Note: Descriptions are shown in the official language in which they were submitted.
CA 022~8183 1998-12-14
WO 98~ PCT/CA97/OOS16
ENHANCED ENCODING OF DTMF
AND OTHER SIGNALLING TONES
BACKGROUND OF THE INVENTION
1. Field of the invention:
The present invention relates to the field of digital
encoding of voice signals. In the present specification including the
appended claims the terrn voice signal is inlended to designate speech
audio music and other signals.
In this context it is often required to encode non-voice
signals such as DTMF (Dual Tone Multi-Frequency) signals and other
signalling tones for dialling transmitting data and/or performing other
transmission functions. The present invention enhances encoding of
20 DTMF signals and other signalling tones so as to prevent their purpose
from being hindered by the digital encoding procedure.
2. Brief descri~ulio,l of the prior art:
Low bit rate speech encoding algorill""s are usually
based on a speech prodllGtion model and II,erefore opti",i~ed for speech
CA 022~8l83 l998-l2-l4
W O ~8/01~1C PCT/CA97/OOS16
signals. As the bit rate is reduced to 8 kbits/second and below, these
encoders meet difficulties in encoding non-speech signals such as DTMF
signals and other signalling tones; this results in occ~sional failures in
detecting these signals at the receiver end.
Central to the speech production model is the par~ln~l,ic
description of the short-term speech spectrum. The most common
approach called "linear prediction" consists of transmitting at regular time
intervals, typically every 10 or 20 milliseconds, a set of so-called linear
prediction (LP) coefficients. Efficient encoding of the LP coefficients
involves quantization tables trained by means of a speech data base.
One modest improvement in encoding DTMF signals is
obtained by including DTMF signals into the speech database used to
train the above mentioned quantization tables. However, this
improvement is limited due to the high disparity that exists between
speech and DTMF spectra and the fact that some form of constrained (or
structured) vector quanli~alion is inevitable to reduce complexity.
OBJECTS OF THE INVENTION
An object of the present invention is to provide a
quantizing method and device capable of overcoming the above
25 described drawbacks of the prior art for example by "reservin~" in the field
of entries to the speech-trained qua~ alion table of LP coefficients some
CA 022~8183 1998-12-14
W 098/04046 PCT/CA97/OOS16
~ entries for representing the short-term spectrum of DTMF signals and
other signalling tones.
Another object of the present invention is to introduce
in a quanli~dliGn method and device a DTMF(or other signalling tones)-
5 specific codebook with minimal change to the conventional qua"Li~alioprocedure.
SUMMARY OF THE INVENTION
More specifically, in accordance with the present
invention, there is provided a method and a device for quantizing a
spectrum vector, supplied at recurrent time intervals, to produce a
15 spectrum index. In these method and device, a spectrum-vector
quanli~dlion codebook including a voice-signal qua"li~dlion-codebook
portion and a non-voice signal quantization codebook portion is provided.
A detection to determine whether the spectrum vector represents a voice
signal or a non-voice signal is made. When the spectrum vector
20 repr~senl~ a voice signal, the voice-signal quantization-codebook portion
is searched for quantizing the spectrum vector and producing the
spectrum index. In the same manner, the non-voice signal qua"Li~alion
codebook portion is searched for quantizing the spectrum vector and
producing the spectrum index when the spectrum vector represents a
25 non-voice signal.
CA 022~8l83 l998-l2-l4
W O~8/0101~ PCT/CA97/00516
The non-voice signal qua"li~dlion codebook portion
searched for encoding the non-voice signal representative spectrum
indexes greatly improves encoding of non-voice signals such as DTMF
signals and other signalling tones.
The present invention also relates to a method and a
device for quantizing a spectrum vector, supplied at recurrent time
intervals, to produce a spectrum index. In these method and device,
there is provided a spectrum-vector quanli~alion codebook including a
voice-signal quantization-codebook portion and a non-voice signal
quantization codebook portion. The voice-signal quanli~dlion-codebook
portion and the non-voice signal quantization codebook portion are
searched by measuring a weighted distance between the spectrum vector
and the entries of the voice-signal quantization-codebook portion, and the
non-voice signal quantization codebook portion. It is detected that the
spectrum vector represents a voice signal when the smallest weighted
distance is the weighted distance measured between the spectrum vector
and one entry of the voice-signal quantization-codebook portion. In the
same manner, it is detected that the spectrum vector represents a non-
voice signal when the smallest weighted distance is the weighted
distance measured between the spectrum vector and one entry of the
non-voice signal quantization codebook portion. When the spectrum
vector represents a voice signal, a spectrum index is produced in relation
to said one entry of the voice-signal quan~ lion-codebook portion.
When the spectrum vector represents a non-voice signal, a spectrum
index is produced in relation to said one entry of the non-voice signal
quantization codebook portion.
CA 022~8183 1998-12-14
W O ~ PCT/CA97/00516
In accGr~a"ce with a prefer,ed embodiment, the
voice-signal quallti~dliG~I-codebook portion co",plises a plurality of
quanli~alion codebook subtables each having a plurality of entries, a
predetermined set of combinations of partial spectrum indexes are
reserved for non-voice signals, and searching the voice-signal
5 quantization-codebook portion comprises searching the quanli~atiol1
codebook subtables and producing corresponding partial spectrum
indexes forming combinations not included in the predeterl"i.)ed set of
combinations of partial spectrum indexes. When the spectrum vector
represents a voice signal, the spectrum index is produced by combining
10 the partial spectrum indexes corlesponding to said one entry of the voice-
signal quantization-codebook portion. When the spectrum vector
represents a non-voice signal, the spectrum index is produced by
selecting, in reldLio-, to said one entry of the non-voice signal quanLi~lion
codebook portion, one combination of the predetermined set.
Preferably, the predetermined set of combinations of
partial spectrum indexes reserved for non-voice signals correspond to
invalid combindLions of entries of respective quantization codebook
subtables.
In accordance with another preferred embodiment, the
spectrum vector has components related to line-spectral-pairs, the
voice-signal quantization-codebook portion comprises at least three
quantization codebook subtables each having a plurality of entries, one
25 combination of the predetermined set is selected to form the spectrum
index, this combination being composed of a non-voice-signal label part
and a second part related to said one entry of the non-voice signal
CA 022~8183 1998-12-14
WO 9~J~; 101C PCT/CA97/00516
quantization codebook portion, and the non-voice-signal label part
corresponds to a combination of entries of two subtables amongst the at
least three quanli~dlion codebook subtables which is logically invalid in
regard to adjacent line-spectral-pair component ordering.
According to a further preferred embodiment, the
quantization codebook subtables are searched in stages including a hrst
stage and at least one subsequent stage, and the predetermined set of
combinations of partial spectrum indexes is formed by considering, at
least, one predetermined partial spectrum index for the first stage
combined with partial spectrum indexes corresponding to entries of the
quantization codebook subtables searched in the subsequent stage(s).
The present invention is further concerned with a
method and a device for quantizing a spectrum vector, supplied at
recurrent time intervals, to produce a spectrum index, which method and
device using a spectrum-vector quanli~dlion codebook including a voice-
signal qua, lli~dlion-codebook portion and a non-voice signal qua~ alion
codebook portion. A weighted distance between the spectrum vector and
the entries of the non-voice signal quantization codebook portion is
measured and it is detected that the spectrum vector represents a non-
voice signal when the woi~llled distance measured bet~,veen the spectrum
vector and one entr,v of the non-voice signal quantization codebook
portion is smaller than a predetermined weighted distance threshold.
Upon detection that the spectrum vector represents a non-voice signal,
a spectrum index including a predetermined non-voice-signal label part
and a second part related to said one entry of the non-voice signal
quanli~alion codebook portion is produced. Upon failure to detect that
CA 022~8183 1998-12-14
W O 98/04046 PCT/CA97/00516
the spectrum vector represents a non-voice signal, the voice-signal
qua"li~dlion-codebook portion is searched for qua"li~ing the spectrum
vector and producing the spectrum index.
In accordance with preferred embodiments:
- the voice-signal quantization-codebook portion comprises a plurality of
quantization codebook subtables each having a plurality of entries, the
voice-signal quanli~dlion-codebook portion comprises addresses which
are related to combinations of entries of the plurality of quantization
10 codebook subtables, the voice-signal quantization-codebook portion is
searched by splitting the spectrum vector into a plurality of subvectors,
searching the quanti~dlion codebook subtables for quantizing the
subvectors, respectively, and producing respective partial spectrum
indexes, and combining the partial spectrum indexes to produce the
15 spectrum index, and an invalid combination of the entries of at least two
quanli,dliG,) codebook subtables is reserved as predetermined non-
voice-signal label part; and
- the voice-signal qual ,li~dliGn-codebook portion and the non-voice signal
20 quanli~dliol) codebook portion comprise a plurality of stages including a
first stage and at least one subsequent stage, each stage having a given
number of entries, at least one entry of the first stage is reserved as the
predetermined non-voice-signal label part, and the at least one entry of
the first stage is combined with at least one entry of the subsequent
25 stage(s) to represent non-voice signals.
CA 022~8183 1998-12-14
W O ~8/01-1~ PCTtCA97/00516
P,t:r~rably, the spectrum vector has components related
to line-spectral-pairs or i"~,r,i~a,)ce-spectral-pairs, the measured weighled
distance is a weighted Euclidean distance, and the non-voice signal
comprises a signalling tone, for example a DTMF signal.
The present invention still further relates to an encoder
for encoding a voice or non-voice input signal, comprising an encoding
section responsive to the voice or non-voice input signal for producing
residual voice or non-voice signal information, a spectrum processing
section responsive to the input voice or non-voice signal for producing a
spectrum index, and means for transmitting the residual signal
information and the spectrum index through a communication channel.
The spectrum processing section comprises means responsive to the
input voice or non-voice signal for producing a spectrum vector at
recurrent time intervals and one of the above described devices for
quantizing the spectrum vector to produce the spectrum index.
In accordance with the present invention, there is finally
provided a cellular communication system for servicing a large
geographical area divided into a plurality of cells, comprising:
mobile transn,iller/receiver units;
cellular base stations respectively situated in the cells;
means for controlling communication between the
cellular base stations; and
a bidirectional wireless communication sub-system
between each mobile unit situ~ted in one cell and the cellular base station
of that cell, this bidirectional wireless communication sub-system
comprising in both the mobile unit and the cellular base station (a) a
CA 022~8183 1998-12-14
W 09~QI-1~ PCT/CA97/00516
trans,t,iller including one of the above described encoders for encoding
a voice or non-voice signal and means for transmitting the encoJed voice
or non-voice signal, and (b) a receiver including means for receiving a
transmitted encoded voice or non-voice signal and means for decoding
the received encoded voice or non-voice signal.
The objects, advantages and other features of the
present invention will become more apparent upon reading of the
following non restrictive descri,ulion of a preferred embodiment thereof,
given by way of example only with reference to the accompanying
10 drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
In the appended drawings:
Figure 1 is a simplified block diagram of a LP voice
encoder, showing spectrum processing modules including a spectrum
20 vector quantization module;
Figure 2 is a block diagram of the spectrum vector
quantization module of the LP voice encoder of Figure 1;
Figure 3 is a simplified, schematic block diagram of a
cellular communication system in which the LP voice encoder of Figure
1 can be used;
CA 022~8183 1998-12-14
W O 38~ PCT/CA97/0~516
Figure 4 is a flow chart illustrating a first method for
labelling and representing DTMF signals;
Figure 5 is a flow chart illuslldli"g a second method for
labelling and representing DTMF signals;
Figure 6 is a flow chart illustrating a first method for
detecting and quantizing DTMF signals; and
Figure 7 is a flow chart illustrating a second method for
10 detecting and quantizing DTMF signals.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENT
Although application of the method and device for
quantizing a spectrum vector according to the invention to a cellular
communication system is disclosed as a non iimitative example in the
present specification, it should be kept in mind that these method and
20 device can be used with the same advantages in many other types of
communication systems in which quantization of a spectrum vector,
supplied at recurrent time intervals, is required.
As well known to those of ordinary skill in the art, a
25 cellular communication system such as 301 (Figure 3) provides a
telecommunication service over a large geographic area by dividing that
large geographic area into a number C of smaller cells. The C smaller
CA 022~8183 1998-12-14
W O 98/04046 PCTICA97/OOS16
- 11
cells are servioed by respective cellular base stations 302" 3022... 302C
to provide each cell with radio signalling, audio and data channels.
The radio signalling channels are used to page mobile
radiotelephones (mobile l,a,lsi,litler/l~ceiver units) such as 303 within the
5 limits of the coverage area (cell) of the cellular base station 302, and to
place calls to other radiotelephones 303 located either inside or outside
the base station's cell or to another network such as the Public Switched
Telephone Network (PSTN) 304.
Once a radiotelephone 303 has successfully placed or
received a call, an audio or data channel is established between this
radiotelephone 303 and the cellular base station 302 COII~S,uOl Idi~ 19 to the
cell in which the radiotelephone 303 is situated, and communication
between the base station 302 and radiotelephone 303 is conducted over
15 that audio or data channel. The radiotelephone 303 may also receive
control ortiming infol",dlio,l overthe signalling channel whilst a call is in
progress.
If a ,~diotelephone 303 leaves a cell and enters another
20 adjacent cell while a call is in progress, the radiotelephone 303 hands
over the call to an available audio or data channel of the new cell base
station. If a radiotelephone 303 leaves a cell and enters another ~dj~cent
cell while no call is in progress, the radiotelephone 303 sends a control
mess~ge over the signalling channel to log into the base station 302 of
25 the new cell. In this manner mobile communication over a wide
geographical area is possible.
CA 022~8183 1998-12-14
W O ~8/01A1~ PCT/CA97/00516
The cellular communication system 301 further
comprises a control leu~i"al 305 to control communication between the
cellular base stations 302 and the PSTN 304, for example during a
communication between a radiotelephone 303 and the PSTN 304, or
between a radiotelephone 303 located in a first cell and a radiotelephone
303 situated in a second cell.
Of course, a bidirectional wireless radio communication
subsystem is required to establish an audio or data channel between a
base station 302 of one cell and a radiotelephone 303 located in that cell.
As illustrated in very simplified form in Figure 3, such a bidirectional
wireless radio communication subsystem typically comprises in the
radiotelephone 303:
- a transmitter 306 including:
- an encoder 307 for encoding the voice signal; and
- a l,dnsmission circuit 308 for transmitting the encode
voice signal from the encoder 307 through an antenna
such as 309; and
- a receiver 310 including:
- a receiving circuit 311 for receiving a transmitted
encoded voice signal through the same antenna 309;
and
- a decoder 312 for decoding the received encoded
voice signal from the receiving circuit 311.
CA 022~8l83 l998-l2-l4
W O 981'~ PCT/CA97/00516
The radiotelephone further co"" rises other conventional circuits 313 to
which the encoder 307 and decoder 312 are connected, which circuits
313 are well known to those of ordinary skill in the art and, accordingly,
will not be further described in the subject patent application.
Also, such a bidirectional wireless radio communication
subsystem typically comprises in the base station 302:
- a transmitter 314 including:
- an encoder 315 for encoding the voice signal; and
- a transmission circuit 316 for trans",itli"g the encoded
voice signal from the encoder 315 through an antenna
such as 317; and
- a receiver 318 including:
- a receiving circuit 319 for receiving a transmitted
encoded voice signal through the same antenna 317;
and
- a decoder 320 for decoding the received encoded
voice signal from the receiving circuit 319.
The base station 302 further cG~ Jrises, typically, a base station controller
321, along with its associated data base 322, for controlling
communication between the control terminal 305 and the transmitter 314
and receiver 318.
As well known to those of ordinary skill in the art, voice
encoding is required in order to reduce the bandwidth necessary to
transmit voice signal, for example speech, across the bidirectional
CA 022~8183 1998-12-14
WO ~~ 16 PCT/CA97/00516
14
wireless radio communication subsystem, i.e. between a radiotelephone
303 and a base station 302.
The aim of the present invention is to provide an erficie, ll
technique usable by the encoders 307 and 315 of Figure 3 for encoding
non-voice signals such as Dual-Tone Multi-Frequency (DTMF) signals
and other signalling tones.
LP voice encoders typically operating at 13 kbits/second
and below such as Code-Excited Linear Prediction (CELP) encoders use
a LP synthesis filter to model the short-term spectral envelope of the
voice signal. The LP information is transmitted, typically, every 10 or 20
ms to the decoder and is extracted at the decoder end.
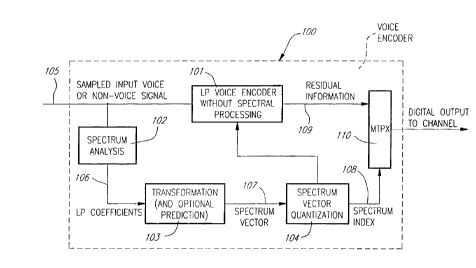
Figure 1 is a simplified block diagram of a LP voice
encoder 100 (that can be used as encoders 307 and 315 of Figure 3)
showing explicitly the spectrum processing modules 102-104 which are
used to extract and quantize the LP information.
Module 101 is used to represent the LP voice encoder
100 without the spectrum processi~ ~y modules 102-104. The structure of
a LP voice encoder is believed to be well known to those of ordinary skill
in the art and, accordingly, module 101 will not be further described in the
present specification. An example of LP voice encoder is illustrated in
Figure 1 of US patent NQ 5,444,816 granted on August 22, 1 9g5 to Jean-
Pierre Adoul and Claude Laflamme. The description of US patent NQ
5,444,816 iS incorporated herein by reference.
CA 022~8183 1998-12-14
wo ~a,~ PCT/CA97/00~16
The spectrum prGcessing modu~es 102-104 co",prise a
spectrum analysis module 102 for extracting a set of LP coerricients 106
from a sar"plcd input voice or non-voice signal 105. To extract the set of
LP coefficients 106 the spectrum analysis module 102 follows the well
known linear-prediction analysis procedure.
The spectrum processing modules 102-104 also
comprise a module 103 for transforming the set of LP coefficients 106
from spectrum analysis module 102 into another domain where
quanti~dlio,1 can be done more efficiently. The most popular LP
10 coerriciei1l transformation is the Line Spectral Pairs (LSP) transrur",dLiol1.
A related transrc r"~alion having properties similar to the properties of the
LSP l,ansformation is the well known Immitance Spectral Pairs (ISP)
transformation .
Transfo""aliGn module 103 therefore produces a
spectrum vector 107 having components in line-spectral-pair parametric
form or in immitance-spectral-pair parametric form. The spectrum vector
107 can be either the LSP (or ISP) vector itself or in other embodiments
a LSP (or ISP) dirrerence vector; this LSP (or ISP) dirr~r~nce vector is the
dirfer~l ,ce between the LSP (or ISP) vector and a prediction vector based
on past excitation. More specifically the modules 102 and 103 are
responsive to the sampl~d input voice or non-voice signal 105 to produce
the spectrum vector 107 at recurrent time intervals.
~ 25 Finally the spectrum processing modules 102-104comprise a spectrum vector quantization module 104. The function of
CA 022~8183 1998-12-14
W O3~/01~1~ PCT/CA97/00516
16
module 104 is to quantize the spectrum vector 107 delivered by the
transformation module 103 in view of producing a spectrum index 108.
Module 101 produces residual voice or non-voice signal
information 109. The residual information 109 from module 101 and the
spectrum index 108 from module 104 are multiplexed through a
multiplexor 110 to produce a digital output propagated through a given
audio or data channel.
Many quantization methods are available. The most
efficient approaches are those using some form of vector quar,li alion
(VQ). Most voice/audio codecs assign a number n of bits to quantize the
spectrum info,malion where, typically, n 2 20. The most efficient method
is to utilize these n bits in relation to a quantization table having as many
addresses, i.e. entries, as contained in the address field spanned by the
n bits. This approach is called "uncon~l,dined" vector quantization (VQ).
Unfortunately, for n 220, the address field contains over one million
addresses (22~ addresses or entries), which makes storing and searching
unpractical. In recent imple",e"ldlions of LP encoders, the spectrum
infGr,,laliol) is quantized by means of "constrained VQ" schemes whereby
the unpractically large VQ table is emulated by combining a number of
small quantization subtables. The two commonly used constrained VQ
schemes are the "M-way split-VQ" and the "multistage VQ" scheme. In
these two commonly used constrained VQ schemes, the quantization
subtables are jointly trained based on a large database using iterative
algorithms such as the LBG or k-means algorithms [Allen Gersho and
Robert M. Gray, "Vector Quantization and signal compression" Kluwer
Academic Publishers, 1992, 732 pages]. The training database consists
CA 022~8183 1998-12-14
wo ~a,~ IG 1~ PCT/CA97/00516
of transformed LP vectors extracted from long voice sequences
consisting mainly of male and female voice and o~ten in several
languages.
Figure 2 is a block diagram of the spectrum vector
5 quantization module 104 of Figure 1. In Figure 2, two quanti~dlion
schemes are compared for best performance, namely a conventional
scheme (Box 1) and a specific scheme (Box 2).
More specifically, Box 1 of Figure 2 represents the
10 conventional scheme depicted herein as an M-way split scheme.
Vector splitting module 201 splits the input spectrum
vector 107from ~,dnsro""alio,) module 103 (Figure 1) into M subvectors
which are independently vector quantized in the M modules 202, 203 ...
204 using codebooks 205, 206 .. 207 of size N, respedively, where M
and N are integers. Codebooks 205, 206 ... 207 are quanli~dlion
subtables trained using mostly voice/audio dat~h~ses. In each vector
qua"ti~dlion modules 202,203...204, the con~sponding codsbook 205,
206 ... 207 is searched to find the nearest partial spectrum index
20 corresponding to the input spectrum subvector. The partial spectrum
indexes from the vector quanli~dliol1 modules 202, 203 ... 204 and
resulting from the M distinct VQ operations are multiplexed by multiplexor
208 to provide a spectrum index 213 according to the conve"lional M-way
split scheme.
The short-term s~ue~;lldl envelope of l:)TMF signals
exhibits spectral shapes which are very different from those of voice
CA 022~8183 1998-12-14
W O 9~ 1C~6 PCT/CAg7/00516
signals. In the following description, the preferred embodiment of the
invention wil! be described with reference to DTMF signals; it should
however be Icept in mind that the present invention can be implemented
in relation to other non-voice signals such as other signalling tones.
Usually, DTMF signals are not included in the training database since
they may affect the quantizer pe, ru, I,,ance. This results in a quan~i~alion
table which has no entries representative of DTMF signals. As the bit
rate is reduced to 8 kbits/second and below, the fewer bits allocated for
modelling the excitation signal (in the decoders such as 312 and 320 in
Figure 3) are not sufficient to properly compensate for the poorly
10 quantized DTMF LP spectrum. This explains the occasional failure to
detect DTMF signals at the decoder output.
The alternative quantization scheme which is aimed at
improving the encoding of DTMF signals of interest will now be described.
Box 2 of Figure 2 represents the above mentioned DTMF-specific
scheme, more specifically a DTMF-specific quanli~alion scheme using
unconstrained VQ.
In module 210, the input spectrum vector 107 is vector
quantized by searching a full-length DTMF codebook 209 to find the
nearest index N corresponding to the input spectrum vector 107.
The procedure used to train the full-length DTMF
codebook 209is the following. Spectrum vectors representing the 16
DTMF signals are obtained by applying the same LP analysis as
performed by the spectrum analysis module 102 and transformation
module 103 of Figure 1 to long sequences of individual DTMF signals.
CA 022~8183 1998-12-14
W O~ PCT/CA97/00516
- 19
- At least one average spectrum vector is retained for each DTMF signal
as entries of the codebook 209.
In the present invention, some addresses amongst the
address field spanned by the n bits assigned to quantizing the spectrum
vector 107 according to some conventional scheme are "reserved" to
represent the short-term spectrum of DTMF signals. Reserving a mere
16 entries for representing the spectrum vectors of the 16 DTMF signals
out of more than one million entries of the address field can hardly affect
the pe,rur",ance. Thus, there is no extra bit needed for using the DTMF-
specific quantization scheme disclosed in the present invention.
Index mapping module 211 is essentially a look-up table
I,lapping each index from the full-length DTMF codebook 209 into one of
the "reserved" addresses of the address field spanned by the n bits
assigned to quantizing the spectrum information according to the
conventional scheme. Index mapping module 211 produces a
corresponding spectrum index 214.
These "~pecial" addiesses can be reserved either at the
design stage by forbidding these addresses during the training on the
voice d~t~h~se or, as will be explained in the following descri,ulion by way
of the two following examples 1 and 2, they can be advantageously
superimposed to some combination of subtables entries that cannot
logically occurs anyway. Thus, whether invalid logically or by fiat, these
"special" addresses are reserved in the address field for indexing the non-
voice signals.
CA 022~8183 1998-12-14
wo ~, a s ~ ~ PCT/CA97/OOS16
- 20
Example 1:
This first example is using 3-way split VQ of LSPs, in
which a 10~ order LSP vector is split into three subvectors of dimension
3,3 and 4, respectively, using 8,9 and 9- bits subtables such as 205,206
5 and 207 for the respective subvectors. According to the ordering property
of LSPs, a LP filter is stable only if the LSPs are ordered, that is when
LSPk is larger than LSPj if k is larger than 1. Since the dynamic ranges of
the individual LSPs are overlapping each other, it is easy to find (step 401
of Figure 4) an invalid combination of the entries of the first two
quantization codebook subtables 205 and 206, from the first two
subvectors in which LSP4 is smaller than LSP3. Thus, this logically invalid
combination of said entries can be "reserved" (step 402 of Figure 4) for
labelling DTMF signals. In that case, the 9 bits in the index of the third
subvector can be used to represent DTMF signals, that is the entry of the
15 full-length DTMF codebook 209. Note that this procedure is not r~ ted
to split-VQ and can be implemented in any existing quantizer in which
certain invalid combinations of partial indexes (i.e. subtable entries) can
be found.
Second example:
This second example is concerned with a two-stage VQ
of LSPs, in which 9-bit subtables are used in each stage. If the quantizer
comprises 511+1 entries in the first stage and 512 entries in the second
25 stage, one entry of the first stage can be reserved (step 501 of Figure 5)
for labelling DTMF signals. Combined with that reserved entry of the first
stage, some of the 512 partial indexes of the above described second
CA 022~8183 1998-12-14
W O 98/04046 PCT/CA97/00516
- 21
stage can be used (step 502 of Figure 5) to represent the DTMF signals,
more specifically the entry of the DTMF codebook 209 (Box 2).
Referring back to Figure 2 of the appended drawings,
the function of selector 212 is to compare the performance of the
5 conventional (Box 1) and DTMF-specific (Box 2) quanli~dlion schemes
and to select, through a switch 215, as outgoing spectrum index 108 the
spectrum index 213 or 214 resulting from the scheme presenting the best
performance. To conduct this comparison of performance, the selector
212 uses the same distance measure, for exa",,cle a weighted Euclidean
10 distance measure, in the two quantization schemes.
Implementation of the VQ scheme according to the
present invention requires a minimal change to the conventional
procedure. Indeed, the search for the best spectrum index is conducted
15 in accGr~ance with the conventional quantization scheme. The minimum
distance measure corresponding to the best spectrum index found (step
601 of Figure 6) using the conventional VQ scheme (Box 1 ) is compared
(step 602 of Figure 6) with the minimum distance obtained with each
entry of the full-length DTMF codebook 209 (Box 2). One embodiment
20 for the index mapping module 211, given as a simple alternate to using
a look-up table, operates as follows. In the 3-way-split VQ example
(Exar"pl~ 1), when an entry of the DTMF codebook 209 gives the overall
smallest distance, a DTMF signal is detected and labelled by setting the
partial indexes of the first two subvectors to the invalid combination (step
25 603). The partial index of the third subvector represents in this case the
entry in the DTMF codebook 209 (step 604). At the receiver, whenever
said invalid combination of the first two partial indexes (i.e. the non-voice
CA 022~8l83 l998-l2-l4
W O ~8/0~ PCT/CA97/00516
signal label) is received, the entry of the full-length DTMF codebook 209
represented by the index of the third subvector is chosen.
It should be pointed out that, in the above described
procedure, the encoder does not allempt to classify the signal as voice,
5 DTMF or other signal, whereby no additional information needs to be
I,ans,r,illecl to the decoder. The additional DTMF codebook 209 can be
seen as superimposed over a small part of the spectral vector codebook
subtables 205 -207 (Figure 2, Box 1), which small codebook part is
specially trained and tailored to DTMF signals. In the rare event where
10 an entry from this special codebook 209 is selected during processing of
an actual voice signal, no harm will result as the encoder will continue to
find the optimum excitation signal in accordance with the usual
procedure.
Therefore, when an entry of the DTMF codebook 209
gives the smallest w_ighled distance, a non-voice signal is detected and
spectrum index 214 is selected by selector 212 through switch 215. On
the contrary, when entries of the quantization codebook subtables such
as 205,206 and 207 give the smallest weighted distance, a voice signal
20 is detected and represented by these entries. Spectrum index 213 is then
selected by selector 212 through switch 215.
For l,~nsmission rates below 5 kbits/second, the bit rate
is not sufficient to encode the excitation signal (including the DTMF
25 signal) so as to enable proper reconstruction of the DTMF signal at the
decoder. In this case the above described DTMF-trained quanli~dlion
codebook 209 can be used to detect DTMF signals at the encoder and
CA 022~8183 1998-12-14
W 098/04046 PCT/CA97/00516
o~m~iol1 as to whether the present frame is voice or a DTMF signal is
transmitted to the decoder using an extra flag bit or, more erric,enlly, by
means of a set of reserved addresses of the address field as described
hereinabove. At the decoder, the DTMF signal is a, lilicially regenerated
whenever a received DTMF frame is detected.
In an alternate implementation, the detection process
can also be performed by the selector 212 as follows prior to LP
quantization. First, a weighted distance, for example the Euclidean
distance, is computed (step 701 of Figure 7) between the input spectrum
10 vector 107 and each individual entry of the full-length DTMF codebook
209. Then, each computed weighted distance is compared (step 702 of
Figure 7) with a predetermined weighted distance threshold. If, for a
given entry of the DTMF codebook 209, the computed weighled distance
is smaller than the predetermined threshold associated to this entry, the
frame is declared (step 703) to be a DTMF frame and the selector 212
positions the switch 215 so as to select (step 704) for transmission
spectrum index 214 from the full-length DTMF codebook 209 of Box 2.
For each entry of the DTMF codebook 209, a precomputed set of
weighting factors is used in the distance measure. The dete~;tion
20 thresholds are deter")i,led in relation to statistics of DTMF signals within
the allowed range of spectral tilt and frequency deviations. The detection
process is very efficient since DTMF signals exhibit spectral shapes which
are very clirrerel1~ from tones of voice signals. Thus, the transformed LP
vectors from module 103 of Figure 1, for example LSP vectors,
25 corresponding to DTMF signals are easily distinguishable from those
corresponding to voice signals.
CA 022~8l83 l998-l2-l4
W 098/~ PCT/CA97/00516
24
If no entry of the DTMF codebook 209 gives a weighted
distance smaller than the predetermined weighted distance threshold
associated to this entry, the frame is declared to be a voice-signal frame,
the quanli alion codebook subtables such as 205, 206 and 207 are
searched to produce the spectrum index 213, and the selector 212
5positions the switch 215 SO as to select the spectrum index 213 as
spectrum index 108 to be transmitted.
The present invention results in a significant
improvement in the performance of the voice encoder 100 for processing
10DTMF signals, and ensures that these signals are properly encoded and
correctly detected and decoded at the receiver.
Although the present invention has been described
hereinabove by way of a preferred embodiment thereof, this embodiment
15can be modified at will, within the scope of the appended claims, without
departing from the spirit and nature of the subject invention.