Note: Descriptions are shown in the official language in which they were submitted.
CA 02230367 1998-02-24
A Method and Apparatus for Authoring
of Customizable Multimedia Documents
This invention relates to a method and apparatus for the authoring of
customizable
multimedia documents and the adaptive generation of versions thereof for
particular uses.
Background of the Invention
Natural Language Generation (NLG) is a young but growing research field,
whose goal is to build computer systems that automatically produce fluent and
effective
texts in various human languages. Generally, NLG systems have used knowledge
databases containing general world knowledge and specific domain knowledge,
together
with various linguistic resources (e.g., lexicons, grammars, discourse
relations), to
produce texts with limited variation in word choice, sentence and discourse
structure, and
virtually no variation in rhetorical style or pragmatic purpose.
While various computational systems have been devised as solutions to the
problem of producing documents with limited expressiveness in form and effect,
none
has presented a general solution to the problem of representing the kinds of
knowledge
that are needed to produce documents tailored to a specific use or audience in
a manner
that is systematic and extensible, and that further provides for the authoring
of such
documents by a non-computer-programmer professional writer. In addition, no
system
has yet presented a general solution for automatically integrating various
aspects of
document design (e.g., text, graphics, and presentation layout) into a single
consistent
representation format.
It is well-known from studies in communication that presentation of
information
in a manner that is tailored to the characteristics of a particular audience
can be
significant both in maintaining the interest of the members of the audience
and in
effectively conveying the meaning of the information. For example, in the
health care
industry, it has been shown that information that is tailored to the
characteristics of an
individual patient can have a far greater effect in producing compliance with
suggested
medical regimens as compared to generic information. (Strecher et al 1994 have
done
pioneering work in this area).
1
CA 02230367 1998-02-24
But as Strecher et al's behavioural studies also showed, a sizeable number of
different medical and personality factors had to be taken into account in
producing
customized health information that would have the desired effect on the
intended patient.
DiMarco et al (1995) noted that this kind of customization involves much more
than
producing each brochure or leaflet in half a dozen different versions for
different
audiences. Rather, the number of different combinations could easily be in the
tens of
thousands. While not all distinct combinations might need distinct
customizations, it is
nonetheless impossible in general to produce and distribute, in advance of
need, the large
number of different editions of each publication that is required for
individual tailoring of
1 o information.
Thus there is a need for a computer system for the automated production of
customized material that would tailor a general-purpose "master document" for
a
particular purpose or individual on demand. It must also be remembered that in
the
present context the term "document" is broadly used to define any textual or
non-textual
data, including multimedia and hypertext, having inter-relationships between
the data,
and that may be displayable or presented to a human audience in one of many
presentations and formats.
As a further example, a master document may refer to the complete superset of
instructions to direct the actions of a robot on an assembly line. In this
instance, there
exists a need to tailor or adaptively generate subsets of combinations of
instructions for
specific robot applications. Whether the master document is to be customized
for a
particular purpose, as in the robot example, or tailored for a specific
audience, as in the
case of health information, this process of adaptive document generation
should be.easily
implementable on a computer system at minimum possible cost and maximum
possible
ease of use to both the author of the master document and the user of the
generation
system.
In the field of natural language processing, or, computational linguistics,
various
computer systems have been implemented which attempt to produce customized
documents. In the simplest cases, simple mail-merge techniques are used which
enable
"personalized" documents to be generated by using hand-coded decision rules
indicating
what information is to be included for various tailoring situations. However,
these
2
CA 02230367 1998-02-24
techniques result in very inflexible, and often, awkwardly structured, and
poorly cohesive
texts. Other systems utilize schema-based techniques to select and organize
the content
data according to simple document-template structures. But these templates are
either
too general-purpose to provide anything more than very coarse-grained
adaptation in the
resulting customized texts or too specific to the application in question to
be appropriate
for general use in adaptive generation systems.
A number of projects have used more sophisticated techniques from NLG
research to build adaptive generation systems for both written texts and
hypertext
documents. The IDAS project (Reiter, Mellish, and Levine 1995) recognized the
need to
tailor both textual and non-textual information, including visual formatting,
hypertext
input, and graphics output. IDAS also tried to address the need for explicit
authoring
tools in the adaptive document generation process, but here the focus was on
authoring at
the knowledge-base level (i.e., at the level of a computer system's internal
representation), while there still exists a need to provide an authoring
tool.that may be
used by a non-computer-programmer professional writer who could compose the
master
document at the level of ordinary English, with additional markup as required
(e.g.,
HTML markup to support an HTML presentation format for a resulting customized
version of the document). IDAS relies mainly on canned texts and aims to
provide the
user with a means of navigating through the whole "hyperspace" of possible
(canned)
texts. There is however a need to provide for a much finer-grained degree of
tailoring
than the IDAS implementation.
While IDAS relies mainly on canned texts, other adaptive generation systems do
use more-dynamic text generation: the Migraine system (Carenini, Mittal, and
Moore
1994) uses an approach to text planning that adaptively selects and structures
the
information to be given to a particular reader. However, Migraine relies on a
large
number of context-sensitive and user-sensitive "text plans" (i.e., text
schemas) so that its
methods of tailoring must of necessity be very specific to its particular
domain. The
PEBA-II system (Milosavljevic and Dale 1996) uses more-general text plans, as
well as
text templates, that it can choose from to adapt information to the individual
reader, but
the tailoring done is very specific, focussing on the user's familiarity with
a topic. The
PIGLET system (Cawsey, Binsted, and Jones 1995) also uses a combination of
text plans
3
CA 02230367 1998-02-24
and text templates, but its tailoring is also quite specific in nature, mainly
concerned with
emphasizing material that is relevant to a particular patient. The ILEX-0
system (Knott,
Mellish, Oberlander, and O'Donnell 1996) is similar to the PIGLET model in its
anticipation of all the possible texts that might be generated, but also
includes annotations
(e.g., a condition on a piece of canned text) to allow some local
customization. However,
very free and flexible use of annotations could lead to problems of repetitive
text and
inappropriate use of referring expressions in the resulting document,
requiring textual
repair.
None of the previous systems provide for a text-repair facility of the kind
described by Hovy and Wanner (1996) and Wanner and Hovy (1996). The paradigm
of
adaptive document generation by "selection and repair", as introduced by
DiMarco, Hirst,
Wilkinson, and Wanner (1995), that is, selection of the relevant pieces of
information
from a master document, and then repair of any syntactic or stylistic problems
in the
resulting document by a text-repair facility, is central to the goals of a
customizable
document system. However, the system should be able to support either an
adaptive
generation system with full facilities for selecting and repairing texts, as
described by
DiMarco, Hirst, Wilkinson, and Wanner (1995) and Hirst, DiMarco, Hovy, and
Parsons
(1997), or a simpler version of the system, based on "generation by selection
only", i.e.,
with no facilities for textual repair, an implementation of which (called
"WebbeDoc") is
described by DiMarco and Foster (1997).
In summary, an author of a customizable document needs to be able to describe
the variations of a document, which may be both textual and non-textual, at
various levels
of the document structure, together with the conditions for selecting each
variation.
The author then needs a means of selecting all the appropriate variations for
a
particular purpose or audience, re-assembling the selected variations into a
coherent
document, and producing an appropriately customized version of the document,
in
potentially many different levels of representation (e.g., surface English, a
deep syntactic
or semantic representation for use in textual repair) and presentation formats
(e.g.,
HTML, LaTeX).
None of the existing adaptive document generation systems has provided a
generally applicable method and apparatus for describing all the different
ways in which
4
CA 02230367 1998-02-24
a document could be customized, or for providing for a non-computer-programmer
author of a customizable document to specify the possible variations, or for
selecting the
appropriate variations and producing a customized version of a document.
Summary of the Invention
It is therefore an object of this invention to provide a system which
mitigates to
some extent the above outlined disadvantages. Also, the methods used by the
present
invention are more general than those used in previous systems, allowing not
only the
potential inclusion of text plans and schemas, text templates, and canned
text, but also the
dynamic generation of text that can then be subjected to very fine-grained
revision and
tailoring by a text-repair facility.
This invention seeks to provide a computer system for customizing an initial
master document containing information for a multiplicity of versions of the
document
intended for the different purposes or different users, for a specific purpose
or for a
specific user.
In accordance with this invention, there is provided a computer system for
customizing an initial master document in accordance with a user-defined set
of purpose
parameters. In accordance with a further aspect of the invention there is
provided a data
structure (i.e., the master document) for specifying relationships between
elements of the
document and between elements of the document and their variations.
A master document will therefore contain all the information that the system
might need to include in any particular customized version of the document,
together
with annotations giving the selection conditions as to when each piece of
information is
relevant and other annotations giving linguistic and formatting information,
including for
multimedia elements of the document.
A further aspect of the invention provides for a method and apparatus for
reading
said data structure into a form implementable on a suitably programmed
processor such
that the implementation of the data structure can store both the form and
content of a
master document, i.e., all the elements of the document and their variations,
and can also
act as the process for selecting the relevant variations of the document,
according to
5
CA 02230367 1998-02-24
given values of input parameters specifying the intended purpose or intended
uses, and
then generating the appropriately customized version of the document
Brief pescriptioQ of the Dt-~awi gs
A better understanding of the invention will be obtained by reference to the
detailed description of a preferred embodiment below and in regard to the
following
drawings in which:
Figure 1 is a schematic diagram showing the architecttue of the system;
Figure 2 shows a genetalised form of a data structure according to an
embodiment of the
present invention;
Figure 3(a) shows a generalised form of a data subsmucctue for use within the
main data
structure,for specifying presezxtation format infmnation for a customized
doctzment;
Figure 3(b) sbows a generalised form of a data substructure for use within the
main data
structure for specifying hypertext links to parts of the main data structure
or to ottxet' data
structures of the form as specified in Figure 2 and provided in other source
datafiles;
Figure 4 is a flowchart of the overaIl process of reading-in as input the data
srructinm and
generating as output a final customized version of the document; and
Figure 5 is a graph showing the resolution process for a customized document
gezzerated
according to an embodiment of the preserit invention;
Detailed Description of A Preferred Embodiment
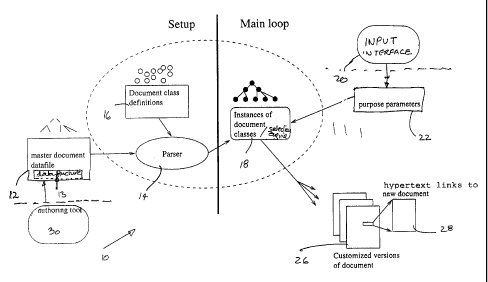
Referring to Figure 1, an architecture of a customizable docuanent system,
"ta[loring engine", is shown generally by numeral 10. The system comprises: a
datafile
12 including a data siructure 13 for defining a master document; a parsez-14
for reading
in the contents of the datafile 12 arnd for creating instances of the document-
class data
structures 18 in accordance with the general defxnitions of docurnent-class
data stzt.tctu=
16: a user input irrterface 20 for reading new values of purpose parameters 22
which are
input by a selection engine 18. "[be selection engine 18 uses the ctuTcnt
values of the
purpose parameters to select the relevant variations of each component of the
document
3o and to generate appropriately custonaized versions 26 of a document, which
may also
6
CA 02230367 1998-02-24
include hypertext links to new documents 28, which may themselves be
customizable
documents of the form illustrated in Figure 2.
The term "purpose parameter" as used herein means a parameter used in
evaluating a selection condition associated with a particular variation of a
document
structure, where this parameter can be used in defining either a particular
intended
purpose or use of a customized version of the document or a particular
intended user or
audience for a customized version. These elements are explained in detail
below.
Furthermore, the datafile may be generated by an authoring tool 30 in
accordance
to with the detailed explanation below.
Referring to figure 2 an embodiment of the data structure 13 according to the
present invention is described, which shows the blocks, sub-blocks, fields,
and subfields
of the data structure.
The data structure 13 has the following main blocks of information:
1. Identification of purpose parameters and representation-level parameters,
and
their possible values.
2. Identification of toplevel object (i.e., the main Document).
3. Definitions of main Document and any subDocuments.
4. Definitions of Sections.
5. Definitions of Topics.
6. Definitions of Sentences.
7. Definitions of Lexicals.
8. Definitions of Words.
9. Definitions of Annotations (replaces previous 9. Definitions of Formats).
10. Definitions of External objects.
Each of these blocks of the data structure will now be described in turn.
Block 1: The purpose parameters. The first block of the data structure
identifies the
purpose parameters, or user parameters, together with their possible values,
that can be
7
CA 02230367 1998-02-24
used in forming the Boolean expressions that give the conditions for selecting
each
variation of a document.
The first block also identifies the representation-level parameters, together
with
their possible values, that can be used in forming the Boolean expressions
that give the
conditions for selecting each SentenceVariation, i.e., each level of
representation of a
document.
Block 2: The toplevel object. The toplevel object identifies the document-
class
instance which is the "root" element of the entire document. It is with this
object that the
1 o resolution process for generating a customized version of the document
begins.
Blocks 3-9: The program structures. Blocks 3-9 describe the program
structures, the
classes that implement the substructures of the data structure that specify
the form and .
content of a customizable document. The program structures are related in the
following
manner:
A datafile describing a set of program structures is a particular example of a
customizable document created for various uses. The datafile may be divided
into
various parts.
Firstly, the data structure may be divided into components, or elements,
referred
to as the classes Document, Section, Topic, Sentence, and Lexical, which each
implement
a substructure of the data structure that defines a component of a
customizable document.
Each such substructure of the data structure also includes the variations of a
component
and the conditions for selecting the appropriate variation of a component.
In addition, the data structure contains basic components which are instances
of
the classes Word and Annotation, and other components, which are instances of
the class
External, for linking to other datafiles.
8
CA 02230367 1998-02-24
Block 3: The Documents.
In Figure 2, Block 3 describes the instances of the class Document. Each
Document
description must specify the following properties:
- A list of its variations. Each variation must be an instance of the class
DocumentVariation.
- A list of its annotations. Each annotation must be an instance of the class
Annotation.
An instance of the class Annotation can specify both textual and non-textual
properties of a document or a component of a document in terms of a particular
document-layout format, structure, or linguistic representation. For example,
an
Annotation object could specify multimedia elements of the document's layout,
such as alignment of text, font size, background colour, text colour, and
graphics;
other Annotation objects could specify linguistic information such as
discourse
relations or coreference links.
Each variation of a Document class is then described as an instance of the
class
DocumentVariation. Each DocumentVariation description specifies the following
properties:
- The condition for selecting this variation. The condition must be a Boolean
expression composed from pairs of purpose parameters and their allowable
values.
- A list of the components of this variation. All components must either be
all
instances of the class Document or all instances of the class Section.
- A list of annotations for this variation. Each annotation must be an
instance of
the class Annotation.
Block 4: The Sections. Block 4 describes the instances of the class Section.
Each
Section description specifies the following properties:
- A list of its variations. Each variation must be an instance of the class
SectionVariation.
9
CA 02230367 1998-02-24
- A list of its annotations. Each annotation must be an instance of the class
Annotation.
Each variation of a Section class is then described as an instance of the
class
SectionVariation. Each SectionVariation description specifies the following
properties:
- The condition for selecting this variation. The condition must be a Boolean
expression composed from pairs of purpose parameters and their allowable
values.
- A list of the components of this variation. All components must either be
instances of the class Section or instances of the class Topic.
- A list of the annotations for this variation. Each annotation must be an
instance of the class Annotation.
Block 5: The Topics. Block 5 describes the instances of the class Topic. Each
Topic
description specifies the following properties:
- A list of its variations. Each variation must be an instance of the class
Topic-
Variation.
- A list of its annotations. Each annotation must be an instance of the class
Annotation.
Each variation of a Topic class is then described as an instance of the class
TopicVariation. Each TopicVariation description specifies the following
properties:
- The condition for selecting this variation. The condition must be a Boolean
expression composed from pairs of purpose parameters and their allowable
values.
- A list of the components of this variation. All components must be instances
of the class Sentence.
- A list of the annotations for this variation. Each annotation must be an
instance of the class Annotation.
Block 6: The Sentences. Block 6 describes the instances of the class Sentence.
Each
Sentence description must specify the following properties:
CA 02230367 1998-02-24
- A list of its variations. Each variation must be an instance of the class
SentenceVariation.
- A list of its annotations. Each annotation must be an instance of the class
Annotation,
Each variation of a Sentence class is then described as an instance of the
class Sentence-
Variation. Each SentenceVariation description must specify the following
properties:
- A list of the components of this variation. All components must be instances
of the class Lexical.
- The condition for selecting this variation. The condition must be a Boolean
expression composed of a single representation-level parameter and an
allowable value.
- A list of annotations for this variation. Each annotation must be an
instance of
the class Annotation.
In the current implementation of the system, a SentenceVariation may be a
character
string, with any Lexical components identified by surrounding reserved
characters. This
is a simplification made for ease of testing system prototypes, and does not
limit the
scope of the invention.
Block 7: The Lexicals. Block 7 describes the instances of the class Lexical.
Each
Lexical description must specify the following property:
- A list of its variations. Each variation must be an instance of the class
LexicalVariation.
- A list of its annotations. Each annotation must be an instance of the class
Annotation.
Each variation of a Lexical class is then described as an instance of the
class
LexicalVariation. Each LexicalVariation description must specify the following
properties:
- The condition for selecting this variation. The condition must be a Boolean
expression composed from pairs of purpose parameters and their allowable
values.
- A character string associated with this LexicalVariation instance.
11
CA 02230367 1998-02-24
- A list of annotations for this variation. Each annotation must be an
instance of
the class Annotation.
- A single component, which may be an instance of any of the classes External,
Word, Lexical, Sentence, Topic, Section, or Document. Each of these cases is
dealt with as follows:
I. If a component is a Word, then it is treated as a simple string to be
concatenated to the result returned.
2. If a component is a Lexical, then it is treated as a set of variations of a
word,
which will be resolved to select the appropriate version of the word.
In this way, near-synonymy can be handled within the system.
3. If a component is a Sentence, Topic, or Section, then it is treated as a
set of
variations of a separate piece of a document, which will be resolved to select
the appropriate version.
In this way, adaptive hypertext can be handled within the system.
4. If a component is a Document, then it is treated as a whole complete
document.
In this way, hyperlinks to other documents internal to the same datafile can
be
handled within the system.
5. If a component is an External object, then it is treated as a whole
complete
customizable document.
In this way, hyperlinks to other customizable documents can be handled
within the system.
Block 8: The Words. Block 8 describes the instances of the class Word. Each
Word
description must specify its associated string and its associated annotations.
Each
annotation must be an instance of the class Annotation.
Block 9: The Annotations. Block 9 describes the instances of the class
Annotation that
will be used to insert all the relevant linguistic and formatting information
into the
customized version of the document to be output. A description of block 9 is
not
12
CA 02230367 1998-02-24
included in figure 2. Instead, the general structure of an Annotation class
object is shown
in figure 3.
The Annotation objects can be grouped into several distinct sub-taxonomies,
one
for each type of linguistic or formatting annotations that will be attached to
the main
master-document data structure. For example, one Annotation sub-taxonomy might
specify details of HTML layout for the overall document and each component of
the
document; another Annotation sub-taxonomy might record properties of the
discourse
structure of the overall document and each component of the document, such as
rhetorical
relations and coreference links. Each Annotation object has a property
"parent" to
reference its immediate ancestor in its (sub-)taxonomy.
Block 10: The Externals. Block 10 describes the instances of the class
External ,
which will be used to create hypertext links to other customizable documents
specified in
other datafiles.
Each External description must specify the following attributes:
- The name of the file containing the external customizable document.
- A user profile. The user profile is a list of parameters that describe the
user or
audience for whom the document customization is being performed.
The data structure 13 according to the present invention allows an author to
describe the structure of a customizable document (i.e., a master document).
The data
structure has a recursive and object-oriented form and can be implemented
using an
object-oriented programming language so that a customizable document described
in the
form of the data structure can be implemented as an object-oriented computer
program.
The elements of the data structure are related by both part relationships and
by
inheritance relationships, so that the relationships between the elements of a
customizable
document described in the form of the data structure and implemented as a
corresponding
object-oriented computer program can be recognized and maintained by the
object
hierarchy and inheritance mechanism of an object-oriented computer program.
Moreover, an object-oriented computer program that implements the data
structure is both the form and content of a customizable document and the
process for
13
CA 02230367 1998-02-24
selecting and generating an appropriately customized version of the document.
Thus the
data structure is generic in the sense that it can implement any customizable
document
given in the form of the data structure.
The data structure 13 describes the corpus text of a specific customizable
document (i.e., a master document) having elements and structure, as shown in
figures
2(a) , 2(b) and 2(c) following.
The form of the data structure is defined by the set of general class objects
16
describing the elements and structure of a customizable document in terms of
object-
oriented program structures. These class objects are related by both part
relationships
and by inheritance relationships to be explained below.
The operation of the system 10 (the "tailoring engine") may be explained as
follows:
The parser program 14 reads in and parses the master-document datafile 12 to
recognize its structure and then maps the contents of the input datafile into
class objects
of name according to class names specified in the input data structure.
Properties of the
classes are also recognized according to information contained in the data
structure.
The parser program 14 also acts as a document-class instantiator program which
uses the parsed contents of the input datafile to dynamically create instances
of the
program structures identified by the general class objects described above.
Properties of
the classes are also dynamically assigned according to information contained
in the data
structure.
An integration of data structures with the main process of the system
comprises
the following:
The instances of the class objects dynamically generated from the input
datafile,
which provide two simultaneous functions:
1. The program data structures describing the elements, structure, and content
of
the master document.
2. The selection process for generating the appropriate customized version of
the
document.
Thus, a feature of the system is that given the current values of the purpose
parameters,
the instances of the program data structures, that is to say, the instances of
the class
14
CA 02230367 1998-02-24
objects describing the elements of the master document, execute themselves to
select and
generate the appropriate customized version of the document.
The core of the system, that is, the integration of program data structures
with the
selection process, is generic in terms of the following properties:
Application-independent. The system core is independent of the application:
the
only items that need be re-defined for a new application are the input
datafile and the
interface for reading the current values of the purpose parameters. This is
discussed
further below.
Platform-independent. The system core is currently implemented in the Java
programming language, so is platform-independent to the same extent as Java
itself.
Processor-independent. The system core is currently implemented in the Java
programming language, but is independent of the underlying programming
language, i.e.,
processor, to the extent that the programming language used must provide an
object-
oriented paradigm and a semantics for property inheritance that is consistent
with the
specification of the resolution process used in the system for generating a
customized
version of a document from the instances of the program data structures.
The process of generating a customized version of a document from the
instances
of the program structures is referred to as resolution and will be discussed
later with
reference to Figure 5.
A customized version of a document can be generated in any number of different
levels of representation of its content (e.g., surface English; a syntactic or
semantic
representation to be used by a text-repair facility; and so on). The different
representations to be generated for any given application must be indicated by
the
representation-level parameters in the description of the document given by
the data
structure in the input datafile. This information is specified in block 1 of
the data
structure as described with reference to figures 2(a), 2(b), and 2(c) above.
Each different representation of the content of a customized version of the
document will be generated along with a list of all the relevant annotations
to the content.
These annotations provide information on the multiple forms in which the
document may
subsequently be presented to a reader, and the linguistic information that may
be used to
guide subsequent repair of the customized document. The customized document
that is
CA 02230367 1998-02-24
generated will also include all annotations to the content concerning the
External objects
that can be used to provide hypertext links to other customizable documents or
to other
applications of the system 10 (the "tailoring engine") from figure 1.
The process of generating a customized version of a master document is shown
in
Figure 4. There are two main stages to this process, the initial setup and the
main
program loop. In the initial setup, the input datafile is read in and parsed,
and the
appropriate instances of the various document classes described above are
created. The
parser program 14 reads in the input datafile 12, which contains the data
structure 13
giving the specification of a customizable document. As it reads in the file,
the driver
program also acts as a class instantiator to create instances of all relevant
document
classes according to the input data structure. Program links, i.e.,
references, are created
between these class instances via the setting of their properties and
assignment of their
property values.
In each iteration of the main program loop, new values of the purpose
parameters
are read in, and a customized version of the document is generated as output
for each
specified level of representation.
A user interface in the form of a reader program 20 obtains new values of the
purpose parameters. A selection engine 18 resolves the document instances
created in the
setup stage according to the current values of the purpose parameters to
generate the
appropriately customized version of the document. The customized document is
output
in all requested presentation formats. The customized document is output in
all specified
levels of representation. If there are no more new purpose-parameter values to
read in,
the main program loop terminates.
The process of selecting the appropriate variation of each document structure
is
called "resolution". Figure 5 is a graph showing the resolution process for a
customized
document generated according to an embodiment of the present invention. The
pseudocode for the Resolve procedures, which implement the resolution process,
is as
follows:
Procedure: Resolve (for VariationContainer classes)
Parameters
16
CA 02230367 1998-02-24
- (input)
An instance of WorkingCondition
(a list of purpose parameters and their current values)
- (input)
An instance of List
(a list of the desired representation levels to output)
- (output)
A set of root nodes of DocumentObjectTrees,
one for each required level of representation
(Note: an instance of DocumentObjectTree is a tree structure
made up of resolved Documents, Sections, Topics,
Sentences, Lexicals, Words, Annotations, and Externals).
Algorithm:
if Resolve has already been called with this WorkingCondition then
result is the previously saved result
// for Document, Section, Topic, Lexical
else
call Satisfies on each variation until
the WorkingCondition is satisfied
call Resolve on this satisfying variation and
return a set of root nodes of DocumentObjectTrees
attach the appropriate annotations for this VariationContainer into
the set of root nodes of DocumentObjectTrees
// for Sentence
else
for each variation
call Satisfies on this variation to check if
17
CA 02230367 1998-02-24
the WorkingCondition is satisfied
if Satisfies returns true then
call Resolve for this variation and
return a root node of a DocumentObjectTree
end for
attach the accumulated annotations for this Sentence into
the set of root nodes of DocumentObjectTrees
(end of else-statement for Sentence)
if no variation satisfies the WorkingCondition then
result is null
else
result is the final modified set of root nodes
end if
Procedure: Resolve (for Variation classes)
Parameters:
- (input)
An instance of WorkingCondition
- (input)
An instance of List
(a list of the desired representation levels to output)
- (output)
A set of root nodes of DocumentObjectTrees,
one for each required level of representation
Algorithm:
for each component in the componentList of this Variation do
create a new set of root nodes of empty DocumentObjectTrees,
one for each level of representation
call Resolve on the current component
18
CA 02230367 1998-02-24
if Resolve returns a non-null result then
attach each root node in the returned set as
a subtree of the appropriate node in the set of root nodes
of DocumentObjectTrees for this Variation
end for
attach the appropriate annotations for this Variation
into the set of root nodes of DocumentObjectTrees
result is the modified set of root nodes of DocumentObjectTrees
The "resolution" of the appropriate annotations for a given input data
structure is handled
as follows:
Each instance of a document class in the input data structure, down to the
level of
a Word instance, has an "annotations" property, which may be null, associated
with it.
This property is a list of all the Annotation objects that apply to this
document-class
instance and must contain one Annotation object for each of the distinct sub-
taxonomies
in the overall class of Annotation objects.
When a document-class instance is being resolved, its set of Annotation
objects,
as specified in its "annotations" property, will be collected and included in
the content of
the customized document.
In summary, an application system which wishes to put the invention into
practice
must execute the following steps:
1. An input datafile of the structure as described with reference to figures
2(a),
2(b), and 2(c) is created;
2. A user interface in the form of a reader program to obtain new values of
purpose parameters is provided. This reader program returns as output an
instance of WorkingCondition which is a set of purpose parameters and their
values (implemented as a hashtable in one embodiment of the invention).
3. The main program first reads in the datafile, then calls the reader program
to
obtain a new instance of WorkingCondition. The main program will then start
19
CA 02230367 1998-02-24
the resolution process for the toplevel Document object by passing it the
WorkingCondition.
4. The output of each iteration of the main program will be a customized
version
of the document in all the levels of representation specified in the input
datafile using the representation-level parameters. Each representation of the
customized document is output for possible later processing by the application
system.
CA 02230367 1998-02-24
References
Giuseppe Carenini, Vibhu O. Mittal, and Johanna D.Moore. "Generating patient-
specific
interactive natural language explanations." Proceedings, Eighteenth Annual
Symposium
on Computer Applications in Medical Care, Washington D.C., November 1994, 5-9.
Alison Cawsey, Kim Binsted, and Ray Jones. "Personalised explanations for
patient
education." Proceedings of the Fifth European Workshop on Natural Language
Generation, 1995, 59-74.
Chrysanne DiMarco and Mary Ellen Foster. "The automated generation of Web
documents that are tailored to the individual reader." Proceeding of the 1997
AAAI
Spring Symposium on Natural Language Processing for the World Wide Web,
Stanford
University, March 1997.
Chrysanne DiMarco, Graeme Hirst, and Eduard Hovy. "Generation by selection and
repair as a method for adapting text for the individual reader." Proceedings
of the
Workshop on Flexible Hypertext, Eighth ACM International Hypertext Conference,
Southampton UK, April 1997.
Chrysanne DiMarco, Graeme Hirst, Leo Wanner, and John Wilkinson. "HealthDoc:
Cus-
tomizing patient information and health education by medical condition and
personal
characteristics." Workshop on Artificial Intelligence in Patient Education,
Glasgow,
August 1995.
Graeme Hirst, Chrysanne DiMarco, Eduard Hovy, and Kimberley Parsons.
"Authoring
and generating health-education documents that are tailored to the needs of
the individual
patient." In: Anthony Jameson, Cdcile Paris, and Carlo Tasso (editors), User
Modeling:
Proceedings of the Sixth International Conference, UM97 (Chia Laguna,
Sardinia, Italy),
Vienna and New York: Springer Wien New York, June 1997, 107-118.
Eduard Hovy and Leo Wanner. "Managing sentence planning requirements."
Proceedings, ECAI-96 Workshop on Gaps and Bridges: New Directions in Planning
and
Natural Language Generation, Budapest, August 1996.
Alistair Knott, Chris Mellish, Jon Oberlander, and Mick O'Donnell. "Sources of
flexibility in dynamic hypertext generation" Proceedings, Eighth International
Natural
Language Generation Workshop, Herstmonceaux Castle, June 1996, 151-160.
Maria Milosavljevic and Robert Dale. "Strategies for comparison in
encyclopaedia
descriptions." Proceedings, Eighth International Natural Language Generation
Workshop, Herstmonceaux Castle, UK, June 1996, 161-170.
Ehud Reiter, Chris Mellish, and John Levine. "Automatic generation of
technical
documentation." Applied Artificial Intelligence, 9, 1995, 259-287.
21
CA 02230367 1998-02-24
Victor J. Strecher, Matthew Kreuter, Dirk-Jan Den Boer, Sarah Kobrin, Harm J.
Hospers,
and Celette S. Skinner. "The effects of computer-tailored smoking cessation
messages in
family practice settings." The Journal of Family Practice, 39(3), September
1994, 262-
270.
Leo Wanner and Eduard Hovy. "The HealthDoc sentence planner." Proceedings of
the
Eighth International Workshop on Natural Language Generation, Brighton, UK,
June
1996.
22
CA 02230367 1998-02-24
Sample Data Structures
Selections from two sample data structures are presented in this section. The
first
example is taken from the customizable home page of the HealthDoc Project at
the
University of Waterloo (Waterloo, Canada). The second example is from a master
document giving basic health information on diabetes.
Note that in the LexicalVariation labelled "lexDiabetesMaster-a" in Example 1,
there is
a link to another completely separate customizable document, contained in a
different
input datafile. This link is made through an instance of the External class.
Example 1: A Customizable Web Page
// The parameters
PurposeParameters ((role (CLexpert physician layperson funder))
(technical (high low))
(age (senior adult child))
(formality (formal informal))
(coolness (cool bland)))
RepresentationLevelParameters (english-output)
// The top-level object
toplevel=Document.webbedoc
// The Documents and DocumentVariations
Document webbedoc
Iname="The HealthDoc Project Home Page"&
variations=doc-a doc-b doc-c doc-d doc-e doc-f doc-g doc-h&
annotations=html-doc-webbedoc-toplevelI
DocumentVariation doc-a
Icondition=(and (coolness cool) (age adult) (role CLexpert))&
componentList=Section.secl Section.sec2 Section.sec3 Section.sec4
Section.sec5 Section.sec6 Section.sec7&
annotations=html-doc-webbedoc-doc-aI
DocumentVariation doc-d
Icondition=(and (coolness bland) (age adult))&
componentList=Section.secl Section.sec2 Section.sec3 Section.sec4
Section.sec5 Section.sec6 Section.sec7&
annotations=html-doc-webbedoc-doc-dI
// The Sections and SectionVariations
Section secl
23
CA 02230367 1998-02-24
Ivariations=secla seclb seclc secld secle seclf
seclg seclh secli seclj seclk secll
seclm secln seclo seclp seclq seclr&
annotations=html-sec-webbedoc-sec 11
SectionVariation sec 1 a
Icondition=
(and (role funder)(technical all)(coolness bland)(formality formal))&
componentList=Section.subs cl-1 Section.subsecl-2&
annotations=html-sec-webbedoc-sec 1 al
Section subsec 1-1
variations=subsec 1-1 a&
annotations=html-sec-webbedoc-subsec 1-1 1
SectionVariation subsecl-1a
condition=()&
componentList=Topic.topic 1 &
annotations=html-sec-webbedoc-subsec 1-1 1
Section sec2
Ivariations=sec2a sec2b&
annotations=html-sec-webbedoc-sec21
Section subsec2-1
Ivariations=subsec2-1 a&
annotations=html-sec-webbedoc-subsec2-1 1
SectionVariation subsec2- 1 a
Icondition=O&
componentList=Topic.topic4 Topic.topic5 Topic.topic6 Topic.topic7&
annotations=html-sec-webbedoc-subsec2-1 1
The Topics and TopicVariations
Topic topic4
Ivariations=topic4a&
annotations=html-topic-webbedoc-default)
TopicVariation topic4a
condition=()&
componentList=Sentence.sent4a-1 Sentence.sent4a-2&
annotations=html-topic-webbedoc-defaultI
Topic topic5
Ivariations=Topic.topic5a Topic.topic5b Topic.topic5c Topic.topic5d&
annotations=html-topic-webbedoc-defaultI
24
CA 02230367 1998-02-24
TopicVariation topic5a
condition=(and (role physician) (technical high))&
componentList=Sentence.sent5a-1 &
annotations=html-topic-webbedoc-defaultI
TopicVariation topic5c
condition=(and (not (role physician)) (technical high))&
componentList=Sentence.sent5c-1 &
annotations=html-topic-webbedoc-defaultI
Topic topic7
ivariations=topic7a topic7b&
annotations=html-topic-webbedoc-defaultI
TopicVariation topic7a
icondition=(technical low)&
componentList=Sentence.sent7a-1 &
annotations=html-topic-webbedoc-defaultI
TopicVariation topic7b
condition=(technical high)&
componentList=Sentence.sent7b-1 &
annotations=html-topic-webbedoc-defaultI
Topic topic-compliance
ivariations=topic-compliance-a&
annotations=html-topic-webbedoc-defaultI
TopicVariation topic-compliance-a
jcondition=()&
componentList=Sentence.sent-compliance-1 Sentence.sent-compliance-2
Sentence.sent-compliance-3 Sentence.sent-compliance-4&
annotations=html-topic-webbedoc-defaultI
// The Sentences and SentenceVariations
Sentence sent4a-1
Ivariations=Sentence.sent4a-1 Basic&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent4a-1Basic
icondition=english-output&
componentList="Why do we want to be able to produce tailored
documents?"I
annotations=html-sent-webbedoc-defaultI
CA 02230367 1998-02-24
Sentence sent4a-2
Ivariations=Sentence.sent4a-2Basic&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent4a-2Basic
conditi on=english-output&
componentList="Because research in communication has shown that
people pay more attention to messages that are aimed
just at them."&
annotations=html-sent-webbedoc-defaultI
Sentence sent5a-1
ivariations=Sentence.sent5a-1 Basic&
annotations=html-sent-webbedoc-defaultJ
SentenceVariation sent5a-1 Basic
condition=english-output&
componentList="Studies have shown that health information that is tailored
to a patient's specific medical condition and personal characteristics
is much more effective than generic information in influencing
~lexCompliance~ and subsequent outcome."&
annotations=html-sent-webbedoc-defaultI
Sentence sent7a-1
variations=Sentence.sent7a-1Basic&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent7a-1 Basic
condition=english-output&
componentList="But it can be very difficult to write and keep track
of many versions of the same ~lexSynonyms 1~."&
annotations=html-sent-webbedoc-defaultI
Sentence sent8a-1
(variations=Sentence.sent8a-1 Basic&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent8a-1 Basic
Icondition=english-output&
componentList="What is needed is a computer system for the production
of tailored health-information and patient-education
documents, that would, on demand, customize a 'master
document' to the needs of a particular individual."&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent8a-2Basic
26
CA 02230367 1998-02-24
condition=english-output&
componentList="The HealthDoc project has currently built the first
~lexDiabetesMaster~ of such a system."&
annotations=html-sent-webbedoc-defaultI
Sentence sent-compliance-1
Ivariations=Sentence. sent-comp liance-1 a&
annotations=html-sent-webbedoc-defaultI
1 o SentenceVariation sent-compliance-1 a
condition=english-output&
componentList="Recent experiments have shown that health-education
material can be much more effective if it is
customized for the individual reader in accordance
with their medical conditions, demographic variables,
personality profile, or other relevant factors."&
annotations=html-sent-webbedoc-defaultI
Sentence sent-compliance-2
Ivariations=Sentence.sent-compliance-2a&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent-compliance-2a
condition=english-output&
componentList="For example, Dr Victor Strecher (now at the
Comprehensive Cancer Center of the University of
Michigan) and colleagues sent unsolicited leaflets to
patients of family practices on topics such as giving
up smoking, improving dietary behaviour, or having a
mammogram."&
annotations=html-sent-webbedoc-defaultI
Sentence sent-compliance-3
Ivariations=Sentence.sent-compliance-3 a&
annotations=html-sent-webbedoc-defaultI
SentenceVariation sent-compliance-3a
Icondition=english-output&
componentList="Each leaflet was 'tailored' to the recipient, on the
basis of data gathered from them in an earlier survey."&
annotations=html-sent-webbedoc-defaultI
Sentence sent-compliance-4
Ivariations=Sentence. sent-compliance-4a&
annotations=html-sent-webbedoc-defaultI
27
CA 02230367 1998-02-24
SentenceVariation sent-compliance-4a
condition=engli sh-output&
componentList="In each study, the 'tailored' leaflets were found to
have a significantly greater effect on the patients'
behaviour than 'generic' leaflets had upon patients
in a control group."&
annotations=html-sent-webbedoc-defaultI
lo // The Lexicals and LexicalVariations
Lexical lexSynonyms 1
variations=lexSynonyms 1 a lexSynonyms I b&
annotations=1
LexicalVariation lexSynonyms 1 a
Icondition=(role physician)&
string="brochure"&
value=Word.brochure&
annotations=1
LexicalVariation lexSynonyms l b
condition=(not (role physician))&
string="information"&
value=Word.information&
annotations=1
Lexical lexCompliance
Ivariations=lexCompliance-a&
annotations=1
LexicalVariation lexCompliance-a
Icondition=(role physician)&
string="tailored health-information"&
value=Topic.topic-compliance&
annotations=1
Lexical lexDiabetesMaster
Ivariations=lexDiabetesMaster-a&
annotations=l
LexicalVariation lexDiabetesMaster-a
Icondition=O&
string="prototype"&
value=External. external-diabetes&
annotations=1
28
CA 02230367 1998-02-24
// The Words
Word brochure
Ivalue=brochurel
Word information
Ivalue=informationj
// The Annotations
1o Annotation html-doc-webbedoc-toplevel
title="The HealthDoc Home Page")
Annotation html-doc-webbedoc-doc-a
jbackground="blue2.gif'&
becolor="#ffffef '&
vlink="#990099"&
alink="#990099"&
link="#990099"&
title-begin="<center><font size = +4 color = \"990099\">"&
title-end="</font></center>"&
image-dir="/-healthdo/images/"&
image-align="alt"&
parent=html-doc-webbedoc-toplevelI
Annotation html-sec-webbedoc-sec 1
ltitle-begin="<font size = +1 color = \"990099\">"&
title-end="</font>"&
title="The goal of the HealthDoc project"&
parent=html-doc-webbedoc-toplevelI
Annotation html-sec-webbedoc-sec 1 a
Jimage="businmen. j pg"&
parent=html-sec-webbedoc-sec 11
Annotation html-sec-webbedoc-sec2
Jtitle-begin="<font size = +1 color = \"990099\">"&
title-end="</font>"&
title="The motivation for the research"&
parent=html-doc-webbedoc-toplevelI
The External objects
External external-diabetes
JfileName="diabetes. master"&
profile=<list of parameters describing current user/audience>1
29
CA 02230367 1998-02-24
Example 2: Customizable Health Information
// The parameters
PurposeParameters ((type (insulin-dependent non-insulin-dependent))
(technical (high-technical moderate-technical low-technical))
(age (senior adult young-adult child))
(locus-of-control (doctor patient)))
RepresentationLevelParameters (spl-output english-output)
// The top-level object
toplevel=Document.diabetes
// The Documents and DocumentVariations
Document diabetes
narne="Treating Your Diabetes"&
variations=doc-a&
annotations=html-doc-diabetes-toplevel discourse-doc-diabetes-toplevelI
DocumentVariation doc-a
Icondition=()&
componentList=Section.secl Section.sec2 Section.sec3 Section.sec4&
annotations=html-doc-diabetes-doc-a discourse-doc-diabetes-toplevelI
// The Sections and SectionVariations
Section secl
variations=sec 1 a&
annotations=html-sec-diabetes-sec 1 discourse-sec-diabetes-sec 1 I
SectionVariation sec 1 a
1condition=()&
componentList=Section. subsec 1-1 Section. subsec 1 -2&
annotations=html-sec-diabetes-sec 1 a discourse-sec-diabetes-sec 11
Section subsecl-1
variations=subsec 1-1 a&
annotations=html-sec-diabetes-subsec 1-1 discourse-sec-diabetes-sec 1 i
SectionVariation subsec 1-1 a
Icondition=O&
componentList=Topic.topic 1 &
annotations=html-sec-diabetes-subsec 1-1 a discourse-sec-diabetes-sec 1 I
Section subsecl-2
Ivariations=subsec 1-2a&
annotations=html-sec-diabetes-subsec 1-2 discourse-sec-diabetes-sec 1 l
CA 02230367 1998-02-24
SectionVariation subsec l -2a
Icondition=()&
componentList=Topic.topic2 Topic.topic3 Topic.topic4
Topic.topic5 Topic.topic6&
annotations=html-sec-diabetes-subsec l-2a discourse-sec-diabetes-sec l
// The Topics and TopicVariations
Topic topicl
Ivariations=topic I a&
annotations=html-topic-diabetes-default discourse-topic-diabetes-topic 1 I
TopicVariation topic I a
Icondition=()&
componentList=Sentence.sentla-1 Sentence.sentla-2&
annotations=html-topic-diabetes-default discourse-topic-diabetes-topic 1 ~
Topic topic3
Ivariations=topic3a topic3b&
annotations=html-topic-diabetes-default discourse-topic-diabetes-topic31
TopicVariation topic3a
Icondition=(type insulin-dependent)&
componentList=Sentence.sent3a-1 &
annotations=html-topic-diabetes-default discourse-topic-diabetes-topic31
TopicVariation topic3b
Icondition=(type non-insulin-dependent)&
componentList=Sentence.sent3b-1 &
annotations=html-topic-diabetes-default discourse-topic-diabetes-topic3
The Sentences and SentenceVariations
Sentence sentla-1
Ivariations=sent 1 a-l-english sent I a-l-spl&
annotations=html-sent-diabetes-default discourse-sent-diabetes-defaultI
SentenceVariation sentla-l-english
icondition=english-output&
componentList=Lexical.lexDiab Lexical.lexis Lexical.lexa Lexical.lexgroup
Lexical.lexof Lexical.lexconds Lexical.lexin Lexical.lexwhich
Lexical.lexglucose Lexical.lexlevels Lexical.lexare
Lexical.lexabnormally Lexical.lexhigh. &
annotations=html-sent-diabetes-default discourse-sent-diabetes-defaultI
SentenceVariation sentla-l-spl
Icondition=spl-output&
31
CA 02230367 1998-02-24
componentList="<an SPL form>"&
annotations=html-sent-diabetes-default discourse-sent-diabetes-defaultI
Sentence sent3 a-1
Ivariations=sent3a-l-english sent3a-l-spl&
annotations=html-sent-diabetes-default discourse-sent-diabetes-defaultI
SentenceVariation sent3a-l-english
Icondition=english-output&
componentList="The condition that you have is insulin-dependent diabetes."&
annotations=html-sent-diabetes-default discourse-sent-diabetes-defaultI
SentenceVariation sent3a-l-spl
icondition=spl-output&
componentList="(asc / ascription
:tense present
:domain (condl / abstraction
:lex condition
:determiner the
:process (have / ownership
:lex have-possession
:tense present
:domain (hearer / person)
:range cond))
:range (diab2 / abstraction
:lex diabetes
:determiner zero
:property-ascription (ins / quality
:lex insulin-dependent)))"&
annotations=html-sent-diabetes-default discourse-sent-diabetes-default)
// The Lexicals and LexicalVariations
Lexical lexDiab
Ivariations=lexDiab-a&
annotations=1
LexicalVariation lexDiab-a
Icondition=()&
string="Diabetes"&
value=Word.Diab&
annotations=1
Lexical lexglucose
Ivariations=lexglucose-a&
annotations=1
32
CA 02230367 1998-02-24
LexicalVariation lexglucose-a
Icondition=()l
string="glucose"&
value=Word.glucose&
annotations=)
Lexical lexhigh
Ivariations=lexhigh-a&
annotations=1
LexicalVariation lexhigh-a
Icondition=()l
string="high"&
value=Word.high&
annotations=1
// The Words
Word Diab
Ivalue=Diabetesl
Word glucose
Ivalue=glucosel
Word high
Ivalue=highl
// The Annotations
// // HTML Annotations
3o Annotation html-doc-diabetes-toplevel
Ititle="About Your Diabetes"I
Annotation html-doc-diabetes-doc-a
(becolor="#ffffef'&
title-begin="<hl align=\"center\">"&title-end="</h1>"&
parent=html-doc-diabetes-toplevel)
Annotation html-sec-diabetes-default
// <default HTML markup for any Section in diabetes document>1
Annotation html-sec-diabetes-sec 1
Ititle="Basic information"&
parent=html-sec-diabetes-defaultI
Annotation html-sec-diabetes-sec 1 a
Ititle-begin="<h2 align=\"center\">"&title-end="</h2>"&
33
CA 02230367 1998-02-24
parent=html-sec-diabetes-sec 1 I
Annotation html-sec-diabetes-subsec 1-1
Ititle="What is diabetes?"&
parent=html-sec-diabetes-sec 1 ~
Annotation html-sec-diabetes-subsec 1-1 a
jsection-end="<p>"&
title-begin="<h3>"&title-end="</h3>"&
parent=html-sec-diabetes-subsec 1-1 I
Annotation html-sec-diabetes-subsec 1-2
Ititle="The two types of diabetes"&
parent=html-sec-diabetes-sec 1 ~
Annotation html-sec-diabetes-subsec 1-2a
jsection-end="<p>"&
title-begin="<h3>"&title-end="</h3>"&
parent=html-sec-diabetes-subsec 1-21
// Linguistic Annotations
Annotation discourse-doc-diabetes-toplevel
Ititle="About Your Diabetes"I
Annotation discourse-sec-diabetes-secl
ititle="Basic information"&
relations="((ord < (topic2a topic3 a))
(ord < (topic2a topic3b))
(ord < (topic2a topic4a))
(ord < (topic2a topic5a))
(ord < (topic2a topic5b))
(ord < (topic2a topic5c))
(ord < (topic2a topic5d))
(ord < (topic2a topic6a))
(ord < (topic2a topic6b))
(ord < (topic3 a topic6a))
(ord < (topic3b topic6b))
(elaboration topic4a topic3b)
(justification topic2a topic3a)
(j ustification topic2a topic3b)
(justification topic2a topic4a)
(elaboration topic4a topic2a)
(elaboration topic5a topic3a)
(elaboration topic5b topic3b)
(elaboration topic5c topic3a)
(elaboration topic5d topic3b)
34
CA 02230367 1998-02-24
(justification topic3a topic6a)
(justification topic3b topic6b)"I
Annotation discourse-sec-diabetes-subsec 1-1
Ititle="What is diabetes?"&
parent=discourse-sec-diabetes-sec 1 I
Annotation discourse-sec-diabetes-subsec 1-2
Ititle="The two types of d:abetes"&
parent=discourse-sec-diabetes-seclI
Annotation discourse-topic-diabetes-topic3
jcorefs="((condl specific cond)
(diab2 specific diab)
(condl generic diab2))"&
parent=discourse-sec-diabetes-sec 1
CA 02230367 1998-02-24
The Pseudocode
The program objects are:
BasicObject.
ResolvableObject.
DocumentObject (i.e., a resolved ResolvableObject).
DocumentObj ectTree.
VariationContainer.
Variation.
Condition.
WorkingCondition.
Annotation.
External.
The Procedures
Procedures used by BasicObject classes
These procedures are used within BasicObject classes (e.g., BasicDocument,
BasicSection, etc.)
Procedure: SetProperty
Parameter:
A list of property names and corresponding values
Algorithm:
for each property in the list
set its value
Procedures used by VariationContainer classes
These procedures are used within VariationContainer classes (e.g., Document,
Section, Topic), which have a list of variations. VariationContainer classes
are extensions
of ResolvableObject and therefore have a Resolve method.
36
CA 02230367 1998-02-24
Procedure: SetProperty
Parameter:
A property name and its value
Algorithm:
if property is a list of variations then
set the class property "variations" to given value
else if property is a list of annotations then
set the class property "annotations" to given value
else if property is defined for this class then
set its value
else signal an error
end if
Procedure: Resolve
Parameters
- (input)
An instance of WorkingCondition
(a list of purpose parameters and their current values)
- (input)
An instance of List
(a list of the desired representation levels to output)
- (output)
A set of root nodes of DocumentObjectTrees,
one for each required level of representation
(Note: an instance of DocumentObjectTree is a tree structure
made up of resolved Documents, Sections, Topics,
Sentences, Lexicals, Words, Annotations, and Externals).
37
CA 02230367 1998-02-24
Algorithm:
if Resolve has already been called with this WorkingCondition then
result is the previously saved result
// for Document, Section, Topic, Lexical
else
call Satisfies on each variation until
the WorkingCondition is satisfied
call Resolve on this satisfying variation and
return a set of root nodes of DocumentObjectTrees
attach the appropriate annotations for this VariationContainer
into the set of root nodes of DocumentObjectTrees
// for Sentence
else
for each variation
call Satisfies on this variation to check if
the WorkingCondition is satisfied
if Satisfies returns true then
call Resolve for this variation and
return a root node of a DocumentObjectTree
end for
attach the accumulated annotations for this Sentence
into the set of root nodes of DocumentObjectTrees
(end of else-statement for Sentence)
if no variation satisfies the WorkingCondition then
result is null
else
result is the final modified set of root nodes
end if
38
CA 02230367 1998-02-24
end if (end of starting if-statement of the algorithm)
Procedures used by Variation classes
These procedures are used within Variation classes (e.g., DocumentVariation,
SectionVariation), which therefore have a selection condition.
Procedure: SetProperty
Parameters: A property name and its value
Algorithm:
if property is a condition then
set the class property "condition" to given value
else if property is a list of annotations then
set the class property "annotations" to given value
else if property is a list of components then
set the class property "componentList" to given value
/I special cases for LexicalVariation
else if property name is "value" then
set the class property "value" to given value
else if property name is "string" then
set the class property "value" to given value
else if property is defined for this class then
set its value
else signal an error
end if (end of the algorithm)
39
CA 02230367 1998-02-24
Procedure: Satisfies
Parameters:
- (input)
An instance of WorkingCondition
- (output)
A Boolean value
Algorithm:
if this variation satisfies the WorkingCondition then
result is true
else
result is false
end if
Procedure: Resolve
Parameters:
- (input)
An instance of WorkingCondition
- (input)
An instance of List
(a list of the desired representation levels to output)
- (output)
A set of root nodes of DocumentObjectTrees,
one for each required level of representation
Algorithm:
for each component in the componentList of this Variation do
create a new set of root nodes of empty DocumentObjectTrees,
one for each level of representation
call Resolve on the current component
CA 02230367 1998-02-24
if Resolve returns a non-null result then
attach each root node in the returned set as
a subtree of the appropriate node in the set of root nodes
of DocumentObjectTrees for this Variation
end for
attach the appropriate annotations for this Variation
into the set of root nodes of DocumentObjectTrees
result is the modified set of root nodes of DocumentObjectTrees
Toplevel Procedures
These are the toplevel procedures used to read in a datafile containing
a master document, create instances of the document-class objects, then loop
to read in
new values of the purpose parameters and generate an appropriately customized
version
of the document, with all appropriate annotations, at each level of
representation as
specified by the representation-level parameters given in the datafile.
Procedure: Parse
Parameter:
Name of datafile to be read in
Algorithm:
while end-of-file has not been reached
read in the next line of the datafile
if the line is a comment or a blank line then
skip over it
else if the line specifies the toplevel object then
set the "toplevel" variable to reference this object
else if the line specifies the purpose parameters and their values then
41
CA 02230367 1998-02-24
set the "purposeParameters" variable
else if the line specifies the possible representation levels then
set the "repLevels" variable
else instantiate the specified document object
(i.e., create a reference to a new instance of specified document-object
class,
assign a name to this instance,
assign its properties)
end of while loop
return reference to the toplevel object,
list of purpose parameters and their possible values
list of representation levels
Procedure: Reader
Algorithm:
call an application-specific interface to:
- read in current values of purpose parameters
- read in desired representation levels
- create an instance of WorkingCondition using these values
Procedure: Main
Parameter:
Name of the input datafile
Algorithm:
call Parse
call Reader
42
CA 02230367 1998-02-24
while new purpose parameters are input
call Resolve on the toplevel object
for each specified level of representation
output the corresponding DocumentObjectTree
end for
call Reader
end of while loop
43