Note: Descriptions are shown in the official language in which they were submitted.
CA 02217262 2000-12-15
ENHANCED INTEGRATED RATE BASED
AVAILABLE HIT RATE SCHEDULER
Technical Field
This application pertains to an available bit
rate (ABR) scheduler for use in asynchronous transfer mode
(ATM) communications involving ABR connections which
require non-zero minimum cell rate (MCR) support.
l0
Background
ATM is a networking protocol which supports a
variety of applications having distinct bandwidth require
ments and distinct tolerances for delay, fitter, cell loss,
etc. ATM networks provide different "service classes" at
different prices which reflect the differing quality of
service (QoS) provided by each class. The QoS can define
minimum levels of available bandwidth, and place bounds on
parameters such as cell loss and delay. The user informs
the network, upon connection set-up, of the expected nature
of the traffic to be sent by the user along the connection,
and of the QoS required for such connection.
The ABR service class supports variable rate data
transmissions without preserving timing relationships
between source and destination. ABR users are provided
guaranteed service with respect to cell loss, and "fair"
access to available bandwidth as determined by predefined
fairness criteria. The user receives only the network's
best attempt to maximize the user's available bandwidth or
allowed cell rate (ACR), through the use of feedback flow
control mechanisms. Such mechanisms facilitate control
over the amount of traffic allowed into the network, and
hence minimization of cell loss due to congestion. A
traffic shaping algorithm, controlling the ACR, is used at
the source to control the traffic rate into the network,
based upon a congestion indicator in the received cells.
CA 02217262 2000-12-15
- 2 -
Pre-defined traffic parameters characterize the
traffic sent over an ATM connection. Parameters such as
minimum cell rate (MCR), peak cell rate (PCR), cell delay
variation tolerance (CDVT), sustainable cell rate (SCR) and
burst tolerance (BT) characterize the traffic stream in
general, although not all parameters are meaningful for all
service classes. For example, in ABR service, the PCR
determines the maximum value of the ACR, which is dynami-
cally controlled by the ATM network, using congestion
control mechanisms, to vary between the MCR and PCR.
When setting up a connection, the requesting node
informs the network of the required service class, the
traffic parameters of the data to be passed in each direc-
tion along the connection, and the QoS requested for each
direction. Establishment of an ATM connection having spec-
ified traffic descriptors constitutes a traffic "contract"
between the user and the network. The network offers a QoS
guarantee appropriate to the service class requested by the
user. In return, the user must confine traffic sent over
the connection in compliance with the attributes of the
traffic contract for the requested service class. ATM
network switches police the user's traffic via algorithms
which determine whether the cell stream is compliant with
the traffic contract.
An ABR scheduler is an essential and integral
part of any ATM implementation offering ABR service. Its
purpose is to determine when cells are ready to be trans-
mitted in a fair and efficient manner. In this context,
"fairness" means that all service classes should be given
an equal opportunity; "efficiency" means that cells should
be transmitted at or near their specified rates. United
States Patent No. 5,706,288 issued 6 January, 1998 (here
after "the '288 patent") describes the implementation of an
ABR scheduler having the necessary attributes of fairness
and efficiency.
In an ATM network, a communication channel may be
characterized by a virtual circuit (VC) defined by pre-
CA 02217262 2000-12-15
- 3 -
selected traffic and QoS parameters. The problem, in
providing ABR service, is to efficiently manage trans-
mission of cells pertaining to different VCs. The allowed
cell rate (ACR) at which a cell belonging to a given VC is
transmitted varies between the minimum cell rate (MCR) and
the peak cell rate (PCR), which are negotiated when the VC
is established. The ACR is a floating point number as
defined in the ATM Forum specifications, and expressed as
ACR = I1 + 512) 2e
where 0 < a < 31 and 0 < m < 511. ACR covers a wide
dynamic range between 1 cell/sec to 32 Gigacells/sec.
In order to permit efficient scheduling of VCs in
an ABR service, the ABR scheduler described in the '288
patent uses a classification scheme in which VCs are
indexed according to their exponents and mantissa to form
groups of "profiles" and "sub-profiles". More particular-
ly, a profile i, 1 < i < p is a collection of VCs whose
ACRs fall within a closed range:
(1 . X x 2p-i , . . . , ~1 + 1 ~ x 2p-~-1J ( 2 )
sp
where p is the number of profiles, sp is the number of sub-
profiles, and 0 < x < 1/sp such that the effective profile
rate is then given by 2''-'. A sub-profile j, 1 <_ j < sp is
a subset of VCs belonging to profile i, 1 < i < p such that
their ACRs default to the nearest and smaller rate given
by:
I1 + ( Sp ~ + 1 ) ~ x 2p-i-1 (
sp
CA 02217262 2000-12-15
- 4 -
For example, if p - sp - 4 then the sub-profile rates
conforming to the above definition are summarized in
Table 1.
Profile Sub-p rofile rates i(cells,/secon~
1 2 3 4
1 8 7 6 5
2 4 3.5 3 2.5
3 2 1.75 1.50 1.25
4 1 0.875 0.750 0.625
Table 1
Note that the rates of sub-profile 1 in each of the four
profiles are identical to the profile rates of 8, 4, 2 and
1 respectively. It can be seen that the larger the number
of sub-profiles, the finer the granularity and therefore
the VCs will be scheduled closer to their ACRs, consequent-
ly increasing hardware and computational requirements.
Whenever a VC is provisioned (i.e. allocated),
the ACR of the corresponding VC is uniquely mapped to one
of the closest and smallest profile/sub-profile rates. The
smaller rate is chosen, since otherwise the negotiated
traffic contract may be violated by scheduling a cell at a
rate faster than the ACR.
By quantizing VCs based on the exponent values of
their rates, a fast deterministic search can be performed
to service the profiles. A linear search on the sub
profiles is then conducted and, using a virtual time
algorithm wherein the next cell time is calculated based on
its ACR, the system clock frequency and the number of
profiles, it can be uniquely determined whether the chosen
VCs are ready for transmission by comparing with the
current cell time.
The ABR scheduler of the '288 patent also main
tains a table (in memory) in which VCs are stored along
with negotiated traffic contract parameters such as PCR,
MCR, etc. A linked list of VCs is attached to each pro-
file/sub-profile. When a particular profile/sub-profile is
ready to be transmitted (as determined by the scheduler
algorithm summarized above), the entire list linked to that
CA 02217262 2000-12-15
- 5 -
profile/sub-profile is serviced and the ATM cells are
placed in the ABR output queue for transmission.
The scheduler also interacts with an ABR contract
module which implements source/destination behaviour
functions in accordance with ATM Forum-defined congestion
management protocols and links/delinks the VCs to the
various profiles/sub-profiles in the table dynamically,
depending on its state. For example, if congestion is
detected in the network, then the ACR for a particular VC
is reduced by a predetermined amount and accordingly the
VC's link to a profile/sub-profile needs to be updated.
The ABR scheduler described in the '288 patent
assumes a negotiated zero MCR for all VCs, and assumes an
available bandwidth equal to the full line rate. By quant
izing the ACR into a finite subset of traffic profiles to
which the provisioned VCs are attached, the ABR scheduler
of the '288 patent searches and outputs a sequence of
traffic profile addresses. For each element in this
sequence, all VCs that are attached to the selected traffic
profile are scanned linearly and dispatched to the output.
The ABR scheduler of the '288 patent performs
well statistically, according to the rate weighted
bandwidth distribution scheme for different degrees of
provisioning (i.e., under, equal or over provisioned
cases). However, it suffers from the problem of "cell
clumping" for the equal and under provisioned cases, due to
the aforementioned linear scanning of each link list. For
these two cases, cell clumping occurs when VCs whose ACRs
are lower than the peak bandwidth are scheduled at the line
rate. The size of each such burst is dependent on the
number of VCs attached to the given traffic profile in the
link list. The longer the link list, the greater the burst
length (cell clumping). Consequently, buffer overflows may
occur in downstream ATM switches and/or at the destination.
Avoidance and/or reduction of such overflows is of para-
mount importance.
CA 02217262 2000-12-15
- 6 -
The ABR scheduler of the '288 patent does not
suffice for ABR connections requiring non-zero MCR support
and accordingly cannot provide a minimum guaranteed
bandwidth; nor does the '288 patent's scheduler accomodate
VC buffer overflow. The present invention addresses these
shortcomings in a manner which satisfies the efficiency and
fairness criteria for bandwidth allocation. The present
invention also provides a flexible arbitration scheme for
mixing ATM cells of various traffic sources such as ABR,
unspecified bit rate (UBR), variable bit rate (VBR) and
constant bit rate (CBR), such that the relative proportion
of each stream can be varied as desired.
Summary of Invention
The invention provides an available bit rate
scheduler for asynchronous transfer mode communication of
a plurality of cells over a communication network in which
each cell is characterized by a virtual circuit communi-
cation channel. An MCR scheduler receives MCR-rate virtual
circuits requiring minimum cell rate transmission service
through the network and outputs the MCR-rate virtual
circuits at a constant bit rate. An ABR' scheduler
receives ABR-rate virtual circuits requiring available bit
rate transmission service through the network and outputs
the ABR-rate virtual circuits at an effective allowed cell
rate ACR; - ACR;-MCR; where 0 < i < (n-1) and n is the total
number of virtual circuits.
A first arbitrator coupled to the MCR scheduler
and to the ABR' scheduler receives the MCR-rate and ABR
rate virtual circuits and outputs them in a merged priority
sequence in which any of the MCR-rate virtual circuits
received from the MCR scheduler are output before any of
the ABR-rate virtual circuits received from the ABR'
scheduler are output. The ABR-rate virtual circuits are
stored in a buffer by the first arbitrator while the MCR-
CA 02217262 1997-10-O1
rate virtual circuits are output. The buffer is of a size
sufficient to store at least two ABR-rate virtual circuits .
A second arbitrator coupled to the first arbitra
tor receives the MCR-rate and ABR-rate virtual circuits
output by the first arbitrator. The second arbitratoris
also coupled to a UBR source of UBR-rate virtual circuits
requiring unspecified bit rate transmission service through
the network. The second arbitrator further has a first
buffer for receiving and storing MCR-rate and ABR-rate
virtual circuits received from the first arbitrator; a
second buffer for receiving and storing UBR-rate virtual
circuits received from the UBR source; first programmable
means for outputting MCR-rate and ABR-rate virtual circuits
from the first buffer at a user-programmable priority rate
between Oo and 1000; and, second programmable means for
outputting UBR-rate virtual circuits from the second buffer
at a priority rate of 100a less said user-programmable
priority rate.
The invention further provides an available bit
rate scheduler for asynchronous transfer mode communication
of a plurality of cells over a communication network in
which each cell is characterized by a virtual circuit
communication channel and in which each virtual circuit is
characterized by one or more profiles. Each profile has a
group of sub-profiles, with each sub-profile having a
unique bandwidth allocation component. The scheduler
incorporates a profile queue buffer for receiving, pairing
and storing the profiles and sub-profiles and, a link list
processor coupled to the profile queue buffer to receive
the profile, sub-profile pairs. The link list processor
detects null profile, sub-profile pairs in thebuffer, and
over-writes them with a selected one of the virtual circuit
profile, sub-profile pairs. A valid pending register of
length p bits, and a memory are coupled to the link list
processor. The memory stores pointers to link lists of
virtual circuits associated with each of the profile, sub-
profile pairs received by the link list processor. The
CA 02217262 1997-10-O1
.
Y
pointers comprise, for each of the link lists, a head
pointer to a first entry in the link list and a next
pointer to a virtual circuit in the link list last associ
ated by the link list processor with one of the profile,
sub-profile pairs.
The invention further provides a method of
scheduling available bit rate cell transmission over an
asynchronous transfer mode communication network character-
ized by a plurality of virtual circuit communication
channels, each virtual circuit being characterized by an
allowed cell rate ("ACR"). MCR-rate virtual circuits
requiring minimum cell rate transmission service through
the network; and, ABR-rate virtual circuits requiring
available bit rate transmission service through the network
are generated. The MCR-rate virtual circuits are output at
a constant bit rate; and, the ABR-rate virtual circuits are
output at an effective allowed cell rate ACRi - ACRi-MCRi
where 0 s i s (n-1) and n is the total number of virtual
circuits.
A bandwidth allocation criteria:
n-i
BW-~ MCRi
CCRi = MCRi + n_i °° *ACR l
A CRS
i=0
is applied to the virtual circuits whenever:
n-1
BW ~ ~ ACRD
ia0
CA 02217262 1997-10-O1
,
The bandwidth allocation criteria is reduced to:
CC12 j = ACRj ff - n-1$~ *AC.ftg
~' ACRi
x=0
whenever:
n-1
~IIC~ij = Q.
~=o
10 Brief Description of DrawincLs
Figure 1 is a block diagram of an ABR scheduler
having an ABR link list processor (ALLP) in accordance with
the invention.
Figure 2 is a block diagram depiction of a local
memory and, data structure for the Figure 1 ABR scheduler.
Figures 3A and 3B collectively comprise a pseudo-
code listing representative of an algorithm for implement-
ing the profile queue dispatcher component of the Figure 1
ABR scheduler.
Figure 4 is a block diagram of an integrated ABR
scheduler in accordance with the invention.
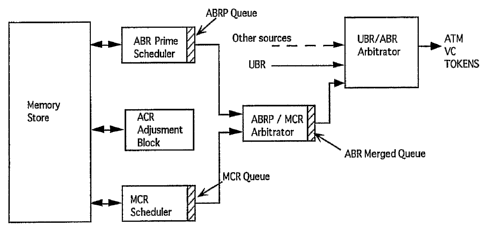
Figure 5 is a block diagram representation of an
MCR/ABR' arbitrator for the integrated ABR scheduler of
Figure 4.
Figures 6A and 6B collectively comprise a pseudo-
code listing representative of an algorithm for implement-
ing the Figure 5 MCR/ABR' arbitrator.
Figure 7 is a block diagram of a simplified
ABR/UBR priority servicer.
CA 02217262 1997-10-O1
' - 10 -
Figure 8 is a pseudo-code listing representative
of an algorithm for implementing the Figure 7 priority
servicer.
Figure 9 is a table illustrating exemplary output
of the Figure 7 priority servicer under various ABR/UBR
loads.
Figure 10 depicts VC distribution in a case study
of simulated equal provisioned operation of an ABR
scheduler supporting zero MCR traffic in accordance with
the invention.
Figure 11 is a table illustrating measured
throughput and bandwidth utilization for the Figure 10 case
study.
Figure 12A shows a prior art cell distribution
pattern exhibiting effects of cell clumping and buffer
overflow. Figure 12B shows a cell distribution pattern for
the Figure 10 case study which avoids/reduces cell clump
ing.
Figure 13 depicts vC distribution in a case study
of simulated under provisioned operation of an ABR
scheduler supporting zero MCR traffic in accordance with
the invention.
Figure 14 is a table illustrating measured
throughput and bandwidth utilization for the Figure 13 case
study.
Figure 15 depicts ZTC distribution in a case study
of simulated over provisioned operation of an ABR scheduler
supporting zero MCR traffic in accordance with the inven-
tion.
Figure 16 is a table illustrating measured
throughput and bandwidth utilization for the Figure 15 case
study.
Figure 17 depicts VC distribution in a case study
of simulated over provisioned operation of the Figure 7
MCR/ABR' arbitrator.
CA 02217262 1997-10-O1
n r
' - 11 -
Figure 18 is a table illustrating bandwidth
allocation for the ABR' scheduler portion of the Figure 17
case study.
Figure 19 is a table illustrating bandwidth
allocation for the MCR scheduler portion of the Figure 17
case study.
Figure 20 is a table illustrating the combined
operation of the ABR' and MCR scheduler portions of the
Figure 17 case study.
Description
1. Introduction
a. Pendinq~ Pointer Mechanism
The present invention overcomes the cell clumping
(or burst length) problem by incorporating a "pending
pointer" mechanism for each traffic profile. Each traffic
profile is serviced such that only one VC is scheduled from
each link list in one cell time. A pending pointer which
points to the next VC in the link list is maintained for
each link list. The pending pointers are processed such
that all VCs are serviced correctly in under provisioned
cases, and serviced fairly in over provisioned cases. The
invention assists in tracking the link list more effective-
ly and interleaves generated VC tokens. Interleaving helps
guarantee that cells of different VCs (perhaps of different
rates) are scheduled in sequence and consequently avoids
and/or reduces cell clumping buffer overflows. The inven
tion's modified interleaving scheme limits the burst. size
to the number of supported sub-profiles, independently of
the link list chain.
b. Independent MCR and ACR' Schedulers
In accordance with the invention, the ABR
scheduler is provided with an MCR scheduler and a separate
ABR' scheduler. The MCR scheduler is similar to a constant
bit rate (CBR) scheduler with guaranteed bandwidth. The
ABR' scheduler is identical to the ABR scheduler described
CA 02217262 2000-12-15
- 12 -
in the '288 patent (for zero MCR support) with an added
pending pointer mechanism, except that the effective ACR it
associates with each VC is given by ACR; - ACR;-MCR; where 0
< 1 < (n-1) and n is the total number of VCs.
In the ABR' scheduler, each VC is mapped to a
given traffic profile, as dictated by ACR'. The ABR'
scheduler automatically performs these arithmetic oper-
ations and performs the link list manipulation on the VCs.
Tokens output by the MCR and ABR' schedulers are
arbitered by giving priority to the MCR scheduler. If no
tokens are output by the MCR scheduler, the ABR' scheduler
is allowed to transmit. Using this arbitration scheme, in
conjunction with the ABR' scheduler's rate weighted band
width allocation, the fairness criterion can be shown to
achieve the following:
n-1
BW - ~ MCRi
CCRi = MCRi + 1-° * ACR ~ (
i
ACRi
i=o
where BW is the available bandwidth and ACR; - ACR;-MCR; is
the current cell rate for each VC output by the scheduler.
c. Minimum Bandwidth Guarantee for ABR. UBR Services
The output of the MCR and ABR' schedulers can be
arbitrated by a UBR/VBR/CBR scheduler. It is important for
a user to have control over the relative weighted prior-
ities of the ABR and UBR token streams. This is achieved
in the present invention by a priority servicer which is
fully controllable by the user.
The priority servicer allocates the available
output bandwidth based on a set of user programmable
weights. For example, the user might set the weights at
75% for ABR and 25% for UBR. A "sliding window" guarantees
servicing of each stream within a predefined interval. If
CA 02217262 2000-12-15
- 13 -
one stream has no data to send, then the time slot is made
available to the other stream. Similarly, during the non-
guaranteed service interval, if no data is available for
transmission in one stream then the time slot is made
available to the other stream. If either stream has no
data when polled at its service interval, then the oppor
tunity is "stored" and may be used later outside of the
service interval when data is available for transmission.
In general, the method guarantees a minimum bandwidth for
a particular stream.
2. Use of Pending Pointers to Avoid VC Bursting
Figure 1 depicts an ABR link list processor
(ALLP) which implements the pending pointer mechanism. A
profile queue buffer interfaces between an external profile
generator (similar to that described in the '288 patent and
the ALLP to facilitate pipelining operations. To improve
efficiency, a double buffering mechanism is preferably used
such that two (profile number, sub-profile vector) pairs
are written to the profile queue by the external profile
generator during each cell period. A cell period corre-
sponds to a real cell time (RCT) of approximately 2.83~s
(for the STS-3c standard). The external profile generator
indicates that a slot is empty by clearing (zeroing) the
two entries for that slot in the profile queue. A pro
file queue-full bit is set to indicate that data is avail
able for the ALLP to read. The ALLP clears this bit after
processing to free the resource. If the profile queue_full
bit is not set the ALLP remains idle or performs other
internal operations.
3. ABR Link List Processor (ALLP~,
The ALLP reads the profile queue entries (i.e.
profile number, sub-profile vector pair) and searches its
local ALLP memory to obtain a VC number. The VC number is
used to access an external memory to retrieve ABR control
and data parameters. For each VC accessed via the external
CA 02217262 1997-10-O1
' ,' - 14 -
memory, the ALLP performs certain end station functions and
detection of cell type. This information, along with the
VC number, is passed to a downstream queue for transmis-
sion. The ALLP avoids cell clumping by keeping track of
empty slots presented by the external profile generator and
fills such empty slots with any pending VCs that are avail
able for scheduling, thus dispersing cells belonging to the
same VC. The ALLP also handles out-of-rate transmission of
resource management (RM) cells whose ACR has dropped below
a predetermined rate.
When instructed by an external provisioning unit
(not shown), the ALLP constructs a suitable link list by
attaching (or detaching) a VC to a selected traffic profile
in the ALLP local memory. The ALLP is also responsible for
performing move operations (to relocate a VC's position) as
a result of rate adjustments performed externally.
4. Cell burst Avoidance
The main function of the ALLP is to dispatch VC
token numbers corresponding to the scheduled sub-profile
number on a non-bursty basis (as far as possible) from the
link list by exploiting empty slot opportunities presented
by the profile generator. The ALLP retrieves VC informa
tion from the ALLP memory for the selected sub-profile for
this purpose. It redistributes the VCs into any available
empty slot (indicated by the external profile generator
through a null entry) in such a fashion that the maximum
burst length is limited to the maximum number of sub-pro-
files (e.g. 16). This interspersed scheduling operation by
the ALLP is of paramount importance in reducing buffer
overflow in ATM switches and simultaneously maintains the
required performance/efficiency criteria.
5. Pendinct Pointer and ALLP Local Memory
A "valid pending register", p bits in length
(corresponding to the number of profiles) facilitates
implementation of the aforementioned "pending pointer"
CA 02217262 1997-10-O1
- 15
mechanism. The pending register is used as an index to
locate a profile having one of the valid pending bits (VPB)
of its subprofiles asserted.
Figure 2 shows the ALLP memory data structure.
The ALLP maintains a head pointer (HP) and a next pointer
(NP) to each queue that is attached to a given sub-profile
stored in the local ALLP memory. The HP points to the
start of the link list, while the NP is used to remember
the last VC serviced for that link list. The ALLP reads a
profile number (p num) and its corresponding sub-profile
vector and performs a merged scheduling operation by
scanning and dispatching a VC from each of the asserted
sub-profiles for a given profile number. In other words,
the ALLP performs a vertical scan choosing exactly one VC
for each sub-profile at a time. Any remaining VCs of each
sub-profile are marked as pending using the valid pending
bit (VPB) and their addresses are stored as the NP in the
ALLP memory. Whenever an empty slot is detected, the ALLP
utilizes this opportunity to retrieve the pending VCs, if
any, starting from the highest traffic rates (within the
selected profile) from the ALLP memory and dispatches them
accordingly.
During each real cell time, the external profile
generator outputs a profile number and a sub-profile vector
(or a null vector) . Up to sp sub-profiles for each pro
file number may be processed and dispatched by the ALLP.
The number of such VCs dispatched by the ALLP (or look-
ahead) during each real cell time is tracked using a
counter n-bits in length (cell count). The variable
cell_count thus enables skipping of empty slots. If the
value of the counter at any time is x, then the ALLP has
sent x cells ahead of the current time. Therefore, when-
ever an empty slot from the external profile generator
arrives, the counter is decremented by one and the slot is
removed. Such empty slots are non-contiguous and dependent
on the number of VCs and their allocation based on their
ACRs. The cell-count counter is therefore of-importance in
CA 02217262 1997-10-O1
' ' - 16 -
under provisioned and equal provisioned cases where non
bursty handling of VCs is required to achieve the required
efficiency/performance criteria. The size of cell count is
implementation dependent and is influenced by the number of
profiles/sub-profiles.
Figures 3A and 3B provide a pseudo code version
of the ALLP algorithm which retrieves the profile queue
entries and performs non-bursty VC scheduling incorporating
the pending pointer mechanism in accordance with the inven
tion.
6. Congestion Management
The transmission source is responsible for
managing local congestion, in an implementation specific
manner. From the scheduler's point of view, congestion
occurs when the sum of the bandwidths of the allocated
connections exceeds the maximum bandwidth supported by the
network i.e, in the over provisioned case. In such a
situation, a given fairness criteria has to be applied such
that the available bandwidth is shared effectively and
efficiently by all users . The present invention implements
a rate weighted bandwidth allocation scheme in which the
available bandwidth is shared depending on the ACRs of the
profiles and the excess bandwidth. As an example, if the
available bandwidth is 16 and the total bandwidth required
is 32, then all the allocated profiles have their ACRs
(which are weighted on their rates) reduced by 50a.
If Bid is the maximum available physical bandwidth
and ACRD is the requested bandwidth for each VC i for
Osisn-1, where n is the total number of provisioned VCs,
and i f
n-1
BW ~ ~ ACR f
.IsO
CA 02217262 1997-10-O1
- 17 -
then the effective bandwidth allocated by the scheduling
algorithm to each VC is given by:
ACRi ff _ n-1BW *ACR1 ( 10 )
ACRD
.i=o
Observe that for the equal-provisioned case where
n-1
BW = ~ ACRi ( 11 )
f=o
1000 efficiencyis achieved. Stated alternatively, the
scheduled VC has an ACR equal to its requested rate.
7. Non-Zero MCR Guarantee Using Independent MCR and ABR'
Schedulers
Figure 4 schematically depicts an integrated ABR
scheduler which provides non-zero MCR support. As can be
seen, separate ABR' and MCR schedulers are provided.
The ABR' queue and the MCR queue contain VC token
information output by the respective ABR' and MCR
schedulers. This token information is passed as input to
the MCR/ABR' arbitrator, which executes the Figure 6A-6B
selection algorithm to choose VC tokens from either stream.
The MCR/ABR' arbitrator outputs the token information as an
ABR merged queue. The ABR merged queue a.s in turn acted
upon by the UBR/ABR arbitrator which chooses cells from
either the ABR merged queueor froman input stream sup-
plied by another traffic schedulers such as UBR, CBR etc.
8. MCR scheduler:
The MCR scheduler depicted in Figure 4 is similar
to a CBR scheduler having guaranteed bandwidth. Each VC is
assigned to a rate as dictated by its MCR and is given its
fair share of bandwidth. For example, an ABR scheduler
having only an external profile generator and an ALLP could
CA 02217262 2000-12-15
- 18 -
be modified to form a simple MCR scheduler by using only a
fixed (coarser) number of profiles to make each profile's
MCR twice as fast as the profile below; and, by simplifying
the provisioning/unprovisioning interface and the ACR
adjustment, such that VCs need not be relocated by the MCR
scheduler when their ACRs change.
More particularly, an MCR scheduler can be con-
structed by refining the ABR scheduler described in the
'288 patent. One refinement is to select the granularity
of the traffic profiles such that there are no finer
divisions on the mantissa (subprofiles) and such that the
profiles are associated with rates that are a power of 2.
Hence, the possible MCR rates supported by the scheduler
are discrete and coarse. The MCR scheduler consists of a
profile generator which outputs a sequence of profile
addresses by searching the availability of VCs in local
memory using a virtual time algorithm as described in the
'288 patent. The profile addresses are retrieved from the
profile buffer and subsequently processed by the ALLP.
Additional refinements include simplification of the pro-
vision/unprovisioning circuitry, since there is no explicit
rate adjustment in the VCs and consequently the VCs do not
shift dynamically from one link-list to another as in the
general ABR case. VCs corresponding to MCR scheduling are
assigned (unassigned) to the link-lists only during connec-
tion-setup (connection-collapse). Each VC is thus guar-
anteed an MCR bandwidth equal to the rate of the profile to
which it is attached. Note that MCR schedulers cannot be
over-provisioned, implying that requested bandwidth (MCR)
cannot be guaranteed if the sum of the bandwidths of all
provisioned VCs exceeds the maximum line rate.
The MCR scheduler is independent of the number of
VCs attached to it, but the effective MCR rates are dis-
cretized and dependent upon the selected granularity.
Other possible implementations could include a modified VBR
scheduler based on counters. In such case the effective
MCR rates could be user programmable, but at the cost of
CA 02217262 2000-12-15
- 19 -
servicing only a fixed number of VCs, due to factors such
as the search time required, the hardware's execution
speed, and length of the link lists.
9. ABR' Scheduler
The ABR' scheduler component of the Figure 4
integrated ABR scheduler can be identical to the ABR
scheduler described in the '288 patent, except that the
effective ACR associated with each VC is now given by ACRD
- ACRi-MCRt where 0 < 1 < (n-1) and n is the total number of
VCs. The ABR' scheduler maps each VC to a given traffic
profile, as dictated by ACRD. The foregoing arithmetic
operations are performed by the ACR adjustment block, which
stores its results in the memory store during provision-
ing/unprovisioning or link list manipulation of VCs whose
relative positions are altered due to feedback from
resource management cells.
Operation of the ABR' and MCR schedulers is seam
less, in that the bifurcation of ACR into MCR and ACR'
components for each VC, its mapping into the appropriate
tables, and book-keeping are totally transparent to the
outside world. Consequently, the required MCR bandwidth
guarantee is sustained, and the required elasticity in ACR'
is maintained for every VC. Note that for a zero MCR VC,
there is no corresponding entry in the MCR scheduler and
consequently tokens for that VC are output only by the ABR'
scheduler. The invention thus provides an integrated ABR
scheduler supportive of all traffic types, with particular
emphasis on efficiency and fairness in bandwidth distribu-
tion including non-zero MCR support whilst avoiding cell
clumping/buffer overflow problems.
10. MCR/ABR' Arbitrator
Figure 5 schematically depicts the MCR/ABR' arbi-
trator. Inputs to the MCR/ABR' arbitrator include the MCR
queue (containing MCR token information output by the
Figure 4 MCR scheduler) and the ABR queue (containing ABR'
CA 02217262 1997-10-O1
"
" ' - 20 -
token information output by the Figure 4 ABR' scheduler).
An ENABLE signal (not shown) initiates the MCR/ABR' arbi-
trator's execution of the Figure 6A-6B algorithm. Pro-
cessed token information is output by the MCR/ABR' arbi-
trator to the ABR merged queue.
As the MCR/ABR' arbitrator processes the token
information in the MCR and ABR' queues, it assigns priority
to the MCR queue. If the MCR queue contains no token
information, then the ABR' queue is allowed to transmit.
Figure 6A-6B illustrates the algorithm executed
by the MCR/ABR' arbitrator. The arbitration scheme uses an
internal ABR buffer (queue) for storing ABR' tokens read
from the ABR' queue. The ABR buffer provides the necessary
smoothing action in handling ABR' traffic for over pro-
visioned cases. Simulation studies (discussed below) have
shown that an ABR' buffer size of 2 is optimal for handling
the arbitration without expending considerable hardware
overhead. The size of the ABR merged queue is implementa-
tion dependent.
The MCR/ABR' arbitrator employs a prioritized
selection scheme, in that MCR traffic is selected a.n
precedence to ABR' traffic. In other words, if a token is
available for transmission in the MCR queue then, regard-
less of the state of the ABR' queue, the MCR queue token is
transmitted. Therefore, each VC in the MCR queue is allo
cated its full bandwidth, as the case may be. Only when
there is an empty slot (invalid data) in the MCR queue is
the ABR buffer scanned and any available ABR' queue
tokens) transmitted. Hence; the bandwidth available for
ABR' tokens is given by:
a-1
BFS~~R = BW - ~' MCRi ( 12 )
i=o
CA 02217262 1997-10-O1
_ 21 _
where BW is the total available bandwidth at the output of
the arbitrator. ACRI is the ACR assigned for each VC i,
where OsZs(n-1) after subtracting the MCR component. If:
n-1
BW~R z ~ACRf (13)
t=o
then the effective bandwidth allocated to each ABR' VC
follows directly from equation (10) by substituting ACR1 =
ACRL. Hence:
ACR~~ff - BW *ACRi
n-z ( 14 )
ACRD
i=o
'~sR ( 15 )
CCRi = MCR~ + ~ BBW ~ *~iCR~eff
where CCRL is the current cell rate of the ATM cells
transmitted by the scheduler. Substituting equation (14)
into equation (15) yields:
A8R
CCRg = 1~'fCRi + ~ BBW ~ * n-1BW *ACRi ( 16 )
ACR
tso
and hence:
n-1
Blt~ ~ MCR~
CCRi = MCR j + n-1 °° *ACR~ ( 17 )
A CR
t=o
CA 02217262 1997-10-O1
' ' - 22 -
11. Degenerate Case
If
n-1
MCR2 = 0 (18)
t=o
(i.e, for the zero MCR case), then equation (17) reduces to
the rate weighted bandwidth allocation criterion given by
equation (10) for the case of the zero MCR scheduler.
12. Weighted Priority Control over ABR and UBR Token
Streams
The foregoing discussion contemplates the gener-
ation of streams of so called "tokens". These tokens are
generated by a scheduler and represent an opportunity for
a downstream unit to transmit a cell from a given VC. The
token streams could be generated by any type of traffic
scheduler, for example a CBR, VBR, ABR or UBR scheduler.
Each such scheduler represents a different type of traffic
class having characteristics which are not relevant here
and which therefore need not be discussed further. The
essential point to note is that the generation of multiple
token streams by multiple token sources (schedulers)
necessitates an arbitration policy to govern the multi-
plexing of such streams.
The relative priority of some of the traffic
sources described above is usually implied by the traffic
class. However, this is not necessarily so for ABR or UBR
traffic. Indeed, ABR service is intended to offer a better
quality of service (QoS) over UBR, guaranteed by the added
complexity of the flow control mechanism. But, it is clear
that there is a requirement for the coexistence of both
services in a network, and therefore a user controllable
weighted priority mechanism is required in a combined
ABR/UBR scheduler, so that the relative shares of the
available bandwidth can be controlled. Figure 7 is a
CA 02217262 1997-10-O1
' ' - 23 -
simplified block diagram of such a ABR/UBR priority ser-
vicer (PS).
The PS queues ABR and UBR tokens generated by the
ABR and UBR schedulers respectively. ThE queuing is
accomplished by a pair of first-in-first-out (FIFO) buffers
which are each two tokens deep. Queued tokens are dis-
patched to a downstream FIFO (not shown) using a programm-
able polling priority mechanism which guarantees a fixed
percentage of the excess bandwidth for either the UBR or
ABR data streams. The polling rate is determined by the
ABR PSEL bits in a general control register. The polling
rate determines the rate at which the ABR token FIFO is
polled per cell time with respect to the polling rate of
the UBR token FIFO. If polling of one of the FIFOs indi-
cates that no token is ready to be transmitted, then the
other FIFO is serviced in that cell slot if it contains a
token.
By way of example, a Oo to 1000 service priority
range can be divided into eight steps of 12.50 each. If Oo
service priority is selected, ABR tokens will never be
transmitted unless the UBR token FIFO is empty. Converse-
ly, if 100a service priority is selected, UBR tokens will
never be transmitted unless the ABR token FIFO is empty.
Figure 8 illustrates the algorithm executed by
the PS. The algorithm assumes that the available output
time slots are counted by an external counter, however
other methods of determining when to service the queues may
be used. If a counter is used, then if the counter reaches
the value defined by the priority select input (selects ABR
priority with respect to UBR), then the ABR FIFO is exam-
ined for availability of a token to be transmitted. If
there is a token to be transmitted, then the ABR token is
removed from the FIFO, and the counter is reset. If there
is no ABR token, then the slot is made available to the UBR
stream. In this case, the counter is held to allow an ABR
token to be transmitted when one is available.
CA 02217262 1997-10-O1
.
' ' - 24 -
Figure 9 shows, in tabular form, how the PS allo-
cates the output bandwidth when presented with varying
loads from the two token sources.
13. Pending Pointer Simulation
To validate the performance of the pending
pointer concept in the above described ABR scheduler for
supporting zero MCR traffic, a Matlab program was written
and several case studies (over/under provisioned) were
simulated. For the sake of tractability and computational
simplicity, the number of profiles was set at p=5 and the
number of sub-profiles was set at sp=4, for a total of 20
entries . The system clock frequency was set at 256 hz (28) .
In the present example, each cell time corresponds to 8
cycles at a rate of 32 cells/second. Profile 1 (with sub-
profile 1) has an ACR of 16, representing the maximum
bandwidth (Line Rate) available. If the sum of the band-
widths of the available sub-profiles exceeds the Line Rate
(16 in this case), then it results in an over-provisioned
case; otherwise the case is under-provisioned. The effec-
tive rate for each profile/sub-profile was measured and the
resultant bandwidth was compared with the specified rates
for a simulation run consisting of 4096 profile visits.
a. Case Study 1: Equal Provisioned Case
Figure 10 depicts a typical equal provisioned
case. Each VC is assigned to one of the closest pro-
files/sub-profiles, as dictated by their ACRs. The rates
of each traffic profile are displayed in the left column.
The profile/sub-profile combinations are denoted by the
values in the boxes. Thus, 1.1 represents profile 1 and
sub-profile 1. Figure 11 tabulates the simulation results
and Figure 12B shows the cell distribution pattern required
for various VCs to avoid/reduce cell bursting (compare Fig-
ure 12A which depicts a prior art cell distribution pattern
exhibiting effects of cell clumping and buffer overflow).
CA 02217262 1997-10-O1
_ 25 _
b. Case Study 2: Under Provisioned Case
Figure 13 depicts an example of an under pro-
visioned case a.n which, for purposes of illustration, the
requested bandwidth is 13.25. The simulation results
(tabulated in Figure 14) clearly show that each VC receives
its fair share of bandwidth as initially requested prior to
setup of the VCs, since the effective sum of the ACRs is
less than the maximum bandwidth (16).
c. Case Study 2: Over Provisioned Case
In Figure 15, 10 VCs are provisioned. The
distribution depicted in Figure 15 results in an over
provisioned case, since the sum of the bandwidth (2x16 +
3x7 + 2x4 + 3x1 - 64) exceeds the available bandwidth.
Figure 16 tabulates the simulation results for the over
provisioned case.
14. MCR/ABR' Arbitrator Simulation
Matlab simulations of the MCR/ACR arbitrator
algorithm were also conducted to analyze the performance of
the MCR/ACR arbitrator. The results obtained for the over
provisioned case are discussed below, since that case is
critical and representative of the arbitrator's internal
algorithm. The simulation assumed the aforementioned
conditions and initial values, viz. clock frequency of 256
Hz, Line Rate - 16, and ACR discretized into 5 profiles
with 4 sub-profiles each. Furthermore, it was assumed that
the ABR' queue and the MCR queue were sufficiently long for
the simulation period of 4096 cycles, such that zero back
pressure was applied to the sources.
Figure 17 depicts the initial allocation of VCs
to the traffic profiles based on their ACRs. Note that the
MCR value for each VC is indicated in brackets. Observe
that the initial traffic table is partitioned such that the
respective VCs are linked appropriately in the ABR' and MCR
schedulers, after subtracting the MCR value from each.
CA 02217262 1997-10-O1~
. _ 26 _ -
15. ABR' Scheduler Output Simulation
Figure 18 shows the results of throughput analy-
sis of VC tokens by the ABR' queue generated by the ABR'
scheduler. It can be seen that the VCs are reassigned to
the traffic profiles based on the value of ACRz for each VC
where ACRz = ACRi - MCRT for i =1, . . , 5 . Note that VC #5 has
an MCR of 1 and hence it is not assigned to any traffic
profile by the ABR' scheduler and therefore receives zero
bandwidth. The results are measured at the ABR' queue for
each VC and the rates ACRQ= are consistent with the rate
weighted bandwidth allocation criterion, as explained
above. (ACRQ= is the effective ACRz measured for each VC
in the ABR' queue.)
16. MCR Scheduler Output Simulation
For the MCR scheduler, the required bandwidth is
only 4, as denoted in Figure 19. The MCR scheduler outputs
the VCs in the MCR queue with an efficiency of 1000. VCs
3, 4, 5 get their requested share (constant bandwidth) as
denoted by MCRQ= (i.e. the effective MCR~ measured for each
VC in the MCR queue). Observe that VCs #1 and #2 have a
zero MCR value and hence there is no contribution from the
MCR scheduler for these two VCs.
17. MCR/ABR' Arbitrator Output Simulation
Figure 20 shows the simulation results of the
output of the MCR/ABR' arbitrator. Note that due to
statistical variation and the finite number of simulation
cycles used in the study, the final measured rate has
3 0 exceeded the maximum l unit ( i . a over 10 0 % ) f or VCs 3 and 4 .
As will be apparent to those skilled in the art
in the light of the foregoing disclosure, many alterations
and modifications are possible in the practice of this
invention without departing from the spirit or scope
thereof. Accordingly, the scope of the invention is to be
CA 02217262 1997-10-O1
E ,
< _ 27 _
construed in accordance with the substance defined by the
following claims.