129995 PCT/US9,4 '16321
2165910
-26-
T'his technique uses a bitmap in which each bit represents a group of one
or more stripes. A typical disk array might have 250,000 stripes. If each
entry
in the bitmap represE.nts a single stripe, the bitmap will be about 32 KB.
Letting
each bit represent a group of' 32 adjacent stripes reduces the size to 1 KB.
After a system failure, this technique is essentially identical to the "list
of stripes" technique, except that the bitmap is used to determine which
stripes
need parity recalculaition instead of the list. All stripes in groups whose
bit is
set in the bitmap have their parity recalculated.
Managing the bitmap during normal operation is slightly different than
managing the list. It is no longer possible to clear a stripe's entry as soon
as the
update is complete, because a single bit can indicate activity in more than
one
stripe. One stripe's update nlay be done, but another stripe sharing the same
bit may still be activeõ
Instead, the appropriate bit for a stripe is set just before the stripe is
updated, but it is not cleared after the update is complete. Periodically,
when
the bitmap has accumiulated too many entries, all blocks are flushed to disk,
ensuring that there caLn be no inconsistent stripes, and the entire bitmap is
cleared. The followirLg pseudo-code implements this:
(1) Read all blocks required to update stripe.
(2) Calculate new parity contents.
(3) Set bitmap entry, for stripe being updated.
(4) Write all disk blocks required to update stripe.
(5) If bitmap is too full, wait for all blocks to reach disk and clear the
entire biixnap.
WO 94/29795 PCT/US941"l;321
2165910
-27-
In case of system failure, the bitmap results in more blocks to dean than
the list, but the savings are still considerable compared with recomputing
parity for all stripes in the system. A typical RAID system has 250,000
stripes,
so even if 2,500 potentially-corrupted stripes are referenced in the bitmap,
that
is just 1% of the stripes in the system.
The bitmap ted:inique is especially useful with write-caching disks
which don't guarantee that data will reach disk in the case of power failure.
Such disks may hold data in RAM for some period before actually writing it.
This means that parity corruption is still a possibility even after the stripe
update phase has completed. The list technique would not work, because the
stripe's parity is still potentially corrupted even though the stripe has been
removed from the lisit.
Thus, using the bitmap technique and instructing each disk to flush its
internal cache at the same time that the bitmap is cleared, allows the
invention
to work in combination with write-caching disk drives.
Data Corruption On 1Nrite ith Broken Disk Using.NV-RAM
The present invention solves this problem for data corruption on
occurrence of a write -with ainalfunctioning disk by saving data from the
broken disk in non-volatile RAM. Figure 7A is a timing diagram of the
present invention for preventing data corruption by storing data from a
malfunctioning disk in NV-RAM. The drawing is discussed with reference to
Figures 11A-C. In Figiure 7A, data is written to disk before parity is
updated. At
time TA, broken data disk 1 is illustrated having a value of 7 indicated
within
WO 94/29795 PCT/US94'~Q21
2165910
-28-
parentheses. The value of 7 within parentheses indicates that data disk 1 is
malfunctioning and that it is the computed value for the disk. This value is
computed by subtraciting the values of 4 and 1 of data disks 0 and 2 from the
value of 12 stored in the parity disk. In step 1109, the stripe is read from
the
RAID array at time TA. The NV-RAM is erased. This is indicated in Figure 7A
by a question mark tutder the heading for NV-RAM.
At time TB, a value of 7 for the malfunctioning data disk 1 is written
into NV-RAM, according to step 1109. The value of 7 for data disk 1 that is
written into NV-RAM is indicated by a rectangular box in Figure 7A. The
system then computes a new- value of parity for the stripe in step 1110 of
Figure
11C.
At time TC, a new value of 2 (indicated by a box) for data disk 0 is written
to the disk before parity for the stripe is updated according to step 1112.
Therefore, at time Tc, the value for data disk 1 is 9 and is indicated within
parentheses accordingly. In the normal case, where the system does not fail, a
new parity value of 10 is written to disk at time TD, and the computed value
of
disk 1 becomes 7 again, which is correct. When a system failure occurs
between times TC anci TD, a new value of parity is updated correctly using
NV-RAM with respect to the value of 2 written to data disk 0 at time TC.
The parity is correctly updated at time TD by first reading the value for
all functioning data dlisks, according to step 1106, stored in NV-RAM, and
recalculating its valui? as follows:
Parity=DataO+NV-1ZAIvt+Data2=2+7+1=10. (12)
WO 94/29795 PCT/US94l1'5321
2165910
-29-
Thus, a correct value of 10 is computed for parity when the present invention
restarts after a system crash. In step 1108, the value of 10 is written to the
parity
disk at time TD, thus returning the computed value of Dl to 1, which is
correct.
At time TE, NV-RAM is cleared in step 1113. Thus, the present invention
prevents data from being corrupted by a system fault when a disk is
malfunctioning by using NV-RAM.
Figure 7B is a iiming ciiagram of the present invention for preventing
data corruption by storing data from a malfunctioning disk in NV-RAM for
the case where parity is written to d.isk before data is updated. At time TA,
broken data disk 1 is ;illustrat:ed having a value of 7 indicated within
parentheses. This value is computed as described above with reference to
Figure 7A. In step 1109, the stripe is read from the RAID array at time TA.
The
NV-RAM is cleared which is indicated by a question mark under the heading
for NV-RAM.
At time TB, a value of 7 for the malfunctioning data disk 1 is written
into NV-RAM according to step 1109. The value of 7 for data disk 1 that is
written into NV-RAM is indicated by a rectangular box in Figure 7B. The
system then computes a new value of parity for the stripe in step 1110 of
Figure
11.
At time TC, a new value of 10 (indicated by a box) for parity is written to
the parity disk in step 1108 before data block 0 is updated. Therefore, at
time
TC, the value for data disk 1 is 5 and is indicated within parentheses
accordingly. When a system failure occurs between times TC and TD, a new
parity value is updated corre,:tly for the parity disk using NV-RAM. At
WO 94/29795 PCTlUS94/n6321
2165910
-30-
decision block 1101 after the system reboots, a check is made if a system
failure
occurred. The decision bloilc accordingly returns true (Yes) in the present
example, and continues at step 1104.
Parity is correctly updated at time TD by recalculating its value as
follows:
Parity = NV-data for broken disk (7) + on-disk data for all non broken
disks = 4 + 7 + 1=12. (13)
Thus, as shown in Figures 7A-7B, when the system is about to write to a
stripe, it saves the value for malfunctioning data disk 1 in non-volatile RAM.
It then writes the new value for data disk 0 (parity) to disk. If a system
crash
occurs after the new value is written to disk 0 (the parity disk) at time TC,
the
value for data disk ',1 is con=upt. After the system failure, the new value of
parity (data disk 0) is calcuiated using the value of 7 stored in NV-RAM
instead
of the computed value of 5 for data disk 1. The value of parity (data disk 0)
is
then written to disk. Once this is completed, NV-RAM is erased.
Simultaneous S,yste:m and Disk Failure Using NV-RAM
The present invention solves the problem of parity and data corruption
when simultaneous system and disk failures occur by saving blocks of stripes
in NV-RAM. Using NV-RAM allows the system to be recovered to a
consistent state when a system crash occurs while updating multiple blocks (in
the following example, data blocks 0 and 1) in the system. Changing these data
blocks further requires that the parity of the stripe be updated. The present
invention always saves into NV-RAM any block that is read from disk (e.g.,
WO 94/29795 PCT/US94/116321
32165910
before updating data block I), read it into NV-RAM) for this purpose. Thus,
stripe information can be recomputed from the data stored in NV-RAM. The
present invention provides two solutions for this using parity by subtraction
and parity by recalccaation.
In parity by subtraction, data induding parity and data blocks is read
from disk before it is; updated. Figure 10A is a timing diagram of the present
invention for preventing parity and data corruption by storing blocks of a
stripe in NV-RAM. 'The drawing is discussed with reference to'Figures 11A-C.
In Figure 10A, data is written to disk before parity is updated. At time TA,
the
parity block and data block 0 are read from the RAID array. The NV-RAM is
erased. This is indicated in Figure 10A by a question mark under the heading
for NV-RAM.
At time TB, the parity block and data block 0 are written into NV-RAM
as they are read frorrt disk. 'rhe parity block and data block 0 that are
written
into NV-RAM are indicated by a rectangular box in Figure 10A. The system
then computes a new value of parity for a value of 2 for data block 0.
At time TC, the new value of 2 (indicated by a box) for data disk 0 is
written to the disk before parity for the stripe is updated. When a system
failure occurs betwern times TC and TD, a disk in the RAID array
malfunctions, and thus the present invention provides solutions for the three
cases of a broken disk: the parity disk; data disk 0; and, data disk 2 (or 3).
At
decision block 1101, a check is made if a system failure occurred. The
decision
block accordingly returns true (Yes) in the present example, and continues at
step 1104. The three cases of a broken disk due to system failure where parity
is
calculated by subtraction are shown in Figures 10A-10C, respectively.
WO 94129795 2 16591 O PCT/US94/A6321
-32-
At time TD in Figure 10A, the parity disk malfunctions due to the
system failure between times TC and TD. In this case, there is nothing to be
done. No data is lost, and :no information can be written to the parity disk.
Referring to Figure 1OB, at time TD, data disk 0 malfunctions due to the
system failure between times Tc and TD. The general equation for
recalculating parity in this case is:
parity := "NV-value for broken disk"
+ "on-disk values for all non-broken disks"
In the present example that becomes:
parity - NV(Data 0) + Data 1 + Data 2= 4+ 7+ 1 = 12
In effect, the :parity is being updated so as to restore the broken disk to
the value stored for it in the NV-RAM. In this particular example, the new
value for parity happens to match the old value. If other data blocks besides
data 0 were also being updated, and if one of them reached disk before the
system failure, then. the new parity value would not match the old.
Referring to ]rigure 10C, at time TD, data disk 1 malfunctions due to the
system failure between times TC and TD. This case is handled by reading the
parity and data dislc 0 values from NV-RAM in step 1114 and writing them to
disk (indicated by a box). Thus, the change to data disk 0 is overwritten, but
the
stripe is returned to a consistent state. Data disk 1 is indicated as being
broken
at times TD and TE by enclosing its value in parentheses. Thus, the value of
wo 94n9795
2165910 PCTIUS94/A6321
-33-
broken data disk 1 is correctly computed to be 7 (indicated by a box) at time
TD
as follows:
Data 1= NV(Parity) -'.[W(Data 0) - Data 2=12 - 4-1 = 7, (14)
where NV(Parity) and NV(Data 0) are the values for parity and data block 0
stored in NV-RAM. At time TE, NV-RAM is cleared. Thus, in Figure 10C, the
stripe is maintained in a consistent state by the present invention although
data disk 1 (a brokeri disk 2 is handled similarly) malfunctions after the
system
failure between times TC and TD.
This case can idso be addressed by first calculating the old contents of the
broken disk as follovvs:
Di-calc = NV-parity
-'NV values for disks being updated".
-"on-disk values of data disks not being updated".
A new parity value is calculated based on:
parity "Dl-calc from stepabove"
on -disk values for all no-busted data disks".
Simultaneous 5yster=n and I)isk Failure with Parity by Recalculation
In parity by recalculation, the data blocks that are not being updated are
first read from disk, and then parity is recalculated based on these values
combined with the new data about to be written. This is typically used in
cases
Wn 94/29795 2165910 PCT/US94/n6321
-34-
where multiple data blocks are being updated at once, because it is more
efficient than parity by subtraction in those cases. For simplicity, in the
present
example, only one block is updated. The techniques shown apply for updates
of any number of blocks.
Figures 12A-12C are timing diagrams for parity by recalculation. For
times TA, TB and Tc., they are all identical.
At time TA in step 1109, blocks Dl and D2 are read from disk. In step
1110, the system coimputes the new parity based on the new data for disk 0
along with the data just read from disks 1 and 2.
At time TB in step 1111, blocks Dl and D2 are written into NV-RAM,
along with an indication of the stripe to which they belong.
At time TC, ciuring step 1112, the new value "2" is written to disk 0. In
the normal case, thie parity block would also have been written during step
1112, and there would be rio corruption.
In the preserit exam;ple, there is a system failure in combination with a
disk failure. When the system reboots after a system failure, execution begins
at step 1101. Because there is a failure, the decision block returns true
(Yes) and
continues at step 11.02 and performs the necessary steps to recover the RAID
sub-system based on the contents of NV-RAM.
.Figure 12A s;hows the case where the parity disk fails. In this case,
nothing needs to be done. There is no possibility of data loss, because no
data
disks have failed.
WO 94/29795 216591 p PCT/US94/06321
-35-
Figure 12B shows the case where the disk being updated fails. Note that
at time TD, the calculated viaue for disk 0 is incorrect. In general, if
multiple
blocks are being updated, there is not enough information in NV-RAM to
reconstruct the lost data block. This is because with parity by recalculation,
it is
the data that is not being updated that is loaded into NV-RAM. The data on
the failed disk is not saved anywhere.
In this case, tt-e present invention computes a new parity value that sets
the contents of the failed disk to zero. The general equation for this is:
parity = sum of non-broken disks
And in this example that is:
parity=D1 +132=7+1 =8
At time TE, th,e new parity value is written, and at time TF, the NV-
RAM values for Dl and D2 are deared.
With a prior-art file system that writes new data in the same location as
old data, zeroing oui: a data block would be unacceptable. But with WAFL,
which always writes new data to unused locations on disk, zeroing a block that
was being written has no harmful effect, because the contents of the block
were
not part of the file system.
WO 94129795 PCT/US941"1;321
2165910
-~-
Figure 12C shows the case where the disk not being updated fails. Note
that at time TD, the calculated value for disk 1 is incorrect. The equation to
recalculate parity is:
parity = 'NV-RAM value for failed disk"
+ "on-disk values for non-failed disks:
In the present example, that is:
parity= 14V(D1)+D0+D2=7+2+1=10
At time TE, the new parity value is written, and at time TF, the NV-
RAM values for Dl imd D2 are cleared.
In this manner, a method and apparatus are disclosed for providing
error correction for an array of disks using non-volatile random access
memory (NV-RAM).