Note: Descriptions are shown in the official language in which they were submitted.
CA 02203649 1997-04-24
W O96/13830 PCTrUS95/13416
_ 1 _
DECISION TREE CLASSIFIER DESIGNED USING HIDDEN MARKOV
MODELS
Field Of The Invention
This invention relates to pattern classification, and more particularly, to
a method and apparatus for classifying unknown speech utterances into
specific word categories.
Backqround Of The Invention
Speech recognition is the process of analyzing an acoustic speech
signal to identify the linguistic message or utterance that was intended so thato a machine can correctly respond to spoken commands. Fluent conversation
with a machine is difficult because of the intrinsic variability and complexity of
speech. Speech recognition difficulty is also a function of vocabulary size,
confusability of words, signal bandwidth, noise, frequency distortions, the
population of speakers that must be understood, and the form of speech to be
processed.
A speech recognition device requires the transformation of the
continuous signal into discrete representations which may be assigned proper
meanings1 and which, when comprehended, may be used to effect responsive
behavior. The same word spoken by the same person on two successive
20 occasions may have different characteristics. Pattern classifications have
been developed to help in determining which word has been uttered
Several methods of pattern classification have been utilized in the field
of speech recognition. Currently, the hidden Markov model is the most popular
statistical model for speech. The hidden Markov model characterizes speech
25 signals as a stochastic state, or random distribution, machine with differentcharacteristic distributions of speech signals associated with each state. Thus,a speech signal can be viewed as a series of acoustic sounds, where each
sound has a particular pattern of harmonic features. However, there is not a
one-to-one relationship between harmonic patterns and speech units. Rather,
30 there is a random and statisttcal relationship between a particular speech
CA 02203649 1997-04-24
W O96/13830 PCTrUS95/13416
sound and a particular harmonic pattern. In addition. the duration of the
sounds in speech does not unduly effect the recognition of whole words. The
hidden Markov model captures both of these aspects of speech, where each
state has a characteristic distribution of harmonic patterns, and the transitions
from state to state describe the durational aspects of each speech sound.
The algorithms for designing hidden Markov models from a collection of
sample utterances of words and sounds are widely known and disclosed in a
book by Lawrence R. Rabiner and ~iing Hwang Juang entitled "Fundamentals
of Speech Recognition" Prentice-Hall, Inc. Englewood Cliffs, 1993, which is
o herein incorporated by reference. A method, commonly referred to as Baum-
Welch re-estimation, allows one to continually refine models of spoken words.
Once the statistical parameters of the model have been estimated, a simple
formula exist for computing the probability of a given utterance being produced
by the trained model. This latter algorithm is used in the design of isolated
word speech recognition systems. By designing a collection of models, one for
each word, one can then use the generated probability estimates as the basis
for deciding the most likely word model to match to a given utterance.
The decision tree classifier is another pattern classification technique.
Decision tree classifiers imply a sequential method of determining which class
to assign to a particular observation. Decision tree classifiers are most
commonly used in the field of artificial intelligence for medical diagnosis and in
botany for designing taxonomic guides. A decision tree can be described as a
guide to asking a series of questions, where the latter questions asked depend
upon the answers to earlier questions. For example, in developing a guide to
identifying bird species, a relevant early question is the color of the bird.
Decision tree design has proven to be a complex problem. The optimal
decision tree classifier for a particular classification task can only be found by
considering all possible relevant questions and all possible orders of asking
them. This is a computationally impossible task even for situations where a
small number of categories and features exist. Instead, methods of designing
near optimal decision trees have been proposed using the measurements
defined by the field of information theory.
- CA 02203649 1997-04-24
W 096/13830 PCTrUS95/13416
- 3 -
Earlier attempts at designing decision tree classifiers for speech
recognition using conventional methods proved unsuccessful. This is because
an unrealistically vast quantity of training utterances would be required for
accurate characterization of speech signals. This is due to the fact that the
decision tree conditions questlons based upon the responses to earlier
questions. In any finite training set, and with each question, the number of
examples of a particular utterance meeting all of the necessary criteria
imposed by earlier questions dwindles rapidly. Thus, as observations
accumulate with deeper nodes of the decision tree, the estimates used in
o designing the decision tree become increasingly inaccurate.
For the application of isolated word recognition, a specific class of
hidden Markov models is employed. commonly referred to as discrete output
hidden Markov models. For discrete output hidden Markov models, the spoken
words are represented by a sequence of symbols from an appropriately
defined alphabet of symbols. The method used to transform a set of acoustic
patterns into a set of discrete symbols is known in the art as vector
quantization.
Prior art implementations of speech recognition systems using hidden
Markov models considered the contribution of all parts of the utterance
simultaneously. The prior art required that the feature extraction and vector
quantization steps be performed on the entire utterance before classification
can begin. In addition, hidden Markov model computations require complex
mathematical operations in order to estimate the probabilities of particular
utterance patterns. These operations include the use of the complex
representation of floating point numbers as well as large quantities of
multiplications, divisions, and summations.
Summar~r Of The Invention
This invention overcomes the disadvantage of the prior art by providing
a speech recognition system that does not use complex mathematical
operations and does not take a great deal of time to classify utterances into
word categories.
CA 02203649 1997-04-24
WO 96/13830 PCT/US95113416
A decision tree classifier. designed using the hidden Markov model,
yields a final classifier that can be implemented without using any
mathematical operations. This invention moves all of the mathematical
calculations to the construction. or design, of the decision tree. Once this is
s completed, the decision tree can be implemented using only logical operations
such as memory addressing and binary comparison operations. This simplicity
allows the decision tree to be implemented directly in a simple hardware form
using conventional logic gates or in software as greatly reduced set of
computer instructions. This differs greatly from previous algorithms which
required that a means of mathematical calculation of probabilities be provided
in the classification system.
This invention overcomes the problems of earlier decision tree classifier
methods by introducing the hidden Markov modeling technique as an
intermediate representation of the training data. The first step is obtaining a
collection of examples of speech utterances. From these examples, hidden
Markov models corresponding to each word are trained using the Baum-Welch
method.
Once the models of the speech utterances have been trained, the
training speech is discarded. Only the statistical models that correspond to
each word are used in designing the decision tree. The statistical models are
considered a smoothed version of the training data. This smoothed
representation helps the decision tree design prevent over-specialization. The
hidden Markov model imposes a rigid parametric structure to the probability
space, preventing variability in the training data from ruining the tree design
process. Estimates for unobserved utterances are inferred based on their
similarity to other examples in the training data set.
In order to employ the information theoretic method of designing
decision trees, it is necessary to derive new methods for estimating the
probability values for specific sequences cf acoustically labeled sounds.
30 These new methods differ from earlier hidden Markov model algorithms in that
they must yield probability values for sequences of sounds that are only
partially specified. From a probabilistic perspective, the solution is to sum upthe probabilities for all possible sequences of sounds for all sounds not
CA 02203649 1997-04-24
WO 96/13830 PCT/US95/13416
specified. However, this method is computationally prohibitive. Instead, a
modification to the hidden Markov model algorithm known as the forward
algorithm can be employed to compute the probabiiities within a reasonable
amount of time.
Using the techniques discussed above, it is possible to design the
decision tree before the finical classification task. This is desirable, as thiseliminates (virtually) all computations from the classification task.
Brief Description Of The Drawinqs
FIG. 1 is a block drawing of a speech recognition system that was
o utilized by the prior art;
FIG. 2 is a block diagram of the apparatus of this invention;
FIG. 3 is the decision tree;
FIG. 4 is a table of the time index and corresponding vector quantizer
symbols for sample utterances; and
lS FIG. 5 is a block diagram of a decision tree design algorithm.
Description Of The Preferred Embodiment
Referring now to the drawings in detail and more particularly to FIG. 1:
the reference character 11 represents a prior art speech recognition system for
the words "yes", "no" and "help". The words "yes", "no" and "help" have been
selected for illustrative purposes. Any words or any number of words may
have been selected. Speech recognition system 11 comprises: a feature
extractor 12; a vector quantizer 13; a hidden Markov Model (HMM) for the word
"yes" 14; a hidden Markov Model (HMM) for the word "no" 15; a hidden Markov
Model (HMM) for the word "help" 16 and a choose maximum 17.
The words "yes", "no" and "help" may be spoken into speech input
device 18. Typically speech input device will consist of a microphone,
amplifier and a A/D converter (not shown). The output of device 18 will be
digitally sampled speech at a rate of approximately 12 Khz and a 16 bit
resolution. The output of device 18 is coupled to the input of feature extractor12.
-
CA 02203649 1997-04-24
W O96tl3830 PCTrUS95113416
Feature extractor 12 consists of a frame buffer and typical speech
recognition preprocessing. Extractor 12 is disclosed in a book by Lawrence R.
Rabiner and Biing Hwang Juang entitled "Fundamentals of Speech
Recognition," Prentice-Hall, Inc.. Englewood Cliffs~ 1993, which is herein
incorporated by reference. An implementation entails the use of a frame buffer
of 45 ms with 30 ms of overlap between frames. Each frame is processed
using a pre-emphasis filter, a Hamming windowing operation, an
autocorrelation measurement with order 10, calculation of the Linear Prediction
Coefficients (LPC's) followed by calculation of the LPC cepstral parameters.
o Cepstral parameters provide a complete source-filter characterization of thespeech. The cepstral parameters are a representation of the spectral contents
of the spoken utterance and contain information that includes the location and
bandwidths of the formants of the vocal tract of the speaker. An energy term
provides additional information about the signal amplitude. The output of
extractor 12 are the aforementioned LPC cepstral parameters of order 10 and
a single frame energy term that are coupled to the input of vector quantizer 13.Vector quantizer 13 utilizes the algorithm disclosed by Rabiner and
Juang in "Fundamentals of Speech Recognition" to map each collection of 11
features received from extractor 12 into a single integer. The above vector
quantizer 13 is developed using a large quantity of training speech data. The
integer sequence that constitutes a discrete version of the speech spectrum is
then coupled to the inputs of HMM for the word "yes" 14, HMM for the word
"no" 15 and HMM for the word "help" 16. HMM 14, HMM 15 and HMM 16 each
individually contains a set of hidden Markov model parameters. When a
sequence of integers representing a single spoken word is presented, the
mathematical operations necessary to compute the observation sequence
probability are performed. In the notation of speech recognition, this algorithmis known as the forward algorithm. HMM 14, HMM 15 and HMM 16 performs
their own computations. These computations are time consuming.
The outputs of HMM 14, HMM 15 and HMM 16 are coupled to the input
of choose maximum 17. Choose maximum 17 is a conventional recognizer
that utilizes a computer program to determine whether HMM 14, HMM 15, or
HMM 16 has the highest probability estimate. If HMM 14 had the highest
CA 02203649 1997-04-24
W O96/13830 PCT~US95/13416
_ _ , _ _
probability esllmate. then the system concludes the word iyes was spoken
into device 18 and if HMM 15 had the highest probability estimate the word
"no" was spoken into device 18. The output of choose maximum 17 is utilized
to effect some command input to other systems to place functions in these
other systems under voice control.
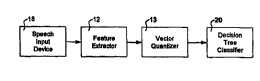
FIG. 2 is a block diagram of the apparatus of this invention. The output
of speech input device 18 is coupled to the input of feature extractor 12 and
the output of feature extractor 12 is coupled to the input of vector quantizer 13.
The output of vector quantizer 13 is coupled to the input of decision tree
o classifier 20.
Decision tree classifier 20 has a buffer that contains the vector
quantizer values of the entire spoken utterance. i.e. yes", "no". "help". The
decision tree classifier 20 may be represented by the data contained in the
table shown in FIG. 3 and the associated procedure for accessing the
aforementioned table. The table shown in FIG. 3 is generated using the
statistical information collected in the hidden Markov models for each of the
words in the vocabulary, i.e. ' yes", "no!' and ' help . FIG 4 contains several
examples of spoken utterances for illustrative purposes. and will be used in thediscussions that follow
The method used to classify utterances with decision tree classifier 20
involves a series of inspections of the symbols at specific time instances, as
guided by the information in FIG 3. We begin with step S0 for each
- classification task. This table instructs us to inspect time index 3 and to
proceed to other steps based on the symbo!s found at time index 3, or to
announce a final classification when no further inspections are required. We
will demonstrate this procedure for three specific utterances chosen from FIG
4.
We always begin the decision tree shown in FIG. 3 at step SO. This
line of the decision tree tells us to look at the vector quantizer symbol
contained at time index 3 (FIG. 4) for any spoken word. Let us assume that
the word "no" was spoken. The symbol at time index 3 for the first word "no" is
7. The column for symbol 7 (FIG. 3) at time 3 tells us to proceed to step S3.
This step tells us to look at time index 6 (FIG. 4!. The word i'no" has a symbol
CA 02203649 1997-04-24
W O96/13830 PCTrUS95/13416
8 -
7 at time index 6. The symbol 7 column of step S3 (FIG. 3) tells us to proceed
to step S8. Step S8 tells us to refer to time index 9 (FIG. 4). At time index 9
for the word "no", we find a symbol value of 8, which informs us to go to column8 of step 8 (FIG. 3). This tells us to classify the answer as a "no", which is
correct.
If the word "yes" was chosen at step S0 of FIG. 3. This line of the table
tells us to look at time index 3 (FIG. 4) for our chosen word. The symbol at
time index 3 for the first sample utterance for the word "yes" is 7. The column
for symbol 7 (FIG. 3) at time 3 tells us to proceed to step S3. This step tells us
to look at time index 6 (FIG 4). The word "yes" has a symbol 3 at time index 6.
The symbol 3 column of step S3 (FIG. 3) tells us to classify this input
correctly, as the word "yes."
If the word "heip" was spoken at step S0 of FIG. 3, this line of the table
tells us to look at time index 3 (FIG. 4) for our chosen word. The symbol at
time index 3 for the word "help" is 6. The column for symbol 6 (FIG. 3) at time
3 tells us to proceed to step S2. This step tells us to look at time index 4 (FIG.
4). The word "help" has a symbol 6 at time index 4. The symbol 6 column of
step S2 (Fig. 3) tells us that the word "help" should be selected.
The "EOW" column of FIG. 3 tells us where to go when the end of a
word has been reached at the time index recuested for observatlon. The label
"n/a" was included for utterances too short to qualify as any of the words in the
training set.
The decision table shown in FIG. 3 can be used to correctly classify all
of the examples presented in FIG. 4. However, the above decision tree and
25 examples would not perform well on a large data set, as it is far too small to
capture the diversity of potential utterances. Real implementations of the
algorithm, which arè hereinafter described, would generate tables with
thousands of lines and at least several dozen columns. The above example is
meant to illustrate the output of the hidden Markov model conversion to
30 decision tree algorithm, and the procedure implemented in decision tree
classifier 20 that uses the resultant data table.
FIG. 5 is a flow chart of a decision tree design algorithm. General
decision tree design principles are disclosed by Rodney M. Goodman. and
CA 02203649 1997-04-24
W O96/13830 PCTAUS95/13416
Padhraic Smyth in their article entitled '`Decision tree design from a
communications theory standpoint", IEEE Transactions on Information Theory,
Vol., 34, No. ~, pp. 979-997 Sept. 1988 which is herein incorporated by
reference. The decision tree is designed using an iterative process. The
precise rule applied for the expansion of each branch of the decision tree is
specified. The desired termination condition depends highly on specific needs
of the application, and will be discussed in broader terms.
In the preferred implementation, a greedy algorithm is specified where
the termination condition is the total number of nodes in the resulting tree.
o This is directly related to the amount of memory available for the storage of the
classifier data structures. Thus, this termination condition is well suited to
most practical implementations.
In order to design the tree, the measure the mutual information between
an arbitrary set of observations and the word category is needed. To find the
mutual information, it is necessary to compute the probability of observing a
partially specified sequence of vector quantizer labels. This is accomplished
using a modified version of the hidden Markov model equations, contained in
block 21 for the word "yes", block 22 for the word "no" and block 23 for the
word "help", normally referred to as the forward algorithm. This modification
involves removing the terms in the forward algorithm associated with
unspecified vector quantizer outputs and replacing their probability values withone (1 ) in the conventional hidden Markov model algorithm.
This algorithm is contained in box 24 and is repeated iteratively,
converting the terminal, or leaf, nodes of the decision tree into internal nodesone at a time, and adding new leaf nodes in proportion to the number of entries
in the vector quantizer. This continues until the prespecified maximum number
of tree nodes has been reached. The resulting data structures can then be
organized into the, decision tree as has been shown in FIG. 3, and stored in
the decision tree classifier 20.
The following decision tree design algorithm may be utilized in block 24:
Before the decision tree algorithm can begin, a collection of discrete output
hidden Markov models must be trained for each word in the recognition
CA 02203649 1997-04-24
WO 96/13830 PCT/US95/13416
-10-
vocaDulary using a suitable training oata set. The hidden Markov moael
parameters for a vocabulary of size Wwill be denoted as
Aj state transition matrix for word i
Bj state output distribution matrix for word j i = {1,2, ..., W
,~j initial state distribution for word i
We further assume that the number of different outputs from the vector
quantizer is denoted by Q, also known as the vector quantizer codebook size.
In addition, we will define the notation for a set of vector auantizer outnl~t.~ ~t
different time indices as
X= {(~,s,),(t~,s,),...,(~",s")}
where the set X consists of pairs of observed symbols and thelr associated
time index.
The tree design algorithm proceeds as follows: Two sets of sets are
defined. The first set, T, is the collection of observation sets associated withinternal tree nodes. The second set, L, is the collection of observation sets
associated with leaf nodes of the tree. Initially, the set T is set to the emptyset, and L is a set that contains one element, and that element is the empty
set. The main loop of the algorithm moves elements from the set L to the set T
one at a time until the cardinality, or number of elements, in set T reaches the pre-specified maximum number.
The determination of which set contained in L should be moved to set T
at any iteration is determined using an information theoretic criterion. Here,
the goal is to reduce the total entropy of the tree specified by the collection of
leaf nodes in L. The optimal greedy selection for the collection of observation
sets is given by
max H(~ X) P(X)
where
with H(l~lX)=-~P(l~ X~Iog~P(lltlX)
SUBSTITUTE SHEET (RULE 26)
CA 02203649 1997-04-24
W O96/13830 1~ PCT~US95/13416
P(X~ ) P(~ P(X~ ) P(~
( I ) P(X) -~P(X~ )P(ll~)
The probability of observing a collection of vector quantizer outputs
conditioned on the word w is computed using the hidden Markov model
equations. One expression of this calculation is given by
~ " . ~ r !~
P(XI~v = i) = ~ nBj[x(~j),sj] 7Tj[X(l)]l _Aj[X(~),x(t ~1)]
2,...,.r~" ~ j=l J~ I I
which can be efficiently calculated using a slightly modified version of the
hidden Markov model equation commonly referred to as the forward algorithm.
With each iteration, the optimal set X contained in L is moved to the set
T. In addition, the optimal set X is used to compute the optimal time index for
o further node expansion. This is done using an information theoretic criteria
specified by Q
arg min ~ H(~l X ~J {(t, s)}) P(X ~J {(~, s)})
S= I
The time index specified by this relationship is used to expand the
collection of leaf nodes to include all possible leaf nodes associated with the
s set X Each of these new sets, which are designated by
L ~ L u {X ~J {(~, s)}} ~s ~ {1,2, , }
are added to the set L and the set X is removed from set L. Once this
operation is completed, the algorithm repeats by choosing the best element of
L to transfer to T, etc. This algorithm is expressed in pseudocode in FIG 6.
The above specification describes a new and improved apparatus and
method for classifying utterances into word categories. It is realized that the
above description may indicate to those skilled in the art additional ways in
which the principles of this invention may be used without departing from the
spirit. It is, therefore, intended that this invention be limited only by the scope
of the appended claims.
i
SUBStltUTE SHEET (RULE 26)