Note: Descriptions are shown in the official language in which they were submitted.
CA 02263~7l l999-02-l6
W O 98/58313 PCT/AU98/00464
TITLE
SYSTEM DEVELOPMENT TOOL FOR DISTRIBUTED OBJECT
ORIENTED COMPUTING
FIELD OF THE IN~/'ENTION
This invention relates to distributed object oriented computing systems,
particularlv large scale distributed object oriented systems (LSDOO). Such a system has
objects associated with many machines, typically machines linked in a computer net~vork,
which cooperate to autonomously perform some business function. Guidelines on the size of
0 system contemplated are typically those including some 1 million to 100 million objects, 100
to 1000 users, executing a total of 1000 to ~0000 operations per second on approximately
100 to 1000 machines.
BAC~GROUN~ TO THE IN~/'ENTION
Distributed~ object oriented (OO) technologies offer developers of
applications for installation on computer networks many potential advantages in deploying
their applications. Object oriented techniques provide a controlled environment in which to
manage complexity and change. Distributed computing allows applications to operate over a
wide geographical area while providing a resilient environment in the event of a failure in
part of the network.
In general terms, LSDOO systems have the potential to provide acceptable
reliability for a minim~l cost, allowing scaling by a factor of ten (with the upper end
approaching global enterprise systems), support standardized interaction with other business-
critical systems and efficiently support operations, not merelv effect data storage.
An example of a kno~n standard for building such svstems developed hy the
Object Mana_ement Group, Inc. (OMG), a consortium of software ~endors and end users, is
the Common Object Request Broker Architecture (CORBA). The CORBA object request
broker (ORB) is an application framework for providing interoperability bet~,veen objects,
which may be implemented in disparate languages and may execute on different machines in
a non-homogeneous enviror~nent. CORBA is a very flexible architecture allowing the
objects to transparently make requests and receive responses within the framework.
Reference may be made to the CO~B,4 2. 0~IIOP Specificatio~l the CORB~ Se~ices
Specificatio~ and other rele-~an~ specifications published by OMG.
Whilst CORBA and similar DOO architectures have a wide range of
applications~ their complexihy results in high development costs for large svstems. These
costs flow first from the problem of assimilating the verv lengthy specifications for these
architectures which provide a multitude of possible choices for addressing particular tasks.
and secondlv from the problem of identifying which combinations of these choices provide
optimal solu~ions to broader design requirements.
CA 02263~71 1999-02-16
W O 98/58313 2 PCT/AU98/00464
~urther, re~ ing the benefits of distributed, object oriented technologies is
challenging, with many developer concerns to be addressed including:
~ Scalability - how to build systems that scale to tens of machines and up to ten million
CORBA objects.
5 ~ Performance - how to build systems with satisfactory performance.
~ Fault tolerance - how to achieve availability for 24 hours of 7 days of every week.
~ Persistence - how to efficiently and securely retain object state in a high performance
distributed environment.
~ Management - how to manage non-ccntralized computer systems.
10 ~ Implem~nt~tion - how to contain development, testing effort and risk, while allowing
high re-use of software.
European Patent Publication EP 727739 in the name of International Business
Machines discloses a prograrnming interface for converting network management application
programs written in an object-oriented language into network communications protocols.
Intemational Patent Publication No. WO 97/22925 in the narne of Object Dvnamics Corp.
discloses a system for designing and constructing software components and systems by
assembling them from independent parts which is compatible with and extends existing
object models. US Patent No. 5699310 in the name of Garloff et al. discloses a computer
system wherein object oriented management techniques are used with a code generator for
generating source code from user entered specifications. However these earlier disclosures
do not describe a development tool and method for building LSDOO systems characterised
by desi~n patterns providing the power and flexibility of those set out below.
Glossar~
Unless otherwise specified or apparent from context of usage, the following
terms take the meanings attnbuted to them below:
"Attribute": an NState datum exposed by get and (usually) set operations.
"Broadcast Delegation": a delegation to all Confederates.
"Bulk Operation": an operation that accesses a lot (or all of) the NState of an object.
"Client": an application .. ;at requires access to one or more services;
"Cluster": the Peer-Clu - distribution model comprises machines orgaruzed into
clusters. Cluslers cooperate as peers and machines within clusters are
specialized.
"Collection": an object that references a set of Members that possess some
commonality; preferably an unordered set of objects;
"Confederates'': the Collections that forrn a Federation.
CA 02263C?71 1999-02-16
WO 98/58313 PCT/AU98/00464
"CORL?A Object": an object for which a client may obtain a CORBA object reference.
"COSS": common object services.
"Dele~ation": one object involving another object to execute an operation.
"Design pattern": a design solution for addressing LSDOO issues that anse in system
design.
]o
"Directed delegation": delegation to an identified subset of Confederates.
"Distribution Model": describes how machines and data links are phvsically organized to
implement a system.
"Explicit Group'': a Group Operation, where the members are listed by identity.
"Factory": an object that creates other objects.
~0 "Federation": a set of Collections cooperating to provide a faster, cheaper or more
reliable service.
"Friend": a relationship wherein objects share IState, but appear to have
independent NState.
2s
"Gateway": a CORBA representation of a non-CORBA environment.
"Generic interface": an interface that identifies underlying problem domain commonality
existing between specific interfaces.
"Graceful failure': a system responding to component failure by continuing to perform
operations not directlv affected by the failure.
"Group operation": an operation where one basic operation is applied to a number of
objects.
"Identitv": an NState datum that has a irnmutable one-to-one relationship with an
object.
"Implicit group'': a Group operation where the members are defined by a search predicate.
"IState': the state stored by an object?s implementation.
"Life-cvcle": the process of creating, copying, relocating and destroying an object.
4~
"LSDOO': Large Scale Distributed OO, typicallv a system that has objects onmanv machines that cooperate to autonomously perfoml some
business function.
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
"Member": an object that is referenced by a Collection.
"Natural collection": a Collection that is re~uired to support svstem functionality.
"Normalized object": an object is normalized if the following are all true:
(i) the state of the object does not overlap with any other object,
~ii) the semantics of the object are defined and implemented by the
object alone; and
(iii) its interface is just sufficient to access all state and change it in
0 any way consistent with the object semantics.
"Normalized system": a system is normalized if all objects in the system are normalized.
"NState": Normalized State, the minimum amount of state needed for an object
to exhibit the correct behaviour.
"Object": The OO concept of object, ie. an atom of state (NState) that hasidentity and is accessed through a defined interface. An object is the
fundarnental component of a LSDOO system~ which mav be a
zo hardware device (such as a printer) or a software application (such as a
print manager).
"Object reference": a pointer to an object that has an irnmutable many-to-one relationship
to the object.
"OOPL": Object Oriented Progr~mming Language.
"Partition": a physical grouping of objects. where each object is associated with
exactly one partition. There is generally a one-one correspondence
between a Partition and a set of computin_ hardware.
"Performance collection'': a Collection that improves s~stem perforrnance by providing
efficient implementation of Group Operations.
"Replica": One of the IState duplicates of a replicated Object.
"Replication": the duplication of an object's IStatc at several physical locations.
"RDBMS": relational database mana~ement svstem.
"Second class object'': an object that cannot be refer: . d by a CORBA Objec
Reference.
"Service'': an abstract provider of functionality, defined by CORBA IDL
4~ interfaces. ( A~ service is typically provided bv logically grouped
objects co-operating with one another.)
"~ree descent'': a form of recursive Dele(~ation. ~ here the delegates form a tree.
CA 02263~71 1999-02-16
W 098/58313 PCT/AU98/00464
"Worm": a form of recursive Delegation, where the delegates from an ~bi
graph.
"Wrapper": an internal interface that protects system components from changes
- s and defects in other components, common services and infrastructure.
OBJECT OF THE INVENTION
It is an object of the present invention to provide a development tool for largescale distributed object oriented computer systems which ameliorates or overcomes at least
o some of the problems associated with the prior art.
It is another object of the present invention to provide a method for
developing large scale distributed object oriented computer systems wnich implements a
small number of powerful CORBA usage models, allowing developers to focus on object
modeling and implementing business logic.
1S It is yet anotner object of the present invention to provide a system
development tool andlor method for large scale distributed object oriented computmg that
provldes:
~ guidelines on system modeling using CORBA;
~ a modeling tool for tr~3n~l~ring abstract object models into deployable CORBA
20 interface design language (IDL);
~ a code generator, including code libraries, for generating infrastructure level code for
producing CORBA clients, servers, factories and collections; and
~ system management functions for distributed configuration, debugging,
~mini.~tration and performance measurement.
Further objects will be evident from the following description.
DISCLOSURE OF IHE INVENTION
In one form, although it need not be the only or indeed the broadest form, the
invention resides in a development tool for building a large scale distributed object oriented
30 computer system, which system includes a plurality of clients, a plurality of servers, and a
distributed object infrastructure for communicating client requests for services to servers,
said development tool comprising:
(a) a series of templates providing predetermined object design patterns, including -
(i) an object identity pattern, facilitating unique identification of each object,
(ii) a collection pattern. facilitating the logical grouping of objects having some
commonality,
(iii) a group operation pattern, facilitating operations targeted at a set of objects,
(iv) a friend pattern, facilitating association of one object with another object
independentl~v of clients, and
(v) a partition pattern~ facilitating physical grouping of objects for performance
.. . .. .... .. . ..
CA 02263~71 1999-02-16
W O 98/58313 6 PCT/AU98/00464
purposes;
(b) a code generator arranged to produce, from an object oriented system model created
by a user for defining desired server processes to be requested by client processes and
incorporating selected ones of the object design pattems~ the following -
(i) a client access layer for each client process. isolating client application code
from the distributed object infrastructure,
(ii) a server access laver for each server process. isolating server application code
from the distributed object infrastructure~ and
(iii) a stub portion of server application code for implementing each service.
including provision for the user to integrate an implementation of server semantics.
Suitably the development tool further comprises a set of basic distributed
services including a service finder service for the discovery of the services available in the
system.
If required, the senes of templates mav further include one or more of the
following object design patterns:
(vi) a federation pattern, a set of collections cooperating to provide an improved
service;
(vii) a unified service pattern, facilitating the optimal choice of a collection from
the set ~vithin a federation; andlor
(viii) a bulk operation pattern, facilitating multiple operations on a particularlv
identified object.
Preferably the object identity is an attribute of an object, is represented usino
a structured narne and allows for object replication.
In preferencc. objects grouped into a collection are known as members and
25 knowledge of a collection s members may be kept e~;plicitly. such as in the forrn of a list. or
implicitly by the application of a rule.
Preferably the set of objects to which a group operation applies is known as
the scope of the gro-lp operation, which scope may be explicitly or implicitly defined.
An explicitly defined group operation is based on an underlyin, operation
30 supported bv objects comprisin~ the service and a parameter to the operation. suitably a list
of object identifiers, defines the scope.
An -eplicitl v defined ~roun operation is not based on an underlying operation
and a client specif. ;llter is applied to th ob1ects to define the scope of Ille operation.
Suit~ .y hVO objects are friends if thev do not appear associated to clients via3~ the distributed object infrastructurc. but appear associated to one another.
Preferably a partition is a phvsical _rouping of objects, wherein each object inthe system is associated ~ith onlv one partition. ~vhich partition corresponds to a set of
computer hardware.
ln preference. ~he collections hl a federation are able to dele~ate opera~ions to
CA 02263~71 1999-02-16
W O 98/58313 1 PCT/AU98/00464
each other in order to provide a faster, more extensive or more reliable service.
Suitably~ a unified service is a federated collection wherein a predetermined
sub-set of collections is transparent to clients.
The client access layer preferably includes agent classes to access the objects
that implement a service and other classes tO represent data structures manipulated by the
agent classes.
In preference, the agent classes separate interface code for the distributed
object infrastmcture from the client application code and encapsulates an object's identity,
interface and the means to address its implementation(s).
lo The server access layer may include service managers for m~n~ing objects
with respect to any partitions and allows for the creation and deletion of objects.
The server access layer preferably includes adapter classes for providing
access to objects that implement a service.
Suitably the set of basic distributed services further includes a file replication
5 service for replicating hles within the system.
The set of basic distributed services are preferably provided by code libraries.If required~ the system utilizes the CORBA standard, wherein:
(a) the distributed object infrastructure comprises an object request broker (ORB);
(b) the object oriented system model is modeled using CORBA concepts; and
20 (c) the server interface is generated in accordance with CORBA interface design
language (IDL).
In further fomm, the invention resides in a method for the development of a
large scale distributed object oriented computer svstem. which system includes a plurality of
clients, a plurality of servers, and a distributed object infrastructure for communicating client
requests for scrvices to servers. said deveiopment method including the steps of:
(a) selecting one or more templates. from a series of templates for predeterrnined object
design patterns, which include -
(i) an object identity pattem, facilitating unique identification of each object,
(ii) a collection pattern, facilitating the logical grouping of objects having some
commonality,
(iii) a group operation pattern, facilitating operations targeted at a set of objects,
(iv) a friend pattern, facilitating association of one object with another object
independentlv of clients, and
(v) a partition pattern. facilitating ph~sical grouping of objects for perforrnance
purposes;
(b) creating an object oriented svstem model for defining desired server processes to be
requested bv client processes. which model incorporates selected object design patterns: and
(c? generating. from the object oriented svstem model~ code modules for the following -
(i) a client access la~er for each client process. isolatinc~ client application code
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
from the distributed object infrastructure,
(ii) a server access layer for each server process. isolating server application code
from the distributed object infrastructure, and
(iii~ a stub portion of the server application code for implementing each service,
including provision for the user to integrate an implementation of server semantics
Preferably the method includes the further step of providing a set of basic
distributed services including a service finder service for the discovery of the services
available in the system.
Preferably the series of templates available for selection in step (c) may
o further include one or more of the following object design patterns:
(vi) a federation pattern. being a set of collections cooperating to provide an
improved service,
(vii) a unified service pattern, facilitating the optimal choice of a collection from
the set within a federation, and/or
(viii) a bulk operalion pattern, facilitating multiple operations on a particularly
identified object;
If the object identity pattern is selected, representing the identity attribute of
an object by using a structured name, which attribute may also allow for object replication.
If the collection pattern is selected, referring to objects grouped into a
collection as members and keeping knowledge of a collection's members either explicitly,
such as in the form of a list. or implicitly by the application of a rule.
If the group operation pattem is selected, referring to the set of objects to
which a group operation applies as the scope of the group operation. which scope may be
explicitly or implicitly defined.
If the friend pattern is sclected. arranging friend objects such that they do not
appear associated to clients via the distributed object infrastructure. but they appear
associated to one another.
If the partition pattern is selected. assigning a physical grouping of objects to
the partition wherein each object in the system is associated with only one such partition,
which partition corresponds to a sct of computer hardware.
If the federation patlern is selected, allowing the collections to delegate
opcrations to each other in order to ~ ~ ide a faster. more extensive or more reliable service.
If the unified service, ;~. rn is sele 'd. arranging a predetermined sub-set of
collections within a federated collection to be Iransparent to clients requestin~ unified
'~ service.
The step of generating a client access laver preferably includes the further
step of generating agent classes to access the objects which implement a selvice and other
classes to represent data structures manipulated bv the agent classes.
The step of ~generalln~ agent classes preferablv includes separating interface
CA 02263~71 1999-02-16
W 098/58313 PCT/AU98/00464
code for the distributed object inf~astructurc from the client application code and
encapsulating an object's identity. interface and providing means to address itsimplementation(s) .
The step of generating a server access laver may include the provision of
service mana~ers for managing o~jects with respect to any partitions and facilitates the
creation and deletion of objects.
The step of generating a server access layer preferably allows for adapter
classes to provide access to objects that implement a service.
The step of providing a set of basic distributed services may further include
0 the step of providing a fiie replication service for replicating files within the system.
In another form the invention resides in a large scale object oriented system
built using the development tool or development method set out in any of the preceding
statements, wherein the object oriented system includes a cornrnon ~lmini.stration interface.
Suitablv the cornrnon ~lministration interface facilitates remote manaEement
of all unified services in the svstem. including the provision of test, enable. disable~ backup
and restart functions.
Most suitably the a(lministration interface also supports a set of attributes for
which each unified service may be queried, including one or more of version nurnber,
copyright inforrnation, status, host machine, process identity or like attributes.
BRIEF DETAILS OF THE DRAWINGS
To assist in understanding the invention preferred embodiments will now be
described with reference to the follo~ving drawing figures in which:
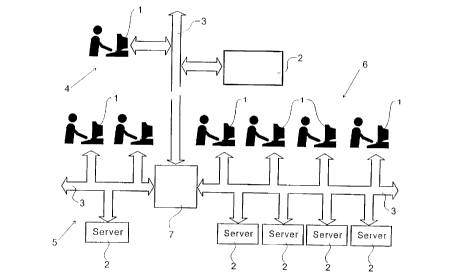
FIG.l is a diagram of a computer network over which objects may be distributed in
a large scale OO system.
FIG.2is a diagram of usage model for the development tool of a firs~ embodiment;FIG.3 is an overview of the architecture of the first embodiment;
FIG.4 is a diagrarn illustrating the graph of a Collection design pattern;
FIG.5 is a diagrarn illustrating a Collection implemented using a Pull model;
FIG.6 is a diagrarn illustrating a Collection implemented using a Push model;
FIG.7 is a diagram showin_ a Group Operation delegating to individual operations:
FIG.~ is a diagram showing a Group Operation delegating to another Group
Operation;
FIG.9 depicts an example of the Friend desi~n pattern;
3' FIG. 10 depicts a Peer-Clus~er Distribution Model wherein Clusters relate to the
Partition desi~n pattern;
FIG.ll shows a Federated Collection;
FIG.l~ illustrates an example of a Transparently Federated Factory;
FIG. I ~ sho~ ~s an arranQement of Federation interfaces existin~ between two
. . ., ~ , .
CA 02263~71 1999-02-16
WO 98/58313 PCT/AU98/00464
Confederate objects;
FIG. 14 illustrates an example of a Unified Service pattern;
FIG. 15 illustrates a typical client/server scenario involving Unified FederatedServers;
FIG. 16 depicts the operation of an object identifier (OID);
FIG. 17 shows the relationship between the Adaptor and Impl classes in a server
process of the embodiment; and
FIG. 18 shows the interaction between tlle ServiceLocator service and a
ServiceManager.
DETAILED DESCRIPTION OF THE DRAWINGS
Overview
FIG. l shows a computer network on which objects of an OO system may be
distributed. The networl~ may include computing machines, such as computer terminals or
PCs l and file or print servers 2 interconnected to a network backbone 3 or other
1~ communications infrastructure for sharing instructions and data with one another. The
computing machines may be located at widely spaced locations 4, 5 and 6, whereby branches
of the networ}c backbone may be interconnected b~ a s~A~itching device, such as router 7. In
this context, an example of an object might be a particular printer 8 and an example of a
service might be a file storage function.
Referring to FIG. 2, integers of the system development tool l 0, as it might beimplemented in the present embodiment, to produce a system compliant with the CORBA
standard is shown. A working knowledge of CORBA is assumed in the following
description, otherwise reference should be made to the CORBA specifications mentioned
above. The developer first conceives a logical object model l l using a common object
modeling technique ~ith the assistance of a design guide l~. In the embodiment the
deveiopment tool further includes a model wizard l 3 which assists the developer to specify a
CORBA system model 14 expressed in a universal modeling language (IJML). In other
embodiments the system model may be produced by some other tool, such as another object
oriented computer aided software engineenng (CASE) tool. or the model wizard might be
30 initialized w ith a pre-existing UML model or other OO model.
When the developer is satisfied that the CORBA system model is correct~ the
code generator in the form of a code wizard l 5 takes the S~rt-m model and produces:
- the CORBA interface design languag ~ (IDL) modui~
- an implementation for the services 17. including h ~i~s for the developer specified
3~ object semantics 1 8; and
- a simplified client interface l9 to the services.
Suitably the devcloper l0 codes object semantics IS in an appropriate language such as
C+l, which is convenientlv the lan~ua(~e used by the code ~izard for the simplified client
interface l9 in the embodiment. Other embodiments mi(Jht use Ja~a. SmallTall~ or lil;e
CA 02263~71 1999-02-16
W O 98/58313 1 PCT/AU98/00464
languages suited to OO sofr~vare. A set of basic distributed services is also provided by the
development tool library 21, which includes other comrnon functions.
A CORBA compliant object request broker (ORB) ~0, the environment
within which the system operates, is also to be supplied. Commercially available products
such as Visigenic's "Visibroker" or Iona Technologies' "Orbi~;" are suitable for this purpose.
It is envisaged that appropriate tar~et operating systems will be Sun Microsvstems~
"Solaris", Hewlett Packard's "HPUX' or MicrosoR Corporation's "NT" or any other suitable
multi-tasking OS.
The executables for the servers 2~ and default client 23 are then produced by
0 linking the generated modules 16, 17, 19 and developer hand coded modules 18 together
with the externally sourced ORB components 20. The developer can extend or modify any
of the code wizard output files in order to modify their initial choices or to use CORBA
concepts that are more complex than those supported by the development tool. Forconvenience, the svstem development tool 10 of the embodiment mav also be referred to
' hereinafter as "ORBMaster".
Architecture
FIG. 3 shows a typical client/server view of a generated service generated by
the embodiment. Key aspects of the ORBMaster architecture shown in this diagrarn are the
Client Application Code 26, the Client Access Layer 27, the Server Access Layer 28, the
20 Server Application Code 29, and the basic services, which include the File Replication
Service 30 and the Service Finder Service 31. It will be appreciated that the client process
32, the server process 33 and basic services communicate via the distributed object
infrastructure. in the form of the ORB 25.
The ORBMaster architecture allows service developers to concentrate
2~ development effort in the areas of application code (Client Application Code and Server
Application Code). It does this by providing some useful distributed services (file replication
and service finding), code of some useful design patterns (group operations, unified service,
etc., as discussed below) The architecture also provides client and server access layers
(CAL and SAL) which separate ORB dependent code from application specific code, and
30 code which implements distribution aspects of the service from code that implements the
other service semantics.
The most fundamental component in the OO architecture is the object. In the
client/ser~rer paradigm~ groups of objects cooperate to provide services~ and services are
accessed by client applications. The ORBMaster architecture. in contrast to CORBA, relies
3~ on the concept of objects that have identity, support interfaces and have implementations.
Identitv is represented using structured names that are the attributes of the objects; interfaces
are defined using IDL ~nd implementations are addressed using CORBA object references.
Accordingiy, ORBMaster obiects are !ust first class CORBA objects with the addition of
identit~ . Identitv is implicit in the design pattems described below.
....
CA 02263~71 1999-02-16
W O 9~/58313 12 PCT/AU98/00464
There is a many-to-one relationship between naming attributes and objects.
Naming attributes are read-only attributes of objects. One of the naming attributes of an
object is designated as its ObjectIdentifier (OID). There is a one-to-one relationship between
OIDs and objects. OIDs are used both as the database key and as the object_key (within the
CORBA Interoperable Object Reference (IOR)) for the object. Object references either
address the current implementation of an object or address nothing. That is, an object
reference for one object can never subsequently be used to address a different object. Object
references may change when an object moves, they therefore cannot represent object
identity. As a consequence object references should not be persistified by clients (OIDs
lo should be used instead). The architecture allows objects to have more than one
implementation, that is~ for objects to be replicated.
A service is functionality, logically grouped to meet some distinguished
business need. A service is implemented by a group of related service provider objects.
Services are identified by OrD (i.e. name). A set of ServiceManagers that all support the
1~ same unified service are effectivelv a single replicated object (with service name as their
OID). There are generally two kinds of service provider objects, as follows:
ServiceManagers - provide the operations of the service which deal with distribution
management, group operations on collections of component objects, life-cycle management
of component objects; and
component objects - the smallest separately identifiable components of the statemanaged by the service. Both ServiceManagers and component objects are implemented
within sen~er processes. The implementation of ServiceManagers and component objects are
separated into the Server Access Layer (SAL) and the Ser~er Application Code as shown in
FIG. ~. The SAL is described in more detail in the section entitled 'Server Access Layer'
below.
One aim of the system development tool at least with respect to client
applications, is to provide full access to the services without the need to understand the
CORBA architecture. The ORBMaster Client Access Laver (CAL) seeks to achieve this
aim. The CAL separates application code from code needed to access the objects that
30 implement the services. The interface between the CAL and the application code does not
expose anv of the C classes generated from the ~nterface Definition Language (IDL) for
the service. The CAL is discussed in m ore detail in the section entitled 'Client Access
Laver' belo~v.
Interface
This section contrasts the role of an interface in LSDOO with OOPL
interfaces. such as C++ header files. The role of an interface is to offer a definition of a
service. The role of an implementation is to implement the service bv acting on the object's
state to perforrn the defined operations. A developer needs a concept of object state to use the
service. Admittedly. this mav not be the actual state used in a real implementatiom rather~ il
CA 02263~71 1999-02-16
W O 98/58313 13 PCT/AU981'~~161
is the concept of "NState" the Normalized state that a reference object would have. ~Tithout
the concept of NState~ the object's operations appear disconnected. For example. consider a
basic name server:
i~lte~face NameSe~erl''
booleall udd(i-2 stri~ anZe. i)l Objec~ ~la~7ted
boolea~l delete(i)l stri~lg name);
Objectfi)ld(in stri~lg ~lame),
,,1,
This IDL precisely specifies the syntax of the interface. The token names imply the
]o operation semantics. AssDg, for example, that the add() operation is associating a 'name'
with a 'named'. If that association is valid (according to some set of rules), the return result
will be true. The single return from find() indicates that narne must be unique. Comments
can increase this underst~n~lin~. It implies inter-operation semantics. It could be assumed
that the find() operation will retum objects that match name and have suffered more
successful add() operations than delete() operations. This understandin~ can be augrnented
through comments that describe NState. It says nothinc~ about qua]ity of service. That is~
how fast, how many, or how reliable?
Failing to expose an ob~ect's NState makes the interface unusable as the
operations have no interconnectedness. As an overreaction to RDBMS, OO designers have
20 traditionall~ gone to great lengths to avoid discussing object state regarding this as merely an
implementation issue. This reticence validly applies to implementation state (IState),
however NState must be discussed. Moreover NState is not an amorphous blob~ it has
structure. One useful NState concept is that of Attribute. An Attribute is an NState datum
which has an operation to ~et and usually set its value. Getting an Attribute does not change
" the ~State. Setting it will either chan~e its value to that proposed or. if it would violate the
object semantics. fail. Setting one Attribute changes no other parts of the NState. A special
type of Attribute is the reiatio~Z this is an Attribute whose tvpe is Object reference.
Another special type of Attribute is a name this is an Attribute that has a many-to-one
relationship with an object. A special type of name is a ~el this is an immutable narne. A
30 special type of key is identitv this is the key that has a one-to-one relationship with an object.
NState that is not exposed as an Attribute will be cxposed throu~h operations consta~
operations are desi~ned to leave NState unchanged.
The concepts of NState. Attribute. relation. key~ name~ constant operations
and qualitv are too imponant to the functionalitv of applications to avoid in interfaces.
3~ However, none of these concepts are intnnsical]v expressible in CORBA's IDL grarnmar.
The IDL attribute is close~ but is sub-functional as it cannot support user defined exceptions.
Therefore. conventions must be de-~eloped~ published. and consistently applied to encode
these concepts in IDL. CORBA does specifv an Interface Repository (I~) service. However.
this service has a ~erv small role because it is solelv a s~ a~- ~eposilo)~ it has no ~ ay of
4~ expressin~ anv of the other complexities that compnse an interface. The IR is probabl~
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
14
solely useful for Gatewavs and rudimentary Browsers. that is~ things which have no concept
of a service beyond that of syntax.
Desi(Jn Patterns
The system deveiopment tool of the embodiment provides an architecture for
building distributed applications based on CORBA. This section describes a number of
ORBMaster design patterns. which are templates for designing systems. Each pattem
addresses one or more LSDOO issues. For further details of design pattern concepts see
Gamma, E. et al.; Desig7ls Patterns, Addison Wesley, New York, 1995 and Mowbray, T. J.
et al., CORBA Desigr~ Patterns, Wiley, 1997. The patterns discussed below are particularly
10 useful and find important roles in servers constructed with the assistance of the system
development tool . The developer can selectively apply tlle design pattems to system design
as indicated by the design guide 12 and the logical model l l, whilst focussing on the patterns
that address the system's most pressing business priorities.
~ Collection Pattem
~5 A Collection is an object that references a set of objects possessing some
cornmonality that addresses issucs of performance and system modeling. This pattern works
with the Friend and Federation pattems described belo-v. A Collection is an object that
references a set of Members. The Members are objects that have some form of commonality
and it is this that the Collection manages. The following are examples of Collections:
20 - a Name server represents a set of objects, each of which has a name. thus the
Collection supports search by name;
- a Topology server represents a set of objects, each of which has relations. Ihus the
Collection supports search-bv-relation;
- a COr~BA-IP ~ateway consists of objects that represent interface protocol (IP)
2~ concepts and a Collection that represents the set of IP objects. thus the Collection suppons
IP-type operations, such as find the object corresponding to a _iven IP address; and
- an Error log is a Collection of error objects, thus the Collection supports the life-
cycle of error objects, their retrieval. and related statistics.
~ A Collection always knows its Members. It may keep this knou~led~e
30 explicitly, for example. as a list of the Members object references or implicitly via some rule~
for example any object with an IP address matching 123.2'.*.*. A Member can be a part of
multiple Collections for example, a Pr;.- ~er object mav be ~ ~ of a name server Collection.
an inventory Collection and a IP object .,.tewav Collection. . he knowledge a Member has
about its Collections can vary. Some Mcmbers have a ti_ht relationship with their Collection
}~ they know its identity and are designed to inter vork with it, for example, gateway members.
Other objects may not be cognisant of who. if anyone, is collecting them. Such objects ma~
support func~ions that easilv allow them to he collected. such as life-cvcle and state-chan_e
noti fications .
Collection is Ihe most pervasive LSDOO pattem and is highly likely to be
CA 02263~71 1999-02-16
W O 98/58313 ~5 PCT/AU98/00464
used in the design process. In an RDBMS system all the data is available in tables for you to
access via a simple query language. In contrast a typical OO system starts with an initial
object, this will reveal other objects, and those objects still others, until all the objects in
which you are interested have been discovered. Any objects that are disconnected from the
~, relation graph are unobtainable. With reference to FIG. 4, the root of the graph is the initial
object reference 35 you obtain from the ORB using a statement such as
CORBA::resolve_initial_references(). The Collections are the non-leaf objects 35. 36, 37
and 3~ in the graph illustrated in FIG 4.
A major function of tradition OO modeling is identifying the Collections.
10 Such identification and the techniques for doing it are similar for ~SDOO. The following are
cornmon situations in which reveal Collections in an object model
- attribute searching, for example, find the printers which are out of paper;
- group operations, eg. find printers which are off-line and set them to on-line;
- naming, eg. find the object with the IP address 12.34.56.78;
5 - containment relationships, eg. return a list of the printed circuit boards in the
equipment; or
- connectivity, eg. find the least-cost path connecting two end-point objects.
Collections may return pointers to some of their members typically modeling
searching, naming or containment, return some NState of their members analogous to table
20 look-up, perform operations on their members (active Collections), manage the life-cycle of
their members such as cascade delete. You can apply the Collection pattern in combination
with other OO concepts. Many Collections have non-Collection aspects, for example, a
printer object may be a Collection of its component objects as well as implementing the
printer function. More examples of combining Collection with other OO concepts are:
~5 - the Federation pattern, which allows Collections to cooperate in answenmg more
wide-ranging queries;
- the Friend pattern, as discussed below;
- the Factory, wherein the combination of Collection and factory has an efficient
implementation see further below; and
30 - Gateway, wherein a gateway to a non-CORBA environment usually has a Coilection
that represents the foreign environment as a whole, and individual objects that represent the
forei~n concept of object.
The interface to a Collection has operations which provide the Collection s
functionality, for example. find members by name; has some operation to add and remove
3~ members (gateway/Collections are a possible exception); usually supports Federation; and
supports cancellation and the incremental return of results~ if results are large or responses
slow. There are a number of approaches for addin~ and removing members. Some useful
ones are a Factorv if a Collection is also a Factorv. everv object created bv the Fac~ory is
automatically a Member: offer a Collection supports an add member and remo~ e member
CA 02263~71 1999-02-16
W O 98/58313 16 PCT/AU98/00464
operation; Gateway if a Collection is a Gateway into a foreign domain. membership of the
Collection is usually expressed in that domain. For example, installing an IP router will
cause membership of the IP Gateway Collection with the corresponding net mask.
Building efficient and flexible Collections is a challenge, scale is the nemesisof the Collection. The problem is how the Collection is able to maintain enough of its
members' state to efficiently execute its operations. For example, a Pnnter Collection that
support return a list of printers that are faulty could execute that operation either by polling
each printer (which is slow if there are many printers) or by searching a local cache of printer
state (which requires the cache to be kept in synchronism with the printer state). The Friend
0 pattern provides one solution to Collective NState a Collection that is a Friend of its
members can quick~y access their IState. For exarnple, finding the printers whose
manufacturer=HP is easy if the printers IState is stored in an RDBMS. The Friendrelationship has some disadvantages that are discussed in the friend pattern.
Non-Friend Collections must m~int:~in a list of Members. This is enough to
support the pull and push data sharing models, as shown in FIGS. ~ and 6:
- the pull model 40 requires the Members 42 to have a State interface 43 that allows
the Collection 41 to access their NState as required. (The pull model can be used to maintain
a cache, delegate on demand, or execute collective operations.)
- the push model 45 requires a Collection to have an Offer interface 47 that can be used
20 to update the collective NState. (The push can come from either the Member 48 or a third
party).
The push model is easy to implement from the Collection's perspective, at the
expense of client complexity. The pull model is more Member-friendly, at the expense of the
Collection. Delegation is usually slow and caches are complex to maintain using the pull
model. Collections can be difficult to design and build and they tend to pervade design.
therefore reuse of standard Collections should be considered. Whilst custom interfaces may
be designed, they should be implemented using standard coded implementations.
Candidate standard Collections are as follows:
- Name Server for any Collection which has onc or more globally unique kevs and
30 returns the corresponding object, for example, an rP gateway which converts an IP address to
an object reference;
- OMG compatible Tra~ r for any Collection which selects one object from many,
based on attribut - s that rarely ~ ,ange for exarnple finding the best printer;- OV Teie. ~ Topology l'~r any Collection where one object establishes some form of
3~ relationship with another object, for example the relationship between owners and owned
objects. There are few good implementations of standard services at the moment. which
somewhat limits this approach. Moreover. a standard solution will always be slower than a
custom built one.
~ Bulk Operation (or Natural Collection) Pattern
CA 02263~71 1999-02-16
W O 98t58313 PCT/AU98/00464
A derivative of the Collection pattern~ which can be referred to as a Natural
Collection~ implements Bulk Operation. Multiple operations on a particu}arly identified
object are considered to be Bulk Operations. A Natural Collection is a Collection required
for a Normalized system model. Natural Collections are Collections that are required to
implement the system's functionality, they are part of a Norrnalized system.
When designing an LSDOO system in common with any OO system, you
start with an abstract object model. This is a model that captures the logic of the system,
without being polluted by implementation issues. You then map the abstract object model
onto the particular implementation technology, in this case CORBA. Natural collections are
0 a mapping of the abstract concept of collection. It is likely to be difficult to recognize the
Natural Collections for a system, as they result from traditional OO modeling. Considered in
object oriented pro~ramming language (OOPL) terms, there are some Natural Collections
that may not reco~nize in an LSDOO system; these are:
- Many OOPLs have the concept of class data~ for example, C~ or Java static member
functions and data. DOO does not have this concept. You should explicitly mode} class data
using Natura} Collection objects.
- The OOPL concepts of construction, for example, the C~ and Java new() operators,
are global operations not performed on any particular object. In DOO the new operation must
be executed on some specific object typically a combined Factory/Collection object. When
20 you perform event traces or CRC to test your object model? be very careful to exarnine how
you found each object and what you used to create it. You must be able to trace each object
back to the initial Object Reference you get from the ORB, that is, using the
CORBA:.resolve_i~2itial_refere~1ces~) statement.
Natural Collection interfaces expand on the interface structure described for
Collections. The following themes often arise in l~atural Collection functionality:
- lookup by narne for details of what constitutes a name. see thc discussion of the role
of Interface, above;
- search for objects conforming to some predicate formed from the object s Attributes;
- object life-cycle operations, particularly cascade delete; and
30 - collective themes specific to your project possible examples are path-selection,
propagation. and best-choice. A comrnon interface expression should be developed for these
common themes. Here are some examples and caveats:
- Name your Collection interfaces predictably for example~ a collection of Xs is called
XCollection.
3~ - There should be consistent support for Bulk Operations. notifications, and the like.
- Look for combining Performance Collection operations with your Natural Collection.
- Use exceptions carefully. For example "Object not found" is rarely an exception
condition. i~ is an expected outcome of searchin and name lookup. A recurrent theme of
Natural Collection interfaces is the operation that returns a list of objects typically search
CA 02263~,71 1999-02-16
W O 98/58313 18 PCT/AU98/00464
operations. There are several options for representing the returned objects:
- Return the object reference if there are not too many and your typical client will not
immediatelv make a 'get attributes' call on each of the retumed references.
- Retum object Identity plus Attributes, if that is what vour typical client needs and the
Attribute size is not too big.
- Return object Identity if there are many objects.
If you return Identity, you must provide a Group Operation for converting Identity to Object
Reference. If you do not, you are implementing non-CORBA compliant or Second class
objects. In implementation. Collection interfaces may show a great deal of similarity (list
o return, cancel, incremental result, Federation and the like). This is all 'house-keeping' code
that you should wrap on the client and server sides.
~ Group Operation (or Performance Collection) Pattem
A further derivative of the Collection pattem. which might be referred to as a
Performance Collection. implements Group Operations. Opera~ions that target many objects
rather than just one are considered to be Group Operations. The effect of a Group Operation
is the same as repeatedly executing a single operation. There are two forms of group
operation, Explicit and Implicit:
- an Explicit group is where the client lists the target objects for example, return the
status attribute of the objects referenced by this list of objects; and
20 - an Implicit group is where the client specifies a membership condition and the group
consists of all objects matchIng that criteria for example, execute self test on each object that
has status faulty.
Performance Collections do not arise from the object modeling process. They
arise from a dilisrent search of a svstem's dvnamic behaviour. using techniques such as event.
2~ There are h~o conditions required for a Group Operation to be worthwhile first clients must
be interested in the planned groupings and secondly the group operation must be
sigruficantly faster than the corresponding single ol~erations. The factors that make an
worthwhile explicit group include:
- the clients must hold a list of references you need to consider how that can happen;
30 (The obvious way is that a client is given a list of object pointers by some operation. such as
a search operation. A more subtle way is a client progressively accumulating individual
pointers~ .
- the clients often perform the exact same opcratioi~ on each l~ect in the list; (~or
example~ a ciient wishes to perforrn the test operation on many of pnnters to which it holds
pointers).
- the ~roup operation must be faster than the single operations. (This depends on issues
discussed in lnterface. A rule-of-thumb is that single operations returning less than 2kb of
data are candidates for group operation).
The factors that make an interestin_ implicit (group are as follows:
CA 02263~7l l999-02-l6
W O 98/58313 PCT/AU98/00464
- some Natural Collection should offer an operation that takes a membership criteria
and returns a list of object pointers typically some forrn of search operation;
- the clients often perforrn the exact same operation on each returned objecl; and
- the ~group operation must be faster than the combined search and single operations.
All implicit group operations meet this criterion. except for e~treme cases.
An important decision on explicit group interface design is how to point to the
target objects? A CORBA Object Reference is a poor choice because it is slow to marshal,
and hard to efficiently delegate (see below for discussion of the Federation Pattern). Some
key attribute is usually a good choice. A Group interface should correspond to its underlying
0 single operation interface. To aid the developers and maintainers of a system, a predictable
correspondence is desirable. For example, the single operation:
Result X::M(in_args, ol~t_args), would correspond to the explicit Group Operation:
sequence~esull >XCollectio~l . :M(sequenc~<Xid>. in_args, sequence<o2lt_args>).
A mapping between the exceptions raised by the Single and the Group Operations should be
defined. Generally. the Group Operation should not raise user exceptions as it will be unclear
exactly to what an exception corresponds.
Irnplicit Groups can suffer population explosion if the Collection has N list
returning operations and its Members have M Single operations, there are N*M implicit
Group Operations on the Collection. This can be reduced to N+M by getting all the list-
returning opcrations to return object Identity; and providing Group Operations on a sequence
of object Identities.
~s A Performance Collection is far more effective w}len its Members are friends
of the Collection. However~ there are certain caveats of the Friend pattern. Friend u ill allo~
you to make these speed improvements:
- for group size N, you will save N- I ORB round trips approximately 5(N- 1 ) ms;
- if the Group Operations use object Identity rather than object reference, si~rnificant
time will be saved in marshalling references, approximately N ms; and
- if the IState is held in an RDBMS, you will get substantially faster operation using
bull; database operations. It is likely to be advantageous to Federate any Perforrnance
Collections. The general approaches to federated delegation are discussed below in relation
to the Federation pattern. However there is a special issue in dele~ating group operations.
3~ Group operations should not dele~gate to a set of single operations as shown in FIG. 7.
inefficienc!. Rather group operations should delegate to group operations as depicted in
FIG. ~, which is more efficient. The initial collection breaks up the group into a set of
groups. each targeted to exactly one implementing collection. This should ensure that group
operation performance is maintained.
40 ~ Friend Pattern
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
One fundamental property of an object is encapsulatio~t~ that is. the object
state is available through a published interface only. Unfortunately. accessing encapsulated
objects through a CORBA interface for current CORBA implementations is a relatively slow
operation, typically allowing only a few hundred operations per second. The friend pattern
50 relaxes the strict encapsulation model as depicted in FIG. 9. Two objects 51 and 52 are
friends if they appear to clients to be encapsulated 53. but do not appear encapsulated to each
other 54. Friend is a useful pattem because the interface through which the friends
cornmunicate is designed to be faster or richer than a published CORBA interface. Friend
objects share IState for perforrnance, but do not share NState. They address perforrnance
0 issues and work with the Collection and Factory pattems.
An example of Friend behaviour is a Printer Collection that implements
'return printers that are off-line' by accessing the database in which the Printer objects store
their IState. Friend behaviour need not be symmetrical. Using the example above, the
Pnnter objects may never access the Collection IState. An ohject can be a friend of many
objects of many types. If objects are implemented by the sarne process, they can share IState
stored in memory. If the objects share the same dis~, they can share IState stored in a
database. Formally, Gateways and their members are inherently Friends the friend interface
is the foreign domain. This discussion avoids this rather obvious case and instead focuses on
where Friend is used for performance reasons.
Friend is an important pattern in extracting reasonable performance from
LSDOO. This is because a friend interface can operate hundreds of times faster than a
CORBA interface, while the overall system retains its essential OO character. Because
Friend conflicts with pure OO concepts, its application should be limited to areas ~vhere it
adds a si~nificant performance benefit. Scarch operations on Natural Collections using the
pull state model. and all operations on Perforrnance Collections will be sigr.uficantlv faster if
the collection and members are friends. Without Friend, these operations have either simple,
inefficient implementations or complex, efficient implementations. With Friend, simple,
efficient implementations are possible.
If one person is the solely responsible for implementation of the objects in a
3() given system, then the ~iend concept will not be a limitation at all and the system will look
OO and pure CORBA from without. If other developers are expected to implement some of
the objects in the syslem. then those points of integration must also be pure CORBA. that is~
not rely on Friend relationships. However it is rarely necessary that every object in your
svstem be re-implementable independently of every other.
A group of objects that must be implemented together is the concept of
extensibility boundary. Outside the boundary objects can be replaced at will, inside the
boundary there are restrictions. By analogy, consider the hardware of a printer-PC svstem.
The pnnter is outside of the extensibilitv boundary of the PC. therefore there is a published
interface and any conforming printer implementation is acceptable. Consider now the toner
CA 02263~7l l999-02-l6
W 098/58313 21 PCT/AU98/00464
cartridge in the printer even though this is an encapsulated unit, it does not h~ve a published
interface and cannot be replaced with a different implementation. The toner cartridge is
inside the extensibility boundary of the printer. Presumably the printer manufacturer could
have negotiated and conformed to a toner cartrid_e industrv standard, however the value of
extensibility at that level of granularity was not worth the costs. In LSDOO terrns. the printer
and toner cartridge are friends, the printer and PC are not It is as unrealistic for e~ery object
in an LSDOO system to be independently re-implementable, than it is to expect every
component in a printer to be so. Friend is a candidate implementation for objects ~vithin an
extensibility boundary.
The external interface to objects that are friends should not be influenced by
that fact. That is, from without, the friend objects should appear as pure CORBA objects.
The interface between the friends is discussed in relation to implementation belo~. Even
though the objects appear to be pure CORBA objects. there are 3 three further levels of
independence:
Dependent, an object is Dependent if it has NState that can not be set to all valid
values via the published interface. The term Dependent implies that there is some non-
CORBA access to the object, this may be from some foreig~n domain or from some other
object via a friend interface;
- Weak Independence, two objects are Weakly Independent if every operation could, in
20 principle be done though a published interface. In practice, that implementation may be
impracticably slow; and
- Strong Independence, two objects are Strongly Independent if one may be replaced
with a ne-v implementation without changing the system ' s function or perforrnance.
Typically, objects within an e~;tensibility boundary are Dependent~ objects outside the
extensible boundary are Stronglv Independent.
There are many techniques for implementing the Friend interface. Some
exarnple approaches are:
- One object can store its state in an RDBMS. and the other object can access the
database. This approach is attractive for implementin~ search operations in Natural
30 Collections, or Group operations in Performance Collections.
- The objects may share in-memory state. either in the same process, or shared memorv
bet~een processes.
- The obJects can use a CORBA interface. and achieve high speed by linking the client
and server into the same process. Note that this is still a friend interface. it does not support
Strong~ Independence.
Weali Independence is achieved throu_h interface design. Strong
Independence requires interface desim and implementation design. Two approaches to
Strong Independence are:
- Add. the Collection supports an add() operation which allo~vs the addition of non-
,.. " .. . .
CA 02263~71 1999-02-16
W O 98/58313 22 PCT/AU98/00464
friends. The Collection is therefore a mix of Friends and non-Friends. Assuming vou want
to provide egalitarian quality of service, an efficient non-Friend implementation has to be
built, thus vou can drop the Friend pattern altogether.
- Federate, the Collection supports a Federation interface which allows a foreign
Collection to participate in implementing your Collection's operations. This provides Strong
Independence and retains your efficient and simple Friend implementation. However, the
foreign developer now has the burden of implementing part of the Collection as well as
Members. In summary, although there appears to be two approaches, the "Add" approach is
considered pointless.
An analogous situation is where IP routers externally expose IP ports,
however, in~ernally and between themselves they need not use IP protocols. As discussed
above, the Friend interface gives two objects a privileged relationship. This privilege is not
available to other developer's objects, therefore the extensibility of the system is reduced.
~ Partition Pattern (or Distribution Model)
s A Distnbution Model describes how objects map onto machines, addressing
the issues of perforrnance, reliability, and manageability within a system. CORBA allows
clients to be unaware of the location of objects the ORB guarantees that the system ~ ill work
where ever objects are located. However, the location substantially affects the svstem s
performance and reliability. A Distribution Model describes the following:
20 - what machines exist in the system, that is, their type, number, and purpose;
- which objects reside on which machines~ that is, how Collections, Members, andReplicas are distributed over the machines; and
- what data flows exist, that is, how much data is transferred between each pair of
machines. .~ Distrihution Model exists as either a Meta-model or a Deployment model. The
Deployed Distribution Model is that implemented bv a particular customer. The Meta
Dis~ribution Model is the complete set of Deplovment models allowed for by the system
deslgner.
Both system and component designers need a Meta Distribution Model.
System designers need a detailed model one that accommodates the needs of tar_et users.
30 Component designers only need a general model but with enough detail to demonstrate that
the component is usefully deployable. System developers have an obligation to end-users to
ensure that they ually design their Deployment Distribution Modei users withou~ a large
system backgro- will not expect to do this themselves. Success without a Dis~nbution
Model is as like I randomly connecting cables~ hubs. and routers would be in producing a
3~ LAN.
Component developers should expose CORBA interfaces to allow the Meta-
model to be instantiated as a Deployment model. System developers can either use CORBA
or foreign interfaces~ such as command line or configuration files. The following
implementation issues should be considered when desi~nin~ a Distribution Model:
CA 02263~71 1999-02-16
WO 98/58313 23 PCTIAU98/00464
- the smallest and largest system size including a post-deployment growth path;
- data flows in parbicular identifying and exploiting cohesion between clients and
servers;
- a system adrninistration strategy including backup, software upgrade~ and machine
5 maintenance; and
- the effects of machine and network failures. Both Meta and Deployment models need
to consider these things the difference is in generality. Meta-model design must interact with
the system object model and interface design to exploit Collection, Federation. Replication
and Friend patterns. Deployment model design must select machines, network bandwidth,
O machine location, system configuration, and end-usage. It is not necessary to be too
ambitious for many reasorls, it is unlikely that the largest deployed system will be more than
ten times larger than the smallest.
The abstract goal of the Distribution Model is to reduce the cost of ownership.
Apart from the obvious cost of ownership issues such as hardware, software~ and the like~ a
s large component will be ~rlmini~tration. Rules of thumb for ~dmini.stration costs are. in a
first order approximation the cost is proportional to the number of database machines~ whilst
in a second order approximation the cost is proportional to the number of things that have to
be configured. The Distribution Model for many current systems is one server machine with
several UI machines. It is reasonable to expect CORBA systems to deploy on tens, to
20 possibly hundreds, of server machines. Beyond this level surprising difficulties may well be
encountered.
FIG. 10 illustrates an example of one useful Distribution Model. the Peer-
Cluster Distribution Model 55 that has the following salient features:
- Machines within each Cluster have special functions. eg. a database machine or an
25 event handler.
- Clusters 56, 57 and 58 are equally functional peers.
- Entry level would have one Cluster comprising one machine, deployment can scale-
up by adding either machines to Clusters or Clusters to the system.
- For many systems, this model will scale to about ten Clusters each of about ten
30 machines.
- Administrative costs are reduced because:
(i) the number of database machines is usually equal to the number of Clusters:
and
(ii) each Cluster is configured with only information about itself and the identit~
of its peers.
- Clusters are located near to external systems 59~ 60 and 61 with which they inter-
work.
- Users 6~ 63 and 6i primarilv inter-work ~vith a nearbv Cluster. ie. Clusters 56~ 5
and 58 respec~ivelv. Ho~e~er. nothin, precludes access to data located anvwhere in the
. .
CA 02263~71 1999-02-16
W O 98/58313 24 PCT/AU98/00464
system.
Clusters establish the concept of Partition. Partition is a design pattern
embodying physical grouping for performance purposes. This is unrelated to the logical
concept of domain, which is a logical grouping of objects for various administrative
purposes. Manv real world svstems exhibit a peer cluster model, for exatnple telephonv
switches are peers which have intemal structure growth occurs by either intemally expanding
the existing switches or by adding new ones. The peer ciuster model rarely scales beyond
1 00 machines.
~ Federation Pattem
Federation allows Collections to cooperate to provide a better service, thereby
addressing the issues of system performance and reliability. Many objects delegate by using
some other object when executing their operations. Collections often use a specific forrn of
delegation called Federation. FIG. l l depicts a Federated Collection 65. Federation occurs
when groups of Collection objects (known as Confederates 66 and 67) are designed to
cooperate to provide a better service than they could individually; ie. a faster, more
extensible and more reliable
Name servers are a good example of Federated Collections. Each narne server
holds a fraction of the name space and has pointers to other name servers. If a ser-~er cannot
answer a request, it delegates to a server that can. The fact that a particular Collection
20 federates is of interest to the client Federation is part of the Collection's NState model. For
example, when using an IP name server, it is important to the client which fraction of the
total IP name space is searched (the NState scope), it is not important how it is searched
(IState model). Federation can also be:
- Transparent. in which case the client is not involved in achieving~ Federalion. The
~nified Service Pattern is a special case of Transparent Federation.
- Translucent, in which case the client has some involvement in achieving Federation.
Another special use of Federation applies to Collection/Factory objects. The COSS Life-
cycle describes some models for an object ~actory and a common theme is "where is the
object located?" One approach is let the client decide the object is located on the same
30 machine as the Factory. Another approach is to let the Federated Factories decide~ thus the
factorics jointly decide location based on some aigorithm unknown to the client. FIG. 12
depicts a Tr iparentlv Federated Factory 70 where, for example, each Confederate (72, 73)
handles a pa.~cular IP address masl~. Creation re~uests 71 are delegated bv the Federation
70 to the correct Confederate. In the example from confederate 72 to confederate 73 which
3~ returns 74 a new object 75.
Federation is a key pattern for scaling up the number of objects mana ed by a
svstem. When a system is scaled up and computers added to the svstem~ more collection
objects wili need to be added. This is an inevitable consequence of phvsical implementation.
However. ciients should be insulated to the greatest extent from physical implementation
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
issues. Federation reconciles the conflict as it allows multiple physical objects while
retaining the illusion of one logical collection. The following situations can be indicators that
Federation is needed, they are illustrated using a PrinterCollection as follows:- A Collection has Members on multiple machines. This indicates local Collections on
each machine, with Federation of the Collections. The local Collections could exploit Friend
implementations for improved performance. For example, a PrinterCollection exists on each
machine that has Printer objects, the PrinterCollections delegate searches to each other.
- A client usually accesses specific subsets of Members but occasionally accesses
more. This indicates Collections that exploit the localized data access pattern but Federate to
o access global data. Loca}ized access, which is often associated with domains, is cornmon in
management systems. For example, PrinterCollection objects are organized on departmental
lines. Most queries can be answered by the department's PrinterCollection, but it wil~
delegate if needed.
- Graceful failure is required~ ie. the system continues to perforrn operations not
directly effected by a component failure. This indicates a Federated Collection that delegates
operations to the working Confederates. For exarnple, if a ~uery requires a PrintcrCollection
that is not working, it will be avoided and a partial result returned.
- Extensibility by others developers is required, particularly where the other
Collections have very different implementations. This indicates a Federated Collection, with
different developers providing their respective implementations. For example~ in a Federated
Collection of IP and common management interface service (CMIS) managed printers, each
Collection will issue requests in its respective protocol and interpret the responses into
CORBA return values.
It is possible that Federation comes naturallv from the Col}ection interface.
2~ For exarnple~ in a COSS Name Service the NameContext objects are Colleclions and the
resolve() operation delegates to the other NameContext objects using their norrnal interface.
Natural interfaces are usually associated with the Worrn, Tree Descent and Directed
Delegation implementations. Sometimes a special Federation interface is required~ this is
usually associated ~vith Broadcast Delegation impiementations.
The interfaces should support Transparent Federation (rather than
. Translucent)~ unless there is inforrnation available to the client that influences the operation
of Federation and that inforrnation is difficult to give to the Collection. Federation is an
algorithm that the Confederates iointly execute implying inter-object cornmunications.
Therefore, Federation and its attendant algonthrn is part of the Collection's ~State model it
3~ is not merely an IState issue. Admittedly, a transparentlv Federated service ~ ill have t-~o
t~pes of clients Confederates and others the others will be uninterested in the Federation
algorithm. Theref'ore. it is clearer to have a general and a Federation interface on the
Confederates. FIG. 13 depicts the Federation interfaces 7() that exist bet~een t~ o
Confederates 71 and 7~. being distinct from the respective general or Client interfaces 73 and
CA 02263~71 1999-02-16
W O 98/58313 ~6 PCT/AU98/00464
74.
When considerinc implementation it is probably true that. for a multi-machine
implemcntation~ all Collections should be federated. Federation can give lots of advantages
for little cost. However, the goal of the federation should be carefillly considered
5 (perfomnance. reliability~ or the like)~ to ensure the implementation does achieve the desired
goal. The pnmary issue for implementing Federation is "how to achieve delegation?" Some
exarnple approaches to delegation include tree descent. worrns, directed and broadcast
delegation.
- Tree Descent requires Members to have a natural tree structure. The Collectiono delegates to other Confederates by descending the tree, for exarnple fully distinguished narne
(FDN) resolution in a M.3100 network representation. Tree Descent has predictable and
acceptable perforrnance.
- Worrns rcquire the Members to be interconnected as a general graph. The Collection
delegates bv traversing the nodes in the graph, for example a 'shortest path algorithrn' for
15 network roulin_ Issues which affect Worrns include cvcle detection, goal seeking, and non-
predictable worst case perfomnance.
- Directed delegation is where the delegating Confederate can directly identify the
delegated Confederate. This often arises in partitioned problems. For exarnple, telephone
number can be separated into a number of directories any number can always be delegated to
20 the correct directory by exarnining the number. Directed Delegation has predictable and
acceptable perforrnance.
- Broadcast delegation is when the delegating Confederate cannot identify a particular
delegate Confederate, therefore~ the only solution is to delegate to all Confederates and
accumulate the responscs. For example. a Federated Alarm Lo~ requires the query find the
alarms that occurred in the last five minutes to be broadcast. Broadcast delegation has
predictable but poor perforrnance. All of these delegation approaches can exhibit _raceful
failure. Tree Descent and Directed delegations can be more authoritative in deciaring they
have totally executed the operation. Womms and Broadcast delegations are more affected by
Members which are not part of the solution~ therefore. these algorithms sometimes
30 incorrectly report partial execution. To avoid a single point of failure, Directed and
Broadcast Federations should offer the client a cho~ce of Collection objects on which to
execute the operations for details see the discussion of the IJnified Service Pattem below.
Some conclusions flowing from the above discussion are as follows:
- Tree descent is a consistently ood perfomner.
35 - Worms can perforrn particularly poorly, howe-er. good performance is possible for
some problems. For example, telecom networks are designed to have a short path (fewer than
say five hops) between any two terrnination points a womm ~ ill perforrn well in discovering
the shortest path in such a network.
- Directed Delegation is a ~ood perfomner. provided the problem can be partitioned
CA 02263~71 1999-02-16
W O 98158313 27 PCT/AU98/00464
such that every Confederate need not be visited. The larger the system gets, the more this
will be required and the more likely it is to be true. For example. if there is three
PrinterCollection objects, a particular ~uery is likely to hit many of them if you have 300, it
will still hit about three.
- Broadcast~ though it responds in constant time~ does not scale verv well. After the
question: "How to delegate?"; comes the question "To wllom?". The Worm and Tree
Descent approaches typically have the delegation target implied in the Member and
Collection interfaces. For example, COSS Naming delegates based on context names that are
NState concepts.
0 Broadcast delegation has a simple solution delegate to all the Confederates
All you need is a method for Confederates to tell each other of their existence a Replicated
registration base is a good approach. Directed Delegation is more complex, it can be broken
into three parts:
- Who are the Confederates? A registration base. as for Broadcast dele~ation, is a good
1~ approach.
- How do they partition the space? You need a partition rule, based on either a natural
key (such as FDN) or a surrogate key (such as a partitioned sequence nurnber). Good
manageability requires each Confederate store its own partition rule. The others inquire of it
when needed this avoids the need for a global configuration base.
20 - Hou to key into the space? Operations make the key explicit, for example passing
object identity or some other key.
One subtle problem that affects broadcast delegation is looping the initial
Confederate broadcasts to its peers that then must know not to re-broadcast. There are many
solutions, some of which pollute the client interface. The best approach is to use a specific
2~ federation mterface whose implementation does not re-broadcast. Efficient dele_ation is
generally important for a distributed system. It is a design decision that is difficult to change
it impacts design of object keys and identity. If done poorly, it will limit your abilitv to scale
and federate. This discussion has identified some implementation approaches, however, a
thorough analysis is required for particular systems.
Analogies to the Federation pattern may be drawn with Name services such as
DNS or X.500, and with a help desk which can answer simple queries, whereas morecomplex ones are delegated to more experienced staff and defects are directed todevelopment engineers.
It is tempting to have a private Federation interface this makes the
Confederates distributed Friends. This breaks the Strong Independence charactenstics of
Friends. As such, it may be acceptable for a product, however, it is rarelv acceptable for a
reusable platform component. The system should preferablv be designed to minimi7e use of
Broadcast and contain the performance of Worrns. It is tempting to desi~n Federated
Collections Ihat can answer globallv scoped queries. This is acceptable for a svstem needin~
CA 02263~71 1999-02-16
W O 98/58313 28 PCT/AU98/00464
one to ten m~chines or Clusters. It fails thereafter, for details see the section above dealing
with the Distribution Model Pattem. You could design a non-CORBA Federation scheme
one approach is to publishin_ a database schema. This low-cost mechanism is a Friend
relationship and. thereforc. has tl1e inherent limitations associated ~vith violatin(~ object
encapsulation.
~ Unified Service Pattern
A Unified Service is a convenient to use and reliable Federated Collection that
accordingly works with the Friend, Collection and Federation patterns. The desirable
characteristics of a Federated Collection is one:
- that is transparently Federated;
- where there is a mechanism for a client to obtain a Confederate based on the name of
the service alone;
- where all Confederates respond to any operation identically with the possible
exception of speed;
s - where the Confederate returned to the client shall be one that has acceptable
(preferably good) performance; and
- where the client can obtain another Confederate if one fails. These characteristics
give a Unified Service reliability and usability.
Any Federated Service implemented using Broadcast or Directed delegation
20 76 should be a Unified Service. Unified Service 75 has an interface 78 to select 76 and re-
select 77 Confederates based on the name of the service. A Unified service is built as a
front-end to a Federated Service~ as depicted in FIG. 14. The front-end requires the ability to
select the 'best' Confederate 79 from those available. It is tempting to implement this as a
Trader operation. However, single point-of-failure can limit this approacl1. Theimplementation of 'best' should consider the following:
- Confederates that are not working are not 'best'.
- Confederates that are lightly ioaded are better than those that are heavily loaded.
- Confederates ~vhich have a shorter network delay and higher bandwidth connectivity
are better.
Ticket agencies are analogous to Unified Services. Thev have many
Confederates (bookin~ clerks), there is ~ ~nfederate selector (phone directory and call
distributor), all Confederates can provide I ame service (b~lt some are slower), and failure
of one Confederate has no effect on the se ce. It shoul~ - noted that Tree Descenl and
Worm delegated Fedcrations execute operations on a i~..ember and are ~lenerally not
candidates for IJnified Services.
FIG. 15 illustrates the operation of United Federated Servers in a clientlsever
scenario 80. There is provided an ORB 81 that is in communication with a client 8'. a first
ser~er 83. a second server 84 and a service finder 85. The operation of Ser~ice Finder
Services is descnbed in more detail belo~. Entities A. B and C are available from first
CA 02263~71 1999-02-16
W O 98/58313 PCT/A U98/00464
29
server 83. whilst entities D and E are available from second server 84. An example of the
operation of the first and second servers, which are United Federated Servers. is as follows:
1. client ~2 requests the service finder 85 for a server (which supports a specified
service) and the service finder returns the first server 83;
2. client 82 invokes operation on the first server 83;
3. first server 83 invo~es operation on the second server ~4~ because the request cannot
be totally serviced by the first server 83;
4. first server 83 retums a result (entity E) to the client 82, which client in turn invokes
operation on entity E.
io Functional View
This section provides a functional view of an ORBMaster generated service.
The ORBMaster architecture recogruzes that there are common functions performed by all
services, which common functions are addressed by the architecture. In many cases they are
completely implemented by generated code or library code. The common funclions are
1~ grouped together into the followin~P categories:
- distribution management;
- group operations;
- management of client/server interactions; and
- component object lifecycle. As described in the introduction to services above~ these
20 functions are performed by ServiceManager objects.
~ Distribution Management
In the ORBMaster architecture all ServiceManagers are unified service
providers. This means that the details of the distribution model adopted bv a service are
hidden from the clients of that service. The unified service design pattem allows clients to
2~ treat all component objects as belonging to a single collection renardless of their distribution.
In order to be able to provide this single collection view, all ServiceMana~ers must support
the following interfaces:
resolve, given an OID, return the object's reference or return the
ORBMasterIDL. . NoSucll Object exception.~0 In addition~ ServiceManagers, which allow clients to create component objects must support:
create, given (at least) the read-only attributes (except OID if the service nenerates
this), create a new object or return the ORBMasterIDL::ObJect.~l) eadl ~xists
exception.
Note: These interfaces are encapsulated within the ORBMaster ~enerated Access Layers;
see the overvie~v above in conjunction with FIG. 3.
The system development tool supports both the replication of component
objects and the partitioninP of component objects for distribution models. If component
ohjects are replicated then their state is stored bv more than one of the ServiceMana~ers for
the ~Piven service. The OE~BMaster architecture enables replication of objects bv separatin_
CA 02263~71 1999-02-16
W O 98/58313 30 PCT/AU98/00464
the concepts of object identity from object implementation. The current embodiment of the
system development tool does not provide direct support for replicating object state.
However, the ORBMaster File Replication Service can be used by ser~ice developers for this
purpose. Other embodiments of the system development too1 will provide more support for
.s replication. If component objects are partitioned then their state is stored by only one
Service~anager. For these services two related issues that must be addressed. namelv OID
resolution and component object location management.
OID resolution (mapping from OID to object reference) for partitioned
component objects is logically a two step process. First find the authoritative
ServiceManager, then ask the authoritative ServiceManager to resolve the OID or return the
O~BMAsterlDL. :NoSuchObject exception
ServiceManagers are authoritative for OIDs if they can determine, ~vithout reference to other
ServiceManagers, whether or not the OrD represents a component object of the service.
Authoritative service managers aiso create the component objects for which the~ are
s ~uthoritati~e (if the service supports object creation~.
When object partitioning is used object resolution is based on an object
registration tree. An object registration tree is a tree where the nodes represent authority for
the sub tree of which they are the root. The nodes have names bound to them and OIDs are
structured names where components correspond to these names. The OID may have more
20 components than those corresponding to nodes in the object registration tree 90, as illustrated
in FIG. 16.
In the exarnple the OIDs consist of three components, service name. chun~
name and id. ie. OID = "printer/chunk2/123/2~,". Whilst object registration trees in the
present embodiment have depth ~. other embodiments mav support arbitrarv OIDs and
2s ob~ect registration trees of any depth. OlDs are absolute names defined relative to a cornmon
root 91. The intermediate nodes 9' and 93 effectively g~roup the services by service name, for
example "printer" node 92. The leaf nodes 94, 95, 96 and 97 in the object registration tree
are ServiceManagers that support the resolve and (if the service supports it) create
operations.
ORBMaster generated services provide support for their users (ty~picallv only
those actin_ in system ~lministrator roles) to specifv where component objects will be
located in t~-s,o ways:
- bv s~ ying which ScrviceManager will create, g~ en component objcct (this is
expressed u , partitioning rule); noting that not all ser~dces allo-v clients to create
component obj ects; and
- by moving component objects after thev are created; wherein nodes in the object
registration tree are objects which support the
CosLifeCvclc. .LifeCl cieob/'?ct. n20ve operation. thus allowin ~
groups of component ob~ects to be moved based on their OIDs. A partitioning mle defines a
CA 02263~71 1999-02-16
PCT/AU98/00464
W O 98/58313
mapping from values for a sub-set of the attributes given to an object when it is created to the
name bound to a leaf node in the object registration tree.
If one of the attributes to the create operation is the OID it is an error if the
operation is invoked with an OID which does not also resolve to the same node in the object
registration tree to which the partitioning rule maps. Object creation (where supported) of
partitioned component objects is logically a two step process:
- find the authoritative ServiceManager, to which the partitioning rule maps; and
- ask the authoritative ServiceManager to create the new object and return its object
reference or return the ORBMasterlDL::ObjectAlreadvExists exception if the object already
0 exists.
~ Group Operations
Group operations are those operations that apply to more than one component
object. The set of objects to which a particular invocation of a group operation applies is
known as the scope of the operation. Group operations are supported by ServiceManagers,
ra~her than component objects. Group operations are cateLorized accordin~ to the following
cntena:
- scope definition;
- support for partial completion;
- delegation method; and
20 - transactional behaviour.
The scope of a group operation is defined either explicitly or implicitly.
Explicitly defined group operations are based on an underlying operation supported by
component objects of the service, are e~uivalent to invoking the underlying component
object operation for every object in the scope, have their scope explicitlv defined by a
parameter to the operation (a list of OIDs)~ exist solely for reasons of implementation
efficiency, and have their interface generated by the system development tool based on the
developer specified underlying component object interface. Whilst implicitly defined group
operations are not based on an underlying operation on an individual component object, have
their scope determined by the selvice by it applying a client specified filter to all the
30 component objects of the service, exist because they implement problem domain semantics
identified bv the developer ~rather than for reasons of implementation efficiency), and have
their interface partially generated by the system development tool based on the developer
specified interface. Impiicitly defined group operations are typicallv query interfaces.
The code generator generates the interface for an explicitly defined scope
group operation from a developer specified component object interface. The component
object interface which is used as the basis of a group operation preferablv should:
- retum void;
- have zero or more in parameters of any type;
- have an optional out parameters which can return any type;
CA 02263571 1999-02-16
W O 98/58313 32 PCT/AU98/00464
- only raise user exceptions that contain an
O~RBMaster/DL::Rett~rnCode structure as their data contents.
Component operations should therefore be of the form:
interface < inte~ face> ~
void <base operation> (
~<in arg list>
out <result tvpe> <Otll param> O
raises ( <exception list> .
o where:
~inte~ face> is the narne of the component object interface defined by the developer;
<base operation> is the developer defined underlying operation on a component
object;
<in arg list> is the optional list of in parameters;
s <result type> is the type of the out pararneter;
<out paranl > is the optional out parameter; and
<exception list> is the optional list of user exceptions raised by the operation.
An exarnple of the IDL generated by the system development tool is:
1. A structure (in the scope of the module that contains <interface>):
struct <interface> <base operation>Result 1
boolean valid
[ ~reh~rn type> <out param> ]
ORBMasterIDL::OID oid;
OhBMasterIDL::Re~urnCode rc,
where:
valid indicates whether the other fields in the structure (except rc which is alwavs
valid) are valid;
<out param> is the value rcturned that is associated with the object identified by oid
(only exists if <base operation> has an out parameter);
oid is the OID of the object for which the structure holds the result; and
rc represents the exception that would have been returned by the component object
operation.
7. A typedef definine a sequence of -inlerface><base operaliol7>Resul~s.
n~pedef seyuence
<
<interface><base operation>Result
> <inte~face>~baseoperalion~ResultList;
3. An operation (defined on the ServiceManaeer interface):
l oid <in~erface><base operallon~Gro7lp ~
CA 02263571 1999-02-16
WO 9~/58313 PCT/AU98/00464
i~l ORBMaslerIDL::OIDList oids
~<in arg list> ~
out <i~te~ace><base operatio~7>ResultList results
),
where:
oids defines the scope of the operation
<in arg list> is the op~ional list of in parameters supported by <base operalio~results is the list of results obtained for the operation.
The following is an example of a component object operation getName for
~ which the developer requires the svstem development tool to generate a group operation:
module ~;xample 1~
inte~ace X ~'
void getName ( out string name);
,~,
1~ ,,1
For this example the system development tool generates the additional IDL shown below:
module ~xample ~
inte~ace X f
void getName f out string ~1ame)
3j
/I Start ORBMaster generated IDL
/1
struct Xget~ameResult
2s boolean valid
string name
ORBMasterIDL. :OID oid;
ORBAqasterIDL:. Retur n Code rc;
';
t!~pedefseyuence< XgetNa~7leResL~lt >
Xget~rameResultList,
i~zte~face XMa~zager t
Xgetl~iameGroup (
i~Z ORBMasterIDL::OIDList oids
out XgetNameResultList results)
~ Il
Il END ORBMaster generated
Il
The C~ CAL and SAL interface classes which encapsulate tlle IDL interfaces defined
above are described in the example provided in the section on 'Access Layers' belo~s The
operations have an implicitlv defined scope are defined by the developer and identified to the
svstem development tool as implicitlv scoped group operations.
4~ Group operations mav also suppon partial completion. By this is meant that
~ ~ ....
CA 02263~71 1999-02-16
W O 98/58313 PCT/A U98/00464
the service which implements the operation will make a best effort to apply the operation to
all objects in the scope. Those that are available to the service will have the operation applied
to them~ It would be desirable for the clients to be inforrned when an object in the scope
could not be contacted. In the case of implicitly scoped group operations, this may not be
s possible because the service may partition the component objects and it may not be able to
detemline which objects are actually in the scope (say if some partitions are unavailable
when the operation is executed). For explicitly scoped group operations the system
development tool requires that services return an ObjectU7lavailable retum code associated
with each object that was not available. For implicitly scoped group operations the system
0 development tool requires that services return a parameter of type
ORBMasterIDL::Res~ltAuthoritv along with the result.
The delegation methods include those set out briefly below:
- none, which applies only to operations on services based on replicated component
objects;
15 - directed, which applies only to operations on services based on partitioned
component objects and to explicitly scoped group operations; and
- broadcast, ~vhich applies only to operations on services based on partitioned
component objects and applies to both implicitly and explicitlv scoped group operations. It
is anticipated that transactional operations will be supported by other embodiments of
20 ORBMaster.
~ Management of Client/Server Interactions (Result Iterators)
Group operations that are queries typically retum a list of individual "results"to their clients. If these queries are implemented using an rDL operation per query the
following will result:
25 - the query client must allocate the memorv requircd to receive all the "results" before
any "result" becomes available; and
- the qucry client cannot start acting on some of the "results" until the whole operation
is complete. Result Iterators are a standard design pattem which are used to solve these
problems. This design pattem consists of a standard form for the IDL which defines these
30 interfaces, a templated class, ORBMaster~ eszlltIferator~class 7~>. which forms part of the
ORBMaster Support Library, and ORBMaster generated agent classes which use the
temrlated class.
The system deve ~rnent tool Resultlterator desi~,n pattem uses three IDL
operations to implement each query:
35 1. an operation which retums the first batch of results;
2. an operation which retums the next batch of results; and
3. a cancel operation ~vhich allows the client to notify his lack of interest in the querv.
A batch of results is a set that contains no more than a client specified number of individual
results The ser~er detemnines the aclual number of results in the batch as described below:
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
- The operation which returns the first batch blocks until either:
(i) at least one result is available; or
(ii) the server determines that all available data has been searched;
and then returns those results that are available (but no more than the client specified
number). The server outputs a resultId that the client uses as the identifier for the
query. It also outputs a boolean isLast which is set to true when all available data has
been searched by the server.
The operation which returns the next batch behaves similarly except that it takes the resultId
as input. Once a result has been returned to the client it is discarded by the server so that
o each result is only ever returned once. The cancel operation is essentially a notification to
the server that the client has no more interest in the query. It has no semantics other than this.
The server may use this notification to release resources that it has allocated to the query
execution.
The following example shows a query, getAII~ which returns a verv long list
of strings:
typedef se4uence< string > ResultList;
interface X ?~
//
//an operation which can return a very
//large list of strings as its result.
//
void getAll(out ResultList vervLongList),
~,
In order to make use of result iterators this query is implemented by the following
operations:
~nodule Lxample ~ interface X '
void get~ll(
in sl~ort batc1lSize,
out ResultList firstBatch,
out string resultId,
out boolean isLast),
void getAll_nextf
in string resullId,
~ in s~zort batc~zSize,
3~ ~ out Resultl ist nextBatch,
out hoolean is~ast),
~oid cancel(
in slring resl{ltld),
~,
4() ,1
~ Life-cvcle management
Some ser-ices allo~v clients to create component objects and some do not. If
clients can create component ob3ects then, ~vhen the object is created. it must alreadv have all
CA 02263~71 1999-02-16
W O 98/58313 36 PCT/AU98/00464
its read-only attributes defined. This means that the create operation must either take, as
input, values for all those attributes. or the service must generate them. Typically the only
read-only attribute that is generated by the service is the OID. Therefore the OID is either
specified by the client as an input parameter to the create operation or it is generated by the
service as part of the implementation of the create operation.
Access Layers
The Client Access Layer (CAL) separates application code from code needed
to access the objects that implement the services. The interface bet~veen the CAL and the
application code does not expose any of the C~ classes generated from the IDL for the
o service. Similarly, the ORBMaster Server Access Layer (SAL) separates the application
code in the server from the IDL generated code used to access it. Further details of the CAL
and SAL of the preferred embodiment are set out below.
Client Access Layer (CAL)
The classes that provide an interface between client app}ication code and the
CAL consist of:
- agent classes used to access the distributed objects which implement a service; and
- classes which represent the data structures manipulated by the agent classes. Agent
classes serve t~,vo main purposes to separate IDL generated code from application code and
to provide a complete encapsulation of the object, ie. one which encapsulates the identity of
20 the object, its interface, and the means to address its implementation(s). In effect, the agent
classes and the supporting data structure classes, are an altemative C~ mapping for IDL.
The next sub-section explains the justification for introducing a non-standard altemate C+~
IDL mapping.
~ Justification for providing an altemate C binding for IDL
~5 There are t~,vo main justifications for the provision of an alternate C ; IDL
mapping:
1. Developers require a large amount of training before they are proficient developers of
CORBA services and the client code that accesses them:
(a) The classes which define the interfaces to the CAL and SAL (unlike the
standard C~ IDL mappings) use the standard template library of ANSI C~. This
means that C~ proficient developers already understand the data structures that are a
major l~art of the interface.
(b~ The statldard IDL mappings present more than one way of doing a task (eg.
th i- more t~lan one model for memory management), by providing a simpler
interface ~vith less options, Ihe SAL and CAL interface classes are consequently easier to use.
(c) The standard IDL mappings expose more complex concepts to users (eg. the
standard obj ect reference is a much more complex concept than the svstem
development tool's agent classes).
CA 02263571 1999-02-16
W O 98/58313 37 PCTIAU98/00464
2. Standard C~ mappings for IDL do not address object identity and object mobility.
(a) CORBA object references do not allow comparison for equality.
(b) CORBA object references may change (eg. if an object is moved from being
implemented by one server to another).
(c) CORBA object references are unsuitable for use as database keys for the
persistent storage of objects since they are too big.
~ Alternale IDL bindings
The altemate client side mappings for the IDL are developed in accordance
with a set of mapping rules. These rules are typically as follows:
0 1, For each IDL interface, a C++ agent class is provided. The name of the C~ agent
class is: <IDL module>_<IDL i~lterface>Agenl.
2. Agent class inheritance (public virtual) mirrors the inheritance of the IDL interfaces,
for example:
//IDL module
module Example 1'
interface X ~
void oppr_x(),
~;
inte~ace Y . X ~
void oppr y();
3,
~,
llC~ agent Classes
class Example_X4gent .
public l lrtual ORBMaste~_Agent
//details of class omitted
,1,
class Example_Y~lgent .
public l~irlual Example_.~4ge~lt
//details of class omitted
~;
3. Agent classes contain a method for each IDL defined operation for the corresponding
interface, All these operations return OVErrors and use STL data types rather than data types
generated bv the IDL compiler.
3~ 4. Agent classes provide assignrnent operators and copy constructors that have the same
semantics as those for ORBMaster_~lgenl.
5. LDL defined structs are represented as C~ classes. The naming convention for these
classes is (depending on the scope of the IDL struct):
<IDL module>_<IDL interface>_<Structure name>; or
<IDL module>_<Structure name>.
6. Classes that represent IDL constructs mana~e their own memorv and have
constrUctors that provide the initial values for all their data members. On construction they
, . .. .
CA 02263~71 1999-02-16
W O 98/58313 PCTiAU98/00464
38
take copies of all the provided data members. They support assignment operators and copy
constructors that result in deep copies of the source objects.
~ Agent Classes
Instances of these agent classes represent the distributed objects from the
point of view of a client of those objects. Agent objects always contain the OID of the
distributed object that they represent. For the case of agents for component objects this is the
OID of the component object, for the case agents for SenviceManager objects this is the
name of the service. When the agent is used to access the object, the CORBA object
reference for the object must also be present. Agent classes obtain these object references
0 when required. Instances of agent classes are bound to distributed objects by the following
methods:
- binding them to stIings which represent OIDs;
- assi~ing one agent to another, following assignment both agents now represent the
same object;
5 - constructing one agent using another as source, fol]owing construction both a~ents
now represent the same object;
- binding them to CORBA object references (only a~ailable to ORBMaster code within
the CAL and SAL- not to application code).
If the CORBA object reference is not present when it is required the agent
20 resolves the OrD to the appropriate CORBA object reference automatically. The agent
classes also intercept system exceptions, and, when they occur, re-resolve OIDs to CORBA
object references. This allows the same agent to be used to access different object
implementations without inten~ention by the client of the object. This is useful in the
following example cases:
2~ - an object is moved by an administrator to balance load;
- one replicated copy of an object fails and is automatically substituted for by another.
An error is returned to the client only if a successful automatic resolution is not possible.
The purpose of the agent classes is to provide a clear separation between
CORBA dependent code and application code. As a consequence of this separation, no
30 CORBA header files or header files generated by the IDL compiler are included in the
header files for agent classes. Implementations of agent classes (-vhich obviously do depend
on ORB Cf ) are obscured by havin~ each agent class include a private data memDer which
is a pointer ~J an instance of a hidden access layer class (the access layer class header file is
not provided for general use but is available only for internal use within the Ciient and
3~ Sen~er Access Layers). The following class is provided as part of the ORBMaster Support
Library of the embodiment to support the agent paradigm ORBII~as~er_Age)lt~ which serves
hvo purposes:
- a base class which is speciali;~ed by agent classes for specific objects implemented by
ORBMasler senvers. ie. it encapsulales the commonalitv of all agent classes; and
CA 02263571 1999-02-16
WO 98/58313 PCT/AU98/00464
39
- can be used to represent any object implemented bv an ORBMaster server.
This class is accessed by the developer and a man page is included for it. as follows:
#include <std/s~ring>
#include <ORBMaster.hh>
#i~zclude <OYError.hh>
class ORBMaste-_AgentAL
class ORBMaster_Agent ~
friend class ORBMaster_AgentAL;
public.
ORBMaster_Agent()
ORBMaster_Agen~(const ORBMaster_Agent~ src);
l~irtual ~ORBMaster_AgentO,
ORBMaster_Agent& operator=(
const ORBMaster_Agent~ rhs);
virtual OVErrorgetOID(
0~2BMaster_StructuredNam~ & theOID)
const; virtual OVErrorge~OR(string& iorStr) const;
virtual void bindfconst ORBMaster_St)~ctl~redName& oid);
virtual OYError exists(bool &result) const;
protected:
ORBMaster_AgentAL *impl
ORBMaster_StmcturedNarne oid; }
2s
The system development tool also generates (from the IDL) the specific agent classes that
inherit from ORBMaster_Agent. The system development tool generates these agent classes
together with their complete impiementation. Like the ORBMaster_Agent classes, the
specific agent classes contain hidden access layer objects. These similarhr~ contain CORBA
30 object references. Also~ like the ORBMns~er_Agcnt class. these specific agent classes allo-
deveiopers to bind the agents to specific CORBA objects using copy constructors,assignrnent operators and the bind method. Note: Because CORBA object references are not
enough to identify the objects which support the system development tool senvices. agents
cannot usually be bound to CORBA object references.
Sen~er Access Layer (SAL)
There are two basic assumptions behind the implementation of the system
development tool servers:
1. Component objects are aiwavs persistently stored by some object storage service.
The object storage service may be a relational, or 00 database or it mav be an
external application (as in the case of a CORBA ~ateway to a legacy system. or to
network devices accessed v ia a network management protocol); and
. Sen~iceManagers l~now the partitioning of component objects. that is. for a given
, . , ,.. .. . . ~ ., .
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
component object they know which ServiceManager is authoritative for it. but they
delegate to the object storage service the knowledge as to whether a given object
actually exists or not.
The object storage service provides an applications program interface (API~ which,
given an OID, either locates the state of the component object or indicates that the
OID does not represent a valid component object.
If the service being implemented supports the concept of objects being created and
deleted then the object storage service provides an API that does this lifecyclemanagement.
0 Note: Although the term r'object storage service" is used, the actual service may do much
more than just store the objects persistently, for example it may be a complete application.
The point is that it should preferably at least: manage lifecycle~ answer object e~istence
queries and store the objects persistently~
The above assumptions then allow the following:
- a distributed service to be built using a non distributed object storage service;
allow the service to scale up to the scalability limit of the object storage service and not be
limited by the ORB;
- the friend relationship which exists between ServiceManagers and the componentobjects for which they are authoritative to be exploited by allowing the internal state of the
20 component objects to be accessed by the ServiceManager;
- avoid the need for ServiceManagers to separately keep track of which objects exist
thereby removing the need for them to synchronize this inforrnation between themselves and
the object storage service; and
- ServiceManagers to swap component object implementation objects into and out of
2~ memory at will because both the object's state and the knowledg~e of the object's existence is
persistentlv stored by the object stora~e service.
The assumptions described above amount to requiring a very clean separation
of responsibilities between the classes that encapsulate the SAL and the classes that
encapsulate the service implementation. In fact this separation is so complete that the
30 ORBMaster approach is essentially an application of the CORBA gateway server design
pattern. This pattem is normaliy on!-~ applied to legacy system encapsulation, however the
system development tool applies it ~ all servers because of the benefits it pro-ides in
decoupiing ORB dependent code fr application cc e. ~IG. 17 shows the interactions
between the server CT+ objects in the server access layer (SAL) and the server application
3~ code.
The SAL includes a ServiceManager Adaptor 100 which manages access and
memorv for the ServiceManager implementation 101 and contains the
ORBMaster_ServerCache 10'. The server cache controls the swapping of the Component
Object Adaptors 103 listed in the LRU. which object adaptors in turn conlrol access and
CA 02263~7l l999-02-l6
W O 98/58313 PCT/AV98/00464
41
memory for the respective Component Object Implementations which are swapped in and
out ofthe Object Storage Service 10~. The Object Storage Service 105 may be an RDBMS,
an OO DBMS or a legacy application, which service:
1. creates and deletes component objects;
2. answers queries re~arding the existence of component objects; and
3 . stores component objects.
~ SAL / SAC Interface
Corresponding to every IDL defined interface are two classes:
- an Impl class which is provided by the system development tool only in the form of a
10 stub; these exist within the Server Application Code as shown in FIG. 3;
- an Adaptor class which is derived from the IDL generated server stubs and is fillly
implemented by the system development tool; these exist within the Server Access Layer
shown in FIG. 3.
Like the agent classes~ the Impl classes support a method for each operation defined
in the IDL interface. In fact~ the name and si~nature of these methods are identical to those in
the corresponding agent class. The suggested naming convention for lrnpl classes is:
<IDL module>_<IDL inteYface>Impl
Developers provide the act~tal implementation of these classes by building on the stub
implementations generated by the system development tool. Developers can choose to
20 implement these classes as stateless gateways to the object storage service or they may cache
component state in them.
The infrastructure classes are derived from the IDL compiler generated server stubs.
These classes provide the access path bet~een the ORB and the developer providedimplementations. The suggested naming convention for infrastructure classes is:
2~ <IDL ~1lodule>_~IDL i)7terface>~dapto~
The server application code never accesses lmpl class methods directly. All access to Impl
objects is via the corresponding Adaptor object. This means that ~vhen an objectimplementation needs to access another object (even of the sarne class), it uses an agent
object. Failure of developers to use agent classes in code that they supply may introduce
30 problems relating to thread safety and memorv addressing.
~ Lifecycle and memorv management
The memorv management of each Impl object is handled by the infrastructure.
That is, developers never directlv construct or destruct a <IDL ~7l0dt~1e>_<IDL
inte7~face>lmpl, this is done by the corresponding <IDL module~_<IDL i~lte~face>Adaptor.
3~ Similarl~, in the case of component objects, the infrastructure (ie. Adaplor classes) is
responsible for initiating the swapping in and out of the component objects. The developer is
only required to provide anv ser~ice specific swap in or swap out implementation.
Clients create and dclete component objects via operalions on a
ServiceManac~er. The create and delete operations used for component object lifecycle
.
CA 02263~71 1999-02-16
W 098/58313 42 PCT/AU98/00464
management are not special to the system development tool. The implementation of these
operations, like all other operations, involves an Adaptor object (in this case the Adaptor
object for the ServiceManager) calling through to its corresponding ServiceManager Impl
object. ServiceManager objects are created when the ser~er process which instantiates them
:- is started with the "install" command line option set. Similarly they are deleted when the
server process ~vhich instantiates them is started with the ~'deinstall cornmand line option
set. In other words, installation afimini.strators explicitly mange the lifecycle of
ServiceManager objects.
~ Distribution issues
0 FIG. 17 shows how instances of the C~ classes in a server interact within a
single process. The Adaptor classes for ServiceManagers have the responsibility for
encapsulating distribution concepts. This means that the Impl classes for ServiceManagers
are not concerned with issues of distribution, they simply implement the service on a single
host. In other words all operations on Lrnpl classes are implemented bv only referring to the
1~ local object storage service. Adaptors provide the distributed view bv delegation to the
appropriate peer ServiceManagers (by using broadcast or directed dele_ation to the peer
ServiceMana~ers as appropriate).
~ C~ Classes
The following classes are provided as part of thc Support Library to help implement
ORBMaster servers:
- ORBMaster_Componen~
an abstract ~ase class for component object implementations;
2~ class Of 2BMaster_Co-nponen~
private.
~irtzlal OYErrorswap_in() = 0,
virtual OVErrorswap_out(bool &refilsed) = 0,
- ORBMaste~_Se~verCache
although part of the support library, developers do not access these objects directly.
The system development tool also generates (from the IDL) an Adaptor and a Impl class for
every IDL interface. For the case of component objects the Impl class inhents from
ORBAlaster_Con~pone7ll. For each se~vice. the svstem development tool also ~enerates a file
which defines a main~) function. ~-'his function instantiates the Adaptor object that
implements a ServiceManager for that service.
Common IDL
The following IDL defines common data t~rpes used bv all services:
4~ ntodule ORBA~aster j'
n pedef OVErrorService::E~t~ Id ~o~tAzo1zorih!~eason
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
43
typedef sequence< Non~utl~o~itvReason >
NonA uthorityReasonList
,1,
Fiie Replication Service
s The File Replication Service supports the replication of files within a CORBA
installation. The Fi]e Replication Service of the embodiment depends on the followin_:
- the particular CORBA ORB;
- the ODBC Access Layer; and .
- a POSIX compliant system interface. This limited dependency enables other services
0 to be built on top of the File Replication Service without the complication ofinterdependencies. The File Replication Service is implemented using objects that
support the standard IDL interfaces ReplicationManager and ReplicationClient. For each
host in the installation there is at most one Replicationl\~anager object. A set of
ReplicationManagers can be formed into a peer group. Within a peer group all
1~ ReplicationManagers keep object references to all other ReplicationManagers in the peer
group.
The purpose of each ReplicationManager is to m~int~in a local copy of a set
of files so that the contents of these local file copies are "approximately" synchronized across
the peer group. Clients of the Replication Service define which files are to be replicated.
20 ReplicationClient objects register themselves with ReplicationManager objects. On
registration~ ReplicationClients specify the files in which they have an interest. Files are
specified using identifiers rather than file names allowing the local version of the file to have
different narnes on different hosts. The service treats a group of files as a single entit~ in that
the group is considered to be modified if any file in the group is modified and all files in the
2~ group are replicatcd when the group is modified.
~ Assumptions
The File Replication Service supports the replication of files subject to the
following restrictions (these typically express orders of magnitude rather then exact limits):
- 10 hosls per peer group;
- 10 files per host;
- 500 characters per file;
- file updates occur rarely (only a few changes per day);
- clocks on all hosts in a peer group are synchronized to ~vithin about 10 seconds:
- modifications to one file are propagated to other copies of the file using distributed
3~ operations: copies may therefore be out of date until chan_es propagate to them
modifications are propagated to all hosts that are reachable by the host on which the
modification w as made within 1 minute of the change occurring;
- if a host looses connecti-itv with the source of a modification then it shall become
ahgned wlth n w Ithm ~ mmutes of regaining connectlvlty.
CA 02263571 1999-02-16
W O 98/58313 PCT/AU98/00464
44
~ Interface Definition module
The following is an example of an interface definition module:
module ORBMasterFR
typedef string Filel~ame;
t,vpedefsequence<FileName> FileNameList,
typedef string FileConfents
typedefsequence~FileContents> FileContentsList
typedef string FileGroupld
typedef se~uence< FileGroupId > FileGroupIdList
struct FileAccessProblem
string fileName; //the file name
string hostName //the host name
string operation //the svstem call
//vhich causes tlle pro~lenl string
errorA1sg //tlte error message
,1
exception File ~l ccessProblem 1~
FileAccessProblem problem //Describes the file problem ~;
exception No~ocalBindings
exception Uninitialized ~J~5
exception WrongNumberOfFiles 1~
unsig7led shon actuallVumber
,3,
11 All clients of the Replication Service must support this
Il interface
interface ReplicationClient
// indicates that the file group has chan~ed
void updatefin FileGroupId modified~ileGroup)
,1,
typedef unsigned long irimeStamp
inte~ face ~eplicationManager
1, Define the local file names for a fi1e group.
Il If narnes alreadv exist for the group then replace them.
void setNamesForGroup~
in FileGroz~pIdfileGrollpId,
in FileNamel ist localNames)
, Get the local narnes fo~ a file group.
/! Returns an empt~ list if no names e~;ist for
CA 02263571 1999-02-16
W O 98/58313 PCT/A U98/00464
/I the given group.
FileNameList getNamesForGroup(
in FileGroupId fileGroupld)
/I Retums a list of all the clints registered.
Il If no clients are registered then the list is ernpty.
ObjectIdList gelClienls(j
// Retllrns a list of the file groups for a given client.
0 // Returns an empty list if the client is not registered.
FileGroz~pIdList getGroupsForClient(
in ObjectId client);
/I Get the version number for the specified file group.
1S 11 A value of zero indicates that the ReplicationManager
Il does not have any local files for this group.
TimeStamp get Yersion f
in FileGroupId f~leGroup);
/I Receive a file group and, if the input group is more
// recent than the local group, update the local group and call
Il the update operation on the registered clients.
Il Updating the file group is atomic so that. if this
Il operation returns successfully, the changes to the file
/I system have been completed.
void upLoad~
in FileG- oupId fileGroupId
in FileContentsLis~ fileGroupCo~ltents
instringsol~rce 1/ hostnameoforiginator
i~l Ti7neSta~t?p vcrsio~t
)
raises i
T~rongNumberO~iles // A registration e~;ists for the
// file group but the number of
// elements in FileGroupContents
// is not the number of files
// in the group FileAccessProblem,
/1 A local file could not be written
),
!/ Registers a client's interesl in a file group.
//Does nothing if the client is alreadv registered
//for the group. Clients can be regis~cred for
//muitiple groups.
//The client is identified bv clientId NOT clientObj.
~ oid registerClient(
i~ ObjectId clientId
i~l Replicario~lClie~tt clie~ltObJ,
i~l FileGrot~pIdfileGrot~pId)
raises ~
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
46
No~ocalBindings, 1/ There are no local file
// names defined for the file group
Uninitialized // clients cannot be registered
1/ until the ReplicationManager
11 is initialized
),
/IRemoves an existing registrations for this client.
//Does nothing if the registration does not exist.
void unregisterClient(
in ObjectId clien~Id,
in ~ileGroupIdfileGroupId );
Il reads well known file/s which stores the
Il object reference of all other RepiicationManagers in a
1I peer group; if the ReplicationManager has not yet been
Il initialized then this operation initializes it
void loadPeers()
raises 1~
FileAccessProblem IICan't load the peers
};
J;
~;
~ Defining a Peer Group
All ReplicationManagers in a peer g~roup m~int~in their own local knowledge
of all other ReplicationManagers in the peer group. They do this using CORBA object
references. If the server process which instantiates a ReplicationManager is started in install
mode it creates a persistent ReplicationManager and stores its CORBA object reference in a
file (in a well known directory) ~ith the same name as the host on which the server is
executing. Whcn the loadPeers operation is invoked. the complete set of CORBA object
references for ReplicationManagers in the peer group must be stored as files in Ihe well-
known directory. It is an a-lministrative task to ensure that the contents of the directory
containing CORBA object references are identical on every host in the peer ,roup. The
loadPeers operation reads the files containing the CORBA object references in order to find
out the all the ReplicationManagers in the peer group. The loadPeers operation s~ores the
object references for the peers in the relational databasc. When ReplicationMana_ers are
started in other than install mode, the database is used to obtain the peers. This means that
the ability for a ReplicalionManager to start only depends on the a-ailabilitv of the loca~
database.
The a~imini.~trative procedure for initialising a peer group is then as follows:- start all servers supporting ReplicationManagers in the peer group in install mode -
each will u~rite their CORBA object reference to a file ~ith the local host name as the file
narne;
- ensure that each host has a complete set of CORBA object reference files Inothino
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
47
required here if the directory containing the CORBA object references is mounted using
NF S);
- invoke the loadPeers operation on each ReplicationManager in the peer group.
Services which depend on the File Replication Service can only be started after the peer
.
group IS IllltlallZed.
~ Managing Client Registrations
The registerClient operation on the ReplicationManager interface defines
which file groups a particular client object is interested in. The unregisterClient undoes a
registration. File groups are identified by strings (not file names). Client registrations are
0 made persistent by ReplicationManagers. Clients are notified when a file group for which
they are registered is modified, however, if a client is not contactable by the
ReplicatiorlManager when a file group is modified, then no attempt is made to inform the
client when it subse~uently becomes available. It is the responsibility of the client to obtain
the latest copy of its files when it starts up to ensure that it aware of anv chan_es which
15 occurred while it was down.
~ Source-push algorithm for file modification
The File Replication Service assurnes that the files that it replicates can be
modified directly via the file system. Each ReplicationManager polls the file system at
regular (configurable~ intervals in order to determine if a file group for which it has client
20 registrations has been modified. Once a ReplicationManager has determined that a file
group has been modified it pushes the modified file group out to all its peers by invoking the
upLoad operation on them. It also notifies all its interested clients by invoking the update
operation on them. When it invokes the upLoad operation it uses the most recent file
modification time (in seconds since 00:00:00 GMT Jan 1 1970) for files in the group as the
2~ file group version nurnber (the version p~rameter to the upLoad operation). It is the
responsibilit~ of the ReplicationManager that detected the modification (the source) to
ensure that the new version is pushed out to all its peers. This means that it will retry the
upLoad operation until it succeeds (even if it is stopped and subsequently restarted). The
retry interval is configurable.
When the upLoad operation is invoked the target ReplicationManaoer checks
whether the input file Proup is more recent than its local copy. It does this by comparing the
input version parameter ~vith its stored vaiue. If these differ bv more than the maximum error
in system clocks (configurable) then the most recent is taken as the larger version number.
Other~vise the version numbers are disregarded and the input host name and local host name
3~ are compared. The most recent is then taken as the one strcmp deterrnines is the greater.
Using this arbitrary ordering on host name means that if t~vo or more different modifications
occur at approximatelv the same time, onlv one modification ~vill succeed. If the input is
more recent then the ReplicationManager updates its local copy, informs its clients and
stores the input version number as the version number for the group. If the input is not more
.... ~.. ~ .. . . .. ..
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
48
recent then the ReplicationManager just returns.
As well as version numbers, ReplicationManagers persistently store the time
stamps associated with each local file. They do this so that they can detect when a file is
modified. On start-up they deterrnine if a file group has been modified while they were down
5 by comparing the persistently stored time-stamps with the values obtained from the file
system. By persistently storing these time-stamps they are able to treat the case of "file
modification while they were down" as a normal file group modification as described above.
~ Peer group start up
When a ReplicationManager is created its stored version numbers and file
0 time stamps are set to zero. As client registrations occur, a ReplicationManager will detect
that the stored time-stamps are less than the actual values and so push the local copies of
files out to all the peers. The most efficient way to start up a peer group is to have only one
copy in the peer group of each file group.
Service Finder Service
~s The Service Finder Service is implemented using objects that support the
interfaces ServiceLocator and ServiceManager. Every host in the in~t~lla~ion has at most
one ServiceLocator. ServiceLocators manage a repository of ServiceManagers and allow
clients to find ServiceManagers based on service name, proxirnity to the ServiceLocator, and
location. The Server Finder Service depends on the following:
20 - the particular CORBA ORB specified;
- the ODBC Access Layer;
- a POSIX compliant system interface;
- the CORBA Notification Service
~ Assumptions
25 The following assumptions apply to the embodiment:
- the installation consists of about 10 hosts
- the hosts in the installation are defined at installation time and not altered; and
- ServiceManagers may be dynamically added and removed from an installation.
~ lnterface Definition~0 module ORBMasterSF ~
tvpedef string Sen~iceName;
tvpedef sequence < Se7~iceName > ServiceNameList
tl r - -lef string Location;
tl ~ef sequence < Locatio~l > LocationList;~5
inte~ face ServiceManager
t!~pedef sequence <ServiceManager> ManagerList
interface Sen~iceLocator
Ivpedefsequence <ServiceLocator> LocatorList~0
e~ception AlreadvRegistered
CA 02263571 1999-02-16
W O 98/58313 PCT/AU98/00464
49
~;
exception NotRegistered
},
interface SenviceManager .
CosLifeCycle. :Factor,v~inder
readonly attribute Sen~iceName serviceName;
readonly attribute Location location;
,1;
interface SenviceLocator ~'
// Registers a ServiceManager, stores the tuple:
// (serviceName, location, ServiceManager).
// ServiceManager is identified by its seIviceName and
// location attributes.
void registerManagerf
in SenviceManager ServiceManagerObj)
raises (
AlreadyRegistered
1/ a ServiceManager is already
// registered with this ServiceLocator for the
1/ service and location
);
// used to distribute notifications about the existence
// of aServiceManager
void notifv~ddManagerf
in Sen~iceName serviceName
in Location location
in SenviceManager ServiceManagerObj~;
// Removes an existing registration.
void tlnregisterManager(
in ServiceName sen~iceName
in Location location)
raises(
NotRegistered
void noti~RemoveManager(
in ServiceNartle se~iceName
in Location location)
// gets a locally registered ServiceManager for the
// specified service. If no matching ServiceManager exists
// returns a NIL object reference.
.. ... ., .. ., .. . ~ ~ --
CA 02263571 1999-02-16
W O 98/58313 PCT/~U98/00464
//If testRequired is tme then the ServiceLocator tests the
//availability of ServiceManagers and does not consider
//unavailable ServiceManagers to exist.
ServiceManager getLocalManager(
in Se~iceName service,
in bool testRequired),
// gets the best ServiceManager for the
Il specified service.If no matching ServiceManager exists
0 /I returns a NIL object reference.
// If testRequired is true then the ServiceLocator tests
/t the availability of ServiceManagers and does not consider
//unavailable managers to exist.
ORBMaster::ResultStatus getBestManager(
in ServiceNamese~ice,
in bool testReq~ired,
out ServiceManager Manager),
/I gets locally registered ServiccManagers.
1I The services parameter is used to filter the results
Il based on service narne.
Il If the services list is empty then no filtering by service narne
ll applies.
/l The locations pararneter is used to filter the results
~5 /l based on location.
Il If the locations list is empt-v then no filtering by location
Il applies.
ManagerList getLocalRegisteredManagers(
in ServiceNameList services,
in LocationList locations),
Il gets all registered Servi cManagers.
ll The services parameter !S ~lsed to filter the results
ll based on service name.
11 If the services list is empty then no filtering by service narne
Il applies.
'I The locations pararneter is used to filter the results
/ based on location.
, ' If the locations list is emptv then no filtering by location
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
1/ applies.
ORBMaster:.~esultStatus getAllRegisteredManagersf
in Se~iceName~ ist services,
in LocationList locations,
out ManagerList Managers),
};
};
~ ServiceLocator
All ServiceLocators in a peer group m~int~in their own local knowledge of all
0 other ServiceLocators in the peer group. They do this in the embodiment using CORBA
object references. If the server process which inct~ntiates a ServiceLocator is started in
install mode it creates a persistent ServiceLocator and stores its CORBA object reference in
a file (in a well known directory) with the sarne name as the host on which the server is
executing.
When the loadPeers operation is invoked, the complete set of CORBA object
references for ServiceLocators in the peer group must be stored as files in the well known
directory. It is an ~(lmirlistrative task to ensure that the contents of the directory containing
CORBA object references are identical on every host in the peer group. The loadPeers
operation reads the files containing the CORBA object references in order to find out the all
the ServiceLocators in the peer group. The loadPeers operation stores the object references
for the peers in the relational database. When ServiceLocators are started, in other than
install mode, the database is used to obtain the peers. This means that the ability for a
ServiceLocator to start only depends on the availability of the local database. A typical
~mini~trative procedure for initi~ ing a peer group is then:
- start all servers supporting ServiceLocator in the peer group in install mode, each will
write their CORBA object reference to a file with the local host narne as the file name;
- ensure that each host has a complete set of CORBA object reference files (nothing
required here if the directory containing the CORBA object references is mounte~ using
NFS); and
- invoke the loadPeers operation on each ServiceLocator in the peer group.
Each ServiceLocater maintains a persistent list of the ServiceManagers that it
has registered. It stores this list in the relational database using the ODBC access layer. A
ServiceLocator does not store the registrations that are managed by its peer ServiceLocators.
Clients make requests for ServiceManagers for specific services by invoking the
3~ getBestManager on any ServiceLocator. ~here are typically two circumstances in which a
client will request a ServiceManager:
1. the client is binding an agent in order to cornrnunicate with a ServiceManauer the
first time; or
2 the client has just got a system exception when a~empting to communica[e with a
CA 02263~71 1999-02-16
W O 98S58313 PCT/AU98/00464
52
ServiceManager.
The service is designed on the assumption that most ServiceManagers are
available when required (ie. case 1 above is the usual case). This means that the service does
not check the availability of ServiceManagers unless the client explicitly requests that it do
so. Clients will only request a check when they have reason to think that a ServiceManager
has become unavailable (ie case 2 above). There would be little point in using a cache when
responding to requests for ServiceManagers if all ServiceManagers were checked for
availability. However, since there is typically no availability check made, a ServiceLocator
can use a cache to good effect when responding to requests. Each ServiceLocator therefore
10 m~int~in.c a local in-memory cache which stores tuples: (service, name, ServiceManager)
obtained from the results of previous attempts to locate ServiceManagers. The tuple stored in
the cache corresponds to the first response to a broadcast request for managers of the service.
Clients set the parameter testRequired to true when they have had a communications failure
else thev set it to false. Processing a getBestManager request then depends on the value of
the testRequired pararneter as described below.
When the getBestManager operation is invoked, the following steps are used
to deterrnine which ServiceManager to return:
- If there is a ServiceManager for the specified service registered with the
ServiceLocator then return it, otherwise;
20 - If there is an entry in the cache for the specified service then return it, otherwise;
- Broadcast a getLocalManager request to all peer ServiceLocators. The testRequired
parameter is set to true for these operations because the extra time to contact the
ServiceManager is not very significant given that a remote broadcast is being done. The first
response obtained is placed in the cache and returned to the client.
2~ When the getBestManager operation is invoked, the following steps are used to
determine which ServiceManager to return:
- If there is a ServiceManager for the specified service registered with the
ServiceLocator then attempt to cornrnunicate with it (say get its location attribute).
- If it can be contacted then return it, otherwise:
30 - If there is an entry in the cache for the specified service then attempt to communicate
with it. If it can be contacted then return it otherwise invalidate the cache entry and:
- Broadcast a getLocalManager request to all p ServiceLocators. The testRequired
parameter is set to true for tnese operations The first response obtained is placed in the cache
and returned to the client.
3 ~ ~ ServiceManager
Defining a peer group can be considered as follows. The members of a peer
group of ServiceManagers can be obtained by invoking the getAllRegisteredManagers
operation on anv ServiceLocaton specifving the appropriate scrver name. This operation uses
a broadcast to locate the ServiceManagers and is therefore a potentially expensive operation.
CA 02263~71 1999-02-16
W O 98/58313 PCT/AU98/00464
53
It is typically members of a particular peer group themselves who need to determine the
other peers in the group. Therefore, as an alternative to the expensive
getAllRegisteredManagers operation, ServiceLocators enable ServiceManagers to store their
own peer groups. They do this by sending notifications whenever members join or leave the
5 peer group.
If ServiceManagers wish to m~int~in thcir own peer group membership lists
then they need to register as notification receivers with their local ServiceLocator as
notification producer. ServiceLocators distribute the knowledge of when members join and
leave the groups using the notifyAddManager and notifyRemoveManager operations, as
o shown diagrammatically in FIG. 18. The steps in the distribution are as follows:
1. ServiceManager for location X 1 l 0 registers the location with the local
ServiceLocator 1 1 1;
2. The local ServiceLocator l l l invokes a notifvAddManager process on each of its
peer Service~ocators 11 2, 11 3 and 114;
15 3. ServiceLocators sends notification cont~ining the ServiceManager's object reference
to the notification service 115, which notification is received by peer
ServiceManagers 1 16 and l 17.
ServiceManagers can then build a cache of their peers using getAllRegisteredMa~agers to
get initial contents and using notifications to m~int~in it.
20 Summ~ry
It will be appreciated from the foregoing that the development tool of the
invention provides the following benefits for developers of large scale object oriented
systems:
(a) reduced training costs for development tearn members - few have to be CORBA
2~ literate, fewer still need to be CORBA expert;
(b) design time is reduced, because the development tool includes pacl~a_ ed usage
models to match particular needs;
(c) coding time is reduced because the code generator and ~ibraries provide proven
reliable modules, and the tool presents a simplified interface to the client and server
30 application code, and
(d) test time is reduced because developers write less of the code, the code they do write
is less complex and they are guided away from erroneous usa_e.
The system development method and tool of Ihe invention allows developers
to focus on providing the functionality of an application. rather than on the distributed,
3~ object oriented infrastructure required to deliver the applications services. It is also important
to understand that the system development tool and method of the invention may be applied
with substantially equal benefits to distributed object oriented svstem architectures other than
OMG's CORBA. The svstem development tool is suitable for adding distribution to an
existinP computer application to extend its performance and scalability or for transparentl~
CA 02263571 1999-02-16
W 098/58313 PCT/AU98/00464
54
federating systems to provide unified access methods. The system development tool is
particularly suited to developing new systems for distributed telecommunications or
financial services.
Throughout the specification the aim has been to describe preferred
5 embodiments of the invention rather than iimiting the invention to one particular
embodiment or specific collection of features.