Note: Descriptions are shown in the official language in which they were submitted.
CA 02202217 1997-04-09
METHOD AND APPARATUS FOR CLASSIFYING
RAW DATA ENTRIES ACCORDING TO DATA PAll~KNS
~F.T,~TF.~ APPTICATION
This is a continuation-in-part of U.S. patent
application Ser. No. 08/514,195, filed August 11, 1995, now
abandoned, entitled Method and Apparatus for Classifying
Raw Data Entries According to Data Patterns.
Io BACKGROUND OF THT~ INV~NTION
The present invention relates generally to a system
for classifying large volumes of raw data and, in
particular, to a method and apparatus for creating an index
to optimally classify a plurality of data entries for
efficient review, inspection, storage, retrieval, sorting,
summarizing and reporting.
Many enterprises generate large volumes of data
entries, each such data entry having associated with it one
or more items representing important information.
Typically, larger enterprises are computerized and the data
entries are inputted into a computer and then transferred
to a mass storage device such as a magnetic disk for later
use in various data analysis and report generating
programs. For example, when a receiving department or a
stock room accepts a delivery of parts to be placed into
inventory, at least the part number and quantity must be
inputted into the computer for later use in inventory,
manufacturing and accounting programs.
Prior art indexes are described as primary vs.
secondary, where primary indexes are ordered by the same
key as the file but secondary indexes refer to a different
attribute of the file record. A dense index identifies
h:~epO9005.97
CA 02202217 1997-04-09
every record of the file whereas a sparse index identifies
logical sections. A single-level index points directly to
the location of the content whereas a multi-level index
accommodates further subdivision of the index at each
level, the final level pointing to the location of the
content. Static indexes are not changed in the normal
operation whereas dynamic indexes are expected to be
altered while an operation is in execution. Regardless of
the method of index, the target of the index reference is
always one specific item. That one specific item may be a
specific record, the first occurrence of a specific value
of a given field, the disk sector on which the data is
found, or something else of a singular definition. The
target is usually defined on (directed to the index from)
individual field(s) of a single record.
Nievergelt, Hinterburger and Sevcik (ACM Transactions
on Database Systems, March, 1984) surveyed combinatorial
indexes. However, their work covered multi-attribute
combinations and disclaimed study of multiple values of a
single data attribute in an index.
Additionally, U.S. Patent No. 5,212,639 shows a method
and electronic apparatus for the classification of
combinatorial data for the summarization and/or tabulation
thereof. An apparatus and a method for creating a database
wherein the data entry, such as a journal entry in
accounting, is the canonical record. A plurality of data
entries to be classified are separate records each
comprised of one or more items having associated quantities
and an entry identifier serving as a pointer to the record.
Each item contains information including at least an item
CA 02202217 1997-04-09
number or label and a quantity. A mapping function is
applied to each data entry to assign item indicators for
the item numbers paired with the associated quantities.
The item indicators for the data entry are sorted into
ascending numerical sequence and an n-dimension sparse
matrix is selected where "n" is the number of items in the
data entry. If the present combination of item indicators
is new, a design record is created for the database based
upon the sparse matrix and including the item indicators,
the associated quantity sums, the total number of data
entries summarized in the design record and a pointer (a
chain of entry identifiers) to the records of the data
entry detail. The quantities for the present data entry
are added to the quantity sums and the entry identifier is
stored in the pointer chain. After all the data entries
have been processed, a search routine can be utilized to
review the various design records as desired. However,
this reference does not teach the utilization of a key
number representing the total number of key fields in the
data entry records group. By utilizing a key number, it is
possible to, for example, minimize the amount of memory
needed to ultimately store the information. Additionally,
the reference fails to teach the retrieval of original data
as well as the creation of any index records. As a result,
the method taught by the reference is more effective when
implemented to audit existing data, rather than to perform
real-time management of data.
Furthermore, U.S. Patent No. 5,390,113 shows a method
and electronic apparatus for electronically performing
bookkeeping upon a plurality of pre-existing accounting
CA 02202217 1997-04-09
journal entries having at least one account number and at
least one data component associated with each account
number. First, a chart of accounts having account numbers
and opening balances associated with the plurality of
journal entries is read electronically. A set of account-
section numbers is then created for each account number.
The journal entries are electronically read individually
and one of the account-section numbers is assigned to each
account number. The assigned account-section numbers and
associated data components are then sorted in a
predetermined order. A design for the predetermined order
is identified and compared with stored design records to
see if such a design already exists. If not, the new
design is stored. If so, the associated data components
are added to the accumulated total for each account-section
number. A tally representing the number of journal entries
summarized is increased by one and an entry identifier is
added to a list for the particular design record. The
process is then repeated for each journal entry. This
reference also fails to teach the utilization of a key
number representing the total number of key fields in the
data entry records group. Additionally, the reference
fails to teach the creation of any index records. As a
result, the teachings of the reference are more effective
when implemented to perform bookkeeping of existing data
rather than to perform real-time management of data.
The difficulties encountered in the prior art
discussed hereinabove are substantially eliminated by the
present invention.
CA 02202217 1997-04-09
SUMMARY OF THE INVFNTION
It is an object of the present invention to select,
index and manage data according to events in order to
achieve true object-oriented programming.
Another object of the present invention is to classify
groups of data.
Still another object of the present invention is to
organize data searches to identify and select data events,
or patterns of data having a common subject, in order to
achieve true object-oriented data organization.
A further object of the present invention is to
improve joint searches by multiple criteria.
Still a further object of the present invention is to
provide a method of classifying a plurality of data entry
records which can be effectively used to perform real-time
data management.
Yet a further object of the present invention is to
provide a method of classifying a plurality of data entry
records and storing the information using a minimum amount
of memory space.
Yet another object of the present invention is to
provide a method of classifying a plurality of data entry
records which provides for the quick storing and retrieval
of information.
Still yet a further object of the present invention is
to provide an apparatus for effectively and efficiently
classifying, storing and retrieving a plurality of data
entry records.
These and other objects of the present invention will
become apparent upon reference to the following
CA 02202217 1997-04-09
specification, drawings and claims.
By the present invention, it is proposed to overcome
the difficulties encountered heretofore. To this end, a
method of classifying a plurality of data entry records is
s provided, and the method comprises reading a data entry
records group from a plurality of data entry records, where
the data entry records group has at least one data entry
record with at least one key field containing an item. The
method further comprises: tallying a key number
representing a total number of key fields in the data entry
records group, creating an index record having a
predetermined number of one or more key fields equal to the
key number, mapping each item in the key fields of the data
entry records group to generate an item indicator in each
of the key fields of the index record, determining whether
each of the item indicators in each of the key fields of
the index record exists in a stored index record. If the
item indicators in each of the key fields of the index
record do not exist in a stored index record, added to the
index record is a pointer enabling the data entry records
group to be located, and the index record is stored. If
the item indicators in each of the key fields of the index
record exist in a stored index record, a pointer scheme
related to the stored index record is altered to enable the
data records group to be located.
In a preferred embodiment of the present invention, a
method of classifying a plurality of data entry records is
provided, and the method comprises: reading a data entry
records group from a plurality of data entry records, where
the data entry records group has at least one key field
CA 02202217 1997-04-09
containing an item, tallying a key number representing a
total number of key fields in the data entry records group,
sorting the key fields in a predetermined sequence,
removing key fields which duplicate, adjusting the key
s number for the key fields removed, creating an index record
having a predetermined number of key fields equal to the
key number, and mapping each item in the key fields of the
data entry records group to generate a corresponding item
indicator in each of the key fields of the index record.
Additionally, an apparatus for classifying a plurality
of data entry records is provided, where the apparatus
comprises computer means connected to a source of data
entry records, at least one of the data entry records
includes at least one key field containing an item. The
apparatus further comprises index records memory connected
to the computer means for storing a plurality of index
records. The computer means is capable of: reading a group
of data entry records from the source, tallying a key
number representing a total number of key fields in the
data entry records group, creating an index record having a
predetermined number of one or more key fields equal to the
key number, mapping each item in the key fields of the data
entry records group to generate an item indicator in each
of the key fields of the index record, determining whether
each of the item indicators in each of the key fields of
the index record exists in a stored index record, if the
item indicators in each of the key fields of said index
record do not exist in a stored index record, the computer
means adds to the index record a pointer to enable the data
entry records group to be located, and stores the index
CA 02202217 1997-04-09
record in the index records memory, and if the item
indicators in each of said key fields of the index record
exist in a stored index record, the computer means alters a
pointer scheme to enable the data entry records group to be
located.
In a preferred apparatus of the present invention, an
apparatus for classifying a plurality of data entry records
is provided, and the apparatus comprises computer means
connected to a source of data entry records, where at least
one of the data entry records comprising at least one key
field containing an item. The computer means is capable
of- reading a group of data entry records from the source,
tallying a key number representing a total number of key
fields in the data entry records group, sorting the key
fields in a predetermined sequence, removing key fields
which duplicate, adjusting the key number for key fields
removed, creating an index record having a predetermined
number of key fields equal to the key number, and mapping
each item in the key fields of the data entry records group
to generate a corresponding item indicator in each of the
key fields of the index record.
BRI~F D~.~CRIPTION OF T~ DRAWINGS
The above, as well as other advantages of the present
invention, will become readily apparent to those skilled in
the art from the following detailed description of a
preferred embodiment when considered in the light of the
accompanying drawings in which:
Fig. l is a schematic perspective view of a three-
dimensional matrix according to the present invention;
Fig. 2a is a schematic representation of a one-
CA 02202217 1997-04-09
dimensional data pattern structure schema according to the
present invention;
Fig. 2b is a schematic representation of a two-
dimensional data pattern structure schema according to the
present invention;
Fig. 2c is a schematic representation of a three-
dimensional data pattern structure schema according to the
present invention;
Fig. 2d is a schematic representation of a four-
dimensional data pattern structure schema according to thepresent invention;
Fig. 3 is a block diagram of the apparatus according
to the present invention; and
Fig. 4 is a flow diagram of the method according to
the present invention.
DF.~CRIPTION OF T~ pREFER~F~n EMBODIMENT
Within the present invention, utilizing index records
results in stored information being much easier to find.
Within the present invention, the source and the target is
a group of items, often times referred to as being an
"event", rather than an individual item, and the data
pattern of the group defines an individual record of the
index. Under these conditions the index records are of
variable length tmultiple fields) rather than a single
field. A search based on one or a small group of items
from a master list discloses all the variable-length index
records which contain the group of items. The retrieved
information comprises the pattern of usage of the group of
items searched.
CA 02202217 1997-04-09
Within the present invention, a data entry records
group is the canonical record. Raw data, typically
provided from a mass storage device, is formed of a
plurality of data entry records. Each data entry records
s group can include one or more key fields each containing an
item of interest to be indexed. Typically, two or more
data entry record groups are related, and therefore need to
be classified or summarized. A master list of all of the
items in the key fields to be found in the raw data can
either be found in storage, or can be created dynamically
by the method and apparatus according to the present
nvent lon .
The present invention can be used to store index
records and to supplement existing, stored index records.
Storing and indexing new index records can be useful in
many situations, including (1) classifying data for real-
time parts analysis, schedules or quality reports, and (2)
managing type hierarchies and sets within object-oriented
programming and object-oriented databases. Other potential
usage can include secondary indexes for existing (1) log
files or (2) relational database tables. Still another
usage involves dynamic operation whereby the index becomes
part of the process of selecting where to place and how to
use newly created data.
Another feature of the index according to the present
invention is management of program branching. A pointer
may be located in each index record to allow the programmer
to specify program action for given patterns of data using
additional instructions. This feature is expected to
simplify some programs.
CA 02202217 1997-04-09
In general, raw data in the form of a plurality of
data entry records is more useful if the data entry record
groups can be sorted based upon items of interest contained
within. A significant savings in data processing time can
be achieved if the data entry records groups can be indexed
or classified by "key" items and such index records stored
for use in subsequent searches, summaries and reports. A
"group" can be defined as one or more data entry records
having a common relationship. A group will have one or
more key fields in which items of interest (key items) are
stored. For example, a simple sales transaction can be
recorded utilizing a first data entry field for the
customer identification, a second data entry field for the
product sold, and a third data entry field for the sales
price. These fields, often termed "attributes", are found
in flat files and database tables as parts of adjacent
records. The customer identification field provides the
basis for grouping within the file or table. Another field
is selected as the key field and the pattern index is
constructed from the data content of the key fields of the
group.
A group having n-key fields can be indexed according
to the present invention by utilizing an n-dimension matrix
with up to Mn values stored where "M" is the number of
items in a master list of key items for all data entry
records in the raw data and "n" is the number of items in
the group. However, not all key item combinations may
occur in any given set of raw data. This allows the use of
a series of sparse matrices, which require space to be
allocated for only those key items which actually exist.
CA 02202217 1997-04-09
For the purposes of illustration, it is assumed that a
plurality of groups of raw data entry records, each group
having three key items of interest, are to be classified.
Potentially then, a three dimensional matrix, such as the
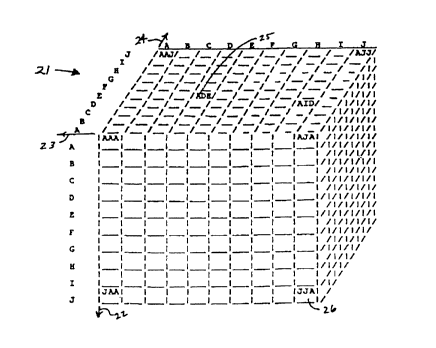
one shown in Fig. 1, could be used to index such raw data.
An example of a three-dimension matrix 21 which
uniquely classifies groups of data entry records each
having a combination of three key items from a master list
of ten items is shown in the Fig. 1. The matrix 21 can
hold up to one thousand values, or different combinations
of the three items in the groups, which is the total number
of cells in the matrix. The items used in the example of
the Fig. 1 are designated by item indicators as the first
ten letters of the English alphabet. The first item of the
group is classified on a "Y" axis 22, the second item is
classified on an "X" axis 23, and the third item is
classified on a "Z" axis 24 of the matrix 21. Thus, a
group of data entry records having key items "ADE" results
in an intersection at a cell 25 and a group of data entry
records having key items "JJA" results in an intersection
at a cell 26.
Shown in Figs. 2a-2d are index records 90, 92, 94, 96,
98, 100, 102, 104, 106 and 108 according to the present
invention. Each index record 90, 92, 94, 96, 98, 100, 102,
104, 106 and 108 includes a variable length record portion
109 which consists of one or more key fields ("key"). As
shown in Fig. 2a, the variable length record portion 109 of
the index record 90 consists of a single key field;
therefore, this index record 90 can be said to be one-
dimensional. In much the same manner, the variable length
CA 02202217 1997-04-09
record portions 109 of the index records 92, 94 and 96
shown in Fig. 2b include two key fields. Therefore, these
index records 92, 94 and 96 can be said to be two-
dimensional. Likewise, the variable length record portions
109 of each of the index records 98, 100, 102 and 104 shown
in fig. 2c have three key fields, and therefore these index
records 98, 100, 102 and 104 can be said to be three-
dimensional. Additionally, the variable length record
portions 109 of each of the index records 106 and 108 shown
in Fig. 2d have four key fields, and therefore these index
records 106 and 108 can be said to be four-dimensional.
Within each of the key fields shown in Figs. 2a-2d is
an item indicator. Each of the item indicators are derived
from a master list which has been previously stored, or can
be created by the method and apparatus of the present
invention. It is the values, or item indicators, in each
key field, substituting for the subscripts of matrix
notation, which define both the pattern and its place in
multidimensional space. Each size variable length record
portion 109 conceptually requires a separate matrix. As
explained above, a three-dimensional sparse matrix is shown
in Fig. 1. Additionally, as shown in Figs. 2a-2d, each
index record includes a pointer ("P1") which enables
corresponding data entry record groups to be located.
Furthermore, each index record may contain a second pointer
("P2") containing additional information.
Assuming that a master list of key items is available
or is created, the matrix design process for each n-
dimension combination involves the steps of: (a) reading a
data entry records group from the source of raw data, (b)
13
CA 02202217 1997-04-09
determining the data pattern structure schema of the data
entry records group in terms of the number of key fields to
be classified, (c) creating an index record for the key
item combination, (d) mapping the key items to generate
s item indicators in key fields in the index record, and (e)
recording pointers in the index to enable the data entry
records group to be located in the raw data. The index may
also include, for example, a second pointer which contains
additional information, and this second pointer may be
utilized for practically any purpose. The result is a
predetermined length index record for each unique data
pattern in the groups of data entry records. After the raw
data has been processed in this manner, each data entry
records group can be located. Thus, the cells in the
matrix shown in the Fig. 1 represent the combinations of
item indicators in the index record key fields
corresponding to any group of data entry records containing
three key items from the master list of "A' through "J".
When the sequential relationship of items within the
master list is fixed, the item indicators substitute for
the subscripts of matrix notation. The sparse matrix
programming technique requires only those records which
exist to be stored in computer memory. Vacant positions or
cells in the matrix shown in the Fig. 1 require no computer
memory.
The index constructed according to the present
invention includes index records which identify the data
patterns of the groups of key items drawn from a master
list. The form of master list file, whether sequential,
array, B+ tree, or some other organization, is not
CA 02202217 1997-04-09
important so long as each master list item is uniquely
identified via the mapping function in the index records.
Furthermore, the master list may be already stored in
memory, or the master list can be constructed dynamically.
One needs primarily to avoid the problems associated with
deleted master records in some file structures. However,
the choice of mapping function and file organization of the
master list does affect the speed of operation of the
process, the comparability of index records over time, and
whether the process can be traced in one or both
directions. The index always identifies a group data
pattern.
Group data patterns represent a new concept in
computer usage. It is a step toward data-driven computing,
long sought by leading writers. The separate analysis of
the patterns of the index at hand provides a new tool for
both computer management and business management. The
index at hand associates a data pattern with a data
location and provides an alternative to methods of
clustering and to the 'join' command of databases. Kimball
and Strehlo (Datamation, June l, 1994) criticized the then-
current practices of query processing in the environment of
relational database and SQL (structured query language).
Although improvement of SQL has reached practice in the
field, the grouping provided by this index has not been
considered.
More than one master list and corresponding index can
be utilized with the same raw data entry records to permit
searching or processing of a particular file or table based
upon another attribute. The index records created from the
CA 022022l7 l997-04-09
groups of data entry records reduce the time required for
searching and organizing the raw data.
A unique feature of search of this index is that it
identifies and retrieves by patterns of keys. Joint
searches cause joint index records to be selected,
therefore only the pertinent data is retrieved from
storage
The application at hand makes use of pointers, a data
structure which contains the address of (the logical next)
data. Other indexes, particularly trees, make use of
pointers, sometimes one per index record, sometimes many
per index record. However, the index at hand, because it
is complete, encourages the usage of pointers to both
program code and data from the same index record. This
feature allows management of process as well as management
of data.
The index at hand and the utilization of index records
as described herein establishes linkage between a group of
master records and one or more identical-key combinations
of records groups composed of data reflecting that specific
master list group. The index at hand may improve
performance of some operations of navigational processing.
The hierarchical database and relational database
organizations do not contain relationships similar to the
index at hand.
Other methods of data management and reporting are
oriented toward individual records of data. Although
individual patterns of data may be constructed using the
other methods, the concepts of complete indexing of, and
comparisons of, data patterns did not exist until the
16
CA 02202217 1997-04-09
present invention.
The group can be the sequential items of transactions
as are found in a log of invoices; or, the items reported
in a summary, such as treatments recorded in hospital
cases.
Data pattern is the term applied to the key items
and/or the associated item identifiers of all the data
entry records of a group. For indexing purposes in
business or social science applications, the order in
and/or the number of times which the key items appear in
the group of data entry records usually is not important.
Thus, in the above described sales transaction example, if
we assign the letters "A" and "B" to the key items of
interest, it would not matter for the purposes of indexing
whether the order in the group was "AB" or "BA" and it
would not matter whether the group was "AAB" or ABB" since
the same two key items are present in each of these
combinations. Thus, the key items can be sorted and
duplicates eliminated before mapping so that synonyms are
not separate, i.e., "AB" and "BA" will map to the same
index record and be considered the same data pattern. An
individual item indicator (the mapped value of the key
field) will be used only once in the combination which
becomes the index record even though the related item
appears more than once in the group of data entry records.
In other words, duplicate occurrences are combined. The
elimination of duplicate occurrences reduces the size of
the index and increases the speed with which the raw data
can be processed. If an item being mapped does not match
any item of the master list, an error message is generated
CA 022022l7 l997-04-09
before the data pattern is included in the index.
In business or social science, a data pattern is the
verified, non-duplicate list of item indicators of the
combination being mapped, typically in ascending sequence.
S Other disciplines may require the index record to reflect
the sequence of the key fields as they appear in the group.
Both types of index records may be required for the same
raw data. For example, the combination of a bolt, washer
and nut can be key items of group of raw data entry
records. For the purposes of purchasing and inventory, the
order in which these items appear in the group is not
important. For the purposes of assembly, the order "bolt",
~washer" and "nut" would be important.
In Fig. 3, there is shown a block diagram of an
lS apparatus for performing the method of creating the index
records. A source of information or raw data entry records
31, such as another computer program or data transmission
from another computer or peripheral data source, has an
output connected to an input of a computer 32. The source
31 may include a master list of items in key fields of the
information being processed. The computer 32 reads the
master list and stores the master list information in a
master list memory device 33 connected to the computer. If
the master list is not present in the source 31, the
2s computer may create and store the master list. Once the
master list has been stored, the computer 32 does not have
to read the master list each time additional raw data
containing items from the master list is to be processed.
The computer 32 reads the items in the key fields of a
group of data entry records from the data source 31. If
18
CA 02202217 1997-04-09
the order in which the items appear in the key fields of
the group is not significant, these key items are sorted
into ascending sequence and duplicates are removed. The
computer 32 can identify the unique set of key items
associated with a specific combination. If the set of key
items is new, an index record containing the appropriate
number of key fields is created. The index records are
stored in an index record memory 34 connected to the
computer 32. The computer also updates the pointer scheme
whereby a pointer locates the associated groups for
subsequent retrieval or processing of the data records. An
output device 35, such as a printer or a CRT, also is
connected to the computer 32 for generating output
information related to the index.
Each index record may be inspected via a search
routine. The search may be according to all of the key
items of the combination which identifies a group of
patterns or any portion of the key items. Less than the
complete combination identifies a group of patterns and
requires additional queries to find the specific index
record. Once the proper index record is found, the
operator may inspect data entry records at the data entry
record location specified by the index record and pointer
scheme.
The hardware associated with this method may consist
of portions of an existing computer program, as a separate
computer system, or as a small computer installed in the
circuitry of a larger computer.
There is shown in Fig. 4 a flow diagram of the present
method. As each key field of the group of data entry
19
CA 02202217 1997-04-09
records to be indexed according to the data pattern is
read, a mapping function is applied to assign the item
identifiers. An item identifier defines an item of the
master list. If the present data pattern is new, a new
record for that pattern is created in the index. After
each data pattern has been processed to the index, the
process can be interrupted. Thus, usage of the index may
be either static or dynamic.
The process of creating and using the index records
10 iS:
A. Read the key fields of all data entry records groups
of a given combination, i.e. a transaction (as in business)
or a case (as in hospital records), and tally the total
number of items in the combination.
B. Determine whether key fields are to be sorted and
duplicates removed. If not, proceed to step E.
C. Sort the key fields read in step A. into a pre-
determined sequence; for example, ascending sequence.
D. Eliminate any key fields of duplicate items and reduce
the tally by the number of duplicate values eliminated.
E. Create a variable length portion of an index record
where the length is the number of index record key fields
equal to the tally and apply the mapping function to each
item in the group key fields to store corresponding item
indicators in the index record key fields.
F. Determine whether the item indicators generated in
step E. require a new index record. If not, go to step G.
If so, complete the index record by establishing pointers
from the new index record to the computer location of the
records underlying the index record and for other desired
CA 02202217 1997-04-09
usage.
G. Update the linkage between the data pointer and the
data read in A.
H Wait for a signal to (1) apply the index to a new
group, (2) begin a search using the index, or (3) cease
data entry record indexing and go to another program
function. In the flow diagram of the method shown in Fig.
4, the computer 32 of Fig. 3 is programmed to perform a
sequence of instructions beginning at a circle 61. The
computer program then enters a decision point 62 to
determine whether a master list of items to be indexed
exists in the source 31. If the master list exists, the
program branches at "YES" to an instruction set 63 wherein
the master list is read and stored in the memory 33. If
the master list does not exist, the program branches at
"NO" to an instruction set 64 wherein the master list is
created and stored in the memory 33. The master list can
be created by reading and storing the items in the key
fields of all of the data entry records groups before
continuing with the program. In the alternative, the
instruction set 64 can direct the program to create the
master list as the data entry records groups are being
processed as described below.
The program then enters a wait loop 65 from both of
the instruction sets 63 and 64. The program idles in the
wait loop 65 until receiving a signal that the raw data is
ready to be processed. When an instruction set 66 receives
the signal that a group of data entry records from the
source of raw data 31 is ready, the computer program enters
an instruction set 67 which causes the key fields of the
CA 02202217 1997-04-09
group to be read into computer memory and a tally of the
number of key fields to be created. If duplicate key
fields are to be eliminated, a sort switch is set. If the
master list is being created, the items in the key fields
are stored in the master list memory 33. The program then
enters a decision point 68. If the sort switch is set, the
program branches at "YES" to an instruction set 69 wherein
the key fields are sorted into ascending sequence,
duplicate key fields are eliminated, and the tally of key
fields eliminated is subtracted from the tally created in
instruction set 67.
The program then enters an instruction set 70 to
create the variable length portion of the index record (see
Figs. 2a-2d) where the length is the tally of the number of
key fields in the specific combination. A mapping function
is applied to each key field of the group to generate the
item indicators in the key fields of the index record. The
instruction set 70 also is entered from the "NO" branch of
the decision point 68 when the sort switch is not set. If
an error occurs in the mapping function, a "YES" branch is
made from a decision point 71 and an indicator is set in an
instruction set 72 for possible intervention. The program
then returns to the wait loop 65. If no error occurs in
the mapping function, the program branches at "NO" from the
decision point 71 to an instruction set 73 wherein the
computer 32 searches the existing index records in the
memory 34 to determine whether the exact combination of key
items being processed already exists. If the variable
length portion of the index record being constructed is
new, the program branches from a decision point 74 at "YES"
22
CA 02202217 1997-04-09
and a new index record is created in an instruction set 75
by (a) extending pointer chains from each master list 64
item referenced in the new record to include the new
record, (b) establishment of a pointer from the new index
record to the group or file which is the object of that
record, and (c) the inclusion of any other pointers to be
associated with that index record. The program enters an
instruction set 76 to guide the inclusion of the address of
the group being processed into the data pointer
organization, then continues to the wait loop 65. If the
partial index record under construction is not new, the
program branches from the decision point 74 at "NO" to the
instruction set 76 and continues to the wait loop 65.
At any time the program is in the wait loop 65 a
branch can be made to an instruction set 77 to search the
existing index records. After the search is completed, the
program returns to the wait loop 65. The program also has
an instruction set 78 which can respond to an indication
that no more groups of data entry records are to be
indexed. The program then exits through a "NO" branch of a
decision point 79 to completion at a circle 80 or through a
"YES" branch to an instruction set 81 if another computer
program is to be executed.
In accordance with the provisions of the patent
statutes, the present invention has been described in what
is considered to represent its preferred embodiment.
However, it should be noted that the invention can be
practiced otherwise than as specifically illustrated and
described without departing from its spirit or scope.
23