Note: Descriptions are shown in the official language in which they were submitted.
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
10
SECRETED PROTEINS AI\rD I'OLYNU~: LEOTIDES ENCODING THEM
This application is a continuation-in-part of the following applications: Ser.
No.
08 / 7=I9,745, filed November 1;, 1996; and Ser. i v o. O8 / 867,678, filed )
une 2, l997.
FIELD OF TIDE I\ VENTION
2 0 The present invention provides novel polvnucleotides and proteins encoded
by
such polynucleotides, along with therapeutic, diagnostic and research
utilities for these
polynucleotides and proteins.
BACKGROUND OF THE INVENTION
2 5 Technology aimed at the discovery of F~rotein factors (including e.g.,
cytokines,
such as lymphokines, interferons, CSFs and interleukins) has matured rapidly
over the
past decade. The now routine hvbridilation cloning and expression cloning
techniques
clone novel polvnucleotides "directly" in the sense that they rely on
information directly
related to the discovered protein (i.e., partial DNA/amino acid sequence of
the protein
3 0 in the case of hybridization cloning; activity of the protein in the case
of expression
cloning). More recent "indirect" cloning techniques such as signal sequence
cloning, which
isolates DNA sequences based on the presence of a now v~~ell-recognized
secretory leader
sequence motif, as well as various PCR-based or low stringency hybridization
cloning
techniques, have advanced the state of the art by making available large
numbers of
3 5 DNA / amino acid sequences for proteins that are known to have biological
activity by
virtue of their secreted nature in the case of leader sequence cloning, or by
virtue of the
cell or tissue source in the case of PCR-based techniques. It is to these
proteins and the
polynucleotides encoding them that the present invention is directed.
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
SUMMAKY OF THE INVENTION
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:l;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:l from nucleotide 68 to nucleotide 430;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:1 from nucleotide l28 to nucleotide 430;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone AJ20_2 deposited under accession
number
ATCC 9826l;
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone AJ20_2 deposited under accession number ATCC 98261;
(f) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone AJ20 2 deposited under accession number ATCC
9826l;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone AJ20_2 deposited under accession number ATCC 98261;
2 0 (h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:2;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:2 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in {a)-(i).
3 0 Preferably, such polynucleotide comprises the nucleotide sequence of SEQ
ID
NO:1 from nucleotide 68 to nucleotide 430; the nucleotide sequence of SEQ ID
NO:l from
nucleotide 128 to nucleotide 430; the nucleotide sequence of the full-length
protein coding
sequence of done AJ20_2 deposited under accession number ATCC 98261; or the
nucleotide sequence of the mature protein coding sequence of clone AJ20_2
deposited
CA 02270873 1999-OS-12
WO 98l21332 PCT/US97/20740
under accession number ,ATCC 98261. In other preferred embodiments, the
polvnucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone AJ20 2 deposited under accession number ATCC 9826l.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID NO:1 or SEQ ID N0:3.
' In other embodiments, the present invention provides a composition
comprising
a protein, wherein said protein comprises an arr~ino acid sequence selected
from the group
consisting of:
(a) the amino acid sequencf~ of SEQ ID N0:2;
(b) fragments of the amino acid sequence of SEQ ID N0:2; and
(c) the amino acid sequence encoded by the cDNA insert of clone
AJ20_2 deposited under accession nurr~ber ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:2.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:5;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
2 0 N0:5 from nucleotide 289 to nucleotide 78();
(c) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone AR440_1 deposited under accession
number ATCC 98261;
(d) a polynucleotide encoding the full-length protein encoded by the
2 5 cDNA insert of clone AR440_1 deposits=d under accession number ATCC 98261;
(e) a polynucleotide compri;~ing the nucleotide sequence of the mature
protein coding sequence of clone AR440_1 deposited under accession number
ATCC 98261;
(f) a polynucleotide encoding the mature protein encoded by the
3 0 cDNA insert of clone AR440_1 deposited under accession number ATCC 98261;
(g) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:6;
(h) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:6 having biological activity;
3
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(i) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(f) above;
(j) a polynucleotide which encodes a species homologue of the protein
of (gj or (h) above ; and
S (k) a polynucleo6de capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(h).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:5 from nucleotide 289 to nucleotide 780; the nucleotide sequence of the
full-length
protein coding sequence of clone AR440_1 deposited under accession number ATCC
98261; or the nucleotide sequence of the mature protein coding sequence of
clone AR440_1
deposited under acression number ATCC 98261. In other preferred embodiments,
the
polvnucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone AIZ4=10_1 deposited under accession number ATCC 98261. In vet other
preferred
embodiments, the present invention provides a polvnucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:6 from amino acid 1 to amino
acid 160.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:5 or SEQ ID N0:4.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
2 0 consisting of:
(a) the amino acid sequence of SEQ ID N0:6;
(b) the amino acid sequence of SEQ ID N0:6 from amino acid 1 to
amino acid 160;
(c) fragments of the amino acid sequence of SEQ ID N0:6; and
2 5 (d) the amino acid sequence encoded by the cDNA insert of clone
AR4~10_l deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:6 or the amino acid
sequence
of SEQ ID N0:6 from amino acid 1 to amino acid 160.
3 0 In one embodiment, the present invention provides a composition comprising
an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7;
4
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97120740
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 76 to nucleotide 1050;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:7 from nucleotide 331 to nucleotide 567;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone AS16~_1 deposited under accession
number ATCC 98261;
(e) a polvnucleotide encoding the full-length protein encoded by the
cDNA insert of clone AS16-1_1 deposited under accession number ATCC 98261;
(f) a polynucleotide compri~;inl; the nucleotide sequence of the mature
protein coding sequence of clone AS16-I_1 deposited under accession number
ATCC 98261;
(g) a polvnucleotide encoding the mature protein encoded by the
cDNA insert of clone AS16~I_1 deposited under accession number ATCC 9826l;
(h) a polynucleotide encoding ~ protein comprising the amino acid
sequence of SEQ ID N0:8;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:8 having biological activity;
(j) a polynucleotide which is an allelic variant of a polvnucleotide of
2 0 (a)-(g) above;
(k) a polynucleotide which enacodes a species homologue of the protein
of (h') or (i) above ; and
(1) a polvnucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(i).
2 5 Preferably, such polynucleotide comprises the nucleotide sequence of SEQ
ID
N0:7 from nucleotide 76 to nucleotide 1050; the nucleotide sequence of SEQ ID
N0:7 from
nucleotide 331 to nucleotide 567; the nucleotide sequence of the full-length
protein coding
sequence of clone AS164_1 deposited under accession number ATCC 98261; or the
nucleotide sequence of the mature protein coding sequence of clone AS164_1
deposited
3 0 under accession number ATCC 98261. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone AS164_1 deposited under accession number ATCC 98261. In yet other
preferred
embodiments, the present invention provides a polvnucleotide encoding a
protein
5
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
comprising the amino acid sequence of SEQ ID N0:8 from amino acid 87 to amino
acid
164.
Other embodiments provide the gene correspondi7g to the cDNA sequence of SEQ
ID N0:7.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
{a) the amino acid sequence of SEQ ID N0:8;
(b) the amino acid sequence of SEQ ID N0:8 from amino acid 87 to
amino acid 164;
(c) fragments of the amino acid sequence of SEQ ID N0:8; and
(d) the amino acid sequence encoded by the cDNA insert of clone
AS16~1_1 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
i 5 protein comprises the amino acid sequence of SEQ ID NO:B or the amino acid
sequence
of SEQ ID N0:8 from amino acid 87 to amino acid 164.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
2 0 N0:9;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 2-I2 to nucleotide 1060;
(c) a polvnucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 596 to nucleotide 1060;
25 (d) a polvnucleotide comprising the nucleotide sequence of SEQ ID
N0:9 from nucleotide 10 to nucleotide 373;
(e) a polvnucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone AX8_1 deposited under accession number
ATCC 98261;
3 0 (f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone AX8_1 deposited under accession number ATCC 98261;
(g) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone AX8_1 deposited under accession number ATCC
98261;
6
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97120740
(h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone AX8_1 deposited under accession number ATCC 98261;
(i) a polynucleotide encoding a protein comprising the arr;ino acid
sequence of SEQ ID N0:10;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:10 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polynucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:9 from nucleotide 242 to nucleotide l060; the nucleotide sequence of SEQ ID
N0:9
i 5 from nucleotide 596 to nucleotide 1060; the nucleotide sequence of SEQ ID
N0:9 from
nucleotide 10 to nucleotide 3i 3; the nucleotide sequence of the full-length
protein coding
sequence of clone AX8_1 deposited under accession number ATCC 98261; or the
nucleotide sequence of the mature protein coding sequence of clone AX8_1
deposited
under accession number ATCC 9826l. In other preferred embodiments, the
2 0 polynucleotide encodes the full-length or mature protein encoded by the
cDNA insert of
clone AX8_1 deposited under accession number ATCC 98261. In yet other
preferred
embodiments, the present invention provide=s a polvnucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:10 from amino acid 1 to amino
acid
4~.
2 5 Other embodiments provide the gene corresponding to the cDNA sequence of
SEQ
ID N0:9.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
3 0 (a) the amino acid sequence of SEQ ID NO:10;
(b) the amino acid sequence of SEQ ID NO:10 from amino acid 1 to
amino acid 44;
(c) fragments of the amino acid sequence of SEQ ID N0:10; and
7
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(d) the amino acid sequence encoded by the cDNA insert of clone
AX~_1 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID NO:10 or the amino acid
sequence
of SEQ ID NO:1() from amino acid 1 to amino acid ~.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polvnucleotide comprising the nucleotide sequence of SEQ ID
N0:11;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
NO:11 from nucleotide 773 to nucleotide 928;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:11 from nucleotide 8I5 to nucleotide 928;
(d) a polynucleotide comprising the nucleotide sequence of the full
length protein coding sequence of clone BD176_3 deposited under accession
number ATCC 98261;
(e) a polynucleotide encoding the Full-length protein encoded by the
cDNA insert of clone BD176_3 deposited under accession number ATCC 9826l;
(f) a polvnucleotide comprising the nucleotide sequence of the mature
2 0 protein coding sequence of clone BD176_3 deposited under accession number
ATCC 98261;
(g) a polvnucleotide encoding the mature protein encoded by the
cDNA insert of clone BD176_3 deposited under accession number ATCC 9826l;
(h) a polynucleotide encoding a protein comprising the amino acid
2 5 sequence of SEQ ID N0:12;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:12 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
3 0 (k) a polynucleoHde which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(i).
8
CA 02270873 1999-OS-12
WO 98/21332 PCT/LTS97/20740
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
NO:11 from nucleotide 773 to nucleotide 928; the nucleotide sequence of SEQ ID
NO:11
from nucleotide 815 to nucleotide 928; the nucleotide sequence of the full-
length protein
coding sequence of clone BD176_3 deposited under accession number ATCC 9826l;
or the
nucleotide sequence of the mature protein coding sequence of clone BD176_3
deposited
under accession number ATCC 98261. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone BD176_3 deposited under accession number ATCC 9826l.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:11 or SEQ ID N0:13.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:12;
1 S {b} fragments of the amino acid sequence of SEQ ID N0:12; and
(c) the amino acid sequenco encoded by the cDNA insert of clone
BD17Co3 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins.
I'referablv such
protein comprises the amino acid sequence of ~~EQ ID NO:12.
2 0 In one embodiment, the present invention provides a composition comprising
an
isolated polvnucleotide selected from the group consisting of:
(a) a polvnucleotide comprising the nucleotide sequence of SEQ ID
N0:14;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
2 5 N0:14 from nucleotide l74 to nucleotide 440;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:14 from nucleotide 1 to nucleotide ~'~13;
(d) a polynucleotide compri,ing the nucleotide sequence of the full-
length protein coding sequence of clone BD339_1 deposited under accession
3 0 number ATCC 98261;
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone BD339_1 deposite~~ under accession number ATCC 9826l;
9
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(f) a polvnucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone BD339_1 deposited under accession number
ATCC 98261;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone BD339_1 deposited under accession number ATCC 98261;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:15;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:15 having biological activity;
(j) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(g) above;
(k) a polvnucleotide which encodes a species homologue of the protein
of {h) or (i) above ; and
{l) a polvnurleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(i).
Preferably, such poiynucleotide comprises the nucleotide sequence of SEQ ID
N0:14 from nucleotide 17=1 to nucleotide 440; the nucleotide sequence of SEQ
ID N0:14
from nucleotide 1 to nucleotide 313; the nucleotide sequence of the full-
length protein
coding sequence of clone BD339_1 deposited under accession number ATCC 98261;
or the
2 0 nucleotide sequence of the mature protein coding sequence of clone BD339_1
deposited
under accession number ATCC 98261. In other preferred embodiments, the
polvnucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone BD339_1 deposited under accession number ATCC 98261. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
2 5 comprising the amino acid sequence of SEQ ID N0:15 from amino acid 1 to
amino acid
46.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:14.
In other embodiments, the present invention provides a composition comprising
3 0 a protein, wherein said protein comprises an amino acid sequence selected
from the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:15;
(b) the amino acid sequence of SEQ ID N0:15 from amino acid 1 to
amino acid 46;
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
(c) fragments of the amino acid sequence of SEQ ID N0:15; and
(d) the amino acid sequence encoded by the cDNA insert of clone
BD339_1 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:15 or the amino acid
sequence
of SEQ ID N0:15 from amino acid 1 to amino acid 46.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:16;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:16 from nucleotide 509 to nucleotide 619;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:16 from nucleotide 1 to nucleotide 580;
(d) a polvnucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone BD427_1 deposited under accession
number ATCC 98261;
(e) a polynucleotide encodi:~g the full-length protein encoded by the
cDNA insert of clone BD427_1 deposited under accession number ATCC 98261;
2 0 (f) a polvnucleotide compri:~ing the nucleotide sequence of the mature
protein coding sequence of clone BD=1.27_1 deposited under accession number
ATCC 98261;
(g) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone BD.127_1 deposited under accession number ATCC 98261;
2 5 (h) a polvnucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:17;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:17 inaving biological activity;
(j) a polvnucleotide which is an allelic variant of a polynucleotide of
(a)-(g} above;
(k) a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polvnucleotide capable of hybridizing under stringent conditions
to anv one of the polynucleotides specified in (a)-(i).
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:16 from nucleotide 509 to nucleotide 619; the nucleotide sequence of SEQ ID
N0:16
from nucleotide 1 to nucleotide 580; the nucleotide sequence of the full-
length protein
coding sequence of clone BD427_1 deposited under accession number ATCC 9826l;
or the
nucleotide sequence of the mature protein coding sequence of clone BD427_1
deposited
under accession number A'TCC 982b1. In other preferred embodiments, the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone BD427_1 deposited under accession number ATCC 98261. In yet other
preferred
embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ ID N0:17 from amino acid 1 to amino
acid
24.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:16.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:17;
(b) the amino acid sequence of SEQ ID N0:17 from amino acid 1 to
amino acid 24;
2 0 (c) fragments of the amino acid sequence of SEQ ID NO:17; and
(d) the amino acid sequence encoded by the cDNA insert of clone
BD427_1 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:17 or the amino acid
sequence
of SEQ ID N0:17 from amino acid 1 to amino acid 24.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:18;
3 0 (b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:18 from nucleotide 300 to nucleotide 360;
(c) a polvnucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone BL229_22 deposited under accession
number ATCC 98261;
12
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
(d) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone BL229_22 deposii:ed under accession number ATCC 98261;
(e) a polynucleotide compr~.sing the nucleotide sequence of the mature
protein coding sequence of clone BL229_22 deposited under accession number
ATCC 98261;
(f) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone BL229_22 deposil:ed under accession number ATCC 98261;
(g) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:19;
(h) a polvnucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:19 having biological activity;
(i) a polvnucleotide which is an allelic variant of a polvnucleotide of
(a)-{f) above;
(j) a polvnucleodde which f=ncodes a species homologue of the protein
of (g) or (h) above ; and
{k) a polynucleotide capable, of hybridizing under stringent conditions
to anv one of the polvnucleotides specified in (a)-(h).
Preferably, such polvnucleotide comprises the nucleotide sequence of SEQ ID
N0:18 from nucleotide 300 to nucleotide 360; the nucleotide sequence of the
full-length
2 0 protein coding sequence of clone BL229_22 deposited under accession number
ATCC
98261; or the nucleotide sequence of the mature protein coding sequence of
clone
BL229_22 deposited under accession number ATCC 98261. In other preferred
embodiments, the polynucleotide encodes the full-length or mahire protein
encoded by
the cDNA insert of clone BL229_22 deposited under accession number ATCC 9826l.
2 5 Other embodiments provide the gene corresponding to the cDNA sequence of
SEQ
ID N0:18 or SEQ ID N0:20.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
3 0 (a) the amino acid sequence of SEQ ID N0:19;
(b) fragments of the amino acid sequence of SEQ ID N0:19; and
(c) the amino acid sequence encoded by the cDNA insert of clone
BL229 22 deposited under accession number ATCC 98261;
13
CA 02270873 1999-OS-12
WO 98I21332 PCT/ITS97120740
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:19.
In one embodiment, the present invention provides a composition comprising an
isolated polynucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21;
{b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21 from nucleotide 604 to nucleotide 771;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:21 from nucleotide 1 to nucleotide 684;
(d) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone BV123_16 deposited under accession
number ATCC 98261;
(e) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone BV123_16 deposited under accession number ATCC 98261;
(f) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone 8V123_16 deposited under accession number
ATCC 98261;
(g) a polynucleotide encoding the mature protein encoded by the
2 0 cDNA insert of clone BV12 3_16 deposited under accession number ATCC
9826l;
(h) a polynucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:22;
(i) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:22 having biological activity;
2 5 (j) a polynucleotide which is an allelic variant of a polvnucleotide of
(a)-(g) above;
(k} a polynucleotide which encodes a species homologue of the protein
of (h) or (i) above ; and
(1) a polynucleotide capable of hybridizing under stringent conditions
3 0 to anv one of the polynucleotides specified in (a)-(i).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:21 from nucleotide 604 to nucleotide 771; the nucleotide sequence of SEQ ID
N0:21
from nucleotide 1 to nucleotide 684; the nucleotide sequence of the full-
length protein
coding sequence of clone BV123_16 deposited under accession number ATCC 98261;
or
14
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
the nucleotide sequence of the mature protein coding sequence of clone
8V123_16
deposited under accession number ATCC 98261. In other preferred embodiments,
the
polynucleotide encodes the full-length or mature protein encoded by the cDNA
insert of
clone 8V123_16 deposited under accession number ATCC 98261. In yet other
preferred
S embodiments, the present invention provides a polynucleotide encoding a
protein
comprising the amino acid sequence of SEQ IL> N0:22 from amino acid 1 to amino
acid
27.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:21.
In other embodiments, the present invention provides a composition comprising
a protein, wherein said protein comprises an amino acid sequence selected from
the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:22;
(b) the amino acid sequence of SEQ ID N0:22 from amino acid 1 to
amino acid 27;
(c) fragments of the amino acid sequence of SEQ ID N0:22; and
(d) the amino acid sequence encoded by the cDNA insert of clone
BVl2p_16 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
2 0 protein comprises the amino acid sequence of SEQ ID N0:22 or the amino
acid sequence
of SEQ ID N0:22 from amino acid 1 to amino acid 27.
In one embodiment, the present invention provides a composition comprising an
isolated polvnucleotide selected from the group consisting of:
(a) a polynucleotide comprising the nucleotide sequence of SEQ ID
2 S N0:23;
(b) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:23 from nucleotide 43 to nucleotide 297;
(c) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:23 from nucleotide 94 to nucleotide 297;
3 0 (d) a polynucleotide comprising the nucleotide sequence of SEQ ID
N0:23 from nucleotide 1 to nucleotide ~~79;
(e) a polynucleotide comprising the nucleotide sequence of the full-
length protein coding sequence of clone CH377_1 deposited under accession
number ATCC 98261;
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(f) a polynucleotide encoding the full-length protein encoded by the
cDNA insert of clone CH377 _1 deposited under accession number ATCC 98261;
(g) a polynucleotide comprising the nucleotide sequence of the mature
protein coding sequence of clone CH377_1 deposited under accession number
ATCC 98261;
(h) a polynucleotide encoding the mature protein encoded by the
cDNA insert of clone CH377_1 deposited under accession number ATCC 98261;
(i) a polvnucleotide encoding a protein comprising the amino acid
sequence of SEQ ID N0:24;
(j) a polynucleotide encoding a protein comprising a fragment of the
amino acid sequence of SEQ ID N0:24 having biological activity;
(k) a polynucleotide which is an allelic variant of a polynucleotide of
(a)-(h) above;
(1) a polvnucleotide which encodes a species homologue of the protein
of (i) or (j) above ; and
(m) a polvnucleotide capable of hybridizing under stringent conditions
to any one of the polynucleotides specified in (a)-(j).
Preferably, such polynucleotide comprises the nucleotide sequence of SEQ ID
N0:23 from nucleotide 43 to nucleotide 297; the nucleotide sequence of SEQ ID
N0:23
2 0 from nucleotide 94 to nucleotide 297; the nucleotide sequence of SEQ ID
N0:23 from
nucleotide 1 to nucleotide 379; the nucleotide sequence of the full-length
protein coding
sequence of clone CH377_1 deposited under accession number ATCC 9826l; or the
nucleotide sequence of the mature protein coding sequence of clone CH377_1
deposited
under accession number ATCC 98261. In other preferred embodiments, the
2 5 polynucleotide encodes the full-length or mature protein encoded by the
cDNA insert of
clone CH377_1 deposited under accession number ATCC 98261.
Other embodiments provide the gene corresponding to the cDNA sequence of SEQ
ID N0:23.
In other embodiments, the present invention provides a composition comprising
3 0 a protein, wherein said protein comprises an amino acid sequence selected
from the group
consisting of:
(a) the amino acid sequence of SEQ ID N0:24;
(b) fragments of the amino acid sequence of SEQ ID N0:24; and
16
CA 02270873 1999-OS-12
WO 98I21332 PCT/LTS97/20740
(c) the amino acid sequence encoded by the cDNA insert of clone
CH377_1 deposited under accession number ATCC 98261;
the protein being substantially free from other mammalian proteins. Preferably
such
protein comprises the amino acid sequence of SEQ ID N0:24.
In certain preferred embodiments, the polynucleotide is operably linked to an
expression control sequence. The invention also provides a host cell,
including bacterial,
yeast, insect and mammalian cells, transformed with such polvnucleotide
compositions.
Processes are also provided for producing a protein, which comprise:
(a) growing a culture of the host cell transformed with such
i 0 polynucleotide compositions in a suitable culture medium; and
(b) purifying the protein fr~~m the culture.
The protein produced according to such methods is also provided by the present
invention. Preferred embodiments include those in which the protein produced
by such
process is a mature form of the protein.
Protein compositions of the present invention may further comprise a
pharmaceutically acceptable carrier. Compositions comprising an antibody which
specifically reacts with such protein are also provided by the present
invention.
Methods are also provided for preventing, treating or ameliorating a medical
condition which comprises administering to a mammalian subject a
therapeutically
2 0 effective amount of a composition comprising a protein of the present
invention and a
pharmaceutically acceptable carrier.
BRIEF DESCRIPTION OF THE DRAWINGS
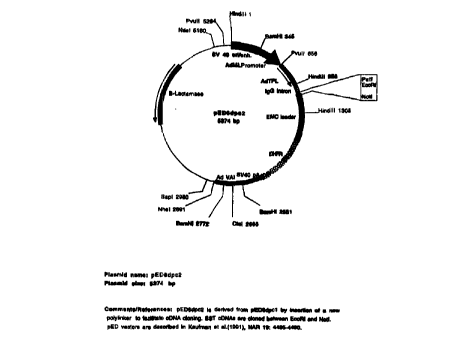
Figures lA and 1B arc: schematic repre=~entations of the pED6 and pNOTs
vectors,
2 5 respectively, used for deposit of clones disclo~~ed herein.
DETAILED DESCRIPTION
ISOLATED PROTEINS AND POLYNUCLEOTIDES
3 0 Nucleotide and amino acid sequences, as presently determined, are reported
below for each clone and protein disclosed in the present application. The
nucleotide
sequence of each clone can readily be determined by sequencing of the
deposited clone
in accordance ~~ith known methods. The predicted amino acid sequence (both
full-length
and mature) can then be determined from such nucleotide sequence. The amino
acid
17
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
sequence of the protein encoded by a particular clone can also be determined
by
expression of the clone in a suitable host cell, collecting the protein and
determining its
sequence. For each disclosed protein applicants have identified what they have
determined to be the reading frame best identifiable with sequence information
available
at the time of filing.
As used herein a "secreted" protein is one which, when expressed in a suitable
host
cell, is transported across or through a membrane, including transport as a
result of signal
sequences in its amino acid sequence. "Secreted" proteins include without
limitation
proteins secreted wholly (e.g., soluble proteins} or partially (e.g. ,
receptors) from the cell
in which they are expressed. "Secreted" proteins also include ~~ithout
limitation proteins
which are transported across the membrane of the endoplasmic reticulum.
Clone "AT20 ?"
A polvnucleotide of the present invention has been identified as clone "AJ20
2"
AJ20_2 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. AJ2()_2 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
2 0 "AJ20_2 protein")
The nucleotide sequence of the 5' portion of AJ20 2 as presently determined is
reported in SEQ ID NO:1. What applicants presently believe is the proper
reading frame
for the coding region is indicated in SEQ ID N0:2. The predicted amino acid
sequence of
the AJ20 2 protein corresponding to the foregoing nucleotide sequence is
reported in SEQ
2 5 ID N0:2. Amino acids 8 to 20 are a predicted leader/signal sequence, with
the predicted
mature amino acid sequence beginning at amino acid 21, or are a transmembrane
domain.
Additional nucleotide sequence from the 3' portion of AJ20_2, including the
polvA tail,
is reported in SEQ ID N0:3.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
3 0 AJ20_2 should be approximately 850 bp.
The nucleotide sequence disclosed herein for Aj20_2 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. No hits were found in the database.
18
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Clone "AR4-IO 1"
A polvnucleotide of the present invention has been identified as clone
"AR440_1".
AR440_1 was isolated from a human adult retina cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. I'at. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. AR44()_1 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "AR 440_1 protein")
The partial nucleotide sequence of AR4~E0_1, including its 3' end and any
identified
polyA tail, as presently determined is reported in SEQ ID N0:7. What
applicants
presently believe is the proper reading frame for the coding region is
indicated in SEQ ID
N0:6. The predicted amino acid seduence of the AR440_1 protein corresponding
to the
foregoing nucleotide sequence is reported in SEQ ID N0:6. Additional
nucleotide
sequence from the 5' portion of AR440_1 is reported in SEQ ID NO:4.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
AR440_1 should be approximately 1400 bp.
The nucleotide sequence disclosed herein for AR440_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
Ff'1STA search protocols. Nc7 hits were found in the database. The nucleotide
sequence
2 0 of AR440_1 indicates that it may contain an A:.u repetitive element.
Clone "AS164 1"
A polvnucleotide of the present invention has been identified as clone
"AS164_1".
AS164_1 was isolated from a human fetal brain cDNA library usins; methods
which are
selective for cDNAs encoding secreted proteins (see U.S. 1'at. No. 5,536,637),
or was
identified as encoding a secreted or transmernbrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. AS164_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
3 0 "AS164_1 protein")
The nucleotide sequence of AS164_l as presently determined is reported in SEQ
ID N0:7. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the AS164_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID NC~:8.
19
CA 02270873 1999-OS-12
WO 98/21332 PCT1LTS97/20740
The EcoRI / NotI restriction fragment obtainable from the deposit containing
clone
AS164_1 should be approximately 1600 bp.
The nucleotide sequence disclosed herein for A5164_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. AS164_1 demonstrated at least some similarity with
sequences
identified as H24668 (y140h10.r1 Homo Sapiens cDNA clone 160771 5'), N29757
{yw90h10.s1 Homo Sapiens cDNA clone 259555 3'), T62184 (yb96d08.r1 Homo
Sapiens
cDNA clone 79023 ~'), Z69706 (I--Iuman DNA sequence from cosmid COS12 from a
contig
from the tip of the short arm of chromosome 16, spanning 2Mb of 16p13.3.
Contains ESTs,
Flanking sequences of 3' alpha globin H), and Z69890 (Human DNA sequence from
cosmid RJ 14 from a contig from the tip of the short arm of chromosome 16,
spanning 2Mb
of 16p13.3. Contains ESTs and CpG island). The predicted amino acid sequence
disclosed
herein for AS16-I_1 was searched against the GenI'ept and GeneSeq amino acid
sequence
databases using the BLASTX search protocol. The predicted A5164_1 protein
1 S demonstrated at least some similarity to sequences identified as A20359_1
(ryanodine
receptor gene product [Homo Sapiens] j and L178866 (putative arginine-
aspartate-rich RNA
binding protein [Arabidopsis thaliana]). Based upon sequence similarity,
AS164_1
proteins and each similar protein or peptide may share at least some activity.
The
predicted AS164_1 protein seduence also contains repeated Asp-Arg RNA-binding
motifs.
Clone "AX8 1 "
A polvnucleotide of the present invention has been identified as clone
"AX8_1".
AX8_1 was isolated from a human adult testes cDNA library using methods which
are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,b37),
or was
2 5 identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. AX8_1 is a full-
length clone,
including the entire coding sequence of a secreted protein (also referred to
herein as
"AX8_1 protein")
The nucleotide sequence of AX8_1 as presently determined is reported in SEQ ID
3 0 N0:9. What applicants presently believe to be the proper reading frame and
the predicted
amino acid sequence of the AX8_l protein corresponding to the foregoing
nucleotide
sequence is reported in SEQ ID N0:10. Amino acids 106 to 118 are a predicted
ieader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 119, or are a transmembrane domain.
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97120740
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
AX8_1 should be approximately 2300 bp.
The nucleotide sequence disclosed herein for AX8_I was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. No hits were found in the database. The TopPredII
computer
program predicts three potential transmembrane domains within the AX8_1
protein
sequence, centered around amino acids 111, 144, and 182 of SEQ ID N0:10.
Clone "BD176 3"
A polvnucleotide of the present invention has been identified as clone
"BD176_3".
BD176_3 was isolated from a human fetal kidney cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. I'at. No. 5,536,637),
or was
identified as encoding a secreted or transme,mbrane protein on the basis of
computer
analysis of the amino acid seduence of the encoded protein. BD176_3 is a full-
length
clone, including the entire coding; sequence of a secreted protein (also
referred to herein
as "BD176_3 protein").
The nucleotide sequence of the 5' portion of BD176_3 as presently determined
is
reported in SEQ ID NO:11. What applicants presently believe is the proper
reading frame
for the coding region is indicated in SEQ 1D NO:I2. The predicted amino acid
sequence
2 0 of the BD176_3 protein corresponding to the foregoing nucleotide sequence
is reported
in SEQ ID N0:12. Amino acids 2 to 14 are a predicted leader/signal sequence)
with the
predicted mature amino acid sequence beginning at amino acid 15, or are a
transmembrane domain. Additional nucleotide sequence from the 3' portion of
BD176_3,
including the polyA tail, is reported in SEQ ID N0:13.
2 5 The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
BD176_3 should be approximately 1300 bp.
The nucleotide sequence disclosed herein for BD176_3 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. BD176_3 demonstrated at least some similarity with
sequences
3 0 identified as AA029679 (ze94g10.r1 Soares fetal heart NbHHI9W Homo Sapiens
cDNA
clone 366690 5'), D45913 (Mouse NLRB-1 mRNA for leucine-rich-repeat protein,
complete
cds), R55610 (yg88h08.r1 Homo Sapiens cDNA clone 40606 5'), and T07640
(EST05530
Homo Sapiens cDNA clone HFBEM16). The predicted amino acid sequence disclosed
herein for BD176_3 was searched against the GenPept and GeneSeq amino acid
sequence
2I
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
databases using the BLASTX search protocol. The predicted BD176 3 protein
demonstrated at least some similarity to sequences identified as D45913
{leucine-rich-repeat protein [Mus musculus]) and M59472 (asparagine-rich
antigen Pfa55-6
[Plasmodium falciparum]). Based upon sequence similarity, 8D176 3 proteins and
each
similar protein or peptide may share at least some activity.
Clone "BD339 1"
A polynucleotide of the present invention has been identified as clone
"BD339_1".
8D339_1 was isolated from a human fetal kidney cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. I'at. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. 8D339_1 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "BD339_1 protein")
The nucleotide sequence of BD339l as presently determined is reported in SEQ
ID N0:14. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the 13D339_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:15.
The EcoRI/Notl restriction fragment obtainable from the deposit containing
clone
2 0 BD339_1 should be approximately 650 bp.
The nucleotide sequence disclosed herein for BD339_1 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLfISTN / BLASTX and
FASTA search protocols. 8D339_1 demonstrated at least some similarity with
sequences
identified as I-I82422 (yu80d08.s1 Homo Sapiens cDNA clone 240l113), N62058
(EST53c05
2 5 Homo Sapiens cDNA clone), U21730 Human 5'-nucleotidase (CD73)), W01979
(ra30h09.r1
Soares fetal liver spleen 1NFLS Homo sapiens cDNA clone 2941l3 5'), and W02015
(za32b11.r1 Soares fetal liver spleen 1NFLS Homo Sapiens cDNA clone 294237
5'). Based
upon sequence similarity, BD339_1 proteins and each similar protein or peptide
may share
at least some activity. The TopPredII computer program predicts three
potential
3 0 transmembrane domains within the BD339_1 protein sequence,centered around
amino
acids 14, 46, and 76 of SEQ ID N0:15.
CA 02270873 1999-OS-12
WO 98l21332 PCT/US97/20740
Clone "BD427 1"
A polvnucleotide of the present invent:,on has been identified as clone
"BD427_1".
8D427_1 was isolated from a human fetal kidney cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. BD427_1 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "BD427_1 protein").
The nucleotide sequence of BD427_7 a:; presently determined is reported in SEQ
ID N0:16. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the 8D427__1 protein correspondinE; to the
foregoing
nucleotide sequence is reported in SEQ ID N0:17.
The EcoPI/Notl restriction fragment obtainable from the deposit containing
clone
8D427_1 should be approxirnatelv 1810 bp.
1 S The nucleotide sequence disclosed herein for 8D427_1 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. BD427_ 1 demonstrated at least some similarity with
sequences
identified as AA027122 (zk04a03.r1 Soares pre~mant uterus NbHPU Homo Sapiens
cDNA
clone 469516 5'), N24735 (yx56b02.s1 Homo sahiens cDNA clone 265707 3'}, and
W8464:1
(zd91a06.r1 Soares fetal heart NbHHI9W Homo Sapiens cDNA clone 3568l8 5').
Based
upon sequence similarity, BD427_1 proteins and each similar protein or peptide
may share
at least some activity.
Clone "BL229 22"
2 5 A polvnucleotide of the present invention has been identified as clone
"BL229 22".
BL229_22 was isolated from a human adult testes cDNA library using methods
which are
selective for cDNAs encoding secreted pr~tE~ins (see U.S. Pat. No. 5,S36,637),
or was
identified as encoding a secreted or transme:mbrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. BL229_22 is a full-
length
3 0 clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "8L229 22 protein").
The nucleotide sequence of the 5' portion of BL229_22 as presently determined
is
reported in SEQ ID N0:18. What applicants presently believe is the proper
reading frame
for the coding region is indicated in SEQ ID N0:19. The predicted amino acid
sequence
23
CA 02270873 1999-OS-12
WO 98/21332 PCTIUS97/20740
of the BL229_22 protein corresponding to the foregoing nucleotide sequence is
reported
in SEQ ID N0:19. Additional nucleotide sequence from the 3' portion of BL229
22,
including the polyA tail, is reported in SEQ ID N0:20.
The EcoRI/NotI restriction fragment obtainable from the deposit containing
clone
BL229 22 should be approximately 870 bp.
The nucleotide sequence disclosed herein for BL229_22 was searched against the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. No hits were found in the database.
Clone "BV123 16"
A polynucleotide of the present invention has been identified as clone
"BV123_16".
BV123_16 was isolated from a human adult brain cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmembrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. BVl2p_16 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "BV123_16 protein")
The nucleotide sequence of $V123_16 as presently determined is reported in SEQ
ID N0:21. What applicants presently believe to be the proper reading frame and
the
2 0 predicted amino acid sequence of the BV123_16 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:22.
The EcoRI/Notl restriction fragment obtainable from the deposit containing
clone
BVI23_l6 should be approximately 1080 bp.
The nucleotide sequence disclosed herein for BV 123_l6 was searched against
the
2 5 GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. BV123_16 demonstrated at least some similarity with
sequences
identified as H29610 (ym61e03.s1 Homo sapiens cDNA clone 52653 3'), H52374
(yq81b12.r1 Homo Sapiens cDNA clone 202175 5'), H66213 (yu16h10.s1 Homo
Sapiens
cDNA), L08092 (Homo Sapiens dystrophin (DMD) gene, intron 7, transposon-like
3 0 sequence), L35670 (Homo Sapiens (subclone H8 1 (7~5 from I'1 35 H5 C8) DNA
sequence),
M62716 (Human CSP-B gene flanking sequence), N46985 (yy83a05.s1 Homo Sapiens
cDNA clone 280112 3'), R94603 (yq38a04.sI Homo Sapiens cDNA clone 198030 3'),
U91321
(Human chromosome 16p13 BAC clone CIT987SK-363E6, complete sequence), and
Z82200
24
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(Human DNA sequence from clone J333E231). Eased upon sequence similarity,
BV123_16
proteins and each similar protein or peptide may share at least some activity.
Clone "CH377 1"
A polvnucleotide of the present invention has been identified as clone
"CH377_1".
CH377_1 was isolated from a human fetal kidney cDNA library using methods
which are
selective for cDNAs encoding secreted proteins (see U.S. Pat. No. 5,536,637),
or was
identified as encoding a secreted or transmernbrane protein on the basis of
computer
analysis of the amino acid sequence of the encoded protein. CH377_1 is a full-
length
clone, including the entire coding sequence of a secreted protein (also
referred to herein
as "CH377_1 protein")
The nucleotide sequence of CH377 _1 as presently determined is reported in SEQ
ID N0:23. What applicants presently believe to be the proper reading frame and
the
predicted amino acid sequence of the CH377_1 protein corresponding to the
foregoing
nucleotide sequence is reported in SEQ ID N0:24. .Amino acids 5 to 17 are a
predicted
leader/signal sequence, with the predicted mature amino acid sequence
beginning at
amino acid 18, or are a transmembrane domain.
The EcoRI/Notl restriction fragment obi:ainable from the deposit containing
clone
CH377_1 should be approximately 570 bp.
2 0 The nucleotide sequence disclosed herei n for CH377_1 was searched against
the
GenBank and GeneSeq nucleotide sequence databases using BLASTN/BLASTX and
FASTA search protocols. CH377_1 demonstrated at least some similarity with
sequences
identified as AA507382 (nh73bOl.s1 NCI CGAI'__Brl.1 Homo Sapiens cDNA clone
IMAGE
964105) and N7(1479 (za74f12.s1 Homo sapier~,s cDNA clone 298319 3'). Based
upon
2 5 sequence similarity, CH377_1 proteins and each similar protein or peptide
may share at
least some activity.
Deposit of Clones
Clones AJ20_2, AR440_1, AS164_l, AX8_I, 8D176_3, BD339_l, BD427_l,
3 0 8L229 22, BV123_16, and CH377_1 were deposited on November 15, 1996 with
the
American Type Culture Collection as an original deposit under the Budapest
Treaty and
were given the accession number ATCC 98261, from which each clone comprising a
particular polvnucleotide is obtainable. All restrictions on the availability
to the public of
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
the deposited material will be irrevocably removed upon the granting of the
patent, except
for the requirements specified in 37 C.F.R. ~ 1.808(b).
Each clone has been transfected into separate bacterial cells (F.. toll) in
this
composite deposit. Each clone can be removed from the vector in which it was
deposited
by performing an EcoRI/NotI digestion (5' site, EcoRI; 3' site, NotI) to
produce the
appropriate fragment for such clone. Each clone was deposited in either the
pED6 or
pNOTs vector depicted in Fig. 1. The pED6dpc2 vector ("pED6") was derived from
pED6dpc1 by Insertion of a new polylinker to facilitate cDNA cloning (Kaufman
et al.,
1991, Nucleic Acicls Res. 19: 4485--1490); the pNOTs vector was derived from
pMT2
(Kaufman et nl., 1989, Mol. Ctll. l3iol. 9: 946-958) by deletion of the DI-iFR
sequences,
insertion of a new polvlinker, and insertion of the M13 origin of replication
in the CIaI site.
In some instances, the deposited clone can become "flipped" (i.e., iv the
reverse
orientation) in the deposited isolate. In such instances, the cDNA insert can
still be
isolated by dit:,estion with EcoRI and Notl. However, NotI will then produce
the 5' site
and EcoRI will produce the 3' site for placement of the cDNA in proper
orientation for
expression in a suitable vector. The cDNA may also be expressed from the
vectors in
which they ~nTere deposited.
E3acterial cells containing a particular clone can be obtained from the
composite
deposit as follo~nw:
2 0 An oligonucleotide probe or probes should be designed to the sequence that
is
known for that particular clone. This sequence can be derived from the
sequences
provided herein, or from a combination of those sequences. The sequence of the
oligonucleotide probe that was used to isolate each full-length clone is
identified below,
and should be most reliable in isolating the clone of interest.
Clone Probe Sequence
AJ20 2 SEQ ID N0:25
AK440_1 SEQ ID N0:26
AS164_1 SEQ ID N0:27
3 0 AX8_1 SEQ ID N0:28
BD176_3 SEQ ID N0:29
BD339_1 SEQ ID N0:30
BD427_1 SEQ ID N0:31
BL229_22 SEQ ID N0:32
26
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
BV123_16 SEQ ID N0:33
CH377_1 SEQ ID N0:34
In the sequences listed above which include an N at position 2, that position
is occupied
in preferred probes/primers by a biotinylated phosphoaramidite residue rather
than a
nucleotide (such as , for example, that produced by use of biotin
phosphoramidite (1-
dimethoxytrityloxv-2-(N-biotinyl-4-aminobutvl)-propyl-3-O-(2-cyanoethyl)-(N,N-
diisopropyl)-phosphoramadite) (Glen Research, cat. no. 10-1953)).
The design of the oligonucleotide probe should preferably follow these
parameters:
(a) It should be designed to an area of the sequence which has the fewest
ambiguous bases ("N's"), if any;
(b) It should be designed to have a I'~, of approx. 80 ° C (assuming
2° for each
A or T and ~l degrees for each C~ or C).
The olfgonucleotide should preferably be labeled with g-'~P ATP (specific
activity 6000
Ci/mmole) and T-1 polynucleotide kinase using commonly employed techniques for
labeling oligonucleotides. Other labeling techniques can also be used.
Unincorporated
label should preferably be removed by gel filtration chromatography or other
established
methods. The amount of radioactivity incorporated into the probe should be
quantitated
2 0 by measurement in a scintillation counter. Preferably, specific activity
of the resulting
probe should be approximately 4e+6 dpm/pmole.
The bacterial culture containing the pc:~ol of full-length clones should
preferably
be thawed and 1()0 ul of the stock used to inoculate a sterile culture flask
containing 25 ml
of sterile I_-broth containing ampicillin at 100 yg/ ml. The culture should
preferably be
2 5 grown to saturation at 37°C) and the saturated culture should
preferably be diluted in
fresh L-broth. Aliquots of these dilutions should preferably be plated to
determine the
dilution and volume which will yield approximately 5000 distinct and well-
separated
colonies on solid bacteriological media containing L-broth containing
ampicillin at 100
ug/ml and agar at 1.5'% in a 150 mm petri dish when grown overnight at
37°C. Other
3 0 known methods of obtaining distinct, well-separated colonies can also be
employed.
Standard colony hybridization proced ures should then be used to transfer the
colonies to nitrocellulose filters and lyre, denature and bake them.
The filter is then preferably incubated at 65°C for 1 hour with gentle
agitation in
6X SSC (20X stock is 175.3 g NaCI/liter, 88.2 g; Na citrate/liter, adjusted to
pH 7.0 with
27
CA 02270873 1999-OS-12
WO 98I21332 PCT/ITS97120740
NaOH) containing 0.5°/, SDS, 100 ug/ml of yeast RNA, and 10 mM EDTA
(approximately
mL per 150 mm filter). Preferably, the probe is then added to the
hybridization mix at
a concentration greater than or equal to le+6 dpm/mL. The filter is then
preferably
incubated at 65°C with gentle agitation overnight. The filter is then
preferably washed in
5 500 mL of 2X SSC/0.5°/a SDS at room temperature without agitation,
preferably followed
by 500 mL of 2X SSC/0.1'%<, SDS at room temperature with gentle shaking for 15
minutes.
A third wash with 0.1X SSC/0.5'% SDS at 65°C for 30 minutes to 1 hour
is optional. The
filter is then preferably dried and subjected to autoradiography for
sufficient time to
visualize the positives on the X-ray film. Other known hybridization methods
can also
10 be employed.
The positive colonies are picked, grown in culture, and plasmid DNA isolated
using standard procedures. The clones can then be verified by restriction
analysis,
hybridization analysis, or DNA sequencing.
Fragments of the proteins of the present invention which are capable of
exhibiting
biological activity are also encompassed by the present invention. Fragments
of the
protein may be in linear form or they may be cyclized using known methods, for
example,
as described in H.U. Saragovi, et nl., Bio/Technology 10, i73-778 (1992) and
in R.S.
McDowell, et nl., J. Amer. Chem. Soc. 114, 9245-9253 (l992), both of which are
incorporated
herein by reference. Such fragments may be fused to carrier molecules such as
2 0 immunoglobulins for many purposes, including increasing the valency of
protein binding
sites. For example, fragments of the protein may be fused through "linker"
sequences to
the Fc portion of an immunoglobulin. For a bivalent form of the protein, such
a fusion
could be to the Fc portion of an IgG molecule. Other immunoglobulin isotypes
may also
be used to generate such fusions. For example, a protein - IgM fusion would
generate a
2 5 decavaient form of the protein of the invention.
The present invention also provides both full-length and mature forms of the
disclosed proteins. The full-length form of the such proteins is identified in
the sequence
listing by translation of the nucleotide sequence of each disclosed clone. The
mature form
of such protein may be obtained by expression of the disclosed full-length
polynucleotide
3 0 (preferably those deposited with ATCC) in a suitable mammalian cell or
other host cell.
The sequence of the mature form of the protein may also be determinable from
the amino
acid sequence of the full-length form.
The present invention also provides genes corresponding to the cDNA sequences
disclosed herein. "Corresponding genes" are the regions of the genome that are
28
CA 02270873 1999-OS-12
WO 98/21332 PCT/LTS97/20740
transcribed to produce the mIZNAs from which the cDNA sequences are derived
and any
contiguous regions of the genome necessary for the regulated expression of
such genes)
including but not limited to coding sequences, 5' and 3' untranslated regions,
alternatively
spliced exons, introns, promoters, enhancers, and silencer or suppressor
elements. The
S corresponding genes can be isolated in accordance with known methods using
the
sequence information disclosed herein. Such methods include the preparation of
probes
or primers from the disclosed sequence information for identification and/or
amplification of genes in appropriate genomic libraries or other sources of
genomic
materials.
Where the protein of the present invention is membrane-bound (e.g., is a
receptor),
the present invention also provides for soluble forms of such protein. In such
forms part
or a11 of the intracellular and transmembrane domains of the protein are
deleted such that
the protein is fully secreted from the cell in which it is expressed. The
intracellular and
transmembrane domains of proteins of the invention can be identified in
accordance with
known techniques for determination of such domains from sequence information.
Proteins and protein fragments of thE: present invention include proteins with
amino acid sequence lengths that are at least 25%(more preferably at least
50°/,, and most
preferably at least 75'ia) of the length of a disclosed protein and have at
least 60°/' sequence
identity (more preferably, at least 75'%> identity; most preferably at least
90 i,> or 95%
2 0 identity) with that disclosed protein, where seduence identity is
determined by comparing
the amino acid sequences of the proteins when aligned so as to maximize
overlap and
identity while minimizing; sequence gaps. Also included in the present
invention are
proteins and protein fragments that contain a segment preferably comprising 8
or more
(more preferably 20 or more, most preferably 30 or more) contiguous amino
acids that
2 5 shares at least 75°/a sequence identity (more preferably, at least
85°/~ identity; most
preferably at least 95°/a identity) with any suet, segment of any of
the disclosed proteins.
Species homologs of the disclosed polvnucleotides and proteins are also
provided
by the present invention. As used herein, a "species homologue" is a protein
or
polynucleotide with a different species of origin from that of a given protein
or
3 0 polynucleotide, but with significant sequence similarity to the Given
protein or
polynucleotide, as determined by those of skill in the art. Species homologs
may be
isolated and identified by making suitable prolr~es or primers from the
sequences provided
herein and screening a suitable nucleic acid source from the desired species.
29
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
The invention also encompasses allelic variants of the disclosed
polvnucleotides
or proteins; that is, naturally-occurring alternative forms of the isolated
polynucleotide
which also encode proteins which are identical, homologous, or related to that
encoded
by the polynucleotides .
The invention also includes polynucleotides with sequences complementary to
those of the polynucleotides disclosed herein.
The present invention also includes polynucleotides capable of hybridizing
under reduced stringency conditions, more preferably stringent conditions, and
most
preferably highly stringent conditions, to polynucleotides described herein.
Examples of
stringency conditions are shown in the table below: highly stringent
conditions are those
that are at least as stringent as, for example, conditions A-F; stringent
conditions are at
least as stringent as, for example, conditions G-L; and reduced stringency
conditions are
at least as stringent as, for example, conditions M-R.
CA 02270873 1999-OS-12
WO 98/21332 PCT/LTS97/20740
StringencyPolvnucleotideHybridHybridization TemperatureWash
and
ConditionHybrid LengthBuffer' Temperature
(bpl' and Buffed
DNA:DNA _50 65-C;IxSSC-or- 65'C;0.3xSSC
-l2 C; lxSSC, 50'io
formamide
B DNA:DNA <a0 T~*; Ix:SSC Tr*; IxSSC
C DNA:RNA _ ~0 fi7~C; lxSSC -or- ti7 C;
0.3xSSC
-15 C; IxSSC, 50/~
formamide
D DNA:RNA () T""; IxSSC T"*; lxSSC
E RNA:RNA = ~0 70 C; lxSSC -or- 70'C; 0.3xSSC
50'C; lxSSC, 50%
formamide
F RNA:RNA < 50 T~"; lxSSC T~*; lxSSC
G DNA:DNA 50 65-C; 4xSSC -or- 65C; IxSSC
-k~ C; =IxSSC, 50t,
formamide
H DNA:DNA ;~i) T"'; -IxSSC I "*; -IxSSC_
1 DNA:RNA ~D F,7 C; -IxSSC -or- F,7 C;
IxSSC
~~ C; -IxSSC, 50%
formamide
] DNA:RNA <50 T,*; 4xSSC: T,*; -IxSSC
K RNA:RNA 50 70C; 4xSSC -or- f,7-C;
lxSSC
50-C; =4xSSC, 50'%
formamide
f, RNA:RNA <,0 T, *; 2xSSC T, *; ?xSSC
M DNA:DNA 3() 50-C; 4xSSC -or- 50 C; 2xSSC
-IO-C; 6xSSC, 50'%,
formamidc
\i DNA:DNA 0 T,.*; 6>;SSC T~*; 6xSSC
C7 DNA:RNA ~0 ~C; 4xSSC -or- 5~-C; 2xSSC
~2-C; 6xSSC, 50'~~
formamide
I' DNA:RNA <50 T,.*; 6xSSC T,.*; 6xSSC
Q RNA:RNA 30 60- C; -IxSSC -or- 60' C;
2xSSC
~45 C; 6xSSC, 50/~
formamide
2 R RNA:RNA <50 Tu"; 4x.SSC T"*; 4xSSC
0
~: The hybrid length is that anticipated for the hybridized regions) of the
hybridizing polynudeotides. When
hybridizing a poivnucleofide to a target polvnudeotide of unknown sequence,
the hybrid length is assumed
to be that of the hybridizing polynucleotide. When polynucleotides of known
sequence are hybridized, the
2 5 hybrid length can be determined by aligning the sequences of the
poivnucleotides and identifying the region
or regions of optimal sequence cornplementaritv.
': SSPE (lxSSPE is O.ISM NaCI, lOmM \aH-_,PO,, aad 1.~5mNl EDTA, pl-I 7.-1)
can be substituted for SSC
(IxSSC is 0.15M NaCI and l5mM sodium citrate) in the hybridization and wash
buffers; washes are
performed for 15 minutes after hybridization is complete.
3 0 *Tt, - T,~: The hybridization temperature for hybrids anticipated to be
less than ~0 base pairs in length should
be 5-10-C less than the melting temperature (T",) of the hybrid, where Tm is
determined according to the
following equations. For hybrids less than 18 base pairs in length, T",(~C) _
~(# of ;a + T bases) + 4(# of G +
C bases). For hybrids between 18 and 49 base pairs in length, T",(=C) = 81.5 +
16.6(log",[Na']) + 0.41('%>G+C)
(600/N), where N is the number of bases in the hybrid, a nd [Na'] is the
concentration of sodium ions in the
3 5 hybridization buffer ([Na'] for IxSSC = O.I6~ M).
31
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
Additional examples of stringency conditions for polynucleotide hybridization
are
provided in Sambrook, J., E.F. Fritsch, and T. Maniatis, 1989, Molecular
Cloning: A
Laboratory lVlnrturtl, Cold Spring Harbor Laboratory Press, Cold Spring
Harbor, NY,
chapters 9 and 11, and Current Protocols in Moleculnr l3iolo'~ry, l995, F.M.
Ausubel et al., eds.,
John Wilev & Sons, Inc., sections 2.10 and 6.3-6.4, incorporated herein by
reference.
Preferably, each such hybridizing polynucleotide has a length that is at least
25%(more preferably at least SO°/~, and most preferably at least 75%)
of the length of the
polynucleotide of the present invention to which it hybridizes, and has at
least 60°/~
sequence identity (more preferably, at least 75'%~ identity; most preferably
at least 90'% or
95% identity) with the polvnucleotide of the present invention to which it
hybridizes,
where sequence identity is determined by comparing the sequences of the
hybridizing
polynucleotides when aligned so as to maximize overlap and idenHtv~ while
minimizing
Sequence gaps.
The isolated polvnucleotide of the invention may be operably linked to an
expression control seduence such as the pMT2 or pED expression vectors
disclosed in
Kaufman et nl., Nucleic Acids Res. 19, 4485-4490 (199l}, in order to produce
the protein
recombinantlv. Many suitable expression control sequences are known in the
art. General
methods of expressing recombinant proteins are also known and are exemplified
in R.
Kaufman, Methods in Enzymology 187, 537-566 (1990). As defined herein
"operably
2 0 linked" means that the isolated polvnucleotide of the invention and an
expression control
sequence are situated within a vector or cell in such a way that the protein
is expressed
by a host cell which has been transformed (transfected) with the ligated
polvnucleotide/expression control sequence.
A number of types of cells may act as suitable host cells for expression of
the
2 5 protein. Mammalian host cells include, for example, monkey COS cells,
Chinese I-lamster
Ovary (CHO) cells, human kidney 293 cells, human epidermal A43I cells, human
Co1o205
cells, 3T3 cells, CV-1 cells, other transformed primate cell lines, normal
diploid cells, cell
strains derived from in vitro culture of primary tissue, primary explants,
HeLa cells,
mouse L cells, BHK, I-IL-60, U937, HaK or lurkat cells.
3 0 Alternatively, it may be possible to produce the protein in lower
eukaryotes such
as yeast or in prokaryotes such as bacteria. Potentially suitable yeast
strains include
Saccharotnaces cerez~isiae, Schizosrtccltarotrtyces pombe, Klmverornuces
strains, Cartdida, or any
yeast strain capable of expressing heterologous proteins. Potentially suitable
bacterial
strains include Escherichia coli, Bacillus subtilis, Salmonella typhimurium,
or any bacterial
J7
CA 02270873 1999-OS-12
WD 98/21332 PCT/US97/20740
strain capable of expressing heterologous proteins. If the protein is made in
yeast or
bacteria, it may be necessary to modify the protein produced therein, for
example by
phosphorvlation or glycosvlation of the appropriate sites, in order to obtain
the functional
protein. Such covalent attachments rnav be accomplished using known chemical
or
enzymatic methods.
The protein may also be produced by operable linking the isolated
polynucleotide
of the invention to suitable control sequences :in one or more insect
expression vectors,
and employing an insect expression system. Materials and methods for
baculovirusi insect cell expression systems are commercially available in kit
form from,
c.~~., Invitro gen, San Diego, California, U.S.A. (the MaxBac ~~ kit), and
such methods are
well known in the art, as described in Summers ;md Smith, Texas Agricultural
Experiment
Station Bulletin No. 1 S55 (19?i7), incorporated herein by reference. As used
herein, an
insect cell capable of expressing a polvn,.~cleotide of the present invention
is
"transformed."
i 5 The protein of the invention may be prepared by culturing transformed host
cells
under culture conditicms suitable to express the recombinant protein. The
resulting
expressed protein may then be purified from s~,zch culture (i.e., from culture
medium or
cell extracts] using known purification processes, such as gel filtration and
ion exchange
chromatography. The purification of the protein may also include an affinity
column
2 0 containing agents which will bind to the protein; one or more column steps
over such
affinity resins as concanavalin A-agarose, heparin-toyopearl ~< or Cibacrom
blue 3GA
SepharoseC'; one or more steps involving hydrophobic interaction
chromatography using
such resins as phenyl ether, butyl ether, or propyl ether; or immunoaffinity
chromatography.
2 5 Alternatively, the protein of the invention may also be expressed in a
form which
will facilitate purification. For example, it may be expressed as a fusion
protein, such as
those of maltose binding protein (MBP), glutathione-S-transferase (GST) or
thioredoxin
(TRX). Kits for expression and purification of such fusion proteins are
commercially
available from New England BioLab (Beverly, MA), Pharmacia (Piscataway, NJj
and
3 0 InV itrogen, respectively. The protein can also be tagged v,~ith an
epitope and
subsequently purified by using a specific antilr~ody directed to such epitope.
One such
epitope ("Flag") is commercially available from Kodak (New Haven, CT).
Finally, one or more reverse-phase high performance liquid chromatography (RP-
HPLC) steps employing hydrophobic RP-HPL.C media, e.g., silica gel having
pendant
33
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
methyl or other aliphatic groups, can be employed to further purify the
protein. Some or
a11 of the foregoing purification steps, in various combinations, can also be
employed to
provide a substantially homogeneous isolated recombinant protein. The protein
thus
purified is substantially free of other mammalian proteins and is defined in
accordance
with the present invention as an "isolated protein."
The protein of the invention may also be expressed as a product of transgenic
animals, e.g., as a component of the milk of transgenic cows, goats, pigs, or
sheep which
are characterized by somatic or germ cells containing a nucleotide sequence
encoding the
protein.
The protein may also be produced by known conventional chemical synthesis.
Methods for constructing the proteins of the present invention by synthetic
means are
known to those skilled in the art. The synthetically-constructed protein
sequences, by
virtue of sharing primary, secondary or tertiary structural and/or
conformational
characteristics ~~ith proteins may possess biological properties in common
therewith,
including protein activity. Thus, they may be employed as biologically active
or
immunological substitutes for natural, purified proteins in screening of
therapeutic
compounds and in immunological processes for the development of antibodies.
The proteins provided herein also include proteins characterized by amino acid
sequences similar to those of purified proteins but into which modification
are naturally
2 0 provided or deliberately enl;ineered. For example, modifications in the
peptide or DNA
sequences can be made by those skilled in the art using known techniques.
Modifications
of interest in the protein sequences may include the alteration, substitution,
replacement,
insertion or deletion of a selected amino acid residue in the coding sequence.
For
example, one or more of the cysteine residues may be deleted or replaced with
another
2 5 amino acid to alter the conformation of the molecule. Techniques for such
alteration,
substitution, replacement, insertion or deletion are well known to those
skilled in the art
(see, e.g., U.S. Patent No. 4,518,584). Preferably, such alteration,
substitution) replacement,
insertion or deletion retains the desired activity of the protein.
Other fragments and derivatives of the sequences of proteins which would be
3 0 expected to retain protein activity in whole or in part and may thus be
useful for screening
or other immunological methodologies may also be easily made by those skilled
in the art
given the disclosures herein. Such modifications are believed to be
encompassed by the
present invention.
34
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
USES AND BIOLOGICAL ACTIVITY
The polynucleotides and proteins of the present invention are expected to
exhibit
one or more of the uses or biological activities (including those associated
with assays
cited herein) identified below. Uses or activities described for proteins of
the present
S invention may be provided by administration o:~ use c?f such proteins or by
admirustraHon
or use of polvnucleotides encoding such proteins (such as, for example, in
gene therapies
or vectors suitable for introduction of DNA).
Kesearch Uses and Utilities
The polvnucleotides provided by the present invention can be used by the
research
community for various purposes. The polvnucleotides can be used to express
recombinant protein for analysis, characteriz,ztion or therapeutic use; as
markers for
tissues in which the corresponding protein is preferentially expressed (either
constitutivelv or at a particular stage of tissue differentiation or
development or in disease
states); as molecular weight markers on Southern gels; as chromosome markers
or tags
(when labeled) to identify chromosomes or to map related gene positions; to
compare
with endogenous DNA sequences in patients to identify potential genetic
disorders; as
probes to hybridize and thus discover novel, related DNA sequences; as a
scaurce of
information to derive PCK primers for genetic fingerprinting; as a probe to
"subtract-out"
2 0 known sequences in the process of discovering other novel polynucleotides;
for selecting
and making oligomers for attachment to a "gene chip" or other support,
including for
examination of expression patterns; to raise anti-protein antibodies using DNA
immunization techniques; and as an antigen to raise anti-DNA antibodies or
elicit another
immune response. Where the polynucleotide encodes a protein which binds or
potentially
2 5 binds to another protein (such as, for example, in a receptor-ligand
interaction), the
polynucleotide can also be used in interaction trap assays (such as, for
example, that
described in Gvuris et al., Cell 75:791-803 (1993)) tc»dentify polynucleotides
encoding the
other protein with which binding occurs or to identify inhibitors of the
binding
interaction.
3 0 The proteins provided by the present invention can similarly be used in
assay to
determine biological activity, including in a panel of multiple proteins for
high-
throughput screening; to raise antibodies or to elicit another immune
response; as a
reagent (including the labeled reagent) in assays designed to quantitatively
determine
levels of the protein (or its receptor) in biological fluids; as markers for
tissues in which
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97120740
the corresponding protein is preferentially expressed (either constitutively
or at a
particular stage of tissue differentiation or development or in a disease
state); and, of
course, to isolate correlative receptors or ligands. Where the protein binds
or potentially
binds to another protein (such as, for example, in a receptor-ligand
interaction), the
protein can be used to identify the other protein with which binding occurs or
to identify
inhibitors of the binding interaction. I-'roteins involved in these binding
interactions can
also be used to screen for peptide or small molecule inhibitors or agonists of
the binding
interaction.
Anv or all of these research utilities are capable of being developed into
reagent
grade or kit format for commercialization as research products.
Methods for performing the uses listed above are well known to those skilled
in
the art. References disclosing such methods include without limitation
"Molecular
Cloning: A Laboratory Manual", 2d ed., Cold Spring Harbor Laboratory Press,
Sambrook,
J., E.F. Fritsch and T. Maniatis eds., 1989, and "Methods In Enzvmolo gy:
Guide to
Molecular Cloning Techniques", Academic Press, Bergen S.L. and A.R. Kimmel
eds., 1987.
Nutritional Uses
Polvnucleotides and proteins of the present invention can also be used as
nutritional sources or supplements. Such uses include without limitation use
as a protein
2 0 or amino acid supplement, use as a carbon source, use as a nitrogen source
and use as a
source of carbohydrate. In such cases the protein or polvnucleotide of the
invention can
be added to the feed of a particular organism or can be administered as a
separate solid
or liquid preparation, such as in the form of powder, pills, solutions,
suspensions or
capsules. In the case of microorganisms, the protein or polynucleotide of the
invention
2 5 can be added to the medium in or on which the microorganism is cultured.
Cytokine and Cell I'roliferation/Differentiation Activity
A protein of the present invention may exhibit cytokine, cell proliferation
(either
inducing or inhibiting) or cell differentiation (either inducing or
inhibiting) activity or may
3 0 induce production of other cvtokines in certain cell populations. Many
protein factors
discovered to date, including all known cytokines, have exhibited activity in
one or more
factor dependent cell proliferation assays, and hence the assays serve as a
convenient
confirmation of cytokine activity. The activity of a protein of the present
invention is
evidenced by any one of a number of routine factor dependent cell
proliferation assays
36
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
for cell lines including, without limitation, ~~2D, DA2, DA1G, T10, B9, B9/11,
BaF3,
MC9/G, M+ (preB M+), 2E8, RBS, DA1, l23, T1165, I-IT2, CTLL2, TF-1, Mo7e and
CMK.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for T-cell or thymocyte proliferation include without limitation those
described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W Strober, Pub. Creme Publishing Associates and Wiley-
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
7 , Immunologic studies in Humans); Takai et al., J. Immunol. l37:3494-3500,
1986;
Bertagnolli et al., J. Immunol. l45:1706-l 712, l990; Bertagnolli et al.,
Cellular Immunology
133:327-3-11, 1991; Bertagnolli, et al., J. Immun.ol. 149:3778-3783, 1992;
Bowman et al., J.
Immunol. l52: 1756-176l, 1994.
Assays for cvtokine production and/or proliferation of spleen cells, lymph
node
cells or thvmocytes include, without limitation, those described in:
I'olyclonal T cell
stimulation, Kruisbeek, A.M. and Shevach) E.M. In Current Protocols in
Irnmunolo~n/. J.E.e.a.
Coligan eds. Vol 1 pp. 3.12.1-3.l2.14, John Wiley and Sons, Toronto. 1994; and
Measurement of mouse and human Interferon ~r, Schreiber, R.D. In Current
Protocols in
Imnucrrnlo~~. J.E.e.a. Coligan eds. Vol 1 pp. 6.8.1-6.8.8, John Wiley and
Sons, Toronto. 1994.
2 0 Assays for proliferation and differentiation of hematopoietic and
lymphopoietic
cells include, without limitation, those described in: Measurement of Human
and Murine
Interleukin 2 and Interleukin 4, Bottomly, K., Davis, L.S. and Lipsky, I'.E.
In Current
Protocols in Immtmolo~~y. J.E.e.a. Coligan eds. Vol 1 pp. 6.3.1-6.3.12, John
Wiley and Sons,
Toronto. 1991; deVries et al., J. Exp. Med. 17 3:1205-l211, 1991; Moreau et
al., Nature
2 5 336:690-692) 1988; Greenberger et al., I'roc. Natl. Acad. Sci. U.S.A.
80:2931-2938, l983;
Measurement of mouse and human interleuk.in 6 - Nordan, R. In Current
Protocols in
Immunology. J.E.e.a. Coligan eds. VoI 1 pp. 6.6.1-6.6.5, John Wiley and Sons,
Toronto. 199l;
Smith et al., I'roc. Natl. Acad. Sci. U.S.A. 83:1857-1861, 1986; Measurement
of human
Interleukin 11 - Bennett, F., Giannotti, J., Clark, ;~.C. and Turner, K. J. In
Current Protocols
3 0 in Immunology/. J.E.e.a. Coligan eds. Vol 1 pp. 6.l5.1 John Wiley and
Sons, 'Toronto. 1991;
Measurement of mouse and human Interleukin. 9 - Ciarletta, A., Giannotti, J.,
Clark, S.C.
and Turner, K.J. In Current Protocols in Immunoio~y. J.E.e.a. Coligan eds. Vol
1 pp. 6.13.1,
John Wiley and Sons, Toronto. 199l.
37
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
Assays for T-cell clone responses to antigens (which will identify, among
others,
proteins that affect AI'C-T cell interactions as well as direct T-cell effects
by measuring
proliferation and cytokine production) include, without limitation, those
described in:
Current Protocols in ImmunologS~, Ed by J. E. Coligan, A.M. Kruisbeek, D.H.
Margulies,
E.M. Sheyach, W Strober, Pub. Greene Publishing Associates and Wilev-
Interscience
(Chapter 3, In Vitro assays for Mouse Lymphocyte Function; Chapter 6,
Cvtokines and
their cellular receptors; Chapter 7, Immunologic studies in Humans);
Weinberger et al.,
I'roc. Natl. Acad. Sci. USA i7:6091-6()95, l980; Weinberger et al., Eur. J.
Immun.
11:405-411, 1981; Takai et al., J. Immunol. 137:3494-3500, 1986; Takai et al.,
J. Immunol.
140:508-512, 1988.
Immune Stimulating or Sttppressin~ Activity
A protein of the present invention may also exhibit immune stimulating or
immune suppressing activity, including without limitation the activities for
which assays
are described herein. A protein may be useful in the treatment of various
immune
deficiencies and disorders (including severe combined immunodeficiency
(SCID)), e.g.,
in regulating (up or down) growth and proliferation of T and/or B lymphocytes,
as well
as effecting the cvtolvtic activity of NK cells and other cell populations.
These immune
deficiencies may be genetic or be caused by viral (e.g., HIV) as well as
bacterial or fungal
2 0 infections, or may result from autoimmune disorders. More specifically,
infectious
diseases causes by viral, bacterial, fungal or other infection may be
treatable using a
protein of the present invention, including infections by HIV, hepatitis
viruses,
herpesviruses, mycobacteria, Leishmania spp., malaria spp. and various fungal
infections
such as candidiasis. Of course, in this regard, a protein of the present
invention may also
2 5 be useful where a boost to the immune system generally may be desirable,
i.e., in the
treatment of cancer.
Autoimmune disorders which may be treated using a protein of the present
invention include, for example, connective tissue disease, multiple sclerosis,
systemic
lupus erythematosus, rheumatoid arthritis, autoimmune pulmonary inflammation,
3 0 Guillain-Barre syndrome, autoimmune thvroiditis, insulin dependent
diabetes mellitis,
myasthenia gravis, graft-versus-host disease and autoimmune inflammatory eye
disease.
Such a protein of the present invention may also to be useful in the treatment
of allergic
reactions and conditions, such as asthma (particularly allergic asthma) or
other respiratory
problems. Other conditions, in v,~hich immune suppression is desired
(including, for
38
CA 02270873 1999-OS-12
WO 98/21332 PCT/US9?/20740
example, organ transplantation), may also be treatable using a protein of the
present
invention.
Using the proteins of the inv ention it m ay also be possible to immune
responses,
in a number of ways. Down regulation may be in the form of inhibiting or
blocking an
immune response already in progress or ma~~ involve preventing the induction
of an
immune response. The functions of activated 't cells may be inhibited by
suppressing T
cell responses or by inducing specific tolerance in T cells, or both.
Immunosuppression
of T cell responses is generally an active, non-antigen-specific, process
which requires
continuous exposure of the T cells to the suppressive agent. Tolerance, which
involves
inducing non-responsiveness or anergy in T cells, is distinguishable from
immunosuppression in that it is generally antigen-specific and persists after
exposure to
the tolerizing agent has ceased, Operationally, tolerance can be demonstrated
by the lack
of a T cell response upon recxposure to specific antigen in the absence of the
tolerizing
agent.
Down regulating or preventing one or more antigen functions (including without
limitation B lymphocyte antigen functions (such as , for example, B7)), e.~.,
preventing
high level Ivmphokine synthesis by activated T cells, will be useful in
situations of tissue,
skin and organ transplantation and in graft-versus-host disease (GVHD). For
example,
blockage of T cell function should result in reduced tissue destruction in
tissue
2 0 transplantation. Typically, in tissue transplants, rejection of the
transplant is initiated
through its recognition as foreign by T cells, followed by an immune reaction
that destroys
the transplant. The administration of a molecule which inhibits or blocks
interaction of
a B7 lymphocyte antigen with its natural ligand(s) on immune cells (such as a
soluble,
monomeric form of a peptide having B7-2 activity alone or in conjunction with
a
2 5 monomeric form of a peptide having an activity of another B lymphocyte
antigen (e. ~~., B7-
1, B7-3) or blocking antibody), prior to transplantation can lead to the
binding of the
molecule to the natural ligand(s) on the immune cells without transmitting the
corresponding costimulatory signal. Blockin,5 B lv mphocyte antigen function
in this
matter prevents cytokine synthesis by immune cells, such as T cells, and thus
acts as an
3 0 immunosuppressant. Moreover, the lack of costimulation may also be
sufficient to
anergize the T cells, thereby inducing tolerance in a subject. Induction of
long-term
tolerance by B lymphocyte antigen-blocking reagents may avoid the necessity of
repeated
administration of these blocking reagents. To achieve sufficient
immunosuppression or
39
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97l20740
tolerance in a subject, it may also be necessary to block the function of a
combination of
B lymphocyte antigens.
The efficacy of particular blocking reagents in preventing organ transplant
rejection or GVHD can be assessed using animal models that are predictive of
efficacy in
humans. Examples of appropriate systems which can be used include allogeneic
cardiac
grafts in rats and xenogeneic pancreatic islet cell grafts in mice, both of
which have been
used to examine the immunosuppressive effects of CTLA4Ig fusion proteins irz
vivo as
described in Lenschovv et al., Science 257:71i9-792 (l992) and Turka et nl.,
Proc. Natl. Acad.
Sci USA, 89:11102-11105 (1992). In addition, murine models of GVHD (see Paul
ed.,
Fundamental Immunology, Raven Press, New York, 1989, pp. 846-847) can be used
to
determine the effect of blocking B lymphocyte antigen function its vivo on the
development
of that disease.
Blocking antigen function may also be therapeutically useful for treating
autoimmune diseases. Many autoimmune disorders are the result of inappropriate
activation of T cells that are reactive against self Hssue and which promote
the production
of cytokines and autoantibodies involved in the pathology of the diseases.
Preventing the
activation of autoreactive T cells may reduce or eliminate disease symptoms.
Administration of reagents which block costimulation of T cells by disrupting
receptor:ligand interactions of B lymphocyte antigens can be used to inhibit T
cell
2 0 activation and prevent production of autoantibodies or T cell-derived
cytokines which
may be involved in the disease process. Additionally, blocking reagents may
induce
antigen-specific tolerance of autoreactive T cells which could lead to long-
term relief from
the disease. The efficacy of blocking reagents in preventing or alleviating
autoimmune
disorders can be determined using a number of well-characterized animal models
of
2 S human autoimmune diseases. Examples include murine experimental autoimmune
encephalitis, systemic lupus erythmatosis in MRL/!pr/Ipr mice or NZB hybrid
mice,
murine autoimmune collagen arthritis, diabetes mellitus in NOD mice and BB
rats, and
murine experimental myasthenia gravis (see Paul ed., Fundamental Immunology,
Raven
Press, New York, l989, pp. 840-856).
3 0 Upregulation of an antigen function (preferably a B lymphocyte antigen
function),
as a means of up regulating immune responses, may also be useful in therapy.
Upregulation of immune responses may be in the form of enhancing an existing
immune
response or eliciting an initial immune response. For ex<lmple, enhancing an
immune
response through stimulating B lymphocyte antigen function may be useful in
cases of
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
viral infection. In addition, systemic viral diseases such as influenza, the
common cold,
and encephalitis might be alleviated by the administration of stimulatory
forms of B
lymphocyte antigens systemically.
Alternatively, anti-viral immune responses may be enhanced in an infected
patient
by removing T cells from the patient, costimulating the T cells in vitro ~~ith
viral antigen-
pulsed APCs either expressing a peptide of the present invention or together
with a
stimulatory form of a soluble peptide of the present invention and
reintroducing the in
vitro activated T cells into the patient. Another method of enhancing anti-
viral immune
responses would be to isolate infected cells from a patient, transfect them
with a nucleic
acid encoding a protein of the present invention as described herein such that
the cells
express all or a portion of the protein on thei r surface, and reintroduce the
transfected
cells into the patient. The infected cells would now be capable of delivering
a
costimulatorv signal to, and thereby activate, I cells i~t viva.
In another application, up regulatic;n or enhancement of antigen function
(preferably B lymphocyte antigen function) may be useful in the induction of
tumor
immunity. Tumor cells (e.~>., sarcoma, melanoma, lymphoma, leukemia,
neuroblastoma,
carcinoma) transfected with a nucleic acid encoding at least one peptide of
the present
invention can be administered to a subject to overcome tumor-specific
tolerance in the
subject. If desired, the tumor cell can be transfected to express a
combination of peptides.
2 0 For example, tumor cells obtained from <3 patient can be transfected es
viva with an
expression vector directing the expression of a peptide having B7-2-like
activity alone, or
in conjunction with a peptide having B7-I-lil<;e activity and/or B7-3-like
activity. The
transfected tumor cells are returned to the patient to result in expression of
the peptides
on the surface of the transfected cell. Alternatively, gene therapy techniques
can be used
2 5 to target a tumor cell for transfection in viva.
The presence of the peptide of the present invention having the activity of a
B
lymphocyte antigens) on the surface of l:he tumor cell provides the necessary
costimulation signal to T cells to induce a T cell mediated immune response
against the
transfected tumor cells. In addition, tumor cells which lack MHC class I or
MHC class II
3 0 molecules, or which fail to reexpress sufficient amounts of MHC class I or
MHC class II
molecules, can be transfectf_d with nucleic z~cid encoding all or a portion of
(e.g., a
cvtoplasmic-domain truncated portion) of an MHC class I a chain protein and
(3,
microglobulin protein or an MHC class II a chain protein and an MHC class II
(3 chain
protein to thereby express MHC class I or N1HC class II proteins on the cell
surface.
41
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Expression of the appropriate class I or class II MHC in conjunction with a
peptide having
the activity of a B lymphocyte antigen (c~.~~.) B7-1, B7-2, B7-3) induces a T
cell mediated
immune response against the transfected tumor cell. Optionally, a gene
encoding an
antisense construct which blocks expression of an MHC class II associated
protein, such
as the invariant chain, can also be cotransfected with a DNA encoding a
peptide having
the activity of a B lymphocyte antigen to promote presentation of tumor
associated
antigens and induce tumor specific immunity. Thus, the induction of a T cell
mediated
immune response in a human subject may be sufficient to overcome tumor-
specific
tolerance in the subject.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Suitable assays for thvmocvte or splenocvte cytotoxicity include, without
limitation, those described in: Current Protocols in Immunology, Ed by J. E.
Coligan, A.M.
Kruisbeek, D.H. Margulies) E.M. Shevach, W Strober, Pub. Greene Publishing
Associates
and Wilev-Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte
Function 3.1-
3.l9; Chapter 7, Immunologic studies in Humans); Herrmann et al., Proc. Natl.
Acad. Sci.
USA 78:2488-2-192, 1981; Herrmann et al.) J. Immunol. 128:1968-1974, 1982;
Handa et al.,
J. Immunol. 135:1564-1572, 1985; 'I-akai et al., J. Immunol. 137:3494-3500,
1986; Takai et al.,
J. Immunol. 1-I0:508-512, 1988; Herrmann et al., I'roc. Natl. Acad. Sci. USA
78:2488-2492,
2 0 1981; Herrmann et al., J. Immunol. 128:1968-1974, 1982; Handa et al., J.
Immunol.
135:l564-1572, 1985; Takai et al., J. Immunol. 137:3494-3500, 1986; Bowmanet
al., J.
Virology 61:1992-1998; Takai et al., J. Immunol. 140:S08-512, 1988;
Bertagnolli et al.,
Cellular Immunology 133:327-34l, 1991; Brown et al., J. Immunol. 1S3:3079-
3092, 1994.
Assays for h-cell-dependent immunoglobulin responses and isotype switching
2 5 (which will identify, among others, proteins that modulate T'-cell
dependent antibody
responses and that affect Th1 /Th2 profiles) include, without limitation,
those described
in: Maliszewski, J. Immunol. l44:3028-3033, 1990; and Assays for B cell
function: In vitro
antibody production, Mond, J.J. and Brunswick, M. In Current Protocols in
Imrnunolo~y.
J.E.e.a. Coligan eds. Vol 1 pp. 3.8.1-3.8.16, John Wiley and Sons, Toronto.
1994.
3 0 Mixed lymphocyte reaction (MLIZ) assays (which will identify, among
others,
proteins that generate predominantly Th1 and CTL responses) include, without
limitation,
those described in: Current Protocols in Immunology, Ed by J. E. Coligan, A.M.
Kruisbeek,
D.H. Margulies, E.M. Shevach, W Strober, Pub. C;reene Publishing Associates
and Wiley-
Interscience (Chapter 3, In Vitro assays for Mouse Lymphocyte Function 3.1-
3.19; Chapter
42
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
7, Immunologic studies in Humans); Takai et ~~1., J. Immunol. 137:3494-3500,
1986; Takai
et al., J. Immunol. 140:508-5l2, 1988; Bertagnolli et al., J. Immunol.
149:3778-3783, 1992.
Dendritic cell-dependent assays (which will identify, among others, proteins
expressed by dendritic cells that activate naive T-cells) include, without
limitation, those
described in: Guery et al., j. Immunol. 134:536-Q44, 1995; Inaba et al.,
Journal of
Experimental Medicine 173:549-559, 1991; Macatonia et al., Journal of
Immunology
154:5071-5079, l995; I'orgador et al., Journal of Experimental Medicine
182:255-260, 1995;
Nair et al., Journal of Virology 67:4062-4069, 1993; Huang et al., Science
264:961-965,
l994; Macatonia et al., Journal of Experimental Medicine 169:1255-l264, 1989;
Bhardwaj
et al., Journal of Clinical Investigation 94:7!a7-807) 1994; and Inaba et al.,
Tournal of
Experimental Medicine 172:631-640, 1990.
Assays for lymphocyte survival/apo~~tosis (which will identify, among others,
proteins that prevent apoptosis after superantigen induction and proteins that
regulate
lymphocyte homeostasis) include, without limitation, those described in:
Darzynkiewicz
et al., Cvtometry 13:795-808, 1992; Gorczvca et al., Leukemia 7:659-670, 1993;
Gorczvca et
al., Cancer Research 5 3:1945-l951, 1993; Itoh et ai., Cell 66:233-243, 1991;
Zacharchuk,
Journal of Immunology l45:4037-4045, 1990; .Zamai et al., Cytometry 14:891-
897, 1993;
Gorczvca et al., International Journal of Oncology 1:639-648, 1992.
Assays for proteins that influence early steps of 'r-cell commitment and
2 0 development include, without limitation, those described in: Antica et
al., Blood
84:111-1l7, 1994; Fine et al., Cellular Immunology 155:111-122) I994; Galy et
al., Blood
8S:2770-2778, 1995; Toki et aL, I'roc. Nat. Acad Sci. USA 88:7548-7551, 1991.
Hematopoiesis Re rug latin~ Activity
2 5 A protein of the present invention may be useful in regulation of
hematopoiesis
and, consequently, in the treatment of myeloid or lymphoid cell deficiencies.
Even
marginal biological activity in support of colony forming cells or of factor-
dependent cell
lines indicates involvement in regulating hematopoiesis, e.g. in supporting
the growth and
proliferation of erythroid progenitor cells alone or in combination with other
cytokines,
3 0 thereby indicating utility, for example, in treating various anemias or
for use in
conjunction with irradiation/chemotherapy ':o stimulate the production of
ervthroid
precursors and /or erythroid cells; in supporting the growth and proliferation
of myeloid
cells such as granulocytes and monocvtes/macrophages (i.e., traditional CSF
activity)
useful, for example, in conjunction with chemotherapy to prevent or treat
consequent
43
CA 02270873 1999-OS-12
WO 98I21332 PCT/CTS97120740
mvelo-suppression; in supporting the growth and proliferation of
megakarvocvtes and
consequently of platelets thereby allowing prevention or treatment of various
platelet
disorders such as thrombocvtopenia, and generally for use in place of or
complimentary
to platelet transfusions; and/or in supporting the growth and proliferation of
hematopoietic stem cells which are capable of maturing to any and a11 of the
above-
mentioned hematopoietic cells and therefore find therapeutic utilih~ in
various stem cell
disorders (such as those usually treated with transplantation, including,
without
limitation, aplastic anemia and paroxysmal nocturnal hemoglobinuria)) as well
as in
repopulating the stem cell compartment post irradiation/chemotherapy, either
in-vivo or
e_r-vivo {i.e., in conjunction with bone marrow transplantation or with
peripheral
progenitor cell transplantation (homologous or heterologous)) as normal cells
or
genetically manipulated for gene therapy.
The activity of a protein of the invention may) among other means, be measured
by the following methods:
Suitable assays for proliferation and differentiation of various hematopoietic
lines
are cited above.
Assays for embryonic stem cell differentiation (which will identify, among
others,
proteins that influence embryonic differentiation hematopoiesis) include,
without
limitation, those described in: Johansson et al. Cellular Biology 15:141-151,
1995; Keller et
2 0 al., Molecular and Cellular Biology 13:473-486, 1993; McClanahan et al.,
Blood
81:2903-2915, 1993.
Assays for stem cell survival and differentiation (which will identify, among
others, proteins that regulate lvmpho-hematopoiesis) include, without
limitation, those
described in: Methvlcellulose colony forming assays, Freshney, M.G. In Culture
of
2 5 Hematopoietic Cells. R.I. Freshnev, et al. eds. Vol pp. 265-268) Wiley-
Liss, Inc., New York,
NY. 1994; Hirayama et al.) Proc. Natl. Acad. Sci. USA 89:5907-5911, 1992;
Primitive
hematopoietic colony forming cells with high proliferative potential, McNiece,
LK. and
Briddell, R.A. In Culture of Hematopoietic Cells. R.I. Freshnev, et aI. eds.
Vol pp. 23-39,
Wilev-Liss, Inc., New York, NY. 1994; Neben et aL, Experimental Hematology
22:353-359,
3 0 1994; Cobblestone area forming cell assay) Ploemacher, R.E. In Culture of
Hematopoietic
Cells. R.I. Freshnev, et nl. eds. Vol pp. 1-21, Wilev-Liss) Inc.., New York,
NY. 1994; Long
term bone marrow cultures in the presence of stromal cells, Spooncer) E.,
Dexter, M. and
Allen, T. In Culture of Hematopoietic CeIIs. R.I. Freshney, et al. eds. Vol
pp. 163-179,
Wiley-Liss, Inc., New York, NY. 1994; Long term culture initiating cell assay,
Sutherland,
44
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
H.J. In Culture of Hematnpoietic Cells. R.I. Freshney, et nl. eds. Vol pp. 139-
1C2, Wiley-Liss,
Inc., New York, NY. 1994.
Tissue Growth Activity
A protein of the present invention also rnay have utility in compositions used
for
bone) cartilage, tendon, ligament and / or nerve tlSSUe growth or
regeneration, as well as
for wound healing and tissue repair and replacement, and in the treatment of
burns,
incisions and ulcers.
A protein of the present invention, whi~~h induces cartilage and/or bone
growth
in circumstances where bone is not normally formed, has application in the
healing of
bone fractures and cartilage damage or defects in humans and other animals.
Such a
preparation employing a protein of the invention may have prophylactic use in
closed as
well as open fracture reduction and also in the improved fixation of
artificial joints. Df°
novo bone formation induced by an osteogenic agent contributes to the repair
of
1 5 congenital, trauma induced, or oncologic resection induced craniofacial
defects, and also
is useful in cosmetic plastic surgery.
A protein of this invention may also loe used in the treatment of periodontal
disease, and in other tooth repair processes. Such agents may provide an
environment
to attract bone-forming cells, stimulate growth of bone-forming cells or
induce
2 0 differentiation of progenitors of bone-forming cells. A protein of the
invention may also
be useful in the treatment of osteoporosis or o~,teoarthritis, such as through
stimulation
of bone and/or cartilage repair car by blocking inflammation or processes of
tissue
destruction (collagenase activity, osteoclast activity, etc.) mediated by
inflammatory
processes.
2 5 Another category of tissue regeneration activity that may be attributable
to the
protein of the present invention is tendon/ligarnent formation. A protein of
the present
invention, which induces tendon/ligament-like tissue or other tissue formation
in
circumstances where such tissue is not normally formed, has application in the
healing of
tendon or ligament tears, deformities and other tendon or ligament defects in
humans and
3 0 other animals. Such a preparation employing a tendon/ligament-like tissue
inducing
protein may have prophylactic use in preventin;~ damage to tendon or ligament
tissue, as
well as use in the improved fixation of tendon or ligament to bone or other
tissues, and
in repairing defects to tendon or ligament tissue. De novo tendon/ligament-
Iike tissue
formation induced by a composition of the present invention contributes to the
repair of
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
congenital, trauma induced, or other tendon or ligament defects of other
origin, and is also
useful in cosmetic plastic surgery for attachment or repair of tendons or
ligaments. The
compositions of the present invention may provide an environment to attract
tendon- or
ligament-forming cells, stimulate growth of tendon- or ligament-forming cells,
induce
differentiation of progenitors of tendon- or ligament-forming cells, or induce
growth of
tendon/ligament cells or progenitors ex vivo for return irt vivo to effect
tissue repair. The
compositions of the invention may also be useful in the treatment of
tendinitis) carpal
tunnel syndrome and other tendon or ligament defects. The compositions may
also
include an appropriate matrix and/or sequestering agent as a carrier as is
well known in
the art.
The protein of the present invention may also be useful for proliferation of
neural
cells and for regeneration of nerve and brain tissue, i.e. for the treatment
of central and
peripheral nervous system diseases and neuropathies, as well as mechanical and
traumatic disorders, which involve degeneration, death or trauma to neural
cells or nerve
tissue. More specifically, a protein may be used in the treatment of diseases
of the
peripheral nervous system, such as peripheral nerve injuries, peripheral
neuropathy and
localized neuropathies, and central nervous system diseases, such as
Alzheimer's,
Parkinson's disease, Huntington's disease, amyotrophic lateral sclerosis, and
Shy-Draper
syndrome. Further conditions which may bc: treated in accordance with the
present
2 0 invention include mechanical and traumatic disorders, such as spinal cord
disorders, head
trauma and cerebrovascular diseases such as stroke. Peripheral neuropathies
resulting
from chemotherapy or other medical therapies may also be treatable using a
protein of the
invention.
Proteins of the invention may also be useful to promote better or faster
closure of
2 5 non-healing wounds, including without limitation pressure ulcers, ulcers
associated with
vascular insufficiency, surgical and traumatic wounds, and the like.
It is expected that a protein of the present invention may also exhibit
activity for
generation or regeneration of other tissues, such as organs (including, for
example,
pancreas, liver, intestine, kidney, skin, endothelium), muscle (smooth,
skeletal or cardiac)
3 0 and vascular (including vascular endothelium) tissue, or for promoting the
growth of cells
comprising such tissues. Part of the desired effects may be by inhibition or
modulation
of fibrotic scarring to allow normal tissue to regenerate. A protein of the
invention may
also exhibit angiogenic activity.
4C~
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
A protein of the present invention may also be useful for gut protection or
regeneration and treatment of lung or liver fibre>sis, reperfusion injury in
various tissues,
and conditions resulting frorr~ systemic cytokine damage.
A protein of the present invention may also be useful for promoting or
inhibiting
differentiation of tissues described above from precursor tissues or cells; or
for inhibiting
the growth of tissues described above.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for tissue generation activity include, without limitation, those
described
in: International Patent Publication No. V~J095/ 16035 (bone, cartilage,
tendon);
International Patent Publication No. W095/05846 (nerve, neuronal);
International Patent
Publication No. W091/U7491 (skin, endothelium ).
Assays for wound healing activity include, without limitation, those described
in:
Winter, )epidermal Wound Healing, pps. 71-11? (Maibach, IwII and Rovee, DT,
eds.), Year
Book Medical Publishers, Inc.) Chicago, as modified by Iaglstein and Mertz, J.
Invest.
Dermatol 7i:382-84 (1978).
Activin/Inhibin Activity
A protein of the present invention may also exhibit activin- or inhibin-
related
2 0 activities. Inhibins are characterized by their ability to inhibit the
release of follicle
stimulating hormone (FSH), while activins and are characterized by their
ability to
stimulate the release of follicle stimulating hormone (FST-I). 'Thus, a
protein of the present
invention, alone or in heterodimers with a member of the inhibin a family, may
be useful
as a contraceptive based on the ability of inhibin.s to decrease fertility in
female mammals
2 5 and decrease spermatogenesis in male mammals. Administration of sufficient
amounts
of other inhibins can induce infertility in these n-iammals. Alternatively,
the protein of the
invention, as a homodimer or as a heterodimer with other protein subunits of
the inhibin-
~3 group, may be useful as a fertility inducing therapeutic, based upon the
ability of activin
molecules in stimulating FSH release from cells of the anterior pituitary.
See, for example,
3 0 United States Patent 4,798,885. A protein of the invention may also be
useful for
advancement of the onset of fertility in sexually immature mammals, so as to
increase the
lifetime reproductive performance of domestic animals such as co~~s, sheep and
pigs.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
47
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
Assays for activin/inhibin activity include, without limitation, those
described in:
Vale et al., Endocrinology 91:562-S72, 1972; Ling et al., Nature 32l:779-782,
1986; Vale et
al., Nature 32l:776-779, 1986; Mason et al., Nature 318:659-663, 1985; Forage
et al., Proc.
Natl. Acad. Sci. USA 83:309l-3095, l986.
Chemotactic/Chemokinetic Activity
A protein of the present invention may have chemotactic or chemokinetic
activity
(e.g., act as a chemokine) for mammalian cells, including, for example,
monocytes,
fibroblasts, neutrophils, T-cells, mast cells, eosinophils, epithelial and /or
endothelial cells.
Chemotactic and chemokinetic proteins can be used to mobilize or attract a
desired cell
population to a desired site of action. Chemotactic or chemokinetic proteins
provide
particular advantages in treatment of wounds and other trauma to tissues, as
well as in
treatment of localized infections. I'or example, attraction of lymphocytes,
monocytes or
neutrophils to tumors or sites of infection may result in improved immune
responses
against the tumor or infecting agent.
A protein or peptide has chemotactic activity for a particular cell population
if it
can stimulate, directly or indirectly, the directed orientation or movement of
such cell
population. Preferably, the protein or peptide has the ability to directly
stimulate directed
movement of cells. Whether a particular protein has chemotactic activity for a
population
2 0 of cells can be readily determined by employing such protein or peptide in
any known
assay for cell chemotaxis.
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assays for chemotactic activity (which will identify proteins that induce or
prevent
2 5 chemotaxis) consist of assays that measure the ability of a protein to
induce the migration
of cells across a membrane as well as the ability of a protein to induce the
adhesion of one
cell population to another cell population. Suitable assays for movement and
adhesion
include, without limitation, those described in: Current Protocols in
Immunology, Ed by
J.E. Coligan, A.M. Kruisbeek, D.H. Margulies, E.M. Shevach, W.Strober, I'ub.
Greene
3 0 Publishing Associates and Wiley-Interscience {Chapter 6.12, Measurement of
alpha and
beta Chemokines 6.12.1-6.l2.28; Taub et al. J. Clin. Invest. 95:1370-1376,
1995; Lind et al.
APMIS 103:140-146, 1995; Muller et al Eur. J. Immunol. 25: 1744-1748; Gruber
et al. J. of
Immunol. 152:5860-5867, 1994; Johnston et al. J. of Immunol. 153: 1762-l768,
1994.
48
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97l20740
Hemostatic and Thrombolvtic Activity
A protein of the invention may also exhibit hemostatic or thrombolytic
activity.
As a result, such a protein is expected to be useful in treatment of various
coagulation
disorders (including hereditary disorders, such as hemophiliac) or to enhance
coagulation
and other hemostatic events in treating wound, resulting from trauma, surgery
or other
causes. A protein of the invention may also be useful for dissolving or
inhibiting
formation of thromboses and for treatment and prevention of conditions
resulting
therefrom (such as, for example, infarction of ca rdiac and central nervous
system vessels
(e.g., stroke).
The activity of a protein of the invention may, among other means, be measured
by the following methods:
Assay for hemostatic and thrombolvtic activity include, without limitation,
those
described in: Linet et al., J. Clin. I'harmacol. 26:131-140, l986; Burdick et
al., Thrombosis
Res. 45:41 ~--119) 1987; Humphrey et al., Fibrinolysis 5:71-79 (1991); Schaub,
Prostaglandins
1 S JJ:46~--1~-1, 1988.
Receptor/Lil;and Activity
A protein of the present invention may also demonstrate activity as receptors,
receptor ligands or inhibitors or agonists of receptor/ligand interactions.
Examples of
2 0 such receptors and ligands include, without limitation, cytokine receptors
and their
ligands, receptor kinases and their ligands, receptor phosphatases and their
ligands,
receptors involved in cell-cell interactions and their ligands (including
without limitation,
cellular adhesion molecules (such as selectins, integrins and their ligands)
and
receptor/ligand pairs involved in antigen presentation, antigen recognition
and
25 development of cellular and humoral immune responses). Receptors and
ligands are also
useful for screening of potential peptide or small molecule inhibitors of the
relevant
receptor l iigand interaction. A protein of the present invention (including,
without
limitation, fragments of receptors and ligands) rnay themselves be useful as
inhibitors of
receptor/ligand interactions.
3 0 The activity of a protein of the invention may, among other means, be
measured
by the following methods:
Suitable assays for receptor-ligand activity include without limitation those
described in:Current Protocols in Immunology, :Ed by J.E. Coligan, A.M.
Kruisbeek, D.H.
Margulies, E.M. Shevach, W.Strober, I'ub. Greene Publishing Associates and
49
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
Wiley-Interscience (Chapter 7.28, Measurement of Cellular Adhesion under
static
conditions 7.28.1-7.28.22), Takai et al., Proc. Natl. Acad. Sci. USA 84:6864-
6868, 1987;
Bierer et al., J. Exp. Ivied. 168:1145-1156, 1988; Rosenstein et al., J. Exp.
Med. 169:149-160
1989; Stoltenborg et al., j. Immunol. Methods 175:59-68, 1994; Stitt et al.,
Cell 80:661-670,
1995.
Anti-Inflammatory Activity
Proteins of the present invention may also exhibit anti-inflammatory activity.
The
anti-inflammatory activity may he achieved by providing a stimulus to cells
involved in
the inflammatory response, by inhibiting or promoting cell-cell interactions
(such as, for
example, cell adhesion), by inhibiting or promoting chemotaxis of cells
involved in the
inflammatory process, inhibiting or promoting cell extravasation, or by
stimulating or
suppressing production of other factors which more directly inhibit or promote
an
inflammatory response. Proteins exhibiting such activities can be used to
treat
inflammatory conditions including chronic or acute conditions), including
without
limitation inflammation associated with infection (such as septic shock,
sepsis or systemic
inflammatory response syndrome (SIRS)), ischemia-reperfusion injury, endotoxin
lethality, arthritis, complement-mediated hyperacute rejection, nephritis,
cytokine or
chemokine-induced lung injury, inflammatory bowel disease, Crohn's disease or
resulting
2 0 from over production of cytokines such as I'NF or IL-1. Proteins of the
invention may also
be useful to treat anaphylaxis and hypersensitivity to an antigenic substance
or material.
Cadherin/Tumor Invasion Suppressor Activity
Cadherins are calcium-dependent adhesion molecules that appear to play major
2 5 roles during development, particularly in defining specific cell types.
Loss or alteration
of normal cadherin expression can lead to changes in cell adhesion properties
linked to
tumor growth and metastasis. Cadherin malfunction is also implicated in other
human
diseases, such as pemphigus vulgaris and pemphigus foliaceus (auto-immune
blistering
skin diseases), Crohn's disease, and some developmental abnormalities.
3 0 The cadherin superfamily includes well over forty members, each with a
distinct
pattern of expression. A11 members of the superfamily have in common conserved
extracellular repeats (cadherin domains), but structural differences are found
in other
parts of the molecule. The cadherin domains bind calcium to form their
tertiary structure
and thus calcium is required to mediate their adhesion. Only a few amino acids
in the
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
first cadherin domain provide the basis for hemophilic adhesion; modification
of this
recognition site can change the specificity of a cadherin so that instead of
recognizing only
itself, the mutant molecule can now also bind to a different cadherin. In
addition, some
cadherins engage in heterophilic adhesion with other cadherins.
E-cadherin, one member of the cadherin superfamily, is expressed in epithelial
cell
types. Pathologically, if E-cadherin expression is lost in a tumor, the
malignant cells
become invasive and the cancer metastasizes. Transfection of cancer cell lines
with
polynucleotides expressing E-cadherin has reversed cancer-associated changes
by
returning altered cell shapes to normal, restoring cells' adhesiveness to each
other and to
their substrate, decreasing the cell growth rate, and drastically reducing
anchorage-
independent cell growth. Thus, reintroducing I:-cadherin expression reverts
carcinomas
to a less advanced stage. It is likely that other cadherins have the same
invasion
suppresser role in carcinomas derived from other tissue types. Therefore,
proteins of the
present invention with cadherin activity, and polvnucleotides of the present
invention
encoding such proteins, can be used to treat cancer. Introducing such proteins
or
polynucleotides into cancer cells can reduce or eliminate the cancerous
changes observed
in these cells by providing normal cadherin expression.
Cancer cells have also been shown to express cadherins of a different tissue
type
than their origin, thus allowing these cells to invade and metastasize in a
different tissue
2 0 in the body. Proteins of the present invention with cadherin activity, and
polynucleotides
of the present invention encoding such proteins, can be substituted in these
cells for the
inappropriately expressed cadherins, restoring normal cell adhesive properties
and
reducing or eliminating the tendency of the cells to metastasize.
Additionally, proteins of the present invention with cadherin activity, and
2 5 polynucleotides of the present invention encoding such proteins, can used
to generate
antibodies recognizing and binding to cadherins. Such antibodies can be used
to block
the adhesion of inappropriately expressed tumor-cell cadherins, preventing the
cells from
forming a tumor elsewhere. Such an anti-cadherin antibody can also be used as
a marker
for the grade, pathological type, and prognosis of a cancer, i.e. the more
progressed the
3 0 cancer, the less cadherin expression there will be, and this decrease in
cadherin expression
can be detected by the use of a cadherin-binding antibody.
Fragments of proteins of the present invention with cadherin activity,
preferably
a polvpeptide comprising a decapeptide of l:he cadherin recognition site, and
poly-
nucleotides of the present invention encoding such protein fragments, can also
be used
51
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
to block cadherin function by binding to cadherins and preventing them from
binding in
ways that produce undesirable effects. Additionally, fragments of proteins of
the present
invention with cadherin activity, preferably truncated soluble cadherin
fragments which
have been found to be stable in the circulation of cancer patients, and
polynucleotides
encoding such protein fragments, can be used to disturb proper cell-cell
adhesion.
Assays for cadherin adhesive and invasive suppressor actiyitv include, without
limitation, those described in: Hortsch et al. ) Biol Chem 270 (32): 18809-
l8817, l995;
Miyaki et al. Oncogene 11: 2547-2552, 1995; Ozawa et al. Cell 63: 1033-1038,
1990.
Tumor Inhibition Activity
In addition to the activities described above for immunological treatment or
prevention of tumors, a protein of the invention may exhibit other anti-tumor
activities.
A protein may inhibit tumor growth directly or indirectly (such as, for
example, via
ADCC). A protein may exhibit its tumor inhibitory activity by acting on tumor
tissue or
tumor precursor tissue, by inhibiting formation of tissues necessary to
support tumor
growth (such as, for example, by inhibiting angiogenesis), by causing
production of other
factors, agents or cell types which inhibit tumor growth, or by suppressing,
eliminating
or inhibiting factors, agents or cell types which promote tumor growth.
2 0 Other Activities
A protein of the invention may also exhibit one or more of the following
additional
activities or effects: inhibiting the growth, infection or function of, or
killing, infectious
agents, including, without limitation, bacteria, viruses, fungi and other
parasites; effecting
(suppressing or enhancing) bodily characteristics, including, without
limitation, height,
2 5 weight, hair color, eye color, skin, fat to lean ratio or other tissue
pigmentation, or organ
or body part size or shape (such as) for example, breast augmentation or
diminution,
change in bone form or shape); effecting biorhythms or caricadic cycles or
rhythms;
effecting the fertility of male or female subjects; effecting the metabolism,
catabolism,
anabolism, processing, utilization, storage or elimination of dietary fat,
lipid, protein,
3 0 carbohydrate, vitamins, minerals, cofactors or other nutritional factors
or component(s);
effecting behavioral characteristics, including, without limitation, appetite,
libido, stress,
cognition (including cognitive disorders), depression (including depressive
disorders) and
violent behaviors; providing analgesic effects or other pain reducing effects;
promoting
differentiation and growth of embryonic stem cells in lineages other than
hematopoietic
52
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
lineages; hormonal or endocrine activity; in th~~ case of enzymes, correcting
deficiencies
of the enzyme and treating deficiency-related diseases; treatment of
hyperproliferative
disorders (such as, for example, psoriasis); immunoglobulin-like activity
(such as) for
example, the ability to bind antigens or complement); and the ability to act
as an antigen
in a vaccine composition to raise an immune response against such protein or
another
material or entity which is cross-reactive with ;such protein.
ADMINISTRATION AND DOSING
A protein of the present invention (from whatever source derived, including
without limitation from recombinant and non-recombinant sources) may be used
in a
pharmaceutical composition when combined with a pharmaceutically acceptable
carrier.
Such a composition may also contain (in addition to protein and a carrier]
diluents, fillers,
salts, buffers, stabilizers, solubilirers, and other materials well known in
the art. The term
"pharmaceutically acceptable" means a non-toxic material that does not
interfere with the
effectiveness of the biological activity of the active ingredient(s). The
characteristics of the
carrier will depend on the route of administration. The pharmaceutical
composition of
the invention may also contain cytokines, lymphokines, or other hematopoietic
factors
such as M-CSF, GM-CSF, TNF, IL-l, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8) IL-
9, IL-10, IL-11,
IL-12, IL-13, IL-14, IL-15, IFN, TNFO, TNFl, TNF2, G-CSF, Meg-CSF,
thrombopoietin, stem
2 0 cell factor, and erythropoietin. The pharmaceutical composition may
further contain other
agents which either enhance the activity of the protein or compliment its
activity or use
in treatment. Such additional factors and/or agents may be included in the
pharmaceutical composition to produce a synergistic effect with protein of the
invention,
or to minimise side effects. Conversely, protein of the present invention may
be included
2 5 in formulations of the particular cytokine, I~~mphokine, other
hematopoietic factor,
thrombolytic or anti-thrombotic factor, or anti-inflammatory agent to minimize
side effects
of the cytokine, lymphokine, other hematopoietic factor, thrombolytic or anti-
thrombotic
factor, or anti-inflammatory agent.
A protein of the present invention may be active in multimers (e.g.,
heterodimers
3 0 or homodimers) or complexes with itself or other proteins. As a result,
pharmaceutical
compositions of the invention may comprise a protein of the invention in such
multimeric
or complexed form.
The pharmaceutical composition of the invention may be in the form of a
complex
of the proteins) of present invention along with protein or peptide antigens.
The protein
53
CA 02270873 1999-OS-12
WO 98/21332 PCT/CTS97/20740
and/or peptide antigen will deliver a stimulatory signal to both B and T
lymphocytes. B
lymphocytes will respond to antigen through their surface immunoglobulin
receptor. T
lymphocytes will respond to antigen through the T cell receptor (TCR)
following
presentation of the antigen by MHC proteins. MHC and structurally related
proteins
including those encoded by class I and class II MHC genes on host cells will
serve to
present the peptide antigens) to T lymphocytes. The antigen components could
also be
supplied as purified MHC-peptide complexes alone or with co-stimulatory
molecules that
can directly silmal T cells. Alternatively antibodies able to bind surface
immunolgobulin
and other molecules on B cells as well as antibodies able to bind the TCR and
other
molecules on T cells can be combined with the pharmaceutical composition of
the
invention.
The pharmaceutical composition of the invention may be in the form of a
liposome
in which protein of the present invention is combined, in addition to other
pharmaceutically acceptable carriers, with amphipathic agents such as lipids
which exist
in aggregated form as micelles, insoluble monolayers, liquid crystals, or
lamellar layers
in aqueous solution. Suitable lipids for liposomal formulation include,
without limitation,
monoglycerides, diglycerides, sulfatides, lysolecithin, phospholipids,
saponin, bile acids,
and the like. Preparation of such liposomal formulations is within the level
of skill in the
art, as disclosed, for example, in U.S. Patent No. 4,235,871; U.S. Patent No.
4,501,728; U.S.
2 0 Patent No. 4,837,028; and LT.S. Patent No. 4,737,323, all of ~n~hich are
incorporated herein
by reference.
As used herein, the term "therapeutically effective amount" means the total
amount of each active component of the pharmaceutical composition or method
that is
sufficient to show a meaningful patient benefit, i.e., treatment, healing,
prevention or
2 S amelioration of the relevant medical condition, or an increase in rate of
treatment, healing,
prevention or amelioration of such conditions. When applied to an individual
active
ingredient, administered alone, the term refers to that ingredient alone. When
applied to
a combination, the term refers to combined amounts of the active ingredients
that result
in the therapeutic effect, whether administered in combination, serially or
simultaneously.
3 0 In practicing the method of treatment or use of the present invention, a
therapeutically effective amount of protein of the present invention is
administered to a
mammal having a condition to be treated. Protein of the present invention may
be
administered in accordance with the method of the invention either alone or in
combination with other therapies such as treatments employing cytokines,
lymphokines
54
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
or other hematopoietic factors. When co-administered with one or more
cytokines,
lymphokines or other hematopoietic factors, protein of the present invention
may be
administered either simultaneously with the cytokine(s}, lymphokine(s), other
hematopoietic factor(s), thrombolytic or anti-thrombotic factors, or
sequentially. If
administered sequentially, the attending physician will decide on the
appropriate
sequence of administering protein of the ~~resent invention in combination
with
cytokine(s), lymphokine(s), other hematopoietic factor(s), thrombolvtic or
anti-thrombotic
factors.
Administration of protein of the present invention used in the pharmaceutical
composition or to practice the method of the present invention can be carried
out in a
variety of conventional ways, such as oral ingestion, inhalation, topical
application or
cutaneous, subcutaneous, intraperitoneal, parenteral or intravenous injection.
Intravenous administration to the patient is preferred.
When a therapeutically effective amount of protein of the present invention is
administered orally, protein of the present invention will be in the form of a
tablet,
capsule) powder) solution or elixir. When administered in tablet form, the
pharmaceutical
composition of the invention may additionally contain a solid carrier such as
a gelatin or
an adjuvant. The tablet, capsule, and powder contain from about 5 to
95°/> protein of the
present invention) and preferably from about 2~~ to 90'i« protein of the
present invention.
2 0 When administered in liquid form, a liquid carrier such as water,
petroleum, oils of animal
or plant origin such as peanut oil, mineral oil, soybean oil, or sesame oil,
or synthetic oils
may be added. The liquid form of the pharmaceutical composition may further
contain
physiological saline solution, dextrose or other saccharide solution, or
glycols such as
ethylene glycol, propylene glycol or polyethylene glycol. When administered in
liquid
2 5 form, the pharmaceutical composition contains from about 0.5 to
90°/« by weight of protein
of the present invention, and preferably frorm about 1 to 50°/~ protein
of the present
invention.
When a therapeutically effective amount of protein of the present invention is
administered by intravenous, cutaneous or subcutaneous injection, protein of
the present
3 0 invention will be in the form of a pyrogen-free, parenterally acceptable
aqueous solution.
The preparation of such parenterally acceptable protein solutions, having due
regard to
pH, isotonicity, stability, and the like, is within the skill in the art. A
preferred
pharmaceutical composition for intravenous, cw:aneous, or subcutaneous
injection should
contain) in addition to protein of the present invention, an isotonic vehicle
such as Sodium
CA 02270873 1999-OS-12
WO 98l21332 PCTlUS97I20740
Chloride Injection, Ringer's Injection, Dextrose Injection, Dextrose and
Sodium Chloride
Injection, Lactated Ringer's Injection, or other vehicle as known in the art.
The
pharmaceutical composition of the present invention may also contain
stabilizers,
preservatives, buffers, antioxidants, or other additives known to those of
skill in the art.
The amount of protein of the present invention in the pharmaceutical
composition
of the present invention will depend upon the nature and severity of the
condition being
treated, and on the nature of prior treatments which the patient has
undergone.
Ultimately, the attending physician will decide the amount of protein of the
present
invention with which to treat each individual patient. Initially, the
attending physician
will administer low doses of protein of the present invention and observe the
patient's
response. Larger doses of protein of the present invention may be administered
until the
optimal therapeutic effect is obtained for the patient, and at that point the
dosage is not
increased further. It is contemplated that the various pharmaceutical
compositions used
to practice the method of the present invention should contain about 0.0l Pg
to about 100
mg (preferably about O.lng to about 10 m~,, more preferably about 0.1 ug to
about 1 mg)
of protein of the present invention per k~ body weight.
The duration of intravenous therapy using the pharmaceutical composition of
the
present invention will vary, depending on the severity of the disease being
treated and
the condition and potential idiosyncratic response of each individual patient.
It is
2 0 contemplated that the duration of each application of the protein of the
present invention
will be in the range of 12 to 2-1 hours of continuous intravenous
administration.
Ultimately the attending physician will decide on the appropriate duration of
intravenous
therapy using the pharmaceutical composition of the present invention.
Protein of the invention may also be used to immunize animals to obtain
2 5 polyclonal and monoclonal antibodies which specifically react with the
protein. Such
antibodies may be obtained using either the entire protein or fragments
thereof as an
immunogen. The peptide immunogens additionally may contain a cvsteine residue
at the
carboxyl terminus, and are conjugated to a hapten such as keyhole limpet
hemocyanin
(KLI-I). Methods for synthesizing such peptides are known in the art, for
example, as in
3 0 R.P. Merrifield, J. Amer.Chem.Soc. 85, 21-I9-2154 (1963); J.L.
Krstenansky, et al., FEBS Lett.
211, 10 (1987). Monoclonal antibodies binding to the protein of the invention
may be
useful diagnostic agents for the immunodetection of the protein. Neutralizing
monoclonal
antibodies binding to the protein may also be useful therapeutics for both
conditions
associated with the protein and also in the treatment of some forms of cancer
where
56
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
abnormal expression of the protein is involved. In the case of cancerous cells
or leukemic
cells, neutralizing monoclonal antibodies against the protein may be useful in
detecting
and preventing the metastatic spread of the cancerous cells, which may be
mediated by
the protein.
For compositions of the present invention which are useful for bone,
cartilage,
tendon or ligament regeneration, the therapeutic method includes administering
the
composition topically, systematically, or locally as an implant or device.
When
administered, the therapeutic composition for use in this invention is, of
course, in a
pyrogen-free, physiologically acceptable form. Further, the composition may
desirably
be encapsulated or injected in a viscous form for delivery to the site of
bone, cartilage or
tissue damage. Topical administration may l:~e suitable for wound healing and
tissue
repair. Therapeutically useful agents other than a protein of the invention
which may also
optionally be included in the composition a:; described above, may
alternatively or
additionally, be administered simultaneously or sequentially with the
composition in the
5 methods of the invention. Preferably for bone and/or cartilage formation,
the
composition would include a matrix capable of delivering the protein-
containing
composition to the site of bone and/or cartila~~e damage, providing a
structure for the
developing bone and cartilage and optimally capable of being resorbed into the
body.
Such matrices may be formed of materials presently in use for other implanted
medical
2 0 applications.
The choice of matrix material is based on biocompatibility, biodegradability,
mechanical properties, cosmetic appearance and interface properties. The
particular
application of the compositions will define the appropriate formulation.
Potential
matrices for the compositions may be biodegradable and chemically defined
calcium
2 5 sulfate, tricalciumphosphate, hydroxyapatite) polylactic acid,
polyglycolic acid and
polyanhydrides. Other potential materials are biodegradable and biologically
well-
defined, such as bone or dermal collagen. Furth~=r matrices are comprised of
pure proteins
or extracellular matrix components. Other potential matrices are
nonbiodegradable and
chemically defined, such as sintered hydroxapatite, bioglass, aluminates, or
other
3 0 ceramics. Matrices may be comprised of combinations of any of the above
mentioned
types of material, such as polylactic acid and hvdroxyapatite or collagen and
tricalciumphosphate. The bioceramics may be altered in composition, such as in
calcium-
aluminate-phosphate and processing to alter pore size, particle size, particle
shape, and
biodegradability.
57
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
Presently preferred is a 50:50 (mole weight) copolymer of lactic acid and
glycolic
acid in the form of porous particles having diameters ranging from 1S0 to 800
microns.
In some applications, it will be useful to utilize a sequestering agent, such
as
carboxymethvl cellulose or autologous blood clot, to prevent the protein
compositions
from disassociating from the matrix.
A preferred family of sequestering agents is cellulosic materials such as
alkylcelluloses (including hydroxvalkylcelluloses), including methylcellulose,
ethylcellulose, hydroxyethvlcellulose, hydroxypropylcellulose, hydroxypropyl-
methvlcellulose, and carboxymethylcellulose, the most preferred being cationic
salts of
carboxvmethvlcellulose (CMC j. Other preferred sequestering agents include
hyaluronic
acid, sodium alginate, polv(ethylene glycol), polyoxyethylene oxide,
carboxyvinyl
polymer and poly(vinvl alcohol). The amount of sequestering agent useful
herein is 0.5-20
wt°/~, preferably 1-10 wt'%~ based on total formulation weight, which
represents the
amount necessary to prevent desorbtion of the protein from the polymer matrix
and to
provide appropriate handling of the composition, yet not so much that the
progenitor cells
are prevented from infiltrating the matrix, thereby providing the protein the
opportunity
to assist the osteogenic activity of the progenitor cells.
In further compositions, proteins of the invention may be combined with other
agents beneficial to the treatment of the bone and/or cartilage defect, wound,
or tissue in
2 0 question. These agents include various growth factors such as epidermal
growth factor
(EGF), platelet derived growth factor (I'DGF), transforming growth factors
(TGF-a and
TGF-(3)) and insulin-like growth factor (1GF).
The therapeutic compositions are also presently valuable for veterinary
applications. Particularly domestic animals and thoroughbred horses, in
addition to
2 5 humans, are desired patients for such treatment with proteins of the
present invention.
The dosage regimen of a protein-containing pharmaceutical composition to be
used in tissue regeneration will be determined by the attending physician
considering
various factors which modify the action of the proteins, e.g., amount of
tissue weight
desired to be formed, the site of damage, the condition of the damaged tissue,
the size of
3 0 a wound, type of damaged tissue (e.g., bone), the patient's age, sex, and
diet, the severity
of any infection, time of administration and other clinical factors. The
dosage may vary
with the type of matrix used in the reconstitution and with inclusion of other
proteins in
the pharmaceutical composition. For example, the addition of other known
growth
factors, such as IGF I (insulin like growth factor I), to the final
composition, may also effect
58
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
the dosage. Progress can be monitored by periodic assessment of tissue/bone
growth
and /or repair, for example, X-rays, histomorp:hometric determinations and
tetracycline
labeling.
Polynucleotides of the present invention can also be used for gene therapy.
Such
polynucleotides can be introduced either in vivo or ex vivo into cells for
expression in a
mammalian subject. I'olynucleotides of the invention may also be administered
by other
known methods for introduction of nucleic acid into a cell or organism
(including, without
limitation, in the form of viral vectors or naked DNA).
Cells may also be cultured ex vivo in the presence of proteins of the present
invention in order to proliferate or to produce a desired effect on or
activity in such cells.
Treated cells can then be introduced in vivo for therapeutic purposes.
Patent and literature references cited herein are incorporated by reference as
if
fully set forth.
59
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
SEQUENCE LISTING
(1) GENERAL INFORMATION:
(i) APPLICANT: Jacobs) :~enneth
McCoy) John M.
LaVallie, Edward R.
Racie, Lisa A.
Merberg, David
Treacy, Maurice
Spaulding, Vikki
:':gos t ino , Michael J .
(ii) TITLE OF INVENTION: SECRETED FROTEINS AND POLYNUCLEOTIDES
ENCODING THEM
(iii) NUMBER OF SEQUENCES: 39
( vvj CORRESPONDS=:~'v ADDR.ESS
(.y) ADDRESSE;: Genetics Institute, 1-nc.
(~} STREE_: Cami~ridgePark Drive
(C) CITY: Cambridge
(D) STATE: :~_A
(E) COUNTR':': U.S.A.
(F) ZIP: 0 140
(v) COMPUTER READABLt; FORM:
(r1) MEDIUI~' TYPE: Floppy disk
(B) COMPUTER: T_BM FC compatible
(C) OPERATI_:G SYSTEM: PC-DOS/MS-DOS
(D) SOFTWARE: PatentIn Release rrl.C, Version #1.3D
(vi) CURRENT APPLICATION DATA:
(A) i~PPLIC:~TION NUi~!BER:
(B) FILING DATE:
(C) CLASSIF'_CATION:
(viii) ATTORNEY/AGENT INFORMATION:
(A) NAME: Sprunger, Suzanne ::.
(B) REGI:~TR?TION NUMBER.: 4l,323
(ix) TELECOMMUNICATION INFORMATION:
(A) TELEPHONE: (o17) 498-8284
(B) TELEFAX: (6l7) 876-5851
(2) INFORMATION FOR SEQ ID NC:1:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 430 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D; TOPOLOGY: linear
n
CA 02270873 1999-OS-12
WO 98I21332 PCT/LTS97120740
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION:
SEQ ID NO:1:
TAAAGATCTG TGTTCAGAGT CATACTGAAYAGAGAC'TTCTGGACTCTATA GAACCCF1CTG60
CCTCCTGATG AAGTCCCTAC TG'PTCACCCTTGCAGTTTTTATGCTCCTGG CCCAATTGGT12O
CTCAGGTAI~T TGGTATGTGA AAACGA.CGTTGGAATTTGCA AGAAGAAGTG180
AAAAGTGTCT
CAAACCTGAA GAGATGCATG TA.AAGAATGGTTGGGCAATGTGCGGCAAAC AAAGCGACTG240
CTGTGTTCCA GCTGACAGAC GTGCTr':.s'1TTATCCTGT'TTTCTGTGTCCAGA CAAAGACTAC300
AAGAr'1TTTCA ACAGTAACAG AACAACAACTTTGATGATGA CTACTGCTTC36O
CAACAACAGC
GATG':'C'_":'CG ATGGC T CCaCTCGTTGAACATTCCF,G CCTCTGTCTC42
CCTA CCCGTTTC T C 0
CTGCTCTAGG 43C
(2) INFORMATION FOR SEQ
ID N0:2:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 121 amino acids
(B) TYPE: amino acid
(C) STRANDEDNE:SS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:2:
Met Lys Ser Leu Leu Phe Thr Leu F,la Val Phe Mec Leu Leu Ala Gln
S 10 15
Leu Val Ser Gly Asn Trp 'I'yr Val L~ys Lys Cys Leu Asn Asp Val Gly
20 .~5 30
Ile Cys Lys Lys Ly_~ Cys Lys Pro G~lu Glu Met His Val Lys Asn Gly
35 40 45
Trp Ala Met Cys Gly Lys Gln Arg F,sp Cys Cys Val Pro Ala Asp Arg
SO 55 6C
Arg Ala Asn Tyr Pro Val Phe Cys Val Gln Thr Lys Thr Thr Arg I1e
65 70 75 80
Ser Thr Val Thr Ala Thr Thr Ala 'I'hr Thr Thr Leu Met Met Thr Thr
85 90 95
61
CA 02270873 1999-OS-12
WO 98l21332 PCT/US97/20740
Ala Ser Met Ser Ser Met Ala L'ro Thr Arg T'he Ser His Trp Leu Asn
100 105 110
Ile Pro Ala Ser Val Ser C'y~ Se. Arg
l15 120
(2) INFORMATION FOR SEQ ID N0:3:
(i) SEQUENCE CHARACTERISTT_CS:
(A) LENGTH: 112 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULr: TYPE: cDNA
(xi) SEQUENCE DESCR IPTION: SEQ ID I'0:3:
TTTCCTGNTT TNGGA'_~CCCC Gi~TTCF:TTAA AGCAANGGGG I';'T'TNAAAF~-.~~ .~iA.AAAAAAA
60
AAAAAAAAAA P,AAAAAAAAA AAAAAAAAAA A.AAP.AAAAAA AA.~AP,AAA.n.A AA 1l2
( 2 ) INF ORM11TION FOR SEQ ID NO : 4
( '~ ) SEQLJENCF CHiIRACTERT_S T ICS
(A) LENGTH: 324 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) '?'OPOLOGY: Linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRT_PTION: :
SEQ ID N0:4
NCTACCCCAA CCTGTGTGGC TGGGCCGCGGTCTCCCCTCAAGGGCCTGGG GCCGTGCCTC60
GGGTGTACNC GTANGGGTCT GTGTGCTGGGGGTGGCTCACCGGGCAGCGT GGGTGAGCGG120
CGCANCGGCG GCAGCGGAGA ACGAGAGAGGGGAGCAGANACAGAATCGCC TAAGCTGAAG180
TGTATTGGCG CCATCATGGC TCACTGCGGCCTCCGGCTCC"_'TGGCTCGG~~ TGATTCTCCT240
GCCTGAGCC'_~ CCCTAGTAGC_' GTGCTGTAGAAGAAAATCAC ATGATTGGTG300
TAGGACTACA
CCCTCAAAP.A ATTGGTGCCr'~. 324
CTTG
(2) INFORMATION FOR SEQ
ID N0:5:
( i ) SEQUENCE CHARr'1CTERI
STICS
62
CA 02270873 1999-OS-12
WO 98121332 PCT/US97/20740
(a-,) LE:JGTH: 794 base pair
(3) TYPE: nucleic acid
(C) STRANDEDNI?SS: double
(D) TOPOLOGY: ~~.inear
(ii) :~IO~ECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION:
SEQ ID N0:5:
CATTATTTCA '_"..'=.CCAGAGAAGCAAi;TAGC ATTGTGAGTC=..=~ACTATTCC6O
ATACACATGC
NAAAGCACAG ~-,'"TC ACCAA':TC~'1TCTGGAT ATCTCAC;\TNN; ~IIVl'1NNNNNNl
CNACACACAC 2
0
TTAACTGATG ~~L~AAAGTF:A GCCCTTGTGG ATGT:TTCTGACGATCCTGGA 180
TGGAACAATT
GCCNATGTAT C'_'P.ACATAC:'1AAAATTTCAA GTCTGGAGA'I''_'=.AACTCAAA240
GC'I'TCAGCAA
GTATCTGAAG = :G ~~AT~F:CA CAGGA'I' CTC'~C G GAA~GCAT 3
GAGAATTAF~.t-~ AAKCATTGAT 0
0
AATGTCT'='AC: ~=~A.AGGCTT FuriAGAGCAAG AGGCCATTTC~_""'~TCAAGAT3
TCTAAAAGAA 6
0
AGATAC AAAG C TTCAGGA AA.r~ICATAAACAAGAF:TTGC, AAGACATGAGG Ar'1AGCTGGT4
2
0
CACGAAGCC C '_ CAGCATTAT T ATAAC~GCAC TACTGCAGTC"_'= CAGTTAAG4
TG'~ GGATGAA 8
0
CAACAAGTAG : = GCTA T TGA ATTTCTGCAlI TTGAGAAACG'~CACACAAG5
AAAACAGTAC A 4
0
TGTGAGGAGT '.GCTAAATGC AGGCTC'.CTTG F~AGTGC'I'AGAT::CAGAGAAG600
TC.?~GCATCAG
GAACTGTTr'1A =.'-.GAAAAAATmTGATTCAGC AATCTCAAGiia-.CAGAAGGAA660
AA.~GGAAGCT
ATATTGGAI~'~ :.:GTGTTTGGA C'.':AAGt~Fr,TA .-'.GTATCCGCT720
GG.~AGAAAGG AAGAGGCATT
GCAAAGCTTG ~~,Ar'~F~GAACC GCr'1:'~ITTTTAA ::C=AAGAAAGA7
AG'rGAAGGr'1T AATTCG T AGA 8
0
rf,AA 7
9
4
(2) INFORMF.=ION FOR SEQ
ID N0:6:
(i) SLQUENCE CHARACTERISTICS:
(=.) LENGTH: lEi4 amine acids
(3) TYPE: amino acid
STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MO~ECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:6:
63
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Met Glu Lys His Asn Val Leu Glu Lys Gly Phe Leu Lys Glu Lys Glu
i 5 i0 15
Gln Glu Ala Ile Ser Phe Gln Asp Arg Tyr Lys Glu Leu Gln Glu Lys
20 25 30
His Lys Gin G1u Leu Glu Asp Met Arg Lys Ala Gly His Glu Ala Leu
35 40 45
Ser Ile T_1~~~ Val a-.sp Glv Tyr Lys Ala Leu Leu Glri Ser Ser Val Lys
50 55 60
Gln Gln Val Glu -~la Ile Glu Lys Gln Tyr Il.e Ser Ala Ile Glu Lys
65 70 75 80
Gln Ana H=s L_ ~ Cvrs C~.Lu Glu i eu l..eu Asn Ala Glr_ His Gln l:rg Leu
'gyp 90 95
Leu Glu Val Leu Asp Thr G.Lu Lys G1u Leu Leu Lys Glu Lys Ile Lys
0 'L '? 110
Glv~ Ala Leu I-_ G=n Glt: Ser Glr: Glu Gln Lys GLu I1e Leu Glu Lys
115 "~20 12'_~
Cys Leu Glu G1u :~lu Arg Gln t:rg Asn Lys Glu Ala Leu Val Ser Ala
130 135 140
Ala Lys Leu G1,. Lys Glu Pro Val Lys Asp Ala laa Leu Lys Phe Val
145 l50 155 160
Glu Glu Glu Arg
(2) INFORMATION FOR SEQ ID N0:7:
(i) SEQUENCE CHARACTERISTICS:
LENGTH: 1494 base hairs
(B) TYPE: rn~cleic acid
(C) STRANDEDNESS: doui~le
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID
N0:7:
CGTTTGTCGACGCCGCTGCCACCGCCTGCCTGAGAGAAGT CGTCGCGGCCGACCCCGTCG 60
CCTCCGCCGGCTACCATGTCCGCCCAGGCGCAGATGCGGG CCCTGCTGGACCAGCTCATG 120
GGCACGGCTCGGGACGGAGACGAAACCAGACAGAGGGTCA AGTTTACAGATGACCGTGTC 180
TGCAAGAGTCACCTTCTGGt'1CTGCTGCCCCCATGACr'~TCC TGGCTGGGACGCGCATGGAT 240
64
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
TTAGGAGAATGTACCAAAAT CCP,CGACTTGGCCCTCCGAGCAGATTF:TGA GF-~TTGCAAGT300
AAAGAAAGi-.GF~CCTGTTTTT TGAATTAGATGCAATG;~ATCACTTGGAGTC CTTTATTGCT360
GAATGTGATCGGAGAACTGA GCTCGCCP.tIGAAGCGGCTGGCAGAAACACF: GGrIGGAAATC420
AGTGCGGAAGTTTCTGCAAA GGCAGGAAAAGTACAT;:AGTTAAATGAAGA :yTAGGAAAA480
CTCCTTGCTAA.AGCCGAACA GCTAGGGGCTGAAGG:'.ATGTGGATGAATC CCAGAAGATT540
CTTATGGAAGTGGAAAAAG'I' TCGTGCGAAGAAAAAA CTGAGGAF,GF: ATACAGAAAT6
~:~Ar'1G 0
0
TCCATGCCTGCATCCAGTTT TCAGCAGCr'1AAAGCTG'GTGTCTGCGAGGT CTGTTCAGCC660
TACCT TCCATGACl::: TGACCGTCGCCTGGC:~:~ACCACTTCGGTGG CAAGTTACAC7
T GG 2
T C 0
TTGGGGTTCATTCAGATCCG AGAGAr'1GCTTGATCF_G'~':'GAGGAAAAG'I'~T CGCTGAAAAG780
CAGGAGAAGAGAAATCAGGA TCGCTTGAGGAGGAG=:,AGGAGAGGGAACG GGAGGAGCGT840
CTGAGCAGGAGGTCGGGA T ~' GATCG~~ G GTCF1C GCTC CCGGGATCGG9
AAGAACCAGA GC,A 0
0
CGTCGGAGGCC:GTCAAGATC TACCTCCCGAGAGCG=.~GGAAA'iTGTCCCG GTCCCGGTCC960
CGAGATAGACATCGGCGCC: CCGCAGCCGTTCCCGG:=,GCCACAGCCGGG~ ACATCGTCGG1020
GCTTCCCGGGF:CCGAAGTGC GAAATACAAGTA.ACT::nTCTGACTCCTTCC: '.=TAGCTGCAA1080
CCAGGAGTTC~_'CCAGF-:GAGC AGAGC~::~T~'CTGGGaGAGCG GGCGGAGCGA1140
CGGCATCCAG
GCGAGGGCCCCCGGACTGGA GGCTTGAGAGCTCCAP.;~GGGAAGATGGC"."_" CACGGAGGTC12O0
AGAAGAGAAGGAGGCCGGCG AGATCTGAACCCCTC:''~CCGGGTGC'I'GTPK ATAGTCTGAT1260
AAACGTTCF,C~CAGTCTAAA ATTACCCTTTATATT'_"'CTGAATACAAC'_'C ATCTTTTGTA1320
GTTTAAA.r.TCTATTGTTT TGGAGCTAGC': GTGAG 'I :AGAAG T G T.=, 13
T T __"TTC CAGAGTTGCT 8
0
CCTGTGTTCCCGGGTCATGT 'PGAGTAGGAAT AAAT T GATGC T G ~': i
~-.A'I'C TCCTGGAAAA 4
4
0
AAAAAA.~1AAAP,~~:?~AAF~AAAA rIAAAAr AP,AF:T,AAAAF, AAAA14
P,1~.~1AAAAAAA ;.AAA 9
4
{2) INFORMATION FOR SEQ :
ID N0:8
(i) S EQUENCE CHARACTERISTICS:
(A) LENGTH: 32~ acids
amino
(B) TYPE: amino
acid
(C) STRANDEDNESS:
(D) TOPOLOGY:
linear
(ii) M OLECULE TYPE:
protein
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:8:
Met Ser Ala Gln Ala Gln Met Arg Ala Leu Leu Asp G-n Leu Met Gly
1 5 10 15
Thr Ala Arg Asp Gly Asp Glu Thr Arg Gln Arg Va1 L_ Phe Thr Asp
20 25 30
Asp Arg Val Cys Lys Ser His Leu Leu Asp Cys Cys Pro His Asp Ile
35 40 45
Leu Ala Gly '.'hr Arg Met Asp Leu Gly Glu Cys Thr Lys Ile His Asp
50 55 60
Leu Ala Leu Arg Ala Asp Tyr Glu Ile Ala Ser Lys Glu Arg Asp Leu
55 70 75 8D
Phe Phe Glu Leu Asp Ala Met. Asp :I is Leu Glu Ser '.:e Ile Ala Glu
85 90 95
Cys Asp Arg Arg 'I'hr Glu Leu r.la Lys Lys Arg Leu Ala Glu Thr Gln
100 105 110
Glu Glu Ile Ser Ala Glu Vai per Ala L,ys Ala Gly L.ys Val His Glu
115 120 125
Leu Asn Glu Glu Ile G.Ly Lys Leu Leu Ala Lys Ala Glu Gln Leu Gly
130 l35 140
Ala Glu Gly Asn Val Asp Glu Ser Gln Lys Ile Leu r:et Glu Val Glu
l45 150 155 160
Lys Val Arg Ala Lys Lys Lys G1u Ala Glu Glu Gl.u 'i'yr Arg Asn Ser
165 l70 175
Met L~ro Ala Ser Ser Phe Gln Gln Gln Lys Leu Arc 'va~~ Cys Glu Val
180 l85 190
Cys Ser Ala Tyr Leu Gly Leu His Asp Asn Asp Arg Arg Leu Ala Asp
195 200 205
His Phe Gly G:Ly Lys Leu His Leu Gly Phe Ile Gln Ile Arg Glu Lys
2l0 215 220
Leu Asp Gln Leu Arg Lys Thr Val Ala Glu Lys G'_~r. Glu Lys Arg Asn
225 230 235 240
Gln Asp Arg Leu Arg Arg Arg Glu Glu Arg Glu Arg Glu Glu Arg Leu
245 250 255
Ser Arg Arg Ser Gly Ser Arg Thr Arg Asp Arg Arg Arg Ser Arg Ser
260 265 270
Arg Asp Arg Arg Arg Arg Arc Ser Arg Ser Thr Ser erg Glu Arg Arg
275 280 28S
66
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Lys Leu Ser Arg Ser Arg Ser Arg A.sp Arg His Arg Arg His Arg Ser
290 295 300
Arg Ser Arg Ser H=.~; Ser Arg Gly H:is Arg Arg Ala Ser Arg Asp Arg
305 310 315 320
Ser Ala Lys Tyr Lye
325
(2) INFORMATION FOR SEQ TD N0:9:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1761 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNE:SS: double
(D) TOPOLOGY: ~~inear
(ii) MOLECULE TYPE: cDNA
(xi) :
SEQUE1CE
DESCRI:PTIOTd:
S~Q
ID N0:9
CAAGGGAAGTTCTGAGGGCTGA~OAGGTTGC':'CA.TTC:GTCAGAGCGTGCTGCCCACCCTCC 60
ACCCCTGCATGGCAGAAACTGTGCAGGGGAC~AGGCCAAGGAA'PCAGGAGACCCAGAGGC 120
AGGGGTGGCCCGGAGACGG'I'GAAGAAACCAA.GACGCACGAGAGGCCAAGCCCCTTGCCTTG 180
GGTCACACAGCC~-~AAGGAGGCA(~AGCCAGAT-.CTCACAACCAGe'1TCCAGAGGCr'~ACAGGGA240
CATGGCCACCTGGGACGAAAAGGCAGTCACCCGCAGGGCCAAGGTGGCTCCCGCTGAGAG 300
GATGAGCAAGT'_~CTTAAGGCi~CTTCACGGTCGTGGGAGACGACTACCATGCCTGGAACAT 360
CAACTACAAGAAATCGGAGAATGAAGAGGAGGAGGAGGAGGAGGAGCAGCCACCACCCAC 420
ACCAGTCTCAGGCGAGGAAGGCAGAGCTGC::GCCCCTGACGTTGCCCCTGCCCCTGGCCC 480
CGCACCCAGGGCCCCCCTTGAC'rTCAGGGGCATGT'T'GAGGE'~AACTGTTCAGCTCCCACAG 540
GTTTCAGGTCATCATCATCTGC'PTGGTGGTTCTGGATGCCCTCCTGGTGCTTGCTGAGCT 600
CATCCTGGACCTGAAGATCATCCAGCCCGACAAGAA.TAAC'IATGCTGCC~:TGGTATTCCA 660
CTACATGAGCATCACCATCTTGGTCTTTTTTATGATGGAGATCATCTTTAAATTATTTGT 720
CTTCCGCCTGGAGTTCTTTCACCACAAGTTTGAGATCCTGGATGCCGTCGTGGTGGTGGT 780
CTCATTCATCCTCGACATTGTCCTCCTGTTCCAGGA.GCACCAGTTTGAGGCTCTGGGCCT 840
GCTGATTCTGCTCCGGCTGTGGCGGGTGGCCCGGATCATCAATGGGATTATCATCTCAGT 900
TAAGACACGTTCAGAACGGCAACTCTTAAGGTTAAAACAGATGAATGTACAATTGGCCGC 960
G7
CA 02270873 1999-OS-12
WO 98/21332 PCT/i1S97/20740
CAAGATTCAA CACCTTGAGT TCAGCTGCTC 1020
TGAGAAGGAA CAAGAAATTG AAP.GACTTAA
CAAACTATTG CGACAGCATG GACTTCTTGG TAGACCCGGA CCAGCTCCCC1080
TGAAGTGAAC
TC.~1AAAAGAA GACACTGTCT CATGGGCCTG AGAGGAACAG C'_"GCCCCTCCi140
TGCTGTCACG
TGGGCCGCTT GGTGAGAGGT TTGGTTTGAT CCCTCCTGCC AGCATGGATT1200
r~.CCTCTGCCT
CTGGGTGGAC ACAGCCTTGT GGAAGGTCCA GAGCTGCCC=: :'CCACTCCCA126O
GTACCACCAA
CCCCACACTG TA'rCAAATG i' ATCACAT~_'TTACACTTTAGC C'_"TAATTGAA13
CTCATGTTGA 2
0
t~ATGAGCAAC AAAGCTGGi-iC :~,ATTGCTAGTP.TTTAATC'T_'C 1380
':'GTATATAAA .'-.CCGAATGTA
CAGTTTTCAA ATTTCACGTG TATATTFAGG TCTGAGCATT C'_"GAAAGAAA1490
AACTGATGCA
GAAAAAGAAG CTACTTTAGC TGCCACCCCA GTCTCTTATT ':TCAAGCTGT1500
TTCTAGAAAA
TCTAAATAGC TTCGTCTCAG "_'TTCCC;~.-'~:AGGCCCCTCC ':''CTGTGTGCC1560
,GGGGTACCC
CCAGC'.T'GCAT CAGCC'AGC'~"?' ':'.~AGG~iGCCTGCCACCT'.~ r:CAACATTTT1620
CT CCATTGTTTT
TCC :'CA.~1TTA CTGTACAACT P.CTGTATAAATACTGTATAA r aTAAACTCT16
?:TAAAACAAC 8
0
C~_'C'."TTTCCC TGGAAAAAAA P~AAA~~u AAAAAAAAP~ ~AAAAAAAA1
~ AAAAAAAAAA 7
9
0
P~,~AAAAAPLAA AAA A 17
61
(2) 1':FORMATION FOR SEQ ID N0:10:
(i) SEQUENCE CHARACTERI~TIC.'~:
(A) LENGTH: 273 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE T'IPE: protein
(xi) SEQUENCE DESCRT_PTIO'd: S~Q ID N0:10:
Me; Ala Thr Trp Asp Glu Lys Ala Val Thr Arg Ar~7 Ala Lys Val Ala
1 5 10 15
Pro Ala Glu Arg Met Ser Lys Phe Leu Arg His Phe T::r Val Val Gly
20 25 30
Asp Asp Tyr His Ala Trp Asn Ile Asn Tyr Lys Lys Trp Glu Asn Glu
35 40 45
Glu Glu Glu Glu Glu Glu Glu Gln Pro Pro Pro T2:r Pro Val Ser Gly
50 55 60
6H
CA 02270873 1999-OS-12
WO 98I21332 PCT/LTS97/20740
Glu Glu Gly Arg Ala Ala Ala Pro Asp Val Ala Pro Ala Pro Gly Pro
65 70 75 80
Ala Pro Arg Ala Pro Leu Asp P:~_e Arg Gly Met Leu Arg Lys Leu Phe
85 90 95
Ser Ser His Arg Phe Gln Val Ile Ile Ile Cys Leu Val Val Leu Asp_
100 105 110
Ala Leu Lcu Val Leu Ala Glu Lc~a I~~ Leu Asp Leu Lys Ile Ile Gln
115 120 l25
Pro Asp Lys Asn Asn Tyr Ala A-~a Met Val Phe flis Tyr Met Ser Ile
130 135 140
Thr Ile Leu 'Jal P!:e Pt:e Met "?et :=lu I1e Iie Pue Lys Leu Phe Val
i45 150 155 160
Phe Arg Leu Glu Phe Phe His :.~ ~ L,ys Phe Glu Ile Leu Asp Ala Val
165 170 l75
Val Vai Vai Vzil per Phe Iie -~u ksp _le Val Leu Leu Phe Gln Glu
.80 185 190
His Gln Phe Giu A1a Lc:u Gly Leu Leu ile Leu Leu Arg Leu Trp Arg
195 200 205
Val Ala r'1rg Ile Ile Asn Gly lie ile Ile Ser Val L.~s Thr Arg Ser
2i0 215 22C
Glu Arg Gln Leu Leu Arg Leu L,ys Sln Met Asn Val Cln Leu Ala Ala
225 230 235 210
Lys Ile Gln :Iis Leu Giu Phe Ser ~ys Se_r Glu Lys Glu Gln Glu Ile
245 250 255
Glu Arg Leu Asn L,ys Leu Lees Arg ~=~~n Ills Gly Leu Leu Gly Glu Val
260 265 270
Asn
(2) INFORMATION FOR Sc.Q ID N0:11:
( i ) SEQUENCE CFWFtACTERISTICS
(A) LENGTI-l: 928 base pairs
(B) TIPS: nucleic acic
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
( i i ) MOLECULE "_'YP~' : cDNA
69
CA 02270873 1999-OS-12
WO 98/21332 PCT/L7S97/20740
(xi)
SEQUENCE
DESCRIPTION:
SEQ
ID N0:11:
AATCGGGAGTCCTGGAAAGT TAATTCCAATGTCATGACGTCAAACTTA.z.A ATGGTCGTCT60
GCCACCATGAAGATTGATAA CCCTCACATAACATATACTGCCAGGGTCCC AGTCGATGTC120
CATGAATACAACCTAACGCA TCTGCAGCCTTCCACAGATTATGAAGTGTG TCTCACAGTG180
TCCAATATTCATCAGCAGAC TCAAAAGTCATGCGTAAATGTCACAACCAA AAATGCCGCC240
TTCGCAGTGGACATCTCTGA TCAAGAAACCAGTACAGCCCTTGCTGCAGT AATGGGGTMT300
ATGTTTGCCGTCATTAGCCT TGCGTCCATTGCTGTGGTACTTTGCCAAAA GATTTAAGAG360
AAAAA.ANT:.CCAC CACTCAT T AAAAAAGTATATGCAAAAAACCTCTTCAi; TCCCACTAAA42
0
TGAGCTGTaCCCACCACTCA TTAACCT'.VTGGGAAGGTGACAGCGAGNAF:G ACAAAGATGG480
TTTTGCAGACACCP.AGCCAA CCCAGGTNGACACATCCAGAAGGTATTACA TGTGGTAANT540
C11GAGGAT::TTTTGCTTCTG GTAGTAAGGAGCAC_'AAP.GACGTTTTTGCT'_' TATTCTGCAA600
RAGTGWCA.=~GTTGAAGACT "_'TTGTATTTT"_'GACTTTCCTAGTTTGTGGC AGAGTGGAGA660
GGACGGGTGGATATTTCAAA TTTTTTTAGTF-_TAGCGTATCGCAAGGG'_~T~' GACACGGCTG720
CCr'~.GCGATAGGCTTCCA GTCTGTGTTGGTTTTTATTCTTATCATT: TTATGATTGT7
C'='C I' 8
0
TATTATAT'='P.TTATTTTAT'I' TTAGTTGTTGTGCTAAACTCAATAATGC~'~ TTCTAACTAC840
AGTGCTCFu;TAAAATGATTA ATGACAGGATGGGGTTCCCCTGTGCTTTT:=. CCAGTAGCAT900
GACCCTTCCTGAAGCCATCC GTAGAAAG 928
( 2 ) ATION FOR SEQ ID :
I NFORNINO : 1
(i) S EQUENCE CHARr'1CTERISTT_CS:
(A) LENGTH: 52 cids
amino a
(B) TYPE: ~~mino
acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(,~i) OLECULE TYPE: protein
Li
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:12:
Met Ile Val Ile Ile Leu Leu Phe Tyr Phe Ser Cy~ Cys Ala Lys Leu
1 5 10 15
Asn Asn Ala Va1 Leu Thr Thr Val Leu Asn Lys Mer Ile Asn Asp Arg
20 25 30
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
Met Gly Phe Pro Cys Ala Phe Thr ~~er Ser Met ~!'hr Leu Pro Glu Ala
35 40 45
Ile Arg Arg Lys
(2) INFORMATION FOR SEQ ID N0:13:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 49 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) ~EQUENCE DESCFIPTION: SEQ ID N0:13:
AAA'~TAAANi~ ?.AAAAAAAAA t~A~~AAAr~~AA AAATAPAGAA t~AAAAAAi~ 49
(2) INFOR_h:ATION FOR SEQ ID N0:14:
(i) .~EQUENCE CHARACTERISTICS:
(A) LENGTH: 597 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
( i i ) I~.OLECULE TYPE : cDNA
(xi) SEQUENCE
DESCRIPTION:
SEQ ID N0:1=:
ATTCTACAAG r.TAACTTCCCAGTACTTTAA AAAAGTCTCA AAGTCATA_:.7CAAGAAAGAA60
CTGAGGGAC: =.TTGCATATTGGAGCGATCT Ar'1AGAAGTAT GGAATTCTTG120
TACAATTTG"_'
ATTAAATCCT GGACCAGCAAAAGGACATTA GTGGGA.~AAT TCATGAAATTCAAATGAGAT18O
CTTATATTGi'-. GTCAGTG Tr'1C ATTTCCTGGT GCAAGTGATT24O
r.GTTAATTGT TTTCATAFi=''''
ATGTAAGGTT "_'GTTAATATTAGGAGCAGCT GGGTAAr'~GGT CTCTATACTA300
TATACAAAF~.
TTTTTGCATT ~TTTTCTGTAGTTTAAAAC ATTTTC(~AAC TAAAAAGTTGA.T~AACACATG360
A
TATTAGAGAC CATGCGTATGTGTCTCTAA TAATCT'CAAA TATATTTAAGATGATAGAAG420
GAATTCTTGA GATAGTAAAATGAAGTCACC AAA.AAACAAA CAAAGAAACaAP.ACGAAATC480
ACCAARATCT ATCAATAAATTTCAGGTAAT ACTTTTC~GCA GATTCATTCCTTTGAGATGGS40
71
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
AGTCTCACTC CCAGTCTGGG CAACGAGCGA AACTCCGTCT AAF~AAAAAA a-~AAAAA 597
(2) INFORMATION FOR SEQ ID N0:15:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 00 amino acids
(E) TYPE: amino acid
( C ) .=TPwP.NDEDNESS'
(D) TOPOLOGY: linear
{ii) MOLECULE TYPE: protein
(xi) ~JQUENCE DESCRIPTION: SEQ 1D N0:15:
Met Arg Se= Tyr Ile G1u Val Asn Cys 'Jal :~:~=- Val His Phe Leu Val
1 S 10 15
Phe Ile Ilc A1a Ser Asp '1'yr 'Jal Arg hhe Vai Asn Ile Arg Ser Ser
2.?~ ?0
Trp V«'_ Lys '~.'al Ile Gln Lys Leu ':'yr Tt:r Ile L'he Ala Pt:e Phe Ser
35 40 45
Val Ser Leu Lys Hi_ I'he Pro 'L'hr Lys Lys Leu L,ys Thr H.is Val Leu
50 55 60
Glu Thr Yis F~la 'I'yr Val Ser Leu I le 1 1 a Leu Asn Il a Phe Lys Met
65 70 75 80
ile Glu Gly Ile Leu Glu Ile Val Lys
(2) INFORMA'='ION FOR SEQ ID N0:15:
( i ) SEQUENCE CIIARACTERIS'PICS
(A) LENGTH: 1804 base pairs
(5) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION: SJQ ID N0:16:
GGAGTTCATT i-~.GGCCAGTGG CACTGATTT~_' TCCTTCCCAT CATAGCTATT TATTCTAGTA 60
AGAGGATAAT AAAAGAAATT TCCTATACAA GAACTGAAAT TTTCCATTTG TATGGATCTA 120
GTCACTTTCA GATTTCAATT TGAGGTTAAG TATATAAAGC ACATCCCAAT TTTATATGCT 180
7
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
GCCTTGAGP.A TGCACGGCAA GATCATTTAA240
AATTACAGGA TTTGT,AGGAA
TTTCAAATGG
ACATTTGP.AAAATTATTTTAAAAACCATCTAGTTTGCTTTTGGATTTTAGACATTAAAGC300
CTATGTTGTCTTGTTAACAGGGGTGGAA'rGTATAACCP.TCAGATTCAGCATGTGATTTCA360
CCTTTGAATCTGAGTATTTCTTCCCTATCTTC"_'TT(~AGTCATTTTTGGAGCAGACTGTCA420
CCAGTATTGATAACTFiAGCATTAA11GGGAAAP.GTT(~CATTGCAACTATGCr.TTGGTTTCC480
TGGAAGAACTTTTCTTTTGTTTTAGTGAATGAAGAC~GCTTGATGGGATCACTTP.CTGTAA54O
CTCCTTCTACATAAGGACCCCTTCTGCAAGCAGAAC=.CAAP..T~GAACATGC~'CAr?GGAGTA60Q
TCCCATTTTCTGGATAAATTGAAGAr?GTTTGCTAGTFv'\TGTCTTTATACTAGCGTCTTCC660
TTGTP.TCCCTTTGCTGGCAAGGGAATACFLAGGCG CCACAGATCAAnACACCCCE?7
T C, 2
=.AGA 0
CATTTGAGTGGAGTCTTAT'PTTTACTCCAF:GAGCr?GTTATTCCCTTCTAGTCTAAAATTG780
GCAGTTTTTTC'_~'_"T'"mmTTAA'1'AAAATTTTT TsAAA~CCAA.zICCAG"_'G~AACt~CAGA84
:?'~TC' 0
CACTGGCTGCAC~'TAGTACT~'C~Ar?AAGCC_'i:r?GGTC:::TTTGCACATr?TTCC.-"":':CAACCTG900
TCGAGF~1TTAGGCC T ~_ A T GGCATC~GAAGTGCATGCATC''_'CTTr'1GCTG9
CACTT AAC CCAA 1' 6
0
GGCr?AI1CAATTATF:CTGT?~GTTGTGATACAACACATGTGGCTTTTATTTG'::.CTGCACAT1020
ATCCACTGTACAGCCACTTGGGAGTATCGTGGTTA~~~CTTGCAGCAACTGC.C'"CTGCATT1080
TATACTGT"_""ATTGCATAT'I'CTTTTCCC Gt~AGTG.'-.e-iAGAGP,AATGTT"_'= I'CTTGTTGC114
T G 0
ATTGATTACATT'~';''i~TAAATTTGCTTAGCTGGAAACi='TTGGGAr?AAGAGGC~'-'u:TT'rGTC1200
AATTGTACAACCGATTG AGCTC '_"GAATP.TT"'"'TACG T T'='AGACATTT12
T GA T AGTG CTGTA 6
0
TCTTTGCAAATC T A GATTGAAA TIoAATC'~Tr'1.~AGATGGTGTr?C.""~CCCAT13
T TGTTC T G AA 11T 2
0
CATGTAAAP.AGCAGGCACCATC~PCTAAGATGGATTT:~?TGCTCATTTTTAAGGCATATAC1380
TCAGCTTCTATTTAAAACTr?TAATTTAAAA'_~AATTCTGTACi-~r?TGAAATGGGGAATATAT1440
ATGGGAATAAATTCTATTCCATT'TATTTCAATTTGA!?TTTCCAAATTGTAATGTTTCCCT150O
TTGTGCTATAGGAATAGGATTAAATGGGGGAAGACTAGGATTTATAAGGCCTGTATATGG156O
GGGGAGGGCAGAGATGGAACAATGAGGGTTGTGATGATAG'I'Gr?ATAGCAAAGAGTGAATT1620
CTGTGTGTTTTTGCTGTAGCACTGAAGTGAAGAGATATTAGCTTTGGCTG':'TCACAAAAT1680
AGAGCATCATGATTTTCAGTGTTTGAGAGAAAATTGATGGAAAAAGTTTGCAGTACTTGA1740
CATGTATTTGCATGCACP.AAA T AAAATTATTTGTCC TP.F~AAAAAAAFu,ANAAAAAA18
ACCT 0
0
AAAp 1804
73
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
(2) INFORMATION FOR SEQ ID N0:17:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 37 amino acids
(B) TYPE: amino acid
(C) STRAhDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:17:
Met Lys Arg L~~u Asp Gly Iic Thr Tyr Cys Asn Ser Phe '?'yr Ile Arg
1 5 10 15
Thr Pro Ser F;la Ser Arg Thr Gin Lys Asn Met Leu Lys Glu Tyr Pro
~0 2 ~ 30
Ile Phe '='r_:~ Ie Asn
( 2 ) INFORMA'='IO:I FOR SEQ ID NO : 18
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 360 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi)
SEQUE~;CE
DESCRIPTION:
SEQ
ID NO:18:
AGAATACCAAGACTGTGTGT ACACGCAGATGTCAGTGGCAGAGAATGAAGATCAGCTTCG 60
TGCAAAGGGT'I.aTGACAAAA CACCAGACT~_'CATTTTACAAGTACCAGTTGCTGTAGAAGG 120
GCACATAATTCACTGGATTG AAAGCAAAGCCTCATTTGGTGATGAATGTAGCCACCACGC 180
CTACCTGCATGACCAGTTCT GGAGCTACTGGAATAGGGTCCCAATATAACAGACAAATGG 240
TGAAACAGAGGGATACTCAC TAGGAAACAGATTTGGGCCAGGC'='TAGTCATCTATTGGTA 300
TGGATTTATCC=~GGAGCTGG ACTGCAACCGGGAAAGGGGCATCCTGCTCAAAGCCTGTTT 360
(2) INFORMATION FOR SEQ ID N0:19:
(i) SEQUENCE CHARACTERISTICS:
74
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(A) LENGTH: 20 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) r-10LECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:19:
Met Asp Le-a Ser Arg Ser Trp Trr Ala Thr Gly Lys Gly Ala Ser Cys
1 5 10 15
Ser Lys Pro Val
(2) INFORMATION FOR SEQ ID N0:20:
( i ) SEQL'E:~ICi~ CHARACTERT_S'_~ICS
(A> .»NGTH: 202 i~ase i~airs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) :fOLECULE TYPE: cDNA
(xl ) SEQ:;Er;CE DESCRIPTT_OI:i : S_,Q ID iVO: 20
P,~~ AAAAAAr y ~~.i :AA.~P.AAAA AAAAAAr'~AAA ~'~AAAP.AAA.A AAAAA AAAAA
?.AAAAAAAAA 6 0
A~ y A.~AF~AAAAAA P.AAAP~AAAA F~ ~.f-.r'1AFIAi~AAA AAF~lI~'11~AF~rI.%y r
~r?,AAAAAAA I 2 0
AAAAAAAAAA F =~AAANTNAA AAF~AAAAAAA ~,~-~AAAAi3AAA p,~~ A~1~~AAAAA
P,~~AAAAAAAA 18 C
p.AA<A p~~.~AAAAAAA AA 2 0 2
(2) INFORMATLON FOR SEQ ID N0:2':
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 1189 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: double
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: cDNA
(xi) SEQUENCE DESCRIPTION: SEQ ID 1A0:21:
CA 02270873 1999-OS-12
WO 98I21332 PCT/US97/20740
GGCCTTCATG GCCTAATCAG ATTTTAGTGG GATGATAGGGAGAAAGAAAG60
CAAGACAGGT
AGTCCTGCCT GTCAAAAGTG GCTGTGCTAT CCTCACAGGTAGCACCTCTC120
ATAI'~J1TGAAC
AGAGAGAATA RATGGTAAA'I' CTTTCTTTTC AAGTGTCAGGCTATCAGTTA180
AGGTCTTTAA
ACCTCTCCTA GATCTCAGFLA :.TGCCTAGAA TGGCTACATCAATGGAAATT240
AGAGAAGTCC
CTCCACAGAT GCAA:,TTTTC TCTACAP.AAG AGAGCCACCTCAGTCTGTTG300
ATGGC'I'TTGC
TCCCTGTAGC AGCCATTTC:i:~ATTATGTCA TTTTGGGGTAAAATATTTTG360
AAGAGATATA
ATTATCTTCA TTAGTATATC TCAATTTTGT CTGAGAGTTATAGTCAGAGG420
CAATACAAAC
TTGAATTTTC ATT'T_'CAAA11T GTTTTCCTAGCTTTTTTGTTTTATTGTAAG480
TTTTTTTTCT
TTGACAATTT ATAATTGTAT ~~AAGTATGA GATGTTATAGCTTP.AGAATA540
GGTACFi~iAGT
CAGTATGGTA TGATTAAA'PC AAGTTATTAA ACGTTAAATGCTTAAATTTT600
CCTATCCTTC
TTGATGAGAt=. CATTTCAAA I' '?"rAC'~C'='TGGAAAATC'rC:GA CCCCCCAA6
AAGGT.~A .G 6
0
ATT A:-~~AGCC:=. TGAAGCTGA.~i '?'TGTGCAACAF'iATGGAAGCTTGTCTTCCAG7
TCC'rC'='"_'CCl1 2
0
GTACF:GAACA AAI~ACAAGAC '='CATTTC~_'TCAGATGTGCF:~."FiTAATTGGCT780
~iCCTG ~GC''I't'1A
CCTCCTTTAC TCCCTTTTTC TCTTCTA_~CA C'_"TGTGTAI-_AATGTAGATTT840
TTCATTA'I'AT
t~:CTGGACACT t'~.=iCTAAAATT '='CACAGGGTTGCC'_~"'ACTGCCTACCTACCT900
GTACCCr;TT'r
GTYTTCCTAC G'I'ACCTTYTC CCCACTTTAA CATATTAAACCTCCCAAAAA960
GGAATGUATA
CYTYTTTAGA AAAATAGCCA CAGGTT'TATC GTGTTTCC!'':'AGATGVACTY1020
TGTGGCTGGT
TAAAGCTGGC TTAATAAACC TCAGTGATTG C'_~CAATCACATTTTGGTT10
AP.AC'I' I'.~, i'CIC C T 8
0
GTCACTGTCT '~ ACCAATTTO AAATGTAAAA C'!'A.~TTAT_~_TTTACCACA 114
TP.TTYT a:CTA T T 0
GTGCAACAGA ACTCNAAAAA AF~'~AAAAAAA iIAA.=iAAAi..~ 118
AF;AAAtl.<iAAA 9
( 2 ) INFORNL~TION FOR SEQ ID NO:
2~~
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 56 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOG'i: linear
(ii) MOLECULE TYPE: protein
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:2?.:
7
CA 02270873 1999-OS-12
WO 98/2l332 PCT/US97/20740
Met Arg 'rhr Phe Glu Ile Tyr Ser ~:'rp Lys Va1 Lys Lys Asn Leu Arg
10 15
Thr Pro Gln Ile Ly;; A1a Met Lys I~eu Asn Cys Aia Thr Ser Ser Ser
20 25 30
Lys Trp Lys Leu Val Phe Gln Val C~ln Asn Lys Asn Lys Tizr His Phe
35 40 45
Phe T~r Cys Leu Lys Met Cys I'):r
50 55
(2) i~IFORMATION FOR SEQ ID N0:23:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 5a:5 base pairs
(B) TYPE: nucleic acid
( C ) S'PRANDEDNES S : double
(D) TOPOLOGY: linear
i i ) L=IOL ECULF TYPE : cDNA
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:23:
CATAACAGCG "_'CAGAGAGAA AGAACTGAC T GAAACC;TTTG: ~GTTCTCCTC6
e'1GA'rGAAGAA C
CTGATCACAG CC ATCTTGGC AGTGGCTG'I"?' GGT'PTCCCAG~ CAGGAACGA12
'I'CTCTCAAG: 0
GAAA.zAAGAA GTATCAGTGA CACJCGATGAA TTAGC'PTCAGGTTCCCTTAC18Q
Gi~TTTT'=":~~T
CCATATCCAT TTCGCCCACT TCCACCAATT CCATTTCCAAGTTTAGACGT240
GATT~_'CCATG
AATT'_""_'CCTA TTCCAATACC TGAATCTGCC CCTACAF~CTCCGAAAAGTAA300
CCCTTCCTl:G
ACAAGAAGGA AAAGTCACGA TAAACCTGGT CACC'rCAAA'I'CCACTTCCTT36C
TGAAATTG,=,G
GAAGF.~TCAA A_Z1TTCCTGT'I' A_A7.'AAAAGAA GCACACAGCt:4
AAACAAATG i' AATTG AAATA 2
0
TTCTCTAGTC .ATATCTTTlI CTGATYTTYT T T AATAAACA~:~RAAAAAAAA4
TGRAAGC: L .-~~ 8
0
A,F~e~ P.~~.AAAAP~A A~~i'~AAAAAAF. AAAAAAAAAA S
AAAAA 2
5
(2) I:d~ORMATION FOR SEQ ID N0:24:
( i. ) SEQUENCE CIiARACTERISTICS
(A) LENGTH: f35 amino acids
(B) TYPE: amino acid
(C) STRANDEDNESS:
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: protein
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:24:
Met Lys Lys Val Leu Leu Leu Ile Thr A1a I1e Lees ~.~a Val Ala Vai
'_ 5 10 15
Gly Phe Pro Val Ser Gln Asp Gln Glu Arg Glu Lys f~rg Ser Ile Ser
20 25 30
Asp Ser Asp Glu Leu Ala Ser Gly Phe Phe Val Phe Pro Tyr Pro Tyr
35 40 45
Pro Phe Arg Pro Leu Pro Pro Ile Pro Phe Pro Arg P_~!e Pro Trp Phe
50 55 60
Arg Arg Asn Phe Pro Ile Pro I've Pro Glu Ser Ala Pro Thr Thr Pro
65 70 75 80
Leu Pro Ser Glu Lvs
3 5
(2) INFORMATION FOR SEQ ID N0:25:
(i) SEQUENCE C~Ai~ACTERISTIC~:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRALIDEDNESS: single
(D) TOPOLOGY: linear
(ii) ~'OLECULE TYPE: other nuc eic acid
(A) DESCRIPTION: idesc -- "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:25:
ANCAGGAGGC: GTGGGTTCTA TAGAG'1'CC 29
(2) INFOR2rIATION FOR SEQ ID 1','0:26:
(i) SEQUENCE CHARACTERT_STICS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: /desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:26:
7g
CA 02270873 1999-OS-12
WO 98I21332 PCTIUS97/20?40
CNCTTGTGTGC CTGTTTCTCA ATTGCAGA 29
( 2 ) INFOR.MATIOI': FOR SEQ ID N0 : 27
(i) SEQUENCE CHARACTERISTICS:
(A} LENGTH: 2'.3 base pairs
(B) TYPE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOG'i: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: ;desc = "oligonucleotide"
(xi) SEQUE~IC~ DESCRIPTIOIJ: SEQ ID N0:21:
CNCTAGCTGTT CGGCTTTAC~ AAGGAGTT 29
(2) I:~IFORM~?TiON FOR_ SF.Q .ID N0:22:
( i ) SEQUENCL: CE'ARAC.'TERI STICS
(A) LENGTt:: 29 base pairs
(c3) TYPE: nucleic acid
(C) STRANDEDNE:SS: single
(D) TOPOLOGY: linear
(i~,) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTIC>N: !desc = "ol.idonuc'~eotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:28:
ANCACGCTCTG i~CGAATGAGC r'~'~CCTCTC 29
(2) INFORMATION FOR SEQ ID N0:29:
(i) SEQUENCE CHARACTERISTICS:
(A) LENGTH: 29 base pairs
(B) 'TYPE: nucleic acid
(C) STRANDEDNE',SS: single
(D) TOPOLOGY: linear
(ii} MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: idesc = "oliaonucieotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:29:
CNAACACAGAC TGGAAGCCTA GAGTCGCT 29
79
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97/20740
(?) INFORMATION FOR SEQ ID N0:30:
(i) SEQUENCE CHARACTERISTICS:
LENGTH: 29 base pairs
(2) T''PE: nucleic acid
(C) STRANDEDNESS: single
(D) TOPOLOGY: linear
(ii) MOLECULE TYPE: other nucleic acid
(A) DESCRIPTION: aesc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTION: SEQ ID N0:30:
GN AAACCAGGF: A.~~-,TGTF.CF:C': GACACr ~'i 29
(2) INFORMATION FOF< 5EQ ID NO:~=:
( i ) EQ:)EN~CE CHt~RACT~:F;I;;TT_;;
S
(::) LENGTH: ~9 b<~se pairs
(R) TYPE: nucleic aci~~
(C) STRANDEDNESS: single
(ai 'TOPOLOGY: l.inea_-
(ii) MOLECULE TYPE: other r~~cieic acid
(?.) DESCRii'TION: idesc: _ "oligonucleotide"
(xi) SEQUENCE DESCRIPTIO_d: ;EQ ID N0:3-! .
TNATCAATACT GGTGACAGTC TGCTCCAA 29
( <' ) iNFORrI~-_TIO:~ FOR SEQ ID i;0 : 3 '::
(i} SEQUENCE CHARACTERISTT_CS:
(A) LENGTH: 29 base pairs
(B) TYPE: nucleic acid
(C) STRP.NDEDNESS: sinc,le
(D) TOPOLOGY: linear J
(ii) MOLECULE TYPE: other nucleic acid
(~:) DESCRIPTION: desc = "oligonucleotide"
(xi) SEQUENCE DESCRIPTIOr?: SEQ ID N0:32:
GNCATAACCCT TTGCACGAAG CTGATCTT 29
(2) INFOR2JIATION FOR SEQ ID N0:33:
CA 02270873 1999-OS-12
WO 98/21332 PCT/US97I2Q7~0
(i) SEQUET:CE CHARACTERISTICS:
(A) L NGTII: '?9 base pairs
(B) '_"'!PE: nucleic acid
(C) S'='T.~ANDED:~1ESS: single
(D) TOPOLOGY: linear
( ii ) '~IOLECL;LE TYPE: other nucleic acid
(A) DESCRIPTION: idesc = "o:L,_gonucleotide"
(xi) SEQUET1~~ DESCR.:LPTION: SEQ ID ~1O:33:
ANATTTAA GC« TT~_'AACG T Gz AGGATAGG
( 2 ) I~IFO:~MATION FOR SEQ ID DIO: 34
( _ ; SEQLJEI~ICE C:IAF.ACTERI5TICS
(.=:) ~.~NG~_'!!: ~~) base pairs
'~'IPr : nucleic acid
(C) ..TRAS1DEDNESS: single
W TOPOLOGY: linear
I
(iij ~fO~EC~LE TYPE: other m.:cleic acid
(i;) D~SCRIPTTON: ,'desc = "oliuonuc=eotide"
(xi) S~QUENC~'. DESCRIPTIOV: SEQ ID ';0:34:
TNAGAGACTGG GAAhCCAACA GCCACTGC zg